Abstract
Antiretroviral therapy (ART) is the common hope for HIV/AIDS-treated patients. Total commitments from individuals and the entire community are the major challenges faced during treatment. This study investigated the progress of ART in the Federal Teaching Hospital in Gombe state, Nigeria by using various records of patients receiving treatment in the ART hospital unit. We combined artificial intelligence (AI)-based models and correspondence analysis (CA) techniques to predict and visualize the progress of ART from the beginning to the end. The AI models employed are artificial neural networks (ANNs), adaptive neuro-fuzzy inference systems (ANFISs) and support-vector machines (SVMs) and a classical linear regression model of multiple linear regression (MLR). According to the outcome of this study, ANFIS in both training and testing outperformed the remaining models given the R2 (0.903 and 0.904) and MSE (7.961 and 3.751) values, revealing that any increase in the number of years of taking ART medication will provide HIV/AIDS-treated patients with safer and elongated lives. The contingency results for the CA and the chi-square test did an excellent job of capturing and visualizing the patients on medication, which gave similar results in return, revealing there is a significant association between ART drugs and the age group, while the association between ART drugs and marital status (93.7%) explained a higher percentage of variation compared with the remaining variables.
1. Introduction
The complicated retrovirus (lentivirus) family, known as human immunodeficiency virus (HIV), is a virus that usually threatens human life, resulting in patient death when treatment is not adequately followed or commences early as prescribed by experts in the clinical field. The destruction of the immune system is the major concern of the virus. As a result of this virus attack, medical researchers developed the current antiretroviral therapy (ART) drug that will reduce and stop the further replication of the virus. Currently, the ART drug is the one that is capable and reliable in handling both HIV-1 and HIV-2 cases [1].
Several researchers have used different statistical models to predict its epidemiology, such as HIV/AIDS-related cases and their development, which have resulted in the current achievement of undetectable and non-transmissible outcomes among people living with the virus [2,3,4]. Some researchers used logistic regression to predict the influence of the early risk factors of SARS-CoV-2 ART associated with the advancement of the disease, and the findings showed that vaccination and early treatment with antivirals have significantly reduced the risk of disease progression. Similarly, the chi-square test and stepwise regression to investigate the longer duration of ART in overcoming barriers to long-term adherence, improving the survival of adolescents and young adults with HIV, and the results supported the global goals for HIV prevention and treatment. Zalla et al. [3] employed binomial distribution to examine the differences in race and ethnicity among people entering HIV care for ART medication, and the results indicated no significant difference in ART medication according to race or ethnicity, but Black and Hispanic patients showed a significant difference compared with White patients receiving ART. Torres et al. [5] used a chi-square analysis and a t test to evaluate the frequency incidence difference between S68G and K65R mutations on the basis of the different types of HIV-1.
Similarly, Kiyingi et al. [6] confirmed that the regression analysis results showed that women living with HIV have a high risk of human papillomavirus infection. However, Hameiri-bowen et al. [7] concluded that there was a significant delay in prevalence and associated factors of ART launching among people living with HIV on the basis of the PCA and logistic regression results. Chaula et al. [8] confirmed that the PCA findings showed there was no sustained medication interruption after examining the effect of azithromycin on the illustration of plasma-soluble biomarkers in adults and children who had chronic lung disease. Jin et al. [9] employed logistic regression and PCA to determine whether the HIV-antibody repertoire can be used to predict the viral reservoir, and the PCA results showed that there was a correlation between the DNA of HIV patients and western blot kits; in addition, the variables were associated with the prevalence, according to the clustered indicators.
Camargo et al. [10] confirmed that the study utilized by MCA demonstrated a relationship between variables related to HIV/AIDS patients’ failure to adhere to ART. Bayon et al. [11] investigated the serum levels of amylase and CD4 in newly diagnosed people living with HIV by using a chi-square test and MLR, and the results suggested that opportunistic infections caused by low CD4 counts could be the primary cause of pancreatic damage. Soogun et al. [12] applied LG and CA to forecast the multidrug support of a staphylococcus aureus nasal isolate with clonal complex in HIV-treated patients, and the CA demonstrated positive associations. Chaula et al. [13] employed correlation and a mixed-effects statistical model to predict the early duration of ART treatment to stabilize the growth of viral reservoirs in HIV-1 patients, and the results showed that early treatment can to some extent decrease the viral load. Alanzi et al. [14] presented factors related to high viral load by using MCA and RF, and the outcomes showed that MCA was the tool that best meets the UNAIDS 95–95–95 target goal in achieving viral load suppression in that the study identified a high proportion of individuals with a lower viral load.
However, several scholars have used AI models to predict the achievement and progress of patients surviving HIV/AIDS. Other such as Rodriguez et al. [15] used RF machine-learning techniques to forecast the history of HIV-treated breastfeeding mothers, and the result showed that RF gave a higher accuracy performance. Besides, artificial neural networks (ANNs) was employed to estimate prokaryotic genomes’ important genes, and the findings revealed that an ANN is the most efficient model. Dimopoulos et al. [16] used the deep-learning method to evaluate empathic conduct in a social dynamic condition, and the results showed that the proposed method surpasses other popular ML methods and did so with high maximum accuracy. Vapnik, et al. [17] developed the conceptual overview of AI based SVM theory and logistic regression, and the results showed that ML techniques such as SVM surpassed logistic regression. In addition, Farhat [18] utilized the radial basis function, SVM, product unit and sigmoid unit to investigate the typology of HIV-treated patients receiving ART medication, and the results showed that radial basis neural networks demonstrated the best performance accuracy.
This study aims to integrate four AI-based models and CA techniques to predict the outcomes of HIV/AIDS patients receiving ART at Federal Teaching Hospital in Gombe state, Nigeria. The proposed AI algorithm was designed to compare the performance of three nonlinear (ANN, ANFIS and SVM) models and one linear (MLR) model. The main purpose of employing AI is to evaluate the influence and effect of taking ART medication for a longer duration while the CA is employed, to examine the visual positioning and contributions of each row and column term as dimensions of the success for the ART medication. The authors have not yet seen any related paper combining artificial intelligence models and correspondence analysis. Section 2 of this paper contains the presentation of material and methods connected to HIV/AIDS examination. This is followed by a discussion of the proposed approach in Section 3 and a conclusion in Section 4.
