Abstract
The primal-dual hybrid gradient (PDHG) method is widely used for convex–concave saddle-point problems, yet its extrapolated variants are typically asymmetric because only one side is extrapolated. We propose a symmetry-preserving refinement, E-PDHG, which performs dual-side extrapolation followed by an explicit correction step. Under standard step-size conditions, we establish global convergence for all and derive a pointwise (non-ergodic) rate for the last iterate. The method does not improve the asymptotic complexity order of PDHG; instead, it enlarges the practically stable parameter region while retaining the same per-iteration cost. Numerical experiments on image deblurring/inpainting and additional machine learning benchmarks (logistic regression and LASSO) demonstrate improved finite-iteration stability and efficiency.
MSC:
49K35; 49M27; 90C25; 65K10
1. Introduction
We study the convex–concave problem
where and are closed convex sets, f and h are convex, and is the conjugate function of h. It is assumed that problem (1) admits at least one saddle-point.
Problem (1) serves as a generic primal-dual formulation that captures a variety of models encountered in practice, including variational methods in imaging, inverse modeling, and learning problems with structured regularization. Representative instances include total variation-type image recovery, segmentation models, and sparse estimation formulations such as the Lasso. In addition, a large class of constrained convex optimization problems and composite minimization models can be transformed into the form (1) through their corresponding Lagrangian representations. Related discussions and examples can be found in Refs. [1,2,3].
The primal-dual hybrid gradient (PDHG) algorithm [4,5] is a widely used first-order approach for solving the saddle-point problem (1). Its iterative scheme is given by
Here, and denote the primal and dual step sizes, respectively, and is an extrapolation parameter. Each PDHG iteration requires solving two proximal subproblems separately, which are often available in closed form or can be computed efficiently to high accuracy. This computational simplicity makes PDHG particularly attractive for large-scale imaging problems; see Refs. [4,6,7] for representative numerical studies.
A basic and widely used configuration is (often called the CPHY scheme [6]). In this case, classical results show that, under standard step-size coupling conditions (e.g., in the basic setting), PDHG converges to a saddle point and achieves an ergodic primal-dual gap rate [4]. The same regime can also be interpreted through a proximal-point viewpoint under an appropriate metric [6]; related operator-splitting equivalences are discussed in Ref. [8]. At the other endpoint, reduces to the Arrow–Hurwicz-type update [3,9], which is symmetric in form but may diverge for fixed step sizes without additional correction mechanisms [6,10,11].
For intermediate extrapolation parameters , PDHG generally loses the direct proximal-point interpretation, and a complete theory for the fully general convex–concave setting is still limited. This has led to several development lines: over-relaxed PDHG variants [6,12,13], inertial primal-dual splitting methods [14,15,16], and accelerated schemes that exploit additional structure such as (partial) strong convexity [4,17,18]. In parallel, sADMM (symmetric ADMM)-type methods, including strictly contractive PRSM-type updates, provide an important external baseline line for related constrained saddle models [19,20]. These methods are not direct PDHG iterations, but are often competitive in practice and relevant for numerical comparison. Overall, these variants improve different aspects (speed, stability, or robustness), but usually require extra parameter coupling rules or stronger assumptions. More recent generalized, coupled-extrapolation, and symmetry-oriented PDHG developments are discussed in Refs. [21,22,23].
Against this background, our goal is to retain the low-cost primal-dual proximal structure while introducing a symmetry-preserving correction mechanism. Table 1 summarizes the positioning of E-PDHG relative to representative PDHG-family baselines.

Table 1.
Algorithmic positioning of E-PDHG versus representative baselines.
Beyond symmetry, E-PDHG in (5) differs from closely related inertial and over-relaxed PDHG variants at the algorithmic level.
First, compared with inertial primal-dual schemes, the extrapolation in (5) is not implemented through an additional momentum anchor or a forward–backward–forward stabilization block. Instead, the inertial effect is embedded directly into the affine predictors and via the fixed parameters and . In particular, no extra damping or adaptive safeguard is required, and each iteration still consists of exactly two proximal subproblems.
