Abstract
To improve synthetic CT (sCT) generation from cone-beam CT (CBCT) in radiotherapy, we propose a multiscale segmentation-guided diffusion framework. The proposed model integrates anatomical priors across multiple spatial resolutions through a segmentation mask pyramid and introduces a scale-specific loss function to guide learning at each level. When evaluated on the SynthRAD2023 brain dataset, our model achieves a mean absolute error (MAE) of 61.82 HU, a peak signal-to-noise ratio (PSNR) of 32.05 dB, and a structural similarity index (SSIM) of 0.90, outperforming baseline models. These results suggest that multiscale anatomical guidance can improve the fidelity and anatomical consistency of sCT images, thus facilitating high-quality CBCT-to-CT translation in radiotherapy applications.
1. Introduction
Image-guided adaptive radiotherapy (IGART) has been widely adopted due to its ability to improve treatment precision. By using real-time imaging to monitor and adapt to anatomical changes, IGART enables dynamic adjustments to radiotherapy plans throughout the course of therapy [1,2]. To support this paradigm, clinical workflows often rely on several imaging modalities, including computed tomography (CT), cone-beam CT (CBCT), and magnetic resonance imaging (MRI). Among these, CT remains the primary adopted imaging modality for treatment planning since it provides electron density information essential for accurate dose calculation [3]. However, repeated CT scans may increase ionizing radiation exposure and introduce additional complexity into clinical workflows [4]. Therefore, CBCT has emerged as a practical alternative to CT. Although CBCT can be seamlessly integrated into linear accelerators and enables frequent imaging, CBCT images suffer from several drawbacks, including artifacts caused by scatter noise, low soft-tissue contrast, and truncated projections, which restrict their direct use in treatment planning [5,6]. Although another substitute, MRI, is free of ionizing radiation and superior in soft-tissue contrast, it is costly and incompatible with conventional radiotherapy infrastructure [7,8]. These challenges have motivated the development of synthetic CT (sCT) techniques, which generate CT-equivalent images from alternative modalities, most notably CBCT, thus facilitating online adaptive radiotherapy without imposing additional radiation burden on the patient [3,9,10].
In recent years, various deep learning models have been applied to improve the accuracy of sCT images, ranging from generative adversarial networks (GANs) to recent conditional diffusion models [11,12]. In particular, conditional diffusion models [13,14] have exhibited outstanding feasibility compared to GANs in different anatomical sites, such as the lung [15] and brain [16]. To further improve the fidelity of sCT, energy-guided diffusion models [17] and frequency-guided diffusion models [18,19] have attracted attention for their efficacy in both paired and unpaired settings. Despite these advances, diffusion models often struggle to reconstruct anatomical consistency [20,21]. This may restrict the clinical utility of generated sCT images, especially when precise delineation of organs is required [22]. To mitigate this limitation, recent studies have introduced anatomical priors into diffusion models by utilizing segmentation masks obtained from planning CTs, which are acquired before treatment [23,24]. Conditioned on this anatomical guidance, diffusion models are capable of recovering the anatomical structures, thus improving spatial alignment between sCT and ground-truth CT images. Nonetheless, these models commonly rely on single-scale segmentation masks, which may be insufficient to capture both global anatomical contours and local structural details. This challenge also arises in medical image segmentation tasks, where multiscale representations have been widely adopted to address this limitation. By integrating textural information across different spatial resolutions, the model learns to handle both global and local features [25,26,27]. For instance, the recent segmentation network designs a multi-scale attention module to extract both detailed and broad features [27].
Motivated by these findings, we propose a multiscale segmentation-guided diffusion framework that takes advantage of anatomical priors in the form of mask pyramids. Segmentation masks are first generated using a state-of-the-art segmentation model and then downsampled to construct a hierarchy of coarse-to-fine guidelines. This mask pyramid is integrated into the conditional diffusion model to provide structural information across multiple scales. Fine-scale masks emphasize detailed local features, while coarse-scale masks preserve broader global information. To complement the multiscale module, we introduce a scale-specific loss function, which computes the mean squared error (MSE) at each scale. This multiscale supervision enables the model to capture both local and global anatomical features, therefore improving the anatomical accuracy of sCT images and advancing the clinical usability of CBCT-to-CT synthesis.
2. Materials and Methods
2.1. Dataset Preparation
We used the brain dataset from the SynthRAD2023 challenge (Task 2), a multi-center benchmark dataset for evaluating synthetic CT (sCT) generation algorithms [28]. It consists of 180 patients with paired CBCT and CT images collected from multiple institutions, covering diverse anatomical sites and acquisition settings. All CBCT and CT images were pre-aligned using a standardized registration pipeline provided by the challenge organizers [28]. No additional deformable registration or intensity-based refinements were applied. For image preprocessing, both CBCT and CT images were clipped to the intensity range of Hounsfield units (HU) to suppress outliers, followed by intensity normalization to for stable model training. All images were resampled to an in-plane resolution of 1.0 × 1.0 mm2 in the axial view.
