Abstract
This study analyzes three availability systems with warm standby units, fault detection delay, and general repair times. The failure times and repair times of failed components were assumed to follow exponential and general distributions, respectively. The detection delay times were assumed to be exponentially distributed. This study exploited the supplementary variable technique to develop a recursive method for deriving the steady-state availability for three systems. By using extensive numerical computations, we compared three systems in terms of system availability based on specific values given to the system parameters. The state transition rate diagrams of the three systems revealed the symmetry property approximately. The three systems were ranked based on the system availability and the cost/benefit for the three various repair time distributions: exponential, three-stage Erlang, and deterministic, where the benefit was system availability.
1. Introduction
System availability plays an increasingly important role in many real-world systems, such as manufacturing systems, computer systems, and power plants. To preserve a high or given level of system availability that is often necessary for these practical systems, standby components are usually used to increase system availability. There are two kinds of standby components. A cold standby component never fails, whereas a warm standby component can fail, where its failure rate is higher than zero but less than that of a primary component. On the other hand, when a primary or standby component fails, many real systems (for example, see Trivedi [1]) require a detection delay period to detect the fault before it can be repaired. Furthermore, the system is assumed to be in a down state during the detection delay (Trivedi [1]). This study proposes a form of steady-state availability analysis of repairable systems with warm standby components, a detection delay, and general repair times. The relevant literature is outlined below.
The supplementary variable was first proposed by Cox [2] to transform a non-Markovian model into a Markovian one. Since then, many studies exploited this technique to analyze different non-Markovian systems in the queueing literature. Hokstad [3] utilized the supplementary variable technique to analyze the M/G/1 queue in 1975. Based on this technique, Gupta and Rao [4] and Gupta and Rao [5] proposed a recursive method to derive the steady-state probability of the M/G/1 machine repair problem without standbys and the M/G/1 machine repair problem with cold standbys, respectively. This technique was applied to analyze the G/M/1 queueing system with an N-policy and finite capacity by Ke and Wang [6]. Zhang and Wu [7] used the supplementary variable technique to propose a method for the reliability analysis of a machine repair system with k out n spare units and an F-policy. Shakuntla et al. [8] exploited this technique to propose reliability analysis for the polytube industry. This technique was utilized to analyze an M/G/1 machine repair system under multiple imperfect coverages by Wang et al. [9]. According to the supplementary variable technique, Ke et al. [10] proposed a method for analyzing the machine repair problem with a working breakdown repairman and standbys having an imperfect switchover.
In the literature regarding the analysis of repairable systems, several studies have addressed the comparison of various systems. Wang and Pearn [11] studied the cost–benefit analysis of series systems with warm standbys. They derived explicit expressions for the mean time to first system failure and system availability for three systems. Wang and Chiu [12] presented the cost–benefit analysis of queueing systems with warm standby components and imperfect coverage. Furthermore, they explored a comparative analysis associated with numerical results to verify the effects of parameters on the cost/benefit ratios. Wang and Chen [13] discussed system availability among three systems with a reboot delay, switching failures, and general repair times. Singh et al. [14] evaluated the transitional state probabilities, system reliability, system availability, mean time to first system failure, and the cost of the system by using the supplementary variable technique. Yu et al. [15] proposed a method to optimize the availability of a system where the objective of their study was to minimize the system cost under the constraint that system availability must maintain a given level.
The concept of a detection delay for a repairable system was introduced by Trivedi [13]. Ke et al. [16] analyzed a machine repair system with detection, imperfect coverage, and reboot using a Bayesian approach. Kleyner and Volovoi [17] proposed an application of stochastic Petri nets to calculate the availability of systems where partial detection was considered. Ke and Liu [18] studied a machine repair system with imperfect coverage and reboot. They derived the steady-state probabilities for the number of down units during an arbitrary period. Moreover, they presented the sensitivity analysis of the steady-state availability with respect to the system parameters for different repair time distributions.