Second, compared with standard over-relaxed PDHG, the modification in (5) is not merely a one-sided extrapolation of the primal or dual variable. The update
introduces an explicit post-primal correction driven by the increment . This term acts as a structured drift-control mechanism, rather than a simple rescaling of extrapolation.
As a result, E-PDHG preserves the classical two-proximal-per-iteration structure of PDHG while incorporating an additional lightweight affine correction step, without increasing the number of proximal evaluations or introducing extra inner loops.
To highlight this issue, consider the equivalent representation of PDHG:
Although problem (1) treats the primal and dual variables symmetrically, the PDHG updates do not: the dual update relies on an extrapolated primal variable, whereas the primal update does not involve a symmetric extrapolation of the dual variable. This observation suggests that PDHG can be viewed as an asymmetric extrapolated scheme.
Motivated by this asymmetry, we ask whether it is possible to design a variant in which extrapolation and correction are applied in a balanced manner. In this paper, we provide an affirmative answer by introducing a modified PDHG scheme that extrapolates the dual variable and incorporates a subsequent correction step:
This modification preserves the two proximal subproblems of PDHG while introducing an explicit dual correction step. Empirically, this correction improves stability for .
For clarity, the method can be written in the cycle form
The cycle form (5) makes the intrinsic primal-dual symmetry of the proposed E-PDHG scheme explicit.
Equivalently, the method can be expressed as
The main contributions of this paper are summarized as follows:
- A symmetry-preserving primal-dual algorithm is proposed for convex–concave saddle-point problems.
- Global convergence of the E-PDHG method is established without imposing additional assumptions on h or f and pointwise convergence rate is proved.
- Numerical experiments on image restoration and machine learning demonstrate the practical efficiency and stability of the proposed method.
Although PDHG-type methods have been extended to nonconvex settings or enhanced via line search and stochastic strategies [12,17], heuristic evolutionary optimization methods have also been explored for related optimization problems [24]. Our analysis deliberately focuses on the fully convex case in order to highlight the core mechanism of the proposed symmetric update. Consequently, the obtained results are broadly applicable.
The remainder of the paper is organized as follows. Section 2 introduces preliminaries. Section 3 and Section 4 establish the global convergence and convergence-rate results for E-PDHG. Numerical experiments on image restoration and machine learning are presented in Section 5. Section 6 closes the paper with concluding remarks.
2. Preliminaries
We first show that the saddle-point problem (1) can be written as a VI problem. More specifically, if is a solution point of the saddle-point problem (1), then we have
Therefore, finding a solution point of (7) is equivalent to solving the VI problem: find such that
where
We denote by the set of all solution points of VI (8). Notice that is convex.
E-PDHG (6) can be split into a prediction part (PDHG subroutine) and a correction part. We denote by the prediction point and by the corrected iterate.
- Prediction.
- Correction.
We reformulate both parts into VI. The optimality conditions of (11) and (13) are
and
respectively. Combining the above VIs and using (12), we obtain:
- Prediction step.
- Correction step.
3. Convergence Analysis
We verify the following convergence conditions briefly and establish the convergence of E-PDHG under these conditions thereafter; see also Ref. [25]. The conditions are sufficient and follow the standard VI framework used for PDHG-type methods; they enforce the positivity of the induced metrics and do not introduce extra structural assumptions on h or f beyond convexity.
- Convergence conditions.
In fact, these two conditions can be verified easily.
Since and , we verify via the Schur complement. Indeed, write
Since , we have ; hence, the lower-right block satisfies . The corresponding Schur complement is
If , then . If , then follows from , and since , we have . Therefore, in all cases, , and by the Schur complement lemma, we conclude that , i.e., L is positive-definite.
When , , K is positive-definite.
Now we are ready to prove the convergence.
Proof.
For the last term of the right-hand side of (28), we have
We prove the contractive property of E-PDHG in the following theorem.
Theorem 2.
Theorem 2 shows that the sequence is Fèjer monotone and the convergence of to a in L-norm is immediately implied.
4. Convergence Rate
We use to measure the solution accuracy. In fact, the duality gap of the prediction point is contained by a constant multiplied by :
In addition, , showing that the Euclidean norm between the prediction and the iteration is also contained by . Thus, it is reasonable to measure the solution accuracy by .
Proof.
