Abstract
Rail-transit hub classification in TOD refers to the categorization of transit stations based on their level of connectivity and ridership and the potential for development around them as part of a Transit-Oriented Development (TOD) strategy. TOD, as an essential concept in developing smart cities and public transportation accessibility, has attracted the focus of many policymakers. To this end, many research projects have been dedicated to classifying the rail-transit stations, although the necessity of integrated models for rail-transit hubs could have been mentioned in previous papers. Therefore, this parametric case study is directed to apply the Node–Place–Ridership–Time (NPRT) model to provide a logical classification model for Chengdu rail-transit hubs at the junctions of high-speed railway and subway stations. Multiple Linear Regression (MLR) provided a series of equations, including the effective parameters of the NPRT model. These equations were then verified by the Artificial Neural Network (ANN) to provide the effect of each node and place values on the integrated ridership of rail-transit hubs in different time periods. The results proved the consistent contribution of the integrated ANN-NPRT-HUB algorithm to the TOD concept for smart cities.
1. Introduction
A rail-transit hub is a transportation center where different modes of rail-based transportation intersect and connect, such as commuter trains, subways, light rail, and high-speed trains. These hubs are designed to facilitate the transfer of passengers and goods between different rail lines and modes of transportation and provide access to other forms of transportation, such as buses, taxis, and bicycles. Rail-transit hubs are typically located in urban areas and are often designed as multi-level structures with multiple platforms, tracks, and concourses. They may also include retail, dining, and other amenities to serve the needs of passengers and visitors. Examples of well-known rail-transit hubs include Grand Central Terminal in New York City, Gare du Nord in Paris, and Shinjuku Station in Tokyo. These hubs are critical transportation network components, providing a convenient and efficient way for people to move within and between cities and regions. Rail transit networks highlight the efficiency of public transportation in reducing air pollution and urban traffic loads, especially in developed cities such as Beijing, Shanghai, Chengdu, and New York [1,2,3].
A smart city is a concept that refers to the integration of technology and data-driven solutions to improve the quality of life, sustainability, and efficiency of urban areas. It uses advanced technologies, such as the Internet of Things (IoT), artificial intelligence (AI), and data analytics, to optimize various aspects of urban living, including transportation, energy, governance, infrastructure, and public services. The classification of railway transportation hubs using ANN, combined with a TOD approach, can help optimize urban transportation, enhance mobility services, improve real-time monitoring and management, and promote sustainable urban development. These elements collectively contribute to the development of smart cities by leveraging technology and data-driven solutions for a better urban living experience.
Critical stations, having the most significant impact on the rail transit network, are essential to smart cities’ transportation accessibility. These influential nodes could create critical areas, including other stations and rail-transit hubs, around themselves to facilitate the highly in-demand ridership destinations. Therefore, an accurate classification method for policymakers and city planners sounds vital to evaluate rail-transit hubs’ efficiency, especially in smart cities where people are encouraged daily to apply public transportation to reach their final destinations.
Transit-Oriented Development (TOD), as an applicable concept for developing smart cities and providing more access to public transportation, has attracted the attention of considerable researchers and municipal governments. TOD approaches supplement the analysis of the node function of the transit hubs, with a focus on the urban context often captured in the idea of place. To date, considerable research works have been conducted to propose station classification methods, such as Node–Place (NP) in 1999 [4], Node–Place–Ridership (NPR) in 2020 [5], and Node–Place–Ridership–Time (NPRT) in 2022 [6]. The NP model proposed by Bertolini provided a simple two-dimensional model for classifying stations with regards to their node and place values. According to this model, each station has five significant classes: Stress, Balance, Dependence, Unbalanced node, and unbalanced place.
Although NP was used for many years, ridership as a critical indicator did not receive any attention in this model. Therefore, Zhejing Cao et al. [5] proposed a new idea of considering ridership and creating a three-dimensional model of NPR. Their proposed model was comparably more accurate than the NP model, but the ridership was considered an independent value that could not prove the precise classification results that Ahad A. Pishro produced in 2022 [6]. Hence, we directed a research project on the effect of time as a critical indication of ridership and proposed a four-dimensional model of NPRT. A comprehensive analysis and comparison between NP, NPR, and NPRT models verified the logically accurate classification results for rail transit stations extracted from the NPRT model. In other words, the ridership is a dependent factor and varies during different time categories over weekdays and weekends [6]. This approach stream aims to enrich the initial NP model with key variables describing hubs and transit stations in their urban context, as an alternative to developing a complete transport model. Inspiration is also taken from the TOD literature with 3Ds and additional parameters [7,8,9]. Although all of the mentioned models have tried to provide classification methods, their focus was on stations and not hubs. An in-depth review of the existing literature showed the importance of having a precise hub rail transit classification method since the previous researchers have not achieved enough progress to propose a four-dimensional model for hubs in smart cities.
Many researchers tried to extend the classification models for a broader scale of rail transit networks by considering the high degree of centrality, betweenness, and topology property indexes while the ridership was neglected [10,11,12]. Zhang et al. [13] investigated the importance of transfer stations in the entire network. Wang et al. [14] applied the participation and z-score coefficient to determine the critical stations of the network in Dublin.
The classification of rail-transit hubs in TOD research is vital for effective planning, land use decision-making, understanding transit demand, promoting equity, and evaluating system performance. It provides a framework for analyzing and addressing the diverse needs of communities and facilitates the creation of sustainable, accessible, and efficient transportation systems. Classifying rail-transit hubs is crucial for understanding their characteristics and functionalities and guiding effective station design and infrastructure development. By categorizing hubs based on size, capacity, connectivity, and accessibility, planners and designers can make informed decisions regarding platform design, pedestrian flow management, parking facilities, and integration with other transportation modes. Additionally, hub classification is vital in determining land use patterns and enabling tailored land use policies and regulations that promote transit-supportive development, including mixed-use developments, higher density, and pedestrian-friendly environments. Understanding transit ridership and demand patterns is facilitated through station and hub classification, allowing researchers to analyze location, connectivity, proximity to residential and commercial areas, and parking availability, providing valuable insights for investment prioritization, resource allocation, and service planning. Moreover, hub classification helps identify disparities in transit access, facilitating efforts to address inequities through station improvements, equitable resource distribution, and targeted investments in underserved areas. Lastly, it supports performance evaluation by comparing metrics such as ridership, efficiency, service quality, and customer satisfaction across hub categories, allowing for benchmarking and targeted interventions to enhance the overall performance of rail transit systems.
This research considered the Chengdu rail transit network as the case study to investigate the NPRT algorithm for classifying the rail-transit hubs and study the correlations between the NPRT effective parameters. The Min–Max normalization method and the integrated NPRT values provided a reliable database for this study. Moreover, an Artificial Neural Network (ANN) was applied to predict and evaluate the results of our proposed NPRT-HUB model. The outcomes of this research aimed to provide new insight into the TOD concept with an exclusive focus on rail transit networks. These results can be implemented by municipal governments, city planners, and policymakers to adapt and improve the efficiency of their rail transit networks.
2. Methodology and Data Acquisition
2.1. Approach
This research is a case study on the Chengdu city rail transit network. Four hub district sizes were identified according to the results of questionnaires and statistical data collected from the riders, residents, and real estate. Each hub includes active rail transit stations which connect the whole district to the hub center. The hubs’ arrangement was assigned according to the counterclockwise direction starting from North. Regarding the statistical data and the questionnaire results, after several trials of integrating the stations’ data and applying the Min–Max normalization method, a 3000 m radius was set as the right active radius for the hubs.
Table 1 presents more details for our case study hubs. The Chengdu rail transit network, including four hubs, is shown in Figure 1.

Table 1.
