1. Introduction
China is the world’s leading producer of coal. The country’s development is significantly impacted by the advancement of green mining practices and the efficient utilization of coal mining resources. In the process of coal mining, the raw coal is mixed with gangue accompanying the coal seam, which is a kind of solid waste with low calorific value, high water content, and high impurity content [
1]. The relatively high content of sulfur dioxide and other harmful substances in gangue has the potential to cause environmental pollution, including contamination of rivers, the atmosphere, and soil. Due to the mining process in different areas of the coal seam and gangue, its distribution situation varies greatly, and the mining working face is also constantly changing, which makes it difficult to obtain accurate content of gangue and the distribution of the situation. To address the call’s comprehensive conservation plan, protect the security of the nation’s resources, aggressively and consistently advance carbon neutrality, and quicken the call’s green transformation, it is of particular importance to conduct research into the sorting of coal gangue in the field of coal mining [
2].
Presently, China’s coal gangue selection employs traditional methods, including the artificial gangue method, the mechanical gangue method, the mechanical dry selection method, and the mechanical wet selection method [
3]. The artificial gangue faces low sorting efficiency, poor working environment, high labor intensity, and high cost; traditional mechanical gangue selection methods generally have low identification accuracy, large footprint, high investment costs, serious environmental pollution, and other shortcomings [
4]. Mechanical dry sorting methods, such as spectroscopy and X-ray diffraction, pose a risk of radiation exposure to the human body; mechanical wet sorting methods cause waste of water and secondary pollution of the environment, and do not meet the needs of green manufacturing. Therefore, computer vision technology provides an effective alternative for the direction of coal gangue sorting in the field of coal mining, using computer vision technology to identify and classify the collected images of coal gangue, thereby facilitating the intelligent construction of coal mines. There are two main methods for detecting coal and gangue using computer vision techniques: traditional image recognition methods and deep learning recognition methods [
5]. Traditional image recognition methods need to manually extract the image features of coal and gangue, which have the disadvantages of low recognition accuracy, sensitivity to image changes, and poor generalization ability [
6]; while deep learning recognition methods have high accuracy, real-time, and robustness.
Deep learning is a machine learning algorithm that focuses on learning representations of data. Deep learning frameworks include the convolutional neural network (CNN), deep confidence network, recursive neural network, and others [
7]. With the continuous progress of artificial intelligence, deep learning algorithms have been increasingly used in the field of coal and gangue identification. Xu et al. [
8] optimized a convolutional neural network-based gangue recognition model by pruning, thereby reducing the size of the model parameters and computational requirements. However, their work did not take the detection speed of the gangue recognition process into account. Cao Xiangang et al. [
9] proposed a deep learning-based method for the recognition of gangue, utilizing an RPN network structure to extract the candidate area of gangue and to evaluate the output of its gangue category. However, the accuracy of this method for the recognition of mixed samples of gangue was found to be only 90.17%. Shi Yikun et al. [
10] on the other hand, employed the YOLOv5s model as the baseline network and introduced the content-aware reassembly of features (CARAFE) module into their backbone network to augment the network’s capacity for feature extraction, but they have not yet implemented the deployment on devices with limited real-world computational resources.
