
Chatbots in Radiology: Current Applications, Limitations and Future Directions of ChatGPT in Medical Imaging

 ,
,  , , , ,
, , , ,
Abstract
1. Introduction
2. Literature Search Strategy
3. Natural Language Processing and Large Language Models
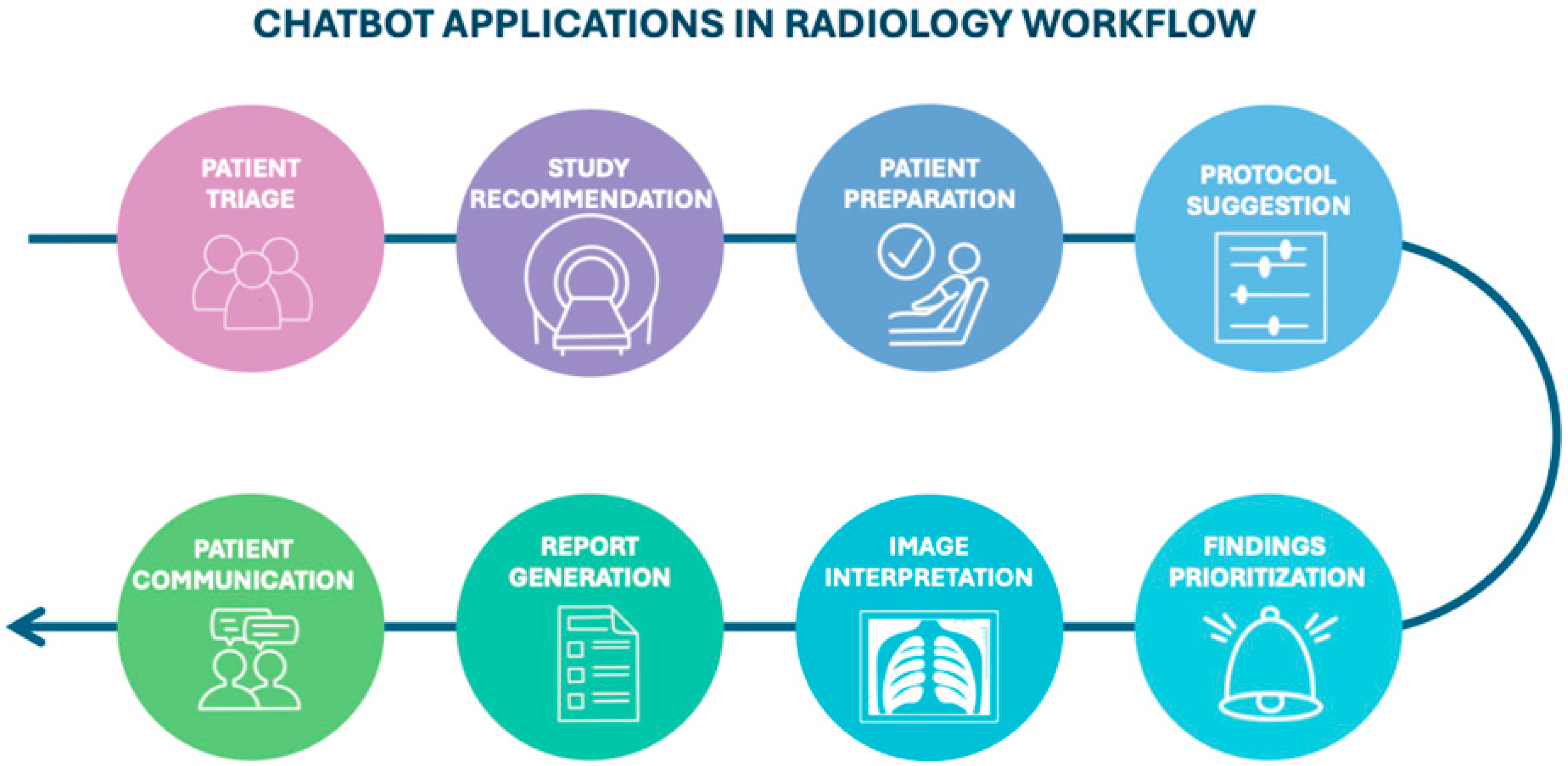
4. Current Applications in Radiology
4.1. Before Imaging: From Study Recommendation to Protocoling
4.2. Interpretation, Data Extraction and Diagnostic Capacity
4.3. Chatbots and Report Generation
- The “indication”, which outlines the clinical context and rationale for the examination.
- The “findings section”, which documents the radiologist’s observations from imaging data.
- The “impression”, which synthetizes key findings to inform potential diagnoses or management recommendations.
