
Forecasting Indoor Air Quality in Mexico City Using Deep Learning Architectures


Abstract
1. Introduction
2. Related Work
3. Materials and Methods
- A Bosch BME680 indoor air quality sensor, which was manufactured in Berlin, Germany in 2009 by Bosch. Additional details can be found in [12].
- A data storage device that gathers and stores the observations from the indoor air quality sensor.
- A set of computing resources for data preprocessing and model training (Section 3.1).
- Data from the indoor air quality sensor and external sources (see Section 3.2, Section 3.3, Section 3.4 for details).
- Collecting air quality data for 17 months (Section 3.2).
- An exploratory data analysis for time-series data (Section 3.4).
- Data cleansing and data transformations (Section 3.5).
- Deep neural network architectures (Section 3.6).
- Model training and evaluation (Section 3.7).

3.1. Computing Environment
3.2. Data Collection
3.3. Data Input and Target Variables
- Data variables collected from a Bosch BME680 sensor:
- -
- Indoor air quality index (IAQ): a discrete variable corresponding to the United States Environmental Protection Agency’s air quality index [11].
- -
- Indoor temperature: a continuous variable in Celsius degrees.
- -
- Indoor pressure: a continuous variable in hectopascals (hPa).
- -
- Indoor relative humidity: a continuous variable expressed as a percentage.
- Data variables collected from SINAICA:
- -
- Outdoor NO: a continuous variable for nitric oxide in parts per billion (ppb).
- -
