
Frequency-Enhanced Transformer with Symmetry-Based Lightweight Multi-Representation for Multivariate Time Series Forecasting


Abstract
1. Introduction
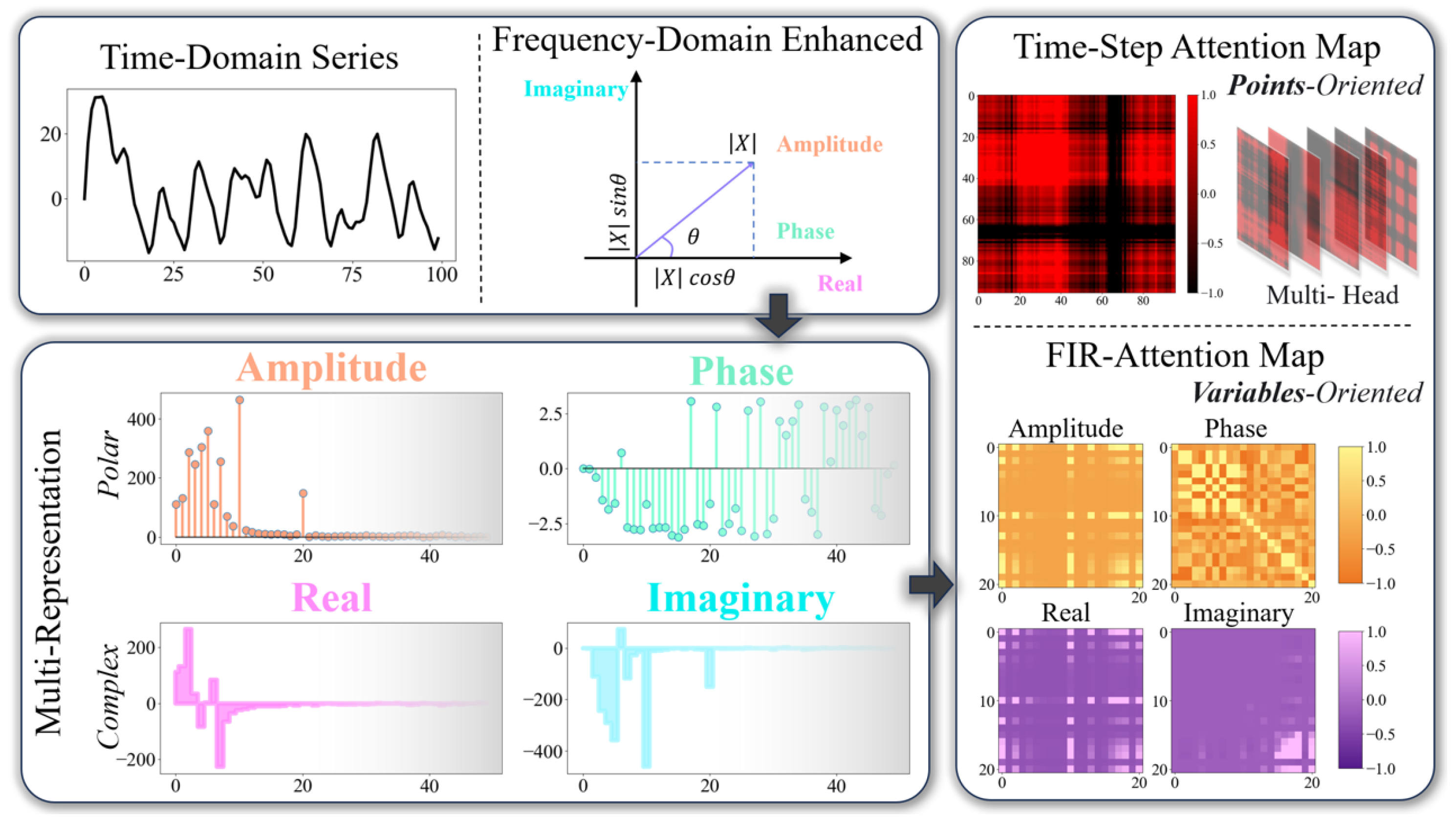
- Points-Oriented Limitations: Embedding multiple variables at the same time step into a single token obscures distinct physical properties and undermines the ability to capture critical inter-variable correlations, thus complicating the effective modeling of variable dependencies.
- Time-Wise Limitations: time domain representations are characterized by inefficiency and redundancy, with critical information often dispersed and sparse across time steps. This results in a lack of cohesive structure, making it difficult to capture and utilize significant temporal patterns effectively.
- We propose a transformer-based frequency-enhanced multivariate time series forecasting method. It takes a compact frequency-wise perspective and uses attention to capture the correlation dependence of frequency domain representations of multivariate interactions.
- We adopt a cutting-off frequency and an equivalent mapping design to ensure the efficiency and lightweightness of the model. Further, we propose FIR-Attention to construct rich frequency representations and reliable attention computation from polar and complex-valued domains.
- Extensive experiments demonstrate that our method achieves similar or even better prediction performance than mainstream transformer-based models with only one percent of space–time consumption. The novel idea of FIR-Attention and two spatial compression schemes are also proven effective.
