
LSTM-Based Condition Monitoring and Fault Prognostics of Rolling Element Bearings Using Raw Vibrational Data





Abstract
1. Introduction
1.1. Related Research and Novelty
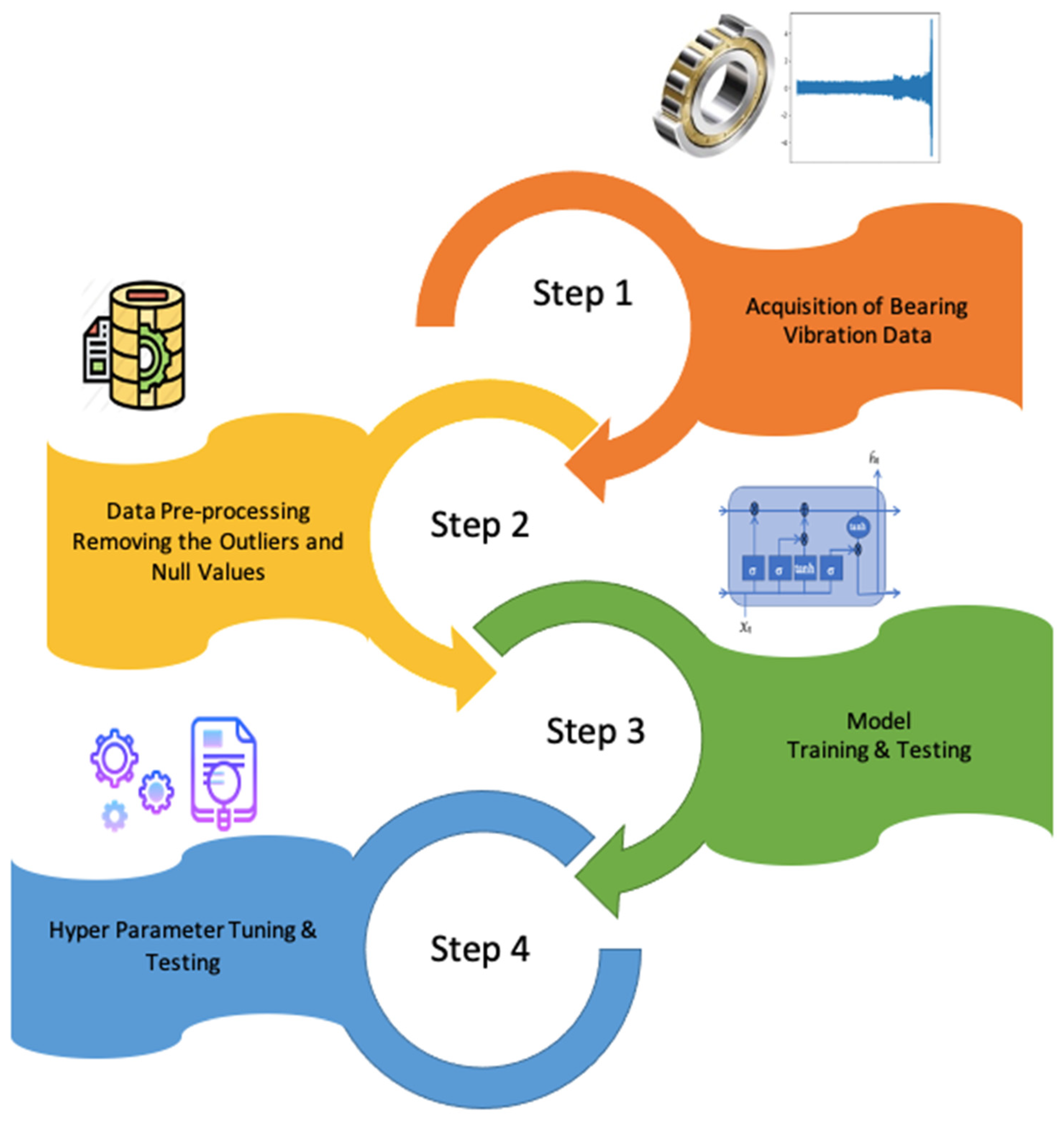
2. Methodology
2.1. Model Selection
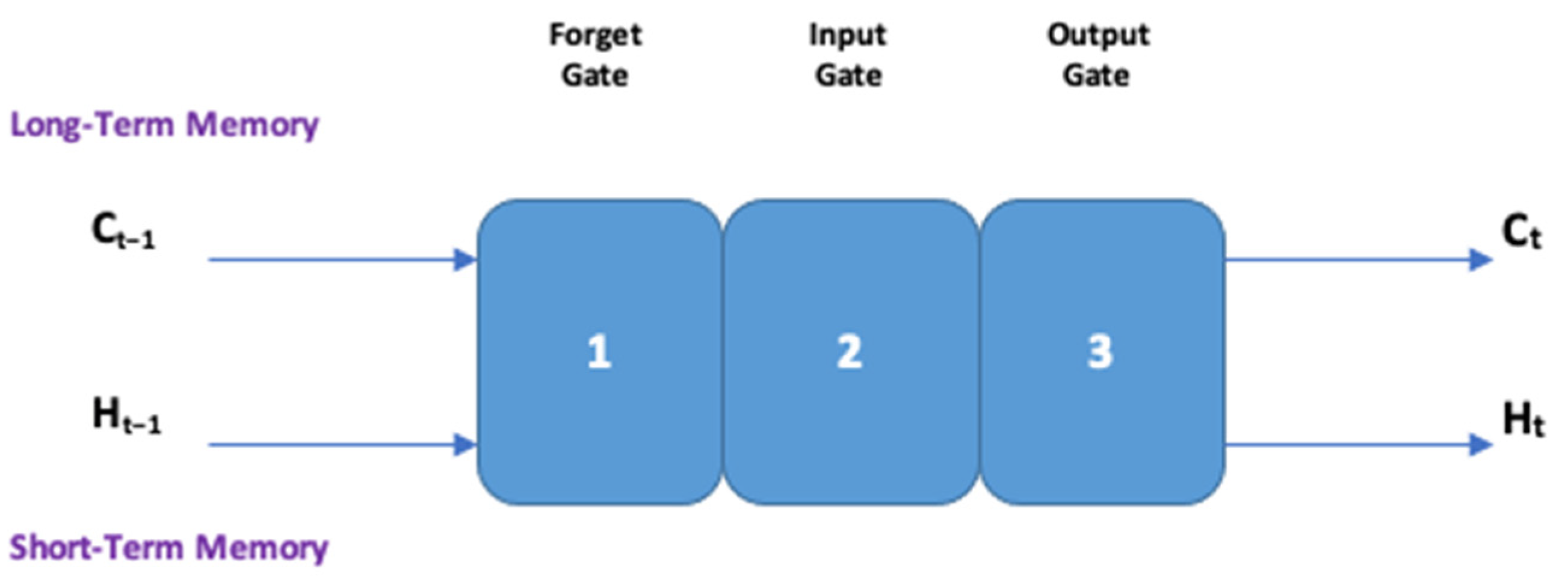
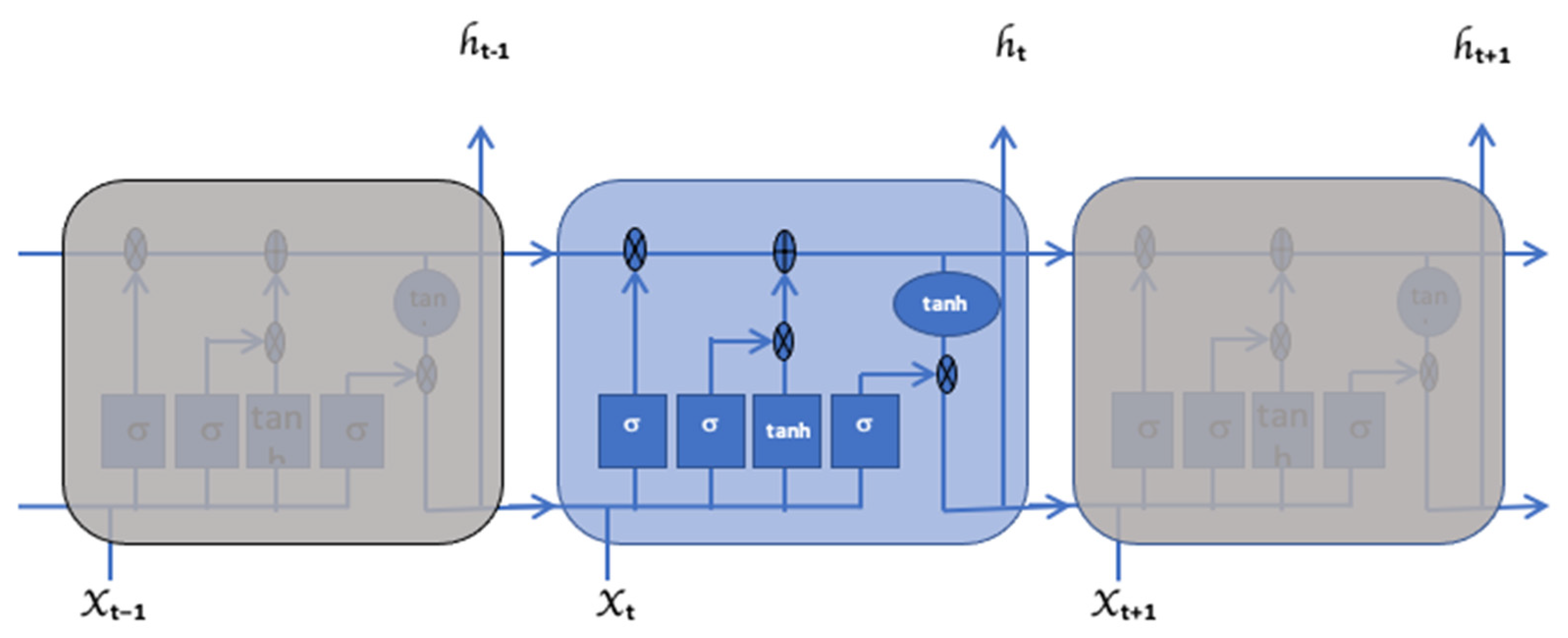
2.2. Long Short-Term Memory (LSTM)
- where:
- Ct−1 represents the cell state of the previous timestamp;
- Ht−1 represents the hidden state of the previous timestamp;
- Ct represents the current cell state;
- Ht represents the current hidden state.
- represents the input to the current timestamp;
- represents the weight matrix associated with the input;
- represents the hidden state of the previous timestamp;
- represents the weight matrix associated with the hidden state.
