Abstract
To extract facial features with different receptive fields and improve the decision fusion performance of network ensemble, a symmetric multi-scale residual network (SMResNet) ensemble with a weighted evidence fusion (WEF) strategy for facial expression recognition (FER) was proposed. Firstly, aiming at the defect of connecting different filter groups of Res2Net only from one direction in a hierarchical residual-like style, a symmetric multi-scale residual (SMR) block, which can symmetrically extract the features from two directions, was improved. Secondly, to highlight the role of different facial regions, a network ensemble was constructed based on three networks of SMResNet to extract the decision-level semantic of the whole face, eyes, and mouth regions, respectively. Meanwhile, the decision-level semantics of three regions were regarded as different pieces of evidence for decision-level fusion based on the Dempster-Shafer (D-S) evidence theory. Finally, to fuse the different regional expression evidence of the network ensemble, which has ambiguity and uncertainty, a WEF strategy was introduced to overcome conflicts within evidence based on the support degree adjustment. The experimental results showed that the facial expression recognition rates achieved 88.73%, 88.46%, and 88.52% on FERPlus, RAF-DB, and CAER-S datasets, respectively. Compared with other state-of-the-art methods on three datasets, the proposed network ensemble, which not only focuses the decision-level semantics of key regions, but also addresses to the whole face for the absence of regional semantics under occlusion and posture variations, improved the performance of facial expression recognition in the wild.
1. Introduction
Facial expression plays an important role in daily communication as it is a natural and universal way for human to convey emotional states [1,2]. Currently, automatic facial expression recognition (FER) has many applications, such as social robots, safe driving, intelligent medicine, and other human–computer interaction fields [3,4]. In recent years, numerous novel methods have been proposed for FER in experimental environments. However, it is challenging to cope with the diversity and complexity of FER in uncontrolled environments (e.g., non-frontal faces, fuzzy faces, partially occluded faces, and spontaneous expressions) [5,6,7,8,9].
At present, FER is divided into feature engineering-based methods and end-to-end deep learning-based methods. Feature engineering-based methods, which include feature extraction and feature classification, have a common difficulty of selecting robust facial features for expression classification [10], and lack compensation and fault-tolerance mechanisms for occlusions and posture variations in the wild. Recently, to reduce the interference of human factors and the errors in manual feature selection, end-to-end deep learning-based methods, especially convolutional neural networks (CNNs), have been rapidly applied to FER [11]. Owing to their rich semantic representation capabilities, CNN-based methods [7,12,13,14] have achieved an advanced recognition rate and outperformed the previous feature engineering-based methods. Research shows that deeper convolution has a wider receptive field for rich semantic features, but is easily affected by occlusions and varying postures [15]. Therefore, a multi-scale Res2Net block was designed to extract features with different receptive fields [16]. However, Res2Net obtains multi-scale features only from left to right in the basic block, which results in a limited range of receptive fields, and how to expand receptive fields for facial features extraction is a problem to be solved in the paper.
In addition, the current end-to-end deep learning-based methods, which only take a whole face image as input, are difficult to accurately capture the subtle changes in key regions of the face and ignore the importance of different facial regions. Psychological research shows that facial expression details focus on the eyebrows, eyes, and mouth regions [17]. Furthermore, human beings can effectively use local regions and the whole face to perceive the semantics transmitted by incomplete faces [18]. Hence, how to highlight the role of key regions and maintain the interoperability of the whole face is the other problem to be solved in this paper.
Recent studies have shown that the performance of a set of multiple networks is better than that of a single network [19,20], and the decision-level-based network ensemble strategy becomes mainstream [21]. In the decision-level network ensemble, the Dempster–Shafer (D-S) evidence theory, which has unique advantages in terms of flexibility and effectiveness of modeling uncertainty and imprecision, has been one of the most competitive fusion strategies [22]. However, the expression semantics of different regions have a certain degree of ambiguity and uncertainty, and the traditional D-S combination rules (DCRs) fail when there are conflicts in evidence [23]. How to reduce the conflicts between the decision-level semantic of different regions is a third problem to be solved.
To solve the above problems, a FER framework based on a symmetric multi-scale residual network (SMResNet) ensemble with a weighted evidence fusion (WEF) strategy was proposed. The overall structure of the proposed framework is shown in Figure 1. It mainly includes a preprocessing module for face alignment and facial key region location, a decision-level semantic extraction based on SMResNet ensemble, and a decision-level semantic fusion with the WEF strategy. In the preprocessing module, due to facial images in unconstrained scenes having complex backgrounds, illuminations, head poses, and local occlusions, a pipeline for face alignment and the location of facial key regions was designed. In the decision-level semantic extraction, to overcome the defect of connecting different filter groups of Res2Net only from one direction, a symmetric multi-scale residual (SMR) block was firstly improved to symmetrically extract the features of different receptive fields from two directions. Secondly, a network ensemble, composed of three networks of SMResNet, was constructed to extract the decision-level semantics of the whole face, eyes, and mouth. In the decision-level semantic fusion, the outputs of three SMResNets were regarded as different evidence, and the D-S evidence theory was addressed to decision-level fusion of these three pieces of evidence. Given the ambiguity and uncertainty of different expression evidence, a WEF strategy was introduced to overcome the conflicts in evidence based on the support degree adjustment. The main contributions of this paper are as follows.
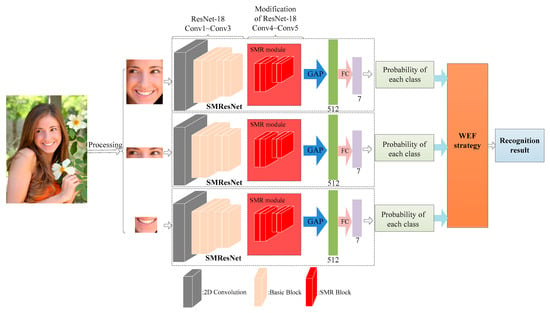
Figure 1.
The overall framework of the proposed method.
- (1)
- To further extract features in a wider range of receptive fields, an SMR block, which symmetrically constructs hierarchical residual-like connections from two directions in a basic block, was improved. It represents the multi-scale feature of fine-grained level and can further expand the receptive field range of each network layer.
- (2)
- To establish the complementarity of global facial features and regional detail features, a network ensemble of SMResNet, which consists of one 2D convolution layer, four basic blocks, one SMR module composed of four cascaded SMR blocks, a global average pooling (GAP) layer, and a full connection (FC) layer, was constructed. The constructed ensemble framework not only focuses on the decision-level semantics of the eye and mouth regions, but also addresses the whole face for the absence of regional semantics under occlusions and posture variations.
