Abstract
This paper investigates the estimation of the stress–strength reliability parameter , where stress (X) and strength are independently modeled by geometric distributions. Objective Bayesian approaches are employed by developing Jeffreys, reference, and probability-matching priors for , and their effects on the resulting Bayes estimates are examined. Posterior inference is carried out using the random-walk Metropolis–Hastings algorithm. The performance of the proposed Bayesian estimators is assessed through extensive Monte Carlo simulations based on average estimates, root mean squared errors, and frequentist coverage probabilities of the highest posterior density credible intervals. Furthermore, the applicability of the methodology is demonstrated using two real data sets.
1. Introduction
The estimation of stress–strength models has long been recognized as a fundamental topic in reliability theory. These models play an important role in various applied fields, particularly in engineering, quality assurance, and medical sciences. A significant portion of the statistical literature has focused on the estimation of the reliability parameter , where X denotes the stress applied to a system, Y represents its strength, and quantifies the probability that the system can withstand the applied stress. It is worth emphasizing that numerous authors have investigated the estimation of the stress–strength reliability parameter using both frequentist and subjective Bayesian approaches across a range of continuous distributions and under various sampling schemes, and this topic continues to attract considerable attention in the statistical literature. For instance, Ref. [1] addressed this problem for the generalized exponential distribution; Ref. [2] studied it for the inverse Pareto distribution under progressively censored data; and Ref. [3] explored it for the exponential distribution based on generalized order statistics. In addition, Ref. [4] examined the Bayesian estimation of for the Lomax distribution under type-II hybrid censoring using an asymmetric loss function. On the other hand, several authors have employed objective Bayesian methods, for instance, Ref. [5] for the Weibull distribution, Ref. [6] for the generalized exponential stress–strength model, and Ref. [7] for the Fréchet stress–strength model. Related investigations based on discrete probability distributions include the works of [8] for Poisson data and [9] for the Poisson-geometric distribution. The geometric distribution has also been studied by [10,11,12] for complete data and for lower record data by [13]. However, in these latter studies, the Bayesian methods applied were subjective and limited in scope.
In this paper, we address the problem of estimating the stress–strength reliability parameter when both the stress X and the strength Y are modeled as independent geometric random variables with parameters and , respectively. Accordingly, the reliability of the stress–strength system is given by
The importance of studying stress–strength reliability under geometric distributions lies in its wide range of real-world applications, where reliable estimates with meaningful interpretation are required. For instance, in manufacturing quality control, let X denote the number of shocks a component tolerates before breaking and Y the number a stronger reference part withstands. The stress–strength reliability then quantifies the probability that the component fails first. Since such failures typically occur after repeated shocks with a constant chance of breaking, the geometric distribution provides a natural model. A similar scenario arises in digital communication systems, where X represents the number of packet retransmissions until failure for a weaker channel and Y for a stronger channel. In this case, gives the probability that the weaker channel fails before the stronger one. Because packet transmissions follow repeated Bernoulli trials, the geometric distribution again offers a suitable framework. Finally, and more importantly, two additional real data examples highlighting the relevance of the stress–strength model are presented in the applications section.
Methods for estimating from discrete distributions have primarily relied on classical approaches, with the most common being the maximum likelihood (ML) estimator and subjective Bayesian methods, as clearly demonstrated in the works of [10,11,12]. While ML estimators have desirable properties, such as invariance and asymptotic efficiency, they are well known to exhibit bias, particularly with small sample sizes. Similar limitations arise when using subjective Bayesian methods, as these often involve multiple hyperparameters that must be elicited. However, the authors in the aforementioned papers employed the subjective Bayesian approach with hyperparameters that were subjectively chosen, rather than explicitly elicited, which can lead to potentially biased results. Specifically, the authors applied independent Beta priors to the parameters of the geometric distribution, i.e., and , and arbitrarily selected the hyperparameters. One might ask why the subjective Bayesian approach did not involve a more rigorous elicitation of these parameters? The answer to this question lies in the criteria used for elicitation. For this case, four parameters need to be elicited, and there are numerous ways to do so, without a clear indication of which method will yield the most robust and reliable results. For example, one might set the mean and variance of the prior distributions, i.e., the considered beta distributions equal to the mean and variance of the geometric distribution. However, this approach can lead to infeasible solutions, such as negative values. Even if an alternative criterion is chosen and produces reasonable values, it still does not guarantee that the method will be applicable in all cases or lead to reliable results. Certainly, the most appealing approach would be to leverage prior information (past knowledge) about the parameters and . Unfortunately, such prior information is often unavailable in many situations. Furthermore, the authors did not train their methods on real data, which limits the generalizability and robustness of their results.
