
A Water Demand Forecasting Model Based on Generative Adversarial Networks and Multivariate Feature Fusion



Abstract
1. Introduction
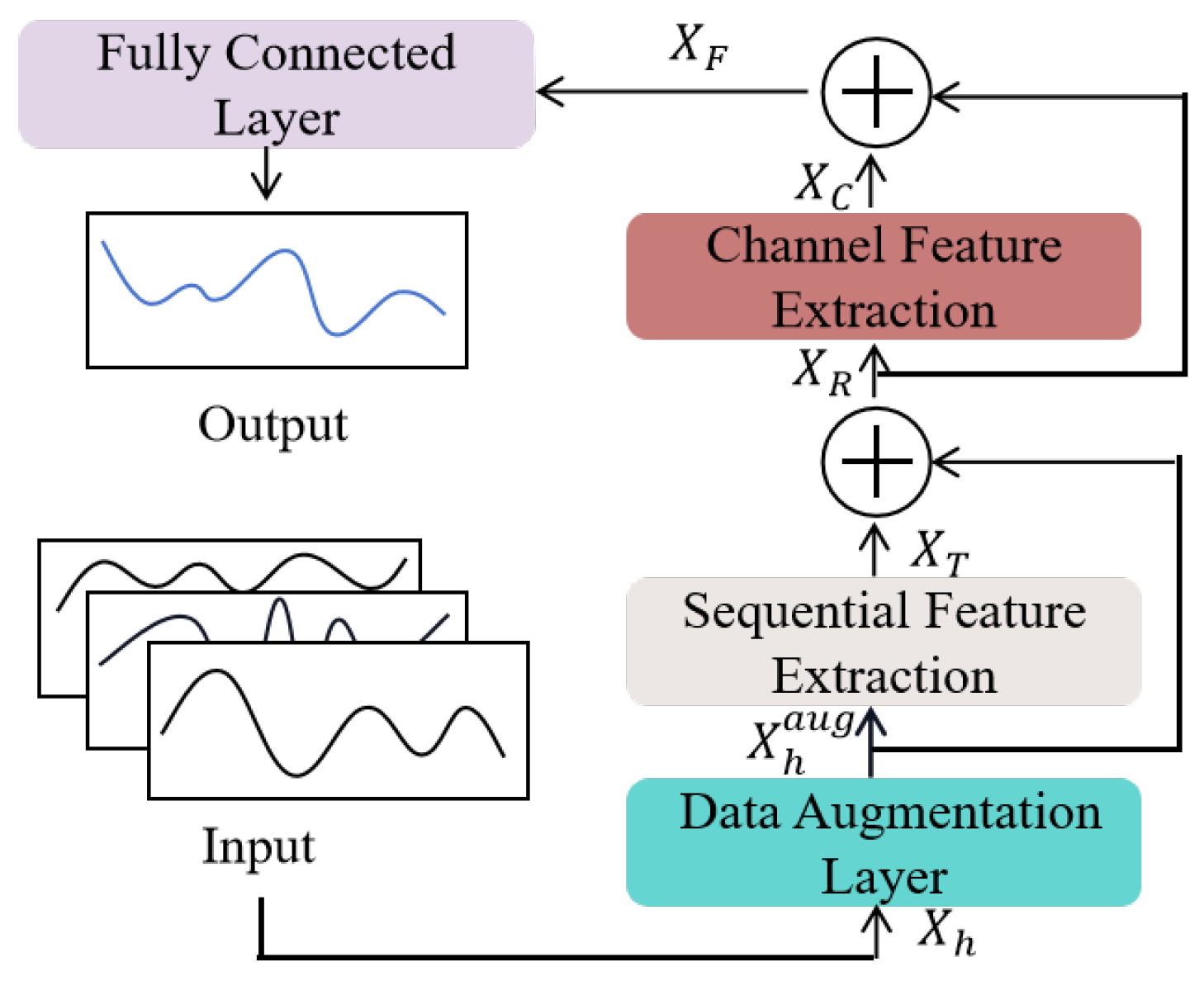
2. Water Demand Forecasting Model Based on WDF-Mixer
2.1. Data Augmentation Layer Based on WGAN-GP
2.2. Temporal Feature Extraction Based on Temporal Factorization
2.3. Channel Feature Extraction Based on Sparse Representation
3. Experiments and Analysis
3.1. Experimental Setup
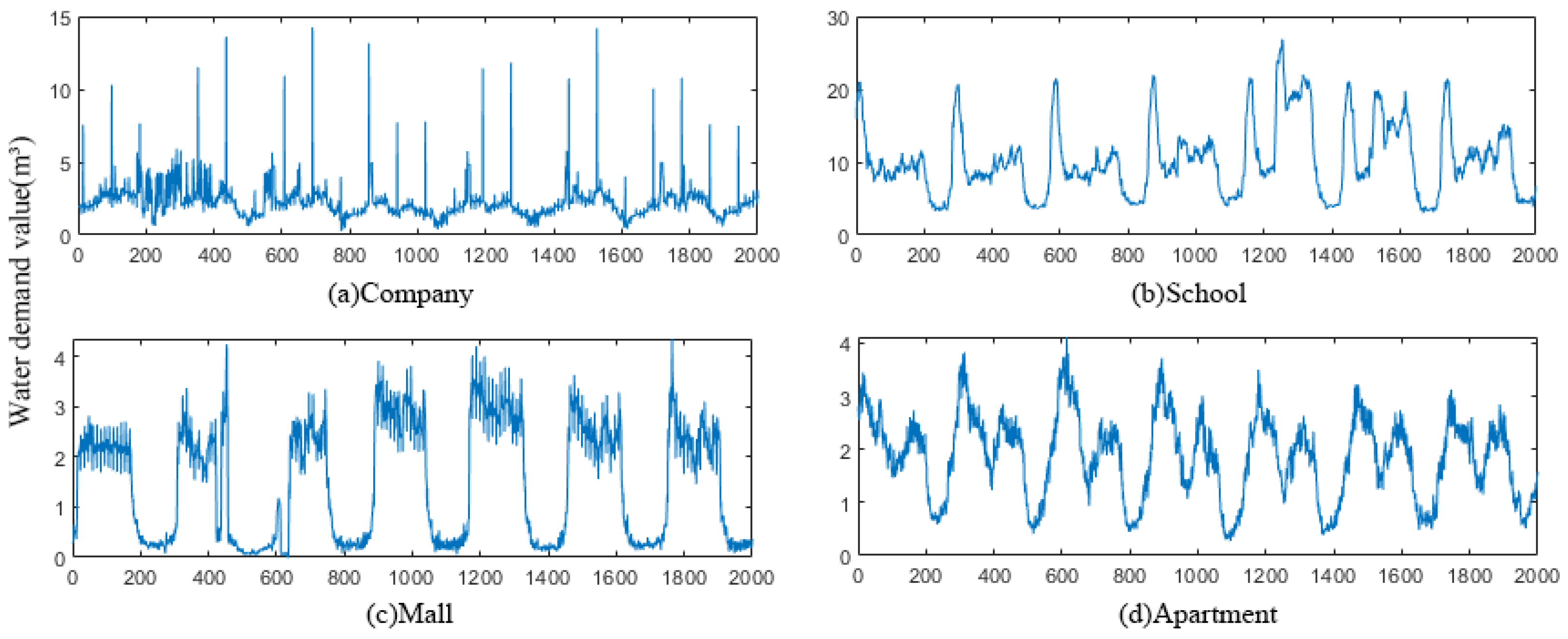
3.1.1. Dataset
3.1.2. Evaluation Metrics
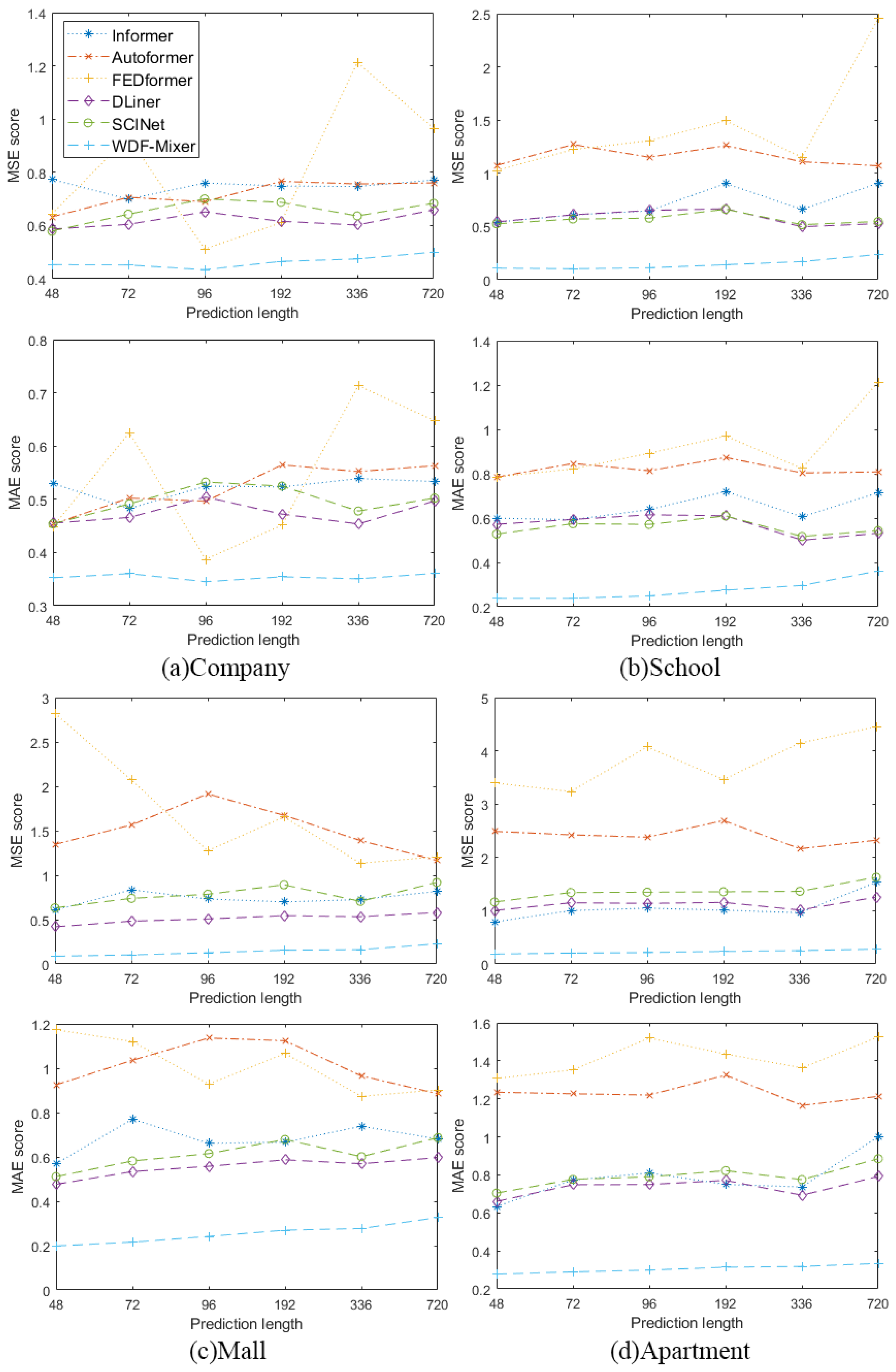
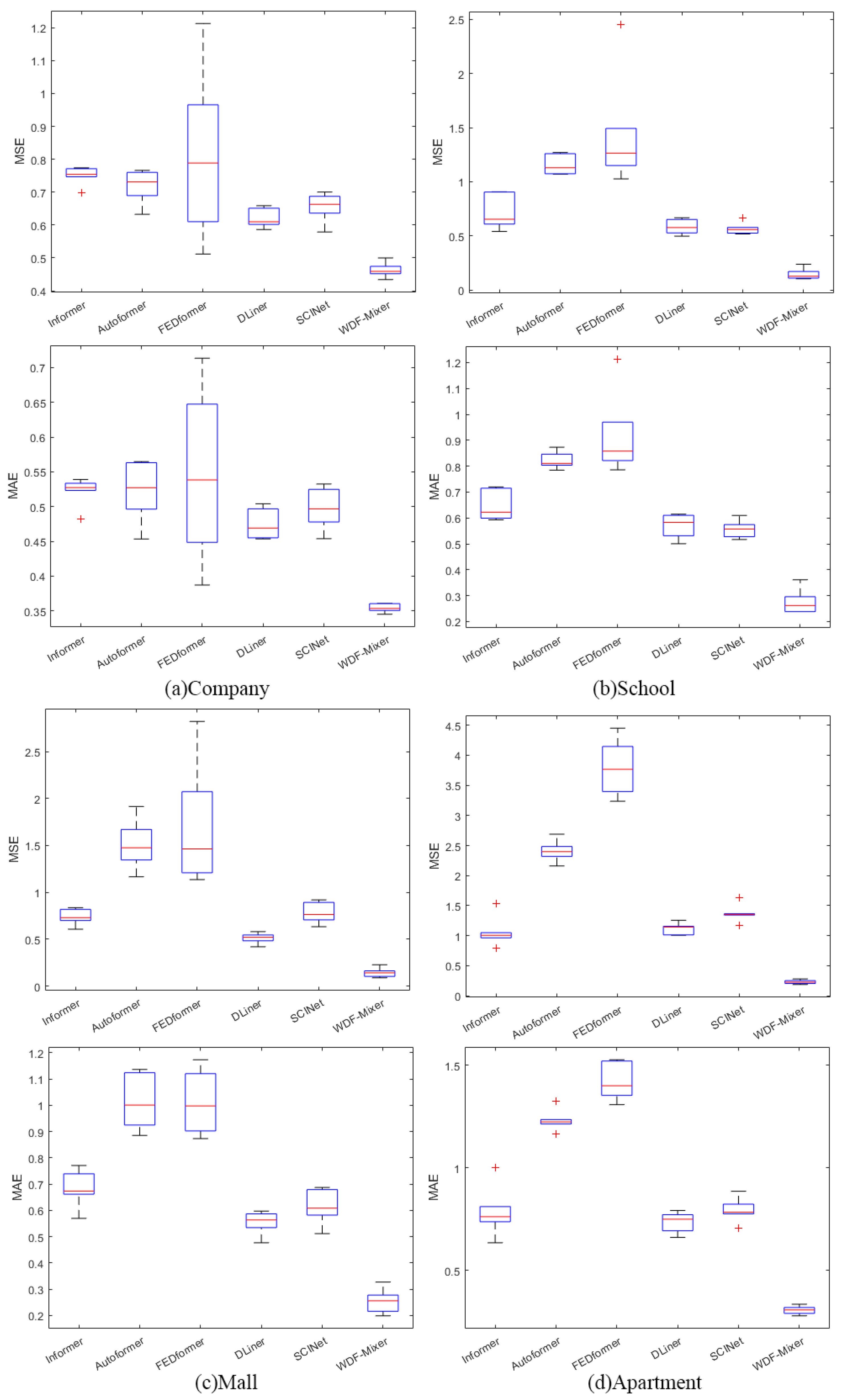
3.2. Results and Discussion
3.3. Ablation Study
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fu, G.; Jin, Y.; Sun, S.; Yuan, Z.; Butler, D. The role of deep learning in urban water management: A critical review. Water Res. 2022, 223, 118973. [Google Scholar] [CrossRef]
- Chen, L.; Yan, H.; Yan, J.; Wang, J.; Tao, T.; Xin, K.; Li, S.; Pu, Z.; Qiu, J. Short-term water demand forecast based on automatic feature extraction by one-dimensional convolution. J. Hydrol. 2022, 606, 127440. [Google Scholar] [CrossRef]
- Zubaidi, S.L.; Hashim, K.; Ethaib, S.; Al-Bdairi, N.S.S.; Al-Bugharbee, H.; Gharghan, S.K. A novel methodology to predict monthly municipal water demand based on weather variables scenario. J. King Saud-Univ.-Eng. Sci. 2022, 34, 163–169. [Google Scholar] [CrossRef]
- Du, B.; Huang, S.; Guo, J.; Tang, H.; Wang, L.; Zhou, S. Interval forecasting for urban water demand using PSO optimized KDE distribution and LSTM neural networks. Appl. Soft Comput. 2022, 122, 108875. [Google Scholar] [CrossRef]
- Mokhtar, A.; Elbeltagi, A.; Gyasi-Agyei, Y.; Al-Ansari, N.; Abdel-Fattah, M.K. Prediction of irrigation water quality indices based on machine learning and regression models. Appl. Water Sci. 2022, 12, 76. [Google Scholar] [CrossRef]