- Outdoor : a continuous variable for nitrogen dioxide in ppb.
- -
- Outdoor : a continuous variable for nitrogen oxide in ppb.
- -
- Outdoor CO: a continuous variable for carbon monoxide in ppb.
- -
- Outdoor : a continuous variable for ozone in ppb.
- -
- Outdoor : a continuous variable for particle matter with a diameter of less than 10 microns expressed in micrograms per cubic meter ().
- -
- Outdoor : a continuous variable for particle matter with a diameter of less than 2.5 microns expressed in μg/m3.
- -
- Outdoor : a continuous variable for sulfur dioxide in ppb.
- Data variables collected from OpenWeather:
- -
- Outdoor temperature: a continuous variable in Celsius degrees.
- -
- Outdoor pressure: a continuous variable in hPa.
- -
- Outdoor relative humidity: a continuous variable expressed as a percentage.
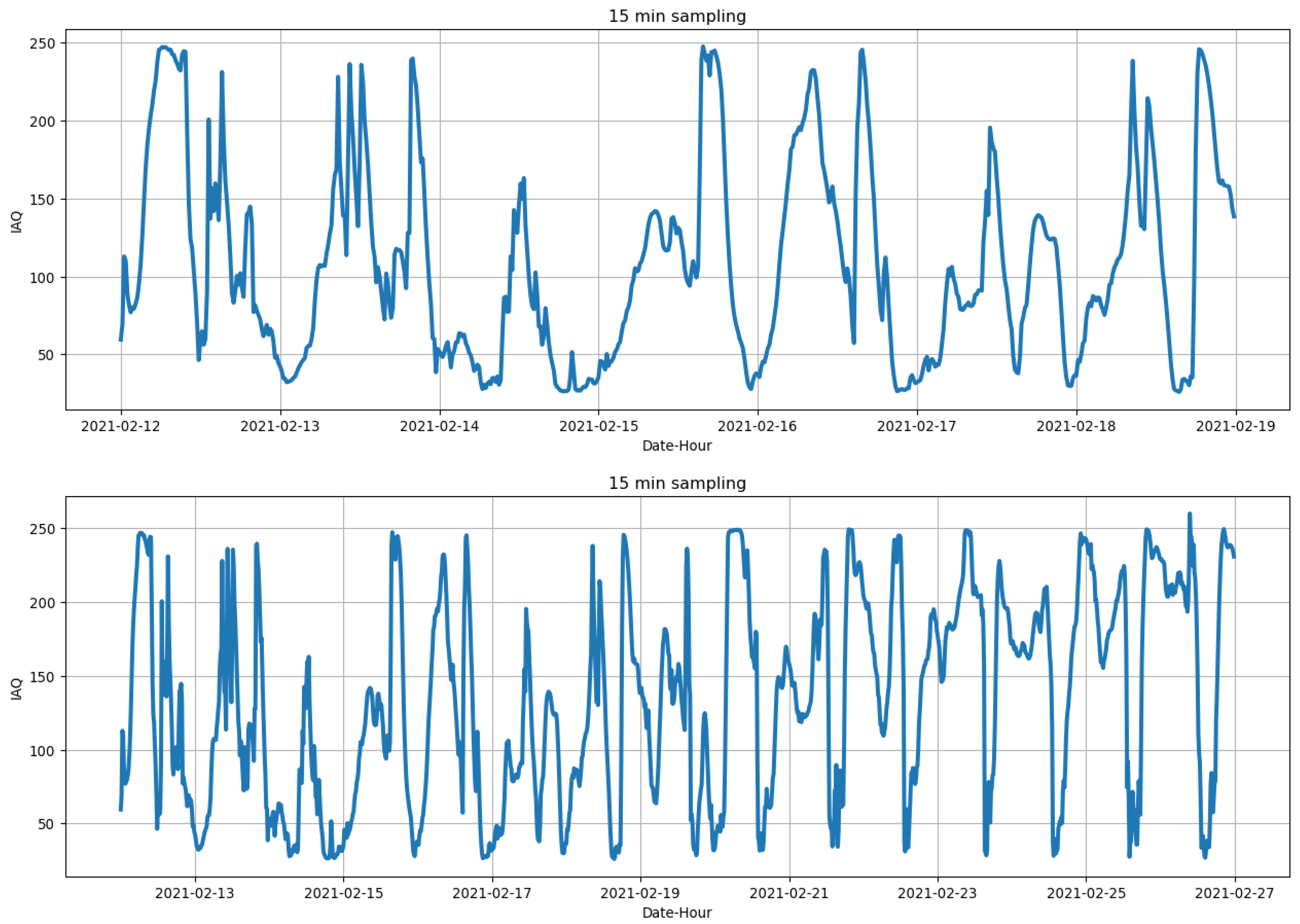
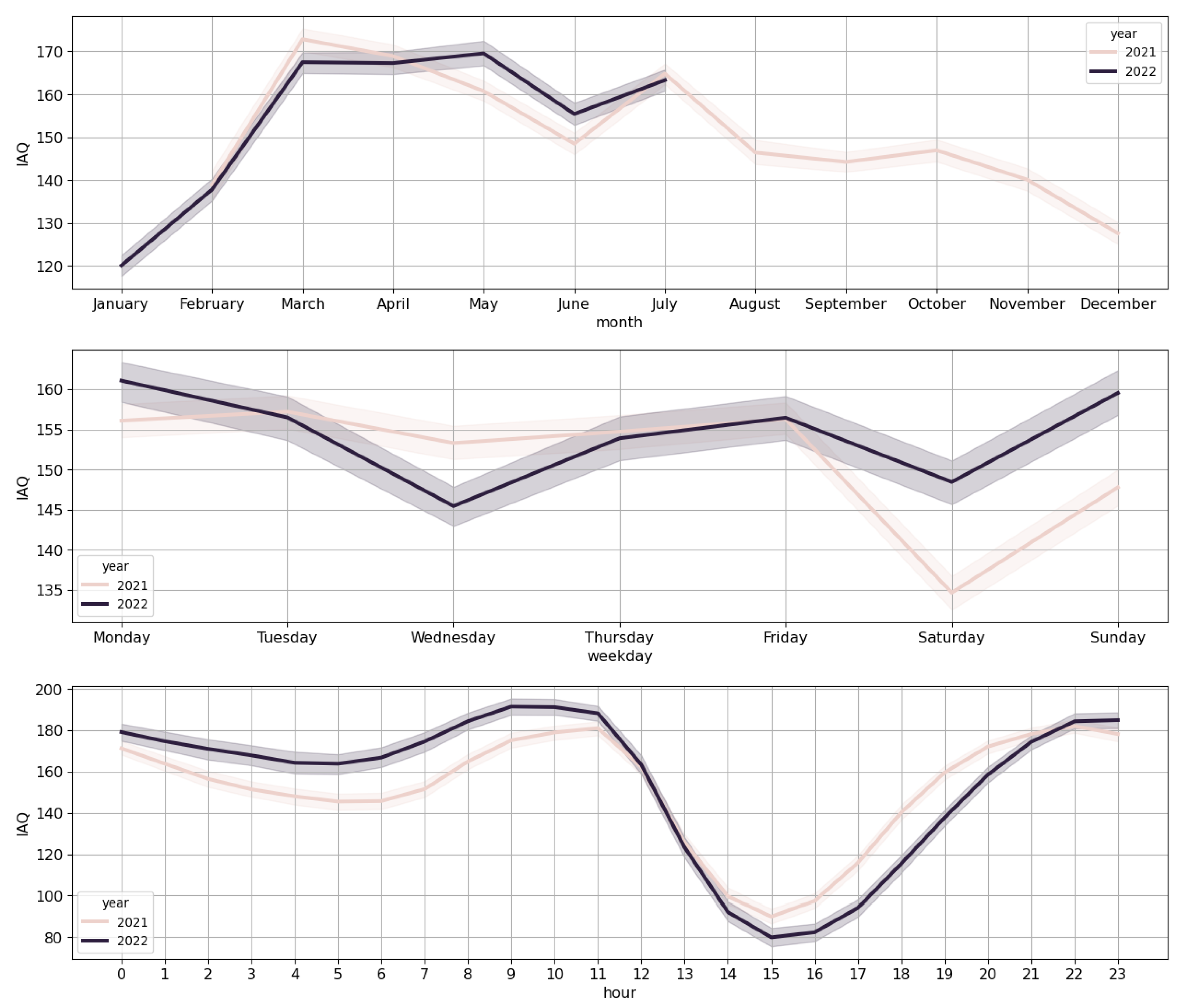
3.4. Exploratory Data Analysis
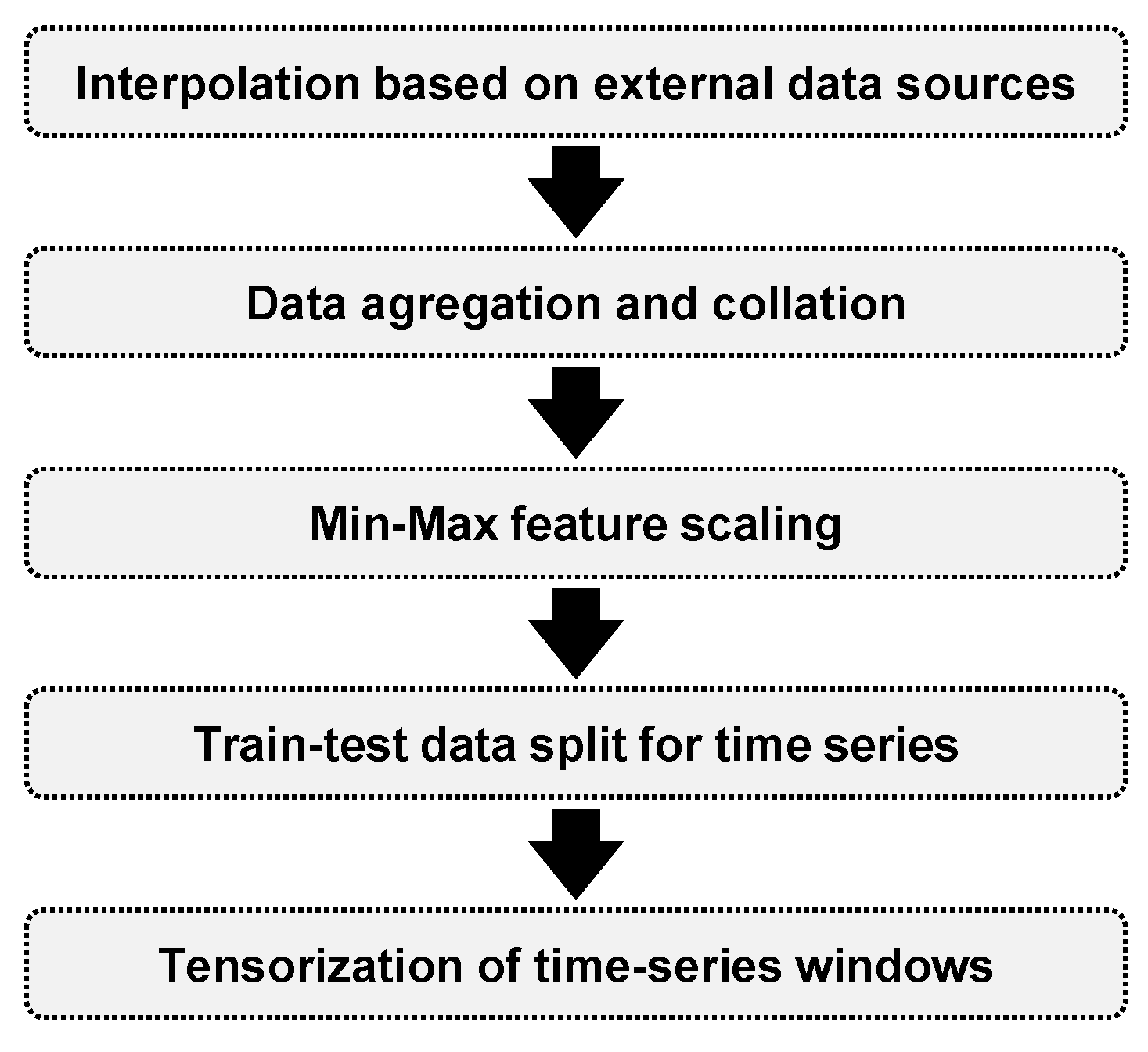
3.5. Data Curation and Preprocessing
3.6. Models
- Dense neural networks (DNNs), also commonly referred to as fully connected neural networks or multilayer perceptrons.
- Long short-term memory (LSTM) neural networks.
- One-dimension convolutional neural networks (CNNs).
- A combination of the above base architectures to exploit their advantages.
3.7. Training-Phase Implementation
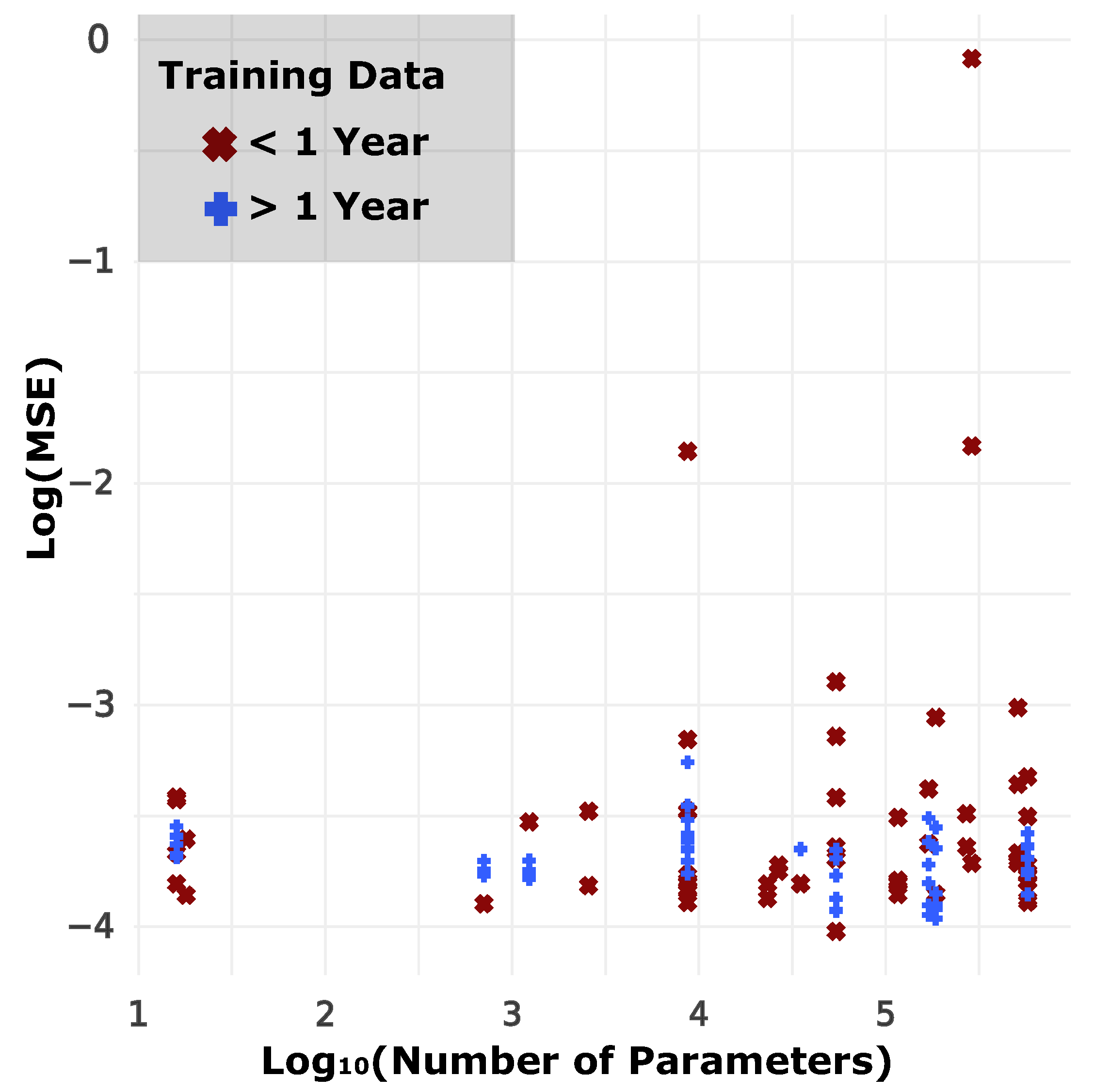
4. Results and Discussion
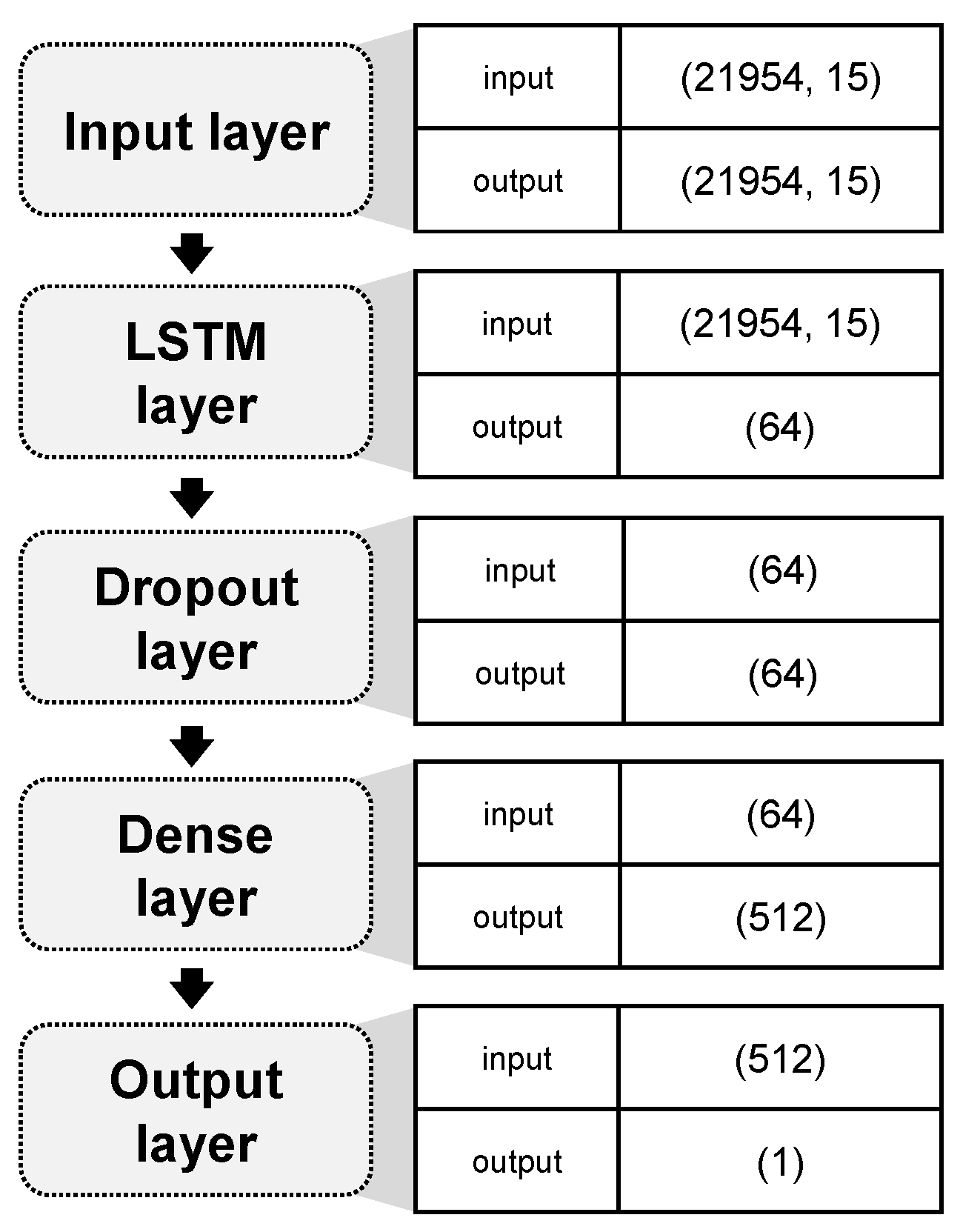
- LSTM02 is a 2-layer model based on LSTM with a dropout layer (see Figure 7).