2. Related Work
2.1. Deep Learning Forecasting Methods
2.2. Transformer-Based Methods
2.3. Frequency-Aware Analysis Model
3. Methodology
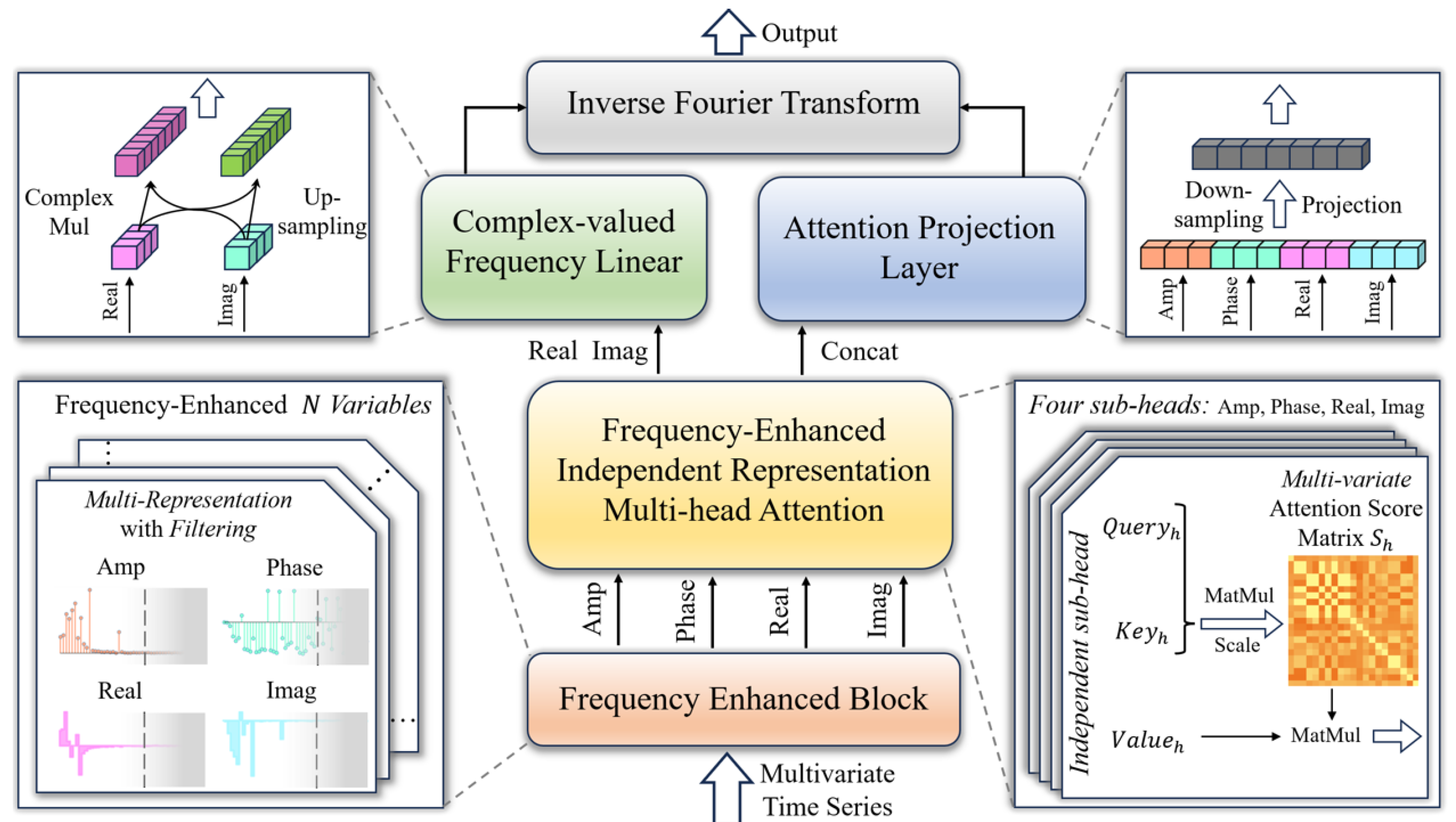
3.1. Overview of the Algorithm
3.2. Frequency-Enhanced Independent Representation Multi-Head Attention
3.3. Complex-Valued Frequency Linear
4. Experiments
4.1. Experimental Settings
4.1.1. Baselines
4.1.2. Implementation Details
4.1.3. Dataset Descriptions
4.2. Comparison with State-of-the-Art Methods
4.2.1. Multivariate Time Series Forecasting
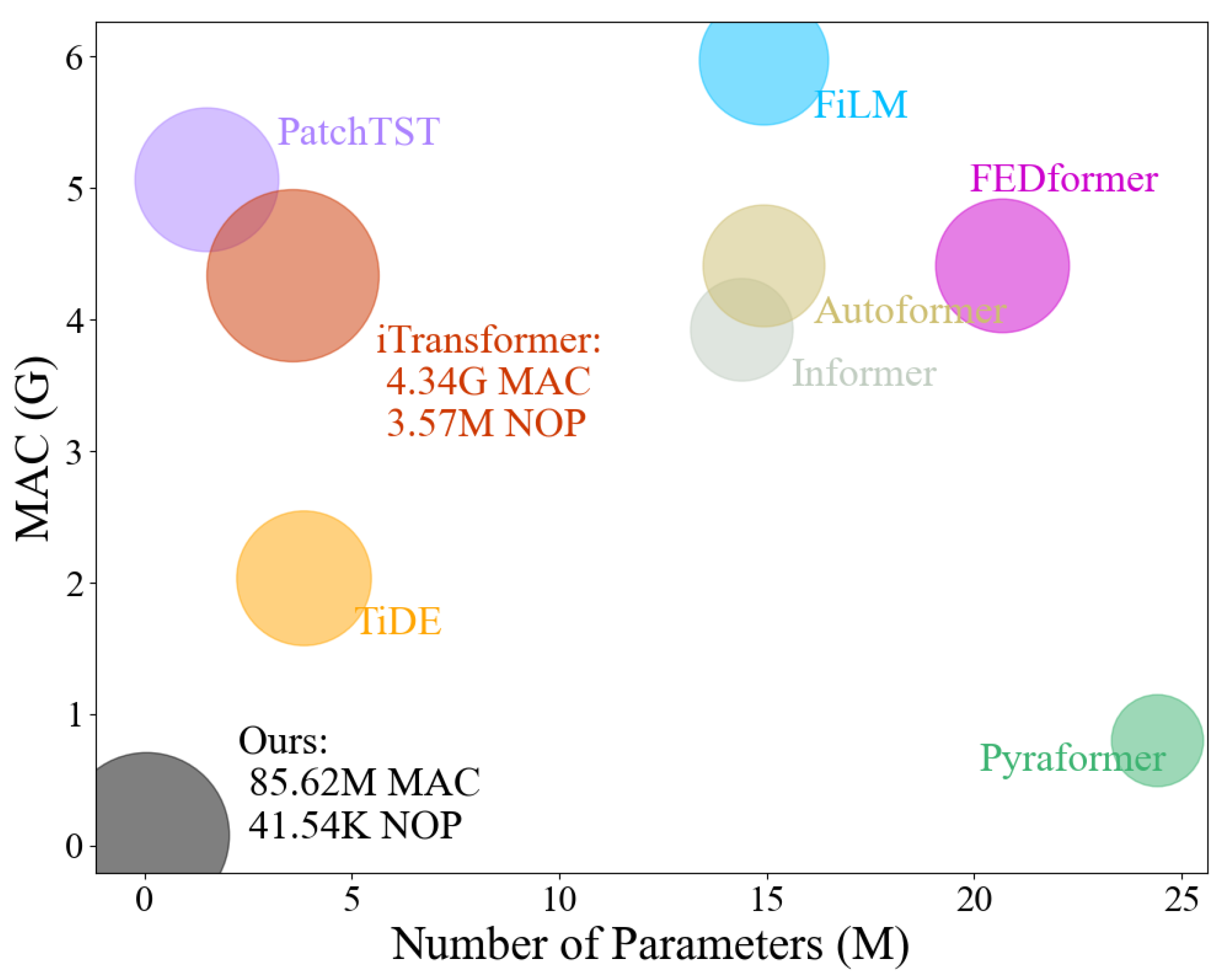
4.2.2. Method Consumption
4.3. Model Analysis
4.3.1. Frequency Domain Multi-Representation Effectiveness Analysis
4.3.2. Independent Multi-Head Representation Effectiveness Analysis
4.3.3. Equivalent Mapping
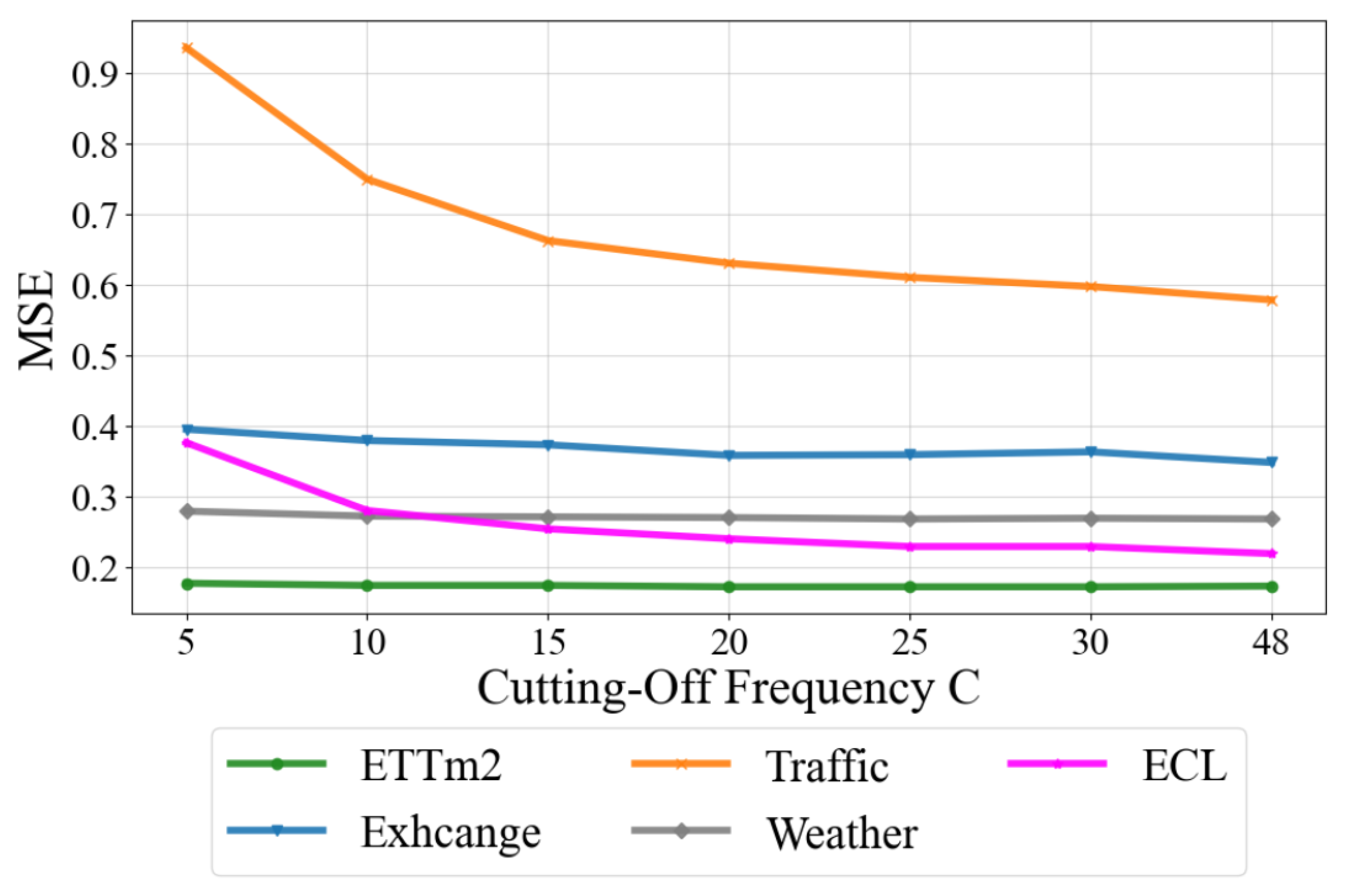
4.3.4. Cutting-Off Frequency
4.3.5. Input Length
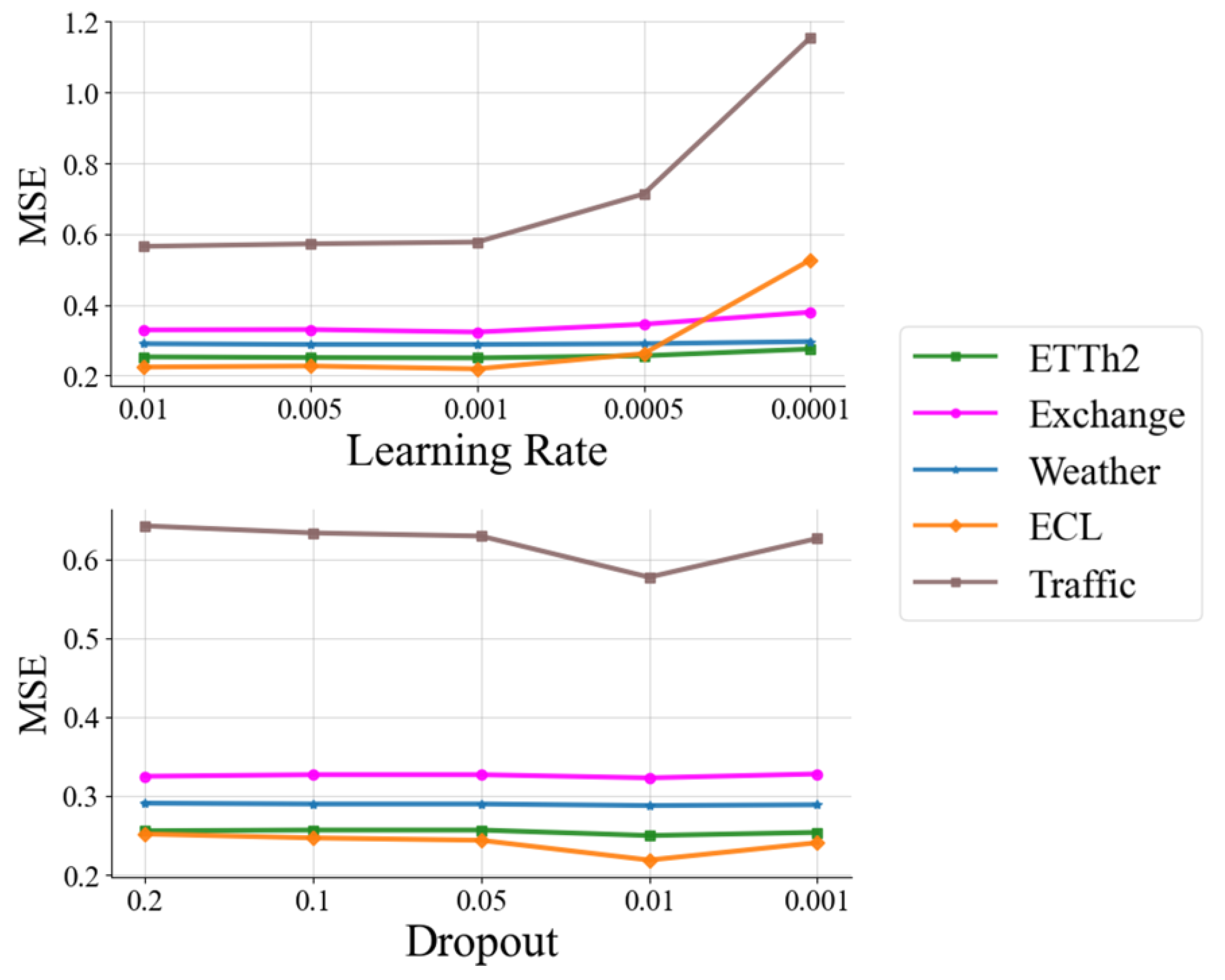
4.3.6. Hyper-Parameter Sensitivity
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yasar, H.; Kilimci, Z.H. US dollar/Turkish lira exchange rate forecasting model based on deep learning methodologies and time series analysis. Symmetry 2020, 12, 1553. [Google Scholar] [CrossRef]
- Alyousifi, Y.; Othman, M.; Sokkalingam, R.; Faye, I.; Silva, P.C. Predicting daily air pollution index based on fuzzy time series markov chain model. Symmetry 2020, 12, 293. [Google Scholar] [CrossRef]
- Cruz-Nájera, M.A.; Treviño-Berrones, M.G.; Ponce-Flores, M.P.; Terán-Villanueva, J.D.; Castán-Rocha, J.A.; Ibarra-Martínez, S.; Santiago, A.; Laria-Menchaca, J. Short time series forecasting: Recommended methods and techniques. Symmetry 2022, 14, 1231. [Google Scholar] [CrossRef]
- Kambale, W.V.; Salem, M.; Benarbia, T.; Al Machot, F.; Kyamakya, K. Comprehensive Sensitivity Analysis Framework for Transfer Learning Performance Assessment for Time Series Forecasting: Basic Concepts and Selected Case Studies. Symmetry 2024, 16, 241. [Google Scholar] [CrossRef]
- Lara-Benítez, P.; Carranza-García, M.; Luna-Romera, J.M.; Riquelme, J.C. Temporal convolutional networks applied to energy-related time series forecasting. Appl. Sci. 2020, 10, 2322. [Google Scholar] [CrossRef]
- Das, M.; Ghosh, S.K. semBnet: A semantic Bayesian network for multivariate prediction of meteorological time series data. Pattern Recognit. Lett. 2017, 93, 192–201. [Google Scholar] [CrossRef]
- Shering, T.; Alonso, E.; Apostolopoulou, D. Investigation of Load, Solar and Wind Generation as Target Variables in LSTM Time Series Forecasting, Using Exogenous Weather Variables. Energies 2024, 17, 1827. [Google Scholar] [CrossRef]
- Martínez-Álvarez, F.; Troncoso, A.; Asencio-Cortés, G.; Riquelme, J.C. A survey on data mining techniques applied to electricity-related time series forecasting. Energies 2015, 8, 13162–13193. [Google Scholar] [CrossRef]
- Chan, S.; Oktavianti, I.; Puspita, V. A deep learning CNN and AI-tuned SVM for electricity consumption forecasting: Multivariate time series data. In Proceedings of the 2019 IEEE 10th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 7–19 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 488–494. [Google Scholar]