- (3)
- To restrain the ambiguity and uncertainty of decision-level semantics from the constructed SMResNet ensemble, a decision-level semantic fusion with WEF strategy was proposed based on the D-S evidence theory. The proposed strategy, which overcomes the conflicts in evidence by the support degree adjustment, is helpful to minimize the influence of evidence with small weight on the decision-making judgment, and reduce conflicting information between evidence to satisfy the DCRs for the decision-level fusion of three pieces of regional evidence.
2. Related Work
This paper addresses facial expression recognition based on network ensemble; hence, current facial expression recognition methods, network ensemble structures, and decision-level fusion strategies were reviewed.
2.1. Facial Expression Recognition Methods
Due to the important role of facial expression recognition in the field of computer vision, research on facial expression recognition methods has received wide public concern. Currently, FER methods can be divided into traditional feature engineering-based methods and end-to-end deep learning-based methods.
The traditional feature engineering-based methods, composed of facial feature extraction and facial expression classification, mainly explore facial expression variations using geometric and appearance features [11], and classify facial expression categories based on support vector machine (SVM) [24] or principal component analysis (PCA) [25]. In general, geometric feature-based methods have the advantages of low dimension and being insensitive to illumination variations, but their ability for local detail description is weak. Appearance feature-based methods, such as Gabor [26], local binary pattern (LBP) [27], and histogram of oriented gradient (HOG) features [28], contain a large amount of expression information and have a relatively stable extraction process, but the extracted features have high dimension and are susceptible to illumination variations, and even mixed with inference data. Hence, the traditional feature engineering-based methods not only have difficulty selecting robust features for expression classification, but also lack compensation and fault-tolerance mechanisms for occlusion and posture variations in the wild. Furthermore, the separate processes of feature extraction and classification cannot be integrated into an end-to-end model.
Due to the increasing amount of data used to train deep models and the improvement in GPU technology, an important part of the advancement in recognition performance is the advent of deep learning methods. The end-to-end deep learning-based methods attempt to capture high-level semantics through multiple hierarchical structures of nonlinear transformations and representations. In addition to subject identity bias, variations in posture, illumination, and occlusions are also common in unconstrained facial expression scenes, which are nonlinearly confused with facial expressions, reinforcing the need for deep networks to address large intra-class variability and learn effective specific expression representations. A survey of the research on deep learning FER can be found in [21,29,30]. Depending on different network structures, the end-to-end deep learning-based methods can be further divided into convolutional neural networks [7,12,13,14], deep belief networks [31], deep autoencoders [32], recurrent neural networks [33], and generative adversarial networks [34]. Compared with other neural networks, CNNs possess unique superiority in facial spatial semantic extraction due to their own convolution and pooling operations, and have better performance for FER in the wild [7,12,13,14].
Li et al. [12] proposed a CNN with an attention mechanism named as ACNN based on VGG-16 [35], which could perceive the occlusion regions of the face and focus on the most discriminative un-occluded regions. Each region of interest (ROI) was weighed via a gate unit that computed a weight from the region itself. To capture the importance of facial region information, and make a reasonable trade-off between the region and global features, Wang et al. [13] proposed the new regional attention network (RAN) using VGG-16 [35] or ResNet-18 [36] as the backbone network. The weight distribution of facial regions was realized by the self-attention module and the region bias loss. The influence of occlusion and irrelevant regions was reduced or eliminated by increasing the attention weight of important regions. The VGGNet increases the network depth and uses filters with a smaller kernel size. A deeper structure can expand the receptive fields, which is very useful for extracting features from a larger scale. However, as the depth of the network increases, the gradient may vanish or explode. Different from VGGNet, the ResNet block introduces a short connection to neural networks to alleviate these problems and can obtain much deeper network structures [36]. Short connections in ResNet allow different combinations of convolution operators to obtain a large number of equivalent feature scales. Recently, hierarchical residual-like connections are introduced into the Res2Net block [16] to enable the variation of receptive fields at a finer granularity for capturing details and global features. The related experimental results have shown that Res2Net is better than ResNet in the context of several representative computer vision tasks. However, Res2Net extracts multi-scale features only from left to right in the basic block, which results in a limited range of receptive fields.
In addition, Zhao et al. [14] extracted global features using multi-scale modules, which reduced the sensitivity of deep convolution to occlusions and posture variations, and then obtained attention semantics from the four regions of middle-level facial features. However, it was necessary to design hyperparameters to balance global features and local features, resulting in achieving decision fusion for expression classification.
2.2. Network Ensemble Structures
Recent advances in deep learning have shown that combining multiple deep learning models can considerably outperform the approach of using only a single deep learning model for challenging recognition problems [19,37]. Cho et al. proposed a novel deep convolutional neural network (DCNN) ensemble for FER in the wild [37]. Karnati [38] designed a texture-based feature-level ensemble parallel network (FLEPNet) for FER, and addressed insufficient training data and intra-class facial appearance variations.
When implementing a network ensemble, two key factors should be considered: sufficient diversity of networks to ensure complementarity and an appropriate ensemble strategy that can effectively aggregate the committee networks [21]. There are many methods to generate network diversity, such as different training data, several preprocessing methods, varying network models, various parameters, and so on. The committee networks that extract local features and global features in our paper are used to construct the network ensemble. Each member of the committee network can be assembled at two different levels: feature-level and decision-level [39]. For the feature-level ensemble, the most commonly used strategy is to concatenate the features learned from different networks. However, the feature-level fusion method has the problem of dimension catastrophe. Therefore, the decision fusion method is chosen in our paper.
2.3. Decision Fusion Strategies
Decision fusion strategies mainly include majority vote and D-S evidence theory. The majority voting strategy is a simple and effective method for decision-level data fusion [40]. However, the majority voting method does not consider the importance and confidence of each individual, and is prone to controversial decision results.
D-S evidence theory, which has the flexibility and effectiveness to model uncertainty and imprecision without considering prior information, has been widely used in various fields of information fusion [41], such as decision-making, pattern recognition, risk analysis, supplier selection, fault diagnosis, and so on. Specifically, the fusion results generated through the DCRs exhibit fault tolerance, enabling them to better support decision-making [42]. However, the D-S evidence theory may lead to counterintuitive results when fusing highly conflicting evidence [43]. To solve this problem, it has been proposed to modify DCRs and preprocess the evidence [44]. Considering the advantages of D-S in decision fusion, and the ambiguity and uncertainty of facial semantics, this paper proposed a decision-level semantic fusion with WEF strategy that integrates D-S evidence theory into a network ensemble framework for FER.
