Abstract
In this paper, we study different methods of scoring linguistic expressions defined on a finite set, in the search for a linear order that ranks all those possible expressions. Among them, particular attention is paid to the canonical extension, and its representability through distances in a graph plus some suitable penalization of imprecision. The relationship between this setting and the classical problems of numerical representability of orderings, as well as extension of orderings from a set to a superset is also explored. Finally, aggregation procedures of qualitative rankings and scorings are also analyzed.
Keywords:
decision making; imprecision; qualitative scales; linguistic expressions; scores; orderings; aggregation MSC:
62C86 (Primary); 03E72; 06A06; 91B06; 91B14 (Secondary)
1. Introduction
Let U stand for a nonempty set, called universe. It is clear that comparing the elements of U through some sort of binary relation such that is immediately understood as “the element u is not worse than the element v” gives less information than assigning scores to each element of U. A scoring function is a real-valued function . The interpretation is obvious: if the score of the element is not smaller than the score of the element v, then the above conclusion, namely, “the element u is not worse than the element v” is also achieved. However, if an ordering given on U through a binary relation is also represented by a scoring function, say , the composition of of the map S with no matter what strictly increasing function also represents the same ordering on U. In other words: holds true for all .
Despite the ordering being the same, the scores have important consequences and collateral meanings. A typical example corresponds to a firm that wants to hire people, and prepares a test or exam consisting of one hundred tasks to be done. Suppose the scores of two candidates u and v have been just and (out of 100). Obviously, we would say that v is better than u, but both of them having such poor results, the firm would reject hiring anyone among them. If, instead, the scores were and , again we would say that v is better than u, but now, quite probably, the firm would be willing to hire both candidates.
The most typical scoring procedures consist of numerical scales. Nevertheless, due to the vagueness and imprecision involved in a wide variety of practical situations in which some sort of evaluation is made, sometimes the use of finite measurement scales based on linguistic terms or expressions seems to be more suitable than just using numerical scales. In this case, if L is a set of linguistic terms (also known as labels), such as {very bad, bad, poor, fair, good, very good, excellent}, a scoring function on U taking values on L is a function that can obviously be interpreted as a qualitative scale of measurement.
From a pure mathematical point of view, whenever L is given a linear order , a scoring procedure on U taking values on L can equivalently be understood through a numerical scoring function , which is obviously a quantitative scale of measurement. Indeed, if denotes the set of linguistic terms and we understand that holds true if and only if , then a scoring function can be immediately interpreted by means of the numerical scoring function , where is given by . In this situation, namely when L is given a linear order, the use of a scoring function taking values on L or an equivalent numerical scoring function is, perhaps, a matter of taste (see García-Lapresta et al. [1]).
However, sometimes, in a higher degree of vagueness or imprecision, and even in the case of using a set of linguistic terms, it could happen that the agents that assign scores to the elements of a nonempty set U may hesitate when, given an element , the score needs to be determined. A typical example is an approximation (based on data as climate, composition of soil, amount of rain water per year, etc.) of the quality of the wine produced in a vineyard. An expert could hesitate here, and instead of saying “no doubt, it will be very good”, she/he could declare something as “from good to excellent”, so using a linguistic expression instead of just a linguistic term.
Our approach concerning the imprecision is based on an adaptation of the absolute order of magnitude spaces introduced by Travé-Massuyès and Dague [2] and Travé-Massuyès and Piera [3]; more specifically in the extensions devised by Roselló et al. [4,5,6] (see also Agell et al. [7] and Falcó et al. [8,9]).
At this stage, several mathematical problems appear, namely
- (i)
- If a set of linguistic terms has been endowed with a linear order , try to define a linear order on the set of linguistic expressions based on L. Needless to say, this “extended” order should preserve or be compatible with when acting on the labels of L considered as special cases of linguistic expressions.
- (ii)
- Compare different linear orders (when available) defined on a set of linguistic expressions, trying to explain which is the most suitable one to be used in some practical concrete situation.
- (iii)
- Study problems of aggregation of a finite number of scorings based on linguistic terms and expressions.
Having in mind these questions, the structure of the paper goes as follows. After the Introduction (Section 1) and a compulsory Section 2 of preliminaries, previous results and necessary background, in Section 3, we study sets of linguistic expressions and define suitable orderings on these kinds of sets. In Section 4, we analyze some questions relative to the aggregation of rankings and scorings based on qualitative scales. A final Section 5 of concluding remarks, suggestions for further research and open questions closes the paper.
