1. Introduction
As an important part of modern decision science, multiple criteria decision-making (MCDM) is the process of finding the best option from all of the feasible alternatives. It consists of a single decision maker (DM), multiple decision criteria and multiple decision alternatives [
1]. However, the increasing complexity of the socioeconomic environment makes it less possible for a single DM to consider all relevant aspects of a problem as many decision-making processes take place in group settings. This makes the multiple criteria group decision-making (MCGDM) become more and more attractive in management [
2,
3,
4,
5,
6]. Due to the complexities of objects and the vagueness of the human mind, it is more appropriate for the DMs to use linguistic descriptors than other descriptors to express their assessments in the actual process of MCGDM [
7,
8,
9]. For example, when evaluating the “comfort” or “design” of a car, terms such as “good”, “medium”, and “bad” are frequently used, and when evaluating a car’s speed, terms such as “very fast”, “fast”, and “slow” can be used instead of numerical values. In such situations, the use of a linguistic approach is necessary. The objective of Linguistic multiple criteria group decision-making (LMCGDM) is to find the optimal solution(s) from a set of feasible alternatives by means of linguistic information provided by the DMs. To realize this objective, aggregating linguistic information is the key point and linguistic aggregation operators are commonly used.
Until now, many linguistic aggregation operators have been proposed and these operators can be classified into six types: (1) the first is based on linear ordering, such as the linguistic max and min operators [
10,
11,
12], linguistic max-min weighted averaging operator [
13], linguistic median operator [
14], ordinal ordered weighted averaging operator [
15], linguistic weighted conjunction operator [
16]; (2) The second is built on the extension principle [
17,
18] and makes computations on fuzzy numbers that support the semantics of the linguistic labels, such as the linguistic OWA operator [
19], and the linguistic weighted OWA operator [
20], the inverse linguistic OWA operator degree [
21], distance measure operator with linguistic information [
22], induced linguistic continuous ordered weighted geometric operator [
23], linguistic distances with continuous aggregation operator [
24], linguistic probabilistic weighted average operator [
25]; (3) The third is based upon 2-tuple representation, including the 2-tuple arithmetic mean operator [
26], 2-tuple OWA operator [
27], dependent 2-tuple ordered weighted geometric operator [
28], 2-Tuple linguistic hybrid arithmetic aggregation operator [
29]; (4) The fourth computes directly with words, such as the linguistic weighted averaging operator [
30], extended ordered weighted geometric operator [
31], linguistic weighted arithmetic averaging operator [
32], linguistic ordered weighted geometric averaging operator [
33], uncertain linguistic weighted averaging operator [
34], induced uncertain linguistic OWA operator [
35], uncertain linguistic geometric mean operator [
36]; (5) The fifth is on the basis of the power ordered weighted average operator [
37], including linguistic power ordered weighted average (LPOWA) operator [
38], the linguistic generalized power average (LGPA) operator [
39]; (6) and the last is a class of cloud aggregation operator which introduces the cloud model [
40], in LMCGDM, such as the cloud weighted arithmetic averaging (CWAA) operator and cloud weight geometric averaging (CWGA) operator [
41], trapezium cloud ordered weighted arithmetic averaging (TCOWA) operator [
42]. A detail description of the operators LPOWA, CCWA, and CWGA will be presented in
Section 2 of the paper.
The above mentioned operators of types (1)–(2) develop approximation processes to express the results in the initial expression domain, but they produce a consequent loss of information and then result in a lack of precision [
26]. This shortcoming of operators of types (1)–(2) is just overcome by those operators of types (3)–(4) which allow a continuous representation of the linguistic information on their domains, and then can represent any counting of information obtained in an aggregation process without loss of information [
26,
27,
28,
29]. However, the operators of types (3)–(4) do not consider the information about the relationship between the values being combined [
38]. The weakness of operators of types (3)–(4) can be corrected by operators of type (5) since they allow exact arguments to support each other in aggregation process and the weighting vectors depend on the input arguments and allow values to be aggregated to support and reinforce each other [
37,
38,
39]. In this way, operators of type (5) consider the information about the relationship between the values being fused, but these operators of type (5) cannot describe the randomness of languages [
41].
The limitation of operators of type (5) can be explained by the following fact. We know that natural languages generally include uncertainty in which randomness and fuzziness are the two most important aspects; here, the fuzziness mainly refers to uncertainty regarding the range of extension of concept, and the randomness implies that any concept is related to the external world in various ways [
42]. The fuzziness and randomness are used to describe the uncertainty of natural languages. For instance, for a linguistic decision-making problem, DM A may think that 75% fulfillment of a task is “good”, but DM B may regard that less than 80% fulfillment of the same task cannot be considered as “good” with the same linguistic term scale. In this way, when considering the degree of certainty of an element belonging to a qualitative concept in a specific universe, it is more feasible to allow a stochastic disturbance of the membership degree encircling a determined central value than to allow a fixed number [
41,
42]. The cloud model, based on the fuzzy set theory and probability statistics [
40,
43,
44], can describe the fuzziness with a normal membership function and the randomness by means of three numerical characteristics (expectation, entropy and Hyper entropy). Hence, the cloud aggregation operators of type (6) just overcome the limitation of operators of type (5). Nevertheless, the cloud aggregation operators of type (6) do not take into account the information about the relationship between the values being fused.
