Abstract
In this paper, we explore how to use topological tools to compare dimension reduction methods. We first make a brief overview of some of the methods often used in dimension reduction such as isometric feature mapping, Laplacian Eigenmaps, fast independent component analysis, kernel ridge regression, and t-distributed stochastic neighbor embedding. We then give a brief overview of some of the topological notions used in topological data analysis, such as barcodes, persistent homology, and Wasserstein distance. Theoretically, when these methods are applied on a data set, they can be interpreted differently. From EEG data embedded into a manifold of high dimension, we discuss these methods and we compare them across persistent homologies of dimensions 0, 1, and 2, that is, across connected components, tunnels and holes, shells around voids, or cavities. We find that from three dimension clouds of points, it is not clear how distinct from each other the methods are, but Wasserstein and Bottleneck distances, topological tests of hypothesis, and various methods show that the methods qualitatively and significantly differ across homologies. We can infer from this analysis that topological persistent homologies do change dramatically at seizure, a finding already obtained in previous analyses. This suggests that looking at changes in homology landscapes could be a predictor of seizure.
MSC:
52A15; 53A70; 54H30; 55R40; 58A05
1. Introduction
In topological data analysis, one is interested in understanding high dimensional structures from low dimensional ones and how discrete structures can be aggregated to form a global structure. It can be a difficult task to even think or believe that high dimensional objects exist beyond three dimensions since we can not visualize objects beyond a three-dimensional space. However, embedding theorems clearly show that these high dimension structures do, in fact, exist, for instance, Whitney [1] and Takens [2] embedding theorems. From a practical point of view, to make inferences on structures embedded in high dimensional ambient spaces, some kind of dimensional reduction needs to occur. From a data analysis point of view, dimension reduction amounts to data compression where a certain amount of information may be lost. This dimension reduction is part of manifold learning, which can be understood as a collection of algorithms for recovering low dimension manifolds embedded into high dimensional ambient spaces while preserving meaningful information, see Ma and Fu [3]. The algorithms for dimension reduction may be classified into linear and nonlinear methods or parametric or nonparametric methods, where the goal is to select or extract coarse features from high dimensional data. Among the pioneering linear methods is the principal component analysis (PCA) introduced by Hotelling in [4]. Its primary goal is to reduce the data to a set of orthogonal linear projections ordered by decreasing variances. Another linear method is multidimensional scaling (MSD), where the data are aggregated using a measure of proximity, which could be a distance or a measure of association such as correlation or any other method describing how close entities can be, see, for instance, Ramsey and Silverman [5]. Linear discriminant analysis (LDA) is a linear method similar to PCA consisting of writing a categorical dependent variable as a linear combination of continuous independent variables, see, for instance, Cohen et al. [6], Friedman [7], or Yu and Yang [8]. As such, it is opposite to an analysis of variance (ANOVA) where the dependent variable is continuous and the independent variables are categorical. The focus of this paper will be on nonlinear techniques, which, similar to their linear counterparts, aim to extract or select low dimensional features while preserving important information. Since there are many such methods, our focus will be on isometric feature mapping (ISOMAP) [9], Laplacian Eigenmaps [10], fast independent component analysis, (Fast-ICA) [11], kernel ridge regression [12], and t-distributed stochastic neighbor embedding (t-SNE) [13]. We will compare them using persistent homology (PH). PH is one the many techniques of topological data analysis (TDA) that can be used to identify features in data that remain persistent over multiple and different scales. This tool can provide new insights into seemingly known or unknown data and has the potential to uncover interesting hidden information embedded within data. For instance, PH was used to provide new insights on the topology of deep neural networks, see [14]. PH was successfully used to provide new perspectives on viral evolution, see [15]. The following examples of successful applications can be found in [16], including but not limited to better understanding of sensor-network coverage, see [17]; proteins, see [18,19]; dimensional structure of DNA, see [20]; cell development, see [21]; robotics, see [22,23,24]; signal processing, see [25,26]; spread of contagions, see [27]; financial networks, see [28]; applications in neuroscience, see [29,30]; time-series output of dynamical systems, see [31]; and EEG epilepsy, see [32]. The approach in the last reference is of particular interest to us. Indeed, in that paper, the authors considered the EEG measured in a healthy person during sleep. They used the method of false nearest neighbors to estimate the embedding dimension. From there, persistent barcode diagrams were obtained and revealed that topological noise persisted at certain dimensions and vanished at some others. This paper has a similar approach and is organized as follows: in Section 2, we review theories behind some dimension reduction methods; then, in Section 3, we give an overview of the essentials of persistent homology; in Section 4, we discuss how to apply persistent homology to the data and compare the methods on an EEG data set using persistent homology. Finally. in Section 5, we make some concluding remarks.
2. Materials and Methods
Let us note that some of the review methods below are extensively described in [3]. To have all of our ideas self-contained, we reintroduce a few concepts. In the sequel, is the euclidian norm in , for some . In the sequel, topological spaces will considered to be second-countable Hausdorff; that is, (a) every pair of distinct points has a corresponding pair of disjoint neighborhoods. (b) Its topology has a countable basis of open sets. This assumption is satisfied in most topological spaces and seems reasonable.
2.1. Preliminaries
Definition 1.
