Abstract
Driven by the global energy transition, mechanized construction—characterized by enhanced safety, efficiency, and quality—is becoming the mainstream approach in power grid development. Mechanization assessment serves as a critical tool for guiding and optimizing this process, yet current practices remain largely manual, resulting in inefficiency, time-consuming operations, and a lack of real-time insights, which severely limit its practical utility for dynamic project guidance. To address these challenges, this study proposes a novel framework that integrates semantic technology (i.e., ontology) and large language models (LLMs). The framework first constructs a semantic model of the power grid construction domain using ontology. An LLM is then employed to convert multi-source project data into structured ontological instances. Building on this, mechanization assessment criteria are formalized into machine-executable Semantic Web Rule Language (SWRL) rules, which enable automated reasoning and scoring through an ontological reasoner. Furthermore, the LLM is utilized to generate comprehensive and intelligible assessment reports based on the reasoning outputs. To validate the proposed method, 126 real-world project cases were applied to the system. The results demonstrate a 96% accuracy rate in mechanization assessment outcomes compared to expert evaluations. The approach facilitates an objective, standardized, and dynamic evaluation of construction mechanization levels, providing a foundation for intelligent and scalable management models in power grid construction.
1. Introduction
With the acceleration of the energy transition, the power grid, as a key national infrastructure, is facing rapid growth in both scale and complexity [1]. Driving the digital and intelligent transformation of power grid construction management has become essential for strengthening industry competitiveness and safeguarding national energy security [2]. In this context, mechanized construction—where machines and equipment replace or reduce manual labor in tasks such as excavation, lifting, and installation—has become the mainstream approach [3]. For example, excavators are used for foundation works, cranes for lifting heavy components, and stringing machines for overhead line installation [4]. Compared with traditional methods, mechanized construction offers clear advantages in safety, efficiency, and quality [5,6]. The mechanization rate is a core indicator for evaluating the technical level and modernization of power grid construction. Establishing a scientific and accurate assessment system for this rate can help enterprises identify gaps in equipment and productivity, support resource optimization and investment decisions, and provide important references for policy-making and industrial upgrading [7].
The importance of mechanization assessment in construction is widely acknowledged, as it serves as a key indicator of productivity, efficiency, and technological advancement. In power grid construction, understanding the level of mechanization is crucial for optimizing resource allocation, improving safety, and guiding strategic investment. However, despite its recognized value, the current practice of evaluating mechanization rates in this sector remains far from automated or intelligent. Extensive enterprise surveys and systematic expert interviews reveal that existing methods for assessing construction mechanization are fragmented [8]. In response to this dilemma, the State Grid Corporation of China has issued the Power Grid Construction Mechanization Evaluation Method (hereinafter referred to as the PGCME-Method), which has gained broad recognition and application [8]. While the PGCME-Method provides meaningful insights, it still depends on manual data collection, processing, and computation. This reliance results in an evaluation paradigm that is neither automated nor intelligent, failing to meet the growing demand for smart and responsive engineering management.
Several persistent challenges hinder progress toward automation. First, automated assessment requires a standardized evaluation process and a semantically consistent structure—an aspect that has received limited scholarly attention. Second, the current manual assessment process is inefficient, time-consuming, and difficult to scale. Data collection and analysis demand substantial human effort, often leading to errors, omissions, and inconsistencies. Moreover, delays from raw data acquisition to final evaluation impede the timely understanding of dynamic changes in mechanization during construction. This gap stands in clear contrast to the broader objective of achieving intelligent construction management and forms the fundamental motivation for this study [9,10].
Against this backdrop, this study proposes an automated scoring framework based on ontologies and LLM for the PGCME-Method (an authoritative assessment method for grid construction mechanization released by the State Grid of China). This system is capable of conducting semantic-consistent, dynamic and data-driven evaluations of the mechanization level in grid construction. The framework follows a structured workflow. First, a domain ontology is constructed to establish a unified semantic foundation for data integration and interpretation. Next, LLMs are leveraged to extract and map heterogeneous project data into standardized ontological instances. The PGCME-Method is then semantically analyzed, and its computational logic is formalized using the Semantic Web Rule Language (SWRL) to create machine-interpretable and executable rules that standardize the evaluation of mechanization across projects. These rules are processed by an ontology reasoner to automatically infer mechanization scores. Finally, LLMs are employed to generate clear and structured assessment reports based on the reasoning outcomes, thereby supporting more transparent and evidence-based decision-making.
The contributions of this work are threefold: (1) we establish a domain ontology for mechanized construction in power grid projects, which integrates semantic knowledge related to mechanization assessment and construction equipment, thereby providing a unified and standardized semantic framework for consistent evaluation; (2) we utilize LLM to perform intelligent interpretation and conversion of multi-source, heterogeneous project data, and subsequently guide the automated generation of mechanization assessment reports through ontology and LLM reasoning; and (3) building on the above approach, we develop an automated and intelligent evaluation system, thereby establishing a foundation for a standardized, scalable, and intelligent evaluation paradigm in the domain of power grid construction mechanization. Furthermore, the methodological framework proposed in this study demonstrates broad applicability and can be extended to various types of construction and infrastructure projects beyond power grid construction. The proposed methodology, which integrates ontology modeling, semantic rule-based reasoning, and large language models, offers a reusable and scalable standardized evaluation paradigm for standardized and intelligent assessment tasks in other engineering domains, such as construction safety risk evaluation and equipment scheduling efficiency assessment. This will contribute to advancing the engineering industry toward automated, knowledge-driven intelligent management.
2. Literature Review
2.1. Mechanization Rate Assessment in Construction and Power Grid Projects
With the rapid development of power grid engineering towards ultra-high voltage and extra-large capacity, unprecedented demands have been placed on the efficiency and precision of construction in the power grid sector [11]. In this context, construction mechanization has become a crucial means to ensure project progress and reduce safety risks [12]. Scientifically and accurately evaluating the mechanization level of power grid engineering plays an indispensable role.
Although the importance of mechanization assessment is widely acknowledged, in-depth enterprise surveys and systematic expert interviews reveal that current practices for evaluating mechanization rates fall far short of being intelligent or scientifically rigorous. In practice, methods for assessing construction mechanization remain fragmented [8]. For instance, qualitatively, some scholars employ the Analytic Hierarchy Process (AHP) [13] and fuzzy comprehensive evaluation methods [14] to evaluate mechanization levels. Quantitatively, others rely on tools such as Excel to process survey data for mechanization assessment [9], or utilize indicators such as equipment utilization rates [15], labor-to-machinery ratios [16], or the proportion of mechanized work hours [17] to measure the degree of mechanization. In response, the State Grid Corporation of China issued the PGCME method [8] to guide the measurement of mechanization levels in power grid construction. While this method provides meaningful guidance, its evaluation approach still relies on manual data entry, expert scoring, or post-facto statistical aggregation. Although some studies have utilized semantic technologies to connect various types of IoT information for construction process monitoring [18,19], the power grid mechanization construction domain still lacks semantic linkages between mechanical equipment and mechanization assessment tasks. This gap hinders the standardization and automation of evaluating mechanization levels in power grid construction.
Therefore, there is a pressing practical need to establish a scientific and standardized knowledge framework for mechanization assessment using semantic technologies, and to enable automated evaluation through reasoning, thereby providing robust support for mechanization assessment practices.
2.2. Ontology-Based Knowledge Modeling in Construction Engineering
In knowledge representation, techniques such as knowledge graphs, concept graphs, and ontology serve distinct purposes. Knowledge graphs [20] model entity relationships for association and retrieval, whereas concept graphs [21] capture conceptual logic to support language understanding. Ontology formally defines concepts, attributes, and constraints to build semantically explicit structured models [22]. Beyond representation, ontology enables semantic search, querying, and—critically—logical reasoning based on defined rules, allowing implicit knowledge to be inferred. This reasoning capability offers a natural advantage in automated decision-making and evaluation applications.
Currently, within the AEC (Architecture, Engineering, and Construction) industry, ontology has been widely adopted for representing domain knowledge and enabling semantic interoperability [23]. Prior studies have developed ontologies for safety risk management [24,25], construction scheduling [26], equipment allocation [27], and BIM-GIS integration [18]. Hwang, S [28] explored an automated hazard identification method for construction activities by leveraging BIM and ontology technology. El-Gohary [29] developed the IC-PRO ontology, which conceptualizes knowledge centered on infrastructure and construction processes, providing a structured framework for understanding. Zheng et al. [30] developed a construction workflow information system based on the Digital Construction (DiCon) ontology, using it to represent domain knowledge and integrate and formalize construction process information. Doukari Omar [31] constructed a BIM knowledge-based ontology model that links BIM data with construction schedules, enabling the automatic generation of project schedules. Mostafa [32] proposed an ontology-based system that can be used for stakeholder-aware planning and design of infrastructure projects. While these studies collectively demonstrate the maturity and effectiveness of ontology-based methods across various AEC sub-domains, research in the specific area of mechanized construction for power grid engineering remains relatively limited. In this domain, semantic formalization holds significant potential for improving knowledge representation and interoperability.
Furthermore, despite the aforementioned progress, insufficient attention has been paid by these scholars to the methodological challenge of transforming multi-source heterogeneous AEC data into the semantic data guided by these ontologies. This gap is not trivial, given that semantic technology (i.e., ontology) itself lacks the capability to automatically convert diverse data sources into semantically compliant formats. Such processes typically rely on external tools or customized procedures, which remain underexplored in the aforementioned literature. To address this limitation, scholars such as Zhang et al. [33] and Da et al. [34] have preliminarily explored the use of LLMs to construct automated frameworks for data processing and integration. This offers an automated pathway for transforming multi-source data into ontology-compatible representations, representing a novel approach.