Segmentation masks were generated from the CT scans using TotalSegmentator (https://github.com/wasserth/TotalSegmentator (accessed on 20 October 2025)) [29], which extracts 117 anatomical structures via a pre-trained nnU-Net [30]. These masks serve as anatomical priors and provide structural guidance to the diffusion model. Although the CT scans used for mask generation are also used as reference targets in training, the masks themselves are not employed as prediction labels. This setup reflects a clinically realistic scenario where anatomical priors, typically available from planning CTs, can assist in guiding CBCT-to-CT synthesis. While this approach does not exactly replicate the clinical use of planning CT-derived masks, it provides a practical approximation for training and evaluating segmentation-guided methods in the absence of dedicated planning CT data. The resulting masks were later used to construct the multiscale mask pyramid, as detailed in Section 2.3. An overview of the proposed framework is illustrated in Figure 1.
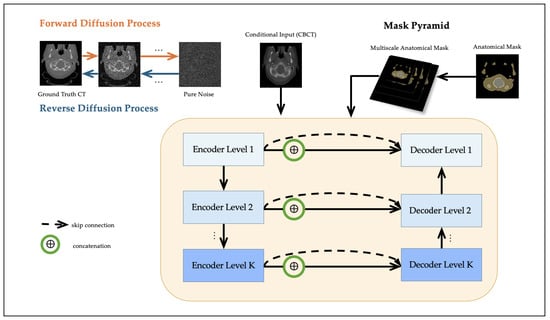
Figure 1.
Workflow of the proposed multiscale segmentation-guided diffusion model. The diffusion model is conditioned on the CBCT image, and a segmentation mask pyramid is injected into the U-Net denoising network through feature concatenation at multiple scales.
2.2. Conditional Diffusion Model
Our method is based on the conditional Denoising Diffusion Probabilistic Model (DDPM) [13], which generates synthetic CT (sCT) images from paired CBCT images y as conditioning inputs. The goal is to learn a conditional distribution using a U-Net-based denoising network.
During the forward diffusion process, Gaussian noise is gradually added to the clean CT image over T steps:
where , and is a fixed variance schedule.
The reverse process denoises to estimate by predicting the added noise using a parameterized model conditioned on the CBCT input y. The reverse distribution is defined as:
where the mean is computed as
and the posterior variance is
The training objective minimizes the MSE between the true noise and the predicted noise:
In our implementation, the CBCT image y is concatenated with the noisy CT input along the channel dimension and jointly passed through the denoising U-Net at each timestep. This conditioning allows the network to leverage anatomical structures present in the CBCT to better reconstruct the clean CT scans.
2.3. Multiscale Mask Pyramid Module
While conditional diffusion models effectively restore intensity distributions, they often struggle to recover subtle soft-tissue structures due to the lack of anatomical guidance. To address this limitation, we propose a multiscale module based on a mask pyramid that encodes anatomical priors at multiple spatial resolutions.
A high-resolution anatomical segmentation mask is first generated for each patient using TotalSegmentator [29]. The binary mask is subsequently downsampled using nearest-neighbor interpolation to construct a set of multiscale masks, denoted as , where each captures structural information at a distinct spatial scale k. Each level of the mask pyramid is spatially aligned with a corresponding decoder level in the UNet. Let denote the feature map at resolution level k. A lightweight convolutional embedding is applied to the segmentation mask, and the result is concatenated with to obtain the anatomically conditioned feature map :
This design enables hierarchical anatomical conditioning, where coarse-scale masks (e.g., ) support global structure alignment in deeper layers and fine-scale masks (e.g., ) guide local detail reconstruction in shallower layers. Unlike prior methods that rely on single-scale anatomical masks [23,24], our framework incorporates explicit multiscale anatomical guidance in both the network architecture and the loss function (described in Section 2.4). This allows the model to leverage anatomical priors across multiple receptive fields, which is particularly beneficial in anatomically heterogeneous regions such as bone–soft tissue boundaries.
2.4. Multiscale Anatomical Loss
To enhance anatomical supervision during training, we propose a multiscale anatomical loss that provides explicit guidance at each resolution level of the mask pyramid. At each scale k (for ), we compute the MSE between the predicted noise and the ground-truth noise , restricted to the spatial region defined by the corresponding downsampled segmentation mask . Formally, the total training objective is formulated as
where ⊙ denotes element-wise multiplication, and is the weight assigned to scale k.
This formulation enables the diffusion model to receive anatomically structured supervision across multiple spatial scales, allowing it to capture both coarse context and fine soft-tissue details during the denoising process. Further implementation details regarding the initialization and optimization of the scale weights are provided in Section 2.6.
2.5. Evaluation Metrics
We evaluated the accuracy of synthetic CT (sCT) generation using both standard image similarity metrics and clinically meaningful dose-relevant indicators. All metrics are computed slice-wise and then averaged across the test set. Let and denote the predicted and ground-truth CT intensities at pixel , over an image of size .