A topological space is called a (topological) manifold if, locally, it resembles a real n-dimensional Euclidian space, that is, there exists such that for all , there exists a neighborhood of x and a homeomorphism . The pair is referred to as a chart on and f is called a parametrization at x.
Definition 2.
Let be a manifold. is said to be smooth if given , the parametrization f at x has smooth or continuous partial derivatives of any order and can be extended to a smooth function such that .
Definition 3.
Let and be differentiable manifolds. A function is an embedding if ψ is an injective immersion.
Next, we introduce the notion of the boundary of the topological manifold, which will be important in the sequel.
Definition 4.
Consider a Hausdorff topological manifold homeomorphic to an open subset of the half-euclidian space . Let the interior of be the subspace of formed by all points s that have a neighborhood homeomorphic to . Then, the boundary of is defined as a complement of in , that is, , which is an -dimensional topological manifold.
2.2. ISOMAP
Isometric feature mapping (ISOMAP) was introduced by Tanenbaum et al. in [9]. The data are considered to be a finite sample from a smooth manifold . The two key assumptions are: (a) an isometric embedding exists where , where the distance on is the geodesic distance or the shortest curve connecting two points; (b) the smooth manifold is a convex region of , where . The implementation phase has three main steps.
- 1.
- For a fixed integer K and real number , perform an -nearest neighbor search using the fact that the geodesic distance between two points on is the same (by isometry) as their euclidian distance in . K is the number of data points selected within a ball of radius .
- 2.
- Having calculated the distance between points as above, the entire data set can be considered as a weighted graph with vertices and edges , where connects with with a distance , considered an associated weight. The geodesic distance between two data points and is estimated as the graph distance between the two edges, that is, the number of edges in the shortest path connecting them. We observe that this shortest path is found by minimizing the sum of the weights of its constituent edges.
- 3.
- Having calculated the geodesic distances as above, we observe that is a symmetric matrix, so we can apply the classical multidimensional scaling algorithm (MDS) (see [33]) to by mapping (embedding) them into a feature space of dimension d while preserving the geodesic distance on . is generated by a matrix whose i-th column represents the coordinates of in .
2.3. Laplacian Eigenmaps
The Laplacian Eigenmaps (LEIM) algorithm was introduced by Belkin and Niyogi in [10]. As above, the data are supposed to be from a smooth manifold . It also has three main steps:
- 1.
- For a fixed integer K and real number , perform a K-nearest neighbor search on symmetric neighborhoods. Note that given two points , their respective K-neighborhood and are symmetric if and only .
- 2.
- For a given real number and each pair of points , calculate the weight if and if . Obtain the adjacency matrix . The data now form a weighted graph with vertices , with edges , and weights , where connects with with distance .
- 3.
- Consider to be a diagonal matrix with and define the graph Laplacian as . Then, is positive definite so let be the matrix that minimizes . Then, can used to embed into a d-dimensional space , whose i-th column represents the coordinates of in .
2.4. Fast ICA
The fast independent component analysis (Fast-ICA) algorithms were introduced by Hyvärinen in [11]. As above, the data are considered to be from a smooth manifold . It is assumed that the data are represented as an matrix that can be flattened into a vector. As in principal component analysis (PCA), in factor analysis, projection pursuit, or independent component analysis (ICA), by considering the data as an -dimensional observed random variable, the goal is to determine a matrix such that , where is a -dimensional random variable having desirable properties such as optimal dimension reduction or other interesting statistical properties such as minimal variance. Optimally, the components of should provide source separation (the original data source is assumed to be corrupted with noise) and feature extraction and be independent of each other. In a regular ICA, the matrix is found by minimizing the mutual information, a measure of dependence between given random variables. In fast-ICA algorithms, the matrix is found by using a Newton fixed point approach, with an objective function taken as the differential entropy, given as , where it is assumed that is such that , and z is the standard normal distribution. G is a function referred to as the contrast function, which includes but is not limited to , where and . From a dynamical system point of view, the fixed point is locally asymptotically stable with the exception of , where stability becomes global. For simplification purposes, let . The key steps are:
- 1.
- Data preparation: it consists of centering the data with respect to the column to obtain . That is, , for . The centered data are then whitened; that is, is linearly transformed into , a matrix of uncorrelated components. This is accomplished through an eigenvalue decomposition of the covariance matrix to obtain two matrices , respectively, of eigenvectors and eigenvalues so that . The whitened data are found as and simply referred to again as for simplicity.
- 2.
- Component extraction: Let for a given constant , where is the optimal weight matrix. Applying the Newton scheme () to the differentiable function , we
- Select a random starting vector .
- For , .
- Normalize as .
- Repeat until a suitable convergence level is reached.
- From the last matrix obtained, let .
