Abstract
This paper explores bimodal skew-symmetric distributions, a versatile family of distributions characterized by parameters that control asymmetry and kurtosis. These distributions encapsulate both symmetrical and well-known asymmetrical behaviors. A simulation study evaluates the model’s estimation accuracy, detailing the score function and the robustness of the observed information matrix, which is proven to be non-singular under specific conditions. We apply the bimodal skew-normal model to protein data from cancer cells, comparing its performance against four established distributions supported on the entire real line. Results indicate superior performance by the proposed model, underscoring its potential for enhancing analytical precision in biological research.
Keywords:
skew-normal distribution; statistical model; bimodality; observed information matrix; protein in cancer cells; simulation MSC:
60E05; 62E15; 62F10
1. Introduction
The family of skew-symmetric distributions has been increasingly recognized for its flexibility and efficacy in modeling real-world data by transforming symmetric probability density functions (PDFs) with specific generators. This family is defined by the following PDF:
where f is a symmetric PDF centered at 0 and G is the cumulative distribution function (CDF) of a continuous random variable that is symmetric around 0. The function w is required to be odd and continuous, meaning .
This framework was initially developed by Azzalini [1,2], who introduced the skew-normal distribution by setting , the PDF of the standard normal distribution, and . This construction allows the skew-symmetric distribution to encapsulate both symmetric and skewed data through the parameter . Over time, various researchers (e.g., Gupta et al. [3], Ma and Genton [4], and Arellano-Valle et al. [5]) have expanded this model to include different forms of w, such as and , broadening its applicability within the skew-symmetric framework.
The general form (1) encompasses a wide range of submodels, from the symmetric density f (when ) to the highly skewed half-f densities (as ). These models can capture varying degrees of skewness in data, making them valuable in many statistical applications. For example, Pewsey [6] examined a subfamily where for . However, the model , , with location parameter and scale parameter , encounters significant challenges in maximum likelihood estimation (MLE) when . Specifically, when , the expected information matrix becomes singular, complicating the estimation process. Pewsey also noted that the observed information matrix fails to have an inverse for the CDF G when .
To address these challenges and further enhance the applicability of skew-symmetric distributions, we propose a novel w function that not only avoids the singularity issues at but also enables the modeling of bimodal data, which is crucial in many practical fields, including medicine. Specifically, we consider for and for . This function, equivalent to , where denotes the sign function, meets the necessary properties of w and introduces bimodality into the model. Some models in the literature that do not present singularity issues in the information matrix are as follows: Bakouch et al. [7] introduce a family of skewed distributions and explore the bimodal skew-normal distribution; Salinas et al. [8] present a two-piece normal distribution for modeling biaxial fatigue data; and Khorsheed et al. [9] propose a flexible form of three-parameter skew-normal distributions, enhancing flexibility for practical and industrial applications.
This proposed w function ensures that the model satisfies the regular conditions required for deriving the asymptotic distribution of the parameter vector. Importantly, the observed information matrix remains non-singular when , overcoming a significant limitation of previous models. The motivation for introducing this function is to address the non-singularity issue at and to incorporate bimodality, which enhances the model’s capability to accurately represent complex data distributions, particularly in fields such as medical research.
The primary objectives of the proposed bimodal skew-symmetric distributions are to provide a flexible framework for accurately modeling data with bimodal and skewed characteristics, which are common in various practical applications. The goals include extending the existing skew-normal distributions to accommodate bimodal features, enhancing the ability to model asymmetric data, and developing practical tools for parameter estimation and goodness-of-fit tests. Additionally, we aim to demonstrate the effectiveness of the proposed model through empirical analyses, such as on protein data from cancer cells, to illustrate its practical value and encourage its adoption in relevant fields.
These distributions are highly relevant in various fields where data exhibit bimodal and skewed characteristics. For example, in biology, they can model the distribution of protein expression levels in cancer cells, where distinct subpopulations of cells exhibit different expression patterns. In finance, these distributions can describe the returns of assets that have two predominant regimes, such as bullish and bearish market conditions, while also accounting for skewness due to market asymmetries. In environmental science, they are useful for modeling pollutant concentrations that show bimodal behavior due to varying sources and conditions. By providing a flexible framework that captures these complex data structures, the proposed distribution offers significant advantages for accurate modeling and inference in real-world applications.
This paper is structured as follows. Section 2 defines the bimodal skew-symmetric distribution and examines its key probabilistic properties as well as certain inferential issues. Section 3 introduces the bimodal skew-normal (BSN) distribution as a special case of the bimodal skew-symmetric family and discusses its properties and estimation. In Section 4, we demonstrate the adaptability of this class of distributions by analyzing data on proteins in cancer cells. Finally, Section 5 provides concluding remarks.
