Abstract
In this paper, we introduce a new dynamic model for time series based on the Chen distribution, which is useful for modeling asymmetric, positive, continuous, and time-dependent data. The proposed Chen autoregressive moving average (CHARMA) model combines the flexibility of the Chen distribution with the use of covariates and lagged terms to model the conditional median response. We introduce the CHARMA structure and discuss conditional maximum likelihood estimation, hypothesis testing inference along with the estimator asymptotic properties of the estimator, diagnostic analysis, and forecasting. In particular, we provide closed-form expressions for the conditional score vector and the conditional information matrix. We conduct a Monte Carlo experiment to evaluate the introduced theory in finite sample sizes. Finally, we illustrate the usefulness of the proposed model by exploring two empirical applications in a wind-speed and maximum-temperature time-series dataset.
1. Introduction
Time series models have become increasingly popular for data analysis in various scientific fields. The widely recognized autoregressive moving average (ARMA) model [1] has been commonly employed for the modeling of univariate time series. However, this model may not always be suitable for all types of data. In many cases, real-world data do not adhere to the assumption of normality that is required for the estimation of ARMA model parameters [2]. Consequently, recent literature has introduced new non-Gaussian time-series models that assume different probability distributions.
A general time-series model, known as the generalized autoregressive moving average (GARMA), was proposed in [3] as an extension of generalized linear models [4], specifically designed for dependent variables belonging to the canonical exponential family. Building upon similar approaches, the authors of [5] developed dynamic models using the beta family distribution, while [6] introduced a dynamic class of models for double-bounded interval data following the Kumaraswamy distribution. The authors of [7] proposed a dynamic regression model based on the Conway–Maxwell–Poisson distribution, and [8] presented a new generalized autoregressive moving average model based on the Bernoulli geometric distribution. Other recent contributions in this field include [9,10]. As a comprehensive reference for non-Gaussian dynamic regression, see [11].
Although numerous time series models have been published in the literature, there remains a limited availability of models specifically designed to handle continuous, asymmetric, and non-negative data. Given these circumstances, this work proposes a dynamic model based on the Chen distribution [12]. This distribution is very flexible and has garnered attention from the scientific community, as evidenced in [13,14,15]. The Chen distribution, which is characterized by shape parameters and has support in the positive real numbers , is defined by its probability density function [12]:
The corresponding cumulative and quantile functions are respectively expressed by:
and
The original formulation of the Chen distribution relies on the parameters and , which may not have direct interpretability. However, for the purpose of regression and/or time-series modeling, it is more convenient to directly model the mean or median parameter of the distribution. Mean-based regression models are commonly employed for the modeling of response variables, but when the variable of interest exhibits asymmetric behavior, the more robust alternative is to use a median-based approach. Hence, in this work, we introduce a median-based reparameterization of the Chen distribution, which will serve as the foundation for a new flexible dynamic regression model for positive continuous data.
In this context, we introduce a novel class of dynamic regression models known as the Chen autoregressive moving average (CHARMA) model, which has specifically been designed for the modeling of asymmetric, continuous, positive, and time-dependent data. The CHARMA model assumes that the conditional distribution of the variable of interest follows the reparameterized Chen distribution. To model the conditional median, we employ a dynamic structure that includes autoregressive and moving average terms, time-varying regressors, and a strictly monotonic and twice-differentiable link function. We utilize the conditional likelihood theory to perform parameter inference for the CHARMA model. Additionally, we introduce closed-form expressions to the conditional score vector and the conditional information matrix, thus enabling computationally efficient inferences to be drawn for the model parameters. Diagnostic analysis and forecasting tools are also discussed to assess the model’s performance and predictive capabilities. To illustrate the practical application of the proposed model, we conduct a time-series analysis of average wind speed data taken from Rio Grande City, Brazil, and a time series analysis of monthly maximum temperature data from Teresina City, Brazil. In both applications, we compare the CHARMA model with other competing models and demonstrate the suitability of our proposed model and theory through empirical results. Overall, our findings highlight the effectiveness of the CHARMA model in modeling asymmetric, continuous, positive, and time-dependent data. The comprehensive analysis and empirical results further validate the practical applicability of our proposed model and theory.
