Abstract
A flexible distribution has been introduced to handle random variables in the unit interval. This distribution is based on an exponential transformation of the truncated positive normal distribution with two parameters and can effectively fit data with varying degrees of skewness and kurtosis. Therefore, it presents an alternative for modeling this type of data. Several mathematical and statistical properties of this distribution have been derived, such as moments, hazard function, the Bonferroni curve, and entropy. Moreover, we investigate the characterizations of the proposed distribution based on its hazard function. Parameter estimation has been performed using both the maximum likelihood method and method of the moments. Because of this, we were able to determine the best critical region and the information matrix, facilitating the calculation of asymptotic confidence intervals. A simulation study is presented to analyze the behavior of the obtained estimators for different sample sizes. To demonstrate the suitability of the proposed distribution, applications and goodness-of-fit tests have been performed on two practical data sets.
Keywords:
entropy; information matrix; estimation; statistical modeling; proportion data; simulation; unit interval MSC:
60E05; 62E15; 62F10
1. Introduction
Data fitting is an essential procedure in statistical analysis to ensure the precision and dependability of outcomes. Recently, there has been a growing interest in developing innovative models for data fitting, particularly within the unit interval. This statistical approach aims to address the challenges associated with manipulating data within a specific range and offers a more robust framework for analysis. In this manuscript, we present a groundbreaking model for data fitting within the unit interval, which exhibits promising potential for enhancing the quality of statistical inferences.
The proposed distribution is particularly useful for modeling data within the unit interval , making it relevant in various areas of life. For instance, in finance, this distribution can be used to model the probability of investment returns, especially in assets with variable risk or volume. In environmental science, it can be applied to model proportion data, such as species coverage in an ecosystem. Additionally, in public health, this distribution can be utilized to analyze data on the incidence or prevalence rates of diseases in a population.
The proposed model is based on the transformation of a random variable that adheres to a truncated positive normal distribution [1]. Utilizing a truncated positive normal (TPN) distribution as the foundation of the suggested model offers several advantages. Firstly, this distribution allows for greater flexibility in data modeling and analysis compared to the conventional semi-normal distribution. Secondly, the proposed model incorporates an additional shape parameter that further enhances its flexibility and enables a more optimal fit. Among the models associated with the normal distribution, the half-normal (HN) model is notable. It emerges as a specific instance within the context of the TPN, where the shape parameter equals zero. This property renders the TPN a more adaptable model in contrast to the HN.
The objective of this study is to propose a flexible distribution for modeling real-world data with support in the interval (0, 1) using the exponential transformation , where Z follows a TPN distribution. Models to which this transformation is applied are called unitary distributions. Various alternative transformations can be employed to achieve a unitary distribution, such as , , , and , where . In the current study, the proposed transformation yields closed-form expressions and a simple structure for the X distribution. Furthermore, this transformation provides statistical properties related to the simple closed-form distribution. For instance, the moment-generating function remains closed, unlike with other transformations.
This range encompasses well-established models, such as the beta and Kumaraswamy distributions. Additionally, the literature presents various unitary distribution models, including the Topp–Leone distribution [2]: unit-gamma [3], log-Lindley [4], two-parameter unit-logistic [5], two-parameter unit-Birnbaum–Saunders [6], unit-Weibull [7], unit-Gompertz [8], unit-inverse Gaussian [9], unit modified Burr-III [10], one-parameter unit-Lindley [11], alpha-unit [12], modified unit-half-normal [13], unit-half-normal [14], unit-exponential [15] and unit upper truncated Weibull [16].
The proposed model provides a somewhat better fit compared to these models. Another crucial feature of the model is its ability to adequately fit small data sets that exhibit extreme right skewness within the unit interval.
The proposed distribution encompasses the behavior and provides superior fits compared to some established lifetime distributions, such as the unit-logistic, beta, and Kumaraswamy distributions. The rationale for introducing the unit-truncated positive normal distribution is based on (i) its ability to model constant, increasing, or inverted risk rates, allowing it to capture different behaviors over time; (ii) suitabilitys for fitting data that are skewed and may not adequately fit other common distributions and its applicability to a variety of problems in diverse fields, such as environmental studies, industrial reliability, and survivability analysis; and (iii) its favorable comparison to three alternative life distributions for testing failure and environmental data based on two practical data applications.