Based on the above analyses, we find that the limitations of linguistic power aggregation operators of type (5) and cloud aggregation operators of type (6) are mutually complementary. In other words, the linguistic power aggregation operators focus on the information about the relationship between the values being fused, while they ignore the randomness of qualitative concept; the cloud aggregation operators can capture the fuzziness and randomness of linguistic information, but they neglect the information about the relationship between values being fused.
Therefore, this paper aims to propose a new cloud generalized power ordered weighted average (CGPOWA) operator so as to overcome the limitations of existing linguistic power aggregation operators of (5) and cloud aggregation operators of (6). The novelty of this paper is as follows.
- (i)
We present an improved generating cloud method to transform linguistic variables into clouds. The key to linguistic decision-making based on cloud models is the transformation between linguistic variables and clouds, for which Wang and Feng [
45] proposed a method of generating five clouds on the basis of the golden ratio, but this method has three weaknesses: (a) it is limited to a linguistic term set of 5 labels; (b) the expectation of clouds sometimes exceeds the range of the universe; and (c) it cannot effectively distinguish the linguistic evaluation scale over the symmetrical interval. Regarding these limitations, we present an improved method by applying the cloud construction principle. This method can transform linguistic term set of any odd labels rather than only five labels, and can guarantee that all the expectations of clouds fall into the range of the universe. Meanwhile, it can effectively distinguish the linguistic evaluation scale over the symmetrical interval. In this way, this method modifies the weaknesses of the classical generating cloud method.
- (ii)
We address some new cloud algorithms such as cloud possibility degree and cloud support degree. Based on “3En rules” of cloud model, a cloud distance is defined. We further put forward to a cloud possibility degree according to this cloud distance, which can be used to compare the clouds, and define a cloud support degree which is a similarity index. That is, the greater the similarity is, the closer the two clouds are, and consequently the more they support each other. The support degree can be used to determine the weights of aggregation operator.
- (iii)
We develop a new CGPOWA operator. By using the cloud support degree we defined and the power aggregation operator [
39], we develop the CGPOWA operator, which overcomes the limitations of existing linguistic power aggregation operators and cloud aggregation operators and simultaneously maintains the advantages of the two types operators. By studying its properties, we find that the CGPOWA operator is idempotent, commutative and bounded. In addition, we investigate the family of the CGPOWA operator which contains a wide range of aggregation operators such as the CGPA operator, CPOWA operator, CPOWGA operator, CPWQA operator, CWAA and CWGA operators, the maximum and minimum operators.
- (iv)
A new approach for LMCGDM is developed by applying the improved generating cloud method and CGPOWA operator. The main advantage of this approach is that it gives a completely objective view of the decision problem because the CGPOWA operator and the weighting method depend on the arguments completely. Comparing our method with three traditional LMCGDM approaches (linguistic symbolic model, linguistic membership function model, 2-tuple linguistic model) and the cloud aggregating method [
41,
42], we find that:
- (a)
Compared with the three traditional LMCGDM approaches, our method takes a multi-granular linguistic assessment scale of great psychological sense, while the three traditional LMCGDM approaches only use a uniform granular linguistic assessment scale. In other words, when the alternatives are assessed, these three traditional approaches only regard the average level as the unique criterion, which leads to the evaluations rough and one-sided. Our method, however, considers not only the average level but also the fluctuation and stability of qualitative concepts via the cloud model;
- (b)
Compared with cloud aggregating method [
41,
42], our method provides a completely objective weighting model by using the cloud support degree, while the weights in Wang et al. [
41,
42] are subjectively given by the DMs which may result in different ranking results if the DMs provide different weight vectors. In addition, the CGPOWA operator considers the relationships between the arguments provided by the DMs, while the cloud aggregating operators in Wang et al. [
41,
42] do not;
- (c)
Our method presents a simple measure to compare different clouds by the cloud possibility degree (Equation (11)) and the ranking vector (Equation (13)), which requires no knowledge about the distribution of cloud drops, this is different from the score function [
41] which needs to know the distribution of cloud drops. This is also an attractive feature because in most case the distribution of cloud drops is unknown and it is rigid to acquire cloud drops.
This approach is also applicable to different linguistic decision-making problems such as strategic decision-making, human resource management, product management and financial management.
The rest of the paper is organized as follows.
Section 2 reviews the LPOWA, CWAA and CWGA operators and the cloud model.
Section 3 presents an improved method of transforming linguistic variables into clouds, and provides some new cloud algorithms.
Section 4 develops the CGPOWA operator and studies its properties.
Section 5 develops an approach for LMCGDM.
Section 6 presents an illustrative example and the conclusions are drawn in
Section 7.
3. An Improved Generating Cloud Method and Cloud Algorithms
This section provides an improved method to transform linguistic values into clouds, and define some new cloud algorithms, such as cloud possibility degree and cloud support degree.