Setting in (17), we get
Note that (17) is also true for . Thus, it holds that
Then, setting in the above inequality, we obtain
Now, we establish the worst-case convergence rate in a non-ergodic sense for E-PDHG (6).
Theorem 3.
Proof.
First, setting and in the identity
we obtain
Inserting (33) into the first term of the right-hand side of the last equality, we obtain
The last inequality holds because the matrix and . We thus have
The sequence is monotonically non-increasing. Then, it follows from and Theorem 2 that there is a constant such that
Furthermore, it follows from (39) that
Therefore, we have
5. Numerical Result
In this section, we present numerical experiments to evaluate the performance of E-PDHG; see also Ref. [26]. All algorithms were implemented in MATLAB R2016a, and the experiments were run on a Windows 10 workstation equipped with an Intel® CoreTM i7-6700K CPU (4.00 GHz) and 8 GB of RAM.
5.1. TV Image Restoration
We consider the standard total variation- (TV-) image restoration model
where H denotes the image domain with area , d is the observed image, ∇ is the discrete gradient, F is the degradation operator (e.g., a space-invariant blur for deblurring or a masking operator for inpainting), and balances data fidelity and TV regularization. As shown in Refs. [3,4,27], (42) admits the saddle-point reformulation
where U is the Cartesian product of unit balls in (see Refs. [3,4,6]) and D is the matrix representation of the divergence operator.
Since (43) is a special instance of (1), the proposed method (6) applies directly. We now derive the associated subproblems; see Refs. [3,4,6] for details. The u-subproblem is
Hence, the solution is given by
where denotes the projection onto U. Since U is a Cartesian product of unit balls in , is computed componentwise. The p-subproblem is
Thus, we solve the linear system
For deblurring, the system is solved efficiently by FFT or DCT; see Ref. [3]. For inpainting, the diagonal masking operator yields a closed-form solution via elementwise division.
We compare CP/PDHG, He4 in Ref. [6], over-relaxed PDHG, inertial PDHG, and E-PDHG.
5.1.1. Denoising and Parameter Sensitivity
We first study the influence of step sizes and extrapolation factor by denoising motion-blurred ‘barbara.png’ () and Gaussian-blurred ‘man.png’ (). We vary from to and scale the default step sizes from to on a uniform grid, and report PSNR/SSIM in Table 3 and Table 4. The metrics are monotone increasing w.r.b to the step size and convav w.r.b over this grid. Since E-PDHG requires and , we adopt the conservative choice and in the remaining experiments. Figure 1 shows the motion-blurred Barbara example, and Figure 2 shows the Gaussian-blurred man example.
Table 3.
PSNR/SSIM of E-PDHG under varying and step-size scale.
Table 4.
PSNR/SSIM.

Figure 1.
Left: original image; right: motion-blurred observation.

Figure 2.
Left: original image; right: Gaussian-blurred observation.
The remaining methods are tuned on the same time budget using the same grid strategy as E-PDHG; see Table 5.
Table 5.
Parameter settings for the compared algorithms.
5.1.2. Image Inpainting
Image inpainting recovers an image from incomplete and/or corrupted observations. The masking operator is diagonal: zeros indicate missing pixels and ones indicate observed pixels.
We test ‘lena.png’ () and ‘pepper.png’ (). For ‘lena.png’, the mask keeps the first row of every eight rows (about missing pixels). For ‘pepper.png’, we use a character-shaped mask with about missing pixels. In both cases, we add zero-mean Gaussian noise with standard deviation to observed pixels. Ground-truth and corrupted images are shown in Figure 3. We set in (42).

Figure 3.
From left to right: original lena.png (), corrupted lena.png, original peppersrgb.png (), and corrupted peppersrgb.png.
The results are reported in Figure 4 and Figure 5 with fixed 300 iterations. Table 6 and Table 7 adopt terminating strategy whenever
or if the maximum number of iterations is reached.
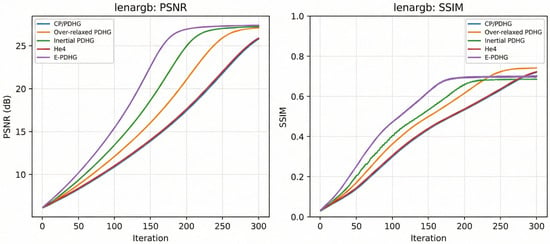
Figure 4.