Building upon knowledge representation, ontology can also perform reasoning based on logical rules [35], accomplishing tasks such as information retrieval [36] and knowledge inference [37]. It should be noted that the reasoning capability of ontologies is inherently constrained by their reliance on predefined logical rules. To enhance this, researchers have pursued various extensions to ontology-based reasoning. For example, Du Gaixia [38] expanded the logical predicates of inference rules, thereby improving both the expressiveness of the rules and the reasoning capacity of the ontology. Similarly, Xu et al. [39] extended ontological reasoning functions to support more complex computational tasks, advancing the flexibility and applicability of ontology reasoning in practical scenarios. In terms of reasoning applications Mehdi [40] adopted ontology and reasoning techniques to propose a decision support system framework for short-term construction planning, addressing the validation of decision effectiveness and plan formulation under multiple constraints. B.T. Zhong [41] clarified the procedural knowledge in construction planning and formed an ontological model. The planning work was divided into plan definition and plan verification/inspection. Plan definition is completed based on existing similar projects [42], while plan review is validated by independent experts. These enhancements to ontological reasoning have enabled the formalization of complex rule semantics. Applying this capability to the mechanized construction domain in power grid engineering offers a reliable approach for automating evaluation rules.
However, few studies have attempted to apply ontology specifically to the assessment of mechanized construction. While some research has developed ontologies in related domains—such as for automated construction planning in power grid projects—these efforts have primarily focused on enabling reasoning for automated construction planning [11,27], without extending into the formalization of evaluation criteria or quantitative performance analytics. Consequently, there remains a gap in leveraging ontology for standardized and automated mechanization evaluation, which this paper seeks to address.
2.3. Large Language Models in Construction Automation
Large Language Models represent a form of artificial intelligence capable not only of generating coherent text but also of demonstrating strong contextual understanding and sophisticated reasoning abilities, thereby driving a paradigm shift in natural language processing [43,44]. Notwithstanding certain limitations such as hallucination and reproducibility challenges [45], these issues can be effectively mitigated through approaches such as knowledge augmentation and prompt engineering [46,47].
The emergence of LLM has enabled new possibilities for automated data interpretation in engineering domains. Recent research explores using LLM to extract structured entities from construction logs, classify hazard reports, or summarize site inspections. Zhang, CH [48] proposed a novel bridge inspection database construction method that utilizes LLM-assisted information extraction, providing a scalable solution for more proactive and data-based bridge maintenance strategies. Oral, M [49], leveraging the powerful natural language processing capabilities of LLM, automatically identifies risks existing in engineering construction and expands their preventive measures. Pu, HX [50] have proposed an AutoRepo framework based on LLM to inspect building risk information and potential safety hazards and automatically generate building inspection reports. Some studies also integrate LLM with BIM or digital twins [51] for conversational querying. For instance, to address the issue of missing BIM geometric and semantic information relied upon by building energy consumption models, Forth, K [52] proposed a new method that utilizes LLM and text similarity to automatically complete the missing BIM information, achieving the automatic completion of BIM information. Guo, PZ [53] introduced a Synergistic BIM Aligners that utilizes LLM to automatically align human queries with BIM domain code functions, thereby achieving automatic information retrieval of BIM data. However, these applications remain largely confined to text comprehension and information extraction. Although large language models exhibit strong capabilities in processing unstructured data, they lack the necessary mechanisms to interpret engineering semantics or perform information processing within structured domain knowledge frameworks.
Furthermore, the capabilities of LLM have been extensively applied in the field of engineering. LLMs are commonly employed to address issues such as construction design, risk identification, and intelligent decision-making. Li et al. [54] integrated LLM with knowledge graphs to develop a compliance-checking method for construction plans, thereby enhancing the application of automated review in construction design. Lee et al. [55] constructed an LLM-based framework for on-site construction management, aiming to proactively provide recommendations for protecting building materials and temporary or incomplete structures against adverse weather impacts. Mustafa Oral et al. [49] utilized AI technology to facilitate decision-making in construction risk assessment. Liu et al. [56] explored an LLM-driven UAV inspection model for infrastructure construction, improving decision-making capabilities through human–machine interaction. Seyed Hossein et al. [57] developed a multi-agent system based on LLMs to support decision-making in construction design, management, and operation for complex tasks in hydraulic engineering. While these studies demonstrate the growing integration of LLMs into engineering workflows, such models are rarely combined with formal knowledge structures—such as ontologies—to support interpretable scoring or decision-making. The full potential of LLMs in facilitating structured evaluation and rule-based assessment remains underexplored.
LLMs have demonstrated remarkable capabilities in semantic understanding, information extraction, and intelligent reasoning [48]. Leveraging these strengths—particularly in semantic comprehension and textual reasoning—to automate the generation of mechanization assessment reports represents a feasible and promising approach.
2.4. Knowledge Gaps and Contributions
In summary, while the mechanization rate is a critical performance indicator for power grid construction [2], existing assessment methods are often constrained by low automation. Ontology research in the construction field provides a foundation for structured knowledge representation and enables the potential integration of domain ontologies with quantitative evaluation logic for mechanization [27], thereby facilitating the sharing and reuse of mechanization assessment knowledge. In terms of ontological reasoning, it allows for the automated evaluation and output of mechanization levels. However, the data generated through ontological reasoning typically exists in the form of triples, which need to be further transformed into structured reports [58]. In this context, LLMs demonstrate significant potential in information extraction and text generation [59]. Leveraging their capabilities to guide and advance the automated and intelligent assessment of construction mechanization constitutes a viable research pathway. This viability stems from the ability of LLM to assist in data processing prior to mechanization assessment and to effectively convert evaluation data into structured report formats. Therefore, to develop a scalable, intelligent, and interpretable mechanization rate assessment mechanism, exploring an approach that integrates ontological reasoning with LLM-based data mapping and report generation is the central objective of this study.
This paper makes significant contributions by introducing an intelligent, ontology-driven framework that revolutionizes the evaluation of mechanization in power grid construction. At its core, we construct the Power Grid Construction Ontology (PGCO), which establishes a foundational semantic knowledge framework to standardize concepts and relationships within this domain, thereby enhancing knowledge sharing and reuse. To overcome the critical bottleneck of integrating diverse and heterogeneous data sources, we design a novel data integration methodology that embodies a key innovation: the pioneering application of LLM to accomplish the entire transformation process from multi-source data (e.g., Excel spreadsheets and textual records) into PGCO-compliant instances. This LLM-powered approach represents a paradigm shift from conventional manual methods, dramatically boosting both the efficiency and quality of data preparation. Building upon this integrated knowledge base, we further design an automated pipeline for generating mechanization assessment reports; this system utilizes SWRL rules for ontological reasoning to compute the mechanization level and subsequently employs an LLM to transform these structured results into a coherent and insightful narrative report. This end-to-end intelligent approach not only provides robust, data-driven support for evaluation tasks but also establishes a feedback loop capable of informing and guiding future improvements in mechanization practices.
3. The Proposed Methodological Framework for Automatic Scoring of Mechanization Rate in Power Grid Construction Projects
This study is structured into four interconnected modules, designed to achieve an automated and intelligent evaluation of the mechanization rate in power grid construction projects, as illustrated in Figure 1.
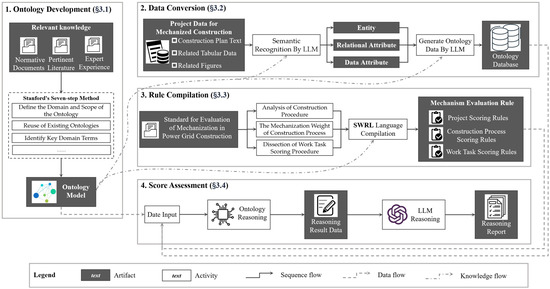
Figure 1.
Methodological framework for evaluating the mechanization rate of power grid construction based on ontology and LLM.
The first module, Ontology Development (Section 3.1), establishes the foundational knowledge architecture. This involves analyzing normative documents, pertinent literature, and expert experience. Following the Stanford seven-step ontology development methodology, domain concepts are formalized into the Power Grid Construction Ontology (PGCOntology), tailored to accommodate data formats specific to the power grid construction domain.
The second module, Data Transformation (Section 3.2), addresses the heterogeneity of power grid construction data. It employs an LLM to semantically recognize multi-source heterogeneous data—including text, tables, and images. The LLM extracts entities, relations, and data attributes from each piece of data and, guided by the semantic framework of PGCOntology, generates corresponding ontological data. This process results in an ontological database that integrates the transformed information.
The third module, Rule Formulation (Section 3.3), systematically analyzes the PGCME-Method published by the electric power infrastructure industry. The analysis focuses on three dimensions: the breakdown of construction procedures, the mechanization weighting for each construction process, and the scoring procedure of a specific work task. Subsequently, using the SWRL rule language, the logic of mechanization assessment is formalized and converted into a set of machine-executable SWRL rules.
The final module, Scoring and Evaluation (Section 3.4), carries out the mechanization rate assessment and generates the final score. It takes PGCOntology, instantiated data, and the mechanization assessment rule set (SWRL rules) as inputs and integrates them into an ontology reasoner. The reasoner infers the specific mechanization evaluation score for the project based on the SWRL rules. Since the raw reasoning output is not human-readable, an LLM is subsequently employed to transform the inferred data into a structured, highly readable evaluation report. This step enhances the transparency and practical utility of the decision-making process.
3.1. Development of the Power Grid Construction Ontology
Ontology has been defined in the field of information technology as “an explicit formal specification of a shared conceptual model”. Developing an ontology model for power grid mechanized construction requires a thorough exploration of the target domain which is characterized by large-scale projects, dispersed construction sites, and a vast and complex mechanized equipment system.
Classic methods for ontology development include the Skeleton method, TOVE method, KACTUS method, and the Stanford seven-step method [60]. Among these, the Stanford seven-step method has developed into a well-established ontology development framework known for its strong practicality and versatility, allowing both domain experts and non-experts to participate in the ontology development process. Therefore, this study adopts the Stanford seven-step method for ontology development, as follows:
Step 1: Define the Domain and Scope of the Ontology. The ontology focuses on representing key concepts related to mechanized construction within power grid projects. Its primary purpose is to support the evaluation and analysis of mechanization rates in power grid construction projects.
