A Design for Genetically Oriented Rules-Based Incremental Granular Models and Its Application



Abstract
:1. Introduction
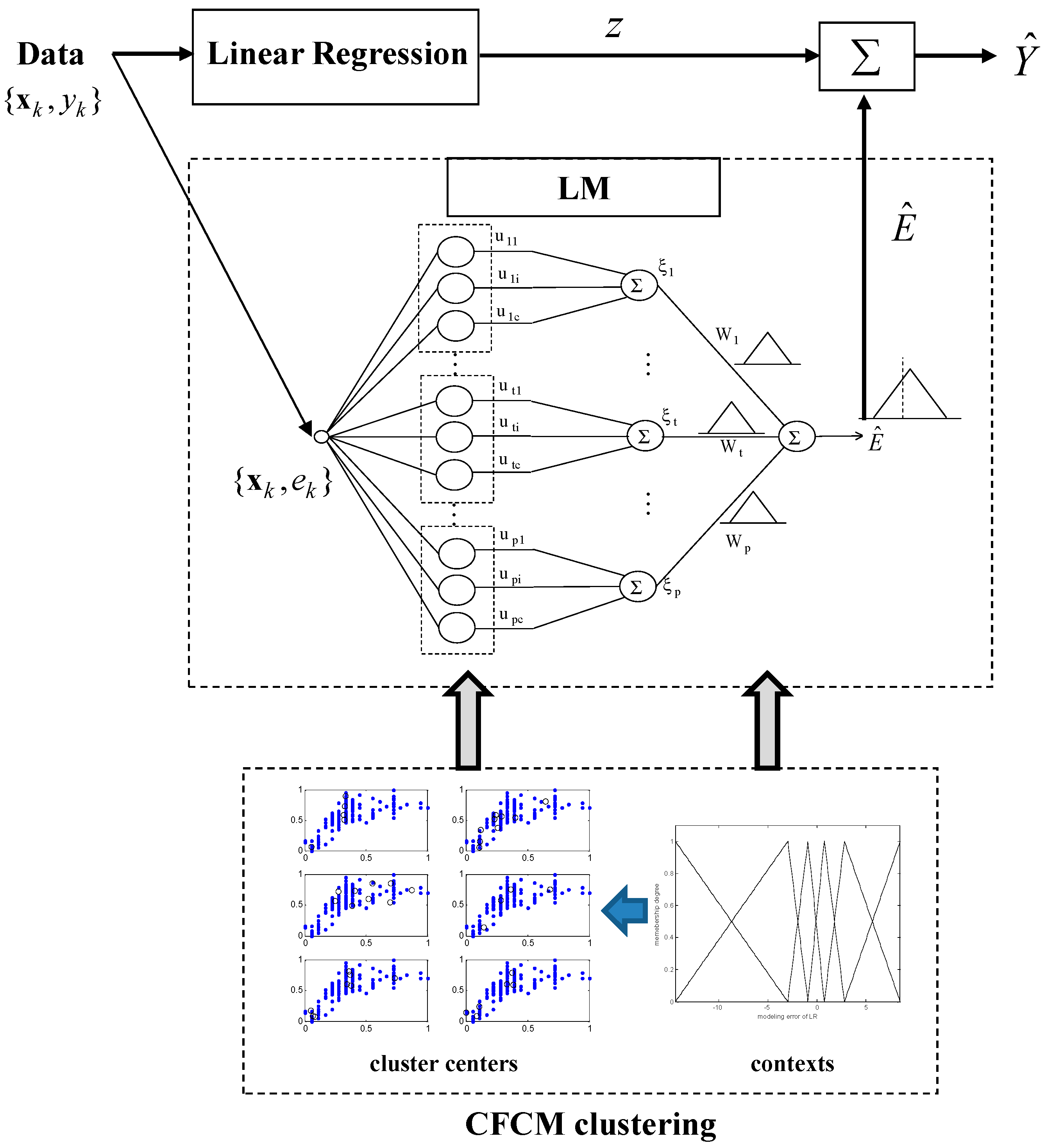
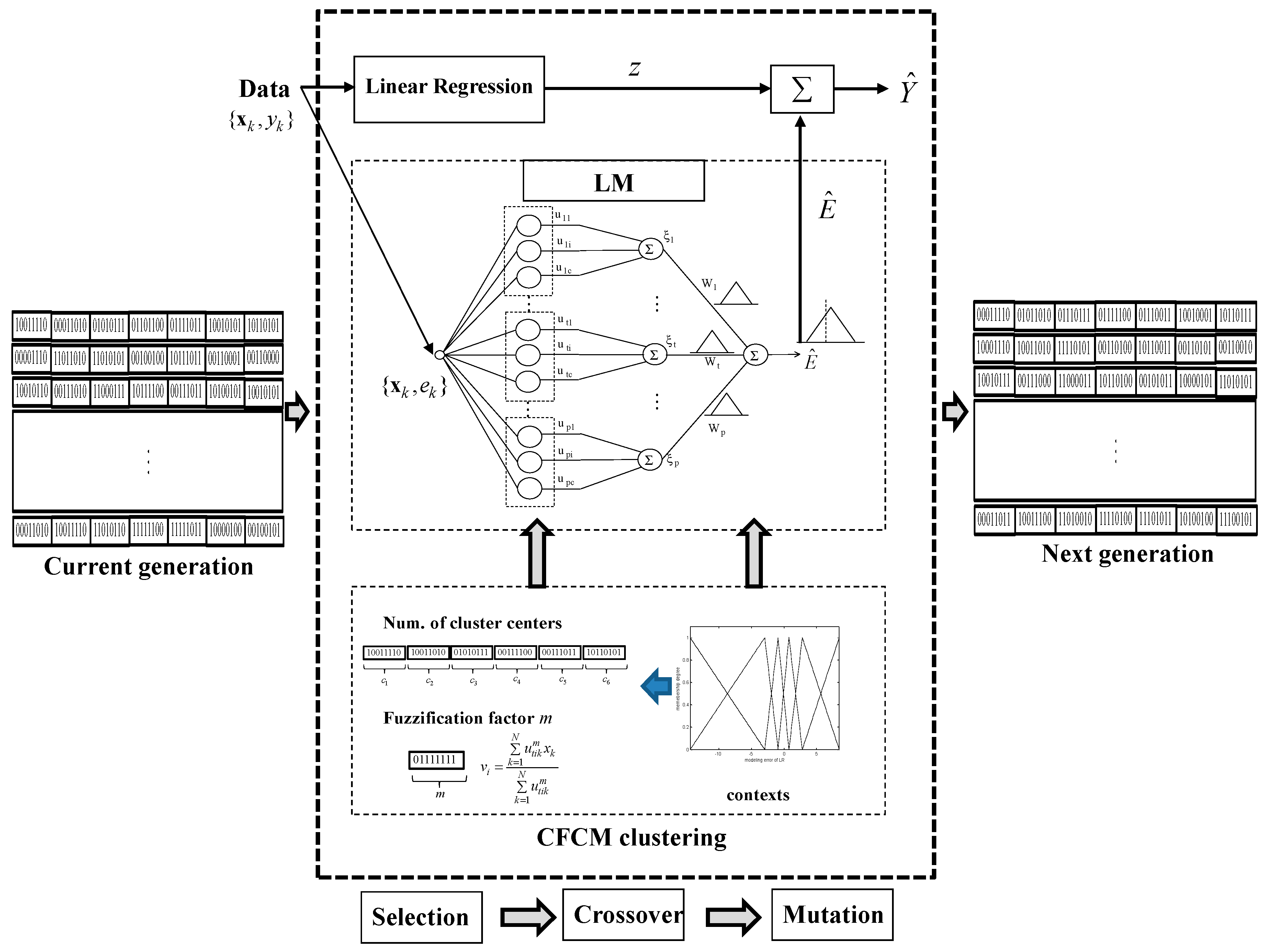
2. Incremental Granular Model (IGM)
2.1. Linear Regression (LR) as a Global Model
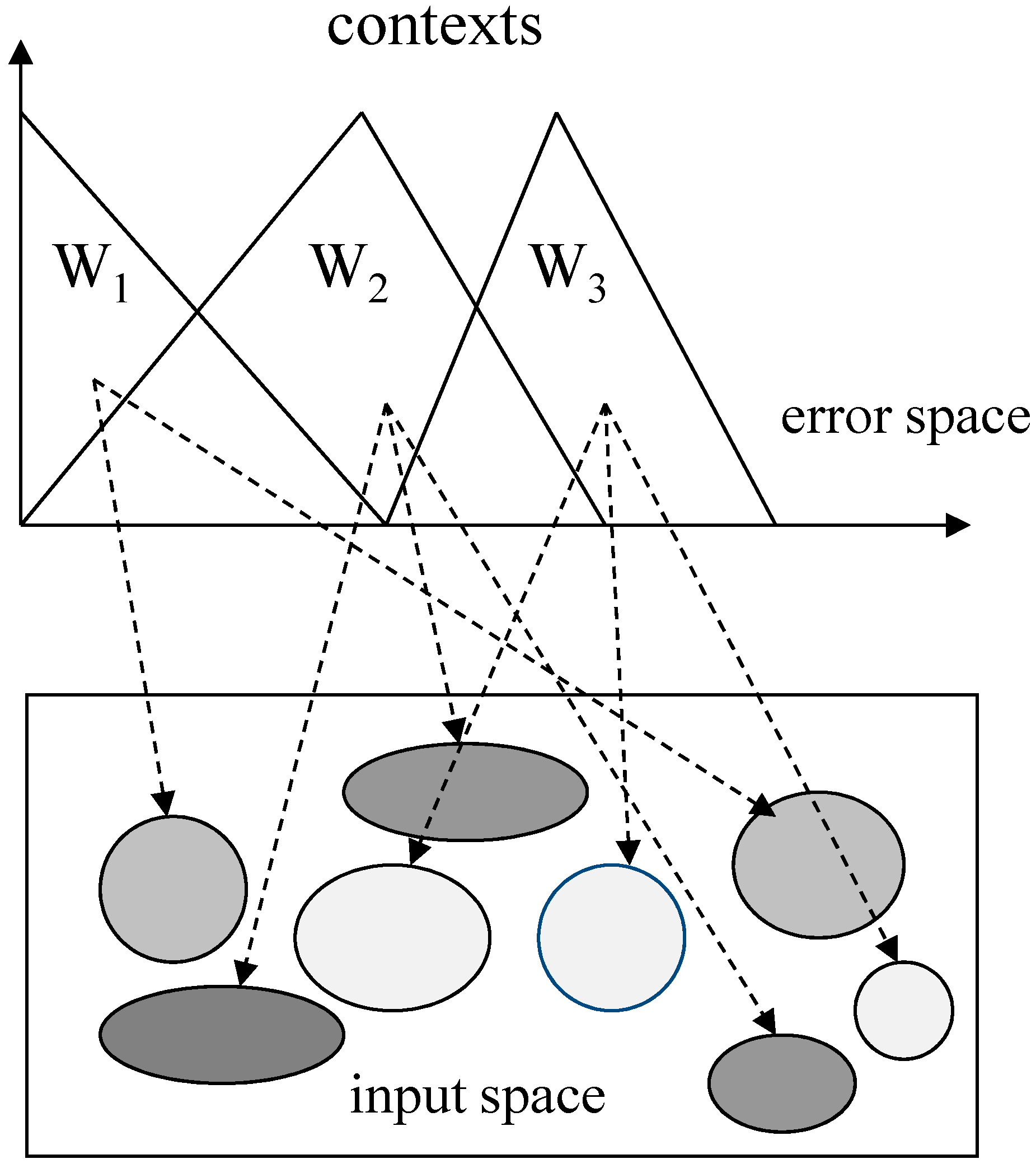
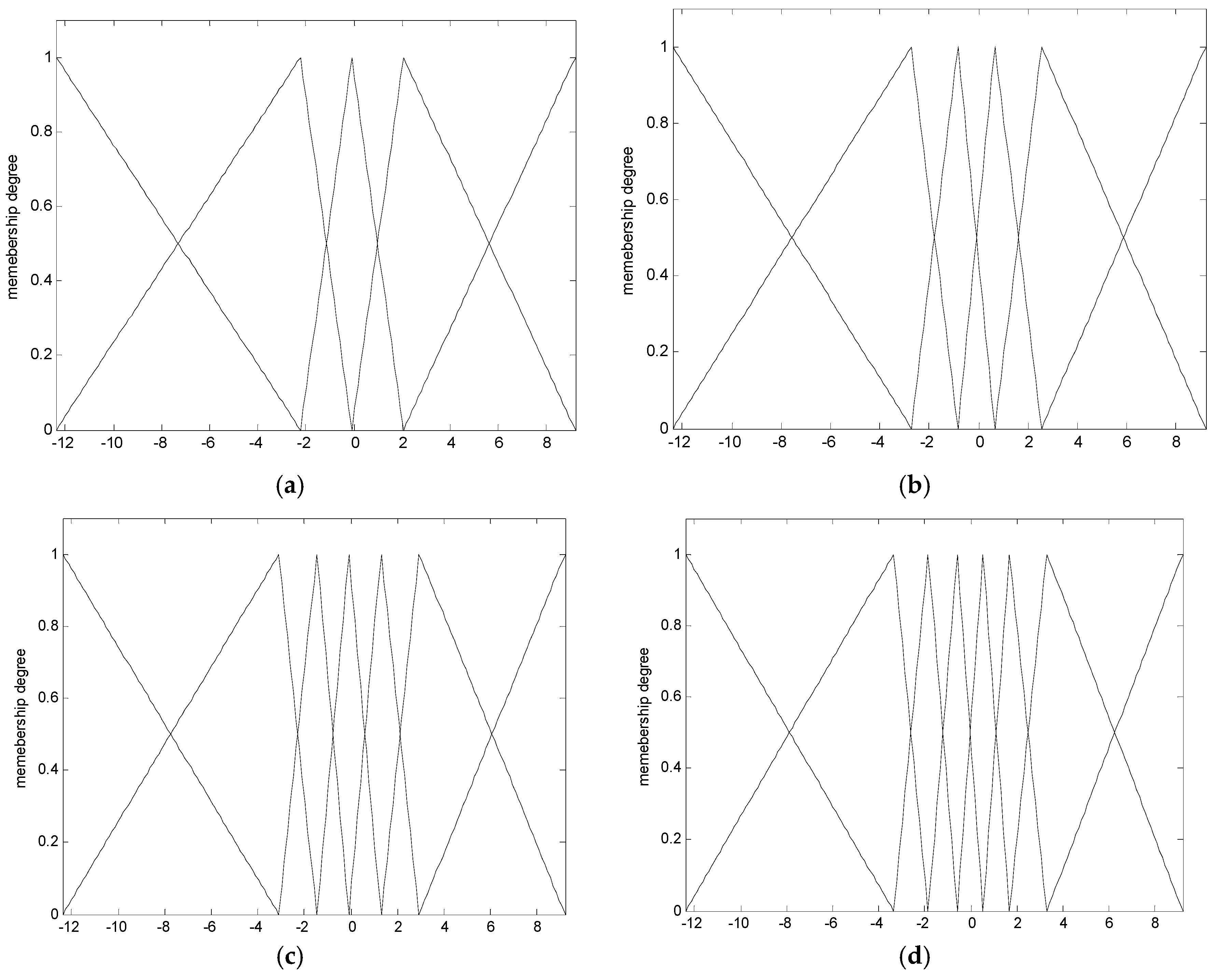
2.2. CFCM Clustering with the Use of Information Granules