- Stańczyk, J.; Kajewska-Szkudlarek, J.; Lipiński, P.; Rychlikowski, P. Improving short-term water demand forecasting using evolutionary algorithms. Sci. Rep. 2022, 12, 13522. [Google Scholar] [CrossRef]
- Pandey, P.; Bokde, N.D.; Dongre, S.; Gupta, R. Hybrid models for water demand forecasting. J. Water Resour. Plan. Manag. 2021, 147, 04020106. [Google Scholar] [CrossRef]
- Niknam, A.; Zare, H.K.; Hosseininasab, H.; Mostafaeipour, A.; Herrera, M. A critical review of short-term water demand forecasting tools—What method should I use? Sustainability 2022, 14, 5412. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, Y.; Zhang, Q. Comparison of EEMD-ARIMA, EEMD-BP and EEMD-SVM algorithms for predicting the hourly urban water consumption. J. Hydroinform. 2022, 24, 535–558. [Google Scholar] [CrossRef]
- Li, H.; Wang, X.; Guo, H. Uncertain time series forecasting method for the water demand prediction in Beijing. Water Supply 2022, 22, 3254–3270. [Google Scholar] [CrossRef]
- Zubaidi, S.L.; Al-Bdairi, N.S.S.; Ortega-Martorell, S.; Ridha, H.M.; Al-Ansari, N.; Al-Bugharbee, H.; Hashim, K.; Gharghan, S.K. Assessing the benefits of nature-inspired algorithms for the parameterization of ANN in the prediction of water demand. J. Water Resour. Plan. Manag. 2023, 149, 04022075. [Google Scholar] [CrossRef]
- Huang, H.; Lin, Z.; Liu, S.; Zhang, Z. A neural network approach for short-term water demand forecasting based on a sparse autoencoder. J. Hydroinform. 2023, 25, 70–84. [Google Scholar] [CrossRef]
- Zanfei, A.; Brentan, B.M.; Menapace, A.; Righetti, M.; Herrera, M. Graph convolutional recurrent neural networks for water demand forecasting. Water Resour. Res. 2022, 58, e2022WR032299. [Google Scholar] [CrossRef]
