Abstract
In this paper, a novel smooth group () regularization method is proposed for pruning hidden nodes of the fully connected layer in convolution neural networks. Usually, the selection of nodes and weights is based on experience, and the convolution filter is symmetric in the convolution neural network. The main contribution of is to try to approximate the weights to 0 at the group level. Therefore, we will be able to prune the hidden node if the corresponding weights are all close to 0. Furthermore, the feasibility analysis of this new method is carried out under some reasonable assumptions due to the smooth function. The numerical results demonstrate the superiority of the method with respect to sparsity, without damaging the classification performance.
1. Introduction
CNNs have been widely applied in many applications, such as intelligent information processing, pattern recognition, feature extraction [1,2,3,4,5], etc. As usual, slightly more hidden layer nodes were selected based on experience in neural networks. However, as is well known, too many nodes and weights in a deep network will increase the computational load, memory size and the risk of overfitting [6]. In fact, some hidden layer nodes and weights have little contribution to improving the performance of the network [7]. Therefore, choosing an appropriate number of hidden layer nodes and weights has become an important research topic in optimizing neural networks. Many algorithms have been proposed in order to optimize the number of nodes and weights in the neural network.
As one of the most effective methods to reduce the number of weights in the network, the regularization terms were introduced into the learning process. This is generally realized with regularization, which penalizes the sum of the weight norm during training. The norm is the sum of the absolute values of the elements in a vector, so as to make the weight value close to zero [8]. In [9], the -norm was combined with the capped -norm to denote the amount of information extracted through the filter and control regularization. Gou et al. [10] proposed a discriminative collaborative representation-based classification (DCRC) method through regularizations to improve the classification capabilities. Xu et al. adopted the regularizer to transform a non-convex problem into a series of regularizer problems, and showed many superior properties, such as robustness, sparsity and oracle properties, compared to the and regularizers [11]. In [12], Xiao introduced sparse logistic regression (SLR) based on regularization to impose a sparsity constraint on logistic regression. The algorithms mentioned above successfully optimize the network only by pruning the weights.
Regularization methods have become more impressive than before, but all of them were designed mainly for pruning the superfluous weights, and the node can be deleted only if all its outgoing weights are close to zero. Then, researchers tried to prune the nodes to optimize the neural network. Simon et al. provided a group lasso method, which produced sparse effects both on and within the group, and showed the expected effect of group-wise and within-group sparsity [13,14,15]. Moreover, [16] considered a more general penalty and blended the lasso with the group lasso, which yielded solutions that are sparse at both the group and the individual feature level. For pruning the nodes of the network, the popular group lasso method () imposes sparsity at the group level, so that either all the weights between nodes in the fully connected layer and all nodes of the output layer approach zero simultaneously, or none of them are close to zero. In other words, the group lasso regularization prunes the nodes of the fully connected layer, but does not prune redundant weights of surviving nodes.
It was shown that combining the regularization with the group lasso () for feedforward neural networks can prune not only hidden nodes but also the redundant weights of the surviving hidden nodes, and can achieve better performance in terms of of sparsity [17]. However, regularization is not smooth at the origin, which results in oscillation during the numerical computation and causes difficulty in the feasibility analysis. To overcome these issues, the regularizer was approximated with a continuous function in our early work [18]. Furthermore, in [19], the smooth was applied to train the Sigma-Pi-Sigma neural network, and achieved better performance regarding both sparsity at the weight level and accuracy compared to the non-smooth .
In this article, we combine the smooth regularization with the group lasso method, and propose a smooth group regularization algorithm. This novel algorithm inherits the advantages of the smooth function and regularization. As an application, the smooth group regularization algorithm is employed for the fully connected layer of CNNs. The main contribution of smooth group is to try to prune unnecessary nodes and control the magnitude of weights for the surviving nodes. In addition, due to the differentiability of the error function with smooth group regularization, it becomes easier to analyze the feasibility of the learning algorithm in theory. In the process of training the network, compared with , , and , smooth group regularization can not only prune the nodes and weights (improve the sparsity), but also overcome the oscillation in .
This paper is organized as follows. We first describe the simple process of the convolutional neural network and the smooth group regularization in the next section. Then, in Section 3, the feasibility analysis of the algorithm in CNNs is given, in which the training convergence with the term is proven theoretically. Numerical comparisons of several methods on four real-world datasets are carried out in Section 4. Finally, some conclusions are drawn in Section 5. In order to highlight the key points of this paper, the theorem proving process is included in the Appendix A.