3. Experiments and Results
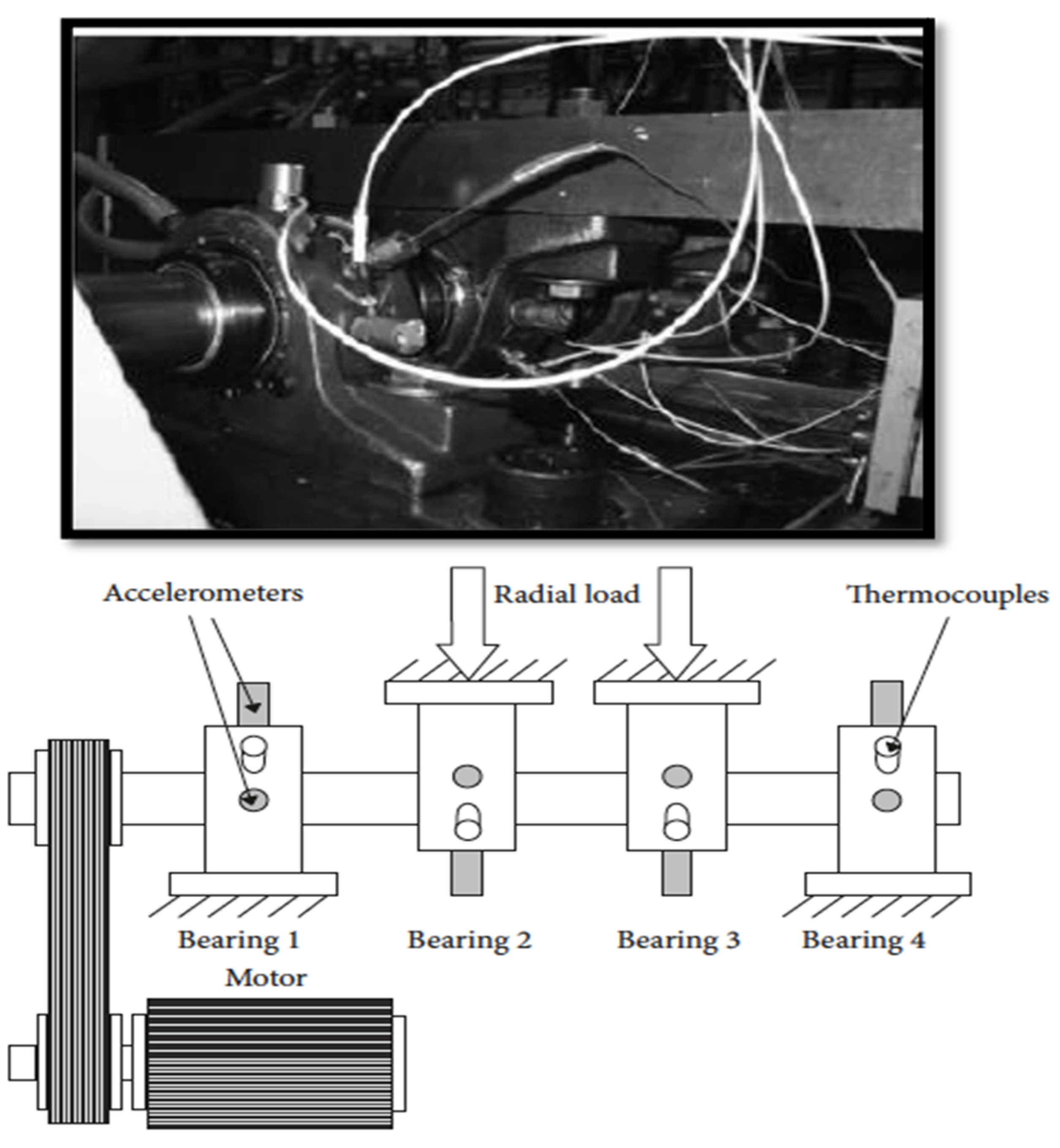
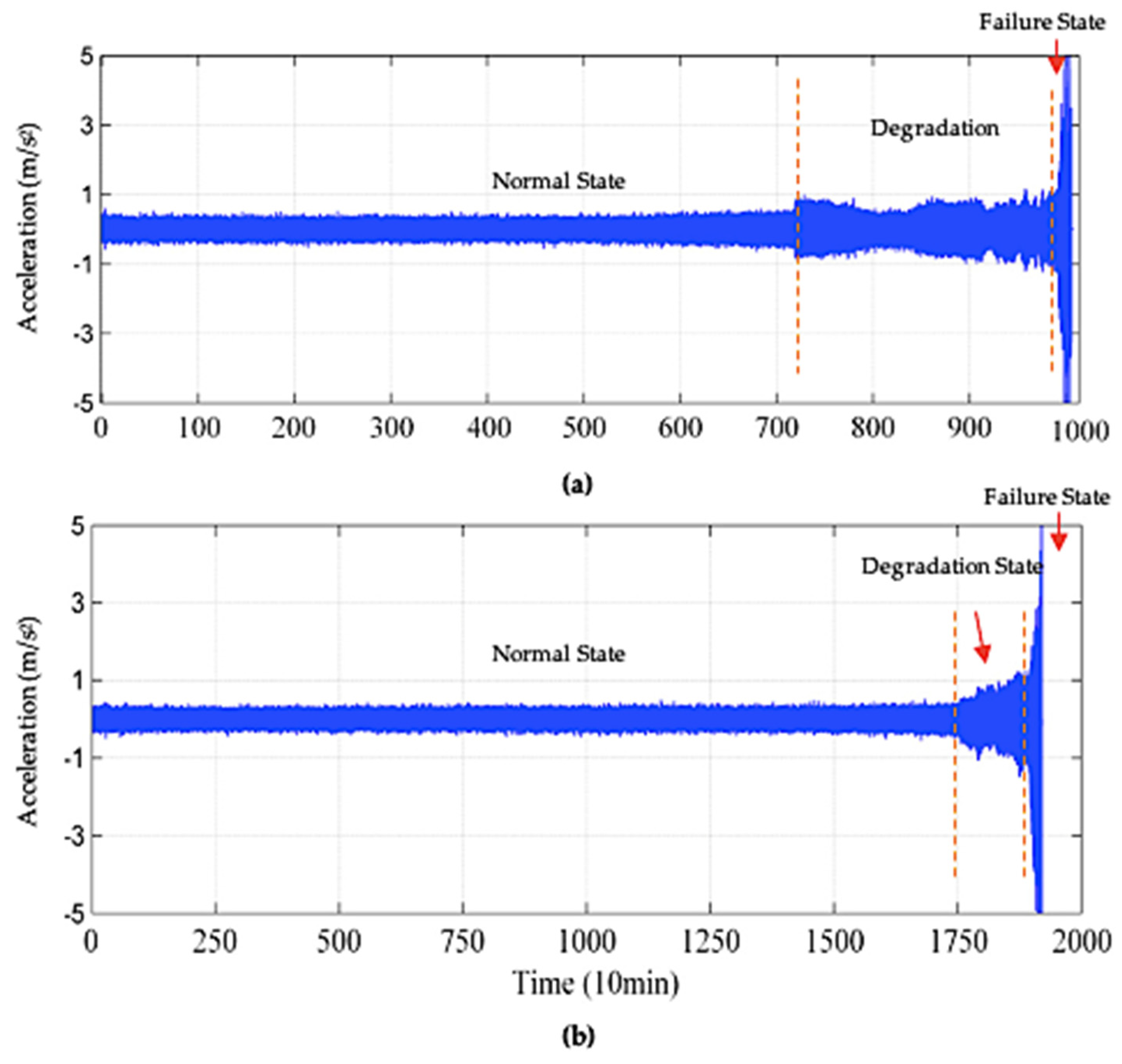
3.1. Dataset
3.2. Experimental Setup
3.2.1. Data Pre-Processing
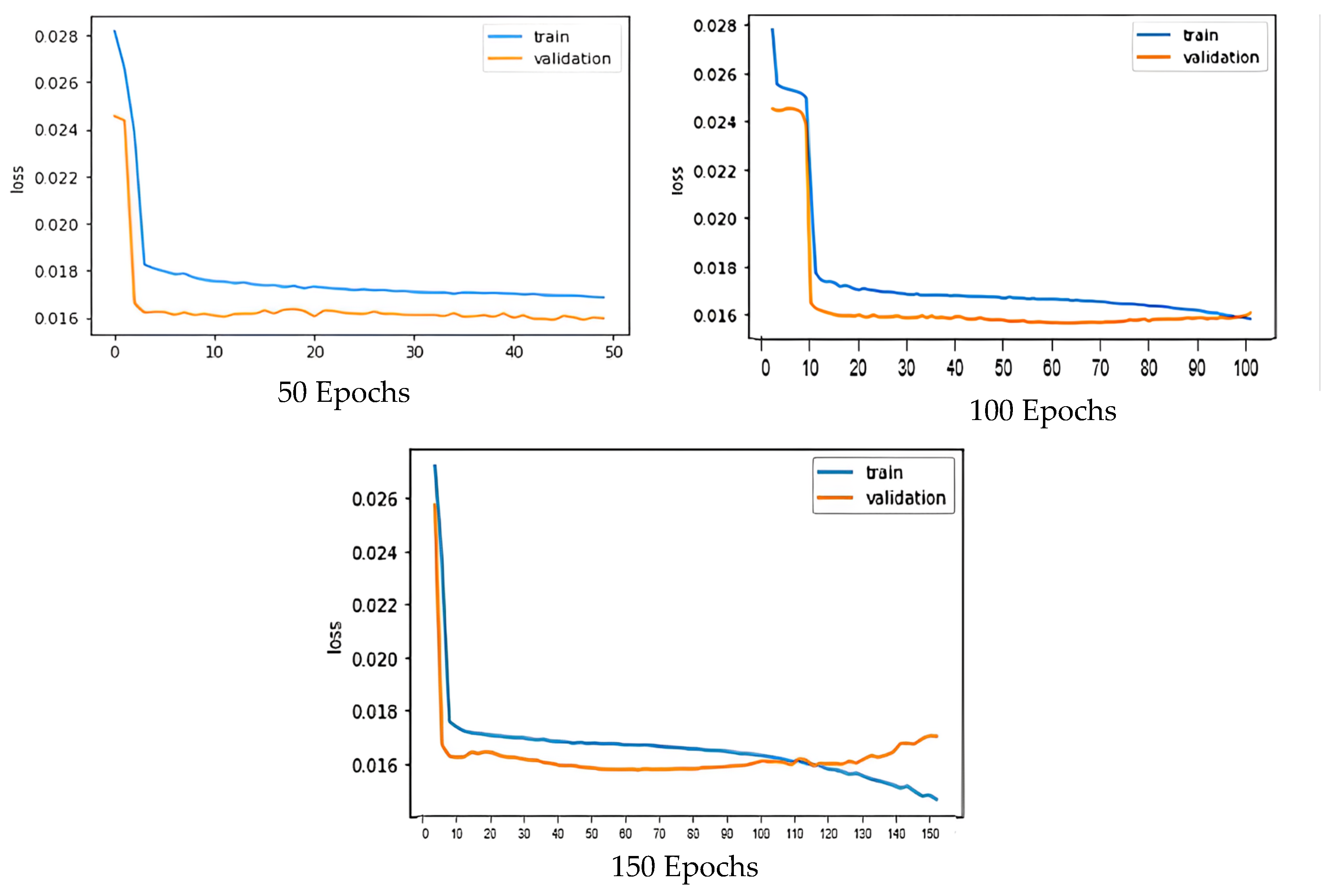
3.2.2. Hyper-Parameter Testing and Fine Tuning
3.3. Evaluation Metrics
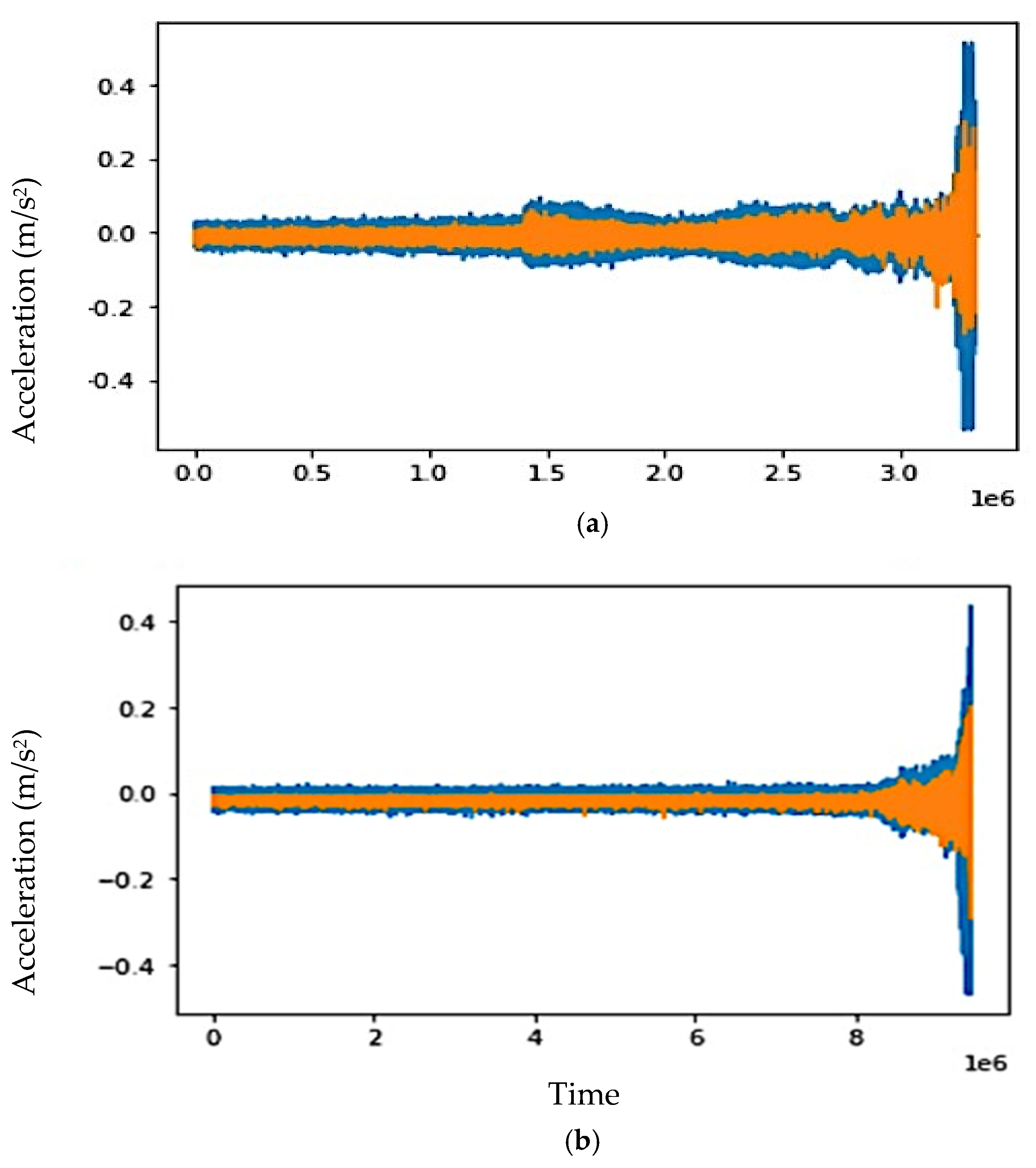
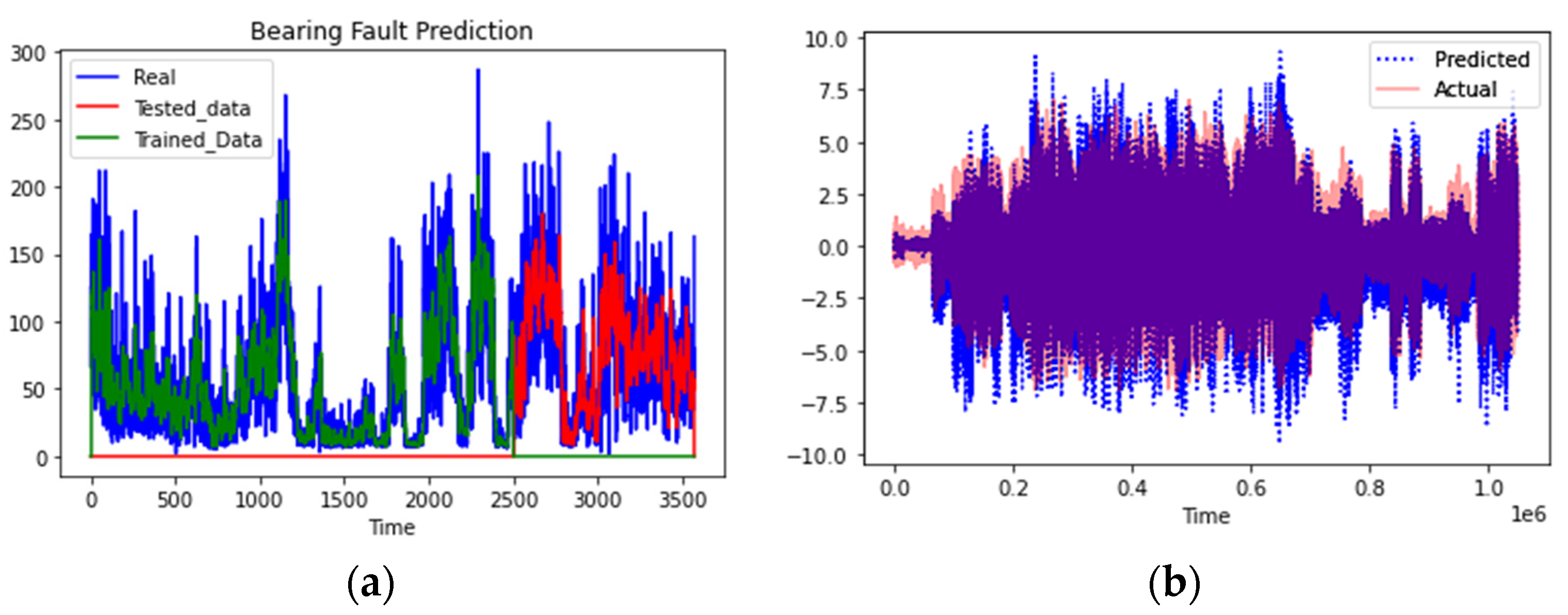
3.4. Results and Discussion
3.5. Generalization Capability of the Model
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kandukuri, S.T.; Klausen, A.; Karimi, H.R.; Robbersmyr, K.G. A review of diagnostics and prognostics of low-speed machinery towards wind turbine farm-level health management. Renew. Sustain. Energy Rev. 2016, 53, 697–708. [Google Scholar] [CrossRef]
- Huang, B.; Di, Y.; Jin, C.; Lee, J. Review of data-driven prognostics and health management techniques: Lessons learned from PHM data challenge competitions. Mach. Fail. Prev. Technol. 2017, 2017, 1–17. [Google Scholar]
- Yu, M.; Wang, D.; Luo, M. Model-based prognosis for hybrid systems with mode dependent degradation behaviors. IEEE Trans. Ind. Electron. 2014, 61, 546–554. [Google Scholar] [CrossRef]
- Jardine, A.K.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Govekar, E.; Gradišek, J.; Grabec, I. Analysis of acoustic emission signals and monitoring of machining processes. Ultrasonics 2000, 38, 598–603. [Google Scholar] [CrossRef]
- Potočnik, P.; Govekar, E.; Grabec, I. Acoustic and acoustic emission based condition monitoring of production processes. In Proceedings of the Second World Congress on Asset Management and the Fourth International Conference on Condition Monitoring, Harrogate, UK, 11–14 June 2007; pp. 11–14. [Google Scholar]
