Abstract
Production scheduling that involves distributed factories, machine maintenance, and resource constraints plays a crucial role in manufacturing. However, these realistic constraints have rarely been considered simultaneously in the hybrid flow shop (HFS). To address this issue, a distributed resource-constrained hybrid flow shop scheduling problem with machine breakdowns (DRCHFSP-MB) is studied. There are two optimization objectives, i.e., makespan and total energy consumption (TEC). To solve the strongly NP-hard problem, a mathematical model is established and a block–neighborhood-based multi-objective evolutionary algorithm (BNMOEA) is developed. In the proposed algorithm, an efficient hybrid initialization method is adopted to obtain high-quality individuals to participate in the evolutionary process of the population. Next, to enhance the search capability of the BNMOEA, three well-designed crossover operators are used in the global search. Then, the convergence of the proposed algorithm is improved by utilizing eight critical factory-based local search operators combined with block–neighborhood. Finally, the BNMOEA is compared with several of the most advanced multi-objective algorithms; the results indicate that the BNMOEA has an outstanding performance in solving DRCHFSP-MB.
1. Introduction
Currently, environmental and energy crises are becoming growing worldwide problems in most countries, and companies must make a trade-off between production and green sustainable development [1,2,3]. Green manufacturing has become a crucial research topic in recent years. In addition, a complex industrial scenario gives increasing challenges to manufacturing with Industry 4.0, especially for a distributed hybrid flow shop scheduling problem (DHFSP). The DHFSP is more practical in real industrial production environments, e.g., family setup time [1] and worker fatigue [2]. Green production has been mostly ignored in the above studies; however, in actual manufacturing processes, companies achieve green production through operations such as time-sharing production [3], adjusting their processing speed [4], and switching off idle machines [5].
Many types of realistic constraints need to be considered in the manufacturing process, such as machine breakdown [6] and resource constraints [7]. Common types of resources include fuels, catalysts, and workers. Machines take up resources to process jobs. When resources are insufficient, the machine will stop processing until the current machine has finished processing before releasing the resources. In actual production settings, machine breakdowns are common. Machine breakdowns are unpredictable, and the duration of repairs varies based on the specific situation of each failure. Estimating machine failure time and repair duration is challenging, and typically, the best approach involves estimating the breakdown distribution while incorporating maintenance strategies to reduce disruptions. In the above literature, only one constraint is considered. In this paper, both resource constraints and machine breakdown are tackled.
The primary contributions of this study are as follows: (1) The DHFSP of resource constraints and machine breakdown are simultaneously considered, and a mathematical model is developed. (2) An improved initialization method is employed for quality assurance and diversity of the initial population. (3) A hybrid method with three crossover operators is employed to ensure diversity in the search space. (4) Local reinforcement based on critical factories is devised to raise the local search effect.
The remaining parts of this paper are organized as follows. The literature review of DHFSP, scheduling problems with resource constraints, and machine breakdown are introduced in Section 2. Section 3 introduces the problem under consideration and presents a mathematical model. Section 4 describes the BNMOEA in detail. In Section 5, an experimental analysis is provided. In Section 6, the conclusion and future work are summarized.
2. Literature Review
In Section 2, a brief review of the relevant literature on the DHFSP, scheduling problems with machine breakdowns, and resource constraints is presented.
2.1. Literature Review of Distributed Hybrid Flow Shop
Considering the globalized economy, the DHFSP has garnered substantial attention. This heightened interest is attributed to its remarkable efficiency, capitalizing on the diverse machining capabilities offered by factories in disparate locations. Ying and Lin addressed the DHFSP by presenting a mixed integer linear programming formulation alongside a self-tuning iterated greedy (SIG) algorithm [8]. Li et al. proposed a two-population balanced multi-objective algorithm to solve the distributed production problem of a steelmaking system considering a fuzzy processing time and a crane handling process [1]. An enhanced discrete artificial bee colony (DABC) algorithm for tackling the DHFSP was introduced by Li et al. [9]. A dynamic search process employing the shuffled frog-leaping algorithm (DSFLA) was investigated by Cai et al. to address the DHFSP, involving multiprocessor tasks [10]. Du et al. proposed a reinforcement learning approach to solve the scheduling problem of considering time-of-day tariffs and machine indicators [11]. Wang et al. proposed a variable neighborhood search method to solve a three-stage HFS [12]. Zheng et al. explored a multi-objective fuzzy DHFSP that involved fuzzy processing times and fuzzy due dates. They utilized a combination of the estimation of distribution algorithm (EDA) and iterated greedy (IG) search for their investigation [13]. Shao et al. proposed an IG algorithm incorporating a multi-search construction [14]. Wang et al. employed a bi-population cooperative memetic algorithm (BCMA) to tackle the DHFSP [15]. Shao et al. examined a multi-objective DHFSP and proposed a multi-objective evolutionary algorithm based on multi-neighborhood local search (MOEALS) [16]. Li et al. proposed a hybrid algorithm combining the whale optimization algorithm (WOA) and local search heuristics to solve a batch-delivered DHFSP [17]. Wang and Wang developed a cooperative memetic algorithm (CMA) that incorporates a reinforcement learning (RL)-based policy agent [18]. Lu et al. addressed the DHFSP by combining the advantages of genetic operators and iterative greedy algorithms [19]. Shao et al. put forward a network memetic algorithm (NMA) to solve the DHFSP with workers and energy constraints [20]. Meng et al. formulated mixed-integer linear programming (MILP) models and a constraint programming (CP) model [21]. Lei et al. introduced a multi-class teaching–learning-based optimization (MTLBO) approach aimed at concurrently minimizing both the makespan and maximum tardiness [22]. Gholami et al. examined the DHFSP involving multiprocessor tasks and introduced a solution approach combining conditional Markov chain search (CMCS) and a hybrid Q-learning–local search algorithm [23].
2.2. Scheduling Problem with Machine Breakdown
Considerable effort has been devoted to investigating machine breakdowns in the context of scheduling problems. Gholami et al. addressed HFSP that involves sequence-dependent setup times (SDSTs) and machines experiencing stochastic breakdowns [24]. Zandieh et al. devised an Immune Algorithm (IA) to address HFSP encompassing SDSTs and machines subjected to stochastic breakdowns [25]. Safari et al. introduced an algorithm for an irrecoverable process shop state where job processing after preventive maintenance restarts from the initial stages [26]. Wang et al. proposed a decomposition-based approach which divided the problem into sub-problems to solve flexible flow shops considering machine breakdowns [27]. A two-stage HFSP in the presence of machine breakdowns was investigated by Mirabi et al. [28]. Wang et al. introduced a fuzzy logic-based hybrid estimation of distribution algorithm (FL-HEDA) for handling discrete permutation flow shop problems (DPFSPs) under machine breakdown conditions [29]. Adressi et al. suggested GA- and SA-based heuristics to address the group scheduling problem within a no-wait flexible flow shop setting [30]. Fazayeli et al. developed an efficient hybrid algorithm by combining GA- and SA- based meta-heuristics to address this problem [31]. Seidgar examined two-stage assembly flow shop problems (TAFSPs) while accounting for machine breakdowns [32]. Han et al. introduced a multi-objective evolutionary robust algorithm to address scheduling problems in a blocking lot-streaming flow shop (BLSFS) environment [33]. Tadayonirad et al. studied a two-stage assembly-based robust scheduling flow shop with random machine breakdowns [34]. Marichelvam et al. introduced a hybrid approach that combines the Firefly Algorithm (FA) with the VNS algorithm to address a time-uncertain flow shop scheduling problem and machine breakdowns [35]. Seidgar et al. considered random machine breakdowns and the two-stage assembly flow shop problem in their investigation [36]. Branda et al. solved a flow shop scheduling problem characterized by machines not continuously available throughout the planning horizon. The periods of unavailability were caused by random faults [37]. Abtahi et al. introduced a predictive robust and stable approach to tackle a two-machine flow shop scheduling problem involving machine disruptions and uncertain job processing times [6].