2.5. Kernel Ridge Regression
The kernel ridge regression (KRR) is constructed as follows: as above, the data are considered to be from a smooth manifold of dimension d. It is assumed that the data are represented as an matrix that can be flattened into a vector. Suppose we are in possession of data corresponding to a response variable and covariates given as , where for . With the least square method, we can find the best linear model between the covariates and the response by minimizing the objective function , where is a vector. Similar approaches include maximum likelihood approaches, see, for instance, [34] or perpendicular offsets [35]. However, regression methods are notorious for overfitting. Overfitting occurs when a model closely fits a training data set but fails to do so on a test data set. In practice, this can lead to dire consequences, see, for instance, the book by Nate Silver [36] for illustrative examples in real life. Numerous solutions were proposed to overcome overfitting; these include but are not limited to training with more data, data augmentation, cross-validation, feature selection, regularization, or penalization (Lasso, Ridge, Elastic net). The ridge regression is a compromise that uses a penalized objective function such as . The solution can be found as . In case the true nature of the relationship between the response and covariates is nonlinear, we can replace with , where is a nonlinear function . In particular, if the response is qualitative, that is, labels, then we have a classification problem, and is referred to as a feature map. Note that when using , the number of dimensions of the problem is considerably high. Put . Replacing with , the solution above becomes . Consider the following identity for the given invertible matrices , and a matrix B. Applying this with and , we have . Therefore, given a new value , the predicted value is , where and . K is referred to as the kernel, which is the only quantity needed to be calculated, thereby significantly reducing the computational time and dimensionality of the problem. In practice, we may use a linear kernel or a Gaussian kernel , for some , where is a norm in and is given a real constant.
2.6. t-SNE
Stochastic neighbor embedding (SNE) was proposed by Hinston and Roweis in [37]. t-SNE followed later and was proposed by van der Maaten and Hinton in [13]. t-distributed stochastic neighbor embedding (t-SNE) is a dimension reduction method that amounts to assigning data to two or three dimensional maps. As above, we consider the data ( with ) to be from a smooth manifold of high dimension, d. The main steps of the method are:
- Calculate the asymmetrical probabilities as , where represents the dissimilarity between and , and is a parameter selected by the experimenter or by a binary search. represents the conditional probability that datapoint is the neighborhood of datapoint if neighbors were selected proportionally to their probability density under a normal distribution centered at and variance .
- Assuming that the low dimensional data are , the corresponding dissimilarity probabilities are calculated under constant variance as , where in the case of SNE, and for t-SNE.
- Then, we minimize the Kullback–Leibler divergence between and , given as , using the gradient descent method with a momentum term with the scheme for for some given T. Note that , where is the identity matrix, is a constant representing a learning rate, and is t-th momentum iteration. We note that for where
- Then, we use as the low dimensional representation of .
3. Persistent Homology
In the sequel, we will introduce the essential ingredients needed to understand and compute persistent homology.
3.1. Simplex Complex
Definition 5.
A real d-simplex S is a topological manifold of dimension d that represents the convex hull of points. In other words:
Example 1.
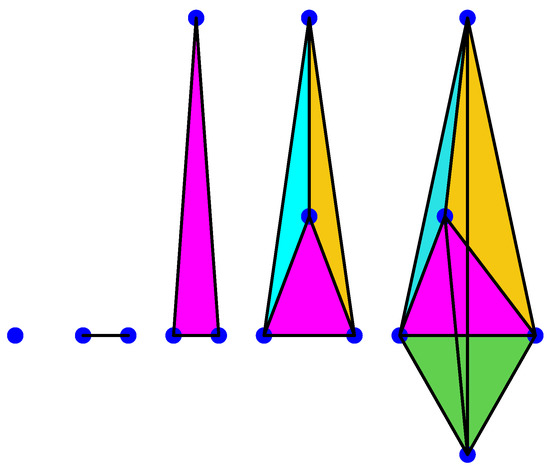
A 0-simplex is a point, a 1-simplex is an edge, a 2-simplex is a triangle, a 3-simplex is a tetrahedron, a 4-simplex is a pentachoron, etc., see for instance Figure 1 below.
Figure 1.
Anillustration of 0, 1, 2, 3, and 4-simplices.
Remark 1.
We observe that a d-simplex S can also be denoted as
We also note that the dimension of is i.
Definition 6.
Given a simplex S, a face of S is another simplex R such that and such that the vertices of R are also the vertices of S.
Example 2.
Given a 3-simplex (a tetrahedron), it has 4 different 2-simplex or 2 dimensional faces, each of them with three 1-simplex or 1-dimensional faces, each with three 0-simplex or 0-dimensional faces.
Definition 7.
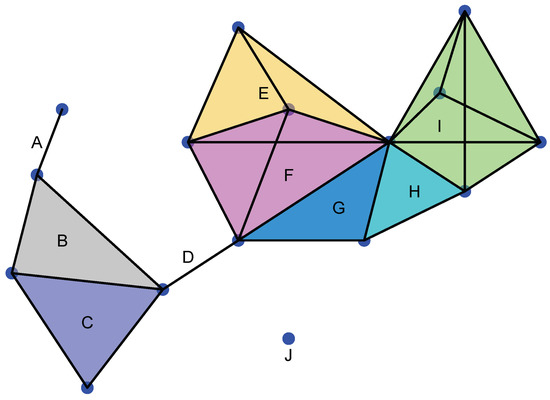
A simplicial complex Σ is a topological space formed by different simplices not necessarily of the same dimension that have to satisfy the gluing condition, that is (see Figure 2):
Figure 2.
Example of a simplicial complex. J is 0-simplex; A and D are 1-simplices; B, C, G, and H are 2-simplices; E and F are 3-simplices; and I is a 4-simplex. We note that A∩ B is a 0-simplex. B∩ C is a 1-simplex and a face of B and C, respectively. E∩ F is a 2-simplex and a face of E and F. G∩ H is a 1-simplex and I∩ H is a 1-simplex.
