
Reduced-Kernel Weighted Extreme Learning Machine Using Universum Data in Feature Space (RKWELM-UFS) to Handle Binary Class Imbalanced Dataset Classification


Abstract
:1. Introduction
- This work is the first attempt that utilized the Universum data in a Reduced-Kernelized Weighted Extreme Learning Machine (RKWELM)-based classification model to handle the class imbalance problem.
- The Weighted Kernelized Synthetic Minority Oversampling Technique (WKSMOTE) [23] is an oversampling-based classification method in which the synthetic samples are created in the feature space of the Support Vector Machine (SVM). Inspired by WKSMOTE, the proposed work creates the Universum samples in the feature space.
- The proposed method uses the kernel trick to create the Universum samples in the feature space between randomly selected instances of the majority and minority classes.
- In a classification problem, the samples located near the decision boundary contribute more to better training. The creation of Universum samples in feature space ensures that the Universum samples lie near the decision boundary.
2. Related Work
2.1. Universum Learning
2.2. Class Imbalance Learning
2.2.1. Data Level Approach
2.2.2. Algorithmic Approach
2.2.3. Hybrid Approach
2.3. Extreme Learning Machine (ELM) and Its Variants to Handle Class Imbalance Learning
2.3.1. Weighted Extreme Learning Machine (WELM)
- Sigmoid node-based Weighted Extreme Learning Machine
- Gaussian kernel-based Weighted Extreme Learning Machine (KWELM)
2.3.2. Reduced Kernel Weighted Extreme Learning Machine (RKWELM)
2.3.3. UnderBagging-Based Kernel Extreme Learning Machine (UBKELM)
2.3.4. UnderBagging-Based Reduced-Kernelized Weighted Extreme Learning Machine
3. Proposed Method
3.1. Generation of Universum Samples in the Input Space
3.2. Generation of Universum Samples in the Feature Space
3.3. Proposed Reduced-Kernel Weighted Extreme Learning Machine Using Universum Samples in Feature Space (RKWELM-UFS)
3.3.1. Computation of
3.3.2. Computation of
3.3.3. Computation of
| Algorithm 1 Pseudocode of the proposed RKWELM-UFS |
| INPUT: Training Dataset |
| Number of Universum samples to be generated: p |
| OUTPUT: |
| 1: Calculate the kernel matrix as shown in Equation (24) for the N number of original training instances using Equation (21). |
| 2: Calculate the kernel matrix as shown in Equation (25) for the N number of training instances and p number of Universum instances as follows. |
| for j = 1 to p |
| Randomly select one majority instance |
| Randomly select one minority instance |
| for i = 1 to N |
| calculate using Equation (22) |
| End |
| End |
| 3: Augment the matrix with the matrix to obtain the reduced kernel matrix using Universum samples shown in Equation (26). |
| 4: To obtain the output weight matrix β use the Equation (23). |
| 5: To determine the class label of an instance x use the Equation (27). |
3.4. Computational Complexity
- The computational complexity of calculating i.e., the kernel matrix shown in Equation (24) is , where n is the number of features of training data in input space.
- The computational complexity of calculating matrix shown in Equation (25) is .
- The computational complexity of the output weights can be calculated as
- 3.1
- Matrix multiplications:Computational complexity:
- 3.2
- Computational complexity of computing the inverse of N × N matrix computed in Step 3.1 is
- 3.3
- Computational complexity of matrix multiplications is
- 3.4
- Computational complexity of matrix multiplication of 2 matrices obtained in Step 3.1 and Step 3.3 is
4. Experimental Setup and Result Analysis
4.1. Dataset Specifications
4.2. Evaluation Matrix
4.3. Parameter Settings
4.4. Experimental Results and Performance Comparison
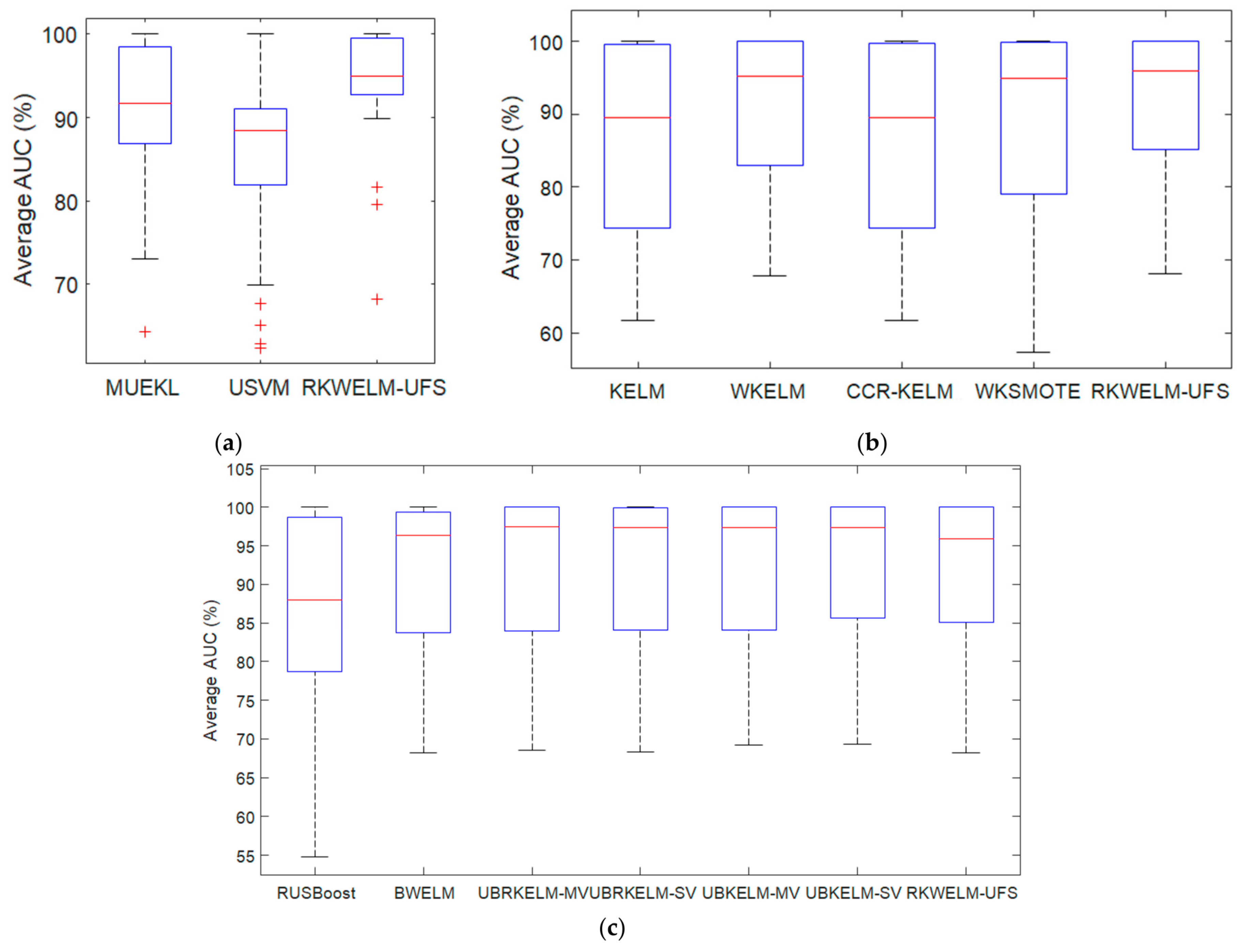
4.4.1. Performance Analysis in Terms of AUC
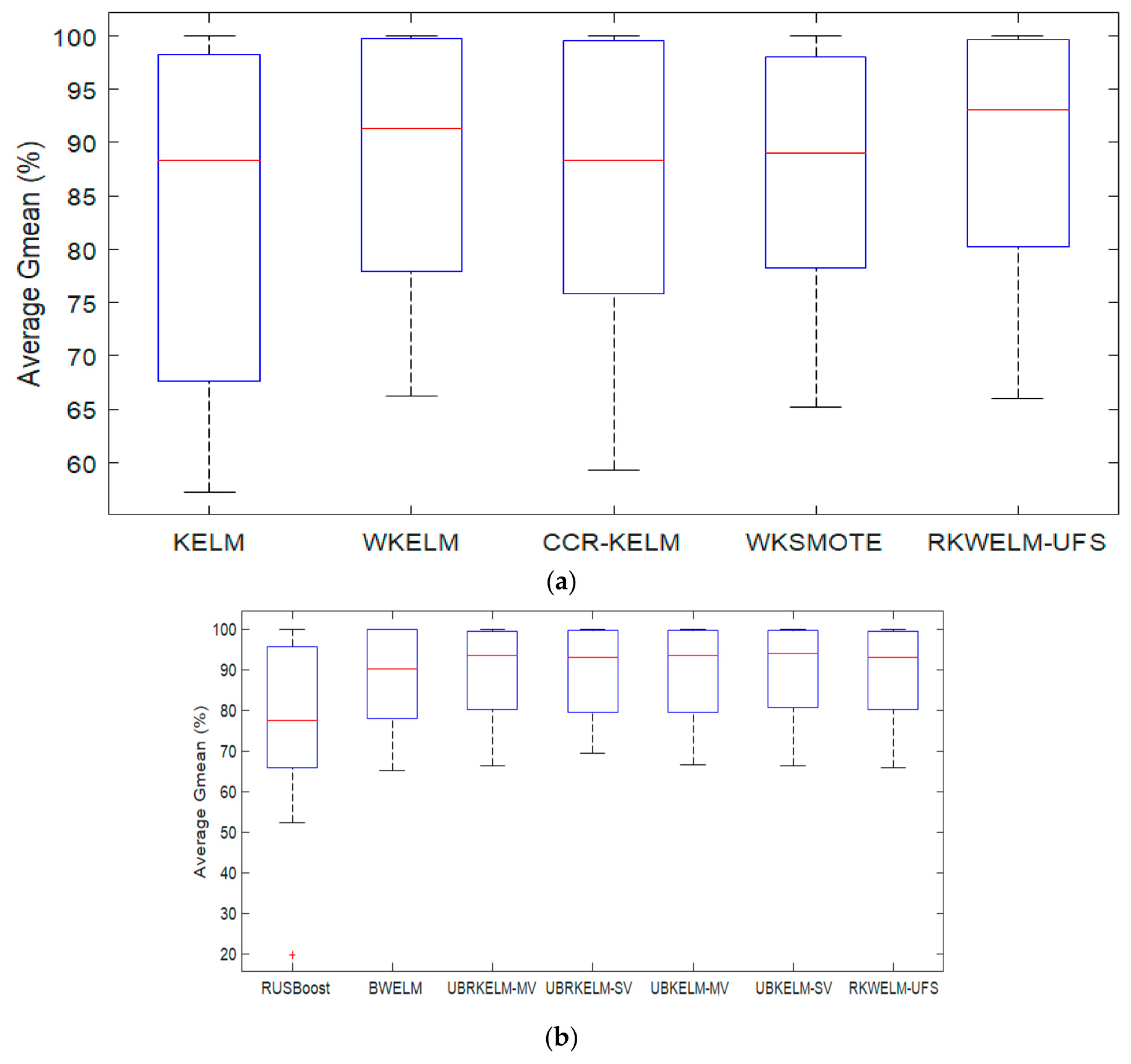
4.4.2. Performance Analysis in Terms of G-mean
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Schaefer, G.; Nakashima, T. Strategies for addressing class imbalance in ensemble classification of thermography breast cancer features. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015; pp. 2362–2367. [Google Scholar]