Alternatively, we adopt a Bayesian approach for estimating using non-informative priors. Our motivation for using such priors, in addition to the importance of studying under geometric distributions, lies in its wide range of real-world applications. The reasons for choosing this approach are as follows: (i) this is the first study to consider objective Bayesian inference for ; (ii) the priors considered in this study are informative yet contain minimal information; (iii) the priors eliminate the need for hyperparameter elicitation; (iv) the priors are obtained using formal rules; and (v) the priors possess the flavor of invariance, or certain modifications that offer improved performance, particularly in high-dimensional parameter settings, or alternative priors capable of producing credible intervals with coverage properties comparable to those of frequentist confidence intervals.
Before proceeding, we would like to point out that is a function of the model parameters. In such cases, constructing non-informative priors requires particular care, except for Jeffreys’ prior, which is invariant by design. Other types of priors, such as matching and reference priors, are generally not invariant under reparameterization. For instance, suppose matching priors are developed under the assumption that is the parameter of interest and is a nuisance parameter, or vice versa. If a one-to-one transformation is then applied to express the model in terms of , the resulting prior is not guaranteed to be a matching prior for . This is because the inverse transformation yields reference or matching priors that are valid for and , depending on which parameter was treated as influential, but not necessarily for a derived parameter like . A similar issue arises with reference priors. While it might be argued, as shown by [14], that reference and matching priors are invariant, this invariance only holds when such priors are developed directly for as a function of and , followed by an appropriate transformation. In that case, the resulting priors retain their desired properties with respect to . A comparable situation is discussed in [15], who provided Bayesian inference for the entropy of the Lomax distribution, a quantity that also depends on the model parameters, and demonstrated that the reference and matching priors for this entropy cannot be derived from those of the model parameters. For further developments and illustrative examples, the reader is referred to [14], who specifically constructed matching priors for functions of model parameters.
The rest of the paper is organized as follows. Likelihood-based inference for is presented in Section 2. In Section 3, we derive non-informative priors for , including Jeffreys, reference, and probability-matching priors. Section 4 reports a simulation study conducted via MCMC to assess the performance of the Bayes estimators of under various objective priors. In this section, we also provide the average estimates, standard errors, and coverage probabilities of the 95% credible intervals. The compatibility of the proposed priors is further examined in Section 5 using the posterior predictive distribution. In Section 6, the practical utility of the stress–strength reliability measure for the geometric distribution is demonstrated through two real data applications. Finally, concluding remarks are given in Section 7.
2. Likelihood-Based Inference for
Let and be independent random samples from and respectively, where GE(.) denotes the geometric distribution. Then, the likelihood function of based on the realizations and is
where and The ML estimates of can be obtained by maximizing the log-likelihood function with a mathematical form given by
The partial derivatives of with and are given below:
On solving the above equations, the ML estimates of are given by and . Since and , the elements of the Fisher information matrix are computed via
and
Therefore, we have that
The following results are required to establish the asymptotic normality of the ML estimate of .
Lemma 1.
The ML estimates and are consistent estimators of and , respectively.
Proof.
We provide only the proof of the consistency of for , and the proof for the other estimator can be handled similarly. Since , it follows from the strong law of large numbers that converges in probability to . Now, since for is a continuous function, it follows that converges to . □
The following theorem establishes that the ML estimates of and are asymptotically bivariate normal. The conditions required for this are as follows: The likelihood function must be identifiable and differentiable, and the true parameter value must lie in the interior of the parameter space. The partial derivatives of the log-likelihood function must be continuous and have a unique solution at the true parameter. Additionally, the observed Fisher information must converge to its expected value as the sample size increases, and the Fisher information matrix must be finite and positive definite. Finally, the log-likelihood function should satisfy smoothness conditions. For more information on these regularity conditions and the establishment of the asymptotic normality of the MLE, see [16] (1993, p. 132).
Theorem 1.
We have that, as and where ⇒ stand for convergence in distribution, and stand for bivariate normal distribution, and
Proof.
Thanks to the exponential family of distributions, which satisfies all the mentioned regularity conditions, asymptotic normality follows. Since the geometric distribution belongs to the exponential family, the asymptotic normality of its MLEs is guaranteed. The above matrix is obtained by virtue of the regularity condition given in the preceding paragraph, which states that the average observed Fisher information must converge to its expected value as the sample size increases. To see this, the average observed Fisher information matrix, after simple rearrangement, is
Since and converges in probability to and in probability as respectively and by mean of the assumption that it follows that converges in probability to Noticed that when implies and hence is the Fisher information matrix of independent geometric distributions per unit of observation, and this completes the proof. □
Theorem 2
([16] (1993, p. 132)). Suppose that were is k-dimensional random vectors, and Σ is the variance-covariance matrix. Let be a real-valued function with and continuous in a neighborhood of Then,
The above theorem is usually referred to as the Delta method. Here, we establish the first results relating to the estimate of .
Theorem 3.
As and we have where
and
Proof.