- 1.
- Given , its face .
- 2.
- Given , either or , the faces of and , respectively.
It is important to observe that a simplicial complex can be defined very abstractly. Indeed,
Definition 8.
A simplicial complex is a collection of non-empty subsets of a set Ω such that
- 1.
- For all , then .
- 2.
- For any set U such that for some , then .
Example 3.
We illustrate the definition above by constructing two simplicial complexes. Let . We can define the following simplicial complexes on Ω.
- 1.
- 2.
- , where is the set of all subsets of Ω.
3.2. Homology and Persistent Homology
Definition 9.
Let Σ be a simplicial complex.
We define the Abelian group generated by the j-simplices of Σ as .
We define a boundary operator associated with as a homeomorphism
We define the chain complex associated with Σ as the collection of pairs
Now, we can define a homology group associated with a simplicial complex.
Definition 10.
Given a simplicial complex Σ, put and . Then, the jth homology group of Σ is defined as the quotient group between and ; that is,
What this reveals is the presence of “holes” in a given shape.
Remark 2.
It is important to observe that , where stands for the span of U, and a cycle is simply a shape similar to a loop but necessarily without a starting point.
Another important remark is that the boundary operator can indeed be defined as
where means not counting the vertices of . This shows that lies in a -simplex.
Another remark is that for .
Now that we know that homology reveals the presence of “holes”, we need to find a way of determining how to count these “holes”.
Definition 11.
Given a simplicial complex Σ, the jth Betti number is the rank of or
In other words, it is the smallest cardinality of a generating set of the group .
In fact, since the elements of are j-dimensional cycles and that of are j-dimensional boundaries, the Betti number counts the number of independent j-cycles not representing the boundary of any collection of simplices of Σ.
Example 4.
Let us be more precise by giving the meaning of the Betti number for three indices .
- 1.
- is the number of connected components of the complex.
- 2.
- is the number of tunnels and holes.
- 3.
- is the number of shells around cavities or voids.
Definition 12.
Let Σ be the simplicial complex, and let N be a positive integer. A filtration of Σ is a nested family of sub-complexes of Σ such that
Now, let be the field with two elements, and let be two integers.
Since , the inclusion map induces an -linear map defined as . We can now define, for any , the j-th persistent homology of a simplicial complex .
Definition 13.
Consider a simplicial complex Σ with filtration for some positive integer N. The j-th persistent homology of Σ is defined as the pair:
In a sense, the j-th persistent homology provides more refined information than the homology of the simplicial complex in that it informs us of the changes in features such as connected components, tunnels and holes, and shells around voids through the filtration process. It can be visualized using a “barcode” or a persistent diagram. The following definition is borrowed from [38]:
Definition 14.
Consider a simplicial complex Σ, a positive integer N, and two integers . The barcode of the j-th persistent homology of Σ is a graphical representation of as a collection of horizontal line segments in a plane whose horizontal axis corresponds to a parameter and whose vertical axis represents an arbitrary ordering of homology generators.
We finish this section with the introduction of the Wasserstein and Bottleneck distances, used for the comparison of persistent diagrams.
Definition 15.
Let X and Y be two diagrams. A matching η between X and Y is a collection of pairs where x and y can occur in at most one pair. It is sometimes denoted as . x and y are referred to as intervals of X and Y respectively.
Example 5.
Suppose and .
Then, is matching between X and Y such that is matched to and , and are unmatched.
Definition 16.
Let be a real number. Given two persistent diagrams X and Y, the p-th Wasserstein distance between X and Y is defined as
where η is a perfect matching between the intervals of X and Y.
The Bottleneck distance is obtained when ; that is, it is given as
4. Results
In the presence of data, simplicial complexes will be replaced by sets of data indexed by a parameter, therefore, transforming these sets into parametrized topological entities. On these parametrized topological entities, the notions of persistent homology introduced above can be computed, especially the Betti number, in the form of a “barcode”. To see how this could be calculated, let us consider the following definitions:
Definition 17.
For a given collection of points in a manifold of dimension n, its Čech complex is a simplicial complex formed by d-simplices obtained from a sub-collection of points such that taken pairwise, their -ball neighborhoods have a point in common.
Definition 18.
For a given collection of points in a manifold of dimension n, its Rips complex is a simplicial complex formed by d-simplices obtained from a sub-collection of points that are pairwise within a distance of δ.
Remark 3.
1. It is worth noting that in practice, Rips complexes are easier to compute than Čech complexes, because the exact definition of the distance on may not be known.
2. More importantly, from a data analysis point of view, Rips complexes are good approximations (estimators) of Čech complexes. Indeed, a result from [17] shows that given , there exists a chain of inclusions . 3. Though Rips complexes and barcodes seem to be challenging objects to wrap one’s head around, there is an ever growing list of algorithms from various languages that can be used for their visualization. All the analysis below was performed using R, in particular, the TDA package in R version 4.3.0, 21 April 2023.
4.1. Randomly Generated Data
We generated 100 data points sampled randomly in the square . In Figure 3 and Figure 4 below, we illustrate the Rips and barcode changes through a filtration.