2. Brief Description of CNNs and Smooth Group Regularization
In this section, we first demonstrate the simple calculation process of the convolutional neural network. After introducing the penalty term, the regularization is briefly described in Section 2.2.
2.1. Convolutional Neural Network
CNNs consist of three building blocks: convolution [20], pooling [21] and the fully connected layer [22]. Generally, the convolution filter is set as a symmetric matrix in CNNs. A filter in a convolution layer carries out a convolution operation on input images to obtain new feature maps, which can be expressed as:
where is the j-th feature map in the l layer, denotes the convolution filter, the convolution operation is denoted by ∗, is the bias, and is a set of feature maps activated by filter in the layer.
After is activated by a function, such as ReLU [23,24], the pooling layer uses the max or mean approach to progressively reduce the spatial size of the representation, as shown in the following equation:
where the pool function can be selected as the maximum or average as needed and the ReLU function can be written as:
A CNN may include several convolution–ReLU–pooling parts. The output of the last pooling layer is flattened as one large vector [25] and is fed to a fully connected layer for classification purposes. The final classification decision is driven by the following equation:
where O is the actual output vector, U denotes the weight of the fully connected layer, represents the activation function, denotes a function to transform a specified matrix into a matrix of specific dimensions. The image is classified to the i-th category if the i-th element of is the largest one. For a two-classification problem, U degenerates into a vector and the activation function is generally the sigmoid function.
2.2. Regularization for Fully Connected Layer
The error in the CNN is usually calculated by the following equation:
where J represents the number of samples, and are the target and actual output vectors of the j-th sample, respectively. Let r be the number of output nodes and q be the number of nodes in the fully connected layer. The error function with a penalty term is defined as
where the vector is the weight vector connecting the k-th node of the fully connected layer and all output nodes, and is the penalty term coefficient. The norm could be the 1-norm, 2-norm or -norm. When , it is the method, while is the method.
Specifically, we take the -norm [26]. Then,
where is the normal absolute value function. When the norm takes the -norm, we call it the method. Nevertheless, the partial derivative of E with respect to does not exist at the origin, which creates difficulties for the gradient descent method. Even though the partial derivative is expressed with a piecewise function, it still causes fluctuations in the process of training. In order to overcome this drawback, a regularization is proposed in this paper:
where represents a smooth function that approximates (the absolute value function). Specifically, the following piecewise polynomial function is used:
where m is a small positive constant. This function has the following characteristics:
when is a small constant. The norm is taken as the -norm, and the absolute value function in the -norm is approximated by a smooth polynomial function near , which is called the method.
3. Feasibility Analysis of the Algorithm in CNNs
Now, it is enough to give the feasibility analysis of the algorithm. In order to obtain the convergence results, we first turn the CNN into mathematical formulae. Then, we proceed to give the convergence results.
3.1. Transform Convolution and Mean Pooling into Mathematical Equations
In regular neural networks, every layer is made up of a set of neurons, where each neuron is fully connected to all neurons in the next layer before. This operation is easily expressed by multiplying matrices. However, in CNNs, the neurons in one layer do not connect to all the neurons in the next layer but only to a small part of it. The convolution operation is often described graphically. Thus, our first task is to transform the convolution operation into mathematical equations.
Although the convolution filter is usually symmetrical, for universal applicability in the proof, we choose a general matrix. Let an input array be filtered by a filter, where the padding is 0 and the step is 1. As shown in Figure 1, when the filter slides over the input, a matrix multiplication of a submatrix of the input and the filter is performed and the sum of the convolution moves into the feature map, i.e., the output of this layer.
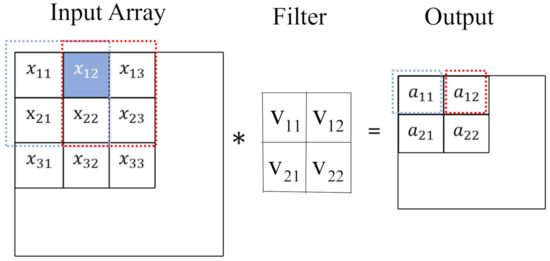
Figure 1.
The convolution operation.
To express this operation with mathematical equations, we squash each submatrix that multiplies with the filter into a vector. More specifically, the red square of the input array in Figure 2 is squashed into the vector . Then, we put all squashed vectors into a matrix X in order of the filter sliding, as shown in Figure 2. The filter is also squashed with a vector accordingly, and then is repeatedly put into the diagonal position of the matrix V, as shown in Figure 3. Other elements of V are 0. With X and V, the operation of the convolutional layer can be described with the matrix multiplication of X and V, as shown in Figure 4, i.e.,

Figure 2.
