Abstract
As efficient separation of variables plays a central role in model reduction for nonlinear and nonaffine parameterized systems, we propose a stochastic discrete empirical interpolation method (SDEIM) for this purpose. In our SDEIM, candidate basis functions are generated through a random sampling procedure, and the dimension of the approximation space is systematically determined by a probability threshold. This random sampling procedure avoids large candidate sample sets for high-dimensional parameters, and the probability based stopping criterion can efficiently control the dimension of the approximation space. Numerical experiments are conducted to demonstrate the computational efficiency of SDEIM, which include separation of variables for general nonlinear functions, e.g., exponential functions of the Karhu nen–Loève (KL) expansion, and constructing reduced order models for FitzHugh–Nagumo equations, where symmetry among limit cycles is well captured by SDEIM.
1. Introduction
When conducting model reduction for nonlinear and nonaffine parameterized systems [1], separation of variables is an important step. During the last few decades, many strategies have been developed to achieve this goal, e.g., empirical interpolation methods (EIM) [2,3,4,5], discrete empirical interpolation methods (DEIM) [6,7], and variable-separation (VS) methods [8]. To result in an accurate linear representation, these methods typically need a fine reduced basis approximation space. To construct the corresponding basis functions, repeated evaluations of expensive parameterized systems are required. The accuracy of the EIM/DEIM approximations depends on candidate parameter samples. Properly choosing the samples is crucial and is especially challenging when the parameter space is high dimensional.
For reduced basis approximations [9,10,11,12,13,14], the work in [15] shows that candidate sample sets for reduced bases can be chosen as a random set of a specified order and the resulting approximation satisfies given accuracies with a probability threshold. Rather than reduced basis approximations, we in this paper focus on separation of variables for nonlinear and nonaffine systems, and propose a stochastic discrete empirical interpolation method (SDEIM). In our SDEIM, the interpolation is processed through two steps: the first is to randomly select sample points to construct an approximation space for empirical interpolation, and the second is to evaluate if the approximation accuracy meets the probability threshold on additional samples. These two steps are repeated until the approximation space satisfies the given accuracy and probability requirements. The probability correctness of the approximation space is reassessed by SDEIM each time the approximation space is updated. We note that SDEIM does not loop over a fine candidate sample set, which significantly reduces the computational cost for empirical interpolation for high-dimensional systems. To demonstrate the efficiency of SDEIM, we utilize it to approximate test functions including the exponential functions of the Karhu nen–Loève (KL) expansion, which is widely used to parameterize random fields. Finally, we use SDEIM to solve ordinary differential equations (ODEs) arising from the FitzHugh–Nagumo (F–N) system [6,16], and all these results show that SDEIM is efficient. It is worth noting that many natural phenomena can have symmetric properties, and symmetry of limit cycles of the F-N system is well captured by SDEIM.
An outline of the paper is as follows. We first present our problem setting, and then review the fine collateral reduced-basis approximation space and EIM in Section 2. After a short introduction of the discrete form, we present SDEIM and analyze its performance in Section 3. Numerical results are discussed in Section 4. Finally, we conclude the paper in Section 5.
2. Problem Formulation
Nonlinear terms and functions in complex systems cause significant difficulties for efficient model reduction, and separation of variables is typically required. In this section, we refer to nonlinear functions under consideration as the target functions. Let (for or 3) be a bounded, connected physical domain and be a high dimensional parameter space. The target function with a general form is written as
The target function is assumed to be nonlinear. In the following, we review EIM [2], which is to approximate with a separate representation for x and .
2.1. The Linear Approximation Space
Before introducing EIM, we first introduce its fine collateral reduced-basis approximation space following [2,6,17,18]. Without loss of generality, we assume that the target function is uniquely defined in some Hilbert space for every . An inner product and a norm of are denoted as and . We define the target manifold as
when the target manifold has a low dimension, a low dimensional linear space can approximate it well. The infimum of the supremum distance between the n-dimensional linear approximation space and the target manifold is called the Kolmogorov n-width [3,19], which is defined as
Here, denotes the orthogonal projection onto , where is an arbitrary linear space, i.e.,
Moreover, from (2) we can get the property
Since the orthogonal projection is linear, (3) means that the error is reduced after the orthogonal projection. However, the space satisfying (1) is nontrivial to reach. The work in [20] has proposed a specific greedy procedure for constructing this n dimensional linear approximation space which optimizes
instead of in a sufficiently fine candidate sample set . Since the candidate set contains a finite number of samples, optimizing is equivalent to search such that
Then, we update the linear approximation space for this target function . A greedy procedure which constructs a linear approximation space satisfying , where is a given tolerance, can be stated as follows. First this procedure initializes the linear approximation space . Then, it selects a new parameter value by
If the error
is greater than , we update the linear approximation space . At the end of this procedure, the linear approximation space is set to and satisfies for all . Moreover, that the candidate sample set is sufficiently fine means that the discrete target manifold
is a -approximation net for target manifold , i.e.,
The inequality (6) means that the standard greedy procedure with a fine candidate sample set can generate a linear approximation space which approximates the target manifold with any tolerance .
