
Predicting Offshore Oil Slick Formation: A Machine Learning Approach Integrating Meteoceanographic Variables

 ,
,  , ,
, ,  ,
,
Abstract
1. Introduction
2. Background and Literature Review
2.1. The Problem of Oil Slick Formation Caused by Produced Water from Marine Offshore Oil Exploration
2.2. TOG as a Method to Monitor Produced Water from Marine Offshore Oil Exploration
2.3. The Role of Meteoceanographic Variables in Oil Slick Formation
2.4. Machine Learning on Oil Slick Classification and Extension
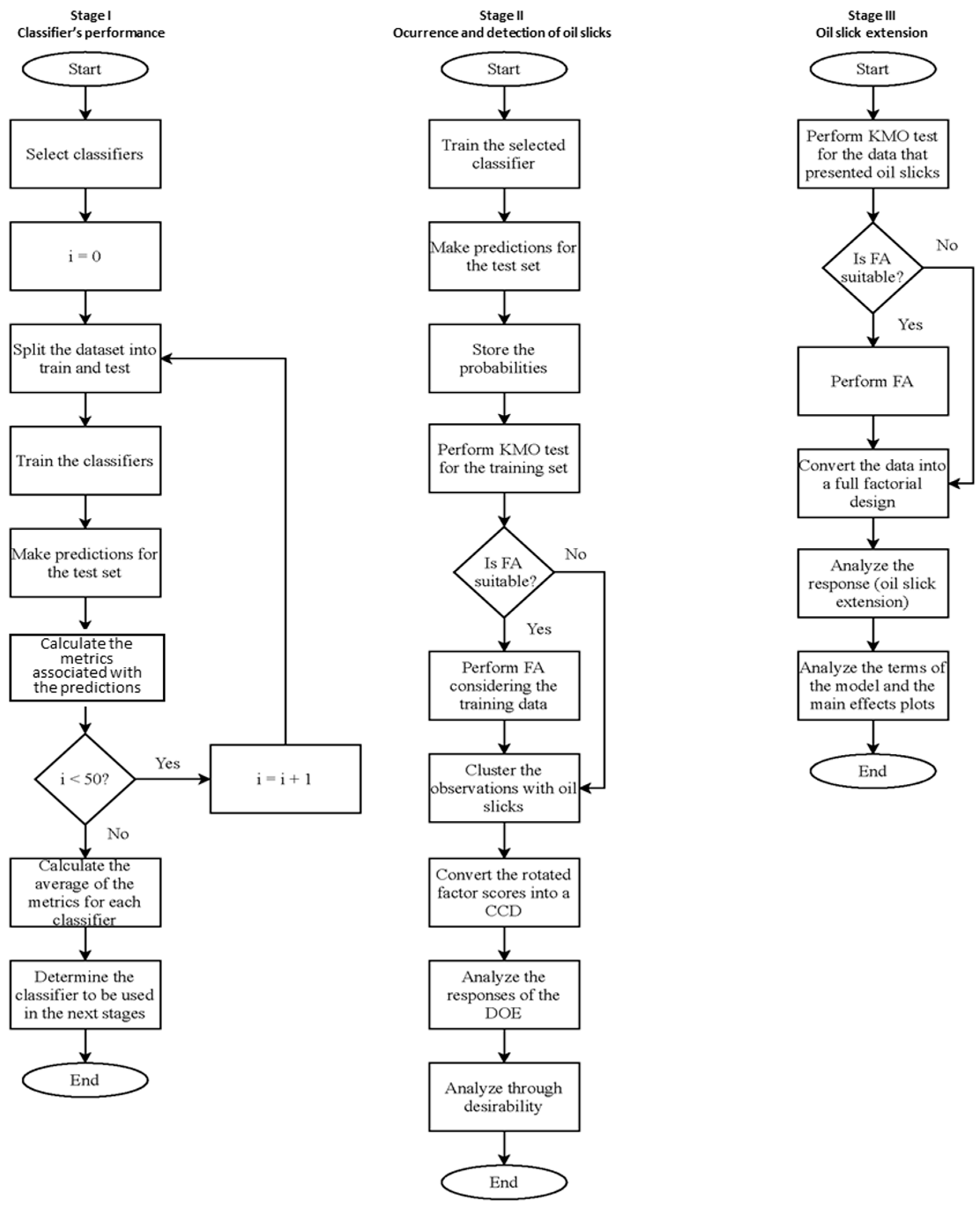
3. Materials and Methods
- I.
- Classifiers’ performance
- II.
- Occurrence and detection of an oil slick
- III.
- Oil slick extension
4. Results
4.1. Classifiers’ Performance
4.2. Occurrence and Detection of an Oil Slick
4.3. Extension of the Oil Slick
5. Discussion and Conclusions
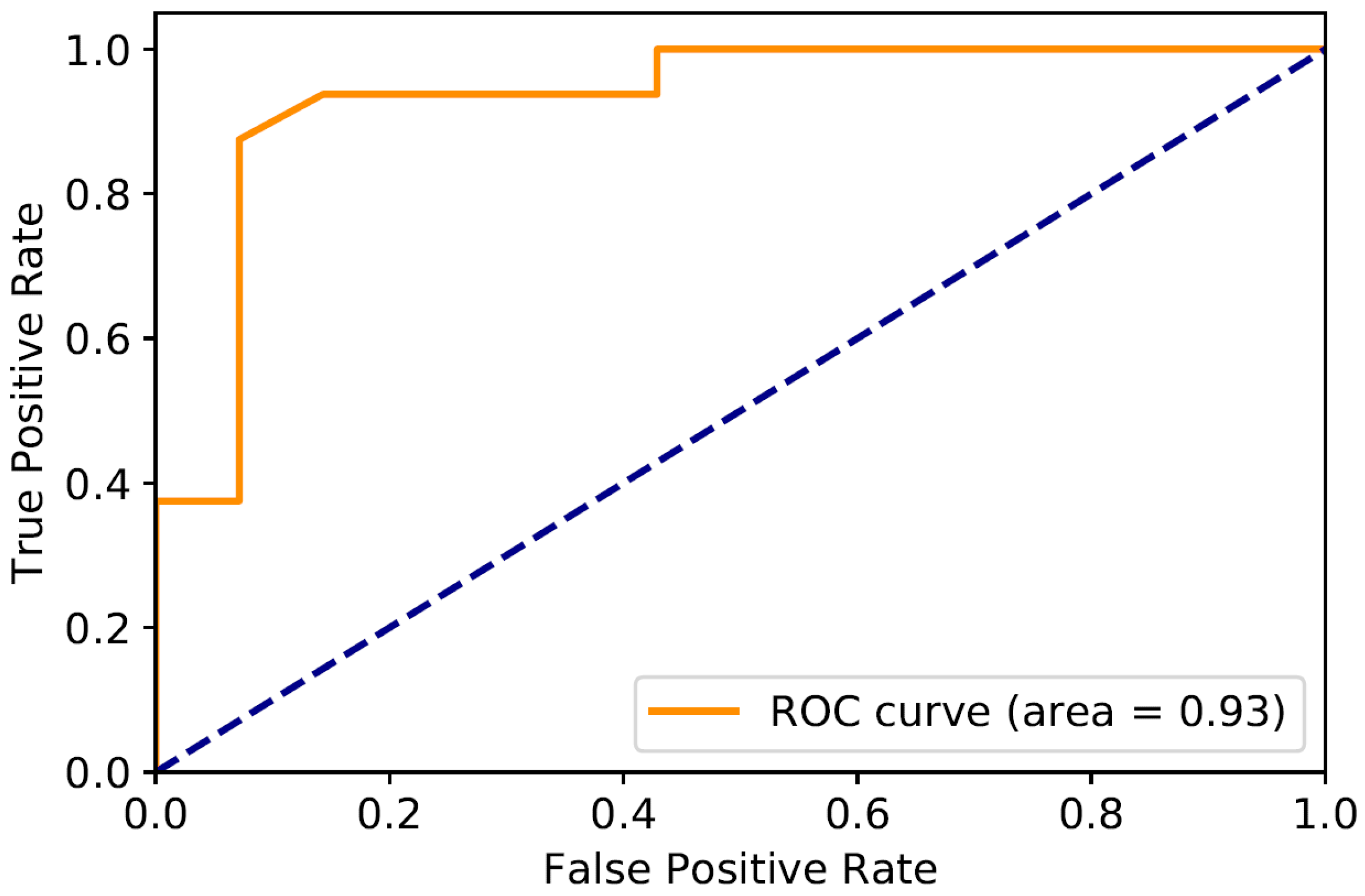
- Among the evaluated methods, random forest (RF) consistently outperformed the others, achieving the highest scores across all the evaluation metrics.