- Ghosh, B.; Basu, B.; O’Mahony, M. Multivariate short-term traffic flow forecasting using time-series analysis. IEEE Trans. Intell. Transp. Syst. 2009, 10, 246–254. [Google Scholar] [CrossRef]
- Shah, I.; Muhammad, I.; Ali, S.; Ahmed, S.; Almazah, M.M.; Al-Rezami, A. Forecasting day-ahead traffic flow using functional time series approach. Mathematics 2022, 10, 4279. [Google Scholar] [CrossRef]
- He, K.; Yang, Q.; Ji, L.; Pan, J.; Zou, Y. Financial time series forecasting with the deep learning ensemble model. Mathematics 2023, 11, 1054. [Google Scholar] [CrossRef]
- Niu, T.; Wang, J.; Lu, H.; Yang, W.; Du, P. Developing a deep learning framework with two-stage feature selection for multivariate financial time series forecasting. Expert Syst. Appl. 2020, 148, 113237. [Google Scholar] [CrossRef]
- Liu, Z.; Zhu, Z.; Gao, J.; Xu, C. Forecast methods for time series data: A survey. IEEE Access 2021, 9, 91896–91912. [Google Scholar] [CrossRef]
- Chen, Z.; Ma, M.; Li, T.; Wang, H.; Li, C. Long sequence time-series forecasting with deep learning: A survey. Inf. Fusion 2023, 97, 101819. [Google Scholar] [CrossRef]
- Ahmed, S.; Nielsen, I.E.; Tripathi, A.; Siddiqui, S.; Ramachandran, R.P.; Rasool, G. Transformers in time-series analysis: A tutorial. Circuits Syst. Signal Process. 2023, 42, 7433–7466. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 27268–27286. [Google Scholar]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are transformers effective for time series forecasting? Proc. AAAI Conf. Artif. Intell. 2023, 37, 11121–11128. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, T.; Zhang, H.; Wu, H.; Wang, S.; Ma, L.; Long, M. iTransformer: Inverted Transformers Are Effective for Time Series Forecasting. arXiv 2023, arXiv:2310.06625. [Google Scholar]
- Valipour, M.; Banihabib, M.E.; Behbahani, S.M.R. Comparison of the ARMA, ARIMA, and the autoregressive artificial neural network models in forecasting the monthly inflow of Dez dam reservoir. J. Hydrol. 2013, 476, 433–441. [Google Scholar] [CrossRef]
- Sapankevych, N.I.; Sankar, R. Time series prediction using support vector machines: A survey. IEEE Comput. Intell. Mag. 2009, 4, 24–38. [Google Scholar] [CrossRef]
- Parmezan, A.R.S.; Souza, V.M.; Batista, G.E. Evaluation of statistical and machine learning models for time series prediction: Identifying the state-of-the-art and the best conditions for the use of each model. Inf. Sci. 2019, 484, 302–337. [Google Scholar] [CrossRef]
- Bontempi, G.; Ben Taieb, S.; Le Borgne, Y.A. Machine learning strategies for time series forecasting. In Proceedings of the Business Intelligence: Second European Summer School, eBISS 2012, Tutorial Lectures 2, Brussels, Belgium, 15–21 July 2013; pp. 62–77. [Google Scholar]
- Han, Z.; Zhao, J.; Leung, H.; Ma, K.F.; Wang, W. A review of deep learning models for time series prediction. IEEE Sens. J. 2019, 21, 7833–7848. [Google Scholar] [CrossRef]