- Rustam, F.; Ishaq, A.; Kokab, S.T.; de la Torre Diez, I.; Mazón, J.L.V.; Rodríguez, C.L.; Ashraf, I. An artificial neural network model for water quality and water consumption prediction. Water 2022, 14, 3359. [Google Scholar] [CrossRef]
- Guo, J.; Sun, H.; Du, B. Multivariable time series forecasting for urban water demand based on temporal convolutional network combining random forest feature selection and discrete wavelet transform. Water Resour. Manag. 2022, 36, 3385–3400. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the International Conference on Machine Learning. PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 27268–27286. [Google Scholar]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are transformers effective for time series forecasting? In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 11121–11128. [Google Scholar]
- Sheng, Z.; Wen, S.; Feng, Z.k.; Gong, J.; Shi, K.; Guo, Z.; Yang, Y.; Huang, T. A survey on data-driven runoff forecasting models based on neural networks. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 1083–1097. [Google Scholar] [CrossRef]
- Sheng, Z.; Wen, S.; Feng, Z.k.; Shi, K.; Huang, T. A Novel Residual Gated Recurrent Unit Framework for Runoff Forecasting. IEEE Internet Things J. 2023, 10, 12736–12748. [Google Scholar] [CrossRef]
- Zhang, C.; Sheng, Z.; Zhang, C.; Wen, S. Multi-lead-time short-term runoff forecasting based on Ensemble Attention Temporal Convolutional Network. Expert Syst. Appl. 2024, 243, 122935. [Google Scholar] [CrossRef]
- Geng, X.; He, X.; Xu, L.; Yu, J. Attention-based gating optimization network for multivariate time series prediction. Appl. Soft Comput. 2022, 126, 109275. [Google Scholar] [CrossRef]
