Abstract
Deep learning-based methods have achieved promising performance in image watermarking tasks due to their powerful capability to fully exploit the rich information present in images, which is crucial for ensuring watermark robustness. Although existing methods have improved robustness against various distortions, directly using deep neural networks for feature extraction and watermark expansion often introduces irrelevant and redundant features, thereby limiting the watermarking model’s imperceptibility and robustness. To address these limitations, in this paper, we introduce a robust image watermarking framework (GCMark) based on Gated Feature Selection and Cover-Guided Expansion, which consists of two key components: (1) the Dual-Stage Gated Modulation Block (DSGMB) that serves as the core backbone of both the encoder and decoder, adaptively suppressing irrelevant or redundant activations to enable more precise watermark embedding and extraction; (2) the Cover-Guided Message Expansion Block (CGMEB), which exploits the cover image’s structural features to guide watermark message expansion. By promoting a structurally consistent and well-balanced fusion between the watermark and host image, this implicit symmetry facilitates stable watermark propagation and enhances resilience against various distortions without introducing noticeable visual artifacts. Extensive experimental results demonstrate that the proposed GCMark framework outperforms existing methods with respect to both robustness and imperceptibility.
1. Introduction
The rapid growth of artificial intelligence and digital media technologies has led to the large-scale creation and dissemination of digital images. Accordingly, robust image watermarking [1] has attracted increasing attention as a fundamental technique for copyright protection and content traceability, where exploiting intrinsic image symmetries and structural regularities is beneficial for achieving stable and distortion-resilient watermark embedding. The objective is to embed specific information (e.g., identifiers, sequences, or fingerprints) into images without noticeably degrading visual quality, while ensuring that the watermark can still be reliably extracted after the image undergoes various attacks (e.g., JPEG compression and Gaussian noise); consequently, robust watermarking methods must satisfy two fundamental requirements: robustness and imperceptibility.
Traditional techniques typically embed watermark messages in either the spatial or frequency domains. The former [2] often involves manipulating the least significant bits of image pixels; this is simple to implement but highly susceptible to detection and modification [3]. Although the latter [4,5] have demonstrated improved robustness, they rely heavily on hand-crafted shallow image features, which restrict their effectiveness against diverse and severe distortions [6]. As a result, these traditional methods lack the capacity to model high-level features and complex nonlinear transformations, leading to an inherent performance bottleneck in robust image watermarking.
To overcome these limitations, a variety of DNN-based models have been proposed for image watermarking [7,8,9,10,11]. By exploiting the strong feature representation capability of DNNs, these methods achieve notable watermarking performance improvements. Most existing DNN-based watermarking frameworks adopt an encoder–noise layer–decoder (END) architecture, as illustrated in Figure 1. The encoder embeds the watermark message into the cover image to generate a watermarked image, which is subsequently processed by a noise layer that simulates various distortions. Finally, a decoder attempts to recover the embedded message from the distorted image.

Figure 1.
The pipeline of the END-based watermarking framework.
Although DNN-based watermarking methods have achieved notable progress, existing frameworks still exhibit several inherent limitations. First, most existing approaches rely on multi-layer convolutional feature extractors or U-Net-style architectures for both the encoder and decoder, yet these backbones lack an explicit mechanism for selective feature modulation. Consequently, the learned representations tend to include excessive irrelevant or noise-sensitive activations, which entangle the watermark signal with semantically unrelated image content and undermine robust extraction, preventing the encoder from effectively embedding the message into robust image features and hindering the decoder’s ability to reliably recover the message under distortions. Second, most existing methods rely on a simple convolution-linear layer or naive feature broadcasting for watermark expansion. Due to the lack of content awareness, such expansion fails to leverage the structural characteristics of the cover image, leading to indiscriminate watermark distribution across image regions. As a result, the embedding strength cannot be adaptively adjusted according to local content, which ultimately degrades watermark robustness under diverse distortions.
To address the aforementioned issues, we propose GCMark, a robust image watermarking framework built upon Gated Feature Selection and Cover-Guided Expansion, which specifically consists of two core modules: the Dual-Stage Gated Modulation Block (DSGMB) and the Cover-Guided Message Expansion Block (CGMEB). The DSGMB integrates a Squeeze-and-Excitation block (SEB) and a Gated Modulation Unit (GMU), with the former adaptively recalibrating channel-wise feature responses by emphasizing informative channels and suppressing less relevant ones, allowing the encoder and decoder to focus on structurally meaningful features. Building on this, the GMU introduces a dynamic gating mechanism that determines which features should be propagated forward and which should be suppressed. This selective feature modulation effectively filters noisy or irrelevant activations while preserving watermark-relevant signals, enabling more precise and content-aware embedding and extraction. The CGMEB leverages cover image structural cues to guide the spatial allocation of expanded watermark features. Rather than relying on naive, content-agnostic feature broadcasting, this module expands the watermark message in a structurally symmetric manner with respect to local image characteristics, allowing watermark information to be distributed in harmony with the host image structure. As a result, watermark energy is preferentially propagated to texture-rich or structurally stable regions while avoiding smooth and visually sensitive areas. This symmetry-consistent, content-guided expansion enhances both watermark robustness and invisibility under various distortions. The experimental results validate the effectiveness of GCMark, showing consistent improvements in robustness and imperceptibility compared with existing methods under diverse distortion conditions.
The main contributions are summarized as follows:
- We propose a Dual-Stage Gated Modulation Block (DSGMB) that integrates SE and GMU to selectively suppress irrelevant activations and enhance watermark-relevant features, enabling content-aware watermark embedding and extraction with improved performance.