Chengdu rail-transit hubs.
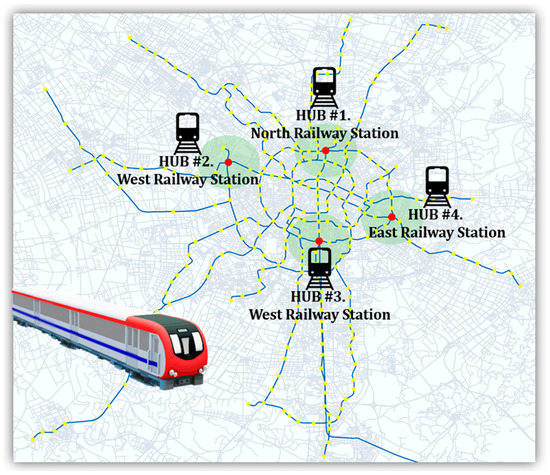
Figure 1.
Chengdu rail-transit hubs.
We integrated the stations’ data and applied Min-Max normalization to provide a reliable database for each hub.
In this study, we employed a comprehensive methodology to analyze and classify rail-transit hubs using various data analysis techniques. First, we applied Min–Max Normalization to standardize the range of our data attributes, ensuring fair comparisons and preventing any attribute from dominating the classification process due to its scale. This normalization technique transformed the attribute values to a standard range between 0 and 1.
To determine the relative importance of attributes in the classification task, we utilized the Improved Entropy Weight (IEW) method. We assessed their diversity and randomness by calculating the entropy for each attribute. Lower entropy values indicated attributes with higher uniformity and specific information for classification. We assigned weights to the attributes based on these values, emphasizing those with lower entropy values. The attribute weights were then normalized to ensure meaningful comparisons and summing up to 1.
Next, we employed the Multiple Linear Regression (MLR) algorithms to build a classification model for rail-transit hubs. MLR allowed us to learn the linear relationship between input features (attributes) and the target variable (rail-transit hub classification). The attribute weights obtained from the IEW method were incorporated into the MLR model, giving higher importance to attributes with lower entropy during the training process.
To evaluate the performance of the MLR model, we utilized several metrics. Mean Squared Error (MSE) measured the average squared difference between the predicted and actual classification values, reflecting the model’s accuracy. (coefficient of determination) indicated the proportion of variance in the target variable that the MLR model could explain. Adjusted adjusted for the number of predictors, considering the model’s complexity and preventing overfitting.
We calculated the Variance Inflation Factor (VIF) to assess multicollinearity, which helped identify attributes with high intercorrelations that might impact the model’s stability and interpretability. Additionally, we employed statistical tests such as the F-Test and T-Test to evaluate the overall significance of the MLR model and the individual significance of the attribute coefficients, respectively. Finally, ANN was applied to predict and verify the results.
By integrating Min–Max Normalization, IEW, MLR, MSE, , Adjusted , VIF, F-Test, and T-test into our analysis pipeline, we gained insights into the classification of rail-transit hubs. These techniques allowed us to preprocess and normalize the data, determine attribute weights, build a classification model, assess its performance and significance, and address potential multicollinearity issues. This comprehensive approach provided a robust framework for analyzing and classifying rail-transit hubs.
This study advocates for a paradigm shift in the classification model by acknowledging and incorporating the time value. By completing three-dimensional models with time as a main dimension, the accuracy and precision of predictions can be significantly improved while also unraveling more profound correlations between various indicators. This approach aligns the classification model with the dynamic nature of real-world data, facilitating a more sophisticated understanding of evolving patterns and trends and ultimately leading to more reliable and insightful analyses.
Using mathematical concepts allows for a systematic and quantitative approach to the classification process. By leveraging mathematical models, factors such as connectivity, accessibility, and spatial patterns can be precisely analyzed and incorporated into the classification framework. This objective and data-driven methodology enhances the accuracy and reliability of the classification results. Moreover, the integration of ANN adds a powerful ML component to the classification process. ANN can effectively learn and recognize complex patterns and relationships within the data, enabling the identification of subtle nuances and hidden features that may not be readily apparent through traditional methods. This combination of mathematical concepts and ANN creates a sophisticated and advanced approach to classifying rail-transit hubs, facilitating a deeper understanding of their characteristics and aiding in the planning and development of transit-oriented communities. Therefore, using mathematical concepts and ANN in classifying rail-transit hubs within the context of TOD represents a cutting-edge and innovative approach that enhances decision-making and fosters sustainable urban development.
Figure 2 presents the research framework applied in this study.
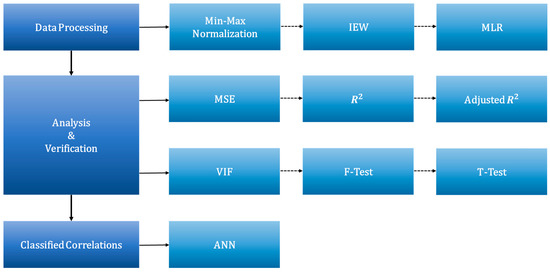
Figure 2.
Research Framework.
2.2. NPRT Indicators
A list of NPR (node, place, and ridership) indicators are provided in Table 2. As mentioned before, the ridership value of each hub cannot be considered a constant or independent value since the number of people using the subway is different during working days and weekends. Moreover, on weekdays, three primary time categories lead to different ridership rates on the day. Therefore, we applied four time classes, T1 to T4, on weekdays and weekends to consider our hubs’ ridership value. Table 2 presents normalized integrated time classes applied in this research.
Table 2.
Normalized Integrated Time class definition for the ANN-NPRT-HUB algorithm.
Table 3 fully describes the node and place value indicators, including relevant sub-branches. The node value has been divided into eight sections from to represented by the principal concepts of TOD mentioned as sub-branches in this table. Moreover, to also provide nine sub-values of Place value.
Table 3.
Node and Place Indicators.
Normalized integrated node, place, and ridership values collected from all stations in each Hub area are presented in Table 4, Table 5 and Table 6, respectively.
Table 4.
Normalized Integrated Node Indicators for each Hub.
Table 5.
Normalized Integrated Place Indicators for each Hub.
Table 6.
Normalized Integrated Ridership for each Hub from IT1 to OT4.
2.3. Information Entropy Weighting (IEW)
Information Entropy Weighting (IEW) [15] was applied to compose the and value indexes into one integrated value of node and place, respectively. To this end, we could process the composed indicators to implement the database analysis started by the decision matrix presented in Equation (1). stations and node value indicators of each hub are consisted in . represents the value of indicator at station . Equation (2) shows the decision matrix normalization:
The proportion of station for indicator is calculated by Equation (3):
To compute the entropy value of indicator , we can apply Equation (4):
If , then
The imbalance coefficient is shown in Equation (5):
Equation (10) provides the weight of indicator indicated by . The result of Equation (6) is used in Equation (7) to compose the (node value index) for station .
To normalize the node value index in [0, 1], we apply Equation (8), in which denotes the index in the array of node values, indicates the number of stations, and is the target station:
2.4. Multiple Linear Regression (MLR)
In this study, we applied Multiple Linear Regression (MLR) to investigate the relationships between the effective parameters (factor variable and multiple variables) on our TOD models and equations.
Regarding the linear Equation (9), and can be determined by applying linear regression of multiple variables using machine learning techniques.
The MLR equations are a regression analysis applying the least-square function to model the argument relationships. This function provides a linear combination of one or more effective parameters, known as regression coefficients [16].
The corresponding model for our n-dimensional feature sample data using linear regression is presented in Equation (10):
A simplified equation considering would be:
The matrix form provides a more concise understanding of the above equations:
where
In Equation (13) denotes the number of samples and presents the number of sample features. We use the Mean Square Error (MSE) as the loss function for our linear regression model. The algebraic equation and the matrix form of the loss function are presented in Equations (14) and (15), respectively.