Structured Reporting
4.4. Role of Chatbots in Patient Communication
5. Performance of Contemporary Chatbots
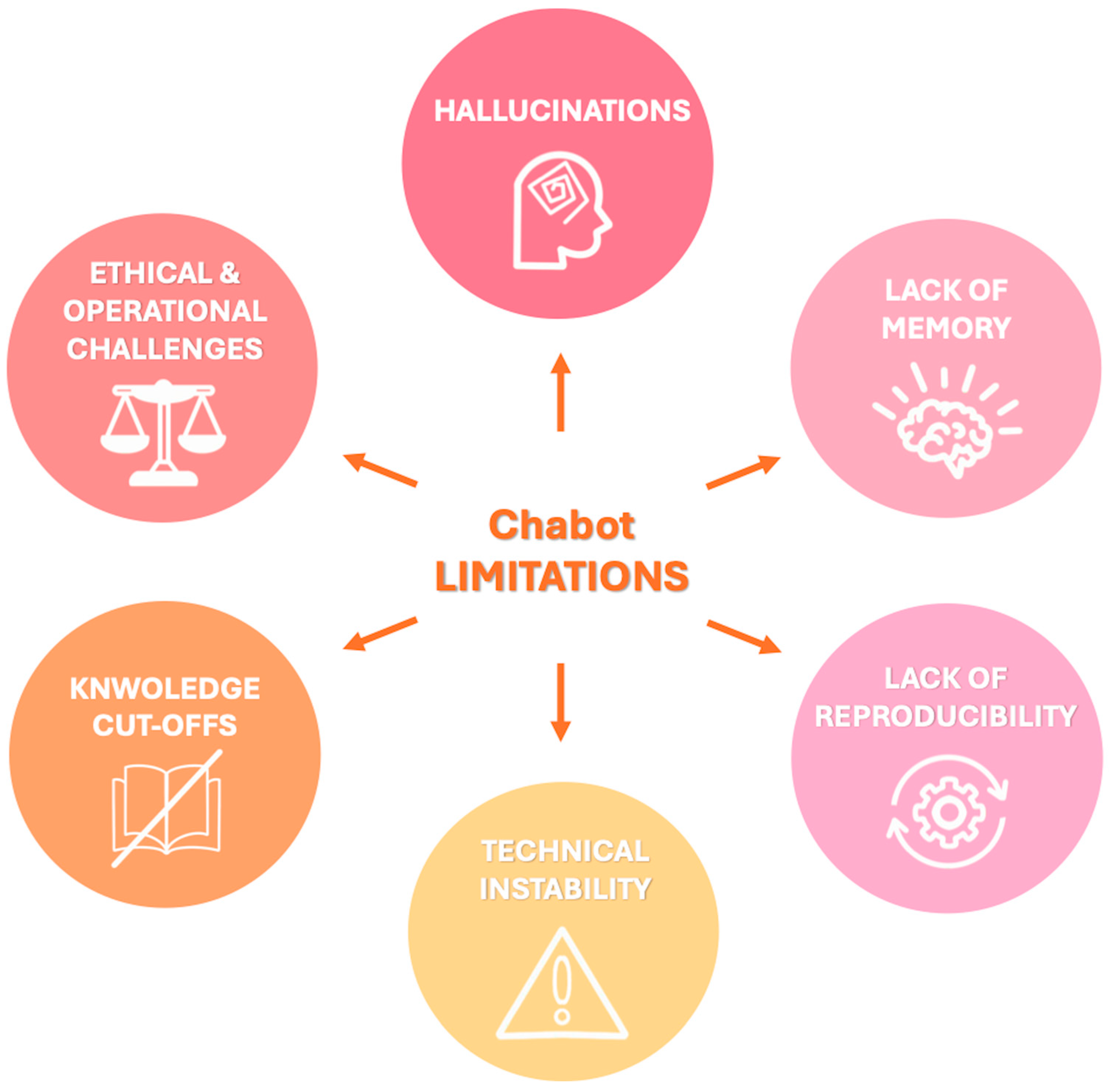
6. Limitations
- Hallucinations: LLMs may generate factually incorrect or fabricated content, a phenomenon known as “hallucination” since they generate responses based on patterns learned during training rather than verified data. For example, when asked about non-existent Lung-RADS categories, both ChatGPT and Bard gave confident but incorrect answers rather than indicating the absence of such categories [59]. The dissemination of inaccurate information by chatbots can have serious consequences for patient care, impacting not only clinical decision-making but also the psychological well-being of patients with increased emotional distress which has been linked to an elevated risk of suicidal behavior, especially among adolescents and young adults following a cancer diagnosis [55,59,60]. To mitigate hallucinations and improve factual consistency, recent developments have explored RAG models [48]. These systems combine LLMs with external information retrieval capabilities, enabling them to cite verifiable sources and improve reliability. For instance, a recent proof-of-concept study introduced the Gastrointestinal Imaging-Aware Chatbot (GIA-CB), a GPT-4–based model enhanced with domain-specific retrieval. When applied to abdominal imaging cases, GIA-CB outperformed standard GPT-4 in suggesting accurate differential diagnoses, demonstrating the value of domain-informed RAG systems [61].
- Lack of memory: Current LLMs do not have persistent memory of prior interactions. Each response is generated independently, without continuity, historical awareness, or contextual integration across sessions. Ongoing research is exploring LLMs with memory-enhanced architectures capable of retaining structured interaction histories and implementing a two-tier memory system—modeled after human short-term and long-term memory—to preserve context and ensure continuity throughout conversations [62]. Another promising approach involves developing longitudinal interaction-aware models that support session continuity or interface with electronic health records (EHRs) to maintain contextual coherence across multiple encounters [63].
- Lack of reproducibility: Responses to the same prompt may vary upon repetition due to the models’ stochastic and non-deterministic nature. While this enhances linguistic versatility, it limits credibility and undermines consistency in clinical applications [38]. To enhance the reproducibility of LLM outputs, several strategies have been employed to reduce response variability, including prompt engineering, modifying sampling techniques (e.g., nucleus sampling), and fixing the random seed; notably, setting the temperature parameter to 0.0 in conjunction with a fixed seed has been shown to produce more deterministic responses and minimize outlier benchmark scores, thereby improving the reliability and interpretability of evaluation results [64].