- Sadewo, W.; Rustam, Z.; Hamidah, H.; Chusmarsyah, A.R. Pancreatic Cancer Early Detection Using Twin Support Vector Machine Based on Kernel. Symmetry 2020, 12, 667. [Google Scholar] [CrossRef] [Green Version]
- Hao, W.; Liu, F. Imbalanced Data Fault Diagnosis Based on an Evolutionary Online Sequential Extreme Learning Machine. Symmetry 2020, 12, 1204. [Google Scholar] [CrossRef]
- Mulyanto, M.; Faisal, M.; Prakosa, S.W.; Leu, J.-S. Effectiveness of Focal Loss for Minority Classification in Network Intrusion Detection Systems. Symmetry 2020, 13, 4. [Google Scholar] [CrossRef]
- Tahvili, S.; Hatvani, L.; Ramentol, E.; Pimentel, R.; Afzal, W.; Herrera, F. A novel methodology to classify test cases using natural language processing and imbalanced learning. Eng. Appl. Artif. Intell. 2020, 95, 103878. [Google Scholar] [CrossRef]
- Furundzic, D.; Stankovic, S.; Jovicic, S.; Punisic, S.; Subotic, M. Distance based resampling of imbalanced classes: With an application example of speech quality assessment. Eng. Appl. Artif. Intell. 2017, 64, 440–461. [Google Scholar] [CrossRef]
- Mariani, V.C.; Och, S.H.; dos Santos Coelho, L.; Domingues, E. Pressure prediction of a spark ignition single cylinder engine using optimized extreme learning machine models. Appl. Energy 2019, 249, 204–221. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Weston, J.; Collobert, R.; Sinz, F.; Bottou, L.; Vapnik, V. Inference with the universum. In Proceedings of the 23rd International Conference on Machine Learning, New York, NY, USA, 25 June 2006; pp. 1009–1016. [Google Scholar]
- Qi, Z.; Tian, Y.; Shi, Y.J. Twin support vector machine with Universum data. Neural Netw. 2012, 36, 112–119. [Google Scholar] [CrossRef]
- Dhar, S.; Cherkassky, V. Cost-sensitive Universum-svm. In Proceedings of the 2012 11th International Conference on Machine Learning and Applications, Boca Raton, FL, USA, 12–15 December 2012; pp. 220–225. [Google Scholar]
- Richhariya, B.; Tanveer, M.J. EEG signal classification using Universum support vector machine. Expert Syst. Appl. 2018, 106, 169–182. [Google Scholar] [CrossRef]
- Qi, Z.; Tian, Y.; Shi, Y. A nonparallel support vector machine for a classification problem with Universum learning. J. Comput. Appl. Math. 2014, 263, 288–298. [Google Scholar] [CrossRef]
- Zhao, J.; Xu, Y.; Fujita, H.J. An improved non-parallel Universum support vector machine and its safe sample screening rule. Knowl. Based Syst. 2019, 170, 79–88. [Google Scholar] [CrossRef]
- Tencer, L.; Reznáková, M.; Cheriet, M.J. Ufuzzy: Fuzzy models with Universum. Appl. Soft Comput. 2017, 59, 1–18. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, S.; Yao, L.; Li, D.; Du, W.; Zhang, J. Multiple universum empirical kernel learning. Eng. Appl. Artif. Intell. 2020, 89, 103461. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Zong, W.; Huang, G.-B.; Chen, Y.J. Weighted extreme learning machine for imbalance learning. Neurocomputing 2013, 101, 229–242. [Google Scholar] [CrossRef]
- Xiao, W.; Zhang, J.; Li, Y.; Zhang, S.; Yang, W. Class-specific cost regulation extreme learning machine for imbalanced classification. Neurocomputing 2017, 261, 70–82. [Google Scholar] [CrossRef]
- Raghuwanshi, B.S.; Shukla, S. Class-specific kernelized extreme learning machine for binary class imbalance learning. Appl. Soft Comput. 2018, 73, 1026–1038. [Google Scholar] [CrossRef]
- Raghuwanshi, B.S.; Shukla, S. Underbagging based reduced kernelized weighted extreme learning machine for class imbalance learning. Eng. Appl. Artif. Intell. 2018, 74, 252–270. [Google Scholar] [CrossRef]
- Raghuwanshi, B.S.; Shukla, S. Class imbalance learning using UnderBagging based kernelized extreme learning machine. Neurocomputing 2019, 329, 172–187. [Google Scholar] [CrossRef]