The paper unfolds as follows. Section 2 introduces a new median-based parameterization for the Chen distribution and the dynamical CHARMA model. The conditional likelihood inference is discussed in Section 3. Section 4 focuses on model selection criteria, diagnostics, and forecasting. Numerical results are discussed in Section 5, wherein Section 5.1 presents a Monte Carlo simulation study, and Section 5.2 and Section 5.3 explore empirical applications in monthly average wind speed data and monthly average maximum temperature data, respectively. Concluding remarks are given in Section 6. Finally, some analytical details are presented in Appendix A.
2. The Proposed Model
Let represent the th quantile of the Chen distribution, and can be expressed as . The probability density function and cumulative distribution function of a Chen-distributed variable Y expressed in terms of its quantile-based parameterization can be given, respectively, by:
and
Note that if we set , the value of will correspond to the median () of variable Y, that is, . Figure 1 illustrates different shapes of the Chen density of the reparameterized distribution, considering various values for and .

Figure 1.
The probability density function of the reparameterized Chen distribution with different parameter values.
Let be a stochastic process, where each —conditioned on the previous information set consisting of observations up to time —follows a Chen distribution, as defined in (1), with . Using the median-based parameterization, the conditional density function of is given by:
where is the conditional median of , and the parameter is considered fixed for all . The dynamical structure of the proposed CHARMA () model is written as follows:
where represents the linear predictor, is an intercept, is an unknown k-dimensional parameter vector associated with exogenous covariates, is the k-dimensional vector of explanatory covariates at time t, and are the vectors of autoregressive and moving average parameters, respectively, and is a strictly monotonic and twice-differentiable link function, where . In this study, the errors were considered as on the predictor scale, following the approach of [6]. Due to the parametric space of , we chose to use the logarithm as the link function because it provides non-negative values for regardless of the values assigned to . The proposed CHARMA () model is defined by (2) and (3), where p and q represent the dimensions of and , respectively, indicating the order of the ARMA dynamic component.
3. Conditional Likelihood Inference
The inference for the parameters of the CHARMA model can be made using the conditional maximum likelihood method, where the conditional maximum likelihood estimators (CMLE) are obtained by maximizing the logarithm of the conditional likelihood function. Let be a sample from the CHARMA () model, and be the -dimensional vector of the parameters. With the conditioning on the first observations, the conditional log-likelihood function is given by:
where
3.1. Conditional Score Vector
The components of the conditional score vector are defined by the first derivatives of the conditional log-likelihood function with respect to each element of the parameter vector . Computing the derivatives of the function in (4) with respect to the i-th element of , , for , we obtain the following:
Note that as , we have . Moreover, the derivative of with respect to is given by:
The partial derivatives of with respect to the unknown parameters are computed recursively as follows:
Finally, the derivative of with respect to is given by the following equation:
Then, the components of the conditional score vector can be written in matrix form as follows:
where , , , , is an -dimensional vector of ones, and are matrices with dimensions , respectively, whose elements are given by the following equation:
The CMLE of , denoted as , is obtained by solving the system , where represents the null vector in . However, this system cannot be solved analytically, and iterative numerical methods must be employed to obtain an approximate solution. In such case, we utilize the Broyden–Fletcher–Goldfarb–Shanno (BFGS) method [16] with analytical derivatives.
3.2. Confidence Intervals and Hypothesis Testing
Inference for the confidence intervals and hypothesis testing parameters of the CHARMA model can be drawn using the asymptotic theory related to the CMLE. Under some mild mathematical regularity conditions, we have the following equation:
where denotes a convergence in distribution and denotes the -dimensional normal distribution, with a mean and a variance–covariance matrix . The derivations and a closed-form expression for the joint observed information matrix for are presented in Appendix A. In order to obtain the proof for these asymptotic results, we need to check if conditions 2.1–2.5 from [17] are fulfilled. Following closely related arguments, as in [6] for CMLE in the KARMA model and in [18] for the partial likelihood inference for time series following generalized linear modes, it is possible to guarantee these regularity conditions for the CHARMA model.