2.2. Empirical Interpolation Method (EIM)
Section 2.1 explains that, when the candidate sample set is fine enough, the greedy procedure can produce a linear approximation space which is a -approximation space for the original target manifold , i.e.,
For this linear approximation space , if we denote a set of orthonormal basis functions of as , the orthogonal projection can be expressed as
Here, are the coefficients corresponding to the basis function . Since the basis functions are orthonormal, the coefficient can be calculated by
However, in order to get the coefficient in (9), we need to evaluate an integration with target function , which is inconvenient.
The interpolation method [2,18,21] is widely used in function approximation. It approximates the target function by restricting the values of this function on n interpolation points . If we denote the approximation function as , the restrictions are
In addition, if we approximate the target function using interpolation methods in a linear approximation space , and denote it as , then (8) and (10) can be written as
Here, , , are the unknown coefficients. Moreover, we denote the matrix as
Then, the coefficient satisfying (11) is the solution of the linear system
Compared with (9), which is evaluated by the interpolation method (12) avoids the integration and only needs to know the value of target function on n interpolation points . The target function can then be approximated by
where the coefficients are the solution of (12). Then, (13) naturally satisfies the restriction (11) by the definition of the coefficients .
In EIM [2,3,17,21], systematical approaches to choose suitable interpolation points are given. Here, approximation basis functions and interpolation points are typically obtained alternately by minimizing the error between the target function and its approximation function , of which the produce can be summarized as follows. First, we initialize , and select a new parameter value as
For the parameter value , if the error
is greater than , the linear approximation space is updated as . Then, we orthonormalize the target function with the basis functions by Schmidt orthogonalization for numerical stability and denote it as , i.e.,
where are the coefficients of the projection of over . The next interpolation point is selected by maximizing the absolute value of the error , i.e.,
The above procedure is repeated until the error (see (14)) for all , and we denote for the final step. The relationship between the error and are discussed in [2] (see [6] for its discrete version).
3. Discrete Empirical Interpolation Method and Its Stochastic Version
We evaluate the values of on a discrete physical domain, that is, computing a vector function
where with components is the discrete version of on physical points . The number of discrete points is usually large to meet certain appropriation accuracy. On the other hand, since the physical domain has been discretized, selecting interpolation points is to find proper indices from . If denote the indices of the interpolation points and denote the matrix of interpolation points defined as
with the i-th canonical unit vector, the values of target function on the interpolation points can be written as . As a result, the corresponding interpolation only needs the values of on components with .
3.1. Discrete Empirical Interpolation Method (DEIM)
Before presenting our stochastic discrete empirical interpolation method, we here review the original DEIM [6]. In the discrete formulation, a linear approximation space can be expressed as
which is an approximation of the discrete target manifold
Denoting a set of orthonormal basis functions of this linear approximation space by , and denoting the matrix of basis functions by , the approximation of the target function corresponding to (8) can be written as
where is the coefficient. The restriction of interpolation points corresponding to (13) is
which gives . Then, it can naturally derive
By the way is obtained, the values of the approximation function are equal to the target function on the components for any , i.e., . Moreover, the calculation of the new matrix of basis functions is required once only. For a new realization , DEIM only computes the values of the target function on the components as the new coefficient .
