Abstract
This paper studies an efficient method for solving stochastic optimization problems formulated as stochastic variational inequalities with a quasi-monotone operator, where the cost function extends the classical monotone and pseudomonotone operators. Our proposed method iterates an adaptive stepsize that adjusts automatically without linesearch and includes a momentum term to accelerate the convergence. Each iteration requires only a single projection onto the feasible set, ensuring low computational complexity. Under standard assumptions, the algorithm achieves almost sure convergence and a proven convergence rate. Furthermore, numerical experiments demonstrate its superior performance, accuracy, stability, and efficiency compared with existing stochastic approximation schemes. We also apply the method to problems such as stochastic network bandwidth allocation, stochastic complementarity problems, and the networked stochastic Nash–Cournot game, showing its strength and practical usefulness. The obtained result is an extension of existing works in the literature.
Keywords:
quasi-monotone; stochastic optimization; bandwidth network allocation; rate of convergence; almost sure convergence MSC:
54E70; 47H25; 90C15
1. Introduction
We consider a stochastic optimization problem of the form:
where x is the decision variable, X is a feasible subset of , is a random variable representing uncertainty, is a random cost function, and denotes its expectation. Problem (1) is known as a stochastic optimization (SO) problem.
Stochastic optimization provides a powerful framework for modeling and solving problems where randomness influences objectives or constraints. Such uncertainty is noticeable in real-world applications, including machine learning, where data are inherently noisy; finance, where markets fluctuate; engineering design, where measurements are imprecise; and energy systems, where renewable sources vary unpredictably (see, [1,2]). Unlike deterministic optimization, SO explicitly incorporates statistical variability into the modeling process, yielding solutions that are not only optimal in expectation but also robust under uncertainty. Its effectiveness lies in balancing exploration of the feasible region with exploitation of informative samples, which mitigates the risk of convergence to poor local minima in nonconvex or high-dimensional settings. Consequently, SO underpins many modern algorithms, such as stochastic gradient descent for deep learning, Monte Carlo-based optimization in engineering, and stochastic portfolio selection in finance.
In general, four classical approaches are used to solve problem (1): the stochastic gradient descent (SGD) method (see, e.g., [3]), the sample average approximation (SAA) [4], the stochastic approximation (SA) method [5], and evolutionary or Monte Carlo-based algorithms [6]. These methods have been extensively analyzed and successfully applied in diverse scientific and engineering domains. In this work, we focus on the SA framework, which is particularly effective when the expected value is difficult or impossible to compute exactly. Our study connects SA methods to the theory of variational inequalities, providing a unified framework for optimization and equilibrium modeling under uncertainty.
The variational inequality problem (VIP), first introduced in [7], is a fundamental model that generalizes many problems in optimization, game theory, and economics. For a nonempty, closed, and convex set , the variational inequality problem (VIP) is expressed as follows:
where F is a nonlinear operator. Optimization problems correspond to VIP with , where g is the objective function; Nash equilibrium conditions arise when F represents the vector of marginal payoffs; and traffic or network equilibrium problems appear when F models congestion effects [8]. Over the years, extensive studies (see, e.g., [9,10,11,12]) have focused on efficient numerical schemes and theoretical properties of deterministic VIP. However, in many practical situations, the operator F cannot be exactly computed due to noise or randomness. Examples include learning systems, where gradients are estimated from samples, financial models with stochastic returns, and network systems with uncertain demand. To address such cases, the notion of the stochastic variational inequality problem (SVIP) was developed in [5].
For clarity, assume that X is a nonempty, closed, and convex subset of , and let denote a probability space. Consider a function that is measurable with respect to the random variable . The SVIP is formulated as
and denotes the expectation over . The SVIP generalizes the deterministic VIP by integrating stochastic effects into the equilibrium conditions and provides a rigorous model for decision-making under uncertainty. It encompasses diverse problems in stochastic optimization, energy markets, game theory, and transportation systems (see, e.g., [13,14]).
Related Works: Problem (3) has inspired substantial research activity. When admits a closed-form expression, it reduces to the deterministic VIP (2), for which numerous efficient algorithms exist (see [11]). When is not explicitly computable, two primary strategies are adopted: the sample average approximation (SAA) and the stochastic approximation (SA) approaches. In SAA, the expectation in (3) is replaced with an empirical average based on N independent samples:
where are independent and identically distributed (i.i.d.) realizations of since the law of large numbers ensures that almost surely as . Many recent studies analyze convergence properties of SAA and its applications to stochastic generalized equations [15], gap-function reformulations [16], and unconstrained settings [4,17,18,19]. In contrast, the SA framework solves (3) by updating iterates using sample-based gradients in an online fashion. The classical Robbins–Monro [5] procedure forms the basis for this approach. A seminal contribution by Jiang and Xu [14] proposed the single-projection SA algorithm:
where denotes the Euclidean projection onto X, and the stepsize sequence satisfies while . Under strong monotonicity and Lipschitz continuity, they proved almost sure (a.s.) convergence to the unique solution of (3). Subsequent improvements have relaxed these assumptions or enhanced convergence properties. Yousefian et al. [20] introduced adaptive step-sizes for Cartesian SVIPs; Koshal et al. [21] proposed parallel and proximal-based methods; and [22] derived asymptotic feasibility and solution rates of and , respectively, under the monotonicity assumption. To further weaken assumptions, Yang et al. [23] developed algorithms for pseudomonotone and Lipschitz continuous operators, achieving sublinear convergence and optimal oracle complexity.