2. Bimodal Skew-Symmetric Family
In this paper, we investigate a family of distributions, called bimodal skew-symmetric distributions, that is generated by Equation (1) using , where . We start by presenting a lemma that characterizes this class of distributions and then proceed to derive several important properties. These properties are relevant for understanding the behavior of this family of distributions and for developing inferential procedures for fitting the model to data.
Lemma 1.
Let f be a symmetric PDF about 0 and let G be the CDF of a continuous random variable that is symmetric around 0. We define the function
which is a PDF for any value of . A random variable Z with a bimodal skew-symmetric distribution and a PDF given by (2) is denoted by .
Proof.
Let . We aim to prove that for all . In fact,
□
2.1. Cumulative Distribution Function
The cumulative distribution function corresponding to the density in (2) is given by
Proposition 1.
Suppose as given in (3), then the following properties are obtained:
- (i)
- , where F is the CDF of f.
- (ii)
- .
- (iii)
- .
- (iv)
- ,
where is the indicator function.
Proof.
- (i)
- , where F is the CDF of f.
- (ii)
- (iii)
- Suppose , then
- (iv)
- Suppose , then
□
2.2. Properties
2.2.1. Basic Properties
The following properties are directly derived from Lemma 1.
Proposition 2.
Using the previous notations, the following properties hold:
- (i)
- .
- (ii)
- .
- (iii)
- .
- (iv)
- .
- (v)
- .
- (vi)
- .
Proof.
Property (i) of Proposition 2 shows that the f distribution belongs to the family of distributions. Properties (ii)–(iv) indicate the distributions of the variables , , and , respectively. Properties (v) and (vi) show the distributions that follow by considering the limiting values of . □
2.2.2. Bimodality Property
The bimodality property of the random variable Z when it follows a BSf distribution with is presented in Proposition 3. To prove this, we differentiate Equation (2) with respect to z and equate it to zero, which yields two different solutions, and . The first solution corresponds to a negative modal point, and the second solution corresponds to a positive modal point. Thus, the random variable Z is a bimodal with two distinct modes at and . This property is useful in modeling real-life situations that exhibit two distinct peaks in their data distribution.
Proposition 3.
Suppose , then the random variable Z is a bimodal for .
Proof.
Differentiating Equation (2) with respect to z and equating to zero implies
where and . Therefore, and are different modal points. Therefore, the random variable Z is a bimodal. □
2.3. Stochastic Representation of the Random Variable
Proposition 4.
Suppose Z∼ with . Then Z can be represented as , where S and Y are dependent random variables with and .
Proof.
Let S and Y be defined as in the statement of the proposition. Using the joint distribution of and the Jacobian method, the marginal distribution of Z is obtained as follows:
If , then and . Therefore, we have
On the other hand, if , then and ,
□
This proof shows that a random variable Z that follows a BSf distribution with location parameter can be represented as a combination of two dependent random variables S and Y. The variable Y has a density function that is twice the absolute value of the density function of Z for positive values of Z and is zero for negative values of Z. The variable S takes the value of 1 with the probability given by the value of the cumulative distribution function of G evaluated at , and the value of with the complement of this probability.
This representation is useful because it provides a way to generate random samples from the BSf distribution using the joint distribution of S and Y. Additionally, it allows for the computation of various statistics and moments of the distribution using the properties of S and Y.
2.4. Calculation of Moments for the Distribution
The random variable Z can be represented as a combination of two dependent random variables S and Y, as shown in Proposition 4. In this section, we derive a formula for computing the r-th moment of a random variable X that follows the distribution, where and , with .
Proposition 5.
The r-th moment of X is given by
where is given by
and is the random variable in the stochastic representation of Z as given in Proposition 4.
Proof.
By utilizing the stochastic representation provided in Proposition 4 and applying the properties of conditional expectation, we can derive the required expression.
The above leads to the conclusion that if k is even, then . On the other hand, if k is odd, then . To obtain , it is possible to apply the binomial theorem along with the basic properties of the expectation. □
The mean and variance of a random variable X with BSf distribution can be easily calculated using the following corollary:
Corollary 1.
Suppose and . Then, the mean and variance of X are given by
where and for .
This result provides a straightforward way to compute the expected value and variance of a BSf-distributed random variable X, where , , , and G are parameters of the distribution. The integrals and can be numerically evaluated, making the calculation of and feasible in practice.
2.5. Observed Information Matrix for the Location–Scale BSf Distribution
Proposition 6 states that if is a random sample from a distribution with a continuous and differentiable symmetric univariate probability density function f and cumulative distribution function G, where , then the solution to the score equations is , , and , and the observed information matrix is non-singular when and and are continuous functions.
Proposition 6.
Let be a realization of the random sample , where are independent and identically distributed random variables following a distribution. Assume that f and G are continuous and a differentiable symmetric univariate probability density function and cumulative distribution function, respectively, with .