2.3. Scheduling Problem with Resource Constraints
Resource constraints have garnered considerable attention in the scheduling field. Li et al. proposed a multi-dimensional co-evolutionary algorithm to solve a multi-objective resource-constrained flexible flow shop with robotic transportation [38]. Leu and Hwang used a search-based genetic algorithm to determine the minimum completion time, considering both resource constraints and mixed production scenarios [39]. Jarboui et al. introduced a combinatorial particle swarm optimization (CPSO) algorithm to address the multi-mode resource-constrained project scheduling problem (MRCPSP) [40]. Behnamian et al. proposed a max–min weighting approach to solving the multi-model resource-constrained scheduling problem [41]. Rajkumar et al. introduced a greedy randomized adaptive search procedure (GRASP) algorithm for addressing FJSP while considering resource constraints [42]. Cheng et al. formulated a resource-constrained two-machine scheduling problem to identify a feasible re-development sequence that minimizes the makespan [43]. Lin et al. introduced a multi-level GA incorporating correlated re-entrant possibilities and production modes into a multi-level chromosome encoding scheme [44]. Bożejko et al. took road construction as an example and proposed two novel optimization algorithms for the problem under consideration: construction and tabu search [45]. Laribi et al. considered non-renewable resource constraints and proposed a fast solution to the resource-constrained m-machine flow shop problem [46]. Li et al. proposed a bi-population balancing a multi-objective algorithm to solve a fuzzy flexible job shop with energy and transportation [1]. Rahman et al. introduced a memetic algorithm (MA) based on GA to address resource-limited scheduling problems [47]. Costa et al. investigated an m-stage HFSP where there is a limited workforce responsible for carrying out setup operations [48]. BOUFELLOUH et al. introduced a bi-objective model that encompasses production scheduling, maintenance planning, and the optimal allocation of diverse resources for production purposes [49]. Chen et al. proposed to solve a flexible job shop with crane transportation and setup times using a genetic programming-based cooperative evolutionary algorithm [50]. Han et al. introduced four hybrid decomposition (HD) methods tailored for four multi-objective evolutionary algorithm hybrids (MOEAHs) [51]. These methods integrate four priority rules for machine and worker assignments. Hosseini et al. examined a two-stage production system comprising a fabrication stage followed by an assembly stage. They proposed a novel MILP model to address this scenario [7]. Hasani et al. tackled optimizing a spring manufacturing plant within the scope of the discussed problem. The problem involves considerations of machine eligibility and sequence-dependent setup times [52].
2.4. Literature Analysis
It is clear from the above that there are constraints on FSP and HFSP and that many algorithms can effectively solve constraint-specific FSP and HFSP. However, there is no literature that uses algorithms to address both resource constraints and machine breakdown in the DHFSP. Therefore, this study proposes an efficient and applicable multi-objective intelligent optimization algorithm for resource constraints and machine breakdown.
3. Problem Description
The proposed DRCHFSP-MB can be divided into three parts: distributed hybrid flow shop scheduling; resource constraints; and machine breakdown. The three components are described in detail as below.
3.1. Distributed Hybrid Flow Shop Scheduling
The considered DHFSP can be described as follows: There are N jobs to be processed through L stages in F identical factories (F > 1). Each factory is considered a hybrid flow shop. Each machine is consistently available to process a job at any given time. Jobs follow a fixed processing order and can only be assigned to one machine at a time. Once a job is assigned to a machine, it cannot be reassigned to another machine subsequently. After completing the processing of a job in the initial stage, the job enters an unbounded buffer space until a machine in the next stage becomes available.
3.2. Resource Constraints
There are L stages in each factory, and there are different types of resources for each stage. Resources in different stages do not affect each other. The total number of each resource in each stage is fixed. Machines in different processing stages require different types of resources. When a job needs to be processed, an idle machine must be selected for processing, and the resources needed for that machine are not occupied. This means that the processing in an initial stage may lead to a shortage of corresponding resources for a machine in a subsequent stage. However, after the completion of processing, machines will release the resources they utilize.
3.3. Machine Breakdown
Due to the type of job, the complexity of the process, and the age of the machine, machine breakdowns are inevitable during processing. It is assumed that each machine has the same failure rate. Each machine can be repaired when it fails, and processing can continue after the repair is complete. Once a machine breaks down, it will retain its resource utilization, causing subsequent machines requiring the same resource to wait. The machine is not available at that time. The resource will only be released once the machine has been repaired. The job continues to be processed after it is repaired with no penalty for time loss or recovery. The probability of machine breakdown can be calculated by the exponential function [53], the number of failures conforms to a Poisson’s distribution, and the repair time follows a random distribution.
In the DRCHFSP-MB, two objectives (makespan and TEC) are considered. TEC incorporates energy usage for processing, energy expenditure during waiting, and energy consumption for general operations.
3.4. Notations and Parameters
Based on the provided description, the notations and parameters are defined as follows:
| Indices | |
| Index of jobs. | |
| Index of stages. | |
| Index of machines. | |
| Index of factories. | |
| Index of resources. | |
| Index of machine processing positions. | |
| Index of failure. | |
| Parameters | |
| Number of stages. | |
| Number of factories. | |
| Number of jobs. | |
| Number of machines. | |
| Number of resource types. | |
| Number of failures. | |
| A large number. | |
| The operation associated with job j at the sth position. | |
| The collection of machines in the sth stage. | |
| Processing time of job j in machine m at stage s. | |
| The beginning time of the operation of job j in factory f during the sth stage. | |
| The end time of the operation of the job j in factory f during the sth stage. | |
| The begin time of processing at the rth position on machine m within factory f. | |
| The end time of processing at the rth position on machine m within factory f. | |
| The start time of a breakdown at the rth position, involving failure b, on machine m within factory f. | |
| The completion time of a breakdown at the rth position, involving failure b, on machine m within factory f. | |
| The start time of waiting for resource res at the rth position on machine m within factory f. | |
| The completion time of waiting for resource res at the rth position on machine m within factory f. | |
| Unit energy consumption except machine energy. | |
| The wait time for resource res for job j on machine m at the rth position in stage s within factory f. | |
| The duration of failure b for job j on machine m at the rth position during stage s in factory f. | |
| Unit energy consumption of waiting resource of machine m. | |
| Unit energy consumption of failure of machine m. | |
| Unit energy consumption of processing machine m. | |
| Decision variables | |
| A binary variable (0/1), assigned the value 1 when job j is being processed at the rth position on machine m during stage s in factory f. | |
| A binary variable (0/1), with the value 1 when job j is being processed with resource res at the rth position on machine m during stage s in factory f. | |
| A binary variable (0/1), with a value of 1 when job j is in the processing stage s within factory f. | |
| A binary variable (0/1), set to 1 when job j is being processed with failure b at the rth position on machine m during stage s in factory f. | |
| The DRCHFSP-MB mathematical model can be formulated. | |
Equations (1)–(3) illustrate that the objectives are to minimize makespan and total energy consumption. Equation (4) describes that the makespan is related to the completion time of each factory. Equation (5) ensures each job has a start time that corresponds to the actual production. Equation (6) ensures that the time at which processing of the job ends is larger than or equal to the time at which processing of the job begins. Equations (7) and (8) guarantee positive time for each operation. Equations (9) and (10) ensure that the start time of the next job processing should be later than the completion time of the previous job. Equations (11)–(14) represent the relationship between resources and machine processing. Equations (15)–(18) represent the relationship between machine breakdown and machine processing. Equations (19) and (20) mean that each operation can only be processed on one machine in one factory. Equation (21) shows that the same factory should be selected for each operation on the same job. Equations (22) and (23) ensure that the first available position on the machine for each operation of processing is used. Equations (24)–(27) establish the connection between the positions of machine processing and the operations assigned to them. Equations (28)–(31) create the relationship between waiting for the resource and the assigned operations. Equations (32)–(35) establish the correlation between machine breakdowns and the operations they are assigned. Equation (36) guarantees that a factory could be selected for each job. Equations (37) and (38) ensure the connection between process priority and the resources within the same stage. Equations (39)–(41) represent processing energy, waiting energy, and other energy.
3.5. Problem-Specific Example
A Gantt chart example can be utilized to explain the interplay of resource constraints and machine breakdowns within the DHFSP context. The example encompasses ten jobs, twelve machines, two stages, and two factories. As shown in Figure 1, both factory 1 and factory 2 are equipped with six machines each. Within each factory, there are three resource types established. The aggregate amount of each resource for every phase within each factory is fixed at two units. The resource requirements for each processing machine in the factory are outlined in Table 1. The number 1 signifies that machine processing necessitates this resource type, while 0 indicates the absence of such a requirement. Importantly, each resource can accommodate a maximum of two units concurrently. The processing times for individual jobs are delineated in Table 2. When a machine experiences a breakdown, it enters a fault state and continues to occupy resources until it is repaired. Finished jobs are processed before resources are released.
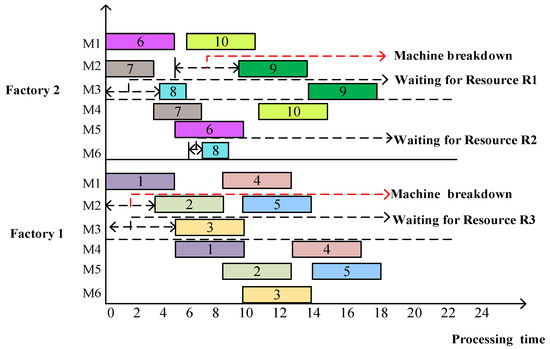
Figure 1.
An example of DRCHFS-MB (rectangle with different colors represent different jobs).

Table 1.
Types of resources required for the machines.
Table 2.
Processing time.