- We design a Cover-Guided Message Expansion Block (CGMEB) that leverages cover image structural features to adaptively allocate the watermark message, enabling a structurally symmetric and well-aligned fusion between the watermark and the host image, thereby improving both robustness and imperceptibility compared with content-agnostic feature broadcasting.
- Extensive experiments demonstrate that GCMark outperforms existing watermarking methods, achieving superior robustness under diverse distortions while maintaining high visual quality.
The remainder of this paper is organized as follows: Section 2 reviews the related work on deep learning-based watermarking and gating in neural networks; Section 3 describes the proposed GCMark framework in detail, including its architectural design and core components; Section 4 presents extensive experiments and ablation studies to evaluate the proposed method’s effectiveness; and finally, Section 5 concludes the paper.
2. Related Work
2.1. Digital Image Watermarking
Traditional digital watermarking techniques typically embed the watermark message in the spatial or frequency domains. Frequency-domain methods embed watermarks into transformed representations such as DCT [4], DFT [5], or DWT [12], and generally achieve better robustness and imperceptibility than spatial-domain approaches; however, their performance is fundamentally constrained by handcrafted feature designs and limited adaptability to diverse distortions.
With the rapid progress of deep learning in computer vision, DNN-based watermarking has gained significant traction. HiDDeN [7] introduced the first end-to-end deep watermarking framework consisting of an encoder, a noise layer, and a decoder. To enhance robustness against black-box and non-differentiable attacks, TSDL [13] proposed a two-stage training strategy, and building on this idea, Fang et al. [14] extended the scheme into a three-stage frequency-enhanced framework to further improve watermark robustness. MBRS [6] addressed the JPEG compression challenge by alternating real and simulated JPEG operations within each mini-batch during training. SepMark [15] developed a separable watermarking architecture to support fragile–robust dual watermark embedding. For robustness against geometric distortions, Ma et al. [16] and Chen et al. [17] proposed Swin Transformer-based watermarking frameworks. In addition, a series of works [10,18,19,20,21,22,23,24] designed task-specific simulated noise layers to simulate non-differentiable or complex real-world attacks, significantly improving model robustness across various distortion types. However, despite these advances, existing DNN-based watermarking methods typically perform feature extraction without explicit feature selection or suppression mechanisms and adopt replication or broadcasting for watermark expansion, causing redundant activations that limit the model’s ability to learn robust representations.
2.2. Gating in Neural Networks
Gating mechanisms have been widely adopted across neural network architectures for their ability to regulate information flow and selectively emphasize task-relevant signals. LSTMs [25] and GRUs [26] employ gating to modulate temporal information retention and suppression, effectively mitigating gradient vanishing and explosion. Highway Networks [27] further extend this idea by introducing gating units that control information propagation in very deep architectures, thereby alleviating training difficulties. Beyond sequence modeling, gating has also seen broad adoption in computer vision tasks. Yu et al. [28] propose gated convolution for free-form image inpainting, where spatially adaptive gates determine pixel-wise feature validity, effectively filtering unreliable information near hole boundaries. Restormer [29] incorporates a Gated-Dconv Feed-forward Network (GDFN), which applies dynamic channel-wise modulation to suppress redundant responses while preserving informative features, achieving strong performance in high-resolution restoration tasks. Moreover, Zatsarynna et al. [30] introduce a Gated Temporal Diffusion (GTD) model that uses gating to jointly model uncertainty in observed and future frames, enabling adaptive information flow across temporal contexts and yielding state-of-the-art results. Inspired by these advances, we develop GCMark, a gating-based framework designed for robust image watermarking.
3. Method
3.1. Motivation
Deep learning-based watermarking methods, such as HiDDeN [7], MBRS [6], and SepMark [15], typically embed the watermark message within deep features using convolutional or U-Net-style networks. However, these architectures lack selective feature modulation and perform message expansion in a content-agnostic manner. As a result, the extracted features often contain redundant or irrelevant activations, and the watermark becomes entangled with noise-sensitive or semantically unrelated patterns, ultimately degrading both robustness and imperceptibility.
We observe that gating mechanisms offer a natural way to selectively regulate information flow, enabling a model to adaptively determine which features should be enhanced or suppressed during both embedding and extraction. Such selective modulation can help to preserve watermark signals under distortion by preventing noisy or irrelevant activations from interfering with watermark-relevant cues. Likewise, when watermark expansion is guided by cover image structural characteristics, the embedding process can allocate watermark energy more judiciously, reinforcing texture-rich or stable regions while avoiding perceptually sensitive areas.
Related ideas on selective feature processing have been explored in other vision tasks. In particular, TTST [31] proposes a Top-k token selective transformer for remote sensing image super-resolution, demonstrating that suppressing redundant features can improve representation discriminability. However, robust image watermarking requirements differ fundamentally from super-resolution, as aggressively discarding features or tokens may cause irreversible loss of watermark-carrying cues and lead to unstable extraction under distortions. Therefore, instead of hard token selection, robust watermarking calls for a soft and content-aware modulation mechanism that preserves spatial integrity while selectively emphasizing watermark-relevant features.
Based on this motivation, we propose GCMark, a robust image watermarking framework built upon gated feature selection and Cover-Guided Expansion, as illustrated in Figure 2. GCMark consists of an encoder E with parameters , a noise layer N, and a decoder D with parameters . The encoder embeds the watermark message into the cover image, after which various distortions are applied by N. Finally, the decoder aims to extract the watermark from the distorted image. In the following sections, we detail the overall training pipeline, the Dual-Stage Gated Modulation Block (DSGMB), and the Cover-Guided Message Expansion Block (CGMEB).