3. Methodology
The recognition framework proposed in this paper mainly includes a preprocessing module for face alignment and facial key region location, a decision-level semantic extraction based on the SMResNet ensemble, and a decision-level semantic fusion with the WEF strategy. At last, to solve the parameters of SMResNets and improve the convergence speed of the network ensemble, the optimization for the SMResNet ensemble was designed.
3.1. A Preprocessing Module for Face Alignment and Facial Key Region Location
Unlike frontal facial images collected in laboratory settings, facial images in the wild have complex backgrounds, head posture deviation, non-uniform illumination, and local occlusion. To suppress redundant information in input images and improve the anti-interference ability of facial regions, a preprocessing module was designed. The pipeline of the proposed preprocessing module mainly included face alignment and facial key region location.
3.1.1. Face Alignment
To learn meaningful features for training deep neural networks, preprocessing is usually required to align and standardize the visual semantic information conveyed by the human face [45]. The face alignment algorithm [46], which is robust to face occlusion, was addressed to the calibrated position of landmarks in our paper. Firstly, 68 facial landmark points, each of which can be defined by coordinates, were detected. The positional relationship of 68 facial landmark points is shown in Figure 2.

Figure 2.
Positional relationship of 68 facial landmark points.
Secondly, twelve landmarks (No. 36 to 47) around the left and right eyes were selected to achieve facial image alignment, as shown in Figure 3. The angle between the horizontal axis and the line segment, running from one eye center to the other eye center, and the inter-eye distance between the centers of the two eyes, are calculated as:
where , represent the abscissa and ordinate of the -th landmark, respectively.

Figure 3.
Face alignment and cropping.
Finally, according to facial proportion structure and human experience, a vertical factor and horizontal factor for ROI of face are delimited 2.2 (considering 0.6 for the region above the eyes and 1.6 for the region below) and 1.8, respectively. The final facial region is cropped from the aligned facial image:
where represents the aligned facial image after rotating the angle, , , and represent the left upper vertex, the width and height of the cropped facial ROI region, respectively. Specifically,
where and are the abscissa and ordinate of landmark , respectively.
3.1.2. Facial Key Region Location
Human facial expressions are not only closely related to the global information presented on the face, but also to the local details of key facial regions such as the eyes and mouth. Therefore, to highlight the important role of different facial regions in FER, six landmarks in are used to achieve localization and cropping of the eye and mouth regions, as shown in Figure 4. The six landmarks in Figure 4 are represented as , where the landmarks represent upper of left eyebrow, upper of right eyebrow, middle of nose, lower of nose, left corner of mouth, and right corner of mouth, respectively.
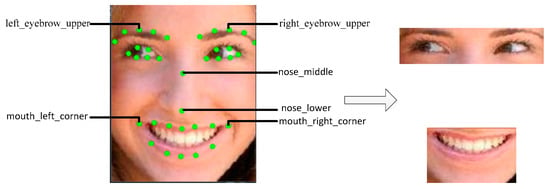
Figure 4.
Selection of key regions.
Firstly, the eye region is calculated from the cropped image :
where , , and represent the left upper vertex, the width and height of the eye region, respectively. Specifically,
where is the function taking the minimum value.
Similarly, the mouth region is calculated from the cropped image :
where , , and represent the left upper vertex, the width and height of the mouth region, respectively.
Through the above pipeline for face alignment and facial key region location, the whole face, eye region, and mouth region can be cropped from the input image. The designed pipeline can suppress redundant information of the input image and improve the anti-interference ability of facial regions.
3.2. A Decision-Level Semantic Extraction Based on SMResNet Ensemble
In this section, we introduce the construction of SMResNet ensemble. Firstly, to extract facial features of different receptive fields with a wider range, an SMR block was proposed. Then, the SMResNet, which embeds SMR blocks, was designed. Finally, the SMResNet ensemble, composed of three SMResNets, was constructed to extract decision-level semantic features of the whole facial region and key facial expression regions such as the eyes and mouth.
3.2.1. SMR Block
To extract multi-scale facial features, the basic block, composed of a group of a 3 × 3 filter, was embedded into ResNet-18 and ResNet-34 [36], as shown in Figure 5a. However, most existing methods based on the basic block represent the multi-scale features in a layer-wise manner. The Res2Net block sought smaller groups of filters, and connected different filter groups in a hierarchical residual-like style [16], as shown in Figure 5b. The Res2Net block represents multi-scale features at a granular level. In the Res2Net block, the hierarchical residual-like connections within a single basic block can increase the range of receptive fields for each network layer. However, the direction of the filter 3 × 3 residual connection is a single direction, thus causing the range of receptive fields for each network layer limited. To extract facial features of different receptive fields with a wider range, an SMR block, which symmetrically learns the multi-scale features from both directions, was proposed, as shown in Figure 5c.
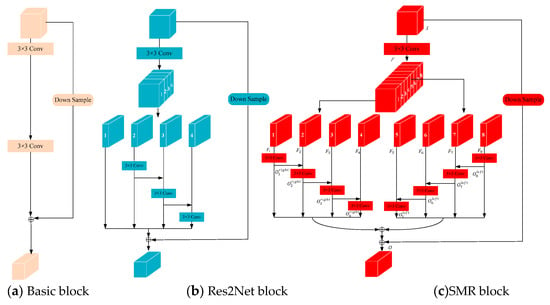
Figure 5.
Comparison of basic block, Res2Net block, and SMR block, (a) Basic block; (b) Res2Net block; (c) SMR block.
Firstly, the output of the previous modules is regarded as the input of SMR block. After the 3 × 3 convolution, the feature map can split into feature map subsets:
where , which has number of channels of the input feature map, represents the -th feature map subset; is the number of feature map subsets.
Secondly, () is carried out a series of 3 × 3 convolutions, and the symmetrical multi-scale features and of can be expressed as:
where , represent the 3 × 3 convolution operation in right branch and the left branch, respectively. Equation (14) shows that the operation can capture all the features from the subset , while Equation (15) shows that the operation can capture all the features from the subset . Since each goes through a 3 × 3 convolution processing, and include a different number and proportion of feature subsets. To obtain more diverse multi-scale features, all and along the channel axis are concatenated. The final output of SMR block can be expressed as:
where indicates the concatenation operation along the channel axis; represents downsampling operation. is the output feature map of the input . When the value of is large, the learned feature contains more scale information, but it will increase the computational cost. In the experiment, set = 8, which is a trade-off between performance and calculation.
Compared with Res2Net, the designed SMR block overcomes the problem of residual network connections being only one-way from left to right, and can extract the facial features from left to right and from right to left, resulting in a wider range of receptive fields.