- Mathew, J.; Pang, C.K.; Luo, M.; Leong, W.H. Classification of imbalanced data by oversampling in kernel space of support vector machines. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 4065–4076. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, C. Selecting informative Universum sample for semi-supervised learning. In Proceedings of the Twenty-First International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 11–17 July 2009. [Google Scholar]
- Zhao, J.; Xu, Y.J. A safe sample screening rule for Universum support vector machines. Knowl. Based Syst. 2017, 138, 46–57. [Google Scholar] [CrossRef]
- Cherkassky, V.; Dai, W. Empirical study of the Universum SVM learning for high-dimensional data. In Proceedings of the International Conference on Artificial Neural Networks, Limassol, Cyprus, 14–17 September 2009; pp. 932–941. [Google Scholar]
- Hamidzadeh, J.; Kashefi, N.; Moradi, M. Combined weighted multi-objective optimizer for instance reduction in two-class imbalanced data problem. Eng. Appl. Artif. Intell. 2020, 90, 103500. [Google Scholar] [CrossRef]
- Lin, W.-C.; Tsai, C.-F.; Hu, Y.-H.; Jhang, J.-S. Clustering-based undersampling in class-imbalanced data. Inf. Sci. 2017, 409, 17–26. [Google Scholar] [CrossRef]
- Ofek, N.; Rokach, L.; Stern, R.; Shabtai, A. Fast-CBUS: A fast clustering-based undersampling method for addressing the class imbalance problem. Neurocomputing 2017, 243, 88–102. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Zhu, T.; Lin, Y.; Liu, Y. Synthetic minority oversampling technique for multiclass imbalance problems. Pattern Recognit. 2017, 72, 327–340. [Google Scholar] [CrossRef]
- Agrawal, A.; Viktor, H.L.; Paquet, E. SCUT: Multi-class imbalanced data classification using SMOTE and cluster-based undersampling. In Proceedings of the 2015 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K), Lisbon, Portugal, 12–14 November 2015; pp. 226–234. [Google Scholar]
- Wang, Z.; Chen, L.; Fan, Q.; Li, D.; Gao, D. Multiple Random Empirical Kernel Learning with Margin Reinforcement for imbalance problems. Eng. Appl. Artif. Intell. 2020, 90, 103535. [Google Scholar] [CrossRef]
- Raghuwanshi, B.S.; Shukla, S. Class-specific extreme learning machine for handling binary class imbalance problem. Neural Netw. 2018, 105, 206–217. [Google Scholar] [CrossRef]
- Guo, W.; Wang, Z.; Hong, S.; Li, D.; Yang, H.; Du, W. Multi-kernel Support Vector Data Description with boundary information. Eng. Appl. Artif. Intell. 2021, 102, 104254. [Google Scholar] [CrossRef]
- Seiffert, C.; Khoshgoftaar, T.M.; Van Hulse, J.; Napolitano, A. RUSBoost: A hybrid approach to alleviating class imbalance. IEEE Trans. Syst. Man Cybern.-Part A Syst. Hum. 2009, 40, 185–197. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Yanan, L.; Xiao, L.; Jinling, L. BPSO-Adaboost-KNN ensemble learning algorithm for multi-class imbalanced data classification. Eng. Appl. Artif. Intell. 2016, 49, 176–193. [Google Scholar] [CrossRef]
- Shen, C.; Wang, P.; Shen, F.; Wang, H. UBoost: Boosting with theUniversum. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 825–832. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.; Abe, N.J. A short introduction to boosting. J. Jpn. Soc. Artif. Intell. 1999, 14, 1612. [Google Scholar]
- Zhang, Y.; Liu, B.; Cai, J.; Zhang, S. Ensemble weighted extreme learning machine for imbalanced data classification based on differential evolution. Neural Comput. Appl. 2017, 28, 259–267. [Google Scholar] [CrossRef]
- Li, K.; Kong, X.; Lu, Z.; Wenyin, L.; Yin, J. Boosting weighted ELM for imbalanced learning. Neurocomputing 2014, 128, 15–21. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.M.; Ding, X.J.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, W.Y.; Ong, Y.S.; Zheng, Q.H. A Fast Reduced Kernel Extreme Learning Machine. Neural Netw. 2016, 76, 29–38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alcala-Fdez, J.; Fernandez, A.; Luengo, J.; Derrac, J.; Garcia, S.; Sanchez, L.; Herrera, F. KEEL Data-Mining Software Tool: Data Set Repository, Integration of Algorithms and Experimental Analysis Framework. J. Mult.-Valued Log. Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Alcala-Fdez, J.; Sanchez, L.; Garcia, S.; del Jesus, M.J.; Ventura, S.; Garrell, J.M.; Otero, J.; Romero, C.; Bacardit, J.; Rivas, V.M.; et al. KEEL: A software tool to assess evolutionary algorithms for data mining problems. Soft Comput. 2009, 13, 307–318. [Google Scholar] [CrossRef]