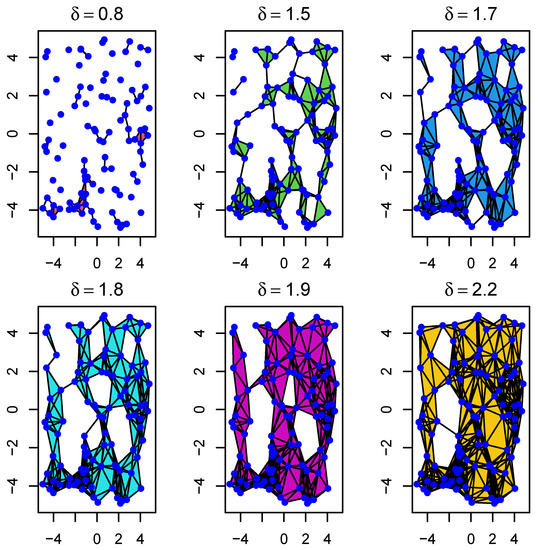
Figure 3.
Example of the evolution of Rips complexes through a filtration with parameter . As we move from left to right, it shows how sample points (blue dots) first form 0-simplices, then 1-simplices, and so on. In particular, it shows how connected components progressively evolve to form different types of holes.
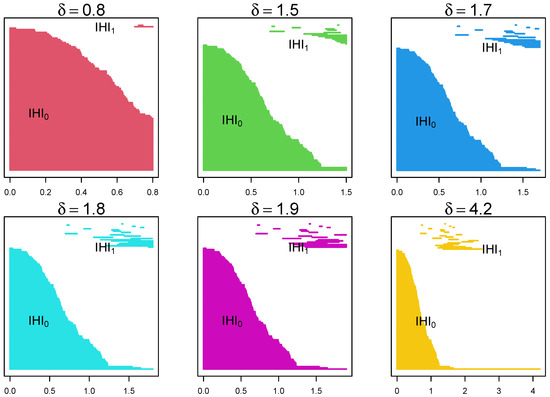
Figure 4.
Example of the evolution of barcodes through a filtration with parameter for the same data as above. As we move from left to right, from top to bottom, it shows the appearance and disappearance of lines () and holes () as the parameter changes. It shows that certain lines and holes persist through the filtration process.
4.2. EEG Epilepsy Data
4.2.1. Data Description
The main purpose of the manuscript is to analyze EEG data. We consider a publicly available (at http://www.meb.unibonn.de/epileptologie/science/physik/eegdata.html, last accessed on 1 June 2023) epilepsy data set. For a thorough description of the data and their cleaning process, see, for instance, [39]. They consist of five sets: A, B, C, D, and E. Each contains 100 single-channel EEG segments of 23.6 s, where A and B represent healthy individuals. Set D represents the data obtained from the epileptogenic zone in patients, and set C represents data obtained from the hippocampus zone. Set E represents the data from seizure prone patients.
4.2.2. Data Analysis
The approach is to first embed the data into a manifold of high dimension. This was already performed in [39]. The dimension was found using the method of false nearest neighbors. Depending on the set used, the size of the data can be very large: for example (), making it very challenging to analyze holistically. In [39], we proposed to construct a complex structure (using all 100 channels for all 5 groups) whose volume changes per group. We would like to analyze the data further from a persistent homology point of view. This would mean analyzing 500 different persistent diagrams and making an inference. We note that simplicial complexes of these data sets are very large (2 Millions+). Fortunately, we can use the Wasserstein distance to compare persistent diagrams. To clarify, we use each of the dimension reduction methods introduced earlier, then proceed with the construction of persistent diagrams. We then compare them by method and by sets (A, B, C, D, and E).
Single-channel Analysis:
Suppose we select at random one channel among the 100 from set D, Figure 5 below represents a three dimensional representation of the embedded data using Takens embedding method (Tak), plotted using the first three delayed coordinates , where , with ms in Figure 5a; then, the first three coordinates in the case of kernel ridge regression (KRR) in Figure 5b; ISOMAP (iso.i) in Figure 5c; Laplacian Eigenmaps (LEIM) in Figure 5d; fast independent component analysis (ICA) in Figure 5e; and t-distributed stochastic neighbor embedding (t-SNE) in Figure 5f. From these three dimensional scatter plots, we can visually observe that the t-SNE plot (Figure 5f) is relatively different from the other five since it seems to have more larger voids. How different is difficult to tell with the naked eye. Figure 6 represents their corresponding barcodes. It is much clearer looking at the the persistent diagram for t-SNE (Figure 6f) that it is very different from the other five when looking at , and . Now, a visual comparison is not enough to really assert a significant difference. Using the Bottleneck distance, we calculate the distance between the respective persistent diagrams for and in Table 1a and in Table 1b below. We observe from the first table that the Bottleneck distances at and for t-SNE are almost twice as large as for the other methods. They are comparable to that of LEIM at . The other methods have comparable Bottleneck distances at , and , confirming what we already suspected visually in Figure 5 and Figure 6.
