Abstract
Extreme learning machines (ELMs) have recently attracted significant attention due to their fast training speeds and good prediction effect. However, ELMs ignore the inherent distribution of the original samples, and they are prone to overfitting, which fails at achieving good generalization performance. In this paper, based on expectile penalty and correntropy, an asymmetric C-loss function (called AC-loss) is proposed, which is non-convex, bounded, and relatively insensitive to noise. Further, a novel extreme learning machine called L1 norm robust regularized extreme learning machine with asymmetric C-loss (L1-ACELM) is presented to handle the overfitting problem. The proposed algorithm benefits from L1 norm and replaces the square loss function with the AC-loss function. The L1-ACELM can generate a more compact network with fewer hidden nodes and reduce the impact of noise. To evaluate the effectiveness of the proposed algorithm on noisy datasets, different levels of noise are added in numerical experiments. The results for different types of artificial and benchmark datasets demonstrate that L1-ACELM achieves better generalization performance compared to other state-of-the-art algorithms, especially when noise exists in the datasets.
Keywords:
extreme learning machine; asymmetric least square loss; expectile; correntropy; robustness MSC:
65E99; 68T01; 68U01
1. Introduction
The single hidden-layer feedforward neural network (SLFN) is one of the most important learning algorithms in data mining and machine learning fields. SLFN has only one hidden layer that connects the input and output layers. Generally, gradient-based algorithms are used to train SLFNs similar to back-propagation algorithms [1], which often leads to slow convergence, overfitting, and local minima. To overcome these problems, Huang et al. [2,3] proposed a widely used method based on the structure of SLFN called extreme learning machine (ELM). Compared to the traditional single hidden layer feedforward neural network, the input weights and thresholds of the hidden layer nodes in ELM are randomly generated, and there is no need for repeated adjustment via iterations. ELM identifies the output weight vector with the smallest norm by calculating the Moore-Penrose inverse. Therefore, the training speed of ELM is much higher than that of SLFN. Moreover, ELM also requires minimal training error and norm of the weights, which facilitates good generalization performance. Since ELM has a higher learning speed and better generalization performance, it has been successfully applied in many fields [4,5,6]. However, ELM still has several shortcomings. For example, ELM is based on empirical risk minimization (ERM) [7] which often leads to overfitting.
To address this issue, many scholars have proposed various algorithms based on ELM to improve the generalization performance. In [8], Deng et al. introduced the weight factor into ELM for the first time and proposed the regularized extreme learning machine (RELM). By adjusting the weight factor , the proportion of empirical risk and structural risk in the actual prediction risk can be optimal, thereby avoiding model overfitting. However, RELM uses the L2 norm which is sensitive to outliers. To reduce the influence of outliers, Rong et al. proposed the pruned extreme learning machine (P-ELM) [9], which can remove irrelevant hidden nodes. P-ELM is only used for classification problems. To further address the regression problem, the optimally pruned extreme learning machine (OP-ELM) [10] was proposed. In OP-ELM, The L1 norm is used to remove irrelevant output nodes and select the corresponding hidden nodes, and then the weight of the corresponding hidden nodes is calculated using the least squares method. Given that the L1 norm is robust to outliers, it is used in various algorithms to improve the generalization performance [11,12]. Balasundaram et al. [13] proposed the L1 norm extreme learning machine, which produces sparse models such that decision functions can be determined using fewer hidden layer nodes. Generally speaking, RELM is composed of empirical risk and structural risk. Structural risk can effectively avoid overfitting, and structural risk is determined by loss function. Traditional RELMs use the squared loss function, which is symmetric and unbounded. The symmetry makes the model unable to take into account the distribution characteristics within the training samples, while unboundedness will cause the model to be sensitive to noise and outliers. In real life, the distribution of data is unbalanced, and noise is generally mixed in the process of data collection. Therefore, it is particularly important to choose an appropriate loss function to construct the model.
Quantiles can reflect completely the distribution of random variables without missing any information Quantile regression can more accurately describe the distribution characteristics of random variables for comprehensive analysis. Therefore, quantile regression is more robust and has been successfully applied to statistical prediction [14,15]. Quantile loss can be thought of as a pinball penalty. Expectile loss is an asymmetric least squares loss, which is the square of the quantile loss function. It is often used in regression problems with imbalanced data [16]. However, the unboundedness of the expectile loss leads to a lack of robustness.