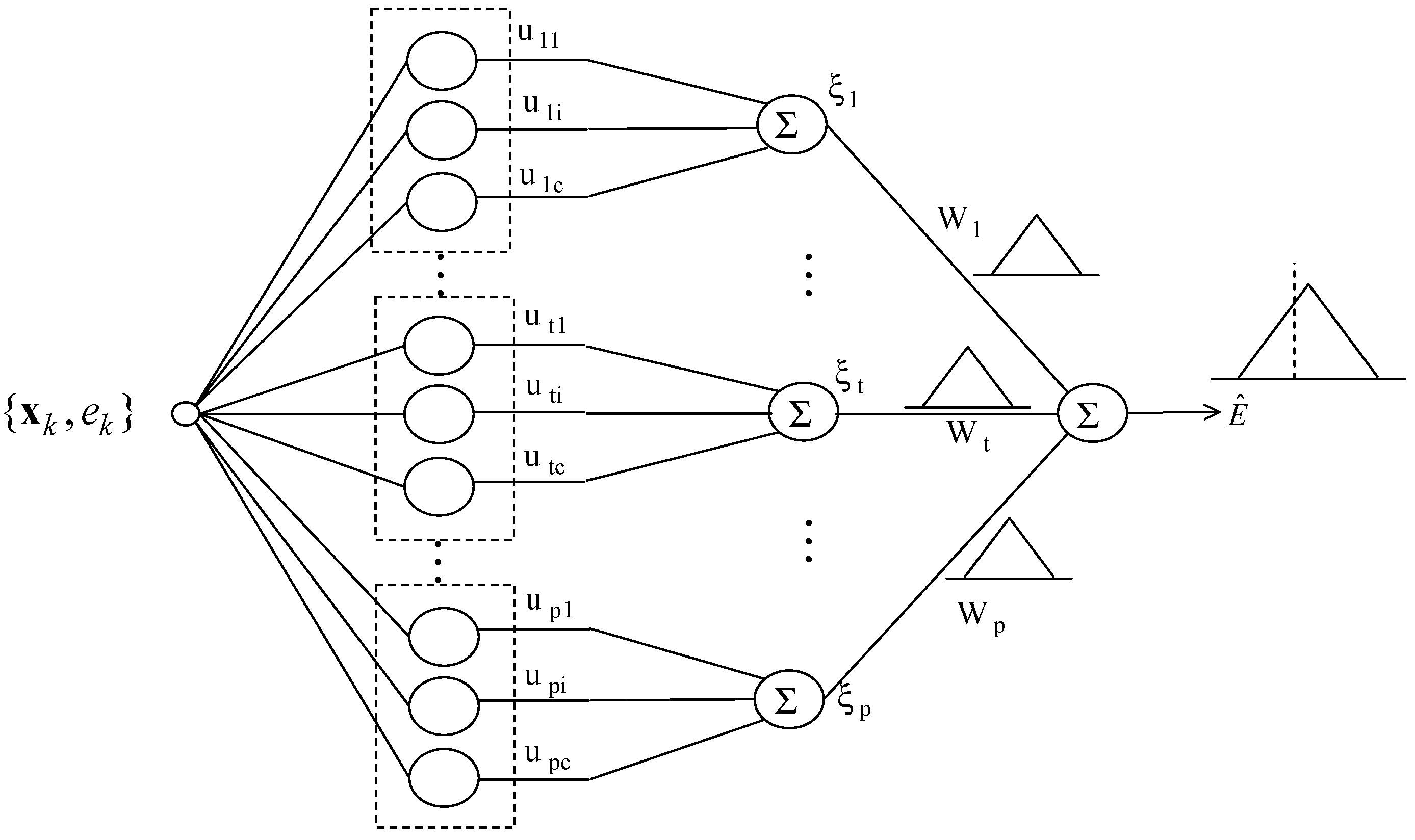
2.3. Linguistic Model (LM) as a Local Model
2.4. Incremental Granular Model (IGM)
- [Step 1]
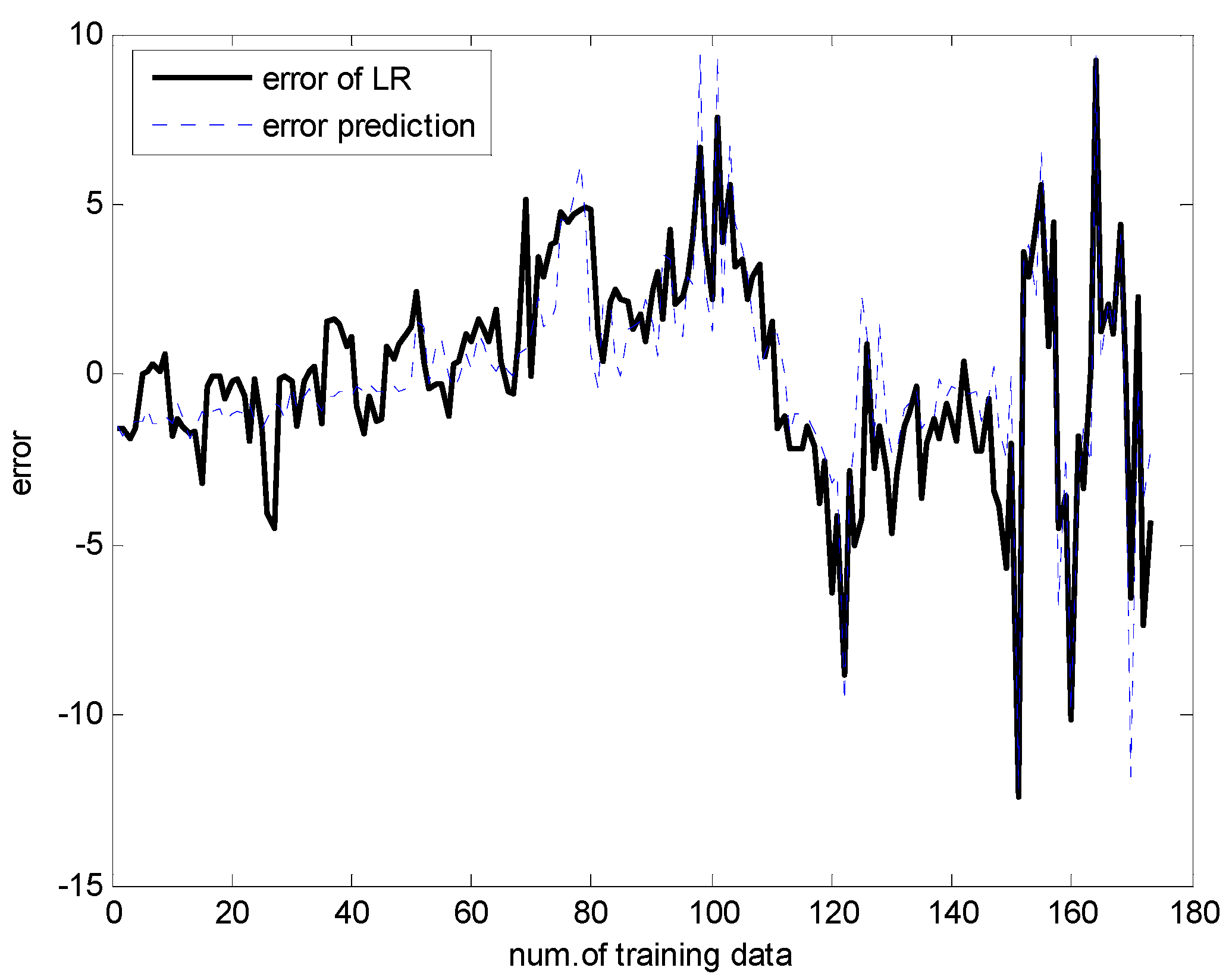
- Perform prediction using LR for the original input–output data pairs. Then, we obtain the modeling errors between the actual output and the model output of LR. From the original data set, a collection of input-error pairs is obtained.