Step 2: Reuse of Existing Ontologies. The development of the ontology in this study is grounded in pre-existing semantic frameworks for the construction domain. While EI-Diraby et al. provided a process-oriented conceptual model, Gao et al. [11] established a set of core classes and a semantic framework specifically for power grid construction. Building upon this foundation, the present ontology inherits the core classes defined by Gao et al. and is further extended with additional classes dedicated to mechanization assessment, thereby forming the PGCOntology proposed in this study.
Step 3: Identify Key Domain Terms. This stage involves recognizing and listing essential concepts, entities, attributes, and relationships pertinent to power grid and mechanized construction. The identification process draws on literature reviews, technical standards, and expert consultations.
Step 4: Define Classes and Class Hierarchy. Based on the terminology collected in the previous step, the study defines core classes and organizes them into a hierarchical structure that reflects the logical and semantic relationships among them.
Step 5: Specify Class Properties. Properties are divided into two main types: object properties, which describe relationships between classes, and data properties, which define the attributes or characteristics of a class. The definition of these properties is guided by relevant regulations, professional guidelines, scholarly literature, and engineering documentation.
Step 6: Define Property Facets and Value Ranges. In this step, each property’s characteristics are detailed, including its domain (the class it belongs to), range (the type of value or class it references), cardinality (the allowable number of values, e.g., single or multiple), and constraints (rules or conditions governing property values).
Step 7: Create Instances. Finally, the ontology is populated with instances—specific examples of classes and their properties—based on real-world data. These instances bring the ontology to life, enabling semantic reasoning and practical application in mechanization rate evaluation.
Following the seven steps, PGCOntology was developed, as illustrated in Figure 2. The PGCOntology provides a structured framework for representing and organizing knowledge related to mechanized construction processes in power grid projects. It comprises six core classes—Project, Process, Actor, Resource, Product, and Mechanism. The Project class serves as an overall abstraction of power grid construction projects, supporting the systematic management of related data and operations. The Process class represents various activities or tasks within a project, such as design, construction, maintenance, and operation. The Actor class encompasses all human participants such as owners, designers, and contractors. The Resource class captures all inputs required for activity implementation, especially the mechanical equipment needed for the activity. The Product class denotes the final deliverables of a project. The Mechanism class encapsulates technical and methodological elements necessary for achieving project objectives. The PGCOntology elaborates its conceptual framework through a structured hierarchy of subclasses under each core class, tailored specifically to the power grid construction domain. Under the Project class, four distinct subclasses are defined: GenerationProject, TransmissionProject, SubstationProject, and DistributionProject, representing the primary types of power grid infrastructure. Correspondingly, the Product class features the subclass ElectricPowerInfrastructure, which is further specialized into PowerGenerationPlant, TransmissionLine, Substation, and DistributionLine, thereby establishing a direct and meaningful correlation between the type of project undertaken and the physical infrastructure it delivers. The Actor, Resource, and Process classes maintain subclasses consistent with general construction conventions—including manager/stakeholder roles, material/equipment/labor resources, and key lifecycle phases. Central to the ontology’s application in mechanization assessment is the specialized extension under the Mechanism class. This begins with the MechanizationRateEvaluationInConstruction subclass, which embodies the general principles for evaluating mechanization rates. This is concretely specified into the MechanizationRateEvaluationOfPowerGridConstruction subclass, narrowing the focus explicitly to the power grid sector. Then, this is operationalized through subclasses representing the evaluation of specific construction processes, enabling granular assessment of mechanization levels across different stages of a power grid project’s execution.
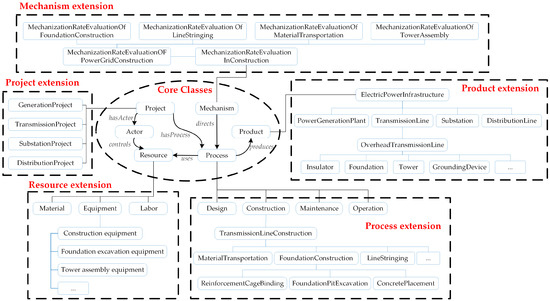
Figure 2.
The ontology model for mechanized construction in power grid projects.
The PGCOntology model also defines object properties and data properties, as summarized in Table 1 and Table 2.

Table 1.
Object properties defined in the ontology.
Table 2.
Data properties defined in the ontology.
Six key object properties are specified: produces, hasActor, controls, directs, hasProcess, and uses. Using these object properties, the semantics underlying PGCOntology are defined as: the Project class is connected to the Process class by the hasProcess property, and the Process class is linked to the Product class by produces; consequently, since project execution hinges on actors that control and coordinate resources, the Project class associates with the Actor class, which holds the controls property over the Resource class, and the Process class uses these resources; finally, the Mechanism class directs the Process class to reflect the constraints imposed by relevant regulations and technical standards on construction activities.
The data properties within the ontology model encompass several key categories, including project parameters, which define the essential technical characteristics of power-grid projects such as geological condition and number of towers; design parameters, which specify the critical design specifications of electrical infrastructure products like foundation type; road parameters, which describe the technical attributes of temporary access roads including width, construction method to support logistical planning; equipment parameters, which detail the operational specifications of construction machinery such as model and chassis type; and mechanization evaluation parameters, which capture the essential elements of the evaluation mechanism. According to the evaluation criteria outlined in the guidelines, the mechanization evaluation parameter comprises evaluation weight, evaluation content, and evaluation score. The evaluation weight attribute specifies the weighting coefficients for mechanization scores during the construction process phase. The evaluation content attribute defines the criteria for mechanization assessment, with its sub-properties further categorized into evaluation content for high-level mechanization, evaluation content for low-level mechanization, and evaluation content for innovative mechanization—the latter referring to the utilization of novel mechanized equipment. These sub-properties represent the evaluation benchmarks under varying degrees of mechanization. The evaluation score attribute describes the mechanization scores at the project, construction process, and work task levels. For the mechanization scoring at the work task level, it can be further extended into two sub-properties: basic points and bonus points. The basic points is derived from the evaluation of mechanization level (high or low), while the assessment of innovative mechanization level grants bonus points.
3.2. LLM-Based Data Conversion and Integration
The practical implementation of the proposed assessment framework necessitates the processing of diverse and heterogeneous data commonly encountered in power grid mechanization projects. To address this challenge, a structured LLM-based data conversion and integration pipeline is established, as illustrated in Figure 3. This pipeline transforms raw, multi-source inputs—including textual descriptions, tables, and images—into structured RDF data that conforms to the PGCOntology through a controlled, semantics-aware procedure. The conversion is guided by a carefully engineered LLM prompt and an enhanced semantic knowledge base, which together ensure the reliability and consistency of the automated transformation process.
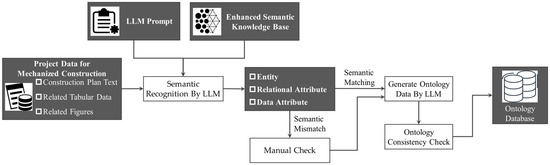
Figure 3.
Semantic data conversion process based on LLM.
The workflow begins with semantic recognition and matching. Under the guidance of the prompt and the knowledge base, the LLM analyzes the input data to identify relevant entities, attributes, and relationships. If the extracted information aligns semantically with the knowledge base, the data proceeds to the next stage. Any discrepancies, ambiguities, or concepts not covered in the knowledge base trigger a “Requires Manual Check” flag, thereby preventing erroneous automated processing and maintaining the integrity of the output. Data that passes this semantic validation is then mapped by the LLM into the predefined ontological structure, generating corresponding RDF triples that instantiate the PGCOntology. Following the LLM-driven conversion, the generated RDF data undergoes formal ontology consistency checking. This step ensures that the instantiated data adheres to the logical constraints defined in the PGCOntology, such as class disjointness, property domains and ranges, and cardinality restrictions. Only data that satisfies these consistency requirements persists into the final ontology database, which serves as a unified, high-quality knowledge source for subsequent automated reasoning and scoring modules.
At the core of this workflow lies the careful design of the LLM Prompt and the Enhanced Semantic Knowledge Base. This design aims to constrain the model’s behavior, mitigate hallucination, and ensure deterministic output.
To ensure that the behavior of the LLM remains delimited within a predefined operational boundary, this study adopts the widely used structured prompting framework known as RTF (Role–Task–Format) [61]. Specifically, the prompt is designed around three core components—role constraint, task definition, and processing steps—as illustrated in Table 3. Role-based prompting has been demonstrated to enhance task adherence and output consistency [62]. In line with this, the role constraint explicitly defines the model as a deterministic data conversion engine. Given the complexity of the task, both the task definition and processing steps serve to further confine the model’s behavior within the intended scope. The task definition stipulates that the LLM’s sole objective is to populate a predefined ontology structure strictly based on the provided “Input Data” and the “Enhanced Semantic Knowledge Base.” The model is explicitly instructed to ground all outputs in evidence derived from these sources and is prohibited from extrapolating, inferring, or generating content based on its internal parametric knowledge. The processing steps are organized into three sequential phases: (1) Semantic Analysis—identifying entities, relations, and attributes from raw data by referencing the enhanced semantic knowledge base; (2) Judgment—verifying whether the recognized elements align semantically with the PGCOntology; if alignment is confirmed, the process proceeds; otherwise, the data is flagged for “Manual Check”; and (3) Ontology Data Generation—mapping the validated information to the corresponding classes and properties of the PGCOntology, and outputting the results as RDF triples (RDF triple is a restriction on the output format). This systematic and structured approach to prompt design enhances the reproducibility and reliability of the data conversion process.
Table 3.
The structure of LLM prompts.
