An Optimization Framework for Codes Classification and Performance Evaluation of RISC Microprocessors

 , and
, and
Abstract
1. Introduction
- Performance modeling of three conventional processor types for commonly seen instructions
- Classification of assembly language codes for code-to-processor mapping using an optimization technique based on symmetry-improving nonlinear transformation
2. Background and Related Work
2.1. Dynamic Partial Reconfiguration
2.2. Processor Design Styles
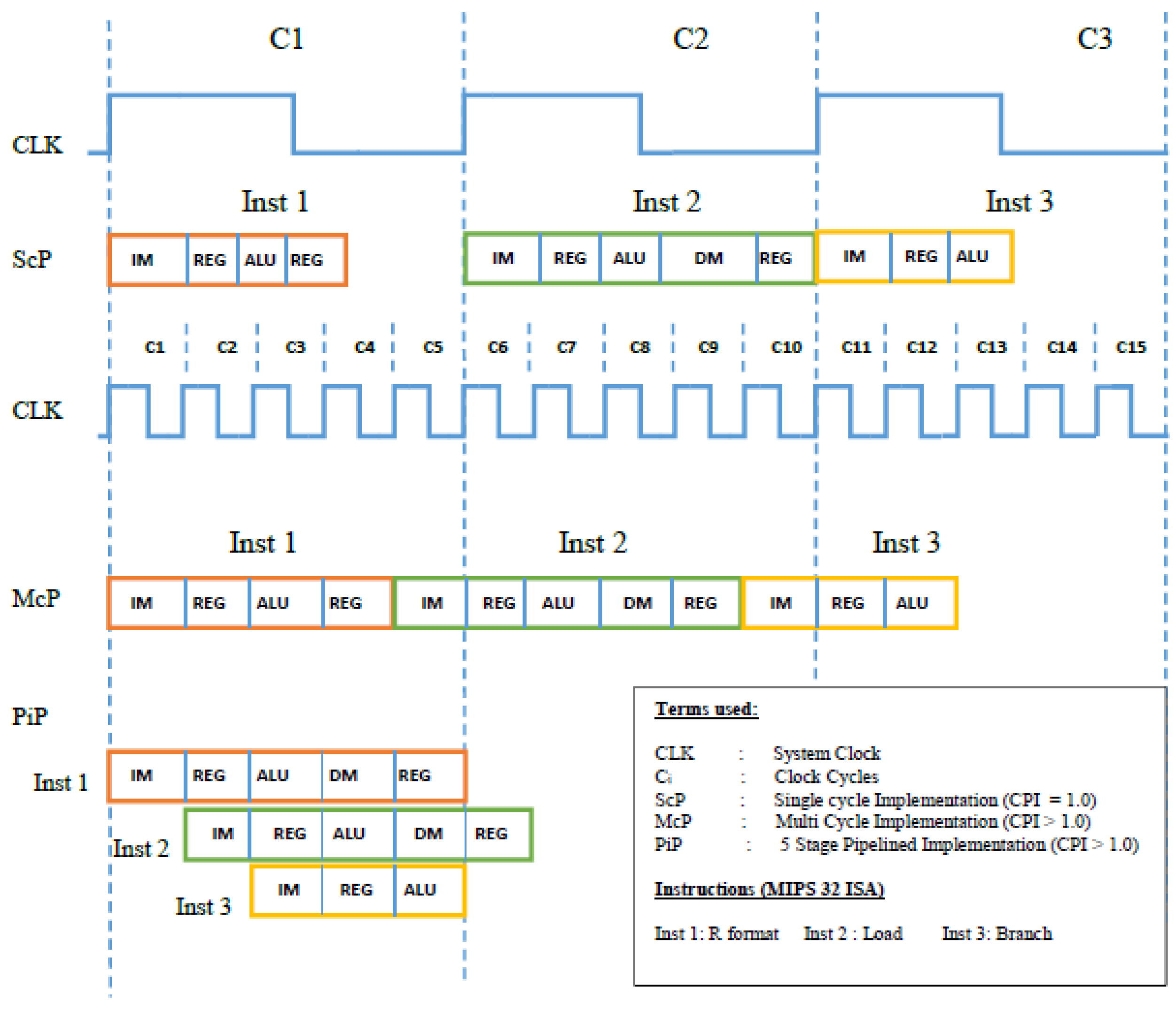
2.2.1. SCP
2.2.2. MCP
2.2.3. PiP
2.2.4. Instruction Types
- Register (R)—Format, in which the source as well as the destination operands belong to the register file.
- Load Word (LW), in which a data item is fetched from data memory and loaded in a register. The physical address is formed by adding a base address, which comes from a register, to an offset encoded in the instruction.
- Store Word (SW), in which the data item is read from a register and moved into a location on data memory, where physical address is computed in the same manner as for LW.
- Branch, in which flow of the program changes based on a condition: instead of fetching the next sequential instruction, instruction present at the target address is fetched on to the processor. The condition is usually checked by the ALU or a comparator on operands from register file. Please note that until the condition is checked (say found true), at least one instruction, usually the one next in line sequentially, may have already been fetched into the pipeline—leading to a control hazard in case of PiP. It is called a hazard since the incorrectly fetched instruction needs to be flushed out of the pipeline before it carries out an erroneous activity, e.g., a memory read/write or a register write.