- Technical instability: ChatGPT and similar systems may experience latency or interruptions during periods of high usage, potentially delaying critical information retrieval [65].
- Knowledge cutoffs: LLMs are limited to the data available at the time of their last training update. They are not capable of incorporating newly published medical evidence, evolving guidelines, or real-time clinical data, resulting in potentially outdated or misleading recommendations [48]. One promising solution to this limitation is the integration of lifelong learning capabilities, which aim to enable LLM-based agents to continuously acquire, retain, and apply new knowledge over time, improving their adaptability to evolving medical contexts and enhancing the relevance and accuracy of their outputs in dynamic clinical environments [66].
- Data privacy: The use of AI tools in radiology often involves handling sensitive patient data. Reliance on cloud-based public platforms introduces risks of data breaches and unauthorized access. A potential solution is to use open-source LLMs within hospital networks. Since their source code is publicly available, they can be downloaded and implemented locally, helping to improve data security, ensure system availability, and promote transparency [67].
- Transparency and traceability: Most LLMs do not provide source references for their responses, complicating validation and undermining clinical trust. Transparency in AI systems requires clear communication about what the system can and cannot do, its purpose, the conditions under which it performs reliably, and its expected accuracy. This information is vital for healthcare providers, but also for patients, who should be informed when AI is involved in their care. Dealing with these ethical challenges in AI will require a multidisciplinary approach: combining technical safeguards, government regulation, oversight mechanisms, and collaborative ethical standards developed with input from clinicians, patients, AI developers, and ethicists [68,69].
- Monopolization of knowledge: The rapid development of LLMs has been dominated by a few large commercial entities (e.g., OpenAI/Microsoft, Google, Meta). To avoid the centralization of medical knowledge and preserve equitable access to AI technologies, support for non-commercial, open-source medical LLMs is crucial [14].
- Regulatory oversight: The absence of standardized policies regarding AI deployment, accountability, and error management poses risks to patient safety. Robust regulatory frameworks are necessary to guide safe and ethical AI integration into radiological workflows [48].
7. Future Directions
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| BERT | Bidirectional encoder representations from transformers |
| CAD-RADS | Coronary artery disease reporting and data system |
| CCTA | Coronary CT angiography |
| DWI | Diffusion-weighted imaging |
| GIA-CB | Gastrointestinal imaging-aware chatbot |
| GPT | Generative pretrained transformer |
| LLMs | Large language models |
| NLP | Natural language processing |
| RAG | Retrieval-augmented generation |
| USPSTF | United States Preventive Services Task Force |
| ViT | Vision transformer |
| ZSL | Zero-shot learning |
References
- Lanzafame, L.R.M.; Bucolo, G.M.; Muscogiuri, G.; Sironi, S.; Gaeta, M.; Ascenti, G.; Booz, C.; Vogl, T.J.; Blandino, A.; Mazziotti, S.; et al. Artificial intelligence in cardiovascular ct and mr imaging. Life 2023, 13, 507. [Google Scholar] [CrossRef]
- Lanzafame, L.R.M.; Gulli, C.; Booz, C.; Vogl, T.J.; Saba, L.; Cau, R.; Toia, P.; Ascenti, G.; Gaeta, M.; Mazziotti, S.; et al. Advancements in computed tomography angiography for pulmonary embolism assessment. Echocardiography 2025, 42, e70116. [Google Scholar] [CrossRef] [PubMed]
- D’Angelo, T.; Caudo, D.; Blandino, A.; Albrecht, M.H.; Vogl, T.J.; Gruenewald, L.D.; Gaeta, M.; Yel, I.; Koch, V.; Martin, S.S.; et al. Artificial intelligence, machine learning and deep learning in musculoskeletal imaging: Current applications. J. Clin. Ultrasound 2022, 50, 1414–1431. [Google Scholar] [CrossRef]
- D’Angelo, T.; Bucolo, G.M.; Kamareddine, T.; Yel, I.; Koch, V.; Gruenewald, L.D.; Martin, S.; Alizadeh, L.S.; Mazziotti, S.; Blandino, A.; et al. Accuracy and time efficiency of a novel deep learning algorithm for intracranial hemorrhage detection in ct scans. Radiol. Med. 2024, 129, 1499–1506. [Google Scholar] [CrossRef]
- Reschke, P.; Gotta, J.; Gruenewald, L.D.; Bachir, A.A.; Strecker, R.; Nickel, D.; Booz, C.; Martin, S.S.; Scholtz, J.E.; D’Angelo, T.; et al. Deep learning in knee mri: A prospective study to enhance efficiency, diagnostic confidence and sustainability. Acad. Radiol. 2025, 32, 3585–3596. [Google Scholar] [CrossRef] [PubMed]