Recent research has focused on improving algorithmic efficiency through the extragradient and subgradient extragradient (SEM) methods. The extragradient method, originally due to Korpelevich [24], has been successfully extended to the stochastic setting (see, e.g., [25,26]). A typical extragradient-type update reads:
where and are independent sample batches. Although effective, this approach requires two projections per iteration, which can be computationally demanding for large-scale or structured feasible sets. To reduce this cost, subgradient extragradient variants [26,27,28,29] were proposed and analyzed for both deterministic and stochastic VIP, yielding promising results under monotonicity and Lipschitz continuity assumptions.
Furthermore, recent research works have introduced self-adaptive stepsize rules and inertial terms to accelerate convergence. In particular, Wang et al. [30] eliminated the need for linesearch-based parameter tuning while maintaining convergence for pseudomonotone operators and adopted self-adaptive strategy to analysis approximate solution to SA. Liu and Qin [31] later incorporated Polyak’s inertial extrapolation [32] (see, also [33,34,35,36,37]) into stochastic extragradient frameworks, achieving almost sure convergence and improved complexity bounds, though still requiring linesearch conditions.
Motivation and Contribution: Despite these advances, most existing SA-based algorithms rely on strong or pseudomonotone assumptions, limiting their applicability to broader problem classes. Moreover, modern schemes often require multiple projections, sensitive parameter tuning, or complex linesearch procedures, which hinder scalability. Motivated by these challenges and the works in [23,27,30,31,32,38,39], we ask the following fundamental question:
Question: Can we design a robust iterative scheme for solving the SVIP (3) that combines self-adaptive step-sizes, stochastic subgradient extragradient techniques, and inertial acceleration for a quasi-monotone operator within the SA framework while ensuring almost sure and convergence rate are guarantees?
The principal objective of this study is to provide an affirmative answer to this question.
Organization of the Paper: Section 2 presents preliminary definitions and essential lemmas. Section 3 introduces the proposed algorithm and underlying assumptions. Section 4 contains the main convergence analysis and proofs. Numerical results and practical applications are presented in Section 5, followed by concluding remarks in Section 6.
2. Preliminaries
In this section, we formally state some basic terminologies that are essential in this work. For any vectors is the standard inner product, is the Euclidean norm. Given a random variable and algebra the notations and denote the expectation of , conditional expectation of with respect to , the variance of and the conditional variance of with respect to . For is the norm of and is the norm of conditional to . The algebra generated by the random variable is denoted by Also, . We say that a random variable is -measurable. We write to mean that is independent of the -algebra . The set of natural number is denoted by . Let there exists a unique element denoted by such that The mapping is called a projection from onto To quantify the inaccuracy in the stochastic evaluation of (3), introduce the error term
For any exponent , we associate with this error the p-moment function
which serves as an indicator of how accurately a stochastic approximation method captures the underlying operator.
We give below a fundamental definition regarding the cost function.
Definition 1.
The mapping T on X is called:
- (i)
- strongly monotone if, there exists a constant such that for all
- (ii)
- monotone if, for all
- (iii)
- pseudomonotone if, for all
- (iv)
- quasi-monotone if, for all
Remark 1.
We obtain from Definition 1 that , but the converse of these statements is not true in general.
The following Lemmas are very important in our work.
Lemma 1
(Lemma 2.1, [30]). Let be a projection from onto Then,
- (i)
- and
- (ii)
- (iii)
- if and only if
- (iv)
- Let Then, for all strictly positive.
Let with and consider For any the projection is given by
Observe that (7) provides a direct formula for computing the projection of an arbitrary point onto a half-space.
Lemma 2
([40]). For any point and any parameter the following bounds are satisfied:
where
Assumption 1
The following assumptions shall be considered:
- (A)
- The solution set
- (B)
- (i) For all and almost everywhere is a measurable function such that for almost(ii) There exists and such that and
- (C)
- The mapping F is quasi-monotone.
- (D)
- Let and a positive sequence such that and Furthermore, as
Lemma 3
([41]). Under Assumption 1, the operators F and are Lipschitz continuous on with constants L and , respectively. This holds for every , where p is the exponent specified in Assumption 1. Moreover, the constants satisfy and Let denote an i.i.d. collection drawn from Ξ, and define
Lemma 4
([41]). Suppose that Assumption 1 holds. Then, for any with p from Assumption 1, there exists a constant such that for any ,
Lemma 5
([41]). Assume that Assumption 1 holds and Let be a random variable for some Define Then, for any there exist positive constants (depending on ) such that
where and
Lemma 6
([42]). Let and denote sequences of nonnegative random variables adapted to the filtration . Suppose that, almost surely, and , and that
Then, with probability one, the sequence converges and
3. Proposed Algorithm
Remark 2.