- Jump, in which flow of the program changes unconditionally. Likewise for the branch instruction in a PiP, Jump will require flushing the pipeline at least once, before the correct instruction is fetched.
2.3. Optimization Methods
3. Mathematical Modeling
3.1. Preliminary Assumptions
3.2. Formulation for SCP
3.3. Formulation for MCP
3.4. Formulation for PiP
3.5. Estimating Worst and Best Case Performance
3.6. Discussion
- The second variant of SCP performs much better for shorter instructions, such as Jump and Branch. So, the more the shorter instructions in the code, the more suitable the SCP should be.
- The performance of the PiP entirely depends upon instruction mix: if there is no hazardous instruction, this type will stand out as the best. However, the more the control hazards in the code, the larger the execution time will be. Furthermore, is dictated by the slowest function step, which means the larger the difference between the latencies of function units, the larger the will be in comparison to .
- In terms of performance, it is difficult for the MCP to beat the other two. The reason for this observation is its of 3 for shorter instructions, which suit the SCP more. On the other hand, the PiP will outclass it for longer instructions.
4. Problem Statement and Proposed Optimization
4.1. Problem Statement & System Model
- x
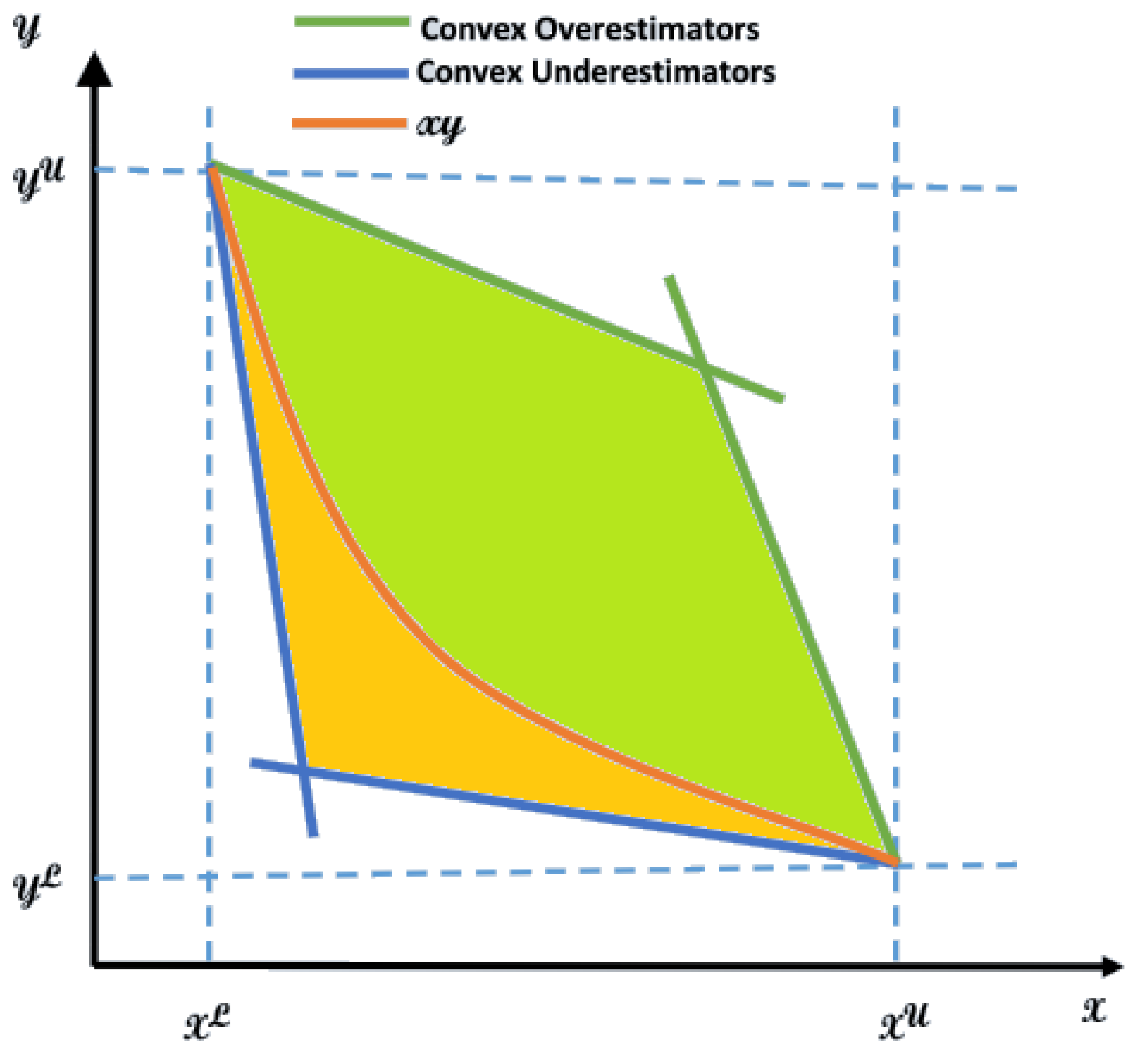
4.2. Convex Relaxation using McCormick’s Envelopes
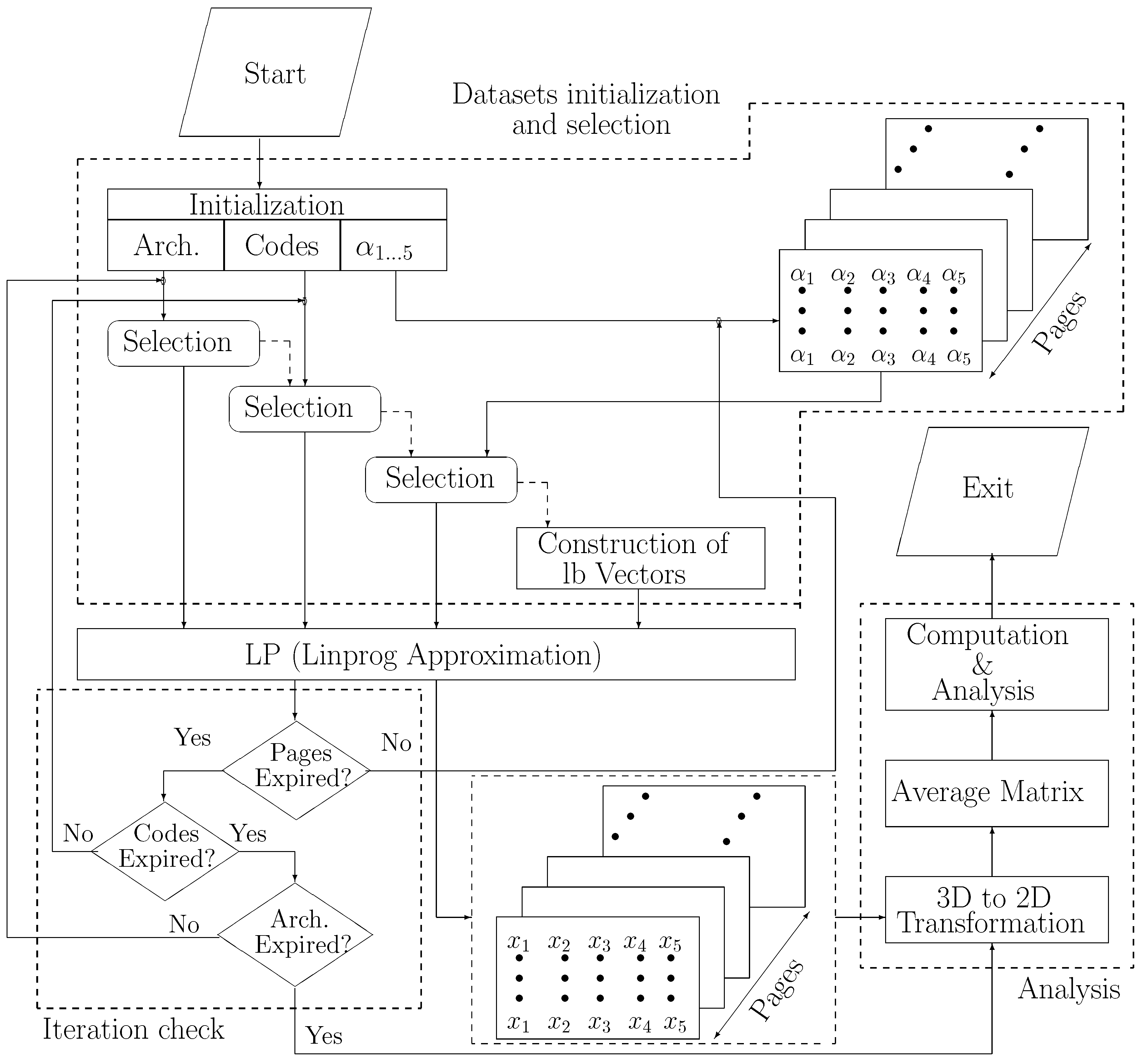
4.3. Proposed Methodology and Algorithm
| Algorithm 1: Proposed Algorithm. |
 |
5. Evaluation and Sample Codes
5.1. Data Initialization
- —representing four different architectures
- —representing propagation delays of function modules. The vector is chosen, as such, for simplicity, since , is technology dependent, and may lie in the range for recent technology nodes. Here, and will always be smaller than the other two, and are randomly selected.
- —representing four different assembly language code lengths. These values will give us a confidence interval for performance of each processor’s variant.