- Laymouna, M.; Ma, Y.; Lessard, D.; Schuster, T.; Engler, K.; Lebouché, B. Roles, users, benefits, and limitations of chatbots in health care: Rapid review. J. Med. Internet Res. 2024, 26, e56930. [Google Scholar] [CrossRef] [PubMed]
- Hindelang, M.; Sitaru, S.; Zink, A. Transforming health care through chatbots for medical history-taking and future directions: Comprehensive systematic review. JMIR Med. Inform. 2024, 12, e56628. [Google Scholar] [CrossRef]
- Avanzo, M.; Stancanello, J.; Pirrone, G.; Drigo, A.; Retico, A. The evolution of artificial intelligence in medical imaging: From computer science to machine and deep learning. Cancers 2024, 16, 3702. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. Chatbots: History, technology, and applications. Mach. Learn. Appl. 2020, 2, 100006. [Google Scholar] [CrossRef]
- Giansanti, D. The chatbots are invading us: A map point on the evolution, applications, opportunities, and emerging problems in the health domain. Life 2023, 13, 1130. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. An overview of chatbot technology. In Artificial Intelligence Applications and Innovations; Springer International Publishing: Cham, Switzerland, 2020; pp. 373–383. [Google Scholar]
- Caldarini, G.; Jaf, S.; McGarry, K. A literature survey of recent advances in chatbots. Information 2022, 13, 41. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Clusmann, J.; Kolbinger, F.R.; Muti, H.S.; Carrero, Z.I.; Eckardt, J.-N.; Laleh, N.G.; Löffler, C.M.L.; Schwarzkopf, S.-C.; Unger, M.; Veldhuizen, G.P.; et al. The future landscape of large language models in medicine. Commun. Med. 2023, 3, 141. [Google Scholar] [CrossRef]
- Bhayana, R. Chatbots and large language models in radiology: A practical primer for clinical and research applications. Radiology 2024, 310, e232756. [Google Scholar] [CrossRef] [PubMed]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef] [PubMed]
- Kalidindi, S.; Baradwaj, J. Advancing radiology with gpt-4: Innovations in clinical applications, patient engagement, research, and learning. Eur. J. Radiol. Open 2024, 13, 100589. [Google Scholar] [CrossRef]
- Liu, L.; Yang, X.; Lei, J.; Liu, X.; Shen, Y.; Zhang, Z.; Wei, P.; Gu, J.; Chu, Z.; Qin, Z. A survey on medical large language models: Technology, application, trustworthiness, and future directions. arXiv 2024, arXiv:2406.03712. [Google Scholar]
- Bautista, A.B.; Burgos, A.; Nickel, B.J.; Yoon, J.J.; Tilara, A.A.; Amorosa, J.K. Do clinicians use the american college of radiology appropriateness criteria in the management of their patients? AJR Am. J. Roentgenol. 2009, 192, 1581–1585. [Google Scholar] [CrossRef]
- Rau, A.; Rau, S.; Zöller, D.; Fink, A.; Tran, H.; Wilpert, C.; Nattenmüller, J.; Neubauer, J.; Bamberg, F.; Reisert, M.; et al. A context-based chatbot surpasses radiologists and generic chatgpt in following the acr appropriateness guidelines. Radiology 2023, 308, e230970. [Google Scholar] [CrossRef]
- Barash, Y.; Klang, E.; Konen, E.; Sorin, V. Chatgpt-4 assistance in optimizing emergency department radiology referrals and imaging selection. J. Am. Coll. Radiol. 2023, 20, 998–1003. [Google Scholar] [CrossRef]
- Gupta, M.; Gupta, P.; Ho, C.; Wood, J.; Guleria, S.; Virostko, J. Can generative ai improve the readability of patient education materials at a radiology practice? Clin. Radiol. 2024, 79, e1366–e1371. [Google Scholar] [CrossRef]
- Kaba, E.; Beyazal, M.; Çeliker, F.B.; Yel, İ.; Vogl, T.J. Accuracy and readability of chatgpt on potential complications of interventional radiology procedures: Ai-powered patient interviewing. Acad. Radiol. 2025, 32, 1547–1553. [Google Scholar] [CrossRef]
- Patil, N.S.; Huang, R.S.; Caterine, S.; Yao, J.; Larocque, N.; van der Pol, C.B.; Stubbs, E. Artificial intelligence chatbots’ understanding of the risks and benefits of computed tomography and magnetic resonance imaging scenarios. Can. Assoc. Radiol. J. 2024, 75, 518–524. [Google Scholar] [CrossRef] [PubMed]
- Elhakim, T.; Brea, A.R.; Fidelis, W.; Paravastu, S.S.; Malavia, M.; Omer, M.; Mort, A.; Ramasamy, S.K.; Tripathi, S.; Dezube, M.; et al. Enhanced procedural information readability for patient-centered care in interventional radiology with large language models (pro-read ir). J. Am. Coll. Radiol. 2025, 22, 84–97. [Google Scholar] [CrossRef] [PubMed]
- Gertz, R.J.; Bunck, A.C.; Lennartz, S.; Dratsch, T.; Iuga, A.-I.; Maintz, D.; Kottlors, J. Gpt-4 for automated determination of radiologic study and protocol based on radiology request forms: A feasibility study. Radiology 2023, 307, e230877. [Google Scholar] [CrossRef]