2. Materials and Methods
2.1. Study Population
The study population consists of 2500 HIV/AIDS patients taking ART at the hospital; most of the patients come from various states of the geopolitical zone comprising Gombe, Bauchi, Yobe, Borno, Adamawa and Taraba. Sociodemographic variables of interest used in retrieving the variables from the ART database of the hospital include age, gender, marital status, hospital status, state visit, viral load and regimen combination of ART drugs.
2.2. Study Design and Analysis Method
A retrospective cohort study was adopted to select the patients visiting the hospital for their ART medication. Patients’ records on ART were randomly selected from the HIV/AIDS hospital database. AI models were employed to predict the ages of patients on follow-up, while the CA was applied to predict the links between all the patient variables during the follow-ups. The AI models’ performance values were rated by using the coefficient of determination (DC) and mean square error (MSE), where the DC concentrates on the accuracy of the model by making sure that the data explained the sufficient goodness of fit, while the MSE minimizes the variables that are less important in the data. The computation of CA is centered on the matrix of rows and columns called dimensions, and it is used to explain the link between the rows and columns for the study variables. Further, the inertia percentage is used to explain the proportion of variation, similar to MCA and PCA. However, before the AI modeling occurred, the data were split into 75% training sets and 25% testing sets. The study secured approval from the research and ethics committee of the Federal Teaching Hospital in Gombe state because it followed the relevant guidelines and regulations of the hospital.
2.3. Machine-Learning Models
Machine learning is a technique that uses a computer to perform a specific task, during which the learning algorithm is performed on the basis of the availability of a data set, and it has the potential to address real-world problems and can be used to develop statistical models [19,20,21,22,23,24].
2.3.1. Artificial Neural Network (ANN)
The ANN is a biological working structure capable of delivering the best results transformed by inputs without affecting the output operation. It is a class of algorithms with an essential ability to deal with a complicated design data set and can forecast model problems similar to how the human brain can [25,26]. The ANN belongs to a group of algorithms that accepts numeric and structured data to be built on several layers or neurons, such as input, hidden and output, sometimes called multilayer perceptron (MLP). However, the input layer serves as the point of entry for the independent variables into the network system, followed by hidden (intermediate) neurons, which help to connect the computation between the input and the output, while the output layer serves as the final neuron to produce the results [27,28]. The ANN is a function based on the principles of neurons, which serve as processing components assembled in an organized pattern in which each separately connects. As a result, the input is united with the weight and the bias of the network in every single neuron, and the structure levels then act as the primary route for the data to pass through the activation function (see Figure 1). Ref. [29] described MLP by calculating the following function:
where x represents the inputs; indicates the function in the output node; represents the activation function at the hidden layer nodes; and define the weight of the matrix linking the output and hidden layers and that of the matrix linking the hidden and the input layers, respectively; and and represent the bias for the hidden and output layers, respectively.
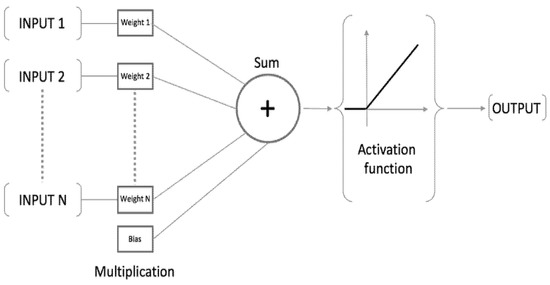
Figure 1.
ANN architecture pattern.
2.3.2. Support-Vector Machine (SVM)
The term SVM in machine learning fits under the category of supervised learning models; it makes use of learning algorithm characteristics to perform analyses for classification and regression [30]. The data can be divided into categories by using the SVM, and the data can then be transformed so that the partition line can be shown as a hyperplane. As a result, the SVM’s operation is focused on classifying data points and then mapping them onto high-dimensional feature space, particularly for data types that are challenging to separate linearly (see Figure 2) [31]. The SVM has more reasonable memory efficiency, capable of handling a clear separation of margin that involves classes. It is more effective in high-dimensional space, especially when the number of dimensions is greater than the number of samples. However, the SVM has major setbacks in dealing with larger values, it is affected by errors, and it performs worse when the traits for each data point surpass the number of samples for the training data and when it has no probabilistic explanation for the classification. Vapnik [17] have stated the ability to conduct learning ideas to achieve the prediction, modeling, regression and categorization of data is the major aim of support-vector machines. The inputs and outputs for the learning process of the modeling are created by . The SVM ensures that it estimates the dependent function of the dependent variable , focusing on the independent variable . Ref. [31] revealed that approximating the function is determined by making use of the entire pairs of alongside the minimum precision , and thereafter, the function of Vapnik is named alongside as , the incentive loss function [30,31].
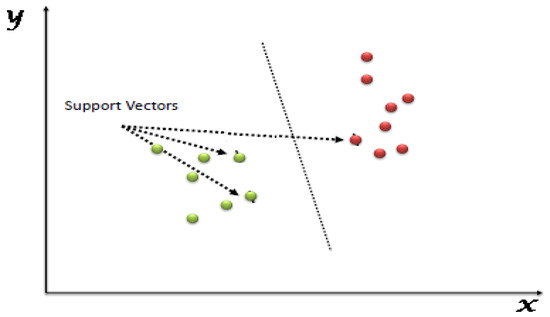
Figure 2.
Support-vector machine.