- Zeng, Y.J.; Xu, X.; Shen, D.Y.; Fang, Y.Q.; Xiao, Z.P. Traffic Sign Recognition Using Kernel Extreme Learning Machines with Deep Perceptual Features. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1647–1653. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Category | Strategy | Method | Basic Idea of the Method |
|---|---|---|---|
| Algorithmic | Cost Sensitive | WELM | This method minimizes the weighted least-square error to handle the class imbalance. |
| CCR-KELM | This method assigns a class-specific regularization parameter to handle class imbalance. | ||
| RKELM | This method uses a reduced number of centroids in kernels function to handle class imbalance | ||
| Data-level | Under-sampling | Random-Under-sampling | This method uses random under-sampling to balance the imbalanced training data. |
| Oversampling | SMOTE | This method creates artificial minority class samples to balance the imbalanced training data. | |
| CSMOTE | This method generates some artificial samples whose dimension is equal to 5 times the number of minority samples. | ||
| Universum | USVM | This method creates Universum data to sift the separating hyper plane of the SVM classifier | |
| MUEKL | This method combines Multiple Empirical Kernel Learning with the Universum learning. | ||
| Hybrid | Data-level combined with Ensemble | RUS-Boost | This method combines RUS with boosting. |
| UBKELM | This method uses random under-sampling with KELM-based ensemble. | ||
| UBRKELM | This method uses random under-sampling with RKELM-based ensemble. | ||
| Cost-sensitive combined with Ensemble | BWELM | This method combines boosting with WELM. | |
| Data-level combined with cost sensitive | RKWELM-UFS (the proposed method) | The proposed method creates a Universum sample in the feature space and uses RKWELM as the classification algorithm. |
| Dataset Name | # Attributes | IR (%) | # Instances | Dataset Name | # Attributes | IR (%) | # Instances |
|---|---|---|---|---|---|---|---|
| abalone9-18 | 8 | 16.70 | 731 | glass6 | 9 | 6.43 | 214 |
| ecoli-01 | 7 | 0.54 | 220 | haberman | 3 | 2.81 | 306 |
| ecoli-013726 | 7 | 43.80 | 281 | iris0 | 4 | 2.00 | 150 |
| ecoli-01235 | 7 | 9.26 | 244 | new-thyroid1 | 5 | 5.14 | 215 |
| ecoli-01465 | 6 | 13.00 | 280 | new-thyroid2 | 5 | 5.14 | 215 |
| ecoli-01472356 | 7 | 10.65 | 336 | page-blocks134 | 10 | 16.14 | 472 |
| ecoli-014756 | 6 | 12.25 | 332 | pima | 8 | 1.87 | 768 |
| ecoli-015 | 6 | 11.00 | 240 | segment0 | 19 | 6.02 | 2308 |
| ecoli-02345 | 7 | 9.06 | 202 | shuttle-c0c4 | 9 | 13.78 | 1829 |
| ecoli-026735 | 7 | 9.53 | 224 | Shuttle-c2c4 | 9 | 24.75 | 129 |
| ecoli-0345 | 7 | 9.00 | 200 | Vehicle0 | 18 | 3.25 | 846 |
| ecoli-03465 | 7 | 9.25 | 205 | Vehicle1 | 18 | 2.91 | 846 |
| ecoli-034756 | 7 | 9.25 | 257 | Vehicle2 | 18 | 2.89 | 846 |
| ecoli-0465 | 6 | 9.13 | 203 | Vehicle3 | 18 | 3.00 | 846 |
| ecoli-06735 | 7 | 9.41 | 222 | vowel0 | 13 | 9.97 | 988 |
| ecoli-0675 | 6 | 10.00 | 220 | wisconsin | 9 | 1.86 | 683 |
| ecoli1 | 7 | 3.39 | 336 | yeast05679vs4 | 8 | 10.00 | 528 |
| Ecoli2 | 7 | 5.54 | 336 | yeast1289vs7 | 8 | 31.00 | 947 |
| glass016vs2 | 9 | 10.00 | 192 | yeast1458vs7 | 8 | 28.00 | 693 |
| glass0123vs456 | 9 | 4.00 | 214 | yeast1vs7 | 7 | 15.00 | 459 |
| glass1 | 9 | 1.85 | 214 | yeast1vs8 | 8 | 24.00 | 482 |
| glass4 | 9 | 16.00 | 214 | yeast3 | 8 | 8.13 | 1484 |
| Dataset | MUEKL Test Result% ± std. | USVM Test Result% ± std. | (KP, C) | RKWELM-UFS Test Result% ± std. |
|---|---|---|---|---|
| abalone9-18 | 75.06 ± 12.53 | 69.92 ± 12.75 | (26, 226) | 94.97 ± 0.52 |
| ecoli-01 | 98.67 ± 1.83 | 97.29 ± 2.5 | (22, 28) | 98.67 ± 0.00 |
| ecoli-01235 | 90.68 ± 17.67 | 85.27 ± 14.45 | (2−2, 2−18) | 92.68 ± 0.00 |
| ecoli013726 | 85.00 ± 22.36 | 92.88 ± 1.63 | (24, 2−2) | 95.99 ± 0.00 |
| ecoli-01465 | 90.00 ± 13.69 | 89.62 ± 11.34 | (210, 250) | 94.34 ± 1.56 |
| ecoli01472356 | 88.00 ± 7.28 | 86.73 ± 9.4 | (22, 26) | 93.95 ± 0.11 |