The problem studied in this paper is more general than the work of Trivedi [1]. To our knowledge, the explicit expression for the availability of a system with a detection delay and the repair time has a general distribution has not been derived. The purpose of this study was to accomplish three objectives. The first was to derive the steady-state availability for three systems by exploiting the supplementary variables treated as the remaining repair times. The explicit expressions for the steady-state availability for three different repair time distributions: exponential (M), k-stage Erlang , and deterministic (D) were obtained. The second was to perform a numerical analysis in terms of and cost/Av for three different repair time distributions. The third was to rank three systems for the and cost/Av based on specific values of system parameters and the unit costs of the components.
The rest of this paper is organized as follows. Three availability systems are described in Section 2. A practical application of this model is also provided in this section. Notations used in this study are defined in Section 3. Section 4 derives the availability of each of the three availability systems based on the supplementary variable technique. Extensive numerical examples are provided and executed to compare the three systems when both Av and cost/Av are considered in Section 5. Finally, Section 6 presents a summary and conclusions.
2. Description of the Three Availability Systems
This study assumed that a data center requires 30 MW of electrical power and that the power of the components is available in units of 30 MW, 15 MW, and 10 MW. To maintain reliable and stable system availability, there were warm standby components, and all primary and warm standby components were continuously monitored using a fault-detecting device to identify whether they fail. When a primary or warm standby component failed, we assumed that it could be repaired. The times to failure for the primary components and those for the warm standby components had exponential distributions with parameters and , respectively, and these failure times were independent of each other. When one primary component failed, a warm standby component (if one is available), with a failure rate , is immediately converted into a primary one with a failure rate . Whenever one component failed, it immediately induced a detection delay. We assumed that the detection delay had an exponential distribution with parameter . When the fault was being detected and the last primary component failed, this study assumed that the system failed. Such a fault is called a near-coincident fault. The system was considered to have failed when the standby components were all emptied, which we defined as the state of system failure (sf). It was assumed that the time taken to repair of all failed components were independent of each other and were identically distributed random variables with a distribution function , a density function , and a mean repair time . As long as the electricity generation capacity of the system was less than 30 MW, it would stop working. When a failed component arrived at the repair facility and observed that a server was available, it would be immediately repaired. If a (primary or standby) component failed, it was repaired based on a first-come, first-served (FCFS) basis. We assumed that a server could repair only one failed component at a time and that the service was independent of the failures of the components. Once a failed component was repaired, it was considered as good as new.
This study designed three availability systems as follows: the first system consisted of one 30 MW primary component and one 30 MW warm standby component. The second system consisted of two 15 MW primary components and one 15 MW warm standby component. We assumed that the standby component could replace either one of the initially working components in the case of its failure. The third system was made of three 10 MW primary components and two 10 MW warm standby components. Each standby component could replace either one of the failed working components. If necessary, a standby component could also replace the first used standby component in the case of its failure.
Before analyzing the three availability systems, a practical problem related to the parallel redundant system is presented for illustrative purposes. The virtualization technology plays a pivotal role in the cluster computing environment, especially in adjusting and distributing computing resources. In order to optimize the performance of virtual machines, the system administrator must keep the software packages and OS kernels up to date, especially in the Linux system. We considered a Linux virtual cluster that provided the Linux software mirror service and was managed by the Open Source Cluster Application Resources (OSCAR) cluster management system. The OSCAR head node received requests from the Internet and transmitted them to the client nodes (treated as the primary units). To ensure that every client node was up and running, the ganglia distributed monitoring system was installed to monitor the state of each client node in the virtual cluster. Whenever a failed client node was detected by ganglia, new coming requests were sent to an available client node, and the breakdown client node was terminated. The failed client node was restarted after the error was detected and fixed (failures could be caused by IP conflict, not enough disk space, or operating system fault). The configuration of this Linux virtual cluster is illustrated in Figure 1.
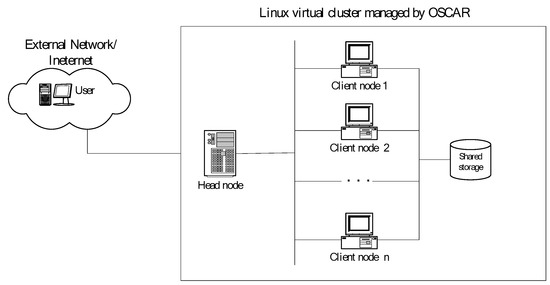
Figure 1.