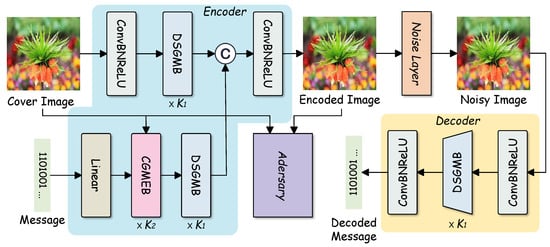
Figure 2.
The pipeline of our GCMark framework. The encoder E takes the cover image and the watermark message as inputs and embeds the message into the cover image through a series of convolutional layers and Dual-Stage Gated Modulation Blocks (DSGMBs), together with the Cover-Guided Message Expansion Block (CGMEB), to generate the encoded image , which is then processed by a noise layer N that simulates various distortions, resulting in the noisy image . Finally, the decoder D, composed of convolutional layers and DSGMBs, attempts to recover the embedded watermark message from , producing the decoded message .
3.2. Overall Training Pipeline
3.2.1. Encoder
E is used to embed the watermark message into the cover image while preserving resulting image visual quality.
Specifically, given a cover image , a ConvBNReLU layer is first applied to extract low-level features, yielding an initial representation . These features are then processed by DSGMBs, as detailed in Section Dual-Stage Gated Modulation Block (DSGMB). Meanwhile, the watermark message is first projected into a latent embedding via a linear layer and then expanded into a spatial watermark feature map through CGMEBs, detailed in Section Cover-Guided Message Expansion Block (CGMEB), with the processed by DSGMBs. Next, the cover image and the watermark features are concatenated and fused through a ConvBNReLU layer, allowing the network to integrate the watermark message in a content-aware manner. Finally, a convolutional layer produces the encoded image , which maintains high perceptual fidelity to the original cover image while carrying the embedded watermark message.
The encoder parameters are optimized by minimizing the reconstruction loss as follows:
where MSE(·) computes the mean square error.
3.2.2. Adversary
To further improve watermarked image visual quality, we incorporate an adversarial discriminator following HiDDeN [7] and MBRS [6], which aims to distinguish between watermarked and original cover images, while the encoder attempts to generate watermarked images that are visually indistinguishable from the cover images. The discriminator consists of several convolutional layers followed by a global average pooling layer.
We define the discriminator loss , which is minimized with respect to the discriminator parameters , as:
where the first term encourages the discriminator to correctly classify watermarked images as fake and the second term encourages correct classification of cover images as real.
Correspondingly, we define the encoder’s adversarial loss, denoted as , which is minimized with respect to the encoder parameters , as:
By minimizing , the encoder is encouraged to generate watermarked images that the discriminator classifies as real, thereby improving the visual imperceptibility of the embedded watermark.
3.2.3. Noise Layer
The noise layer N plays an essential role in improving learned watermark representation robustness. During training, we apply a set of differentiable image distortion operations within N to transform the encoded image into a perturbed version , enabling the model to learn to withstand various degradation types. To comprehensively evaluate the proposed method’s robustness, various commonly used image distortions are applied in the experiments. The detailed configurations of these distortions are described as follows:
Gaussian Noise (GN): Gaussian noise is introduced by adding random values sampled from a normal distribution to each pixel. In our experiments, the noise has zero mean, while the variance is controlled by the parameter , which determines the noise intensity.
Salt-and-Pepper Noise (SPN): This distortion randomly selects a subset of pixels with probability and replaces them with either the minimum or maximum intensity values.
Gaussian Blur (GB): Gaussian blur smooths the image by convolving it with a Gaussian kernel. The blurring strength is determined by the kernel size (set to ) and the standard deviation , which controls the Gaussian function spread.
Median Blur (MB): Median blur applies a nonlinear filtering operation where each pixel is replaced by the median value of its local neighborhood. The filter size, such as , defines the operation’s spatial extent.
JPEG Compression (JPEG): To mimic lossy image compression, a differentiable approximation of the JPEG process is employed during training, following the implementation adopted in MBRS [6], enabling end-to-end optimization while simulating quantization effects.
Dropout: Pixel dropout randomly discards a portion of pixels with probability r by substituting them with corresponding pixels from the original cover image.
Cropout: Cropout involves randomly selecting a rectangular region of the image and replacing the pixels inside this with those from the original cover image. The cropout ratio controls the removed region’s relative area.
3.2.4. Decoder
D is used to recover the embedded watermark message from , which has been degraded by various noise or attacks.
Specifically, given a noisy image , a ConvBNReLU layer is first applied to extract low-level representations, generating an initial feature map , which is subsequently processed by DSGMBs with integrated downsampling. After gated feature refinement, the resulting feature map is fed into a convolutional layer to reduce the multi-channel tensor to a single-channel prediction. The output is then reshaped and passed through a fully connected layer to obtain the decoded message .
To train the decoder effectively, its parameters are optimized to minimize the reconstruction error between and . We adopt an MSE loss defined as:
The final loss function L consists of image, message, and adversarial loss, which can be formulated by:
where , , and are weight factors.
3.3. Dual-Stage Gated Modulation Block (DSGMB)
To enable selective feature modulation, we design the Dual-Stage Gated Modulation Block (DSGMB), as illustrated in Figure 3, which consists of two components: the Squeeze-and-Excitation Block (SEB) and Gated Modulation Unit (GMU). While the SEB adaptively recalibrates channel responses, the GMU performs dynamic feature gating to suppress redundant activations and strengthen watermark-relevant cues. Combining these two modules allows DSGMB to effectively filter noise-sensitive features during both embedding and extraction.