| ecoli-014756 | 91.51 ± 4.76 | 88.13 ± 4.05 | (212, 242) | 94.93 ± 0.04 |
| ecoli-015 | 91.59 ± 10.77 | 88.41 ± 9.62 | (28, 234) | 95.91 ± 0.04 |
| ecoli-02345 | 93.89 ± 7.89 | 88.93 ± 10.36 | (28, 234) | 94.53 ± 0.08 |
| ecoli-026735 | 86.51 ± 11.9 | 78.82 ± 12.03 | (22, 24) | 90.22 ± 0.09 |
| ecoli-0345 | 92.22 ± 11.73 | 91.11 ± 11.65 | (28, 240) | 91.59 ± 3.29 |
| ecoli-03465 | 91.96 ± 6.76 | 88.24 ± 7.94 | (210, 244) | 97.15 ± 0.07 |
| ecoli-034756 | 94.49 ± 5.20 | 88.40 ± 11.89 | (210, 240) | 95.55 ± 0.00 |
| ecoli-0465 | 92.23 ± 10.97 | 89.19 ± 11.15 | (26, 234) | 94.70 ± 0.06 |
| ecoli-06735 | 89.50 ± 16.97 | 86.00 ± 16.62 | (2−2, 20) | 92.68 ± 0.06 |
| ecoli-0675 | 91.75 ± 7.05 | 87.50 ± 7.55 | (26, 240) | 91.59 ± 0.21 |
| ecoli1 | 90.48 ± 6.29 | 87.16 ± 5.03 | (22, 211) | 93.62 ± 0.29 |
| ecoli2 | 94.31 ± 4.47 | 88.78 ± 5.23 | (20, 28) | 95.35 ± 0.04 |
| glass1 | 79.66 ± 7.41 | 67.64 ± 4.64 | (2−4, 24) | 81.67 ± 0.25 |
| glass6 | 93.06 ± 7.08 | 90.63 ± 6.33 | (26, 210) | 93.41 ± 0.21 |
| haberman | 64.27 ± 4.35 | 62.84 ± 4.56 | (28, 242) | 68.17 ± 0.73 |
| new-thyroid1 | 100.00 ± 0.00 | 96.03 ± 3.7 | (2−4, 224) | 100.00 ± 0.00 |
| new-thyroid2 | 100.00 ± 0.00 | 94.37 ± 4.49 | (28, 242) | 99.98 ± 0.04 |
| page-blocks134 | 84.21 ± 19.45 | 71.49 ± 16.64 | (20, 212) | 100.00 ± 0.00 |
| pima | 73.03 ± 3.11 | 70.16 ± 5.63 | (20, 24) | 79.62 ± 0.05 |
| Segment0 | 99.22 ± 0.90 | 89.02 ± 3.74 | (2−4, 22) | 99.93 ± 0.00 |
| shuttle-c0c4 | 100.00 ± 0.00 | 99.77 ± 0.27 | (22, 2−8) | 100.00 ± 0.00 |
| shuttle-c2c4 | 100.00 ± 0.00 | 100.00 ± 0.00 | (24, 218) | 100.00 ± 0.00 |
| vehicle0 | 99.18 ± 0.66 | 81.28 ± 6.51 | (24, 234) | 99.88 ± 0.13 |
| vehicle1 | 77.43 ± 4.15 | 62.37 ± 5.14 | (26, 232) | 90.26 ± 0.45 |
| vehicle2 | 99.15 ± 0.68 | 83.59 ± 1.52 | (22, 228) | 99.73 ± 0.00 |
| vehicle3 | 76.47 ± 4.81 | 65.08 ± 3.32 | (28, 240) | 89.88 ± 0.25 |
| vowel0 | 100.00 ± 0.00 | 93.61 ± 3.63 | (2−10, 2−18) | 100.00 ± 0.00 |
| wisconsin | 97.99 ± 0.61 | 97.09 ± 1.77 | (212, 242) | 99.08 ± 0.09 |
| yeast3 | 87.72 ± 2.18 | 89.60 ± 2.12 | (210, 238) | 95.09 ± 0.12 |
| Average | 90.26 ± 6.73 | 85.34 ± 6.83 | 94.15 ± 0.25 |
| Dataset | KELM Test Result% | WKELM Test Result% | CCR-KELM Test Result% | WKSMOTE Test Result% | (KP, C) | RKWELM-UFS Test Result% ± std. |
|---|---|---|---|---|---|---|
| abalone9vs18 | 83.81 | 95.24 | 83.81 | 90.91 | (26, 226) | 94.97 ± 0.52 |
| ecoli01vs5 | 89.50 | 92.39 | 89.50 | 96.22 | (28, 234) | 95.91 ± 0.04 |
| glass0123vs456 | 93.84 | 97.03 | 93.84 | 98.86 | (2−2, 24) | 97.66 ± 0.54 |
| glass016vs2 | 81.36 | 84.11 | 81.36 | 83.52 | (216, 240) | 88.25 ± 0.16 |
| glass4 | 88.08 | 93.37 | 88.00 | 94.86 | (28, 236) | 93.34 ± 0.07 |
| haberman | 63.91 | 67.81 | 63.91 | 67.34 | (28, 242) | 68.17 ± 0.73 |
| iris0 | 100.00 | 100.00 | 100.00 | 100.00 | (2−10, 2−18) | 100.00 ± 0.00 |
| newthyroid1 | 99.60 | 100.00 | 99.60 | 99.71 | (2−4, 224) | 100.00 ± 0.00 |
| newthyroid2 | 99.60 | 100.00 | 99.60 | 99.92 | (28, 242) | 99.98 ± 0.04 |
| pageblock13vs4 | 98.00 | 100.00 | 98.00 | 99.96 | (20, 212) | 100.00 ± 0.00 |
| pima | 74.14 | 78.30 | 74.14 | 79.18 | (20, 24) | 79.62 ± 0.05 |
| segment0 | 97.89 | 98.07 | 99.80 | 99.91 | (2−4, 22) | 99.93 ± 0.00 |
| shuttleC0vsC4 | 100.00 | 100.00 | 100.00 | 100.00 | (22, 2−8) | 100.00 ± 0.00 |
| shuttleC2vsC4 | 100.00 | 100.00 | 100.00 | 100.00 | (24, 218) | 100.00 ± 0.00 |
| vowel0 | 100.00 | 100.00 | 100.00 | 57.38 | (2−10, 2−18) | 100.00 ± 0.00 |
| wisconsin | 98.15 | 98.75 | 98.15 | 98.8 | (212, 242) | 99.08 ± 0.09 |
| yeast05679vs4 | 74.54 | 85.72 | 74.54 | 78.8 | (2−2, 26) | 85.63 ± 0.37 |
| yeast1289vs7 | 65.45 | 78.73 | 65.45 | 77.51 | (26, 228) | 79.96 ± 0.66 |
| yeast1458vs7 | 61.76 | 70.63 | 61.76 | 74.91 | (26, 218) | 71.49 ± 0.41 |
| yeast1vs7 | 72.15 | 81.00 | 72.15 | 82.89 | (24, 216) | 83.67 ± 0.10 |
| yeast2vs8 | 79.39 | 83.55 | 79.39 | 85.55 | (2−2, 248) | 85.56 ± 0.00 |
| Average | 86.72 | 90.70 | 86.81 | 88.87 | 91.58 ± 0.18 |
| Dataset | RUSBoost TstR ± std. | BWELM TstR | UBRKELM MV TstR ± std. | UBRKELM SV TstR ± std. | UBKELM MV TstR ± std. | UBKELM SV TstR ± std. | (KP, C) | RKWELM UFS TstR ± std. |