From [17], the bounded loss function is less sensitive to noise and outliers than the unbounded loss function, whereas convex functions are usually unbounded. To further improve the robustness of ELM, researchers have proposed various non-convex loss functions to replace the convex loss functions [18,19,20]. Examples of common convex loss functions include square loss, hinge loss, and Huber loss, which allow for the determination of global optimal solutions and are easy to solve. However, the unboundedness of the convex loss function implies that it is not suited for handling outliers. Compared to convex loss functions, non-convex loss functions are more robust to outliers. Recently, Singh et al. [21] proposed a correntropy-based loss function called C-loss. Based on information theory and the kernel method, correntropy [22,23] is considered to be a generalized local similarity measure between two random variables. As a non-convex, bounded loss function, the C-loss function has been widely used in machine learning to improve robustness. In 2019, Zhao et al. [24] applied the C-loss function to ELM for the first time. They proposed the C-loss based ELM (CELM), and also experimentally demonstrated that the generalization performance was better compared to that of other algorithms.
In real life, the distribution of datasets tends to be asymmetric, and the training samples are easily contaminated by noise. In order to better consider the distribution characteristics inside the data and improve the generalization ability of the algorithm, a non-convex robust loss function is proposed, called asymmetric C-loss (AC-loss). A robust extreme learning machine based on the asymmetric C-loss and L1-norm (called L1-ACELM) is then developed. The main contributions of this report are as follows:
- (1)
- Based on the expectile penalty and correntropy loss function, a new loss function (AC-loss) is developed. AC-loss retains some important properties of C-loss such as non-convexity and boundedness. AC-loss is asymmetric, and it can handle unbalanced noise.
- (2)
- A novel approach called the L1-norm robust regularized extreme learning machine with asymmetric C-loss (L1-ACELM) is proposed by applying the proposed AC-loss function and the L1-norm in the objective function of ELM to enhance robustness to outliers.
- (3)
- The non-convexity of the AC-loss function makes it difficult for L1-ACELM to be solved. The half-quadratic optimization algorithm [25,26,27] is used to address these problems. Moreover, the convergence of the proposed algorithms is analyzed.
The remainder of this paper is structured as follows. Section 2 briefly reviews ELM, RELM, C-loss function, and the half-quadratic optimization algorithm. In Section 3, we propose the asymmetric C-loss function and the L1-ACELM model. Next, the half-quadratic optimization algorithm is used to solve L1-ACELM. In addition, we analyze the convergence of the algorithm. The experimental results for the artificial and benchmark datasets are presented in Section 4. Section 5 summarizes the main conclusions and further study.
2. Related Work
2.1. Extreme Learning Machine (ELM)
ELM is a new single hidden layer feedforward neural network that is first proposed by Huang et al. [2]. Unlike traditional SLFN, the input weights and thresholds of the hidden layer in ELM are randomly generated and the output weights can be determined using the least square method. Hence, it is much faster than traditional SLFN. In addition, ELM has good generalization ability.
Given arbitrary distinct samples , and are the input samples and the corresponding output vectors, respectively. The output of a standard SLFN with L hidden nodes can be expressed as follows:
where is the input weight vector that connects the input node to the j-th hidden layer node and is the bias of the j-th hidden node. is the output weight vector that connects the j-th hidden layer node to the output node, and is the output of the j-th hidden layer node with respect to the input . denotes the actual output vector of SLFN.
For ELM, the input weight vector and the bias that connects the input node to the hidden layer node are randomly assigned instead of being updated. Therefore, it can be converted to a linear model:
where
Here, is the output matrix of the hidden layer. Thus, the output weight vector that connects the hidden layer node to the output node can be determined by solving the following equation:
ELM requires the approximation of the training samples with zero error. Therefore, Equation (3) can be written as:
The output weight is the least squares solution of Equation (4), which can be obtained as follows:
where is the Moore-Penrose generalized inverse of the matrix .
To avoid overfitting of the model, regularized ELM is proposed, which facilitates better generalization performance by minimizing the sum of the training error and the norm of the output weights [28]. RELM can be expressed as follows:
The optimal solution to RELM is computed as follows:
where is an identity matrix.
