Abstract
Based on the Support Vector Machine (SVM) and Twin Parametric Margin SVM (TPMSVM), this paper proposes two sparse models, named Sparse SVM (SSVM) and Sparse TPMSVM (STPMSVM). The study aims to achieve high sparsity, rapid prediction, and strong generalization capability by transforming the classical quadratic programming problems (QPPs) into linear programming problems (LPPs). The core idea stems from a clear geometric motivation: introducing an -norm penalty on the dual variables to break the inherent rotational symmetry of the traditional -norm on the normal vector. Through a theoretical reformulation using the Karush–Kuhn–Tucker (KKT) conditions, we achieve a transformation from explicit symmetry-breaking to implicit structural constraints—the penalty term does not appear explicitly in the final objective function, while the sparsity-inducing effect is fundamentally encoded within the objective functions and their constraints. Ultimately, the derived linear programming models naturally yield highly sparse solutions. Extensive experiments are conducted on multiple synthetic datasets under various noise conditions, as well as on 20 publicly available benchmark datasets. Results demonstrate that the two sparse models achieve significant sparsity at the support vectors level—on the benchmark datasets, SSVM, and STPMSVM reduce the number of support vectors by an average of 56.21% compared with conventional SVM, while STPMSVM achieves an average reduction of 39.11% compared with TPMSVM—thereby greatly improving prediction efficiency. Notably, SSVM maintains accuracy comparable to conventional SVM under low-noise conditions while attaining extreme sparsity and prediction efficiency. In contrast, STPMSVM offers enhanced robustness to noise and maintains a better balance between sparsity and accuracy, preserving the desirable properties of TPMSVM while improving prediction efficiency and robustness.
1. Introduction
Machine learning methods are popular and extremely efficient for solving classification and regression problems [1], attracting the attention of many researchers. Various algorithms for supervised and unsupervised learning have been proposed and extensively studied in the past few decades. Among them, Support Vector Machine (SVM) [1,2,3,4,5] and its variants [6,7,8,9,10] are widely recognized as some of the most powerful supervised learning algorithms based on kernel techniques. SVM was first proposed by Cortes and Vapnik [2] for classification and later extended to regression problems. It maps the samples into a higher-dimensional feature space and generates a pair of parallel optimal linear separating hyperplanes with maximal margin. Due to its extraordinary generalization capability, discriminative power, and strong theoretical properties [2,3,4,5], SVM has been widely applied in diverse research fields [6,11,12,13,14,15,16,17,18,19].
In recent years, several enhanced SVM formulations have been developed to improve flexibility and predictive performance. To increase the predictive power of SVM, par-v-SVM [7] was proposed, introducing a flexible parametric margin, where the parameter can control the number of support vectors and margin errors. Khemchandani et al. [8] proposed Twin SVM (TWSVM) for binary datasets. Instead of determining two parallel hyperplanes as in traditional SVM, TWSVM determines one hyperplane for each class, ensuring each hyperplane is as close as possible to one of the two classes and as far as possible from the other. This approach requires solving two lower-dimensional quadratic programming problems (QPPs) instead of one large optimization problem in the classical SVM method, making TWSVM almost four times faster than the standard SVM classifier. In 2011, combining TWSVM and par-v-SVM, a novel Twin Parametric Margin SVM (TPMSVM) [9] was proposed, where again two nonparallel parametric-margin separating hyperplanes are generated. Like TWSVM, TPMSVM also solves two QPPs but introduces adaptive margins to enhance flexibility, drawing inspiration from par-v-SVM. It has also been extended to improve robustness and handle multiclass problems [20].
With the growing demand for efficient machine learning in resource-constrained environments such as edge computing, achieving sparsity in SVMs has become increasingly important. Reducing the number of support vectors can lower memory and computational requirements while accelerating prediction without compromising generalization performance. Several approaches have been explored to induce sparsity in SVMs: Some methods introduce non-convex loss functions [19,21,22] or non-convex regularization terms [23,24,25,26] to promote sparsity, but these typically require complex optimization algorithms; Another line of work imposes sparsity constraints on SVMs to directly control the number of support vectors [27,28], achieving effective sparsity, but both involve theoretically intricate frameworks and rely on iterative optimization procedures, which reduces their simplicity and scalability. Meanwhile, classical regularization [29] primarily induces sparsity at the feature level, while support vector sparsity still largely stems from the natural sparsity of the hinge loss.
Motivated by these limitations, we propose sparse SVM (SSVM) and sparse TPMSVM (STPMSVM) based on our previous work [30,31]. Both models directly impose an penalty on the dual variables to induce sparsity at the support vector level. By reformulating the original QPPs via the Karush–Kuhn–Tucker (KKT) conditions, we achieve a key novelty of our work: their structural transformation into convex linear programming problems (LPPs). Critically, while the classical -norm SVM also yields an LPP, its objective involves a non-smooth -norm. In contrast, our reformulation results in a standard LPP with an inherently linear objective, which presents a more compact structure for the solver and thereby enables efficient solution, ensures principled sparsity, and significantly improves prediction efficiency—all without compromising generalization performance. Table 1 further summarizes the main conceptual differences between the classical -norm SVM and the proposed sparse models in this paper, highlighting dual-level sparsity and LPP reformulation.

Table 1.
Conceptual comparison of classical -norm SVM and proposed sparse models.
The main contributions of this paper are summarized as follows:
- Two Novel Sparse Models: We propose two novel sparse models: Sparse SVM (SSVM) and Sparse TPMSVM (STPMSVM), with sparsity as a central design objective.
- Symmetry-Driven Sparsification: Sparsity is induced by breaking the rotational symmetry of the -norm through an penalty on the dual variables, a geometric motivation that is then implicitly encoded into the model structure via the KKT conditions.
- Novel KKT-based reformulations transform the traditional QPPs into corresponding LPPs for both models.
- Significant Prediction Efficiency: The LPPs, combined with induced sparsity at the support vector level, allow faster prediction compared with the traditional QPP-based methods.
- Extensive Experimental Validation: Comprehensive experiments on synthetic and benchmark datasets verify that the proposed models achieve an advantageous trade-off among sparsity, prediction speed, and generalization performance.
The remainder of this paper is organized as follows. Section 2 briefly describes the fundamentals of the classical SVM and TPMSVM models. Section 3 then introduces the proposed SSVM and STPMSVM models, accompanied by theoretical analysis and discussion. Extensive numerical experiments are conducted in Section 4 using multiple synthetic datasets and 20 publicly available benchmark datasets. Finally, the conclusions and further work are presented in Section 5.
2. Fundamentals of SVM and TPMSVM Models
Since most of the practical problems are nonlinear in nature, in this paper we mainly discuss the nonlinear classification case. We will review the classical SVM model and TPMSVM model in this section. First, we briefly describe some notations used in this paper.
2.1. Notations
The set of real numbers will be denoted by . All vectors are column vectors and will be denoted with lowercase Latin letters. The space of the matrices with real components will be indicated by . Matrices will be indicated with uppercase Roman letters.
We assume that the training set
is given. Other notations are listed in Table 2.