Reshape the input array with a matrix X.
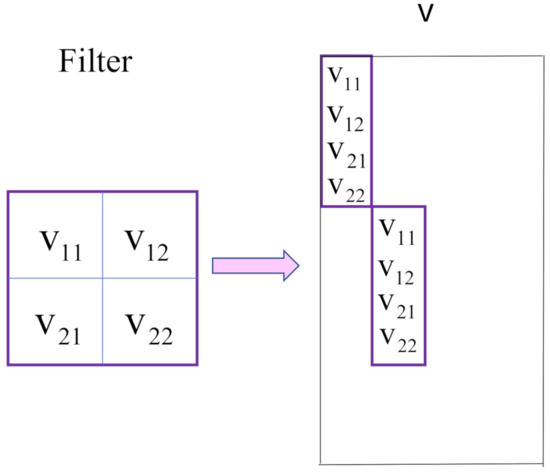
Figure 3.
Reshape the filter with a matrix V.

Figure 4.
The convolution operation is described with the matrix multiplication of the reshaped input array and filter.
The mean pooling is assumed to be applied in patches of the feature map with a stride of . It can also be expressed with the matrix multiplication, as shown in Figure 5. Each patch of the feature map is flattened into a vector and all the vectors are merged into a matrix as a reshaped feature map, as shown in Figure 5. The sliding mean window is flattened as a vector and is repeatedly put into the diagonal position of the mean matrix M, as shown in Figure 5. As in Equation (10), the mean pooling operation can be expressed with the matrix multiplication:
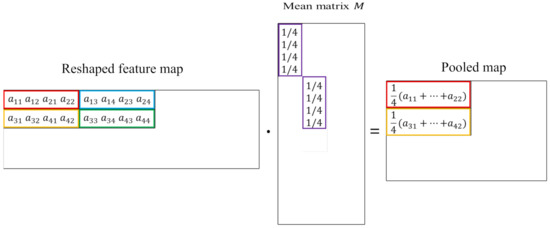
Figure 5.
The mean pooling is described with the matrix multiplication of the reshaped feature map and the mean matrix.
Now, given an input array X, the processing procedure from the convolution to the output layer can be expressed by mathematical equations. The output of the convolution layer is
where the function G means the reshape operation shown in Figure 2. After the ReLU layer, the matrix is reshaped as . In the pooling layer, the mean function is used
Then, the output matrix of the pooling layer is vectorized by column scan and this process is denoted by
where the function F denotes the layer vectorized by the column. Finally, the fully connected layer is
3.2. Convergence Results
To prove that our proposed method is feasible, here, we give the convergence results. For ease of understanding, we take the simplest single-layer CNN case as an example. This CNN includes one convolution, one pooling and one fully connected layer, where the convolution filter size is and the mean pooling size is .
Given the training sample set , each is assumed to be the input array and is the vector. According to Equations (12)–(15), the error function of Equation (8) can be expressed as
where , is the i-th row vector of U.
Training a CNN involves finding a suitable V and U so that E reaches the minimum [27]. For this reason, the gradient descent method [28] is adopted. Notice that the mean matrix M does not need to be trained. In the backpropagation algorithm, V and U are changed according to the gradient descent direction of E. The partial derivative of E with respect to the element of U is as follows:
The partial derivative of E with respect to the element of the convolution filter V is the same as the original CNN because the partial derivative of the penalty term in Equation (16) with respect to is zero. That is,
where is the derivative function of the rectified linear units function:
Thus far, we have given the step direction of U and V by (17) and (18), respectively. Now, we proceed to give the step direction of the biases. The partial derivative of the biases can be computed similarly as shown in [29]; the reader can refer to this article for more details.
We combine all weights and biases into a large vector W. Then, the parameter updating algorithm of is defined as follows:
where is the learning rate and n is the iteration step.
The convergence proof needs some Assumptions as follows:
- (1)
- are uniformly bounded, where is the error of the n-th step.
- (2)
- and are chosen to satisfy , where , and are constants defined below.
- (3)
- There exists a compact set such that and contains finite points.
Theorem 1.
Let the error function be Equation (8) and the weight sequence be generated by Equation (19) with any initial value . If Assumptions (1)–(2) are available, then
- (i)
- (ii)
- There exists , such that ;
- (iii)
- The weak convergence holds, i.e., .
In addition, if the assumption (3) also holds, then the strong convergence result holds:
- (iv)
- There exists a point such that .