Curve comparison (lenargb.png).
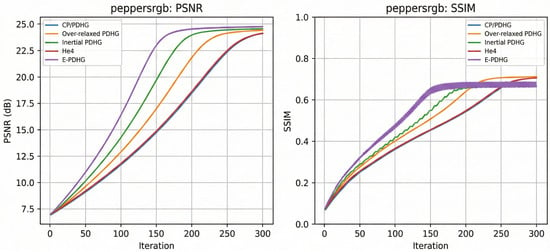
Figure 5.
Curve comparison (peppersrgb.png).
Table 6.
Inpainting results on lena.png ().
Table 7.
Inpainting results on peppers.png ().
Overall, E-PDHG achieves the best PSNR on both inpainting tasks (Table 6 and Table 7) while also delivering the shortest runtime among the compared methods. Although over-relaxed PDHG attains the highest SSIM in both cases, its PSNR is lower and its runtime is longer. The curve comparisons in Figure 4 and Figure 5 further indicate faster and more stable convergence for E-PDHG, suggesting a favorable accuracy–efficiency trade-off for inpainting.
5.2. Machine Learning Models and Experimental Setup
To present the machine learning evidence in a unified optimization form, we use the composite model
with the equivalent saddle formulation
The two task instances are
The primal subproblem has the closed form
For the LASSO dual block , we use
For the logistic dual block , each coordinate solves
and we compute (56) by projected Newton iterations.
5.2.1. LASSO
For LASSO, we use the same model templates (48)–(50) with and , and apply the protocol in Table 8. The compared methods are CP/PDHG, over-relaxed PDHG, inertial PDHG, accelerated PDHG, He4, and E-PDHG (). Inertial PDHG uses a training/validation-only response clipping patch (1–99%) to control oscillation; final reported metrics remain on the original data domain. The time-to-target threshold is
Table 8.
Machine learning protocol used in the logistic and LASSO benchmarks.
Table 9 shows that E-PDHG reaches the target objective in the fewest iterations. Its final objective is close to the best value (accelerated PDHG), while test MSE remains comparable. This supports an objective- and time-to-target-oriented advantage in this sparse-regression setting. Figure 6 reports the full LASSO benchmark trajectories for the six compared methods.
Table 9.
LASSO diabetes benchmark final metrics (objective-oriented view; ↓ means lower is better).
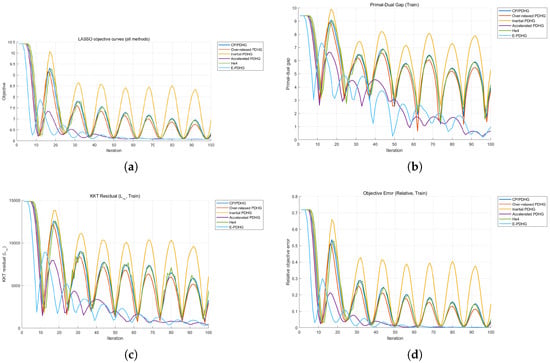
Figure 6.
Additional LASSO benchmark curves for the six methods (including He4): objective, primal-dual gap, KKT residual, and relative objective error. (a) Objective curve. (b) Primal-dual gap curve. (c) KKT residual curve. (d) Relative objective error curve.
Under the same strict step_scale-only profile in Table 8, we further evaluate LASSO parameter robustness with the validation objective as the scoring quantity. The results indicate that E-PDHG keeps lower objective fluctuation while maintaining a competitive robust region. Figure 7 summarizes the corresponding LASSO sensitivity evidence across the scanned step-scale grid.