- Randall, R.B. Vibration-Based Condition Monitoring: Industrial, Aerospace and Automotive Applications; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Ruiz-Cárcel, C.; Jaramillo, V.H.; Mba, D.; Ottewill, J.R.; Cao, Y. Combination of process and vibration data for improved condition monitoring of industrial systems working under variable operating conditions. Mech. Syst. Signal Process. 2016, 66, 699–714. [Google Scholar] [CrossRef]
- Mohanty, A.R. Machinery Condition Monitoring: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Lei, Y. Intelligent Fault Diagnosis and Remaining Useful Life Prediction of Rotating Machinery; Butterworth-Heinemann: Oxford, UK, 2016. [Google Scholar]
- Rao, M.; Zuo, M.J. A new strategy for rotating machinery fault diagnosis under varying speed conditions based on deep neural networks and order tracking. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1214–1218. [Google Scholar]
- Sarma, S.; Agrawal, V.; Udupa, S.; Parameswaran, K. Instantaneous angular position and speed measurement using a DSP based resolver-to-digital converter. Measurement 2008, 41, 788–796. [Google Scholar] [CrossRef]
- Peeters, C.; Leclère, Q.; Antoni, J.; Lindahl, P.; Donnal, J.; Leeb, S.; Helsen, J. Review and comparison of tacholess instantaneous speed estimation methods on experimental vibration data. Mech. Syst. Signal Process. 2019, 129, 407–436. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, B.; Lin, Y. Machine Learning Based Bearing Fault Diagnosis Using the Case Western Reserve University Data: A Review. IEEE Access 2021, 9, 155598–155608. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Fernandes, M.; Corchado, J.M.; Marreiros, G. Machine learning techniques applied to mechanical fault diagnosis and fault prognosis in the context of real industrial manufacturing use-cases: A systematic literature review. Appl. Intell. 2022, 52, 14246–14280. [Google Scholar] [CrossRef] [PubMed]
- Iatsenko, D.; McClintock, P.V.; Stefanovska, A. Extraction of instantaneous frequencies from ridges in time–frequency representations of signals. Signal Process. 2016, 125, 290–303. [Google Scholar] [CrossRef]