The proof process is not the focus of this article, so we include it in the Appendix A.
4. Numerical Experiments and Discussion
We evaluate in different ways, such as nodes [30] and weights sparsity [31], training and testing accuracy, the norm of weight gradient and the convergence speed, on four typical benchmark datasets: Mnist [32], Letter Recognition [33], Cifar 10 [34] and Crowded Mapping. For parameter sparsity, is compared with some conventional and sparse algorithms including , and . Moreover, we investigate the test accuracy by comparing with the above regularization algorithms.
For the following numerical experiments, we refer to the arithmetic optimization algorithm [35] and adopt a five-fold cross-validation technique [36,37,38]. We randomly divide the dataset into five parts, where the sample size is equal (or almost equal). The network learning of these four algorithms is carried out five times. Each time, one of the five parts is selected in turn as the test sample set, and the other four parts are used as the training sample sets. Then, we rearrange the five-part samples and start the process again. This process is repeated twenty times. The experiment process is given in Algorithm 1.
| Algorithm 1 The experiment process. |
|
Finally, for each dataset and algorithm, we obtain one hundred classification results. Each result contains the rate of pruned nodes (Rate of PN) (cf. Equation (20)), the rate of pruned weights of the remaining nodes (Rate of PW) (cf. Equation (21)), training accuracy (Training Acc.) and test accuracy (Test Acc.). The averages of these numerical results are listed in Table 1, Table 2, Table 3 and Table 4 for these four datasets.

Table 1.
Mnist: Comparison of Rate of PN, Rate of PW, Training Acc. and Test Acc. by using , , and learning algorithms.
Table 2.
Letter: Comparison of Rate of PN, Rate of PW, Training Acc. and Test Acc. by using , , and learning algorithms.
Table 3.
Cifar 10: Comparison of Rate of PN, Rate of PW, Training Acc. and Test Acc. by using , , and learning algorithms.
Table 4.
Crowded Mapping: Comparison of Rate of PN, Rate of PW, Training Acc. and Test Acc. by using , , and learning algorithms.
For an output node, the ideal output value is 1 or 0. When we evaluate the error between the ideal and real output values, we use the following “40-20-40” standard [39]: The actual output values of the output nodes between and are regarded as 0, values between and are regraded as 1, and values between and are regraded as uncertain and are considered incorrect.
4.1. Mnist Problem
MNIST is a dataset for the study of handwritten numeral recognition, which contains 70,000 examples of pixel images of the digits 0–9. For these four algorithms, we set the learning rate . The maximum iteration training step is 1000. In order to show the sparsity, we give the node sparsity and weight sparsity performances for of these four algorithms (see Figure 6; y-axis represents the percentage of the number of pruned nodes and pruned weights of the remaining nodes, respectively). The sparsity will become worse when . Therefore, we choose to compare these algorithms. The performances of these four group lasso algorithms are compared in Table 1. We can see that, in terms of the sparsity, the performance of is better than , and . In terms of of accuracy, is also the best. Figure 7a presents the loss functions of these four group lasso algorithms. Obviously, we can see that the approach has the lowest error after training, and has a large fluctuation during the training process.
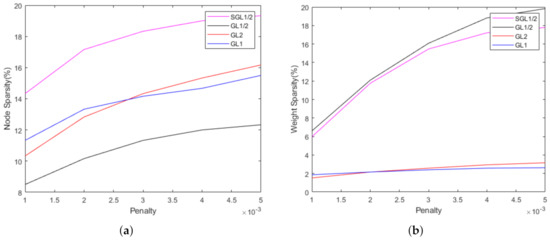
Figure 6.
Sparsity of , , and algorithms in Mnist dataset. (a) Node sparsity, (b) Weight sparsity.

Figure 7.
Loss and gradient of , , and algorithms in Mnist dataset. (a) Loss function, (b) Norm of gradient.
4.2. Letter Recognition Problem
The Letter Recognition dataset consists of 20,000 samples with 16 attributes. Each 16-dimensional instance within this database represents a capital typewritten letter in one of twenty fonts. For these four algorithms, we set the learning rate . The maximum iteration training step is 1000. In order to show the sparsity, we give the node sparsity and weight sparsity performances for of these four algorithms (see Figure 8). The sparsity will become worse when . Therefore, we choose to compare these algorithms. The performances of , , and are compared in Table 2. We see that, in terms of sparsity, the performance of is better than , and . In terms of accuracy, is also the best among the above-mentioned four algorithms. Figure 9a presents the loss functions of these four group lasso algorithms. Obviously, we can see that the approach has the lowest error after training, and has a large fluctuation during the training process.