2. Previous Concepts and Results
Intuitively, a ranking on a universe U is some kind of ordering defined on U, usually defined through a binary relation on U, such that means “the element u is at least as good as the element v”. A scoring function on U is a map . Notice that a scoring function S immediately defines a ranking on U, by declaring , for all . For finite sets, a sort of converse is also true, namely, each ranking can be represented by a scoring function (see e.g., the first three chapters in Bridges and Mehta [10] for further details).
Let us formalize all this through some definitions.
Definition 1.
Let U denote a universe. A preorder on U is a binary relation on U which is reflexive and transitive.
An antisymmetric preorder is said to be a partial order. A total preorder on U is a preorder such that or holds true for all . A total order is also called a linear order.
If is a preorder on U, then the associated asymmetric relation is denoted by , whereas stands for the associated equivalence relation. These relations are respectively defined by and not , and and , for all . Notice that if is a linear order, then and .
Definition 2.
Let U denote a universe. Let ≽ stand for a total preorder defined on U. We say that ≽ is representable if there exists a real-valued function such that holds true for all .
As commented before, it happens that, provided that U is finite, any total preorder defined on U is representable (see Bridges and Mehta [10]). A function S that represents a total preorder ≽ defined on U is usually said to be a utility function for ≽.
Remark 1.
Notice that a ranking (e.g., a total preorder) on a universe U is a qualitative scale of measurement, whereas a scoring function is a quantitative scale. Other typical sorts of qualitative scales are those based on labels and linguistic expressions (see next Definition 3). If S is a utility function that represents a total preorder ≽ on a universe U, and is a strictly increasing function, it is straightforward to see that the composition is also a utility function that represents ≽. Consequently, there are infinitely many utility functions that represent a given total preorder on a finite universe U.
Definition 3.
Let denote a finite nonempty set of linguistic terms (labels), with . The set of linguistic expressions associated with L is defined as
where . Since the linguistic expression is the singleton , by convention, it can be replaced by the label . In this way, .
Remark 2.
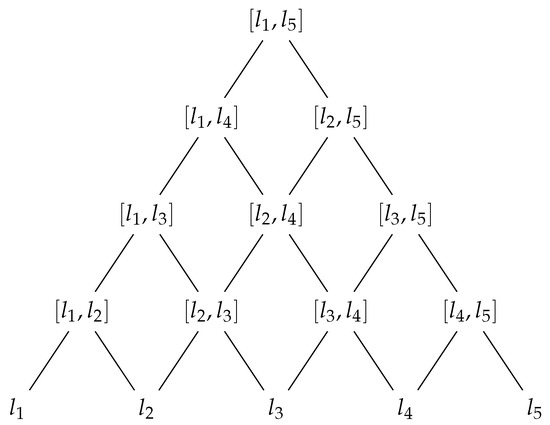
The set of linguistic expressions can be represented by a graph . In the graph, the lowest layer represents the linguistic terms , the second layer represents the linguistic expressions created by two consecutive labels , the third layer represents the linguistic expressions generated by three consecutive labels , and so on up to last layer, where we represent the linguistic expression . As a result, the higher an element of the graph is, the more imprecise it becomes.
The vertices in are the elements of and the edges , where and , or and . Figure 1 shows the graph representation for .
Figure 1.
Graph representation of the linguistic expressions for .
3. Defining Orderings on Sets of Linguistic Expressions
Suppose that the set of linguistic terms is endowed with the linear order ≽ given by , for all .
We want now to extend the linear order ≽ to a new linear order defined on the whole set of linguistic expressions on L. This problem has several positive solutions.
Remark 3.
To extend the linear order ≽ on L to a new linear order defined on , first, we may consider a partial order defined on as follows: (reflexivity), and also , for all (compatibility with ≽ on L).
Then, we may apply the well-known Szpilrajn’s theorem ([11]) that ensures that any partial order on a given set can be extended to a linear order on that set.
3.1. Constructive Extensions: The Lexicographic Order and the Canonical Order
Instead of using a powerful result as Szpilrajn’s theorem as commented in Remark 3, when , we can directly furnish some extensions in a constructive way, as stated in Proposition 1 and Proposition 2, whose straightforward proofs are omitted for the sake of brevity.
Proposition 1.
The binary relation on defined as
is a linear order that preserves the given order ≽ on . It is called the lexicographic order on .
Notice that the real valued function given by is a utility representation for .
Proposition 2.
([8]) The binary relation on defined as
is a linear order, and it is called the canonical order on . It also preserves the given order on .
Example 1.