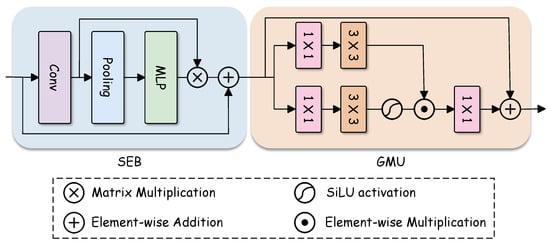
Figure 3.
Illustration of Dual-Stage Gated Modulation Block, which consists of a Squeeze-and-Excitation Block (SEB) and a Gated Modulation Unit (GMU). The SEB performs channel-wise recalibration via global pooling and an MLP, while the GMU applies spatial gating using parallel and convolutions with SiLU activation.
3.3.1. Squeeze-and-Excitation Block (SEB)
The SEB follows the channel attention mechanism introduced in SENet [32]. Given an input feature map , the feature is first transformed by convolutional layers, producing an intermediate feature representation . To model channel-wise dependencies, SEB applies global average pooling to aggregate spatial information and obtain a channel descriptor . z is fed into a bottleneck MLP to compute channel-wise attention weights , and the intermediate feature map is subsequently recalibrated via channel-wise multiplication with w. Finally, the feature map is obtained by adding the recalibrated features to the identity mapping. In this way, SEB emphasizes informative channels while suppressing less relevant ones.
3.3.2. Gated Modulation Unit (GMU)
After the SEB, is further processed by the GMU for fine-grained gated feature modulation. As illustrated in Figure 3, is first fed into two parallel branches, where a convolution and a depth-wise convolution are applied, respectively, to capture local spatial contextual information. The convolution focuses on channel-wise transformation and feature projection, enabling efficient channel information reweighting without introducing additional spatial smoothing. In contrast, the depth-wise convolution captures local neighborhood-level structural variations within each channel, providing spatially aware cues for gating while maintaining a favorable balance between spatial sensitivity and robustness. One branch generates transformed feature responses , while the other applies an SiLU activation function to generate the gating signal . The two are then combined through element-wise multiplication, yielding a gated feature map .
Subsequently, a convolution is applied to project back to the original channel dimension, resulting in . Finally, a residual connection is added between and the input feature , producing the final GMU output. Through this gated modulation process, the GMU effectively suppresses noise-sensitive activations while preserving watermark-relevant structures, thereby enhancing robustness in both watermark embedding and extraction.
3.4. Cover-Guided Message Expansion Block (CGMEB)
Unlike conventional message expansion modules that uniformly propagate watermark features across spatial locations, CGMEB leverages texture information from the cover image to guide the expansion process, as illustrated in Figure 4. By selectively strengthening message features in texture-rich regions while suppressing expansion in smooth areas, CGMEB effectively reduces visible artifacts and enhances robustness against distortions. From a structural perspective, this guidance establishes a form of symmetry consistency between the watermark and host image; instead of imposing an independent or uniform spatial distribution, the expanded watermark features are modulated to follow the cover image’s intrinsic structural layout. As a result, watermark energy spatial allocation becomes aligned with image regions that are inherently more robust to distortions, making the watermark distribution structurally consistent with the host image content.
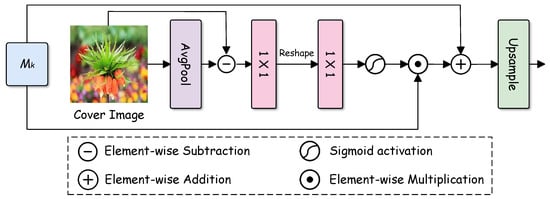
Figure 4.
Illustration of Cover-Guided Message Expansion Block, which extracts guidance from the cover image using average pooling, followed by convolutions and a sigmoid to generate a spatial mask. The mask modulates message features through element-wise multiplication and the expanded features are upsampled to match the cover image resolution.
Specifically, CGMEB extracts a spatial texture guidance map from the cover image and injects this into the message expansion process through spatial gating. Given a cover image , CGMEB first derives a texture-sensitive representation through a high-pass filtering operation. The high-frequency residual is computed as
where emphasizes local intensity variations and edge structures that are indicative of texture-rich regions.
Then, is projected using a convolution to obtain a texture feature map . At the k-th expansion stage, is resized via bilinear interpolation to , matching the message feature map spatial resolution at the corresponding stage. Based on , a spatial gating map is generated using a convolution followed by a sigmoid activation. The gating map encodes the cover image’s local texture strength, assigning higher values to texture-rich regions and lower values to smooth areas.
Let denote the message feature map before expansion. To incorporate cover-aware guidance, CGMEB applies spatially adaptive gating to modulate the message features prior to expansion:
where ⊙ denotes element-wise multiplication and is a learnable scaling parameter that controls texture-guided modulation strength. In our implementation, is initialized to and optimized jointly with the network parameters during training.
4. Experiments and Analysis
4.1. Experimental Settings
4.1.1. Experimental Details
All images are reshaped to a size of and all experiments conducted using the PyTorch framework on an NVIDIA GeForce RTX 3090 GPU. We train the model with a batch size of 12 for a total of 200 training epochs, and the loss function weight factors are defined as , , and . The default watermark length L is set to 64. In our implementation, is empirically chosen as a practical trade-off between gated feature modulation capacity and model complexity. For message expansion, each CGMEB upsamples the message by a factor of two, and thus is deterministically set so that the final message representation exactly matches the spatial resolution of the cover image.
