Interval Intuitionistic Fuzzy Clustering Algorithm Based on Symmetric Information Entropy


Abstract
1. Introduction
2. Preliminaries
2.1. Some Basic Concepts of Intuitionistic Fuzzy Set
- (a)
- If , , and , then .
- (b)
- If , , and , then .
2.2. Continuous Aggregation Operators
3. Continuous OOWIFQ Operator for Aggregating Interval Intuitionistic Fuzzy Numbers Based on Chi-Squared Deviation
- (a).
- When is strictly monotonic increasing, then , holds. As a result, we haveSince is also strictly monotonic increasing, we get
- (b).
- On the contrary, when is strictly monotonic decreasing, then , holds. It follows thatwhich can be further expressed as
- (a)
- If is strictly monotonic increasing, then . Thus, for all , we have . It follows thatand
- (b)
- If is strictly monotonic decreasing, then . Thus, for all , we have . Similarly, we haveand
- (a)
- When function is strictly monotonic increasing, for any , we have
- (b)
- When function is strictly monotonic decreasing, for any , we have
- (a)
- when function is strictly monotonic increasing, then .
- (b)
- when function is strictly monotonic decreasing, then . Since , we have
4. Distance Measure of Interval Intuitionistic Fuzzy Numbers Based on Symmetric Information Entropy
- (a)
- .
- (b)
- if and only if interval intuitionistic fuzzy numbers and reduce to and or and .
- (c)
- .
- (d)
- , then and .
- (a)
- From Equation (23), we have, , therefore we have and . It is clear that holds. Since is an increasing function of and , takes the maximum of 1 when .
- (b)
- the proof of this property can be analyzed by the following two cases.
- (i)
- is an increasing function of independent various and , therefore the maximum value is obtained when and . From and , we can get that and or and .
- (ii)
- When and or and , can be brought into Equation (23) to get .
- (c)
- According to Equation (23), obviously, the symmetry of distance measure is holds.
- (d)
- When , from Definition 3, we have , , and . Denoting , , and , respectively. It is clear that and . Therefore, we get . In the same way, also holds. □
5. Interval Intuitionistic Fuzzy Clustering Algorithm
- Step 1
- Select an strictly monotonic function and BUM function , and enter the cluster number k and the sample attribute matrix , where .
- Step 2
- is calculated by Equation (12), where .
- Step 3
- Select a random sample from as the initial clustering center .
- Step 4
- Firstly, calculate the shortest distance between each object and the existing clustering center, denoted by ; then calculate the probability that each object is selected as the next cluster center. Finally, a cluster center is selected according to the roulette method.
- Step 5
- Repeat Step 4 until cluster centers are selected.
- Step 6
- For each object () in , its symmetric entropy distance to the k cluster center is calculated by the Equation (23) and divided into the class corresponding to the cluster center with the smallest distance.
- Step 7
- For each category , recalculate its cluster center .
- Step 8
- Repeat Steps 6 and 7 until the position of the cluster center does not change.
- Step 9
- End.
6. Numerical Example
- Step 1
- Input the sample attribute matrix , set , , and the classification number .
- Step 2
- Calculate each with Equation (12), and the calculated result is .
- Step 3
- Intuitionistic fuzzy matrix is calculated, shown in Table 2.
- Step 4
- Randomly select a sample from as the initial cluster center No. 1.
- Step 5
- Calculate the shortest distance between each object and the existing clustering center, denoted by ; then calculate the probability that each object is selected as the next cluster center. A cluster center is selected according to the roulette method.