- Mean Absolute Error (MAE) measures the average voxel-wise intensity difference:
- Peak Signal-to-Noise Ratio (PSNR) is a logarithmic metric quantifying signal fidelity:where denotes the dynamic range of intensities. In our study, we set HU, corresponding to the intensity clipping range of HU.
- Structural Similarity Index (SSIM) evaluates structural agreement in local image patches:where x and y are local image patches from sCT and CT; , , and denote mean, variance, and covariance. Constants and are defined as and , where L is the dynamic range of the image. We set , corresponding to the intensity clipping range.
- HU Bias reflects the global intensity offset between sCT and reference CT, which is critical for dose calculation. A smaller HU bias (ideally close to 0) indicates better calibration of synthetic intensities:
- Gradient Root Mean Square Error (Grad-RMSE) is a common metric to assess anatomical sharpness and structural fidelity:where ∇ denotes the image gradient operator (e.g., Sobel or central difference), capturing spatial intensity changes. Lower Gradient RMSE indicates better preservation of anatomical boundaries, making it particularly important for downstream applications such as segmentation or dose calculation near organ interfaces.
- Dice Similarity Coefficient (DSC) is computed to quantify the structural agreement between anatomical segmentations derived from sCT and CT images. Specifically, we apply tools such as TotalSegmentator to extract segmentation masks from both domains and compute their overlap:where A and B denote the predicted and reference segmentation masks. A higher Dice score indicates improved anatomical consistency and potentially greater dosimetric reliability.
- To quantify tissue-wise accuracy, we also compute the MAE within three HU-defined anatomical regions: air (HU < ), soft tissue (HU between and 300), and bone (HU > 300). Let denote the set of pixels belonging to region r. The region-specific MAE is computed asThese region-specific errors provide a more clinically meaningful evaluation of synthetic CT accuracy, particularly in capturing air-tissue interfaces, soft tissue contrast, and bone density.
2.6. Implementation Details
All experiments were conducted on NVIDIA A100 GPUs. The base architecture is a conditional DDPM with the UNet backbone comprising residual and attention blocks, following Peng et al. [16]. The UNet consists of four resolution levels with feature channel dimensions of . Each level contains two residual blocks, and attention layers are applied at the two lowest resolutions (i.e., spatial sizes of 64 and 32).
The diffusion process uses timesteps with a cosine noise scheduler. We used the Adam optimizer with an initial learning rate of , cosine annealing learning rate decay, and a batch size of 4. All models were trained for 200 epochs using automatic mixed precision (AMP) to accelerate convergence. During training, we evaluated model performance on the validation set after each epoch. The checkpoint with the lowest validation loss was selected for final testing.
For anatomical supervision, a segmentation mask pyramid was constructed by downsampling the full-resolution binary mask . Each scale-specific mask is spatially aligned with a decoder stage in the UNet, and its embedding is injected as described in Section 2.3. To assess the effect of multiscale anatomical guidance, we experimented with different numbers of active mask levels, e.g., (only including ), (using ), and (using ). For each setting, the anatomical loss was only applied at the selected scales. The scale weights were initialized as and implemented as learnable scaler parameters jointly optimized with the model.
To prevent trivial minimization of the anatomical loss (e.g., all reduces to 0), we applied Dropout () in the decoder and used early stopping based on validation loss. These implicit regularization strategies encouraged the model to retain meaningful anatomical supervision at multiple scales. Empirically, all scale weights remained non-zero throughout training.
3. Results
3.1. Experimental Setup
We conducted all experiments on the SynthRAD2023 brain dataset, which was split at the patient level into 160 training, 20 validation, and 20 testing cases using a fixed random seed to ensure reproducibility. To prevent data leakage, each patient was assigned to only one subset. All CBCT and CT volumes were preprocessed by clipping to a fixed intensity range of HU and normalized to . During evaluation, predictions were rescaled to HU using the inverse of the normalization transformation.
All metrics were computed on 2D axial slices and then averaged across the entire test set. We reported MAE, PSNR, SSIM, HU bias, gradient RMSE, DSC, and region-specific MAE (air, soft tissue, bone). SSIM was calculated per slice using a Gaussian window and masked to exclude background voxels. As a reference baseline, we also included CBCT-versus-CT comparisons to reflect the initial image fidelity prior to synthesis.
3.2. Ablation Study
We compared the following configurations to systematically evaluate the impact of anatomical guidance and multiscale supervision.
- CBCT: Raw CBCT images directly compared with the ground-truth CT, without any synthesis.
- Baseline Diffusion [16]: A conditional DDPM with a UNet backbone, trained without anatomical supervision.
- SegGuided Diffusion (Single-scale, ) [23]: The baseline DDPM trained with a single binary anatomical mask derived from TotalSegmentator as structural guidance.