A Linux virtual cluster providing mirror service.
Client nodes are virtual machines and hence can be assumed to be capable of being repaired. Suppose each of the client nodes failed independently of the state of the others and the time-to-failure of each client node was exponentially distributed with a parameter . Whenever one client node fails, OSCAR immediately searches for available client nodes and transmits user requests to them. It was assumed that the detection delay has an exponential distribution with parameter . When one client nodes failed, the corresponding virtual machine process was terminated and restarted by the ganglia. Once the client node was restarted, it was considered to be as good as a new one. This study assumed that the times to repair of all failed client nodes were independent to one another with identically distributed random variables with a distribution function , a density function , and a mean repair time .
3. Notations
The following notations and probabilities were defined and used in this study:
4. Availability Analysis
We assumed that the operating system required at least 30 MW power electricity. For each system, the transition rate diagram was drawn, and then the differential equation of each state at time t was derived based on the diagram. Next, we took the Laplace transform on both sides of the differential equation. Finally, the system availability was achieved by working on these Laplace transform equations. In order to manage the general repair times, the following supplementary variable was defined: remaining repair time for a given component being repaired. The state of the system at time t is given by:
The following were also defined:
Let such that the following steady-state probabilities can be obtained as follows:
and
4.1. Availability System 1
Availability system 1 included one 30 MW primary component and one 30 MW warm standby component. The state-transition-rate diagram of availability system 1 is shown in Figure 2. Considering the system at time and in Figure 2, the following equations of the probability of each state can be derived as follows:
where the state (1,1) denotes the detection stage. The transition from state (1,1) to state (1,0) (at rate () indicates the detection of the fault. The state labeled sf denotes the system failure.
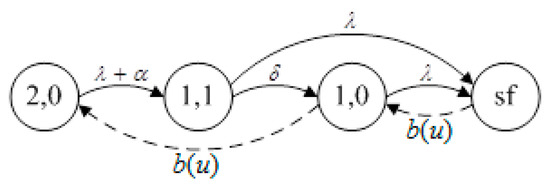
Figure 2.
The state transition rate diagram of availability system 1.
We defined:
The steady-state equations were obtained from Equations (1)–(4). Next, the Laplace transform was taken on both sides of these equations. By working on the Laplace transform equations, the steady-state availability of availability system 1, , can be explicitly derived below:
The detailed derivation is provided in Appendix A.
Special Cases
This study investigated three special cases for three different repair time distributions: exponential (M), -stage Erlang , and deterministic (D). The following expressions for the , and for three different repair time distributions are shown explicitly below.
Case 1. Exponential repair time
The repair time had an exponential distribution in this case. The mean repair time was set to , where was the repair rate. By taking the Laplace transform, we found:
From Equation (6), the expression for the was obtained explicitly as:
Setting in the expression of , the steady-state probability for the exponential case is given by:
From the result of p. 458 of Trivedi [1], the steady-state probability for exponential case is given by
where
After doing the algebraic manipulation, it is shown that the expression for is identical to that for .
Case 2. -stage Erlang repair time
The repair time had a -stage Erlang distribution in this case. The -stage Erlang distribution consists of independent and identical exponential stages, each with a mean . Taking the Laplace transform, we obtained:
From Equation (6) again, the following expression for the was found:
Case 3. Deterministic repair time
The repair time distribution was deterministic in this case. In this case, the distribution function of the repair time had the following Laplace transform:
From Equation (6), the expression for the is derived explicitly to give:
4.2. Availability System 2
Availability system 2 included two 15 MW primary components and one 15 MW warm standby component. The state-transition-rate diagram of availability system 2 is presented in Figure 3. From Figure 3, the following steady-state equations were derived:
where we defined:
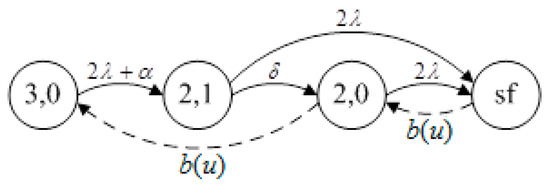
Figure 3.