2.2. Correntropy-Induced Loss (C-Loss)
Correntropy is a generalized similarity measure between two random variables in a small neighborhood defined by the kernel width . For a regression problem, the choice of the loss function could ensure that the similarity between the actual output and the target value is maximized, which is equivalent to the maximization of correntropy. Thus, the C-loss function [21] is proposed by Singh et al., which is defined as:
As a bounded non-convex loss function, the C-loss loss function is more robust to outliers than the traditional squared loss function.
2.3. Half-Quadratic Optimization
The half-quadratic optimization algorithm based on the conjugate function theory [29] is usually used for convex optimization and non-convex optimization problems. This method transforms the original non-convex objective function into a half-quadratic objective function by introducing auxiliary variables. As such, the objective function cannot be solved directly, and a two-step alternating minimization method is required. The specific operations are as follows: given the original variables, the auxiliary variables are optimized. The variables are then optimized, and the original variables are determined.
The minimization problem is as follows:
where , is a potential loss function with and is a convex penalty function.
Considering the half-quadratic optimization algorithm, we introduce an auxiliary variable into , which can then be expressed as:
where is a half-quadratic function, which can be represented in the additive form or the multiplicative form .
Substituting Equation (10) into Equation (9), we obtain the following optimization problem:
where is determined using a function , which is the conjugate function of . Alternatively, Equation (11) can then be optimized as follows:
where t represents the t-th iteration.
3. Main Contributions
3.1. Asymmetric C-Loss Function (AC-Loss)
As a measure of risk, the expectile is an extension of the quantile, which represents the distributional information of a random variable. The expectile loss is essentially a squared pinball loss, which can also be considered as an asymmetric squared loss. The asymmetric least square loss function can be expressed as:
However, given that the asymmetric least square loss is an unbounded loss function, it is more sensitive to outliers. Therefore, we construct an asymmetric C-loss (AC-loss) function, based on the C-loss function and the expectile loss function, which is a non-convex, asymmetric, and bounded function for dealing with outliers and noise. The AC-loss function is defined as follows:
The plot of the AC-loss function is shown in Figure 1.
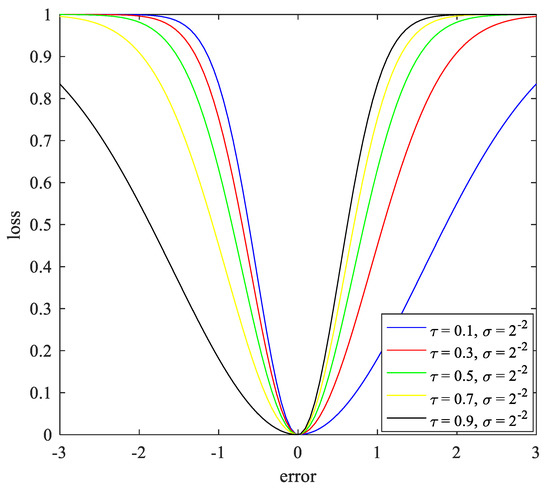
Figure 1.
Asymmetric C-loss function.
3.2. L1-ACELM
To improve the generalization performance of RELM, the proposed loss function is introduced to replace the squared loss function. To further enhance robustness to outliers, the L2 norm of structural risk in RELM is replaced with the L1 norm. Therefore, we propose a new robust ELM (called L1-ACELM):
where is a regularized parameter.
Since AC-loss is a non-convex loss function, it is difficult to directly optimize the objective function. The half-quadratic optimization algorithm is usually applied to optimize non-convex problems. Therefore, we chose the half-quadratic optimization algorithm to find the optimal solution of the objective function.
3.3. Solving Method
For the function , there exists a convex function , which is expressed as follows:
where , and the conjugate function of the function is defined as:
where
By substituting Equation (19) into Equation (18), we have
Now, let and , then Equation (18) can be expressed as:
where
By combining Equations (21) and (16), we have
where . Equation (23) can be simplified as:
The optimal solution can be obtained by solving Equation (24) using the alternating optimization method.