- (i)
- The solution to the score equations is , , and .
- (ii)
- When , the observed information matrix is non-singular.
Proof.
- (i)
- Let be the log-likelihood function. Assuming exists, and denoting , the first-order partial derivatives of the log-likelihood are as follows:where and , which is defined to be . Note that the log-likelihood function depends on the parameter . Therefore, the partial derivative measures the sensitivity of the log-likelihood with respect to changes in .The score equations for the family are given bywhere and .Solving these equations yields , , and for any solution. If , then the score equations require . In this case, we have and . Thus, , , and are a solution to the score equations of the family , regardless of the choice of G.We observe that the condition and are a solution to the score equations only if we can select a density f such that . Therefore, we conclude that the estimators of the family for and coincide with the class studied by Pewsey [6].
- (ii)
- Assuming that and exist, we can obtain the second-order partial derivatives of the log-likelihood by defining and . With these definitions, the partial derivatives can be computed as follows:From the score equations, we can see that and . Moreover, if there exists a solution to these equations such that , then we have , , , and for any solution.Note that many symmetric densities around zero are differentiable at this point, including popular ones such as the normal, logistic, and Student’s t densities. This means that for these distributions, we have . However, there are exceptions to this rule, such as the double exponential density, which is not differentiable at zero.When we set and , we can calculate that and . We can then define standardized scores as , which have a mean of zero and a variance of one: and .
Using these standardized scores, we can express the first derivative of as . This gives us , , , and .
Conversely, we can find the second derivative of by using the formula . We can calculate that and . Additionally, we have .
The second-order partial derivatives for this solution are given by
where is the mean absolute deviation and is the kurtosis. This leads to the observed information matrix:
which is always non-singular, except when g is not differentiable at the origin. This result ensures the regularity conditions necessary to obtain the asymptotic distribution of the MLE for . It should be noted that this condition was not met with the distribution studied by Azzalini and others. □
Remark 1.
The functions discussed in Proposition 6 are crucial for addressing the singularity issue in statistical models. They are designed to ensure the non-singularity of the observed information matrix, which is essential for accurate parameter estimation and model performance.
The function introduced in this research paper, denoted as , is defined as for and for . This function is equivalent to , where denotes the sign function.
The significance of this function lies in its ability to introduce bimodality into the model while avoiding singularity issues at . By incorporating bimodality, the model can more accurately represent complex data distributions, particularly in fields like medical research.
The proposed w function ensures that the model satisfies the regular conditions required for deriving the asymptotic distribution of the parameter vector. It effectively overcomes the singularity issue at , a significant limitation in previous models.
These functions provide a robust solution to the singularity problem by maintaining the non-singularity of the observed information matrix except when g is not differentiable at the origin.
By resolving the singularity issue, these functions enhance the model’s reliability and accuracy in estimating parameters, making it a valuable tool for analyzing complex datasets, such as the protein data from cancer cells studied in this research paper.
Overall, these functions not only address the singularity problem but also contribute to the model’s capability to handle bimodal data effectively, showcasing their significance in statistical modeling and data analysis.
3. Bimodal Skew-Normal Model
In this section, we provide a detailed description of the BSN distribution and investigate some of its key properties. To evaluate the performance of the resulting estimate, we conduct a simulation study that examines the basic inference obtained through the maximum likelihood approach.
3.1. Shape Case
In the shape case, we can derive the probability density function using Lemma 1 with , which yields
where and are the PDF and CDF of the standard normal distribution, respectively. The PDF (9) can be represented as a composition of two functions, that is,
where .
Proposition 7.
If , then the CDF is given by
where
Proof.
For ,
and for ,
□
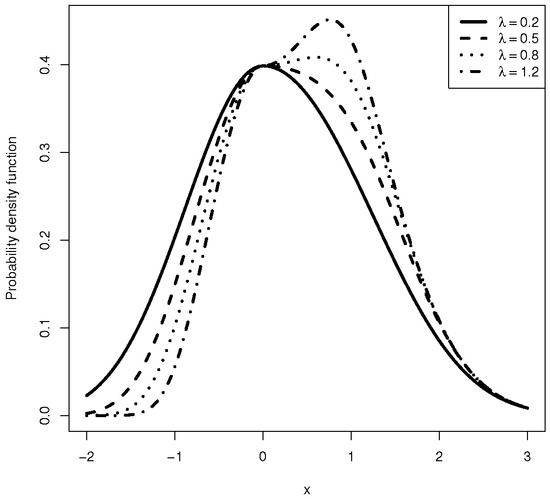
Figure 1.
Plot of density function of BSN for different values of .