In Figure 1, the sequence {J1, J2, J3, J4, J5, J6, J7, J8, J9, J10} signifies the order in which jobs are introduced into the factory for processing. Obviously, J8 completes its initial processing stage by time 6, but the second stage of processing was not started until time 7. This delay is attributed to machine 4 and machine 5 in the second stage of factory 2 requiring one unit of resource R3 for processing. As a result, the operation of machine 6 must wait for the completion of the processing of machine 4 and the release of 1 unit of resource R3 before J8 can proceed. Furthermore, J9 should be processed at time 5. However, a machine breakdown occurred at that moment, impeding processing until the machine underwent repair. Consequently, the processing of J9 could only commence at time 9. The discrepancy of 4 time units between these instances corresponds to the duration of the machine breakdown.
3.6. Problem-Specific Properties
Definition 1.
Critical factory (denoted as fkey) is the factory that has the longest completion time compared with all other factories.
Lemma 1.
Cmax can only be reduced by reducing the completion time of a critical factory (if there is only one factory).
Proof.
To prove the correctness of the lemma, assuming that the completion time of the non-critical factory is reduced, it can be seen through Equation (42) that the total completion time is related to the factory with the maximum completion time, which is called the critical factory. Therefore, Cmax must be unchanged. If Equation (42) demonstrates a reduction in the total completion time, it implies that the completion time of the critical factory must also be decreased.
In Figure 2, the Gantt chart is used to explain the reduction in total completion time through critical factory operations. □
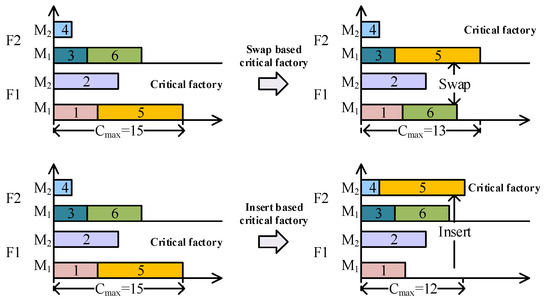
Figure 2.
An example of operation of critical factory (rectangles with different colors represent different jobs).
4. The Proposed Algorithm
4.1. BNMOEA
The primary structure of the BNMOEA outlined in Figure 3 is derived from the AGEMOEAII algorithm, which is itself grounded in the Pareto frontier and is known for its strong convergence and diversity characteristics. The differences between BNMOEA and AGEMOEAII are as follows: (1) Replace the original initialization method with a hybrid initialization method. (2) Replace order crossover with three crossover operators. (3) To further enhance the local search capability, a variable neighborhood search strategy is introduced, which is centered around critical factories.
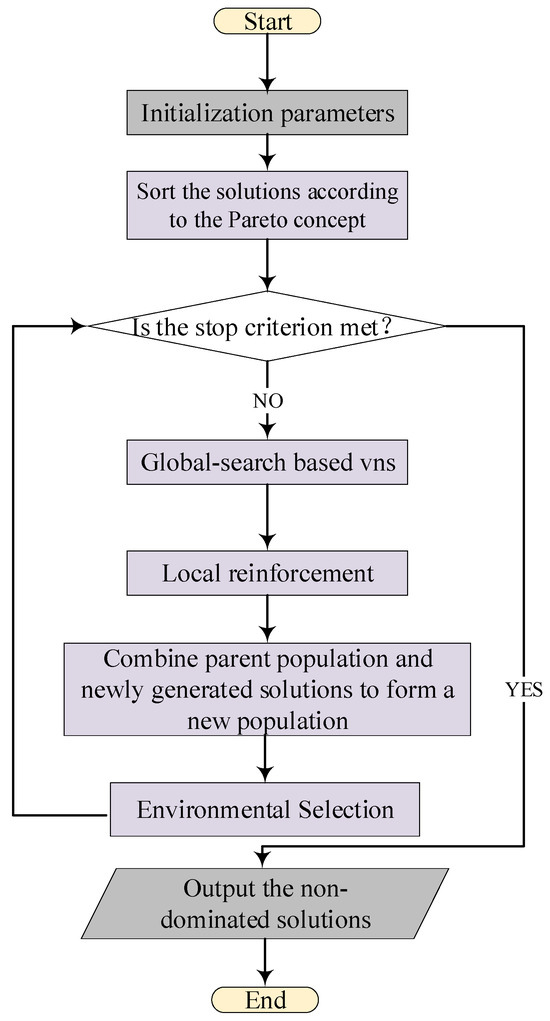
Figure 3.
A framework of the BNMOEA.
4.2. Encoding
Within the algorithm under consideration, a two-dimensional vector is used to represent each solution. The vector in the first dimension pertains to factory assignment, which guarantees that each job will be assigned to a factory. The number of jobs determines the length of the first-dimension vector. The second dimension is named the scheduling vector , which means that the sequence of job processing can be determined through the second dimension. The number of jobs also determines the length of the second-dimension vector.
Figure 4 and Figure 5 give a solution representation example, where the first dimension of a solution is equal to the number of factories and each location represents a factory and is associated with a dimension of values. The second dimension represents the scheduling sequence of the whole process. The scheduling sequence for each factory can be obtained. It can be seen in Figure 5 that several values represent the machine’s dependency on resources. This gives the dependence of the different machines on resources.
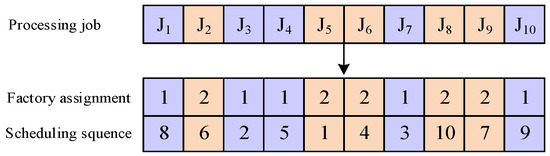
Figure 4.
An example of factory assignment scheduling sequence.
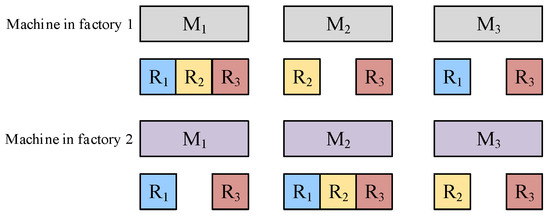
Figure 5.
An example of resource constraints for machines.
The different colors indicate that the jobs are allocated to different factories, namely, J1, J3, J4, J7 and J10, are processed in the first factory, whereas J2, J5, J6, J8 and J9 are assigned to the second factory. The encoding representation also specifies the scheduling sequence of each job within each factory. The scheduling sequence obtained in Figure 4 is the overall scheduling sequence, i.e., the jobs are in the scheduling sequence of both tasks. For example, for factory 1, J1, J3, J4, J7 and J10 are assigned, and the resulting scheduling sequence is then rearranged in ascending order to obtain a new processing order, which means {J3, J7, J4, J1, J10}. The processing time of the job is randomly generated as an integer unit of time from 50 to 100. For instance, J1 has an associated processing time of 55, J7 has an associated processing time of 61, and the processing time of J10 is 69. For resource constraints, the different colors of the machines represent the different factories in which they are located and each machine has different resources to match. As shown in Figure 5, machine 1 would require R1, R2, and R3 in factory 1, whereas machine 1 would require R1 and R3 in factory 2 and R2 is not required in factory 2. In other words, even the same machine has different dependencies on resources.
4.3. Decoding
According to the two dimensions encoding a mechanism, two problems need to be solved, i.e., which factory the jobs should be assigned to and which machine the jobs should be processed on. Considering the problems, a decoding mechanism grounded in the first-come, first-served (FCFS) principle, an earliest-available-first-served (EAFS) rule, is proposed. Firstly, in the first stage, tasks are carried out sequentially according to the order of the scheduling sequence until all machines are in the working state. It is also worth noting that when a machine is down or waiting for resources, the corresponding machine is in an unavailable state. When the machines are available, the following tasks will immediately enter the processing period. Secondly, in the after stage, according to the processing sequence of the first stage, the earlier the job is processed, the earlier it enters the after stage for processing. The specifics of the decoding mechanism are outlined in Algorithm 1.
| Algorithm 1 Decoding mechanism |
 |
4.4. Population Initialization
The algorithm’s effectiveness heavily relies on the quality of the initial population. A diverse initial population of high quality may lead to faster convergence to an accurate solution. Recently, the Nawaz–Enscore–Ham (NEH) heuristic has gained significant popularity for generating high-quality initial solutions to scheduling problems. Given the outstanding capabilities exhibited by NEH, a hybrid initialization method is proposed, as shown in Algorithm 2. Each individual in the initial population contains three components, i.e., job scheduling, factory allocation, and resource assignment. The NEH heuristic is acknowledged as a highly efficient construction heuristic for HFSP that adheres to the maximum expansion criterion. By combining NEH and stochastic method, it is possible to ensure that the solutions are more diverse.
| Algorithm 2 Hybrid initialization method |
 |
4.5. Global Search
Utilizing the encoding scheme as a basis, a hybrid crossover method is proposed which consists of three parts: position-based crossover, linear order crossover, and two-point crossover. The details of the global search are shown in Algorithm 3.