Table 2.
List of notations.
2.2. SVM Model
The primal problem for the classical SVM for the nonlinear case (for the linear cases, the kernel function is just the identity function) is as follows:
where is the regularization factor and is the slack vector. The Wolfe dual problem [32] of (1) is as follows:
where is the dual variable, , , and is the kernel function. From the KKT conditions, we also obtain the following:
This expression connects the normal vector w with the dual variables , which will be fundamental in deriving our SSVM models in the subsequent sections. After solving the dual problem (2), the vector w can be obtained from (3) and the bias term:
can be calculated, where N is the index set of the training samples satisfying . Finally, the decision hyperplane is given by the following:
The two margin hyperplanes are and , respectively. Geometrically, these two margins are symmetric with respect to the decision hyperplane. A new sample x can be assigned to the class +1 or–1 according to the sign of the decision function in (5).
Note that the prediction efficiency of SVM, as indicated by its decision function (5), depends critically on the number of the support vectors in (3). Although the standard SVM naturally acquires some sparsity through the hinge loss, it does not actively enforce it.
2.3. TPMSVM Model
For the TPMSVM model, the following two symmetric hyperplanes in the feature space are considered as follows:
The TPMSVM is then formulated as a pair of symmetric QPPs, whose primal problems are as follows:
where and are regularization parameters, and are slack vectors. Next, we introduce the following notations for convenience:
Obviously, and are symmetric matrices and . By introducing the Lagrangian function for (7) and (8), respectively, and from the KKT conditions, we obtain the following:
and
where and are the dual variables. Similar to the classical SVM, the hyperplane normal vector is expressed in terms of the dual variables and the samples from the negative class; a corresponding expression for involves and the positive class samples. We especially point out that the expression of and in formulas (10) and (12) will be the important basis on which we later construct the STPMSVM model.
The Wolfe dual problems of (7) and (8) are, respectively, as follows:
and
After solving the symmetric dual problems (14) and (15), we can obtain and according to (10) and (12). In addition, the bias term can be computed as follows:
where and are the index sets of positive and negative samples satisfying and , respectively. The decision function of the TPMSVM can be constructed after solving the dual QPPs (14) and (15) as follows:
where . A new point x will be assigned to class +1 or −1 according to (17).
While TPMSVM introduces non-parallel hyperplanes for enhanced flexibility, its sparsity—Inherited naturally from the hinge loss similar to SVM—is limited due to the lack of an explicit sparsity mechanism. A more critical limitation arises from its decision function: unlike SVM, which relies solely on support vectors, the normal vector of TPMSVM (as shown in (10) and (12)) is determined by both its own support vectors and all samples from the other class. This inherent dependency, evident in the decision function (17), suggests that under comparable conditions, TPMSVM is theoretically less prediction-efficient than SVM.
2.4. Geometric Insight: vs. Regularization
The fundamental difference between and regularization can be illustrated through their geometry. The -norm is rotationally symmetric; its spherical isosurfaces favor solutions where parameters are generally non-zero, leading to dense models. In contrast, the -norm is not rotationally symmetric; its diamond-like (or cross-polytope) isosurfaces are aligned with the coordinate axes. This axis-aligned geometry inherently breaks the rotational symmetry and favors solutions that lie on the axes, where many parameters are exactly zero, thus inducing sparsity. This well-established geometric property provides the theoretical motivation for our approach. It suggests that imposing an penalty on the dual variables is expected to explicitly promote sparser solutions at the support vector level. Building on this insight, we develop two novel sparse models (SSVM and STPMSVM) by incorporating such a penalty into the SVM and TPMSVM frameworks, respectively, to actively induce sparsity while preserving their respective advantages.
3. Two Novel Sparse Models
In this section, we will describe the framework of our novel sparse models based on SVM and TPMSVM, respectively.
3.1. SSVM Model
To describe the SSVM model, we substitute (3) into the first constraint of the optimization problem (1) to obtain the following:
By replacing in (1) with the -norm of the dual variable , substituting the first constraint of (1) with (18), and incorporating the constraints from (2), we obtain the following:
The optimization problem (19) represents the embryonic form of the SSVM model. We point out that the first term of the objective function in (19) performs a global optimization over the dual variables, which inherently ensures a highly sparse solution, while the final two constraints originate from the KKT conditions. The remaining terms retain the same interpretation as in standard SVM, as they are obtained through the substitution described above.
Note that in (19), thus can be expressed as , then (19) can be rewritten as follows:
The optimization problem (20) represents the final SSVM model. We note that the SSVM model (20) is a single LPP that simultaneously solves for both the dual variables and the bias term . The normal vector w can then be recovered from (3), and the resulting decision hyperplane remains identical in form to that of SVM (5). In the final LPP, the original -norm regularization appears as a linear term. Geometrically, this term breaks the rotational symmetry of the -norm and guides the solution toward a sparse solution. Although the linear objective may admit multiple optimal solutions in degenerate cases, support vector level sparsity is still guaranteed by the KKT-derived constraints, thereby ensuring both structural simplicity.
3.2. STPMSVM Model
To construct the STPMSVM model, instead of solving the dual problems (14) and (15), we modify the primal problems (7) and (8) in the similar way as in SSVM.
For the convenience in the following calculation, we first note that
Consider the optimization problem (7) and transform it. We first substitute (10) into the second term of the objection function and the first constraint in (7), thus obtaining the following:
and
We now substitute the expressions from (22) and (23) for their corresponding terms in the primal problem of TPMSVM (7) and discard the constant terms that are independent of the dual variable .
Next, we replace in (7) with the -norm of the dual variable , as done in SSVM. Finally, we add (11) to the constraints. By following these steps, (7) is converted to the following form:
In the same way, we can transform (8) into the following:
The above optimization problems (24) and (25) constitute the prototype of our new sparse model based on TPMSVM, which we refer to as STPMSVM. The first term of the objective function minimizes the number of non-zero dual variables for each class to enforce model sparsity. The last two constraints are introduced through the KKT conditions, while all other components retain the same interpretation as in TPMSVM [9], since they are derived directly from the aforementioned transformation.
We observe the constraints of the optimization problem (24) and note that there are two conditions: and . Thus, we have , which is independent of the optimization variables. Consequently, (24) can be rewritten as follows:
Similarly, we have , and the optimization problem (25) can be rewritten as follows:
The optimization problems (26) and (27) represent the finalized STPMSVM model. We note that although the original -norm penalty on the dual variables initially serves to induce sparsity, after applying the KKT conditions, this term becomes a constant in the final LPPs (as shown in (26) and (27)). Nevertheless, the support vector level sparsity is still implicitly enforced through the constraints derived from the KKT reformulation. This mechanism parallels the geometric symmetry-breaking rationale in SSVM and ensures that the final solution remains sparse, while STPMSVM maintains two nonparallel hyperplanes, balancing sparsity and predictive accuracy. Unlike SSVM, which solves for a single set of global optimization variables, STPMSVM solves two separate problems for the variables (dual variables and bias terms) of each class. However, like SSVM, the optimization process for each hyperplane in STPMSVM is straightforward and simultaneously determines both the dual variables and the bias term.