- Hallinan, J.; Leow, N.W.; Ong, W.; Lee, A.; Low, Y.X.; Chan, M.D.Z.; Devi, G.K.; Loh, D.D.; He, S.S.; Nor, F.E.M.; et al. Mri spine request form enhancement and auto protocoling using a secure institutional large language model. Spine J. 2025, 25, 505–514. [Google Scholar] [CrossRef]
- Koyun, M.; Taskent, I. Evaluation of advanced artificial intelligence algorithms’ diagnostic efficacy in acute ischemic stroke: A comparative analysis of chatgpt-4o and claude 3.5 sonnet models. J. Clin. Med. 2025, 14, 571. [Google Scholar] [CrossRef] [PubMed]
- Kasalak, Ö.; Alnahwi, H.; Toxopeus, R.; Pennings, J.P.; Yakar, D.; Kwee, T.C. Work overload and diagnostic errors in radiology. Eur. J. Radiol. 2023, 167, 111032. [Google Scholar] [CrossRef]
- Horiuchi, D.; Tatekawa, H.; Shimono, T.; Walston, S.L.; Takita, H.; Matsushita, S.; Oura, T.; Mitsuyama, Y.; Miki, Y.; Ueda, D. Accuracy of chatgpt generated diagnosis from patient’s medical history and imaging findings in neuroradiology cases. Neuroradiology 2024, 66, 73–79. [Google Scholar] [CrossRef]
- Mitsuyama, Y.; Tatekawa, H.; Takita, H.; Sasaki, F.; Tashiro, A.; Oue, S.; Walston, S.L.; Nonomiya, Y.; Shintani, A.; Miki, Y.; et al. Comparative analysis of gpt-4-based chatgpt’s diagnostic performance with radiologists using real-world radiology reports of brain tumors. Eur. Radiol. 2024, 35, 1938–1947. [Google Scholar] [CrossRef]
- Rezaei, M.; Shahidi, M. Zero-shot learning and its applications from autonomous vehicles to covid-19 diagnosis: A review. Intell. Based Med. 2020, 3, 100005. [Google Scholar] [CrossRef]
- Kelly, B.S.; Duignan, S.; Mathur, P.; Dillon, H.; Lee, E.H.; Yeom, K.W.; Keane, P.A.; Lawlor, A.; Killeen, R.P. Can chatgpt4-vision identify radiologic progression of multiple sclerosis on brain mri? Eur. Radiol. Exp. 2025, 9, 9. [Google Scholar] [CrossRef] [PubMed]
- Dehdab, R.; Brendlin, A.; Werner, S.; Almansour, H.; Gassenmaier, S.; Brendel, J.M.; Nikolaou, K.; Afat, S. Evaluating chatgpt-4v in chest ct diagnostics: A critical image interpretation assessment. Jpn. J. Radiol. 2024, 42, 1168–1177. [Google Scholar] [CrossRef]
- Haver, H.L.; Bahl, M.; Doo, F.X.; Kamel, P.I.; Parekh, V.S.; Jeudy, J.; Yi, P.H. Evaluation of multimodal chatgpt (gpt-4v) in describing mammography image features. Can. Assoc. Radiol. J. 2024, 75, 947–949. [Google Scholar] [CrossRef] [PubMed]
- Koyun, M.; Cevval, Z.K.; Reis, B.; Ece, B. Detection of intracranial hemorrhage from computed tomography images: Diagnostic role and efficacy of chatgpt-4o. Diagnostics 2025, 15, 143. [Google Scholar] [CrossRef]
- Nickel, B.; Ayre, J.; Marinovich, M.L.; Smith, D.P.; Chiam, K.; Lee, C.I.; Wilt, T.J.; Taba, M.; McCaffery, K.; Houssami, N. Are ai chatbots concordant with evidence-based cancer screening recommendations? Patient Educ. Couns. 2025, 134, 108677. [Google Scholar] [CrossRef]
- Kim, S.; Lee, C.-K.; Kim, S.-S. Large language models: A guide for radiologists. Korean J. Radiol. 2024, 25, 126–133. [Google Scholar] [CrossRef] [PubMed]
- Hu, D.; Zhang, H.; Li, S.; Wang, Y.; Wu, N.; Lu, X. Automatic extraction of lung cancer staging information from computed tomography reports: Deep learning approach. JMIR Med. Inform. 2021, 9, e27955. [Google Scholar] [CrossRef]
- Zhou, S.; Wang, N.; Wang, L.; Liu, H.; Zhang, R. Cancerbert: A cancer domain-specific language model for extracting breast cancer phenotypes from electronic health records. J. Am. Med. Inform. Assoc. 2022, 29, 1208–1216. [Google Scholar] [CrossRef]
- Fink, M.A.; Bischoff, A.; Fink, C.A.; Moll, M.; Kroschke, J.; Dulz, L.; Heußel, C.P.; Kauczor, H.U.; Weber, T.F. Potential of chatgpt and gpt-4 for data mining of free-text ct reports on lung cancer. Radiology 2023, 308, e231362. [Google Scholar] [CrossRef]
- Tozuka, R.; Johno, H.; Amakawa, A.; Sato, J.; Muto, M.; Seki, S.; Komaba, A.; Onishi, H. Application of notebooklm, a large language model with retrieval-augmented generation, for lung cancer staging. Jpn. J. Radiol. 2024, 43, 706–712. [Google Scholar] [CrossRef]
- Sun, Z.; Ong, H.; Kennedy, P.; Tang, L.; Chen, S.; Elias, J.; Lucas, E.; Shih, G.; Peng, Y. Evaluating gpt-4 on impressions generation in radiology reports. Radiology 2023, 307, e231259. [Google Scholar] [CrossRef] [PubMed]
- Temperley, H.C.; O’Sullivan, N.J.; Curtain, B.M.M.; Corr, A.; Meaney, J.F.; Kelly, M.E.; Brennan, I. Current applications and future potential of chatgpt in radiology: A systematic review. J. Med. Imaging Radiat. Oncol. 2024, 68, 257–264. [Google Scholar] [CrossRef]