|---|---|---|---|---|---|---|---|---|
| abalone9vs18 | 93.67 ± 0.87 | 94.13 | 96.74 ± 1.21 | 96.84 ± 0.68 | 96.79 ± 0.55 | 96.55 ± 0.50 | (26, 226) | 94.97 ± 0.52 |
| ecoli01vs5 | 93.94 ± 2.37 | 93.94 | 97.53 ± 0.30 | 97.00 ± 0.09 | 94.90 ± 2.34 | 94.13 ± 2.25 | (28, 234) | 95.91 ± 0.04 |
| glass0123vs456 | 97.48 ± 0.72 | 96.57 | 97.61 ± 0.97 | 97.40 ± 0.34 | 97.36 ± 0.80 | 97.35 ± 0.00 | (2−2, 24) | 97.66 ± 0.54 |
| glass016vs2 | 59.25 ± 4.34 | 85.43 | 87.10 ± 1.39 | 87.00 ± 1.40 | 86.07 ± 0.46 | 86.74 ± 1.58 | (216, 240) | 88.25 ± 0.16 |
| glass4 | 96.18 ± 2.78 | 96.37 | 97.51 ± 2.49 | 97.51 ± 1.91 | 97.38 ± 0.19 | 97.83 ± 0.00 | (28, 236) | 93.34 ± 0.07 |
| haberman | 70.38 ± 4.29 | 68.22 | 68.50 ± 0.15 | 68.36 ± 0.22 | 69.25 ± 0.97 | 69.32 ± 1.46 | (28, 242) | 68.17 ± 0.73 |
| iris0 | 54.85 ± 5.12 | 100.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.0 ± 0.0 | (2−10, 2−18) | 100.0 ± 0.0 |
| newthyroid1 | 99.70 ± 0.51 | 100.00 | 100.00 ± 0.00 | 100.00 ± 1.11 | 100.00 ± 0.00 | 100.00 ± 0.00 | (2−4, 224) | 100.00 ± 0.00 |
| newthyroid2 | 99.60 ± 0.21 | 100.00 | 100.00 ± 0.00 | 99.98 ± 0.52 | 100.00 ± 0.00 | 100.00 ± 0.00 | (28, 242) | 99.98 ± 0.04 |
| pageblock13vs4 | 99.86 ± 0.2 | 98.00 | 99.97 ± 1.90 | 99.91 ± 0.13 | 100.00 ± 0.00 | 99.68 ± 0.28 | (20, 212) | 100.00 ± 0.00 |
| pima | 79.91 ± 0.93 | 79.10 | 80.03 ± 1.14 | 80.78 ± 0.48 | 79.87 ± 0.42 | 80.55 ± 0.48 | (20, 24) | 79.62 ± 0.05 |
| segment0 | 100.0 ± 0.0 | 99.89 | 99.95 ± 0.00 | 99.91 ± 0.13 | 99.84 ± 0.00 | 99.64 ± 5.80 | (2−4, 22) | 99.93 ± 0.00 |
| shuttleC0vsC4 | 80.00 ± 6.67 | 99.20 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | (22, 2−8) | 100.00 ± 0.00 |
| shuttleC2vsC4 | 81.91 ± 7.10 | 99.20 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | (24, 218) | 100.00 ± 0.00 |
| vowel0 | 100.00 ± 0.00 | 100.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.0 ± 0.0 | (2−10, 2−18) | 100.0 ± 0.00 |
| wisconsin | 98.37 ± 0.31 | 98.15 | 99.05 ± 0.00 | 98.98 ± 0.14 | 98.72 ± 0.15 | 99.08 ± 0.14 | (212, 242) | 99.08 ± 0.09 |
| yeast05679vs4 | 87.97 ± 1.02 | 84.08 | 86.09 ± 0.30 | 86.25 ± 1.28 | 85.86 ± 0.84 | 88.75 ± 1.07 | (2−2, 26) | 85.63 ± 0.37 |
| yeast1289vs7 | 74.91 ± 1.81 | 78.44 | 80.59 ± 0.84 | 80.60 ± 0.53 | 80.52 ± 0.08 | 80.59 ± 0.07 | (26, 228) | 79.96 ± 0.66 |
| yeast1458vs7 | 65.94 ± 2.14 | 70.72 | 72.77 ± 0.00 | 72.77 ± 1.08 | 72.98 ± 2.11 | 73.08 ± 1.37 | (26, 218) | 71.49 ± 0.41 |
| yeast1vs7 | 86.53 ± 2.05 | 82.89 | 82.90 ± 1.17 | 82.41 ± 0.76 | 84.06 ± 1.29 | 86.09 ± 0.58 | (24, 216) | 83.67 ± 0.10 |
| yeast2vs8 | 79.92 ± 2.45 | 84.42 | 84.32 ± 2.14 | 84.62 ± 1.29 | 84.08 ± 0.12 | 84.35 ± 0.00 | (2−2, 248) | 85.56 ± 0.00 |
| Average | 85.73 ± 2.19 | 90.89 | 91.94 ± 0.67 | 91.92 ± 0.58 | 91.79 ± 0.49 | 92.08 ± 0.74 | 91.58 ± 0.18 |
| Methods Compared | Stats | p | H (0.05) |
|---|---|---|---|
| MUEKL vs. RKWELM-UFS | [−5.610820138186867; −2.152174147527417] | 6.32 × 10−5 | 1 |
| USVM vs. RKWELM-UFS | [−11.440221923933274; −6.167915218923865] | 8.34 × 10−8 | 1 |
| KELM vs. RKWELM-UFS | [−6.93534639982032; −2.78405360017968] | 8.98 × 10−5 | 1 |
| WKELM vs. RKWELM-UFS | [−1.46246304953657; −0.301698855225338] | 4.81 × 10−3 | 1 |
| CCR-KELM vs. RKWELM-UFS | [−6.88366104582675; −2.66145323988753] | 1.33 × 10−4 | 1 |
| WKSMOTE vs. RKWELM-UFS | [−6.99623994510679; 1.56922089748774] | 2.01 × 10−1 | 0 |
| RUSBoost vs. RKWELM-UFS | [−11.4335320049264; −0.266820376026017] | 0.040906 | 1 |
| BWELM vs. RKWELM-UFS | [−1.21328125091469; −0.165166368132924] | 0.012527 | 1 |
| UBRKELM-MV vs. RKWELM-UFS | [−0.169420432040612; 0.87763947965966] | 0.17363 | 0 |
| UBRKELM-SV vs. RKWELM-UFS | [−0.196630485917308; 0.872468581155405] | 0.20219 | 0 |
| UBKELM-MV vs. RKWELM-UFS | [−0.352563193428057; 0.776972717237582] | 0.44236 | 0 |
| UBKELM-SV vs. RKWELM-UFS | [−0.184407389564474; 1.18500738956447] | 0.14312 | 0 |
| Methods Compared | Zval | Signedrank | p-Value | H (0.05) |
|---|---|---|---|---|
| MUEKL vs. RKWELM-UFS | −4.62478463 | 12.00 | 3.75 × 10−6 | 1 |