After solving (26) and (27) directly, with the help of (10) and (12), we can finally obtain the decision function according to (17). Note that, as for TPMSVM, our STPMSVM model still needs to determine a pair of nonparallel hyperplanes as (6) in .
3.3. Theoretical Analysis
The SSVM model is relatively easy to understand. To theoretically analyze the proposed STPMSVM model (24) and (25), let us first introduce the following definition relative to the parameters in our model.
Definition 1.
The fractions of positive and negative support vectors are:
respectively.
Definition 2.
The fractions of positive and negative margin errors are as follows:
respectively.
The core aspect of the STPMSVM model can be captured in the following theorem.
Theorem 1.
Suppose that STPMSVM obtains the nontrivial positive and negative parametric-margin hyperplanes. Then we obtain the following:
(i) and are lower bounds on the fractions of positive and negative support vectors, respectively.
(ii) and are upper bounds on the fractions of positive and negative margin errors, respectively.
Proof of Theorem 1.
By (24), .
For a support vector of positive class, according to Definition 1 and from the KKT conditions, the condition must be satisfied.
Suppose the number of support vectors for positive class is , from (24) (or (26)), we have , then we can obtain . This means that is a lower bound on the fraction of positive support vectors.
By the same token, we can obtain that is a lower bound on the fraction of negative support vectors. So the conclusion is proved.
According to Definition 2 and from the KKT conditions, we know that a positive margin error point with must be satisfied: .
Suppose the number of all the points with is , where , then from (24) (or (26)) we have , and it follows immediately. That is, is a upper bound on the fraction of positive margin errors.
By the same token, we can obtain that is a upper bound on the fraction of negative margin errors. The conclusion is also proved. □
The following remark can help to further understand the role of the parameters for the proposed STPMSVM.
Remark 1.
Theorem 1 states that the values of and can control the fractions of SVs and margin errors of the two classes. Intuitively, this means that by adjusting the ratio , we can directly influence how many support vectors are used and how many margin errors are tolerated, providing a simple handle to balance sparsity and generalization. Obviously, the values of are not larger than for the STPMSVM classifier. While ρ serves as the regularization coefficient in both SSVM and STPMSVM, in STPMSVM adjusts the discrimination strength between the two classes and is best understood via the ratio .
Remark 2.
For larger value of the sparsity and margin errors of the model can get worse. However, if the value of is too small, it may lead to underfitting as the model becomes overly sparse and fails to capture essential data patterns, thereby impairing its generalization ability. In simple terms, this means that serves as a practical “knob”: decreasing it reduces sparsity and may underfit, while increasing it too much allow more margin errors. Therefore, tuning this ratio carefully is key for model performance.
3.4. Sparsity and Symmetry-Breaking Mechanism
In this paper, the sparsity of the proposed models is guaranteed through a symmetry-breaking design, which undergoes a critical structural transformation. The process begins with a clear geometric motivation: the introduction of an -norm penalty on the dual variables, explicitly intended to break the rotational symmetry inherent in traditional -regularized models and to leverage the axis-aligned, sparsity-inducing geometry of the -norm.
The key to the derivation is the reapplication of the KKT conditions, which absorbs and transforms the explicit penalty into the structure of the optimization problem: it becomes a linear term in SSVM and reduces to a constant in STPMSVM. As a result, the final models are transformed into LPPs, where the linear nature of the objective function, combined with the constraints, naturally favors sparse vertex solutions. Although the models no longer contain an explicit -norm term, the pursuit of sparsity is structurally encoded into their framework through this transformation.
We note that the KKT-based substitution of the normal vectors in terms of dual variables assumes that the primal QPPs are feasible and have strictly positive regularization parameters. Since the primal problem has linear constraints, the KKT conditions hold and constraint qualifications are automatically satisfied. The resulting LPPs inherit convexity and feasibility. Although the linear objective may admit multiple optimal solutions in degenerate cases, support-vector level sparsity is still guaranteed by the constraints derived from the KKT conditions.
Sparsity at the support vector level improves model stability and lowers the risk of overfitting, thereby enhancing generalization capability. This sparsity is structurally realized through two inherent mechanisms of the resulting LPPs: (i) The feasible region is defined by equality constraints derived from the -norm motivation, combined with box constraints; (ii) According to linear programming theory, an optimal solution lies at a vertex of this feasible region, which in high-dimensional spaces is typically sparse—causing many dual variables to automatically become zero. Thus, the initial symmetry-breaking motivation is implicitly enforced by the final problem structure, ensuring that the models naturally yield sparse solutions.
Furthermore, it is important to note that SSVM is built upon the conventional SVM framework, while STPMSVM is derived from TPMSVM. This difference stems from their underlying optimization structures: SSVM performs a single global optimization over all dual variables, leaving no inherent redundancy, whereas STPMSVM optimizes the dual variables for each class separately, a process that may introduce structural redundancy between the two hyperplanes. Theoretically, SSVM is expected to yield sparser solutions than STPMSVM, which has been confirmed by experimental results presented later.
Finally, we point out that our study focuses on binary classification with convex loss functions and linear or kernelized features; extensions to multiclass classification, structured outputs, or nonconvex settings may require further investigation.
3.5. Computational Complexity
The theoretical computational complexity of STPMSVM and SSVM is comparable to that of standard SVM and TPMSVM, i.e., , but the introduction of sparsity and linear objectives generally improves prediction efficiency in practice.
Unlike conventional SVM and TPMSVM, which solve QPPs, SSVM and STPMSVM only involve LPPs. Their complexity depends on the number of optimization variables and constraints, which may grow faster with large-scale datasets. Both sparse models optimize all variables simultaneously, roughly doubling the number of variables and constraints compared to traditional models. However, the linear objectives and sparsity significantly reduce the overall computational burden, as solving QPPs is generally more time-consuming than LPPs, all else being equal. Specifically, each SSVM problem has variables and constraints, roughly twice that of SVM, which may increase computational cost for large samples. Nevertheless, the linear objective keeps overall complexity at . STPMSVM, in contrast, only solves two smaller subproblems, each with about half the variables and constraints of SSVM, yielding roughly one-fourth of SSVM’s computational cost theoretically.
By reducing the number of support vectors, the sparse models accelerate prediction, making them suitable for real-time or large-scale applications. While SSVM training may be costly for large datasets, the reduced support vectors partly offset this overhead. STPMSVM achieves a balanced trade-off between sparsity and computational efficiency. From a regularization perspective, the -norm of the weight vector in conventional SVM and TPMSVM controls structural complexity, whereas the -norm of dual variables in the sparse models initially induces sparsity and, under the KKT conditions, appears in the LPPs as a linear term or constant, ensuring sparsity while reducing optimization complexity.
In addition, we note that, for large-scale kernel problems, storage and computation of the kernel matrix may become a bottleneck; the proposed LPPs could be combined with low-rank approximations such as Nyström or random features, which we leave for future work.