Applying Equations (16) and (17) and parameter estimation of the MLR model leads to minimizing of the loss function.
Then,
Thus, the following multilinear regression model is achieved.
3. Machine Learning Application in TOD
An Artificial Neural Network (ANN), as an application of Machine Learning (ML), is widely used to predict outcomes, classify the results, and check the accuracy of research achievements. Seven main steps create the primary process of ANN applications: importing the data, cleaning the data, splitting the data into training/test sets, model creation, model training, predictions, and model evaluation and improvement.
The ANN structure is created by three main layers, shown in Figure 3. For simplicity, the activation function is not shown in the figure; therefore, we use the same one between two adjacent layers.
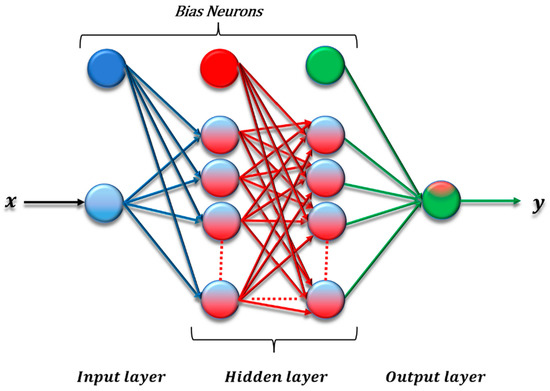
Figure 3.
ANN structure [17].
The ANN structure directs the input to output in one-way information processing. After receiving the input data by the ANN, the error value is calculated. Each layer contains groups of neurons that have their importance determined by assigned weight. The backpropagation algorithm leads to learning and solving errors based on the data of the input and output layers. Mean Square Error (MSE) provides a valuable loss function for regression problems to predetermine the logical minimum error [16,17,18].
In this research, the neurons’ activation function () supports the Rectified Linear Unit function, as shown in Figure 4.
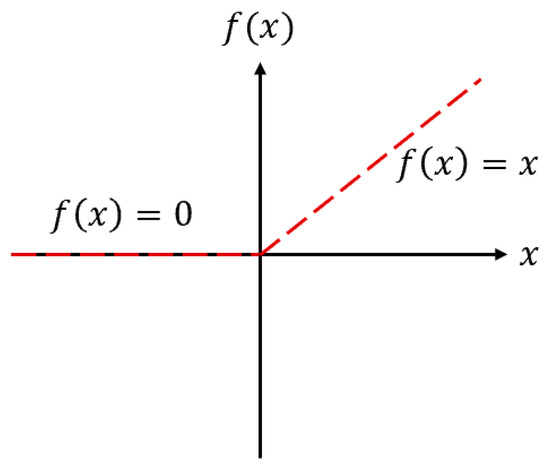
Figure 4.
The neurons’ activation function () [17].
Based on the existing applications of deep learning methods [19,20,21,22,23,24], this study applied the MSE loss function, shown in Figure 5. Moreover, adaptive moment estimation (ADAM) was used to optimize the convergence and enhance the model accuracy.
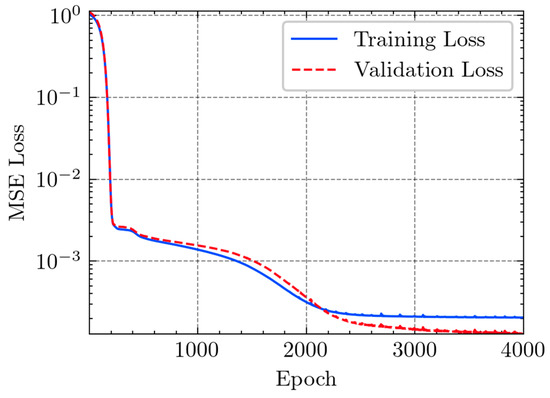
Figure 5.
Loss function, MSE.
Model Evaluation Method
As mentioned before, to verify the Multiple Linear regression (MLR) equations’ accuracies of fit in the regression method, we used the Mean Square Error (MSE), presented in Equation (21).
The Multiple Determination Coefficients , a valuable indicator to evaluate the convergence of MLR equations, reflects the proportions described by the estimated regression equations in the variance of the factor variable , calculated as the proportion of progression squares to the sum of total squares [25].
Regarding Equations (22)–(24), shows the model forecast value, stands for the average of , indicates the Regression Sum of Squares, represents the Error Sum of Squares, and denotes the Total Sum of Squares [16,17,25].
4. Results and Discussion
4.1. The NPRT Variables’ Correlations
We applied Python as a high-level programming language for creating our ANN-NPRT-HUB algorithm and investigated the correlations between independent values (node and place) and dependent values (integrated ridership-time). Using Python’s pandas and numpy libraries, the correlations between the positive or negative variables were obtained and presented in Table 7. A positive correlation is a statistical measure that signifies a simultaneous increase in one variable as the other variable also experiences an increase. This phenomenon implies that the two variables exhibit a coherent behavior, moving in the same direction. Conversely, a negative correlation denotes an inverse relationship, wherein an increase in one variable corresponds to a decrease in the other variable. This indicates a tendency for the variables to move in opposite directions. A correlation coefficient is employed to ascertain the magnitude of the correlation, offering a numerical representation of the relationship between the variables. The correlation coefficient ranges from −1 to 1, providing valuable insights into the strength and direction of the correlation. A correlation coefficient close to 1 or −1 implies a robust correlation, with the variables exhibiting a highly consistent pattern of behavior. In contrast, a coefficient closer to 0 suggests a weaker correlation, indicating that the variables have less synchrony in their variations.
Table 7.
The correlations between dependent and independent values.
Using the correlations between the values provided in Table 7, we can adjust and improve the efficiency of each rail-transit hub by increasing or decreasing the corresponding value(s). The correlation between variables can provide valuable insights into optimizing the efficiency of rail-transit hubs. By focusing on these critical factors, improvements can be targeted where they have the most significant impact.
4.2. MLR Equations for the ANN-NPRT-HUB Model
This research applied Multiple Linear Regression (MLR) to extract eight regression equations for the proposed ANN-NPRT-HUB model. A comprehensive form for the MLR equations is presented in Equation (25). This equation is made of three main terms. indicates the intercept, while and represent the coefficients of node and place values, respectively. To determine the three parameters of , , and , from the sklearn.linear_model of Python, we imported the LinearRegression function.
Appendix A provides a list of constants and variable coefficients for the dependent variable of IT1 to OT4. The complete results of our MLR models are presented in Table 8.
Table 8.
MLR models results.
The Ad.R2 indicates how well the model fits the data, with a value of 1 indicating a perfect fit. Generally, a value of Ad.R2 greater than 0.2 is considered acceptable for the fitted model. In statistical analysis, the significance level of a result is typically represented by the p value, where a smaller p value corresponds to a more substantial effect of the independent variable on the dependent variable. The coefficient of variation (CV) indicates the impact of an independent variable on a dependent variable. A higher CV value indicates a more substantial influence of the independent variable on the dependent variable. And a negative CV implies a negative correlation between the independent and dependent variables.
Applying the constant and coefficient values from Table 8 to Equation (25), we can construct a series of eight MLR equations for the rail-transit hubs provided in Table 9.
Table 9.
Extracted MLR Equations.
Multiple Linear Regression (MLR) equations can be highly beneficial for analyzing ridership in rail-transit hubs. MLR models provide a statistical framework for understanding the relationships between multiple independent variables and the dependent variable of ridership. By considering various factors influencing ridership, MLR equations offer valuable insights into understanding and forecasting the demand for rail-transit services.