- Iglesias, G.; Talavera, E.; González-Prieto, Á.; Mozo, A.; Gómez-Canaval, S. Data augmentation techniques in time series domain: A survey and taxonomy. Neural Comput. Appl. 2023, 35, 10123–10145. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Y.; Liang, J.; Liu, L. DAFA-BiLSTM: Deep autoregression feature augmented bidirectional LSTM network for time series prediction. Neural Netw. 2023, 157, 240–256. [Google Scholar] [CrossRef]
- Shangguan, A.; Xie, G.; Fei, R.; Mu, L.; Hei, X. Train wheel degradation generation and prediction based on the time series generation adversarial network. Reliab. Eng. Syst. Saf. 2023, 229, 108816. [Google Scholar] [CrossRef]
- Luleci, F.; Catbas, F.N.; Avci, O. Generative adversarial networks for labeled acceleration data augmentation for structural damage detection. J. Civ. Struct. Health Monit. 2023, 13, 181–198. [Google Scholar] [CrossRef]
- Pérez, J.; Arroba, P.; Moya, J.M. Data augmentation through multivariate scenario forecasting in Data Centers using Generative Adversarial Networks. Appl. Intell. 2023, 53, 1469–1486. [Google Scholar] [CrossRef]
- Demir, S.; Mincev, K.; Kok, K.; Paterakis, N.G. Data augmentation for time series regression: Applying transformations, autoencoders and adversarial networks to electricity price forecasting. Appl. Energy 2021, 304, 117695. [Google Scholar] [CrossRef]
- Geng, Z.; Guo, M.H.; Chen, H.; Li, X.; Wei, K.; Lin, Z. Is attention better than matrix decomposition? arXiv 2021, arXiv:2109.04553. [Google Scholar]
- Liu, M.; Zeng, A.; Chen, M.; Xu, Z.; Lai, Q.; Ma, L.; Xu, Q. Scinet: Time series modeling and forecasting with sample convolution and interaction. Adv. Neural Inf. Process. Syst. 2022, 35, 5816–5828. [Google Scholar]
- Chen, Z.; Ma, M.; Li, T.; Wang, H.; Li, C. Long sequence time-series forecasting with deep learning: A survey. Inf. Fusion 2023, 97, 101819. [Google Scholar] [CrossRef]