4.1.2. Datasets
The proposed model is trained on the DIV2K [33] dataset. For evaluation, we employ the DIV2K validation subset, along with an additional 2000 images randomly sampled from the COCO [34] and ImageNet [35] datasets.
4.1.3. Metrics
In our evaluation, visual imperceptibility is quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). In addition, the robustness of the watermarking scheme is measured by the bit-wise extraction accuracy (ACC) of the recovered watermark. Minor variations in PSNR values may occur due to quantization effects introduced during image saving, where floating-point representations are converted to 8-bit integers.
4.1.4. Baseline
To evaluate the imperceptibility and robustness of the proposed GCMark, we compare it with several SOTA watermarking methods, including four CNN-based END methods (HiDDeN [7], MBRS [6], SepMark [15], and Zhu et al. [36]). All SOTA methods are implemented under identical experimental settings to ensure a fair comparison.
4.2. Imperceptibility and Robustness Against Specific Distortion Training
In this section, we conduct distortion-specific training for each of the seven distortion types introduced in Section 4.2, with a dedicated model trained for each individual distortion. This allows for a fair and detailed evaluation of GCMark’s imperceptibility and robustness and the baseline methods under different distortions. Figure 5 presents GCMark’s visual results under various distortions, while Figure 6 reports the quantitative PSNR comparisons between GCMark and the baseline approaches.

Figure 5.
Watermarked images and their corresponding distorted versions. From top to bottom: the cover image ; the encoded image ; the distorted image ; and the residual image −.
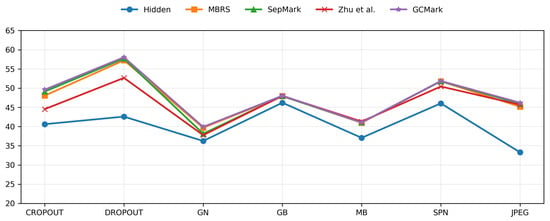
Figure 6.
The PSNR of the encoded images with different models (HiDDeN [7], MBRS [6], SepMark [15], and Zhu et al. [36]).
Cropout: During training, a cropout ratio of 0.4 is employed. During testing, the cropout ratio is varied from 0.1 to 0.5 to evaluate model performance under different degrees of spatial removal. As reported in Figure 6, GCMark achieves the highest PSNR under cropout attacks, which indicates its ability to preserve visual quality despite localized information loss. Moreover, as illustrated in Figure 7a, GCMark consistently maintains high extraction accuracy (ACC), remaining above 0.7% even at large cropout ratios. In contrast, the baseline approaches exhibit noticeable performance degradation as the severity increases.
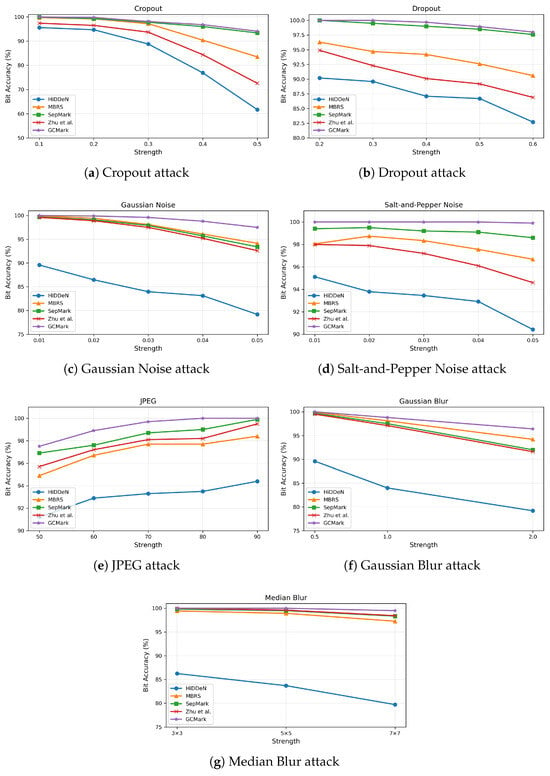
Figure 7.
Extraction accuracies of different methods (HiDDeN [7], MBRS [6], SepMark [15], and Zhu et al. [36]) under various distortions.
Dropout: During training, a dropout ratio of 0.4 is employed, while during evaluation, it is varied from 0.2 to 0.6 to assess model performance under different distortion strengths. Under pixel dropout attacks, GCMark demonstrates strong resilience to partial information loss. As reported in Figure 6, the proposed method achieves higher PSNR values than the baseline approaches, indicating improved imperceptibility. Furthermore, as illustrated in Figure 7b, GCMark maintains stable extraction accuracy even when a substantial portion of pixels is removed, validating its robustness against random pixel removal.
Gaussian Noise (GN): In our experiments, Gaussian noise is introduced during training with variance values sampled from 0.001 to 0.04. During testing, the noise variance is adjusted within the range of 0.01 to 0.05 to assess the model’s robustness under varying noise intensities. As reported in Figure 6, under Gaussian noise (GN) attacks, GCMark achieves the highest PSNR of 39.91 dB. Furthermore, as illustrated in Figure 7c, GCMark consistently attains higher extraction accuracy (ACC) across different noise levels while maintaining high visual quality, demonstrating superior robustness compared with the baseline approaches.
