1. Introduction
Genomic prediction (GP) is transforming plant breeding by enabling scientists to identify high-performing genetic profiles earlier in the breeding process, significantly reducing the time and costs associated with developing improved crop varieties. Unlike traditional breeding, which relies heavily on observable traits and lengthy field trials, GP leverages genomic data to predict plant performance, even for complex traits like yield stability and disease resistance. By integrating vast amounts of genetic information with machine learning algorithms, GP allows breeders to make faster and more accurate selection decisions, improving both the precision and efficiency of breeding programs. As a result, it is now possible to breed plants that are better adapted to specific climates and stresses, supporting food security and resilience against climate change worldwide. This shift towards data-driven selection is helping to sustain agricultural productivity in the face of environmental challenges, ultimately benefiting both breeders and farmers globally [
1,
2].
Implementing genomic prediction in plant breeding remains challenging due to complex genetic and statistical factors. One significant hurdle is the high dimensionality of genomic data, where the number of markers often exceeds the sample size, creating multicollinearity issues. This complexity demands sophisticated statistical models that can handle these data intricacies, especially for polygenic traits controlled by numerous small-effect loci. Additionally, genotype-by-environment (G × E) interactions complicate predictions, as the performance of genotypes can vary widely across environments. Accounting for these interactions requires advanced models to capture genetic correlations across diverse environments, which increases computational demands. Another challenge is the high cost of genotyping large populations, especially in developing countries where resources may be limited, further slowing the adoption of genomic selection technologies [
1,
3,
4].
For this reason, many strategies have been implemented in GP with the goal of improving its efficiency. One of these strategies is called sparse testing. Sparse testing is crucial in genomic prediction as it enables the evaluation of a wide variety of cultivars across multiple environments without the cost and logistical constraints of fully testing each of them in every environment. By strategically selecting and testing only a subset of genotypes in specific environments, sparse testing helps generate sufficient data to build accurate prediction models that account for G × E, allowing breeders to predict untested combinations effectively. This approach is particularly beneficial in large-scale breeding programs, where it reduces field trial costs and resource demands while maintaining the prediction power required for selecting cultivars suited to varied environmental conditions. Moreover, sparse testing supports data efficiency, enhancing the ability to predict performance in unobserved environments, ultimately accelerating the breeding cycle and improving genetic gains across diverse climates [
1,
5].
Recent developments in machine learning have led to the integration of non-linear and deep learning models into genomic prediction, offering the potential to capture complex trait architectures and G × E interactions more effectively than traditional linear methods. Models such as convolutional neural networks (CNNs), multilayer perceptrons (MLPs), and hybrid ensemble frameworks have demonstrated competitive performance, especially when dealing with high-dimensional genomic and environmental data [
6]. While these models offer advantages in flexibility and potential accuracy, they also require large datasets and careful tuning, which may not always be feasible in breeding contexts with limited training data. Thus, GBLUP remains a robust and widely used benchmark model for evaluating genomic prediction strategies, including those involving sparse testing.
In plant breeding, multi-environment trials (METs) are critical for accurately evaluating genotype performance and stability under diverse environmental conditions. Genomic prediction (GP) models that incorporate genotype-by-environment (G × E) interactions have significantly advanced breeding programs by predicting the performance of unobserved genotype–environment combinations. In crop improvement, many cultivars (varieties) (called genotypes) have been observed in different places or years (called environments). Breeders have data from those varieties in some environments, but not in others, and we must predict how those same varieties would do in the missing environments. So, breeders train the model using the observed environments and then test the model by predicting the performance in the environments where varieties were not observed. The cross-validation (CV2-type cross-validation scheme), initially introduced by Burgueño et al. (2012) [
7], specifically addresses realistic scenarios encountered in plant breeding programs where some genotype–environment combinations are deliberately masked, simulating situations where genotypes have incomplete environmental testing due to resource limitations or logistical constraints. This approach allows for a realistic assessment of genomic prediction models’ capability to estimate genotype performance in environments where no direct phenotypic data exist.
Since its initial proposal, the CV2 methodology has evolved to reflect practical constraints and opportunities within breeding programs. For example, Montesinos et al. (2024) [
8] integrated sparse testing methodologies, applying incomplete block and random allocation designs to further simulate realistic breeding scenarios. Additionally, this study further expanded upon the CV2 concept by strategically enriching training datasets with related environmental data, aiming to enhance predictive accuracy in untested environments. These advancements illustrate the versatility and adaptability of CV2-based strategies within modern genomic selection practices.
In this research, we will explore sparse testing for tested lines in untested environments. This type of sparse testing allows breeders to predict the performance of tested genotypes in untested environments by leveraging information from strategically tested lines in various conditions. This approach helps to identify robust genotypes capable of thriving across different environments, even when complete testing in all conditions is impractical. Sparse testing frameworks rely on statistical and genomic models that use data from tested genotypes to infer the potential of similar but untested genotypes, addressing GE with fewer resources. By optimizing the selection of test sites and genotypes, sparse testing improves efficiency, reducing costs and labor while maintaining high predictive accuracy. This method is particularly advantageous in large-scale breeding programs with limited testing budgets and in regions with diverse and variable climates, where anticipating genotype adaptation is essential [
1,
5,
7].