- Truhn, D.; Weber, C.D.; Braun, B.J.; Bressem, K.; Kather, J.N.; Kuhl, C.; Nebelung, S. A pilot study on the efficacy of gpt-4 in providing orthopedic treatment recommendations from mri reports. Sci. Rep. 2023, 13, 20159. [Google Scholar] [CrossRef]
- Sorin, V.; Klang, E.; Sklair-Levy, M.; Cohen, I.; Zippel, D.B.; Lahat, N.B.; Konen, E.; Barash, Y. Large language model (chatgpt) as a support tool for breast tumor board. NPJ Breast Cancer 2023, 9, 44. [Google Scholar] [CrossRef]
- Adams, L.C.; Truhn, D.; Busch, F.; Kader, A.; Niehues, S.M.; Makowski, M.R.; Bressem, K.K. Leveraging gpt-4 for post hoc transformation of free-text radiology reports into structured reporting: A multilingual feasibility study. Radiology 2023, 307, e230725. [Google Scholar] [CrossRef] [PubMed]
- Grewal, H.; Dhillon, G.; Monga, V.; Sharma, P.; Buddhavarapu, V.S.; Sidhu, G.; Kashyap, R. Radiology gets chatty: The chatgpt saga unfolds. Cureus 2023, 15, e40135. [Google Scholar] [CrossRef] [PubMed]
- Maroncelli, R.; Rizzo, V.; Pasculli, M.; Cicciarelli, F.; Macera, M.; Galati, F.; Catalano, C.; Pediconi, F. Probing clarity: Ai-generated simplified breast imaging reports for enhanced patient comprehension powered by chatgpt-4o. Eur. Radiol. Exp. 2024, 8, 124. [Google Scholar] [CrossRef]
- Salam, B.; Kravchenko, D.; Nowak, S.; Sprinkart, A.M.; Weinhold, L.; Odenthal, A.; Mesropyan, N.; Bischoff, L.M.; Attenberger, U.; Kuetting, D.L.; et al. Generative pre-trained transformer 4 makes cardiovascular magnetic resonance reports easy to understand. J. Cardiovasc. Magn. Reson. 2024, 26, 101035. [Google Scholar] [CrossRef]
- Tepe, M.; Emekli, E. Decoding medical jargon: The use of ai language models (chatgpt-4, bard, microsoft copilot) in radiology reports. Patient Educ. Couns. 2024, 126, 108307. [Google Scholar] [CrossRef]
- Encalada, S.; Gupta, S.; Hunt, C.; Eldrige, J.; Evans, J., 2nd; Mosquera-Moscoso, J.; de Mendonca, L.F.P.; Kanahan-Osman, S.; Bade, S.; Bade, S.; et al. Optimizing patient understanding of spine mri reports using ai: A prospective single center study. Interv. Pain. Med. 2025, 4, 100550. [Google Scholar] [CrossRef]
- Can, E.; Uller, W.; Vogt, K.; Doppler, M.C.; Busch, F.; Bayerl, N.; Ellmann, S.; Kader, A.; Elkilany, A.; Makowski, M.R.; et al. Large language models for simplified interventional radiology reports: A comparative analysis. Acad. Radiol. 2025, 32, 888–898. [Google Scholar] [CrossRef] [PubMed]
- Jeblick, K.; Schachtner, B.; Dexl, J.; Mittermeier, A.; Stüber, A.T.; Topalis, J.; Weber, T.; Wesp, P.; Sabel, B.O.; Ricke, J.; et al. Chatgpt makes medicine easy to swallow: An exploratory case study on simplified radiology reports. Eur. Radiol. 2024, 34, 2817–2825. [Google Scholar] [CrossRef]
- Rahsepar, A.A.; Tavakoli, N.; Kim, G.H.J.; Hassani, C.; Abtin, F.; Bedayat, A. How ai responds to common lung cancer questions: Chatgpt vs google bard. Radiology 2023, 307, e230922. [Google Scholar] [CrossRef] [PubMed]
- Doshi, R.; Amin, K.; Khosla, P.; Bajaj, S.; Chheang, S.; Forman, H.P. Utilizing large language models to simplify radiology reports: A comparative analysis of chatgpt3.5, chatgpt4.0, google bard, and microsoft bing. medRxiv 2023. [Google Scholar] [CrossRef]
- Silbergleit, M.; Tóth, A.; Chamberlin, J.H.; Hamouda, M.; Baruah, D.; Derrick, S.; Schoepf, U.J.; Burt, J.R.; Kabakus, I.M. Chatgpt vs gemini: Comparative accuracy and efficiency in cad-rads score assignment from radiology reports. J. Imaging. Inform. Med. 2024. [Google Scholar] [CrossRef] [PubMed]
- Nakamura, Y.; Kikuchi, T.; Yamagishi, Y.; Hanaoka, S.; Nakao, T.; Miki, S.; Yoshikawa, T.; Abe, O. Chatgpt for automating lung cancer staging: Feasibility study on open radiology report dataset. medRxiv 2023, 2023.12.11.23299107. [Google Scholar] [CrossRef]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst. 2025, 43, 1–55. [Google Scholar] [CrossRef]
- Lu, D.; Fall, K.; Sparén, P.; Ye, W.; Adami, H.O.; Valdimarsdóttir, U.; Fang, F. Suicide and suicide attempt after a cancer diagnosis among young individuals. Ann. Oncol. 2013, 24, 3112–3117. [Google Scholar] [CrossRef]
- Rau, S.; Rau, A.; Nattenmüller, J.; Fink, A.; Bamberg, F.; Reisert, M.; Russe, M.F. A retrieval-augmented chatbot based on gpt-4 provides appropriate differential diagnosis in gastrointestinal radiology: A proof of concept study. Eur. Radiol. Exp. 2024, 8, 60. [Google Scholar] [CrossRef]
- Liu, N.; Chen, L.; Tian, X.; Zou, W.; Chen, K.; Cui, M. From llm to conversational agent: A memory enhanced architecture with fine-tuning of large language models. arXiv 2024, arXiv:2401.02777. [Google Scholar]