Since and are consistence estimators by the mean of Lemma 1 an approximate confidence interval of is
3. Bayes Inferences: Objective Priors
In this section, we construct several important objective (non-informative) priors for the parameter , including the Jeffreys prior, reference priors, and probability matching priors. These priors are developed to ensure minimal informativeness while retaining desirable inferential properties. Following the construction of each prior, we examine the propriety and finiteness of the resulting posterior distributions. We then proceed to derive the Bayes estimates of under the squared error loss (SEL). To facilitate the construction of certain priors, particularly the reference and matching priors, we reparameterize the original model in terms of the parameter . While the Jeffreys prior is invariant under one-to-one transformations and thus can be obtained directly without reparameterization, such transformations are crucial for deriving the reference and matching priors, as they depend explicitly on the parameter of interest. Therefore, we consider a one-to-one transformation from
where
along with the inverse of the transformation,
Therefore, the likelihood function of based on is
We now aim to obtain the Fisher information matrix corresponding to the parameters and . To this end, we first evaluate the Jacobian matrix of the transformation which is given by
Using Equations (3) and (8), the Fisher information matrix for the parameters and denoted by , is obtained through the relation This result is summarized in the following lemma.
Theorem 4.
The Fisher information matrix of has the following form
3.1. Jeffreys Prior
The first non-informative prior we consider is the Jeffreys prior, which is commonly used in Bayesian inference due to its simple derivation from the Fisher information matrix and its invariance property. In general, this type of prior is improper, as are many other non-informative priors. Additionally, it may be inappropriate when the dimensionality of the model increases. Therefore, from Equation (9), the Jeffreys prior of is
The joint posterior of under in (10) is
Theorem 5.
The posterior is proper if and only if and
Proof.
We have that for sufficiently small values we have that and hence Similarly, for the values , we have that So, we have that
Thus, the expression is finite and positive if and only if and . Next, when the values of are close to the singularity, i.e., , we consider the first-order Taylor expansion of around . We then obtain and it follows that
where in the last equation we used the transformation and Now, to check the finitess of the above double integral, we consider the transformation and with Jacobian of transformation
Hence, the right-hand side of the above equation is finite and positive, provided that . □
3.2. Approximate Reference Priors
The reference prior, originally introduced by [17] and further refined in the same work, serves as an enhancement of Jeffreys’ prior, particularly in multi-parameter settings where Jeffreys’ prior may not perform well; see [18]. A key feature of this approach is the partitioning of model parameters into groups based on their inferential priority. The derivation of the reference prior follows a general algorithm outlined in [17]. Notably, one significant result arising from this algorithm, which proves useful in various applications, is that it avoids the need for nested compact subsets in the nuisance parameter space. This is formally presented in the following proposition.
Proposition 1
([19] (2000, p. 328)). Let ψ be the parameter of interest and suppose that λ is the nuisance parameter. Let
where is the Fisher information matrix and is the bottom-right element of If the parameter of interest ψ is independent of the nuisance parameter space and if
then the reference prior with respect to the ordered group is
It is worth emphasizing that neither the procedure outlined in [17] nor the result in Proposition 1 yields an explicit form of the reference prior for . As an alternative, we construct an approximate reference prior by leveraging the result in Proposition 1.
Proposition 2.
The approximate reference prior for the ordered group parameters is
- (i)
- for sufficiently small
- (ii)
- for we have that
Proof.
We provide the proof only for part (i). We have that
where and Now
where and In view of Proposition 1, it follows that the approximate reference prior for the ordered group is the one given in (13). □
Theorem 6.
Under the assumption of Theorem 5, the posterior distributions under and are proper distributions.
Proof.
We provide the proof for The proof of is quite similar to the proof in Theorem. Since is a decreasing function in we have
Therefore, we have that
where Similar to the proof in Theorem 5, we have for sufficiently small values of and that it then follows that the posterior distribution is finite, i.e., When and are close to it then follows for and that Finally, when the values of close to the first-order Taylor expansion for around implies that it then follows that
Therefore, we have that
Similarly to the analysis of (12), the above integral is finite. □
3.3. Probability Matching Prior
Probability matching priors for the parameter of interest were introduced by [20] to ensure that the posterior probabilities of specified intervals exactly or approximately match their corresponding frequentist coverage probabilities. Mathematically speaking, let be be a given prior of with parameter of interest and is the nuisance parameter and is the th percentile of the marginal posterior distribution of , where and are the sample data. Then, is called a second-order probability matching prior if
holds for all It is worth emphasizing that Jeffreys prior achieves probability matching with an asymptotic error of order when there is only a single parameter, as shown in [20]. However, this desirable property does not necessarily extend to models involving multiple parameters, which are common in many statistical applications. According to the results in [20], a prior is a matching prior if and only if it satisfies the following partial differential equation
where is the th-element of the inverse of Fisher information matrix in (9) and Clearly, this approach can be used to derive a matching prior for using the Fisher information matrix given in (9). However, when the parameter of interest is a function of the model parameters (as in our case, where is such a function), it is first necessary to obtain the transformed Fisher information in terms of . This is then followed by solving a partial differential equation, as shown in (15). A natural question arises: can a similar representation to (15) be developed using the Fisher information matrix of the original model parameters to obtain a matching prior? Interestingly, [21] successfully demonstrates that matching priors can be constructed not only for individual parameters but also for functions of these parameters. Specifically, let be a real-valued function of Then, the gradient of is given as and defined as
Then, is a matching prior for if and only if it satisfies the partial differential equation
Since is a function of and the matching prior for can thus be derived directly without requiring an explicit one-to-one transformation into the space, using the Fisher information matrix in terms of the original parameters as given in (3).