- Mandal, A.K.; Sen, R.; Goswami, S.; Chakraborty, B. Comparative study of univariate and multivariate long short-term memory for very short-term forecasting of global horizontal irradiance. Symmetry 2021, 13, 1544. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling long-and short-term temporal patterns with deep neural networks. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 95–104. [Google Scholar]
- Almuammar, M.; Fasli, M. Deep learning for non-stationary multivariate time series forecasting. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2097–2106. [Google Scholar]
- Saini, U.; Kumar, R.; Jain, V.; Krishnajith, M. Univariant Time Series forecasting of Agriculture load by using LSTM and GRU RNNs. In Proceedings of the 2020 IEEE Students Conference on Engineering & Systems (SCES), Prayagraj, India, 10–12 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Torres, J.F.; Hadjout, D.; Sebaa, A.; Martínez-Álvarez, F.; Troncoso, A. Deep learning for time series forecasting: A survey. Big Data 2021, 9, 3–21. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A 2021, 379, 20200209. [Google Scholar] [CrossRef]
- Wen, Q.; Zhou, T.; Zhang, C.; Chen, W.; Ma, Z.; Yan, J.; Sun, L. Transformers in time series: A survey. arXiv 2022, arXiv:2202.07125. [Google Scholar]
- Benidis, K.; Rangapuram, S.S.; Flunkert, V.; Wang, Y.; Maddix, D.; Turkmen, C.; Gasthaus, J.; Bohlke-Schneider, M.; Salinas, D.; Stella, L.; et al. Deep learning for time series forecasting: Tutorial and literature survey. ACM Comput. Surv. 2022, 55, 1–36. [Google Scholar] [CrossRef]
- Miller, J.A.; Aldosari, M.; Saeed, F.; Barna, N.H.; Rana, S.; Arpinar, I.B.; Liu, N. A survey of deep learning and foundation models for time series forecasting. arXiv 2024, arXiv:2401.13912. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Shih, S.Y.; Sun, F.K.; Lee, H.Y. Temporal pattern attention for multivariate time series forecasting. Mach. Learn. 2019, 108, 1421–1441. [Google Scholar] [CrossRef]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-attention with linear complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Liu, S.; Yu, H.; Liao, C.; Li, J.; Lin, W.; Liu, A.X.; Dustdar, S. Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
- Du, D.; Su, B.; Wei, Z. Preformer: Predictive transformer with multi-scale segment-wise correlations for long-term time series forecasting. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Lee-Thorp, J.; Ainslie, J.; Eckstein, I.; Ontanon, S. Fnet: Mixing tokens with fourier transforms. arXiv 2021, arXiv:2105.03824. [Google Scholar]
- Wu, H.; Hu, T.; Liu, Y.; Zhou, H.; Wang, J.; Long, M. Timesnet: Temporal 2d-variation modeling for general time series analysis. In Proceedings of the The Eleventh International Conference on Learning Representations, Vienna, Austria, 7–11 May 2022. [Google Scholar]
- Xu, Z.; Zeng, A.; Xu, Q. FITS: Modeling Time Series with 10 k Parameters. arXiv 2023, arXiv:2307.03756. [Google Scholar]