3.1. An Improved Generating Cloud Method
For an LMCGDM problem, natural languages generally include vague and imprecise information which is too complex and ill-defined to describe by using conventional quantitative expressions, and thus there is a barrier for transforming linguistic information into quantitative values. The cloud model describes linguistic concepts via three numerical characteristics which realize the objective and interchangeable transformation between qualitative concepts and quantitative values. Hence, it is necessary to transform linguistic variables into clouds. The key of this transformation is to select a transformation method. As for this, Wang and Feng [
45] proposed a classical method for generating five clouds on the basis of the golden ratio, which is equal of
.
Let
n be the linguistic evaluation scale and
be an effective universe given by the DMs. Assume that the intermediate cloud is expressed by
. The adjacent clouds around
are respectively expressed by:
The numerical characteristics of five clouds are shown as follows (Wang and Feng, [
45]):
Here is given beforehand.
However, we find that there are three weaknesses in the method of Wang and Feng [
45].
First, the expectation of clouds may exceed the range of the universe . For example, if , then , and .
Second, the method of Wang and Feng [
45] can not be widely used for it is only limited to five labels of the linguistic evaluation scale.
And third, the method cannot effectively distinguish the linguistic evaluation scale over the symmetrical interval. For instance, if , then the expectation values , which results in the linguistic evaluation scale undistinguished.
To overcome the above weaknesses, we present an improved method to transform linguistic variables into clouds by means of the cloud construction principle, which is shown as follows.
Procedure for transforming linguistic variables into clouds:
Step 3. Calculate
, here is given beforehand.
The following Theorem proves that our method can overcome the weaknesses of method given by Wang and Feng [
45].
Theorem 1. Let n be the linguistic evaluation scale and be a valid universe given by the DMs. If are the cloud in , then , , and .
Proof. - (1)
First, we prove that the expectations of clouds are different from each other.
Let
, according to Step 1 of the procedure for transforming linguistic variables into clouds, we get:
It follows from expressions (6) and (7) that expectations of clouds are different from each other.
- (2)
Second, we prove that all the expectations of clouds fall within the range of the universe.
From Step 1 of the procedure for transforming linguistic variables into clouds, we see that:
Since
it can be concluded that:
Similarly, note that
, we then have:
Therefore, the expectations of clouds fall into the range of the universe.
By the same token, it is easy to verify that the expectations of clouds fall into the range of the universe. Based on the above analysis, we can conclude that all the expectations of clouds fall into the range of the universe.☐
Remark 3. Theorem 1 shows that the improved generating cloud method can guarantee that all the expectations fall into the range of the universe, and meanwhile this method can effectively distinguish the linguistic evaluation scale over the symmetrical interval and transform linguistic term set of any odd labels into cloud rather than only five labels.
Example 1. Let and the linguistic assessment set . Then the five clouds can be obtained by using the classical method and the improved generating cloud method, respectively.
The classical method given by Wang and Feng [45]: The improved generating cloud method:
From Example 1, we find that some expectations of clouds obtained by the classical method exceed the range of the universe, e.g., . In particular, we see that , , That is, cloud is absolutely better than cloud . This is obviously inconsistent with the fact that linguistic variable is absolutely better than . Fortunately, these weaknesses have been corrected by the improved generating cloud method.
3.2. New Algorithms of the Cloud Model
This subsection defines the cloud distance, cloud possibility degree and cloud support degree, which will be used for cloud comparison and the weight determination, respectively.
Based on “3En rules” of cloud model, the distance between clouds is defined as follows.
Definition 6. Let and be two clouds in the universe .
Then, the distance of these clouds and is given by:where ,
and .
Proposition 1. The cloud distance has the following properties:
- (i)
;
- (ii)
;
- (iii)
For
where stands for the collection of all clouds in .
Remark 4. If , then the cloud will degenerate into a real number, in this case,
Based on the cloud distance, a cloud possibility degree can be defined as follows.
Definition 7. Let and be two clouds in universe ,
and be the positive ideal cloud, then the cloud possibility degree is defined as: where and are the distances between and ,
,
respectively. Definition 7 shows that the cloud possibility degree is described by the distance and . The larger the distance between and is, the larger the cloud possibility degree is. The cloud possibility degree can be used for clouds comparison.
From Definition 7, we can easily obtain the following properties of cloud possibility degree.
Proposition 2. Let , and be three cloud variables. Then, the cloud possibility degree has the following properties:
- (i)
;
- (ii)
;
- (iii)
;
- (iv)
particularly, ;
- (v)
if and , then ;
- (vi)
if , then .
To rank clouds ,
following Wan and Dong [46] who ranked interval-valued intuitionistic fuzzy numbers via possibility degree, we can construct a fuzzy complementary matrix of cloud possibility degree as follows:where ,
and .
Then, the ranking vector is determined by: and consequently, the clouds can be ranked in descending order via values of .
That is, the smaller the value of is, the larger the corresponding order of is. The advantage of utilizing the vector for ranking clouds lies in the fact that fully uses the decision-making information and makes the calculation simple.
Proposition 3. Suppose that and are two clouds in the universe , if , , , then .
Example 2. Let , , , be four normal clouds, and these clouds can be ranked by the values of .
Note that the positive ideal cloud and according to Equation (10), we have that , , and .