2.3.3. Neuro-Fuzzy (NF)
Neuro-fuzzy is a technique used for resolving uncertainty events, which is used in the uncertainty about human thinking to explain the knowledge through numeric computation on the basis of the imprecise judgment generated by neural networks. NF can use intelligence techniques to handle data processing by using neural networks and fuzzy logic. It is utilized as a concept of partially true and partially false outcomes that can address real-world estimate processes and physical functions, classed as Mamdani, Sugeno and Tsumoto, in which the surgeons produce a larger performance application. The operation of NF is focused on the fuzzy system, which can be manipulated by using neural network principles to train the learning algorithms. The NF is very simple and has acceptable quality, but the rationale is not always exact, because it is sometimes misidentified as a likelihood hypothesis, and it has a well-taught assignment for guiding accuracy and enrollment. Other researchers viewed NF as the process of learning an algorithm from sample data during the modeling process to construct a neural network that can handle specific parameters. Inputting data into fuzzy values for any amendment that requires membership functions (MFs), which are categorized as follows: Gaussian, trapezoidal and triangular sigmoid. They can manage a range of values between 0 and 1. Despite functioning as the membership function, it is designed to link the input performance and the output performance. Therefore, the fuzziness is based on and as the input and the output , which will generate the first-order Sugeno fuzziness as follows:
Theory 1.
Assuming is an is then .
Theory 2.
Assuming is and is then .
where , and explain the constraints and serve as the membership function while the inputs as the output parameter function, and the planning structure of ANFIS was developed on the basis of five layers of neural network design (see Figure 3).
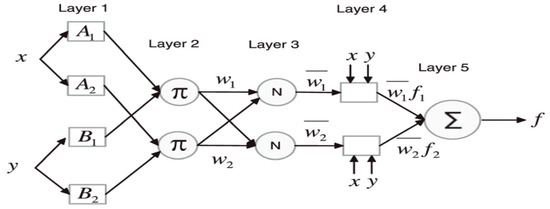
Figure 3.
Sketching of neuro-fuzzy application.
2.3.4. Multiple Linear Regression (MLR)
MLR is a concept that can produce a straight line and simultaneously can estimate the bond between numeric dependent variables and that between two or more independent variables. Granting the researcher access to determining the strength of the relationship between a response variable on various predictor variables is the major operation of the MLR. Aside from the underfitting issues, the MLR is a user-friendly technique that, when used, can produce acceptable results for easier understanding and interpretation within the possible time by using a simple mathematical equation, as seen in Figure 4. MLR is a mathematical approach that can model the relationship between numerous explanatory (independent) factors and a dependent or scalar variable. Linear regression modeling is carried out in two ways: simple linear, which uses with only an independent variable, and multiple linear, which uses with more than one predictor variable. Hence, it can be achieved with linear function data. MLR is used to examine the typical conditions of how a mean variable linearly depends on a set of coefficients, while the error term is computed by using a Gaussian distribution.
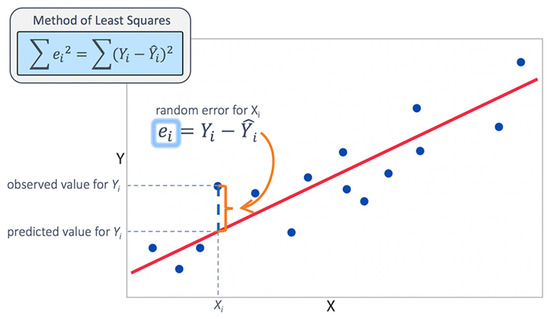
Figure 4.
Multiple linear regression.
2.4. Correspondence Analysis (CA)
The CA is a dimensional space or dimensional reduction approach that can reduce as much data to the bare-minimum level and then portray it as a cloud. The CA shares similar characteristics of application to PCA, MCA and FA, especially when the number of variables can be fitted in a two-way table. Table 1 features the rows and the columns forming a two-by-three contingency table. CA was defined as a multivariate analysis that deals with the computation of statistics by using exploratory strategies to examine correlations between variables; it uses a similar pattern to that of PCA in terms of finding a relationship between two variables, and both may visually communicate their respective idea in a low-dimensional design. By categorical data in the form of a family tree, remarkable progress has been achieved in statistical applications on the basis of the pattern of association between them. As a consequence of the reciprocal average, centroid position, optimal scaling and homogeneity calculation, it is displayed in the form of a family tree. Similarly, CA is a multidimensional nonlinear scaling or bivariate network analysis that deals with dual scaling, homogeneity analysis, quantification theory, optimal scaling and the method of reciprocal averages. CA allows us to examine how two groups interact in a two- or three-dimensional plot on the basis of using correlations between two or more categories of data. Additionally, CA has a strategy for exploring categorical data using exploratory analysis.

Table 1.
Cross-tabulation of 2 × 3 contingency table (gender vs hospital status).
Literature showed that the capability of the CA to analyze research topics in various fields encouraged scholars from different fields to utilize it for analyzing categorical variables. CA has become more popular in ecological research and marketing research because researchers in these areas frequently collect categorical data thanks to the data’s simplicity. It was proved that CA is a multivariate graphical tool for exploring correlations among categorical variables, which is useful in epidemiology to access relationships between variables. The usual purpose of CA is to graphically represent these relative frequencies according to the distance between individual row and column profiles from a contingency table and the distance to the average row and column profile, respectively, so that the relationship among the variables can be visualized in a low-dimensional space. However, CA distance is measured using a chi-square, defined as the metric between row and row given by
where and are the relative frequencies for row and in column and is the marginal relative frequency or mass for . Therefore, the chi-square distance for two dimensions is defined as , and
denotes the chi-square distance between the row profile and the average row profile.