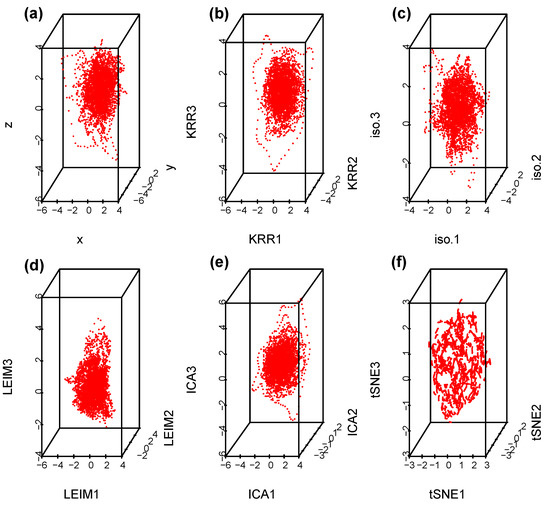
Figure 5.
Scatterplots for a Takens projection method (a), KRR method (b), ISOMAP (c), LEIM (d), ICA (e), and t-SNE (f).
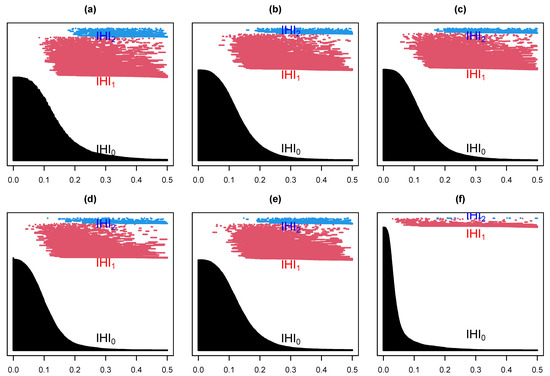
Figure 6.
Barcodes for a Takens projection method (a), KRR method (b), ISOMAP (c), LEIM (d), ICA (e), and t-SNE (f).

Table 1.
Bottleneck distance between the persistent diagrams above at (a), at and at (b).
The analysis above was performed using a single channel, selected at random from the set D. It seems to suggest that the t-SNE method is different from the other five dimension reduction methods discussed above. Strictly speaking, non zero Bottleneck distances are an indication of structural topological differences. What they do not say, however, is if the differences observed are significant. To address the issue of significance, we perform a pairwise permutation test. Practically, from set j and channel i, we obtain a persistent diagram where , and is the true underlying distribution of persistent diagrams; see [40] for the existence of these distributions. We conduct a pairwise permutation test with null hypothesis and alternative hypothesis . We use landscape functions (see [41]) to obtain test statistics. The p.values obtained were found to be very small, suggesting that the differences above are indeed all significant across , and .
Multiple-channel Analysis:
- (a)
- Within set analysis
In each set, we make a random selection of 15 channels, and we compare the Bottleneck distances obtained. This means having 15 tables of distance, such as Table 1b above. There is consistency if the cell value in Table k, where and , is barely different from of Table . Large differences are an indication of topological differences between the methods within the sets. In Figure 7 below, the y-axis represents Bottleneck distances, and the x-axis represents channels indices. The red color is indicative of the Bottleneck distance between persistent diagrams on and the blue color on from the data generated from each of the methods above. We see that overall, while there are small fluctuations from channels to channels on , the largest fluctuations actually occur on . A deeper analysis reveals that in fact, the large fluctuations are due to a large distance between t-SNE and the other five methods. This confirms the earlier observations (refer to Figure 6 and Table 1 above) that persistent diagrams are really different on . Topologically, this means that shells around cavities or voids that persist are not the same when using different dimension reduction methods. However, the small fluctuations on do not mean that tunnels and holes that persist are the same. Rather, what they do indicate is that they may not be all very different.
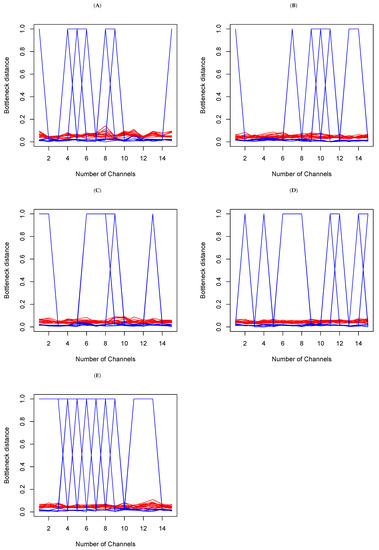
Figure 7.
Bottleneck distances between the persistent diagrams for 15 channels within each set (A–E) on and for each of the methods introduced above. The red lines represent the Bottleneck distances between persistent diagrams on and the blue are their counterparts on .
- (b)
- Between set analysis
To analyze the data of the Bottleneck distances between sets, we need summary statistics for each set from the data above. It is clear from Figure 7 that the mean would not be a great summary statistic for , as there seem to be too many outliers. We will use the median instead and perform a pairwise Wilcoxon–Mann–Whitney test. Table 2 below shows the p.value on and . The take-away is that the last row of the table suggests that set E is statistically topologically different from others on , at a significance level of . In a way, this is a confirmation of the results obtained in [39] where set E (seizure) was already shown to be statistically different from other sets.
Table 2.
P values of Wilcoxon–Mann–Whitney tests between sets of median Bottleneck distances.