Consequently, based on Equation (11), the possibility degree matrix can be derived as follows: According to Equation (13), we further derive the ranking vector . So the ranking of the normal clouds is:
Following Yager [37], we can define the cloud support degree. Definition 8. Let be the set of all clouds and support (hereafter, Sup) a mapping from to R. For any and , if the term Sup satisfies:
- (i)
;
- (ii)
;
- (iii)
if . where is a distance measure for clouds.
Then is called the support degree for from .
Note that Sup measure is essentially a similarity index, meaning that the greater the similarity is, the closer the two clouds are, and consequently the more they support each other. The support degree will be used to determine the weights of aggregation operator.
4. Cloud Generalized Power Ordered Weighted Average Operator
For an LMCGDM problem, when the linguistic information is converted to clouds, an aggregation step must be performed for a collective evaluation. In this section, we provide a cloud generalized power ordered weighted average (CGPOWA) operator and study its family which includes many different operators.
Following LPOWA operator of Xu, Merigó and Wang [
38] and using the cloud support degree, we can define a cloud generalized power ordered weighted average (CGPOWA) operator as follows.
Definition 9. Let be the set of all clouds and be a subset of .
A mapping is defined as a cloud generalized power ordered weighted average (CGPOWA) operator,where is a parameter satisfying ,
and is the jth largest cloud of for all ,
the function is a BUM function which satisfies ,
and if .
There is a noteworthy theorem that can be deduced from the definition given above.
Theorem 2. The CGPOWA operator is still a cloud and such that: Proof. From operational rules of the cloud given by Li, Liu and Gan [
44], we have
and
Therefore, from Definition 9, we derive that
The GPOWA operator given in Definition 9 has the following properties.☐
Proposition 4. - (i)
(Idempotency). If for , then .
- (ii)
(Commutativity). If is any permutation of , then .
- (iii)
(Boundedness). If and , we then have , and .
Remark 5. The CGPOWA operator possesses the following attractive features: (a) it considers the importance of the ordered position of each input argument, here each input argument is a cloud; (b) it has the basic features of LPOWA operator, for instance, it considers the relationships between the arguments and gauges the similarity degrees of the arguments; (c) the weighting vectors associated with the CGPOWA operator can be determined by Equation (15), which provides an objective weighting model based on the objective data rather than relying on the preferences and knowledge of the DMs, moreover, it will reduce the influence of those unduly high (or low) arguments on the decision result by using the support measure to assign them lower weights; (d) the CGPOWA operator considers the decision arguments and their relationships, which are neglected by existing cloud aggregation operators; in addition, it can describe the randomness of linguistic terms, whereas linguistic power aggregation operators cannot do this work; (e) if the linguistic information is converted to a sequence of random variables with certain distribution and moment properties, it is possible to formulate the CGPOWA operator in an abstract stochastic model.