In summary, SSVM and STPMSVM introduce a novel sparsity inducing framework via -norm regularization on dual variables and reformulating QPPs as LPPs using the KKT conditions. This approach guarantees sparse solutions and provides a clear geometric and theoretical foundation, guiding the experiments in Section 4 to systematically evaluate sparsity, generalization, and computational efficiency.
4. Numerical Experiments
To validate the sparsity and the generalization performance of the proposed SSVM and STPMSVM models, we compare the results obtained by SSVM and STPMSVM with SVM and TPMSVM on several synthetic datasets and 20 benchmark datasets. All algorithms are implemented in MATLAB 2022B on a PC with an Intel Core i7 processor and 4 GB RAM. All optimization problems (QPPs and LPPs) were solved using MOSEK 10.2 via CVX, with the default stopping criteria and tolerances, and with CVX precision high to ensure higher numerical accuracy.
This consistent methodology ensures that any performance differences are attributable to the models themselves, and all experiments were conducted under the same software and hardware settings to guarantee comparability and reproducibility.
4.1. Parameters Setting
The parameter settings are the same for the four algorithms applied to all datasets in this paper. For simplicity, we set and for TPMSVM and STPMSVM. The regularization parameter being selected from the set for all the models. Based on Theorem 1, we set the value of to be from the set , and the Gaussian kernel parameter is chosen from the set . All models are tuned using 5-fold cross-validation on a tuning set, which is either randomly selected from the training set (40% of training data) for Ripley and benchmark datasets, or independently generated from the same distribution for other datasets. After parameter selection, final training and testing are performed using 10-fold cross validation unless otherwise specified in the experiments section. The random seed is fixed to 42 for all experiments to ensure reproducibility.
4.2. Synthetic Datasets
4.2.1. Example 1
The first example is the famous Ripley’s synthetic dataset, which includes 250 training points and 1000 test points. For these datasets, the model is trained and tested once. The learning results for the linear and nonlinear cases are presented in Figure 1 and Figure 2, respectively, with detailed quantitative comparisons provided in Table 3.
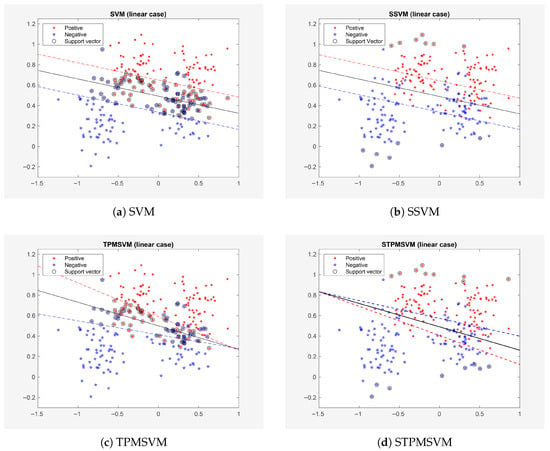
Figure 1.
Results on Example 1 (Ripley’s dataset, linear case).
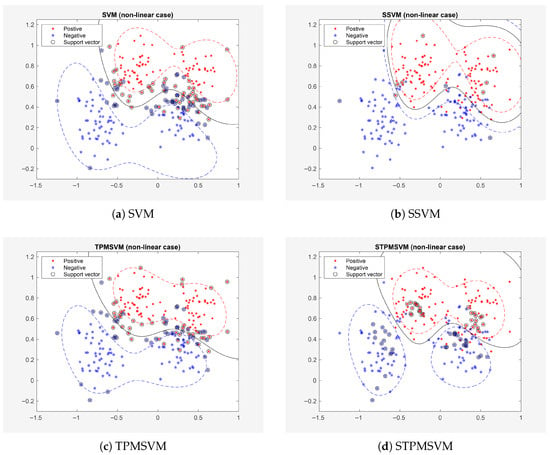
Figure 2.
Results on Example 1 (Ripley’s dataset, non-linear case).
Table 3.
Final Final results on Example 1 (Ripley’s dataset).
As shown in Figure 1 and Figure 2 and Table 3, both SSVM and STPMSVM exhibit a reduction in the number of suport vectors, training time and testing time—without compromising prediction accuracy—in comparison to the traditional methods under both linear and nonlinear settings. Specifically, in the linear case, SSVM reduces the number of support vectors by 87.27% compared with SVM, and STPMSVM reduces 79.52% compared with TPMSVM; in the nonlinear case, the reductions are 89.58% and 30.49%, respectively. These quantitative results clearly demonstrate the sparsity of the proposed methods. It should also be noted that SSVM outperforms SVM in terms of accuracy. In fact, STPMSVM not only matches the performance of other algorithms but also attains the highest accuracy in both linear and nonlinear scenarios. Furthermore, all four algorithms demonstrate improved accuracy in nonlinear cases compared to linear cases. In addition, SSVM requires the fewest SVs and the shortest training and testing times in this experiment, and STPMSVM delivers the best comprehensive performance.
Moreover, we observe that the SVs of SSVM and STPMSVM (see Figure 1 and Figure 2) are not within the margins as they are in the corresponding traditional methods. Instead, they represent some “prototype” points from the datasets. This occurs because (in SSVM), and (in STPMSVM) are no longer the original dual variables in our new sparse model. This is a distinct difference between our sparse methods and classical methods.
The sparsity of the proposed models can also be interpreted from a geometric perspective. In the conventional SVM and TPMSVM, support vectors include not only those on the margin boundary but also those inside the margin and misclassified samples beyond it. As a result, the margin-maximization principle inherently leads to a relatively large number of support vectors, limiting the sparsity of the model. In contrast, the proposed sparse models select class prototype vectors as support vectors, whose quantity is not constrained by the large-margin principle. This allows the models to achieve high sparsity with only a small set of representative support vectors.
4.2.2. Example 2
The second example we consider is still a two-dimensional synthetic dataset (denoted as A0), where data of the two classes is randomly generated as follows.
- Class +1: , where ,
- Class −1: , , where is Gaussian noise.
The tuning set consists of 200 points (balanced across the two classes), and the training/testing set contains 200 points (also balanced). The results are illustrated in Figure 3 and summarized in Table 4 (The results reported in the following table are presented as “mean ± variance” over the 10 folds. It is evident that, while maintaining prediction accuracy, SSVM and STPMSVM have significantly fewer support vectors and require shorter training time and testing time compared to SVM and TPMSVM, respectively.
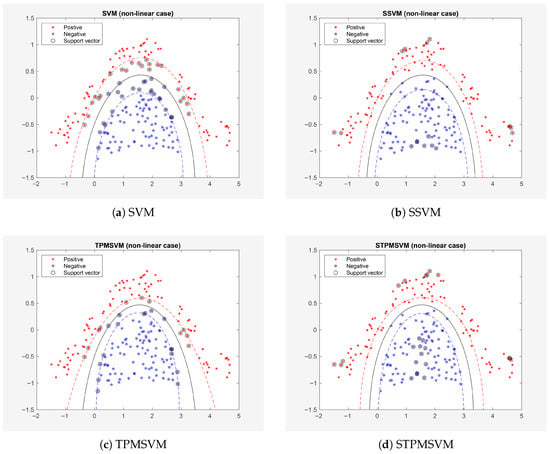
Figure 3.