4.3. Classification Results
Applying the MLR equations of Table 9 and the NP (Node, Place) values, we can achieve the actual ridership values of the NPRT model for rail-transit hubs. Moreover, we used the ANN to predict the NPRT model results presented in this research. Table 10 shows a list of predicted values provided by the ANN and the MLR equations’ actual results. In this table, p denotes the predicted value.
Table 10.
Predicted and actual results.
The ANN-predicted ridership for individual rail-transit hubs holds significant importance in various technical aspects. It primarily enables effective demand forecasting, capacity planning, resource allocation, service optimization, revenue estimation, and decision-making. Leveraging the capabilities of ANN models empowers transit authorities to make well-informed decisions to enhance operational efficiency, improve the passenger experience, and ensure the sustainable growth and development of rail transit systems.
In Table 10, the predicted ridership by the ANN is based on the underlying patterns and associations discovered during the model training. By leveraging the power of the ANN, which excels in capturing intricate relationships in complex datasets, transit authorities gain insights into the anticipated demand for each rail-transit hub.
Figure 6 illustrates a comparison between the actual NPRT-HUB results created by MLR equations and the predicted ones by the ANN. As mentioned before, the predicted classes can be distinguished by the letter p before the name of the class. This figure shows that the ANN could logically predict the NPRT model ridership values. For example, the ANN predicted that the class covers 19% of the ridership of HUB#1 (North Railway Station), while the actual MLR value is 17%. This logical prediction comes true while looking at the other hubs’ classes, such as and for HUB#4 (East Railway Station), with values of 24% and 23%, respectively. Therefore, applying the ANN in classifying and assessing the efficiency of rail-transit hubs could bring new insight into TOD.
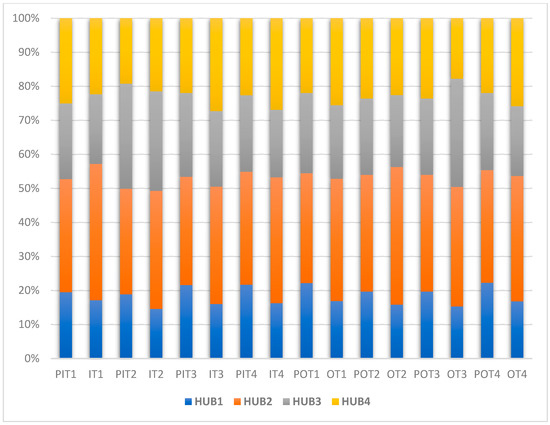
Figure 6.
Comparison between the predicted and actual NPRT-HUB results.
ANNs can be helpful for city planners in assessing the rail-transit hubs because they can assist in identifying significant patterns and relationships within large and complex datasets. In the case of rail-transit hubs, ANNs can be used to analyze data on passenger flows, station usage, train schedules, and other factors that affect the efficiency and effectiveness of a hub. Using ANNs, city planners can create predictive models to help them make informed decisions about optimizing a rail-transit hub’s performance. For example, ANNs can forecast passenger demand at different times of the day or during special events, allowing transit planners to adjust train schedules and allocate resources accordingly. ANNs can also identify patterns in passenger behavior, such as how they move through a station or which routes they tend to take, which can inform decisions about station design and layout. In addition to these practical applications, ANNs can also be used to test hypothetical scenarios and predict the potential impact of different planning decisions. For example, planners can use ANNs to simulate the effects of adding new train lines or changing the location of a station, helping them make informed decisions that will benefit both passengers and the city as a whole.
Rail-transit hub classification empowers city planners and policymakers to optimize network efficiency. It guides network optimization, service planning, infrastructure development, land use decisions, and policy formulation. By using the results of hub classification, cities can create more efficient and sustainable rail transit networks that cater to the diverse needs of their residents and visitors. Classification helps identify key hub types, such as significant transfer or high-demand ones, which require specific infrastructure and operational considerations. Planners can strategically allocate resources, prioritize investments, and optimize service frequencies to ensure efficient connectivity and minimize delays and congestion. For example, a city may identify a particular hub as a central transfer point between multiple rail lines and allocate additional platform space and staffing to facilitate smooth transfers and reduce overcrowding. Hub classification assists in determining service patterns and frequencies based on hub types. Planners can allocate more frequent service to high-demand hubs, ensuring efficient transportation access for a larger population.
Conversely, lower-demand hubs may receive less frequent service, optimizing resource utilization. For instance, a city may identify specific hubs as high-demand destinations due to their proximity to employment centers or popular tourist attractions. Higher service frequencies can be scheduled during peak hours to accommodate commuter and tourist travel.
By understanding the characteristics of different hub types, city planners can make informed decisions about infrastructure development and station design. For example, if a hub is classified as a major transfer point, planners can allocate sufficient space for platform-to-platform transfers, install clear wayfinding signage, and ensure adequate accessibility features. This promotes smooth passenger flow and minimizes bottlenecks, contributing to overall network efficiency. Rail-transit hub classification informs land use and development strategies around hubs. Planners can identify hubs with potential for transit-oriented development (TOD) and focus on creating vibrant, mixed-use neighborhoods with a high-density residential and commercial mix. This fosters a walkable environment, reducing the dependence on private vehicles and enhancing the efficiency of the overall transit network. For instance, a city may classify a hub near a university as a potential hub for mixed-use development, with student housing, retail establishments, and recreational facilities. Hub classification provides valuable data for policymakers to make informed decisions regarding transit policies and investments. It helps prioritize funding and resources for infrastructure improvements, station upgrades, and system expansion. Planners can identify hubs in underserved areas and allocate targeted investments to enhance accessibility and connectivity. Additionally, policymakers can use hub classification results to shape transportation policies, such as promoting transit-oriented development, implementing fare integration systems, or introducing innovative mobility solutions.
ANNs can analyze diverse data sets obtained from railway transportation hubs, including passenger flow, peak hours, and travel patterns. By utilizing this data, ANNs can effectively detect areas of congestion and optimize transportation planning, enabling city authorities to make well-informed decisions regarding infrastructure development, scheduling, and resource allocation. Additionally, ANNs can be leveraged to develop predictive models anticipating the demand for transportation services. By analyzing historical data and current trends, cities can optimize the deployment of transportation resources, such as trains, buses, and shared mobility services, ensuring efficient and reliable mobility options for residents and visitors.
Moreover, ANNs can monitor and analyze real-time data from railway transportation hubs, encompassing train arrival and departure times, passenger volumes, and service disruptions. This valuable information empowers city authorities to respond to dynamic conditions promptly, improve service reliability, and deliver timely updates to passengers, thus significantly enhancing the overall transportation experience.
In the context of sustainable urban development, integrating Transit-Oriented Development (TOD) with ANN-based classification of railway transportation hubs becomes pivotal. By strategically designing compact and mixed-use neighborhoods around transit stations, cities can effectively diminish reliance on private vehicles, foster the adoption of walking and cycling, and foster vibrant communities. ANN plays a critical role in identifying optimal locations for TOD by considering crucial factors such as population density, land use patterns, and proximity to transit infrastructure.
This research explored and incorporated the time dimension into the classification model, recognizing its critical importance in enhancing predictive accuracy. By conducting an in-depth review of existing research works [5,26,27], it became evident that two and three-dimensional models lacked the crucial element of time. Thus, the necessity arose to complete these models by incorporating time as a main dimension, providing a more comprehensive and precise analysis.
One of the key benefits of integrating time into the classification model is the ability to establish stronger correlations between indicators. As time plays a significant role in various processes and trends, taking it into account enables a more accurate understanding of the relationships between different indicators. This, in turn, leads to improved predictions and a deeper insight into the dynamics of the phenomena under investigation.