Table 1 shows that the CGPOWA operator can degenerate into many aggregation operators (here
), such as cloud power ordered weighted quadratic average (CPOWQA) operator, cloud power ordered weighted average (CPOWA) operator, cloud power ordered weighted geometric average(CPOWGA) operator, CGPA operator, CGM operator, cloud power weighted quadratic average (CPWQA) operator, CWAA and CWGA operator (See
Appendix B for a proof).
By taking different weighting vector
in CGPOWA operator, we can obtain some other aggregation operators such as the maximum operator, the minimum operator, the cloud generalized mean operator and the Window-CGPOWA operator (See
Table 2).
5. An Approach for LGDM Based on the CGPOWA Operator
The LMCGDM problem is the process of finding the best alternative from all of the feasible alternatives which can be evaluated according to a number of criteria values with linguistic information. In general, LMCGDM problem includes multiple experts (or the DMs), multiple decision criteria and multiple alternatives.
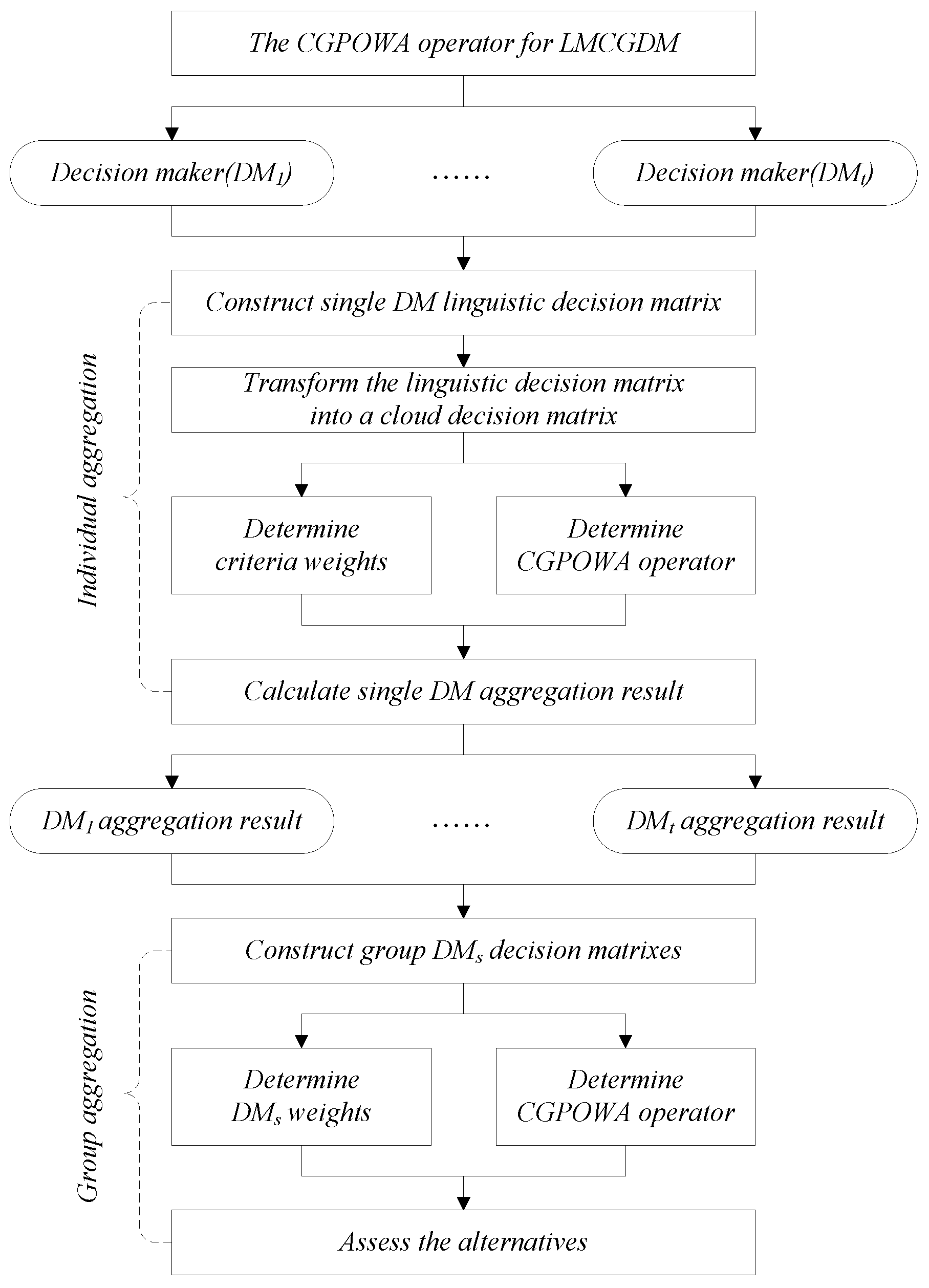
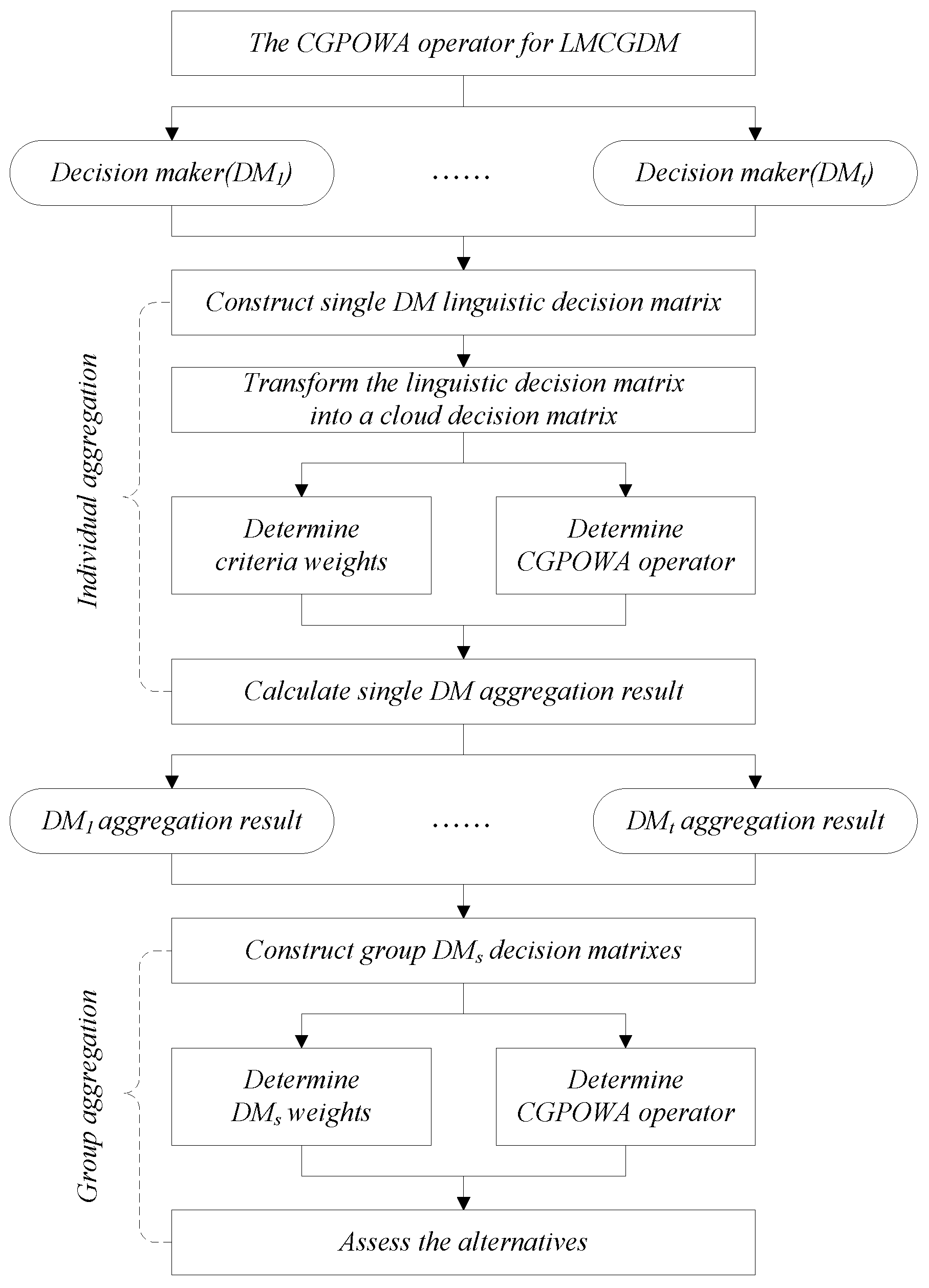
To better understand the procedure for solving LMCGDM problem on the basis of a cloud model, we develop a general framework for LMCGDM aggregation procedure (see,
Figure 2) which contains two stages: (i) individual aggregation, which is a MCDM process for each DM; and (ii) group aggregation, which is a multiple experts decision-making process composed by multiple experts and multiple alternatives. For individual aggregation, we need to determine the weights of criteria, and then aggregate the criteria values of each alternative into one collective value by means of the CGPOWA operator and consequently, we derive a collective decision matrix composed by the DMs and alternatives; For group aggregation, we need to determine the weights of the DMs based on the collective decision matrix, and further aggregate the collective values of each alternative into one result by using the CGPOWA operator. Finally, we can assess the alternatives.
We develop a new algorithm for LMCGDM based on the improved generating cloud method and CGPOWA operator with the weight information being completely unknown. The algorithm is summarized in a simple algorithm through six steps. We first describe the algorithm inputs.
Input data of our new LMCGDM algorithm. Let
be the set of
m alternatives,
be the set of
n criteria, and
be the set of
t DMs. Assume that the DM
provides his/her preference value
for the alternative
w. r. t. the criterion
, where
takes the form of linguistic variable, and consequently we can construct a decision matrix
for
. We summarize all input data below:
Given the input data in (17), our objective is to determine the optimal alternative . We give a new LMCGDM approach below.
An LMCGDM algorithm.
Step 1. Transform the linguistic information into clouds.
Transform the linguistic decision matrix
into a cloud decision matrix