We highlight the benefits Algorithm 1 as follow:
- 1.
- In the Step 1 of the proposed algorithm, we incorporate the inertial term also called momentum-based method inspired by Nesterov acceleration and Polyak’s heavy-ball method. It promises faster convergence rates, variance reduction, better stability for ill-conditioned problems, and improved practical performance. It is obvious that without inertia, SA can become stuck in flat regions or plateaus caused by noise. In stochastic games, inertial SA often requires fewer iterations to achieve a desired accuracy. These facts underscore the need for adopting it in the algorithm, and it is an improvement over [5,21,23,25,27,28,30,39,41].
- 2.
- The algorithm involves the subgradient extragradient (SEG) method, which involves one projection onto the feasible set. It handles non-smooth problems, improves feasibility maintenance, which ensures all iterates remain feasible, a key requirement in constrained stochastic optimization problems. It is, therefore, preferable to those algorithms that involve two projections onto the feasible set per iteration. Hence, it contributes positively to the literature when compared with works in [5,14,15,20,21,22,25,27,33,41,42].
- 3.
- Since the SA-based algorithm is very sensitive to the stepsize or the step-length, we consider a self-adaptive stepsize that adjusts dynamically, ensuring robustness across problem scales and conditions. In fact, self-adaptive stepsize in SA accelerates convergence, reduces sensitivity to noise, eliminates heavy manual turning, ensures stability, and equally improves efficiency near the solution. Unlike Armijo linesearch methods that consume a large amount of time, thereby affecting the performance of iterative algorithms (see, e.g., [4,13,14,15,17,21,31,33,40,41,42,42]) and cited references contained therein.
- 4.
- It is known that real-world stochastic systems often have non-symmetric or partially monotone structures. This necessitated the very essence of considering a quasi-monotone operator, which is weaker, so that the proposed scheme can handle nonlinear, asymmetric, or discontinuous mappings more realistically. It is important to note that quasi-monotone operators avoid the need for projection correctness or strong-regularization techniques required for non-monotone problems. To this end, Algorithm 1 offers greater modeling flexibility, wider applicability, reduced assumptions for convergence, and lower computational cost compared to strict monotonicity, monotonicity, and pseudo-monotonicity commonly found in the literature. Therefore, our scheme improves many already announced results in this research direction.
| Algorithm 1 Inertial Self-Adaptive Subgradient Extragradient Algorithm |
| Step 0: Select Take Take the sample rate with Set Step 1: Given the current iterates construct the inertial term as follows: Step 2: Draw an i.i.d. sample from and compute Step 3: Consider a constructible set and calculate |
4. Convergence Analysis
In this section, we present the technical proofs for two convergence analyses of the proposed Algorithm 1: almost sure convergence and the rate of convergence. The former establishes pathwise convergence without quantifying the speed of approach, whereas the latter measures the convergence speed rather than probabilistic pathwise certainty. We begin with the proof of almost surely convergence.
4.1. Almost Surely Convergence
Remark 3.
1.
Our investigation of the proposed method will be based on filtration .
So,
Increasingly, and We see clearly that adding provides more information, so Since is a measurable function of It follows that
- 2.
- From the Algorithm 1, and (7) it follows that for any givenprovided that This is one of striking advantage of Algorithm 1. Its execution is merely a single projection onto creating efficiency and smooth running of the scheme.
- 3.
- Let From Algorithm 1, Step 2, we know that i.e., is the projection of onto Using projection property, we understand thatwhere z is the point being projected, i.e., Using the definition of from the algorithm, we understand that for allSo,
- 4.
- In view of (5), we define and the oracle errors for all If for some thenIndeed, assume that for some positive We know from Lemma 1 (i) thatNoting that we quickly have thatIndeed, for all defines a martingale difference, i.e., This follows from the fact that since and we understand thatTaking in (13)Therefore,
We shall break our main theorem into Lemmas.
Lemma 7.
The limit of a.s. exists. Let as Then, where
Proof.
By the definition of in the algorithm, we obtain
which shows that the sequence is monotone nonincreasing, and moreover for every k.
Hence is bounded below by 0 and thus convergent almost surely to a finite limit .
Now, define
where is the random Lipschitz modulus from Assumption 1 and are the sampled random variables at iteration k.
The Lipschitz-type bound implies that
If , then
Thus,
Iterating this inequality gives
Assume, for contradiction, that
Choose such that
Since almost surely as there exists (a.s.) such that for all , . By definition of , whenever we must have
Hence, for all large k,
But since the are i.i.d. Therefore , implying , which contradicts .
Thus, the assumption is false, and we conclude that
□
Remark 4.
The expectation step is justified because is the empirical mean of i.i.d. random variables , so that . The contradiction argument uses that if for all large k, then , contradicting . This gives a transparent probabilistic justification for the bound.
The following Lemma will be needed in the sequel.