By acknowledging the importance of the time value, this study tried to bridge the gap between traditional static models and the dynamic nature of real-world data. The classification model’s capabilities are significantly enhanced by considering time as a main dimension, paving the way for more sophisticated and reliable analysis.
5. Conclusions
This research study aimed to analyze and assess Chengdu rail-transit hubs using the integrated Node, Place, Ridership, and Time (NPRT) method. The investigation employed a temporal segmentation into four distinct time periods, uncovering a direct correlation between ridership and time. Combining mathematical techniques and machine learning, we developed a series of eight Multiple Linear Regression (MLR) equations for each hub. These MLR equations incorporated node and place values as independent variables to examine their influence on ridership throughout different time periods. Integrating MLR analysis into planning, resource allocation, and policy formulation processes facilitates well-informed decision-making, optimized ridership levels, and enhanced efficiency of rail-transit systems. The identified correlations highlight the significance of NPRT models as valuable tools for policymakers and city planners in evaluating the effectiveness of rail transportation hubs. In Transit-Oriented Development (TOD) context, evaluating factors like station location, ridership, and connectivity is essential for efficiency. NPRT models contribute to establishing development objectives and formulating effective strategies. Moreover, the inclusion of Artificial Neural Networks (ANNs) in assessing rail-transit hubs provides valuable insights that inform decision-making and support the creation of transportation systems that are efficient, effective, and sustainable.
6. Possible Directions for Future Studies
This study conducted a case study on Chengdu rail-transit hubs to investigate the effect of node and place values on ridership in different time periods. Although the study provided accurate results, applying other methods, such as Partial Differential Equations (PDE), to study the correlations between dependent and independent variables sounds interesting for future studies. Utilizing PDEs for studying correlations between variables in a rail-transit hub classification model provides a powerful and flexible approach to analyzing the complex dynamics of the system, making predictions, optimizing operations, and validating the model against real-world data.
Additionally, future research should consider the significance of the economy; ecology; and sociodemographic factors, such as the proportion of people using public transportation, the frequency of household outings, and the distribution of age groups concerning the NPRT model for rail-transit hubs. Moreover, applying train schedules, infrastructure capacity, and operational efficiency can improve the limitations of the 3D indicators presented in this study.
Author Contributions
Conceptualization, A.A.P. and A.L.; Data curation, D.C., M.A.P., Z.Z., J.L., Y.Z. and L.Z.; Formal analysis, D.C. and M.A.P.; Funding acquisition, A.A.P.; Investigation, A.A.P., M.A.P., J.L., Y.Z. and L.Z.; Methodology, A.A.P.; Resources, D.C., Z.Z. and Y.Z.; Software, D.C., M.A.P., J.L. and L.Z.; Supervision, A.L.; Validation, A.A.P. and A.L.; Visualization, M.A.P. and Z.Z.; Writing—original draft, A.A.P.; Writing—review and editing, A.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the following: 1. Science and Technology Department of Sichuan Province (2022YFWZ0010). 2. Bridge Non-destructive Testing (NDT) and Engineering Computation Sichuan Provincial University Key Laboratory (2022QYY01).
Data Availability Statement
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
Acknowledgments
The authors would like to acknowledge the Sichuan University of Science and Engineering, Université Gustave Eiffel, and Southwest Jiaotong University.
Conflicts of Interest
The authors declare no competing interest.
Appendix A. Constants and Variable Coefficients of MLR Models
Table A1.
Dependent variable: IT1—Coefficient a.
Table A1.
Dependent variable: IT1—Coefficient a.
| Model | Unstandardized Coefficient | Standardization Coefficient | Time | Significance | 95.0% Confidence Interval for B | |||
|---|---|---|---|---|---|---|---|---|
| B | Standard Error | Min | Max | |||||
| 1 | Constant | −4595.878 | 12,944.799 | −0.355 | 0.723 | −30,338.030 | 21,146.274 | |
| N1 | −25.376 | 181.741 | −0.019 | −0.140 | 0.889 | −386.789 | 336.037 | |
| N2 | 7.483 | 69.518 | 0.045 | 0.108 | 0.915 | −130.762 | 145.728 | |
| N3 | 561.364 | 448.738 | 0.585 | 1.251 | 0.214 | −331.002 | 1453.729 | |
| N4 | −449.041 | 196.083 | −0.689 | −2.290 | 0.025 | −838.974 | −59.108 | |
| N5 | −867.804 | 394.813 | −1.085 | −2.198 | 0.031 | −1652.932 | −82.676 | |
| N6 | 234.298 | 165.839 | 0.427 | 1.413 | 0.161 | −95.491 | 564.088 | |
| N7 | 326.503 | 419.123 | 0.126 | 0.779 | 0.438 | −506.969 | 1159.975 | |
| N8 | 3.800 | 2.615 | 0.582 | 1.453 | 0.150 | −1.400 | 8.999 | |
| P1 | 0.004 | 0.062 | 0.007 | 0.065 | 0.948 | −0.119 | 0.127 | |
| P2 | −33.321 | 10.529 | −0.500 | −3.165 | 0.002 | −54.258 | −12.384 | |
| P3 | 0.028 | 0.077 | 0.035 | 0.357 | 0.722 | −0.126 | 0.181 | |
| P4 | 16.891 | 7.476 | 0.496 | 2.259 | 0.026 | 2.024 | 31.759 | |
| P5 | −0.111 | 0.065 | −0.256 | −1.719 | 0.089 | −0.240 | 0.018 | |
| P6 | −2.658 | 4.872 | −0.139 | −0.546 | 0.587 | −12.347 | 7.031 | |
| P7 | −31.787 | 46.503 | −0.114 | −0.684 | 0.496 | −124.264 | 60.690 | |
| P8 | 22.276 | 20.802 | 0.184 | 1.071 | 0.287 | −19.091 | 63.643 | |
| P9 | 157.088 | 71.323 | 0.240 | 2.203 | 0.030 | 15.255 | 298.922 | |
Table A2.
Dependent variable: IT2—Coefficient a.
Table A2.
Dependent variable: IT2—Coefficient a.
| Model | Unstandardized Coefficient | Standardization Coefficient | Time | Significance | 95.0% Confidence Interval for B | |||
|---|---|---|---|---|---|---|---|---|
| B | Standard Error | Min | Max | |||||
| 2 | Constant | 12,022.143 | 25,839.016 | 0.465 | 0.643 | −39,361.575 | 63,405.861 | |
| N1 | −657.282 | 362.773 | −0.214 | −1.812 | 0.074 | −1378.695 | 64.131 | |
| N2 | −48.441 | 138.765 | −0.127 | −0.349 | 0.728 | −324.391 | 227.509 | |
| N3 | 630.500 | 895.723 | 0.287 | 0.704 | 0.483 | −1150.744 | 2411.744 | |
| N4 | −815.953 | 391.400 | −0.548 | −2.085 | 0.040 | −1594.294 | −37.611 | |
| N5 | −1129.194 | 788.082 | −0.617 | −1.433 | 0.156 | −2696.383 | 437.994 | |
| N6 | 570.856 | 331.030 | 0.455 | 1.724 | 0.088 | −87.434 | 1229.146 | |
| N7 | 2316.741 | 836.608 | 0.391 | 2.769 | 0.007 | 653.054 | 3980.428 | |
| N8 | −0.784 | 5.219 | −0.053 | −0.150 | 0.881 | −11.163 | 9.595 | |
| P1 | −0.030 | 0.123 | −0.022 | −0.243 | 0.808 | −0.275 | 0.215 | |
| P2 | 96.926 | 21.016 | 0.636 | 4.612 | 0.000 | 55.134 | 138.719 | |
| P3 | 0.030 | 0.154 | 0.017 | 0.195 | 0.846 | −0.277 | 0.337 | |
| P4 | 12.614 | 14.924 | 0.162 | 0.845 | 0.400 | −17.063 | 42.291 | |
| P5 | 0.057 | 0.129 | 0.057 | 0.441 | 0.660 | −0.200 | 0.314 | |
| P6 | −7.990 | 9.726 | −0.182 | −0.822 | 0.414 | −27.331 | 11.350 | |
| P7 | −183.022 | 92.825 | −0.288 | −1.972 | 0.052 | −367.615 | 1.570 | |
| P8 | −7.219 | 41.522 | −0.026 | −0.174 | 0.862 | −89.791 | 75.352 | |
| P9 | −52.297 | 142.367 | −0.035 | −0.367 | 0.714 | −335.408 | 230.815 | |
Table A3.