In hypothesis testing, we consider the interest in testing versus , where is a specific value for the unknown parameter . Let , the i-th element of the parameter vector . Based on approximation (5),
holds for a large n, where is the estimator of , is the asymptotic standard error of , and is the i-th element of the diagonal of . The test statistic used in this context is the square root of Wald’s statistic, which can be expressed as follows:
Under and in large sample sizes, z has an approximately standard normal distribution. The null hypothesis is rejected for values of higher than the upper quantile of the standard normal distribution.
The asymptotic normality of the CMLE provides the means to construct confidence intervals. The asymptotic confidence interval of for each parameter is given by:
where is the upper quantile of the standard normal distribution.
4. Model Selection, Diagnosis, and Prediction
In this section, we introduce several diagnostic measures for the assessment of the adequacy and goodness-of-fit of the proposed model. For model selection, we recommend utilizing the Akaike Information Criterion (AIC) [19] and the Bayesian Information Criterion (BIC). From among various competing fitted models, the preferred model is the one with the lowest AIC and BIC value.
Residual analysis is important for assessing the goodness-of-fit of a statistical model [11]. In this study, we consider the quantile residual, which is defined as follows [20]:
where is the standard normal cumulative distribution function. If the model is well-fitted, is approximated distributed as a standard normal distribution, independently of the distribution of the response variable. These residuals are also expected to be independent, with a zero mean and a constant variance [1,21]. To evaluate the assumption that residuals are not auto-correlated, we suggest using the Ljung-Box test [22]. This test is conducted under the null hypothesis that the first auto-correlations of the residuals are zero.
A fitted model that successfully passes all diagnostic checks can be utilized for both in-sample and out-of-sample predictions. Predictions for the conditional median of the CHARMA model can be carried out by considering the estimation of , replacing with in (3). Thus, the in-sample predictions, starting at , are calculated as follows:
where . For predictions h steps ahead, with , the forecasts are calculated by the following equation:
where , , and
To assess the quality of both in-sample and out-of-sample predictions, some accuracy measures can be employed. For this purpose, we recommend utilizing the mean absolute percentage error (MAPE) and mean squared error (MSE) as figures-of-merit to quantify the differences between the predicted values from the fitted model and the observed values. These measures are commonly used when comparing competing models [23,24,25].
5. Numerical Results
In this section, we aim to evaluate the CMLE of the CHARMA model parameters through the use of a Monte Carlo simulation study. Additionally, we will assess the performance of the proposed model in two empirical applications. Section 5.1 is focused on a simulated time series, while in Section 5.2 and Section 5.3, the numerical results based on two real datasets are presented. The R language [26] implementations used to fit the CHARMA model are available in https://github.com/RenataStone/CHARMA.git (accessed on 1 July 2023).
5.1. Monte Carlo Simulation
The Monte Carlo simulation study is presented to evaluate some of the CMLE properties of the proposed model parameters. The computational implementation was developed in the R language [26]. The number of Monte Carlo replications was set at 5000, and the sample sizes considered were . We evaluate the mean, the percentage relative bias (RB%), defined as , and the mean squared error (MSE) of the estimators.
In the simulation results, it was expected that as the sample size increased: (i) the mean of the estimates would be closer to the fixed parameter value, indicating that the estimators are asymptotically unbiased, and (ii) the MSE would be closer to zero, evidencing the consistency of the estimators. Table 1 presents the results of the Monte Carlo simulation in evaluating the CMLE introduced in Section 3 for three different scenarios: CHARMA, CHARMA, and CHARMA. The parameter values considered in each scenario are also shown in Table 1. It is worth noting that even in the smallest simulated sample size (), we observed good performance for the CMLE. As the sample size increased, the MSE value approached zero, thus providing numerical evidence for estimator consistency. Therefore, the simulation results bring evidence in favor of the introduced theory, the asymptotic properties of CMLE, and the computational implementations, which would allow for further empirical applications.