- Sousa, J.; Henriques, R. Intersecting reinforcement learning and deep factor methods for optimizing locality and globality in forecasting: A review. Eng. Appl. Artif. Intell. 2024, 133, 108082. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Name of the Dataset | Data Sources | Number of Channels | Total Amount of Data |
|---|---|---|---|
| Company | The city’s commercial center. | 7 | 105,120 |
| School | Universities in the city. | 7 | 105,120 |
| Mall | The city malls. | 7 | 105,120 |
| Apartment | Residential areas of the city. | 7 | 105,120 |
| Models | Informer | Autoformer | FEDformer | |||||||
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | ||||
| Company | 48 | 0.7739 | 0.5298 | 0.3472 | 0.6325 | 0.4534 | 0.1331 | 0.6434 | 0.4485 | 0.4022 |
| 72 | 0.6987 | 0.4827 | 0.3078 | 0.7060 | 0.5024 | 0.3765 | 0.9338 | 0.6252 | 0.4085 | |
| 96 | 0.7599 | 0.5248 | 0.3088 | 0.6896 | 0.4963 | 0.2843 | 0.5118 | 0.3872 | 0.2571 | |
| 192 | 0.7483 | 0.5232 | 0.0643 | 0.7660 | 0.5647 | 0.2838 | 0.6102 | 0.4515 | 0.4025 | |
| 336 | 0.7466 | 0.5389 | 0.2752 | 0.7563 | 0.5521 | 0.1461 | 1.2126 | 0.7135 | 0.4127 | |
| 720 | 0.7713 | 0.5335 | −0.0006 | 0.7601 | 0.5632 | 0.2957 | 0.9654 | 0.6474 | −0.0401 | |
| School | 48 | 0.5416 | 0.5991 | 0.5569 | 1.0745 | 0.7847 | 0.0101 | 1.0266 | 0.7859 | 0.1506 |
| 72 | 0.6090 | 0.5926 | 0.3478 | 1.2706 | 0.8463 | −0.1795 | 1.2234 | 0.8215 | 0.0198 | |
| 96 | 0.6479 | 0.6387 | 0.5732 | 1.1509 | 0.8133 | 0.0567 | 1.3061 | 0.8922 | −0.0949 | |
| 192 | 0.9056 | 0.7198 | 0.2810 | 1.2605 | 0.8732 | −0.1783 | 1.4936 | 0.9700 | −0.0840 | |
| 336 | 0.6603 | 0.6060 | 0.4273 | 1.1084 | 0.8037 | 0.0703 | 1.1498 | 0.8241 | 0.0122 | |
| 720 | 0.9077 | 0.7147 | 0.1281 | 1.0709 | 0.8081 | 0.0245 | 2.4551 | 1.2135 | 0.0367 | |
| Mall | 48 | 0.6060 | 0.5694 | 0.7100 | 1.3458 | 0.9247 | −0.0620 | 2.8219 | 1.1730 | 0.0193 |
| 72 | 0.8361 | 0.7704 | 0.5244 | 1.5640 | 1.0359 | 0.0322 | 2.0716 | 1.1201 | −0.3236 | |