Salt-and-Pepper Noise (SPN): During training, Salt-and-Pepper noise is injected using a randomly sampled corruption ratio ranging from 0.001 to 0.04. During testing, the noise ratio is varied between 0.01 and 0.05 to assess how different models perform under increasing noise levels. Under Salt-and-Pepper noise attacks, GCMark consistently outperforms the baseline methods in terms of visual fidelity, as indicated by its superior PSNR reported in Figure 6. Moreover, even with severe impulse noise, GCMark maintains stable watermark extraction performance. As shown in Figure 7d, the extraction accuracy (ACC) of GCMark remains above 99%, demonstrating a clear advantage over the compared approaches.
JPEG Compression (JPEG): During training, the noise layer is configured with a JPEG quality factor (QF) of 50, while to evaluate robustness against JPEG compression, the trained models are tested over a range of QF values from 50 to 90. JPEG compression introduces pronounced quantization artifacts that can severely impair embedded watermark signals. As reported in Figure 6, GCMark achieves the highest PSNR among all compared methods under JPEG compression, indicating superior imperceptibility. Furthermore, as illustrated in Figure 7e, GCMark consistently maintains high extraction accuracy across different qualities, demonstrating strong robustness to lossy compression.
Gaussian Blur (GB): For Gaussian blur distortion, a fixed blur variance of 2 is employed in the noise layer during training. During testing, the blur variance is progressively increased from 0.05 to 2 to assess both the imperceptibility and robustness of the compared methods. As summarized in Figure 6, GCMark achieves a higher PSNR than all baseline approaches, which indicates its ability to preserve image quality under spatial smoothing. Moreover, as illustrated in Figure 7f, GCMark maintains reliable watermark extraction accuracy as the blur strength increases.
Median Blur (MB): To enhance robustness during training, a fixed blurring kernel of size is adopted. During testing, robustness is further assessed using multiple kernel sizes, including , , and . Median blur is widely regarded as a particularly destructive operation for embedded signals; nevertheless, as reported in Figure 6, GCMark achieves competitive PSNR performance under this attack. More importantly, as illustrated in Figure 7g, GCMark maintains consistently high extraction accuracy, significantly outperforming baseline methods and demonstrating the proposed design’s robustness against nonlinear filtering.
4.3. Training Imperceptibility and Robustness Against Combined Distortions
In addition, we replace the single distortion noise layer with a combined distortion noise layer during training, where a single model is trained to withstand multiple types of distortions simultaneously, aiming to further evaluate the robustness of GCMark and the baseline approaches under more challenging and realistic conditions. The combined noise layer consists of identity, GN (), SPN (), GB (), MB (), JPEG (), dropout (), and cropout (), where identity corresponds to the original image.
Table 1 reports the PSNR results of GCMark and the baseline approaches under the combined distortion training scenario, while Table 2 summarizes the corresponding watermark extraction accuracy (ACC). In terms of imperceptibility, GCMark consistently outperforms the baseline methods, achieving the highest PSNR of 35.87 dB, which is 0.46 dB higher than that of the strongest competing approach.

Table 1.
The PSNRs of GCMark and the baseline approaches.
Table 2.
Robust performance with different attacks.
In terms of robustness, GCMark also exhibits strong performance across most distortion types. As shown in Table 2, GCMark achieves the highest or comparable extraction accuracy under all attack scenarios, including JPEG, GN, GB, MB, SPN, cropout, and dropout. Overall, these results validate that the proposed gated feature selection and Cover-Guided Message Expansion are effective in achieving a favorable trade-off between imperceptibility and robustness under diverse and combined distortion conditions.
Furthermore, Table 3 presents the robustness comparison under combined attack scenarios, where two distortions are applied simultaneously. As shown, the performance of all methods degrades compared to single-attack cases due to increased compound degradation difficulty. Nevertheless, GCMark consistently maintains the highest extraction accuracy across all combined attack settings. In particular, under challenging combinations such as GN and SPN and MB and JPEG, GCMark outperforms the competing methods by a clear margin, demonstrating stronger resilience to multiple distortions interacting. These results further confirm that the proposed gating mechanism and Cover-Guided Message Expansion effectively enhance robustness not only against individual distortions but also against more realistic combined attack scenarios.
Table 3.
Robust performance under combined attacks.
4.4. Ablation Study
In this section, we perform a series of ablation experiments to analyze the individual contributions of the GMU and CGMEB in the proposed GCMark framework, as well as the impact of several key hyperparameters. All experiments are conducted on the test set, where different distortion types are randomly applied, and the watermark extraction accuracy (ACC) is evaluated under each configuration.
4.4.1. Effectiveness of GMU
The Gated Modulation Unit (GMU) is designed to enhance feature representations through fine-grained gated modulation. To assess its effectiveness, we perform an ablation study by removing the GMU from the network while keeping all other components unchanged. The quantitative results in terms of PSNR and ACC are reported in Table 4, and per-attack ablation results are reported in Table 5. With GMU inclusion, GCMark achieves an improvement of approximately 0.84 dB in PSNR and 1.15% in extraction accuracy, which can be attributed to the selective modulation mechanism introduced by GMU, which effectively suppresses noise-sensitive activations while reinforcing watermark-relevant features. These results indicate that GMU plays a crucial role in enhancing both imperceptibility and robustness.
Table 4.
Ablation study of GMU and CGMEB.
Table 5.
Per-attack ablation study of GMU within DSGMB.