- LSTM05 is a 5-layer model based on LSTM.
- DEEP17 is a 17-layer deep learning model combining LSTM, MLP, and CNNs.
- CONV02 is a 2-layer model based on 1-dimension CNNs.
- DNN03 is a 3-layer dense neural network, i.e., a fully connected or multilayer perceptron model.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Type | Layers | Params | Stride | Sampling Rate | Training Data | MSE | MAE |
|---|---|---|---|---|---|---|---|
| LSTM02 | 2 | 54,273 | 1 | 2 | <1 Year | 0.0179 | 0.1038 |
| LSTM05 | 5 | 185,345 | 2 | 2 | >1 Year | 0.0190 | 0.1162 |
| DEEP17 | 17 | 169,795 | 1 | 2 | >1 Year | 0.0193 | 0.1205 |
| LSTM02 | 2 | 54,273 | 2 | 2 | >1 Year | 0.0197 | 0.1219 |
| LSTM02 | 2 | 54,273 | 1 | 2 | >1 Year | 0.0197 | 0.1227 |
| LSTM05 | 5 | 185,345 | 1 | 2 | >1 Year | 0.0198 | 0.1218 |
| DEEP17 | 17 | 169,795 | 2 | 2 | >1 Year | 0.0202 | 0.1243 |
| LSTM05 | 5 | 185,345 | 2 | 2 | >1 Year | 0.0203 | 0.1219 |
| CONV02 | 2 | 706 | 2 | 2 | <1 Year | 0.0203 | 0.1303 |
| DNN03 | 3 | 8705 | 2 | 2 | <1 Year | 0.0204 | 0.1268 |
| DT | – | – | 1 | 2 | <1 Year | 0.0293 | 0.1418 |
| DT | – | – | 1 | 2 | >1 Year | 0.0208 | 0.1239 |
| RF | – | – | 1 | 2 | <1 Year | 0.0260 | 0.1358 |
| RF | – | – | 1 | 2 | >1 Year | 0.0177 | 0.1130 |
- DT is a decision tree with a Poisson split criterion, a maximum depth of three levels, and as many features as the square root of the initial number of input variables.
- RF is a random forest model with 30 trees, a maximum depth of three levels, and as many features as the square root of the initial number of input variables.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Related Work Comparison
| Work | Input Variables | Target Variables | Forecast Horizons | Geographic Area of Interest | Data Collection Time Frame | Techniques | Task Type | Best Results |
|---|---|---|---|---|---|---|---|---|
| Abdullah et al. [32] | Traffic volume, taxi and car volume, bus volume, van volume, heavy lorries volume, light lorries volume, motorcycle volume, time spent on the road, vehicle speed, relative humidity, wind speed, and temperature | Outdoor concentration levels of CO, NO, , and | 1 h | Kuala Lumpur, Malaysia | 3 years | A multilayer perceptron (MLP) model trained with the help of a genetic algorithm, an MLP, a decision tree, and a random forest | Forecast | An MSE of 0.0247 for CO; an MSE of 0.0365 for NO; an MSE of 0.0542 for , and an MSE of 0.1128 for |
| Cakir and Sita [33] | Wind speed, pressure, temperature, relative humidity, lagged , lagged , and lagged | Outdoor concentration levels of , , and | 1 day | Nicosia, Cyprus | 3 years | Multiple linear regressions and MLPs | Forecast | An RMSE of 7.39 for ; an RMSE of 12.82 for ; and an RMSE of 3.69 for |
| Shukla et al. [34] | NO, , , CO, , , , , , , , and | An outdoor air quality index | Not applicable | Indian cities | Not specified | A hybrid between artificial neural network and linear vector quantization, gradient boosting, decision trees, and recurrent neural networks | Classification | A sensitivity of 90%; an accuracy of 97.59%; and a specificity of 99.46% |
| Saad et al. [35] | , CO, , , , , volatile organic compounds, temperature, and relative humidity | Source affecting indoor air quality (namely, ambient air, chemical presence, fragrance presence, food and beverages, and human activity) | Not applicable | Malaysia | 26 days | An MLP | Classification | An accuracy of 99.1% |
| Kapoor et al. [36] | Number of occupants, office area, an indoor air quality index, temperature, relative humidity, and wind speed | Indoor concentration level of | 1 h | Roorkee, India | 1 month | MLPs, support vector machines, decision trees, Gaussian process regressions, linear regressions, and ensemble learning | Forecast | An RMSE of 4.2006 and an MAE of 3.3509 |
| Ahn et al. [37] | , lagged fine dust, lagged temperature, lagged relative humidity, lagged light quantity, and lagged volatile organic compounds | Indoor temperature, indoor relative humidity, indoor level of fine dust, indoor light quantity, and indoor concentration levels of volatile organic compounds | 1 h | Korea | 7 months | Linear regressions, gated recurrent unit networks, and long short-term memory (LSTM) neural networks | Forecast | A custom metric based on classification accuracy and adapted to forecast of 84.69% |