Lemma 8.
For any , the following estimate holds almost surely:
where
Proof.
Recall from the inertial term step that and for any using definition of and we obtain
Hence,
Therefore, there exists such that
for some
In view of the fact that holds for all and for each with Lemma 1 (ii), (20) and for any we understand that
That is,
Since lies in it follows that
which further implies that
Indeed, we know that
Taking inner product with using linearity gives
Re-arranging the above inequality, we obtain (21). Furthermore, applying Cauchy–Schwartz inequality, utilizing the definition of given in Algorithm 1, one obtains
The next Lemma controls the error bound arising from our computations.
Lemma 9.
Assume that Assumption 1 holds. Then, for any a.s. we have
Proof.
Nothing that utilizing the nonexpansivity of the Lipschitz continuity of F and noting that we obtain
Now, applying Lemmas 4 and 5, and (25), one obtains
where with and as defined in Lemma 5.
We are now ready to provide the main theorem of this paper.
Theorem 1.
Suppose that Assumption 1 holds. Then, the sequence generated by Algorithm 1 a.s. converges to a point
Proof.
We know from Lemma 7 that the limit of exists, noting that is nonincreasing, for all where Utilizing the definition given in Algorithm 1,the Oracle error, and applying Lemmas 2 and 3, we understand that
It follows from the above estimate that
where Utilizing Lemma 4, and setting we obtain that
Recall that in Lemma 9 It follows from Lemma 8 that On the other hand, since for all we can find some and an index such that for every Taking these observations into account, and recalling that we deduce from Lemma 8, (28), and (29) that
Taking in (30) and noting and applying (19), we obtain
Setting
Let and set for all
it follows from (31) that
Since we conclude from Lemma 6 and (32) that a.s. the sequence is convergent and
Thus, a.s. the sequence is bounded and
By virtue of a.s. boundedness of we can find a subsequence of that a.s. converges to a point We understand from this fact that
which shows that
Note further that, since the limit of exists almost surely for every , it follows that
This establishes the claim and thus completes the proof of Theorem 1. □
4.2. Rate of Convergence
We provide the most insightful part of the proposed algorithm, which describes how quickly the recursive sequence approaches its limit Moving forward from here, we consider the following Lemma, which is needed in the sequel.
Lemma 10.
Under Assumption 1, we have
Proof.
From the previous estimate, we know that, from using the uniform bound on and the previous estimates, we obtain
We now state the following theorem for the rate of convergence. In this setting, the cost function satisfies a strong pseudo-monotonicity property, meaning that
Theorem 2.
Assume that the Assumption 1 is satisfied. Then, the following condition holds
where is a well-defined positive constant.
Proof.
Consider where is given as the limit of Noting that a.s. we obtain a.s. that for all It is known from Remark 3 (iv) that if for some
From Lemma 3, we can observe that if
then necessarily,
Therefore, to establish the convergence rate of Algorithm 1, it is sufficient to analyze the rate at which the sequence converges. Building on this observation, and applying Lemma 7 together with the previously defined quantity , we obtain
Now, taking sum from to m in (37), we obtain
Now, using the bound
and recalling that Q is finite (see Lemma 10), it follows from (37) together with
that the asserted estimate holds. □
The next lemma will be instrumental in establishing the convergence rate of Algorithm 1.
Lemma 11.
Let where is a fixed constant, , and is a positive sequence satisfying Then
Proof.
To establish this result, it suffices to show that for each is bounded. Indeed,
It then follows that Consequently, we obtain □
We now present the theorem that characterizes the convergence rate of Algorithm 1.
Theorem 3.
Assume that Assumption 1 is satisfied, the cost function is strongly pseudomonotone on C, and let Then there exists a positive integer K such that
where and are appropriately chosen constants, and is defined in Lemma 11.
Proof.
Using the definition of strongly pseudomonotone and our estimate in (23), we obtain
Noting that and from (39), we obtain for all
From (40) we obtain
Let where Noting that we then conclude that Thus, Setting it follows that has both positive and negative root. Take Noting and we conclude that
For all , we observe that
5. Applications and Numerical Illustrations
System Set Up: All experiments were executed on a 64-bit Windows machine powered by an Intel(R) Core(TM) i7-6600U CPU @ 2.60 GHz (2 cores, 4 threads) with 8 GB RAM. Python 3.9 environment was used for numerical computation, data analysis, and visualization with the help of some essential python libraries like: NumPy, SciPy Pandas, and Matplotlib.
We consider four experiments in this research and compare the performance of our proposed algorithm with the existing ones (see Table 1). In particular, Algorithm 1 of Nwawuru et al. will be compared with Wang et al. 2022 (see, (Algorithm 3.1, [30])), Liu and Qin, 2024 (see (Algorithm 1, [31])), Li et al. 2023 (see (Algorithm 3, [43])) and Long and He, 2023 (see (Algorithm 1, [38])). The comparison relates to the CPU time by averaging across 20 sample paths.

Table 1.
Comparison of the algorithms considered against the proposed scheme and their main features.