| USVM vs. RKWELM-UFS | −5.086213249 | 0.00 | 3.65 × 10−7 | 1 |
| KELM vs. RKWELM-UFS | −3.621365173 | 0 | 2.93 × 10−4 | 1 |
| WKELM vs. RKWELM-UFS | 0 | 10 | 2.62 × 10−3 | 1 |
| CCR-KELM vs. RKWELM-UFS | −3.621365173 | 0 | 2.93 × 10−4 | 1 |
| WKSMOTE vs. RKWELM-UFS | −1.763789403 | 45 | 7.78 × 10−2 | 0 |
| RUSBoost vs. RKWELM-UFS | −2.015964161 | 51 | 0.043803724 | 1 |
| BWELM vs. RKWELM-UFS | −2.765775456 | 22 | 0.005678762 | 1 |
| UBRKELM-MV vs. RKWELM-UFS | 1.189301687 | 91 | 0.234320972 | 0 |
| UBRKELM-SV vs. RKWELM-UFS | 0.930757842 | 86 | 0.351978842 | 0 |
| UBKELM-MV vs. RKWELM-UFS | 0 | 73 | 0.488708496 | 0 |
| UBKELM-SV vs. RKWELM-UFS | 1.241010456 | 92 | 0.214601886 | 0 |
| Dataset | KELM Test Result% | WKELM Test Result% | CCR-KELM Test Result% | WKSMOTE Test Result% | (KP, C) | RKWELM-UFS TestResult% ± std. |
|---|---|---|---|---|---|---|
| abalone9vs18 | 72.71 | 89.76 | 76.56 | 91.94 | (26, 226) | 92.23 ± 0.57 |
| ecoli01vs5 | 88.36 | 91.34 | 88.36 | 88.00 | (210, 242) | 93.01 ± 0.11 |
| glass0123vs456 | 93.26 | 95.41 | 93.26 | 94.19 | (2−2, 24) | 96.06 ± 0.55 |
| glass016vs2 | 63.20 | 83.59 | 81.36 | 79.00 | (216, 240) | 84.46 ± 0.50 |
| glass4 | 85.93 | 91.17 | 87.22 | 89.00 | (28, 236) | 91.49 ± 0.14 |
| haberman | 57.23 | 66.26 | 59.71 | 65.21 | (24, 212) | 66.02 ± 0.57 |
| iris0 | 100.00 | 100.00 | 100.00 | 100.00 | (2−10, 2−18) | 100.00 ± 0.00 |
| newthyroid1 | 99.16 | 99.72 | 99.16 | 88.69 | (2−2, 212) | 99.44 ± 0.00 |
| newthyroid2 | 99.44 | 99.72 | 99.44 | 90.72 | (2−6, 2−18) | 99.44 ± 0.00 |
| pageblock13vs4 | 97.89 | 98.07 | 97.84 | 97.38 | (20, 216) | 100.00 ± 0.00 |
| pima | 71.16 | 75.58 | 73.61 | 74.00 | (20, 24) | 75.60 ± 0.19 |
| segment0 | 97.89 | 98.07 | 99.57 | 100.00 | (2−8, 2−18) | 99.54 ± 0.00 |
| shuttleC0vsC4 | 100.00 | 100.00 | 100.00 | 100.00 | (22, 2−8) | 100.00 ± 0.00 |
| shuttleC2vsC4 | 94.14 | 100.00 | 100.00 | 100.00 | (24, 218) | 100.00 ± 0.00 |
| vowel0 | 100.00 | 100.00 | 100.00 | 100.00 | (2−10, 2−18) | 100.00 ± 0.00 |
| wisconsin | 97.22 | 97.70 | 97.18 | 96.33 | (212, 242) | 97.89 ± 0.07 |
| yeast05679vs4 | 68.68 | 82.21 | 82.24 | 81.00 | (2−2, 26) | 81.03 ± 0.47 |
| yeast1289vs7 | 60.97 | 71.41 | 59.28 | 69.83 | (2−2, 20) | 73.35 ± 0.05 |
| yeast1458vs7 | 59.89 | 69.32 | 66.24 | 67.00 | (2−4, 26) | 67.54 ± 0.09 |
| yeast1vs7 | 64.48 | 77.72 | 68.32 | 76.00 | (22, 22) | 77.77 ± 0.15 |
| yeast2vs8 | 77.24 | 77.89 | 78.91 | 80.00 | (20, 226) | 81.36 ± 1.42 |
| Average | 83.28 | 88.81 | 86.11 | 87.06 | 89.74 ± 0.17 |
| Dataset | RUSBoost TstR ± std. | BWELM TstR | UBRKELM MV TstR ± std. | UBRKELM SV TstR ± std. | UBKELM MV TstR ± std. | UBKELM SV TstR ± std. | (KP, C) | RKWELM UFS TstR ± std. |
|---|---|---|---|---|---|---|---|---|
| abalone9vs18 | 86.40 ± 1.33 | 90.12 | 92.28 ± 0.00 | 92.30 ± 0.00 | 91.53 ± 0.96 | 91.07 ± 3.45 | (26, 226) | 92.23 ± 0.57 |
| ecoli01vs5 | 88.92 ± 1.55 | 89.36 | 93.53 ± 0.00 | 93.09 ± 0.09 | 93.63 ± 0.43 | 94.02 ± 1.07 | (210, 242) | 93.01 ± 0.11 |
| glass0123vs456 | 93.74 ± 0.84 | 94.21 | 95.67 ± 0.68 | 95.91 ± 0.51 | 95.24 ± 0.90 | 95.45 ± 0.25 | (2−2, 24) | 96.06 ± 0.55 |
| glass016vs2 | 52.46 ± 3.04 | 84.21 | 84.26 ± 0.50 | 84.42 ± 0.35 | 84.48 ± 0.43 | 83.89 ± 1.29 | (216, 240) | 84.46 ± 0.50 |
| glass4 | 87.31 ± 2.82 | 90.30 | 91.69 ± 2.10 | 91.57 ± 2.86 | 92.91 ± 2.82 | 92.86 ± 3.30 | (28, 236) | 91.49 ± 0.14 |
| haberman | 53.36 ± 7.21 | 65.14 | 66.34 ± 0.13 | 70.20 ± 4.23 | 66.70 ± 0.88 | 66.49 ± 1.50 | (24, 212) | 66.02 ± 0.57 |
| iris0 | 19.85 ± 10.38 | 100.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | (2−10, 2−18) | 100.0 ± 0.0 |
| newthyroid1 | 98.05 ± 0.95 | 100.00 | 99.55 ± 0.20 | 99.61 ± 0.14 | 99.29 ± 0.49 | 99.47 ± 0.13 | (2−2, 212) | 99.44 ± 0.00 |
| newthyroid2 | 96.94 ± 0.91 | 99.72 | 99.44 ± 0.13 | 99.44 ± 0.13 | 99.13 ± 0.00 | 99.30 ± 0.08 | (2−6, 2−18) | 99.44 ± 0.00 |
| pageblock13vs4 | 97.96 ± 1.21 | 99.89 | 99.41 ± 0.12 | 99.91 ± 0.13 | 100.00 ± 0.00 | 100.00 ± 0.00 | (20, 216) | 100.00 ± 0.00 |
| pima | 70.34 ± 1.45 | 75.48 | 76.11 ± 0.21 | 76.22 ± 0.22 | 75.76 ± 0.31 | 75.84 ± 0.34 | (20, 24) | 75.60 ± 0.19 |