5. Concluding Remarks
In this paper, we have revisited the mathematical descriptions of six dimension reduction methods. We have given a brief introduction to the very vast topic of persistent homology. We discussed how to apply persistent homology to the data. In the presence of data (say in three dimensions) obtained either by projecting the data from a high dimension into a smaller dimension (as in Takens) or by performing some sort of dimension reduction, it is not always clear what we see or how different one method is compared to another. From their mathematical description, they seem to represent different objects. Furthermore, obtaining theoretically a clear discrimination procedure between these procedures seems a daunting, if not an outright impossible, task. Topology may offer a solution by looking at persistent artifacts through filtration. From Figure 5, it seems clear that the methods were different, but Figure 6 offers a different perspective. In the end, through the calculation of Bottleneck distances and hypothesis tests, we can safely conclude that the methods are different, topologically speaking, in that the connected components, the tunnels and holes and the shells around cavities or voids, do not match perfectly. Since these methods are indiscriminately used in many applications, the message is that the replication of results from one method to the next may not be guaranteed in the grand scheme of things. It does not, however, render them useless. In fact, our analysis is limited to one data set, meaning that another data set may yield different conclusions. Furthermore, due to the cost in calculation, we were limited to only a handful of samples. Additionally, the Wasserstein distances for are extremely costly in time to calculate on a regular computer. Even for , the Bottleneck distance is also very costly in time to calculate, especially for . This explains why, at some point, we did not provide the comparison for . Given that some EEG epilepsy data are known to contain some deterministic chaos, it might be worthwhile to study whether persistent homology can also be used for the better understanding of chaotic data in dynamical systems.
Funding
This research received no external funding.
Data Availability Statement
The data from EEG are available at http://www.meb.unibonn.de/epileptologie/science/physik/eegdata.html, last accessed on 1 June 2023.
Conflicts of Interest
The author declare no conflict of interest.
References
- Whitney, H. Differentiable manifolds. Ann. Math. 1936, 37, 645–680. [Google Scholar] [CrossRef]
- Takens, F. Detecting strange attractors in turbulence dynamical systems and turbulence. Lect. Notes Math. 1981, 898, 366–381. [Google Scholar]
- Ma, Y.; Fu, Y. Manifold Learning: Theory and Applications; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 498–520. [Google Scholar] [CrossRef]
- Ramsay, J.O.; Silverman, B.W. Functional Data Analysis, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Cohen, J.; West, S.G.; Aiken, L.S. Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences, 3rd ed.; Lawrence Erlbaum Associates Publishers: Mahwah, NJ, USA, 2003. [Google Scholar]
- Friedman, J.H. Regularized discriminant analysis. J. Am. Stat. Assoc. 1989, 84, 165–175. [Google Scholar] [CrossRef]
- Yu, H.; Yang, J. A direct lda algorithm for high-dimensional data—With application to face recognition. Pattern Recognition 2001, 34, 2067–2069. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; de Siva, V.; Langford, J.C. A global geometric frameworkfor nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. In Advances in Neural Information Processing Systems 14; Dietterich, T.G., Becker, S., Ghahramani, Z., Eds.; MIT Press: Cambridge, MA, USA, 2002; pp. 585–591. [Google Scholar]
- Hyvärinen, A. Fast and robust fixed-point algorithms for independent component analysis. IEEE Trans. Neural Netw. 1999, 13, 411–430. [Google Scholar] [CrossRef]
- Theodoridis, S. (Ed.) Chapter 11—Learning in reproducing kernel hilbert spaces . In Machine Learning, 2nd ed.; Academic Press: Cambridge, MA, USA, 2020; pp. 531–594. Available online: https://www.sciencedirect.com/science/article/pii/B9780128188033000222 (accessed on 28 June 2023).