We use numpy.random.rand() and numpy.random.randn() in Python to generate samples from and terminate the algorithms when the total number of iterations reaches 250. Furthermore, we set with and for all the selected algorithms. Moreso, we take .
We consider the following examples.
Example 1.
For where with and are randomly generated from uniform distribution on with to be a deterministic skew symmetric matrix generated from uniform distribution on to be a diagonal matrix generated from uniform distribution on and is randomly generated from uniform distribution on
Figure 1 below demonstrate of the performance of Algorithm 1, Wang et al. [30], Liu and Qin [31], Li et al. [43], and Long and He [38].
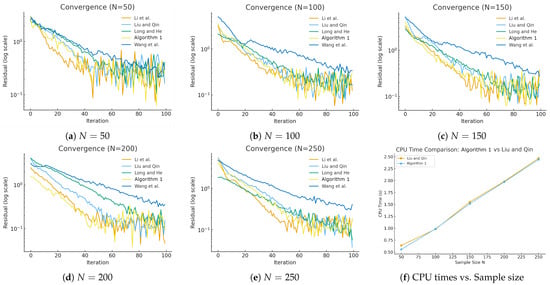
Figure 1.
Comaprsion for (Algorithm 1,30,31,38,43]).
Table 2 below shows all algorithms converging across sample sizes. Algorithm 1 achieve balanced performance, requiring fewer iterations than Wang et al. [30] and Liu and Qin [31], while maintaining a competitive speed similar to Li et al. [43]. Its strength lies in combining stability with efficiency, offering reliable convergence under varying sample sizes. However, it should be noted that Long and He [38] achieve the fastest. Their algorithm is non-monotone, Lipschitz continuous with one oracle call per iteration, while Algorithm 1 have two oracle calls per iteration (see [38], Remark 1(i), Table 1).
Table 2.
Convergence summary for the five algorithms across different sample sizes N.
Example 2. (Network Bandwidth allocation) We consider a communication network in which individual users, acting selfishly, compete for shared bandwidth resources. The set of all users in a network is indexed by Noting that each user can access multiple routes, one assumes that is the set of routes governed by users For let denotes the number of elements in and Let be the flow rate for users s through which route r goes. The set of all links is denoted by The set of routes is denoted by For one assumes that is the set of links through which route goes. Suppose that
When the flow rate is allocated to a user participating in a network, it derives a utility modeled as the value of a concave function. The utility function of each user is parametrized by the uncertainty, which is defined by
where is the flow rate decision vector of users, is the random weighted parameter route and The flow rate allocated to each user is regulated with a control mechanism to prevent network congestion in the bandwidth allocation. Such a mechanism ensures that the sum of the transmission rate for users sharing the link is less than or equal to the limited capacity of the link that is,
where is the capacity of link Set
We now formulate this model as a stochastic optimization problem given by
Let denote the adjacency matrix that describes the correlation between the set of links and the set of routes We assumes that if route goes through link otherwise We observe that problem (46) can be captured by an SVI in a compact form:
Find such that
for any where
and
Now, we consider the bandwidth allocation problem on a network that consists of 10 nodes, 10 links, and 2 users. It is observed that and
In this experiment, the weighted parameters are i.i.d. and drawn randomly from the uniform distribution according to Table 1. Beside, the links have limited capacity with the values given Table 2. One can check that the involved operator in (47) is quasi-monotone and Lipschitz continuous in with the constant
Figure 2 below shows a network of 10 nodes, 10 links, and 5 routes connecting two users. Core links carry higher capacities to support aggregate flows, while edge links act as potential bottlenecks. Shared routes between users highlight congestion risks, emphasizing the importance of efficient bandwidth allocation and resource management.
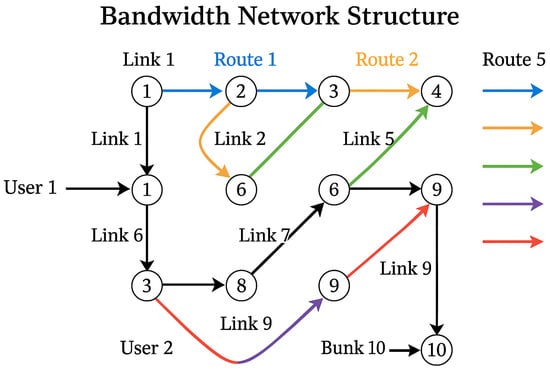
Figure 2.
The bandwidth allocation network structure.
Table 3 presents uniform distributions of random parameters for each user’s routes. These ranges capture uncertainty in flow performance, modeling variability in network conditions, and ensuring fairness during bandwidth allocation.
Table 3.
Uniform distribution of randomly generated parameters for each user-route pair.
Table 4 below reveals how different links are utilized in optimized flow allocation. Heavily loaded links like 4 and 8 should be carefully monitored or upgraded in real networks, while lightly loaded links like 6 and 7 might indicate insufficient routing or a redundant path. NB:Mbps means megabits per second and Gbps means gigabits per second.