Results on Example 2 (Dataset A0).
Table 4.
Results on Example 2.
To examine the noise resistance of our proposed sparse methods, we conducted experiments on 9 datasets with different noise intensity based on dataset A0, denoted as A1–A9. For each point of dataset A0, we add different noise vectors, all following normal distributions with mean and covariance matrices , , , , , , , , and , respectively. The results are also reported in Table 3. The bottom of Table 3 provides the corresponding Wilcoxon test results, including p-values and effect sizes (denoted as r; the same presentation is used in the subsequent tables). In addition, the average percentage reductions in the number of support vectors (Avg. SV-Reduction) of the sparse models compared with their baseline counterparts are presented to quantitatively demonstrate the sparsity improvement.
As we can see from Table 4 and Figure 3, the sparse models significantly reduce the number of support vectors (with SSVM and STPMSVM achieving average reductions of 57.46% and 13.54%, respectively, compared with the baseline models), as well as training and prediction times, while maintaining comparable prediction accuracy. Moreover, as noise intensity increases, STPMSVM demonstrates a more pronounced advantage in prediction accuracy, whereas SSVM achieves the shortest training and testing times. A detailed comparison shows that SSVM’s accuracy degrades relative to STPMSVM at higher noise levels, even when Wilcoxon tests are not statistically significant. This degradation is mainly caused by SSVM’s very small number of support vectors, which can induce underfitting and reduce its ability to capture noisy structure. By contrast, STPMSVM retains a more flexible decision boundary and a larger set of prototype points (support vectors), yielding stronger generalization and greater stability under noise—consistent with our theoretical expectations. Overall, STPMSVM is more robust to noise contamination.
To further test the performance stability of our method, we generate another 15 datasets consisting of 200 points with the same distribution as datasets A0 and A7, respectively, and the same number of samples for both classes. The results are shown in Table 5 and Table 6, respectively. At the bottom of the two tables, in addition to the previously reported Wilcoxon test results and average support vector reduction percentages, means, standard deviations (Std) and the medians (Med) of the four performance metrics for the four models are also reported, providing a more comprehensive comparison.
Table 5.
Results on 16 datasets with the same distribution of dataset A0.
Table 6.
Results on 16 datasets with the same distribution of dataset A7.
From Table 5 and Table 6, it is evident that, overall, under both conditions, the sparse methods significantly outperform their corresponding traditional counterparts in all other metrics while maintaining comparable prediction accuracy, and SSVM exhibits the highest prediction efficiency. In particular, in the two scenarios, the average number of support vectors was reduced by 15.46% and 19.67% for STPMSVM, and by 61.65% and 67.11% for SSVM, respectively, compared with their baseline models. The mean values of accuracy reveal a trend: on the 15 datasets sharing the same distribution as A0, SSVM achieves noticeably higher accuracy than SVM, while STPMSVM attains nearly identical accuracy to TPMSVM. On the 15 noisy datasets derived from A7, however, STPMSVM achieves the highest mean prediction accuracy among the four algorithms. This is consistent with the previous results, demonstrating that STPMSVM maintains greater robustness under strong noise conditions. Overall, STPMSVM demonstrates strong sparsity, and stable predictive performance under both noiseless and high-noise conditions, while SSVM achieves the highest prediction efficiency and better accuracy than SVM under low noise conditions. Thus, STPMSVM is more robust and delivers the best overall performance.
To investigate the performance trends of the proposed models as the number of training samples increases, we generate training and test sets independently following the same distributions as datasets A2 (low noise) and A8 (strong noise). The training set sizes are gradually increased from 200 to 2000 in steps of 200, while the testing set is fixed at 600 samples for each case. For each training set, the models are trained once and evaluated on the corresponding fixed test set. The results are presented in Figure 4 and Figure 5.
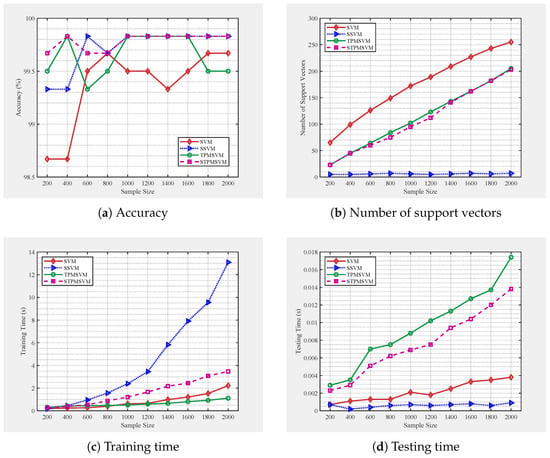
Figure 4.
Performance of four algorithms under different training sample sizes, following the same distribution as A2.
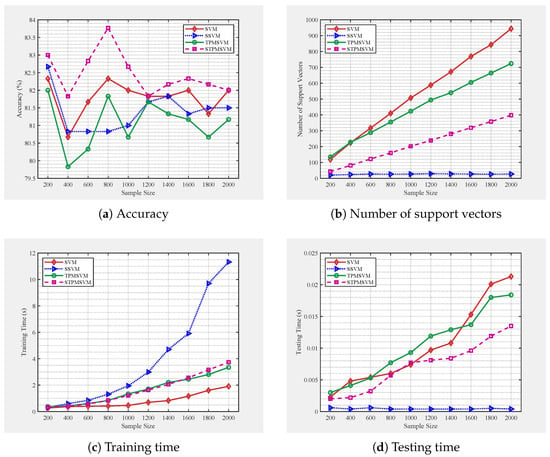
Figure 5.
Performance of four algorithms under different training sample sizes, following the same distribution as A8.
From Figure 4 and Figure 5, we observe clear performance trends as the number of training samples increases. Both SSVM and STPMSVM produce consistently fewer support vectors than their respective baselines (SVM and TPMSVM), with SSVM achieving the highest sparsity and exhibiting a stable number of support vectors that remain nearly unchanged with growing sample size. This confirms that the proposed models effectively enhance sparsity through their structural reformulation. The reduced number of support vectors directly leads to faster prediction speed. Moreover, SSVM achieves the lowest and most consistent testing time, while the other methods show increasing prediction cost as the training size grows. This efficiency improvement stems from the sparsity induced by the LPPs. In contrast, TPMSVM exhibits the fastest increase in prediction time under low-noise conditions, whereas under high noise, SVM becomes slower in prediction speed due to reduced margin robustness. Regarding training time, SSVM increases most rapidly with sample size, reflecting its higher computational complexity, whereas STPMSVM achieves a moderate trade-off—slightly higher than TPMSVM under low noise but comparable under high noise. Although STPMSVM incurs a somewhat higher cost, its linear formulation and sparsity contribute to balanced learning efficiency. In terms of generalization performance, under low noise conditions both sparse models perform comparably or better than their baselines. Under high noise, STPMSVM maintains the best accuracy, while SSVM shows performance degradation due to excessive sparsity, indicating mild underfitting. Overall, SSVM offers superior sparsity and prediction efficiency, whereas STPMSVM achieves the most favorable balance among sparsity, robustness, and generalization stability as sample scale increases.