- The RF model effectively predicted oil slick occurrence using metoceanographic variables and spectrophotometric TOG measurements, producing a highly satisfactory confusion matrix and a strong area under the ROC curve (AUC), indicating reliable classification performance.
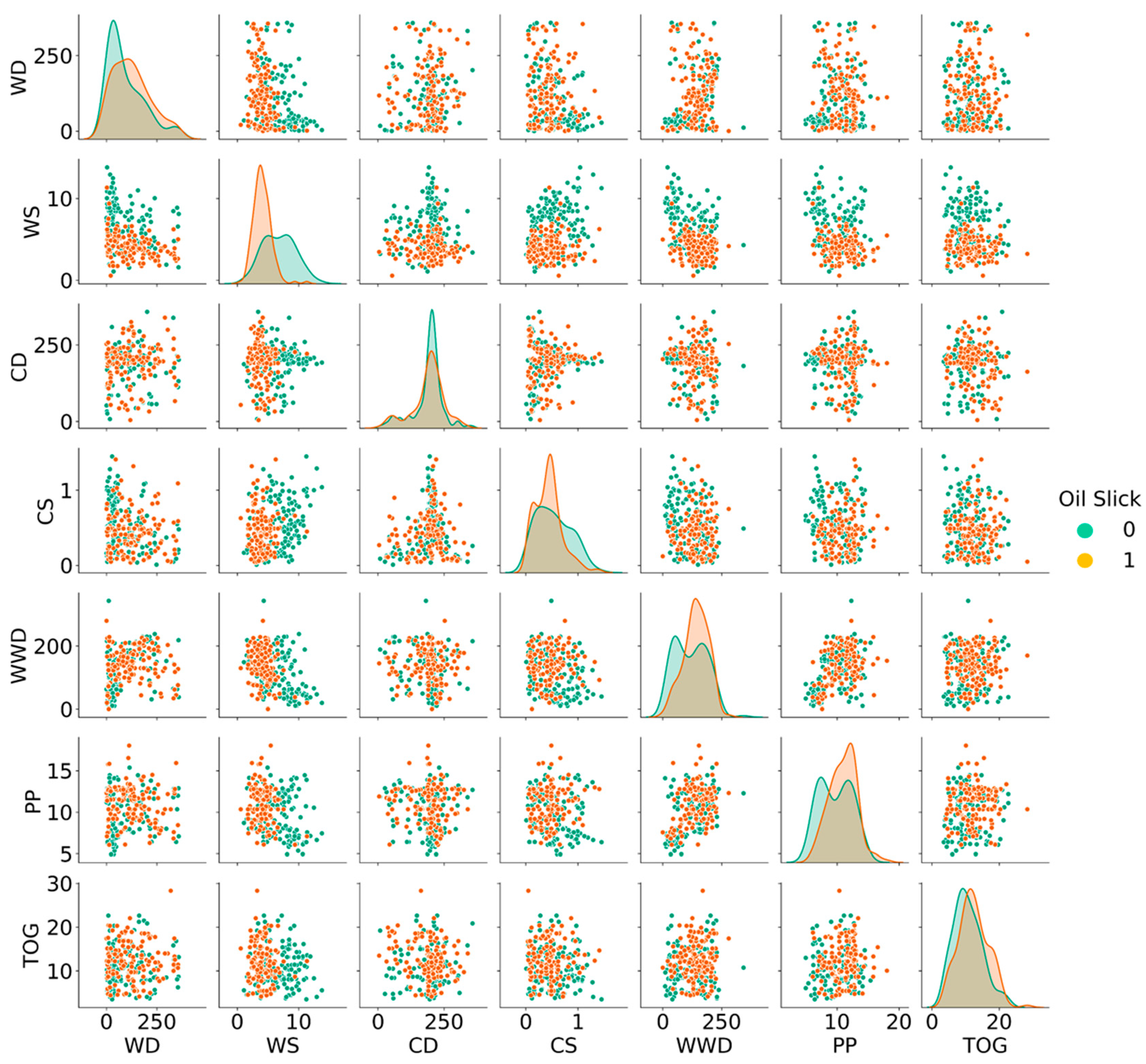
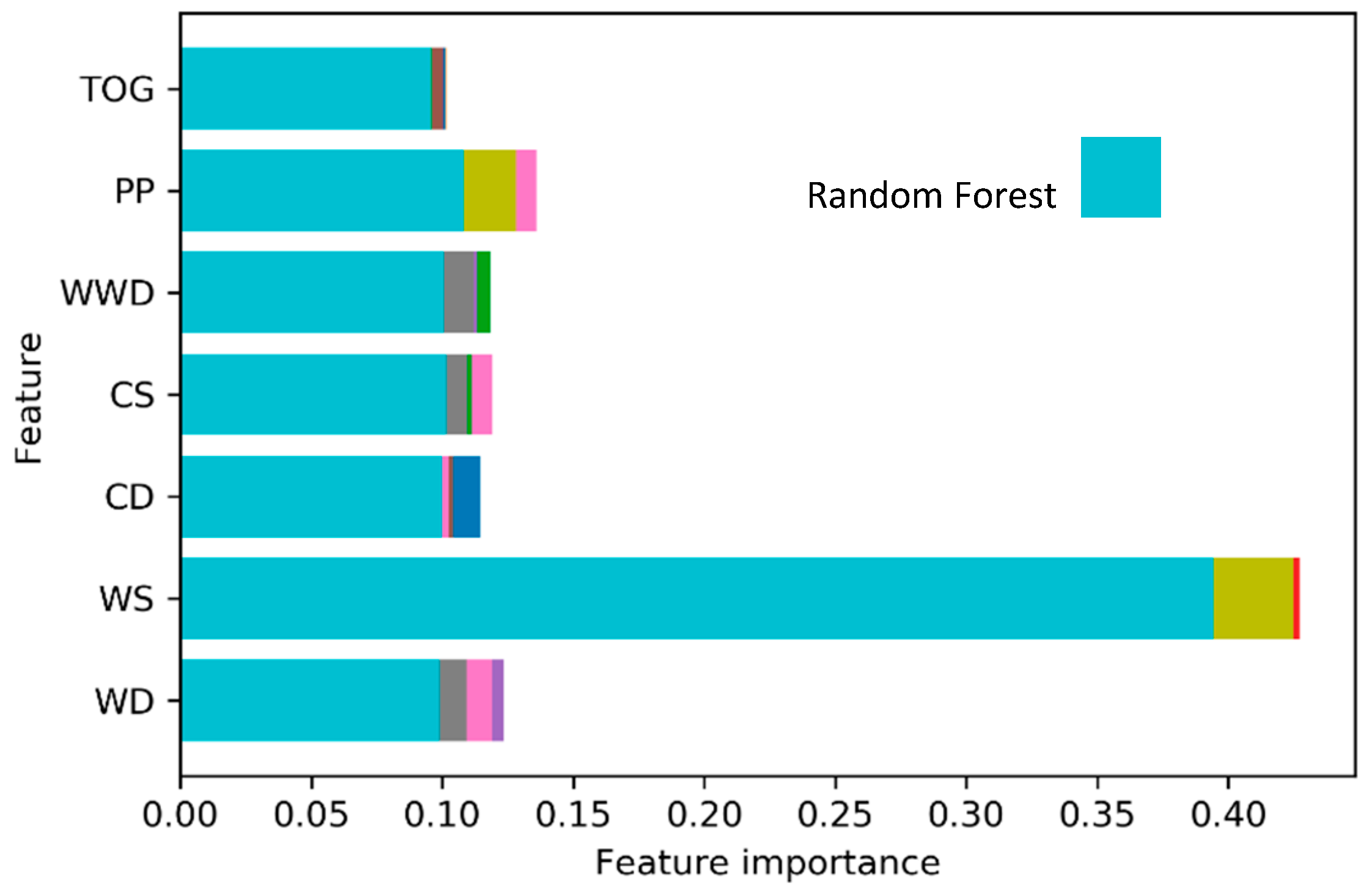
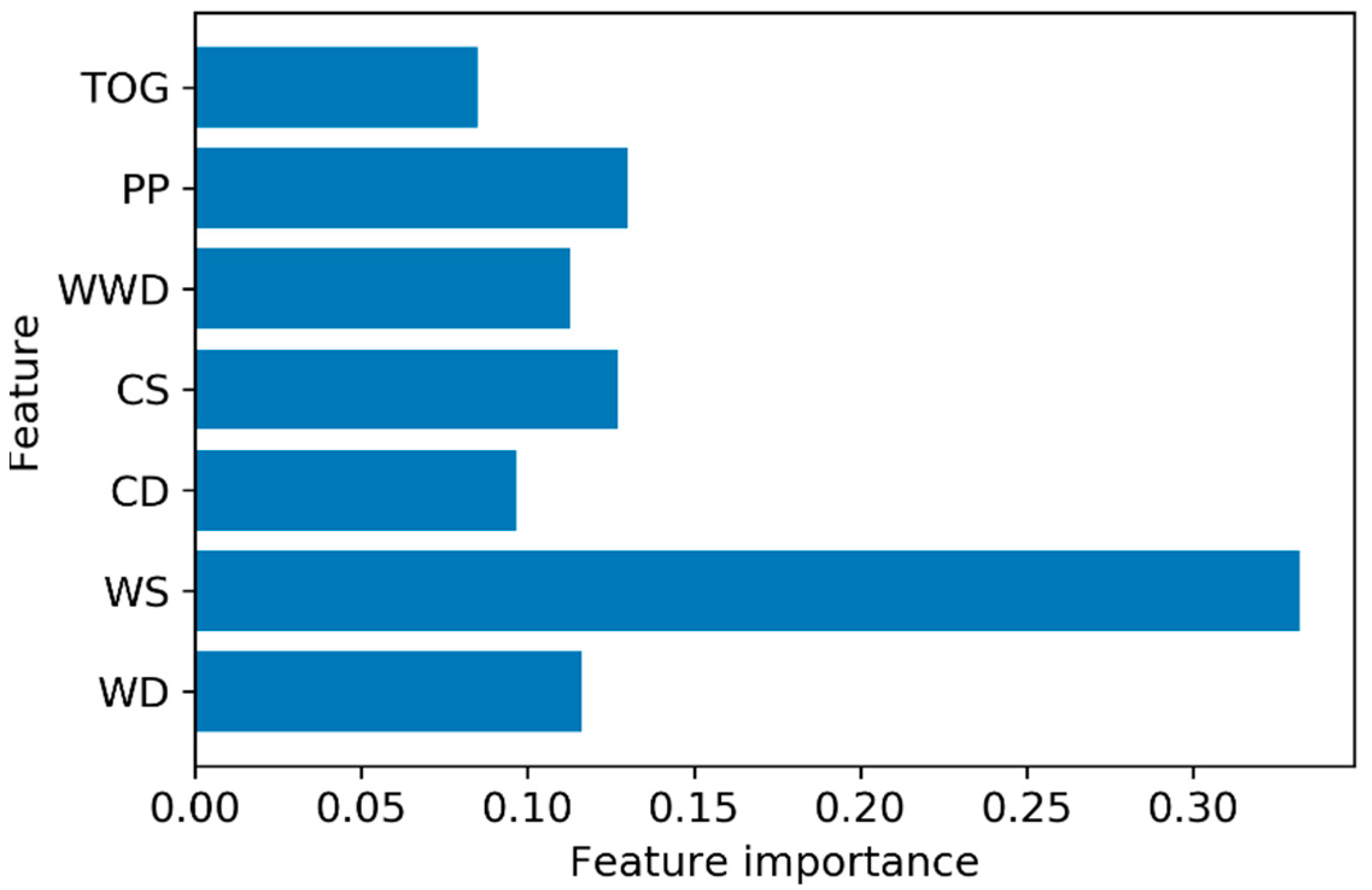
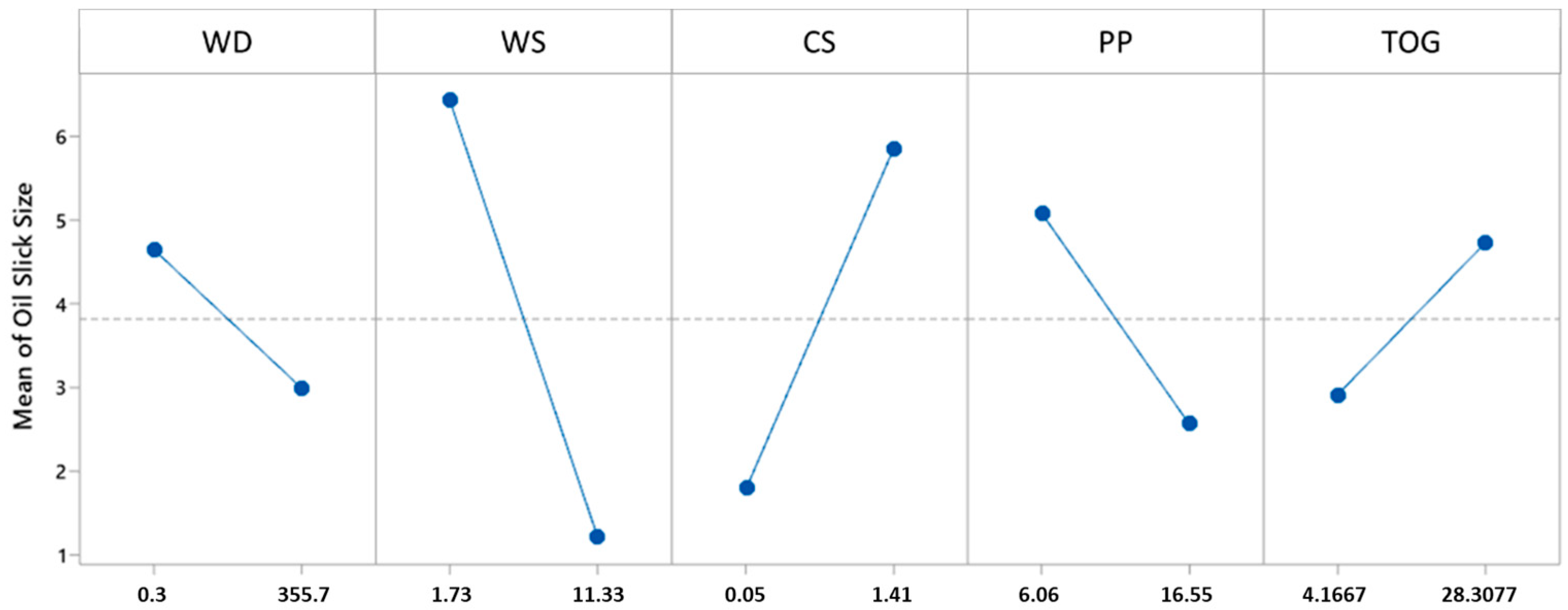
- The variable importance analysis identified WS as the most influential factor for class separation.