| 96 | 0.7327 | 0.6614 | 0.4732 | 1.9132 | 1.1360 | −0.2640 | 1.2737 | 0.9279 | −0.0661 | |
| 192 | 0.6998 | 0.6662 | 0.5222 | 1.6717 | 1.1238 | −0.3695 | 1.6539 | 1.0669 | −0.0341 | |
| 336 | 0.7266 | 0.7387 | 0.1852 | 1.3890 | 0.9653 | −0.2076 | 1.1364 | 0.8731 | 0.0684 | |
| 720 | 0.8182 | 0.6806 | 0.2306 | 1.1664 | 0.8849 | −0.3694 | 1.2084 | 0.9022 | −0.1449 | |
| Apartment | 48 | 0.7917 | 0.6339 | 0.5966 | 2.4858 | 1.2347 | −0.1841 | 3.3957 | 1.3073 | 0.1156 |
| 72 | 1.0033 | 0.7727 | 0.6712 | 2.4219 | 1.2265 | −0.1487 | 3.2344 | 1.3523 | 0.0530 | |
| 96 | 1.0495 | 0.8105 | 0.5759 | 2.3767 | 1.2201 | −0.2571 | 4.0719 | 1.5199 | −0.2556 | |
| 192 | 1.0101 | 0.7500 | 0.6602 | 2.6900 | 1.3247 | −0.2848 | 3.4608 | 1.4361 | −0.0409 | |
| 336 | 0.9650 | 0.7366 | 0.5740 | 2.1608 | 1.1653 | −0.0947 | 4.1460 | 1.3630 | 0.1820 | |
| 720 | 1.5341 | 1.0018 | 0.4750 | 2.3209 | 1.2129 | −0.0387 | 4.4506 | 1.5262 | −0.0281 | |
| Models | DLiner | SCINet | WDF-Mixer | |||||||
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | ||||
| Company | 48 | 0.5864 | 0.4551 | 0.2015 | 0.5789 | 0.4539 | 0.2279 | 0.4528 | 0.3526 | 0.4575 |
| 72 | 0.6043 | 0.4659 | 0.1748 | 0.6426 | 0.4913 | 0.1341 | 0.4519 | 0.3604 | 0.4582 | |
| 96 | 0.6512 | 0.5041 | 0.1033 | 0.7002 | 0.5324 | 0.0680 | 0.4341 | 0.3451 | 0.4613 | |
| 192 | 0.6158 | 0.4722 | 0.1526 | 0.6873 | 0.5248 | 0.0501 | 0.4651 | 0.3544 | 0.4449 | |
| 336 | 0.6019 | 0.4536 | 0.1916 | 0.6362 | 0.4779 | 0.1468 | 0.4743 | 0.3506 | 0.4400 | |
| 720 | 0.6588 | 0.4968 | 0.1188 | 0.6834 | 0.5023 | 0.1041 | 0.4999 | 0.3609 | 0.4103 | |
| School | 48 | 0.5437 | 0.5720 | 0.3692 | 0.5253 | 0.5278 | 0.3905 | 0.1099 | 0.2384 | 0.8826 |
| 72 | 0.6106 | 0.5937 | 0.2915 | 0.5705 | 0.5744 | 0.3380 | 0.1041 | 0.2384 | 0.8884 | |
| 96 | 0.6515 | 0.6147 | 0.2481 | 0.5785 | 0.5712 | 0.3324 | 0.1133 | 0.2494 | 0.8781 | |