- Zhou, T.; Ma, Z.; Wen, Q.; Sun, L.; Yao, T.; Yin, W.; Jin, R. Film: Frequency improved legendre memory model for long-term time series forecasting. Adv. Neural Inf. Process. Syst. 2022, 35, 12677–12690. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [PubMed]
- Bridle, J.S. Probabilistic interpretation of feedforward classification network outputs, with relationships to statistical pattern recognition. In Neurocomputing: Algorithms, Architectures and Applications; Springer: Berlin/Heidelberg, Germany, 1990; pp. 227–236. [Google Scholar]
- Liu, M.; Zeng, A.; Chen, M.; Xu, Z.; Lai, Q.; Ma, L.; Xu, Q. Scinet: Time series modeling and forecasting with sample convolution and interaction. Adv. Neural Inf. Process. Syst. 2022, 35, 5816–5828. [Google Scholar]
- Das, A.; Kong, W.; Leach, A.; Sen, R.; Yu, R. Long-term forecasting with tide: Time-series dense encoder. arXiv 2023, arXiv:2304.08424. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Adam, K.D.B.J. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DataSet | Timesteps | Sampling | Dim | Area |
|---|---|---|---|---|
| ETTh1, ETTh2 | 17,420 | Hourly | 7 | Power |
| ETTm1, ETTm2 | 69,680 | 15 min | 7 | Power |
| Exchange | 7588 | Daily | 8 | Economy |
| Weather | 52,696 | 10 min | 21 | Weather |
| ECL | 26,304 | Hourly | 321 | Electricity |
| Traffic | 17,544 | Hourly | 862 | Transportation |
| Models Metric | Ours | iTransformer | FEDformer | TimesNet | TiDE | SCINet | Autoformer | Informer | Pyraformer | LogTrans | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| Exchange | 96 | 0.086 | 0.201 | 0.095 | 0.215 | 0.148 | 0.278 | 0.107 | 0.234 | 0.094 | 0.218 | 0.267 | 0.396 | 0.197 | 0.323 | 0.847 | 0.752 | 0.376 | 1.105 | 0.968 | 0.812 |
| 192 | 0.176 | 0.301 | 0.193 | 0.313 | 0.271 | 0.380 | 0.226 | 0.344 | 0.184 | 0.307 | 0.351 | 0.459 | 0.300 | 0.369 | 1.204 | 0.895 | 1.748 | 1.151 | 1.040 | 0.851 | |
| 336 | 0.323 | 0.415 | 0.376 | 0.445 | 0.460 | 0.500 | 0.367 | 0.448 | 0.349 | 0.431 | 1.324 | 0.853 | 0.509 | 0.524 | 1.672 | 1.036 | 1.874 | 1.172 | 1.659 | 1.081 | |
| 720 | 0.807 | 0.677 | 0.927 | 0.727 | 1.195 | 0.841 | 0.964 | 0.746 | 0.852 | 0.698 | 1.058 | 0.797 | 1.447 | 0.941 | 2.478 | 1.310 | 1.943 | 1.206 | 1.941 | 1.127 | |
| Avg | 0.348 | 0.399 | 0.398 | 0.425 | 0.518 | 0.500 | 0.416 | 0.443 | 0.370 | 0.413 | 0.750 | 0.626 | 0.613 | 0.539 | 1.550 | 0.998 | 1.485 | 1.159 | 1.402 | 0.968 | |
| ECL | 96 | 0.196 | 0.280 | 0.151 | 0.241 | 0.193 | 0.308 | 0.168 | 0.272 | 0.237 | 0.329 | 0.247 | 0.345 | 0.201 | 0.317 | 0.274 | 0.368 | 0.386 | 0.449 | 0.258 | 0.357 |
| 192 | 0.202 | 0.287 | 0.164 | 0.253 | 0.201 | 0.315 | 0.184 | 0.289 | 0.236 | 0.330 | 0.257 | 0.355 | 0.222 | 0.334 | 0.296 | 0.386 | 0.386 | 0.443 | 0.266 | 0.368 | |
| 336 | 0.219 | 0.306 | 0.179 | 0.269 | 0.214 | 0.329 | 0.198 | 0.300 | 0.249 | 0.344 | 0.269 | 0.369 | 0.231 | 0.338 | 0.300 | 0.394 | 0.378 | 0.443 | 0.280 | 0.380 | |
| 720 | 0.261 | 0.337 | 0.212 | 0.297 | 0.246 | 0.355 | 0.220 | 0.320 | 0.284 | 0.373 | 0.299 | 0.390 | 0.254 | 0.361 | 0.373 | 0.439 | 0.376 | 0.445 | 0.283 | 0.376 | |