- Carrasco-Ribelles, L.A.; Llanes-Jurado, J.; Gallego-Moll, C.; Cabrera-Bean, M.; Monteagudo-Zaragoza, M.; Violán, C.; Zabaleta-del-Olmo, E. Prediction models using artificial intelligence and longitudinal data from electronic health records: A systematic methodological review. J. Am. Med. Inform. Assoc. 2023, 30, 2072–2082. [Google Scholar] [CrossRef] [PubMed]
- Blackwell, R.E.; Barry, J.; Cohn, A.G. Towards reproducible llm evaluation: Quantifying uncertainty in llm benchmark scores. arXiv 2024, arXiv:2410.03492. [Google Scholar]
- Lecler, A.; Duron, L.; Soyer, P. Revolutionizing radiology with gpt-based models: Current applications, future possibilities and limitations of chatgpt. Diagn. Interv. Imaging 2023, 104, 269–274. [Google Scholar] [CrossRef]
- Zheng, J.; Shi, C.; Cai, X.; Li, Q.; Zhang, D.; Li, C.; Yu, D.; Ma, Q. Lifelong learning of large language model based agents: A roadmap. arXiv 2025, arXiv:2501.07278. [Google Scholar]
- Bluethgen, C.; Van Veen, D.; Zakka, C.; Link, K.E.; Fanous, A.H.; Daneshjou, R.; Frauenfelder, T.; Langlotz, C.P.; Gatidis, S.; Chaudhari, A. Best practices for large language models in radiology. Radiology 2025, 315, e240528. [Google Scholar] [CrossRef] [PubMed]
- Smuha, N.A. Regulation 2024/1689 of the Eur. Parl. & Council of June 13, 2024 (eu artificial intelligence act). Int. Leg. Mater. 2025, 1–148. [Google Scholar] [CrossRef]
- Brady, A.P.; Allen, B.; Chong, J.; Kotter, E.; Kottler, N.; Mongan, J.; Oakden-Rayner, L.; Santos, D.P.D.; Tang, A.; Wald, C.; et al. Developing, purchasing, implementing and monitoring ai tools in radiology: Practical considerations. A multi-society statement from the acr, car, esr, ranzcr & rsna. Insights Imaging 2024, 15, 16. [Google Scholar] [CrossRef] [PubMed]
- Tejani, A.S.; Cook, T.S.; Hussain, M.; Schmidt, T.S.; O’Donnell, K.P. Integrating and adopting ai in the radiology workflow: A primer for standards and integrating the healthcare enterprise (ihe) profiles. Radiology 2024, 311, e232653. [Google Scholar] [CrossRef]
- Barreda, M.; Cantarero-Prieto, D.; Coca, D.; Delgado, A.; Lanza-León, P.; Lera, J.; Montalbán, R.; Pérez, F. Transforming healthcare with chatbots: Uses and applications—A scoping review. Digit. Health 2025, 11, 20552076251319174. [Google Scholar] [CrossRef]
- Fgaier, M.; Zrubka, Z. Cost-effectiveness of using chatbots in healthcare: A systematic review. In Proceedings of the 2022 IEEE 22nd International Symposium on Computational Intelligence and Informatics and 8th IEEE International Conference on Recent Achievements in Mechatronics, Automation, Computer Science and Robotics (CINTI-MACRo), Budapest, Hungary, 21–22 November 2022; p. 000305-10. [Google Scholar] [CrossRef]
- Lastrucci, A.; Iosca, N.; Wandael, Y.; Barra, A.; Lepri, G.; Forini, N.; Ricci, R.; Miele, V.; Giansanti, D. Ai and interventional radiology: A narrative review of reviews on opportunities, challenges, and future directions. Diagnostics 2025, 15, 893. [Google Scholar] [CrossRef]
- Ballard, D.H.; Antigua-Made, A.; Barre, E.; Edney, E.; Gordon, E.B.; Kelahan, L.; Lodhi, T.; Martin, J.G.; Ozkan, M.; Serdynski, K.; et al. Impact of chatgpt and large language models on radiology education: Association of academic radiology—Radiology research alliance task force white paper. Acad. Radiol. 2024, 32, 3039–3049. [Google Scholar] [CrossRef] [PubMed]
- Bhayana, R.; Krishna, S.; Bleakney, R.R. Performance of chatgpt on a radiology board-style examination: Insights into current strengths and limitations. Radiology 2023, 307, e230582. [Google Scholar] [CrossRef] [PubMed]
- Lourenco, A.P.; Slanetz, P.J.; Baird, G.L. Rise of chatgpt: It may be time to reassess how we teach and test radiology residents. Radiology 2023, 307, e231053. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| Model/Tool | Description |
|---|---|
| GPT-4o | Multimodal model capable of processing and generating text, images, and audio in real time. GPT-4o offers faster performance and reduced costs compared to its predecessors. |
| GPT-4V | Extension of GPT-4 with vision capabilities, enabling the model to analyze and interpret image inputs. |
| ChatGPT-3.5 | Text-based model based on GPT-3.5 architecture, known for its proficiency in general reasoning tasks but with limitations in handling complex queries. |
| Claude 3.5 Sonnet | Mid-tier model in the Claude 3.5 family, optimized for reasoning and coding tasks, offering a balance between performance and efficiency. |
| Claude 3 (Opus, Sonnet, Haiku) | Family of large language models with varying capabilities, supporting extended context windows and multimodal inputs. |
| Gemini 1.5 (Pro, Flash) | Multimodal models with extended context lengths up to 1 million tokens. Pro offers comprehensive capabilities, while Flash is optimized for speed. |