by applying the improved generating cloud method developed in
Section 3.
Step 2. Determine the weights of criteria.
Calculate the cloud support degrees:
which satisfy the support conditions (i)–(iii) in Definition 8. Here, the cloud distance measure is expressed by Equation (10), and
denotes the similarity between the
sth largest cloud preference value
and the
qth largest cloud preference value
. We further calculate the weights of criteria by means of Equation (15).
Step 3. Aggregate the criteria values of each alternative into a collective value.
Utilize Equation (14) to aggregate all cloud decision matrices into a collective cloud decision matrix .
Step 4. Calculate the weights of the DMs.
Calculate the cloud support degrees:
which satisfy the support conditions (i)–(iii) in Definition 8. Here, the cloud distance measure is calculated by Equation (10). According to Equation (15), we can calculate the weights of the DMs.
Step 5. Aggregate the collective values of each alternative into one result.
Utilize Equation (14) to compute the collective overall preference value of the alternative .
Step 6. Rank the alternatives and choose the best one(s).
According to the cloud possibility degree (11) and the ranking vector (13), we can rank the collective overall preference values in descending order and consequently select the best one in the light of the collective overall preference values .
Remark 6. Compared with the traditional linguistic approaches (e.g., linguistic membership function model, linguistic symbolic model, 2-tuple linguistic model) and the existing cloud aggregating method (e.g., [41]), the attractive features of our approach are as follows.
- (a)
The three traditional LMCGDM approaches only use a uniform granular linguistic assessment scale, while ours takes a multi-granular linguistic assessment scale of great psychological sense. In other words, when assessing the alternatives, these three traditional approaches only regard the average level as the unique criterion, which leads to the evaluations rough and one-sided. Our method, however, considers not only the average level but also the fluctuation and stability of qualitative concepts by using and ,
respectively. Such statements can also be examined by the numerical analysis in Section 6.2. - (b)
In addition, the corresponding aggregation operators for the three traditional LMCGDM methods are the linguistic power average (LPA) operator, triangular fuzzy weighted averaging (TFWA) operator and 2-tuple weighted averaging (TWA) operator, respectively. Note that these operators have their own weaknesses when describing the randomness, while our aggregation operator can effectively reduce the loss and distortion of information in aggregating process, and correspondingly improve the precision of the results.
For instance, LPA and TWA operators cannot precisely depict the randomness because when converting the linguistic variables into real numbers, they directly transform the random decision-making information into the precise domain, therefore, partial linguistic information is lost. TFWA operator can describe the fuzziness whereas it cannot describe the randomness.