- Multiscale SegGuided Diffusion (): An extension of the SegGuided model that incorporates a multiscale mask pyramid by downsampling the original mask to K additional resolutions, aligned with the encoder. Here, K denotes the number of auxiliary mask levels beyond the full-resolution input .
- Multiscale SegGuided Diffusion with Multiscale Loss: The above model is further enhanced by a multiscale anatomical loss applied at each decoder resolution to enforce anatomical consistency across scales.
All models were trained under identical optimization settings and number of training iterations. To ensure fair comparison, the model architecture was kept constant across all ablation variants. The number of parameters (83.4M), FLOPs (479.1 GFLOPs), and inference time (around 30 s per 2D slice) remained consistent, as all anatomical branches and mask embeddings were pre-defined in the model and dynamically activated during inference.
Quantitative results on the testing set are summarized in Table 1. The raw CBCT input shows substantial deviation from ground-truth CT, with a high MAE of 507.32 HU and a low SSIM of 0.65, underscoring the need for accurate sCT synthesis in clinical practice. The baseline diffusion model significantly reduces this gap, achieving an MAE of 69.78 HU and an SSIM of 0.87, demonstrating the efficacy of conditional diffusion models for sCT generation. Introducing single-scale anatomical guidance (SegGuided Diffusion, ) further improves performance across all metrics, confirming the importance of structural supervision. Extending to a multiscale anatomical module yields the best performance at , reaching an MAE of 62.69 HU and SSIM of 0.89. We observed slightly worse results at (possibly due to limited hierarchical context), and diminishing returns at (suggesting oversaturation of redundant spatial priors).

Table 1.
Ablation study evaluating the impact of anatomical supervision and multiscale components on CBCT-to-CT synthesis. ↓ stands for lower is better, and ↑ stands for higher is better. The bold values indicate the best performance across all methods for each metric.
Ultimately, the combination of multiscale anatomical conditioning and multiscale supervision loss yields the best overall performance, achieving an MAE of 61.82 HU and a PSNR of 32.05 dB. Compared to the original CBCT, this represents an 88% reduction in intensity error and an improvement of over 10 dB in image quality. These results highlight the potential of multiscale anatomical guidance to improve pixel-level accuracy and structural consistency in sCT generation, thereby promoting CBCT-to-CT translation for radiotherapy applications.
3.3. Quantitative Results
We compared our proposed multiscale framework with several baseline architectures for CBCT-to-CT translation, including CycleGAN [31], UNet [32], UNet++ [33], and Swin-UNet [34], as summarized in Table 2.
Table 2.
Performance of different architectures for CBCT-to-CT translation. ↓ stands for lower is better, and ↑ stands for higher is better. The bold values indicate the best performance across all methods for each metric.
Compared to the raw CBCT input, which exhibits poor image fidelity (MAE: 507.32 HU, SSIM: 0.65) and large HU bias (−219.36 HU), all deep learning-based models reduce reconstruction error. CycleGAN improves overall structure but still suffers from high variance and residual HU bias, possibly due to mode collapse or training instability. Swin-UNet, a transformer-based architecture, offers moderate improvements, but its performance is generally comparable to that of the GAN model. In contrast, UNet and UNet++ achieve lower MAEs (64.60 HU and 62.04 HU, respectively) and reduce HU bias to ±5 HU. They also improve region-specific accuracy, particularly in air and bone regions, and achieve DSC exceeding 0.94.
Our proposed model, Multiscale SegGuided Diffusion, further outperforms these baseline models across all metrics. Notably, the model combining multiscale anatomical priors with multiscale supervision (Multiscale SegGuided Diffusion with Multiscale Loss) achieves the best results: PSNR of 32.05 dB, SSIM of 0.90, and a nearly zero HU bias (−0.72 HU). It also yields the lowest gradient RMSE (696.86), indicating improved preservation of anatomical boundaries. For tissue-specific metrics, our model reports the lowest MAEs across air (21.0 HU), soft tissue (34.84 HU), and bone (113.06 HU), demonstrating its robustness across different regions.
As shown in Figure 2, our method exhibits both the lowest average MAE and the narrowest interquartile range among all the compared methods. In contrast, CycleGAN and Swin-UNet display wider spreads with higher upper tails, indicating less consistent performance among patients. Combined with the results of Table 2, this supports the clinical robustness of our multiscale-guided framework.
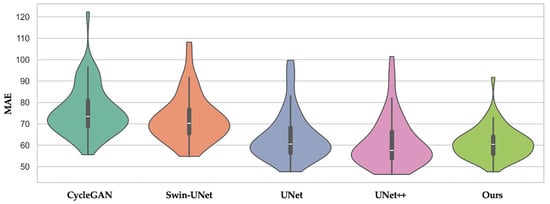
Figure 2.
Violin plot of MAE across patients for CycleGAN, Swin-UNet, UNet, UNet++, and our proposed method. The distribution shows that our method not only achieves lower average MAE but also exhibits less inter-patient variance.