- Step 6
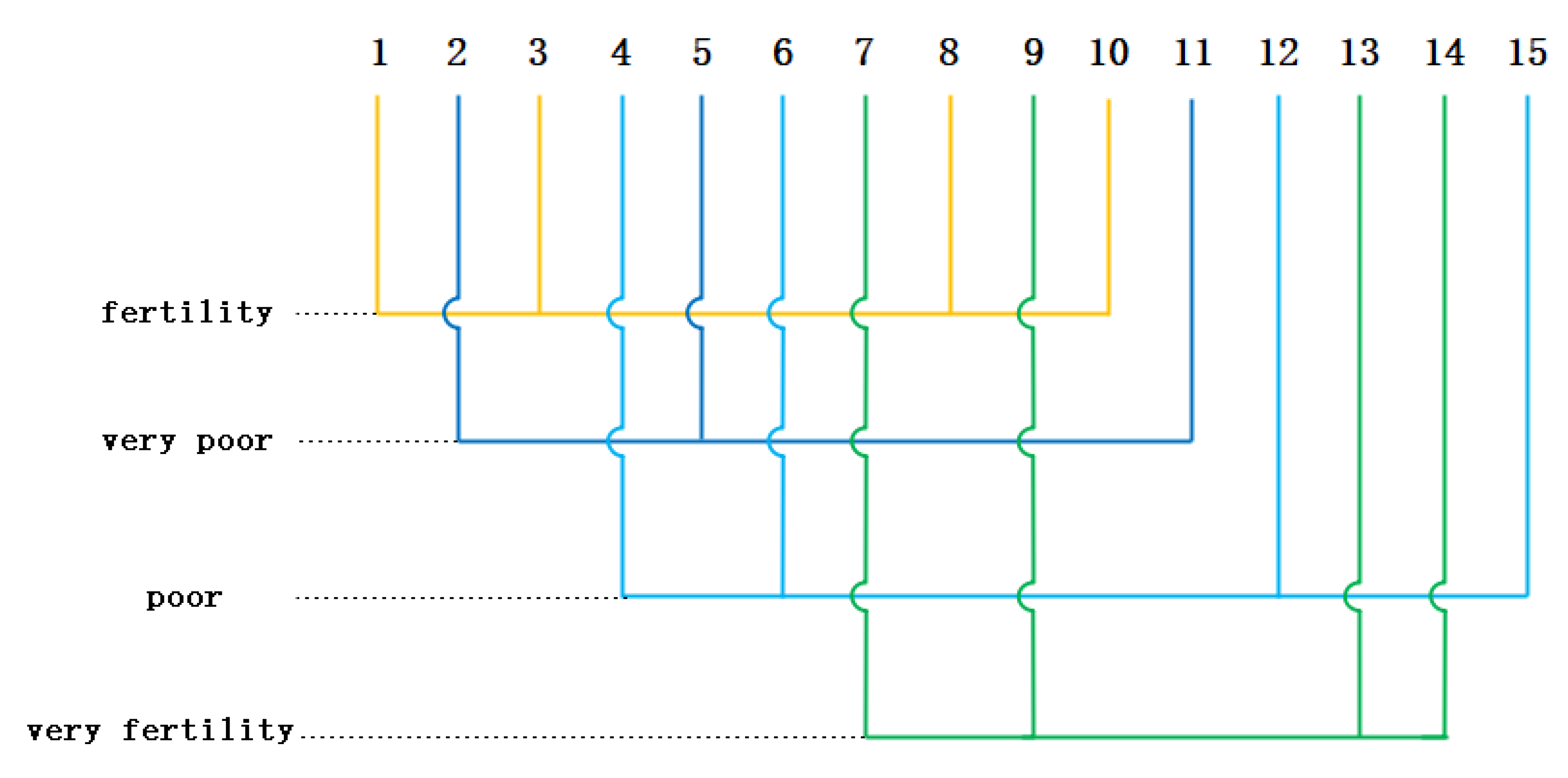
- Repeat Step 4 until cluster centers are selected. An initial clustering center is shown in Table 3.
- Step 7
- For each object () in , the symmetric entropy distance from the cluster center is calculated by Equation (22) and divided into the class corresponding to the cluster center with the smallest distance.
- Step 8
- For each category , recalculate its cluster center .
7. Conclusions
- (1)
- Compared with traditional clustering and fuzzy clustering, interval intuitionistic fuzzy clustering describes the fuzzy nature of things more delicately.
- (2)
- The symmetric information entropy based distance measure considers all the information in the continuous interval. Thus, the distortion and loss of information are avoided, and the result is more accurate and effective.
- (3)
- The C-OOWIFQ takes into account the preferences of decision makers.