- [Step 2]
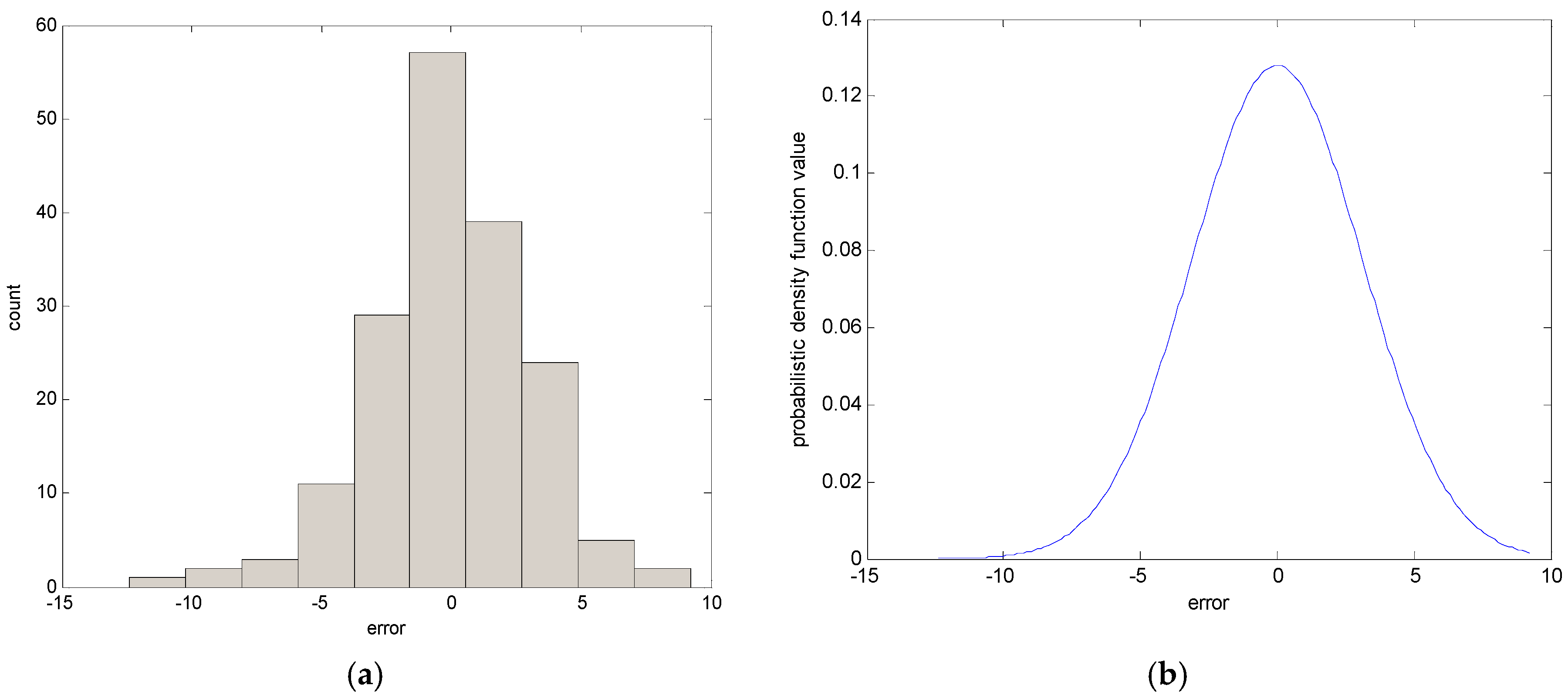
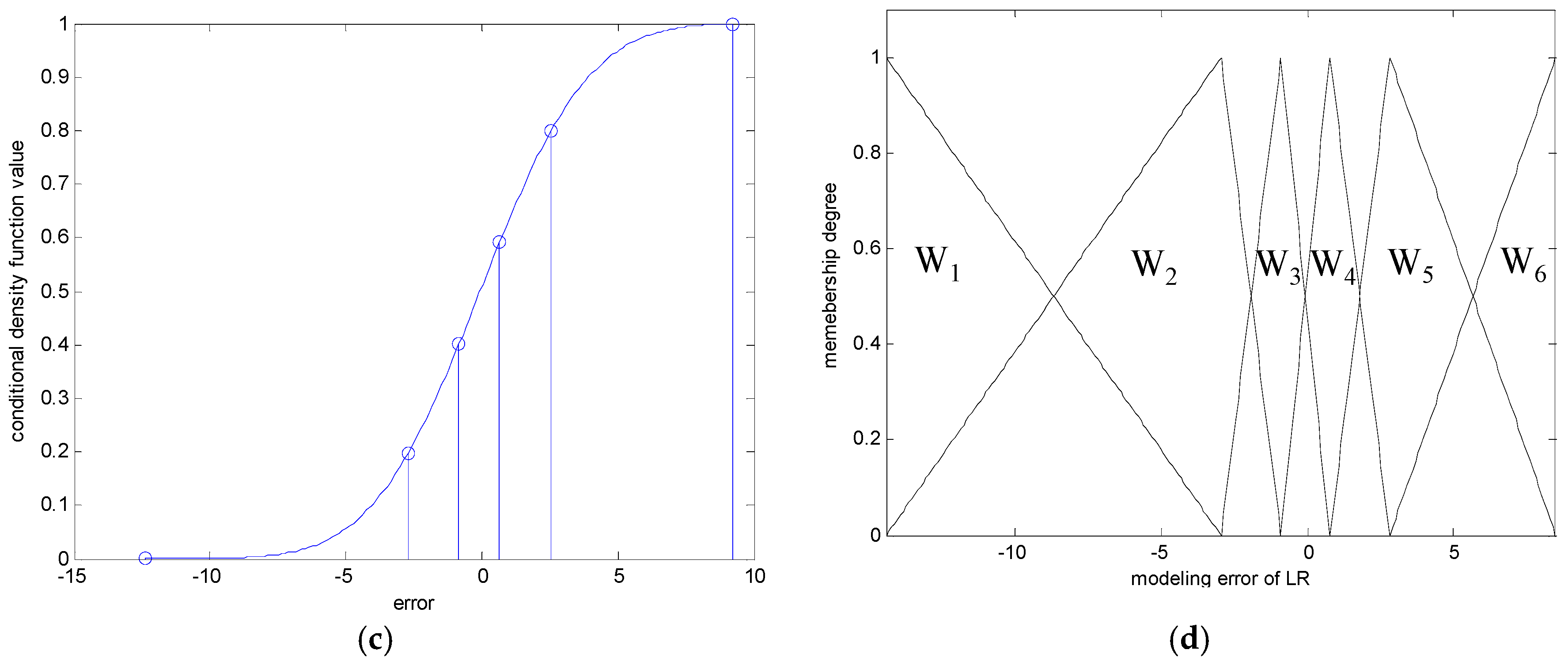
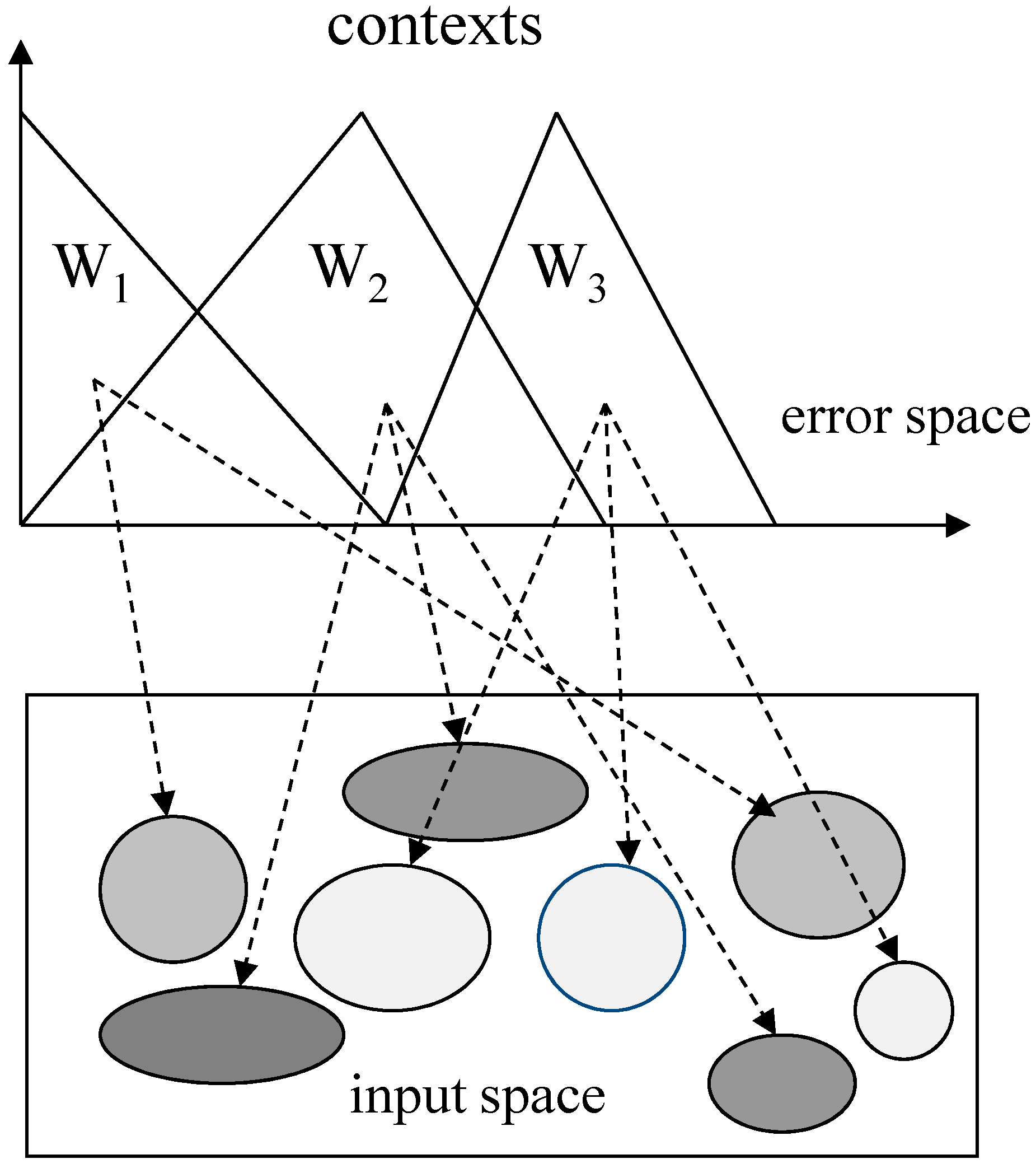
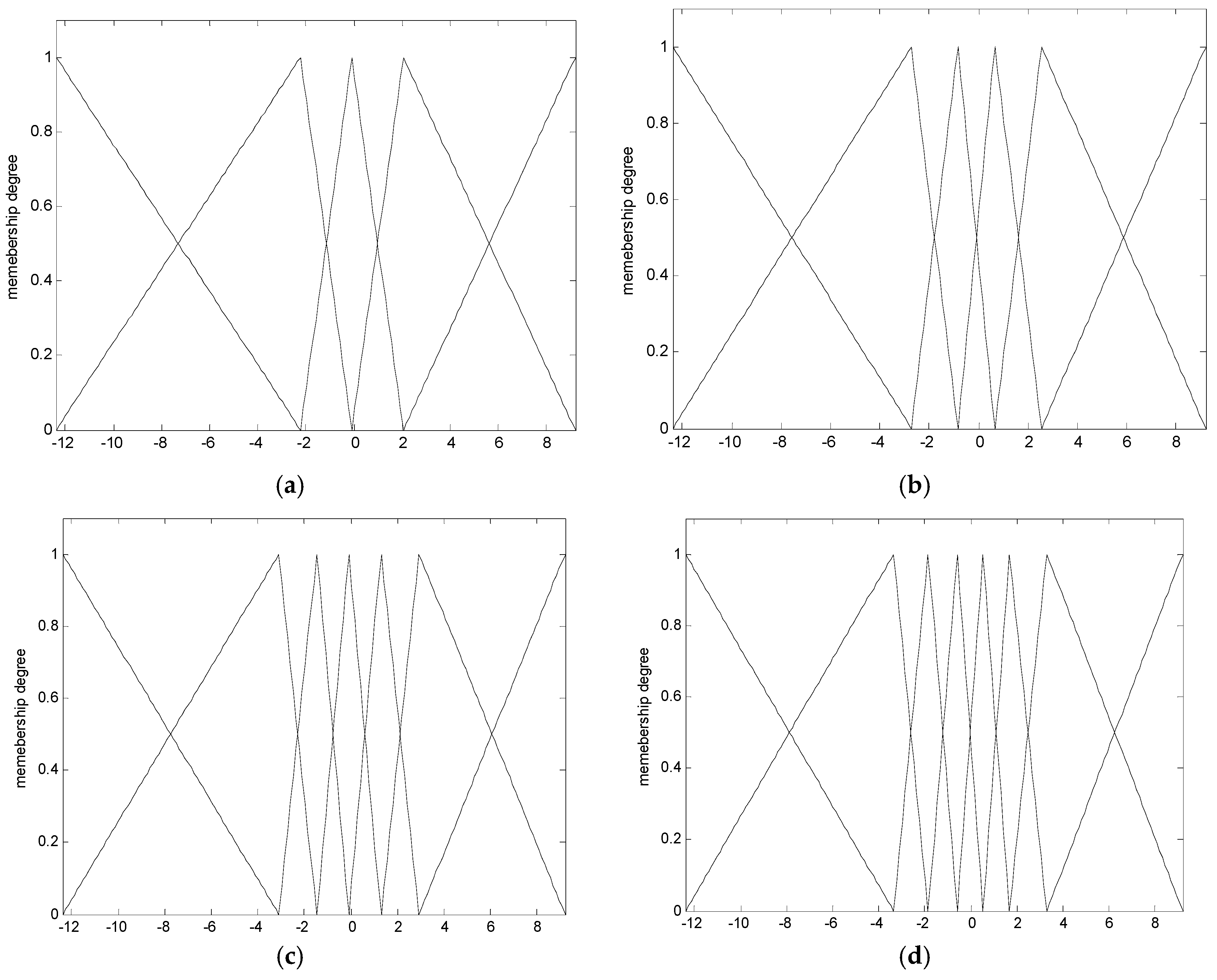
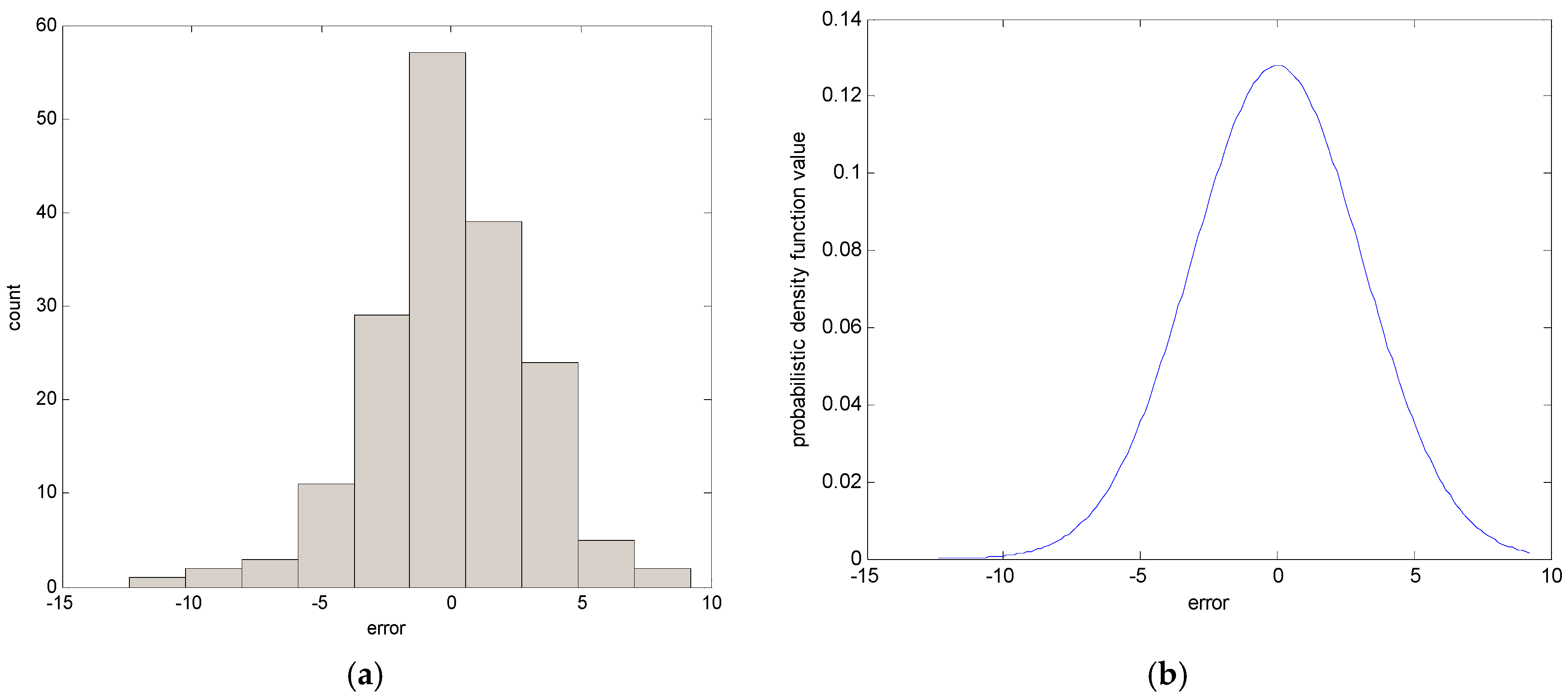
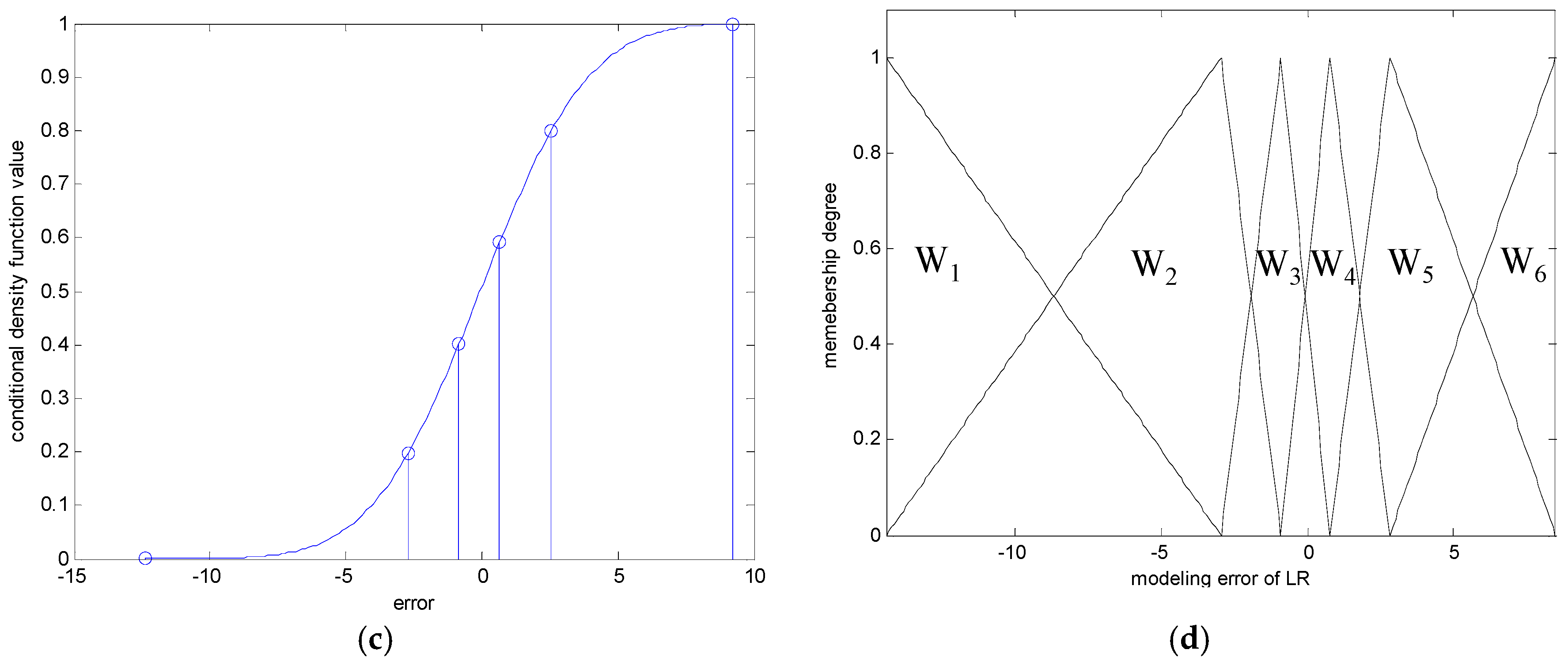
- Generate the contexts in the error space. The contexts are obtained by the statistical characteristics of data distribution.