3. Results and Discussion
3.1. Results of the AI Models
In this section, we used HIV/AIDS patients receiving ART at the Federal Teaching Hospital in Gombe state to predict the number of years during which patients took ART drugs, by using nonlinear (ANN, SVM and ANFIS) and linear (MLR) AI models, and the CA was applied to examine, during follow-ups, how the patients’ variables contributed to or were associated with ART medication. Criteria evaluation indices, such as coefficient of determination (DC), known as R-square (R2) value; mean square error (MSE); percentage of inertia; and dimensions, were used to achieve the results of this analysis. The single models in both training and testing for the ANN, SVM, ANFIS and MLR gave R2 values of 0.90–0.89, 0.89–0.89, 0.89, 0.89, 0.90–0.90 and 0.89–0.98 respectively. Additionally, their MSE gave 8.23–3.95, 8.42–9.38, 7.96–3.75 and 8.71–9.72, respectively—as seen in Table 2. According to some researchers presented R2 as a tool for measuring the goodness of fit of the model, which is capable of measuring the dependent variable’s projected success from the independent variables, which has a better chance of explaining the proportion of variance by using the regression model. Further, the MSE is the deviation or distance of a value from a hypothetical, unobserved (unexplained) value. Therefore, the ANFIS model outperforms the remaining models, with the lowest error in both the training and testing phases. It has proved to be a unique and promising model capable of handling nonlinear data (see Figure 5, Figure 6, Figure 7 and Figure 8).
Table 2.
Training and testing performance of single models.
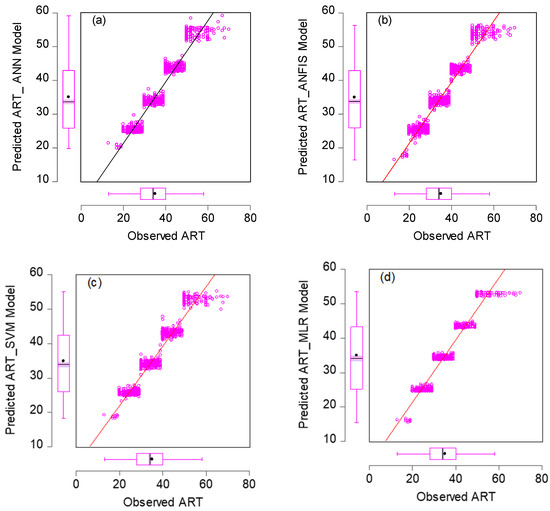
Figure 5.
Scatter plots for (a) ANN, (b) ANFIS, (c) SVM and (d) MLR models in the training phase.
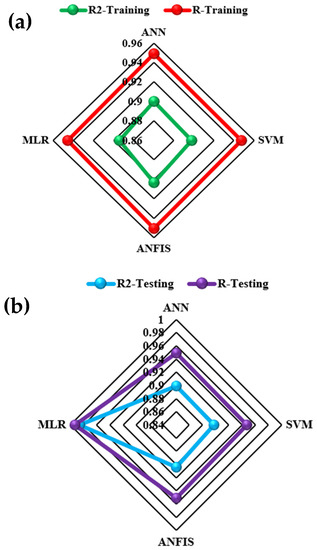
Figure 6.
Radar plot for (a) training and (b) testing performance.
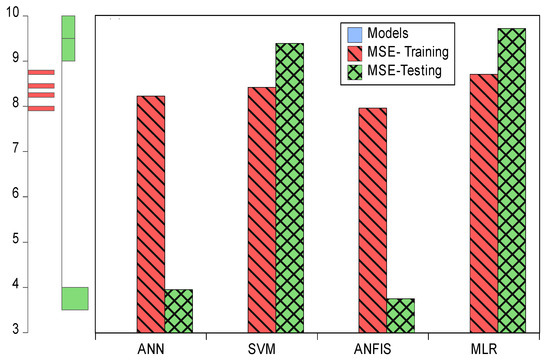
Figure 7.
Error plots for MSE in both training and testing.
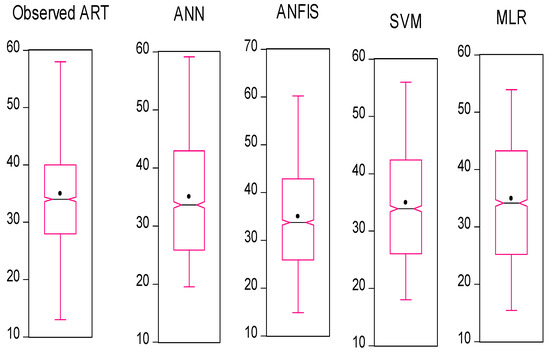
Figure 8.
Box plot and whisker plot for all the models.
3.2. Correspondence Analysis Results and Discussion
3.2.1. Descriptive Results for Contingency Table
CA involves the application of a matrix to form a rectangle, which in return gives a contingency table. The rows and columns refer to the marginal frequency count in the contingency table. In this section, all the tables have two types of qualitative variables, such as drugs with marital status in Table 3, drugs with hospital status in Table 4, drugs with a state visit in Table 5 and drugs with age group in Table 6. The study used 2500 patients receiving HIV/AIDS treatment at the Federal Teaching Hospital in Gombe state. Each table has an active margin (marginal row and marginal column) attached to it. In Table 3, drugs are presented in the row, while marital status is presented in the column, revealing that marital status for those that were married (1703) has the highest total number of patients on ART, while divorced (89) has the least total number of patients on ART. The drug ABC-DDI-LPV/r (682) was the most common drug combination that patients used, while thedrug AZT-3TC-EFV (117) was the least commonly taken drug. The hospital status of alive patients (2407), in Table 4, gave a higher number of patients that are doing well, followed by transfer (62) and death (31), in that order, while ABC-DDI-LPV/r remained the most commonly taken drug and AZT-3TC-EFV remained the least commonly taken drug. State visits showed that the mother state, Gombe (1576), had the highest number of patients in attendance, while states (43) outside the North East Zone recorded a lower number of patients in attendance; moreover, ABC-DDI-LPV/r remained the leading drug taken, with AZT-3TC-EFV as the least common drug (see Table 5). Finally, Table 6 shows that the age group 30 to 39 (956) was the group that was most commonly on medication, while the age group 10 to 19 (21) was the group least commonly on medication. ABC-DDI-LPV/r maintained its lead as the highest prescribed drug, and AZT-3TC-EFV was the least prescribed drug.
Table 3.
Drug vs marital status.
Table 4.
Drug vs hospital status.