- Position-based Crossover
Position-based crossover for scheduling sequences: Firstly, several genes in a pair of chromosomes (parent) are randomly selected at non-contiguous positions, but both chromosomes are selected at the same position. Subsequently, offspring are produced, ensuring that the selected genes in the offspring maintain identical positions to those in the parent. Finally, determine the location of the gene chosen in the initial step within the other parent and proceed to sequentially place the remaining genes in the offspring produced during the previous step. The specific operation based on positional crossover is shown in Figure 6.
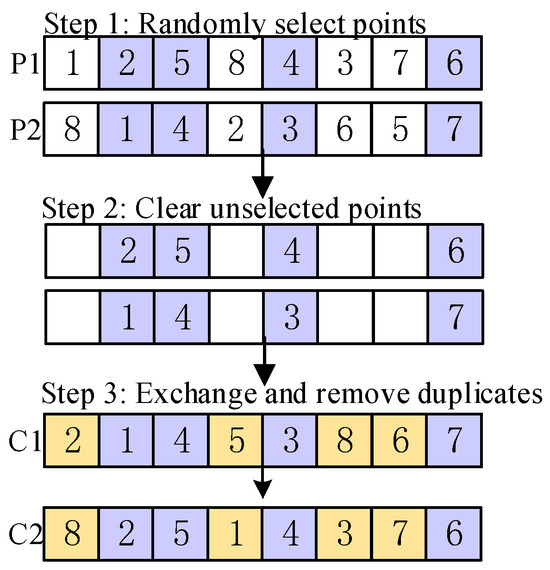
Figure 6.
Details of position-based crossover.
| Algorithm 3 Global search |
 |
- 2.
- Linear order crossover
Linear order crossover for scheduling sequences is shown in Figure 7. Randomly chosen starting and ending positions in the two paternal chromosomes facilitated the copying of genes from the corresponding segment of paternal chromosome 1 to the equivalent positions in offspring 1. Subsequently, any missing genes in offspring 1 were inserted sequentially from paternal chromosome 2. Another offspring is obtained in a similar manner.
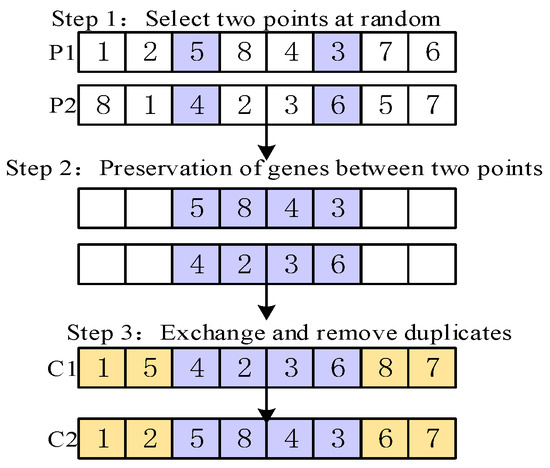
Figure 7.
Details of linear order crossover.
- 3.
- Two-points crossover
A two-point crossover involves the random selection of two crossover points within the chromosomes of individual, which is then followed by a partial exchange of genes between the chromosomes. The details of two-point crossover are shown in Figure 8.
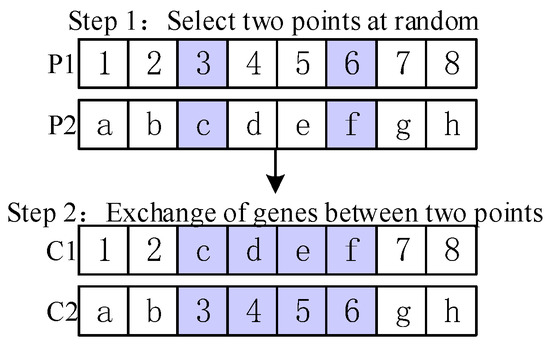
Figure 8.
Details of two-point crossover.
4.6. Local Reinforcement-Based Critical Factory
In the DHFSP, the makespan is decided by the critical factory fkey with the highest completion time. Reducing the makespan of fkey is a productive method for investigating lower fitness individuals. Thus, eight sub-sequence-based operators are designed for the fkey in the local reinforcement strategy, i.e., the sub-sequence internal swap based on critical factory (SIS_cf), the sub-sequence external insert based on critical factory (SEI_cf), the sub-sequence internal insert based on critical factory (SII_cf), the sub-sequence external swap based on critical factory (SES_cf), two sub-sequence swaps between critical factory and random factory (TSS_crf), two sub-sequence insert between critical factory and random factory (TSI_crf), select points swap between critical factory and random factory (SPS_crf), and the select point insert between critical factory and random factory (SPI_crf). An illustration of the eight operators is shown in Figure 9. , are the job scheduling sequences in the critical factory and random factory, respectively.
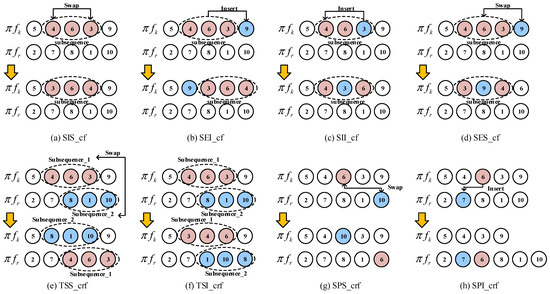
Figure 9.
The details of local reinforcement.
SIS_cf: Randomly choose consecutive jobs form the fkey to create the sub-sequence. The swap operator is employed on the jobs in the sub-sequence jobs.
SEI_cf: Randomly choose consecutive jobs form the fkey to create the sub-sequence. A random job is selected, which is the external sub-sequence. Insert the selected job into the sub-sequence.
SII_cf: Randomly choose consecutive jobs form the fkey to create the sub-sequence. Insert operator is performed on the jobs in the sub-sequence.
SES_cf: Randomly choose consecutive jobs form the fkey to create the sub-sequence. A random job is selected, which is external to the sub-sequence. Swap the selected job with a job in the sub-sequence.
TSS_crf: Randomly select a different factory from the fkey. Then select two sub-sequences with equal length in the fkey and the chosen factory. A swap operator is employed on the two sub-sequences.
TSI_crf: Randomly select a different factory from the fkey. Then select two sub-sequences with equal length in the fkey and the chosen factory. Swap and insert operators are employed on the two sub-sequences.
SPS_crf: Randomly select a different factory from the fkey. Select a random job from each of the two factories. Swap the two jobs in different factories.
SPI_crf: Randomly select a different factory from the fkey. Select a random job in the fkey. Then insert the selected job into the chosen factory.
Eight operators are grouped into four operator sets: OS1 = {SIS_cf, SEI_cf}, OS2 = {SIS_cf, SEI_cf}, OS3 = {SIS_cf, SEI_cf}, and OS4 = {SIS_cf, SEI_cf}. To maintain offspring dispersion and enhance the quality of the solution, the four operator sets are executed using the variable neighborhood search strategy (VNS) framework. Algorithm 4 outlines the steps involved in implementing the local reinforcement strategy.
| Algorithm 4 Local reinforcement-based critical factory |
 |
5. Experimental Results
5.1. Experimental Settings
To demonstrate the performance of the proposed algorithm, four algorithms are chosen from the PlatEMO [54], including NSGA-II [55], AGEMOEAII [56], CMOPSO [57], and BiGE [58]. NSGA-II is a widely used classical multi-objective optimization algorithm and has been validated in many fields with a good performance, while CMOPSO, BiGE, and AGEMOEAII are relatively new multi-objective algorithms with good performances. All comparison algorithms utilized the coding and decoding heuristics discussed in Section 4.2 and Section 4.3, respectively, to adapt to solving the problems considered. For each instance, each comparison algorithm performs 30 independent runs and the stop criterion for each run is set to 1000 iterations.
The population size for each comparison algorithm is set to 20 considering the computational cost. For fair comparisons, all parameters of the compared algorithms are set to the recommended values as in the PlatEMO platform, which are shown as follows: (1) NSGA-II: the values for the crossover probability and mutation probability are set to 0.9 and 1/n, respectively; (2) AGEMOEAII: the crossover probability is set to 1, the mutation probability is set to 1/n, and the distributed index for SBX and mutation are set to 30 and 20, respectively; (3) CMOPSO: the elite particle size is set to 10; (4) BiGE: the crossover probability is set to 1 and the mutation probability is set to 1/n.
Ying and Lin (2018) [8] provided 570 instances, which are available at http://swlin.cgu.edu.tw/data/DHFSP.zip (access on 5 October 2025). To demonstrate the performance of the BNMOEA, 27 test instances of different sizes are generated based on the instances from Ying and Lin and extended according to the constraints in this study in a random way. The 27 test instances are a combination of different jobs, stages, factories, and resources. Specifically, it is a combination of the following parameters: j = {20, 60, 100}, s = {2, 3, 4}, f = {2, 3, 4}, r = {3, 4, 5}. For example, ‘20 × 2 × 2 × 3’ means that there are twenty jobs that are to be completed in two factories, with each job requiring two processing stages, and there are three types of resources available to the machine at each stage. In addition, the processing time of each job is distributed in [50, 100] in a random way. The instances, experimental data, and codes can be downloaded at https://github.com/DATAdriving/Public_Machines.git (access on 5 October 2025).