The enhanced semantic knowledge base plays an equally crucial role by providing essential domain grounding for the LLM. It integrates two complementary components: a standardized terminology dictionary containing canonical terms and their mappings to ontological constructs, and the PGCOntology itself, which supplies the formal schema for data representation. The terminology dictionary is constructed in accordance with the requirements of this study—namely, the transformation of heterogeneous data into ontology-conforming representations with consistent semantics. It is systematically structured into four components: Standard Terminology, Common Expressions, Description, and Subordinate Concept of PGCOntology. The linkage between standard terminology and common expressions serves to harmonize heterogeneous knowledge and linguistic variants into a unified and standardized terminological form. The relationship between standard terminology and its corresponding subordinate concept within the PGCOntology aligns these unified terms with the ontological semantics—a crucial mechanism for guiding the LLM in transforming multi-source data into ontology-conforming representations. The Description component provides explanatory definitions for each standard term, further enhancing clarity and interpretability. Partial examples of the terminology dictionary are illustrated in Table 4. Collectively, these components significantly reduce lexical and conceptual ambiguity, enabling the LLM to generate semantically consistent interpretations of raw input data.
Table 4.
The example of terminology dictionary.
To demonstrate the operational mechanism of the LLM-based conversion pipeline, a concrete example is presented using the textual description: “A crane with a load capacity of 50 tons is used for hoisting steel structures”. The conversion workflow for this data is exemplified in Figure 4.
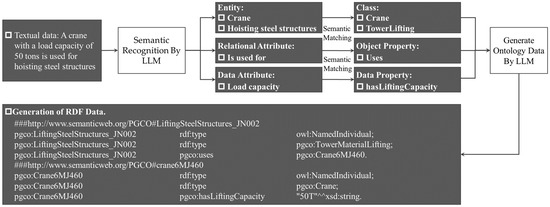
Figure 4.
An example of data transformation based on LLM.
Upon receiving this input, the LLM, guided by the structured prompt, first performs semantic recognition. It identifies key entities such as “crane” and “hoisting steel structures,” extracts the relational phrase “is used for” indicating a usage relationship, and recognizes “load capacity” as a numerical attribute associated with the crane. The LLM then references the Enhanced Semantic Knowledge Base for semantic validation and mapping. The term “crane” is matched to the standardized concept Crane in the terminology dictionary, while “hoisting steel structures” is aligned with the predefined activity TowerLifting. The attribute “load capacity” is mapped to the ontology property hasLiftingCapacity. All identified elements conform to the knowledge base, allowing the process to proceed to the data generation stage. Subsequently, the LLM performs ontology-aware instantiation. It maps the recognized concepts to corresponding classes and properties within the PGCOntology framework. For instance: The activity “hoisting steel structures” is instantiated as an individual of the class TowerLifting, with a generated instance identifier (LiftingSteelStructures_JN002); The equipment “crane” is instantiated as an individual of the class Crane (Crane6MJ460); The relationship “is used for” is formalized using the object property uses, resulting in the triple-“LiftingSteelStructures_JN002—uses → Crane6MJ460”. The data property hasLiftingCapacity is assigned with the value ‘50 t’, yielding the triple-“Crane6MJ460—hasLiftingCapacity → ‘50 t’”. Finally, the generated RDF triples undergo consistency checking against the PGCOntology to ensure compliance with domain and range constraints, as well as datatype validity. Once validated, the instance data is stored in the ontology database, thereby enriching the structured knowledge repository available for subsequent reasoning and evaluation modules.
This example illustrates how the pipeline transforms a fragment of unstructured textual description into formal, semantically grounded, and machine-actionable knowledge, highlighting the role of prompt-guided LLM processing and ontology-based mapping in achieving reliable data integration.
3.3. Compilation of Evaluation Rules Using SWRL
This section elaborates on the formalization of mechanization scoring logic using semantic rule languages, which involves transforming specified quantitative evaluation criteria for mechanized construction into a set of machine-executable SWRL rules. This process requires the deconstruction of mechanization evaluation logic and a detailed analysis of its underlying mechanisms and specific procedures. During the formalization of scoring rules, the derived mechanisms and procedural steps of mechanization evaluation are systematically translated into corresponding SWRL rules.
Through the structural analysis of mechanized evaluation logic, it can be understood that the evaluation of mechanized construction applications in power grid projects is a comprehensive process that assesses the actual utilization of mechanical equipment across various construction stages or processes. Specifically, the quantitative evaluation mechanism for mechanized construction entails three components: the scientific breakdown of construction procedures, the allocation of mechanization weights to construction processes, and the scoring procedure for work tasks.
The scientific breakdown of construction procedures applies the principles of Work Breakdown Structure (WBS) to decompose the entire power grid construction project into manageable construction processes and well-defined work tasks. This decomposition allows each major process to be treated as an independent statistical unit for subsequent analysis, thereby establishing a clear hierarchical framework for evaluation. The allocation of mechanization weights is based on a comprehensive analysis—including technical requirements, operational complexity, risk levels, and overall impacts on project schedule, quality, and safety—to assign a relative degree of importance to each construction process and work task. Following this principle, the mechanization level of each project and construction process is determined by the mechanization evaluation scores and corresponding weights of its subordinate works. The scoring procedure for work tasks within the mechanization assessment mechanism adopts a dual-factor approach, comprising a basic score out of 100 points and a bonus score of up to 10 points. The basic score is further differentiated, with specific evaluation criteria designed for scenarios of both high and low mechanization rates, ensuring appropriateness across varying operational conditions. The bonus score is exclusively awarded for the utilization of innovative machinery or advanced equipment within the work task, serving as an incentive for technological adoption. It is explicitly stipulated that the total score for any work task, combining basic score and bonus score, shall not exceed the ceiling of 100 points, maintaining assessment consistency and fairness across the project.
Based on the analysis of the logical structure of the mechanization assessment, the degree of mechanization in power grid construction is evaluated across three hierarchical levels: project level, construction process level, and work task level. The mechanization assessment rules are summarized in Table 5.
Table 5.
The mechanization assessment rules.
The mechanization score at the project level is derived from the sum of the mechanization scores of all construction processes. The mechanization score of each construction process is calculated by multiplying the mechanization score of each subordinate work task by its corresponding weight, followed by summation. The mechanization score of a work task consists of basic score and bonus score. The basic score is determined by taking the higher value between the high mechanization score and the low mechanization score, while the high mechanization score, low mechanization score, and bonus score are assigned in accordance with the detailed mechanization assessment specifications.
Upon clarifying the quantitative scoring mechanism for mechanized construction, this framework is subsequently translated into computer-readable and interpretable rules using the SWRL rule language. It should be noted that SWRL rules follow the if-then logical paradigm, and their condition statements primarily support the built-in logical connective of conjunction (AND). Consequently, more complex logical expressions, such as those involving disjunction (OR) or negation, cannot be directly represented within a single rule. To address this limitation, such expressions must be logically transformed into conjunctive forms or expressed through multiple complementary SWRL rules. Furthermore, to enhance the maintainability and reusability of SWRL rules, this study employs a rule repository for the unified storage of compiled rules. The repository organizes rules through multi-dimensional classification based on activity level (including project level, construction process level, and work task level), scoring type (including scoring rules for high-level mechanization, scoring rules for low-level mechanization, bonus point scoring rules, basic point scoring rules, and mechanization scoring rules), and rule identifiers, thereby enabling structured organization and efficient retrieval. Furthermore, each rule is accompanied by clear descriptive information that outlines its applicable scenarios and computational logic, supporting intuitive understanding, flexible invocation, and ongoing maintenance by users.
Taking overhead transmission line projects as an example, this paper employs SWRL to transform the quantitative scoring mechanism for mechanized construction into computer-readable inference rules. Rule compilation adheres to the hierarchical scoring structure of the evaluation framework, spanning across the project level, construction process level, and work task level. The overhead transmission line project comprises four construction processes and eleven work tasks, with its detailed work breakdown structure presented in Table 6.
Table 6.
The work breakdown structure of overhead transmission line projects.
For each hierarchical level of construction activity, corresponding SWRL rules are formulated based on the computational logic outlined in Table 5. The examples of SWRL rules for mechanization assessment at the project, construction process, and work task levels of overhead transmission line projects are provided in Table 7.
Table 7.
Example SWRL rules for evaluation.
At the project level, the mechanization score of the entire project is calculated as the sum of the scores of its subordinate construction processes. The rule “MR-MaterialTransportation(?evaulate1)^evaluationScore(?score1)” retrieves the score data for the material transportation process, while “swrlb:groupAdd(?score, ?score1, ?score2, ?score3, ?score4)” aggregates the mechanization scores of all construction processes, assigning the total to the project’s mechanization score.
At the construction process level, taking foundation construction as an example, the mechanization score for foundation construction is derived by summing the weighted mechanization scores of its subordinate work tasks. The rule “MR-FoundationPitExcavation(?evaulate1)^evaluationScore(?score1)” retrieves the score data for the foundation pit excavation task. The statement swrlb:multiply(?scoreA, ?score1, 0.2) multiplies this task score by its assigned weight. The same retrieval and weighting process is applied to the other work tasks, such as reinforcement cage binding and concrete pouring. Subsequently, the expression swrlb:groupAdd(?score, ?scoreA, ?scoreB, ?scoreC) aggregates the weighted scores of each work task. The resulting total is then assigned as the mechanization score for the foundation construction process.
At the task level, taking the basic score of high-level mechanization calculation rule for foundation pit excavation as an example. The statement “MR-FoundationPitExcavation(?evaluate)^EvaluationContent-ForHighLevelMechanization(?evaluate, ?text)” retrieves the evaluation specification related to high-level mechanization associated with the foundation pit excavation activity. The expression “directs(?evaluate, ?activity)^uses(?activity, ?machine)^type(?machine, ?type)” identifies the type of machinery employed in the foundation pit excavation activity. The clause “swrlb:contains(?text, ?type)” checks whether the equipment type used in the foundation pit excavation matches the equipment type specified in the evaluation specification. If a match is successfully identified, a score of 100 or 80 is assigned accordingly.