Firstly, given the original variables , we can obtain the optimal solution for the auxiliary variables . When is given, the minimization problem is given as follows:
According to the half-quadratic optimization algorithm, the auxiliary variables can be obtained by solving Equation (24). Thus, we have:
Secondly, the auxiliary variables are fixed and the optimal solution of the original variable can be obtained by solving the following minimization problem:
Equation (27) is equivalent to
Since the L1 norm exists in the objective function, the proximal gradient descent (PGD) algorithm is applied to solve the optimization problem Equation (28). The objective function can be written as
where
is differentiable and its derivative is as follows:
Since satisfies the L-Lipschitz continuity condition, there is a constant such that
The second-order Taylor expansion of the function can be expressed as
where is a constant that is independent of .
Introducing into the objective function, the iterative equation of the proximal gradient descent can be expressed as
Let . Then, the closed-form solution of Equation (34) can be written as:
where and represent the i-th component of and , respectively. We develop a half-quadratic optimization to solve the proposed model, and the pseudo code is presented in Algorithm 1.
| Algorithm 1. Half-quadratic optimization for L1-ACELM |
| Input: The training dataset , the number of hidden layer nodes L, the activation function , the regularization parameter , the maximum number of iterations , window width , a small number and the parameter . Output: the output weight vector . Step 1. Randomly generate input weight and hidden layer bias with L hidden nodes. Step 2. Calculate hidden output matrix . Step 3. Compute by Equation (7). Step 4. Let and , set . Step 5. While or do calculate by Equation (26). update using Equation (35). compute by Equation (29). update t: = t + 1. End while Step 6: Output result given by . |
3.4. Convergence Analysis
Proposition 1.
The sequencegenerated by Algorithm 1 is convergent.
Proof.
Let and be the optimal solution to the objective function (23) after t iterations. In the half-quadratic optimization problem, the conjugate function satisfies . When is fixed, we can obtain the optimal solution of at the (t + 1)-th iteration from Equation (26), then we have:
Next, when is fixed, we can optimize (28) to obtain the solution of at the (t + 1)-th iteration. Then we have:
Combining Inequation (36) with Inequality (37), we have:
Hence, the optimization problem is bounded, and the sequence is convergent. □
4. Experiments
4.1. Experimental Setup
To evaluate the performance of the proposed L1-ACELM algorithm, we performed numerical simulations using two artificial datasets and ten standard benchmark datasets. To show the effectiveness of the L1-ACELM algorithm compared to traditional algorithms including extreme learning machine (ELM), regularized ELM (RELM), and C-loss based ELM (CELM), several experiments were performed. All experiments were implemented in Matlab2016a on a PC with an i5-7200U Intel(R) Core (TM) processor (2.70 GHz) 4 GB RAM.
To evaluate the prediction performance of the L1-ACELM algorithm, the regression evaluation metrics are defined as follows:
- (1)
- The root mean square error (RMSE)
- (2)
- Mean absolute error (MAE)
- (3)
- The ratio of the sum squared error (SSE) to the sum squared deviation of the sample SST (SSE/SST) is given as:
- (4)
- The ratio between the interpretable sum deviation SSR and SST (SSR/SST) is given by:
Since the original algorithms and the proposed algorithm involve many parameters, to ensure the best performance, ten-fold cross-validation is used to determine the optimal parameters. In ELM and RELM, the number of hidden layer nodes is fixed. For RELM, CELM, and L1-ACELM, the optimal value of the regularization parameter is selected from the set {2−50, 2−49, …, 249, 250}. For CELM and L1-ACELM, the window width is selected from the range {2−2, 2−1, 20, 21, 22}. For L1-ACELM, the parameter is obtained from the set {0.1, 0.2, …, 0.9}.
4.2. Performance on Artificial Datasets
To verify the robustness of the proposed L1-ACELM, two artificial datasets were generated using six different types of noise, both of which consisted of 2000 data points. Table 1 shows the specific forms of two artificial datasets and different types of noise. indicates that has a normal distribution with a mean of zero and variance of , means that has a uniform distribution in the interval , indicates that has a t-distribution with degrees of freedom.

Table 1.
Artificial datasets with different types of noise.
Figure 2 shows different types of noise graphs, the graphs of the sinc function, and the graphs of the sinc function with different noises.