| 192 | 0.6670 | 0.6101 | 0.2630 | 0.6620 | 0.6096 | 0.2685 | 0.1415 | 0.2748 | 0.8496 | |
| 336 | 0.4977 | 0.5004 | 0.4482 | 0.5174 | 0.5170 | 0.2463 | 0.1709 | 0.2962 | 0.8203 | |
| 720 | 0.5275 | 0.5314 | 0.4071 | 0.5477 | 0.5439 | 0.3844 | 0.2377 | 0.3616 | 0.7490 | |
| Mall | 48 | 0.4188 | 0.4764 | 0.4660 | 0.6336 | 0.5112 | 0.1921 | 0.0876 | 0.1984 | 0.8999 |
| 72 | 0.4828 | 0.5339 | 0.3619 | 0.7400 | 0.5815 | 0.0219 | 0.1029 | 0.2157 | 0.8815 | |
| 96 | 0.5076 | 0.5578 | 0.3179 | 0.7864 | 0.6148 | −0.0567 | 0.1268 | 0.2416 | 0.8532 | |
| 192 | 0.5447 | 0.5866 | 0.2500 | 0.8927 | 0.6788 | −0.2292 | 0.1549 | 0.2696 | 0.8175 | |
| 336 | 0.5331 | 0.5691 | 0.2514 | 0.7062 | 0.6011 | 0.0085 | 0.1621 | 0.2771 | 0.8042 | |
| 720 | 0.5809 | 0.5968 | 0.1581 | 0.9193 | 0.6869 | −0.3324 | 0.2271 | 0.3268 | 0.7161 | |
| Apartment | 48 | 1.0060 | 0.6605 | 0.3289 | 1.1648 | 0.7041 | 0.2230 | 0.1870 | 0.2780 | 0.8458 |
| 72 | 1.1499 | 0.7483 | 0.2185 | 1.3434 | 0.7764 | 0.0869 | 0.2046 | 0.2900 | 0.8299 | |
| 96 | 1.1389 | 0.7495 | 0.2143 | 1.3491 | 0.7898 | 0.0693 | 0.2158 | 0.2991 | 0.8194 | |
| 192 | 1.1564 | 0.7710 | 0.1970 | 1.3570 | 0.8224 | 0.0577 | 0.2363 | 0.3144 | 0.8024 | |
| 336 | 1.0138 | 0.6926 | 0.3116 | 1.3656 | 0.7752 | 0.0727 | 0.2514 | 0.3184 | 0.7920 | |
| 720 | 1.2561 | 0.7916 | 0.1707 | 1.6307 | 0.8850 | −0.0765 | 0.2793 | 0.3342 | 0.7721 | |
| Dataset | FL | WDF-mixer (None) | WDF-mixer (C) | WDF-mixer (E) | WDF-mixer (C,E) |
|---|---|---|---|---|---|
| Company | 48 | 0.6387 | 0.5818 | 0.4880 | 0.4528 |
| 72 | 0.6501 | 0.6533 | 0.5017 | 0.4519 | |
| 96 | 0.6315 | 0.5993 | 0.5154 | 0.4341 | |
| 192 | 0.6509 | 0.6305 | 0.5400 | 0.4651 | |
| 336 | 0.6180 | 0.6180 | 0.5452 | 0.4743 | |
| 720 | 0.6841 | 0.6790 | 0.5889 | 0.4999 | |