The evaluation procedure for mechanization in overhead transmission line construction begins at the work task level, with the assessed scores then multiplied by their respective weights and aggregated to the corresponding construction process level. Finally, the mechanization score at the project level is derived from the sum of the mechanization scores of all construction processes. The sequential scoring order for mechanization assessment is as follows:
- (1)
- Execute Rules C1.1.1, C1.1.2, and C1.1.3 to assign the high/low-level mechanization point;
- (2)
- Execute Rule C2.1.1 and C2.1.2 to assign the basic score;
- (3)
- Execute Rule C3.1.1 to assign the bonus score;
- (4)
- Execute Rule C4.1.1 and S4.1.2 to compute the mechanization score for the work task;
- (5)
- Execute Rule B1.1 to compute the mechanization score for the construction process; and
- (6)
- Execute Rule A1.1 to compute the mechanization score for the project.
As previously described, the codification of mechanization assessment rules establishes the foundation for automated evaluation. The same principles and procedures can also be applied to formulate mechanization assessment rules for other types of power grid construction projects, such as substation engineering and cable engineering, though these are not elaborated here for brevity.
This rule compilation enables the reasoning engine to automatically perform quantitative evaluations of mechanized construction applications in power grid projects. Built on a rigorous logical foundation, SWRL excels in expressing explicit cause–effect relationships between premises and conclusions. This capability allows developers to formalize complex business logic, domain knowledge, and commonsense reasoning into structured rules, thereby endowing intelligent systems with robust, transparent, and explainable reasoning capabilities.
3.4. Hybrid Reasoning for Score Assessment and Reporting
The automatic generation of mechanization scores and reports relies on a hybrid reasoning framework that combines ontological reasoning and LLM-based reasoning. In this framework, ontological reasoning takes the ontology model and data as inputs, triggers the mechanized construction scoring rules, computes the scores for each construction process and work task, and stores the results in the form of triples. LLM-based reasoning is then responsible for converting these triple-based outputs from ontological reasoning into highly readable mechanization evaluation reports for use by relevant management personnel.
During the process of ontological reasoning, three core components are fed into a semantic reasoner: PGCOntology, which provides the conceptual model and relational constraints for the domain; the instantiated multi-source data in RDF, which encapsulates the factual information of a specific power grid project; and the compiled SWRL rule sets, which encode the scoring logic for evaluating mechanized construction applications. When the individuals and their properties within the RDF data satisfy the antecedent of a particular SWRL rule, the rule is triggered. The reasoner then executes the operation defined in the rule’s consequent, such as calculating a mechanization score for a specific work task, and asserts this newly inferred result back into the knowledge base (RDF triple store). Upon the completion of the reasoning process, all results (e.g., various scores) are stored within the knowledge base as new property values or individuals. The SPARQL query language is subsequently employed to precisely retrieve the scoring results from the knowledge base. For example, the following SPARQL query is designed to retrieve the mechanization score of the foundation excavation work task.
| PREFIX rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns# PREFIX owl: http://www.w3.org/2002/07/owl# PREFlX rdfs: http://www.w3.org/2000/01/rdf-schema# PREFIX xsd: http://www.w3.org/2001/XMLSchema# PREFIX MPCOntology:<http://www.semanticweb.org/admin/MPCOntology#> SELECT ?work_task ?mechanization_score WHERE { ?work_task a “FoundationExcavation”. ?evaluation MPCOntology:directs ?work_task. ?evaluation MPCOntology:evaluationScore ? mechanization_score. } |
This query is positioned at the foundation excavation entity within the construction process, then links to the mechanized evaluation entity used to guide the work task based on the “directs” property, and subsequently reads its mechanized score through the “evaluationScore” property. Thus, the data retrieval process is completed.
Noting that the direct output of SPARQL queries is typically presented as a data list with poor readability and fails to intuitively convey the scoring logic, weight distribution, and relationships among the individual points for assessing the final score, this presents a significant barrier to analysis and comprehension for end-users, such as project managers, who may lack specialized technical expertise. Consequently, a higher-level intelligent layer is required to transform this data into an interpretable report.
During the LLM reasoning process, the LLM functions as a post-processing and semantic interpretation layer, thereby enhancing the interpretability and practical utility of the evaluation results. In this layer, the SPARQL query results from the knowledge base are combined with relevant mandatory and recommended standards for construction mechanization, forming semantically structured prompts that are input into the LLM. It is important to emphasize that the core function of the LLM in this layer is not to perform numerical calculations (a task already handled by the underlying ontological reasoning mechanism), but rather to conduct deep semantic understanding, logical alignment, and explanatory reasoning. Specifically, the model automatically identifies and matches the relationships between each specific sub-clause in the scoring criteria and the corresponding data, thereby systematically elucidating the logical basis and decision-making process behind each scoring result, and producing semantically clear and well-structured output. The reasoning capability of the LLM heavily relies on systematic and structured prompt engineering.
In this study, an LLM prompt engineering process is developed in Python (version 3.10.9) for the intelligent evaluation of mechanized applications in power grid construction, as shown in Figure 5. This LLM prompt engineering consists of two core modules—the RDF data parsing module and the LLM instruction module—and encompasses five key sequential steps: (1) RDF data parsing, (2) mechanization score analysis, (3) recommendation generation, (4) report template setting, and (5) specification referencing. First, the RDF data parsing module is responsible for semantically parsing and converting RDF triples inferred via ontological reasoning into natural language. This module addresses the LLM’s inherent difficulty in directly interpreting structured RDF data and provides high-quality input for subsequent processing. Subsequently, the LLM instruction module integrates three key parameters—the parsed RDF data files, a library of relevant standard texts, and a predefined report output template—to construct a semantically clear and task-specific structured instruction system. Specifically, the mechanization score analysis step evaluates the mechanization level across three dimensions: the overall project level, the construction process level, and the work task level. This step employs explicit threshold criteria; for example, if the total mechanization score of a project exceeds 90 points, the system automatically classifies the mechanization level as “Excellent.” The recommendation generation step produces targeted suggestions or compliance confirmations based on both mandatory and recommended requirements from the standard texts and the score-based level determinations from the previous step. For instance, if the standard stipulates that the total mechanization rate for power grid construction must not fall below 75%, and the project achieves a rate of 87%, the system generates a confirmation statement: “The total mechanization rate meets the standard requirements”. The report template setting step standardizes the overall structure, paragraph organization, and key content of the reasoning report generated by the LLM through a predefined structured output format, ensuring consistency in style and logical clarity. The specification referencing automatically identifies and cites the specific standard clauses and their sources referenced by the LLM during the reasoning process. This enhances the traceability, interpretative transparency, and authority of the reported results.

Figure 5.
LLM prompt engineering process for intelligent evaluation of mechanized applications.
Finally, within the Python environment, the LLM inference engine can be invoked along with the aforementioned LLM prompt engineering framework to generate a comprehensive reasoning report. This report includes the following key sections: a title, analysis of the overall mechanization level and total mechanization score of the project, analysis and scoring of mechanization levels across different construction processes, evaluation of mechanization levels and scores for specific work tasks, and overall recommendations. A representative example of the generated reasoning report is illustrated in the accompanying Figure 6.

Figure 6.
An example of an inference report based on LLM.
4. Application Case Illustration
4.1. Case Description
This study utilizes a dataset of 126 overhead transmission line projects, serving as a robust empirical basis for validating the proposed ontology-driven and LLM-integrated assessment framework. The dataset consists of 87 high-voltage projects (35 kV–220 kV) and 39 extra-high-voltage projects (330 kV–750 kV). For each project, detailed construction plans were manually analyzed to extract relevant mechanization-related information. These plans systematically describe the construction sequences, work tasks, applied technologies, types and specifications of machinery, personnel assignments, and scheduling details. The extracted data—including project metadata, involved construction processes, work tasks, and associated mechanical equipment—were organized into structured tables, as exemplified in Table 8.
Table 8.
Example of construction equipment deployment.
This empirical dataset provides foundational input for applying and validating the proposed ontology and LLM-integrated assessment framework. By aligning real-world construction data with the semantic knowledge framework, it enables rigorous, data-driven evaluation of mechanization levels and operational efficiency across diverse practical scenarios, thereby supporting assessment in real-world construction environments.
4.2. Application Demonstration
To facilitate the automated assessment of the mechanization rate in power grid construction, this paper has developed the Power Grid Mechanization Rate Evaluation System. Its core backend logic is developed primarily in Python, handling tasks such as ontology processing and integration with LLM APIs. The ontological reasoning module is built upon the Protégé-OWL API to execute the formalized SWRL rules. The key graphical user interfaces of the system are illustrated in Figure 7, offering users an intuitive and interactive platform for evaluating the Mechanization Rate.
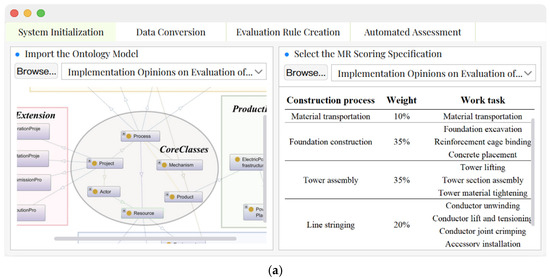
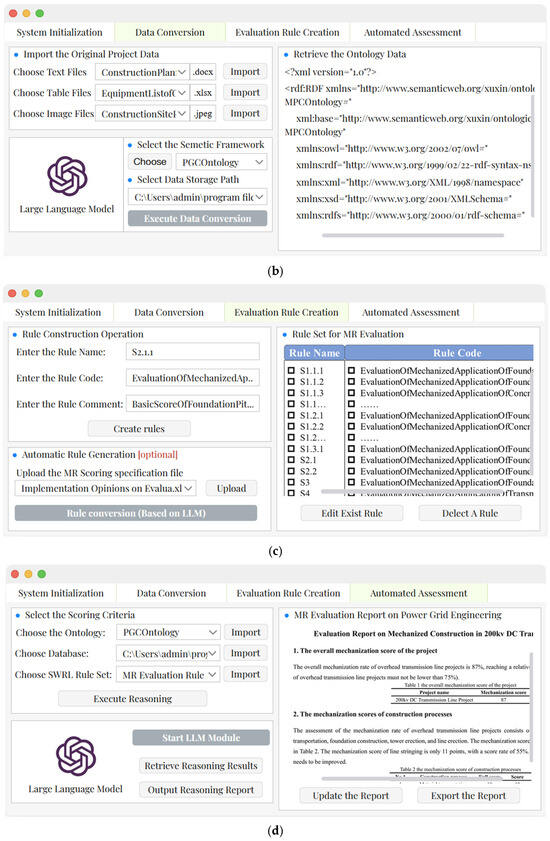
Figure 7.