The state transition rate diagram of availability system 2.
We should note that the state labeled (2,1) represents the detection stage. The transition from state (2,1) to state (2,0) indicates the detection of the fault.
A similar argument led to the explicit expression for the steady-state availability of availability system 2, , which was given by:
The detailed derivation of is provided in Appendix B.
Special Cases
For availability system 2, three cases for three different repair time distributions: exponential, -stage Erlang, and deterministic are presented. The expressions for the , and for three different repair time distributions are listed explicitly as follows:
4.3. Availability System 3
Availability system 3 included three 10 MW primary components and two 10 MW warm standby components. The state-transition-rate diagram of availability system 3 is shown in Figure 4. From Figure 4, the steady-state equations were obtained as follows:
where we defined:1
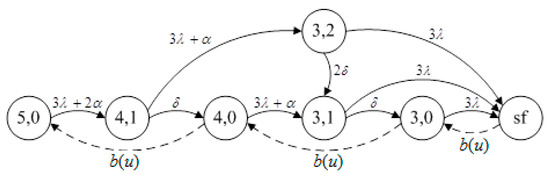
Figure 4.
The state transition rate diagram of availability system 3.
We note that the states labeled (4,1) and (3,1) represent detection stages. The transition from state (4,1) to state (4,0), and from state (3,1) to state (3,0) indicate the detection of the respective faults.
Using similar argument led to the explicit expression for the steady-state availability, , which is given by:
The detailed derivation of is provided in Appendix C.
Special Cases
For availability system 3, by substituting for three different repair time distributions—exponential, -stage Erlang, and the deterministic distribution in Equation (19)—the following expressions for , and were obtained:
where
5. Comparison of the Three Availability Systems
In this section, we compare the three availability systems in terms of and cost/benefit ratios for three different repair time distributions, where benefit is defined as . Basically, the following values of various parameters were set as follows:
or
5.1. Comparisons of Availability for the Three Systems
First, the following three cases were performed to obtain a comparison between the ’s of the three availability systems when the three repair time distributions were set to be exponential, three-stage Erlang, and deterministic, respectively.
Case 1. We fixed , , and varied the values of from 0.001 to 0.02.
Case 2. We fixed , , , and varied the values of from 0.05 to 0.16.
Case 3. We fixed , , , and varied the values of from 1 to 10.
Numerical results of the , , and for each availability system i (i = 1, 2, 3) are shown in Table 1, Table 2 and Table 3 for cases 1–3, respectively. From Table 1, Table 2 and Table 3, it can be observed that system 1 was the best system based on the availability comparison. However, note that each system consumed different costs during their construction; therefore, the cost/Av ratio was fairer than Av as the criterion for comparing the three systems.

Table 1.
Comparison of the availability systems 1, 2, 3 for Av ().
Table 2.
Comparison of the availability systems 1, 2, 3 for Av ().
Table 3.
Comparison of the availability systems 1, 2, 3 for Av ().
5.2. Comparisons of the Cost/Benefit Ratios for the Three Availability Systems
Next, we considered that the systems with different power capacities may have different costs. These costs should be considered when different systems are fairly compared. The capacity-proportional costs for the primary components and warm standby components are listed in Table 4. From Table 4, the cost for each availability system i (i = 1, 2, 3) was calculated and are shown in Table 5.
Table 4.
The size-proportional cost for the primary and warm standby components.
Table 5.
The cost of each availability system.
Let denote the cost of availability system , and be the benefit of availability system , where is and . Based on the cost/benefit ratio, comparisons of the three systems were made. We ranked the three availability systems under specific values of system parameters , , and , as well as the costs given in Table 5. The results of the rank (cost/benefit) are shown in Table 6, Table 7 and Table 8 for ranges of , , and , respectively. We can easily observe from Table 6, Table 7 and Table 8 that system 2 was the best model when considering the cost/Av value for most cases. It can be observed that this system 2 is the dominant optimal model in terms of the cost/Av value independent of both the distributions of the repair time and the ranges of , , and .
Table 6.
Rank of for .
Table 7.
Rank of for .
Table 8.
Rank of for .