- Dziedziech, K.; Jablonski, A.; Dworakowski, Z. A novel method for speed recovery from vibration signal under highly non-stationary conditions. Measurement 2018, 128, 13–22. [Google Scholar] [CrossRef]
- Schmidt, S.; Heyns, P.S.; De Villiers, J.P. A tacholess order tracking methodology based on a probabilistic approach to incorporate angular acceleration information into the maxima tracking process. Mech. Syst. Signal Process. 2018, 100, 630–646. [Google Scholar] [CrossRef]
- Khan, N.A.; Jönsson, P.; Sandsten, M. Performance comparison of time-frequency distributions for estimation of instantaneous frequency of heart rate variability signals. Appl. Sci. 2017, 7, 221. [Google Scholar] [CrossRef]
- Urbanek, J.; Barszcz, T.; Sawalhi, N.; Randall, R.B. Comparison of amplitude-based and phase-based method for speed tracking in application to wind turbines. Metrol. Meas. Syst. 2011, 18, 295–303. [Google Scholar] [CrossRef]
- Urbanek, J.; Barszcz, T.; Antoni, J. A two-step procedure for estimation of instantaneous rotational speed with large fluctuations. Mech. Syst. Signal Process. 2013, 38, 96–102. [Google Scholar] [CrossRef]
- Cardona-Morales, O.; Avendaño, L.; Castellanos-Dominguez, G. Nonlinear model for condition monitoring of non-stationary vibration signals in ship driveline application. Mech. Syst. Signal Process. 2014, 44, 134–148. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lin, J.; Zhou, X.; Lu, N. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mech. Syst. Signal Process. 2016, 72, 303–315. [Google Scholar] [CrossRef]
- Ali, M.Z.; Shabbir, M.N.S.K.; Liang, X.; Zhang, Y.; Hu, T. Machine Learning-Based Fault Diagnosis for Single- and Multi-Faults in Induction Motors Using Measured Stator Currents and Vibration Signals. IEEE Trans. Ind. Appl. 2019, 55, 2378–2391. [Google Scholar] [CrossRef]