Figure 8.
Sparsity of , , and algorithms in Letter Recognition dataset. (a) Node sparsity, (b) Weight sparsity.
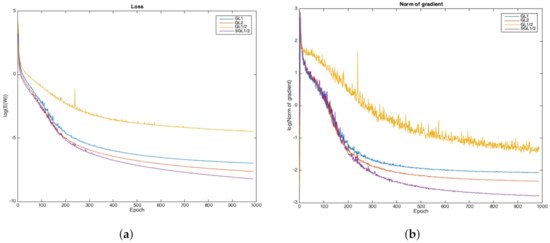
Figure 9.
Loss and gradient of , , and algorithms in Letter Recognition dataset. (a) Loss function, (b) Norm of gradient.
4.3. Cifar 10 Problem
The Cifar 10 dataset consists of 60,000 images, each of which is a color map. This dataset contains 10 classes (airplane, automobile, bird, cat, deer, dog, frog, horse, ship and truck), with 6000 images per class. There are 50,000 training images and 10,000 test images. For these four algorithms, we set the learning rate . The maximum iteration training step is 1000. In order to show the sparsity, we give the node sparsity and weight sparsity performances for of these four algorithms (see Figure 10). The sparsity will become worse when . Therefore, we choose to compare these algorithms. The performances of these four group lasso algorithms are compared in Table 3. We see that, in terms of of sparsity, the performance of is better than , and . In terms of accuracy, is also the best. Figure 11a presents the loss functions of these four group lasso algorithms. Obviously, we can see that the approach has the lowest error after training, and has a large fluctuation during the training process.

Figure 10.
Sparsity of , , and algorithms in Cifar 10 dataset. (a) Node sparsity, (b) Weight sparsity.

Figure 11.
Loss and gradient of , , and algorithms in Cifar 10 dataset. (a) Loss function, (b) Norm of gradient.
4.4. Crowded Mapping
The Crowded Mapping dataset consists of 10,546 samples with 28 attributes, and these samples are divided into six classes. For these four algorithms, we set the learning rate . The maximum iteration training step is 1000. In order to show the sparsity, we give the node sparsity and weight sparsity performances for of these four algorithms (see Figure 12). The sparsity will become worse when . Therefore, we choose to compare these four algorithms. The performances of the , , and methods are compared in Table 4. We see that, in terms of sparsity, the performance of is better than , and . In terms of accuracy, is also the best among the above-mentioned four algorithms. Figure 13a presents the loss functions of these four group lasso algorithms. Obviously, we can see that the algorithm has the lowest error after training, and has a large fluctuation during the training process.

Figure 12.
Sparsity of , , and algorithms in Crowded Mapping dataset. (a) Node sparsity, (b) Weight sparsity.

Figure 13.
Loss and gradient of , , and algorithms in Crowded Mapping dataset. (a) Loss function, (b) Norm of gradient.
We show the gradient norms of , , and in Figure 13b, where the oscillation of is presented. From Figure 13, we find that the regularizer eliminates the oscillation and guarantees the convergence, as predicted in Theorem 1.
From the above experiments on the four datasets, it is easy to see that the and algorithms have better sparsity at the node level, and the algorithm has better sparsity at the weight level. In some applications, the sparsity at the weight level is also of great significance. If the sparseness of the integrated node and weight level is better, the number of weights that need to be calculated and updated will be reduced in the process of training the CNNs. Furthermore, it also leads to a reduction in the amount of calculation and saves storage space. Compared with the and algorithms, the algorithm has better sparsity at the node level and the weight level, and can also improve the classification performance. Compared with the algorithm, the theoretical analysis and numerical experiment are carried out to verify that the algorithm improves the sparsity at the node level, and at the same time improves the classification performance.
4.5. Discussion
Table 1, Table 2, Table 3 and Table 4, respectively, show the performance comparison of PN, PW, training accuracies and test accuracies under these four methods. In terms of the sparsity, the PN calculation results of the method are much better than the other three methods, especially the method. As for the PW, although the surviving node of the has a higher rate of pruned weights of surviving weights, the rate of pruned nodes is too low, such that the sparsity of the method is still far lower than that of the method. In terms of classification accuracy, the method is slightly higher than other methods, which means that this method can improve the sparsity without damaging the classification accuracy.
We can find that the specificity of CNNs is not actually used in the experiments, so the method can be widely applied to other neural network models.