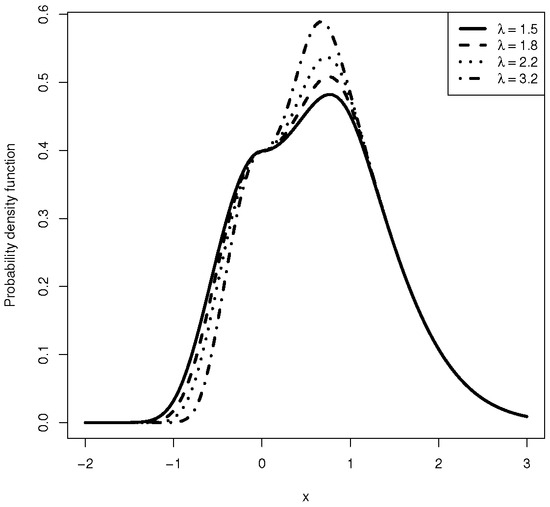
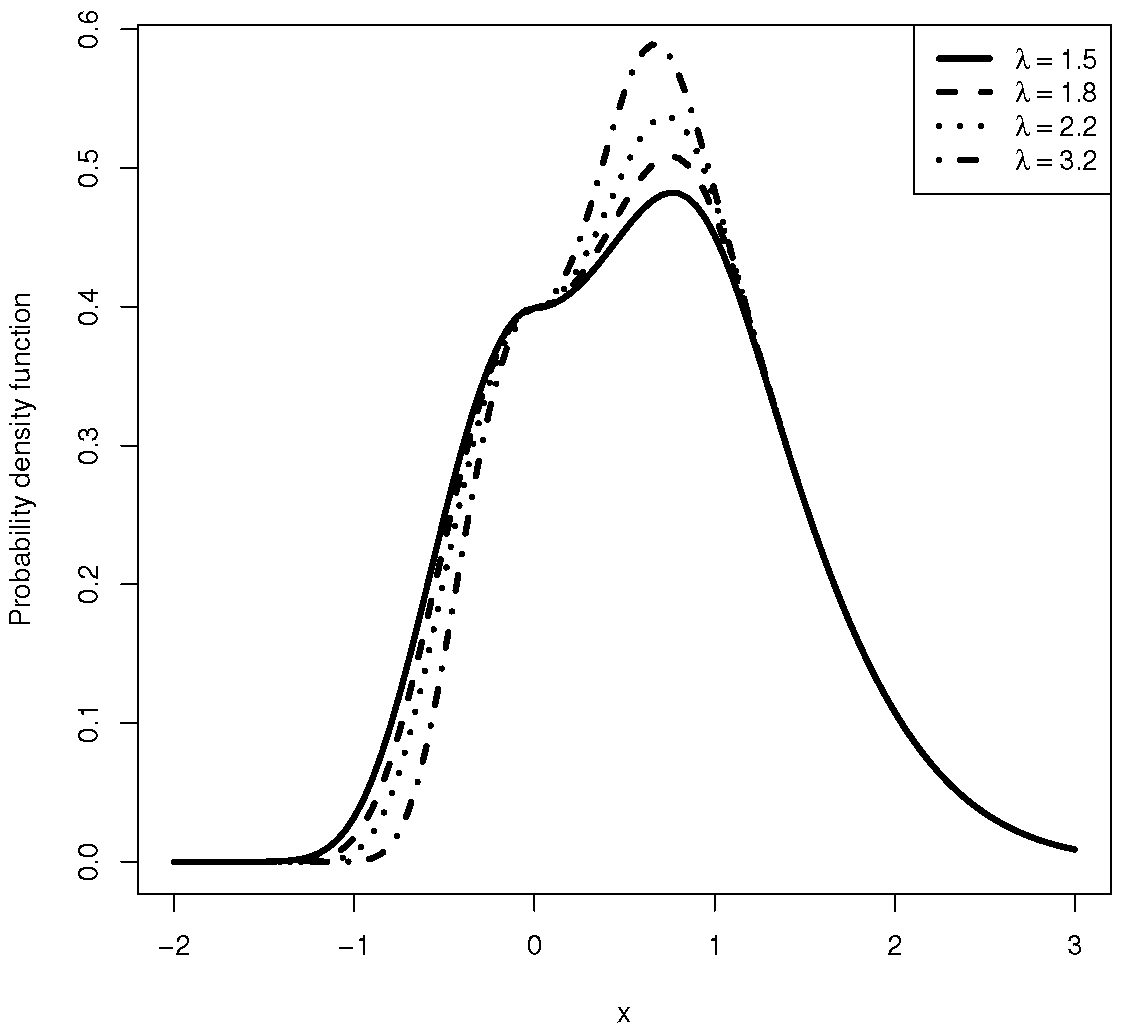
Figure 2.
Plot of density function of BSN for different values of .