- Khalid, S.; Lim, W.; Kim, H.S.; Oh, Y.T.; Youn, B.D.; Kim, H.-S.; Bae, Y.-C. Intelligent Steam Power Plant Boiler Waterwall Tube Leakage Detection via Machine Learning-Based Optimal Sensor Selection. Sensors 2020, 20, 6356. [Google Scholar] [CrossRef] [PubMed]
- Ma, M.; Sun, C.; Chen, X. Discriminative deep belief networks with ant colony optimization for health status assessment of machine. IEEE Trans. Instrum. Meas. 2017, 66, 3115–3125. [Google Scholar] [CrossRef]
- Afridi, Y.S.; Ahmad, K.; Hassan, L. Artificial intelligence based prognostic maintenance of renewable energy systems: A review of techniques, challenges, and future research directions. Int. J. Energy Res. 2022, 46, 21619–21642. [Google Scholar] [CrossRef]
- He, M.; He, D. Deep Learning Based Approach for Bearing Fault Diagnosis. IEEE Trans. Ind. Appl. 2017, 53, 3057–3065. [Google Scholar] [CrossRef]
- Zhuang, L.; Xu, A.; Wang, X.-L. A prognostic driven predictive maintenance framework based on Bayesian deep learning. Reliab. Eng. Syst. Saf. 2023, 234, 109181. [Google Scholar] [CrossRef]
- Jagatheesaperumal, S.K.; Rahouti, M.; Ahmad, K.; Al-Fuqaha, A.; Guizani, M. The Duo of Artificial Intelligence and Big Data for Industry 4.0: Review of Applications, Techniques, Challenges, and Future Research Directions. arXiv 2021, arXiv:2104.02425. [Google Scholar] [CrossRef]
- Khan, A.; Hwang, H.; Kim, H.S. Synthetic Data Augmentation and Deep Learning for the Fault Diagnosis of Rotating Machines. Mathematics 2021, 9, 2336. [Google Scholar] [CrossRef]
- Habbouche, H.; Benkedjouh, T.; Zerhouni, N. Intelligent prognostics of bearings based on bidirectional long short-term memory and wavelet packet decomposition. Int. J. Adv. Manuf. Technol. 2021, 114, 145–157. [Google Scholar] [CrossRef]