Together, these findings suggest that integrating multiscale anatomical guidance and multiscale supervision into the diffusion framework not only enhances image quality but also improves clinical reliability by reducing HU error and and preserving anatomical consistency.
3.4. Qualitative Results
Figure 3 and Figure 4 present representative cases from the testing set. Both include sCT images predicted by different models, as well as the corresponding error maps compared to the ground-truth CT scans. As seen in both cases, UNet++ successfully recovers anatomical outlines but tends to produce blurring in soft-tissue regions. In contrast, our proposed Multiscale SegGuided Diffusion model supervised with multiscale loss displays improved anatomical contrast and edge continuity. These qualitative observations are consistent with the quantitative results reported in Table 1, denoting the significance of multiscale anatomical guidance to improve both numerical precision and visual quality.
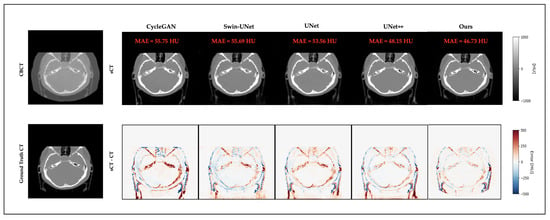
Figure 3.
Qualitative comparison on a representative brain slice. Top: CBCT and sCT images generated by different models. Bottom: ground-truth CT and error maps compared to ground-truth CT.
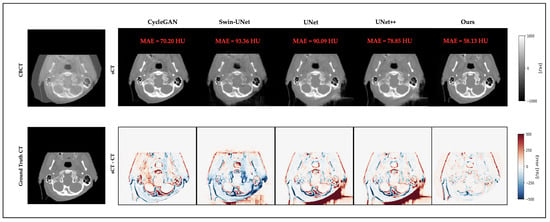
Figure 4.
Another representative example of a brain slice. Top: CBCT and sCT images generated by different models. Bottom: ground-truth CT and error maps compared to ground-truth CT.
Despite the overall strong performance of our model, Figure 5 presents three representative failure cases. In these examples, the presence of severe artifacts and limited field of view (FOV) in the CBCT inputs significantly hinders model performance. These challenges result in missing tissues or anatomical distortions in the generated sCT images, revealing the limitations of our model under incomplete or noisy acquisition conditions.
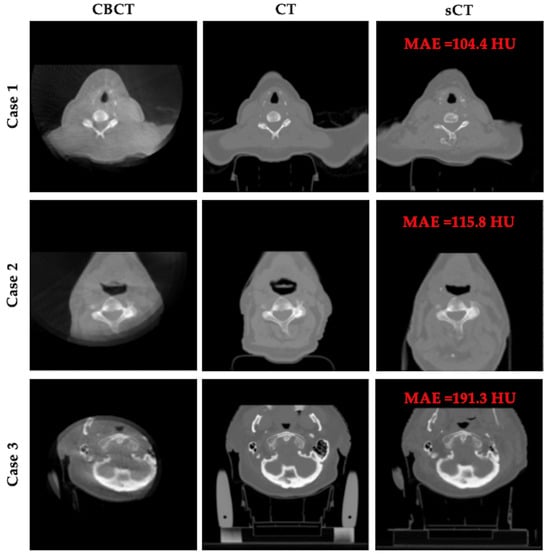
Figure 5.
Representative failure cases. Each row shows CBCT, planning CT, and sCT results for a patient.
4. Discussion
This study aims to evaluate whether incorporating multiscale segmentation guidance into a diffusion framework can enhance the fidelity and anatomical consistency of sCT images generated from CBCT inputs. While diffusion models have demonstrated remarkable success in medical image synthesis due to stability and generative capacity [15,16,35,36], their lack of explicit anatomical guidance can result in suboptimal structural accuracy, especially in critical soft-tissue regions [23,24,37].
To address this limitation, segmentation-based anatomical priors were introduced into the diffusion process, where they demonstrated their efficacy in significantly enhancing structural consistency [23,24]. Building upon this direction, we propose a multiscale segmentation-guided framework, motivated by the hypothesis that anatomical priors should not be limited to a single spatial scale. The multiscale module has been proven to improve model performance in medical image segmentation by capturing both local anatomical details and global structural information [25,26,27]. To synchronize the multiscale anatomical guidance, we introduce a multiscale loss function that supervises structural consistency at each resolution level. Both quantitative and qualitative results demonstrate that our proposed framework not only decreases intensity error between original CBCT and reference CT images but also reconstructs better anatomical details.