6. Conclusions
This study first exploited the supplementary variable technique to derive the steady-state availability of three availability systems with warm standby components, fault detection delays, and general repair times. Next, for each availability system, the expressions for the of three different repair time distributions, namely exponential, three-stage Erlang, and deterministic, were explicitly derived. We demonstrated that the first system generalized Trivedi’s two-component system with a fault detection delay. Finally, we performed a numerical investigation in terms of both Av and the cost/Av for three availability systems and ranked the three systems based on Av and the cost/Av for three different repair time distributions. The numerical results demonstrated that availability system 2 outperformed the other two systems based on the criterion of cost/Av, which is fairer than using criterion Av for most cases. In a real-life situation, if the exponential distributions are reasonable for modeling the failures and detection delay times, the results of this paper can provide decision-makers with a practical tool for designing systems.
Author Contributions
All authors contributed equally and significantly in writing this paper. All authors read
and approved the final manuscript.
Funding
Both this research and the APC were partially supported by Ministry of Science and Technology, Taipei, ROC under contracts MOST- 108-2221-E-126-001 -.
Acknowledgments
The authors are extremely indebted to the anonymous referees for their helpful comments to polish the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Derivation of
From Equations (1)–(4), we obtained the following steady-state equations:
From Equations (A1) and (A2), we obtained:
and
Further, we defined the following Laplace transform (LST) expressions:
After taking the LST on both sides of Equation (A3), we obtained:
Taking turns at setting and in Equation (A7) yielded:
Substituting Equations (A5) and (A6) into Equation (A8) gave:
Similarly, after substituting Equations (A5), (A6), and (A10) into Equation (A9), we obtained:
Next, after taking the LST on both sides of Equation (A4), we obtained:
Differentiating (A12) with respect to s and finally yielded:
where denotes the mean repair time.
Again, after differentiating Equation (A7) with respect to s and we obtained:
Substituting Equations (A11), (A6), and (A10) into Equation (A14) and undertaking the algebraic manipulation gave:
Again, substituting Equations (A6) and (A15) into Equation (A13) yielded:
Finally, after substituting Equations (A6), (A11), and (A16) into the following normalizing condition , we obtained:
where:
Using Equation (A17) in Equations (A6), (A11), and (A16) gave:
We assumed that the detection state (1,1) was a system down state. For availability system 1, the explicit expression for the steady-state availability, , was given by:
Appendix B. Derivation of
From Equations (7) and (8), we obtain
Taking the LST on both sides of Equation (9) yielded:
Setting and in Equation (A21) and undertaking the algebraic manipulation, we finally obtained:
Next, taking the LST on both sides of Equations (10) yielded:
Differentiating Equation (A24) with respect to s and setting yielded:
where denotes the mean repair time.
After differentiating Equation (A23) with respect to s and setting we finally obtained:
After substituting Equations (A19), (A20), and (A22) into Equation (A26) and undertaking the algebraic manipulation, we finally obtained:
Again, substituting Equations (A20) and (A27) into Equation (A25) yielded:
In order to find , we substituted Equations (A20), (A23), and (A28) into the following normalizing condition and obtained:
where:
Thus:
We assumed that the detection state (2,1) was a system down state. For availability system 2, the explicit expression for the steady-state availability, , was given by:
Appendix C. Derivation of
It follows from Equations (12), (13), and (16) that:
Taking the LST on both sides of Equations (14) and (17), respectively, we obtained:
Setting and in Equation (51) yielded:
This implies from Equations (A31) and (A32) that:
where:
After substituting Equations (A31), (A32), and (A36) into Equation (A37), we obtained:
Substituting Equations (A33) and (A37) into Equation (15) yielded:
where:
Setting and in Equation (A35) and doing the algebraic manipulation yielded:
After taking the LST on both sides of Equation (18), we obtained:
Differentiating Equation (60) with respect to s and setting yielded:
where denotes the mean repair time.
After differentiating Equation (A35) with respect to s and setting , we finally obtained:
From Equations (A40)–(A42), if was found that:
Applying Equation (A33), (A40), and (A46) to Equation (A44) yielded:
where:
Using the following normalizing condition:
and doing some arduous algebraic manipulation, we obtained . The expression for is too ample to be shown here.