- (c)
Compared with the cloud aggregating method (cf., [41]), our method provides a completely objective weighting model by using the cloud support degree, while the weights in Wang et al. [41] are subjectively given by the DMs which may result in different ranking results if the DMs provide different weight vectors. In addition, the CGPOWA operator considers the relationships between the arguments provided by the DMs, while the cloud aggregating operators in Wang et al. [41] do not. - (d)
Our method presents a simple measure for comparing different clouds by the cloud possibility degree Equation (11) and the ranking vector Equation (13), which requires no knowledge about the distribution of cloud drops, this is different from the score function [41] which needs to know the distribution of cloud drops. This is also an attractive feature because in most case the distribution of cloud drops is unknown and it is rigid to acquire cloud drops.
7. Conclusions
LMCDM problems are widespread in various fields such as economics, management, medical care, social sciences, engineering, and military applications. However, traditional aggregation methods are not robust enough to convert qualitative concepts to quantitative information in LMCDM problems. Among the existing aggregation operators, linguistic power aggregation operators and cloud aggregation operators have the most merits, but they have their own weaknesses. If combined together, the two types of operators can overcome their own weaknesses, that is, the characters of two types of operators are mutually complementary. This paper developed a new class of aggregation operator which successfully unified the advantages of the existing linguistic power aggregation operators