Table 1.
Monte Carlo simulation results based on different orders of the CHARMA model with different sample sizes.
5.2. Application to Monthly Average Wind-Speed Time Series in the City of Rio Grande
Wind speed is an important variable in climate studies involving economic factors, such as in applications associated with wind energy. Wind energy is considered to be one of the most mature renewable energy technologies and has experienced rapid growth in the past decade. It stands out in the planning carried out by national governments, who aim to diversify their renewable energy resources while minimizing environmental impact [27,28]. Despite the importance of studies on wind speed, a significant limitation observed in the literature is that most statistical studies that analyzed this variable did not account for the dependence between the observations in the time series. Therefore, the proposed model is suitable for wind-speed modeling, given that the support provided by the data is the set of positive real values and that the proposed CHARMA model considers the temporal dependence structure of this type of dataset.
In Brazil, one of the places considered to have the greatest wind energy potential is the country’s southern region. To illustrate the applicability of the proposed model, we developed an application for wind-speed data from a city in Rio Grande do Sul (RS) estate. Here, we utilized the average wind-speed data (or simply wind speed, abbreviated WS) obtained from the city of Rio Grande, which was sourced from the Instituto Nacional de Meteorologia (INMET—Brazilian National Institute of Meteorological Research), available on INMET’s website (https://bdmep.inmet.gov.br/, (accessed on 17 July 2022)). The dataset comprised the period from December 2009 to January 2016, with 74 monthly observations. This time period was selected in order to have as large a sample size as possible without missing any values in the time series. The last 12 observations were reserved only for the purpose of comparing forecasting results, where the first observations were used for estimation. However, 2 of the last 12 observations, which correspond to the months of February and March 2015, were missing, and so the fitted models were used to input these 2 missing values. Then, the time series used in the estimation considered the period from December 2009 to January 2015 and showed an average monthly speed of m/s and a median of m/s, with the maximum average speed reaching m/s and the minimum being at m/s. Figure 2 presents some graphs of the time series under study. Figure 2a shows the time series, while Figure 2b evidences the seasonal pattern in the data; the sample auto-correlation function (ACF) is shown in Figure 2c. It is evident from the analysis that seasonality is present in the data. During the winter months, the WS tends to be generally lower compared to its level in the summer months.
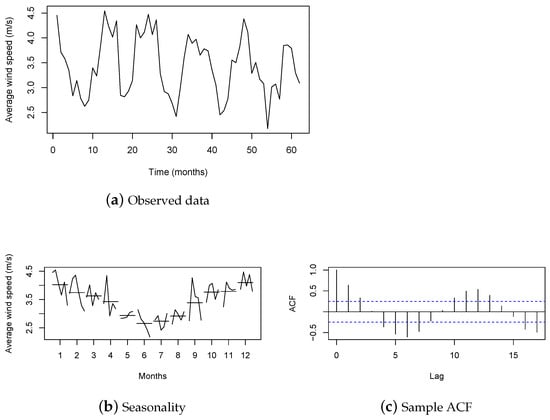
Figure 2.
Time series of monthly WS in the city of Rio Grande in the period from December 2009 to January 2015.
To incorporate the seasonality pattern into the model, a covariate containing the deterministic seasonality component obtained from the decompose function of software R [26] was included in the fitted model. This function decomposed the time series into three components and estimated each one: trend, seasonality, and random. In addition, to determine the order of the models, we conducted a series of analyses using different combinations of orders and used the AIC and BIC to select the best one, followed by a residual analysis. The five best models according to the AIC and BIC are presented in Table 2. The most appropriate model was the CHARMA with a seasonal covariate. Table 3 presents the fitted model. We note that all the parameters were considered to be significant at the level of .
Table 2.
Information criteria for the five best CHARMA models fitted to the monthly WS time series.
Table 3.
CHARMA model fitted to the WS time series in the city of Rio Grande from December 2009 to January 2015.