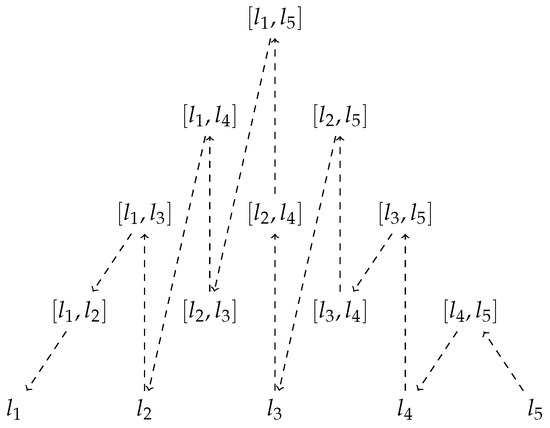
For , the elements of are ordered as follows with respect to the lexicographic order:
Moreover, through the canonical order (see also Figure 2), we get:
Figure 2.
Canonical order in for .
3.2. Numerical Representation of the Canonical Order Based on the Geodesic Metric
The canonical order on can be represented by utility functions in such a way that , for all .
Among the infinite possible utility representations of the canonical order on , we are interested in those based on distances. In addition, concerning metrics on a graph, perhaps the most typical one is the so-called geodesic metric.
Definition 4.
The geodesic metric is defined as
for all .
Remark 4.
Notice that for every , so that becomes uniform, in the sense that adjacent linguistic terms are equidistant (see e.g., Herrera et al. [12] and García-Lapresta and Pérez-Román [13,14] for dealing with non uniform qualitative scales).
Given , with , we denote the cardinality of , i.e., the number of labels in the interval : .
In the following result, we establish that the canonical order on introduced in Proposition 2 can be defined through the geodesic distances to the highest possible assessment and the cardinality of the linguistic expressions.
Proposition 3.
For all , it holds
Proof.
It follows from Proposition 2 and Equation (1). ☐
Remark 5.
To distinguish between elements , the second condition that appears in the statement of Proposition 3, namely the one that reads “or and ” is crucial. In fact, suppose that on we use only a scoring function S based on the geodesic metric, and given by . Then, it is straightforward to see that two nodes that appear in the same vertical in the graph are assigned the same score, which is . This scoring function S defines an ordering on by declaring , for all . However, since , it happens that is a total preorder, but not a linear order. In other words, the geodesic distance is, so-to-say, miopic since it cannot detect the difference between two elements in the same vertical in . For instance, if {very bad, bad, poor, fair, good, very good, excellent}, the linguistic expressions “very good” and “from good to excellent” would be assigned the same score through the geodesic metric.
3.3. GeodesIc Metric Matching Penalization of Imprecision
Another important feature that carries the second condition in the statement of Proposition 3 and says “or and ” is warning us about the role played by imprecision. If a linguistic expression consists of more labels than another one , we understand that “ is more imprecise than ” or, equivalently, “ is more accurate than ”. Taking this fact into account, it seems interesting to search for measurements or scoring methods that, someway, penalize the imprecision when comparing terms in , as next Proposition 4 does.
Proposition 4.
For every , the function , defined as
i.e.,
for all , is a metric, and it is called the metric associated with α.
Proof.
Since is a positive linear combination of the geodesic metric and the pseudometric defined as , then is a metric. ☐
Proposition 5.
Given , the following statements are equivalent:
- .
- , where , if g is odd, and , if g is even.
Proof.
) Consider g is odd. By Proposition 2, we have
Then, by hypothesis, we have
Then, from Inequality (3), we obtain , i.e.,
In order to prove that , suppose by way of contradiction that . By Proposition 2, we have
Then, by hypothesis, we have
Taking into account Equation (2),
which is a contradiction. Consequently, .
We now consider that g is even. By Proposition 2, we have
Then, by hypothesis, we have
Taking into account Equation (2),
Then, from Inequality (4), we obtain , i.e.,
In order to prove that , suppose by way of contradiction that . As mentioned above, we have
However, taking into account Equation (2),
we obtain a contradiction. Consequently, .
) It is a routine. ☐
Definition 5.
Given , the scoring function is defined as
for every .
It is easy to see that, for every , it holds
Proposition 6.
Given , for all , it holds
Proof.
By Proposition 5. ☐
Example 2.