4.2.3. Extension of Example 2: Increased Complexity Experiments
To further comprehensively evaluate the robustness of the proposed sparse models under different types of noise perturbations, we design three groups of experiments: label noise, class imbalance, and heteroscedastic noise. All sets are independently generated from the same distribution.
Label noise: Based on the distributions of A0 and A5, we randomly flip the labels of both classes with rates of 0%, 5%, 10%, and 15%. The resulting training sets are denoted as A0-00, A0-05, A0-10, A0-15, A5-00, A5-05, A5-10, and A5-15. For each set, the tuning set and the training set contain 400 samples, respectively, with both classes equally balanced. The results are shown in Table 7 (in order to provide a more comprehensive evaluation of model performance, we also report the Brier score in Table 7, Table 8 and Table 9).
Table 7.
Results on label flipping datasets.
Table 8.
Results on class imbalance datasets.
Table 9.
Results on heteroscedastic datasets.
Class imbalance: We generate training sets based on the distributions of A0 and A6, with varying positive-to-negative class sizes: 100–200, 200–100, 100–300, and 300–100. The resulting datasets are denoted as A0-P1N21 (100 positive, 200 negative; others are defined in the same way), A0-P2N1, A0-P1N3, A0-P3N1, A6-P1N21, A6-P2N1, A6-P1N3, and A6-P3N1. The tuning sets are drawn from the same distributions as their corresponding training sets, and the numbers of positive and negative samples are identical to those in the training sets. The remaining cases are constructed in the same manner. Results for these imbalanced datasets are reported in Table 8.
Heteroscedastic noise: For the heteroscedastic datasets, we generate 800-point training sets with 400 points for training and 400 points for tuning, balanced across positive and negative classes. Each class is drawn from different distributions used in the previous section, corresponding to varying noise strengths. The resulting combined datasets are denoted as PA3-NA4 (positive-class samples follow the same distribution as A2, while negative-class samples follow the same distribution as A4, and similarly for the others), PA4-NA3, PA4-NA6, PA6-NA4, PA2NA7, PA7NA2, PA5NA7, PA7NA5, and the results are reported in Table 9.
From Table 7, Table 8 and Table 9, the following observations can be made across different types of noisy datasets.
Sparsity. Overall, the sparse models exhibit significant sparsity, with the exception of a few datasets. SSVM generally achieves fewer support vectors than STPMSVM. On the imbalanced datasets, the Wilcoxon test indicates that the sparsity difference between STPMSVM and TPMSVM is not statistically significant. Detailed inspection reveals that, for two datasets, STPMSVM has slightly more support vectors than TPMSVM, whereas in the remaining datasets, STPMSVM still demonstrates sparse solutions.
Testing time. Thanks to the sparsity and linear optimization structure, all sparse models achieve lower prediction times than their corresponding traditional counterparts.
Accuracy. Across all datasets, the sparse models maintain comparable prediction accuracy to the traditional models, indicating that sparsity does not compromise predictive performance. In fact, in many cases, the accuracy of sparse models is even higher than that of traditional models.
Training time. For the label-flipping and heteroscedastic datasets, SSVM exhibits lower training time than SVM, while for other datasets, no significant differences are observed between sparse and traditional models. These results indicate that, for the smaller-sized datasets in this study, the computational complexity of sparse models is generally comparable to that of traditional models, and in some cases slightly lower. However, as discussed in the previous section, larger sample sizes can substantially increase the training cost for SSVM.
Brier score. For label-flipping and heteroscedastic datasets, the differences in Brier scores between the models are not statistically significant. On imbalanced datasets, the two sparse models achieve significantly lower Brier scores than their corresponding traditional models, with STPMSVM exhibiting slightly lower Brier scores than SSVM. These results indicate that SSVM and STPMSVM provide better-calibrated probabilistic predictions under imbalanced settings.
In summary, the sparse models offer a clear advantage in sparsity and prediction efficiency while generally maintaining comparable accuracy.
As a complementary analysis, we examined the margin distributions for six representative datasets across the above different noise types. The mean and standard deviation of the margins, as well as the margin values corresponding to the peaks, are reported in Table 10. To visualize the results, Figure 6 shows the probability density of margins for SVM and SSVM across the six representative datasets, and Figure 7 presents the corresponding densities for TPMSVM and STPMSVM. The two groups are presented separately because SVM-based models and TPMSVM-based models cannot be directly compared on the same dataset. The x-axis represents the margin values for each sample, and the y-axis represents the estimated probability density obtained via kernel density estimation.
Table 10.
Summary of margin distribution statistics on six representative datasets.
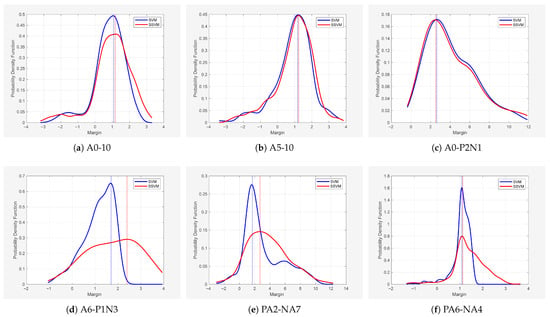
Figure 6.
Distribution of classification margins for SVM vs. SSVM across six representative datasets.
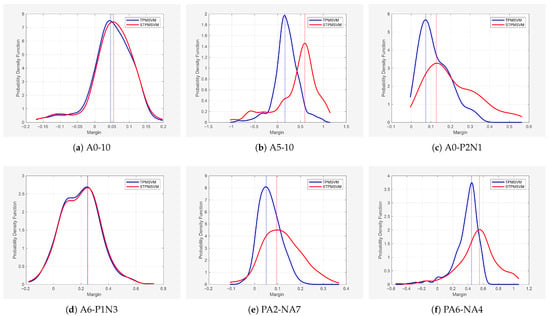
Figure 7.
Distribution of classification margins for TPMSVM vs. STPMSVM across six representative datasets.
From Table 10 and Figure 6 and Figure 7, it is evident that the sparse models consistently achieve higher mean margins than their corresponding traditional models, and the peak margin values are generally larger as well. This suggests that the sparse models not only maintain better class separation but also produce more robust decision boundaries, which may help explain their improved generalization performance across different noise types.
4.2.4. Theorem Verification
In order to verify the conclusion of Theorem 1, we apply STPMSVM for the linear and nonlinear cases on Ripley’s dataset with different parameter values () and Gaussian kernel parameter fixed at 1 for the nonlinear case. Figure 8 and Figure 9 show the relations between the parameters and the fraction of SVs and margin errors in the linear case and nonlinear case, respectively. For a clear view, we also show the relations between and the fraction of SVs and margin errors when . It can be seen from Figure 8 and Figure 9 that the values of can effectively control the bounds of SVs and margin errors as pointed out by Theorem 1.