The following summary provides an overview of the remaining sections of the paper. The proposed distribution is presented in Section 2 along with a discussion of its basic characteristics. In Section 3, the expected Fisher information matrix and estimators of the unknown parameters by the maximum likelihood (ML) technique are presented. Section 4 conducts Monte Carlo simulations to assess the effectiveness of the ML estimators and the parameters’ asymptotic confidence intervals. Two sets of real-world data are analyzed and presented in Section 5. The paper is finally concluded in Section 6.
2. The Model and Its Properties
In this section, we outline the proposed bounded distribution based on transforming a truncated positive normal variable, as described in [1].
A random variable Z follows the TPN, denoted as , if its cumulative distribution function (CDF) is given by
where , is a shape parameter, is a scale parameter, and represents the CDF of the standard normal (SN) distribution.
Let Z be a non-negative random variable following the TPN distribution. Its probability density function (PDF) is expressed as
where represents the PDF of the SN distribution.
The quantile function (the inverse of CDF given in (1)) of the variable Z is given by
where is the SN distribution’s quantile function.
Proposition 1.
Using the transformation , we derive a new distribution with support on the interval , known as the unit-TPN distribution, denoted as . Its PDF is defined as
where and are the parameters for shape and scale, respectively.
Proof.
Using the change-of-variable approach and the symmetry of the SN (), then the random variable takes values within the interval and has the density function
□
2.1. Characterizations of the UTPN Distribution Based on Its Hazard Function
Characterizing a PDF using the hazard function is essential for grasping temporal event dynamics. This linkage offers a valuable understanding of how event probabilities evolve over time and with pertinent factors. Particularly in survival analysis, it aids in predicting survival probabilities, while in reliability engineering, it assists in evaluating failure rates and directing maintenance strategies. In essence, this characterization proves to be a potent instrument for analyzing time-to-event data and facilitating informed decision-making across diverse domains. Various researchers, including Glänzel [17,18] and Hamedani [19], have delved into different techniques for such characterizations of continuous probability distributions.
According to Akhila et al. [20], the PDF and the hazard function are related in the following manner:
where is the PDF and is the hazard function.
For the following result, we will redefine the two earlier functions of the UTPN distribution as follows: Let represent and represent .
Theorem 1.
Let be a continuous random variable. Equation (3) provides the PDF of X if and only if the next differential equation is satisfied by its hazard function, :
2.2. Shapes
The UTPN distribution’s PDF is unimodal and log-concave. Indeed, the second derivative of is
Figure 1 and Figure 2 present the different curves for the PDF and the HR function, respectively, of the UTPN distribution for varying values of and . Figure 1 reveals that there are four possible behaviors for the UTPN distribution: increasing, unimodal, reversed J-shaped, and right-skewed. Figure 2 demonstrates that the HR function of the UTPN distribution can have a bathtub-inverted shape, be increasing, or remain constant. An advantage of the UTPN distribution over the TPN distribution is that the latter is unable to describe situations with an inverted bathtub-shaped hazard function.
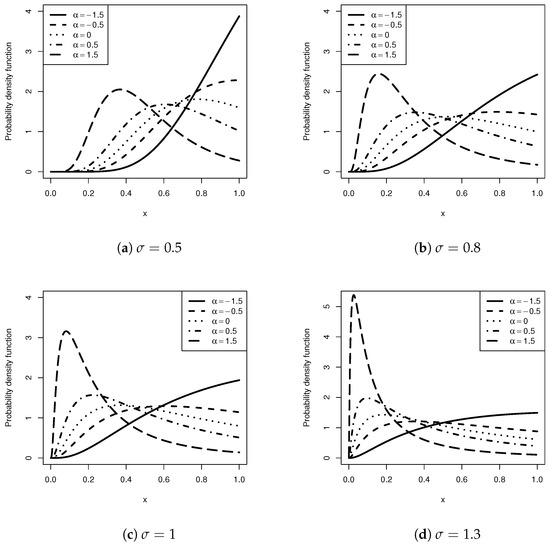
Figure 1.
Graph of the UTPN densities for various values of and .
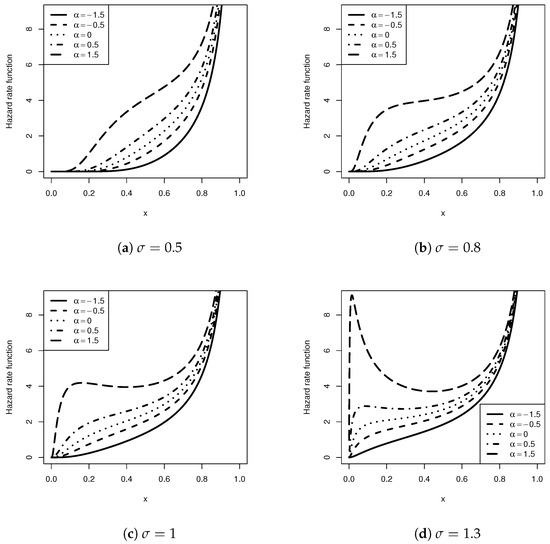
Figure 2.