5.2. Performance Indicators
Hypervolume (HV) [38,59,60,61,62] and inverse generational distance (IGD) [12,63,64,65,66,67] are used to evaluate the performance of the algorithm. To prove the effectiveness of the proposed algorithm, the results which are non-dominated solutions after 30 independent runs of the algorithm are taken out for comparison. In addition, because there are non-benchmarks for the problem considered, no Pareto front can be found to calculate the IGD results. Therefore, we collect all the results obtained by running the comparison algorithms for 3000 iterations and construct the Pareto front.
The relative percentage increase (RPI) was used to compare the performance of the algorithms. The specific formula is shown below:
where f denotes the evaluation metric of the current algorithm, while fb represents the highest value among all current algorithmic evaluation metrics. The evaluation indicator is HV or IGD.
5.3. Parameter Setting
During the experiments, there are two main parameters including crossover and mutation probability that affect the performance of the algorithm. To demonstrate the efficient performance of the algorithm, a full analytical factorial design is performed for both parameters to select better parameters. There are five levels of each parameter in the design, as shown in Table 3.
Table 3.
Parameter settings and factor levels.
To increase the efficiency of implementation and evaluation of experiments, the Taguchi method was widely utilized with a well-designed structure for evaluating production processes because the required number of experiments is reduced significantly [68]. For these five levels and two parameters, we generated 25 different combinations for the Taguchi experiments. The design-of-experiments (DOE) calculations were performed on 25 various combinations to compute the average HV (Ave_HV), as shown in Table 4.
Table 4.
The parameter combinations and response values of DOE.
Figure 10 gives the trend of the two parameters. According to Figure 10, the combination of pc = 0.8 and pm = 0.4 gives the optimal indicator value. To better reflect the performance of the algorithm, the crossover probability is set to 0.8 and the mutation probability is set to 0.4.
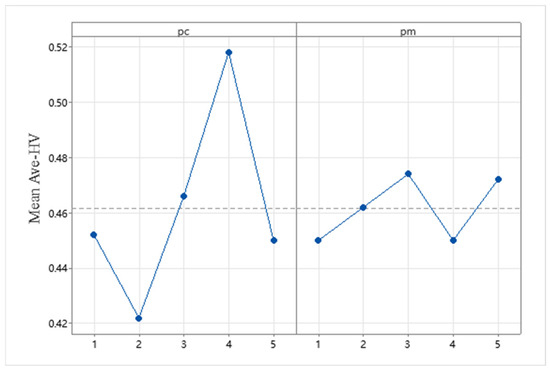
Figure 10.
Trends in pc and pm parameters.
5.4. Ablation Experiments
To investigate the effectiveness of each component embedded in the proposed algorithm, including the initialization method, global search, and local search heuristics, we compared the proposed algorithm with the following three extensions: (1) the first type is the one without the proposed three crossover operators called E1; (2) the second one is the version with a random initialization approach rather than the proposed initialization approach, which is called E1; (3) the last one is the version without the local reinforcement method named E3.
Table 5 illustrates the results of the ablation comparisons for the HV values, where the first column indicates the size of the instance. The second column shows the best results collected by the four compared algorithms. The following four columns list the HV results obtained by the BNMOEA, E1, E2, and E3, respectively. The last four columns show the RPI values for the four algorithms, respectively. It can be observed that (1) the proposed BNMOEA with all the initialization, global, and local search heuristics can find all the best results for the given 27 instances; (2) the average performance shown in the last line verifies the robustness of the BNMOEA; (3) the average RPI values for E1, E2, and E3 show that the global search component contributes most to performance, and the following components are the initialization method and the local search part.
Table 5.
Ablation comparison results of the HV values.
The Friedman test and the Kruskal–Wallis one-way analysis of variance are two commonly used non-parametric test methods. To test whether the comparison results are statistically significant, both non-parametric test methods are utilized. The Kruskal–Wallis comparisons and Friedman’s test results for the HV values are illustrated in Figure 11 and Figure 12, respectively, which further verify the efficiency of the proposed components.
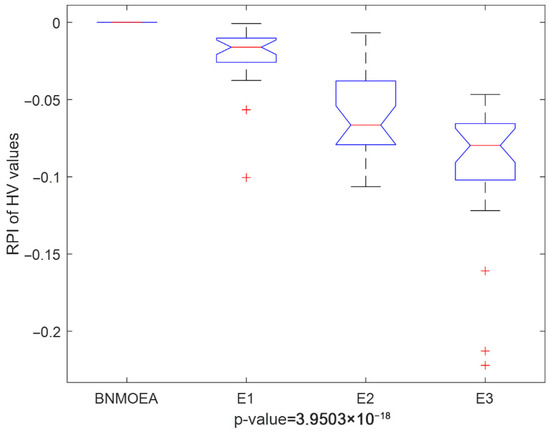
Figure 11.
Kruskal–Wallis’s comparisons for the ablation experiments (HV values).
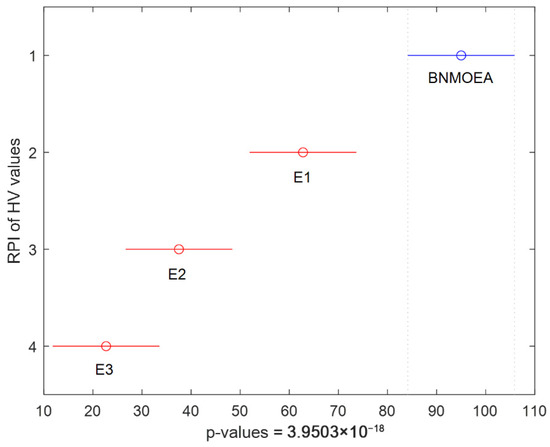
Figure 12.
Friedman’s comparisons for the ablation experiments (V values).
Table 6 shows the results of the ablation comparisons for the IGD values, while Figure 13 and Figure 14 illustrate the comparison results of the IGD values obtained by the Kruskal–Wallis comparisons and the Friedman test, respectively. It can be observed that (1) considering the IGD values, the method with all three components can obtain all the best results; (2) the global search component contributes the most to the performance.
Table 6.
Ablation comparison results of the IGD values.
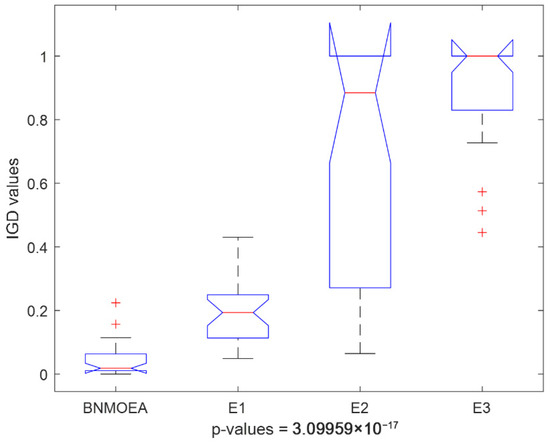
Figure 13.
Kruskal–Wallis’s comparisons for the ablation experiments (IGD values).
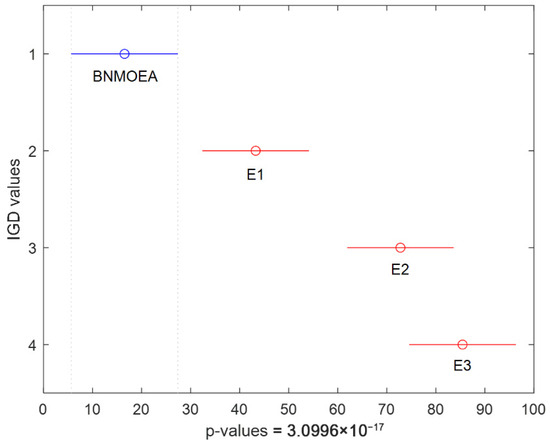
Figure 14.
Friedman’s comparisons for the ablation experiments (IGD values).
To further verify the validity of the operators, the eight operators are divided into four parts, i.e., OS1 = {SIS_cf, SEI_cf}, OS2 = {SIS_cf, SEI_cf}, OS3 = {SIS_cf, SEI_cf}, and OS4 = {SIS_cf, SEI_cf}. The impact of each part on the results was verified separately as shown in Figure 15, where op-1 denotes the removal of the OS1 operator and op-null means there are no operators. As can be seen from Figure 15a,b, all the HV values of the four-part operator operation are larger and the IGD values are smaller than those without the operator operation, so the four-part operator improves the algorithm’s performance.
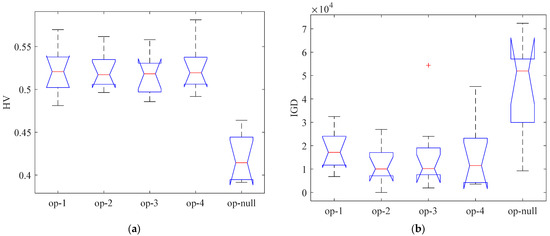
Figure 15.