| School | 48 | 0.2882 | 0.3098 | 0.1671 | 0.1099 |
| 72 | 0.3809 | 0.3465 | 0.1546 | 0.1041 | |
| 96 | 0.3725 | 0.3409 | 0.1619 | 0.1133 | |
| 192 | 0.4144 | 0.3426 | 0.2096 | 0.1415 | |
| 336 | 0.3293 | 0.3253 | 0.2176 | 0.1709 | |
| 720 | 0.4439 | 0.4147 | 0.3032 | 0.2377 | |
| Mall | 48 | 1.1114 | 0.7198 | 0.1981 | 0.0876 |
| 72 | 1.0280 | 0.9236 | 0.2031 | 0.1029 | |
| 96 | 1.5054 | 1.3083 | 0.2349 | 0.1268 | |
| 192 | 1.1978 | 1.0126 | 0.2460 | 0.1549 | |
| 336 | 0.9921 | 1.1655 | 0.2238 | 0.1621 | |
| 720 | 1.0310 | 0.9160 | 0.2996 | 0.2271 | |
| Apartment | 48 | 2.9785 | 3.4051 | 0.2318 | 0.1870 |
| 72 | 3.1928 | 3.5035 | 0.2721 | 0.2046 | |
| 96 | 3.4504 | 3.6843 | 0.2874 | 0.2158 | |
| 192 | 2.9378 | 3.5552 | 0.3153 | 0.2363 | |
| 336 | 2.4787 | 2.2405 | 0.3039 | 0.2514 | |
| 720 | 3.5042 | 4.1476 | 0.3421 | 0.2793 | |
| Improvement over WDF-mixer | 2.48% | 58.24% | 67.14% | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, C.; Meng, J.; Liu, B.; Wang, Z.; Wang, K. A Water Demand Forecasting Model Based on Generative Adversarial Networks and Multivariate Feature Fusion. Water 2024, 16, 1731. https://doi.org/10.3390/w16121731
Yang C, Meng J, Liu B, Wang Z, Wang K. A Water Demand Forecasting Model Based on Generative Adversarial Networks and Multivariate Feature Fusion. Water. 2024; 16(12):1731. https://doi.org/10.3390/w16121731
Chicago/Turabian StyleYang, Changchun, Jiayang Meng, Banteng Liu, Zhangquan Wang, and Ke Wang. 2024. "A Water Demand Forecasting Model Based on Generative Adversarial Networks and Multivariate Feature Fusion" Water 16, no. 12: 1731. https://doi.org/10.3390/w16121731
APA StyleYang, C., Meng, J., Liu, B., Wang, Z., & Wang, K. (2024). A Water Demand Forecasting Model Based on Generative Adversarial Networks and Multivariate Feature Fusion. Water, 16(12), 1731. https://doi.org/10.3390/w16121731