The majority of the aforementioned research solely concentrates on the target identification of coal and gangue; nevertheless, knowing the coal and gangue’s center position is also essential for the subsequent separation processes that involve robotic arms, blowing mechanisms, and other components [
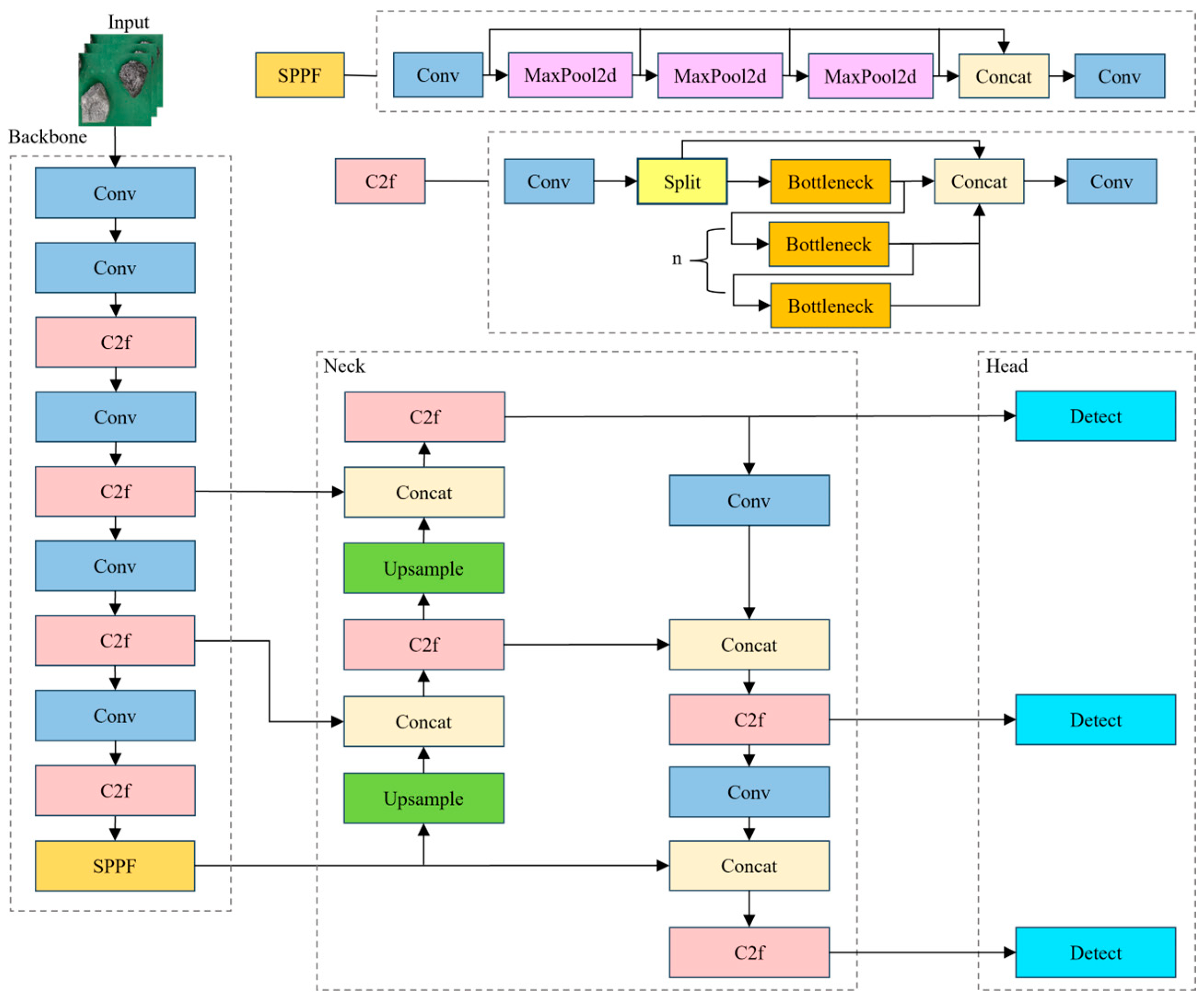
11]. In addition to applying to the actual intelligent sorting of coal gangue, it is necessary to take into account the size of the model of detection and the detection speed. In the area of target detection, YOLOv5 is widely used in embedded scenarios, and although it has certain advantages, it is difficult to meet the real-time requirements of the system on devices with limited computing resources. YOLOv8, on the other hand, is a new model that improves YOLOv5 and is able to increase the detection accuracy while reducing the number of parameters. Compared with it, it is more suitable for the requirements of intelligent coal gangue sorting for light and real time. Therefore, a lightweight, real-time, and efficient DEL_YOLOV8s algorithmic model for intelligent coal gangue sorting is proposed, which combines the EfficientViT module, the DRBNCSPELAN4 module, and the Detect_LSCD detection header to make the model have less of a number of parameters and floating-point operations, which improves the recognition speed of the model, and is easier to deploy to the end of edge devices such as the Raspberry Pi and other similar edge devices.