The BSN distribution, denoted by , is a distribution that is gaining attention as a valid competitor to the skew-normal model (SN) [1]. This is because both models control the degree of skewness using the same scalar parameter, . If , then the model is reduced to the symmetric normal model. However, as demonstrated in this study, a significant advantage of the BSN model over the SN model is that in the presence of the location parameter, the BSN information matrix is non-singular at . Consequently, under the null hypothesis of normality given by , the conventional regularity conditions leading to the ordinary asymptotic normal distribution of the MLE hold.
3.2. Some Basic Properties
Proposition 2 yields several important properties of the BSN distribution. First, if , then . This means that the distribution is symmetric with respect to the origin. Second, , which indicates that the distribution of the squared BSN variable follows a chi-squared distribution with one degree of freedom. Finally, , where denotes the half-normal distribution. This property implies that the absolute value of a BSN variable follows an HN distribution with mean zero and variance one. These properties are useful for analyzing and interpreting data modeled with the BSN distribution.
3.2.1. Quantile Function
The quantile function of the BSN distribution is derived by inverting Equation (11), as follows:
This inverse does not have a closed expression and has to be calculated using some suitable numerical method. Note that , , and stand for median, first quartile, and third quartile of the BSN distribution, correspondingly.
3.2.2. Moments, Skewness, and Kurtosis
The even moments of are equal to the corresponding even moments of a standardized normal random variable. The odd moments can be computed from the result in Proposition 5, as follows:
where . In particular, the first four moments are
where
By using the moments above and the standard definitions, we can calculate the skewness and kurtosis of the BSN distribution directly.
3.2.3. Entropy
A measure of the uncertainty’s variation is the entropy of a random variable Z with a certain PDF. Greater data uncertainty is indicated by a high entropy value. The Rényi entropy [10], , for Z is defined as
where and . Suppose Z has the BSN distribution; then, by substituting (9) in (14), we obtain
So, one obtains the Rényi entropy as follows:
Shannon entropy [11] defined by is the particular case of Equation (14) when . Both and do not have closed expressions and must be calculated using some suitable numerical method.
3.2.4. Order Statistics
Let and be a random sample of independent and identically distributed variables with CDF given in (11) and PDF given in (9). Define the random variable . It is known that the CDF of the sample minimum is given by
and its PDF is
On the other hand, define the random variable . It is known that the CDF of the sample maximum is given by
and its PDF is
In general, the PDF of the k-th-order statistic from a random sample of size n drawn from the distribution of Z is
3.2.5. Maximum Likelihood Estimates for
The log-likelihood function for can be defined for a random sample of size n from , as given below:
where denotes the sample data. This log-likelihood function helps to estimate the parameter of the BSN distribution. The likelihood equation induced from this function is given by
The solution to this likelihood equation provides the MLE of for the bimodal skew-normal distribution. The numerical values of can be determined via any statistical software.
3.3. Simulation Study
In this section, we evaluate the effectiveness of the MLE method for estimating the parameter in the BSN distribution. We generate random samples of various sizes: n = 50, 100, 150, and 200, keeping fixed.
3.3.1. Generating Samples from BSN()
To generate random samples, follow these steps:
- (i)
- Set the parameter and choose the sample size n.
- (ii)
- Generate a standard normal random variable .
- (iii)
- Compute .
- (iv)
- Generate a Bernoulli random variable S with success probability .
- (v)
- Set if , otherwise .
3.3.2. Analyzing with MLE
After obtaining the samples, is estimated using the MLE method. We assess the performance of this estimation by calculating the standard error (SE), bias, and mean square error (MSE) in programming language [12]:
- (i)
- For a chosen , simulate a sample of size n as described.
- (ii)
- Estimate using MLE.
- (iii)
- Repeat the above steps 1000 times.
- (iv)
- Compute the mean, SE, bias, and MSE of these 1000 estimates:
The mean, SE, bias, and MSE of are given by
and
respectively. Here, represents the MLE of for the ith iteration under a specific sample size n, corresponds to the mean of the parameter estimates obtained, for example, , and denotes the actual value of the parameter.
Table 1 displays the mean estimates, SEs, biases, and MSEs of for various sample sizes. The performance of the MLE was investigated for a wide range of initial values for , and in all cases, the MLE converged well. The results in Table 1 were obtained by setting the initial value of to 1.00, irrespective of its actual value. Thus, any choice of initial value for is expected to yield similar results, as shown in Table 1.

Table 1.
Simulation results.
Overall, Table 1 reveals that as n increases, the SEs, biases, and MSEs decrease, indicating that the MLE provides consistent estimates.