The key graphical user interfaces of the system: (a) the system initialization interface; (b) the interface for data transformation; (c) the interface for rule construction; (d) the interface for mechanization rate automated scoring.
Figure 7a presents the System Initialization interface, which serves as the initialization stage for the assessment workflow. Its first function allows users to import the pre-designed PGCOntology from Section 3, establishing the essential semantic foundation for subsequent data conversion and reasoning processes. Upon import, a graphical view of the ontology model is rendered, enabling users to visualize its hierarchical structure and relationships. The second function facilitates the import of the official mechanization rate scoring specifications. The system parses these documents and presents the scoring mechanisms in a structured format, providing a clear reference for the rules that will be formalized later.
The Data Conversion interface, illustrated in Figure 7b, is dedicated to transforming heterogeneous project data into a semantically consistent knowledge base. Users begin by inputting the raw data to be converted, which can be in various formats including text, structured tables, and image files. A critical step involves selecting the imported PGCOntology to serve as the semantic framework that guides the LLM during the conversion process. After specifying an output path for the converted data, users can initiate the LLM, which processes the multi-source inputs to generate instances (individuals) and properties that conform to the ontology. The successfully converted ontological data is then displayed in a panel on the right-hand side for user review and validation.
Figure 7c showcases the mechanization rate Evaluation Rule Creation interface, which supports the formalization of scoring logic. This interface offers dual modalities for creating SWRL rules. For manual creation, users can input a rule name, the actual SWRL code, and a natural language description. Alternatively, the automatic creation feature enables users to upload the scoring specification document directly to an LLM. The LLM then performs the rule transformation, generating the corresponding SWRL rules based on the textual guidelines. The right panel of the interface displays the current rule set, allowing users to view, edit, or delete specific rules as needed.
Finally, the mechanization rate of the Automated Assessment interface, shown in Figure 7d, executes the core reasoning and reporting pipeline. Users must first load the required inputs: the PGCOntology, the instantiated ontological data, and the SWRL rule set. Upon clicking the “Execute Reasoning” button, these components are processed by the underlying reasoning engine. The engine applies the rules to the data, inferring preliminary scores. However, these raw results are often unstructured and not readily interpretable. To address this, the interface provides an option to activate the LLM engine. The LLM processes the inference results, contextualizing them against the scoring specifications to generate a structured and comprehensive assessment report. This final report, which is clear and user-friendly, can be viewed and exported from the right-hand panel, delivering actionable insights to end-users such as project managers and engineers. Figure 8 displays the mechanized evaluation report inferred by the system in the context of the case study of this research.
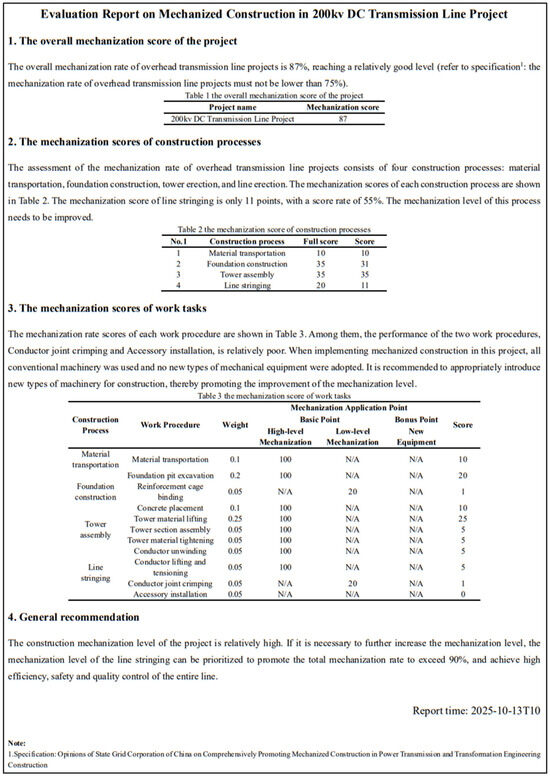
Figure 8.
The example of the mechanization rate evaluation report inferenced by LLM.
4.3. Evaluation of the System Feasibility and Accuracy
To rigorously validate the automated assessment methodology for construction mechanization proposed in this study, along with the developed Power Grid Mechanization Rate Evaluation System, a comprehensive evaluation was conducted focusing on two critical aspects: (1) the feasibility of the methodological framework embedded in the system—specifically, whether its automated processes rigorously and accurately adhere to the requirements stipulated in official normative documents; and (2) the accuracy of its evaluation outcomes, benchmarked against assessments rendered by human experts.
The feasibility of the system is fundamentally determined by its ability to correctly operationalize the official mechanization rate assessment mechanism. To verify this, a structured, clause-by-clause comparative analysis was performed between the SWRL rule set and the source normative documents (e.g., national standards or industry guidelines). This process involved mapping each article, clause, and calculation formula from the textual documents to a corresponding SWRL rule within the system. The evaluation confirmed that the entire scoring workflow, from low-level work tasks to the project-level composite mechanization rate score, was correctly implemented, thereby establishing the system’s strong conformance and feasibility.
The accuracy of the proposed system was evaluated using a comprehensive dataset of 126 overhead transmission line projects. For each project, the system processed detailed input data—including equipment deployment, task sequencing, and resource allocation down to the work task level—to generate an overall mechanization rate score. These automatically computed scores were then rigorously compared against corresponding scores obtained from independent expert assessments.
The comparative analysis revealed inconsistencies in 5 out of the 126 cases. As detailed in Table 9, all observed discrepancies were specifically related to the allocation of bonus points. The underlying cause was identified as a discrepancy between real-world technological advancements and the scope of the existing normative documents. Specifically, continuous innovations in construction machinery and equipment have introduced new types of assets that are not explicitly covered in the current evaluation guidelines.
Table 9.
The mechanized assessment result comparison.
For instance, during the tower assembly phase, the evaluation guideline specifies that bonus points for the “tower material hoisting” task are awarded if “novel tower cranes or monitoring systems are used.” In project “XC0035,” a crawler-type intelligent tower assembly device—a newer technology—was deployed. While the expert assessment awarded bonus points based on professional judgment recognizing this innovation, the rule-based system did not, as this specific equipment type was not enumerated in the formal evaluation specifications.
The results indicate a system accuracy of 121/126 (approximately 96.0%). This demonstrates the system’s high reliability in operationalizing established evaluation standards. The observed inaccuracies are attributable not to a flaw in the system’s reasoning logic, but to a limitation in the scope of the formal rules upon which it is based. The findings underscore a key challenge in automated assessment systems: their dependency on up-to-date and exhaustive formal knowledge sources.
To further enhance accuracy, approaches for real-time updates to the system’s evaluation specifications remain to be explored. Such a mechanism would facilitate the seamless integration of new machinery types and revised scoring criteria, ensuring that the system stays aligned with technological advancements and sustains high accuracy over the long term.
5. Discussion and Conclusions
5.1. Discussion
Accurately assessing the level of mechanization is crucial for guiding strategic planning in technology adoption and operational improvement within the power grid construction industry. This discussion focuses on three interrelated themes central to advancing the field: semantic standardization in power grid mechanized construction through ontology; an ontology- and LLM-based methodology for mechanization assessment, and the transferability of this methodology to other construction domains.
The use of ontology establishes a formal semantic foundation for knowledge sharing, reuse, and automated reasoning. While prior research has developed domain ontologies for construction planning automation [27], this study extends such efforts by creating the PGCOntology, which formally represents knowledge specific to power grid mechanization. Furthermore, the mechanization assessment methodology published by the electric power infrastructure industry has been analyzed and translated into computer-executable SWRL rules, thereby encoding assessment logic into a machine-interpretable format. This semantic structuring transforms mechanization evaluation into a standardized and automated process. Beyond assessment, the ontological approach is inherently extensible, capable of integrating with complementary digital tools such as BIM and IoT [18,19]. For example, ontology-based semantic alignment can link domain knowledge with BIM components or real-time sensor data, supporting dynamic, data-driven decision-making and fostering a more integrated intelligent construction ecosystem.
Building on this semantic foundation, the methodology integrates an LLM to enable automated and interpretable assessment. The LLM contributes critically in two phases: multi-source data conversion and report generation. During data conversion, the LLM operates under the guidance of a structured prompt and an Enhanced Semantic Knowledge Base—comprising the PGCOntology and a domain-specific terminology glossary—which effectively constrains the model’s outputs and mitigates the risk of hallucination. In report generation, the LLM transforms the formal RDF outputs from ontological reasoning into coherent narrative reports, significantly enhancing the accessibility and practical utility of assessment results. This hybrid approach, which combines rigorous semantic reasoning with flexible natural language generation, represents a meaningful step toward intelligent, scalable, and explainable evaluation systems in construction.
The proposed methodology exhibits strong potential for replication and adaptation in other construction domains, and its general application framework is illustrated in Figure 9. At a micro-level, the core logic of formalizing assessment criteria into ontologies and executable rules can be directly applied to evaluate mechanization in domains such as highway engineering and tunnel construction. The processes of defining domain-specific classes (equipment, activities), properties, and scoring rules are fundamentally similar. On a macro-level, the overarching paradigm of combining a formal knowledge base (ontology) with a flexible language model (LLM) for automated interpretation and assessment has broader applicability. This framework could be adapted for other critical construction management tasks, such as safety risk assessment, environmental impact evaluation, or schedule compliance analysis. In each case, industry standards and expert knowledge would first be formalized into a domain ontology and a set of rules. LLM could then be employed to parse unstructured project data (reports, logs, sensor summaries) against this knowledge base, enabling automated, consistent, and auditable evaluations. The key to successful transfer lies in the careful development of the domain-specific ontology and the curated knowledge base that anchors the LLM, ensuring the system’s reliability and relevance to the new context.