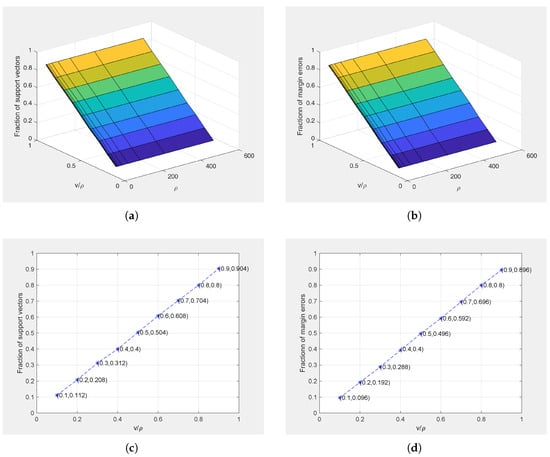
Figure 8.
Relations between () and the fractions of support vectors and margin errors on Ripley’s dataset for linear case. (a) 3D graph of the relationship between () and the fraction of support vectors; (b) 3D graph of the relationship between () and the fraction of margin errors; (c) Relationship between and the fraction of support vectors (); (d) Relationship between and the fraction of margin errors ().
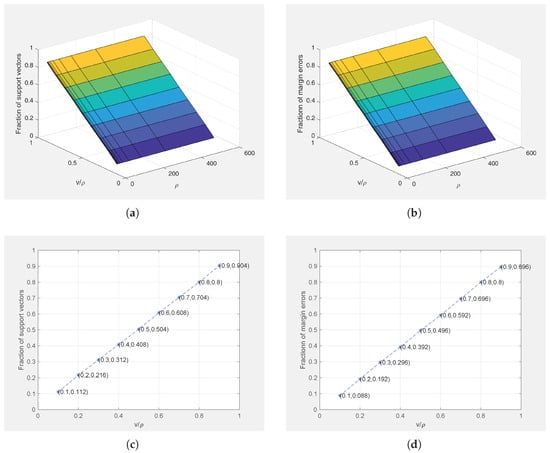
Figure 9.
Relations between () and the fractions of support vectors and margin errors on Ripley’s dataset for the non-linear case (). (a) 3D graph of the relationship between () and the fraction of support vectors; (b) 3D graph of the relationship between () and the fraction of margin errors; (c) Relationship between and the fraction of support vectors (); (d) Relationship between and the fraction of margin errors ().
4.3. Benchmark Datasets
To further test the performance of SSVM and STPMSVM, we apply the four algorithms to carry out experiments on 20 publicly available benchmark datasets (For some multi-class datasets, we take the first two classes for analysis) as follows: Balance (B1), banana (B2), bank note authentication (B3), Breast cancer (B4), cervical cancer behavior risk (B5), chemical composion of ceramic (B6), divorce predictors (B7), fertility diagnosis (B8), glass (B9), heart failure clinical records (B10), ionosphere (B11), iris (B12), movement libras (B13), Plrx (B14), seeds (B15), thyroid (B16), user knowledge modeling (B17), Wifi localization (B18), wine (B19), WDBC (B20).
The results are reported in Table 11, with learning time (the total of the training time and testing time) reported. Combined with the Wilcoxon test results, they lead to the following main findings: In terms of sparsity and efficiency, both sparse models significantly outperform their traditional counterparts. Specifically, SSVM reduces the number of support vectors by an average of 56.21% compared to SVM, while STPMSVM achieves an average reduction of 39.11% compared to TPMSVM, with STPMSVM having slightly more support vectors only on dataset B15. In terms of prediction accuracy, the differences are not statistically significant. STPMSVM achieves the highest accuracy on 12 out of 20 datasets and does not underperform TPMSVM on 18 of them. Similarly, SSVM does not underperform SVM on 13 datasets. Regarding computational cost, SSVM and STPMSVM generally require less learning time than their traditional counterparts on most datasets. The exceptions are set B3, where SSVM exhibits the longest training time. This observation aligns with our previous analysis on the impact of sample size, indicating that despite its linear objective, SSVM can still be computationally demanding for relatively large datasets.
Table 11.
Results on 20 benchmark datasets.
These results indicate that although SSVM employs a linear objective, its training can still be time—consuming on relatively large datasets. In practice, for smaller datasets where prediction speed is critical, SSVM remains a viable option, despite its generally lower accuracy than STPMSVM under noisy conditions. In contrast, STPMSVM not only provides sparse solutions and reduced computational complexity but also maintains—and in many cases enhances—generalization performance, making it the more robust and effective choice overall.
Beyond the above quantitative metrics, the experimental outcomes in this paper provide profound insights into the underlying mechanism. The collective results consistently demonstrate that the proposed SSVM and STPMSVM models achieve a significant reduction in the number of SVs compared to their standard counterparts. This pervasive phenomenon provides strong empirical validation that the initial geometric motivation of employing an -norm penalty—to break rotational symmetry—has been successfully translated, via the KKT conditions, into the final models’ operational principle. The resulting sparsity of the solutions stands as direct empirical evidence for the successful implementation of the initial symmetry-breaking design.
5. Conclusions and Future Work
In this paper, we present two novel sparse models, SSVM and STPMSVM, which achieve high sparsity and computational efficiency benefits from the LPPs by fundamentally rethinking the regularization geometry. In the SSVM model, a pair of parallel hyperplanes, similar to those in SVM, is constructed, while in the STPMSVM model, a pair of non-parallel hyperplanes is obtained, following the spirit of TPMSVM. The core of our approach lies in a symmetry-breaking design: we replace the rotationally symmetric -norm with the axis-aligned -norm on the dual variables to induce sparsity. This explicit geometric motivation is then structurally transformed via the KKT conditions. The -norm penalty is absorbed into the model’s framework, emerging as a linear term in SSVM or reduced to a constant (and thereby vanishing) in STPMSVM. This key transformation allows the original QPPs to be reformulated as more efficient LPPs. Consequently, sparsity is no longer an explicitly penalized term but an implicitly enforced property of the solution, governed by the problem constraints and the geometry of linear programming. Numerical experiments on synthetic and benchmark datasets confirm the efficacy of this paradigm. Both models achieve superior sparsity and faster prediction speeds. Specifically, SSVM excels in producing the sparsest solutions, while STPMSVM robustly combines high accuracy with strong sparsity, inheriting the benefits of the TPMSVM architecture.
Despite these advantages, we note that several limitations remain in this study. The proposed models currently rely on kernel computations for nonlinear cases, which may limit scalability to very large datasets, though they are suitable for real-time prediction in edge computing scenarios. Potential solution: degeneracy can occur due to linear programming vertex solutions. In addition, comparisons with other sparse models are limited in this study.
Future work includes extending SSVM/STPMSVM to multiclass, online/streaming, or structured-output settings; integrating low-rank kernel approximations (e.g., Nyström, random features) for scalable large-scale training, developing more efficient and accurate hyperparameter tuning strategies, and exploring comparisons with additional sparse approaches to provide a more comprehensive evaluation and further investigate sparsity and generalization performance.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/sym17112004/s1, A minimal reproducibility package.