| Avg | 0.220 | 0.302 | 0.176 | 0.265 | 0.212 | 0.327 | 0.192 | 0.295 | 0.251 | 0.344 | 0.268 | 0.365 | 0.227 | 0.338 | 0.311 | 0.397 | 0.381 | 0.445 | 0.272 | 0.370 | |
| Traffic | 96 | 0.562 | 0.372 | 0.413 | 0.270 | 0.587 | 0.366 | 0.593 | 0.321 | 0.805 | 0.493 | 0.788 | 0.499 | 0.613 | 0.388 | 0.719 | 0.391 | 2.085 | 0.468 | 0.684 | 0.384 |
| 192 | 0.560 | 0.366 | 0.431 | 0.276 | 0.604 | 0.373 | 0.617 | 0.336 | 0.756 | 0.474 | 0.789 | 0.505 | 0.616 | 0.382 | 0.696 | 0.379 | 0.867 | 0.467 | 0.685 | 0.390 | |
| 336 | 0.577 | 0.372 | 0.449 | 0.284 | 0.621 | 0.383 | 0.629 | 0.336 | 0.762 | 0.477 | 0.797 | 0.508 | 0.622 | 0.337 | 0.777 | 0.420 | 0.869 | 0.469 | 0.734 | 0.408 | |
| 720 | 0.613 | 0.389 | 0.483 | 0.304 | 0.626 | 0.382 | 0.640 | 0.350 | 0.719 | 0.449 | 0.841 | 0.523 | 0.660 | 0.408 | 0.864 | 0.472 | 0.881 | 0.473 | 0.717 | 0.396 | |
| Avg | 0.578 | 0.375 | 0.444 | 0.284 | 0.609 | 0.376 | 0.620 | 0.336 | 0.760 | 0.473 | 0.804 | 0.509 | 0.628 | 0.379 | 0.764 | 0.665 | 1.175 | 0.469 | 0.705 | 0.394 | |
| Weather | 96 | 0.188 | 0.227 | 0.192 | 0.245 | 0.217 | 0.296 | 0.172 | 0.220 | 0.202 | 0.261 | 0.221 | 0.306 | 0.266 | 0.336 | 0.300 | 0.384 | 0.896 | 0.556 | 0.458 | 0.490 |
| 192 | 0.238 | 0.267 | 0.246 | 0.279 | 0.276 | 0.336 | 0.219 | 0.261 | 0.242 | 0.298 | 0.261 | 0.340 | 0.307 | 0.367 | 0.598 | 0.544 | 0.622 | 0.624 | 0.658 | 0.589 | |
| 336 | 0.288 | 0.302 | 0.292 | 0.299 | 0.339 | 0.380 | 0.280 | 0.306 | 0.287 | 0.335 | 0.309 | 0.378 | 0.359 | 0.395 | 0.578 | 0.523 | 0.739 | 0.753 | 0.797 | 0.652 | |
| 720 | 0.359 | 0.348 | 0.369 | 0.348 | 0.403 | 0.428 | 0.365 | 0.359 | 0.351 | 0.386 | 0.377 | 0.427 | 0.419 | 0.428 | 1.059 | 0.741 | 1.004 | 0.934 | 0.869 | 0.675 | |
| Avg | 0.268 | 0.286 | 0.275 | 0.293 | 0.309 | 0.360 | 0.259 | 0.287 | 0.271 | 0.320 | 0.292 | 0.363 | 0.338 | 0.382 | 0.634 | 0.548 | 0.815 | 0.717 | 0.696 | 0.601 | |
| ETTm1 | 96 | 0.390 | 0.413 | 0.373 | 0.401 | 0.380 | 0.419 | 0.338 | 0.375 | 0.364 | 0.387 | 0.418 | 0.438 | 0.505 | 0.475 | 0.672 | 0.571 | 0.543 | 0.510 | 0.600 | 0.546 |
| 192 | 0.443 | 0.435 | 0.440 | 0.437 | 0.425 | 0.441 | 0.374 | 0.387 | 0.398 | 0.404 | 0.439 | 0.450 | 0.553 | 0.496 | 0.795 | 0.669 | 0.557 | 0.537 | 0.837 | 0.700 | |
| 336 | 0.525 | 0.481 | 0.509 | 0.475 | 0.444 | 0.462 | 0.410 | 0.411 | 0.428 | 0.425 | 0.490 | 0.485 | 0.621 | 0.537 | 1.212 | 0.871 | 0.754 | 0.655 | 1.124 | 0.832 | |
| 720 | 0.580 | 0.519 | 0.574 | 0.518 | 0.543 | 0.490 | 0.478 | 0.450 | 0.487 | 0.461 | 0.595 | 0.550 | 0.671 | 0.561 | 1.166 | 0.823 | 0.908 | 0.724 | 1.153 | 0.820 | |
| Avg | 0.484 | 0.461 | 0.474 | 0.457 | 0.447 | 0.453 | 0.400 | 0.406 | 0.419 | 0.419 | 0.485 | 0.481 | 0.587 | 0.517 | 0.961 | 0.733 | 0.690 | 0.606 | 0.928 | 0.724 | |
| ETTm2 | 96 | 0.121 | 0.233 | 0.123 | 0.235 | 0.203 | 0.287 | 0.187 | 0.267 | 0.207 | 0.305 | 0.286 | 0.377 | 0.255 | 0.339 | 0.365 | 0.453 | 0.435 | 0.507 | 0.768 | 0.642 |
| 192 | 0.151 | 0.262 | 0.155 | 0.267 | 0.269 | 0.328 | 0.249 | 0.309 | 0.290 | 0.364 | 0.399 | 0.445 | 0.281 | 0.340 | 0.533 | 0.563 | 0.730 | 0.673 | 0.989 | 0.757 | |