Graphs of the HR function for the UTPN distribution with varying values of and .
2.3. Quantile Function
The quantile function of the UTPN distribution is derived by inverting Equation (4) as follows:
Note that , , and stand for median, first quartile, and third quartile of the UTPN distribution, correspondingly.
2.4. Mode
The mode of is the root of the equation
Therefore, if ,
this means that is the sole point where reaches its maximum.
2.5. Hazard Rate Function
Lemma 1.
Given that , for , is a twice-differentiable density function of a positive real-valued continuous random variable with an HR function , let . Consequently, (i) if decreases (increases) as x increases, then increases (decreases) as x increases, and (ii) if follows a bathtub (inverted bathtub) pattern, then will also follow a bathtub (inverted bathtub) pattern.
The proof of this result is provided by Glaser [21]. Based on this finding, the shape of the HR function of the UTPN distribution can be inferred as follows.
Proposition 2.
The HR function of the UTPN distribution exhibits an inverted bathtub shape.
Proof.
Given that
it follows that
Consequently, by , the global maximum of is , because
This demonstrates that exhibits an inverted bathtub shape. Therefore, according to Glaser’s Lemma, also exhibits an inverted bathtub shape. Additionally, with for , , and , it follows that is an increasing function. □
2.6. Moments and Moment Generating Function
Here, we derive the expressions for the moments and moment-generating function of the distribution, which are crucial for any statistical analysis, particularly in applied research. The distribution’s moments, including its mean, variance, skewness, and kurtosis, provide insight into its most significant characteristics.
Proposition 3.
If the random variable X follows a UTPN distribution, its r-th moment about zero can be calculated as
Proof.
Using the stochastic representation , where , one can write
and defining implies
This is accomplished using some simplifications and minor algebraic manipulation. □
Corollary 1.
(i) Let ; then, the mean, variance, skewness (), and kurtosis () coefficients are, respectively, given as
(ii) As a result of the central limit theorem, let be independent random variables, and utilizing the identical distribution of , then, if , one has
where
In Figure 3, the UTPN distribution’s mean, variance, skewness, and kurtosis are displayed as functions of and . Observations indicate that as varies, the mean decreases independently of the values of . In terms of variance, the curves exhibit concavity and unimodality for all values, with values decreasing as decreases. On the other hand, negative skewness is observed for , while positive skewness is observed for . In addition, smaller values are associated with reduced skewness, while larger values are associated with increased skewness. Finally, kurtosis decreases as decreases, which occurs for (approximately).
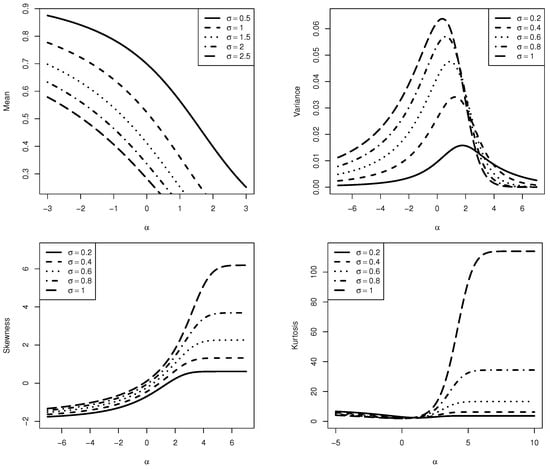
Figure 3.
Graph of the UTPN distribution’s mean, variance, skewness, and kurtosis for various values of and .
Proposition 4.
If the random variable X is UTPN distributed, then its moment-generating function is given by
Proof.
The moment-generating function’s definition implies
using the exponential series and taking the change of variables
□
2.7. Curves of Bonferroni and Lorenz
Bonferroni and Lorenz curves [22] are commonly used in economics to study income and poverty, although they are also helpful in other domains, including reliability, insurance, demography, and medicine. The definition of the Bonferroni curve is
where and . The Lorenz curve is obtained by the expression . Specifically, the Bonferroni curve for the UTPN distribution can be calculated as
Figure 4 illustrates the Bonferroni curve for the UTPN distribution with , showing different values for . It is clear that the Bonferroni value increases as decreases. Additionally, the graph indicates that as the probability p increases, the Bonferroni value also increases.