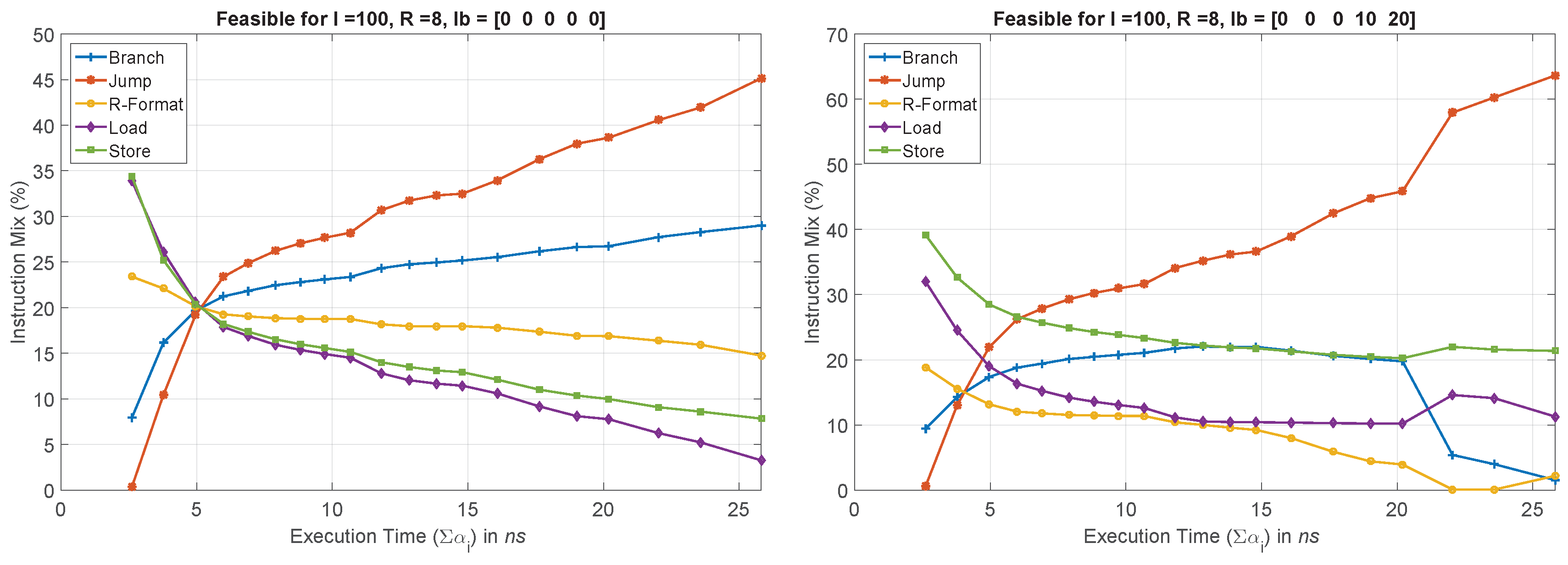
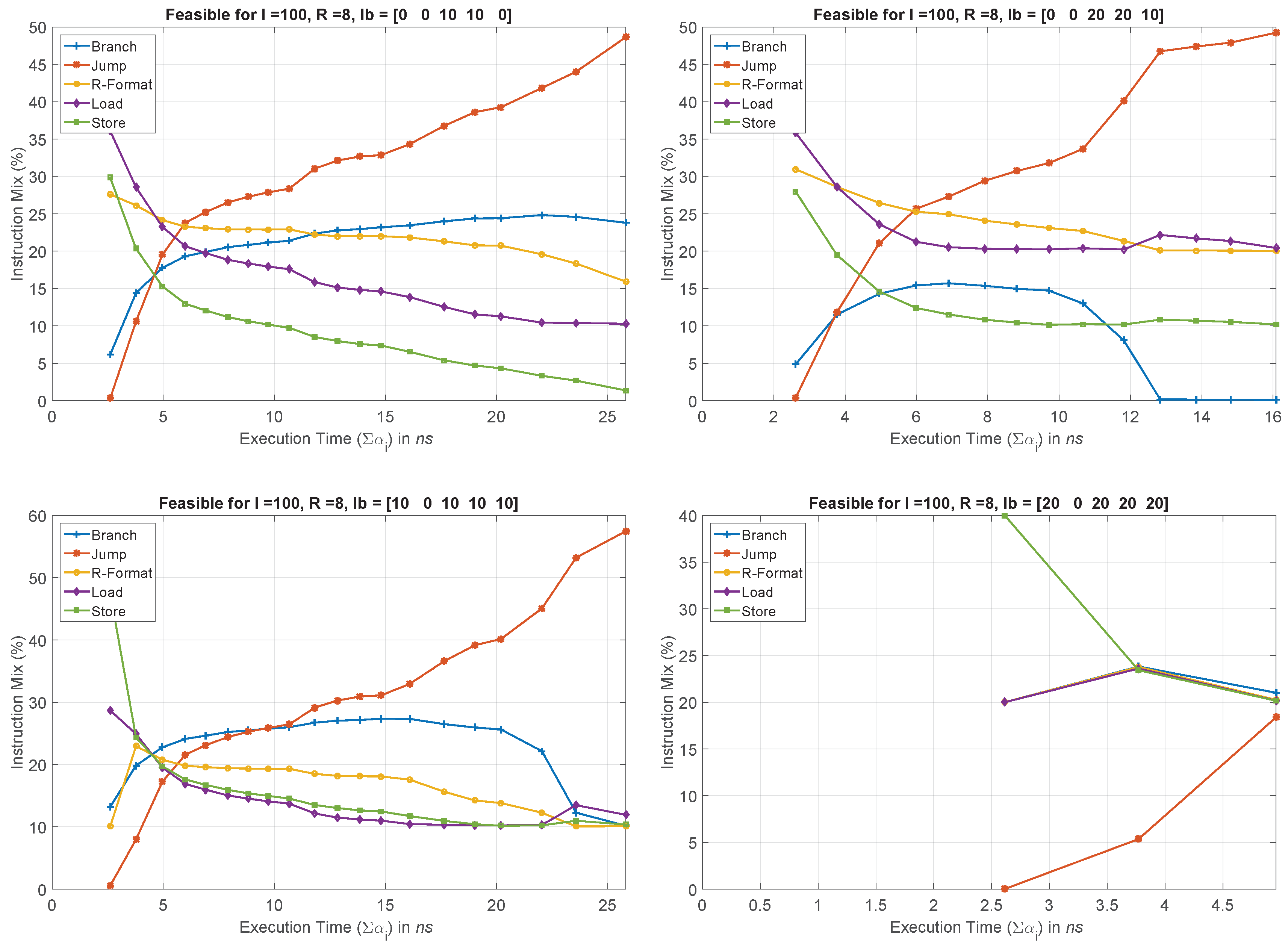
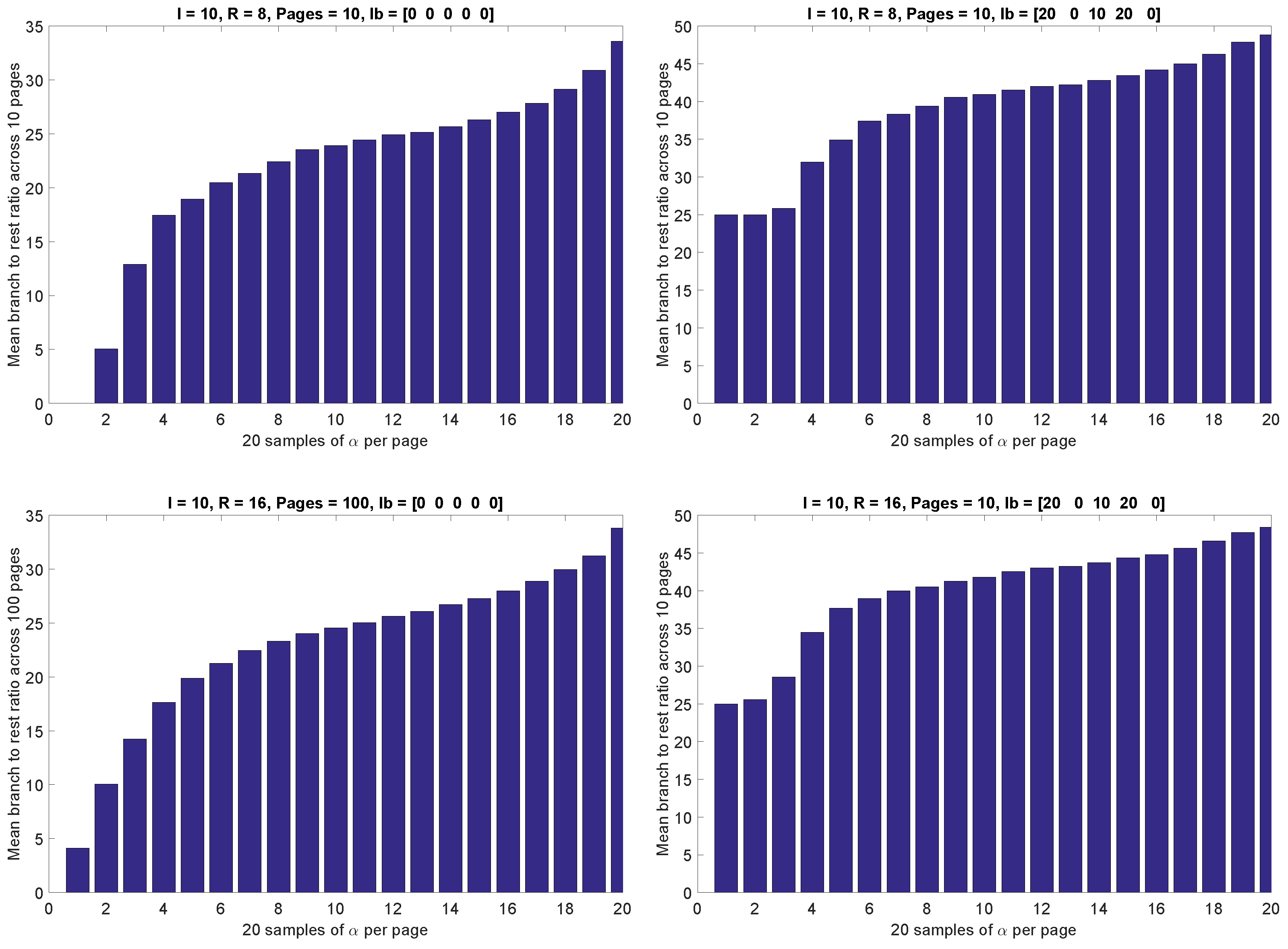
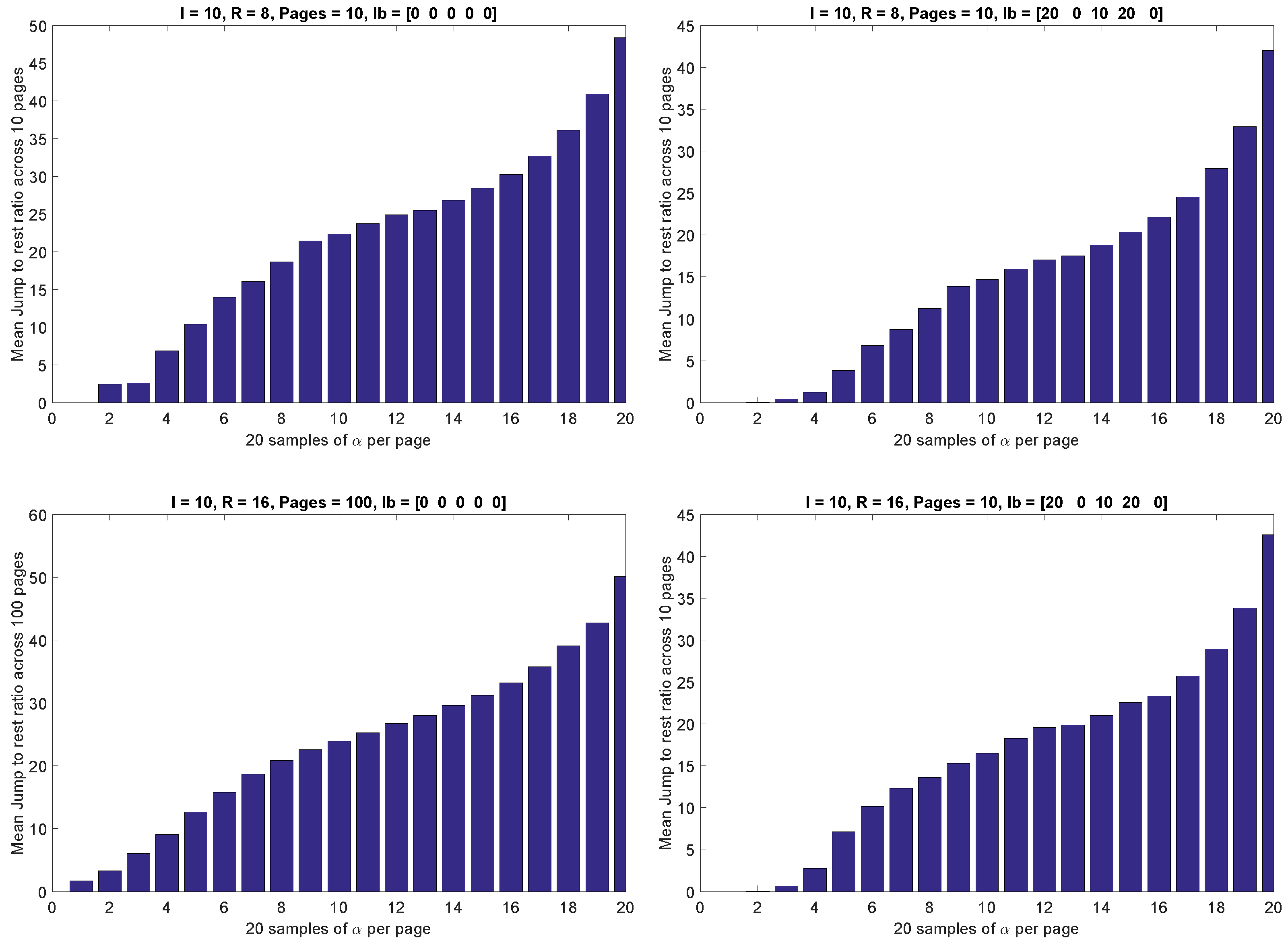
- — representing lb on each type of instructions, , in percentage. Since we already know that jump is the shortest instruction, and will matter the most in yielding feasible solutions to the optimization problems, we do not constrain its lb, and rather treat it as an output. Therefore, . Whereas, we iteratively vary the rest between , resulting in assembly language codes with different instruction mix.
5.2. Simulation Results
5.3. Sample Codes and Mapping
| ORG 8100H | |
| MOV TMOD, #02H | ;8-bit auto-reload mode |
| MOV TH0, #-50 | ;-50 reload value in TH0 |
| SETB TR0 | ;start timer |
| LOOP: JNB TF0 LOOP | ;wait for overflow |
| CLR TF0 | ;clear timer overflow flag |
| CPL P1.0 | ;toggle port bit |
| SJMP LOOP | ;repeat |
| END |
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Patterson, D.A.; Sequin, C.H. RISC I: A Reduced Instruction Set VLSI Computer. In Proceedings of the 8th Annual Symposium on Computer Architecture ISCA ’81, Minneapolis, MN, USA, 12–14 May 1981; IEEE Computer Society Press: Los Alamitos, CA, USA, 1981; pp. 443–457. [Google Scholar]
- Patterson, D.A.; Hennessy, J.L. Computer Organization and Design MIPS Edition: The Hardware/Software Interface; Newnes: Bathurst, Australia, 2013. [Google Scholar]
- Kumar, R.; Pawar, L.; Aggarwal, A. Smartphones hardware Architectures and Their Issues. Int. J. Eng. Res. Appl. 2014, 4, 81–83. [Google Scholar]
- Fu, H.; Liao, J.; Yang, J.; Wang, L.; Song, Z.; Huang, X.; Yang, C.; Xue, W.; Liu, F.; Qiao, F.; et al. The Sunway TaihuLight supercomputer: system and applications. Sci. China Inf. Sci. 2016, 59, 072001. [Google Scholar] [CrossRef]
- David, A.P.; John, L.H. Computer Organization and Design: The Hardware/Software Interface; Morgan Kaufmann Publishers: San mateo, CA, USA, 2005; Volume 1, p. 998. [Google Scholar]
- Obaidat, M.; Abu-Saymeh, D.S. Performance of RISC-based multiprocessors. Comput. Electr. Eng. 1993, 19, 185–192. [Google Scholar] [CrossRef]