Table 5.
Drug vs state visit.
Table 6.
Drug vs age group.
3.2.2. Relationships among Row Dimensions
In CA, dimensions represent the rows (m) and columns (n) in any given set of data computed using the chi-square table of the matrix. The rows and column tell us whether there is a larger or smaller difference within or among the data set. In each dimension, the variables that have a smaller difference in any row or column have a better relationship or link with the variables, while the variables that have a larger difference in any row or column do not have a good relationship. The contingency table (cross-tabulation table), which was developed by a well-known researcher to characterize the measures of divergence from complete independence between the row and column structures based on a rectangle, where the total number of dimensions determines the number of rows or columns present. In this section, we used the row (a combination of ART medications) to study the variable that is closer to zero. Each patient variable in the row that is closer to zero is considered as the variable that meaningfully contributed to the combination of drugs. Table 7 represents the effect of ART medication on married couples, revealing in row 1 that AZT-3TC-NPV (0.001), TDF-3TC-EFV (0.000), TDF-3TC-LPV/r (0.001) and TDF-FTC-NPV (0.000) contributed more to treatment in married couples compared with the remaining drugs, while ABC-DDI-LPV/r (0.003), AZT-3TC-EFV (0.005), TDF-3TC-ATV/r (0.001) and TDF-3TC-EFV (0.005) in row II more meaningfully contributed to treatment for the married couples than did the remaining drugs.
Table 7.
Row dimensions for marital status, for patients placed on an ART drug.
Subsequently, Table 8 explains the relationships between ART drugs for the patients’ hospital status, indicating that row 1 showed that AZT-3TC-ATV/r (0.001), AZT-3TC-LPV/r (0.001), TDF-3TC-EFV (0.001), TDF-3TC-NPV (0.000), TDF-FTC-ATV/r (0.007) and TDF-FTC-NPV (0.000) contributed more to treatment according to hospital status compared with the remaining drugs, while in row II, AZT-3TC-EFV (0.007), AZT-3TC-NPV (0.004) and TDF-3TC-ATV/r (0.005) contributed more to treatment according to hospital status compared with the remaining drugs. The relationship between drugs according to visits to the hospital from various locations showed that ABC-DDI-LPV/r (0.007), AZT-3TC-EFV (0.000), AZT-3TC-LPV/r (0.002), and TDF-FTC-ATV/r (0.000) contributed more to treatment according to state visits, in row I, while in row II, ABC-DDI-LPV/r (0.000), AZT-3TC-NPV (0.004), TDF-FTC-EFV (0.006) and TDF-FTC-LPV/r (0.001) contributed more to treatment according to state visits compared with the remaining drugs (see Table 9).
Table 8.
Row dimensions for hospital status, for patients placed on an ART drug.
Table 9.
Row dimensions for state visits, for patients placed on an ART drug.
Lastly, the influence of the drugs on patients’ age groups, shown in Table 10, indicated that AZT-3TC-EFV (0.005), TDF-3TC-NPV (0.008), TDF-FTC-ATV/r (0.000) and TDF-FTC-LPV/r (0.000), in row I, contributed more to treatment according to age group, while AZT-3TC-LPV/r (0.002), TDF-3TC-EFV (0.005), TDF-3TC-NPV (0.000), TDF-FTC-EFV (0.003) and TDF-FTC-LPV/r (0.002), in row II, contributed more to treatment according to age group compared with the remaining drugs. Figure 9 shows the contribution of inertia to the row dimensions (ART drug) as measured against marital status, hospital status, state visit and age group.
Table 10.
Row dimensions for age group, for patients placed on an ART drug.
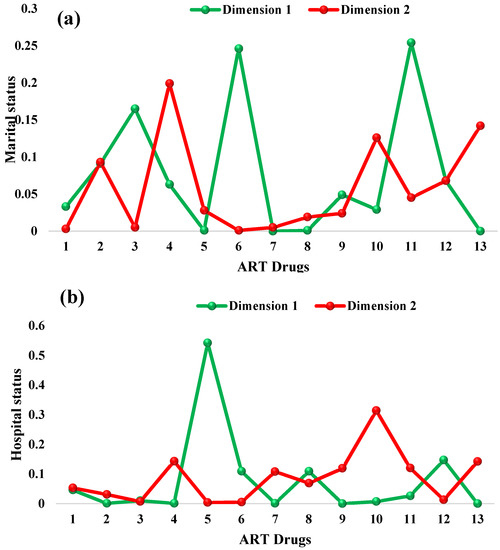
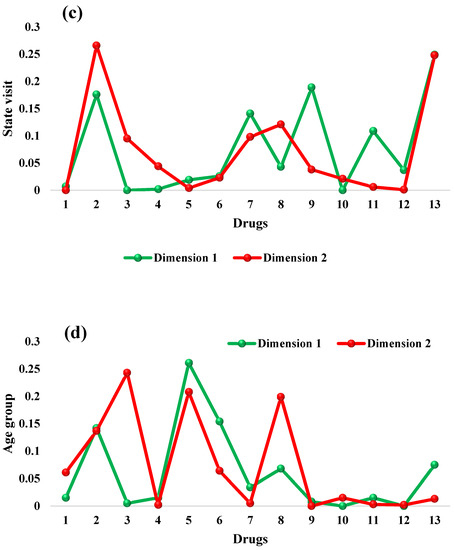
Figure 9.
Point contribution to inertia for the row dimensions (ART drugs), measured against (a) marital status, (b) hospital status, (c) state visit and (d) age group.