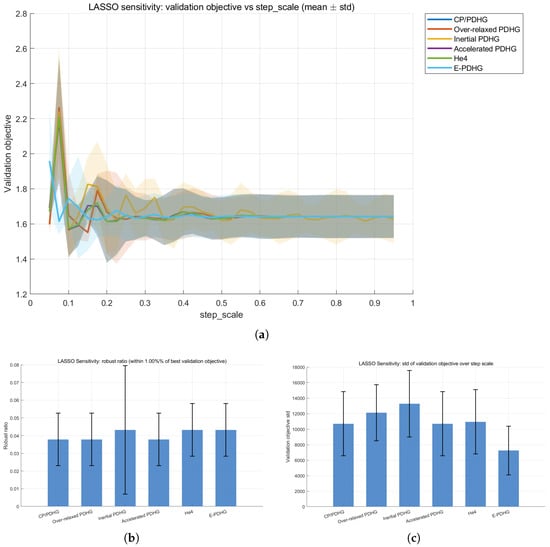
Figure 7.
Additional LASSO sensitivity evidence over five seeds under strict step-scale-only profiles (including He4). (a) Validation objective vs. step_scale. (b) Robust ratio (higher is better). (c) Validation objective std (lower is better).
5.2.2. Logistic Classification
Using (48)–(50) and the protocol in Table 8, we compare CP/PDHG, over-relaxed PDHG, inertial PDHG, accelerated PDHG, He4, and E-PDHG () on the breast-cancer task. Notice that the problem is no longer strongly convex; hence, accelerated PDHG does not guarantee convergence. All methods stop at iteration 200 in this setting and attain the same predictive quality (test accuracy , precision , recall , F1 ). Hence, the comparison is determined by optimization quality indicators under matched prediction metrics.
Table 10 shows that, at matched classification quality, E-PDHG attains the smallest objective value and the lowest residual-style indicators. This indicates better optimization accuracy for the same predictive operating point. Figure 8 shows the corresponding optimization trajectories for the logistic benchmark.
Table 10.
Logistic benchmark final metrics (same prediction quality across methods; ↓ means lower is better).
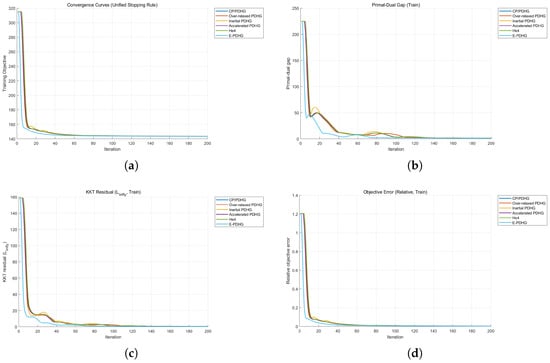
Figure 8.
Additional logistic benchmark curves for the six methods (including He4). (a) Training objective curve. (b) Primal-dual gap curve. (c) KKT residual curve. (d) Relative objective error curve.
We next evaluate parameter robustness under the strict profile listed in Table 8. Let S be the scanned step_scale grid, the validation prediction error at , and . The reported indicators are
and normalized robust span over the accepted set.
As summarized in Table 11, E-PDHG has the largest robust region and the smallest fluctuation over the scanned grid in this protocol. These statistics support a stronger parameter robustness trend for E-PDHG in this logistic task. Figure 9 displays the corresponding logistic sensitivity evidence over the scanned step-scale grid.
Table 11.
Sensitivity summary (mean over five seeds; ↑ means higher is better and ↓ means lower is better).
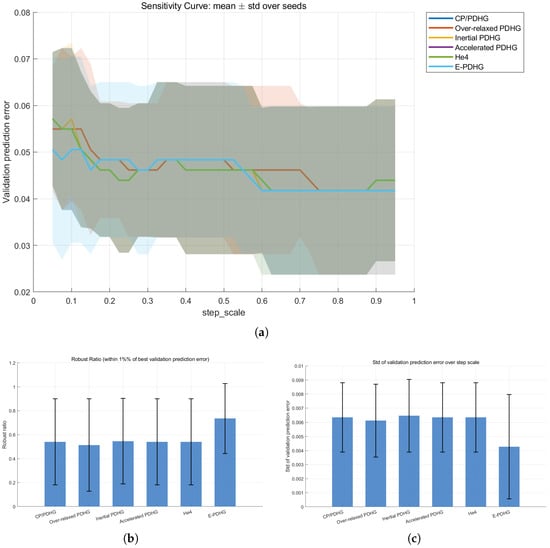
Figure 9.