Figure 3 presents the residual diagnostic plots of the fitted model. We can observe some indications that the model is capable of portraying the behavior of the data and is appropriate for out-of-sample forecasting. Figure 3a shows that the residuals are randomly distributed around zero without the presence of outliers. The quantile–quantile plot (QQ-Plot) in Figure 3b demonstrates a good fit, indicating that the residuals are approximately normally distributed. The residuals also do not show significant auto-correlation, as shown by the residual ACF in Figure 3c and the residual partial auto-correlation function (PACF) in Figure 3d. The Ljung-Box test confirms the goodness-of-fit with a p-value > .

Figure 3.
Diagnostic plots of the CHARMA model fitted to the WS time series.
For comparison purposes, we also considered the seasonal autoregressive moving average model (SARMA) [1], where p and q represent the orders of the non-seasonal part of the model, P and Q are the orders of the seasonal part of the model, and is the period. After conducting a residual analysis and the Ljung-Box test, the SARMA model was selected. In the SARMA fitted model, all the parameters were different from zero at a significance level of . The model presented AIC and BIC values equal to and , respectively.
In order to compare the fitted models, we evaluated the in-sample and out-of-sample predictions. For the out-of-sample evaluation, we reserved the last twelve observations solely for the purpose of comparing the forecasts. Figure 4 presents the time series of the mean WS together with the in-sample prediction and out-of-sample forecast of both competitor models. It can be observed that both models present a good fit in the time series.
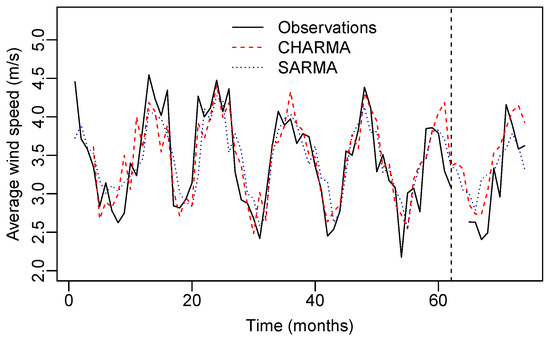
Figure 4.
Observed and predicted WS values from the CHARMA and SARMA models, which considered the fit period (in-sample) and the forecast period (out-of-sample) twelve steps ahead.
In Table 4, the observed and out-of-sample predicted values from the CHARMA and SARMA models are presented. It can be observed that the CHARMA model produces predictions that are close to the observed values of WS in five of the ten observations with recorded values. To further evaluate the predictive performance of the models, we calculated the MAPE% and the MSE between the observed and the fitted values. The results of these figure-of-merit measurements are presented in Table 5. It can be noted that the CHARMA model has the best performance in modeling the WS. When both measurements are considered, the selected model demonstrates the lowest values, indicating that it is the most suitable approach for modeling the WS dataset in the city of Rio Grande in the period from December 2009 to January 2016.
Table 4.
Observed and forecast WS values for the CHARMA and SARMA fitted models.
Table 5.
In-sample and out-of-sample prediction accuracy measurements of the CHARMA( and SARMA fitted models for the WS times series.
5.3. Application to Monthly Average Maximum Temperature Time Series in the City of Teresina
Climate is a determining factor for natural and human life. Variations in wind intensity, as well as temperature fluctuations, are important subjects in applied studies. According to [29], accurately predicting temperature is crucial for the prevention of unforeseen dangers caused by temperature variations, which can lead to human and financial losses. In this climatic context, statistical models are necessary to be able to analyze and predict variables while considering the serial dependence in the time series. The monthly average maximum temperature variable (or simply maximum temperature, abbreviated as MT) is an example of a parameter that enhances studies on climate change, wildfire prevention, and health problems. The CHARMA model is suitable for modeling this variable, given that the MT consists of a set of positive real values, and the model takes into account the temporal dependence structure of the data.