3. Experimental Results and Analysis
3.1. Experimental Environment
This experimental environment uses PyTorch 2.1.1 as the framework, CUDA version 12.0, Python as the programming language, Python 3.8 as the interpreter, and a hardware environment comprising NVIDIA GeForce RTX 3090 GPUs and Intel Xeon(R) Silver 4210R CPUs. In addition, a Linux-based Raspberry Pi 4B and display are equipped for verifying the performance of the model.
In the training phase, the input image size is 320 × 320 pixels, the epoch is set to 200 rounds, and the model is optimized using a stochastic gradient descent (SGD) optimizer with an initial learning rate of 0.01 and a momentum factor of 0.937.
3.2. Datasets
This experiment makes use of the coal gangue open dataset and Anhui Province Huaibei City Zhuzhuang coal mine mining coal and gangue as a sample of homemade dataset for the combination of a total of 3264 pictures after the production of a new dataset for the experimental object. During the image acquisition process, industrial environmental conditions such as temperature, light, and dirt will impact the acquisition of sample images. If the temperature is too high, image sensors can cause the sample image of coal and gangue noise, color shift, and other problems. If the lighting conditions are too strong, the image of coal and gangue will be overexposed, resulting in the appearance of coal and gangue not being obvious, losing important features of the details of the part; if the light is not enough, it will lead to the acquisition of a dim image, and it will be difficult to distinguish between coal and gangue. In addition, if the lens is dirty, the sample image taken will have some blurred areas, which will affect the feature extraction of coal and gangue. The horizontal placement of the samples on a conveyor belt was achieved at random. Two types of equipment were employed to capture the images: firstly, coal and gangue images were captured by an OpenMV-enabled programmable camera; secondly, the sample data were captured by an industrial camera. Each of these images contain four to eight coals and gangue. The dataset is shown in
Figure 6. After that, all the captured images are manually labeled with coal and gangue categories and location information using the “Labelimg” labeling software tool to generate xml label files and txt label files using format conversion code in PyCharm. Eventually, the images in the dataset are disrupted and divided into training, validation, and testing sets according to 7:2:1.
3.3. Evaluation Indicators
To provide a comprehensive evaluation of the performance and efficiency of the algorithmic model in coal and gangue recognition and classification, several key indicators were selected for analysis. These included the model size, parameters, floating point operations per second (FLOPs), precision (P), recall (R), and mean average precision (mAP@50–95). The two metrics, FLOPs and parameters, are used to assess the complexity of the model or algorithm and the size of the model, respectively. A lower value indicates that the model is more lightweight in nature.
Gangue sorting is a binary classification problem, and the confusion matrix is represented in
Table 1.
TP indicates the total number correctly identified as coal or gangue.
FP represents the total number of coal and gangue that are not coal or gangue but have been misclassified as coal or gangue.
FN signifies the total number of coals or gangue that were not identified.
TN denotes the total number of coals or gangue that are not coal or gangue and have not been identified.
Precision (P) is a measure of how accurately the model predicts instances of the positive class. Recall (R) is the proportion of instances correctly recognized by the model as positive class to all actual positive class instances. The
F1 score is a reconciled average of precision and recall [
32]. It provides a comprehensive picture of the model’s performance. The mean average precision (
mAP) is a frequently utilized performance evaluation metric in target detection tasks to measure the average accuracy of a model across different categories and different intersections over union (IoU). The mAP@50–95 refers to the average of the mean accuracies (
AP) of the computational models across all categories, calculated over a range of IoU thresholds from 0.5 to 0.95 (with values at 0.05 intervals, for a total of 10 thresholds). It is an essential metric for evaluating the performance of target detection models, taking into account the model’s performance at varying IoU levels to provide a more comprehensive assessment [
33]. The metric is calculated as follows:
where
AP is average precision, which refers to the average of the precision rates at all possible levels of recall for the model. Therefore,
mAP is calculated by averaging the
AP values for all categories.