- Shen, J.P.; Lipasti, M.H. Modern Processor Design: Fundamentals of Superscalar Processors; Waveland Press: Long Grove, IL, USA, 2013. [Google Scholar]
- Vargas, V.; Ramos, P.; Méhaut, J.F.; Velazco, R. NMR-MPar: A fault-tolerance approach for multi-core and many-core processors. Appl. Sci. 2018, 8, 465. [Google Scholar] [CrossRef]
- Wang, S.H.; Peng, W.H.; He, Y.; Lin, G.Y.; Lin, C.Y.; Chang, S.C.; Wang, C.N.; Chiang, T. A software-hardware co-implementation of MPEG-4 advanced video coding (AVC) decoder with block level pipelining. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2005, 41, 93–110. [Google Scholar] [CrossRef][Green Version]
- Khan, S.; Rashid, M.; Javaid, F. A high performance processor architecture for multimedia applications. Comput. Electr. Eng. 2018, 66, 14–29. [Google Scholar] [CrossRef]
- Liu, Q.; Xu, Z.; Yuan, Y. High throughput and secure advanced encryption standard on field programmable gate array with fine pipelining and enhanced key expansion. IET Comput. Digit. Tech. 2015, 9, 175–184. [Google Scholar] [CrossRef]
- Mukhtar, N.; Mehrabi, M.; Kong, Y.; Anjum, A. Machine-Learning-Based Side-Channel Evaluation of Elliptic-Curve Cryptographic FPGA Processor. Appl. Sci. 2019, 9, 64. [Google Scholar] [CrossRef]
- Tummala, R.; Nedumthakady, N.; Ravichandran, S.; DeProspo, B.; Sundaram, V. Heterogeneous and homogeneous package integration technologies at device and system levels. In Proceedings of the Pan Pacific Microelectronics Symposium (Pan Pacific), Waimea, HI, USA, 5–8 February 2018; pp. 1–5. [Google Scholar]
- Hussein, F.; Daoud, L.; Rafla, N. HexCell: a Hexagonal Cell for Evolvable Systolic Arrays on FPGAs. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018; p. 293. [Google Scholar]
- Skvortsov, V.V.; Zvyagina, M.I.; Skitev, A.A. Sharing resources in heterogeneous multitasking computer systems based on FPGA with the use of partial reconfiguration. In Proceedings of the 2018 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Moscow, Russia, 29 January–1 February 2018; pp. 370–373. [Google Scholar]