Table 4.
Link capacities (sample values). Units: flow units (replace with Mbps/Gbps as needed).
Example 3. (Networked stochastic Nash–Cournot game) In this experiment, we consider a networked Nash–Cournot game adopted in [44] under uncertainty data, in which the cost-minimizing agents compete in quantity levels when facing a price function associated with aggregate output. Suppose that there are Ω firms that compete over a network of Λ nodes in supplying a homogeneous product in a non-cooperative sense. Let denote the level of sales of firm and at a node . Assume that the firm is characterized by a random linear cost function for some parameters where is a mean zero random variable. We assume that the price at node j represented by is a stochastic linear function corrupted by noisy where indicates the price when then production is zero, is the slope at the inverse demand function while is a zero-mean random disturbance. Assume that the transport cost is zero. Except for non-negativity constraints in we suppose that the firms production at node j is capacitated by We now transform the firm into stochastic optimization problem given below:
Under some dominated conditions, when we interchange the others of expectation and derivative, the above stochastic Nash–Cournot game may be transformed into problem (3) with and with Just like in [44], we consider a network with firms, markets and the capacity for each and each In the experiment, the parameters in the payoffs were set as for all and where denotes the uniform distribution over an interval where For the random data in the model, we assume and for all the algorithm.
Figure 3 shows performance comparison of algorithms across convergence behavior, computational efficiency, and underlying network structure.
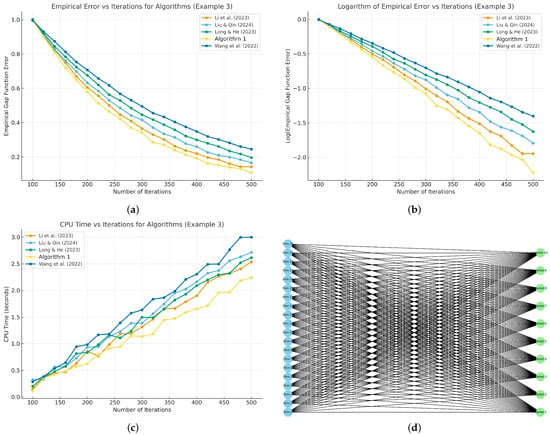
Figure 3.
Networked stochastic Nash–Cournot game. (a) Empirical gap-function error, the error decreases across all algorithms, with Algorithm 1 converging fastest, Li et al. [43] closely following, while Liu and Qin [31], Long and He [38], and Wang et al. [30] converge slower. (b) Logarithm of empirical error, the plot shows faster convergence for Algorithm 1, while Wang et al. [30] lags behind, confirming differences in algorithmic efficiency. (c) CPU time, Algorithm 1 requires the least computation, reflecting efficiency, while Wang et al. [30] consumes the most, indicating higher computational overhead. (d) Network structure, twenty firms are interconnected with ten markets, highlighting competitive supply interactions and capacity-constrained distribution across nodes.
Table 5 below highlights uniform link capacities of two across all firm–market connections, while market prices vary stochastically through demand parameters. This structure reflects balanced competition, ensuring equal production opportunities for all firms, while random price variations across markets capture uncertainty and heterogeneity in the Nash–Cournot game environment.
Table 5.
Capacity with respect to price, market, and firm.
6. Conclusions
This work introduced an adaptive inertial stochastic projection framework for solving stochastic variational inequalities whose cost function is quasi-monotone, and the developed scheme was applied to stochastic complementary problems, networked stochastic Nash–Cournot game, and bandwidth allocation problem. By combining inertia with adaptive stepsize selection, the method accelerates convergence while preserving robustness under uncertainty. Stochastic projections ensure feasibility with link capacity constraints, preventing congestion and promoting fairness. Numerical experiments demonstrate superior efficiency, scalability, and stability compared to conventional techniques. Beyond bandwidth allocation, the approach offers a versatile tool for stochastic optimization problems in uncertain environments. In a nutshell, the algorithm delivered a resilient and computationally efficient solution, advancing both theory and practice in modern network resource management.
Author Contributions
F.O.N., J.N.E., and M.D., conceptualized the research idea, with all three contributing significantly to the manuscript’s writing and revision. F.O.N., and I.A.-D. carried out the computations and established the appropriate convergence analysis, proving almost surely the rate of convergence. F.O.N. and J.N.E. performed the numerical experiments, created figures and tables, and analyzed performance data. All authors discussed the results and provided critical feedback, which improved the quality of the manuscript. F.O.N., M.D., and I.A.-D. coordinated the research activities and ensured integration of all contributions. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-DDRSP2502).
Data Availability Statement
There were no data analyzed in this project.
Acknowledgments
The authors are grateful to the three anonymous reviewers for their constructive comments and valuable suggestions, which have significantly improved the quality of this paper.
Conflicts of Interest
The authors declare no competing interest.