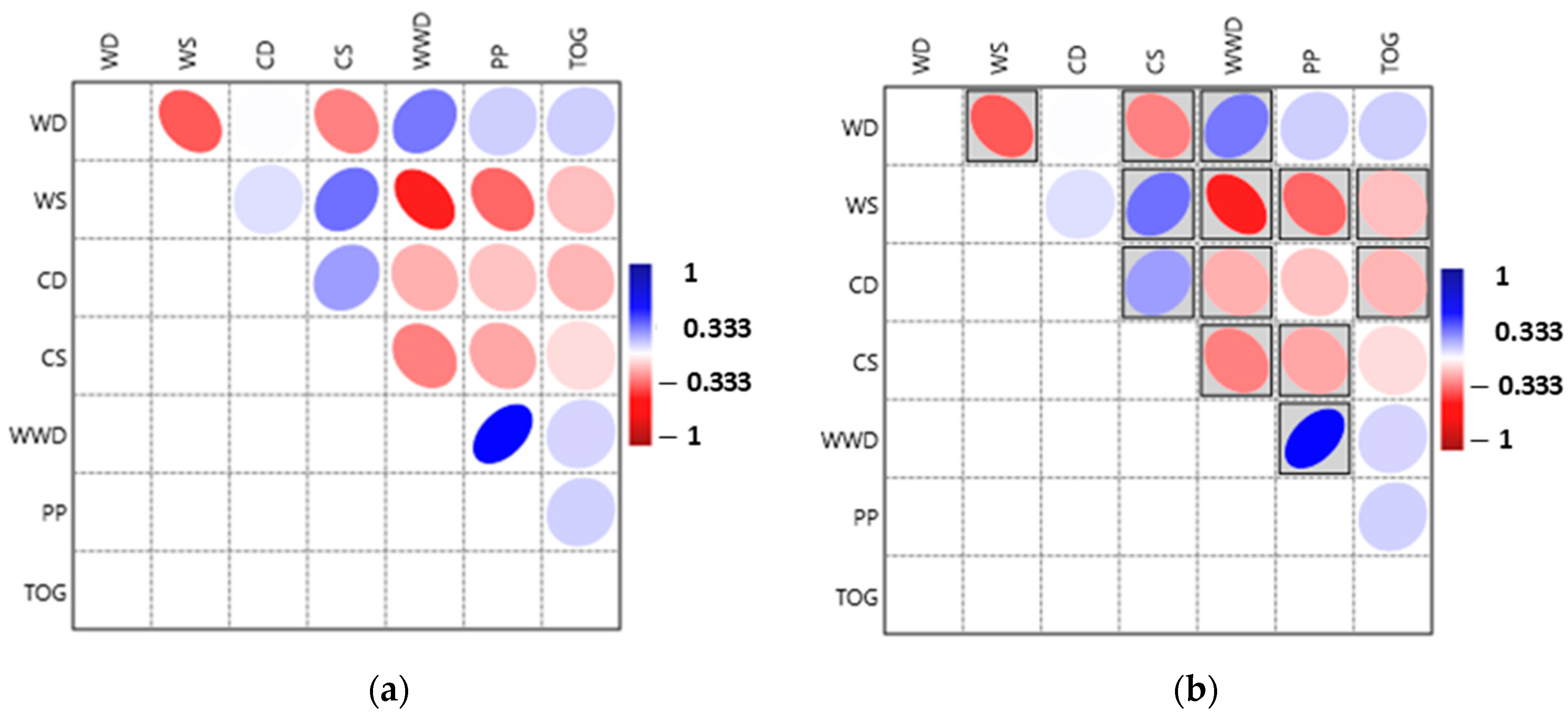
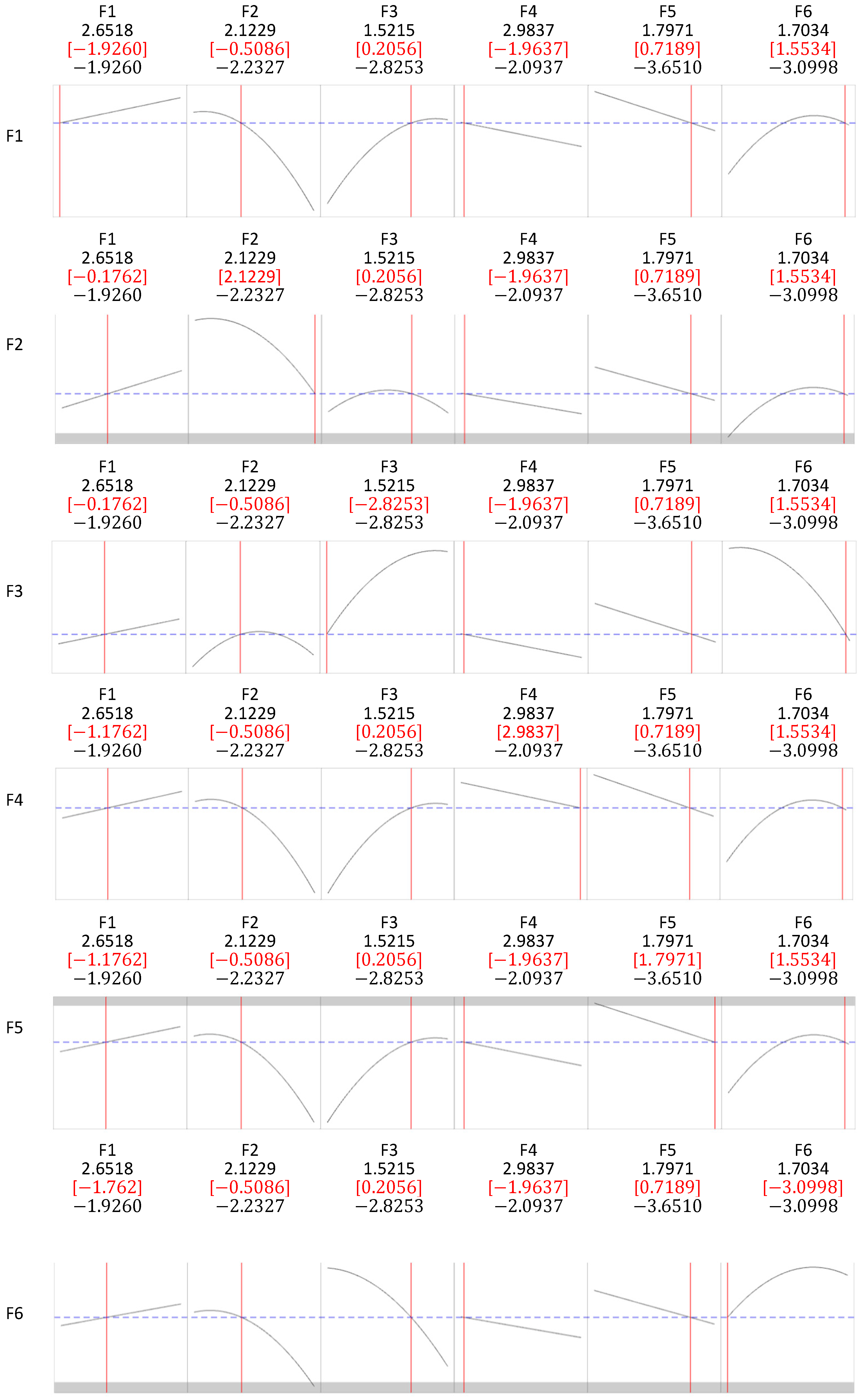
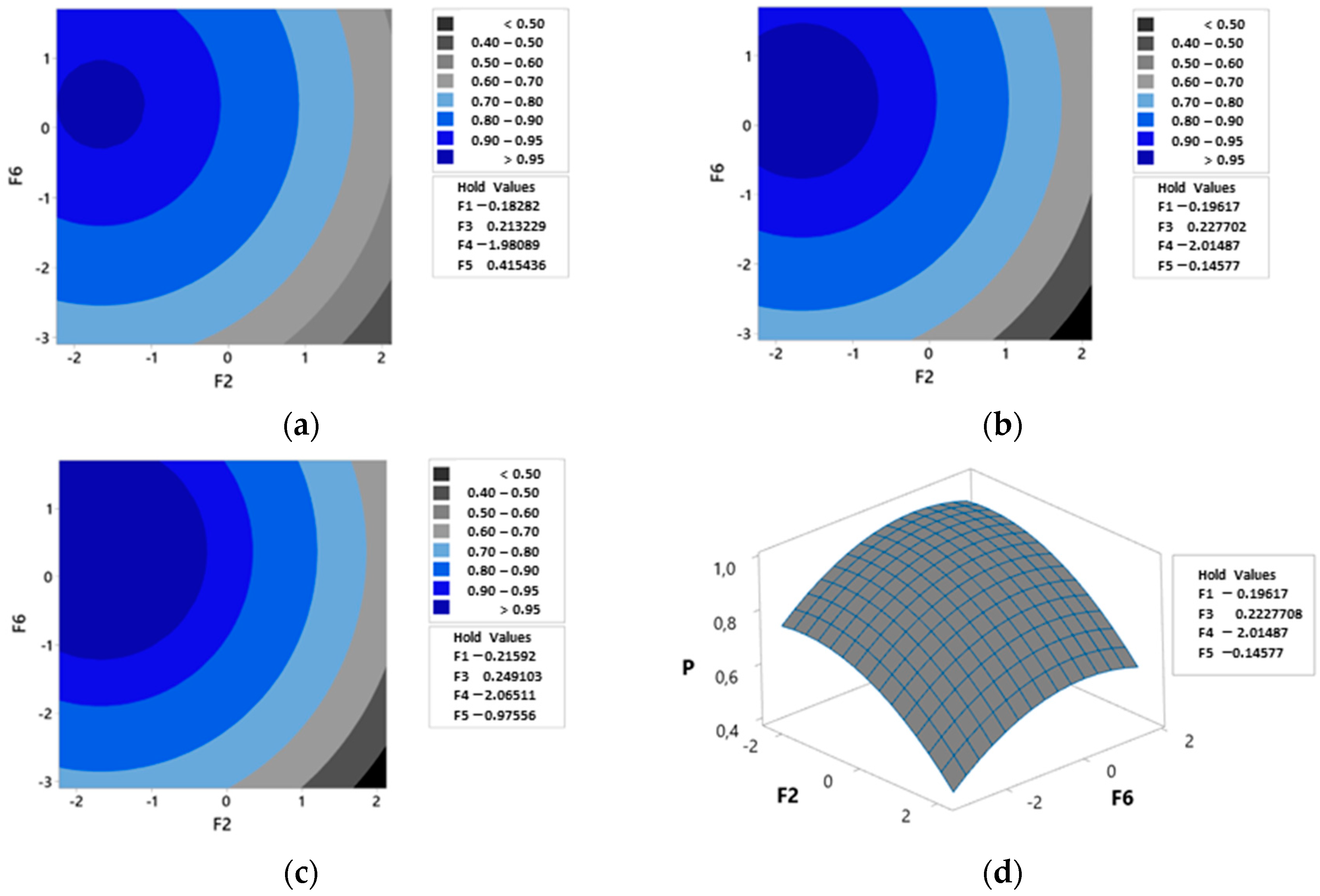
- Moderate but statistically significant correlations among predictor variables led to factor analysis, improving the model by reducing redundancy. The rotated factor scores were then converted into a central composite design (CCD) array, where the probabilities of oil slick occurrence and detection served as response variables. Optimization using the desirability technique facilitated a sensitivity analysis of the variables.