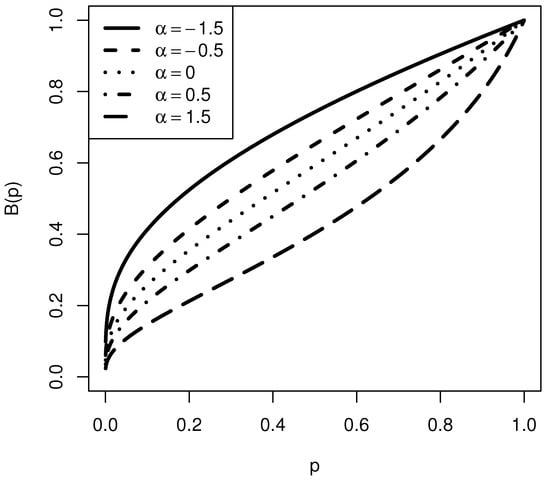
Figure 4.
Bonferroni curve for the UTPN distribution for and .
2.8. Entropy
A measure of the uncertainty’s variation is the entropy of a random variable X with a certain PDF. Greater data uncertainty is indicated by a high entropy value. The Rényi entropy [23], , for X is defined as
where and . Suppose X has the UTPN distribution, then by substituting (3) in (18), we obtain
So one obtains the Rényi entropy as follows:
Shannon entropy [24] defined by is the particular case of Equation (18) when . Then calculating the and using L’Hospital’s rule, after some algebraic work, one obtains the result that
3. Estimation and Inference
In this section, we use the maximum likelihood and moments approaches to estimate the distribution parameters with the related inference.
3.1. Moments Estimator
Assume that the collection of realizations comes from a size-n random sample selected from the UTPN distribution with parameters and . For the moments estimation, let , , and . By equating the theoretical moments obtained by Corollary 1 with the sample moments given above, one obtains the following equations:
The moment estimators for and are calculated by simultaneously solving these equations with an appropriate numerical method.
3.2. Maximum Likelihood Estimator
Here, we derive the maximum likelihood estimators (MLEs) and the observed Fisher information matrix for complete samples of the UTPN distribution. Let denote the observed values obtained from a size-n random sample selected from the UTPN distribution with parameters and . We assume that both and are unknown and aim to estimate them based on . In this context, we adopt the maximum likelihood approach. The likelihood function for and , given , is expressed as
Hence, the following is an expression for the log-likelihood function:
The function is well defined for all values of the model parameters. It is continuous and concave with respect to the parameters, ensuring the existence of a unique global maximum. Additionally, the parameter space is bounded, which contributes to the uniqueness of the MLE. These properties guarantee that the MLE is unique and exists for the proposed distribution (Casella and Berger [25]). Therefore, in accordance with the conditions described above, the MLEs of and are defined by
That is, and fulfill the score equations linked to ,
and implies
We focus on the existence and uniqueness of each MLE of the distribution parameters in the following theorems, assuming that the other parameter is known; for additional details on this method, see Popović et al. [26] and Alomair et al. [27].
Proposition 5.
Given (19), there exists a unique solution to the equation for .
Proof.
We have
We know that as , as , and as . Thus, as and as . On the other hand, it follows that (because and ) and . Therefore, there exists at least one root, say , such that . To prove uniqueness, we need to verify that . Indeed, for all , because
and
Therefore, there exists a solution to and the root is unique. □
Proposition 6.
Given (20), there exists a solution for equation for , and the solution is unique when , where
Proof.
Solving is equivalent to solving , where
For known , and knowing that for all , we have the limit values of as follows
Thus we can ensure that there is at least one root, say , such that . To prove uniqueness, we have to show that ; that is,
which implies
Hence, we find that . Therefore, there exists a solution to , and the root is unique when . □
From (19), it follows immediately that the MLE of can be obtained as
Using (20) and (21), the MLE of satisfies the following equation
where and .
The numerical values of and can be determined via any statistical software. Theoretical results guarantee the convergence of the MLEs in any sense, as well as the desired asymptotic normality.
The proof of the MLEs’ asymptotic normality is provided in the following proposition.
Proposition 7.
Let and suppose that the regularity conditions (Casella and Berger [25]) hold for such that exists and its absolute value is bounded by a function such that .