3.2.2. SMResNet Ensemble for Decision-Level Semantic Extraction
To expand the receptive fields and extract regional facial expressions information, the SMResNet, which embeds SMR blocks, was designed, as shown in Figure 1. The designed SMResNet consisted of one 2D convolution layer, four basic blocks, one SMR module composed of four cascaded SMR blocks, a GAP layer, and an FC layer. The structural parameters of SMResNet are listed in Table 1.

Table 1.
Structure parameters of SMResNet.
As opposed to directly taking global facial semantics from the facial ROI region as the input [11], the SMResNet ensemble, composed of three SMResNets, was constructed to extract decision-level semantic features of the whole facial region and key facial expression regions such as the eyes and mouth, as shown in Figure 1. Set the decision-level semantic of the SMResNet from -th region is :
where , , and represent the decision-level semantic of the whole face, eyes region and mouth region, respectively. represents the th output signal in the softmax output layer of the -th SMResNet. = 7 represents seven classes of facial expressions.
3.3. A Decision-Level Semantic Fusion with WEF Strategy
The decision-level semantics, outputted from the softmax layer of individual SMResNet, not only have a certain degree of ambiguity and uncertainty in the same region, but also have conflicts between different regions. How to integrate decision-level semantic across different regions is the focus of this section. The D-S evidence theory, which has unique advantages in terms of flexibility and effectiveness of modeling uncertainty and imprecision, is widely used in various fields of information decision fusion. Hence, the D-S evidence theory was used to achieve multi-region decision-level semantics fusion. In addition, considering the semantic conflicts among different regions, a decision-level semantic fusion with WEF strategy was proposed for FER.
3.3.1. Basic Probability Assignment in D-S Evidence Theory
Let Θ be a finite set of mutually exclusive and exhaustive hypotheses on a problem domain, which is referred to as the framework of discernment. If ⊆ , then ⟶ [0, 1], and the conditions defined in Equation (18) are satisfied.
where is the basic probability assignment (BPA) function on , and can be interpreted as a measure of the belief that one is willing to commit exactly to . If , then is called a focal element. Let two BPAs and on the frame of discernment of Θ and assuming that these BPAs are independent. The DCRs [43] are defined as follows:
where B and C are the elements of is the conflict coefficient between two pieces of evidence.
The FER framework is a 7-tuple containing seven different expressions, where , , , , , and represent seven different expressions of happiness, sadness, surprise, disgust, anger, fear and neutral, respectively. At the same time, the decision-level semantics from the whole face region, eyes region and mouth region are regarded as three pieces of evidence. The BPA of evidence for the category is given as:
3.3.2. WEF Strategy Using Support Degree of Evidence
The decision-level semantics from the whole face, eyes, and mouth regions have significant conflicts, and the traditional DCRs fail when there are conflicts between evidences [43,44]. Hence, the WEF is proposed. The flowchart of WEF is shown in Figure 6. Firstly, belief Jensen-Shannon (BJS) divergence [43] was used to describe the degree of conflict between each piece of evidence, which was then transformed into the degree of support between each piece of evidence. The weighting coefficient, which represents the degree of importance of the evidence, was determined by the degree of support. Secondly, the weighted coefficient was used to adjust the BPA based on the idea of the discount rate. Finally, the adjusted BPAs were synthesized using the DCRs.

Figure 6.
Flowchart of WEF strategy.
The decision-level semantics of the face, eyes, and mouth regions were regarded as the evidence set . The distance metric of two pieces of evidence and can be calculated by the BJS divergence [43]:
where (k = 1, 2, …N) is a hypothesis of belief function, and (i = 1, 2, …, n) and (j = 1, 2, …, n) are two BPAs on the same frame of discernment Θ, containing mutually exclusive and exhaustive hypotheses, where n = 3.
According to (21), a conflict matrix of the evidence set can be expressed as:
Given that = and , the conflict matrix is a symmetric matrix. If there was a smaller conflict between any two pieces of evidence, the similarity was higher between them. Thus, the conflict matrix was transformed into a similarity matrix :
where represents the degree of similarity between the evidence and . The confidence degree of the evidence supported by other evidence is given as:
computes the sum of all other elements of each row, except for its own similarity in the similarity matrix , and it reflects the extent to which is supported by other evidence. As is well known, if the similarity between one evidence and other evidence is high, they are considered mutually supportive; conversely, they are assumed to have a low degree of mutual support. Hence, the weight of the evidence in the fusion system can be calculated as:
To highlight the importance of different regional evidence and improve the reliability and fault tolerance of the fusion results, the mutual support was used to modify the BPA of each piece of evidence. The weight was transformed into the initial BPAs of evidence based on the idea of discount rate.
where represents the BPA after adjustment of . From Equation (26), the deterministic information provided by the evidence element with low mutual support is reduced, and Equation (27) increases the uncertainty information provided by the uncertainty element of the evidence . This phenomenon reduces the impact of evidence with low mutual support on the overall fusion result.
Finally, the adjusted BPAs are synthesized using the DCRs.
where is the coefficient of revaluation. Based on the proposed WEF strategy, the final facial expression category of decision-level fusion can be expressed as:
3.4. Optimization for SMResNet Ensemble
To solve the parameters of SMResNets and improve the convergence speed of the ensemble optimization, the strategies of independent optimization within branches and joint optimization between branches were carried out. In the independent optimization, the cross-entropy loss is regarded as the optimization function for the whole face branch, eyes region branch, and mouth region branch, respectively.
where and represent the ground truth and predicted decision-level semantic of the -th branch of SMResNet.
In the joint optimization, taking the independent optimization parameters as the initial values, the total loss of three branches was regarded as the objective function for the fine-tuning of each branch parameter:
where and represent the ground truth and the final output of SMResNet ensemble with the WEF strategy. This coarse-to-fine tuning strategy, which maximizes the information interaction among branches, can obtain better performance for FER.
4. Experimental Results and Analysis
In this section, the experimental evaluations were presented. Before showing the results, we firstly describe the datasets and experimental settings. Then, the experimental results on different datasets, an ablation analysis, and a comparison with the state-of-the-art FER methods are provided. Finally, we conclude the experiment results and analysis.
4.1. Datasets and Experimental Settings
To verify the proposed SMResNet with the WEF strategy, experiments are carried out on three facial expression datasets, including FERPlus, RAF-DB, and CAER-S. The FERPlus dataset contains 35,887 facial expression images [47] and eight classes of expressions, including 28,709 images as the training set, 3589 images as verification set and 3589 images as test set. Due to its ease of comparison with other methods and analysis of generalization ability, the proposed expression recognition framework focuses on the classification of seven classes of expressions. Therefore, the contempt expression in the FERPlus dataset was not considered in the experiment. The RAF-DB dataset [48] contains 30,000 facial images annotated with basic or compound expressions. In our experiment, only seven basic expressions were used, and the training set and test set include 12,271 and 3068 images, respectively. CAER-S dataset [49], created by selecting static frames from CAER dataset, contains 65,983 images, and is divided into two sets: training set (44,996 samples) and test set (20,987 samples). Each image was labeled to one of seven expressions.