Theorem 7.
The matching prior for ρ given in (1) is
Proof.
Put it then follows that
where is defined in Theorem 3. Next, let
Therefore, is a matching prior for if and only if
A solution of the above partial differential equation is given in (17). □
Remark 1.
The reference prior for irrespective of which the parameter of interest or is
The reference prior in (19) is straightforward to derive since the Fisher information matrix is diagonal. Interestingly, the corresponding prior is also a matching prior. However, the prior in (19) is not equal to the prior in (17), which implies that the prior in (19) cannot serve as a matching prior for ρ. Specifically, if a one-to-one transformation is performed to express the parameters in terms of ρ and using the prior in (19), the resulting prior, though now a function of ρ and cannot be regarded as a matching prior for ρ. In contrast, applying the same transformation to the prior in (17) does yield a valid matching prior for ρ, as also confirmed by the invariance results of [14].
Now the default matching prior for is given in (17). Since any 1-1 transformation preserves the matching prior propriety, we use the transformation (6) and consequently the matching prior is then given by
Theorem 8.
Under the assumption of Theorem 5, the posterior is proper.
Proof.
We have that
where It can be verified, in conjunction with the analysis of (12), that the above integral is finite. □
4. Numerical Computations
In this section, we investigate the performance of Bayes estimators for under the squared error loss function (SELF) using Jeffreys, reference, and matching priors, and also consider the maximum likelihood estimate. The comparison is based on bias and root mean squared error, along with the frequentist coverage probabilities of the highest posterior density (HPD) credible intervals derived from these priors.
4.1. Random Walk Metropolis–Hastings Algorithm
The Bayes estimates of under the various non-informative priors examined in this study do not admit closed-form solutions. Likewise, the marginal posterior distribution of cannot be expressed analytically. To handle this, we apply the random walk Metropolis–Hastings (MH) algorithm to generate Markov Chain Monte Carlo (MCMC) samples, denoted by . This approach is selected for its versatility in producing samples from a wide variety of proposal distributions, particularly when the conditional posterior distributions of the parameters are not available in explicit form. In our implementation, we adopt a symmetric random-walk MH algorithm with a bivariate normal proposal to draw samples from the joint posterior distribution of . These samples of are subsequently used to construct HPD credible intervals for the reliability parameter . The procedure for generating samples from the joint posterior distribution via the random walk MH algorithm is outlined in Algorithm 1.
| Algorithm 1 Metropolis–Hastings Algorithm for Estimating and |
|
4.2. Simulation Experiment
We perform a simulation Study to evaluate the performance of Bayes estimators of under the non-informative priors considered in this paper. The investigation emphasizes small sample sizes and different parameter configurations. Specifically, we examine sample size combinations together with parameter pairs provided in Table 1. For each scenario, independent samples and are generated from geometric distributions with parameters and , respectively. Bayes estimates are computed under the squared error loss function (SELF). For a given sample, the algorithm described in Algorithm 1 is applied to produce 5500 MCMC draws, discarding the first 500 as burn-in. The remaining samples are then used to obtain Bayes estimates and construct credible intervals. The estimators are assessed over 1000 replications of size in terms of average estimate (ES), standard errors (SD), frequentist coverage probability (CP) of the 95% HPD credible intervals. A detailed summary of the results is presented in Table 1. From these tables, several finding can be concluded:

Table 1.
Simulation results showing estimates (Est), standard errors (SE), and coverage probabilities (CP) for different methods under various parameter settings.
- While the sample sizes considered in this article are relatively small, it is observed that the performance of all estimators of improves as the sample size increases, with the average estimates approaching the true values and the standard deviations decreasing. The reduction in standard deviations demonstrates the consistency of these estimators.
- It is interesting to note that the Bayes estimator based on outperforms the other estimators, as its 95% HPD credible intervals achieve frequentist coverage probabilities that remain close to 0.95 across all considered scenarios.
- For the Bayes estimator based on and the ML estimator outperform the other estimators by exhibiting smaller standard deviations across all considered scenarios. Moreover, both estimators provide good frequentist coverage probabilities that approach 0.95, with the Bayes estimator based on showing better convergence than the ML estimator.
- For the Bayes estimators using and perform much better than the other two estimators in terms of exhibiting smaller standard deviations. However, the Bayes estimator under is superior in terms of frequentist coverage probabilities, which remain close to 0.95, followed closely by the ML estimator.