| Bakht et al. [38] | Lagged indoor and outdoor , lagged indoor and outdoor , indoor and outdoor , outdoor , and CO | Indoor and indoor | 30 min | Korea | 1 month | An MLP, (bidirectional) LSTMs, a recurrent neural network, a convolution neural network (CNN), and a hybrid CNN-LSTM-MLP | Forecast | An RMSE of 8.94 and an MAE of 6.4 |
| Sharma et al. [39] | Lagged indoor and outdoor , lagged indoor and outdoor lagged indoor and outdoor , indoor and outdoor , indoor and outdoor , indoor and outdoor CO, indoor and outdoor temperature, indoor and outdoor relative humidity, wind direction, wind speed, number of room occupants, room size, and number of fans in the room | Indoor and indoor | From 5 to 30 min | India | 1 month | An LSTM, a bidirectional LSTM, a deep bidirectional and unidirectional LSTM, and a modified LSTM without forget gates | Forecast | An MAPE of 4% |
| Rastogi et al. [41] | Indoor CO, , , and a lagged indoor air quality index | Return periods for each state of an indoor air quality index | 1 min | Delhi, India | 13 months | A discrete-time Markov chain model | Forecast | An average absolute prediction error of 4.75% |
| Authors’ present work | Indoor and outdoor temperature; indoor and outdoor pressure; indoor and outdoor relative humidity; and outdoor NO, , , CO, , , , and | Indoor air quality index | 5, 10, and 15 min | Mexico City, Mexico | 17 months | MLPs, LSTMs, CNNs, and hybrid models | Forecast | An MSE of 0.0179 and an MAE of 0.1038 |
References
- Tran, H.M.; Tsai, F.J.; Lee, Y.L.; Chang, J.H.; Chang, L.T.; Chang, T.Y.; Chung, K.F.; Kuo, H.P.; Lee, K.Y.; Chuang, K.J.; et al. The impact of air pollution on respiratory diseases in an era of climate change: A review of the current evidence. Sci. Total Environ. 2023, 898, 166340. [Google Scholar] [CrossRef] [PubMed]
- Liao, M.; Braunstein, Z.; Rao, X. Sex differences in particulate air pollution-related cardiovascular diseases: A review of human and animal evidence. Sci. Total Environ. 2023, 884, 163803. [Google Scholar] [CrossRef] [PubMed]
- Cole-Hunter, T.; Zhang, J.; So, R.; Samoli, E.; Liu, S.; Chen, J.; Strak, M.; Wolf, K.; Weinmayr, G.; Rodopolou, S.; et al. Long-term air pollution exposure and Parkinson’s disease mortality in a large pooled European cohort: An ELAPSE study. Environ. Int. 2023, 171, 107667. [Google Scholar] [CrossRef] [PubMed]
- Tian, F.; Qi, J.; Qian, Z.; Li, H.; Wang, L.; Wang, C.; Geiger, S.D.; McMillin, S.E.; Yin, P.; Lin, H.; et al. Differentiating the effects of air pollution on daily mortality counts and years of life lost in six Chinese megacities. Sci. Total Environ. 2022, 827, 154037. [Google Scholar] [CrossRef]
- Liu, Y.; Tong, D.; Cheng, J.; Davis, S.J.; Yu, S.; Yarlagadda, B.; Clarke, L.E.; Brauer, M.; Cohen, A.J.; Kan, H.; et al. Role of climate goals and clean-air policies on reducing future air pollution deaths in China: A modelling study. Lancet Planet. Health 2022, 6, e92–e99. [Google Scholar] [CrossRef]
- Tsai, S.S.; Chen, C.C.; Yang, C.Y. The impacts of reduction in ambient fine particulate (PM2. 5) air pollution on life expectancy in Taiwan. J. Toxicol. Environ. Health Part A 2022, 85, 913–920. [Google Scholar] [CrossRef] [PubMed]
- Shetty, S.S.; Deepthi, D.; Harshitha, S.; Sonkusare, S.; Naik, P.B.; Suchetha, K.N.; Madhyastha, H. Environmental pollutants and their effects on human health. Heliyon 2023, 9, e19496. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Li, T.; Liu, J.; Xie, P.; Du, S.; Teng, F. An overview of air quality analysis by big data techniques: Monitoring, forecasting, and traceability. Inf. Fusion 2021, 75, 28–40. [Google Scholar] [CrossRef]
- Saini, J.; Dutta, M.; Marques, G. A comprehensive review on indoor air quality monitoring systems for enhanced public health. Sustain. Environ. Res. 2020, 30, 6. [Google Scholar] [CrossRef]
- Kumar, P.; Kumar, P. A critical evaluation of air quality index models (1960–2021). Environ. Monit. Assess. 2022, 194, 324. [Google Scholar] [CrossRef]
- AirNow. Air Quality Index (AQI) Basics. 2024. Available online: https://www.airnow.gov/aqi/aqi-basics/ (accessed on 1 November 2024).
- Bosch. Bosch BME680 Datasheet. 2024. Available online: https://www.bosch-sensortec.com/media/boschsensortec/downloads/datasheets/bst-bme680-ds001.pdf (accessed on 1 November 2024).