Taking into account the condition appearing in Proposition 5 for , i.e., , and Equation (5), we have
3.4. Extensions Based on Different Criteria
As we have already seen, both the lexicographic and the canonical linear orders on extend the given order on L. Although it is always possible to extend a linear order from a given finite set U to its power set, a typical question that, as a matter of fact, gave rise to a battery of classical papers from the 1970s (see e.g., Gärdenfors [15], Kannai and Peleg [16], Barberà and Pattanaik [17], Fishburn [18], Bossert [19] and Bossert et al. [20]) is whether or not it is possible to perform an extension that follows a list of criteria imposed a priori.
Sometimes, the extension is not possible because the criteria used are, so-to-say, contradictory. However, perhaps surprisingly, there are other situations in which the extension is not possible because of a combinatorial explosion, which, due to the much bigger cardinality of the power set of U, does not leave room to accommodate all terms of the power set, in an extended linear order, accomplishing all the criteria. Perhaps the most famous result in this direction is the so-called theorem of impossibility of extension due to Kannai and Peleg [16] (for a detailed account, see Barberà et al. [21]).
Consider the following example.
Example 3.
Let be a finite universe. Assume that U is endowed with a linear order ≽ such that . Consider the following two criteria for an extension, say of ≽ to the power set of U.
- (i)
- A criterion [M] based on the idea of a mean value, so that if in U, then holds true.
- (ii)
- A criterion [C] based on the idea of cardinality, in the sense “the bigger, the better”, so that given such that , then and also hold true.
In this example, it is clear that these two criteria are contradictory. Unless the set U is a singleton, no extension can at the same time satisfy [M] and [C].
By the way, suppose that we use the criterion [C], jointly with a rule [B] that pays attention to the best elements of the corresponding subsets, as follows: when two subsets have the same cardinality, pay attention to the best elements as regards ≽. If , then pay attention to and , and so on. We proceed this way until we declare or .
Starting with the set of labels , we extend the usual ordering not to the whole power set of L, but to the set of linguistic expressions , and accomplishing the criteria [C] and [B], and it is well understood that [C] is accomplished in this context if, for every such that it holds , and for every such that , it holds that .
Calling to the extended linear order on , for , we get:
The linear order is said to be the cardinality-maximality extension of ≽.
Remark 6.
The canonical order on only satisfies the criterion [M], well understood that [M] is accomplished in this context if, for every such that , it holds that .
The lexicographic order fails to satisfy both [M] and [C].
The cardinality-maximality extension satisfies [C], but not [M].
Taking into account the last ideas in Example 3, in which an extended order was defined on but not necessarily on the whole power set of L, we may realize that, at this stage, an interesting question appears. Suppose that we are given a set of criteria for extension of a linear order from a set U to its power set. Assume also that, as it is the case of Kannai–Peleg’s theorem ([16]), such set of criteria provokes an impossibility result. Even if this happens, when we try to extend the ordering ≽ defined on the set of labels, to its corresponding set of linguistic expressions, it may still happen that an extension that accomplishes the criteria is possible. The reason is that is much smaller than the whole power set of L. Sometimes, due to this restriction of domain, the extension could still be obtained. Similar questions, namely impossibility theorems in which the intrinsic impossibility actually disappears when a suitable restriction of domain is done, have been analyzed in depth in the contexts of Social Choice (see e.g., Gaertner [22]).
Let us explore this fact in more detail. Given a finite set endowed with a linear order ≽ such that , suppose that we want to define an extension on the power set of U. We say that satisfies:
- (i)
- The Gärdenfors principle [G] (see Gärdenfors [15]) if, for all and , it holds that and .
- (ii)
- The weak monotonicity principle [W] if, for all and , it holds that .
A version of the key Kannai–Peleg impossibility theorem (see Kannai and Peleg [16], Fishburn [18], Barberà et al. [17] and Bossert [19]) reads as follows.
Theorem 1.
Let be a finite set with at least six elements , endowed with the linear order ≽ defined as . Then, there is no extension that satisfies both [G] and [W] and is a total preorder on the power set of U.
However, after a suitable restriction of domain, the impossibility stated in the Kannai–Peleg theorem could actually disappear, if built in our context of linguistic terms and expressions, as the next Remark 7 clearly shows.
Remark 7.
When we consider the set of labels endowed with the usual linear order ≽, we may observe that the canonical order on satisfies both [G] and [W], well understood that here in this context where a restriction of domain plays a crucial role, [G] and [W] should read as follows:
- (i)
- [G] is accomplished in this context if, for every , the following conditions hold:
- , whenever ,
- , whenever .
- (ii)
- [W] is satisfied in this context if for all , the following conditions hold:
- , whenever ,
- , whenever .