and cloud aggregation operators, and simultaneously overcame their limitations. First, we presented an improved method to transform linguistic variables into clouds, which corrects the weaknesses of the classical generating cloud method. Based on this method, we developed some new cloud algorithms such as the cloud possibility degree and cloud support degree, which can be used for cloud comparison and the weight determination, respectively. Furthermore, a new CGPOWA operator was developed, which considers the decision arguments and their relationships and characterizes the fuzziness and randomness of linguistic terms. By studying the properties of CGPOWA operator we found that it is commutative, idempotent, bounded. Moreover, CGPOWA operator can degenerate into many different operators, including CGPA operator, CPOWA operator, CPOWGA operator, CPWQA operator, CWAA and CWGA operators, the maximum operator and the minimum operator. In particular, based on the new generating cloud method and CGPOWA operator, a new approach for LGDM was developed. In the end, to show the effectiveness and the good performance of our approach in practice, we provided an example of investment selection and made a comparative analysis.
In further research, it would be very interesting to extend our analysis to the case of more sophisticated situation such as introducing the behavior theory of the DMs in the context of CGOWPA operator. Nevertheless, we leave that point to future research, since our methodology cannot be applied to that extended framework, which will result in more sophisticated calculation and which we cannot tackle here.

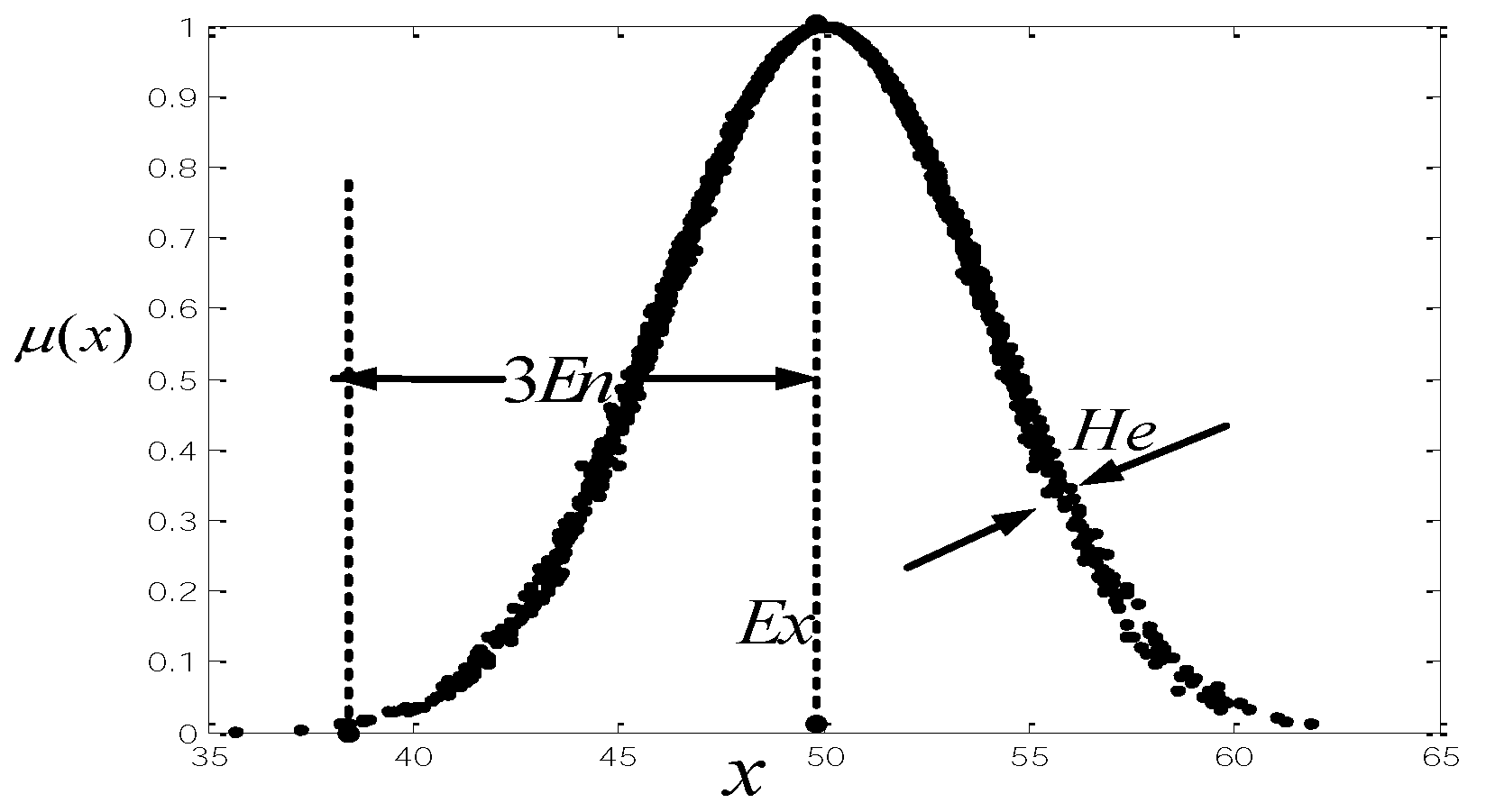

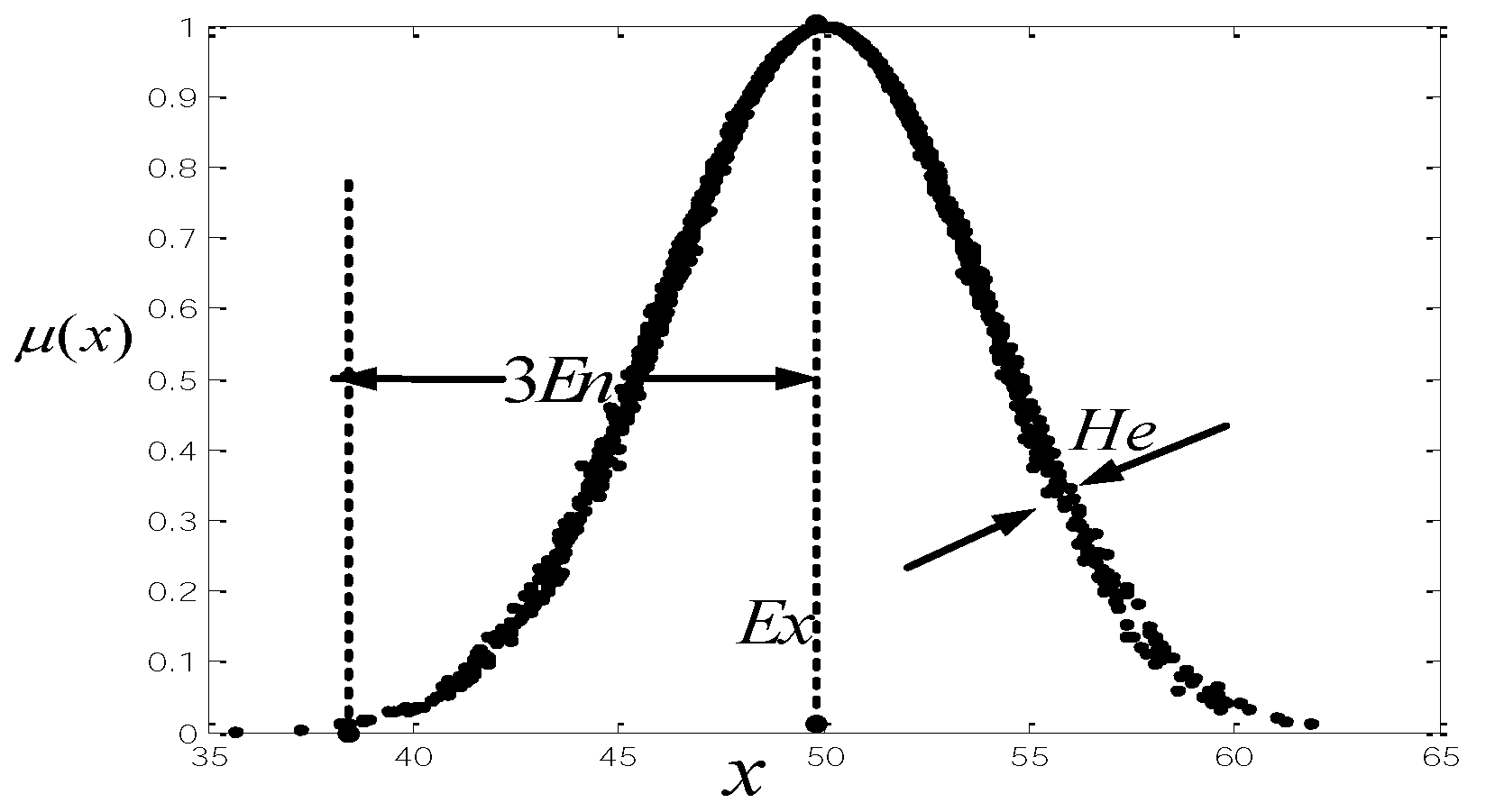{kind=link}
{kind=link}