- For the Bayes estimator based on performs significantly better than the others in terms of exhibiting smaller standard deviations, followed closely by the Bayes estimator under Moreover, the Bayes estimator based on outperforms the one using in terms of achieving frequentist coverage probabilities that remain close to 0.95.
5. Posterior Predictive Assessment of the Model
Once posterior propriety has been established under the proposed priors, the subsequent task is to assess how well the model represents the observed data. A widely used strategy in Bayesian analysis is to perform posterior predictive checks, which consist of drawing predictive samples from the model by conditioning on the posterior distribution of the parameters and then comparing these replications with the actual data through graphical diagnostics. To complement the visual assessment, we also consider the posterior predictive p-value, originally suggested by [23] and later formalized by [24], as a quantitative measure of fit. This method requires the specification of a discrepancy statistic, ideally one that does not involve unknown parameters. In this study, we use the discrepancy statistic, Naturally, other discrepancy measures may also be considered, such as or where and denote the sample variances. An algorithm for computing the posterior predictive p-value is provided below.
The posterior predictive p-value is then approximated by
6. Real Data Analysis
In this section, we consider two real data sets to illustrate the proposed methodology. The first data set relates to post-weld treatment methods designed to improve the fatigue life of welded joints, while the second consists of recorded lifetimes of steel specimens tested under varying stress levels. Both data sets are analyzed using the estimation methods developed in this article.
6.1. Data I
The first data set concerns post-weld treatment methods aimed at enhancing the fatigue life of welded joints. It was initially investigated by [25] and later revisited in [26]. The primary goal of these studies was to identify effective treatment techniques that could be applied in large-scale production of crane components. Two post-weld treatments are considered: burr grinding (BG) and TIG dressing, with their performance compared against the untreated, as-welded (AW) condition. The data set provides an opportunity to assess whether BG and TIG dressing improve fatigue strength relative to AW. In our analysis, since we are interested in a stress–strength setup, we treat the number of cycles to failure of specimens under BG, denoted by X, as the stress variable, while the cycles to failure under TIG, denoted by Y, represent the strength variable. The observed values are and It is worth noting that this data set was also reported in [26], where the authors further established that the data follow geometric distributions.
We employ Algorithm 1 to generate samples from the posterior distribution based on the specified prior assumptions and the observed data. The posterior variance-covariance matrix is approximated using the Laplace method, and with a chosen scale parameter of , the resulting acceptance rate is approximately 41%, which falls within the recommended range of 10–40% reported by [22]. For initialization of the random walk Metropolis–Hastings algorithm, we use the maximum likelihood estimates of and . The Markov chain is executed for 5500 iterations, discarding the first 500 as burn-in, with the remaining draws utilized to compute Bayes estimates under squared error loss (SELF) for the priors introduced in this work. As shown in Figure 1, the conditional posterior distribution of is well approximated by a Gaussian distribution. Furthermore, graphical diagnostics, including trace plots and auto-correlation function (ACF) plots of under the different prior settings, indicate good mixing: the trace plots exhibit random fluctuation around the mean values (denoted by solid red line), while the ACFs decay reasonably toward zero, suggesting minimal auto-correlation. To further check the convergence of the MCMC, we run three chains and compute the Gelman–Rubin statistics (); a value close to 1 or below 1.05 indicates convergence [27]. We found that is 1.0003 for , 1.0012 for , 1.0007 for , and 1.0008 for . Clearly, the Gelman–Rubin statistics under the four priors are well below the threshold of 1.05, confirming convergence. To further examine the suitability of the prior choices, we implement Algorithm 2, presenting histograms and kernel density estimates of the discrepancy statistics in Figure 2. The results demonstrate that replications from the Bayesian predictive density closely align with the observed data. In addition, the posterior predictive p-values, for , for , for , and for confirm the compatibility of the proposed priors.
| Algorithm 2 Posterior Predictive Assessment |
|
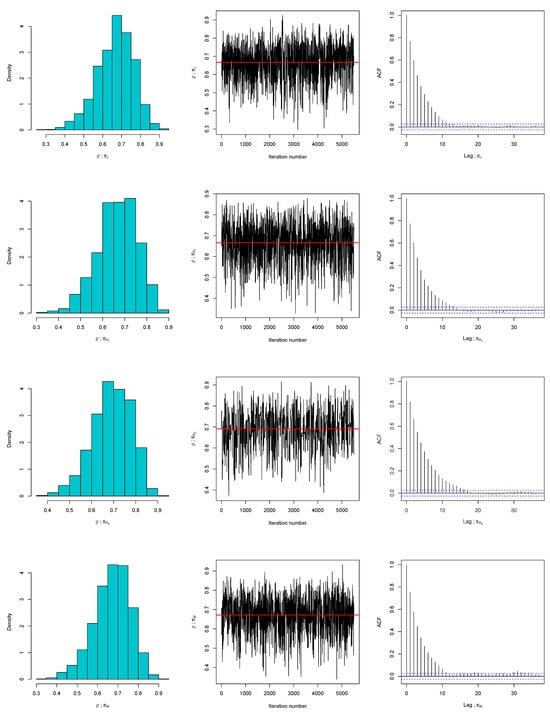
Figure 1.