Author Contributions
Funding
Conflicts of Interest
References
- Horn, D.; Gottlieb, A. Algorithm for data clustering in pattern recognition problems based on quantum mechanics. Phys. Rev. Lett. 2001, 88, 018702. [Google Scholar] [CrossRef] [PubMed]
- Huntsherger, T.; Jacobs, C.; Cannon, R.L. Iterative fuzzy image segmentation. Pattern Recognit. 1985, 18, 131–138. [Google Scholar] [CrossRef]
- Kuang, Z.; Kuh, A. A combined self-organizing feature map and multilayer perceptron for isolated word recognition. IEEE Trans. Signal Process. 1992, 40, 2651–2657. [Google Scholar] [CrossRef]
- Minnix, J.I.; McVey, E.S.; Inigo, R.M. A multilayered self-organizing artificial neural network for invariant pattern recognition. IEEE Trans. Knowl. Data Eng. 1992, 4, 162–167. [Google Scholar] [CrossRef]
- Cerreto, F.; Nielsen, B.F.; Nielsen, O.A.; Harrod, S.S. Application of data clustering to railway delay pattern recognition. J. Adv. Transp. 2018, 2018. [Google Scholar] [CrossRef]
- Dhanachandra, N.; Manglem, K.; Chanu, Y.J. Image Segmentation Using K -means Clustering Algorithm and Subtractive Clustering Algorithm. Procedia Comput. Sci. 2015, 54, 764–771. [Google Scholar] [CrossRef]
- Choy, S.K.; Shu, Y.L.; Yu, K.W.; Lee, W.Y.; Leung, K.T. Fuzzy model-based clustering and its application in image segmentation. Pattern Recognit. 2017, 68, 141–157. [Google Scholar] [CrossRef]
- Li, Z.; Chen, J. Superpixel segmentation using Linear Spectral Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Pham, T.X.; Siarry, P.; Oulhadj, H. Integrating fuzzy entropy clustering with an improved PSO for MRI brain image segmentation. Appl. Soft Comput. 2018, 65, 230–242. [Google Scholar] [CrossRef]
- Huang, H.; Meng, F.; Zhou, S.; Jiang, F.; Manogaran, G. Brain image segmentation based on FCM clustering algorithm and rough set. IEEE Access 2019, 7, 12386–12396. [Google Scholar] [CrossRef]
- Dutt, A.; Ismail, M.K.; Mahroeian, H.; Aghabozrgi, S. Clustering Algorithms Applied in Educational Data Mining. Int. J. Inf. Eng. Electron. Bus. 2015, 5. [Google Scholar] [CrossRef]
- Schubert, E.; Koos, A.; Emrich, T.; Zufle, A.; Schmid, K.A.; Zimek, A. A framework for clustering uncertain data. VLDB Endow. 2015, 8, 1976–1979. [Google Scholar] [CrossRef]
- Sarkar, B.; Omair, M.; Choi, S.-B. A multi-objective optimization of energy, economic, and carbon emission in a production model under sustainable supply chain management. Appl. Sci. 2018, 8, 1744. [Google Scholar] [CrossRef]
- Macqueen, J. Some Methods for Classification and Analysis of MultiVariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965. [Google Scholar]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms. Adv. Appl. Pattern Recognit. 1981, 22, 203–239. [Google Scholar]
- Guha, S.; Rastogi, R.; Shim, K.; Guha, S.; Rastogi, R.; Shim, K. CURE: An Efficient Clustering Algorithm for Large Databases. Inf. Syst. 1998, 26, 35–58. [Google Scholar] [CrossRef]
- Karypis, G.; Han, E.H.; Kumar, V. Chameleon: Hierarchical Clustering Using Dynamic Modeling. Computer 2002, 32, 68–75. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.-P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Philadelphia, PA, USA, 1–3 June 1999; pp. 49–60. [Google Scholar]