The procedure of DEIM to construct a linear approximation space and select interpolation points can be stated as follows. For a fine candidate sample set , it first chooses
where is the vector norm for a discrete function. Then, we orthonormalize as and denote with
The index of the first interpolation point is initialized as
and we let . For the -th basis function and interpolation point, a parameter value is chosen from the candidate sample set by finding the maximum error between the target function and its approximation in the linear approximation space , i.e.,
If the error is greater than a given tolerance , we orthonormalize with by Schmidt orthogonalization and denote it as , that is,
Then, the matrix of basis functions is updated as . The residual of interpolation projecting to the linear approximation space can be written as
An index of -th interpolation point is selected by finding the maximum component of residual , i.e.,
and we update . Finally, we denote , and . This linear approximation space then satisfies
The whole procedure is stated in Algorithm 1, where means the error in (14) or its discrete form (17).
| Algorithm 1 Discrete empirical interpolation method (DEIM) [6] |
| Input: A candidate sample set and a target function . |
| 1: Initialize and orthonormalize as . |
| 2: Initialize . |
| 3: Initialize and . |
| 4: while do |
| 5: Compute the error for , . |
| 6: Let . |
| 7: Compute through orthonormalizing with by (18). |
| 8: Solve the equation for . |
| 9: Compute the residual . |
| 10: Select the interpolation index as . |
| 11: Update and . |
| 12: end while |
| Output: The matrix of basis functions and the matrix of interpolation points . |
3.2. Stochastic Discrete Empirical Interpolation Method (SDEIM)
For standard EIM (or DEIM), to satisfy the -approximation (see (7)), the candidate sample set typically needs to be fine enough (i.e., the condition (5) holds). However, if the size of is large, it can be expensive to construct the DEIM approximation (15). In this section, we propose a stochastic discrete empirical interpolation method (SDEIM). In SDEIM, we accept the approximation with probability instead of giving a threshold with certainty, and we then avoid fine candidate sample sets. We note that a weight EIM strategy is developed in [4], while the purpose of our work is to give a stochastic criterion for updating training sets.
Our problem formulation is still to approximate the target manifold with a linear approximation space , such that it satisfies
However, assuming that a probability measure exists in the parameter space , we herein do not ensure for all , but concern about the failure probability
which measures the size of the parameter set where the approximation is not accurate enough. While the probability p can hardly be exactly evaluated, we evaluate its empirical probability among N samples
where is the indicator function defined as
The probability (22) is to calculate the average number of occurrences of on N samples. By the law of large numbers [22], the empirical probability converges to the probability p with probability one as N goes to infinite, i.e.,
Since the implicit constant p reflects the probability that does not satisfy the tolerance , we hope that p is small enough. On the other hand, p can not be evaluated explicitly, and the empirical probability is an approximation of p. In SDEIM, therefore, is set to be small enough. For convenience, we take in the verifying stage and use the sample size N to control the accuracy of to approximate p.
The procedure of SDEIM has two steps: constructing a linear approximation space , and verifying whether the empirical probability for this linear approximation space in N consecutive samples. Our SDEIM algorithm can be described as follows. First, a sample is randomly selected, and the target function is normalized as . The linear approximation space is initialized as and the matrix of basis function is denoted as . The index of the first interpolation point is initialized in the same way as (16) and the matrix of interpolation point is denoted as . Then, the empirical probability is verified for this linear approximation space . We sample N consecutive samples. If one of these N samples makes , we orthonormalize for this sample , find the index of the -th interpolation point as DEIM in (19) and (20) and update . The linear approximation space is updated as and the matrix of the basis function is updated as . Then, the empirical probability is verified again for this linear approximation space . The above steps are repeated alternately until there is a linear approximation space such that for N consecutive samples. Finally, a linear approximation space is obtained, such that the empirical probability for N consecutive samples. Details of SDEIM are stated as Algorithm 2.
| Algorithm 2 Stochastic discrete empirical interpolation method (SDEIM) |
| Input: A constant number N and a target function . |
| 1: Sample randomly. |
| 2: Evaluate the target function and initialize . |
| 3: Initialize . |
| 4: Initialize and . |
| 5: Initialize the counting index . |
| 6: while (if , it means that in verifying stage) do |
| 7: Sample randomly. |
| 8: if error then |
| 9: Set counting index . |
| 10: Compute through orthonormalizing with the by (18). |
| 11: Solve for . |
| 12: Compute the residual . |
| 13: Select the interpolation index as . |
| 14: Update and . |
| 15: else |
| 16: Update . |
| 17: end if |
| 18: end while |
| Output: The matrix of basis functions and the matrix of interpolation points . |
3.3. Performance and Complexity of SDEIM
In SDEIM, we ensure that the empirical probability for N consecutive samples in the verifying stage, i.e., the number of such that is zero in these N consecutive samples. The probability p is adjusted through the samples size N, which affects the accuracy of for approximating p. For any tolerance and sample size N, there is always a linear approximation space such that for N consecutive samples—in the worst case, when the dimension of the linear approximation space , this linear approximation space obviously satisfies the condition.