References
- Royset, J.O. Risk-adaptive approaches to stochastic optimization: A survey. SIAM Rev. 2025, 67, 3–70. [Google Scholar] [CrossRef]
- Liang, H.; Zhuang, W. Stochastic modeling and optimization in a microgrid: A survey. Energies 2014, 7, 2027–2050. [Google Scholar] [CrossRef]
- Sclocchi, A.; Wyart, M. On the different regimes of stochastic gradient descent. Proc. Natl. Acad. Sci. USA 2024, 121, e2316301121. [Google Scholar] [CrossRef]
- Dong, D.; Liu, J.; Tang, G. Sample average approximation for stochastic vector variational inequalities. Appl. Anal. 2023, 103, 1649–1668. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Farh, H.M.H.; Al-Shamma’a, A.A.; Alaql, F.; Omotoso, H.O.; Alfraidi, W.; Mohamed, M.A. Optimization and uncertainty analysis of hybrid energy systems using Monte Carlo simulation integrated with genetic algorithm. Comput. Electr. Eng. 2024, 120, 109833. [Google Scholar] [CrossRef]
- Stampacchia, G. Formes bilinéaires coercitives sur les ensembles convexes. Comptes Rendus l’Académie Sci. Série A 1964, 258, 4413–4416. [Google Scholar]
- Nagurney, A. Network Economics: A Variational Inequality Approach; Kluwer Academic: Dordrecht, The Netherlands, 1999. [Google Scholar]
- Shehu, Y.; Iyiola, O.S.; Reich, S. A modified inertial subgradient extragradient method for solving variational inequalities. Optim. Eng. 2022, 23, 421–449. [Google Scholar] [CrossRef]
- Liu, L.; Cho, S.Y.; Yao, J.C. Convergence analysis of an inertial Tseng’s extragradient algorithm for solving pseudomonotone variational inequalities and applications. J. Nonlinear Var. Anal. 2021, 2, 47–63. [Google Scholar]
- Nwawuru, F.O.; Echezona, G.N.; Okeke, C.C. Finding a common solution of variational inequality and fixed point problems using subgradient extragradient techniques. Rend. Circ. Mat. Palermo II Ser. 2024, 73, 1255–1275. [Google Scholar] [CrossRef]
- Dilshad, M.; Alamrani, F.M.; Alamer, A.; Alshaban, E.; Alshehri, M.G. Viscosity-type inertial iterative methods for variational inclusion and fixed point problems. AIMS Math. 2024, 9, 18553–18573. [Google Scholar] [CrossRef]
- Facchinei, F.; Pang, J.S. Finite-Dimensional Variational Inequalities and Complementarity Problems; Springer: New York, NY, USA, 2003. [Google Scholar]
- Jiang, H.; Xu, H. Stochastic approximation approaches to stochastic variational inequality problems. IEEE Trans. Autom. Control 2008, 53, 1462–1475. [Google Scholar] [CrossRef]
- Shapiro, A. Monte Carlo sampling methods. In Handbooks in Operations Research and Management Science: Stochastic Programming; Ruszczyński, A., Shapiro, A., Eds.; Elsevier: Amsterdam, The Netherlands, 2003; pp. 353–425. [Google Scholar]
- Wang, M.Z.; Lin, G.H.; Gao, Y.L.; Ali, M.M. Sample average approximation method for a class of stochastic variational inequality problems. J. Syst. Sci. Complex. 2011, 24, 1143–1153. [Google Scholar] [CrossRef]
- He, S.X.; Zhang, P.; Hu, X.; Hu, R. A sample average approximation method based on a D-gap function for stochastic variational inequality problems. J. Ind. Manag. Optim. 2014, 10, 977–987. [Google Scholar] [CrossRef]
- Cherukuri, A. Sample average approximation of conditional value-at-risk based variational inequalities. Optim. Lett. 2024, 18, 471–496. [Google Scholar] [CrossRef]
- Zhou, Z.; Honnappa, H.; Pasupathy, R. Drift optimization of regulated stochastic models using sample average approximation. arXiv 2025, arXiv:2506.06723. [Google Scholar] [CrossRef]
- Yousefian, F.; Nedić, A.; Shanbhag, U.V. Distributed adaptive steplength stochastic approximation schemes for Cartesian stochastic variational inequality problems. arXiv 2013, arXiv:1301.1711. [Google Scholar] [CrossRef]
- Koshal, J.; Nedić, A.; Shanbhag, U.V. Regularized iterative stochastic approximation methods for stochastic variational inequality problems. IEEE Trans. Autom. Control 2013, 58, 594–609. [Google Scholar] [CrossRef]
- Iusem, A.N.; Jofré, A.; Thompson, P. Incremental constraint projection methods for monotone stochastic variational inequalities. Math. Oper. Res. 2019, 44, 236–263. [Google Scholar] [CrossRef]
- Yang, Z.P.; Zhang, J.; Wang, Y.; Lin, G.H. Variance-based subgradient extragradient method for stochastic variational inequality problems. J. Sci. Comput. 2021, 89, 4. [Google Scholar] [CrossRef]
- Korpelevich, G.M. The extragradient method for finding saddle points and other problems. Matekon 1976, 12, 747–756. [Google Scholar]