- Higher WS, WD, and CS values were associated with a lower probability of oil slick occurrence and detection.
- Conversely, higher TOG, PP, WWD, and CD values increased the probability of oil slick occurrence and detection.
- In the oil slick extension model, WS had the strongest negative effect, meaning higher wind speeds significantly reduced oil slick extension.
- CS had the strongest positive effect, meaning faster currents caused larger slicks.
- All the predictor variables were statistically significant, confirming that each variable meaningfully influenced oil slick extension.
- Higher WD, WS, and PP values were associated with smaller oil slicks, while increases in CS and TOG led to larger slicks.
- No severe multicollinearity issues were found in the model (VIF < 5), indicating model stability.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Machine Learning and Statistical Methods
- Random forest
- K-nearest neighbors
- Artificial Neural Networks
- Binary logistic regression
- Support vector machine
- Factor analysis
References
- Klemz, A.C.; Damas, M.S.P.; Weschenfelder, S.E.; González, S.Y.G.; Pereira, L.d.S.; Costa, B.R.d.S.; Junior, A.E.O.; Mazur, L.P.; Marinho, B.A.; de Oliveira, D.; et al. Treatment of real oilfield produced water by liquid-liquid extraction and efficient phase separation in a mixer-settler based on phase inversion. Chem. Eng. J. 2021, 417, 127926. [Google Scholar] [CrossRef]
- CONAMA Resolution No. 393/2007. Available online: http://www.braziliannr.com/brazilian-envi%0Aronmentallegislation/conama-resolution-39307/ (accessed on 4 May 2021).
- National Oceanic and Atmospheric Administration (NOAA). Open Water Oil Identification Job Aid (NO-AA-CODE) for Aerial Observation; NOAA/ORCA: Silver Spring, MD, USA, 2016.
- Office of Response and Restoration. Trajectory Analysis Handbook; National Oceanic and Atmospheric Administration (NOAA): Silver Spring, MD, USA, 2012. Available online: https://response.restoration.noaa.gov/sites/default/files/Trajectory_Analysis_Handbook.pdf (accessed on 23 April 2021).
- Röhrs, J.; Dagestad, K.F.; Asbjørnsen, H.; Nordam, T.; Skancke, J.; Jones, C.E.; Brekke, C. The effect of vertical mixing on the horizontal drift of oil spills. Ocean Sci. 2018, 14, 1581–1601. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, W.; Liang, D.; Wu, W.; Zhao, Y.; Wu, L. Effect of Wind-Wave-Current Interaction on Oil Spill in the Yangtze Estuary. J. Mar. Sci. Eng. 2023, 11, 494. [Google Scholar] [CrossRef]
- Elliott, A.J.; Hurford, N. The effects of wind and turbulence on the spreading of oil slicks. N. Z. J. Mar. Freshw. Res. 1977, 11, 311–321. [Google Scholar] [CrossRef]
- Drozdowski, A.; Nudds, S.; Hannah, C.G.; Niu, H.; Peterson, I. Modeling oil spill transport and fate in the Arctic: A review. Arct. Sci. 2018, 4, 314–339. [Google Scholar] [CrossRef]
- Hoult, D.P. Oil spreading on the sea. Annu. Rev. Fluid Mech. 1979, 4, 341–368. [Google Scholar] [CrossRef]
- Reed, M.; Turner, C.; Odulo, A. Oil spill modeling: Risk analysis and response strategies. In Oil Spill Science and Technology, 2nd ed.; Spaulding, M.L., Ed.; Elsevier: Amsterdam, The Netherlands, 2018; pp. 163–220. [Google Scholar] [CrossRef]
- Ren, L.; Wang, Y.; Zhang, W.; Yang, H.; Wang, H.; Wei, J.; Flores Mateos, L.M. Characterizing wind fields at multiple temporal scales: A case study of the adjacent sea area of Guangdong–Hong Kong–Macao Greater Bay Area. Energy Rep. 2022, 8, 212–223. [Google Scholar] [CrossRef]
- Albergel, C.; Polcher, J.; Mahendran, A.; Prigent, C. Impact of wind and precipitation on oil slick drift. Ocean Sci. 2019, 15, 725–741. [Google Scholar] [CrossRef]
- Larasati, A.; Husrin, S.; Pranowo, W.S. Spatial and temporal oil spill distribution analysis using remote sensing data in the Makassar Strait. AIP Conf. Proc. 2023, 3069, 020133. [Google Scholar] [CrossRef]
- Le Hénaff, M.; Kourafalou, V.H.; Srinivasan, A.; Beron-Vera, F.J.; Reniers AJ, H.M.; Shay, L.K. Surface transport pathways connecting the Deepwater Horizon oil spill regions to the Florida Keys and Southeast Florida. J. Phys. Oceanogr. 2014, 44, 145–164. [Google Scholar] [CrossRef]
- Pisano, A.; De Dominicis, M.; Biamino, W.; Bignami, F.; Gherardi, S.; Colao, F.; Coppini, G.; Marullo, S.; Sprovieri, M.; Trivero, P.; et al. An oceanographic survey for oil spill monitoring and model forecasting validation using remote sensing and in situ data in the Mediterranean Sea. Deep. Sea Res. Part II Top. Stud. Oceanogr. 2016, 133, 132–145. [Google Scholar] [CrossRef]
- Zatsepa, S.N.; Ivchenko, A.A.; Korotenko, K.A.; Solbakov, V.V.; Stanovoy, V.V. The Role of Wind Waves in Oil Spill Natural Dispersion in the Sea. Oceanology 2018, 58, 517–524. [Google Scholar] [CrossRef]
- Daneshgar Asl, S.; Dukhovskoy, D.S.; Bourassa, M.; MacDonald, I.R. Hindcast modeling of oil slick persistence from natural seeps. Remote Sens. Environ. 2017, 189, 96–107. [Google Scholar] [CrossRef]
- Xu, J.; Cheng, M.; Li, B.; Chu, L.; Dong, H.; Yang, Y.; Qian, S.; Huang, Y.; Yuan, J. Oil Slick Identification in Marine Radar Image Using HOG, Random Forest and PSO. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Ebecken, N.F.F.; de Miranda, F.P.; Landau, L.; Beisl, C.; Silva, P.M.; Cunha, G.; Lopes, M.C.S.; Dias, L.M.; Carvalho, G.d.A. Computational Oil-Slick Hub for Offshore Petroleum Studies. J. Mar. Sci. Eng. 2023, 11, 1497. [Google Scholar] [CrossRef]