Diagnostic plots of the random walk MH algorithm for under , , , and for the first data set.
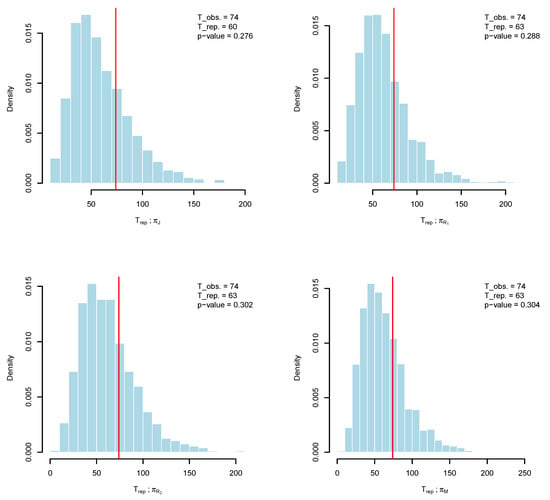
Figure 2.
Histogram and kernel density of along with its mean (red line) using , , , and (clockwise from the top left) for the first data set.
Before presenting the Bayes estimates of obtained under different priors, we first provide the empirical estimate, defined as
Table 2 reports all estimates of together with their standard deviations (SDs) and 95% HPD credible intervals. Among them, the Bayes estimate based on outperforms the others by achieving the smallest SD, the narrowest 95% credible interval, and remaining closest to the empirical estimate. The Bayes estimate under ranks second in terms of proximity to the empirical estimate. Furthermore, the Bayes estimate using demonstrates better performance than both the Bayes estimate under and the ML estimate, as it yields a smaller SD and a shorter 95% credible interval.
Table 2.
The summary of Bayesian estimates of for the first data.
6.2. Data-II
The second data set comprises the recorded lifetimes of steel specimens tested under 14 different stress levels. These data were originally reported by [28] and subsequently analyzed in greater detail by [26,29]. To illustrate our theoretical results, we focus on the lifetimes corresponding to a stress level of 32, which we denote by the stress variable X, with the following observed values: 1144, 231, 523, 474, 4510, 3107, 815, 6297, 1580, 605, 1786, 206, 1943, 935, 283, 1336, 727, 370, 1056, 413, 619, 2214, 1826, and 597. Similarly, the lifetimes measured at a stress level of 32.5 are treated as the strength variable Y, given by the following values: 4257, 879, 799, 1388, 271, 308, 2073, 227, 347, 669, 1154, 393, 250, 196, 548, 475, 1705, 2211, 975, and 2925. It is worth noting that the data set can be reasonably modeled using the geometric distribution, as confirmed by [26].
In a similar manner, Algorithms 1 and 2 are employed to draw posterior samples under the assumed priors and observed data, and to evaluate the adequacy of these priors, respectively. As illustrated in Figure 3, the posterior distribution of is well captured by a symmetric Gaussian proposal. Diagnostic plots further support this conclusion: the trace plots display stable fluctuations around the posterior means (marked by solid lines), and the corresponding autocorrelation functions (ACFs) decrease toward zero, indicating efficient mixing and low serial dependence. To assess prior suitability more thoroughly, Algorithm 2 is applied, with histograms and kernel density estimates of the discrepancy statistics shown in Figure 4. These results reveal that replicated samples from the Bayesian predictive distribution align closely with the observed data. Similarly, we run three MCMC chains and compute the Gelman–Rubin statistics. We found that is 1.0016 for , 1.0003 for , 1.0013 for , and 1.00041 for . Since all values of the statistic are well below the threshold of 1.05, the convergence of the MCMC is confirmed. Additionally, the posterior predictive p-values, for , for , for , and for , provide further evidence in favor of the compatibility of the proposed priors.
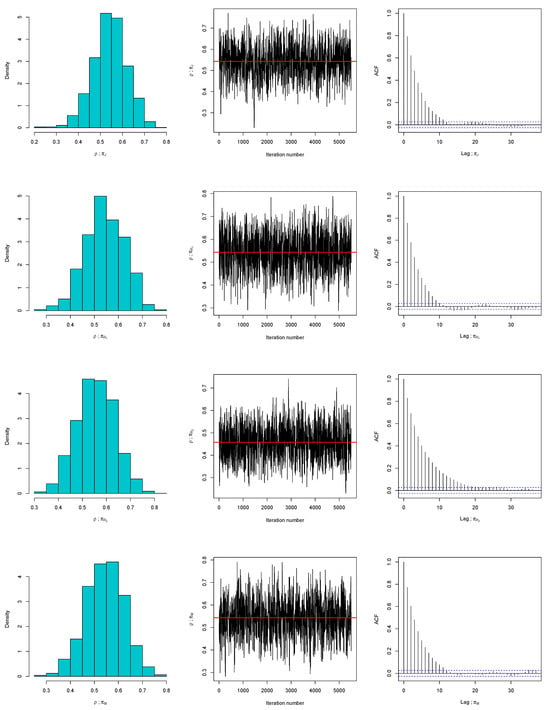
Figure 3.