Additional logistic sensitivity evidence over five seeds (including He4). (a) Validation prediction error vs. step_scale. (b) Robust ratio (higher is better). (c) Prediction error std (lower is better).
The machine learning results extend the empirical scope beyond imaging to classification and sparse regression, while keeping a single first-order primal-dual implementation framework. Across logistic and LASSO protocols, the comparisons are reported with both prediction-side and optimization-side indicators, enabling direct operational interpretation.
From a complexity perspective, these results are interpreted conservatively. We do not claim an improved asymptotic order over standard PDHG in the convex regime; the contribution is a symmetry-preserving correction mechanism that improves finite-iteration stability and objective-side quality under comparable predictive performance.
For reproducible use, the experiments provide a practical default: E-PDHG with fixed and moderate step scale is a stable baseline choice, and remains competitive without aggressive parameter search.
6. Conclusions
We presented E-PDHG, a symmetry-preserving refinement of PDHG that combines dual-side extrapolation with an explicit correction step. The method keeps the same low-cost proximal structure as standard PDHG while restoring primal-dual symmetry.
Theoretical analysis establishes global convergence for all under standard step-size conditions and provides a pointwise (non-ergodic) rate for the last iterate. These results clarify the intermediate extrapolation regime without claiming any improvement in asymptotic complexity order.
Empirically, we expanded evaluation beyond imaging by adding logistic regression and LASSO benchmarks with unified protocols. Across deblurring, inpainting, and machine learning tasks, E-PDHG shows improved finite-iteration stability and competitive accuracy under comparable per-iteration cost. The sensitivity studies further support robust behavior near close to 1 within the admissible range.
Future work includes adaptive step-size strategies, extensions to strongly convex or nonconvex settings, and stochastic or large-scale variants.
Author Contributions
Conceptualization, X.Z.; Methodology, X.Z.; Formal analysis, X.Z. and S.Z.; Writing—original draft, X.Z., W.L. (Wenzhuo Li), B.C., W.L. (Wei Liu), and S.Z.; Writing—review and editing, W.L. (Wenzhuo Li), B.C., W.L. (Wei Liu), and S.Z.; Visualization, W.L. (Wenzhuo Li), B.C., W.L. (Wei Liu), and S.Z.; Software, W.L. (Wenzhuo Li), B.C., W.L. (Wei Liu), and S.Z.; Validation, W.L. (Wenzhuo Li), B.C., W.L. (Wei Liu), and S.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data generated or analyzed during this study are available from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chambolle, A.; Pock, T. An introduction to continuous optimization for imaging. Acta Numer. 2016, 25, 161–319. [Google Scholar] [CrossRef]
- Weiss, P.; Blanc-Feraud, L.; Aubert, G. Efficient schemes for total variation minimization under constraints in image processing. SIAM J. Sci. Comput. 2009, 31, 2047–2080. [Google Scholar] [CrossRef]
- Zhu, M.; Chan, T.F. An Efficient Primal-Dual Hybrid Gradient Algorithm for Total Variation Image Restoration; CAM Report 08-34; UCLA: Los Angeles, CA, USA, 2008. [Google Scholar]
- Chambolle, A.; Pock, T. A first-order primal-dual algorithms for convex problem with applications to imaging. J. Math. Imaging Vis. 2011, 40, 120–145. [Google Scholar]
- Pock, T.; Chambolle, A. Diagonal preconditioning for first order primal-dual algorithms in convex optimization. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1762–1769. [Google Scholar]
- He, B.S.; Yuan, X.M. Convergence analysis of primal-dual algorithms for a saddle-point problem: From contraction perspective. SIAM J. Imaging Sci. 2012, 5, 119–149. [Google Scholar]