The inference time of the model was recorded during validation on the Raspberry Pi to assess its real-time performance on the Raspberry Pi.
3.4. Model Training Performance
To demonstrate the effectiveness of the training, YOLOv8 was used as the baseline model to train the gangue for target detection, and an in-depth analysis of the model’s performance was carried out from multiple dimensions.
Figure 7 illustrates the F1-confidence curve for the final model. It can be seen that as the confidence level gradually increases, the F1 value tends to increase and then decrease. When the confidence level reaches 0.537, the F1 value for all categories reaches 0.95, indicating that the model achieves a better balance between precision and recall at this confidence level.
The loss function curve can reflect the convergence and stability of the model during the training process.
Figure 8 shows the box_loss, cls_loss, and dfl_loss curves during training and validation, as well as the metric curves for precision, recall, mAP50, and mAP50–95 in metrics. The high value of train/box_loss at the beginning of the training phase, which is about 4, signifies that the model exhibits reduced efficacy in localizing the target object in the initial phase, consequently leading to a large prediction bias. As the number of training rounds increases, the parameters are constantly optimized and adjusted, and the positional features of the target are gradually learned. train/box_loss decreases rapidly and then tends to stabilize, indicating that the model’s prediction of the target’s bounding box is becoming more accurate. The initial value of train/cls_loss training is around 3.5, and the model has difficulty in accurately extracting coal and gangue features in the early stages. As the training depth increased, train/cls_loss decreased significantly and eventually stabilized at around 0.6, indicating that the model was able to discriminate more accurately between coal and gangue. The train/dfl_loss at the beginning of training is about 4. As the model learns the degree of refinement of the target frame regression, the loss value decreases steadily and eventually stabilizes at about 1.2, indicating that the model achieved better results in the fine positioning of the target frame regression. val/cls_loss in the initial phase due to the relatively random parameters and the large deviation of the predicted sample categories, which caused an initial break in the curve. The model learns the coal and gangue characteristics efficiently, and the loss values decrease rapidly after about 20 rounds. As the number of training rounds increased, the val/cls_loss exhibited a gradual decrease and then stabilized at approximately 0.3. The overall trend of the loss function curves on the validation set is similar to that of the training set, both decreasing and then stabilizing. In addition, the curves for the four assessment metrics, precision, recall, mAP50, and mAP50–95, are consistently increasing and then converging. As a result, the model is currently not overfitting, indicating that the model has good generalization ability and can show good performance on new data. From the metrics/precision (B) curve, it can be seen that the precision rate is close to 0 at the beginning of the training, and as the training proceeds, the precision rate starts to increase substantially, approaching 1.0 by the 200th round, indicating that the proportion of samples predicted by the model to be positive instances is becoming higher and higher. The metrics/recall (B) curve shows that the relatively weak ability to recognize the target object at the beginning of the training period due to the random initialization of the model leads to an unstable calculation of the recall rate, and the curve produces an interruption, which is manifested as a rapid increase in the recall rate followed by an immediate decrease. As the number of training rounds increases, the model performs fast extraction and learning for coal and gangue features, and the recall increases rapidly, reaching around 0.8 near the 50th round. The curve then rises gradually due to the decrease in new valid features available for learning and eventually stabilizes, indicating that the model is able to correctly detect most of the actual positive case samples. The metrics/mAP50 (B) curve eventually approaches 1.0, indicating that the model demonstrates a high average detection accuracy for all types of targets at an IoU threshold of 0.5. The final value of the metrics/mAP50–95 (B) curve is about 0.8, indicating that the model still has good detection performance in the tighter IoU threshold range (0.5–0.95).