Let be a consistent sequence of roots of , i.e., , where is the true value of the parameter. Then,
where
Proof.
We perform a second-order Taylor expansion of the score function around and evaluate it at :
where . Dividing by we get
By the central limit theorem,
since are i.i.d. random variables with mean zero and variance and .
Also, by the weak law of large numbers,
Using the law of large numbers, we have
i.e., is bounded in probability by the constant k: for any , the probability that it is less than approaches 1. Finally, since , we have
Employing Equation (22) and combining the previous results, we obtain
and by Slutsky’s theorem, we conclude that
□
In the Appendix A of this article, the entries of the information matrix are calculated, resulting in
On the other hand, using the previous results, we have that , where
is the inverse of the observed information matrix and is the determinant of the matrix , where .
By using (23), we find that approximately asymptotic confidence intervals for and are
where is the upper -th percentile of the SN distribution.
We will use the Kolmogorov–Smirnov (K-S) test to assess the goodness-of-fit for the proposed models. The K-S test statistic D is defined as the maximum absolute difference between the empirical cumulative distribution function (ECDF) of the sample and the CDF of the reference distribution: , where is the ECDF of the sample and is the theoretical CDF. Additionally, to evaluate the fit of various models, we will employ the maximum likelihood technique and well-known fitting criteria, specifically the Hannan–Quinn information criterion (HQIC), the Bayesian information criterion (BIC), the consistent Akaike’s information criterion (CAIC), and the Akaike information criterion (AIC). For the UTPN model, these criteria are defined as follows:
where m is the number of parameters. The R programming language (see [28]) will be utilized for the simulation and practical aspects, as discussed in the next section.
4. Simulation Study
This section examines the performance of the MLEs and the asymptotic confidence intervals for the parameters indexing the UTPN distribution through Monte Carlo simulations. The sample size is set at , 35, 50, 100, 200, and 500, while the parameters are fixed at −, 0.3, and 4.5, with and 2.3. For each combination, pseudo-random samples are generated from the UTPN distribution using the inverse CDF method, meaning
where u is a uniform observation.
To assess the performance of the MLEs and their asymptotic confidence intervals, the bias (Bias), standard error (SE), root mean squared error (RMSE), and coverage probability (CP) of the 95% confidence intervals are calculated. Insights can be gleaned from Table 1.

Table 1.
Empirical mean, bias, SE, RMSE, and 95% CP for the ML estimates of and in the UTPN distribution across different combinations of and parameters.
The simulation study, detailed in Table 1, provides valuable insights into the performance of ML estimates for the UTPN distribution under varying sample sizes (n) and true values of the scale parameter (). Notably, the estimates exhibit commendable convergence as sample size increases, reflecting the robustness of the ML method. When is a positive value, for a true value of , the estimates of and approach stability as n grows. The bias diminishes, SE decreases, and the RMSE converges, indicating the dependability and accuracy of the ML estimates. The CP of the 95% confidence intervals consistently approaches the nominal level, highlighting the precision of the estimates. Similarly, when the true value of , the ML estimates exhibit convergence properties as the sample size increases. The bias decreases, SE reduces, and RMSE stabilizes, reflecting the consistency and efficiency of the estimation approach. The CP of the confidence intervals remains close to the expected 95% level, underscoring the dependability of the ML estimates even under larger-scale values. When is a negative value, the asymptotic convergence is slow for small sample sizes. In summary, the simulation results affirm the suitability and robustness of the ML estimation approach for the UTPN distribution, particularly in achieving reliable parameter estimates as sample sizes increase, regardless of variations in the true scale parameter. These findings contribute to the methodological robustness of the UTPN distribution, enhancing its applicability in diverse statistical modeling scenarios.
5. Data Analysis
5.1. The Rock Dataset
The rock dataset from the R [28] library provides a detailed analysis of the chemical composition of 48 samples of igneous and metamorphic rocks, as seen in Table 2. Collected in the 1920s, these samples have served as a valuable tool for teaching statistics and data analysis. Table 3 presents a descriptive summary of the variable shape, which quantifies the ratio between the perimeter (measured in pixels) and the square root of the area of the pore space (measured in pixels) for the 48 rock samples from a petroleum reservoir. This data set is right-skewed and has a big kurtosis with a small data sample. On the other side, the results of the K-S test show a maximum difference of 0.10462 between the data and the theoretical UTPN distribution. With a p-value of 0.6696, the null hypothesis that the data come from the UTPN distribution is not rejected, indicating an adequate fit.
Table 2.
Shape ratios for rock dataset.