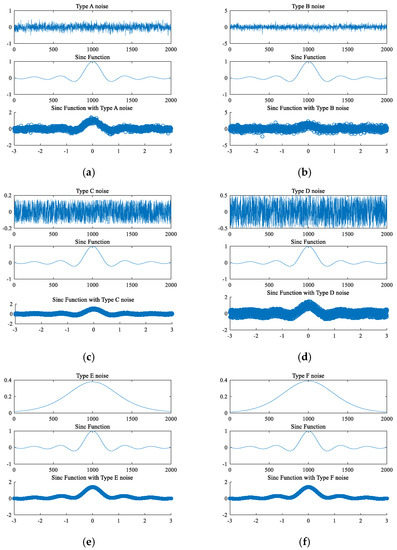
Figure 2.
Graphs of the sinc function with different noises.
Figure 3 shows different types of noise graphs, the graphs of the self-defining function, and the graphs of the self-defining function with different noises.
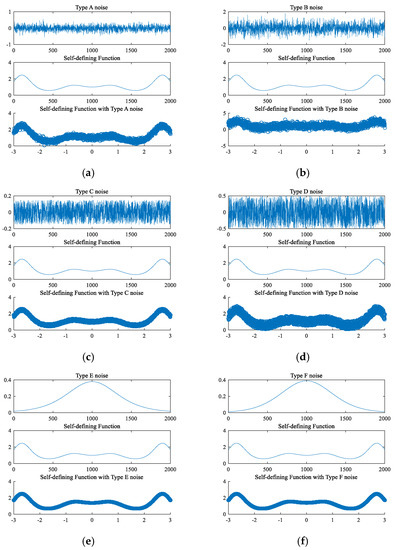
Figure 3.
Graphs of the self-defining function with different noises.
In our experiments, we randomly selected 1600 samples as the training dataset and the remaining 400 samples as the testing dataset. To evaluate the effectiveness of the proposed algorithm, we compared its performance to that of ELM, RELM, and CELM. Table 2 shows the optimal RMSE, MAE, SSE/SST, and SSR/SST of the four algorithms that were obtained based on the optimal parameters selected using the ten-fold cross-validation method. Table 2 also lists the optimal parameters for each algorithm. The regression fitting results of ELM, RELM, CELM, and L1-ACELM on two artificial datasets with noise are shown in Figure 4 and Figure 5.
Table 2.
Experiment results on artificial datasets with different types of noise.
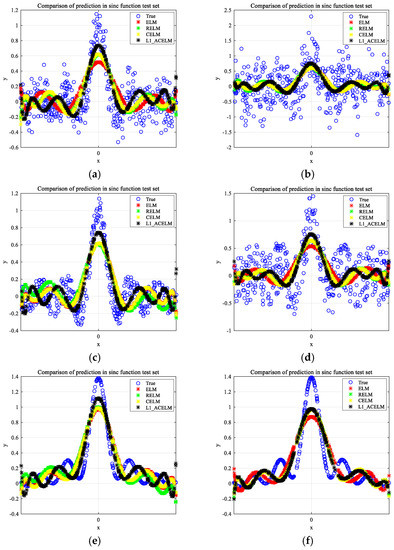
Figure 4.
Fitting results of the sinc function with different noises.
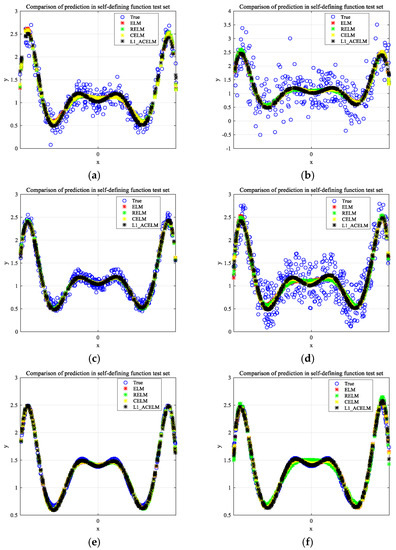
Figure 5.
Fitting results of the self-defining function with different noises.
Figure 4 and Figure 5 demonstrate the fitting effect of the four algorithms on the two artificial datasets. Based on these figures, it is observed that the fitting curve of L1-ACELM is the closest to the real function curve compared to the other three algorithms. In Table 2, the best test results are shown in bold.