3.5. Ablation Experiments
Ablation experiments were conducted to better test the effectiveness of each improved module for coal and gangue identification optimization. Experiment 1 is the original model, which is notated as Base. Experiment 2 models the EfficientViT network by replacing the backbone network with the EfficientViT network, notated Base_EviT, and notated EfficientViT as EViT. Experiment 3 replaces the C2f module with the DRBNCSPELAN4 module, designated as Base_DRBNCSPELAN. Experiment 4 changed the detection head to the lightweight shared convolutional detection head Detect_LSCD, henceforth referred to as Base_LSCD. Experiment 5 combined Experiments 2 and 4, denoted as Base_EViT+LSCD. Experiment 6 integrated the methodologies of Experiments 3 and 4, resulting in the designation Base_DRBNCSPELAN+LSCD. Experiment 7 is the final model DEL-YOLOv8s after combining all modules. This model has been designated as DEL-YOLOv8s.
Table 2 displays the experimental findings.
As illustrated in
Table 2, the dimensional size, number of parameters, and GLOPs of the base model are 21.4 M, 11.13 M, and 28.4, respectively. When the three improved modules are combined with the base model alone, the model size, number of parameters, and FLOPs are all reduced while maintaining similar accuracy, indicating that all three modules exhibit varying degrees of lightweight efficacy and are well-suited for coal gangue sorting scenarios. The model after the two-by-two combination of the three modules shows a substantial reduction in model size, the number of parameters, and FLOPs, with the most significant change in the number of parameters. Upon combining the three modules, the DEL-YOLOv8s model size is reduced to 10.2 M, the number of parameters is only 4.97 M, and the FLOPs are 14.1 G. This represents a reduction of 11.2 M, 6.16 M, and 14.3 G, respectively, in comparison to the base model. In addition, the inference speed test conducted on a Raspberry Pi 4B device yielded a result of 937.7 ms/frame, which is a speed improvement of 20.87% compared to the base model. The model has been demonstrated to effectively reduce the complexity and computational requirements of the original model while maintaining high performance. It has also been shown to shorten the inference time, which is conducive to improving operational efficiency in the practical application of coal gangue sorting.
3.6. Comparative Experiments
To further verify the effectiveness of the improved model for recognizing the coal gangue, different models of YOLOv3s, YOLOv5s, and YOLOv6s are compared for experiments under the condition of guaranteeing the use of the same dataset and experimental environment configurations mentioned above. The results of the experiment are presented in
Table 3.
From the table, the final model and the above models have a significant reduction in model size, number of parameters, and FLOPs, while mAP@50–95 is 83%, second only to YOLOv6s, which is 0.2% lower in comparison. in the Raspberry Pi 4B device, test speed is not as good as the YOLOv3s model, but all other indicators are better than YOLOv3s. When considered collectively, the DEL-YOLOv8s model exhibits notable advantages across multiple key performance indicators, with a more lightweight model, balanced detection accuracy, and it is more suitable for deployment on Raspberry Pi for practical coal gangue sorting applications, with a wide range and practicality.
3.7. Visualization Analysis
To more effectively demonstrate the enhanced efficiency of the revised algorithm for coal gangue sorting, once the weight files of the baseline model and the improved model have been obtained, a portion of the coal and gangue is identified and predicted. The main categories are normal, low light, strong light, and dusty industrial environments, and there is the prediction of homemade laboratory datasets. The resulting prediction effect is illustrated in
Figure 9. In this case, the yellow dashed box indicates a missed or duplicate detection, and the red dashed box indicates a category detection error. While the baseline model can predict coal and gangue under normal circumstances, problems of misclassification and duplicate detection can occur. The baseline model also suffers from duplicate detections in low-light environments. Additionally, the baseline model misidentifies areas that are not gangue as gangue under strong lighting. For dusty environments and homemade datasets, the detection effect between the two is relatively insignificant. Overall, it is observed from the
Figure 9. that the upgraded model has better detection of coal and gangue. As can be seen from the
Figure 10, the mAP@50–95 curves during training of the improved model are broadly in line with the baseline model, but DEL-YOLOv8s’ accuracy is generally higher than that of the baseline model from round 175 onwards.