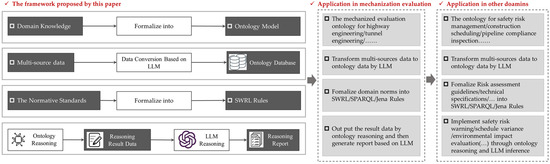
Figure 9.
The general application framework of proposed framework.
However, the broader application of such ontology-based methods faces notable challenges, particularly concerning the translation of industry evaluation standards into formal semantic rules. This process is inherently constrained by the expressive limitations of existing rule languages. For example, while the SWRL employed in this study effectively handles conjunctive (“and”) logic, its capacity to represent disjunctive (“or”) or negational (“not”) conditions—which are frequently encountered in complex evaluation scenarios—remains restricted. Consequently, rule formulation often demands restructuring or the incorporation of supplementary reasoning layers, thereby increasing both conceptual and technical complexity. Furthermore, semantic reasoning capabilities often fall short in supporting multidimensional analysis within intricate, real-world contexts. Practical assessments typically involve nuanced relationships—such as temporal dependencies, spatial interactions, or fuzzy constraints—that extend beyond the scope of SWRL’s limited set of built-in functions. To address such advanced analytical requirements, extending SWRL’s function library or coupling it with external computational modules becomes necessary, which may in turn affect the flexibility, scalability, and maintainability of the overall approach. To facilitate the broader adoption of this method, future work should focus on enhancing the expressive power of rule languages and exploring integration with more advanced computational engines or hybrid reasoning architectures. Such improvements would strengthen the system’s applicability and robustness in complex and dynamic environments.
5.2. Conclusions
This study introduces a novel framework that integrates ontology with LLM to automate the assessment of mechanization rates in power grid construction, addressing semantic heterogeneity and data diversity in project documentation.
The main contributions of this work are fourfold. First, we constructed the PGCOntology, which provides a unified semantic framework and standardized vocabulary for the domain of power grid mechanized construction. Second, we introduced LLM to intelligently interpret and convert multi-source, heterogeneous project data. This conversion is guided by a structured prompt and an Enhanced Semantic Knowledge Base—comprising the PGCOntology and a domain-specific terminology glossary—resulting in structured ontological instance data while minimizing hallucination risks. Third, we formalized the assessment logic of the current industry standards by encoding the mechanization evaluation mechanism into machine-readable and executable SWRL rules based on the PGCOntology, enabling automated logical reasoning and score computation through an ontological reasoner. Finally, the LLM was leveraged to post-process the formal RDF outputs generated by the reasoner, transforming them into comprehensive and intelligible natural language assessment reports.
The proposed methodology was validated through the development of a prototype assessment system. Its effectiveness was confirmed by aligning the SWRL rule set with official normative documents, ensuring logical consistency. Accuracy was evaluated using 126 real-world cases, achieving a 96.0% agreement rate with expert assessments. Discrepancies were primarily due to novel machinery not yet covered in existing guidelines, highlighting the need for mechanisms to dynamically update evaluation standards in response to technological innovation.
In summary, this research demonstrates how the integration of formal ontologies and LLM can enable robust, scalable, and transparent automation of domain-specific evaluations. The proposed framework not only advances the state of mechanization assessment in power grid construction but also offers a replicable paradigm for intelligent evaluation systems in other engineering and construction domains.
Author Contributions
Conceptualization, J.C. and X.X.; Methodology, J.C., J.L. and J.Z.; Formal analysis, J.C., X.X. and J.L.; validation, Y.G., J.G. and Z.D.; Data curation, Y.G., M.Z. and Y.H.; Writing—original draft preparation, J.G., Z.D. and M.Z.; Writing—review and editing, J.Z. and Y.H.; Supervision, X.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (grant number 72401090).
Data Availability Statement
The data used in this study are not publicly available due to confidentiality and privacy reasons but are available from the corresponding author on reasonable request and subject to necessary permissions.
Acknowledgments
The authors acknowledge the employment of ChatGPT 4.0 (OpenAI, http://openai.com) to aid in detecting and rectifying grammatical inaccuracies, encompassing corrections to spelling, modifier-noun constructions, and third-person verb tense agreement.
Conflicts of Interest
Authors Jun Liu, Mao Zhang and Juncheng Zhu were employed by the company China Construction Second Engineering Bureau Co., Ltd. Author Yunyun Gao was employed by the company Guodian Electric Shuangwei Inner Mongolia Shanghai Temple Energy Co., Ltd. Author Zhuqing Ding was employed by the company Jiangsu Huaiyin Water Conservancy Construction Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Liu, L.; Meng, L.; Liu, J.; Lu, J.; Li, Z.; Zhang, P. Evaluation on the Construction of New Power System of Different Cities. In Proceedings of the 2024 9th International Conference On Power and Renewable Energy; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Ma, Y.; Mao, P. Multiple Benefits Evaluation of Mechanized Construction of 110 kV Transmission Lines. In Proceedings of the 2023 International Conference on Wireless Power Transfer; Springer: Singapore, 2024. [Google Scholar]
- Liu, C.; Tang, G.; Hao, Y.; Peng, F. Study on construction organization measures of transmission line. In Proceedings of the 6th International Conference on Mechatronics, Materials, Biotechnology and Environment (ICMMBE 2016), Yinchuan, China, 13–14 August 2016; Atlantis Press: Dordrecht, The Netherlands, 2016. [Google Scholar]
- Jing, Z.; Zhang, H.; Yang, P. Research on the Optimal Allocation Model of Total Cost for Mechanized Cluster Construction of Transmission Line Engineering. In Proceedings of the 2024 6th Asia Energy and Electrical Engineering Symposium (AEEES); IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Xie, D.; Guo, T.; Zhou, F.; Wu, Y.; Zhuan, X. Optimization of mechanized construction scheme of overhead transmission line based on mechanization rate. In Proceedings of the 2020 39th Chinese Control Conference (CCC); IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Zhou, Y.; Tang, J.; Luo, H.; Liu, H. Analysis on the Impact Factors of Mechanized Construction of Transmission Line Project. In Proceedings of the 2nd International Conference on Engineering Management and Information Science, EMIS 2023, Chengdu, China, 24–26 February 2023. [Google Scholar]
- Zheng, W.; Zhang, Q.; Ding, S.; Jiang, M. Management of Mechanized Construction of Transmission Lines. China Electr. Power Enterp. Manag. 2019, 561, 66–67. [Google Scholar]
- Xun, S. Research on Evaluation Method for Mechanization Rate of Overhead Transmission Line Construction. New Technol. New Prod. China 2017, 23, 79–80. [Google Scholar]
- Hwang, B.G.; Shan, M.; Ong, J.M.; Krishnankutty, P. Mechanization in building construction projects: Assessment and views from the practitioners. Prod. Plan. Control. 2020, 31, 613–628. [Google Scholar] [CrossRef]
- Qiu, X. Research on Mechanical Construction Plan for Main Network Transmission Lines. Rural Electrif. 2024, 11, 107–109. [Google Scholar]
- Gao, X.; Li, Y.; Wang, R.; Sun, J.; Wu, J. Research on Ontology Construction and Intelligent generation of mechanized construction plans for power grid projects. Proj. Manag. Technol. 2025, 23, 111–118. [Google Scholar]
- Waris, M.; Liew, M.S.; Khamidi, M.F.; Idurs, A. Investigating the Awareness of Onsite Mechanization in Malaysian Construction Industry. In Proceedings of the 2014 4th International Symposium on Infrastructure Engineering in Developing Countries (IEDC); Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Mehdi, H.; Reza, M.; Mohammad, A.; Khalokakaei, R.; Akhyani, M. Development a New Classification for Assessing the Coal Mine Mechanization. Arch. Min. Sci. 2013, 58, 217–226. [Google Scholar] [CrossRef]
- Hou, Y.; Zhang, Y.; Liao, J. Performance evaluation of mechanized construction of overhead transmission lines based on FUCOM-F-CM. Eng. Res. Express 2025, 7, 035576. [Google Scholar] [CrossRef]
- Isaak, M.; Yahya, A.; Razif, M.; Mat, N. Mechanization status based on machinery utilization and workers’ workload in sweet corn cultivation in Malaysia. Comput. Electron. Agric. 2020, 169, 105208. [Google Scholar] [CrossRef]
- Ge, Z.; Li, X.; Zhang, Q.; Wan, J.; Jiang, M. Research on the Evaluation Method of Construction Mechanization Rate for Overhead Transmission Line Engineering. Smart Grid 2016, 4, 1252–1256. [Google Scholar]
- Wu, F.; Chen, W.; Chen, L. Innovation and Practice of a Mechanized Construction System Adapting to the Whole Process, Whole Region, and All-round Requirements of New Power Grid Construction. Innov. Manag. Pract. Chin. Electr. Power Enterp. 2025, 410–414. [Google Scholar] [CrossRef]
- Shi, J.; Pan, Z.; Jiang, L.; Zhai, X. An ontology-based methodology to establish city information model of digital twin city by merging BIM, GIS and IoT. Adv. Eng. Inform. 2023, 57, 102114. [Google Scholar] [CrossRef]