For all datasets, face images were preprocessed based on the pipeline for face alignment and facial key region location, and resized to 224 × 224 pixels. The experiments were implemented in the server environment of Tesla T4 based on Python 3.7, Pytorch 1.3.0, and Cuda10.2. The related parameter settings are shown in Table 2.
Table 2.
Related parameter settings.
4.2. Experimental Results on Different Datasets
The FER rates of different regions and the proposed network ensemble are shown in Table 3. On the one hand, Table 3 shows that the performance of SMResNet based on three regions is excellent, which explains that each region retains most of the information for FER. On the other hand, compared to the individual sub-network, decision-level fusion increases the recognition rate by 2–4%, which illustrates the effectiveness and feasibility of the proposed WEF strategy.
Table 3.
Experimental results on different datasets.
Figure 7 shows the FER rate of SMResNet ensemble on FERlus, RAF-DB, and CAER-S. For simplicity, the expressions of happiness, sadness, surprise, disgust, anger, fear, and neutral are expressed as Ha, Sa, Su, Di, An, Fe, and Ne. On all kinds of datasets, the proposed method not only has a high recognition rate for expressions such as happiness and surprise with rich details, but also maintains a high recognition rate for expressions such as sadness and disgust with insignificant local features and mutual confusion.
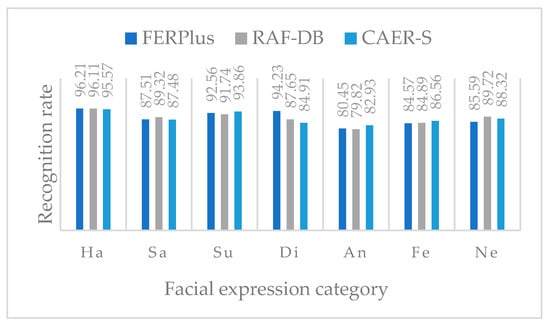
Figure 7.
FER rate of SMResNet ensemble on FERlus, RAF-DB, and CAER-S.
Specially, the confusion matrix of the seven expressions on the FERPlus dataset is shown in Table 4. As can be seen from Table 4, we found that the result of happiness expression was the best (96.21%), the result of anger expression was the lowest (80.45%), and the larger inter-class error rate occurred between anger and sadness (8.84%).
Table 4.
Confusion matrix of the FERPlus dataset.
The confusion matrix of the seven expressions on the RAF-DB dataset is shown in Table 5. As can be seen from Table 5, we found that the result of happiness expression was the best (96.11%), the result of anger expression was the lowest (79.82%), and the larger inter-class error rate occurred between fear and anger (9.72%).
Table 5.
Confusion matrix of the RAF-DB dataset.
The confusion matrix of the seven expressions on the CAER-S dataset is shown in Table 6. As can be seen from Table 6, we found that the result of happiness expression was the best (95.57%), the result of anger expression was the lowest (82.93%), and the larger inter-class error rate occurred between fear and sadness (7.94%).
Table 6.
Confusion matrix of the CAER-S dataset.
After analyzing the data in Table 4, Table 5 and Table 6, it can be concluded that the result of happiness expression is the best, which can be attributed to the fact that it has the characteristics of upturned corners of mouth and narrowed eyes. The expression with the lowest recognition rate was anger, which is due to certain similarities between anger expression and fear as well as sadness. It can also be seen that the error recognition rate between various expressions did not exceed 10%. This also indicates that the proposed weighted fusion strategy based on support degree can suppress evidence conflicts, improve the credibility of regional evidence, and enhance inter-class discrimination.
4.3. Ablation Analysis
To validate the effectiveness of each component in our recognition framework, we conducted an ablation analysis. In our experiments, different network structures and different decision-level fusion methods were studied, respectively.
4.3.1. Comparison of Different Network Structures
To prove the effectiveness for feature extraction, three network structures, the baseline network of ResNet-18, the multi-scale Res2Net-18, and symmetric multi-scale SMResNet, were carried out on the FERPlus dataset, the RAF-DB dataset, and the CAER-S dataset, respectively. The comparison of FER with different network structures for the whole facial region is shown in Table 7. From Table 7, we can see that the experimental results of SMResNet for the whole facial region were the best.
Table 7.
Comparison of FER with different network structures for the whole facial region.
The comparison of FER with different network structures for the network ensemble is shown in Table 8. In Table 8, compared with the baseline network of ResNet-18, the hierarchical residual-like connections are integrated into SMR block, thus improving by 1.70%, 1.90%, and 2.89% on FERPlus, RAF-DB, and CAER-S datasets, respectively. Compared with Res2Net-18, the designed SMR block overcame the problem of residual network connections being only one-way from left to right, and could extract the facial features from left to right and from right to left, resulting in an increase of 0.88%, 0.73%, and 1.67% on the FERPlus, RAF-DB, and CAER-S datasets, respectively. This indicates that the proposed SMR block can effectively extract facial expression features from different regions, thereby improving the FER rate.
Table 8.
Comparison of FER with different network structures for the network ensemble.
To better explain the effect of the SMR module with the basic ResNet, Res2Net, we further conducted visualization of the proposed module through gradient-weighted class activation mapping (Grad-CAM) [50]. A comparison of Grad-CAM with different modules is shown in Figure 8. In Figure 8, SMR can pay attention to specific regions which are beneficial to facial expression recognition, even if there are occlusion and non-frontal pose issues in the facial images. For one thing, the SMR module added shallow geometric features to deep semantic information, for another, the range of receptive fields was wider since the multi-scale direction of SMR module is bidirectional. Hence, the constructed SMR module, which reduces the sensitivity of the deeper convolutions towards occlusion and variant pose, can obtain a more complete representation of the features.

Figure 8.
Comparison of Grad-CAM with different network modules.
4.3.2. Comparison of Different Decision-Level Fusion Methods
To verify the superiority of the proposed decision-level fusion strategy, the WEF was compared with other decision-level fusion methods, as shown in Table 9. In Table 9, compared with the majority vote, WEF overcame the shortcomings of not reflecting the credibility of evidence, thus improving by 0.78%, 1.74%, and 2.38% on the FERPlus, RAF-DB, and CAER-S datasets, respectively. Compared with D-S evidence fusion, WEF suppresses conflicts between evidence and effectively solves the ambiguity and uncertainty of regional expressions, thus improving by 0.63%, 0.82%, and 1.29% on the FERPlus, RAF-DB and CAER-S datasets, respectively.