- [Step 3]
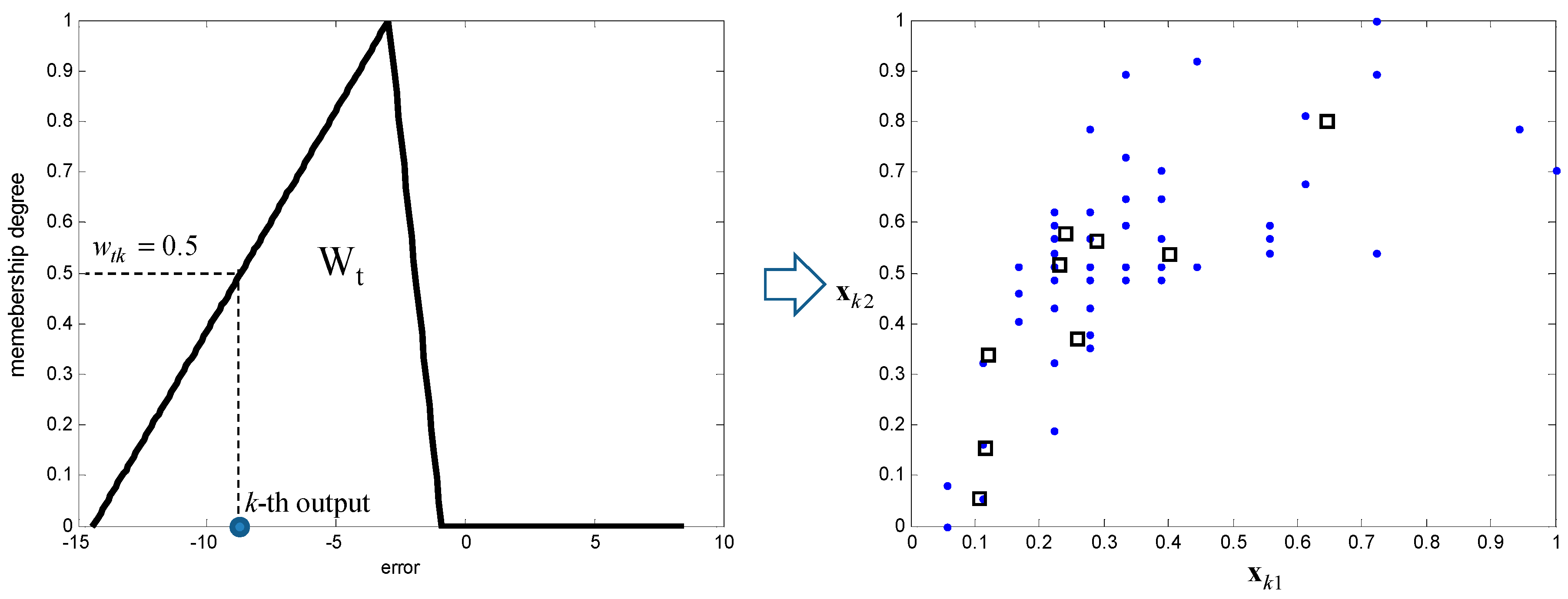
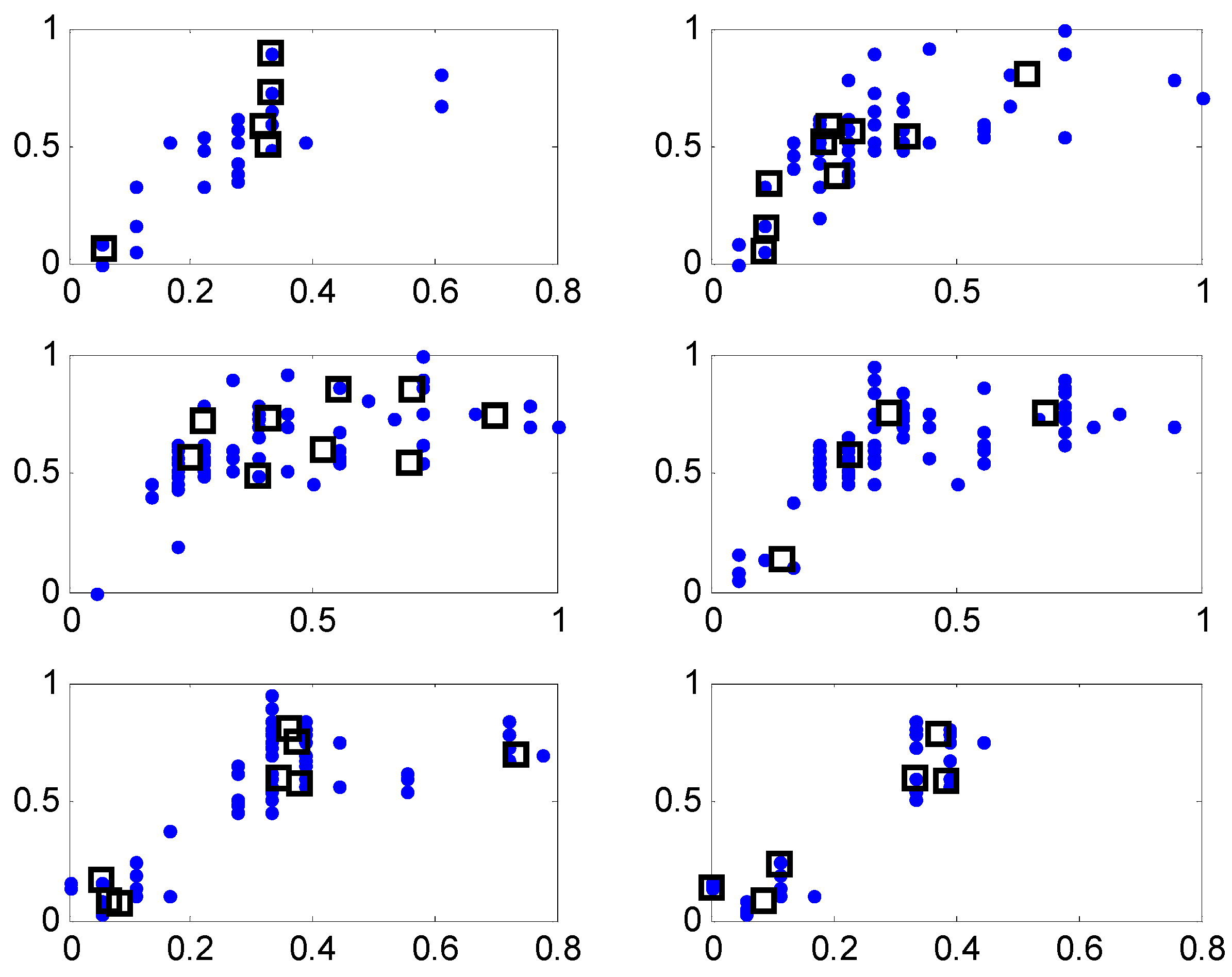
- Perform the CFCM clustering in the input space associated with the contexts generated in the error space. In the design of a conventional LM, we obtain clusters for contexts with clusters in each context. However, we need to determine the number of clusters that reflect the inherent characteristics of some input data pairs assigned from each context. Thus, we find the optimized number of cluster centers based on an evolutionary algorithm such as GA, described in the next section.