The data in Table 2 demonstrate that L1-ACELM exhibits better performance in most cases when compared to the other three algorithms for the two artificial datasets with different noises. It is evident that L1-ACELM has smaller RMSE, MAE, and SSE/SST, and larger SSE/SSR. This indicates that L1-ACELM is more robust to noise. For example, for the sinc function, except for F noise, the performance of the proposed algorithm is superior to that of the other algorithms for different types of noise. Moreover, it is seen that L1-ACELM has better generalization performance in the case of unbalanced noise data. In conclusion, L1-ACELM is more stable in a noisy environment.
4.3. Performance on Benchmark Datasets
To further test the robustness of L1-ACELM, experiments were performed on ten UCI datasets [30] with different levels of noise, including noise-free datasets, datasets with 5% noise, and datasets with 10% noise. Noise datasets were only added to the target output value of the training datasets. Among them, datasets with 5% noise indicate that the noisy data are 5% of the training dataset. The data in the noisy dataset are randomly taken from the set , where d is the average of the target output values of the training datasets.
In the experiment, we randomly selected 80% of the data as the training dataset and the remaining 20% as the testing dataset for each benchmark dataset. The specific description is shown in Table 3.
Table 3.
Description of benchmark datasets.
To better reflect the performance of the proposed algorithm L1-ACELM, the RMSE, MAE, SSE/SST, and SSR/SST were compared with those of ELM, RELM, and CELM. The evaluation indicators and the ranking of each algorithm for different noise environments are listed in Table 4, Table 5 and Table 6, and the best test results are shown in bold. From Table 4 to Table 6, it is observed that the performance of each algorithm decreases as the noise level increases. However, compared to the other algorithms, the performance of L1-ACELM is still the best in most cases. From Table 4, it can be concluded that L1-ACELM performs best on nine datasets out of a total of ten datasets in term of the RMSE and SSR/SST values. Similarly, for the MAE and SSE/SST values, L1-ACELM exhibits the best performance on all the datasets. Table 5 shows that after adding 5% noise, the performance of each algorithm decreases, and according to the RMSE value, the proposed algorithm performed well on eight of the ten datasets. For the MAE, SSE/SST, and SSR/SST values, L1-ACELM performs better for nine datasets. Moreover, for the RMSE, MAE, and SSR/SST values, it exhibits superior performance in nine cases and for the SSE/SST values, it has better performance in all ten datasets.
Table 4.
Performance of different algorithms under noise-free environment.
Table 5.
Performance of different algorithms under 5% noise environment.
Table 6.
Performance of different algorithms under 10% noise environment.
To further illustrate the difference between the proposed algorithm and traditional algorithms, we conducted statistical analysis on the experimental results. Friedman’s test [31] is a well-known test for comparing the performance of various algorithms on datasets. Table 7, Table 8 and Table 9 list the average ranks of four algorithms on four performance measures under a noise-free environment and noisy environment.
Table 7.
Average ranks of benchmark algorithms under noise-free environment.
Table 8.
Average ranks of benchmark algorithms under 5% noise environment.
Table 9.
Average ranks of benchmark algorithms under 10% noise environment.
The Friedman statistic variable can be expressed as follows:
which is distributed according to with degrees of freedom, where is the average rank of the algorithms as listed in Table 7, Table 8 and Table 9. and are the number of datasets and the number of the algorithms, respectively. The Friedman statistic follows an F-distribution:
with and degrees of freedom. Table 10 shows the results of the Friedman test on the dataset without noise, with 5% noise, and with 10% noise. For , the critical value of is 2.960. For the four algorithms, ELM, RELM, CELM, and L1-ACELM, is achieved by comparing the results from Table 10. Therefore, the assumption that all the algorithms perform the same is rejected. To further contrast the differences between paired algorithms, the Nemenyi test [32] is often used as a post hoc test.
Table 10.
Relevant values in the Friedman test on benchmark datasets.
The critical difference can be expressed as:
where the critical value of is 2.569. Here, we can compare the average rank difference between the proposed algorithm and other algorithms using the CD value. If the average rank difference is greater than the CD value, this implies that the proposed algorithm is superior to the other algorithms. Otherwise, there is no difference between the two algorithms. Therefore, we can analyze the difference between the proposed algorithm and other algorithms in the following three cases:
- (1)
- Under noise-free environment. For the RMSE and SSR/SST index, the performance of L1-ACELM is better than that of ELM . For the MAE index, the performance of L1-ACELM is better than that of ELM and RELM . There is no significant difference between L1-ACELM and CELM.