The extension is a total preorder order because it is indeed a linear order. Therefore, Kannai–Peleg impossibility theorem is no longer valid when we extend linear orders from L to , that, obviously, is much smaller than the power set of L.
Another classical question in this approach consists in, starting from a finite set U endowed with a linear order, in order to characterize orderings on the power set of U (but not necessarily extensions of the given order on U) that satisfy a set of criteria imposed a priori.
Let us see an example of this situation.
Example 4.
Suppose that a total preorder ≽, defined directly on the power set of a finite set U, satisfies the following conditions:
- (i)
- and also hold true for all such that .
- (ii)
- For all and , it holds that .
Then, it can be straightforwardly proved that ≽ is, exactly, the so-called cardinal ordering on the power set of U, namely holds true for all (see Pattanaik and Xu [23] for a proof of this last fact).
Having these ideas in mind, and coming back to our context of labels and linguistic expressions, we may see that the lexicographic extension on is characterized as follows.
Proposition 7.
Consider the set of labels , endowed with the usual linear order ≽. An extension to the set of linguistic expressions satisfies the following conditions:
- (i)
- For all , it holds that .
- (ii)
- For all , it holds that .
- (iii)
- For all , it holds that ,
if and only if .
Proof.
It is in immediate consequence of the mere definition of the lexicographic extension on . ☐
The cardinality-maximality extension can be characterized as follows.
Proposition 8.
Consider the set of labels , endowed with the usual linear order ≽. An extension to the set of linguistic expressions satisfies the following conditions:
- (i)
- For all , it holds that .
- (ii)
- For all , it holds that .
- (iii)
- For all with , it holds ,
if and only if .
Proof.
It is in immediate consequence of the mere definition of the cardinality-maximality extension on . ☐
We may also point out that these characterizations can reflect practical situations. In fact, they could reflect particular methods of assigning scores, perhaps discriminating between expressions that have the same score, as the next Examples 5 and 6 show. Notice that sometimes people use more than one score: first, there is one method of scoring, but if this leads to a tie, then a second method of scoring is used, and so on, using more methods of scorings if necessary, until the tie is broken.
Example 5.
Consider the set of labels , two scoring functions and the following total preorder on
- (i)
- If and , then is the canonical extension on .
- (ii)
- If and , then is the lexicographic extension on .
- (iii)
- If and , then is the cardinality-maximality extension on .
Example 6.
An expert is forecasting the quality of the forthcoming new harvest in a piece of land. To do so, she/he uses labels as {very bad, bad, poor, fair, good, very good, excellent}. Moreover she/he can hesitate and show imprecision, so that the forecast could be an expression as, for instance, “from fair to very good”. From the point of view of the land keepers, a forecast is more positive than another one if the “average” is more favorable. Among two forecasts with identical average, it is important to avoid imprecision so that the most accurate is declared the more positive. The extension defined this way is the lexicographic one, , on .
4. Aggregation of Qualitative Assessments and Scorings
4.1. Some Facts about the Aggregation of Assessments and Scorings
Suppose now that a finite number of experts, agents, decision-makers or individuals show their assessments on a finite set, called universe of alternatives, . To do so, each individual could establish a qualitative ranking on X, based on linguistic terms , or perhaps they show some imprecision and use the set of linguistic expressions that come from L. Once the opinions of all the individuals have been established, a typical problem consists in aggregating them into a social ranking that somewhat reflects a decision that could be shared by all the individuals, as a society or collective, following some rules of “common sense” on which all the agents could agree. To put a trivial example, if each agent has ranked the elements of X in an identical manner, it seems compulsory that the social ranking should keep this, making no changes on the label or linguistic expression assigned to each one of the alternatives, and consequently showing respect for unanimity. It could also happen that each agent has already defined a sort of numerical scoring on the alternatives, so that the problem of aggregation translates in defining some sort of average of the individual numerical scores.
Notice that any scoring function immediately defines a total preorder on X by just declaring , for all . An important fact that comes from the aggregation problem is that, even in the case of any individual scoring function defining a linear order on X—that is, provided that ties never occur at the individual level—the final social aggregated scoring function could fail to be a linear order. Ties could appear after aggregation, so that total preorder is all the best that we may expect a priori as the ordering coming from a social scoring function.
Moreover, at this stage, it is relevant to say that even imposing mild restrictions of so-to-say “common sense” to the rules that aggregate individual preferences into a social one, the existence of a social rule in those conditions could become impossible, as proved in the famous Arrow’s impossibility theorem in Social Choice (see e.g., Arrow [24], Kelly [25], Campbell and Kelly [26] and Campión et al. [27] for further information on this topic).