- Gunatilaka, D.; Sanbundit, P.; Puengchim, S.; Boontham, C. AiRadar: A Sensing Platform for Indoor Air Quality Monitoring. In Proceedings of the 2022 19th International Joint Conference on Computer Science and Software Engineering, Bangkok, Thailand, 8–10 June 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Streuber, D.; Park, Y.M.; Sousan, S. Laboratory and Field Evaluations of the GeoAir2 Air Quality Monitor for Use in Indoor Environments. Aerosol Air Qual. Res. 2022, 22, 220119. [Google Scholar] [CrossRef] [PubMed]
- Markozannes, G.; Pantavou, K.; Rizos, E.C.; Sindosi, O.A.; Tagkas, C.; Seyfried, M.; Saldanha, I.J.; Hatzianastassiou, N.; Nikolopoulos, G.K.; Ntzani, E. Outdoor air quality and human health: An overview of reviews of observational studies. Environ. Pollut. 2022, 306, 119309. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, C.; Dong, S.; Feng, J.; Wang, H. A novel spatiotemporal multigraph convolutional network for air pollution prediction. Appl. Intell. 2023, 53, 18319–18332. [Google Scholar] [CrossRef]
- Ge, L.; Wu, K.; Zeng, Y.; Chang, F.; Wang, Y.; Li, S. Multi-scale spatiotemporal graph convolution network for air quality prediction. Appl. Intell. 2021, 51, 3491–3505. [Google Scholar] [CrossRef]
- Mannan, M.; Al-Ghamdi, S.G. Indoor air quality in buildings: A comprehensive review on the factors influencing air pollution in residential and commercial structure. Int. J. Environ. Res. Public Health 2021, 18, 3276. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Yan, L.; Meng, X.; Zhang, C. A review on indoor green plants employed to improve indoor environment. J. Build. Eng. 2022, 53, 104542. [Google Scholar] [CrossRef]
- Shaw, D.; Carslaw, N. INCHEM-Py: An open source Python box model for indoor air chemistry. J. Open Source Softw. 2021, 6, 3224. [Google Scholar] [CrossRef]
- Liu, N.; Liu, W.; Deng, F.; Liu, Y.; Gao, X.; Fang, L.; Chen, Z.; Tang, H.; Hong, S.; Pan, M.; et al. The burden of disease attributable to indoor air pollutants in China from 2000 to 2017. Lancet Planet. Health 2023, 7, e900–e911. [Google Scholar] [CrossRef] [PubMed]
- Tian, S.; Wang, L.; Liu, Q.; Luo, L.; Qian, C.; Wang, B.; Liu, Y. Associations between Indoor and Outdoor Size-Resolved Particulate Matter in Urban Beijing: Chemical Compositions, Sources, and Health Risks. Atmosphere 2024, 15, 721. [Google Scholar] [CrossRef]
- Salthammer, T.; Zhao, J.; Schieweck, A.; Uhde, E.; Hussein, T.; Antretter, F.; Künzel, H.; Pazold, M.; Radon, J.; Birmili, W. A holistic modeling framework for estimating the influence of climate change on indoor air quality. Indoor Air 2022, 32, e13039. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.W.; Kumar, P.; Cao, S.J. Evaluation of ventilation and indoor air quality inside bedrooms of an elderly care centre. Energy Build. 2024, 313, 114245. [Google Scholar] [CrossRef]
- Vasile, V.; Catalina, T.; Dima, A.; Ion, M. Pollution Levels in Indoor School Environment—Case Studies. Atmosphere 2024, 15, 399. [Google Scholar] [CrossRef]
- Morawska, L.; Allen, J.; Bahnfleth, W.; Bennett, B.; Bluyssen, P.M.; Boerstra, A.; Buonanno, G.; Cao, J.; Dancer, S.J.; Floto, A.; et al. Mandating indoor air quality for public buildings. Science 2024, 383, 1418–1420. [Google Scholar] [CrossRef]
- Mohammed, M.A.; Ahmed, L.A. Forecasting wind speed using the proposed wavelet neural network. Discret. Dyn. Nat. Soc. 2023, 2023, 9940038. [Google Scholar] [CrossRef]
- Kolambe, M.; Arora, S. Forecasting the future: A comprehensive review of time series prediction techniques. J. Electr. Syst. 2024, 20, 575–586. [Google Scholar]
- Zhang, L.; Dou, H.; Zhang, K.; Huang, R.; Lin, X.; Wu, S.; Zhang, R.; Zhang, C.; Zheng, S. CNN-LSTM Model Optimized by Bayesian Optimization for Predicting Single-Well Production in Water Flooding Reservoir. Geofluids 2023, 2023, 5467956. [Google Scholar] [CrossRef]
- SINAICA. Sistema Nacional de Información de la Calidad del Aire del Gobierno Federal México. 2024. Available online: https://sinaica.inecc.gob.mx/ (accessed on 1 November 2024).
- OpenWeather. History Bulk Weather Data. 2024. Available online: https://openweathermap.org/history-bulk (accessed on 1 November 2024).