The results for each operator. (a) HV evaluation indicator; (b) IGD evaluation indicator.
5.5. Analysis of Comparative Algorithms
To verify the efficiency of the proposed algorithm compared with the other efficient multi-objective optimization algorithms, we chose four efficient ones, including NSGA-II [55], AGEMOEAII [56], CMOPSO [57], and BiGE [58].
Table 7, Table 8 and Table 9 illustrate the HV comparison results where the best, worst, and average results are shown in the three tables, respectively. It can be observed that (1) considering the best performance for each algorithm, the proposed BNMOEA obtained all the better values for the given 27 different-sized instances; (2) the average HV values obtained by the BNMOEA are 0.7036, 0.6318, and 0.6460 for best, worst, and average cases, which are better than the other comparison algorithms; (3) from the performance shown in the last line in the three tables, the second-best algorithm is AGEMOEAII; (4) considering the average performance, CMOPSO performs slightly better than BiGE and NSGA-II.
Table 7.
Comparison of HV metric performance across algorithms (best values).
Table 8.
Comparison of HV metric performance across algorithms (worst values).
Table 9.
Comparison of HV metric performance across algorithms (average values).
Table 10, Table 11 and Table 12 report the IGD comparison results between the five comparison algorithms, which further verify the efficiency of the proposed BNMOEA from the best, worst, and average performance aspects.
Table 10.
Comparison of IGD metric performance across algorithms (best values).
Table 11.
Comparison of IGD metric performance across algorithms (worst values).
Table 12.
Comparison of IGD metric performance across algorithms (average values).
Figure 16 illustrates the Kruskal–Wallis comparisons for HV values among the five comparison algorithms, while Figure 17 reports the trend of HV values with increasing instances scale. The two figures verify the efficiency of the proposed algorithm considering the HV indicator. Figure 18 illustrates the Kruskal–Wallis comparisons for the BNMOEA, AGEMOEAII, BiGE, CMOPSO, and NSGAII considering the IGD values, while the trend of IGD values with increasing scale was reported in Figure 19. The two figures also verify the effectiveness of the proposed algorithm considering the IGD indicator.
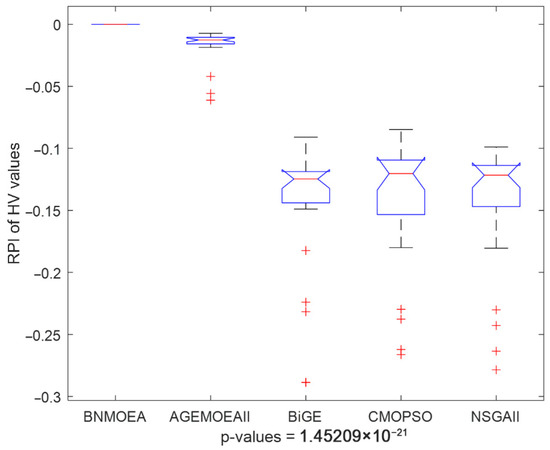
Figure 16.
Kruskal–Wallis’s comparisons for BNMOEA, AGEMOEAII, BiGE, CMOPSO, and NSGAII (HV values).
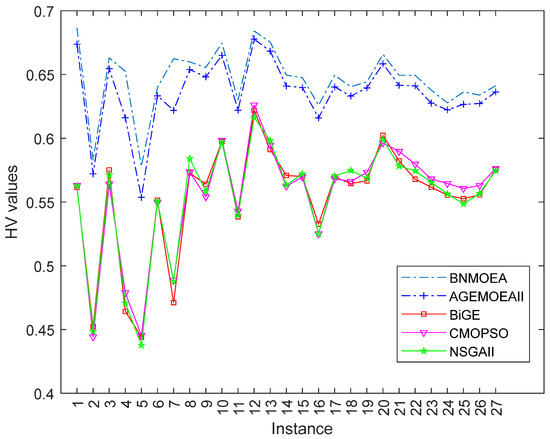
Figure 17.
Change trend of HV values with increasing instances scale.
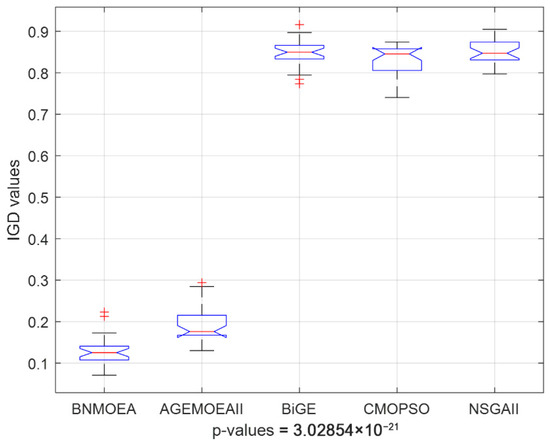
Figure 18.
Kruskal–Wallis’s comparisons for BNMOEA, AGEMOEAII, BiGE, CMOPSO, and NSGAII (IGD values).
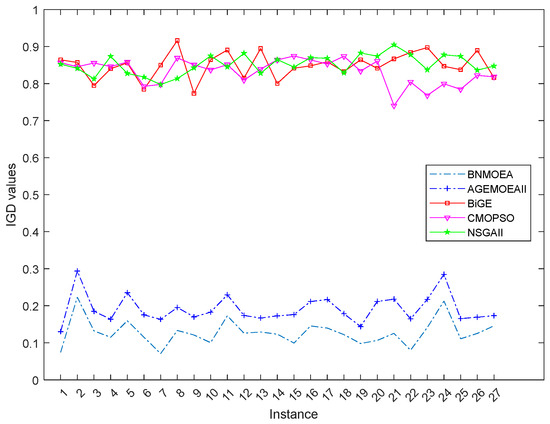
Figure 19.
Change trend of IGD values with increasing instances scale.
In addition, we have tested the above comparison algorithms using the Empirical Achievement Function (EAF) [65]. In the EAF, the color indicates the difference in the probability of this algorithm dominating the corresponding solution compared with another algorithm. The higher the difference, the darker the color, and the higher the probability that the result obtained here will dominate the solution compared with another algorithm. In short, the darker the color and the larger the area, the better the algorithm. The following conclusions can be obtained from Figure 20: (1) The shaded portion of the BNMOEA is larger than the other comparison algorithms, which proves that the BNMOEA has a better performance. (2) The BNMOEA also outperforms the other four comparative algorithms under different scheduling environments. Therefore, the EAF demonstrates that the BNMOEA has an excellent performance.
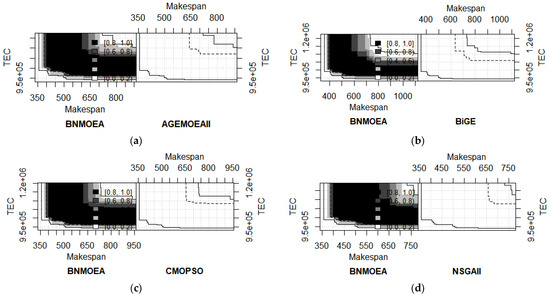
Figure 20.
EAF differences between BNMOEA and other algorithms for instance 20 × 2 × 2 × 3. (a) The differences between BNMOEA and AGEMOEAII; (b) the differences between BNMOEA and BiGE; (c) the differences between BNMOEA and CMOPSO; (d) the differences between BNMOEA and NSGAII.
6. Conclusions
A more practical problem with resource constraints and machine breakdown in the DHFSP was considered and solved using a BNMOEA. The BNMOEA improves the searching capability, which includes a hybrid initialization method and local reinforcement-based critical factories. The effect of hybrid initialization methods and local search on the BNMOEA is tested through extensive experiments. The BNMOEA was also compared with four comparison algorithms. The experimental results show that the BNMOEA is a great solution to address DRCHFSP-MB.
The main limitations of the current study are as follows: (1) because there are few studies considering both limited resource and machine breakdown constraints simultaneously in the DHFSP, the benchmarks should be generated in a more reasonable manner; (2) the algorithm embeds the initialization heuristic and global and local search operators, but how to design problem-specific components with a more efficient performance is still a challenging task.
Therefore, future work can consider the following aspects: (1) apply the proposed multi-objective optimization to solve the DHFSP with limited resources and machine breakdown constraints in distributed heterogeneous factories; (2) design benchmarks for the considered problem and provide the Pareto front results; (3) design more problem-specific and efficient strategies to enhance both the global and local search capabilities; (4) consider other realistic constraints and objectives, such as random job arrival, random order cancelation, and economic objectives.
Author Contributions
Y.X.: Conceptualization, Methodology, Idea, Software, Experiments, Writing—Original Draft, Visualization. S.L.: Data Curation, Writing—Original Draft. J.L.: Writing—review and editing, Supervision, Resources All authors have read and agreed to the published version of the manuscript.