Brazil is known for having regions with high temperatures, such as the northeast region. To illustrate the applicability of the proposed model, we developed an empirical application of the proposed model using MT data taken from the capital of the Piauí estate, the city of Teresina, Brazil. The data were sourced from the INMET, available at https://bdmep.inmet.gov.br/ (accessed on 21 August 2023). The dataset comprised monthly observations from February 2010 to December 2015. This time period was selected to have the largest possible sample size, considering the missing values in the observed time series. The last nine observations were reserved only for the purpose of comparing the forecasting results, whereas the first observations were used for estimation. One of the last nine observations, corresponding to April 2015, was missing, and so the fitted models were used to input this missing value. Therefore, the time series used for estimation considered the period from February 2010 to March 2015, with observations, an average MT of °C, median of °C, the maximum temperature reached was °C, and the minimum was °C.
Figure 5 contains some graphs that indicate the behavior of the time series along the time period. Figure 5a shows the time series of MT, while Figure 5b evidences the seasonal pattern in the data. The sample ACF is shown in Figure 5c, which has been noted to have the presence of seasonality in the data. During the months of August and September, higher MT can be observed, whereas in the months from February to April, the temperatures are lower.

Figure 5.
Time series of MT in the city of Teresina in the period from February 2010 to March 2015.
To be able to select the best model for the MT time series, we fitted the CHARMA models with different orders. In all the fitted models, we considered a covariate from the deterministic seasonality component obtained by the decompose R function. Table 6 presents the five models with the lowest AIC values among the competing models with different p and q orders. The model exhibiting the lowest AIC and BIC values was selected. Table 7 presents the adjustment of the CHARMA model with a seasonal covariate. All parameters are considered to be significant at the significance level of 5%.
Table 6.
Information criteria for the five best CHARMA models fitted to the MT time series.
Table 7.
The CHARMA model fitted to the MT time series for the city of Teresina from February 2010 to March 2015.
Figure 6 shows some graphs for the diagnostic analysis of the fitted CHARMA. In Figure 6a, we can see that the residuals are randomly distributed between without the presence of outliers. The QQ-Plot indicates that the Chen model is suitable for this application. Figure 6c,d and the Ljung-Box test (p-value ) evidence that the residuals are not auto-correlated.

Figure 6.
Diagnostic plots of the CHARMA model fitted to the MT time series.
In order to compare the prediction performance of the proposed model with the most usual methodology in the time-series field [1], we used the auto.arima function from the package forecast of the software R. This function returns the best SARMA model, taking into account the AIC value of models with different order combinations, as well as autoregressive (), moving averages (), seasonal autoregressive (), and seasonal moving averages () terms. The model with the lowest AIC was ARMA, with AIC and BIC. Additionally, all model parameters were considered to be significant at the significance level of 5%. The Ljung-Box test for the fitted ARMA model residuals resulted in p-value; thus, the hypothesis assuming the independence of the residuals was not rejected.
For the comparison of the fitted CHARMA and ARMA models, we evaluated the in-sample and out-of-sample predictions. The out-of-sample forecast is shown in Table 8. Note that the predicted values based on the proposed model are generally closer to the observed ones. Graphic representations of the in-sample and out-of-sample predictions can be seen in Figure 7.
Table 8.
Observed and forecast MT values for the CHARMA and ARMA fitted models.
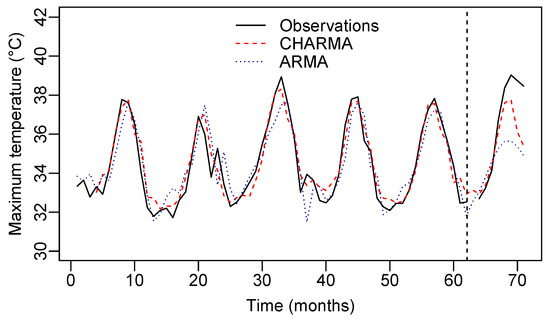
Figure 7.
Observed and predicted MT values from the CHARMA and ARMA models, which considered the fit period (in-sample) and the forecast period (out-of-sample) nine steps ahead.
Finally, the prediction accuracy measurements confirm the superiority of the CHARMA model, which can be seen in Table 9. In both in-sample and out-of-sample prediction measurements, the values of MAPE (%) and MSE are lower than those of the classical ARMA model.
Table 9.