Several recent works have explored the SynthRAD2023 Task 2 dataset, offering diverse solutions to the CBCT-to-CT translation problem. In ARTInp [38], a two-stage framework is proposed that first inpaints missing CBCT regions before applying a translation model, achieving a PSNR of around 27 dB. STF-RUE [24] combined single-mask segmentation guidance with uncertainty quantification, highlighting the clinical relevance of structure-aware synthesis. GLFC [39] introduced Mamba-enhanced global–local contrast learning and achieved a top SSIM of 0.915. These methods underscore the importance of anatomical fidelity and model robustness. Compared to these approaches, our proposed Multiscale SegGuided Diffusion model achieves competitive or superior performance, with a PSNR of 32.05 dB and SSIM of 0.90 while maintaining nearly zero HU bias. In contrast to ARTInp, which relies on explicit image inpainting, our framework operates end-to-end and dynamically incorporates multiscale anatomical priors during denoising, with an additional multiscale supervision loss at multiple resolutions. Although STF-RUE focuses on uncertainty bounds, our method emphasizes structural guidance through multiscale supervision, although it faces challenges in regions with severe CBCT artifacts or truncated fields of view. Taken together, our results demonstrate that diffusion models incorporated with multiscale segmentation priors offer a promising direction for robust and anatomically faithful CBCT-to-CT translation.
However, our approach has several limitations. First, the current framework requires both segmentation masks and CBCT images during training, which may not be readily available in various clinical settings. Second, while our method improves the overall quality of sCT images, it struggles to restore fine anatomical details in high-frequency regions such as the skull. To address this, future work will investigate the integration of frequency-guided diffusion models [18,19] and anatomical priors. Additionally, the current implementation is based on 2D slices, which may restrict spatial continuity and volumetric consistency. Extending the framework to a 3D model can further strengthen its clinical usability in sCT generation. To assess the generalizability of the model, we will also incorporate center-held-out validation schemes where all patients from one institution are excluded from training. This will allow a more rigorous evaluation of domain robustness under institutional shifts. Future work also includes evaluating dose-aware endpoints such as DVH and gamma analysis once treatment plans become available.
5. Conclusions
In this study, we proposed a multiscale segmentation-guided diffusion framework for CBCT-to-CT synthesis. By integrating a multiscale segmentation mask pyramid and a scale-specific anatomical loss, our method demonstrates improved fidelity and anatomical consistency in synthetic CT images on the SynthRAD2023 brain dataset. While the results show promising improvements over baseline diffusion and convolutional models, they are currently validated on a single anatomical site. Future extensions will involve 3D volumetric models, multi-site validation, and assessments toward real-time clinical deployment in adaptive workflows.
Author Contributions
Conceptualization, Y.G., Y.L. and K.D.; methodology, Y.G. and Y.L.; software, Y.G.; validation, Y.G. and K.D.; formal analysis, Y.G. and K.D.; investigation, Y.G. and K.D.; resources, K.D.; data curation, Y.G. and K.D.; writing—original draft preparation, Y.G. and K.D.; writing—review and editing, Y.G., Y.L., H.H., R.Z., X.F., Q.C., W.N. and K.D.; visualization, Y.G.; supervision, K.D.; project administration, K.D.; funding acquisition, W.N. and K.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Cancer Institute of the National Institutes of Health grant number R25CA288263 and R37CA229417.
Institutional Review Board Statement
The study used the publicly available SynthRAD2023 dataset, which contains de-identified human imaging data. Ethical approval for data collection was obtained by the original data providers. No additional ethical approval was required for this analysis.
Informed Consent Statement
Not applicable. The study used the publicly available SynthRAD2023 dataset, which contains de-identified human imaging data collected with informed consent by the original data providers.
Data Availability Statement
The original data presented in the study are openly available in Zenodo at https://doi.org/10.5281/zenodo.7260704 or [28].
Acknowledgments
This work was supported in part by the CaREER (Cancer Research Education Excellence in Radiotherapy) program at Johns Hopkins University. We gratefully acknowledge the support provided by this program.