- Goldstein, T.; Li, M.; Yuan, X.M.; Esser, E.; Baraniuk, R. Adaptive primal-dual hybrid gradient methods for saddle-point problems. arXiv 2013, arXiv:1305.0546. [Google Scholar]
- O’Connor, D.; Vandenberghe, L. On the equivalence of the primal-dual hybrid gradient method and Douglas–Rachford splitting. Math. Prog. 2020, 179, 85–108. [Google Scholar]
- Arrow, K.J.; Hurwicz, L.; Uzawa, H. Studies in Linear and Non-Linear Programming; With contributions by Chenery, H.B., Johnson, S.M., Karlin, S., Marschak, T. and Solow, R.M.; Stanford Mathematical Studies in the Social Science; Stanford University Press: Stanford, CA, USA, 1958; Volume II. [Google Scholar]
- He, B.S.; You, Y.F.; Yuan, X.M. On the convergence of primal-dual hybrid gradient algorithm. SIAM J. Imaging Sci. 2014, 7, 2526–2537. [Google Scholar] [CrossRef]
- He, B.S. PPA-like contraction methods for convex optimization: A framework using variational inequality approach. J. Oper. Res. Soc. China 2015, 3, 391–420. [Google Scholar] [CrossRef]
- Condat, L. A primal-dual splitting method for convex optimization involving Lipschitzian, proximable and linear composite terms. J. Optim. Theory Appl. 2013, 158, 460–479. [Google Scholar] [CrossRef]
- Cai, X.; Han, D.; Xu, L. An improved first-order primal-dual algorithm with a new correction step. J. Glob. Optim. 2013, 57, 1419–1428. [Google Scholar]
- Lorenz, D.A.; Pock, T. An inertial forward-backward algorithm for monotone inclusions. J. Math. Imaging Vis. 2015, 51, 311–325. [Google Scholar] [CrossRef]
- Boţ, R.I.; Csetnek, E.R. An inertial forward-backward-forward primal-dual splitting algorithm for solving monotone inclusion problems. Numer. Algorithms 2016, 71, 519–540. [Google Scholar]
- Valkonen, T. Inertial, corrected, primal-dual proximal splitting. SIAM J. Optim. 2020, 30, 1391–1420. [Google Scholar] [CrossRef]
- Chambolle, A.; Pock, T. On the ergodic convergence rates of a first-order primal-dual algorithm. Math. Prog. 2016, 159, 253–287. [Google Scholar]
- Valkonen, T.; Pock, T. Acceleration of the PDHGM on partially strongly convex functions. J. Math. Imaging Vis. 2017, 59, 394–414. [Google Scholar] [CrossRef]
- He, B.; Tao, M.; Yuan, X. Alternating direction method with Gaussian back substitution for separable convex programming. SIAM J. Optim. 2012, 22, 313–340. [Google Scholar] [CrossRef]
- He, B.; Liu, H.; Wang, Z.; Yuan, X. A strictly contractive Peaceman–Rachford splitting method for convex programming. SIAM J. Optim. 2014, 24, 1011–1040. [Google Scholar]
- He, B.S.; Ma, F.; Yuan, X.M. An algorithmic framework of generalized primal-dual hybrid gradient methods for saddle point problems. J. Math. Imaging Vis. 2017, 58, 279–293. [Google Scholar] [CrossRef]
- Wu, J.; Ma, F. A primal-dual algorithm with coupled extrapolation: Bridging the Chambolle–Pock and Peaceman–Rachford methods. Numer. Algorithms 2025, 1–39. [Google Scholar] [CrossRef]
- Ma, F.; Li, S.; Zhang, X. A symmetric version of the generalized Chambolle-Pock-He-Yuan method for saddle point problems. Comput. Optim. Appl. 2025, 1–26. [Google Scholar]
- Ma, F. A revisit of Chen-Teboulle’s proximal-based decomposition method. arXiv 2020, arXiv:2006.11255. [Google Scholar] [CrossRef]
- He, B.; Ma, F.; Xu, S.; Yuan, X. A rank-two relaxed parallel splitting version of the augmented Lagrangian method with step size in (0, 2) for separable convex programming. Math. Comput. 2023, 92, 1633–1663. [Google Scholar] [CrossRef]
- Ma, S.; Li, S.; Ma, F. Preconditioned golden ratio primal-dual algorithm with linesearch. Numer. Algorithms 2025, 98, 1281–1311. [Google Scholar] [CrossRef]
- Esser, E.; Zhang, X.; Chan, T.F. A general framework for a class of first order primal-dual algorithms for TV minimization. SIAM J. Imaging Sci. 2010, 3, 1015–1046. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.