Although the probability value p cannot be evaluated explicitly, the empirical probability approximates the probability p with probability one as N goes to infinite. Hence, for a given threshold and a confidence , we can consider this question, whether there is
By the law of large numbers, the answer is always correct for a suitable N. Before describing the relationship between N and the probability p, the threshold and the confidence level , we first introduce the Hoeffding’s inequality as Lemma 1.
Lemma 1
(Hoeffding’s inequality [23]). Let random variables be independent and identically distributed with values in the interval and expectation , then for any
The Hoeffding’s inequality characters the relationship between the arithmetic mean and its expectation for bounded random variables. In SDEIM, when a linear approximation space is given, the error can only be greater than tolerance or not greater than for any realization . Hence, the indicator is a random variable taking value of zero or one with expectation . Note that we set the empirical probability in the verifying stage. Then, the problem (23) can be answered with Theorem 1.
Theorem 1.
For any significant level δ () and threshold ε, the linear approximation space is produced by SDEIM with sample size N. Then, if , we have
Proof.
By Lemma 1 and in SDEIM, we have
□
Moreover, the relationship between probability p and the sample size N, the threshold , the confidence , can be explicitly described as Theorem 2.
Theorem 2.
For any significance level δ (), the linear approximation space is produced by SDEIM with sample size N. There is at least confidence satisfying
It means that, if the error estimator in SDEIM is set to , with confidence , we have
and
Proof.
Theorem 2 ensures that the linear approximation space given by the SDEIM algorithm (Agorithm 2), can approximate the target function with the tolerance and the probability threshold . Actually, in Algorithm 2, we reset the counting index each time occurs, which means that there are more than N samples such that . Hence, is a more strict upper bound.
In the procedure of Algorithm 2, the best situation is that n consecutive samples are compared to generate the linear approximation space with dimension and then N samples are compared to verify the error . In this case, the number of comparisons is . The worst situation is that, each sample is found with at the end of the N comparisons for verification and this procedure is repeated n times. It is clear that, the number of comparisons in SDEIM is much smaller than that in standard DEIM, where large training sets typically need to be looped over.
4. Numerical Experiments
In this section, four test problems are considered to show the efficiency of SDEIM. The first one is a nonlinear parameterized function with spatial points in one dimension. The second one is to extend the first experiment to two dimensions. The third one focuses on the property of SDEIM for random fields. The last experiment is a nonlinear ordinary differential equation arising in neuron modeling.
4.1. A Nonlinear Parameterized Function with Spatial Points in One Dimension
Consider a nonlinear parameterized function defined by
where and for a constant T. For a given parameter , the function has the period . Figure 1 plots the function for different and 8. It shows that the target function can have different complexities for different parameter ranges. Let be a uniform grid points in for , and define as
for . Let the range of the parameter be for and let be selected uniformly over with for DEIM. The tolerance is set to and the confidence is set to () for Algorithms 1 and 2.
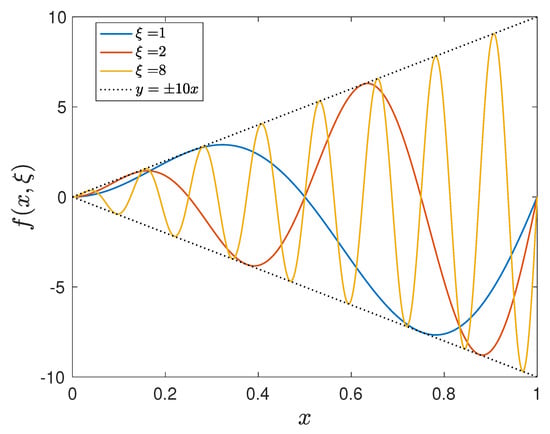
Figure 1.
The parameterized function for and 8.
Figure 2 shows the training procedures for different methods. Figure 2a is the training procedure of SDEIM with threshold . An epoch in Figure 2a is a training procedure for a new realization . The black curve indicates that the error changes in the training procedure. The green point is the first successful sample with . In DEIM, after traversing the candidate sample set, if the sample with the largest error is less than tolerance , the algorithm stops and the linear approximation space satisfies for all . In SDEIM, we continue to find whether there are failed samples (the red crosses) in with . The SDEIM algorithm (Algorithm 2) stops when the samples satisfy for N consecutive samples. In this case, the probability for the appearance of a failed sample is considered to be very low in SDEIM. Figure 2b shows the relationship between the number of comparisons and the average error in the training procedure for SDEIM (with and ) and DEIM, where the average error is computed on samples defined as
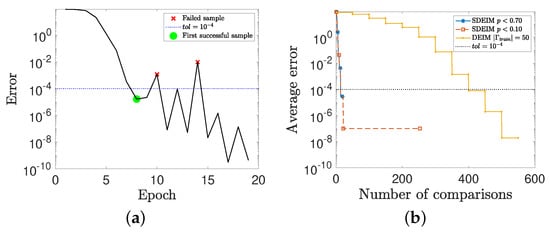
Figure 2.