5. Conclusions
Our main task was to introduce the algorithm. Based on the and algorithms, replacing 1-norm and 2-norm with -norm can greatly improve the sparsity of the network weight level, but it does not help to achieve better sparsity of the node level. The non-smooth penalty term at the origin is the root cause of the poor sparsity of the algorithm at the node level.
To this end, in this paper, a smooth group () regularization term is introduced into the batch gradient learning algorithm to prune the CNN. The feasibility analysis of the method for the fully connected layer of the CNN is performed. Numerical experiments show that the sparsity and convergence of give better results in terms of both the rate of pruned hidden nodes and weights of the remaining hidden nodes compared to , and . In addition, the regularizer not only overcomes the oscillation phenomenon during the training process, but also achieves better classification performance.
In fact, the regularization algorithm provides a strategy to improve the sparsity of hidden layers of neural networks, not only for CNNs. Therefore, the performance of the regularization algorithm on other neural network models is also worthy of further verification. However, the algorithm is not particularly obvious in improving the classification accuracy. In future work, we will focus on continuing to improve the algorithm to achieve better classification performance of the neural network.
Author Contributions
Conceptualization, Y.B. and S.Y.; methodology, S.Y.; software, S.Y.; validation, Y.B., S.Y. and Z.L. (Zhaobin Liu); formal analysis, S.Y.; investigation, Z.L. (Zhongxuan Luo); resources, Z.L. (Zhongxuan Luo); data curation, Z.L. (Zhaobin Liu); writing—original draft preparation, Y.B. and S.Y.; writing—review and editing, Y.B., S.Y., Z.L. (Zhongxuan Luo) and Z.L. (Zhaobin Liu); funding acquisition, Z.L. (Zhongxuan Luo). All authors have read and agreed to the published version of the manuscript.
Funding
This project is supported by the National Natural Science Foundation of China (No. 61720106005).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets in this paper are both available at http://archive.ics.uci.edu/ml/datasets.php (accessed on 6 May 2020).
Acknowledgments
The authors would like to thank the referees for their careful reading and helpful comments.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof for (i) of Theorem 1.
In , each input array is fed to the CNN to compute the corresponding output. Specifically, at the n-th iteration, when is fed to the CNN, the flattened vector S is . Let and . By the error function (16) and Taylor’s formula [42], we have
where
for some real-valued vector , and . For the first term of Equation (A1), we obtain
If we extract the first term of each sign (the case of and ) and sum them together, we can obtain
Similar processing can be applied to other terms of (other 24 cases). Thus, it follows from Equation (A3) that
For the second term of Equation (A1), we obtain
For the third term of Equation (A1), it is apparent that the second partial derivatives of the function are bounded. Thus, there exists a positive constant such that
Notice that
and the operation F, G and the matrix M are linear. There exist two positive constants and such that
Then, from Equation (A6),
where and .
With Taylor’s formula, for the fourth term of Equation (A1), we have
for some vector . Because of the existence of the derivative of and the boundedness of , there exists some positive constant such that the inequality of Equation (A8) is true.
As long as Assumption (2) is satisfied, it can yield . The proof for (i) of the theory is completed. □
Proof for (ii).
From the conclusion of (i), we know that the nonnegative sequence monotonically decreases. Hence, there must exist a such that . □
Proof for (iii).
Let . From Equation (A9) and (ii), we can obtain
That is,
If , we have
Before proving (iv), we need to review the following lemma [43]:
Lemma A1.
(Wu, Li, Yang, Liu, 2010, Lemma 1). On a bounded closed region , let be continuous and differentiable. If the set contains only finite points and the sequence satisfies and , then there exists such that .
□
Proof for (iv).