- (2)
- Under 5% noise environment. For the RMSE index, the performance of L1-ACELM is better than that of ELM , RELM , and CELM . For the MAE and SSE/SST index, the performance of L1-ACELM is better than that of ELM (, ) and RELM (, ). For the SSR/SST index, the performance of L1-ACELM is better than that of ELM and CELM .
- (3)
- Under 10% noise environment. Similarly, for the RMSE, MAE, and SSE/SST index, the performance of L1-ACELM is better than that of ELM, RELM, and CELM. For the SSR/SST index, the performance of L1-ACELM is better than that of ELM and RELM.
5. Conclusions
In this paper, a novel asymmetric, bounded, smooth non-convex loss function based on the expected loss and the correntropy loss is proposed, termed AC-loss. The AC-loss loss function and L1 norm are introduced into the regularized extreme learning machine, and an improved robust regularized extreme learning machine is proposed for regression. Owing to the non-convexity of the AC-loss function, it is difficult to solve L1-ACELM. As such, the half-quadratic optimization algorithm is applied to address the nonconvex optimization problem. To prove the effectiveness of L1-ACELM, experiments are conducted on artificial datasets and benchmark datasets with different types of noise, respectively. The results demonstrate the significant advantages of L1-ACELM in generalization performance and robustness, especially when the data distribution with noise and outliers are asymmetric.
The PGD algorithm is used to solve the L1-ACELM in this paper. Since it is an iterative process, the training speed is reduced. In the future, we will research a faster method to solve this optimization problem.
Author Contributions
Conceptualization, Q.W. and F.W.; methodology, Q.W.; software, F.W.; validation, F.W., Y.A. and K.L.; writing—original draft preparation, F.W.; writing—review and editing, Q.W.; visualization, Y.A.; funding acquisition, Q.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under Grant (51875457), the Key Research Project of Shaanxi Province (2022GY-050, 2022GY-028), the Natural Science Foundation of Shaanxi Province of China (2022JQ-636, 2021JQ-701, 2021JQ-714), and Shaanxi Youth Talent Lifting Plan of Shaanxi Association for Science and Technology (20220129).
Data Availability Statement
The data presented in the article are freely available and are listed at the reference address in the bibliography.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ding, S.; Su, C.; Yu, J. An optimizing BP neural network algorithm based on genetic algorithm. Artif. Intell. Rev. 2011, 36, 153–162. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Budapest, Hungary, 25–29 July 2004; pp. 985–990. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Silva, B.L.; Inaba, F.K.; Evandro, O.T.; Ciarelli, P.M. Outlier robust extreme machine learning for multi-target regression. Expert Syst. Appl. 2020, 140, 112877. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Chen, Z.; Zou, R. Bayesian robust multi-extreme learning machine. Knowl. -Based Syst. 2020, 210, 106468. [Google Scholar] [CrossRef]
- Liu, X.; Ge, Q.; Chen, X.; Li, J.; Chen, Y. Extreme learning machine for multivariate reservoir characterization. J. Pet. Sci. Eng. 2021, 205, 108869. [Google Scholar] [CrossRef]
- Catoni, O. Challenging the empirical mean and empirical variance: A deviation study. Annales de l’IHP Probabilités et Statistiques 2012, 48, 1148–1185. [Google Scholar] [CrossRef]
- Deng, W.; Zheng, Q.; Chen, L. Regularized extreme learning machine. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; pp. 389–395. [Google Scholar]
- Rong, H.J.; Ong, Y.S.; Tan, A.H.; Zhu, Z. A fast pruned-extreme learning machine for classification problem. Neurocomputing 2008, 72, 359–366. [Google Scholar] [CrossRef]
- Miche, Y.; Sorjamaa, A.; Bas, P.; Simula, O.; Jutten, C.; Lendasse, A. OP-ELM: Optimally pruned extreme learning machine. IEEE Trans. Neural Netw. 2009, 21, 158–162. [Google Scholar] [CrossRef]