- Boje, C.; Guerriero, A.; Kubicki, S.; Rezgui, Y. Towards a semantic Construction Digital Twin: Directions for future research. Autom. Constr. 2020, 114, 103179. [Google Scholar] [CrossRef]
- Song, Y.; Li, W.; Dai, G.; Shang, X. Advancements in Complex Knowledge Graph Question Answering: A Survey. Electronics 2023, 12, 4395. [Google Scholar] [CrossRef]
- Hou, W.; Liu, Q.; Cao, L. Cognitive Aspects-Based Short Text Representation with Named Entity, Concept and Knowledge. Appl. Sci. 2020, 10, 4893. [Google Scholar] [CrossRef]
- Deng, H.; Xu, Y.; Deng, Y.; Lin, J. Transforming knowledge management in the construction industry through information and communications technology: A 15-year review. Autom. Constr. 2022, 142, 104530. [Google Scholar] [CrossRef]
- Farghaly, K.; Soman, R.K.; Zhou, S.A. The evolution of ontology in AEC: A two-decade synthesis, application domains, and future directions. J. Ind. Inf. Integr. 2023, 36, 100519. [Google Scholar] [CrossRef]
- Jiang, S.; Zhang, J.; Shi, J.; Wu, Y. Adaptive information retrieval for enhanced building safety management leveraging BIM. Eng. Constr. Archit. Manag. 2024, 33, 336–360. [Google Scholar] [CrossRef]
- Speiser, K.; Seiss, S.; Boukamp, F.; Melzner, J.; Teizer, J. From fragmented data to unified construction safety knowledge: A process-based ontology framework for safer work. Autom. Constr. 2025, 176, 106293. [Google Scholar] [CrossRef]
- Wu, Z.; Ma, G. Automatic generation of BIM-based construction schedule: Combining an ontology constraint rule and a genetic algorithm. Eng. Constr. Archit. Manag. 2023, 30, 5253–5279. [Google Scholar] [CrossRef]
- Gao, X.; Li, Y.; Wang, R.; Ding, X.; Wang, X.; Xu, X. Ontology-Guided Generation of Mechanized Construction Plan for Power Grid Construction Project. Buildings 2024, 14, 3271. [Google Scholar] [CrossRef]
- Hwang, S.; Jung, S.; Lee, S. Automated inference of context-specific hazards in construction using BIM and Ontology. Autom. Constr. 2025, 177, 106338. [Google Scholar] [CrossRef]
- El-Gohary, N.; El-Diraby, T. Domain Ontology for Processes in Infrastructure and Construction. J. Constr. Eng. Manag. 2010, 136, 730–744. [Google Scholar] [CrossRef]
- Zheng, Y.; Torma, S.; Seppanen, O. A shared ontology suite for digital construction workflow. Autom. Constr. 2021, 132, 103930. [Google Scholar] [CrossRef]
- Doukari, O.; Seck, B.; Greenwood, D. The Creation of Construction Schedules in 4D BIM: A Comparison of Conventional and Automated Approaches. Buildings 2022, 12, 1145. [Google Scholar] [CrossRef]
- Mostafa, M.; El-Gohary, N. Semantic system for stakeholder-conscious infrastructure project planning and design. J. Constr. Eng. Manag. 2015, 141, 04014075. [Google Scholar] [CrossRef]
- Zhang, Z.; Groth, P.; Calixto, I.; Schelter, S. Directions Towards Efficient and Automated Data Wrangling with Large Language Models. In Proceedings of the 40th International Conference on Data Engineering Workshops (ICDEW); IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Shi, D.; Meyer, O.; Oberle, M.; Bauernhansl, T. Dual data mapping with fine-tuned large language models and asset administration shells toward interoperable knowledge representation. Robot. Comput.-Integr. Manuf. 2025, 91, 102837. [Google Scholar] [CrossRef]
- Spyns, P.; Meersman, R.; Jarrar, M. Data modelling versus Ontology engineering. Sigmod Rec. 2002, 31, 12–17. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Lei, G.; Liu, S.; Liang, P. An Enhanced Information Retrieval Method Based on Ontology for Bridge Inspection. Appl. Sci.-Basel 2022, 12, 10599. [Google Scholar] [CrossRef]
- Shi, D.; Gan, S.; Zurada, J.; Guan, J.; Wang, F.; Weichbroth, P. A multi-model approach to construction site safety: Fault trees, Bayesian networks, and ontology reasoning. Expert Syst. Appl. 2025, 288, 127817. [Google Scholar] [CrossRef]
- Du, G. Study on the SWRL Extended Rule with Built-ins Predicate and Applying It to the Ontology Mapping. Master’s Thesis, Sun Yat-sen University, Guang Zhou, China, 2010. [Google Scholar]
- Xu, Y.; Ji, G.; Zhang, S. Research on Spatial Knowledge Representation Method of Underground Pipeline Based on Geo-ontology. J. Nanjing Norm. Univ. 2013, 36, 127–132. [Google Scholar]
- Tavakolan, M.; Mohammadi, S.; Zahraie, B. Construction and resource short-term planning using a BIM-based ontological decision support system. Can. J. Civ. Eng. 2021, 48, 75–88. [Google Scholar] [CrossRef]
- Zhong, B.T.; Ding, L.Y.; Love, P.; Luo, H.B. An ontological approach for technical plan definition and verification in construction. Autom. Constr. 2015, 55, 47–57. [Google Scholar] [CrossRef]
- Ryu, H.; Lee, H.; Park, M. Construction planning method using case-based reasoning. J. Comput. Civ. Eng. 2007, 21, 410–422. [Google Scholar] [CrossRef]
- Han, S.; Wang, M.; Zhang, J.; Li, D.; Duan, J. A Review of Large Language Models: Fundamental Architectures, Key Technological Evolutions, Interdisciplinary Technologies Integration, Optimization and Compression Techniques, Applications, and Challenges. Electronics 2024, 13, 5040. [Google Scholar] [CrossRef]
- Yao, H.; Jian, L.; Zhan, Q. Poison prompt: Backdoor Attack on Prompt-Based Large Language Models. In Proceedings of the 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW 2024), Seoul, South Korea, 14-19 April 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Ma, L.; Zhao, X.; Jiang, R.; Wu, C.; Liao, L.; Yang, Z.; Tan, J. Adopting Large Language Models in the Construction Industry: Drivers, Barriers, and Strategic Implications from China. Buildings 2025, 15, 4296. [Google Scholar] [CrossRef]
- Han, M.; Cao, Z.; Wang, J.; Duan, L.; Wang, J. Enterprise Carbon Emission Analysis and Knowledge Question-Answering System Based on Large Language Models. Comput. Eng. Appl. 2025, 61, 370–382. [Google Scholar]
- Liu, G.; Pan, M.; Ma, Z.; Gu, M.; Yang, L.; Qin, J. Similarity-Based Prompt Construction for Large Language Model in Medical Tasks. In Health Information Processing. Evaluation Track Paper; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Zhang, C.; Lei, X.; Xia, Y.; Sun, L. Automatic bridge inspection database construction through hybrid information extraction and large language models. Dev. Built Environ. 2024, 20, 100549. [Google Scholar] [CrossRef]
- Oral, M.; Alboga, O.; Aydinli, S.; Erdis, E. Usability of large language models for building construction safety risk assessment. Eng. Constr. Archit. Manag. 2025. [Google Scholar] [CrossRef]
- Pu, H.; Yang, X.; Li, J.; Guo, R. AutoRepo: A general framework for multimodal LLM-based automated construction reporting. Expert Syst. Appl. 2024, 255, 124601. [Google Scholar] [CrossRef]
- Xia, Y.; Dittler, D.; Jazdi, N.; Chen, H.; Weyrich, M. LLM Experiments with Simulation: Large Language Model Multi-Agent System for Simulation Model Parametrization in Digital Twins. In Proceedings of the 2024 29th Conference on Emerging Technologies and Factory Automation-ETFA-Annual; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Forth, K.; Borrmann, A. Semantic enrichment for BIM-based building energy performance simulations using semantic textual similarity and fine-tuning multilingual LLM. J. Build. Eng. 2024, 95, 110312. [Google Scholar] [CrossRef]
- Guo, P.; Xue, H.; Ma, J.; Cheng, J. Advancing BIM information retrieval with an LLM-based query-domain-specific language and library code function alignment system. Autom. Constr. 2025, 178, 106374. [Google Scholar] [CrossRef]
- Li, H.; Yang, R.; Xu, S.; Xiao, Y.; Zhao, H. Intelligent Checking Method for Construction Schemes via Fusion of Knowledge Graph and Large Language Models. Buildings 2024, 14, 2502. [Google Scholar] [CrossRef]
- Lee, J.; Jang, K.; Sparkling, A.; Kang, K. Large Language Model–Based Construction Site Management for Severe Weather Preparedness. J. Constr. Eng. Manag. 2026, 152, 04025220. [Google Scholar] [CrossRef]
- Liu, J.; Li, H.; Chai, C.; Chen, K.; Wang, D. A LLM-informed multi-agent AI system for drone-based visual inspection for infrastructure. Adv. Eng. Inform. 2025, 68, 103643. [Google Scholar] [CrossRef]
- Seyed, H.; Zolghadr-Asli, B.; Tenkanen, H.; Madni, K.; Matin, M.; Demir, I.; Ostfeld, A.; Singh, V.; Savic, D. Making waves: A conceptual framework exploring how large language model-based multi-agent systems could reshape water engineering. Water Res. 2026, 291, 125157. [Google Scholar]
- Hazber, M.; Li, R.; Gu, X.; Xu, G.; Li, Y. Semantic SPARQL Query in a Relational Database Based on Ontology Construction. In Proceedings of the 2015 11th International Conference on Semantics; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Varma, S.; Shivam, S.; Roy, S.; Ray, B. A Rule-Based Expert System for Automated Document Editing. In Proceedings of the 20th International Conference on Computing and Information Technology; Springer: Berlin/Heidelberg, Germany, 2024. [Google Scholar]
- Brian, H.; Goh, Y. Ontology for design of active fall protection systems. Autom. Constr. 2017, 82, 138–153. [Google Scholar] [CrossRef]
- Moura, V.; Hadar, P.; Murphy, S.; Moura, L. AI Prompt Engineering for Neurologists and Trainees. Semin. Neurol. 2025. ahead of print. [Google Scholar] [CrossRef] [PubMed]
- Ma, Q.; Peng, W.; Yang, C.; Shen, H.; Koedinger, K.; Wu, T. What Should We Engineer in Prompts? Training Humans in Requirement-Driven LLM Use. Assoc. Comput. Mach. 2025, 34, 1–27. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.