- Roy, S.; Bhattacharyya, D. An approach to find embedded clusters using density based techniques. In Proceedings of the International Conference on Distributed Computing and Internet Technology, Bhubaneswar, India, 22–24 December 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 523–535. [Google Scholar]
- Agrawal, R.; Gehrke, J.; Gunopulos, D.; Raghavan, P. Automatic subspace clustering of high dimensional data. Data Min. Knowl. Discov. 2005, 11, 5–33. [Google Scholar] [CrossRef]
- Wang, W.; Yang, J.; Muntz, R. STING: A statistical information grid approach to spatial data mining. VLDB 1997, 97, 186–195. [Google Scholar]
- Sheikholeslami, G.; Chatterjee, S.; Zhang, A. Wavecluster: A multi-resolution clustering approach for very large spatial databases. In Proceedings of the 24th VLDB Conference, New York, NY, USA, 24–27 August 1998; pp. 428–439. [Google Scholar]
- Yanchang, Z.; Junde, S. GDILC: A grid-based density-isoline clustering algorithm. In Proceedings of the 2001 International Conferences on Info-Tech and Info-Net. Proceedings (Cat. No. 01EX479), Beijing, China, 29 October–1 November 2001; pp. 140–145. [Google Scholar]
- Fisher, D.H. Improving Inference through Conceptual Clustering. AAAI 1987, 87, 461–465. [Google Scholar]
- Gennari, J.H.; Langley, P.; Fisher, D. Models of incremental concept formation. Artif. Intell. 1989, 40, 11–61. [Google Scholar] [CrossRef]
- Ruspini, E.H. A new approach to clustering. Inf. Control 1969, 15, 22–32. [Google Scholar] [CrossRef]
- Tamura, S.; Higuchi, S.; Tanaka, K. Pattern classification based on fuzzy relations. IEEE Trans. Syst. Man Cybern. 1971, SMC-1, 61–66. [Google Scholar] [CrossRef]
- Backer, E.; Jain, A.K. A clustering performance measure based on fuzzy set decomposition. IEEE Trans. Pattern Anal. Mach. Intell. 1981, 3, 66–75. [Google Scholar] [CrossRef] [PubMed]
- Zadeh, L.A. Similarity relations and fuzzy orderings. Inf. Sci. 1971, 3, 177–200. [Google Scholar] [CrossRef]
- Dunn, J. A graph theoretic analysis of pattern classification via Tamura’s fuzzy relation. IEEE Trans. Syst. Man Cybern. 1974, 3, 310–313. [Google Scholar] [CrossRef]
- Le, K. Fuzzy relation compositions and pattern recognition. Inf. Sci. 1996, 89, 107–130. [Google Scholar] [CrossRef]
- Wu, Z.; Leahy, R. An optimal graph theoretic approach to data clustering: Theory and its application to image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1101–1113. [Google Scholar] [CrossRef]
- Esogbue, A.O. Optimal clustering of fuzzy data via fuzzy dynamic programming. Fuzzy Sets Syst. 1986, 18, 283–298. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic fuzzy sets. Control Theory Appl. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Atanassov, K.; Gargov, G. Interval valued intuitionistic fuzzy sets. Fuzzy Sets Syst. 1989, 31, 343–349. [Google Scholar] [CrossRef]
- Yager, R.R. OWA Aggregation Over a Continuous Interval Argument With Applications to Decision Making. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2004, 34, 1952–1963. [Google Scholar] [CrossRef]