Table 3.
Summary statistics for the rock dataset.
Now, we evaluate the UTPN model against a set of competing models, which are as follows.
- (i)
- Unit-logistic distribution [5]: The unit-logistic distribution, with two parameters, is defined by the PDFwhere represents the median of X, and is the shape parameter.
- (ii)
- Kumaraswamy distribution [29]: The two-parameter Kumaraswamy distribution is defined by the PDFwhere and .
- (iii)
- Beta distribution [30]: The two-parameter beta distribution is characterized by the PDFwhere and .
Based on the results presented in Table 4, meaningful conclusions can be drawn regarding the suitability of the evaluated models to adequately represent the distribution of the rock dataset. The K-S test statistic D values for each evaluated model are presented. The UTPN model exhibits the highest log-likelihood value (57.94) among the considered models, indicating a superior fit to the observed data. Furthermore, information criteria AIC, BIC, CAIC, and HQIC support the superiority of the UTPN model by presenting the lowest values in each case. This body of evidence underscores the utility of the UTPN model compared to the unit-logistic (ULO), beta (B), and Kumaraswamy (KAM) models in accurately representing the distribution of igneous and metamorphic rock samples. Parameter estimates and their respective standard deviations provide detailed insights into the shape and variability of the UTPN model.
Table 4.
Model parameter estimates, log-likelihood values, and goodness-of-fit measures for the rock dataset.
Figure 5 displays histograms and CDF for the dataset, accompanied by fitted distributions using ML estimates in UTPN, ULO, beta, and Kumaraswamy models. This analysis underscores their robust and efficient ability to model data within the interval (0, 1). These findings suggest that the UTPN model could be a valuable alternative in modeling similar phenomena, especially in situations involving small sample sizes. Overall, the UTPN model emerges as the preferred choice for modeling the rock dataset, underscoring its suitability and precision compared to the competing models.
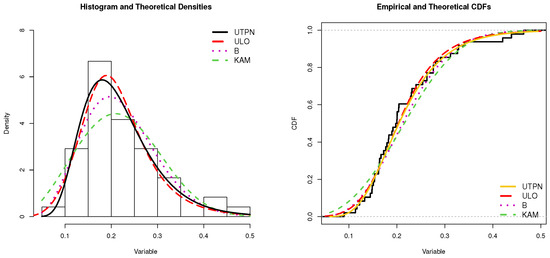
Figure 5.
Models and estimated CDFs for the rock dataset.
5.2. Computation Time of P3 Algorithms
Information on the computational time of P3 algorithms, as presented in Table 5, can be found in a study by Caramanis et al. [31]. The authors of [31] used them to fit a novel statistical model that encompasses univariate and bivariate approaches. Table 6 illustrates the right-skewed nature of the dataset. Notably, the sample size is small, approximately 20, which presents a challenge for modeling. On the other side, the maximum difference between the data and the theoretical UTPN distribution, according to the K-S test results, is 0.1480. With a p-value of 0.7211, the null hypothesis, according to which the data come from the UTPN distribution, is accepted, which implies an adequate fit.
Table 5.
Computational times of P3 algorithms.
Table 6.
Summary statistics for the dataset on the computational duration of P3 algorithms.
The outcomes derived from the analysis presented in Table 7 offer valuable insights into the performance of the evaluated models in capturing the underlying distribution of the P3 algorithm dataset. The test statistic D values from the K-S test are provided for each evaluated model. Notably, the UTPN model exhibits a log-likelihood value of 8.07, suggesting a favorable fit to the data. This is further supported by the information criteria (AIC, BIC, CAIC, and HQIC) consistently presenting the lowest values for the UTPN model compared to alternative models, namely the ULO, B, and KAM distributions. The parameter estimates provide nuanced understanding, with and shedding light on the shape and variability of the UTPN model. While uncertainty is inherent in parameter estimation, the UTPN model, characterized by and , emerges as a promising candidate for effectively modeling data within the (0, 1) interval.
Table 7.
Model parameter estimates, log-likelihood values, and goodness-of-fit measures for the P3 algorithms dataset.
Graphically, Figure 6 clearly demonstrates that the UTPN distribution exhibits the most favorable performance. The figure showcases a histogram overlaid with the fitted density function, alongside a plot illustrating the empirical distribution with the estimated CDF of these fitted distributions.