Table 9.
Comparison of different decision-level fusion methods.
Specially, to illustrate the effect of the proposed WEF strategy, the disgust expression of RAF-DB dataset is chosen as an example. The BPAs and the modified BPAs are shown in Table 10. Table 10 illustrates that the calculated conflict coefficient between two pieces of evidence of the facial region and the eyes region is close to 1, so in this case data fusion applying D-S theory is not feasible. The results obtained by different regions are inconsistent, but the validity of the WEF in recognizing facial expressions can be seen from the fusion results.
Table 10.
Results of data fusion using the WEF.
4.4. Comparison with State-of-the-Art Methods
To illustrate the performance of FER, we compared the proposed method with the state-of-art methods on the three datasets described above. The experimental results are shown in Table 11, Table 12 and Table 13.
Table 11.
Comparison with state-of-the-art methods on FERPlus dataset.
Table 12.
Comparison with state-of-the-art methods on RAF-DB dataset.
Table 13.
Comparison with state-of-the-art methods on CAER-S dataset.
Table 11 shows the comparison of the proposed method with several state-of-the-art methods on FERPlus dataset. The results in Table 11 show that the proposed SMResNet ensemble reaches 88.73%, which achieves a higher recognition rate and outperforms other recent state-of-the-art methods.
We also performed a comparison with advanced methods on RAF-DB dataset, as shown in Table 12. Consistent with other methods, we verified the effectiveness of SMResNet ensemble by recognizing seven basic expressions. The results in Table 12 show that the proposed method achieves recognition rate of 88.46% on RAF-DB, and obtained a higher recognition rate than the other six methods.
The FER recognition results of our proposed method and some state-of-the-art methods on CAER-S dataset are shown in Table 13. Since CAER-S dataset was released recently, only [49] has evaluated method on it. This paper has conducted several experiments using some state-of-the-art networks on it (such as ResNet-18, ResNet-50, Res2Net-18 and Res2Net-50). From Table 13, we can see that the proposed method achieves higher recognition rate even compared with the deeper network such as Res2Net-50.
4.5. Summary of Experiment
The effectiveness of the proposed method was verified on the FERPlus, RAF-DB, and CAER-S datasets. The experimental results demonstrate that the FER rates achieved 88.73%, 88.46%, and 88.52% on three datasets, respectively. In particular, the confusion matrix of the seven facial expressions, the FER results of different face regions, and the network ensemble were discussed. The comparative results indicated the proposed network ensemble not only had a high recognition rate for expressions such as happiness and surprise with rich details, but also maintained good recognition results for expressions such as sadness and disgust with insignificant local features and mutual confusion. This also showed that the WEF strategy based on the support degree can improve the credibility of regional evidence, thus enhancing the inter-class discrimination of different facial expression categories. Subsequently, the ablation experiments, which introduce the ensemble of different network structures, the visualization of different network modules, and the different decision-level fusion strategies, indicated that the proposed ensemble framework can focus the decision-level semantics of key regions and address the whole face for the absence of regional semantics under occlusions and posture variations. Particularly, the modified BPAs of the disgust expression showed the WEF strategy effectively solves the ambiguity and uncertainty of regional expressions, thus further boosting the effectiveness of FER. Finally, comparisons with state-of-the-art methods were made on the three databases. The experimental results illustrated that the proposed scheme improved the performance of FER in the wild.
5. Conclusions
To highlight the role of different facial regions with different receptive fields and implement the decision-level fusion of the network ensemble, the FER method based on the SMResNet ensemble with WEF strategy was proposed. Firstly, the pipeline for face alignment and facial key region location was designed to suppress redundant information of the input image and improve the anti-interference ability of facial regions. Secondly, to extract features with a wider range of different receptive fields, the SMR block, which learned symmetrically the multi-scale features from both directions, was improved. Meanwhile, the SMResNet, which consisted of one 2D convolution layer, four basic blocks, and one SMR module composed of four cascaded SMR blocks, a GAP layer, and a FC layer, was designed. Instead of directly feeding global facial semantics of the facial ROI region into a deep neural network, the SMResNet ensemble, composed of three SMResNets, was constructed to extract decision-level semantic features of the whole face, eye, and mouth regions. Finally, the decision-level semantics extracted from the three regions were regarded as three pieces of evidence to realize decision fusion. Meanwhile, the WEF strategy, which overcame the conflicts between evidence by the support degree adjustment, was proposed to restrain the ambiguity and uncertainty of regional semantics based on D-S evidence theory.
The effectiveness of the proposed network ensemble was verified by experiments on the FERPlus, RAF-DB, and CAER-S datasets. The impact of different network structures and decision-level fusion strategies were discussed. The experimental results demonstrated that the FER rates achieved 88.73%, 88.46%, and 88.52% on three datasets, respectively. Compared with other state-of-the-art methods on three datasets, the proposed ensemble framework had a higher recognition rate, and improved the performance of facial expression recognition in the wild. The ablation experiments and visualization results based on Grad-CAM indicate that the proposed ensemble framework not only focused the decision-level semantics of key regions, but also addressed the whole face for the absence of regional semantics under occlusions and posture variations.
The advantages of our proposed method are as follows:
- (1)
- The pipeline for face alignment and facial key region location was designed. The designed pipeline can suppress redundant information in the input image and improve the anti-interference ability of facial regions.
- (2)
- The SMR block, which symmetrically constructs a hierarchical residual-like connection from two directions in a basic block, was improved. The proposed block represents the multi-scale feature of fine-grained level and can further expand the receptive field range of each network layer.
- (3)
- The SMResNet ensemble, which is composed of three SMResNets, is constructed for decision-level semantics extraction of the whole face, eye, and mouth regions. The ensemble framework not only focuses on the decision-level semantics of key regions, but also addresses the whole face, thus perceiving the semantics transmitted by incomplete faces under occlusions and posture variations.
- (4)
- The WEF strategy for decision-level semantic fusion was proposed based on D-S evidence theory. The proposed strategy minimizes the influence of evidence with a small weight on the decision-making judgment, and reduces conflicting information between evidence to satisfy the decision-level fusion of three regional pieces of evidence.
Although the proposed network ensemble focused on comprehensive information by cropping facial and two key regions to achieve a good recognition rate, the current network ensemble, which extracts facial features with different receptive fields and fuses regional decision-level semantics with WEF strategy, was mainly addressed to the image-based FER. With the emergence of multimedia technology, exploring multi-modal compensation mechanisms for robustness in the interference environment and improving SMResNet with contextual temporal attention for video-based FER is our next step.