(a) The training procedure of SDEIM with probability threshold , i.e., , where each epoch is to test a new sample for updating the basis. (b) The relationship between the number of comparisons and the average error in the training procedure for SDEIM (with and ) and DEIM.
Since a basis function is found after searching the candidate sample set in DEIM, its average error decreases in a ladder shape. In SDEIM, errors for an extra N consecutive samples need to be computed, and its numbers of comparisons have a long flat tail.
Table 1 shows more details for the linear approximation space produced by the two methods. The average errors for different methods are computed using (26) with samples and the empirical probabilities are calculated using (22) with the same samples which are the approximation of p. The number of comparisons is the times in different methods to compare the error . From Table 1, it can be seen that since SDEIM does not need to search the sample in a candidate sample set , it has fewer comparisons.

Table 1.
The average error , the number of basis functions n for the approximation space , the empirical probability and the number of comparisons for SDEIM (with and ) and DEIM (with ).
Figure 3a,b show the first six basis functions (i.e., the first six columns of matrix ) for DEIM and SDEIM. Figure 3c shows the samples which generate the basis functions for DEIM and SDEIM. The black dots in Figure 3c are the samples in the candidate sample set , and the black dots circled by the blue circles are the samples selected by DEIM. The numbers above them are the order in which they are selected. The red stars are the samples selected by SDEIM, which are generated in random order. Note that the consecutive samples in DEIM are separated further because they are selected after searching the fine candidate sample set .
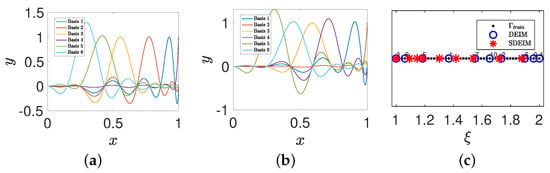
Figure 3.
(a) The first six basis functions for DEIM. (b) The first six basis functions for SDEIM. (c) The samples for generating the basis functions.
4.2. A Nonlinear Parameterized Function with Spatial Points in Two Dimensions
Consider a nonlinear parameterized function defined by
where and for a constant T. Similarly to Section 4.1, for a large (or ), changes more quickly in the (or ) direction. Let be a uniform grid in for , and define as
for . Let the range of the parameter be for . Figure 4 shows the image of for . The tolerance is set to and the confidence is set to for for Algorithms 1 and 2.
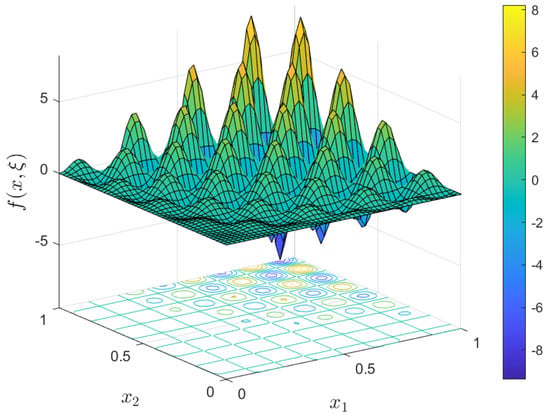
Figure 4.
The parameterized function for .
Figure 5 shows the training procedures for the two methods. Where Figure 5a is the training procedure of SDEIM with threshold . An epoch in Figure 5a is a comparison of the error for a new realization of . The trend of black dots is the trend of errors, which decrease rapidly at early epochs. For these early epochs, the linear approximation space is updated for each realization in this stage. After the first successful sample (the green point with ), the error becomes relatively stable near the . Then, for SDEIM, the linear approximation space is updated only for the failed samples (the red crosses with ), and Algorithm 2 stops when the samples satisfy for N consecutive samples. Figure 5b shows the relationship between the number of comparisons and the average error among samples in the training procedure for SDEIM and DEIM. Compared with DEIM, SDEIM has fewer comparisons.