3.2.3. Relationships among Column Dimensions
In this section, we use the column (marital status, hospital status, state visit and age group) results to examine those variables that are closer to zero. Each patient variable in the column that is closer to zero is considered as the variable that meaningfully contributed to the study’s demographic variables. Therefore, the relationship between marital status and a patient placed on an ART drug showed that divorced (0.044) and married (0.053) patients are doing well on ART medication compared with the remaining marital statuses, in column 1, while in column II, married (0.001) and single (0.000) patients are doing better on treatment than the other marital statuses (see Table 11) are. Consequently, as shown in Table 12, alive patients (0.025) are doing better on ART medication, in column 1 and column II (0.025 and 0.012), compared with the remaining hospital statuses. Table 13 showed that patients visiting the hospital from Yobe (0.000), Borno (0.000) and other areas outside the northeast zone (0.007), in column I, have a better relationship with treatment, while patients visiting from Gombe (0.007) state and other states (0.000), in column II, contributed more to drug treatment compared with those from the remaining states who were visiting the hospital. Finally, age groups 10–19 (0.007) and 30–39 (0.006), as shown in column I and column II of Table 14, are doing better on treatment compared with the other age groups. Figure 10 represents the contribution of inertia to the column dimensions (marital status, hospital status, state visit and age group), for patients placed on an ART drug.
Table 11.
Column dimensions for marital status, for patients placed on an ART drug.
Table 12.
Column dimensions for hospital status, for patients placed on an ART drug.
Table 13.
Column dimensions for state visit, for patients placed on an ART drug.
Table 14.
Column dimensions for age group, for patients placed on an ART drug.
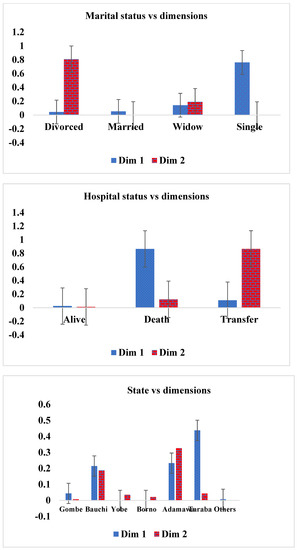
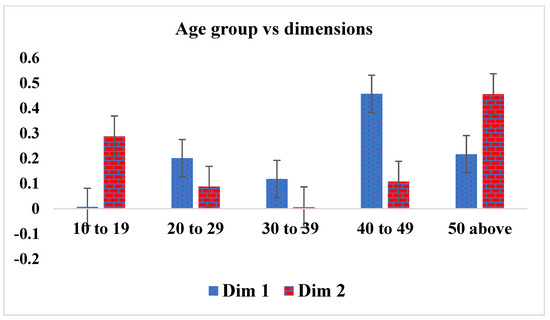
Figure 10.
Contribution to inertia for the column dimensions (ART drugs) against marital status, hospital status, state visit and age group.
3.2.4. Contingency Table Results for CA, Chi-Square and Percentage of Explained Variation
The results for the CA and chi-square test, as shown in Table 15, were similar to the results in several other studies in the literature (see Figure 11). Comparisons of the results from both the CA and the chi-square test showed the following: drugs and marital status gave ( = 45.252, p = 0.139 and R2 = 93.7%), drugs and hospital status gave ( = 16.334, p = 0.876, and R2 = 70.6%), drugs and state visit gave ( = 68.886, p = 0.582, and R2 = 58.9%) and drugs and age group gave ( = 68.733, p = 0.026, and R2 = 79.4%). This showed only that the relationship drugs and age group was significant (p = 0.026), and the remaining variables (marital status, hospital status and state visit) were not significant. Nonetheless, drugs and marital status (93.7%) explained the highest total proportion of variation compared with the remaining variables, as indicated in Table 15. It was confirmed CA as a statistical approach that uses the same standards as the chi-square approach, aiming at measuring the weight and distance between the exhibited points that appear on the biplot.
Table 15.
CA, chi-square and percentage of variation results.
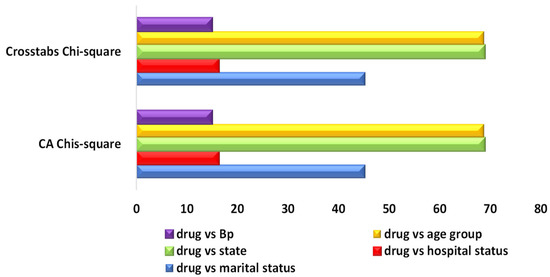
Figure 11.
CA and crosstab results analysis.
4. Conclusions
A combination of artificial intelligence models and correspondence analysis techniques was employed in this study to predict and examine HIV/AIDS-treated patients at the Federal Teaching Hospital in Gombe state. The single nonlinear model and linear models (ANN, ANFIS, SVM and MLR), including CA, were measured by using evaluation index criteria terms such as R2, MSEs, percentages of inertia, dimensions, active margins, p-values and chi-square tests. The comparison results for the study showed that ANFIS R2 (0.903 and 0.904) with MSE (7.961 and 3.751) outperformed the remaining models in both training and testing. This revealed that patients’ lives become safer and healthier as their time on ART medicine increases. The descriptive results showed that ABC-DDI-LPV/r (682) was the most prescribed drug for the patients. Marital status for those that were married (1703) recorded a high number of patients in attendance; hospital status showed alive patients (2407) on treatment were doing well in that only a few deaths were recorded while patients received ART treatment; a state visit showed that Gombe (1576) has the highest number of patients in attendance; and the 30 to 39 age group (956 patients) was the group most committed to undergoing treatment.
The results from the dimensions showed that drugs AZT-3TC-NPV (0.001), TDF-3TC-EFV (0.000), TDF-3TC-LPV/r (0.001) and TDF-FTC-NPV (0.000) contributed more according to marital status, in row I, compared with the remaining drugs, while in row II, drugs ABC-DDI-LPV/r (0.003), AZT-3TC-EFV (0.005) TDF-3TC-ATV/r (0.001) and TDF-3TC-EFV (0.005) contributed more to marital status than the other drugs did. Subsequently, in row I, AZT-3TC-ATV/r (0.001), AZT-3TC-LPV/r (0.001), TDF-3TC-EFV (0.001), TDF-3TC-NPV (0.000), TDF-FTC-ATV/r (0.007) and TDF-FTC-NPV (0.000) contributed more according to hospital status compared with the other drugs, while AZT-3TC-EFV (0.007), AZT-3TC-NPV (0.004) and TDF-3TC-ATV/r (0.005) contributed more according to hospital status, in row II, compared with the remaining drugs.