- Alfian, G.; Syafrudin, M.; Yoon, B.; Rhee, J. False Positive RFID Detection Using Classification Models. Appl. Sci. 2019, 9, 1154. [Google Scholar] [CrossRef]
- Gu, X.; Fang, L.; Liu, P.; Hu, Q. Multiple Chip Multiprocessor Cache Coherence Operation Method and Multiple Chip Multiprocessor. U.S. Patent 16/138,824, 24 January 2019. [Google Scholar]
- Pezzarossa, L.; Kristensen, A.T.; Schoeberl, M.; Sparsø, J. Can Real-Time Systems Benefit from Dynamic Partial Reconfiguration? In Proceedings of the Nordic Circuits and Systems Conference (NORCAS): NORCHIP and International Symposium of System-on-Chip (SoC), Linköping, Sweden, 23–25 October 2017.
- Pezzarossa, L.; Schoeberl, M.; Sparsø, J. Reconfiguration in FPGA-based multi-core platforms for hard real-time applications. In Proceedings of the 11th International Symposium on Reconfigurable Communication-centric Systems-on-Chip (ReCoSoC), Tallinn, Estonia, 27–29 June 2016; pp. 1–8. [Google Scholar]
- Hassan, A.; Mostafa, H.; Fahmy, H.A.; Ismail, Y. Exploiting the Dynamic Partial Reconfiguration on NoC-Based FPGA. In Proceedings of the 2017 New Generation of Exploiting the Dynamic Partial Reconfiguration on NoC-Based FPGA, Genoa, Italy, 6–9 September 2017; pp. 277–280. [Google Scholar]
- Becher, A.; Bauer, F.; Ziener, D.; Teich, J. Energy-aware SQL query acceleration through FPGA-based dynamic partial reconfiguration. In Proceedings of the 24th International Conference on IEEE Field Programmable Logic and Applications (FPL), Munich, Germany, 2–4 September 2014; pp. 1–8. [Google Scholar]
- Johnson, A.P.; Liu, J.; Millard, A.G.; Karim, S.; Tyrrell, A.M.; Harkin, J.; Timmis, J.; McDaid, L.J.; Halliday, D.M. Homeostatic Fault Tolerance in Spiking Neural Networks: A Dynamic Hardware Perspective. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 687–699. [Google Scholar] [CrossRef]
- Birk, Y.; Fiksman, E. Dynamic reconfiguration architectures for multi-context FPGAs. Comput. Electr. Eng. 2009, 35, 878–903. [Google Scholar] [CrossRef]
- Emami, S.; Sedighi, M. An optimized reconfigurable architecture for hardware implementation of decimal arithmetic. Comput. Electr. Eng. 2017, 63, 18–29. [Google Scholar] [CrossRef]