- Van der Maaten, L.J.P.; Hinton, G.E. Visualizing data using t-sne. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Naizait, G.; Zhitnikov, A.; Lim, L.-H. Topology of deep neural networks. J. Mach. Learn. Res. 2020, 21, 7503–7542. [Google Scholar]
- Chan, J.M.; Carlsson, G.; Rabadan, R. Topology of viral evolution. Proc. Natl. Acad. Sci. USA 2013, 110, 18566–18571. [Google Scholar] [CrossRef]
- Otter, N.; Porter, M.A.; Tillman, U.; Grindrod, P.; Harrington, H.A. A roadmap for the computationof persistent homology. EPJ Data Sci. 2017, 6, 17. [Google Scholar] [CrossRef]
- De Silva, V.G.; Ghrist, R. Coverage in sensor networks via persistent homology. Algebr. Geom. Topol. 2007, 7, 339–358. [Google Scholar] [CrossRef]
- Gameiro, M.; Hiraoka, Y.; Izumi, S.; Mischaikow, K.M.K.; Nanda, K. A topological measurement of proteincompressibility. Jpn. J. Ind. Appl. Math. 2015, 32, 1–17. [Google Scholar] [CrossRef]
- Xia, K.; Wei, G.-W. Persistent homology analysis of protein structure, flexibility, and folding. Int. J. Numer. Methods Biomed. Eng. 2014, 30, 814–844. [Google Scholar] [CrossRef] [PubMed]
- Emmett, K.; Schweinhart, N.; Rabadán, R. Multiscale topology of chromatin folding. In Proceedings of the 9th EAIinternational Conference on Bio-Inspired Information and Communications Technologies, BICT’15, ICST 2016, New York City, NY, USA, 3–5 December 2015; pp. 177–180. [Google Scholar]
- Rizvi, A.; Camara, P.; Kandror, E.; Roberts, T.; Schieren, I.; Maniatis, T.; Rabadán, R. Single-cell topological rna-seqanalysis reveals insights into cellular differentiation and development. Nat. Biotechnol. 2017, 35, 551–560. [Google Scholar] [CrossRef] [PubMed]
- Bhattacharya, S.; Ghrist, R.; Kumar, V. Persistent homology for path planning in uncertain environments. IEEE Trans. Robot. 2015, 31, 578–590. [Google Scholar] [CrossRef]
- Pokorny, F.T.; Hawasly, M.; Ramamoorthy, S. Topological trajectory classification with filtrations of simplicialcomplexes and persistent homology. Int. J. Robot. Res. 2016, 35, 204–223. [Google Scholar] [CrossRef]
- Vasudevan, R.; Ames, A.; Bajcsy, R. Persistent homology for automatic determination of human-data based costof bipedal walking. Nonlinear Anal. Hybrid Syst. 2013, 7, 101–115. [Google Scholar] [CrossRef]
- Chung, M.K.; Bubenik, P.; Kim, P.T. Persistence diagrams of cortical surface data. In Information Processing in Medical Imaging. Lecture Notes in Computer Science; Prince, J.L., Pham, D.L., Myers, K.J., Eds.; Springer: Berlin, Germany, 2009; Volume 5636, pp. 386–397. [Google Scholar]
- Guillemard, M.; Boche, H.; Kutyniok, G.; Philipp, F. Persistence diagrams of cortical surface data. In Proceedings of the 10th International Conference on Sampling Theory and Applications, Bremen, Germany, 1–5 July 2013; pp. 309–312. [Google Scholar]
- Taylor, D.; Klimm, F.; Harrington, H.A.; Kramár, M.; Mischaikow, K.; Porter, M.A.; Mucha, P.J. Topological data analysis ofcontagion maps for examining spreading processes on networks. Nat. Commun. 2015, 6, 7723. [Google Scholar] [CrossRef]
- Leibon, G.; Pauls, S.; Rockmore, D.; Savell, R. Topological structures in the equities market network. Proc. Natl. Acad. Sci. USA 2008, 105, 20589–20594. [Google Scholar] [CrossRef]
- Giusti, C.; Ghrist, R.; Bassett, D. Two’s company and three (or more) is a simplex. J. Comput. Neurosci. 2016, 41, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Sizemore, A.E.; Phillips-Cremins, J.E.; Ghrist, R.; Bassett, D.S. The importance of the whole: Topological data analysis for the network neuroscientist. Netw. Neurosci. 2019, 3, 656–673. [Google Scholar] [CrossRef]
- Maletić, S.; Zhao, Y.; Rajković, M. Persistent topological features of dynamical systems. Chaos 2016, 26, 053105. [Google Scholar] [CrossRef] [PubMed]
- Chung, M.K.; Ramos, C.G.; Paiva, J.; Mathis, F.B.; Prabharakaren, V.; Nair, V.A.; Meyerand, E.; Hermann, B.P.; Binder, J.R.; Struck, A.F. Unified topological inference for brainnetworks in temporal lobe epilepsy using thewasserstein distance. arXiv 2023, arXiv:2302.06673. [Google Scholar]
- Torgerson, W.S. Multidimensional scaling: I. theory and method. Psychometrika 1952, 17, 410–419. [Google Scholar] [CrossRef]
- Jäntschi, L. Multiple linear regressions by maximizing the likelihood under assumption of generalized gauss-laplace distribution of the error. Comput. Math. Methods Med. 2016, 2016, 8578156. [Google Scholar] [CrossRef] [PubMed]
- Jäntschi, L. Symmetry in regression analysis: Perpendicular offsets—The case of a photovoltaic cell. Symmetry 2023, 15, 948. [Google Scholar] [CrossRef]
- NSilver, The Signal and Noise: Why So Many Predictions Fail—But Some Dont; The Penguin Press: London, UK, 2012.
- Hinton, G.E.; Roweis, S. Stochastic neighbor embedding. In Advances in Neural Information Processing Systems; Becker, S., Thrun, S., Obermayer, K., Eds.; MIT Press: Cambridge, MA, USA, 2002; Volume 15. [Google Scholar]
- Ghrist, R. Barcodes: The persistent topology of data. Bull. Amer. Math. Soc. 2008, 45, 61–75. [Google Scholar] [CrossRef]
- Kwessi, E.; Edwards, L. Analysis of eeg time series data using complex structurization. Neural Comput. 2021, 33, 1942–1969. [Google Scholar] [CrossRef]
- Mileyko, Y.; Mukherjee, S.; Harer, J. Probability measures on the space of persistence diagrams. Inverse Probl. 2011, 27, 124007. [Google Scholar] [CrossRef]
- Berry, E.; Chen, Y.-C.; Cisewski-Kehe, J.; Fasy, B.T. Functional summaries of persistence diagrams. J. Appl. Comput. Topol. 2020, 4, 211–262. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).