| segment0 | 99.99 ± 0.00 | 99.89 | 99.80 ± 0.13 | 99.68 ± 0.28 | 99.63 ± 1.10 | 99.64 ± 5.80 | (2−8, 2−18) | 99.54 ± 0.00 |
| shuttleC0vsC4 | 60.00 ± 13.33 | 100.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | (22, 2−8) | 100.00 ± 0.00 |
| shuttleC2vsC4 | 68.50 ± 15.89 | 100.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | (24, 218) | 100.00 ± 0.00 |
| vowel0 | 100.00 ± 0 | 100.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | (2−10, 2−18) | 100.00 ± 0.00 |
| wisconsin | 95.46 ± 0.77 | 97.18 | 97.81 ± 0.00 | 97.81 ± 0.00 | 97.72 ± 0.20 | 97.79 ± 0.18 | (212, 242) | 97.89 ± 0.07 |
| yeast05679vs4 | 77.55 ± 1.63 | 80.96 | 81.82 ± 1.98 | 82.62 ± 0.09 | 82.24 ± 0.33 | 83.45 ± 2.29 | (2−2, 26) | 81.03 ± 0.47 |
| yeast1289vs7 | 67.83 ± 2.96 | 72.67 | 75.54 ± 0.84 | 75.27 ± 0.12 | 74.28 ± 1.05 | 74.73 ± 1.72 | (2−2, 20) | 73.35 ± 0.05 |
| yeast1458vs7 | 59.59 ± 3.43 | 69.87 | 69.54 ± 1.48 | 69.54 ± 1.74 | 71.24 ± 1.69 | 70.15 ± 1.31 | (2−4, 26) | 67.54 ± 0.09 |
| yeast1vs7 | 73.49 ± 1.79 | 77.72 | 78.90 ± 7.44 | 78.41 ± 0.76 | 77.73 ± 0.00 | 77.90 ± 1.54 | (22, 22) | 77.77 ± 0.15 |
| yeast2vs8 | 72.16 ± 1.83 | 78.35 | 80.77 ± 2.42 | 80.10 ± 0.22 | 80.05 ± 2.44 | 81.69 ± 1.51 | (20, 226) | 81.36 ± 1.42 |
| Average | 77.39 ± 3.59 | 89.34 | 90.08 ± 0.80 | 90.30 ± 0.58 | 90.08 ± 0.58 | 90.10 ± 1.21 | 89.74 ± 0.17 |
| Methods Compared | Stats | p | H (0.05) |
|---|---|---|---|
| KELM vs. RKWELM-UFS | [−8.97586793133104; −3.15547492581182] | 3.12 × 10−4 | 1 |
| WKELM vs. RKWELM-UFS | [−1.10027216529072; 0.0251197843383338] | 6.01 × 10−2 | 0 |
| CCR-KELM vs. RKWELM-UFS | [−5.34275272694909; −1.13049489209853] | 4.44 × 10−3 | 1 |
| WKSMOTE vs. RKWELM-UFS | [−3.63784233634963; −0.927786235078946] | 2.18 × 10−3 | 1 |
| RUSBoost vs. RKWELM-UFS | [−20.961933935114; −3.45036130298126] | 0.0086978 | 1 |
| BWELM vs. RKWELM-UFS | [−1.12033850136527; 0.0575670727938417] | 7.45 × 10−2 | 0 |
| UBRKELM-MV vs. RKWELM-UFS | [−0.0326448040855254; 0.626063851704572] | 0.074868 | 0 |
| UBRKELM-SV vs. RKWELM-UFS | [−0.0440133837744108; 0.984099098060123] | 0.070939 | 0 |
| UBKELM-MV vs. RKWELM-UFS | [−0.207557995239237; 0.715262757143997] | 0.26467 | 0 |
| UBKELM-SV vs. RKWELM-UFS | [−0.0647504586179029; 0.780074268141712] | 0.092621 | 0 |
| Methods Compared | Zval | Signed Rank | p-Value | H (0.05) |
|---|---|---|---|---|
| KELM vs. RKWELM-UFS | −3.723555406 | 0 | 1.96 × 10−4 | 1 |
| WKELM vs. RKWELM-UFS | −1.822772421 | 38 | 6.83 × 10−2 | 0 |
| CCR-KELM vs. RKWELM-UFS | −3.289998425 | 7 | 1.00 × 10−3 | 1 |
| WKSMOTE vs. RKWELM-UFS | −3.479350852 | 3 | 5.03 × 10−4 | 1 |
| RUSBoost vs. RKWELM-UFS | −3.882597643 | 1 | 1.03 × 10−4 | 1 |
| BWELM vs. RKWELM-UFS | −1.917193327 | 36 | 5.52 × 10−2 | 0 |
| UBRKELM-MV vs. RKWELM-UFS | 1.585826579 | 110 | 0.112778655 | 0 |
| UBRKELM-SV vs. RKWELM-UFS | 1.917193327 | 117 | 0.055213376 | 0 |
| UBKELM-MV vs. RKWELM-UFS | 0.723922766 | 82 | 0.469113152 | 0 |
| UBKELM-SV vs. RKWELM-UFS | 1.525663664 | 97.5 | 0.127093648 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choudhary, R.; Shukla, S. Reduced-Kernel Weighted Extreme Learning Machine Using Universum Data in Feature Space (RKWELM-UFS) to Handle Binary Class Imbalanced Dataset Classification. Symmetry 2022, 14, 379. https://doi.org/10.3390/sym14020379
Choudhary R, Shukla S. Reduced-Kernel Weighted Extreme Learning Machine Using Universum Data in Feature Space (RKWELM-UFS) to Handle Binary Class Imbalanced Dataset Classification. Symmetry. 2022; 14(2):379. https://doi.org/10.3390/sym14020379
Chicago/Turabian StyleChoudhary, Roshani, and Sanyam Shukla. 2022. "Reduced-Kernel Weighted Extreme Learning Machine Using Universum Data in Feature Space (RKWELM-UFS) to Handle Binary Class Imbalanced Dataset Classification" Symmetry 14, no. 2: 379. https://doi.org/10.3390/sym14020379
APA StyleChoudhary, R., & Shukla, S. (2022). Reduced-Kernel Weighted Extreme Learning Machine Using Universum Data in Feature Space (RKWELM-UFS) to Handle Binary Class Imbalanced Dataset Classification. Symmetry, 14(2), 379. https://doi.org/10.3390/sym14020379