Since the error function is continuous and differentiable, from Equation (19), Assumption (3) and Lemma A1, we can easily achieve the desired result; there exists a point such that . □
References
- Sharma, P.; Singh, A.; Singh, K.K.; Dhull, A. Vehicle identification using modified region based convolution network for intelligent transportation system. Multimed. Tools Appl. 2021, 1–25. [Google Scholar] [CrossRef]
- Nguyen, K.C.; Nguyen, C.T.; Nakagawa, M. Nom document digitalization by deep convolution neural networks. Pattern Recognit. Lett. 2020, 133, 8–16. [Google Scholar] [CrossRef]
- Jogin, M.; Mohana; Madhulika, M.S.; Divya, G.D.; Meghana, R.K.; Apoorva, S. Feature Extraction using Convolution Neural Networks (CNN) and Deep Learning. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information and Communication Technology (RTEICT), Bangalore, India, 18–19 May 2018; pp. 2319–2323. [Google Scholar]
- Li, G.; Tang, H.; Sun, Y.; Kong, J.; Jiang, G.; Jiang, D.; Tao, B.; Xu, S.; Liu, H. Hand gesture recognition based on convolution neural network. Clust. Comput. 2019, 22, 2719–2729. [Google Scholar] [CrossRef]
- Brachmann, A.; Redies, C. Using convolutional neural network filters to measure left-right mirror symmetry in images. Symmetry 2016, 8, 144. [Google Scholar] [CrossRef] [Green Version]
- Yu, D. A new pose accuracy compensation method for parallel manipulators based on hybrid artificial neural network. Neural Comput. Appl. 2021, 33, 909–923. [Google Scholar] [CrossRef]
- Wang, J.; Cai, Q.; Chang, Q.; Zurada, J.M. Convergence analyses on sparse feedforward neural networks via group lasso regularization. Inf. Sci. 2017, 381, 250–269. [Google Scholar] [CrossRef]
- Ng, A.Y. Feature selection, L1 vs. L2 regularization, and rotational invariance. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 78. [Google Scholar]
- Bilal, H.; Kumar, A.; Yin, B. Pruning filters with L1-norm and capped L1-norm for CNN compression. Appl. Intell. 2021, 51, 1152–1160. [Google Scholar]
- Gou, J.; Hou, B.; Yuan, Y.; Ou, W.; Zeng, S. A new discriminative collaborative representation-based classification method via L2 regularizations. Neural Comput. Appl. 2020, 32, 9479–9493. [Google Scholar] [CrossRef]
- Xu, Z.; Chang, X.; Xu, F.; Zhang, H. L1/2 regularization: A thresholding representation theory and a fast solver. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1013–1027. [Google Scholar]
- Xiao, R.; Cui, X.; Qiao, H.; Zheng, X.; Zhang, Y. Early diagnosis model of Alzheimer’s Disease based on sparse logistic regression. Multimed. Tools Appl. 2020, 80, 3969–3980. [Google Scholar] [CrossRef]
- Goulart, J.; Oliveira, P.; Farias, R.C.; Zarzoso, V.; Comon, P. Alternating Group Lasso for Block-Term Tensor Decomposition and Application to ECG Source Separation. IEEE Trans. Signal Process. 2020, 68, 2682–2696. [Google Scholar] [CrossRef]
- Diwu, Z.; Cao, H.; Wang, L.; Chen, X. Collaborative Double Sparse Period-Group Lasso for Bearing Fault Diagnosis. IEEE Trans. Instrum. Meas. 2020, 70, 1–10. [Google Scholar] [CrossRef]
- Zheng, S.; Ding, C. A group lasso based sparse KNN classifier. Pattern Recognit. Lett. 2020, 131, 227–233. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. A note on the group lasso and a sparse group lasso. arXiv 2010, arXiv:1001.0736. [Google Scholar]
- Alemu, H.Z.; Zhao, J.; Li, F.; Wu, W. Group L1/2 regularization for pruning hidden layer nodes of feedforward neural networks. IEEE Access 2019, 7, 9540–9557. [Google Scholar] [CrossRef]
- Wu, W.; Fan, Q.; Zurada, J.M.; Wang, J.; Yang, D.; Liu, Y. Batch gradient method with smoothing L1/2 regularization for training of feedforward neural networks. Neural Netw. 2014, 50, 72–78. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Yang, D.; Mohamed, K.S.; Wang, J.; Wu, W. Convergence of batch gradient learning algorithm with smoothing L1/2 regularization for Sigma–Pi–Sigma neural networks. Neurocomputing 2015, 151, 333–341. [Google Scholar] [CrossRef]
- Kwon, H.; Go, B.H.; Park, J.; Lee, W.; Lee, J.H. Gated dynamic convolutions with deep layer fusion for abstractive document summarization. Comput. Speech Lang. 2021, 66, 101–159. [Google Scholar] [CrossRef]
- Husain, S.S.; Bober, M. REMAP: Multi-layer entropy-guided pooling of dense CNN features for image retrieval. IEEE Trans. Image Process. 2019, 28, 5201–5213. [Google Scholar] [CrossRef] [Green Version]
- Richter, O.; Wattenhofer, R. TreeConnect: A Sparse Alternative to Fully Connected Layers. In Proceedings of the 2018 IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI), Volos, Greece, 5–7 November 2018. [Google Scholar]
- Eckle, K.; Schmidt-Hieber, J. A comparison of deep networks with ReLU activation function and linear spline-type methods. Neural Netw. 2019, 110, 232–242. [Google Scholar] [CrossRef]
- Guo, Z.Y.; Shu, X.; Liu, C.Y.; Lei, L.I. A Recognition Algorithm of Flower Based on Convolution Neural Network with ReLU Function. Comput. Technol. Dev. 2018, 05. Available online: http://en.cnki.com.cn/Article_en/CJFDTotal-WJFZ201805035.htm (accessed on 1 November 2021).