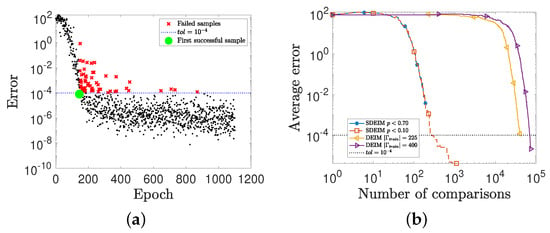
Figure 5.
(a) The training procedure of SDEIM with probability threshold , i.e., , where each epoch is to test a new sample for updating the basis. (b) The relationship between the number of comparisons and the average error in the training procedure for DEIM and SDEIM with different parameters.
Table 2 shows more details for DEIM and SDEIM with different parameters, where the average errors and the empirical probability for different parameters are computed using (22) and (26) on the same samples. It can be seen that the empirical probability for DEIM is similar to that of SDEIM. Moreover, by comparing DEIM with the size of candidate sample set and SDEIM with probability threshold , the number of comparisons for SDEIM is far less than DEIM.
Table 2.
The average error , the number of basis functions n for the approximation space , the empirical probability and the number of comparisons for SDEIM with ( and ) and DEIM with ( and ).
4.3. Random Fields
Consider a nonlinear parameterized function defined by
where and is assumed to be a stochastic process with mean function and covariance function defined as
Here and L is the correlation length. The Karhu nen–Loève (KL) expansion (see [24,25] for details) gives a representation of as
where are the orthonormal eigenfunctions and are the corresponding eigenvalues of the covariance function . Moreover, are mutually uncorrelated random variables. In this example, we truncate the expansion to M terms as our surrogate model according the retaining of the energy for :
where is the parameter in the surrogate model whose distribution is assumed to be a uniform distribution in and M satisfies
Here, is the area of the physical domain and the standard deviation is set to for (27). We focus on the cases and in this experiment, and the corresponding dimensions of the parameter spaces are and respectively. The physical grid is set to a uniform grid with . We consider the nonlinear parameterized function defined by
for , where .
Figure 6a,b show the error for SDEIM with dimensions and for samples respectively. The tolerance is set to , the threshold is set to and the confidence is set to for in Algorithm 2. Here the black points are the samples satisfying and the red crosses are the failed samples satisfying . The empirical probabilities are and , which are both smaller than our probability threshold .
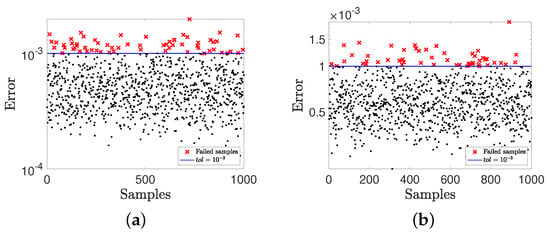
Figure 6.
(a) The error for SDEIM with . (b) The error for SDEIM with . Each point or fork corresponds to a sample of the parameter.
Table 3 shows more details about the property of SDEIM in different parameter settings. The data in Table 3 are calculated with samples and the data in Figure 6 are the first of these samples. From Table 3, it can be seen that for different dimensions of parameter spaces ( and ) and different tolerances (), SDEIM can produce a linear approximation space satisfying different probability thresholds (). Table 4 shows the average number of comparisons for each basis function in SDEIM with different parameter settings. The average number of comparisons is the ratio of the number of comparisons to the number of basis functions for the linear approximation space . It is clear that SDEIM has a very small number of comparisons to generate each basis function.
Table 3.
The empirical probability for different parameter settings in SDEIM.
Table 4.
The average number of comparisons for each basis function in SDEIM with different parameter settings.
4.4. The FitzHugh–Nagumo (F-N) System
This test problem considers the F-N system, which is a simplified model of spiking neuron activation and deactivation dynamics [6,16]. Within the F-N system, the nonlinear function is defined as
where v is the voltage and satisfies the F-N system
with , and . The variable w represents the recovery of voltage, and the variable L is set to . Following the settings in [6], initial and boundary conditions are set to
where the stimulus . We discretize the physical domain using a uniform grid with . The dimension of the finite difference system is 2500. We take 2501 time nodes at evenly in the interval , of which 500 are randomly selected as the candidate sample set for DEIM and SDEIM training, and the remainder are utilized to test the probability features.