4. Practical Data Analysis
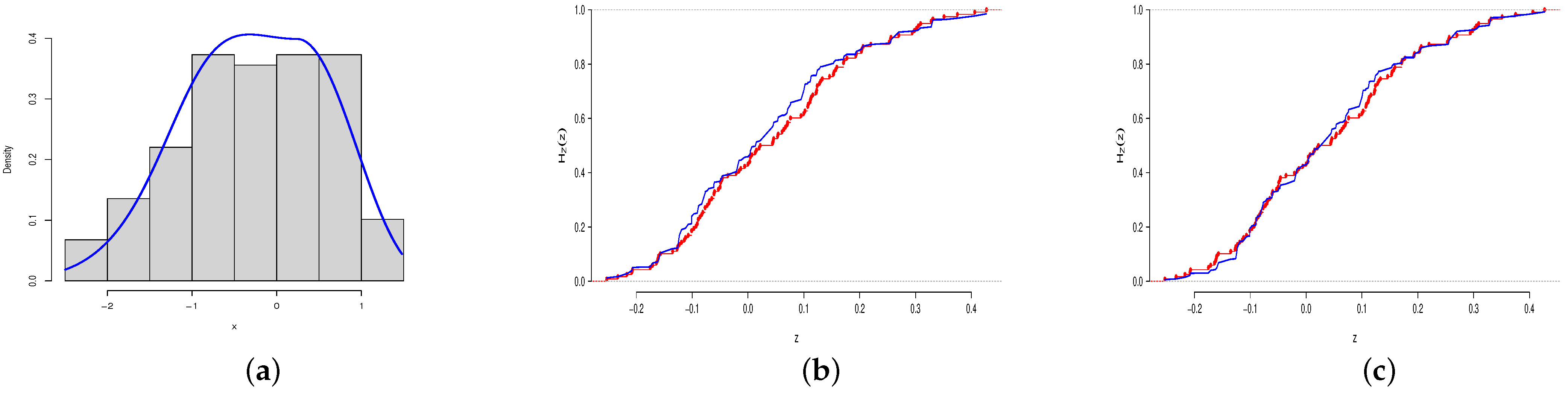
In this section, we illustrate the modeling capabilities of the BSN distribution by fitting it to 118 observations of the Homo sapiens PIG7 data in Çankaya [13] using the MLE method. To ensure computational stability, we scaled the data by before fitting the distributions. The data are left-skewed with the Pearson’s moment coefficient of skewness of and appear to be bimodal, as seen in the empirical density plot in Figure 3a. Some of the descriptive statistics of the data include a minimum value of , a maximum value of , a mean value of , a variance value of , a median value of , a first quartile value of , and a third quartile value of . The resulting MLE of is , with a corresponding SE of . To assess the goodness-of-fit of the BSN distribution to the empirical data, we employed the Kolmogorov–Smirnov (K-S) test, with a test statistic defined as , where is the ith data value. For large sample size n, the p-value of the K-S test is given by , where is the estimated CDF of the theoretical distribution, see Kolmogorov [14] and Smirnov [15]. The K-S test measures the disparity between the empirical and estimated cumulative distribution functions (CDFs), with a smaller difference indicating a better fit. In general, if the p-value of the K-S test is greater than , we conclude that the model provides a good fit for the data. The fitted BSN distribution gives a K-S statistic of with a p-value of 0.1337 (>0.05). Therefore, based on this evidence and visual inspection through the plot of the CDFs in Figure 3b, we conclude that the one-parameter BSN distribution provides a good fit for the data.
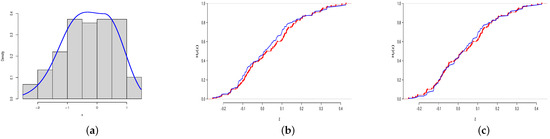
Figure 3.
The plot of the empirical (rectangular bars) and estimated (blue line) PDF (a), estimated CDF of the uncentered BSN distribution (blue line) with the empirical CDF (red line) (b), and estimated CDF of the centered BSN distribution (blue line) with the empirical CDF (red line) (c).
We compare the fit of the BSN distribution with that of four other distributions, namely, the normal distribution, double Lindley distribution [16], Laplace distribution, and Student’s t-distribution. The PDFs of these distributions are as follows:
- (i)
- Normal distribution with PDF given bywhere is the standard normal PDF.
- (ii)
- Double Lindley distribution with PDF given by
- (iii)
- Laplace distribution with PDF given by
- (iv)
- Student’s t-distribution with PDF given bywhere is the beta function.
We used the K-S test to compare the goodness-of-fit of these distributions with that of the BSN distribution. The K-S test statistic measures the maximum distance between the empirical CDF of the data and the CDF of the fitted distribution, with a smaller test statistic indicating a better fit. The p-values of the K-S tests for each distribution were computed, and if the p-value was larger than , we concluded that the distribution provided a good fit for the data.