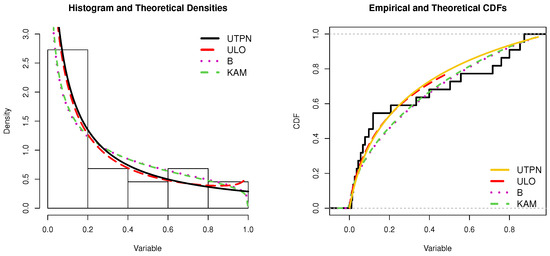
Figure 6.
Models and estimated CDFs for P3 algorithms dataset.
6. Conclusions
In numerous applied scientific fields, various metrics, such as indicators, percentages, proportions, ratios, and rates, measured on the scale of (0, 1) serve as crucial study variables for characterizing diverse phenomena. However, the current statistical literature offers limited model options for handling these variables. The beta and Kumaraswamy distributions are two of the main models. This study introduces a flexible two-parameter probability distribution with a bounded domain, derived using an exponential transformation of a truncated positive normal variable, this transformation provides statistical properties related to the distribution in simple and closed form. We investigate several statistical properties of the proposed distribution, including maximum likelihood analyses conducted on two practical datasets. Notably, the obtained findings demonstrate that the proposed distribution exhibits greater flexibility compared to commonly used statistical distributions, such as beta, Kumaraswamy, and unit-logistic distributions. Particularly in the realm of modeling small samples, the obtained results underscore the superior performance of the UTPN distribution. On the other hand, the study’s findings suggest that the UTPN distribution may not be ideal for modeling lifetime data with a decreasing HR function or a bathtub-shaped HR, which includes burn-in and wear-out phases along with extended periods of low, constant hazard. Therefore, further research may aim to improve the distribution to overcome these limitations. Moreover, future research avenues could explore the derivation of alternative models from the TPN distribution using different transformations, as well as the examination of the proposed model within the quantile regression framework.
Author Contributions
Conceptualization, H.S.S. and H.S.B.; methodology, H.S.S., H.S.B., W.E.C. and L.B.-B.; software, F.E.A., W.E.C., L.B.-B. and O.A.; validation, F.E.A., W.E.C. and L.B.-B.; formal analysis, H.S.S., W.E.C., L.B.-B. and F.E.A.; writing—original draft preparation, H.S.S., W.E.C. and L.B.-B.; writing—review and editing, H.S.S., H.S.B., W.E.C. and L.B.-B.; visualization, W.E.C., L.B.-B., F.E.A. and O.A.; supervision, H.S.S. and H.S.B.; funding acquisition, F.E.A. and O.A. All authors have read and agreed to the published version of the manuscript.
Funding
The paper was funded by King Faisal University, Saudi Arabia (Grant No. 6059).
Data Availability Statement
Within the paper, references to the data analyzed are listed.
Acknowledgments
This work was supported by the Deanship of Scientific Research, Vice Presidency for Graduate Studies and Scientific Research, King Faisal University, Saudi Arabia (Grant No. 6059).
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
The following are the second derivatives of the log-likelihood function and the elements of the Fisher information matrix:
and
References
- Gómez, H.J.; Olmos, N.M.; Varela, H.H.; Bolfarine, H. Inference for a truncated positive normal distribution. Appl. Math. J. Chin. Univ. Ser. B 2018, 33, 163–176. [Google Scholar] [CrossRef]
- Topp, C.W.; Leone, F.C. A family of J-shaped frequency functions. J. Am. Stat. Assoc. 1955, 50, 209–219. [Google Scholar] [CrossRef]
- Grassia, A. On a family of distributions with argument between 0 and 1 obtained by transformation of the gamma and derived compound distributions. Aust. J. Stat. 1977, 19, 108–114. [Google Scholar] [CrossRef]
- Gómez-Déniz, E.; Sordo, M.A.; Calderín-Ojeda, E. The log-Lindley distribution as an alternative to the beta regression model with applications in insurance. Insur. Math. Econ. 2013, 54, 49–57. [Google Scholar] [CrossRef]
- Menezes, A.F.B.; Mazucheli, J.; Dey, S. The unit-logistic distribution: Different methods of estimation. Braz. Oper. Res. Soc. 2018, 38, 555–578. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. The unit-birnbaum-saunders distribution with applications. Chil. J. Stat. 2018, 9, 47–57. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Fernandes, L.B.; de Oliveira, R.P.; Ghitany, M.E. The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the dodeling of quantiles conditional on covariates. J. Appl. Stat. 2020, 47, 954–974. [Google Scholar] [CrossRef] [PubMed]