- Yager, R.R.; Xu, Z. The continuous ordered weighted geometric operator and its application to decision making. Fuzzy Sets Syst. 2006, 157, 1393–1402. [Google Scholar] [CrossRef]
- Chen, H.; Liu, J.; Wang, H. A class of continuous ordered weighted harmonic (C-OWH) averaging operators for interval argument and its applications. Syst. Eng. Theory Pract. 2008, 28, 86–92. [Google Scholar]
- Liu, J.; Lin, S.; Chen, H.; Zhou, L. The Continuous Quasi-OWA Operator and its Application to Group Decision Making. Group Decis. Negot. 2013, 22, 715–738. [Google Scholar] [CrossRef]
- Yager, R.R. Quantifier guided aggregation using OWA operators. Int. J. Intell. Syst. 1996, 11, 49–73. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| No. | TN | TP | OM | AN | AP | AK |
|---|---|---|---|---|---|---|
| 1 | ([0.6,0.6], [0.3,0.3]) | ([0.1,0.7], [0.2,0.3]) | ([0.1,0.5], [0.0,0.1]) | ([0.3,0.3], [0.1,0.4]) | ([0.3,0.4], [0.1,0.1]) | ([0.2,0.7], [0.0,0.1]) |
| 2 | ([0.1,0.1], [0.5,0.5]) | ([0.6,0.9], [0.1,0.1]) | ([0.1,0.1], [0.1,0.1]) | ([0.2,0.2], [0.1,0.2]) | ([0.3,0.3], [0.0,0.3]) | ([0.0,0.3], [0.2,0.2]) |
| 3 | ([0.2,0.4], [0.1,0.2]) | ([0.6,0.8], [0.0,0.1]) | ([0.0,0.7], [0.0,0.1]) | ([0.0,0.0], [0.1,0.1]) | ([0.5,0.8], [0.1,0.2]) | ([0.5,0.9], [0.0,0.0]) |
| 4 | ([0.4,0.6], [0.2,0.2]) | ([0.3,0.4], [0.1,0.3]) | ([0.5,0.6], [0.2,0.3]) | ([0.0,0.1], [0.1,0.1]) | ([0.4,0.9], [0.1,0.1]) | ([0.0,0.1], [0.1,0.5]) |
| 5 | ([0.0,0.0], [0.6,0.7]) | ([0.0,0.5], [0.0,0.0]) | ([0.0,0.1], [0.0,0.3]) | ([0.3,0.4], [0.1,0.2]) | ([0.5,0.8], [0.0,0.0]) | ([0.1,0.3], [0.0,0.0]) |
| 6 | ([0.1,0.6], [0.3,0.4]) | ([0.2,0.3], [0.1,0.6]) | ([0.0,0.8], [0.2,0.2]) | ([0.5,0.5], [0.3,0.5]) | ([0.2,0.2], [0.3,0.4]) | ([0.0,0.3], [0.3,0.4]) |
| 7 | ([0.6,0.6], [0.1,0.1]) | ([0.2,0.4], [0.0,0.1]) | ([0.1,0.2], [0.0,0.1]) | ([0.1,0.2], [0.2,0.3]) | ([0.4,0.7], [0.0,0.2]) | ([0.1,0.2], [0.1,0.1]) |
| 8 | ([0.4,0.5], [0.0,0.1]) | ([0.0,0.1], [0.6,0.8]) | ([0.1,0.9], [0.0,0.0]) | ([0.2,0.4], [0.3,0.6]) | ([0.0,0.5], [0.0,0.1]) | ([0.3,0.9], [0.0,0.1]) |
| 9 | ([0.6,0.7], [0.1,0.2]) | ([0.0,0.6], [0.0,0.0]) | ([0.3,0.8], [0.0,0.1]) | ([0.1,0.1], [0.3,0.6]) | ([0.0,0.0], [0.0,0.2]) | ([0.1,0.6], [0.1,0.1]) |
| 10 | ([0.2,0.4], [0.0,0.2]) | ([0.0,0.7], [0.1,0.1]) | ([0.2,0.2], [0.2,0.4]) | ([0.5,0.8], [0.0,0.1]) | ([0.6,0.9], [0.0,0.1]) | ([0.6,0.8], [0.0,0.0]) |
| 11 | ([0.0,0.1], [0.3,0.6]) | ([0.4,0.9], [0.0,0.0]) | ([0.1,0.1], [0.0,0.0]) | ([0.3,0.5], [0.1,0.5]) | ([0.2,0.2], [0.1,0.6]) | ([0.1,0.1], [0.1,0.5]) |
| 12 | ([0.3,0.3], [0.4,0.6]) | ([0.1,0.1], [0.1,0.2]) | ([0.5,1.0], [0.0,0.0]) | ([0.4,0.7], [0.1,0.1]) | ([0.1,0.6], [0.4,0.4]) | ([0.1,0.2], [0.2,0.6]) |
| 13 | ([0.7,0.8], [0.0,0.0]) | ([0.2,0.9], [0.0,0.0]) | ([0.1,0.5], [0.0,0.1]) | ([0.0,0.1], [0.5,0.8]) | ([0.0,0.0], [0.3,0.7]) | ([0.0,0.1], [0.4,0.5]) |
| 14 | ([0.4,0.4], [0.4,0.5]) | ([0.5,1.0], [0.0,0.0]) | ([0.7,0.8], [0.1,0.1]) | ([0.3,0.4], [0.1,0.6]) | ([0.1,0.1], [0.5,0.7]) | ([0.0,0.3], [0.1,0.3]) |
| 15 | ([0.3,0.5], [0.1,0.3]) | ([0.4,0.6], [0.2,0.3]) | ([0.2,0.6], [0.0,0.0]) | ([0.3,0.5], [0.1,0.2]) | ([0.3,0.4], [0.0,0.1]) | ([0.0,0.0], [0.0,0.1]) |