In-sample and out-of-sample prediction accuracy measurements of the CHARMA( and ARMA fitted models for the MT times series.
6. Conclusions
In this work, we proposed a dynamic model for modeling Chen-distributed and auto-correlated data. We introduced the median-based reparameterization of the Chen distribution, and we included a regression, autoregressive, and moving averages structure for the modeling of the conditional median. We discussed the model selection criteria and the use of quantile residuals to evaluate the model assumptions. The simulation results indicated that the conditional maximum likelihood estimators exhibit good properties in finite sample sizes. In addition to the theoretical proposition and the numerical evaluation of the introduced estimation theory, we verified the applicability of the proposed model on two real datasets of WS and MT. In both applications, the proposed CHARMA model demonstrated a good fit in terms of AIC, BIC, MAPE, and MSE, outperforming the classical SARMA and ARMA models in terms of prediction evaluation.
Author Contributions
Conceptualization, R.F.S. and L.H.L.; methodology, R.F.S., L.H.L. and M.S.M.; writing—original draft preparation, R.F.S., L.H.L., M.S.M. and F.M.B.; writing—review and editing, R.F.S., L.H.L., M.S.M. and F.M.B. All authors contributed equally and significantly to the writing of this paper. All authors read and approved the final manuscript.
Funding
This research was partially funded by Fundação de Amparo à Pesquisa do Estado do Rio Grande do Sul (FAPERGS), Brazil, grant numbers 23/2551-0000813-0 and 21/2551-0002048-2, and Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq), Brazil.
Data Availability Statement
Publicly available datasets were analyzed in this study. These datasets can be found here: https://bdmep.inmet.gov.br/ (accessed on 1 July 2023).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CHARMA | Chen autoregressive moving average |
| ARMA | Autoregressive moving average |
| GARMA | Generalized autoregressive moving average |
| CMLE | Conditional maximum likelihood estimators |
| BFGS | Broyden–Fletcher–Goldfarb–Shanno |
| AIC | Akaike Information Criterion |
| BIC | Bayesian Information Criterion |
| MAPE | Mean absolute percentage error |
| MSE | Mean squared error |
| RB | Relative bias |
| WS | Average wind speed |
| INMET | Brazilian National Institute of Meteorological Research |
| ACF | Sample autocorrelation function |
| PACF | Partial autocorrelation function |
| SARMA | Seasonal autoregressive moving average |
| MT | Average maximum temperature |
Appendix A. Conditional Observed Information Matrix
In this appendix, we present the conditional observed information matrix, which is obtained by taking the negative value of the second-order partial derivative of the log-likelihood function, that is:
For and , for , we can show that
Note that:
Now, taking the second derivative of the conditional log-likelihood function with respect to , we obtain the following:
In addition, observe that:
Now, considering derivatives with respect to , we obtain the following:
where
and
Let , , , , , and , , , , be the matrices with a dimension of whose -th elements are given by the equation below:
In addition, let , , , and have the dimensions , , , and , respectively, given by the following equations:
The joint observed information matrix for is as follows:
where , , , , , , , , , , , , , , and .