In the present Section 4, we will not pay attention to these last kinds of questions. Instead, we will introduce some aggregation procedures for qualitative assessments and/or scorings over a finite set, disregarding the fact of the aggregation procedure satisfying the typical conditions (e.g., independence of irrelevant alternatives, non-dictatorship, etc.) arising in the Arrovian model or similar settings.
Let us introduce now some necessary concepts to deal with an aggregation procedure.
Definition 6.
Let be a finite set of alternatives. Suppose that a finite set of agents declare their assessments on the elements of X by means of linguistic expressions. A profile V is a matrix consisting of m rows and n columns (Notice that here the superindex a will correspond to a row (that depends on agents), whereas the subindex i corresponds to a column (that depends on alternatives)) of linguistic expressions, where the element represents the linguistic assessment given by the agent to the alternative . Then,
Therefore, each entry is a linguistic expression , which corresponds to the assessment that the a-th agent or expert has done on the i-th element of the set X of alternatives. Both and will depend on the position in which is located in the matrix V, namely in the a-th row and i-th column.
Taking into account the interval appearing in Proposition 5 and the scoring function introduced in Definition 5, we now define the scoring function as
for each profile .
We now establish the procedure for ranking the alternatives.
Proposition 9.
Given and a profile , the binary relation on X defined as
is a total preorder on X.
Proof.
Just notice that any scoring function immediately defines a total preorder on X by declaring .
Consider now that agents should assess each alternative from different criteria, so that represents the set of criteria available to the agents. Then, we have r profiles , , ⋯, , where is the assessment given by the agent to the i-th alternative with respect to the q-th criterion .
Since each criterion may have different importance in the decision, we will also consider a weighting vector , satisfying .
Given , the profiles , , ⋯, and a weighting vector satisfying , we now define the scoring function as
Proposition 10.
Given , the profiles , , ⋯, and a weighting vector satisfying , the binary relation on X defined as
is a total preorder on the set X of alternatives.
Proof.
The proof is immediate and leans on the same fact as the proof of Proposition 9. ☐
Remark 8.
Similar constructions could also be done using, instead of the arithmetic mean, other kinds of aggregation functions as, e.g., medians, trimmed means and so on.
We note that García-Lapresta and González del Pozo [28] propose a multi-criteria decision-making procedure in the same framework, but using a purely ordinal approach.
4.2. A Field Experiment
As described with more detail in García-Lapresta et al. [1], the proposed use of qualitative rankings and scorings based on linguistic expressions, their numerical representation by means of the geodesic distance plus a penalization of imprecision, as well as the subsequent method of aggregation just described in Proposition 10, have actually been tested in a field experiment carried out in Trigo restaurant in Valladolid, Spain (30 November 2013), under appropriate conditions of temperature, light and service.
A total of six experts trained in the sensory analysis of wines and wild mushrooms were recruited through the Gastronomy and Food Academy of Castile and Leon. When the test was being carried out, there was no communication between the experts and the samples were given to them without any identification.
The six experts assessed the products included in Table 1 through the five linguistic terms of Table 2 (or the corresponding linguistic expressions, when they hesitated) under three criteria: appearance (A), smell (S) and taste (T).

Table 1.
Alternatives.
Table 2.
Linguistic terms.
Five of the six experts sometimes hesitated about their opinions, and they assigned linguistic expressions with two labels. This happened in 19 of the 108 ratings, i.e., of the cases. The ratings provided by the experts appear in Table 3.
Table 3.
Ratings.
We now show the outcomes in five cases.
- When only considering appearance, i.e., , and the parameter , we obtain:Then, .
- When only considering smell, i.e., , and the parameter , we obtain:Then, .
- When only considering taste, i.e., , and the parameter , we obtain:Then, .
- Taking into account the weights (These weights are quite usual in this kind of tasting.), for appearance, for smell and for taste, i.e., , and the parameter , we obtain:Then, .
- Taking into account the weights for appearance, for smell and for taste, i.e., , and the parameter , we obtain the following outcomes:Then, .
Although we have considered the specific value of in the previous calculations, we have to notice that in all cases the alternatives are ranked in the same way for all the values of . Thus, the parameter has been irrelevant in this field experiment. The reason is the low number of assessments with more than one linguistic term ( of the cases). However, if applying the procedure of Proposition 9 to the field experiment presented in Agell et al. [29], where five experts assessed five fruits with respect to their suitability to combine with dark chocolate, and of the assessments were linguistic expressions with two or more linguistic terms, the ranking depending on the value of the parameter .