The solution of the F-N system has a limit cycle for each spatial variable x, and we display the phase-space diagram of v and w at various spatial positions in Figure 7. Symmetry in the limit cycles of the F-N system is well captured by SDEIM, as seen in Figure 7. Tolerances are set to for solutions and for nonlinear function . The probability of errors exceeding the corresponding tolerances among 1500 verifying samples are depicted in Figure 8a. The probabilities of v converge to a constant value in this case, because the accuracy of the solution v is dependent on the accuracy of the solution w for both DEIM and SDEIM. Figure 8b shows the number of comparisons increases as the number of basis functions increases. The black dotted line represents the number of comparisons in DEIM, which is (n is the number of the basis functions). It is clear that SDEIM is very efficient solve this F-N system.
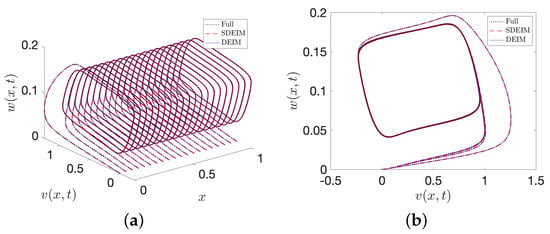
Figure 7.
(a) Phase-space diagram of v and w at different spatial points x from the FD system (), DEIM reduced system () and SDEIM reduced system (). (b) Corresponding projection of the solution onto the plane.
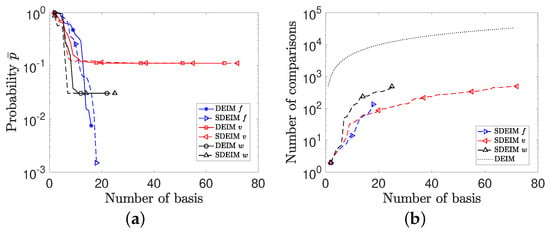
Figure 8.
(a) Probability properties for DEIM reduced system and SDEIM reduced system. (b) The number of comparisons for DEIM reduced system and SDEIM reduced system.
5. Conclusions
Empirical interpolation is a widely used model reduction method for nonlinear and nonaffine parameterized systems through a separate representation of the spatial and the parametric variables. This kind of method typically requires a fine candidate sample set, which can lead to high computational costs. With a focus on randomized computational methods, we in this paper propose a stochastic discrete empirical interpolation method (SDEIM). In SDEIM, large candidate sample sets are replaced by gradually generated random samples, such that the computational costs of constructing the corresponding interpolation formulation can be dramatically reduced. With our analysis, the stopping criterion based on a probability threshold in SDEIM can guarantee the interpolation is accurate with a given confidence. Our numerical results show that this randomized approach is efficient, especially for variable separation for high dimensional nonlinear and nonaffine systems. However, as we use the Hoeffding’s inequality to estimate the failure probability in the verifying stage, SDEIM is efficient when this probability is not too small, but it can be inefficient when the probability is very small. For applying SDEIM to systems which require high reliability, current efforts are focused on combining subset simulation methods, and implementing such strategies will be the focus of our future work.
Author Contributions
Conceptualization, D.C. and Q.L.; methodology, D.C. and Q.L.; software, D.C. and C.Y.; validation, D.C.; writing—original draft preparation, D.C. and C.Y.; writing—review and editing, D.C. and Q.L.; supervision, Q.L.; project administration, Q.L.; funding acquisition, Q.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the Science and Technology Commission of Shanghai Municipality (No. 20JC1414300) and the Natural Science Foundation of Shanghai (No. 20ZR1436200).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Benner, P.; Gugercin, S.; Willcox, K. A survey of projection-based model reduction methods for parametric dynamical systems. SIAM Rev. 2015, 57, 483–531. [Google Scholar] [CrossRef]
- Barrault, M.; Maday, Y.; Nguyen, N.C.; Patera, A.T. An ‘empirical interpolation’ method: Application to efficient reduced-basis discretization of partial differential equations. C. R. Math. 2004, 339, 667–672. [Google Scholar] [CrossRef]
- Maday, Y.; Mula, O. A generalized empirical interpolation method: Application of reduced basis techniques to data assimilation. In Analysis and Numerics of Partial Differential Equations; Springer: Berlin/Heidelberg, Germany, 2013; pp. 221–235. [Google Scholar]