- [Step 4]
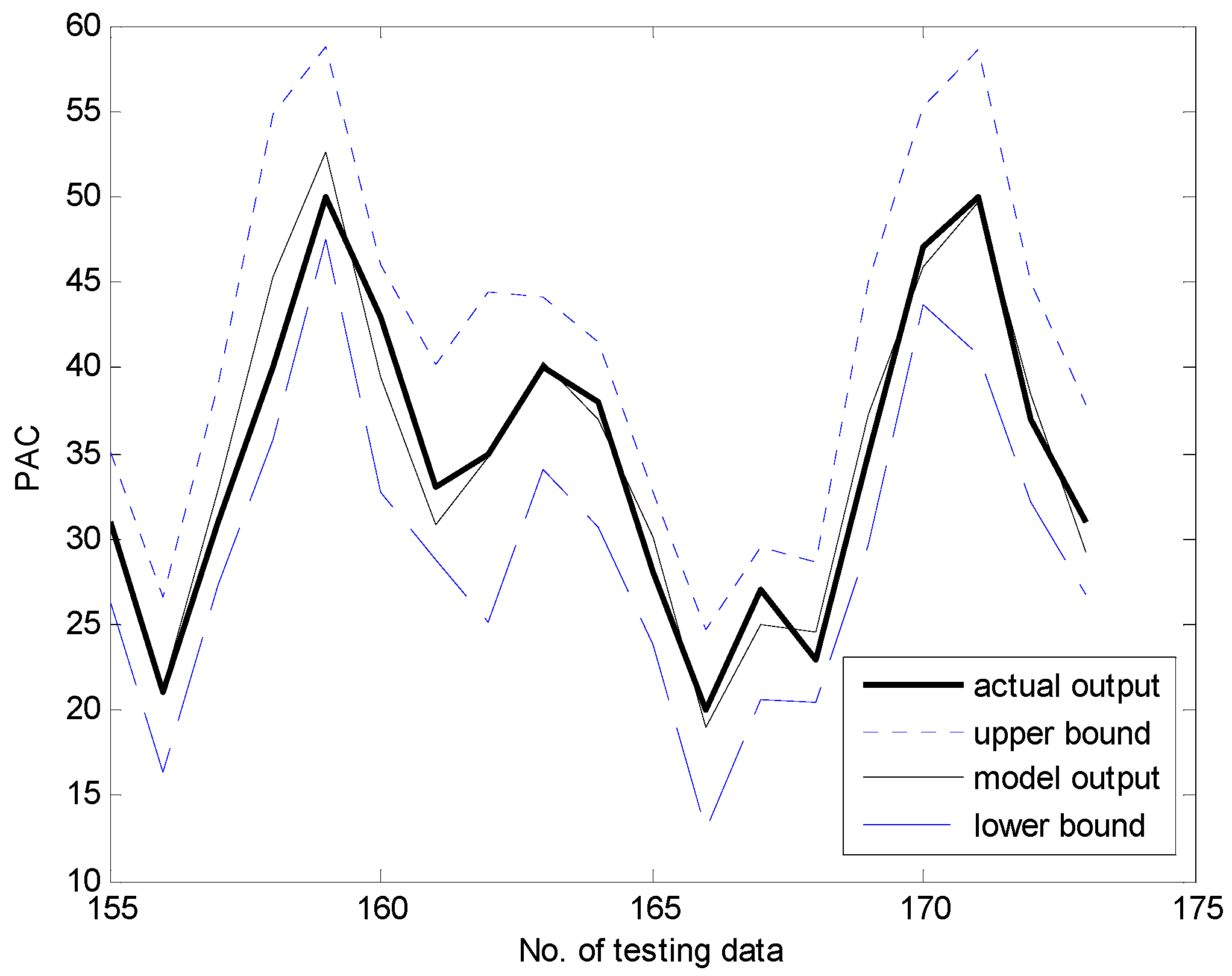
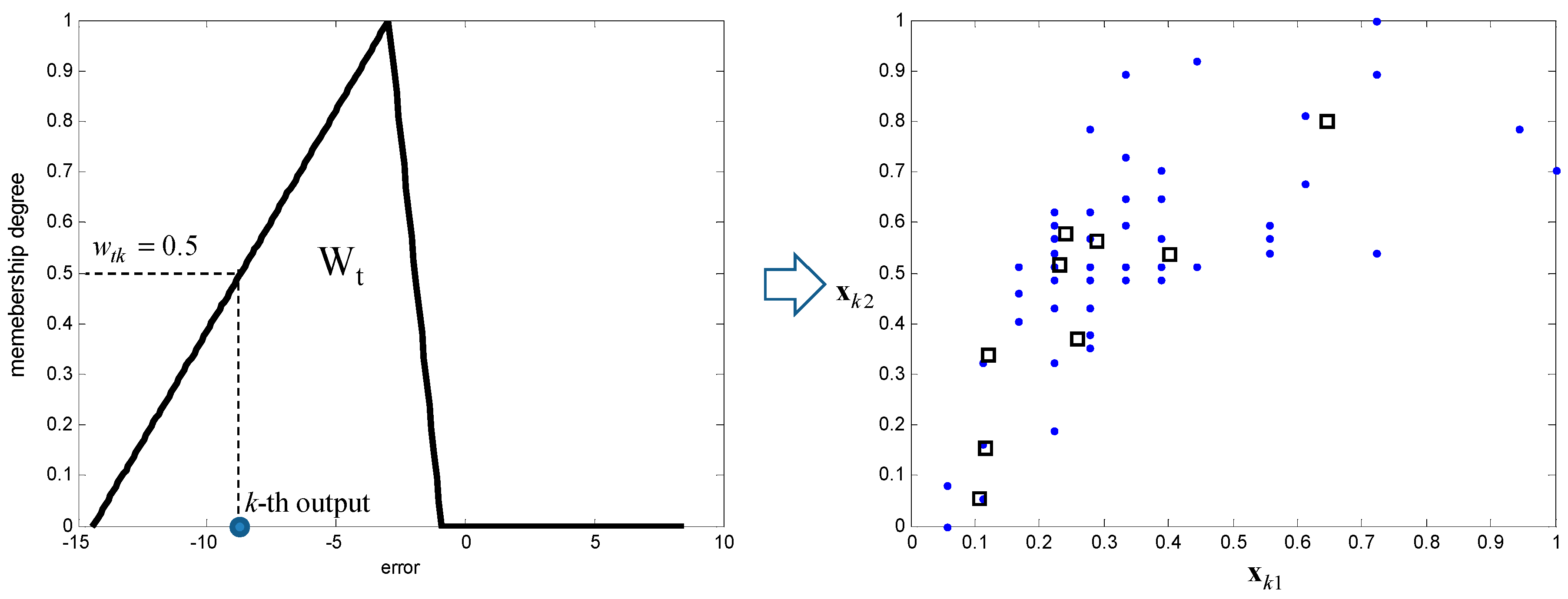
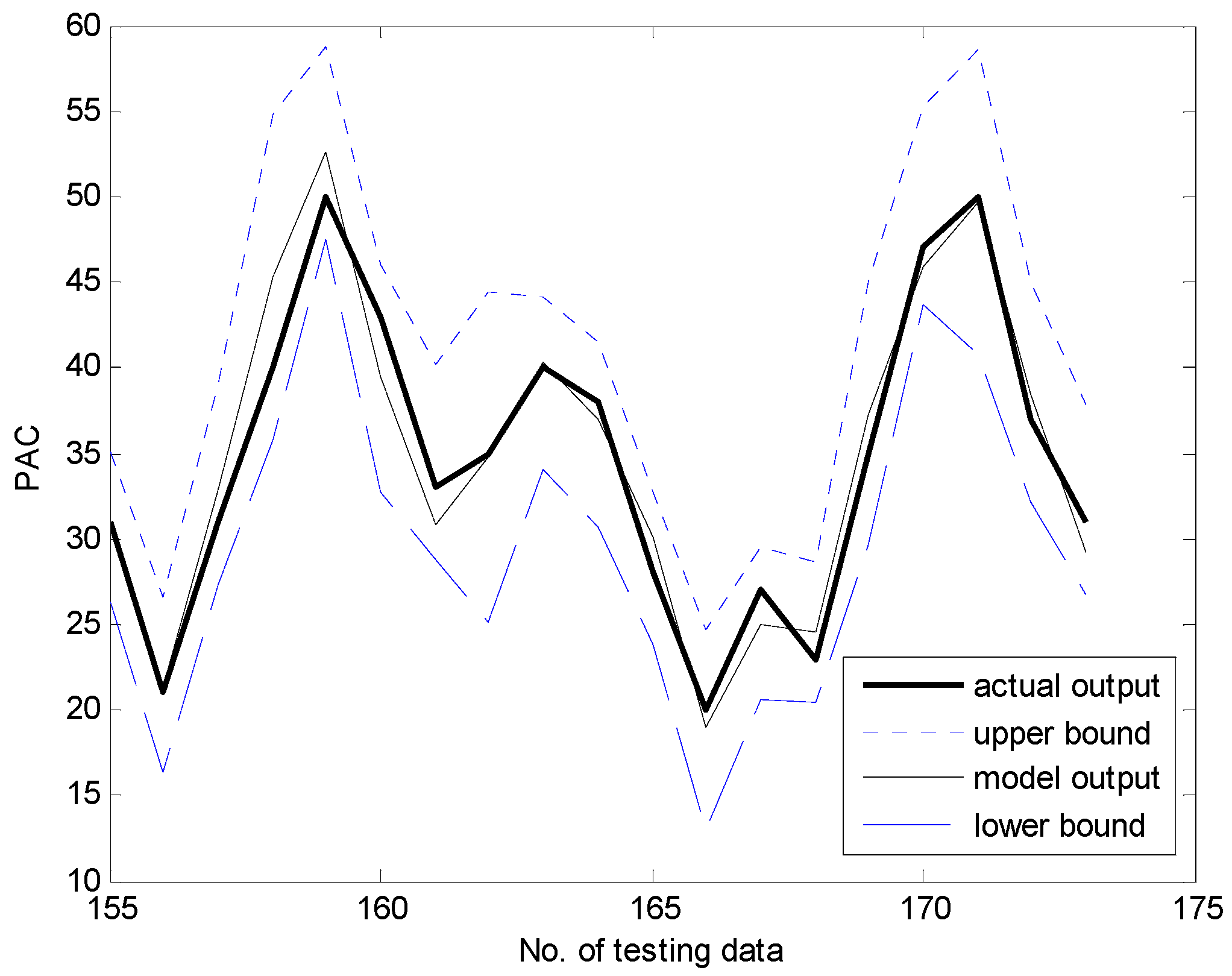
- Obtain the activation levels of the clusters produced by the corresponding contexts, and compute the overall aggregation by weighting through fuzzy sets of contexts. As a result, the IGM output yields a triangular fuzzy number, as shown in Figure 7.
- [Step 5]
- Combine the output of LR with the granular result of LM. Consequently, the final prediction is obtained as .
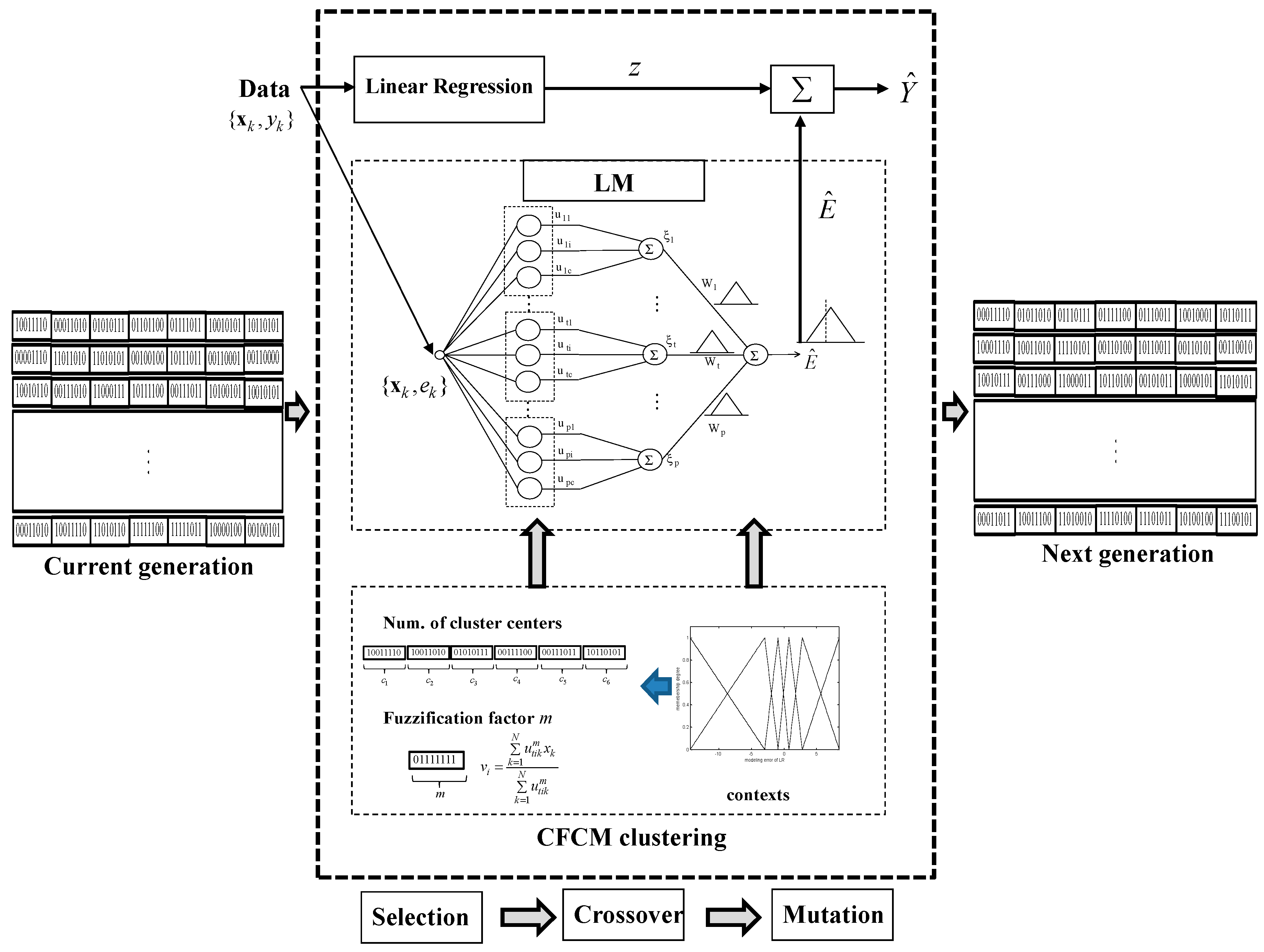
3. Genetically Optimized Incremental Granular Model
- [Step 1]
- Initialize a population with randomly generated individuals, and set the crossover and mutation rates and bit number. In this paper, we adopt a bit number of eight, because we limit the number of clusters to between two and nine in each context.