Author Contributions
Conceptualization and Formal analysis, S.Q.; methodology, S.Q. and R.D.L.; validation, S.Q. and M.H.; visualization, S.Q. and M.H.; writing—original draft, S.Q.; writing—review and editing, S.Q., R.D.L., and M.H.; funding acquisition, R.D.L. and S.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the European Union—TextGenerationEU under the Italian Ministry of University and Research (MUR) National Innovation Ecosystem grant ECS00000041– VITALITY–CUP J13C22000430001.
Data Availability Statement
The artificial datasets generated in this study are described in Section 4.2, where the generation procedure is detailed. Ripley dataset is available at https://www.stats.ox.ac.uk/pub/ (accessed on 20 January 2025). The benchmark datasets used in this study are publicly available at https://archive.ics.uci.edu/datasets?skip=0&take=10&sort=desc&orderBy=NumHits&search (accessed on 15 March 2025). A minimal reproducibility package with MATLAB scripts and example datasets is provided as Supplementary Materials.
Acknowledgments
The authors would like to thank the reviewers for their valuable comments and suggestions, and the editorial staff for their efforts in improving the quality of this manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SVM | Support Vector Machine |
| SSVM | Sparse SVM |
| TPMSVM | Twin Parametric Margin SVM |
| STPMSVM | Sparse TPMSVM |
| KKT | Karush–Kuhn–Tucker |
| QPP | Quadratic programming problem |
| LPP | Linear programming problem |
| Acc. | Accuracy |
| Num-SVs | Number of support vectors |
| Tr-time | Training time |
| Te-time | Testing time |
| Avg. SV-Reduction | Average percentage reduction in the number of support vectors |
| Std | Standard deviation |
| Med | Median |
References
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Hao, P.Y. New support vector algorithms with parametric insensitive/margin model. Neural Netw. 2010, 23, 60–73. [Google Scholar] [CrossRef] [PubMed]
- Khemchandani, R.; Jayadeva; Chandra, S. Twin support vector machines for pattern classification. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 905–910. [Google Scholar] [CrossRef]
- Peng, X. TPMSVM: A novel twin parametric-margin support vector machine for pattern recognition. Pattern Recognit. 2011, 44, 2678–2692. [Google Scholar] [CrossRef]
- Tanveer, M.; Rajani, T.; Rastogi, R.; Shao, Y.H.; Ganaie, M.A. Comprehensive review on twin support vector machines. Ann. Oper. Res. 2024, 339, 1223–1268. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, L. Application of support vector machine algorithm in predicting the career development path of college students. Int. J. High Speed Electron. Syst. 2025, 2540230. [Google Scholar] [CrossRef]
- Chandra, M.A.; Bedi, S.S. Survey on SVM and their application in image classification. Int. J. Inf. Technol. 2021, 13, 1–11. [Google Scholar] [CrossRef]
- Zeng, S.; Chen, M.; Li, X.; Wu, Y. A financial distress prediction model based on sparse algorithm and support vector machine. Math. Probl. Eng. 2020, 2020, 5625271. [Google Scholar] [CrossRef]
- Madhu, B.; Rakesh, A.; Rao, K.S. A comparative study of support vector machine and artificial neural network for option price prediction. J. Comput. Commun. 2021, 9, 78–91. [Google Scholar] [CrossRef]
- Kok, Z.H.; Chua, L.S.; Aziz, N.A.; Ismail, W.I.W. Support vector machine in precision agriculture: A review. Comput. Electron. Agric. 2021, 191, 106546. [Google Scholar] [CrossRef]
- Abdullah, D.M.; Abdulazeez, A.M. Machine learning applications based on SVM classification: A review. Qubahan Acad. J. 2021, 1, 81–90. [Google Scholar] [CrossRef]
- Malashin, I.; Tynchenko, V.; Gantimurov, A.; Nelyub, V.; Borodulin, A. Support vector machines in polymer science: A review. Polymers 2025, 17, 491. [Google Scholar] [CrossRef]
- Khyathi, G.; Indumathi, K.P.; Jumana Hasin, A.; Lisa Flavin Jency, M.; Krishnaprakash, G.; Lisa, F.J.M. Support vector machines: A literature review on their application in analyzing mass data for public health. Cureus 2025, 17, e000000. [Google Scholar] [CrossRef]
- Yang, L.; Dong, H. Support vector machine with truncated pinball loss and its application in pattern recognition. Chemom. Intell. Lab. Syst. 2018, 177, 89–99. [Google Scholar] [CrossRef]
- De Leone, R.; Maggioni, F.; Spinelli, A. A multiclass robust twin parametric margin support vector machine with an application to vehicles emissions. In Proceedings of the International Conference on Machine Learning, Optimization, and Data Science, Grasmere, UK, 22–26 September 2023; Springer Nature: Cham, Switzerland, 2023; pp. 299–310. [Google Scholar]
- Wang, H.; Shao, Y. Fast truncated Huber loss SVM for large-scale classification. Knowl.-Based Syst. 2023, 260, 110074. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, H.; Li, W. Sparse and robust support vector machine with capped squared loss for large-scale pattern classification. Pattern Recognit. 2024, 153, 110544. [Google Scholar] [CrossRef]
- Sui, Y.; He, X.; Bai, Y. Implicit regularization in over-parameterized support vector machine. Adv. Neural Inf. Process. Syst. 2023, 36, 31943–31966. [Google Scholar]
- Moosaei, H.; Hladík, M. Sparse solution of least-squares twin multi-class support vector machine using ℓ0 and ℓp-norm for classification and feature selection. Neural Netw. 2023, 166, 471–486. [Google Scholar] [CrossRef]
- Tang, Q.; Li, G. Sparse L0-norm least squares support vector machine with feature selection. Inf. Sci. 2024, 670, 120591. [Google Scholar] [CrossRef]
- Li, N.; Zhang, H.H. Sparse learning with non-convex penalty in multi-classification. J. Data Sci. 2021, 19, 1–20. [Google Scholar] [CrossRef]
- Zhou, S. Sparse SVM for sufficient data reduction. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5560–5571. [Google Scholar] [CrossRef] [PubMed]
- Lu, S.; Li, Q. A majorization penalty method for SVM with sparse constraint. Optim. Methods Softw. 2023, 38, 474–494. [Google Scholar] [CrossRef]
- Zhu, J.; Rosset, S.; Hastie, T.; Tibshirani, R. 1-norm support vector machines. Adv. Neural Inf. Process. Syst. 2003, 16. [Google Scholar]
- Qu, S.; De Leone, R.; Huang, M. Sparse learning for linear twin parameter-margin support vector machine. In Proceedings of the 3rd Asia Conference on Algorithms, Computing and Machine Learning, Shanghai, China, 22–24 March 2024; pp. 50–55. [Google Scholar]
- Qu, S.; Huang, M.; De Leone, R.; Maggioni, F.; Spinelli, A. An efficient sparse twin parametric insensitive support vector regression model. Mathematics 2025, 13, 2206. [Google Scholar] [CrossRef]
- Wolfe, P. A duality theorem for non-linear programming. Q. Appl. Math. 1961, 19, 239–244. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).