References
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Tiku, M.L.; Wong, W.K.; Vaughan, D.C.; Bian, G. Time series models in non-normal situations: Symmetric innovations. J. Time Ser. Anal. 2000, 21, 571–596. [Google Scholar] [CrossRef]
- Benjamin, M.A.; Rigby, R.A.; Stasinopoulos, D.M. Generalized autoregressive moving average models. J. Am. Stat. Assoc. 2003, 98, 214–223. [Google Scholar] [CrossRef]
- McCullagh, P.; Nelder, J. Generalized Linear Models, 2nd ed.; Chapman and Hall: London, UK, 1989. [Google Scholar]
- Rocha, A.V.; Cribari-Neto, F. Beta autoregressive moving average models. Test 2009, 18, 529–545. [Google Scholar] [CrossRef]
- Bayer, F.M.; Bayer, D.M.; Pumi, G. Kumaraswamy autoregressive moving average models for double bounded environmental data. J. Hydrol. 2017, 555, 385–396. [Google Scholar] [CrossRef]
- Melo, M.S.; Alencar, A.P. Conway-Maxwell-Poisson autoregressive moving average model for equidispersed, underdispersed, and overdispersed count data. J. Time Ser. Anal. 2020, 41, 830–857. [Google Scholar] [CrossRef]
- Sales, L.O.; Alencar, A.P.; Ho, L.L. The BerG generalized autoregressive moving average model for count time series. Comput. Ind. Eng. 2022, 168, 108104. [Google Scholar] [CrossRef]
- Bayer, F.M.; Pumi, G.; Pereira, T.L.; Souza, T.C. Inflated beta autoregressive moving average models. Comput. Appl. Math. 2023, 42, 183. [Google Scholar] [CrossRef]
- de Araújo, F.J.M.; Guerra, R.R.; Peña-Ramírez, F.A. The Burr XII autoregressive moving average model. Comput. Sci. Math. Forum 2023, 7, 46. [Google Scholar]
- Kedem, B.; Fokianos, K. Regression Models for Time Series Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Chen, Z. A new two-parameter lifetime distribution with bathtub shape or increasing failure rate function. Stat. Probab. Lett. 2000, 49, 155–161. [Google Scholar] [CrossRef]
- Xie, M.; Tang, Y.; Goh, T. A modified Weibull extension with bathtub-shaped failure rate function. Reliab. Eng. Syst. Saf. 2002, 76, 279–285. [Google Scholar] [CrossRef]
- Dey, S.; Kumar, D.; Ramos, P.L.; Louzada, F. Exponentiated Chen distribution: Properties and estimation. Commun. Stat. Simul. Comput. 2017, 46, 8118–8139. [Google Scholar] [CrossRef]
- Alotaibi, R.; Rezk, H.; Park, C.; Elshahhat, A. The discrete exponentiated-Chen model and its applications. Symmetry 2023, 15, 1278. [Google Scholar] [CrossRef]
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes in C. 2; Cambrige University: Cambridge, UK, 1992. [Google Scholar]
- Andersen, E.B. Asymptotic properties of conditional maximum-likelihood estimators. J. R. Stat. Soc. Ser. B Methodol. 1970, 32, 283–301. [Google Scholar] [CrossRef]
- Fokianos, K.; Kedem, B. Partial likelihood inference for time series following generalized linear models. J. Time Ser. Anal. 2004, 25, 173–197. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Dunn, P.K.; Smyth, G.K. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
- Scott, M.; Chandler, R. Statistical Methods for Trend Detection and Analysis in the Environmental Sciences; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Ljung, G.M.; Box, G.E. On a measure of lack of fit in time series models. Biometrika 1978, 65, 297–303. [Google Scholar] [CrossRef]
- Prass, T.S.; Bravo, J.M.; Clarke, R.T.; Collischonn, W.; Lopes, S.R. Comparison of forecasts of mean monthly water level in the Paraguay River, Brazil, from two fractionally differenced models. Water Resour. Res. 2012, 48, 5. [Google Scholar] [CrossRef]
- Abdel-Aal, R. Univariate modeling and forecasting of monthly energy demand time series using abductive and neural networks. Comput. Ind. Eng. 2008, 54, 903–917. [Google Scholar] [CrossRef]
- Suganthi, L.; Samuel, A.A. Energy models for demand forecasting—A review. Renew. Sustain. Energy Rev. 2012, 16, 1223–1240. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Zhang, L.; Zhou, D.Q.; Zhou, P.; Chen, Q.T. Modelling policy decision of sustainable energy strategies for Nanjing City: A fuzzy integral approach. Renew. Energy 2014, 62, 197–203. [Google Scholar] [CrossRef]
- Wang, C.; Prinn, R.G. Potential climatic impacts and reliability of very large-scale wind farms. Atmos. Chem. Phys. 2010, 10, 2053–2061. [Google Scholar] [CrossRef]
- Paul, R.K.; Anjoy, P. Modeling fractionally integrated maximum temperature series in India in presence of structural break. Theor. Appl. Climatol. 2018, 134, 241–249. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).