- [Step 2]
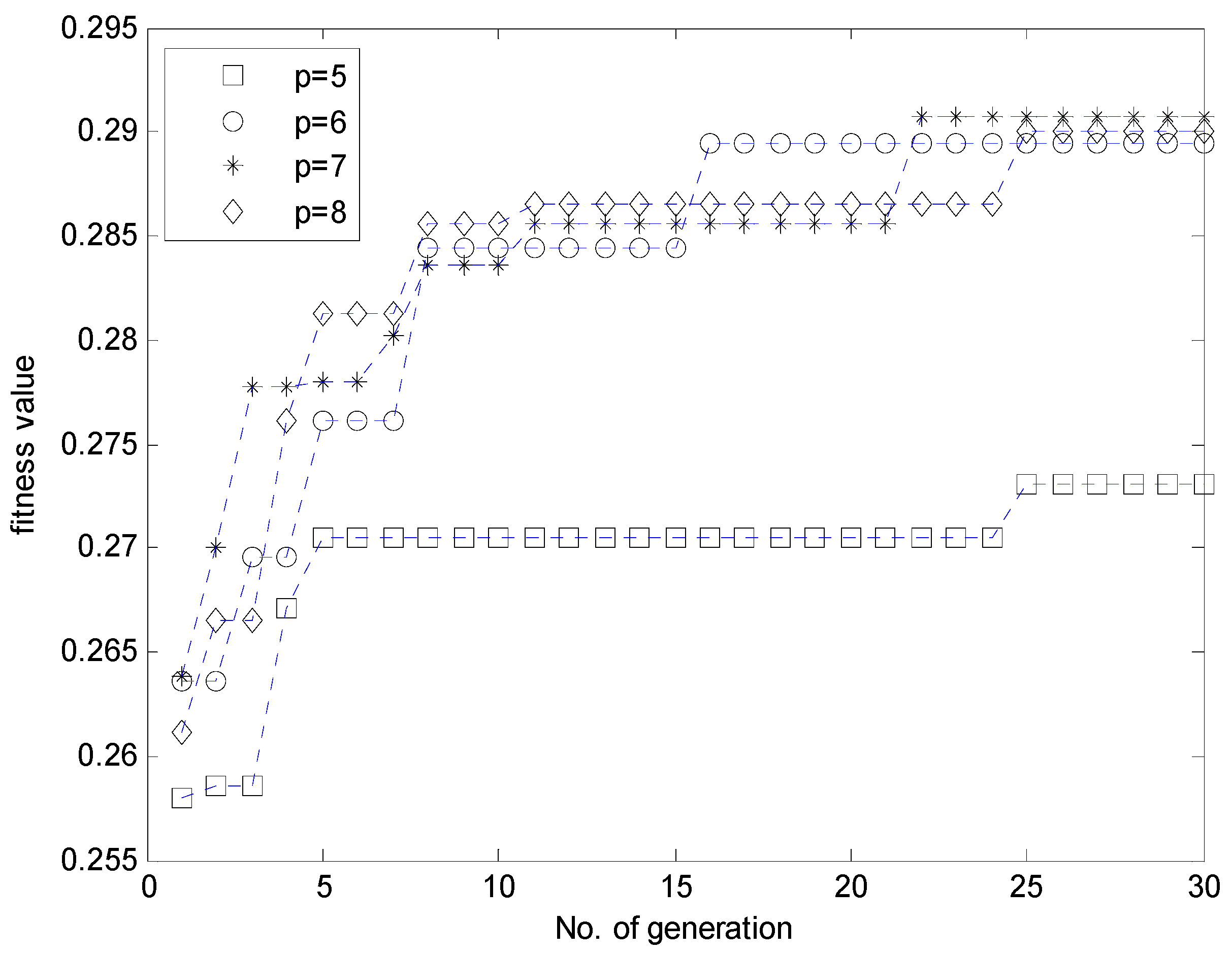
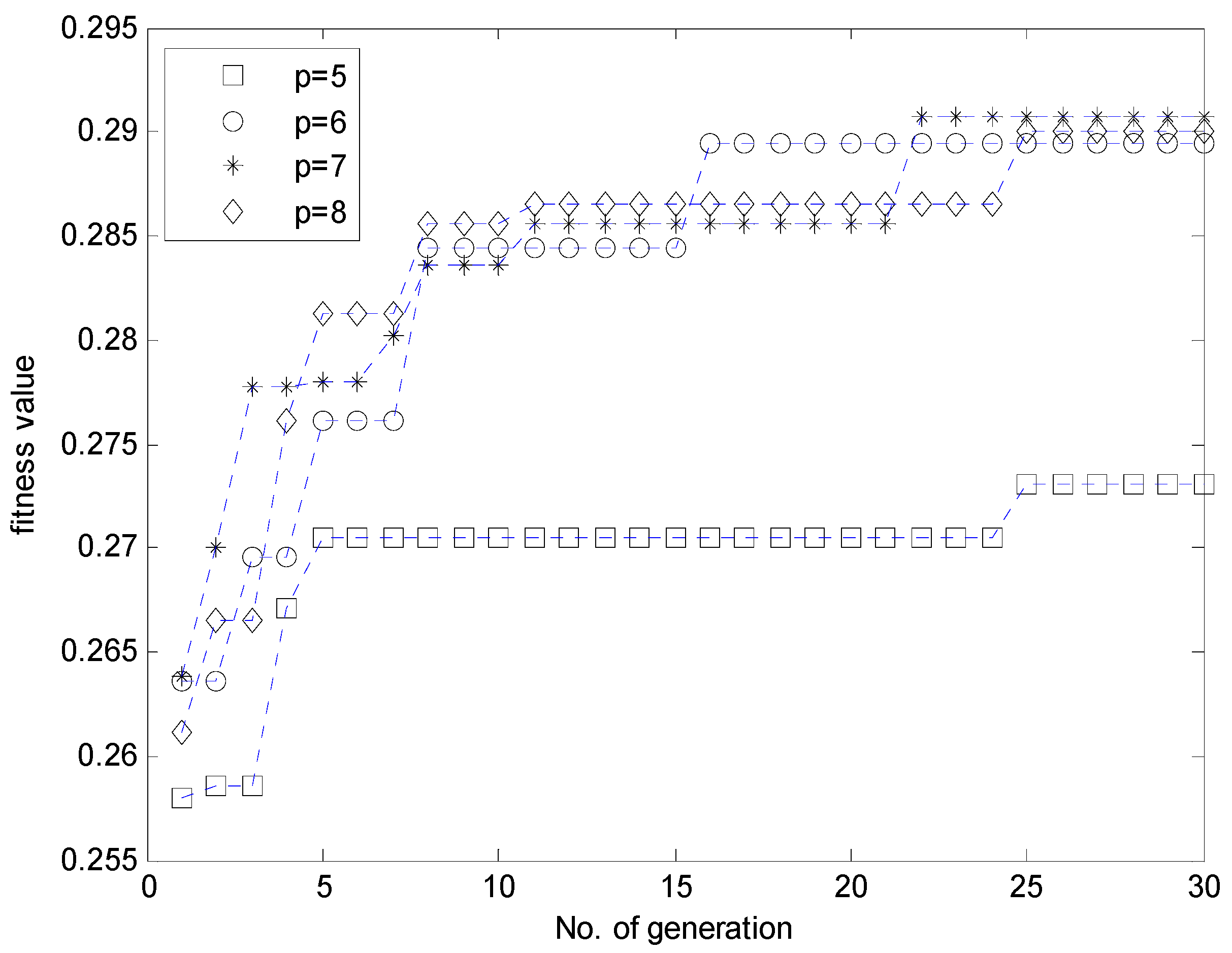
- Evaluate the fitness value for each individual for the fitness function. The GA simultaneously performs a parallel search through the populations, with the number of different contexts ranging from five to eight. Thus, the number of parameters to be optimized varies for each population.
- [Step 3]
- Select two individuals from the population with probabilities proportional to the fitness values in each population. The coding scheme involves arranging the numbers of clusters generated by each context and the weighting factor into a chromosome, such that the representation preserves certain good properties after recombination, as specified by the crossover and mutation operators.
- [Step 4]
- Apply crossover and mutation with a certain probability for crossover and mutation rates, respectively.
- [Step 5]
- Repeat Steps 2 to 4 until a stopping criterion is met.
4. Experimental Results
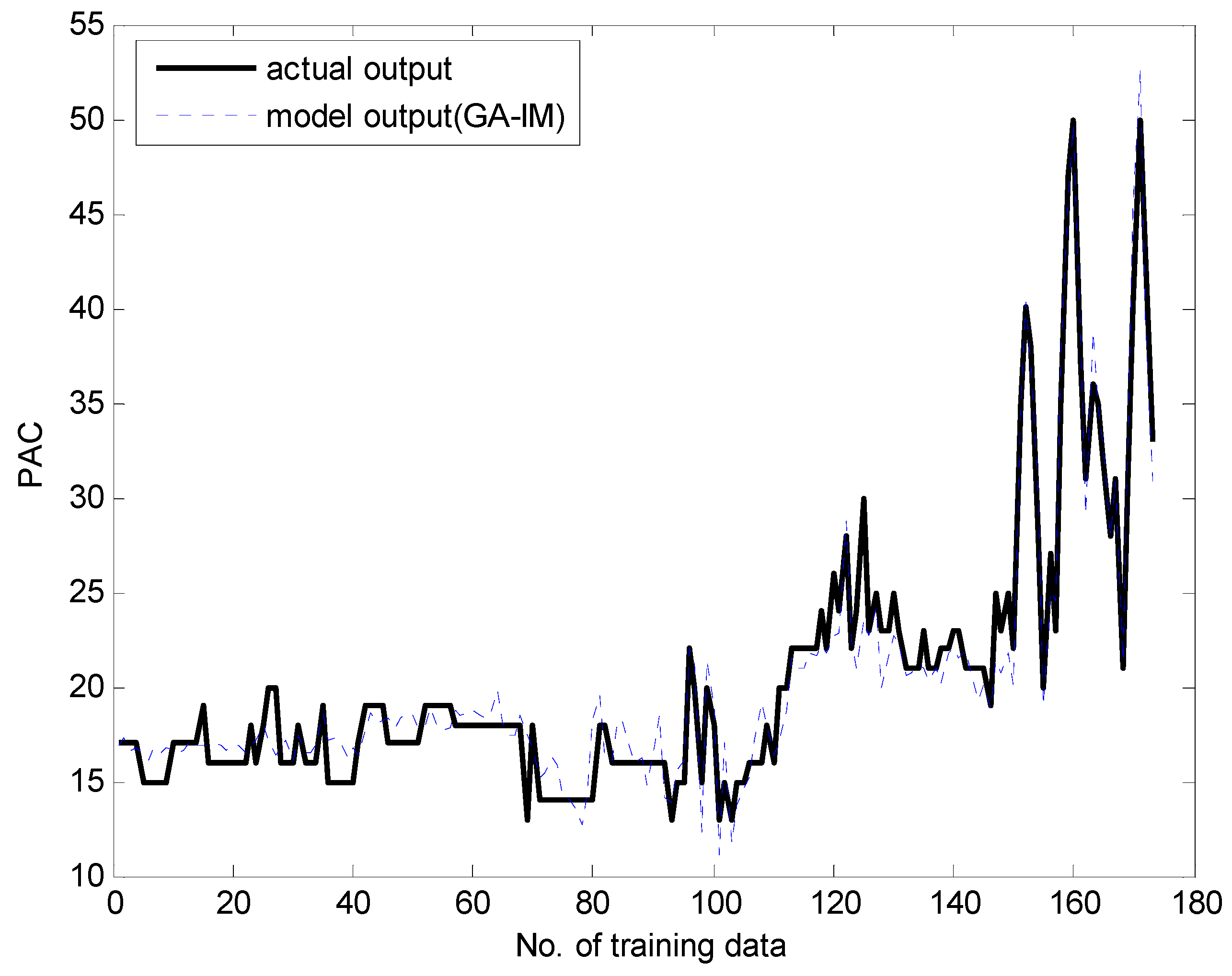
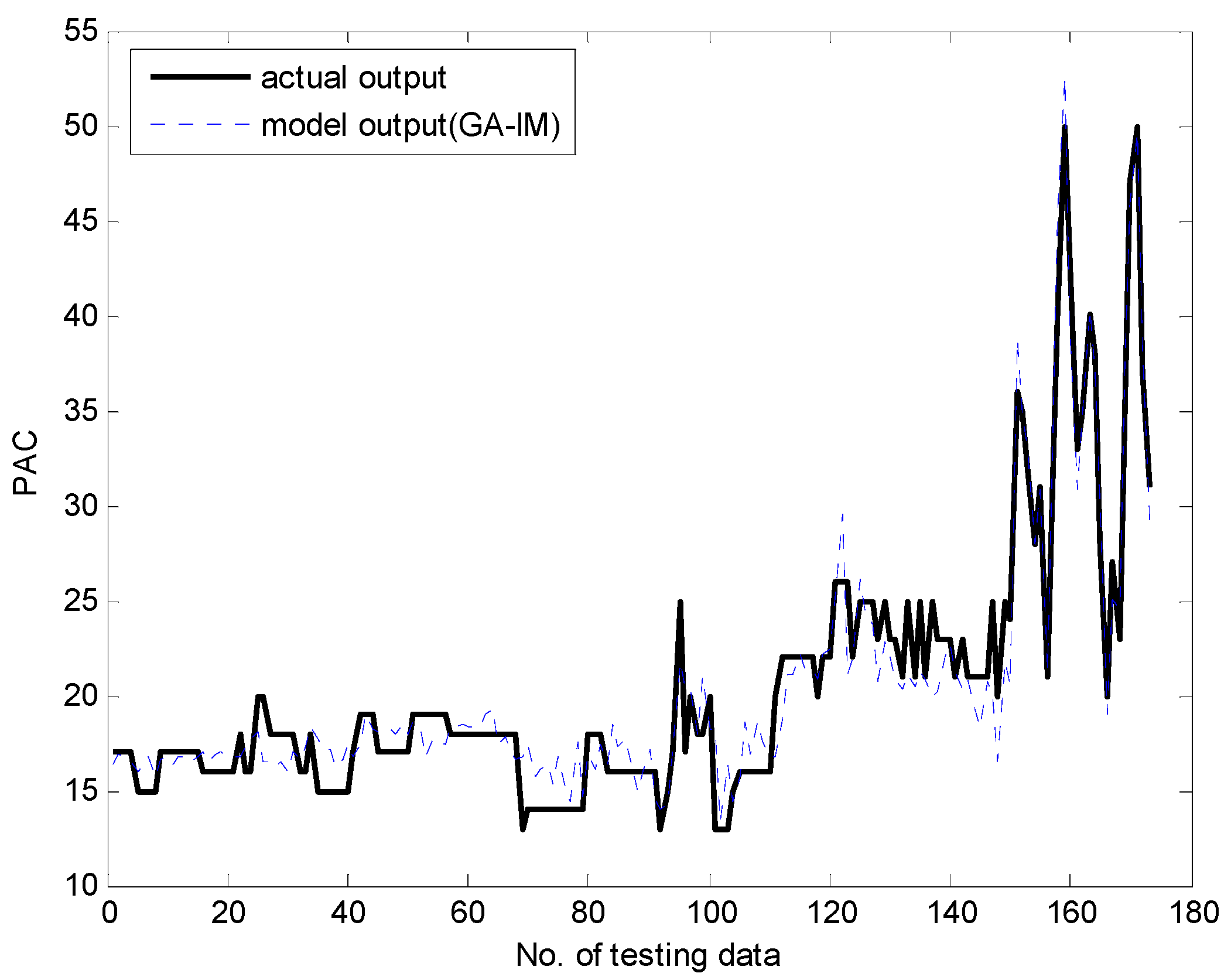
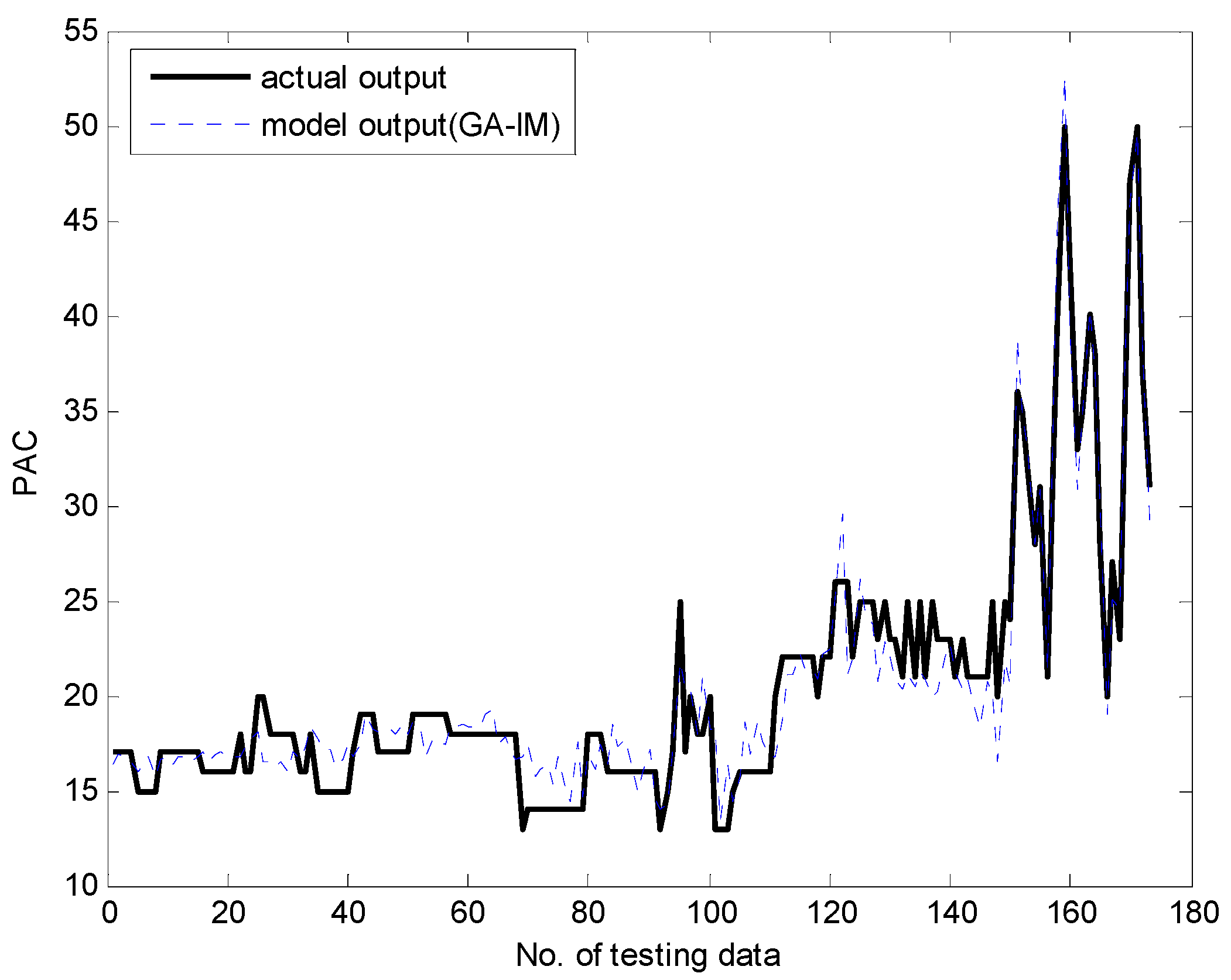
4.1. Coagulant Dosing Process in a Water Purification Plant
4.2. Automobile mpg Prediction and Boston Housing Data Sets
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Jang, J.S.R.; Sun, C.T.; Mizutani, E. Neuro-Fuzzy and Soft Computing: A Computational Approach to Learning and Machine Intelligence; Prentice Hall: Upper Saddle River, NJ, USA, 1997. [Google Scholar]
- Pedrycz, W.; Gomide, F. Fuzzy Systems Engineering: Toward Human-Centric Computing; IEEE Press: New York, NY, USA, 2007. [Google Scholar]
- Miranian, A.; Abdollahzade, M. Developing a local least-squares support vector machines-based neuro-fuzzy model for nonlinear and chaotic time series prediction. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 207–218. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Hu, X.; Gravina, R.; Fortino, G. A neuro-fuzzy fatigue-tracking and classification system for wheelchair users. IEEE Access 2017, 5, 19420–19431. [Google Scholar] [CrossRef]
- Tsai, J.T.; Chou, J.H.; Lin, C.F. Designing micro-structure parameters for backlight modules by using improved adaptive neuro-fuzzy inference system. IEEE Access 2015, 3, 2626–2636. [Google Scholar] [CrossRef]
- Siminski, K. Interval type-2 neuro-fuzzy system with implication-based inference mechanism. Expert Syst. Appl. 2017, 79, 140–152. [Google Scholar] [CrossRef]
- Shvetcov, A. Models of neuro-fuzzy agents in intelligent environments. Procedia Comput. Sci. 2017, 103, 135–141. [Google Scholar] [CrossRef]
- Jelusic, P.; Zlender, B. Discrete optimization with fuzzy constraints. Symmetry 2017, 9, 87. [Google Scholar] [CrossRef]
- Ramos, G.A.R.; Akanji, L. Data analysis and neuro-fuzzy technique for EOR screening: Application in Angolan oilfields. Energies 2017, 10. [Google Scholar] [CrossRef]
- Chen, W.; Panahi, M.; Pourghasemi, H.R. Performance evaluation of GIS-based new ensemble data mining techniques of adaptive neuro-fuzzy inference system (ANFIS) with genetic algorithm (GA), differential evolution (DE), and particle swarm optimization (PSO) for landslide spatial modeling. CATENA 2017, 157, 310–324. [Google Scholar] [CrossRef]
- Shihabudheen, K.V.; Pillai, G.N. Regularized extreme learning adaptive neuro-fuzzy algorithm for regression and classification. Knowl.-Based Syst. 2017, 127, 100–113. [Google Scholar]
- Kumaresan, N.; Ratnavelu, K. Optimal control for stochastic linear quadratic singular neuro Takagi-Sugeno fuzzy system with singular cost using genetic programming. Appl. Soft Comput. 2014, 24, 1136–1144. [Google Scholar] [CrossRef]