- Chen, P.; Quarteroni, A.; Rozza, G. A weighted empirical interpolation method: A priori convergence analysis and applications. ESAIM Math. Model. Numer. Anal. 2014, 48, 943–953. [Google Scholar] [CrossRef][Green Version]
- Elman, H.C.; Forstall, V. Numerical solution of the parameterized steady-state Navier–Stokes equations using empirical interpolation methods. Comput. Methods Appl. Mech. Eng. 2017, 317, 380–399. [Google Scholar] [CrossRef]
- Chaturantabut, S.; Sorensen, D.C. Nonlinear model reduction via discrete empirical interpolation. SIAM J. Sci. Comput. 2010, 32, 2737–2764. [Google Scholar] [CrossRef]
- Peherstorfer, B.; Butnaru, D.; Willcox, K.; Bungartz, H.J. Localized discrete empirical interpolation method. SIAM J. Sci. Comput. 2014, 36, A168–A192. [Google Scholar] [CrossRef]
- Li, Q.; Jiang, L. A novel variable-separation method based on sparse and low rank representation for stochastic partial differential equations. SIAM J. Sci. Comput. 2017, 39, A2879–A2910. [Google Scholar] [CrossRef]
- Veroy, K.; Rovas, D.V.; Patera, A.T. A posteriori error estimation for reduced-basis approximation of parametrized elliptic coercive partial differential equations: “Convex inverse” bound conditioners. ESAIM Control. Optim. Calc. Var. 2002, 8, 1007–1028. [Google Scholar] [CrossRef]
- Quarteroni, A.; Rozza, G. Numerical solution of parametrized Navier–Stokes equations by reduced basis methods. Numer. Methods Partial Differ. Equ. Int. J. 2007, 23, 923–948. [Google Scholar] [CrossRef]
- Chen, P.; Quarteroni, A.; Rozza, G. Comparison between reduced basis and stochastic collocation methods for elliptic problems. J. Sci. Comput. 2014, 59, 187–216. [Google Scholar] [CrossRef]
- Jiang, J.; Chen, Y.; Narayan, A. A goal-oriented reduced basis methods-accelerated generalized polynomial chaos algorithm. SIAM/ASA J. Uncertain. Quantif. 2016, 4, 1398–1420. [Google Scholar] [CrossRef]
- Elman, H.C.; Liao, Q. Reduced basis collocation methods for partial differential equations with random coefficients. SIAM/ASA J. Uncertain. Quantif. 2013, 1, 192–217. [Google Scholar] [CrossRef][Green Version]
- Liao, Q.; Lin, G. Reduced basis ANOVA methods for partial differential equations with high-dimensional random inputs. J. Comput. Phys. 2016, 317, 148–164. [Google Scholar] [CrossRef]
- Cohen, A.; Dahmen, W.; DeVore, R.; Nichols, J. Reduced basis greedy selection using random training sets. ESAIM Math. Model. Numer. Anal. 2020, 54, 1509–1524. [Google Scholar] [CrossRef]
- Rocsoreanu, C.; Georgescu, A.; Giurgiteanu, N. The FitzHugh–Nagumo Model: Bifurcation and Dynamics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 10. [Google Scholar]
- Grepl, M.A.; Maday, Y.; Nguyen, N.C.; Patera, A.T. Efficient reduced-basis treatment of nonaffine and nonlinear partial differential equations. ESAIM Math. Model. Numer. Anal. 2007, 41, 575–605. [Google Scholar] [CrossRef]
- Maday, Y.; Stamm, B. Locally adaptive greedy approximations for anisotropic parameter reduced basis spaces. SIAM J. Sci. Comput. 2013, 35, A2417–A2441. [Google Scholar] [CrossRef]
- Temlyakov, V.N. Nonlinear Kolmogorov widths. Math. Notes 1998, 63, 785–795. [Google Scholar] [CrossRef]
- Cuong, N.N.; Veroy, K.; Patera, A.T. Certified real-time solution of parametrized partial differential equations. In Handbook of Materials Modeling; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1529–1564. [Google Scholar]
- Kristoffersen, S. The Empirical Interpolation Method. Master’s Thesis, Institutt for Matematiske Fag, Trondheim, Norway, 2013. [Google Scholar]
- Dudley, R.M. Real Analysis and Probability; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Hoeffding, W. Probability inequalities for sums of bounded random variables. In The Collected Works of Wassily Hoeffding; Springer: Berlin/Heidelberg, Germany, 1994; pp. 409–426. [Google Scholar]
- Ghanem, R.G.; Spanos, P.D. Stochastic Finite Elements: A Spectral Approach; Courier Corporation: Chelmsford, MA, USA, 2003. [Google Scholar]
- Lord, G.J.; Powell, C.E.; Shardlow, T. An Introduction to Computational Stochastic PDEs; Cambridge University Press: Cambridge, UK, 2014; Volume 50. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).