Dependent variable: IT3—Coefficient a.
Table A3.
Dependent variable: IT3—Coefficient a.
| Model | Unstandardized Coefficient | Standardization Coefficient | Time | Significance | 95.0% Confidence Interval for B | |||
|---|---|---|---|---|---|---|---|---|
| B | Standard Error | Min | Max | |||||
| 3 | Constant | 18,104.908 | 37,781.340 | 0.479 | 0.633 | −57,027.431 | 93,237.246 | |
| N1 | −1318.949 | 530.439 | −0.350 | −2.487 | 0.015 | −2373.786 | −264.112 | |
| N2 | −106.723 | 202.900 | −0.228 | −0.526 | 0.600 | −510.212 | 296.766 | |
| N3 | 500.433 | 1309.710 | 0.186 | 0.382 | 0.703 | −2104.070 | 3104.936 | |
| N4 | −942.555 | 572.298 | −0.515 | −1.647 | 0.103 | −2080.632 | 195.522 | |
| N5 | −1366.881 | 1152.320 | −0.608 | −1.186 | 0.239 | −3658.396 | 924.633 | |
| N6 | 850.038 | 484.027 | 0.552 | 1.756 | 0.083 | −112.502 | 1812.578 | |
| N7 | 3954.057 | 1223.273 | 0.544 | 3.232 | 0.002 | 1521.445 | 6386.670 | |
| N8 | −2.142 | 7.631 | −0.117 | −0.281 | 0.780 | −17.318 | 13.034 | |
| P1 | −0.047 | 0.180 | −0.028 | −0.259 | 0.796 | −0.405 | 0.311 | |
| P2 | 63.024 | 30.729 | 0.336 | 2.051 | 0.043 | 1.915 | 124.133 | |
| P3 | 0.137 | 0.226 | 0.062 | 0.607 | 0.546 | −0.312 | 0.586 | |
| P4 | 18.805 | 21.821 | 0.196 | 0.862 | 0.391 | −24.588 | 62.198 | |
| P5 | 0.031 | 0.189 | 0.026 | 0.166 | 0.869 | −0.345 | 0.408 | |
| P6 | −10.479 | 14.221 | −0.195 | −0.737 | 0.463 | −38.758 | 17.800 | |
| P7 | −151.554 | 135.727 | −0.194 | −1.117 | 0.267 | −421.461 | 118.354 | |
| P8 | 15.054 | 60.713 | 0.044 | 0.248 | 0.805 | −105.681 | 135.789 | |
| P9 | −73.514 | 208.166 | −0.040 | −0.353 | 0.725 | −487.475 | 340.447 | |
Table A4.
Dependent variable: IT4—Coefficient a.
Table A4.
Dependent variable: IT4—Coefficient a.
| Model | Unstandardized Coefficient | Standardization Coefficient | Time | Significance | 95.0% Confidence Interval for B | |||
|---|---|---|---|---|---|---|---|---|
| B | Standard Error | Min | Max | |||||
| 4 | Constant | 11,838.943 | 32,274.532 | 0.367 | 0.715 | −52,342.502 | 76,020.388 | |
| N1 | −964.227 | 453.125 | −0.307 | −2.128 | 0.036 | −1865.317 | −63.138 | |
| N2 | −89.607 | 173.326 | −0.229 | −0.517 | 0.607 | −434.286 | 255.071 | |
| N3 | 393.954 | 1118.814 | 0.175 | 0.352 | 0.726 | −1830.931 | 2618.838 | |
| N4 | −854.403 | 488.883 | −0.561 | −1.748 | 0.084 | −1826.600 | 117.793 | |
| N5 | −1196.002 | 984.364 | −0.639 | −1.215 | 0.228 | −3153.517 | 761.513 | |
| N6 | 761.852 | 413.477 | 0.594 | 1.843 | 0.069 | −60.393 | 1584.097 | |
| N7 | 3022.925 | 1044.975 | 0.499 | 2.893 | 0.005 | 944.877 | 5100.973 | |
| N8 | −0.798 | 6.519 | −0.052 | −0.122 | 0.903 | −13.762 | 12.166 | |
| P1 | −0.044 | 0.154 | −0.031 | −0.285 | 0.777 | −0.350 | 0.262 | |
| P2 | 39.064 | 26.250 | 0.250 | 1.488 | 0.140 | −13.138 | 91.266 | |
| P3 | 0.144 | 0.193 | 0.078 | 0.748 | 0.457 | −0.239 | 0.528 | |
| P4 | 27.532 | 18.640 | 0.345 | 1.477 | 0.143 | −9.536 | 64.600 | |
| P5 | 0.030 | 0.162 | 0.029 | 0.186 | 0.853 | −0.291 | 0.351 | |
| P6 | −8.525 | 12.148 | −0.190 | −0.702 | 0.485 | −32.683 | 15.632 | |
| P7 | −172.084 | 115.944 | −0.264 | −1.484 | 0.141 | −402.652 | 58.483 | |
| P8 | 3.561 | 51.864 | 0.013 | 0.069 | 0.945 | −99.576 | 106.699 | |
| P9 | −85.692 | 177.825 | −0.056 | −0.482 | 0.631 | −439.316 | 267.933 | |
Table A5.
Dependent variable: OT1—Coefficient a.
Table A5.
Dependent variable: OT1—Coefficient a.
| Model | Unstandardized Coefficient | Standardization Coefficient | Time | Significance | 95.0% Confidence Interval for B | |||
|---|---|---|---|---|---|---|---|---|
| B | Standard Error | Min | Max | |||||
| 5 | Constant | 8425.112 | 35,054.394 | 0.240 | 0.811 | −61,284.395 | 78,134.620 | |
| N1 | −1083.452 | 492.154 | −0.308 | −2.201 | 0.030 | −2062.153 | −104.750 | |
| N2 | −67.367 | 188.255 | −0.154 | −0.358 | 0.721 | −441.734 | 306.999 | |
| N3 | 431.010 | 1215.179 | 0.171 | 0.355 | 0.724 | −1985.507 | 2847.528 | |
| N4 | −846.086 | 530.991 | −0.496 | −1.593 | 0.115 | −1902.020 | 209.848 | |
| N5 | −1289.399 | 1069.149 | −0.616 | −1.206 | 0.231 | −3415.519 | 836.720 | |
| N6 | 781.668 | 449.091 | 0.544 | 1.741 | 0.085 | −111.399 | 1674.734 | |
| N7 | 3267.770 | 1134.981 | 0.482 | 2.879 | 0.005 | 1010.736 | 5524.804 | |
| N8 | −0.252 | 7.081 | −0.015 | −0.036 | 0.972 | −14.332 | 13.829 | |
| P1 | −0.061 | 0.167 | −0.039 | −0.368 | 0.714 | −0.394 | 0.271 | |
| P2 | 53.189 | 28.511 | 0.305 | 1.866 | 0.066 | −3.509 | 109.887 | |
| P3 | 0.165 | 0.209 | 0.080 | 0.787 | 0.433 | −0.252 | 0.582 | |
| P4 | 26.859 | 20.246 | 0.301 | 1.327 | 0.188 | −13.402 | 67.120 | |
| P5 | 0.054 | 0.176 | 0.047 | 0.306 | 0.760 | −0.295 | 0.403 | |
| P6 | −10.502 | 13.194 | −0.209 | −0.796 | 0.428 | −36.740 | 15.737 | |
| P7 | −177.163 | 125.930 | −0.243 | −1.407 | 0.163 | −427.590 | 73.263 | |
| P8 | 12.022 | 56.331 | 0.038 | 0.213 | 0.832 | −99.999 | 124.042 | |
| P9 | −50.335 | 193.141 | −0.029 | −0.261 | 0.795 | −434.417 | 333.748 | |
Table A6.