Diagnostic plots of the random walk MH algorithm for under , , , and for the second data set.
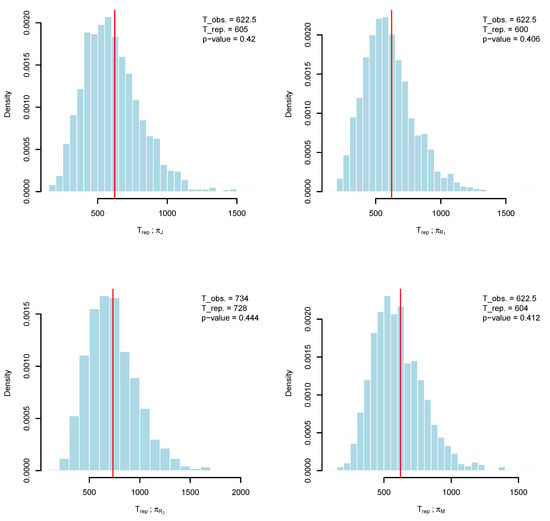
Figure 4.
Histogram and kernel density of along with its mean (red line) using , , , and (clockwise from the top left) for the second data set.
Similarly, Table 3 presents the estimates of along with their standard deviations (SDs) and 95% HPD credible intervals. The ML and the Bayes estimates are relatively close to empirical estimate. On the other hand, the Bayes estimates obtained under and perform best, yielding the smallest SDs, the narrowest credible intervals, and the closest agreement with the empirical estimate. Furthermore, the Bayes estimates based on and also outperform the ML estimate, as they are associated with smaller SDs and shorter intervals.
Table 3.
The summary of Bayesian estimates of for the second data.
7. Conclusions
In this paper, we investigated maximum likelihood (ML) and Bayesian estimation procedures for the stress–strength parameter of the geometric distribution. We derived the ML estimator of and established its asymptotic distribution. For the Bayesian approach, we developed objective priors for , namely Jeffreys, approximate reference, and matching priors. A key advantage of the Jeffreys prior is its invariance: the Bayes estimator of remains the same whether it is obtained directly in terms of or via a one-to-one transformation of the original model parameters. By contrast, reference and matching priors cannot in general be derived from those of the original parameters, since is a function of and . This underscores the importance of constructing these priors directly in terms of , ensuring that invariance is preserved upon transformation back to the original parameters.
We also examined the posterior distribution under these priors, noting that they are improper but lead to valid posteriors. Since closed-form Bayes estimates under the squared error loss function (SELF) are not available, we employed MCMC methods to compute them. Simulation studies demonstrated that the proposed Bayes estimators perform very well, with the matching prior generally outperforming both the other Bayesian approaches and the ML estimator, making it particularly suitable for practical use. Finally, two real data applications confirmed these findings: Bayesian estimates consistently outperformed ML estimates, with the matching prior yielding the best results overall, although the reference prior provided competitive performance in the first data set.
As in any study, a limitation of this work is that the proposed noninformative priors, including Jeffreys, reference, and matching priors, for the geometric stress–strength reliability may suffer from stability issues when the parameters lie close to the boundaries of the parameter space. This motivates us to further investigate such cases in future research. In addition, the methodology developed in this paper can be extended to other settings, such as record values or type-II censored data, which are frequently encountered in real applications, particularly in hydrology and lifetime studies. Under these two schemes, the likelihood remains tractable, making the use of the developed priors feasible.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
The author thanks the editor and the three reviewers for their constructive comments and suggestions, which greatly enhanced the earlier revision of this article.
Conflicts of Interest
The author declares that there are no conflicts of interest.