4.4.2. Effectiveness of CGMEB
The Cover-Guided Message Expansion Block (CGMEB) is designed to adaptively expand the watermark message by leveraging texture features from the cover image. To evaluate its contribution, we replace CGMEB with a simple convolution-linear expansion module. As shown in Table 4, this leads to a noticeable performance degradation, particularly in terms of robustness. Specifically, the extraction accuracy (ACC) drops by approximately 0.62%, while PSNR decreases by 0.66 dB, suggesting that content-agnostic expansion based on a simple convolution-linear layer fails to account for local image characteristics, resulting in suboptimal message allocation across different regions. In contrast, CGMEB strengthens message features in texture-rich areas while suppressing expansion in smooth and visually sensitive regions, thereby achieving a more favorable trade-off between imperceptibility and robustness. Overall, the results confirm the importance of cover-guided expansion during the message expansion stage.
4.4.3. Loss Weight Analysis
Table 6 analyzes the influence of loss weights on watermark invisibility and robustness. When and are fixed, reducing from four to one leads to a noticeable decrease in PSNR but results in a substantial improvement in ACC, indicating significantly enhanced watermark robustness at the cost of moderate visual quality degradation. Furthermore, when and are fixed, increasing from 0.0001 to 0.001 causes a reduction in ACC (99.36% to 99.20%) and a marginal increase in PSNR (35.87 dB to 35.92 dB), suggesting that a larger adversarial loss weight does not bring additional benefits and may negatively affect training stability. Overall, the configuration , , and achieves the best trade-off between watermark robustness and imperceptibility.
Table 6.
Analysis of different loss weights.
4.4.4. Different Texture Operators Ablation Study
Table 7 compares different texture guidance extraction methods in the CGMEB module. Although Sobel and Laplacian operators emphasize sharp edges, they tend to amplify noise and compression artifacts, leading to unstable guidance under distortions. In contrast, the AvgPool-based guidance produces smoother and more stable structural cues, which are better aligned with the soft modulation mechanism of CGMEB. As a result, AvgPool achieves superior performance in terms of both PSNR and extraction accuracy, providing a more effective balance between imperceptibility and robustness.
Table 7.
Ablation study of different texture guidance extraction methods in CGMEB.
4.4.5. Adversary Effectiveness
Table 8 shows the impact of the adversarial component on watermark imperceptibility and robustness. Removing the adversary leads to a noticeable decrease in PSNR, indicating more visible artifacts in the watermarked images, while the extraction accuracy remains largely unchanged. With the adversary enabled, PSNR improves by nearly 1 dB, confirming that the adversarial loss effectively enhances visual quality without sacrificing robustness.
Table 8.
Adversary ablation study.
5. Conclusions
In this paper, we propose GCMark, a robust image watermarking framework that achieves a favorable balance between imperceptibility and robustness under diverse distortion scenarios by maintaining structural symmetry and consistency between watermark information and host image representations. GCMark incorporates two key components: the Dual-Stage Gated Modulation Block (DSGMB) and the Cover-Guided Message Expansion Block (CGMEB). DSGMB enhances feature representations via channel-wise recalibration and gated modulation, effectively suppressing noise-sensitive activations while preserving watermark-relevant structures. In parallel, CGMEB exploits texture information from the cover image to guide message expansion in a symmetry-consistent, content-aware manner, selectively reinforcing watermark embedding in texture-rich regions while reducing visual artifacts in smooth areas. Extensive experimental results demonstrate that GCMark consistently outperforms baseline methods in terms of both imperceptibility and watermark extraction accuracy.
Although the proposed gating mechanism and mask-guided design effectively improve watermark robustness and imperceptibility, the current framework is still based on a CNN backbone, which mainly captures local features with limited ability to model long-range spatial dependencies. Consequently, the robustness remains constrained against complex geometric attacks, such as large rotations or severe scaling. In future work, we plan to incorporate the proposed gating and mask-guided strategies into Transformer-based watermarking frameworks, where global self-attention can better preserve spatial relationships and further enhance robustness against geometric desynchronization.
Author Contributions
Conceptualization, L.Z. and Y.L.; methodology, L.Z.; software, L.Z. and Y.L.; validation, L.Z.; writing—original draft preparation, L.Z.; writing—review and editing, Y.L. and W.L.; supervision, W.L.; funding acquisition, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Grant No. 42201444) and the Postgraduate Research & Practice Innovation Program of Jiangsu Province (Grant No. KYCX25_3972).
Data Availability Statement
The data associated with this research are available online. The DIV2K dataset is available at https://data.vision.ee.ethz.ch/cvl/DIV2K/ (accessed on 4 November 2025). The ImageNet dataset is available at https://www.image-net.org/ (accessed on 4 November 2025). The COCO dataset is available at https://cocodataset.org/ (accessed on 4 November 2025). At the same time, we have made appropriate citations in this paper.