- Iusem, A.N.; Jofré, A.; Oliveira, R.I.; Thompson, P. Extragradient method with variance reduction for stochastic variational inequalities. SIAM J. Optim. 2017, 27, 686–724. [Google Scholar] [CrossRef]
- Nwawuru, F.O. Approximation of solutions of split monotone variational inclusion problems and fixed point problems. Pan-Am. J. Math. 2023, 2, 1. [Google Scholar] [CrossRef]
- Iusem, A.N.; Jofré, A.; Oliveira, R.I.; Thompson, P. Variance-based extragradient methods with line search for stochastic variational inequalities. SIAM J. Optim. 2019, 29, 175–206. [Google Scholar] [CrossRef]
- Censor, Y.; Gibali, A.; Reich, S. The subgradient extragradient method for solving variational inequalities in Hilbert space. J. Optim. Theory Appl. 2011, 148, 318–335. [Google Scholar] [CrossRef]
- Nwawuru, F.O.; Ezeora, J.N.; ur Rehman, H.; Yao, J.-C. Self-adaptive subgradient extragradient algorithm for solving equilibrium and fixed point problems in Hilbert spaces. Numer. Algorithms 2025. [Google Scholar] [CrossRef]
- Wang, S.; Tao, H.; Lin, R.; Cho, Y.J. A self-adaptive stochastic subgradient extragradient algorithm for the stochastic pseudomonotone variational inequality problem with application. Z. Angew. Math. Phys. 2022, 73, 164. [Google Scholar] [CrossRef]
- Liu, L.; Qin, X. An accelerated stochastic extragradient-like algorithm with new stepsize rules for stochastic variational inequalities. Comput. Math. Appl. 2024, 163, 117–135. [Google Scholar] [CrossRef]
- Polyak, B.T. Some methods of speeding up the convergence of iterative methods. USSR Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]
- Nwawuru, F.O.; Ezeora, J.N. Inertial-based extragradient algorithm for approximating a common solution of split-equilibrium problems and fixed-point problems of nonexpansive semigroups. J. Inequalities Appl. 2023, 2023, 22. [Google Scholar] [CrossRef]
- Ezeora, J.N.; Enyi, C.D.; Nwawuru, F.O.; Ogbonna, R.C. An algorithm for split equilibrium and fixed-point problems using inertial extragradient techniques. Comput. Appl. Math. 2023, 42, 103. [Google Scholar] [CrossRef]
- Nwawuru, F.O.; Narian, O.; Dilshad, M.; Ezeora, J.N. Splitting method involving two-step inertial iterations for solving inclusion and fixed point problems with applications. Fixed Point Theory Algorithms Sci. Eng. 2025, 2025, 8. [Google Scholar] [CrossRef]
- Enyi, C.D.; Ezeora, J.N.; Ugwunnadi, G.C.; Nwawuru, F.O.; Mukiawa, S.E. Generalized split feasibility problem: Solution by iteration. Carpathian J. Math. 2024, 40, 655–679. [Google Scholar] [CrossRef]
- Nesterov, Y.E. A method for solving a convex programming problem with convergence rate O(1/k2). Dokl. Akad. Nauk SSSR 1983, 269, 543–547. [Google Scholar]
- Long, X.J.; He, Y.H. A fast stochastic approximation-based subgradient extragradient algorithm with variance reduction for solving stochastic variational inequality problems. J. Comput. Appl. Math. 2023, 420, 114786. [Google Scholar] [CrossRef]
- Zhang, X.; Du, X.; Yang, Z.; Lin, G. An infeasible stochastic approximation and projection algorithm for stochastic variational inequalities. J. Optim. Theory Appl. 2019, 183, 1053–1076. [Google Scholar] [CrossRef]
- Fang, C.; Chen, S. Some extragradient algorithms for variational inequalities. In Advances in Variational and Hemivariational Inequalities; Han, W., Migórski, S., Sofonea, M., Eds.; Advances in Mechanics and Mathematics; Springer: Cham, Switzerland, 2015; Volume 33, pp. 145–171. [Google Scholar]
- Ezeora, J.N.; Nwawuru, F.O. An inertial-based hybrid and shrinking projection methods for solving split common fixed point problems in real reflexive spaces. Int. J. Nonlinear Anal. Appl. 2023, 14, 2541–2556. [Google Scholar]
- Robbins, H.; Siegmund, D. A convergence theorem for nonnegative almost supermartingales and some applications. In Optimizing Methods in Statistics; Rustagi, J.S., Ed.; Academic Press: New York, NY, USA, 1971; pp. 233–257. [Google Scholar]
- Li, T.; Cai, X.; Song, Y.; Ma, Y. Improved variance reduction extragradient method with line search for stochastic variational inequalities. J. Glob. Optim. 2023, 87, 423–446. [Google Scholar] [CrossRef]
- Yang, Z.P.; Lin, G.H. Variance-based single-call proximal extragradient algorithms for stochastic mixed variational inequalities. J. Optim. Theory Appl. 2021, 190, 393–427. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).