- Ye, Q.; Yang, J.; Liu, F.; Zhao, C.; Ye, N.; Yin, T. L1-norm distance linear discriminant analysis based on an effective iterative algorithm. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 114–129. [Google Scholar] [CrossRef]
- Li, C.N.; Shao, Y.H.; Deng, N.Y. Robust L1-norm non-parallel proximal support vector machine. Optimization 2016, 65, 169–183. [Google Scholar] [CrossRef]
- Balasundaram, S.; Gupta, D. 1-Norm extreme learning machine for regression and multiclass classification using Newton method. Neurocomputing 2014, 128, 4–14. [Google Scholar] [CrossRef]
- Dong, H.; Yang, L. Kernel-based regression via a novel robust loss function and iteratively reweighted least squares. Knowl. Inf. Syst. 2021, 63, 1149–1172. [Google Scholar] [CrossRef]
- Dong, H.; Yang, L. Training robust support vector regression machines for more general noise. J. Intell. Fuzzy Syst. 2020, 39, 2881–2892. [Google Scholar] [CrossRef]
- Farooq, M.; Steinwart, I. An SVM-like approach for expectile regression. Comput. Stat. Data Anal. 2017, 109, 159–181. [Google Scholar] [CrossRef]
- Razzak, I.; Zafar, K.; Imran, M.; Xu, G. Randomized nonlinear one-class support vector machines with bounded loss function to detect of outliers for large scale IoT data. Future Gener. Comput. Syst. 2020, 112, 715–723. [Google Scholar] [CrossRef]
- Gupta, D.; Hazarika, B.B.; Berlin, M. Robust regularized extreme learning machine with asymmetric Huber loss function. Neural Comput. Appl. 2020, 32, 12971–12998. [Google Scholar] [CrossRef]
- Ren, Z.; Yang, L. Correntropy-based robust extreme learning machine for classification. Neurocomputing 2018, 313, 74–84. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, Q.; Li, D.; Tian, Y. LINEX support vector machine for large-scale classification. IEEE Access. 2019, 7, 70319–70331. [Google Scholar] [CrossRef]
- Singh, A.; Pokharel, R.; Principe, J. The C-loss function for pattern classification. Pattern Recognit. 2014, 47, 441–453. [Google Scholar] [CrossRef]
- Zhou, R.; Liu, X.; Yu, M.; Huang, K. Properties of risk measures of generalized entropy in portfolio selection. Entropy 2017, 19, 657. [Google Scholar] [CrossRef]
- Ren, L.R.; Gao, Y.L.; Liu, J.X.; Shang, J.; Zheng, C.H. Correntropy induced loss based sparse robust graph regularized extreme learning machine for cancer classification. BMC Bioinform. 2020, 21, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.P.; Tan, J.F.; Wang, J.J.; Yang, Z. C-loss based extreme learning machine for estimating power of small-scale turbojet engine. Aerosp. Sci. Technol. 2019, 89, 407–419. [Google Scholar] [CrossRef]
- He, Y.; Wang, F.; Li, Y.; Qin, J.; Chen, B. Robust matrix completion via maximum correntropy criterion and half-quadratic optimization. IEEE Trans. Signal Process. 2019, 68, 181–195. [Google Scholar] [CrossRef]
- Ren, Z.; Yang, L. Robust extreme learning machines with different loss functions. Neural Process. Lett. 2019, 49, 1543–1565. [Google Scholar] [CrossRef]
- Chen, L.; Paul, H.; Qu, H.; Zhao, J.; Sun, X. Correntropy-based robust multilayer extreme learning machines. Pattern Recognit. 2018, 84, 357–370. [Google Scholar]
- Huang, G.; Huang, G.B.; Song, S.; You, K. Trends in extreme learning machines: A review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef]
- Robini, M.C.; Yang, F.; Zhu, Y. Inexact half-quadratic optimization for linear inverse problems. SIAM J. Imaging Sci. 2018, 11, 1078–1133. [Google Scholar] [CrossRef]
- Blake, C.L.; Merz, C.J.; UCI Repository for Machine Learning Databases. Department of Information and Computer Sciences, University of California, Irvine. 1998. Available online: http://www.ics.uci.edu/~mlearn/MLRepository.html (accessed on 15 June 2022).
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Benavoli, A.; Corani, G.; Mangili, F. Should we really use post-hoc tests based on mean-ranks? J. Mach. Learn. Res. 2016, 17, 152–161. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).