Next, ABC-DDI-LPV/r (0.007), AZT-3TC-EFV (0.000), AZT-3TC-LPV/r (0.002) and TDF-FTC-ATV/r (0.000) contributed more according to various state visits to the hospital, in row I, compared with the remaining drugs, while ABC-DDI-LPV/r (0.000), AZT-3TC-NPV (0.004), TDF-FTC-EFV (0.006) and TDF-FTC-LPV/r (0.001) contributed more according to state visits, in row II. Finally, AZT-3TC-EFV (0.005), TDF-3TC-NPV (0.008), TDF-FTC-ATV/r (0.000) and TDF-FTC-LPV/r (0.000) contributed more according to age groups, in row I, while in row II, AZT-3TC-LPV/r (0.002), TDF-3TC-EFV (0.005), TDF-3TC-NPV (0.000), TDF-FTC-EFV (0.003) and TDF-FTC-LPV/r (0.002) contributed more according to age groups compared with the remaining drugs.
However, the dimension results showed that divorced (0.004) and married (0.053) patients were doing better on drugs than the remaining marital statuses, in column I, while in column II, married (0.001) and single (0.000) patients were doing better on the drug compared with the remaining marital statuses. Alive patients (0.025), in column I and column II (0.012), were doing better on drugs than the remaining hospital statuses were. State visit data showed that Yobe state (0.000), Borno state (0.000) and other states (0.007) were doing better on the drug, in column I, compared with the remaining states, while Gombe state (0.007) and other states (0.000), in column II, were doing well on the drug compared with the remaining states. The age-group category revealed that age group 10–19 (0.007), in column I, and age group 30–39 (0.006), in column II, were doing better on the drug than the remaining age groups. The CA and the chi-square test yielded similar results, revealing that only the relationship between drug and age group was significant ( = 68.733, p = 0.026, and R2 = 79.4%), but in terms of performance, the relationship between drugs and marital status (93.7%) explained a higher percentage of variation compared with what the remaining variables could. A combination of different AI models and multivariate exploratory analysis techniques are required in future studies to evaluate epidemiological data other than HIV data.
Author Contributions
Conceptualization, K.B., S.I.A., I.E. and A.G.U.; validation and supervision, I.E. and S.I.A.; writing—draft and original manuscript, K.B., A.G.U. and S.I.A.; formal analysis, A.G.U. and S.I.A., software, A.G.U. and S.I.A.; methodology, K.B., S.I.A., I.E. and A.G.U. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors are grateful to Near East University, North Cyprus, Mersin-10, Türkiye, for supporting this study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- De Vito, A.; Colpani, A.; Saderi, L.; Puci, M.; Zauli, B.; Fiore, V.; Fois, M.; Meloni, M.C.; Bitti, A.; Di Castri, C.; et al. Impact of Early SARS-CoV-2 Antiviral Therapy on Disease Progression. Viruses 2023, 15, 7. [Google Scholar] [CrossRef] [PubMed]
- Toska, E.; Zhou, S.; Chen-Charles, J.; Gittings, L.; Operario, D.; Cluver, L. Factors Associated with Preferences for Long-Acting Injectable Antiretroviral Therapy Among Adolescents and Young People Living with HIV in South Africa. AIDS Behav. 2023. [Google Scholar] [CrossRef]
- Zalla, L.C.; Cole, S.R.; Eron, J.J.; Adimora, A.A.; Vines, A.I.; Althoff, K.N.; Silverberg, M.J.; Horberg, M.A.; Marconi, V.C.; Coburn, S.B.; et al. Association of Race and Ethnicity with Initial Prescription of Antiretroviral Therapy Among People with HIV in the US. JAMA 2023, 329, 52–62. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Ouyang, J.; Zhao, B.; An, M.; Wang, L.; Ding, H.; Zhang, M.; Han, X. The S68G polymorphism is a compensatory mutation associated with the drug resistance mutation K65R in CRF01_AE strains. BMC Infect. Dis. 2020, 20, 123. [Google Scholar] [CrossRef] [PubMed]
- Torres, M.C.; Gómez, M.; Schjetnan, P.; Terán, G.R.; Briceño, O.; Ríos, S.Á.; Alejandra, K.; Mora, R.; Cardoso, S.P. The vaginal microbiota of women living with HIV on suppressive antiretroviral therapy and its relation to high-risk human papillomavirus infection. BMC Microbiol. 2023, 23, 21. [Google Scholar] [CrossRef]
- Kiyingi, M.; Nankabirwa, J.I.; Sekaggya-Wiltshire, C.; Nangendo, J.; Kiweewa, J.M.; Katahoire, A.R.; Semitala, F.C. Predictors of delayed Anti-Retroviral Therapy initiation among adults referred for HIV treatment in Uganda: A cross-sectional study. BMC Health Serv. Res. 2023, 23, 40. [Google Scholar] [CrossRef]
- Hameiri-bowen, D.; Yindom, L.; Sovershaeva, E.; Bandason, T.; Mayini, J.; Rehman, A.M.; Simms, V.; Gift, L.; Flagestad, T.; Jarl, T.; et al. The effect of 48-weeks azithromycin therapy on levels of soluble biomarkers associated with HIV-associated chronic lung disease. Int. Immunopharmacol. 2023, 116, 109756. [Google Scholar] [CrossRef]
- Rocca, S.; Zangari, P.; Cotugno, N.; De Rossi, A.; Ferns, B.; Petricone, D.; Rinaldi, S.; Giaquinto, C.; Bernardi, S.; Rojo, P.; et al. Human Immunodeficiency Virus (HIV)-Antibody repertoire estimates reservoir size and time of antiretroviral therapy initiation in virally suppressed perinatally HIV-infected children. J. Pediatr. Infect. Dis. Soc. 2019, 8, 433–438. [Google Scholar] [CrossRef]