We assumed that the detection states (4,1), (3,2), and (3,1) were system down states. For availability system 3, the explicit expression for the steady-state availability, , was given by:
References
- Trivedi, K.S. Probability and Statistics with Reliability, 2nd ed.; John Wiley and Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Cox, D.R. The analysis of non-Markovian stochastic processes by the inclusion of supplementary variables. Math. Proc. Camb. Philos. Soc. 1955, 51, 433–441. [Google Scholar] [CrossRef]
- Hokstad, P. A supplementary variable technique applied to the M/G/1 queue. Scand. J. Stat. 1975, 2, 95–98. [Google Scholar]
- Gupta, U.C.; Rao, T.S.S.S. A recursive method compute the steady state probabilities of the machine interference model: (M/G/1)/K. Comput. Oper. Res. 1994, 21, 597–605. [Google Scholar] [CrossRef]
- Gupta, U.C.; Rao, T.S.S.S. On the M/G/1 machine interference model with spares. Eur. J. Oper. Res. 1996, 89, 164–171. [Google Scholar] [CrossRef]
- Ke, J.-C.; Wang, K.-H. A recursive method for the N policy G/M/1 queueing system with finite capacity. Eur. J. Oper. Res. 2002, 142, 577–594. [Google Scholar] [CrossRef]
- Zhang, Y.L.; Wu, S. Reliability analysis for a k/n (F) system with repairable repair-equipment. Appl. Math. Model. 2009, 33, 3052–3067. [Google Scholar] [CrossRef]
- Shakuntla, S.; Lal, A.K.; Bhatia, S.S.; Singh, J. Reliability analysis of Polytube industry using supplementary variable technique. Appl. Math. Comput. 2011, 218, 3981–3992. [Google Scholar] [CrossRef]
- Wang, K.-H.; Su, J.-H.; Yang, D.-Y. Analysis and optimization of an M/G/1 machine repair problem with multiple imperfect coverage. Appl. Math. Comput. 2014, 242, 590–600. [Google Scholar] [CrossRef]
- Ke, J.-C.; Liu, T.-H.; Yang, D.-Y. Modeling of machine interference problem with unreliable repairman and standbys imperfect switchover. Reliab. Eng. Syst. Saf. 2018, 174, 12–18. [Google Scholar] [CrossRef]
- Wang, K.-H.; Pearn, W.L. Cost benefit analysis of series systems with warm standby components. Math. Methods Oper. Res. 2003, 58, 247–258. [Google Scholar] [CrossRef]
- Wang, K.-H.; Chiu, L.-W. Cost benefit analysis of availability systems with warm standby units and imperfect coverage. Appl. Math. Comput. 2006, 172, 1239–1256. [Google Scholar] [CrossRef]
- Wang, K.-H.; Chen, Y.-J. Comparative analysis of availability between three systems with general repair times, reboot delay and switching failures. Appl. Math. Comput. 2009, 215, 384–394. [Google Scholar] [CrossRef]
- Singh, V.V.; Singh, S.B.; Ram, M.; Goel, C.K. Availability, MTTF and cost analysis of a system having two units in series configuration with controller. Int. J. Syst. Assur. Eng. Manag. 2013, 4, 341–352. [Google Scholar] [CrossRef]
- Yu, H.; Chu, C.; Chatelet, E. Availability optimization of a redundant system through dependency modeling. Appl. Math. Model. 2014, 38, 4574–4585. [Google Scholar] [CrossRef]
- Ke, J.-C.; Lee, S.-L.; Hsu, Y.-L. On a repairable system with detection, imperfect coverage and reboot: Bayesian approach. Simul. Model. Pract. Theory 2008, 16, 353–367. [Google Scholar] [CrossRef]
- Kleyner, A.; Volovoi, V. Application of petri nets to reliability prediction of occupant safety systems with partial detection and repair. Reliab. Eng. Syst. Saf. 2010, 95, 606–613. [Google Scholar] [CrossRef]
- Ke, J.-C.; Liu, T.-H. A repairable system with imperfect coverage and reboot. Appl. Math. Comput. 2014, 246, 148–158. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).