Dependent variable: OT2—Coefficient a.
Table A6.
Dependent variable: OT2—Coefficient a.
| Model | Unstandardized Coefficient | Standardization Coefficient | Time | Significance | 95.0% Confidence Interval for B | |||
|---|---|---|---|---|---|---|---|---|
| B | Standard Error | Min | Max | |||||
| 6 | Constant | −2767.615 | 17,788.204 | −0.156 | 0.877 | −38,141.409 | 32,606.179 | |
| N1 | −346.841 | 249.741 | −0.198 | −1.389 | 0.169 | −843.479 | 149.798 | |
| N2 | −8.610 | 95.529 | −0.039 | −0.090 | 0.928 | −198.580 | 181.361 | |
| N3 | 612.772 | 616.638 | 0.488 | 0.994 | 0.323 | −613.479 | 1839.024 | |
| N4 | −654.006 | 269.449 | −0.768 | −2.427 | 0.017 | −1189.835 | −118.177 | |
| N5 | −1075.195 | 542.535 | −1.029 | −1.982 | 0.051 | −2154.085 | 3.695 | |
| N6 | 443.716 | 227.889 | 0.619 | 1.947 | 0.055 | −9.467 | 896.899 | |
| N7 | 1137.145 | 575.941 | 0.336 | 1.974 | 0.052 | −8.178 | 2282.467 | |
| N8 | 2.893 | 3.593 | 0.339 | 0.805 | 0.423 | −4.252 | 10.038 | |
| P1 | −0.007 | 0.085 | −0.009 | −0.081 | 0.936 | −0.175 | 0.162 | |
| P2 | −6.939 | 14.468 | −0.080 | −0.480 | 0.633 | −35.710 | 21.832 | |
| P3 | 0.093 | 0.106 | 0.091 | 0.877 | 0.383 | −0.118 | 0.305 | |
| P4 | 23.934 | 10.274 | 0.537 | 2.330 | 0.022 | 3.503 | 44.364 | |
| P5 | −0.052 | 0.089 | −0.091 | −0.584 | 0.561 | −0.229 | 0.125 | |
| P6 | −3.731 | 6.695 | −0.149 | −0.557 | 0.579 | −17.045 | 9.583 | |
| P7 | −95.857 | 63.903 | −0.264 | −1.500 | 0.137 | −222.935 | 31.221 | |
| P8 | 10.351 | 28.585 | 0.065 | 0.362 | 0.718 | −46.494 | 67.195 | |
| P9 | 81.313 | 98.009 | 0.095 | 0.830 | 0.409 | −113.588 | 276.214 | |
Table A7.
Dependent variable: OT3—Coefficient a.
Table A7.
Dependent variable: OT3—Coefficient a.
| Model | Unstandardized Coefficient | Standardization Coefficient | Time | Significance | 95.0% Confidence Interval for B | |||
|---|---|---|---|---|---|---|---|---|
| B | Standard Error | Min | Max | |||||
| 7 | Constant | 3947.471 | 19,451.734 | 0.203 | 0.840 | −34,734.434 | 42,629.377 | |
| N1 | −403.968 | 273.097 | −0.154 | −1.479 | 0.143 | −947.051 | 139.115 | |
| N2 | 4.441 | 104.463 | 0.014 | 0.043 | 0.966 | −203.296 | 212.177 | |
| N3 | 567.266 | 674.305 | 0.301 | 0.841 | 0.403 | −773.663 | 1908.195 | |
| N4 | −525.296 | 294.648 | −0.411 | −1.783 | 0.078 | −1111.235 | 60.643 | |
| N5 | −781.117 | 593.272 | −0.498 | −1.317 | 0.192 | −1960.903 | 398.670 | |
| N6 | 308.789 | 249.201 | 0.287 | 1.239 | 0.219 | −186.775 | 804.353 | |
| N7 | 1772.962 | 629.802 | 0.350 | 2.815 | 0.006 | 520.531 | 3025.394 | |
| N8 | 0.325 | 3.929 | 0.025 | 0.083 | 0.934 | −7.489 | 8.138 | |
| P1 | −0.038 | 0.093 | −0.033 | −0.415 | 0.680 | −0.223 | 0.146 | |
| P2 | 96.265 | 15.821 | 0.737 | 6.085 | 0.000 | 64.804 | 127.727 | |
| P3 | −0.014 | 0.116 | −0.009 | −0.122 | 0.903 | −0.245 | 0.217 | |
| P4 | −1.666 | 11.234 | −0.025 | −0.148 | 0.882 | −24.007 | 20.675 | |
| P5 | 0.038 | 0.097 | 0.045 | 0.392 | 0.696 | −0.156 | 0.232 | |
| P6 | −6.474 | 7.321 | −0.172 | −0.884 | 0.379 | −21.034 | 8.085 | |
| P7 | −84.048 | 69.879 | −0.154 | −1.203 | 0.232 | −223.010 | 54.914 | |
| P8 | 2.942 | 31.258 | 0.012 | 0.094 | 0.925 | −59.219 | 65.102 | |
| P9 | 41.508 | 107.174 | 0.032 | 0.387 | 0.700 | −171.620 | 254.636 | |
Table A8.
Dependent variable: OT4—Coefficient a.
Table A8.
Dependent variable: OT4—Coefficient a.