We may conclude that this method, based on geodesic distances on linguistic expressions, plus a penalization of imprecision, and using a weighting vector according to different criteria, could be considered as a suitable one in these practical experiments, at least in the field of sensory analysis.
5. Conclusions
The definition of ratings and/or scorings on a finite set has been associated with a wide sort of theoretical questions, namely:
- (i)
- The existence of a numerical representation for a total preorder on a finite set, so translating qualitative scales into quantitative (numerical) ones.
- (ii)
- The selection of a suitable method of scoring or numerical representation of a qualitative scale.
- (iii)
- The search for a compatible extension of a ranking defined on a finite set to its power set—or at least to a suitable superset of the given set—following a list of criteria established a priori.
- (iv)
- The implementation of aggregation procedures on profiles of individual ratings and/or scorings, in the search for a new scoring that reflects a social average.
- (v)
- The comparison between different ways of rating, scoring and aggregating, in the search for the most suitable one in view of some practical circumstances to be used in field experiments, and so on.
As a matter of fact, each of these questions, studied separately, could give raise to a wide sort of results in the literature. Indeed most of them have already been considered and analyzed, at least partially, by many authors.
However, many open problems remain. To provide only a few examples, we could say at this point that:
- (i)
- A systematic study of criteria to extend a linear order from a set to its power set, trying to classify the criteria in, so-to-say, contradictory families, so that any two criteria coming from different families give raise to an impossibility result.
- (ii)
- The systematic development of a standard procedure to determine which rating, scoring and/or aggregation procedure is the most suitable, maybe taking into account some previous criteria.
Needless to say, all of this leaves enough room for further research to be developed in the future.
Acknowledgments
This work has been partially supported by the Spanish Ministerio de Economía y Competitividad (projects ECO2015-65031-R, MTM2015-63608-P, ECO2016-77900-P and TIN2016-77356-P), ERDF and the Research Services of the Universidad Pública de Navarra (Spain). Thanks are also given to Remedios Marín and Íñigo Arozarena (Departamento de Tecnología de Alimentos, Universidad Pública de Navarra, Pamplona, Spain) for their valuable suggestions and comments.
Author Contributions
The authors contributed equally to this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- García-Lapresta, J.L.; Aldavero, C.; de Castro, S. A linguistic approach to multi-criteria and multi-expert sensory analysis. In Proceedings of the International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems (IPMU), Montpellier, France, 15–19 July 2014; Volume 443, pp. 586–595. [Google Scholar]
- Travé-Massuyès, L.; Dague, P. (Eds.) Modèles et Raisonnements Qualitatifs; Hermes Science: Paris, France, 2003. [Google Scholar]
- Travé-Massuyès, L.; Piera, N. The orders of magnitude models as qualitative algebras. In Proceedings of the 11th International Joint Conference on Artificial Intelligence, Detroit, Michigan, 20–25 August 1989; pp. 1261–1266. [Google Scholar]
- Roselló, L.; Prats, F.; Agell, N.; Sánchez, M. Measuring consensus in group decisions by means of qualitative reasoning. Int. J. Approx. Reason. 2010, 51, 441–452. [Google Scholar] [CrossRef]
- Roselló, L.; Prats, F.; Agell, N.; Sánchez, M. A qualitative reasoning approach to measure consensus. In Consensual Processes, STUDFUZZ; Herrera-Viedma, E., García-Lapresta, J.L., Kacprzyk, J., Nurmi, H., Fedrizzi, M., Zadrȯzny, S., Eds.; Springer: Berlin, Germany, 2001; Volume 267, pp. 235–261. [Google Scholar]
- Roselló, L.; Sánchez, M.; Agell, N.; Prats, F.; Mazaira, F.A. Using consensus and distances between generalized multi-attribute linguistic assessments for group decision-making. Inf. Fusion 2014, 17, 83–92. [Google Scholar] [CrossRef]