- Genovez, P.C.; Ponte, F.F.d.A.; Matias, Í.d.O.; Torres, S.B.; Beisl, C.H.; Mano, M.F.; Silva, G.M.A.; Miranda, F.P.d. Development and Application of Predictive Models to Distinguish Seepage Slicks from Oil Spills on Sea Surfaces Employing SAR Sensors and Artificial Intelligence: Geometric Patterns Recognition Under a Transfer Learning Approach. Remote Sens. 2023, 15, 1496. [Google Scholar] [CrossRef]
- Wang, L.; Lu, Y.; Wang, M.; Zhao, W.; Lv, H.; Song, S.; Wang, Y.; Chen, Y.; Zhan, W.; Ju, W. Mapping of oil spills in China Seas using optical satellite data and deep learning. J. Hazard. Mater. 2024, 480, 135809. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar]
- Musbah, H.; Aly, H.H.; Little, T.A. Energy management of hybrid energy system sources based on machine learning classification algorithms. Electr. Power Syst. Res. 2021, 199, 107436. [Google Scholar] [CrossRef]
- Dai, B.; Gu, C.; Zhao, E.; Qin, X. Statistical model optimized random forest regression model for concrete dam deformation monitoring. Struct. Control Health Monit. 2018, 25, 1–15. [Google Scholar] [CrossRef]
- Sanquetta, C.R.; Piva, L.R.; Wojciechowski, J.; Corte, A.P.; Schikowski, A.B. Volume estimation of Cryptomeria japonica logs in southern Brazil using artificial intelligence models. South. For. J. For. Sci. 2018, 80, 29–36. [Google Scholar] [CrossRef]
- Zuo, W.; Zhang, D.; Wang, K. On kernel difference-weighted k-nearest neighbor classification. Pattern Anal. Appl. 2008, 11, 247–257. [Google Scholar] [CrossRef]
- Zhang, S.; Cheng, D.; Deng, Z.; Zong, M.; Deng, X. A novel kNN algorithm with data-driven k parameter computation. Pattern Recognit. Lett. 2018, 109, 44–54. [Google Scholar] [CrossRef]
- Ezzat, A.; Elnaghi, B.E.; Abdelsalam, A.A. Microgrids islanding detection using Fourier transform and machine learning algorithm. Electr. Power Syst. Res. 2021, 196, 107224. [Google Scholar] [CrossRef]
- El-Dahshan, E.S.A.; Bassiouni, M.M. Computational intelligence techniques for human brain MRI classification. Int. J. Imaging Syst. Technol. 2018, 28, 132–148. [Google Scholar] [CrossRef]
- Zhang, S. Nearest neighbor selection for iteratively kNN imputation. J. Syst. Softw. 2012, 85, 2541–2552. [Google Scholar] [CrossRef]
- Swetapadma, A.; Mishra, P.; Yadav, A.; Abdelaziz, A.Y. A non-unit protection scheme for double circuit series capacitor compensated transmission lines. Electr. Power Syst. Res. 2017, 148, 311–325. [Google Scholar] [CrossRef]
- Ganbold, G.; Chasia, S. Comparison Between Possibilistic c-Means (PCM) and Artificial Neural Network (ANN) Classification Algorithms in Land Use/Land Cover Classification. Int. J. Knowl. Content Dev. Technol. 2017, 7, 57–78. [Google Scholar]
- Islam, M.S.; Hannan, M.A.; Basri, H.; Hussain, A.; Arebey, M. Solid waste bin detection and classification using Dynamic Time Warping and MLP classifier. Waste Manag. 2014, 34, 281–290. [Google Scholar] [CrossRef]
- Olson, J.; Valova, I.; Michel, H. WSCISOM: Wireless sensor data cluster identification through a hybrid SOM/MLP/RBF architecture. Prog. Artif. Intell. 2016, 5, 233–250. [Google Scholar] [CrossRef]
- Puggina Bianchesi, N.M.; Romao, E.L.; Lopes, M.F.B.P.; Balestrassi, P.P.; De Paiva, A.P. A design of experiments comparative study on clustering methods. IEEE Access 2019, 7, 2953528. [Google Scholar] [CrossRef]
- Yilmaz, I.; Kaynar, O. Multiple regression, ANN (RBF, MLP) and ANFIS models for prediction of swell potential of clayey soils. Expert. Syst. Appl. 2011, 38, 5958–5966. [Google Scholar] [CrossRef]
- Kuo, H.F.; Faricha, A. Artificial Neural Network for Diffraction Based Overlay Measurement. IEEE Access 2016, 4, 7479–7486. [Google Scholar] [CrossRef]
- Balestrassi, P.P.; Popova, E.; Paiva, A.P.; Marangon Lima, J.W. Design of experiments on neural network’s training for nonlinear time series forecasting. Neurocomputing 2009, 72, 1160–1178. [Google Scholar] [CrossRef]
- Aizenberg, I.; Sheremetov, L.; Villa-Vargas, L.; Martinez-Muñoz, J. Multilayer Neural Network with Multi-Valued Neurons in time series forecasting of oil production. Neurocomputing 2016, 175, 980–989. [Google Scholar] [CrossRef]
- Silva, I.N.; Spatti, D.H.; Flauzino, R.A.; Liboni, L.; Alves, S.F.D.R. Artificial Neural Networks: A Practical Course; Springer International Publishing AG: Cham, Switzerland, 2017. [Google Scholar]
- Lin, S.K.; Hsiu, H.; Chen, H.S.; Yang, C.J. Classification of patients with Alzheimer’s disease using the arterial pulse spectrum and a multilayer-perceptron analysis. Sci. Rep. 2017, 11, 8882. [Google Scholar] [CrossRef]
- Peres, A.M.; Baptista, P.; Malheiro, R.; Dias, L.G.; Bento, A.; Pereira, J.A. Chemometric classification of several olive cultivars from Trás-os-Montes region (northeast of Portugal) using artificial neural networks. Chemom. Intell. Lab. Syst. 2011, 105, 65–73. [Google Scholar] [CrossRef]
- Wang, H.; Moayedi, H.; Kok Foong, L. Genetic algorithm hybridized with multilayer perceptron to have an economical slope stability design. Eng. Comput. 2020, 37, 3067–3078. [Google Scholar] [CrossRef]
- Chau, N.L.; Tran, N.T.; Dao, T.P. A hybrid approach of density-based topology, multilayer perceptron, and water cycle-moth flame algorithm for multi-stage optimal design of a flexure mechanism. Eng. Comput. 2021, 38 (Suppl. S4), 2833–2865. [Google Scholar] [CrossRef]