- Aagaard, M.; Leeser, M. Reasoning about pipelines with structural hazards. In Theorem Provers in Circuit Design; Springer: Berlin, Germany, 1995; pp. 13–32. [Google Scholar]
- Alghunaim, S.A.; Sayed, A.H. Distributed coupled multi-agent stochastic optimization. IEEE Trans. Autom. Control 2019. [Google Scholar] [CrossRef]
- Abed-alguni, B.H. Island-based Cuckoo Search with Highly Disruptive Polynomial Mutation. Int. J. Artif. Intell. 2019, 17, 57–82. [Google Scholar]
- Shams, M.; Rashedi, E.; Dashti, S.M.; Hakimi, A. Ideal gas optimization algorithm. Int. J. Artif. Intell. 2017, 15, 116–130. [Google Scholar]
- Soares, A.; Râbelo, R.; Delbem, A. Optimization based on phylogram analysis. Expert Syst. Appl. 2017, 78, 32–50. [Google Scholar] [CrossRef]
- Precup, R.E.; David, R.C. Nature-Inspired Optimization Algorithms for Fuzzy Controlled Servo Systems; Butterworth-Heinemann: Oxford, UK, 2019. [Google Scholar]
- Esbensen, H. Computing near-optimal solutions to the Steiner problem in a graph using a genetic algorithm. Networks 1995, 26, 173–185. [Google Scholar] [CrossRef]
- Oulghelou, M.; Allery, C. Hyper bi-calibrated interpolation on the Grassmann manifold for near real time flow control using genetic algorithm. arXiv, 2019; arXiv:1903.03611. [Google Scholar]
- Fushchich, W.I.; Shtelen, W.; Serov, N. Symmetry Analysis and Exact Solutions of Equations of Nonlinear Mathematical Physics; Springer: Berlin, Germany, 1997. [Google Scholar]
- Zoutendijk, G. Methods of Feasible Directions: A Study in Linear and Non-Linear Programming; Elsevier: Amsterdam, The Netherlands, 1960. [Google Scholar]
- Bazaraa, M.S.; Sherali, H.D.; Shetty, C.M. Nonlinear Programming: Theory andAlgorithms; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Zhang, S.; Huang, J.; Yang, J. Raising Power Loss Equalizing Degree of Coil Array by Convex Quadratic Optimization Commutation for Magnetic Levitation Planar Motors. Appl. Sci. 2019, 9, 79. [Google Scholar] [CrossRef]