Acknowledgments
During the preparation of this manuscript, the authors used GPT-5.2 and Gemini-3 for the purposes of language polishing and grammatical checking. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chang, C.S.; Shen, J.J. Features Classification Forest: A Novel Development that is Adaptable to Robust Blind Watermarking Techniques. IEEE Trans. Image Process. 2017, 26, 3921–3935. [Google Scholar] [CrossRef] [PubMed]
- van Schyndel, R.; Tirkel, A.; Osborne, C. A digital watermark. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; Volume 2, pp. 86–90. [Google Scholar] [CrossRef]
- Dumitrescu, S.; Wu, X.; Wang, Z. Detection of LSB steganography via sample pair analysis. IEEE Trans. Signal Process. 2003, 51, 1995–2007. [Google Scholar] [CrossRef]
- Fang, H.; Zhang, W.; Zhou, H.; Cui, H.; Yu, N. Screen-Shooting Resilient Watermarking. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1403–1418. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Niu, Z.; Xu, Y.; Keskinarkaus, A.; Seppänen, T.; Sun, X. Real-time and screen-cam robust screen watermarking. Knowl.-Based Syst. 2024, 302, 112380. [Google Scholar] [CrossRef]
- Jia, Z.; Fang, H.; Zhang, W. Mbrs: Enhancing robustness of dnn-based watermarking by mini-batch of real and simulated jpeg compression. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 41–49. [Google Scholar]
- Zhu, J.; Kaplan, R.; Johnson, J.; Fei-Fei, L. HiDDeN: Hiding Data with Deep Networks. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 682–697. [Google Scholar] [CrossRef]
- Ahmadi, M.; Norouzi, A.; Karimi, N.; Samavi, S.; Emami, A. ReDMark: Framework for residual diffusion watermarking based on deep networks. Expert Syst. Appl. 2020, 146, 113157. [Google Scholar] [CrossRef]
- Fang, H.; Qiu, Y.; Chen, K.; Zhang, J.; Zhang, W.; Chang, E.C. Flow-based robust watermarking with invertible noise layer for black-box distortions. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 5054–5061. [Google Scholar]
- Fang, H.; Chen, K.; Qiu, Y.; Ma, Z.; Zhang, W.; Chang, E.C. DERO: Diffusion-Model-Erasure Robust Watermarking. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; pp. 2973–2981. [Google Scholar]
- Sun, N.; Fang, H.; Lu, Y.; Zhao, C.; Ling, H. ENDˆ 2: Robust Dual-Decoder Watermarking Framework Against Non-Differentiable Distortions. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; pp. 773–781. [Google Scholar]
- Huang, D.; Liu, J.; Huang, J.; Liu, H. A DWT-based image watermarking algorithm. In Proceedings of the IEEE International Conference on Multimedia and Expo, Tokyo, Japan, 22–25 August 2001; ICME 2001; IEEE Computer Society: Los Alamitos, CA, USA, 2001; p. 80. [Google Scholar]
- Liu, Y.; Guo, M.; Zhang, J.; Zhu, Y.; Xie, X. A novel two-stage separable deep learning framework for practical blind watermarking. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1509–1517. [Google Scholar]
- Fang, H.; Jia, Z.; Zhou, H.; Ma, Z.; Zhang, W. Encoded feature enhancement in watermarking network for distortion in real scenes. IEEE Trans. Multimed. 2022, 25, 2648–2660. [Google Scholar] [CrossRef]
- Wu, X.; Liao, X.; Ou, B. Sepmark: Deep separable watermarking for unified source tracing and deepfake detection. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 1190–1201. [Google Scholar]
- Ma, L.; Fang, H.; Wei, T.; Yang, Z.; Ma, Z.; Zhang, W.; Yu, N. A Geometric Distortion Immunized Deep Watermarking Framework with Robustness Generalizability. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 268–285. [Google Scholar]
- Chen, W.; Li, Y.; Zhang, J.; Ge, C.; Wu, D.; Susilo, W.; Palaiahnakote, S. GResMark: A Swin Transformer-based Watermarking Framework with Geometric Attack Resilience. Expert Syst. Appl. 2025, 304, 130807. [Google Scholar] [CrossRef]
- Tancik, M.; Mildenhall, B.; Ng, R. Stegastamp: Invisible hyperlinks in physical photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2117–2126. [Google Scholar]
- Fang, H.; Jia, Z.; Ma, Z.; Chang, E.C.; Zhang, W. Pimog: An effective screen-shooting noise-layer simulation for deep-learning-based watermarking network. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 2267–2275. [Google Scholar]
- Liu, G.; Si, Y.; Qian, Z.; Zhang, X.; Li, S.; Peng, W. WRAP: Watermarking Approach Robust Against Film-coating upon Printed Photographs. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 7274–7282. [Google Scholar]
- Wang, G.; Ma, Z.; Liu, C.; Yang, X.; Fang, H.; Zhang, W.; Yu, N. MuST: Robust Image Watermarking for Multi-Source Tracing. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; pp. 5364–5371. [Google Scholar]
- Liang, X.; Liu, G.; Si, Y.; Hu, X.; Qian, Z. ScreenMark: Watermarking Arbitrary Visual Content on Screen. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; pp. 26273–26280. [Google Scholar]
- Liu, G.; Cao, S.; Qian, Z.; Zhang, X.; Li, S.; Peng, W. Watermarking One for All: A Robust Watermarking Scheme Against Partial Image Theft. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 8225–8234. [Google Scholar]
- Rao, C.; Liu, G.; Li, S.; Zhang, X.; Qian, Z. DynMark: A Robust Watermarking Solution for Dynamic Screen Content with Small-size Screenshot Support. In Proceedings of the 33rd ACM International Conference on Multimedia, Dublin, Ireland, 27–31 October 2025; pp. 7463–7471. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; IEEE: New York City, NY, USA, 2017; pp. 1597–1600. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv 2015, arXiv:1505.00387. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Zatsarynna, O.; Bahrami, E.; Farha, Y.A.; Francesca, G.; Gall, J. Gated temporal diffusion for stochastic long-term dense anticipation. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 454–472. [Google Scholar]
- Xiao, Y.; Yuan, Q.; Jiang, K.; He, J.; Lin, C.W.; Zhang, L. TTST: A Top-k Token Selective Transformer for Remote Sensing Image Super-Resolution. IEEE Trans. Image Process. 2024, 33, 738–752. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhu, L.; Zhao, Y.; Fang, Y.; Wang, J. A novel robust digital image watermarking scheme based on attention U-Net++ structure. Vis. Comput. 2024, 40, 8791–8807. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.