- Abdullah, A.; Usmani, R.S.A.; Pillai, T.; Marjani, M.; Abaker, I.; Hashem, I. An Optimized Artificial Neural Network Model using Genetic Algorithm for Prediction of Traffic Emission Concentrations. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 794–803. [Google Scholar] [CrossRef]
- Cakir, S.; Sita, M. Evaluating the performance of ANN in predicting the concentrations of ambient air pollutants in Nicosia. Atmos. Pollut. Res. 2020, 11, 2327–2334. [Google Scholar] [CrossRef]
- Kumbhar, V.S.; Sohi, S.S.; Jayaram, V.; Sreelekshmy, P.G.; Shukla, S.K.; Abhilash, K.S. Hybrid artificial neural network algorithm for air pollution estimation. Int. J. Health Sci. 2022, 6, 2094–2106. [Google Scholar] [CrossRef]
- Saad, S.; Andrew, A.; Shakaff, A.; Saad, A.; Kamarudin, A.; Zakaria, A. Classifying Sources Influencing Indoor Air Quality (IAQ) Using Artificial Neural Network (ANN). Sensors 2015, 15, 11665–11684. [Google Scholar] [CrossRef]
- Kapoor, N.R.; Kumar, A.; Kumar, A.; Kumar, A.; Mohammed, M.A.; Kumar, K.; Kadry, S.; Lim, S. Machine learning-based CO2 prediction for office room: A pilot study. Wirel. Commun. Mob. Comput. 2022, 1–16. [Google Scholar] [CrossRef]
- Ahn, J.; Shin, D.; Kim, K.; Yang, J. Indoor air quality analysis using deep learning with sensor data. Sensors 2017, 17, 2476. [Google Scholar] [CrossRef]
- Bakht, A.; Sharma, S.; Park, D.; Lee, H. Deep Learning-Based Indoor Air Quality Forecasting Framework for Indoor Subway Station Platforms. Toxics 2022, 10, 557. [Google Scholar] [CrossRef] [PubMed]
- Sharma, P.K.; Mondal, A.; Jaiswal, S.; Saha, M.; Nandi, S.; De, T.; Saha, S. IndoAirSense: A framework for indoor air quality estimation and forecasting. Atmos. Pollut. Res. 2021, 12, 10–22. [Google Scholar] [CrossRef]
- Pourkiaei, M.; Romain, A.C. Scoping review of indoor air quality indexes: Characterization and applications. J. Build. Eng. 2023, 75, 106703. [Google Scholar] [CrossRef]
- Rastogi, K.; Barthwal, A.; Lohani, D.; Acharya, D. An IoT-based discrete time Markov chain model for analysis and prediction of indoor air quality index. In Proceedings of the 2020 IEEE Sensors Applications Symposium, Kuala Lumpur, Malaysia, 9–11 March 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Yue, Q.; Song, Y.; Zhang, M.; Zhang, X.; Wang, L. The impact of air pollution on employment location choice: Evidence from China’s migrant population. Environ. Impact Assess. Rev. 2024, 105, 107411. [Google Scholar] [CrossRef]
- Altamirano-Astorga, J.; Santiago-Castillejos, I.A.; Hernández-Martínez, L.; Roman-Rangel, E. Indoor Air Pollution Forecasting Using Deep Neural Networks. In Pattern Recognition; Vergara-Villegas, O.O., Cruz-Sánchez, V.G., Sossa-Azuela, J.H., Carrasco-Ochoa, J.A., Martínez-Trinidad, J.F., Olvera-López, J.A., Eds.; Springer: Cham, Switzerland, 2022; pp. 127–136. [Google Scholar] [CrossRef]
- Liu, J.; Huang, X.; Li, Q.; Chen, Z.; Liu, G.; Tai, Y. Hourly stepwise forecasting for solar irradiance using integrated hybrid models CNN-LSTM-MLP combined with error correction and VMD. Energy Convers. Manag. 2023, 280, 116804. [Google Scholar] [CrossRef]
- Li, H.; Rakhlin, A.; Jadbabaie, A. Convergence of Adam Under Relaxed Assumptions. In Advances in Neural Information Processing Systems, Proceedings of the NIPS ’23 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2023; Volume 36, pp. 52166–52196. [Google Scholar]
- Sclocchi, A.; Wyart, M. On the different regimes of stochastic gradient descent. Proc. Natl. Acad. Sci. USA 2024, 121, e2316301121. [Google Scholar] [CrossRef]
- Katzir, S. BreezoMeter’s Continuous Accuracy Testing for Reliable Air Quality Data. 2024. Available online: https://blog.breezometer.com/air-quality-accuracy-testing (accessed on 1 November 2024).


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Altamirano-Astorga, J.; Gutierrez-Garcia, J.O.; Roman-Rangel, E. Forecasting Indoor Air Quality in Mexico City Using Deep Learning Architectures. Atmosphere 2024, 15, 1529. https://doi.org/10.3390/atmos15121529
Altamirano-Astorga J, Gutierrez-Garcia JO, Roman-Rangel E. Forecasting Indoor Air Quality in Mexico City Using Deep Learning Architectures. Atmosphere. 2024; 15(12):1529. https://doi.org/10.3390/atmos15121529
Chicago/Turabian StyleAltamirano-Astorga, Jorge, J. Octavio Gutierrez-Garcia, and Edgar Roman-Rangel. 2024. "Forecasting Indoor Air Quality in Mexico City Using Deep Learning Architectures" Atmosphere 15, no. 12: 1529. https://doi.org/10.3390/atmos15121529
APA StyleAltamirano-Astorga, J., Gutierrez-Garcia, J. O., & Roman-Rangel, E. (2024). Forecasting Indoor Air Quality in Mexico City Using Deep Learning Architectures. Atmosphere, 15(12), 1529. https://doi.org/10.3390/atmos15121529