- Agell, N.; Sánchez, M.; Prats, F.; Roselló, L. Ranking multi-attribute alternatives on the basis of linguistic labels in group decisions. Inf. Sci. 2012, 209, 49–60. [Google Scholar] [CrossRef]
- Falcó, E.; García-Lapresta, J.L.; Roselló, L. Aggregating imprecise linguistic expressions. In Human-Centric Decision-Making Models for Social Sciences; Guo, P., Pedrycz, W., Eds.; Springer: Berlin, Germany, 2014; pp. 97–113. [Google Scholar]
- Falcó, E.; García-Lapresta, J.L.; Roselló, L. Allowing agents to be imprecise: A proposal using multiple linguistic terms. Inf. Sci. 2014, 258, 249–265. [Google Scholar] [CrossRef]
- Bridges, D.S.; Mehta, G.B. Representations of Preference Orderings; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Szpilrajn, E. Sur l’extension de l’ordre partiel. Fundam. Math. 1930, 16, 386–389. [Google Scholar]
- Herrera, F.; Herrera-Viedma, E.; Martínez, L. A fuzzy linguistic methodology to deal with unbalanced linguistic term sets. IEEE Trans. Fuzzy Syst. 2008, 16, 354–370. [Google Scholar] [CrossRef]
- García-Lapresta, J.L.; Pérez-Román, D. Ordinal proximity measures in the context of unbalanced qualitative scales and some applications to consensus and clustering. Appl. Soft Comput. 2015, 35, 864–872. [Google Scholar] [CrossRef]
- García-Lapresta, J.L.; Pérez-Román, D. Aggregating opinions in non-uniform ordered qualitative scales. Appl. Soft Comput. 2017, in press. [Google Scholar] [CrossRef]
- Gärdenfors, P. Manipulation of social choice functions. J. Econ. Theory 1976, 13, 227–228. [Google Scholar] [CrossRef]
- Kannai, Y.; Peleg, B. A note on the extension of an order on a set to the power set. J. Econ. Theory 1984, 32, 172–175. [Google Scholar] [CrossRef]
- Barberà, S.; Pattanaik, P.K. Extending an order on a set to the power set: some remarks on Kannai and Peleg’s approach. J. Econ. Theory 1984, 32, 185–191. [Google Scholar] [CrossRef]
- Fishburn, P.C. Comment on the Kannai–Peleg impossibility theorem for extending orders. J. Econ. Theory 1984, 32, 176–179. [Google Scholar] [CrossRef]
- Bossert, W. On the extension of preferences over a set to the power set: An axiomatic characterization of a quasi-ordering. J. Econ. Theory 1989, 49, 84–92. [Google Scholar] [CrossRef]
- Bossert, W.; Pattanaik, P.; Xu, Y. Ranking opportunity sets: an axiomatic approach. J. Econ. Theory 1990, 63, 326–345. [Google Scholar] [CrossRef]
- Barberà, S.; Bossert, W.; Pattanaik, P.K. Ranking sets of objects. In Handbook of Utility Theory, Volume II: Extensions; Barberà, S., Hammond, P.J., Seidl, C., Eds.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2004; pp. 893–977. [Google Scholar]
- Gaertner, W. Domain Conditions in Social Choice; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Pattanaik, P.K.; Xu, Y. On ranking opportunity sets in terms of freedom of choice. Rech. Écon. Louvain 1990, 56, 383–390. [Google Scholar]
- Arrow, K.J. Social Choice and Individual Values, 2nd ed.; Wiley: New York, NY, USA, 1963. [Google Scholar]
- Kelly, J.S. Social Choice Theory; Springer: New York, NY, USA, 1988. [Google Scholar]
- Campbell, D.E.; Kelly, J.S. Impossibility theorems in the Arrovian framework. In Handbook of Social Choice and Welfare; Arrow, K.J., Sen, A.K., Suzumura, K., Eds.; North Holland: Amsterdam, The Netherlands, 2002; Volume 1, pp. 35–44. [Google Scholar]
- Campión, M.J.; Candeal, J.C.; Catalán, R.G.; de Miguel, J.R.; Induráin, E.; Molina, J.A. Aggregation of preferences in crisp and fuzzy settings: Functional equations leading to possibility results. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2011, 19, 89–114. [Google Scholar] [CrossRef]
- García-Lapresta, J.L.; González del Pozo, R. An ordinal multi-criteria decision-making procedure in the context of uniform qualitative scales. In Soft Computing Applications for Group Decision-Making and Consensus Modeling; Collan, M., Kacprzyk, J., Eds.; Studies in Fuzziness and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2017; in press. [Google Scholar]
- Agell, N.; Sánchez, G.; Sánchez, M.; Ruiz, F.J. Selecting the best taste: A group decision-making application to chocolates design. In Proceedings of the 2013 IFSA-NAFIPS Joint Congress, Edmonton, AB, Canada, 24–28 June 2013; pp. 939–943. [Google Scholar]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).