| Google Bard | Conversational AI interface initially powered by PaLM 2 and later integrated with Gemini models, facilitating interactive dialogues and information retrieval. |
| NotebookLM | AI-powered research assistant designed to help users organize, summarize, and generate content from their documents, enhancing productivity and comprehension. |
| Med-PaLM 2 | Medical-domain-tuned version of PaLM 2, achieving expert-level performance on medical question-answering benchmarks such as MedQA. |
| BioGPT | Domain-specific LLM trained on biomedical literature, effective in biomedical named-entity recognition, question answering, and text-generation tasks. |
| PubMedBERT | Transformer model pretrained from scratch on PubMed abstracts and full texts, tailored for biomedical natural language processing tasks. |
| CancerBERT | BERT-based model trained on oncology-specific literature and electronic health records, designed for cancer-related text mining and analysis. |
| Clinical Camel | Open biomedical language model trained on clinical dialogues and notes, aiming to democratize access to clinical AI tools. |
| GatorTron | LLM trained on extensive clinical records and notes, targeting medical summarization, concept extraction, and decision support applications. |
| LLaVA-Med | Vision–language model fine-tuned on medical images and captions, adapted from LLaVA for medical visual question answering and image-captioning tasks. |
| Workflow Stage | Application Area | Potential Benefits | Limitations |
|---|---|---|---|
| Before Imaging |
|
|
|
| Interpretation, Data Extraction, and Diagnostic Capacity |
|
|
|
| Report Generation |
|
|
|
| Patient Communication |
|
|
|
| Scenario | Clinical Applications | Research Applications |
|---|---|---|
| Information Retrieval and Decision Support | Clinical decision-making support (e.g., appropriateness criteria), imaging protocol selection | Literature review, guideline analysis, and identification of relevant studies or datasets |
| Data Extraction and Structuring | Extraction of clinical history from notes, structured report generation from free text | Automated extraction of variables from radiology reports and clinical notes for data analysis |
| Image and Report Interpretation | Multimodal report generation (e.g., combining image and text), impression summarization | Evaluation of multimodal LLMs for diagnostic accuracy and radiologic pattern recognition |
| Communication and Language Simplification | Patient-facing explanations of radiology reports, response generation for FAQs, multilingual support | Natural language generation for lay summaries, survey creation, and dissemination of results |
| Analytical Processing and Computation | Risk stratification tools, real-time response systems, model-assisted triage | Preliminary data cleaning, visualization, and statistical modeling using LLM-integrated environments |
| Ethics, Bias and Sustainability | Privacy-preserving model deployment, mitigation of clinical bias, responsible AI use in care settings | Study of bias propagation, environmental impact of training/deployment, evaluation of open-source model utility |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lanzafame, L.R.M.; Gulli, C.; Mazziotti, S.; Ascenti, G.; Gaeta, M.; Vogl, T.J.; Yel, I.; Koch, V.; Grünewald, L.D.; Muscogiuri, G.; et al. Chatbots in Radiology: Current Applications, Limitations and Future Directions of ChatGPT in Medical Imaging. Diagnostics 2025, 15, 1635. https://doi.org/10.3390/diagnostics15131635
Lanzafame LRM, Gulli C, Mazziotti S, Ascenti G, Gaeta M, Vogl TJ, Yel I, Koch V, Grünewald LD, Muscogiuri G, et al. Chatbots in Radiology: Current Applications, Limitations and Future Directions of ChatGPT in Medical Imaging. Diagnostics. 2025; 15(13):1635. https://doi.org/10.3390/diagnostics15131635
Chicago/Turabian StyleLanzafame, Ludovica R. M., Claudia Gulli, Silvio Mazziotti, Giorgio Ascenti, Michele Gaeta, Thomas J. Vogl, Ibrahim Yel, Vitali Koch, Leon D. Grünewald, Giuseppe Muscogiuri, and et al. 2025. "Chatbots in Radiology: Current Applications, Limitations and Future Directions of ChatGPT in Medical Imaging" Diagnostics 15, no. 13: 1635. https://doi.org/10.3390/diagnostics15131635
APA StyleLanzafame, L. R. M., Gulli, C., Mazziotti, S., Ascenti, G., Gaeta, M., Vogl, T. J., Yel, I., Koch, V., Grünewald, L. D., Muscogiuri, G., Booz, C., & D’Angelo, T. (2025). Chatbots in Radiology: Current Applications, Limitations and Future Directions of ChatGPT in Medical Imaging. Diagnostics, 15(13), 1635. https://doi.org/10.3390/diagnostics15131635