| 336 | 0.182 | 0.286 | 0.187 | 0.293 | 0.325 | 0.366 | 0.321 | 0.351 | 0.377 | 0.422 | 0.637 | 0.591 | 0.339 | 0.372 | 1.363 | 0.887 | 1.201 | 0.845 | 1.334 | 0.872 | |
| 720 | 0.241 | 0.329 | 0.245 | 0.336 | 0.421 | 0.415 | 0.408 | 0.403 | 0.558 | 0.524 | 0.960 | 0.735 | 0.433 | 0.432 | 3.379 | 1.338 | 3.625 | 1.451 | 3.048 | 1.328 | |
| Avg | 0.173 | 0.277 | 0.177 | 0.282 | 0.304 | 0.349 | 0.291 | 0.333 | 0.358 | 0.404 | 0.571 | 0.537 | 0.327 | 0.370 | 1.410 | 0.810 | 1.497 | 0.869 | 1.534 | 0.899 | |
| ETTh1 | 96 | 0.456 | 0.465 | 0.454 | 0.463 | 0.376 | 0.419 | 0.384 | 0.402 | 0.479 | 0.464 | 0.654 | 0.599 | 0.449 | 0.459 | 0.865 | 0.713 | 0.664 | 0.612 | 0.878 | 0.740 |
| 192 | 0.506 | 0.496 | 0.506 | 0.496 | 0.420 | 0.448 | 0.436 | 0.429 | 0.525 | 0.492 | 0.719 | 0.631 | 0.500 | 0.482 | 1.008 | 0.792 | 0.790 | 0.681 | 1.037 | 0.824 | |
| 336 | 0.560 | 0.532 | 0.555 | 0.525 | 0.459 | 0.465 | 0.491 | 0.469 | 0.565 | 0.515 | 0.778 | 0.659 | 0.521 | 0.496 | 1.107 | 0.809 | 0.891 | 0.738 | 1.238 | 0.932 | |
| 720 | 0.780 | 0.660 | 0.704 | 0.618 | 0.506 | 0.507 | 0.521 | 0.500 | 0.594 | 0.558 | 0.836 | 0.699 | 0.514 | 0.512 | 1.181 | 0.865 | 0.963 | 0.782 | 1.135 | 0.852 | |
| Avg | 0.575 | 0.538 | 0.554 | 0.525 | 0.440 | 0.457 | 0.458 | 0.450 | 0.541 | 0.507 | 0.747 | 0.647 | 0.496 | 0.512 | 1.040 | 0.794 | 0.827 | 0.703 | 1.072 | 0.837 | |
| ETTh2 | 96 | 0.178 | 0.287 | 0.186 | 0.292 | 0.346 | 0.388 | 0.340 | 0.374 | 0.400 | 0.440 | 0.707 | 0.621 | 0.358 | 0.397 | 3.755 | 1.525 | 0.645 | 0.597 | 2.116 | 1.197 |
| 192 | 0.220 | 0.320 | 0.223 | 0.321 | 0.429 | 0.439 | 0.402 | 0.414 | 0.528 | 0.509 | 0.860 | 0.689 | 0.456 | 0.452 | 5.602 | 1.931 | 0.788 | 0.683 | 4.315 | 1.635 | |
| 336 | 0.250 | 0.341 | 0.257 | 0.348 | 0.496 | 0.487 | 0.452 | 0.452 | 0.643 | 0.571 | 1.000 | 0.744 | 0.482 | 0.486 | 4.721 | 1.835 | 0.907 | 0.747 | 1.124 | 1.614 | |
| 720 | 0.317 | 0.390 | 0.326 | 0.396 | 0.463 | 0.474 | 0.462 | 0.468 | 0.874 | 0.679 | 1.249 | 0.838 | 0.515 | 0.511 | 3.647 | 1.625 | 0.963 | 0.783 | 3.188 | 1.540 | |
| Avg | 0.241 | 0.334 | 0.248 | 0.339 | 0.433 | 0.447 | 0.414 | 0.427 | 0.611 | 0.550 | 0.954 | 0.723 | 0.452 | 0.461 | 4.431 | 1.729 | 0.825 | 0.702 | 2.686 | 1.496 | |
| 1st Count | 15 | 17 | 10 | 12 | 5 | 0 | 9 | 12 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Metric Models | MAC | NOP | ||
|---|---|---|---|---|
| Ours | iTrans | Ours | iTrans | |
| ETT-96 | 170.5 K | 35.18 M | 10.81 K | 3.25 M |
| ETT-192 | 247.56 K | 35.97 M | 15.54 K | 3.3 M |
| ETT-336 | 363.14 K | 37.15 M | 22.63 K | 3.38 M |
| ETT-720 | 671.36 K | 40.3 M | 41.54 K | 3.57 M |
| Weather-96 | 512.67 K | 92.35 M | 10.81 K | 3.25 M |
| Weather-192 | 743.84 K | 94.42 M | 15.54 K | 3.3 M |
| Weather-336 | 1.09 M | 97.52 M | 22.63 K | 3.38 M |
| Weather-720 | 2.02 M | 105.78 M | 41.54 K | 3.57 M |
| Electricity-96 | 8.22 M | 1.41 G | 10.81 K | 3.25 M |
| Electricity-192 | 11.76 M | 1.44 G | 15.54 K | 3.3 M |
| Electricity-336 | 17.06 M | 1.49 G | 22.63 K | 3.38 M |