Conflicts of Interest
Quan Chen and Xue Feng are co-founders of Carina Medical LLC. The other authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CT | Computed tomography |
| sCT | Synthetic CT |
| CBCT | Cone-beam computed tomography |
| IGART | Image-guided adaptive radiotherapy |
| GAN | Generative adversarial networks |
| HU | Hounsfield units |
| DDPM | Denoising diffusion probabilistic model |
| MSE | Mean squared error |
| MAE | Mean absolute error |
| PSNR | Peak signal-to-noise ratio |
| SSIM | Structural similarity index |
| Grad-RMSE | Gradient mean squared error |
| DSC | Dice similarity coefficient |
References
- Lavrova, E.; Garrett, M.D.; Wang, Y.F.; Chin, C.; Elliston, C.; Savacool, M.; Price, M.; Kachnic, L.A.; Horowitz, D.P. Adaptive Radiation Therapy: A Review of CT-based Techniques. Radiol. Imaging Cancer 2023, 5. [Google Scholar] [CrossRef]
- Riou, O.; Prunaretty, J.; Michalet, M. Personalizing radiotherapy with adaptive radiotherapy: Interest and challenges. Cancer/Radiothérapie 2024, 28, 603–609. [Google Scholar] [CrossRef]
- Sherwani, M.K.; Gopalakrishnan, S. A Systematic Literature Review: Deep Learning Techniques for Synthetic Medical Image Generation and Their Applications in Radiotherapy. Front. Radiol. 2024, 4, 1385742. [Google Scholar] [CrossRef]
- Whitebird, R.R.; Solberg, L.I.; Bergdall, A.R.; López-Solano, N.; Smith-Bindman, R. Barriers to CT Dose Optimization: The Challenge of Organizational Change. Acad. Radiol. 2021, 28, 387–392. [Google Scholar] [CrossRef]
- Schulze, R.; Heil, U.; Groß, D.; Bruellmann, D.; Dranischnikow, E.; Schwanecke, U.; Schoemer, E. Artefacts in CBCT: A review. Dentomaxillofacial Radiol. 2011, 40, 265–273. [Google Scholar] [CrossRef]
- Altalib, A.; McGregor, S.; Li, C.; Perelli, A. Synthetic CT Image Generation From CBCT: A Systematic Review. IEEE Trans. Radiat. Plasma Med. Sci. 2025, 9, 691–707. [Google Scholar] [CrossRef]
- Hehakaya, C.; Van der Voort van Zyp, J.R.; Lagendijk, J.J.W.; Grobbee, D.E.; Verkooijen, H.M.; Moors, E.H.M. Problems and Promises of Introducing the Magnetic Resonance Imaging Linear Accelerator Into Routine Care: The Case of Prostate Cancer. Front. Oncol. 2020, 10, 1741. [Google Scholar] [CrossRef]
- Arnold, T.C.; Freeman, C.W.; Litt, B.; Stein, J.M. Low-field MRI: Clinical promise and challenges. J. Magn. Reson. Imaging 2022, 57, 25–44. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Schaal, D.; Curry, H.; Clark, R.; Magliari, A.; Kupelian, P.; Khuntia, D.; Beriwal, S. Review of cone beam computed tomography based online adaptive radiotherapy: Current trend and future direction. Radiat. Oncol. 2023, 18, 144. [Google Scholar] [CrossRef] [PubMed]
- Ghaznavi, H.; Maraghechi, B.; Zhang, H.; Zhu, T.; Laugeman, E.; Zhang, T.; Zhao, T.; Mazur, T.R.; Darafsheh, A. Quantitative Use of Cone-Beam Computed Tomography in Proton Therapy: Challenges and Opportunities. Phys. Med. Biol. 2025, 70, 09TR01. [Google Scholar] [CrossRef] [PubMed]
- Landry, G.; Kurz, C.; Thummerer, A. Perspectives for Using Artificial Intelligence Techniques in Radiation Therapy. Eur. Phys. J. Plus 2024, 139, 883. [Google Scholar] [CrossRef]
- Mastella, E.; Calderoni, F.; Manco, L.; Ferioli, M.; Medoro, S.; Turra, A.; Giganti, M.; Stefanelli, A. A Systematic Review of the Role of Artificial Intelligence in Automating Computed Tomography-Based Adaptive Radiotherapy for Head and Neck Cancer. Phys. Imaging Radiat. Oncol. 2025, 33, 100731. [Google Scholar] [CrossRef] [PubMed]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. arXiv 2020. [Google Scholar] [CrossRef]
- Song, J.; Meng, C.; Ermon, S. Denoising Diffusion Implicit Models. arXiv 2022. [Google Scholar] [CrossRef]
- Chen, X.; Qiu, R.L.J.; Peng, J.; Shelton, J.W.; Chang, C.W.; Yang, X.; Kesarwala, A.H. CBCT-based Synthetic CT Image Generation Using a Diffusion Model for CBCT-guided Lung Radiotherapy. Med. Phys. 2024, 51, 8168–8178. [Google Scholar] [CrossRef]
- Peng, J.; Qiu, R.L.J.; Wynne, J.F.; Chang, C.W.; Pan, S.; Wang, T.; Roper, J.; Liu, T.; Patel, P.R.; Yu, D.S.; et al. CBCT-Based Synthetic CT Image Generation Using Conditional Denoising Diffusion Probabilistic Model. Med. Phys. 2024, 51, 1847–1859. [Google Scholar] [CrossRef]
- Fu, L.; Li, X.; Cai, X.; Miao, D.; Yao, Y.; Shen, Y. Energy-Guided Diffusion Model for CBCT-to-CT Synthesis. Comput. Med. Imaging Graph. 2024, 113, 102344. [Google Scholar] [CrossRef]