- Shachar, N.; Mitelpunkt, A.; Kozlovski, T.; Galili, T.; Frostig, T.; Brill, B.; Marcus-Kalish, M.; Benjamini, Y. The importance of nonlinear transformations use in medical data analysis. JMIR Med. Inform. 2018, 6, e27. [Google Scholar] [CrossRef]
- Westerlund, T.; Lundell, A.; Westerlund, J. On convex relaxations in nonconvex optimization. Chem. Eng. Trans. 2011, 24, 331–336. [Google Scholar]
- Castro, P.M. Tightening piecewise McCormick relaxations for bilinear problems. Comput. Chem. Eng. 2015, 72, 300–311. [Google Scholar] [CrossRef]
- Hinder, O.; Ye, Y. A one-phase interior point method for nonconvex optimization. arXiv, 2018; arXiv:1801.03072. [Google Scholar]
- MacKenzie, I.S.; Phan, R.C.W. The 8051 Microcontroller; Prentice Hall: Upper Saddle River, NJ, USA, 1999; Volume 3. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instruction | Expression | ||
|---|---|---|---|
| = | |||
| = | |||
| = | |||
| = | |||
| = | |||
| Instruction | Number of Clock Cycles | ||
|---|---|---|---|
| = | 3 | ||
| = | 3 | ||
| = | 4 | ||
| = | 5 | ||
| = | 4 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naqvi, S.R.; Roman, A.; Akram, T.; Alhaisoni, M.M.; Naeem, M.; Haider, S.A.; Chughtai, O.; Awais, M. An Optimization Framework for Codes Classification and Performance Evaluation of RISC Microprocessors. Symmetry 2019, 11, 938. https://doi.org/10.3390/sym11070938
Naqvi SR, Roman A, Akram T, Alhaisoni MM, Naeem M, Haider SA, Chughtai O, Awais M. An Optimization Framework for Codes Classification and Performance Evaluation of RISC Microprocessors. Symmetry. 2019; 11(7):938. https://doi.org/10.3390/sym11070938
Chicago/Turabian StyleNaqvi, Syed Rameez, Ali Roman, Tallha Akram, Majed M. Alhaisoni, Muhammad Naeem, Sajjad Ali Haider, Omer Chughtai, and Muhammad Awais. 2019. "An Optimization Framework for Codes Classification and Performance Evaluation of RISC Microprocessors" Symmetry 11, no. 7: 938. https://doi.org/10.3390/sym11070938
APA StyleNaqvi, S. R., Roman, A., Akram, T., Alhaisoni, M. M., Naeem, M., Haider, S. A., Chughtai, O., & Awais, M. (2019). An Optimization Framework for Codes Classification and Performance Evaluation of RISC Microprocessors. Symmetry, 11(7), 938. https://doi.org/10.3390/sym11070938