- Lin, C.J. An efficient immune-based symbiotic particle swarm optimization learning algorithm for TSK-type neuro-fuzzy networks design. Fuzzy Sets Syst. 2008, 159, 2890–2909. [Google Scholar] [CrossRef]
- Oh, S.K.; Kim, W.D.; Pedrycz, W.; Park, B.J. Polynomial-based radial basis function neural networks (P-RBF NNs) realized with the aid of particle swarm optimization. Fuzzy Sets Syst. 2011, 163, 54–77. [Google Scholar] [CrossRef]
- Pedrycz, W. Conditional fuzzy clustering in the design of radial basis function neural networks. IEEE Trans. Neural Netw. 1998, 9, 601–612. [Google Scholar] [CrossRef] [PubMed]
- Pedrycz, W.; Kwak, K.C. Linguistic models as a framework of user-centric system modeling. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2006, 36, 727–745. [Google Scholar] [CrossRef]
- Pedrycz, W. A dynamic data granulation through adjustable fuzzy clustering. Pattern Recognit. Lett. 2008, 29, 2059–2066. [Google Scholar] [CrossRef]
- Chalmers, E.; Pedrycz, W.; Lou, E. Human experts’ and a fuzzy model’s predictions of outcomes of scoliosis treatment: A comparative analysis. IEEE Trans. Biomed. Eng. 2015, 62, 1001–1007. [Google Scholar] [CrossRef] [PubMed]
- Reyes-Galaviz, O.F.; Pedrycz, W. Granular fuzzy models: Analysis, design, and evaluation. Int. J. Approx. Reason. 2015, 64, 1–19. [Google Scholar] [CrossRef]
- Kim, E.H.; Oh, S.K.; Pedrycz, W. Reinforced rule-based fuzzy models: Design and analysis. Knowl.-Based Syst. 2017, 119, 44–58. [Google Scholar] [CrossRef]
- Kwak, K.C.; Pedrycz, W. A design of genetically oriented linguistic model with the aid of fuzzy granulation. In Proceedings of the 2010 IEEE World Congress on Computational Intelligence, Barcelona, Spain, 18–23 July 2010. [Google Scholar]
- Kwak, K.C. A design of genetically optimized linguistic models. IEICE Trans. Inf. Syst. 2012, E95D, 3117–3120. [Google Scholar] [CrossRef]
- Climino, M.G.C.A.; Lazzerini, B.; Marcelloni, F.; Pedrycz, W. Genetic interval neural networks for granular data regression. Inf. Sci. 2014, 257, 313–330. [Google Scholar] [CrossRef]
- Oh, S.K.; Kim, W.D.; Pedrycz, W.; Seo, K. Fuzzy radial basis function neural networks with information granulation and its parallel genetic optimization. Fuzzy Syst. 2014, 237, 96–117. [Google Scholar] [CrossRef]
- Pedrycz, W.; Song, M. A genetic reduction of feature space in the design of fuzzy models. Appl. Soft Comput. 2012, 12, 2801–2816. [Google Scholar] [CrossRef]
- Hu, X.; Pedrycz, W.; Wang, X. Development of granular models through the design of a granular output spaces. Knowl.-Based Syst. 2017, 134, 159–171. [Google Scholar] [CrossRef]
- Pedrycz, W.; Kwak, K.C. The development of incremental models. IEEE Trans. Fuzzy Syst. 2007, 15, 507–518. [Google Scholar] [CrossRef]
- Li, J.; Pedrycz, W.; Wang, X. A rule-based development of incremental models. Int. J. Approx. Reason. 2015, 64, 20–38. [Google Scholar] [CrossRef]
- Pedrycz, W. Conditional fuzzy c-mans. Pattern Recognit. Lett. 1996, 17, 625–631. [Google Scholar] [CrossRef]
- Kwak, K.C.; Kim, D.H. TSK-based linguistic fuzzy model with uncertain model output. IEICE Trans. Inf. Syst. 2006, E89D, 2919–2923. [Google Scholar] [CrossRef]
- Kwak, K.C.; Kim, S.S. Development of quantum-based adaptive neuro-fuzzy networks. IEEE Trans. Syst. Man Cybern. Part B 2010, 40, 91–100. [Google Scholar]
- UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/datasets (accessed on 26 November 2017).