To ensure a fair comparison between the fits of the normal distribution, Laplace distribution, and BSN distribution, it is important to center the BSN distribution about the mean (), as both the normal and Laplace distributions are centered around the mean. To accomplish this, we introduce an additional parameter to the BSN distribution, resulting in a centered BSN distribution with PDF for . To determine the best-fitting model for the data, we use the information criteria listed below along with the K-S test:
- (i)
- Akaike information criterion (AIC), given by AIC = .
- (ii)
- Bayesian information criterion (BIC), given by BIC = .
- (iii)
- corrected AIC (AICc), given by AICc = AIC + .
Here, denotes the estimated log-likelihood value, n represents the number of data points, is the unknown parameter, and k indicates the number of parameters in the model. A smaller value of the information criterion indicates a better fit. Table 2 and Table 3 present the results of the fitted distributions. Based on these tables, we can observe that the centered BSN distribution outperformed all other considered distributions, with the smallest K-S statistic, largest p-value of K-S, and smallest values of AIC, BIC, and AICc. This is also evident from Figure 3c, where we can see that the CDF of the estimated centered BSN distribution closely mimics the empirical CDF.
Table 2.
Fit results for different distributions.
Table 3.
Model fit discrimination.
In Table 4, descriptive statistics obtained from the empirical distribution and the estimated centered BSN distribution are compared. From the results, we can conclude that the fitted centered BSN distribution accurately captured the important features of the empirical distribution, as the first three moments and the standard deviation (std) of the estimated centered BSN distribution are similar to those of the empirical distribution. It is noteworthy that the direction of skewness is the same for both distributions. However, a slight difference in skewness values is observed, which may be due to rounding errors in the numerical integration of the k-th-order moments. The code used to compute the descriptive statistics is provided in Appendix A.
Table 4.
Some descriptive statistics for the empirical and centered BSN distributions.
5. Concluding Remarks
In this study, we introduced a new family of continuous distributions known as bimodal skew-symmetric distributions. The BSN distribution, which is essential to this family, is distinguished by the single parameter that causes its asymmetry. The statistical properties of this distribution have been thoroughly discussed, emphasizing its flexibility and applicability.
Utilizing the MLE method, we estimated this sole asymmetry parameter, demonstrating the practicality and effectiveness of the BSN model when applied to real-world data. The analysis highlights the BSN distribution’s capability to adeptly model data features, such as skewness and bimodality, which are often encountered in practical datasets but are challenging to address with more traditional models.
To enhance the utility of the BSN distribution and facilitate its comparison with more conventional distributions like the normal and Laplace distributions, both of which are two-parameter models centered about the mean, we plan to extend the BSN distribution by centering it about the mean in future applications. This adjustment will allow the BSN distribution to be directly comparable to these models, providing a fair basis for performance evaluation.
The results from this study are promising, showing that the two-parameter BSN distribution not only meets but exceeds the performance of the four considered competing distributions for the dataset in question. This superior performance underscores the potential of the BSN distribution as a robust and versatile tool in statistical modeling, particularly suitable for complex real-world data that exhibit asymmetry and bimodality.
This study contributes to an application of bimodal skew-symmetric distributions to the analysis of cancer cell protein data, addressing the inherent bimodality and asymmetry of such data. The proposed model enhances the flexibility and accuracy of statistical representations, leading to improved parameter estimation and robust analysis even in the presence of noise. By incorporating regularization techniques to prevent singularity issues and leveraging the model’s adaptability to capture complex biological variability, this research provides an effective tool for identifying subpopulations and characterizing protein profiles in cancer cells. These contributions not only advance the field of statistical modeling in bioinformatics but also have practical implications for biomarker discovery and proteomics analysis, paving the way for more precise and meaningful insights into cancer biology.
The implications of these findings are significant, suggesting that the BSN distribution can serve as an alternative to traditional models, offering enhanced flexibility and better fit for specific types of data. Future studies will focus on further developing this model, improving its statistical inference procedures, and extending its application to a broader range of datasets.
Author Contributions
Conceptualization, H.S.S., H.S.B. and I.E.O.; methodology, H.S.S., H.S.B. and I.E.O.; software, H.S.B., I.E.O. and G.A.; validation, H.S.S., H.S.B., I.E.O., and G.A.; writing—original draft preparation, H.S.S. and I.E.O.; writing—review and editing, H.S.S., H.S.B., I.E.O., G.A. and O.A.; visualization, H.S.S., H.S.B. and I.E.O.; funding acquisition, G.A. and O.A. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by King Faisal University, Saudi Arabia [GRANT KFU241133].
Data Availability Statement
Data are accessible from the authors upon request.
Acknowledgments
This work was supported by the Deanship of Scientific Research, Vice Presidency for Graduate Studies and Scientific Research, King Faisal University, Saudi Arabia [GRANT KFU241133].