| Electricity-720 | 31.19 M | 1.62 G | 41.54 K | 3.57 M |
| Ratio Metric | 0.25 | 0.5 | 1 | 2 | 4 | 8 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| ETTm1 | Avg | 0.505 | 0.478 | 0.510 | 0.482 | 0.477 | 0.462 | 0.508 | 0.481 | 0.508 | 0.480 | 0.507 | 0.479 |
| ETTm2 | Avg | 0.177 | 0.283 | 0.177 | 0.283 | 0.173 | 0.278 | 0.176 | 0.282 | 0.175 | 0.282 | 0.176 | 0.281 |
| ETTh1 | Avg | 0.659 | 0.579 | 0.658 | 0.580 | 0.570 | 0.535 | 0.663 | 0.582 | 0.655 | 0.579 | 0.660 | 0.583 |
| ETTh2 | Avg | 0.251 | 0.344 | 0.251 | 0.345 | 0.244 | 0.337 | 0.250 | 0.343 | 0.250 | 0.344 | 0.250 | 0.343 |
| ECL | Avg | 0348 | 0.424 | 0.346 | 0.423 | 0.240 | 0.328 | 0.344 | 0.422 | 0.341 | 0.420 | 0.341 | 0.419 |
| Exchange | Avg | 0.365 | 0.410 | 0.363 | 0.409 | 0.359 | 0.405 | 0.366 | 0.412 | 0.365 | 0.411 | 0.368 | 0.412 |
| Traffic | Avg | 0.892 | 0.527 | 0.893 | 0.526 | 0.440 | 0.460 | 0.871 | 0.517 | 0.863 | 0.513 | 0.860 | 0.512 |
| Weather | Avg | 0.275 | 0.293 | 0.274 | 0.293 | 0.271 | 0.289 | 0.273 | 0.292 | 0.272 | 0.292 | 0.273 | 0.292 |
| 1st Count | 0 | 0 | 0 | 0 | 8 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | |
| CutFreq C Metric | 5 | 10 | 15 | 20 | 25 | 30 | 48 | |
|---|---|---|---|---|---|---|---|---|
| MSE | MSE | MSE | MSE | MSE | MSE | MSE | ||
| ETTm1 | Avg | 0.511 | 0.489 | 0.493 | 0.486 | 0.488 | 0.488 | 0.484 |
| ETTm2 | Avg | 0.177 | 0.174 | 0.174 | 0.172 | 0.172 | 0.172 | 0.173 |
| ETTh1 | Avg | 0.675 | 0.582 | 0.572 | 0.570 | 0.559 | 0.577 | 0.575 |
| ETTh2 | Avg | 0.251 | 0.248 | 0.243 | 0.244 | 0.244 | 0.240 | 0.241 |
| ECL | Avg | 0.376 | 0.280 | 0.254 | 0.240 | 0.229 | 0.229 | 0.219 |
| Exchange | Avg | 0.395 | 0.379 | 0.373 | 0.358 | 0.359 | 0.363 | 0.348 |
| Traffic | Avg | 0.935 | 0.749 | 0.662 | 0.630 | 0.610 | 0.597 | 0.578 |
| Weather | Avg | 0.279 | 0.272 | 0.271 | 0.270 | 0.268 | 0.269 | 0.268 |
| 1st Count | 0 | 0 | 0 | 1 | 3 | 2 | 5 | |
| NOP (K) | 4.20 | 9.3 | 15.43 | 22.63 | 30.85 | 40.16 | 82.29 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Zhang, Z.; Wang, X.; Liu, M.; Chen, L.; Pi, J. Frequency-Enhanced Transformer with Symmetry-Based Lightweight Multi-Representation for Multivariate Time Series Forecasting. Symmetry 2024, 16, 797. https://doi.org/10.3390/sym16070797
Wang C, Zhang Z, Wang X, Liu M, Chen L, Pi J. Frequency-Enhanced Transformer with Symmetry-Based Lightweight Multi-Representation for Multivariate Time Series Forecasting. Symmetry. 2024; 16(7):797. https://doi.org/10.3390/sym16070797
Chicago/Turabian StyleWang, Chenyue, Zhouyuan Zhang, Xin Wang, Mingyang Liu, Lin Chen, and Jiatian Pi. 2024. "Frequency-Enhanced Transformer with Symmetry-Based Lightweight Multi-Representation for Multivariate Time Series Forecasting" Symmetry 16, no. 7: 797. https://doi.org/10.3390/sym16070797
APA StyleWang, C., Zhang, Z., Wang, X., Liu, M., Chen, L., & Pi, J. (2024). Frequency-Enhanced Transformer with Symmetry-Based Lightweight Multi-Representation for Multivariate Time Series Forecasting. Symmetry, 16(7), 797. https://doi.org/10.3390/sym16070797