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz distribution with applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Ghitany, M.E.; Mazucheli, J.; Menezes, A.F.B.; Alqallaf, F. The unit-inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval. Commun. Stat. Theory Methods 2019, 48, 3423–3438. [Google Scholar] [CrossRef]
- Haq, M.A.; Hashmi, S.; Aidi, K.; Ramos, P.L.; Louzada, F. Unit modified Burr-III distribution: Estimation, characterizations and validation test. Ann. Data Sci. 2020, 10, 415–440. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Chakraborty, S. On the one parameter unit-Lindley distribution and its sssociated regression model for proportion data. J. Appl. Stat. 2019, 46, 700–714. [Google Scholar] [CrossRef]
- Concha-Aracena, M.S.; Barrios-Blanco, L.; Elal-Olivero, D.; Ferreira da Silva, P.H.; Nascimento, D.C.D. Extending normality: A case of unit distribution generated from the moments of the standard normal distribution. Axioms 2022, 11, 666. [Google Scholar] [CrossRef]
- Alvarez, P.I.; Varela, H.; Cortés, I.E.; Venegas, O.; Gómez, H.W. Modified unit-half-normal distribution with applications. Mathematics 2023, 12, 136. [Google Scholar] [CrossRef]
- Bakouch, H.S.; Nik, A.S.; Asgharzadeh, A.; Salinas, H.S. A flexible probability model for proportion data: Unit-half-normal distribution. Commun. Stat. Case Stud. Data Anal. Appl. 2021, 7, 271–288. [Google Scholar] [CrossRef]
- Bakouch, H.S.; Hussain, T.; Tošić, M.; Stojanović, V.S.; Qarmalah, N. Unit exponential probability distribution: Characterization and applications in environmental and engineering data modeling. Mathematics 2023, 11, 4207. [Google Scholar] [CrossRef]
- Okorie, I.E.; Afuecheta, E.; Bakouch, H.S. Unit upper truncated Weibull distribution with extension to 0 and 1 inflated model—Theory and applications. Heliyon 2023, 9, e22260. [Google Scholar] [CrossRef] [PubMed]
- Glänzel, W. A characterization theorem based on truncated moments and its application to some distribution families. In Mathematical Statistics and Probability Theory; Bauer, P., Konecny, F., Wertz, W., Eds.; Springer: Dordrecht, The Netherlands, 1987; pp. 75–84. [Google Scholar]
- Glänzel, W. A characterization of the normal distribution. Stud. Sci. Math. Hung. 1988, 2, 89–91. [Google Scholar]
- Hamedani, G.G. Characterizations of Cauchy, normal, and uniform distributions. Stud. Sci. Math. Hung. 1993, 3, 243–248. [Google Scholar]
- Akhila, P.; Girish Babu, M.; Bakouch, H.S. A versatile probabilistic model based on Yun-G family of distributions and its applications in engineering sector. J. Kerala Stat. Assoc. 2023, 34, 52–83. [Google Scholar]
- Glaser, R.E. Bathtub and related failure rate characterization. J. Am. Stat. Assoc 1980, 75, 667–672. [Google Scholar] [CrossRef]
- Bonferroni, C.E. Elementi di Statistica Generale; Seeber: Firenze, Italy, 1930. [Google Scholar]
- Rényi, A. On measures of information and entropy. In 4th Berkeley Symposium on Mathematical Statistics and Probability; Neymann, J., Ed.; University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Casella, G.; Berger, R.L. Statistical Inference; Duxbury Advanced Series Thomson Learning: Pacific Grove, CA, USA, 2002. [Google Scholar]
- Popović, B.V.; Ristić, M.M.; Cordeiro, G.M. A two-parameter distribution obtained by compounding the generalized exponential and exponential distributions. Mediterr. J. Math 2016, 13, 2935–2949. [Google Scholar] [CrossRef]
- Alomair, G.; Akdoğan, Y.; Bakouch, H.S.; Erbayram, T. On the maximum likelihood estimators’ uniqueness and existence for two unitary distributions: Analytically and graphically, with application. Symmetry 2024, 16, 610. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2024; Available online: https://www.R-project.org/ (accessed on 10 January 2024).
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, 2nd ed.; Chapter 25: Beta Distributions; Wiley: Hoboken, NJ, USA, 1955; Volume 2. [Google Scholar]
- Caramanis, M.; Stremel, J.; Fleck, W.; Daniel, S. Probabilistic production costing: An investigation of alternative algorithms. Int. J. Electr. Power Energy Syst. 1983, 5, 75–86. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).