- Li, Y.; Shao, H.C.; Liang, X.; Chen, L.; Li, R.; Jiang, S.; Wang, J.; Zhang, Y. Zero-Shot Medical Image Translation via Frequency-Guided Diffusion Models. IEEE Trans. Med. Imaging 2023, 43, 980–993. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, L.; Wang, J.; Yang, X.; Zhou, H.; He, J.; Xie, Y.; Jiang, Y.; Sun, W.; Zhang, X.; et al. Texture-Preserving Diffusion Model for CBCT-to-CT Synthesis. Med. Image Anal. 2025, 99, 103362. [Google Scholar] [CrossRef]
- Kazerouni, A.; Aghdam, E.K.; Heidari, M.; Azad, R.; Fayyaz, M.; Hacihaliloglu, I.; Merhof, D. Diffusion models in medical imaging: A comprehensive survey. Med. Image Anal. 2023, 88, 102846. [Google Scholar] [CrossRef] [PubMed]
- Khader, F.; Müller-Franzes, G.; Tayebi Arasteh, S.; Han, T.; Haarburger, C.; Schulze-Hagen, M.; Schad, P.; Engelhardt, S.; Baessler, B.; Foersch, S.; et al. Denoising diffusion probabilistic models for 3D medical image generation. Sci. Rep. 2023, 13, 7303. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Chen, L.; Nguyen, D.; Zhou, Z.; Gu, X.; Yang, M.; Wang, J.; Jiang, S. Synthetic CT generation from CBCT images via deep learning. Med. Phys. 2020, 47, 1115–1125. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, Z.; Sun, Y.; Strittmatter, A.; Raj, A.; Allababidi, A.; Rink, J.S.; Zöllner, F.G. seg2med: A bridge from artificial anatomy to multimodal medical images. arXiv 2025. [Google Scholar] [CrossRef]
- Poch, D.V.; Estievenart, Y.; Zhalieva, E.; Patra, S.; Yaqub, M.; Taieb, S.B. Segmentation-Guided CT Synthesis with Pixel-Wise Conformal Uncertainty Bounds. arXiv 2025. [Google Scholar] [CrossRef]
- Sinha, A.; Dolz, J. Multi-scale self-guided attention for medical image segmentation. IEEE J. Biomed. Health Inform. 2020, 25, 121–130. [Google Scholar] [CrossRef]
- Rahman, M.M.; Munir, M.; Marculescu, R. Emcad: Efficient multi-scale convolutional attention decoding for medical image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 11769–11779. [Google Scholar]
- Kolahi, S.G.; Chaharsooghi, S.K.; Khatibi, T.; Bozorgpour, A.; Azad, R.; Heidari, M.; Hacihaliloglu, I.; Merhof, D. MSA2Net: Multi-scale Adaptive Attention-guided Network for Medical Image Segmentation. arXiv 2024, arXiv:2407.21640. [Google Scholar]
- Thummerer, A.; van der Bijl, E.; Galapon, A., Jr.; Verhoeff, J.J.C.; Langendijk, J.A.; Both, S.; van den Berg, C.N.A.T.; Maspero, M. SynthRAD2023 Grand Challenge Dataset: Generating Synthetic CT for Radiotherapy. Med. Phys. 2023, 50, 4664–4674. [Google Scholar] [CrossRef]
- Wasserthal, J.; Breit, H.C.; Meyer, M.T.; Pradella, M.; Hinck, D.; Sauter, A.W.; Heye, T.; Boll, D.T.; Cyriac, J.; Yang, S.; et al. TotalSegmentator: Robust Segmentation of 104 Anatomic Structures in CT Images. Artif. Intell. 2023, 5, e230024. [Google Scholar] [CrossRef]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A Self-Configuring Method for Deep Learning-Based Biomedical Image Segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2020. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. arXiv 2020. [Google Scholar] [CrossRef] [PubMed]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. arXiv 2021. [Google Scholar] [CrossRef]
- Chen, J.; Ye, Z.; Zhang, R.; Li, H.; Fang, B.; Zhang, L.b.; Wang, W. Medical Image Translation with Deep Learning: Advances, Datasets and Perspectives. Med. Image Anal. 2025, 103, 103605. [Google Scholar] [CrossRef]
- Altalib, A.; Li, C.; Perelli, A. Conditional Diffusion Models for CT Image Synthesis from CBCT: A Systematic Review. arXiv 2025. [Google Scholar] [CrossRef]
- Chen, Y.; Konz, N.; Gu, H.; Dong, H.; Chen, Y.; Li, L.; Lee, J.; Mazurowski, M.A. ContourDiff: Unpaired Image-to-Image Translation with Structural Consistency for Medical Imaging. arXiv 2024. [Google Scholar] [CrossRef]
- Brioso, R.C.; Crespi, L.; Seghetto, A.; Dei, D.; Lambri, N.; Mancosu, P.; Scorsetti, M.; Loiacono, D. ARTInp: CBCT-to-CT Image Inpainting and Image Translation in Radiotherapy. arXiv 2025. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, J.; Zhao, H.; Chen, L.; Zhang, S.; Wang, G. GLFC: Unified Global-Local Feature and Contrast Learning with Mamba-Enhanced UNet for Synthetic CT Generation from CBCT. arXiv 2025. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).