Figure 11 illustrates the visualization between the number of parameters and the model size through the MATLAB R2023b software, as the number of parameters in the model decreases, so does the model size. It can be observed that experiment 7 has the lowest number of parameters and the smallest model size of the several experiments. Consequently, the final model achieves a smaller model size while being able to maintain a lower number of parameters, which is especially advantageous for edge devices or resource-constrained environments.
As illustrated in
Figure 12, the physical diagram for validating the model on the Raspberry Pi is presented.
Furthermore, in order to show more clearly the performance of different models in testing inference speed on Raspberry Pi, using FLOPs as an example, scatter plots of FLOPs versus inference speed on the Raspberry Pi for each model were generated using MATLAB R2023b software. The results are shown in
Figure 13. The
Figure 13. demonstrates the relationship between the aforementioned two indicators for the seven models. As evidenced by the
Figure 13., it can be seen that the inference speed shows a certain decreasing trend as the FLOPs decrease. Models 2, 3, and 4 showed a small decrease in the speed of reasoning while maintaining similar or slightly lower FLOPs. Models 5 and 6 achieve relatively fast inference speeds while further reducing FLOPs. The combination of all modules yields the final model with the lowest FLOPs, which significantly reduces the consumption of computational resources, and the inference speed in the real-time coal gangue sorting task demonstrates superior performance compared with the other six models, providing substantial evidence in support of the realization of the intelligent transformation of coal mines.
The above visualization analysis intuitively presents the good results of the model in the coal gangue target detection task based on the existing dataset. However, since this study has not yet obtained coal and gangue samples from other mining environments for testing and validating the data, the generalization ability of the model may fluctuate when dealing with data from other mining areas.
4. Conclusions
In order to adapt to different light, shape, and other complex conditions in real-time high-precision identification of coal and gangue so as to achieve the coal gangue sorting, the DEL_YOLOv8s model is designed to address the issue of coal and gangue misdetection and omission detection. Firstly, the EfficientViT module is introduced in the backbone region to replace the backbone network of YOLOv8s, with the objective of extracting multi-layered and multi-scale image feature information. Secondly, the C2f module was replaced with the DRBNCSPELAN4 module in the neck network to enhance the model’s feature extraction and fusion capabilities, thereby reducing the computational complexity. Finally, Detect_LSCD, a self-developed lightweight detection head, is used to further improve the detection accuracy. In the end, the mAP@50–95, model weight size, number of parameters, and floating-point operations of the model for coal and gangue recognition detection are 83%, 10.2 MB, 4.97 M, and 14.1 G, respectively. In comparison to the YOLOv8s model, the DEL_YOLOv8s model exhibits a reduction in the size of 11.2 MB, a 55.35% reduction in the number of parameters, a 50.35% reduction in the number of floating-point operations, and a 1.2% improvement in the mAP@50–95. Concurrently, the processing of input coal and gangue images was accelerated by 20.87% after deployment in a Raspberry Pi 4B edge computing device. In summary, the model is able to maintain high accuracy and real-time identification of coal and gangue while necessitating reduced computation and accelerated inference. In addition, the model can provide accurate location information of gangue for deployment into edge computing devices for real-time gangue sorting applications in conjunction with STM32 microcontroller-controlled robotic arms. The model also has some limitations, although the dataset integrates the public dataset and the homemade dataset, but the samples of coal and gangue covered at present are limited in variety, and there are differences in the characteristics of coal and gangue in different mines, which may lead to insufficient generalization ability of the model when dealing with the data from other mines. On this basis, we will continue to optimize the network structure in order to be more lightweight, and further acquire different types of coal and gangue samples from multiple locations, make datasets to add to the existing dataset, and improve the adaptability of the model, so that the model can be better applied to the actual coal and gangue sorting scenarios.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}