- Lee, K.; Kim, J.K.; Kim, J.; Hur, K.; Kim, H. Stacked convolutional bidirectional LSTM recurrent neural network for bearing anomaly detection in rotating machinery diagnostics. In Proceedings of the 2018 1st IEEE International Conference on Knowledge Innovation and Invention (ICKII), Jeju, Republic of Korea, 23–27 July 2018; pp. 98–101. [Google Scholar]
- Berghout, T.; Benbouzid, M.; Mouss, L.H. Leveraging Label Information in a Knowledge-Driven Approach for Rolling-Element Bearings Remaining Useful Life Prediction. Energies 2021, 14, 2163. [Google Scholar] [CrossRef]
- Akpudo, U.E.; Hur, J.-W. Towards bearing failure prognostics: A practical comparison between data-driven methods for industrial applications. J. Mech. Sci. Technol. 2020, 34, 4161–4172. [Google Scholar] [CrossRef]
- Akpudo, U.E.; Hur, J.-W. A feature fusion-based prognostics approach for rolling element bearings. J. Mech. Sci. Technol. 2020, 34, 4025–4035. [Google Scholar] [CrossRef]
- Ali, J.B.; Fnaiech, N.; Saidi, L.; Chebel-Morello, B.; Fnaiech, F. Application of empirical mode decomposition and artificial neural network for automatic bearing fault diagnosis based on vibration signals. Appl. Acoust. 2015, 89, 16–27. [Google Scholar]
- Yang, C.; Ma, J.; Wang, X.; Li, X.; Li, Z.; Luo, T. A novel based-performance degradation indicator RUL prediction model and its application in rolling bearing. ISA Trans. 2021, 121, 349–364. [Google Scholar] [CrossRef]
- Wu, H.; Huang, A.; Sutherland, J.W. Avoiding Environmental Consequences of Equipment Failure via an LSTM-Based Model for Predictive Maintenance. Procedia Manuf. 2020, 43, 666–673. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Lee, J.; Qiu, H.; Yu, G.; Lin, J. Rexnord Technical Services, “Bearing Data Set”. In IMS, University of Cincinnati. NASA Ames Prognostics Data Repository; NASA Ames: Moffett Field, CA, USA, 2007. Available online: https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/ (accessed on 18 July 2021).