| Model | Unstandardized Coefficient | Standardization Coefficient | Time | Significance | 95.0% Confidence Interval for B | |||
|---|---|---|---|---|---|---|---|---|
| B | Standard Error | Min | Max | |||||
| 8 | Constant | 5025.627 | 32,361.785 | 0.155 | 0.877 | −59,329.332 | 69,380.587 | |
| N1 | −943.496 | 454.350 | −0.295 | −2.077 | 0.041 | −1847.022 | −39.971 | |
| N2 | −58.054 | 173.795 | −0.146 | −0.334 | 0.739 | −403.664 | 287.556 | |
| N3 | 368.891 | 1121.839 | 0.161 | 0.329 | 0.743 | −1862.008 | 2599.790 | |
| N4 | −770.442 | 490.204 | −0.495 | −1.572 | 0.120 | −1745.267 | 204.384 | |
| N5 | −1142.524 | 987.025 | −0.598 | −1.158 | 0.250 | −3105.331 | 820.283 | |
| N6 | 714.178 | 414.595 | 0.545 | 1.723 | 0.089 | −110.290 | 1538.646 | |
| N7 | 2934.299 | 1047.800 | 0.475 | 2.800 | 0.006 | 850.633 | 5017.965 | |
| N8 | 0.170 | 6.537 | 0.011 | 0.026 | 0.979 | −12.829 | 13.170 | |
| P1 | −0.055 | 0.154 | −0.038 | −0.354 | 0.724 | −0.361 | 0.252 | |
| P2 | 45.053 | 26.321 | 0.283 | 1.712 | 0.091 | −7.290 | 97.396 | |
| P3 | 0.165 | 0.193 | 0.088 | 0.854 | 0.396 | −0.219 | 0.550 | |
| P4 | 28.477 | 18.691 | 0.350 | 1.524 | 0.131 | −8.692 | 65.645 | |
| P5 | 0.057 | 0.162 | 0.055 | 0.352 | 0.726 | −0.265 | 0.379 | |
| P6 | −9.079 | 12.181 | −0.198 | −0.745 | 0.458 | −33.301 | 15.144 | |
| P7 | −173.106 | 116.257 | −0.261 | −1.489 | 0.140 | −404.296 | 58.085 | |
| P8 | 2.635 | 52.004 | 0.009 | 0.051 | 0.960 | −100.781 | 106.051 | |
| P9 | −72.751 | 178.306 | −0.046 | −0.408 | 0.684 | −427.332 | 281.829 | |
References
- Gonzalez-Gil, A.; Palacin, R.; Batty, P.; Powell, J.P. A systems approach to reduce urban rail energy consumption. Energy Convers. Manag. 2014, 80, 509–524. [Google Scholar] [CrossRef]
- Xin, X.; Wu, Y.; Guo, Y.Y.; Song, T. Study on the reasonable scale of the urban rail transit network: A case of Xi’an city. Appl. Mech. Mater. 2013, 253, 1829–1832. [Google Scholar] [CrossRef]
- Zhang, T.; Dong, S.; Zeng, Z.; Li, J. Quantifying multi-modal public transit accessibility for large metropolitan areas: A time-dependent reliability modeling approach. Int. J. Geogr. Inf. Sci. 2018, 32, 1649–1676. [Google Scholar] [CrossRef]
- Bertolini, L. Spatial development patterns and public transport: The application of an analytical model in the Netherlands. Plan. Pract. Res. 1999, 14, 199–210. [Google Scholar] [CrossRef]
- Cao, Z.; Asakura, Y.; Tan, Z. Coordination between node, place, and ridership: Comparing three transit operators in Tokyo. Transp. Res. Part D 2020, 87, 102518. [Google Scholar] [CrossRef]
- Pishro, A.A.; Yang, Q.; Zhang, S.; Pishro, M.A.; Zhang, Z.; Zhao, Y.; Postel, V.; Huang, D.; Li, W. Node, Place, Ridership, and Time model for Rail-Transit Stations: A Case Study. Sci. Rep. 2022, 12, 16120. [Google Scholar] [CrossRef] [PubMed]
- Robert, C.; Kockelman, K. Travel Demand and the 3Ds: Density, Diversity and Design. Transp. Res. Part D 1997, 2, 199–219. [Google Scholar] [CrossRef]
- Huang, R.; Anna, G.; Mafalda, M.; Mark, B. Measuring Transit-Oriented Development (TOD) Network Complementarity Based on TOD Node Typology. J. Transp. Land Use 2018, 11, 305–324. [Google Scholar] [CrossRef]
- The Role of 6Ds: Density, Diversity, Design, Destination, Distance, and Demand Management in Transit Oriented Development (TOD)—University of Johannesburg. n.d. Available online: https://ujcontent.uj.ac.za/esploro/outputs/9911634007691?institution=27UOJ_INST&skipUsageReporting=true&recordUsage=false (accessed on 3 May 2023).
- Du, Y.; Gao, C.; Hu, Y.; Mahadevan, S.; Deng, Y. A new method of identifying influential nodes in complex networks based on TOPSIS. Phys. A 2014, 399, 57–69. [Google Scholar] [CrossRef]
- Bian, T.; Deng, Y. A new evidential methodology of identifying influential nodes in complex networks. Chaos Solitons Fractals 2017, 103, 101–110. [Google Scholar] [CrossRef]
- Sheikhahmadi, A.; Nematbakhsh, M.A.; Shokrollahi, A. Improving detection of influential nodes in complex networks. Phys. A Stat. Mech. Appl. 2015, 436, 833–845. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, S.; Zhang, Z.; Zou, K.; Zhan, S. Characteristics on hub networks of urban rail transit networks. Phys. A Stat. Mech. Appl. 2015, 447, 502–507. [Google Scholar] [CrossRef]
- Sun, Y.; Mburu, L.; Wang, S. Analysis of community properties and node properties to understand the structure of the bus transport network. Phys. A Stat. Mech. Appl. 2016, 450, 523–530. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Champaign, IL, USA, 1949. [Google Scholar]
- Pishro, A.A.; Zhang, S.; Huang, D.; Xiong, F.; Li, W.; Yang, Q. Application of artificial neural networks and multiple linear regression on local bond stress equation of UHPC and reinforcing steel bars. Sci. Rep. 2021, 11, 15061. [Google Scholar] [CrossRef] [PubMed]
- Pishro, A.A.; Zhang, Z.; Pishro, M.A.; Liu, W.; Zhang, L.; Yang, Q. Structural Performance of EB-FRP-Strengthened RC T-Beams Subjected to Combined Torsion and Shear Using ANN. Materials 2022, 15, 4852. [Google Scholar] [CrossRef] [PubMed]
- Pishro, A.A.; Zhang, S.; Zhang, Z.; Zhao, Y.; Pishro, M.A.; Zhang, L.; Yang, Q.; Postel, V. Structural Behavior of FRP-Retrofitted RC Beams under Combined Torsion and Bending. Materials 2022, 15, 3213. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Manning, C. Fast dropout training. In Proceedings of the 30th International Conference on Machine Learning (ICML-13), Atlanta, GA, USA, 17–19 June 2013; pp. 118–126. [Google Scholar]
- Ilya, S.; James, M.; George, D.; Geoffrey, H. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning (ICML-13), Atlanta, GA, USA, 17–19 June 2013; pp. 1139–1147. [Google Scholar]
- Sohl-Dickstein, J.; Poole, B.; Ganguli, S. Fast large-scale optimization by unifying stochastic gradient and quasi-newton methods. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), Beijing, China, 21–26 June 2014; pp. 604–612. [Google Scholar]
- Eric, M.; Francis, B.R. Non-asymptotic analysis of stochastic approximation algorithms for machine learning. Adv. Neural Inf. Process. Syst. 2011, 24, 451–459. [Google Scholar]
- Alex, G.; Abdel-Rahman, M.; Geoffrey, H. Speech recognition with deep recurrent neural networks. In Proceedings of the Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 6645–6649. [Google Scholar]
- Li, D.; Li, J.; Huang, J.-T.; Yao, K.; Yu, D.; Seide, F.S.; Michael, Z.G.; He, X.; Williams, J.; Gong, Y.; et al. Recent advances in deep learning for speech research at microsoft. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP-88, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar] [CrossRef]
- Pishro, A.A.; Zhang, Z.; Pishro, M.A.; Feng, X.; Zhang, L.; Yang, Q.; Matlan, S.J. UHPC-PINN-Parallel Micro Element System for the Local Bond Stress–Slip model subjected to monotonic loading. Structures 2022, 46, 570–597. [Google Scholar] [CrossRef]
- Jia, J.; Chen, Y.; Wang, Y.; Li, T.; Li, Y. A new global method for identifying urban rail transit key station during COVID-19: A case study of Beijing, China. Phys. A 2021, 565, 125578. [Google Scholar] [CrossRef] [PubMed]
- Dou, M.; Wang, Y.; Dong, S. Integrating Network Centrality and Node-Place Model to Evaluate and Classify Station Areas in Shanghai. ISPRS Int. J. Geo-Inf. 2021, 10, 414. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).