Funding
This research is partially supported by the Yunnan Key Laboratory of Modern Analytical Mathematics and Applications (No. 202302AN360007).
Informed Consent Statement
The authors declare that our research is ethical. This article does not contain any animal or human studies.
Data Availability Statement
The data that supports the findings of this study are available from the corresponding author, upon reasonable request.
Conflicts of Interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and publication of this article.
References
- Li, J.; Li, J.; Gao, K.; Duan, P. A hybrid graph-based imitation learning method for a realistic distributed hybrid flow shop with family setup time. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 7291–7304. [Google Scholar] [CrossRef]
- Song, H.; Li, J.; Du, Z.; Yu, X.; Xu, Y.; Zheng, Z.; Li, J. A Q-learning driven multi-objective evolutionary algorithm for worker fatigue dual-resource-constrained distributed hybrid flow shop. Comput. Oper. Res. 2025, 175, 106919. [Google Scholar] [CrossRef]
- Luo, H.; Du, B.; Huang, G.Q.; Chen, H.; Li, X. Hybrid flow shop scheduling considering machine electricity consumption cost. Int. J. Prod. Econ. 2013, 146, 423–439. [Google Scholar] [CrossRef]
- Wei, Z.; Liao, W.; Zhang, L. Hybrid energy-efficient scheduling measures for flexible job-shop problem with variable machining speeds. Expert Syst. Appl. 2022, 197, 116785. [Google Scholar] [CrossRef]
- Liu, Q.; Pan, Q.K.; Gao, L.; Li, X. Multi-objective flexible job shop scheduling problem considering machine switching off-on operation. Procedia Manuf. 2019, 39, 1167–1176. [Google Scholar] [CrossRef]
- Abtahi, Z.; Sahraeian, R. Robust and Stable Flow Shop Scheduling Problem Under Uncertain Processing Times and Machines Disruption. Int. J. Eng. Trans. A Basics 2021, 34, 935–947. [Google Scholar]
- Hosseini, S.M.H.; Sana, S.S.; Rostami, M. Assembly flow shop scheduling problem considering machine eligibility restrictions and auxiliary resource constraints. Int. J. Syst. Sci. Oper. Logist. 2022, 9, 512–528. [Google Scholar] [CrossRef]
- Ying, K.C.; Lin, S.W. Minimizing makespan for the distributed hybrid flowshop scheduling problem with multiprocessor tasks. Expert Syst. Appl. 2018, 92, 132–141. [Google Scholar] [CrossRef]
- Li, Y.; Li, F.; Pan, Q.K.; Gao, L.; Tasgetiren, M.F. An artificial bee colony algorithm for the distributed hybrid flowshop scheduling problem. Procedia Manuf. 2019, 39, 1158–1166. [Google Scholar] [CrossRef]
- Cai, J.; Zhou, R.; Lei, D. Dynamic shuffled frog-leaping algorithm for distributed hybrid flow shop scheduling with multiprocessor tasks. Eng. Appl. Artif. Intell. 2020, 90, 103540. [Google Scholar] [CrossRef]
- Du, Y.; Li, J.; Chen, X.; Duan, P.; Pan, Q. Knowledge-Based Reinforcement Learning and Estimation of Distribution Algorithm for Flexible Job Shop Scheduling Problem. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 7, 1036–1050. [Google Scholar] [CrossRef]
- Wang, S.; Wu, R.; Chu, F.; Yu, J. Variable neighborhood search-based methods for integrated hybrid flow shop scheduling with distribution. Soft Comput. 2020, 24, 8917–8936. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, L.; Wang, J. A cooperative coevolution algorithm for multi-objective fuzzy distributed hybrid flow shop. Knowl.-Based Syst. 2020, 194, 105536. [Google Scholar] [CrossRef]
- Shao, W.; Shao, Z.; Pi, D. Modeling and multi-neighborhood iterated greedy algorithm for distributed hybrid flow shop scheduling problem. Knowl.-Based Syst. 2020, 194, 105527. [Google Scholar] [CrossRef]
- Wang, J.; Wang, L. A Bi-Population Cooperative Memetic Algorithm for Distributed Hybrid Flow-Shop Scheduling. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 947–961. [Google Scholar] [CrossRef]
- Shao, W.; Shao, Z.; Pi, D. Multi-objective evolutionary algorithm based on multiple neighborhoods local search for multi-objective distributed hybrid flow shop scheduling problem. Expert Syst. Appl. 2021, 183, 115453. [Google Scholar] [CrossRef]
- Li, Q.; Li, J.; Zhang, X.; Zhang, B. A wale optimization algorithm for distributed flow shop with batch delivery. Soft Comput. 2021, 25, 13181–13194. [Google Scholar] [CrossRef]
- Wang, J.; Wang, L. A Cooperative Memetic Algorithm with Learning-Based Agent for Energy-Aware Distributed Hybrid Flow-Shop Scheduling. IEEE Trans. Evol. Comput. 2022, 26, 461–475. [Google Scholar] [CrossRef]
- Lu, C.; Liu, Q.; Zhang, B.; Yin, L. A Pareto-based hybrid iterated greedy algorithm for energy-efficient scheduling of distributed hybrid flowshop. Expert Syst. Appl. 2022, 204, 117555. [Google Scholar] [CrossRef]
- Shao, W.; Shao, Z.; Pi, D. A network memetic algorithm for energy and labor-aware distributed heterogeneous hybrid flow shop scheduling problem. Swarm Evol. Comput. 2022, 75, 101190. [Google Scholar] [CrossRef]
- Meng, L.; Gao, K.; Ren, Y.; Zhang, B.; Sang, H.; Zhang, C. Novel MILP and CP models for distributed hybrid flowshop scheduling problem with sequence-dependent setup times. Swarm Evol. Comput. 2022, 71, 101058. [Google Scholar] [CrossRef]
- Lei, D.; Su, B. A multi-class teaching–learning-based optimization for multi-objective distributed hybrid flow shop scheduling. Knowl.-Based Syst. 2023, 263, 110252. [Google Scholar] [CrossRef]
- Gholami, H.; Sun, H. Toward automated algorithm configuration for distributed hybrid flow shop scheduling with multiprocessor tasks. Knowl.-Based Syst. 2023, 264, 110309. [Google Scholar] [CrossRef]
- Gholami, M.; Zandieh, M.; Alem-Tabriz, A. Scheduling hybrid flow shop with sequence-dependent setup times and machines with random breakdowns. Int. J. Adv. Manuf. Technol. 2008, 42, 189–201. [Google Scholar] [CrossRef]
- Zandieh, M.; Gholami, M. An immune algorithm for scheduling a hybrid flow shop with sequence-dependent setup times and machines with random breakdowns. Int. J. Prod. Res. 2009, 47, 6999–7027. [Google Scholar] [CrossRef]
- Safari, E.; Sadjadi, S.J. A hybrid method for flowshops scheduling with condition-based maintenance constraint and machines breakdown. Expert Syst. Appl. 2011, 38, 2020–2029. [Google Scholar] [CrossRef]
- Wang, K.; Choi, S.H. A decomposition-based approach to flexible flow shop scheduling under machine breakdown. Int. J. Prod. Res. 2011, 50, 215–234. [Google Scholar] [CrossRef]
- Mirabi, M.; Ghomi, S.M.T.F.; Jolai, F. A two-stage hybrid flowshop scheduling problem in machine breakdown condition. J. Intell. Manuf. 2011, 24, 193–199. [Google Scholar] [CrossRef]
- Wang, K.; Huang, Y.; Qin, H. A fuzzy logic-based hybrid estimation of distribution algorithm for distributed permutation flowshop scheduling problems under machine breakdown. J. Oper. Res. Soc. 2017, 67, 68–82. [Google Scholar] [CrossRef]
- Adressi, A.; Tasouji Hassanpour, S.; Azizi, V. Solving group scheduling problem in no-wait flexible flowshop with random machine breakdown. Decis. Sci. Lett. 2016, 5, 157–168. [Google Scholar] [CrossRef]
- Fazayeli, M.; Aleagha, M.R.; Bashirzadeh, R.; Shafaei, R. A hybrid meta-heuristic algorithm for flowshop robust scheduling under machine breakdown uncertainty. Int. J. Comput. Integr. Manuf. 2016, 29, 709–719. [Google Scholar] [CrossRef]
- Seidgar, H.; Rad, S.T.; Shafaei, R. Scheduling of assembly flow shop problem and machines with random breakdowns. Int. J. Oper. Res. 2017, 29, 273–293. [Google Scholar] [CrossRef]
- Han, Y.; Gong, D.; Jin, Y.; Pan, Q. Evolutionary Multiobjective Blocking Lot-Streaming Flow Shop Scheduling with Machine Breakdowns. IEEE Trans. Cybern. 2019, 49, 184–197. [Google Scholar] [CrossRef] [PubMed]