Author Contributions
Conceptualization, J.L., M.H., Y.W. and Z.H.; methodology and investigation, J.L., Y.W., Z.H. and J.J.; resources, J.L., Y.W. and M.H.; writing—original draft preparation, J.L., M.H., Y.W. and Z.H.; writing—review and editing, J.L., M.H., Z.H. and J.J.; supervision, M.H. and J.J.; project administration, J.L., Y.W. and M.H.; funding acquisition, J.L., M.H., Z.H. and J.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under grant 62176084, the Natural Science Foundation of Anhui Province of China under Grant 1908085MF195 and 2008085MF193, and the Natural Science Research Project of the Education Department of Anhui Province under Grant 2022AH051038 and KJ2020A0508.
Data Availability Statement
Not applicable.
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under grant 62176084, the Natural Science Foundation of Anhui Province of China under Grant 1908085MF195 and 2008085MF193, and the Natural Science Research Project of the Education Department of Anhui Province under Grant 2022AH051038 and KJ2020A0508. We acknowledge the use of the facilities and equipment provided by the Hefei University of Technology. We would like to thank every party stated above for providing help and assistance in this research.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
A list of all acronyms:
| Basic probability assignment | BPA |
| Convolutional neural networks | CNNs |
| Deep convolutional neural network | DCNN |
| Dempster–Shafer | D-S |
| D-S combination rules | DCRs |
| Facial expression recognition | FER |
| Feature-level ensemble parallel network | FLEPNet |
| Full connection | FC |
| Global average pooling | GAP |
| Gradient-weighted class activation mapping | Grad-CAM |
| Histogram of oriented gradient | HOG |
| Local binary pattern | LBP |
| Principal component analysis | PCA |
| Region of interest | ROI |
| Regional attention network | RAN |
| Support vector machine | SVM |
| Symmetric multi-scale residual network | SMResNet |
| Weighted evidence fusion | WEF |
References
- Tong, X.Y.; Sun, S.L.; Fu, M.X. Adaptive Weight based on Overlapping Blocks Network for Facial Expression Recognition. Image Vision Comput. 2022, 120, 104399. [Google Scholar] [CrossRef]
- Khan, S.; Chen, L.; Yan, H. Co-clustering to Reveal Salient Facial Features for Expression Recognition. IEEE Trans. Affect. Comput. 2020, 11, 348–360. [Google Scholar] [CrossRef]
- Zhao, Y.; Xu, J. An Improved Micro-Expression Recognition Method Based on Necessary Morphological Patches. Symmetry 2019, 11, 497. [Google Scholar] [CrossRef]
- Zhang, Z.Y.; Sun, X.; Li, J. MAN: Mining Ambiguity and Noise for Facial Expression Recognition in the Wild. Pattern. Recognit. Lett. 2022, 164, 23–29. [Google Scholar] [CrossRef]
- Tang, Y.; Pan, Z.; Pedrycz, W.; Ren, F.; Song, X. Viewpoint-based Kernel Fuzzy Clustering with Weight Information Granules. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 342–356. [Google Scholar] [CrossRef]
- Tang, Y.; Huang, J.; Pedrycz, W.; Li, B.; Ren, F. A Fuzzy Cluster Validity Index Induced by Triple Center Relation. IEEE Trans. Cybern. 2023. [Google Scholar] [CrossRef]
- Ma, F.; Sun, B.; Li, S. Robust Facial Expression Recognition with Convolutional Visual Transformers. arXiv 2021, arXiv:2103.16854. [Google Scholar] [CrossRef]
- Liu, C.; Hirota, K.; Dai, Y.P. Patch Attention Convolutional Vision Transformer for Facial Expression Recognition with Occlusion. Inform. Sci. 2023, 619, 781–794. [Google Scholar] [CrossRef]
- Jiang, B.; Zhang, Q.W.; Li, Z.H.; Wu, Q.G.; Zhang, H.L. Non-frontal Facial Expression Recognition based on Salient Facial Patches. EURASIP J. Image Video Process. 2021, 2021, 15. [Google Scholar] [CrossRef]
- Majumder, A.; Behera, L.; Subramanian, V.K. Automatic Facial Expression Recognition System using Deep Network-based Data Fusion. IEEE Trans. Cybern. 2018, 48, 103–114. [Google Scholar] [CrossRef]
- Lopes, A.T.; Aguiar, E.D.; Souza, A.F.D.; Oliveira-Santos, T. Facial Expression Recognition with Convolutional Neural Networks: Coping with Few Data and the Training Sample Order. Pattern. Recogn. 2017, 61, 610–628. [Google Scholar] [CrossRef]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion Aware Facial Expression Recognition using CNN with Attention Mechanism. IEEE Trans. Image Process. 2019, 28, 2439–2450. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J. Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Q.; Wang, S. Learning Deep Global Multi-Scale and Local Attention Features for Facial Expression Recognition in the Wild. IEEE Trans. Image Process. 2021, 30, 6544–6554. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergusr, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; pp. 818–833. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Philip, T. Res2Net: A New Multi-scale Backbone Architecture. IEEE Trans. Patten. Anal. 2021, 43, 652–662. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, Q.S.; Peng, Y.; Liu, B.; Metaxas, D.N. Learning Active Facial Patches for Expression Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2562–2569. [Google Scholar] [CrossRef]
- Yovel, G.; Duchaine, B. Specialized Face Perception Mechanisms Extract both Part and Spacing Information: Evidence from Developmental Prosopagnosia. J. Cogn. Neurosci. 2006, 18, 580–593. [Google Scholar] [CrossRef]
- Pons, G.; Masip, D. Supervised Committee of Convolutional Neural Networks in Automated Facial Expression Analysis. IEEE Trans. Affect. Comput. 2018, 9, 343–350. [Google Scholar] [CrossRef]
- Wen, G.; Zhi, H.; Li, H.; Li, D.; Xun, E. Ensemble of Deep Neural Networks with Probability-based Fusion for Facial Expression Recognition. Cogn. Comput. 2017, 9, 5155. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2022, 13, 1195–1215. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L.; Li, Z.; Ding, L. Improved Fuzzy Bayesian Network-Based Risk Analysis with Interval-Valued Fuzzy Sets and D–S Evidence Theory. IEEE Trans. Fuzzy. Syst. 2020, 18, 2063–2077. [Google Scholar] [CrossRef]