- Yang, S.C. A study on using deviation function method to reshape a rack cutter. Int. J. Adv. Manuf. Technol. 2006, 30, 385–394. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, H.; Wang, Y.; Chang, X.; Liang, Y. L1/2 regularization. Sci. China Inf. Sci. 2010, 53, 1159–1169. [Google Scholar] [CrossRef] [Green Version]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 3rd ed.; Prentice Hall: Hoboken, NJ, USA, 1998. [Google Scholar]
- Baldi, P. Gradient descent learning algorithm overview: A general dynamical systems perspective. IEEE Trans. Neural Netw. 1995, 6, 182–195. [Google Scholar] [CrossRef]
- Zhang, Z. Derivation of Backpropagation in Convolutional Neural Network (CNN); University of Tennessee: Knoxville, TN, USA, 2016. [Google Scholar]
- Wu, Y. Sparsity of Hidden Layer Nodes Based on Bayesian Extreme Learning Machine. Control Eng. China 2017, 24, 2539–2543. [Google Scholar]
- Özgür, A.; Nar, F.; Erdem, H. Sparsity-driven weighted ensemble classifier. Int. J. Comput. Intell. Syst. 2018, 11, 962–978. [Google Scholar] [CrossRef] [Green Version]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef]
- Bouma, H. Interaction effects in parafoveal letter recognition. Nature 1970, 226, 177–178. [Google Scholar] [CrossRef]
- Carvalho, E.F.; Engel, P.M. Convolutional sparse feature descriptor for object recognition in cifar-10. In Proceedings of the 2013 Brazilian Conference on Intelligent Systems, Fortaleza, Brazil, 19–24 October 2013; pp. 131–135. [Google Scholar]
- Abualigah, L.; Diabat, A.; Mirjalili, S.; Abd Elaziz, M.; Gandomi, A.H. The arithmetic optimization algorithm. Comput. Methods Appl. Mech. Eng. 2021, 376, 113609. [Google Scholar] [CrossRef]
- Moreno-Torres, J.G.; Sáez, J.A.; Herrera, F. Study on the impact of partition-induced dataset shift on k-fold cross-validation. IEEE Trans. Neural Networks Learn. Syst. 2012, 23, 1304–1312. [Google Scholar] [CrossRef]
- Burman, P. A comparative study of ordinary cross-validation, v-fold cross-validation and the repeated learning-testing methods. Biometrika 1989, 76, 503–514. [Google Scholar] [CrossRef] [Green Version]
- Wiens, T.S.; Dale, B.C.; Boyce, M.S.; Kershaw, G.P. Three way k-fold cross-validation of resource selection functions. Ecol. Model. 2008, 212, 244–255. [Google Scholar] [CrossRef]
- Ampazis, N.; Perantonis, S.J. Two highly efficient second-order algorithms for training feedforward networks. IEEE Trans. Neural Netw. 2002, 13, 1064–1074. [Google Scholar] [CrossRef] [PubMed]
- Zubic, S.; Wahlroos, A.; Altonen, J.; Balcerek, P.; Dawidowski, P. Managing Post-fault Oscillation Phenomenon in Compensated MV-networks. In Proceedings of the 13th IET International Conference on Developments in Power System Protection (DPSP 2016), Edinburgh, UK, 7–10 March 2016. [Google Scholar]
- Yin, J.; Bian, L.; Fan, Q.; Fan, X.; Ai, H.; Tian, L. Oscillation phenomenon and its mechanism of an energy-saving and emission-reduction system. Int. J. Energy Sect. Manag. 2018, 12, 314–322. [Google Scholar] [CrossRef]
- Dragomir, S.S. New estimation of the remainder in Taylor’s formula using Grüss’ type inequalities and applications. Math. Inequalities Appl. 1999, 2, 183–193. [Google Scholar] [CrossRef]
- Wu, W.; Li, L.; Yang, J.; Liu, Y. A modified gradient-based neuro-fuzzy learning algorithm and its convergence. Inf. Sci. 2010, 180, 1630–1642. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).