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Wavelet filter-based weak signature detection method and its application on rolling element bearing prognostics. J. Sound Vib. 2006, 289, 1066–1090. [Google Scholar] [CrossRef]
- Ding, H.; Yang, L.; Cheng, Z.; Yang, Z. A remaining useful life prediction method for bearing based on deep neural networks. Measurement 2021, 172, 108878. [Google Scholar] [CrossRef]
- He, M.; Zhou, Y.; Li, Y.; Wu, G.; Tang, G. Long short-term memory network with multi-resolution singular value decomposition for prediction of bearing performance degradation. Measurement 2020, 156, 107582. [Google Scholar] [CrossRef]
- Huang, G.; Li, H.; Ou, J.; Zhang, Y.; Zhang, M. A reliable prognosis approach for degradation evaluation of rolling bearing using MCLSTM. Sensors 2020, 20, 1864. [Google Scholar] [CrossRef] [PubMed]
- Ge, Y.; Guo, L.; Dou, Y. Remaining useful life prediction of machinery based on KS distance and LSTM neural network. Int. J. Perform. Eng. 2019, 15, 895. [Google Scholar]
- Chen, Z.; Liu, Y.; Liu, S. Mechanical state prediction based on LSTM neural network. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 3876–3881. [Google Scholar]
- Tang, G.; Zhou, Y.; Wang, H.; Li, G. Prediction of bearing performance degradation with bottleneck feature based on LSTM network. In Proceedings of the 2018 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Houston, TX, USA, 14–17 May 2018; pp. 1–6. [Google Scholar]
- Yaqub, M.F.; Gondal, I.; Kamruzzaman, J. Inchoate Fault Detection Framework: Adaptive Selection of Wavelet Nodes and Cumulant Orders. IEEE Trans. Instrum. Meas. 2012, 61, 685–695. [Google Scholar] [CrossRef]
- Hu, Q.; He, Z.; Zhang, Z.; Zi, Y. Fault diagnosis of rotating machinery based on improved wavelet package transform and SVMs ensemble. Mech. Syst. Signal Process. 2007, 21, 688–705. [Google Scholar] [CrossRef]
- Zhang, R.; Peng, Z.; Wu, L.; Yao, B.; Guan, Y. Fault diagnosis from raw sensor data using deep neural networks considering temporal coherence. Sensors 2017, 17, 549. [Google Scholar] [CrossRef]
- Eren, L.; Ince, T.; Kiranyaz, S. A generic intelligent bearing fault diagnosis system using compact adaptive 1D CNN classifier. J. Signal Process. Syst. 2018, 91, 179–189. [Google Scholar] [CrossRef]
- Wind Power Project, Gearbox Bearing Vibration Dataset. Available online: http://urn.kb.se/resolve?urn=urn:nbn:se:ltu:diva-70730 (accessed on 15 January 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Bearings | Double Rows Rexnord ZA-2115 |
| No. of Bearings | Four (04) |
| Shaft Load | 6000 lbs |
| Shaft Rotational Speed | 2000 rpm |
| Type of Accelerometers | High Sensitivity Quartz ICP |
| No. of Accelerometers (Test 01) | Two (02) Accelerometers on x-axis and y-axis |
| No. of Accelerometers (Test 02 & Test 03) | One (01) Accelerometer |
| Sampling Rate | 20 kHz |
| Type | Stacked LSTM |
| No. of Hidden Layers | Two (02) |
| No. of Memory Units | Layer 01: 128 Layer 02: 64 |
| Optimizer | Adam |
| Batch Size | 50 |
| No. of Epochs | 100 |
| Model | RMSE | MAE | NMAE | MAPE |
|---|---|---|---|---|
| LSTM using raw bearing vibration values | 0.0102 | 0.0108 | 0.0002 | 0.0107 |
| References | Year | Model | RMSE Value |
|---|---|---|---|
| Habbouche, H. et al. [34] | 2021 | LSTM Bi-LSTM | 0.015 0.010 |
| Lee, K. et al. [35] | 2018 | CNN Bi-LSTM Uni-LSTM | 0.973 |
| Berghout, T. et al. [36] | 2021 | LSTM | 0.214 |
| Akpudo et al. [37] | 2020 | Gaussian Process Regression (GPR) Deep Belief Network (DBN) | 0.015 0.013 |
| Yang et al. [40] | 2020 | LSTM DLSTM | 0.030 0.010 |
| Ding, H. et al. [46] | 2020 | LSTM | 0.045 |
| He, M. et al. [47] | 2020 | LSTM MRSVD-LSTM | 0.025 0.012 |
| Huang, G. et al. [48] | 2020 | MLSTM | 0.766 |
| Ge, Y. et al. [49] | 2019 | LSTM | 0.020 |
| Chen, Z. et al. [50] | 2018 | LSTM | 0.109 |
| Tang, G. et al. [51] | 2018 | LSTM | 0.055 |
| This Research | 2023 | LSTM | 0.014 & 0.010 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Afridi, Y.S.; Hasan, L.; Ullah, R.; Ahmad, Z.; Kim, J.-M. LSTM-Based Condition Monitoring and Fault Prognostics of Rolling Element Bearings Using Raw Vibrational Data. Machines 2023, 11, 531. https://doi.org/10.3390/machines11050531
Afridi YS, Hasan L, Ullah R, Ahmad Z, Kim J-M. LSTM-Based Condition Monitoring and Fault Prognostics of Rolling Element Bearings Using Raw Vibrational Data. Machines. 2023; 11(5):531. https://doi.org/10.3390/machines11050531
Chicago/Turabian StyleAfridi, Yasir Saleem, Laiq Hasan, Rehmat Ullah, Zahoor Ahmad, and Jong-Myon Kim. 2023. "LSTM-Based Condition Monitoring and Fault Prognostics of Rolling Element Bearings Using Raw Vibrational Data" Machines 11, no. 5: 531. https://doi.org/10.3390/machines11050531
APA StyleAfridi, Y. S., Hasan, L., Ullah, R., Ahmad, Z., & Kim, J.-M. (2023). LSTM-Based Condition Monitoring and Fault Prognostics of Rolling Element Bearings Using Raw Vibrational Data. Machines, 11(5), 531. https://doi.org/10.3390/machines11050531