References
- Kundu, D.; Gupta, R.D. Estimation of P(Y < X) for generalized exponential distribution. Metrika 2005, 61, 291–308. [Google Scholar]
- Kumar, I.; Kumar, K. On estimation of P(V < U) for inverse pareto distribution under progressively censored data. Int. J. Syst. Assur. Eng. Manag. 2022, 13, 189–202. [Google Scholar]
- Khan, M.; Khatoon, B. Statistical inferences of R=P(X < Y) for exponential distribution based on generalized order statistics. Ann. Data Sci. 2020, 7, 525–545. [Google Scholar]
- Yadav, A.S.; Singh, S.; Singh, U. Bayesian estimation of stress–strength reliability for lomax distribution under type-II hybrid censored data using asymmetric loss function. Life Cycle Reliab. Saf. Eng. 2019, 8, 257–267. [Google Scholar] [CrossRef]
- Sun, D.; Ghosh, M.; Basu, A.P. Bayesian analysis for a stress-strength system under noninformative priors. Can. J. Stat. 1998, 26, 323–332. [Google Scholar]
- Kang, S.G.; Lee, W.D.; Kim, Y. Objective bayesian analysis for generalized exponential stress–strength model. Comput. Stat. 2021, 36, 2079–2109. [Google Scholar] [CrossRef]
- Abbas, K.; Tang, Y. Objective bayesian analysis of the Fréchet stress–strength model. Stat. Probab. Lett. 2014, 84, 169–175. [Google Scholar] [CrossRef]
- Barbiero, A. Inference on reliability of stress-strength models for Poisson data. J. Qual. Reliab. Eng. 2013, 2013, 530530. [Google Scholar] [CrossRef]
- Obradovic, M.; Jovanovic, M.; Milošević, B.; Jevremović, V. Estimation of P(X ≤ Y) for geometric-poisson model. Hacet. J. Math. Stat. 2015, 44, 949–964. [Google Scholar]
- Ahmad, K.E.; Fakhry, M.E.; Jaheen, Z.F. Bayes estimation of P(Y > X) in the geometric case. Microelectron. Reliab. 1995, 35, 817–820. [Google Scholar] [CrossRef]
- Maiti, S.S. Estimation of P(X ≤ Y) in the geometric case. J. Indian Stat. Assoc. 1995, 33, 87–91. [Google Scholar]
- Mohamed, M. Inference for reliability and stress-strength for geometric distribution. Sylwan 2015, 159, 281–289. [Google Scholar]
- Mohamed, M. Estimation of R for geometric distribution under lower record values. J. Appl. Res. Technol. 2020, 18, 368–375. [Google Scholar] [CrossRef]
- Datta, G.S.; Ghosh, M. On the invariance of noninformative priors. Ann. Stat. 1996, 24, 141–159. [Google Scholar] [CrossRef]
- Dong, G.; Shakhatreh, M.K.; He, D. Bayesian analysis for the shannon entropy of the lomax distribution using noninformative priors. J. Stat. Comput. Simul. 2024, 94, 1317–1338. [Google Scholar] [CrossRef]
- Sen, P.K.; Singer, J.M. Large Sample Methods in Statistics: An Introduction with Applications; Chapman & Hall: London, UK, 1993. [Google Scholar]
- Berger, J.O.; Bernardo, J.M. Ordered group reference priors with application to the multinomial problem. Biometrika 1992, 79, 25–37. [Google Scholar] [CrossRef]
- Bernardo, J.M. Reference analysis. Handb. Stat. 2005, 25, 17–90. [Google Scholar]
- Bernardo, J.M.; Smith, A.F. Bayesian Theory; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 405. [Google Scholar]
- Welch, B.L.; Peers, H. On formulae for confidence points based on integrals of weighted likelihoods. J. R. Stat. Soc. Ser. B (Methodol.) 1963, 25, 318–329. [Google Scholar] [CrossRef]
- Datta, G.S.; Ghosh, J.K. On priors providing frequentist validity for Bayesian inference. Biometrika 1995, 82, 37–45. [Google Scholar] [CrossRef]
- Neal, P.; Roberts, G. Optimal scaling for random walk metropolis on spherically constrained target densities. Methodol. Comput. Appl. Probab. 2008, 10, 277–297. [Google Scholar] [CrossRef]
- Guttman, I. The use of the concept of a future observation in goodness-of-fit problems. J. R. Stat. Soc. Ser. B (Methodol.) 1967, 29, 83–100. [Google Scholar] [CrossRef]
- Meng, X.-L. Posterior predictive p-values. Ann. Stat. 1994, 22, 1142–1160. [Google Scholar] [CrossRef]
- Pedersen, M.M.; Mouritsen, O.Ø; Hansen, M.R.; Andersen, J.G.; Wenderby, J. Comparison of post-weld treatment of high-strength steel welded joints in medium cycle fatigue. Weld. World 2010, 54, R208–R217. [Google Scholar] [CrossRef]
- Nayal, A.S.; Singh, B.; Tyagi, A.; Chesneau, C. Classical and bayesian inferences on the stress-strength reliability R=P[Y < X < Z] in the geometric distribution setting. AIMS Math. 2023, 8, 20679–20699. [Google Scholar]
- Brooks, S.P.; Gelman, A. General Methods for Monitoring Convergence of Iterative Simulations. J. Comput. Graph. Stat. 1998, 7, 434–455. [Google Scholar] [CrossRef]
- Kimber, A. Exploratory data analysis for possibly censored data from skewed distributions. J. R. Stat. Soc. Ser. C Appl. Stat. 1990, 39, 21–30. [Google Scholar] [CrossRef]
- Crowder, M. Tests for a family of survival models based on extremes. In Recent Advances in Reliability Theory; Birkhäuser: Boston, MA, USA, 2000. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).