- Bissacot, A.C.G.; Salgado, S.A.B.; Balestrassi, P.P.; Paiva, A.; Souza, A.Z.; Wazen, R. Comparison of neural networks and logistic regression in assessing the occurrence of failures in steel structures of transmission lines. Open Electr. Electron. Eng. J. 2016, 10, 11–26. [Google Scholar] [CrossRef]
- Hosmer, J.R.; Lemeshow, S.; Sturdvant, R.X. Applied Logistic Regression, 3rd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2013. [Google Scholar]
- Mitiche, I.; Morison, G.; Nesbitt, A.; Hughes-Narborough, M.; Stewart, B.G.; Boreham, P. Classification of EMI discharge sources using time–frequency features and multi-class support vector machine. Electr. Power Syst. Res. 2018, 163, 261–269. [Google Scholar] [CrossRef]
- Simões, L.D.; Costa, H.J.D.; Aires, M.N.O.; Medeiros, R.P.; Costa, F.B.; Bretas, A.S. A power transformer differential protection based on support vector machine and wavelet transform. Electr. Power Syst. Res. 2021, 197, 107297. [Google Scholar] [CrossRef]
- Erişti, H.; Uçar, A.; Demir, Y. Wavelet-based feature extraction and selection for classification of power system disturbances using support vector machines. Electr. Power Syst. Res 2010, 80, 743–752. [Google Scholar] [CrossRef]
- Yu, X.; Yu, Y.; Zeng, Q. Support vector machine classification of streptavidin-binding aptamers. PLoS ONE 2014, 9, e99964. [Google Scholar] [CrossRef]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Rencher, A.C.; Christensen, W.F. Methods of Multivariate Analysis, 3rd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2012. [Google Scholar]
- Aquila, G.; Peruchi, R.S.; Rotela, P., Jr.; Rocha, L.C.S.; de Queiroz, A.R.; de Oliveira Pamplona, E. Analysis of the wind average speed in different Brazilian states using the nested GR&R measurement system. Measurement 2018, 115, 217–222. [Google Scholar] [CrossRef]
- Aquila, G.; de Queiroz, A.R.; Balestrassi, P.P.; Rotela Junior, P.; Rocha LC, S.; Pamplona, E.O.; Nakamura, W.T. Wind energy investments facing uncertainties in the Brazilian electricity spot market: A real options approach. Sustain. Energy Technol. Assess. 2020, 42, 100876. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Learning Algorithm | Main Parameters | Acc | Sp | Sn |
|---|---|---|---|---|
| RF | Estimators = 150 Max features = 3 | 0.77 | 0.73 | 0.82 |
| KNN | k = 5 | 0.74 | 0.65 | 0.84 |
| MLP | Number of hidden layers = 2 Number of units = 4 Activation function = Relu Solver = LBFGS α = 0.05 Learning rate = invscaling | 0.71 | 0.68 | 0.76 |
| BLR | Link function = logit | 0.74 | 0.70 | 0.80 |
| SVM | Kernel = RBF γ = 0.1 C = 1 | 0.75 | 0.65 | 0.85 |
| Prediction | |||
|---|---|---|---|
| Class 0 | Class 1 | ||
| Actual | Class 0 | 12 | 2 |
| Class 1 | 1 | 15 | |
| WS | CD | CS | WWD | PP | TOG | |
|---|---|---|---|---|---|---|
| WD | −0.325 0.000 | 0.003 0.957 | −0.247 0.000 | 0.267 0.000 | 0.098 0.109 | 0.097 0.110 |
| WS | 0.063 0.302 | 0.281 0.000 | −0.430 0.000 | −0.298 0.000 | −0.128 0.035 | |
| CD | 0.193 0.001 | −0.158 0.009 | −0.119 0.050 | −0.146 0.016 | ||
| CS | −0.251 0.000 | −0.176 0.004 | 0.070 0.252 | |||
| WWD | 0.482 0.000 | 0.083 0.176 | ||||
| PP | 0.092 0.132 |
| Variable | F1 | F2 | F3 | F4 | F5 | F6 | Communality |
|---|---|---|---|---|---|---|---|
| PP | 0.924 | −0.036 | 0.04 | 0 | −0.073 | 0.09 | 0.87 |
| WWD | 0.719 | −0.359 | −0.228 | 0.147 | 0.026 | 0.061 | 0.724 |
| WS | −0.204 | 0.941 | 0.14 | −0.004 | 0.068 | −0.133 | 0.969 |
| WD | 0.079 | −0.14 | −0.971 | −0.02 | −0.049 | 0.116 | 0.985 |
| CD | −0.078 | 0.013 | −0.018 | −0.985 | 0.075 | −0.093 | 0.992 |
| TOG | 0.044 | −0.057 | −0.046 | 0.073 | −0.991 | 0.021 | 0.996 |
| CS | −0.113 | 0.127 | 0.117 | −0.098 | 0.022 | −0.972 | 0.998 |
| Var. | 1.4393 | 1.0542 | 1.0322 | 1.0081 | 1.0019 | 0.9973 | 6.5329 |
| % Var. | 0.206 | 0.151 | 0.147 | 0.144 | 0.143 | 0.142 | 0.933 |
| Term | Effect | Coefficient | Standard Error | t-Value | p-Value | VIF |
|---|---|---|---|---|---|---|
| Constant | 3.818 | 0.103 | 37.24 | 0.000 | ||
| WD | −1.655 | −0.827 | 0.107 | −7.72 | 0.000 | 1.57 |
| WS | −5.234 | −2.617 | 0.186 | −14.04 | 0.000 | 1.79 |
| CS | 4.066 | 2.033 | 0.156 | 13.06 | 0.000 | 1.61 |
| PP | −2.522 | −1.261 | 0.139 | −9.05 | 0.000 | 1.89 |
| TOG | 1.823 | 0.912 | 0.13 | 7.03 | 0.000 | 3.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Streitenberger, S.C.; Romão, E.L.; Almeida, F.A.; de Souza, A.C.Z.; Orlando, A.E., Jr.; Balestrassi, P.P. Predicting Offshore Oil Slick Formation: A Machine Learning Approach Integrating Meteoceanographic Variables. Water 2025, 17, 939. https://doi.org/10.3390/w17070939
Streitenberger SC, Romão EL, Almeida FA, de Souza ACZ, Orlando AE Jr., Balestrassi PP. Predicting Offshore Oil Slick Formation: A Machine Learning Approach Integrating Meteoceanographic Variables. Water. 2025; 17(7):939. https://doi.org/10.3390/w17070939
Chicago/Turabian StyleStreitenberger, Simone C., Estevão L. Romão, Fabrício A. Almeida, Antonio C. Zambroni de Souza, Aloisio E. Orlando, Jr., and Pedro P. Balestrassi. 2025. "Predicting Offshore Oil Slick Formation: A Machine Learning Approach Integrating Meteoceanographic Variables" Water 17, no. 7: 939. https://doi.org/10.3390/w17070939
APA StyleStreitenberger, S. C., Romão, E. L., Almeida, F. A., de Souza, A. C. Z., Orlando, A. E., Jr., & Balestrassi, P. P. (2025). Predicting Offshore Oil Slick Formation: A Machine Learning Approach Integrating Meteoceanographic Variables. Water, 17(7), 939. https://doi.org/10.3390/w17070939