| No. | TN | TP | OM | AN | AP | AK |
|---|---|---|---|---|---|---|
| 1 | (0.60,0.30) | (0.43,0.25) | (0.31,0.05) | (0.30,0.26) | (0.35,0.10) | (0.47,0.05) |
| 2 | (0.10,0.50) | (0.76,0.10) | (0.10,0.10) | (0.20,0.15) | (0.30,0.16) | (0.16,0.20) |
| 3 | (0.30,0.15) | (0.70,0.05) | (0.39,0.05) | (0.00,0.10) | (0.66,0.15) | (0.71,0.00) |
| 4 | (0.50,0.20) | (0.35,0.20) | (0.55,0.25) | (0.05,0.10) | (0.67,0.10) | (0.05,0.31) |
| 5 | (0.00,0.65) | (0.27,0.00) | (0.05,0.16) | (0.35,0.15) | (0.66,0.00) | (0.20,0.00) |
| 6 | (0.37,0.35) | (0.25,0.37) | (0.45,0.20) | (0.50,0.40) | (0.20,0.35) | (0.16,0.35) |
| 7 | (0.60,0.10) | (0.30,0.05) | (0.15,0.05) | (0.15,0.25) | (0.56,0.10) | (0.15,0.10) |
| 8 | (0.45,0.05) | (0.05,0.70) | (0.55,0.00) | (0.30,0.46) | (0.27,0.05) | (0.63,0.05) |
| 9 | (0.65,0.15) | (0.33,0.00) | (0.57,0.05) | (0.10,0.46) | (0.00,0.10) | (0.37,0.10) |
| 10 | (0.30,0.10) | (0.39,0.10) | (0.20,0.30) | (0.66,0.05) | (0.76,0.05) | (0.70,0.00) |
| 11 | (0.05,0.46) | (0.67,0.00) | (0.10,0.00) | (0.40,0.31) | (0.20,0.37) | (0.10,0.31) |
| 12 | (0.30,0.50) | (0.10,0.15) | (0.77,0.00) | (0.56,0.10) | (0.37,0.40) | (0.15,0.41) |
| 13 | (0.75,0.00) | (0.59,0.00) | (0.31,0.05) | (0.05,0.66) | (0.00,0.51) | (0.05,0.45) |
| 14 | (0.40,0.45) | (0.77,0.00) | (0.75,0.10) | (0.35,0.37) | (0.10,0.60) | (0.16,0.20) |
| 15 | (0.40,0.20) | (0.50,0.25) | (0.41,0.00) | (0.40,0.15) | (0.35,0.05) | (0.00,0.05) |
| No. | TN | TP | OM | AN | AP | AK |
|---|---|---|---|---|---|---|
| 1 | (0.60,0.30) | (0.43,0.25) | (0.31,0.05) | (0.30,0.26) | (0.35,0.10) | (0.47,0.05) |
| 2 | (0.50,0.20) | (0.35,0.20) | (0.55,0.25) | (0.05,0.10) | (0.67,0.10) | (0.05,0.31) |
| 3 | (0.05,0.46) | (0.67,0.00) | (0.10,0.00) | (0.40,0.31) | (0.20,0.37) | (0.10,0.31) |
| 4 | (0.30,0.15) | (0.70,0.05) | (0.39,0.05) | (0.00,0.10) | (0.66,0.15) | (0.71,0.00) |
| No. | TN | TP | OM | AN | AK | AK |
|---|---|---|---|---|---|---|
| 1 | (0.54,0.16) | (0.32,0.25) | (0.40,0.03) | (0.25,0.31) | (0.31,0.08) | (0.32,0.07) |
| 2 | (0.54,0.18) | (0.40,0.19) | (0.44,0.17) | (0.20,0.39) | (0.29,0.32) | (0.09,0.37) |
| 3 | (0.21,0.48) | (0.57,0.06) | (0.43,0.05) | (0.38,0.23) | (0.24,0.38) | (0.14,0.28) |
| 4 | (0.20,0.30) | (0.45,0.05) | (0.21,0.17) | (0.34,0.10) | (0.69,0.07) | (0.54,0.00) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, J.; Duan, G.; Tian, Z. Interval Intuitionistic Fuzzy Clustering Algorithm Based on Symmetric Information Entropy. Symmetry 2020, 12, 79. https://doi.org/10.3390/sym12010079
Lin J, Duan G, Tian Z. Interval Intuitionistic Fuzzy Clustering Algorithm Based on Symmetric Information Entropy. Symmetry. 2020; 12(1):79. https://doi.org/10.3390/sym12010079
Chicago/Turabian StyleLin, Jian, Guanhua Duan, and Zhiyong Tian. 2020. "Interval Intuitionistic Fuzzy Clustering Algorithm Based on Symmetric Information Entropy" Symmetry 12, no. 1: 79. https://doi.org/10.3390/sym12010079
APA StyleLin, J., Duan, G., & Tian, Z. (2020). Interval Intuitionistic Fuzzy Clustering Algorithm Based on Symmetric Information Entropy. Symmetry, 12(1), 79. https://doi.org/10.3390/sym12010079