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Codes
order ordinary moments for the centered BSN distribution
moments<-function(z,k)
{
lambda<--0.7720
xi<-0.2444
f<-function(z)z^k*2*dnorm(z-xi)*pnorm(lambda*(z-xi)*abs(z-xi))
out<-integrate(f,lower=-Inf,upper=Inf)$value
out
}
first<-moments(z,1)
second<-moments(z,2)
third<-moments(z,3)
variance<-second-first^2
std<-sqrt(var)
skew<-(third-3*first*variance-first^3)/std^3
cbind(first,second,third,variance,std,skew)
Simulation
sim<-function(lambda,nn,N)
{
m<-length(nn)
esthat<-0
sdhat<-0
bias<-0
mse<-0
for(n in 1:m)
{
loop<-function(nn,N)
{
t<-0
result<-matrix(0,N,1)
while(t<N)
{
t<-t+1
sim<-function(lambda,n)
{
t<-0
z<-0
while(t<n)
{
t<-t+1
u<-rnorm(1)
y<-abs(u)
p<-pnorm(lambda*y^2)
s<-rbinom(1,1,p)
if(s==1)
{
z[t]<-y
}else{
z[t]<--y
}
}
z
}
x<-sim(lambda,nn[n])
ff=function (q)
{
tt=1.0e20
lambda=q[1]
tt=-sum(log(2*dnorm(x)*pnorm(lambda*x*abs(x))))#MLE
if (is.na(tt)) tt=1.0e20
if (abs(tt)>1.0e20) tt=1.0e20
return(tt)
}
est=nlm(ff,p=c(1))
result[,1][t]=est$estimate[1]#lambda
}
result
}
est<-loop(nn,N)[,1]
esthat[n]=mean(est)
sdhat[n]=sd(est)
bias[n]=mean(est-lambda)
mse[n]=mean((est-lambda)**2)
}
data.frame(nn,esthat,sdhat,bias,mse)
}
References
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Azzalini, A. Further results on a class of distributions which includes the normal ones. Statistica 1986, 46, 199–208. [Google Scholar]
- Gupta, A.K.; Chang, F.C.; Huang, W.J. Some skew–symmetric models. Random Oper. Stoch. Equ. 2002, 10, 113–140. [Google Scholar] [CrossRef]
- Ma, Y.; Genton, M.G. Flexible class of the skew-symmetric distributions. Scand. J. Stat. 2004, 31, 459–468. [Google Scholar] [CrossRef]
- Arellano-Valle, R.B.; Gómez, H.W.; Quintana, F.A. A new class of skew-normal distributions. Commun. Stat. Theory Methods 2004, 33, 1465–1480. [Google Scholar] [CrossRef]
- Pewsey, A. Some observations on a simple means of generating skew distributions. In Advances in Distribution Theory, Order Statistics, and Inference Part of the Series Statistics for Industry and Technology; Springer: New York, NY, USA, 2006; pp. 75–84. [Google Scholar]
- Bakouch, H.S.; Salinas, H.S.; Mamode Khan, N.; Chesneau, C. A new family of skewed distributions with application to some daily closing prices. Comput. Math. Methods 2021, 3, e1154. [Google Scholar] [CrossRef]
- Salinas, H.; Bakouch, H.; Qarmalah, N.; Martínez-Flórez, G. A flexible class of two-piece normal distribution with a regression illustration to biaxial fatigue data. Mathematics 2023, 11, 1271. [Google Scholar] [CrossRef]
- Khorsheed, E.; Salinas, H.S.; Bakouch, H.S. A new family of skew-normal lifetime distributions for industrial applications. In Proceedings of the 2020 International Conference on Data Analytics for Business and Industry: Way Towards a Sustainable Economy (ICDABI), Sakheer, Bahrain, 26–27 October 2020; pp. 1–4. [Google Scholar]
- Rényi, A. On measures of information and entropy. In Proceedings of the 4th Berkeley Symposium on Mathematical Statistics and Probability, Los Angeles, CA, USA, 20–30 June 1960; Neymann, J., Ed.; University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell. Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2024; Available online: https://www.R-project.org/ (accessed on 10 January 2024).
- Çankaya, M.N. Asymmetric bimodal exponential power distribution on the real line. Entropy 2018, 20, 23. [Google Scholar] [CrossRef] [PubMed]
- An, K. Sulla determinazione empirica di una legge didistribuzione. Giorn. Dell’inst. Ital. Degli Att. 1933, 4, 89–91. [Google Scholar]
- Smirnov, N. Table for estimating the goodness of fit of empirical distributions. Ann. Math. Stat. 1948, 19, 279–281. [Google Scholar] [CrossRef]
- Nitha, K.; Krishnarani, S. A new family of heavy tailed symmetric distribution for modeling financial data. J. Stat. Appl. Probab. 2017, 6, 577–586. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).