- Liu, X.; Liu, S.; Xiang, J.; Sun, R. A Conflict Evidence Fusion Method based on the Composite Discount Factor and the Game Theory. Inform. Fusion. 2023, 94, 281–296. [Google Scholar] [CrossRef]
- Turan, C.; Neergaard, K.D.; Lam, K.M. Facial Expressions of Comprehension (FEC). IEEE Trans. Affect. Comput. 2022, 13, 335–346. [Google Scholar] [CrossRef]
- Saurav, S.; Saini, R.; Singh, S. Facial Expression Recognition using Dynamic Local Ternary Patterns with Kernel Extreme Learning Machine Classifier. IEEE Access 2021, 9, 120844–120868. [Google Scholar] [CrossRef]
- Verma, K.; Khunteta, A. Facial Expression Recognition using Gabor Filter and Multi-layer Artificial Neural Network. In Proceedings of the International Conference on Information, Communication, Instrumentation and Control, Indore, India, 17–19 August 2017; pp. 1–5. [Google Scholar]
- He, Y.; Chen, S. Person-Independent Facial Expression Recognition based on Improved Local Binary Pattern and Higher-Order Singular Value Decomposition. IEEE Access 2020, 8, 190184–190193. [Google Scholar] [CrossRef]
- Wang, H.; Wei, S.; Fang, B. Facial Expression Recognition using Iterative Fusion of MO-HOG and Deep Features. J. Supercomput. 2020, 76, 3211–3221. [Google Scholar] [CrossRef]
- Rouast, P.V.; Adam, M.; Chiong, R. Deep Learning for Human Affect Recognition: Insights and New Developments. IEEE Trans. Affect. Comput. 2021, 12, 524–543. [Google Scholar] [CrossRef]
- Fan, Y.R.; Li, V.O.K.; Lam, J.C.K. Facial Expression Recognition with Deeply-Supervised Attention Network. IEEE Trans. Affect. Comput. 2022, 13, 1057–1071. [Google Scholar] [CrossRef]
- Vasudha; Kakkar, D. Facial Expression Recognition with LDPP & LTP using Deep Belief Network. In Proceedings of the International Conference on Signal Processing and Integrated Networks, Noida, India, 22–23 February 2018; pp. 503–508. [Google Scholar] [CrossRef]
- Chen, L.; Su, W.; Wu, M.; Pedrycz, W.; Hirota, K. A Fuzzy Deep Neural Network with Sparse Autoencoder for Emotional Intention Understanding in Human–Robot Interaction. IEEE Trans. Fuzzy Syst. 2020, 28, 1252–1264. [Google Scholar] [CrossRef]
- Lee, J.; Kim, S.; Kim, S.; Sohn, K. Multi-Modal Recurrent Attention Networks for Facial Expression Recognition. IEEE Trans. Image Process. 2020, 29, 6977–6991. [Google Scholar] [CrossRef]
- Hajarolasvadi, N.; Ramírez, M.A.; Beccaro, W.; Demirel, H. Generative Adversarial Networks in Human Emotion Synthesis: A Review. IEEE Access 2020, 8, 218499–218529. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Choi, J.Y.; Lee, B. Combining Deep Convolutional Neural Networks with Stochastic Ensemble Weight Optimization for Facial Expression Recognition in the Wild. IEEE Trans. Multimed. 2023, 25, 100–111. [Google Scholar] [CrossRef]
- Karnati, M.; Seal, A.; Yazidi, A.; Krejcar, O. FLEPNet: Feature Level Ensemble Parallel Network for Facial Expression Recognition. IEEE Trans. Affect Comput. 2022, 13, 2058–2070. [Google Scholar] [CrossRef]
- Georgescu, M.I.; Ionescu, R.T.; Popescu, M. Local Learning with Deep and Handcrafted Features for Facial Expression Recognition. IEEE Access 2019, 7, 64827–64836. [Google Scholar] [CrossRef]
- Baumgartner, S.; Huemer, M.; Lunglmayr, M. Efficient Majority Voting in Digital Hardware. IEEE Trans. Circuits-II: Express Briefs 2022, 69, 2266–2270. [Google Scholar] [CrossRef]
- Zhao, G.; Chen, A.; Lu, G.; Liu, W. Data Fusion Algorithm based on Fuzzy Sets and D-S Theory of Evidence. Tsinghua Sci. Technol. 2020, 25, 12–19. [Google Scholar] [CrossRef]
- Gao, S.; Deng, Y. An Evidential Evaluation of Nuclear Safeguards. Int. J. Distrib. Sens. Netw. 2019, 15, 12–19. [Google Scholar] [CrossRef]
- Xiao, F. Multi-sensor Data Fusion based on the Belief Divergence Measure of Evidences and the Belief Entropy. Inform. Fusion. 2019, 46, 23–32. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, S. An Uncertainty Measure for Interval-Valued Evidences. Int. J. Comput. Commun. 2017, 12, 631–644. [Google Scholar] [CrossRef]
- Martinez, B.; Valstar, M.F.; Jiang, B.; Pantic, M. Automatic Analysis of Facial Actions: A Survey. IEEE Trans. Affect. Comput. 2019, 10, 325–347. [Google Scholar] [CrossRef]
- Zhang, J.; Kan, M.; Shan, S. Occlusion-free Face Alignment: Deep Regression Networks Coupled with De-corrupt Autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3428–3437. [Google Scholar] [CrossRef]
- Barsoum, E.; Zhang, C.; Ferrer, C. Training Deep Networks for Facial Expression Recognition with Crowd-sourced Label Distribution. In Proceedings of the International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 279–283. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Reliable Crowdsourcing and Deep Locality Preserving Learning for Unconstrained Facial Expression Recognition. IEEE Trans. Image Process. 2019, 28, 356–370. [Google Scholar] [CrossRef]
- Lee, J.; Kim, S.; Park, J. Context-aware Emotion Recognition Networks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10143–10152. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2983–2991. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing Uncertainties for Large-scale Facial Expression Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 13–19 June 2020; pp. 6897–6906. [Google Scholar] [CrossRef]
- Zeng, J.; Shan, S.; Chen, X. Facial Expression Recognition with Inconsistently Annotated Datasets. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 222–237. [Google Scholar] [CrossRef]
- Li, Y.; Lu, Y.; Li, J.; Lu, G. Separate Loss for Basic and Compound Facial Expression Recognition in the Wild. In Proceedings of the Asian Conference on Machine Learning, Nagoya, Japan, 17–19 November 2019; pp. 897–911. [Google Scholar]
- Chen, S.; Wang, J.; Chen, Y.; Shi, Z.; Geng, X.; Rui, Y. Label Distribution Learning on Auxiliary Label Space Graphs for Facial Expression Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 13–19 June 2020; pp. 13984–13993. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).