- Jin, Y.; Yang, T.; Xia, T.; Shen, Z.; Ma, T. Association between serum amylase levels and CD4 cell counts in newly diagnosed people living with HIV: A case-control study. Medicine 2023, 102, e32638. [Google Scholar] [CrossRef]
- He, S.; Lin, J.; Li, L.; Cai, W.; Ye, J.; Li, Y.; Zhang, W.; Liu, N.; Gong, Z.; Ye, X.; et al. Multidrug-resistant Staphylococcus aureus nasal carriage among HIV-positive outpatients in Guangzhou, China: Prevalence, risk factors, phenotypic and molecular characteristics. J. Infect. Chemother. 2021, 27, 218–225. [Google Scholar] [CrossRef]
- Bayón-Gil, Á.; Puertas, M.C.; Urrea, V.; Bailón, L.; Morón-López, S.; Cobarsí, P.; Brander, C.; Mothe, B.; Martinez-Picado, J. HIV-1 DNA decay dynamics in early treated individuals: Practical considerations for clinical trial design. J. Antimicrob. Chemother. 2020, 75, 2258–2263. [Google Scholar] [CrossRef] [PubMed]
- Soogun, A.O.; Kharsany, A.B.M.; Zewotir, T.; North, D.; Ogunsakin, R.E. Identifying Potential Factors Associated with High HIV viral load in KwaZulu-Natal, South Africa using Multiple Correspondence Analysis and Random Forest Analysis. BMC Med. Res. Methodol. 2022, 22, 174. [Google Scholar] [CrossRef] [PubMed]
- Chaula, R.B.; Justo, G.N. A Robust Random Forest Prediction Model for Mother-to-Child HIV Transmission Based on Individual Medical History. Tanzan. J. Eng. Technol. 2022, 41, 64–71. [Google Scholar] [CrossRef]
- Alanazi, S.A.; Shabbir, M.; Alshammari, N.; Alruwaili, M.; Hussain, I. Prediction of Emotional Empathy in Intelligent Agents to Facilitate Precise Social Interaction. Appl. Sci. 2023, 13, 1163. [Google Scholar] [CrossRef]
- Rodriguez, S.D.; Pascual, M.S.; Oletto, A.; Barnabas, S.; Zuidewind, P.; Dobbels, E.; Danaviah, S.; Behuhuma, O.; Lain, M.G.; Vaz, P.; et al. Machine learning outperformed logistic regression classification even with limit sample size: A model to predict pediatric HIV mortality and clinical progression to AIDS. PLoS ONE 2022, 17, e0276116. [Google Scholar] [CrossRef]
- Dimopoulos, Y.; Bourret, P.; Lek, S. Use of some sensitivity criteria for choosing networks with good generalization ability. Neural Process. Lett. 1995, 2, 1–4. [Google Scholar] [CrossRef]
- Vapnik, V.N. An Overview of Statistical Learning Theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef]
- Farhat, N.H. Photonit neural networks and learning mathines the role of electron-trapping materials. IEEE Expert-Intell. Syst. Appl. 1992, 7, 63–72. [Google Scholar] [CrossRef]
- Abba, S.I.; Hadi, S.J.; Abdullahi, J. River water modelling prediction using multi-linear regression, artificial neural network, and adaptive neuro-fuzzy inference system techniques. Procedia Comput. Sci. 2017, 120, 75–82. [Google Scholar] [CrossRef]
- Elkiran, G.; Nourani, V.; Abba, S.I. Multi-step ahead modelling of river water quality parameters using ensemble artificial intelligence-based approach. J. Hydrol. 2019, 577, 123962. [Google Scholar] [CrossRef]
- Nourani, V.; Kisi, Ö.; Komasi, M. Two hybrid Artificial Intelligence approaches for modeling rainfall—Runoff process. J. Hydrol. 2011, 402, 41–59. [Google Scholar] [CrossRef]
- Marill, K.A. Advanced Statistics: Linear Regression, Part II: Multiple Linear Regression. Acad. Emerg. Med. 2004, 11, 94–102. [Google Scholar] [CrossRef] [PubMed]
- Abba, S.I.; Hadi, S.J.; Sammen, S.S.; Salih, S.Q.; Abdulkadir, R.A.; Pham, Q.B.; Yaseen, Z.M. Evolutionary computational intelligence algorithm coupled with self-tuning predictive model for water quality index determination. J. Hydrol. 2020, 587, 124974. [Google Scholar] [CrossRef]
- Grégoire, G. Multiple linear regression. EAS Publ. Ser. 2015, 66, 45–72. [Google Scholar] [CrossRef]
- Beh, E.J.; Lombardo, R. A genealogy of correspondence analysis. Aust. N. Z. J. Stat. 2012, 54, 137–168. [Google Scholar] [CrossRef]
- Beh, E.J. Simple correspondence analysis: A bibliographic review. Int. Stat. Rev. 2004, 72, 257–284. [Google Scholar] [CrossRef]
- De Leeuw, J. Journal of statistical software. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 128–129. [Google Scholar] [CrossRef]
- Hoffman, D.L.; Franke, G.R. Correspondence Analysis: Graphical Representation of Categorical Data in Marketing Research. J. Mark. Res. 1986, 23, 213. [Google Scholar] [CrossRef]
- Kudlats, J.; Money, A.; Hair, J.F. Correspondence analysis: A promising technique to interpret qualitative data in family business research. J. Fam. Bus. Strategy 2014, 5, 30–40. [Google Scholar] [CrossRef]
- Sourial, N.; Wolfson, C.; Zhu, B.; Quail, J.; Fletcher, J.; Karunananthan, S.; Bandeen-Roche, K.; Béland, F.; Bergman, H. Correspondence analysis is a useful tool to uncover the relationships among categorical variables. J. Clin. Epidemiol. 2010, 63, 638–646. [Google Scholar] [CrossRef]
- Brzezińska, J. The analysis of the structure of university positions in Poland using classification methods. Econometrics 2020, 24, 71–81. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).