- Tadayonirad, S.; Seidgar, H.; Fazlollahtabar, H.; Shafaei, R. Robust scheduling in two-stage assembly flow shop problem with random machine breakdowns: Integrated meta-heuristic algorithms and simulation approach. Assem. Autom. 2019, 39, 944–962. [Google Scholar] [CrossRef]
- Marichelvam, M.K.; Geetha, M. A hybrid algorithm to solve the stochastic flow shop scheduling problems with machine break down. Int. J. Enterp. Netw. Manag. 2019, 10, 162–175. [Google Scholar] [CrossRef]
- Seidgar, H.; Fazlollahtabar, H.; Zandieh, M. Scheduling two-stage assembly flow shop with random machines breakdowns: Integrated new self-adapted differential evolutionary and simulation approach. Soft Comput. 2020, 24, 8377–8401. [Google Scholar] [CrossRef]
- Branda, A.; Castellano, D.; Guizzi, G.; Popolo, V. Metaheuristics for the flow shop scheduling problem with maintenance activities integrated. Comput. Ind. Eng. 2021, 151, 106989. [Google Scholar] [CrossRef]
- Li, J.; Li, R.; Li, J.; Yu, X.; Xu, Y. A multi-dimensional co-evolutionary algorithm for multi-objective resource-constrained flexible flowshop with robotic transportation. Appl. Soft Comput. 2025, 170, 112689. [Google Scholar] [CrossRef]
- Leu, S.S.; Hwang, S.T. GA-based resource-constrained flow-shop scheduling model for mixed precast production. Autom. Constr. 2002, 11, 439–452. [Google Scholar] [CrossRef]
- Jarboui, B.; Damak, N.; Siarry, P.; Rebai, A. A combinatorial particle swarm optimization for solving multi-mode resource-constrained project scheduling problems. Appl. Math. Comput. 2008, 195, 299–308. [Google Scholar] [CrossRef]
- Behnamian, J.; Fatemi Ghomi, S.M.T. Hybrid flowshop scheduling with machine and resource-dependent processing times. Appl. Math. Model. 2011, 35, 1107–1123. [Google Scholar] [CrossRef]
- Rajkumar, M.; Asokan, P.; Anilkumar, N.; Page, T. A GRASP algorithm for flexible job-shop scheduling problem with limited resource constraints. Int. J. Prod. Res. 2011, 49, 2409–2423. [Google Scholar] [CrossRef]
- Cheng, T.C.E.; Lin, B.M.T.; Huang, H.L. Resource-constrained flowshop scheduling with separate resource recycling operations. Comput. Oper. Res. 2012, 39, 1206–1212. [Google Scholar] [CrossRef]
- Lin, D.; Lee, C.K.; Ho, W. Multi-level genetic algorithm for the resource-constrained re-entrant scheduling problem in the flow shop. Eng. Appl. Artif. Intell. 2013, 26, 1282–1290. [Google Scholar] [CrossRef]
- Bożejko, W.; Hejducki, Z.; Uchroński, M.; Wodecki, M. Solving Resource-Constrained Construction Scheduling Problems with Overlaps by Metaheuristic. J. Civ. Eng. Manag. 2014, 20, 649–659. [Google Scholar] [CrossRef]
- Laribi, I.; Yalaoui, F.; Belkaid, F.; Sari, Z. Heuristics for solving flow shop scheduling problem under resources constraints. IFAC-Pap. 2016, 49, 1478–1483. [Google Scholar] [CrossRef]
- Rahman, H.; Chakrabortty, R.; Ryan, M. Memetic algorithm for solving resource constrained project scheduling problems. Autom. Constr. 2020, 111, 103052. [Google Scholar] [CrossRef]
- Costa, A.; Fernandez-Viagas, V.; Framinan, J. Solving the hybrid flow shop scheduling problem with limited human resource constraint. Comput. Ind. Eng. 2020, 146, 106545. [Google Scholar] [CrossRef]
- Boufellouh, R.; Belkaid, F. Bi-objective optimization algorithms for joint production and maintenance scheduling under a global resource constraint: Application to the permutation flow shop problem. Comput. Oper. Res. 2020, 122, 104943. [Google Scholar] [CrossRef]
- Chen, X.; Li, J.; Wang, Z.; Chen, Q.; Gao, K.; Pan, Q. Optimizing dynamic flexible job shop scheduling using an evolutionary multi-task optimization framework and genetic programming. IEEE Trans. Evol. Comput. 2025, 29, 1502–1516. [Google Scholar] [CrossRef]
- Han, W.; Deng, Q.; Gong, G.; Zhang, L.; Luo, Q. Multi-objective evolutionary algorithms with heuristic decoding for hybrid flow shop scheduling problem with worker constraint. Expert Syst. Appl. 2021, 168, 114282. [Google Scholar] [CrossRef]
- Hasani, A.; Hosseini, S.M.H. Auxiliary resource planning in a flexible flow shop scheduling problem considering stage skipping. Comput. Oper. Res. 2022, 138, 105625. [Google Scholar] [CrossRef]
- Zuo, Y.; Zhao, F.; Yu, Y. Two-stage learning scatter search algorithm for the distributed hybrid flow shop scheduling problem with machine breakdown. Expert Syst. Appl. 2025, 259, 125344. [Google Scholar] [CrossRef]
- Tian, Y.; Cheng, R.; Zhang, X.; Jin, Y. PlatEMO: A MATLAB platform for evolutionary multi-objective optimization [educational forum]. IEEE Comput. Intell. Mag. 2017, 12, 73–87. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Panichella, A. An improved Pareto front modeling algorithm for large-scale many-objective optimization. In Proceedings of the Genetic and Evolutionary Computation Conference, Boston, MA, USA, 9–13 July 2022; pp. 565–573. [Google Scholar]
- Zhang, X.; Zheng, X.; Cheng, R.; Qiu, J.; Jin, Y. A competitive mechanism based multi-objective particle swarm optimizer with fast convergence. Inf. Sci. 2018, 427, 63–76. [Google Scholar] [CrossRef]
- Li, M.; Yang, S.; Liu, X. Bi-goal evolution for many-objective optimization problems. Artif. Intell. 2015, 228, 45–65. [Google Scholar] [CrossRef]
- Du, Y.; Li, J.; Li, C.; Duan, P. A Reinforcement Learning Approach for Flexible Job Shop Scheduling Problem with Crane Transportation and Setup Times. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 5695–5709. [Google Scholar] [CrossRef]
- Du, Z.S.; Li, J.Q.; Song, H.N.; Gao, K.Z.; Xu, Y.; Li, J.K.; Zheng, Z.X. Solving the permutation flow shop scheduling problem with sequence-dependent setup time via iterative greedy algorithm and imitation learning. Math. Comput. Simul. 2025, 234, 169–193. [Google Scholar] [CrossRef]
- Duan, J.; Liu, F.; Zhang, Q.; Qin, J.; Zhou, Y. Genetic programming hyper-heuristic-based solution for dynamic energy-efficient scheduling of hybrid flow shop scheduling with machine breakdowns and random job arrivals. Expert Syst. Appl. 2024, 254, 124375. [Google Scholar] [CrossRef]
- Duan, J.; Liu, F.; Zhang, Q.; Qin, J. Tri-objective lot-streaming scheduling optimization for hybrid flow shops with uncertainties in machine breakdowns and job arrivals using an enhanced genetic programming hyper-heuristic. Comput. Oper. Res. 2024, 172, 106817. [Google Scholar] [CrossRef]
- Li, J.; Han, Y.; Gao, K.; Xiao, X.; Duan, P. Bi-population balancing multi-objective algorithm for fuzzy flexible job shop with energy and transportation. IEEE Trans. Autom. Sci. Eng. 2024, 21, 4686–4702. [Google Scholar] [CrossRef]
- Li, J.; Li, J.; Xu, Y. HGNP: A PCA-based heterogeneous graph neural network for a family distributed flexible job shop. Comput. Ind. Eng. 2025, 200, 110855. [Google Scholar] [CrossRef]
- López-Ibáñez, M.; Paquete, L.; Stützle, T. Exploratory analysis of stochastic local search algorithms in biobjective optimization. In Experimental Methods for the Analysis of Optimization Algorithms; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Wang, Y.; Li, J.; Yang, Z.; Zhang, H.; Li, J.; Duan, P.; Du, Y.; Ning, C. An adaptive collaborative optimization algorithm for hybrid flow shop with group setup times and consistent sublots. Appl. Math. Model. 2025, 150, 116354. [Google Scholar] [CrossRef]
- Wang, Z.; Li, J.; Chen, X.; Duan, P.; Li, J. Uncertain Interruptibility Multiobjective Flexible Job Shop via Deep Reinforcement Learning Based on Heterogeneous Graph Self-Attention. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 18598–18612. [Google Scholar] [CrossRef]
- Candan, G.; Yazgan, H. Genetic algorithm parameter optimisation using Taguchi method for a flexible manufacturing system scheduling problem. Int. J. Prod. Res. 2015, 53, 897–915. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).