- Zhu, X.; Pedrycz, W.; Li, Z. Granular encoders and decoders: A study in processing information granules. IEEE Trans. Fuzzy Syst. 2017, 25, 1115–1126. [Google Scholar] [CrossRef]
- Huang, W.; Oh, S.K.; Pedrycz, W. Fuzzy wavelet polynomial neural networks: Analysis and design. IEEE Trans. Fuzzy Syst. 2017, 25, 1329–1341. [Google Scholar] [CrossRef]
- Ding, Y.; Cheng, L.; Pedrycz, W.; Hao, K. Global nonlinear kernel prediction for large data set with a particle swarm-optimized interval support vector regression. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2521–2534. [Google Scholar] [CrossRef] [PubMed]


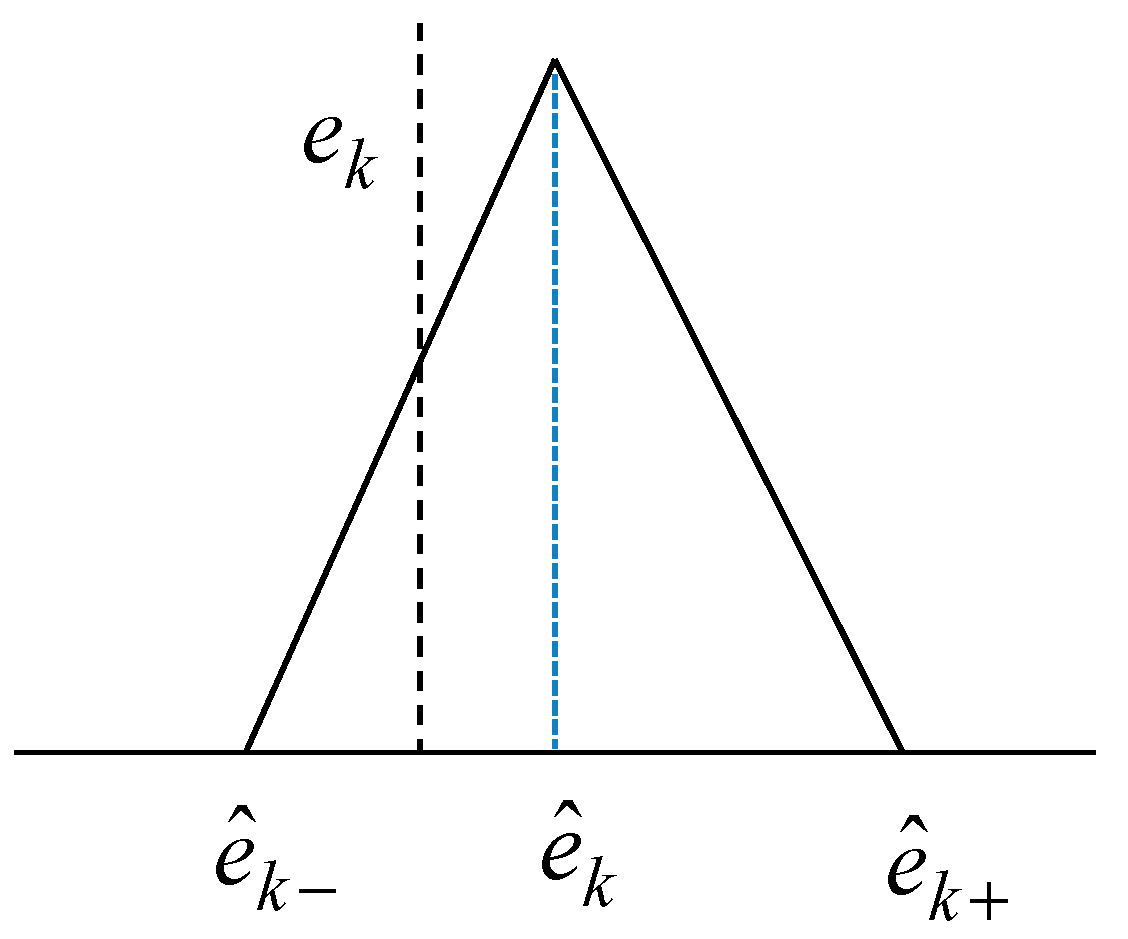




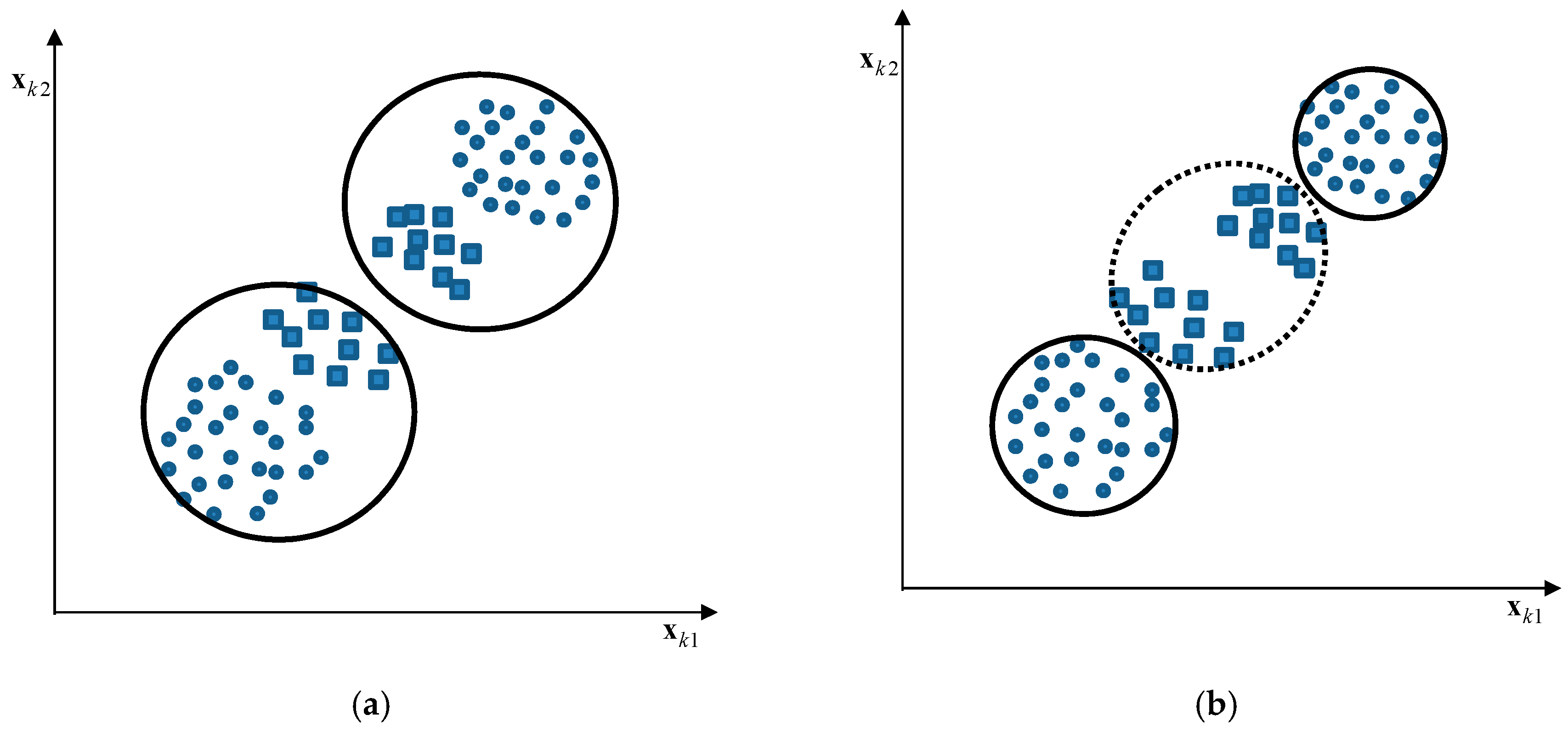{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
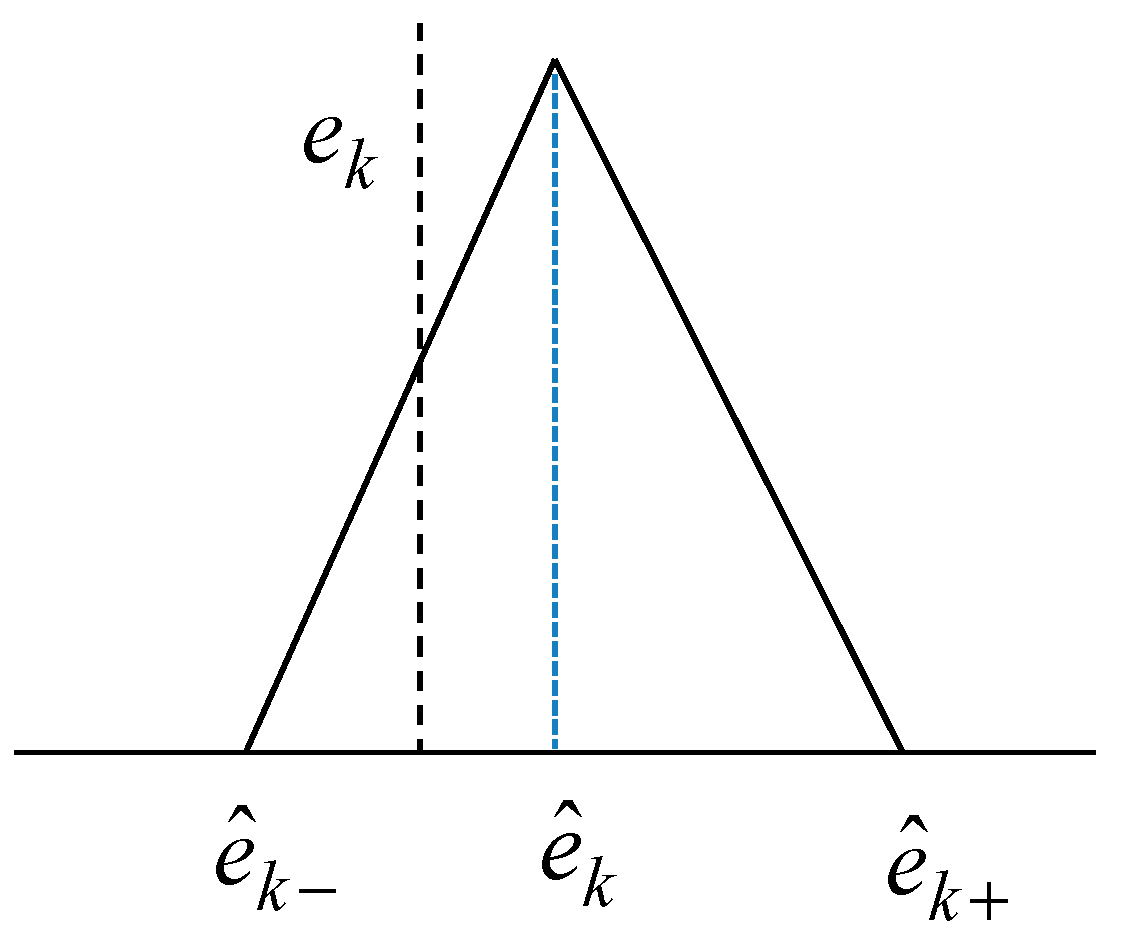{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| p | No. of Cluster Center in Each Context | No. of Rule | Weighting Exponent |
|---|---|---|---|
| 5 | [5, 9, 2, 9, 7] | 32 | 2.1428 |
| 6 | [5, 9, 9, 4, 8, 6] | 41 | 1.9285 |
| 7 | [3, 9, 4, 5, 9, 7, 6] | 43 | 1.9285 |
| 8 | [3, 9, 8, 9, 7, 8, 9, 8] | 61 | 1.9285 |
| Method | No. of Rule | RMSE (Training) | RMSE (Testing) | |
|---|---|---|---|---|
| LR | - | 3.508 | 3.578 | |
| MLP | 45 * | 3.191 | 3.251 | |
| CFCM-RBFNN [15] | 45 * | 3.048 | 3.219 | |
| LM [16] (p = 8) | c = 6 | 48 | 2.549 | 2.820 |
| c = 7 | 56 | 2.526 | 2.835 | |
| c = 8 | 64 | 2.427 | 2.800 | |
| TSK-LFM [29] | 45 | 2.514 | 2.661 | |
| GA-based LM [22] | 47 | 2.060 | 2.290 | |
| IGM [27,28] | p = c = 6 | 36 | 2.228 | 2.364 |
| p = c = 7 | 49 | 1.971 | 2.117 | |
| p = c = 8 | 64 | 1.790 | 2.009 | |
| p = c = 9 | 81 | 1.855 | 2.084 | |
| GA-based IGM | p = 5 | 32 | 1.712 | 1.949 |
| p = 6 | 41 | 1.567 | 1.915 | |
| p = 7 | 43 | 1.607 | 1.832 | |
| p = 8 | 61 | 1.597 | 1.850 | |
| p | No. of Cluster Center in Each Context | No. of Rule | Weighting Exponent |
|---|---|---|---|
| 5 | [5, 6, 2, 9, 8] | 30 | 2.5714 |
| 6 | [5, 7, 8, 4, 9, 9] | 42 | 2.3571 |
| 7 | [5, 8, 9, 6, 5, 8, 9] | 50 | 2.1428 |
| 8 | [6, 5, 8, 5, 9, 8, 8, 9] | 58 | 1.9285 |
| Method | No. of Rule | RMSE (Training) | RMSE (Testing) | |
|---|---|---|---|---|
| LM [16] | 36 | 2.788 | 3.337 | |
| GA-based LM [22] | 52 | 2.328 | 3.120 | |
| IGM [27,28] | 36 | 2.418 | 3.175 | |
| GA-based IGM | p = 5 | 30 | 2.231 | 3.050 |
| p = 6 | 42 | 2.183 | 2.989 | |
| p = 7 | 50 | 2.108 | 2.964 | |
| p = 8 | 58 | 2.058 | 2.932 | |
| p | No. of Cluster Center in Each Context | No. of Rule | Weighting Exponent |
|---|---|---|---|
| 5 | [7, 8, 2, 9, 2] | 28 | 1.9285 |
| 6 | [9, 9, 4, 5, 9, 7] | 43 | 1.9285 |
| 7 | [4, 8, 9, 9, 5, 9, 2] | 46 | 1.5000 |
| 8 | [6, 8, 8, 2, 4, 7, 9, 3] | 47 | 1.7142 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Byeon, Y.-H.; Kwak, K.-C. A Design for Genetically Oriented Rules-Based Incremental Granular Models and Its Application. Symmetry 2017, 9, 324. https://doi.org/10.3390/sym9120324
Byeon Y-H, Kwak K-C. A Design for Genetically Oriented Rules-Based Incremental Granular Models and Its Application. Symmetry. 2017; 9(12):324. https://doi.org/10.3390/sym9120324
Chicago/Turabian StyleByeon, Yeong-Hyeon, and Keun-Chang Kwak. 2017. "A Design for Genetically Oriented Rules-Based Incremental Granular Models and Its Application" Symmetry 9, no. 12: 324. https://doi.org/10.3390/sym9120324
APA StyleByeon, Y.-H., & Kwak, K.-C. (2017). A Design for Genetically Oriented Rules-Based Incremental Granular Models and Its Application. Symmetry, 9(12), 324. https://doi.org/10.3390/sym9120324