In this study, we assess the predictive capacity of sparse testing under tested lines in untested environments using a real-world dataset from South Asian Target Population of Environments (TPEs), encompassing 25 unique site–year combinations. Our analysis simulates scenarios where specific genotypes are evaluated in certain environments but are absent in others. These approaches include methods for predicting missing lines for a specific environment using information on other environments with related lines.
This work builds upon our previous study [
8], which evaluated sparse testing under random and incomplete block designs. Here, we focus on a more realistic and operationally relevant sparse testing scenario—predicting tested lines in untested environments—while leveraging multi-year, multi-environmental data enrichment. By explicitly comparing enriched versus non-enriched training sets, this study adds new insights into the transferability of genomic predictions under practical field conditions.
3. Results
The results are presented in four sections.
Section 3.1,
Section 3.2,
Section 3.3 and
Section 3.4 contain the results for the datasets TPE_1_2021_2022, TPE_2_2021_2022, and TPE_3_2022_2023 and across, respectively. Meanwhile,
Section 3.4 provides the results across all datasets (Across data). Finally,
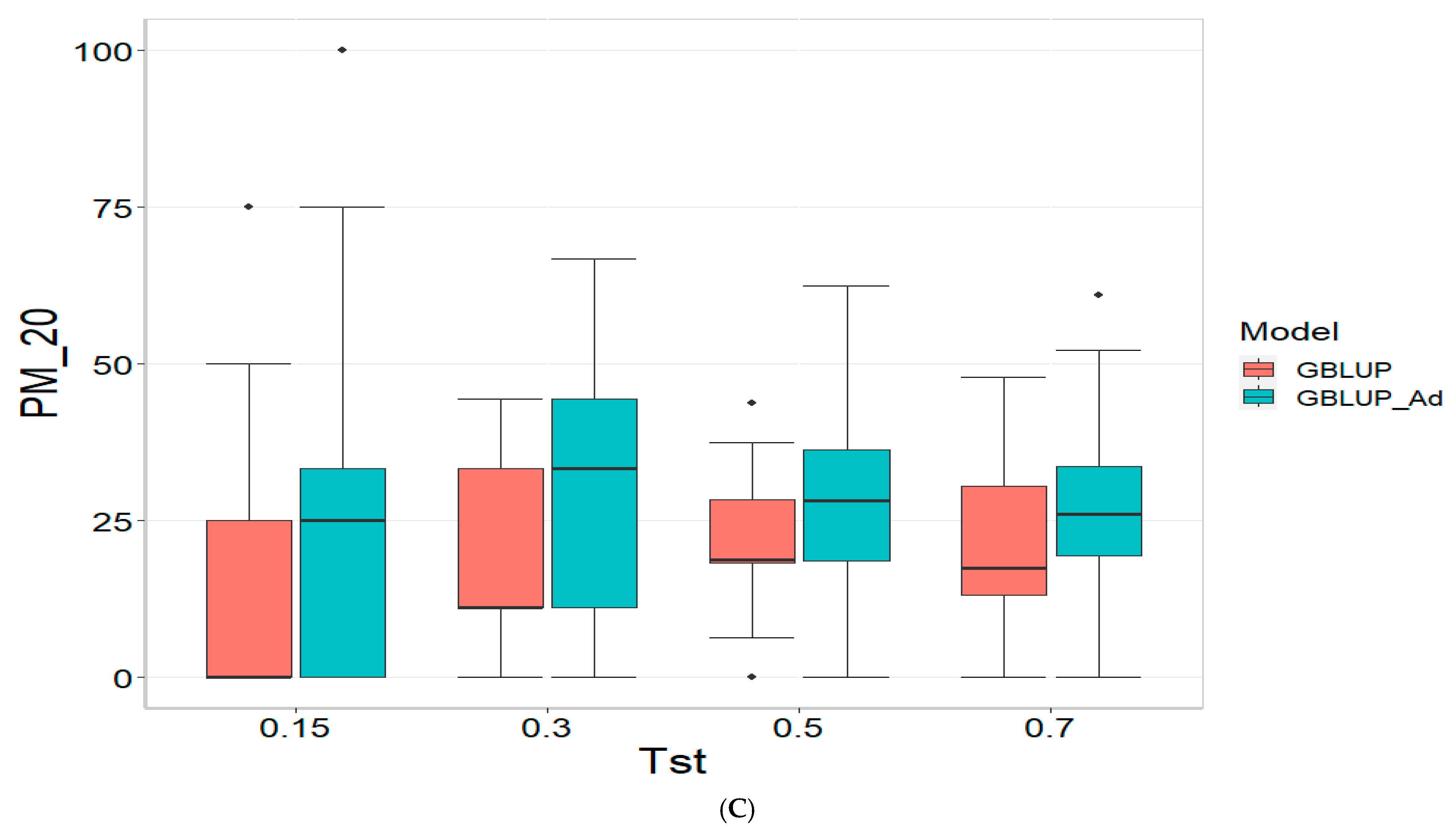
Appendix B and
Appendix C provide the figures and tables corresponding to the datasets TPE_1_2022_2023, TPE_2_2022_2023, and TPE_3_2021_2022. The results are presented in terms of three metrics: the Pearson’s Correlation (COR), Percentage of Matching in the top 10% (PM_10), and Percentage of Matching in the top 20% (PM_20) for each dataset.
In some scenarios, the baseline GBLUP model produced negative Pearson’s correlation values or extreme relative efficiency (RE) scores. These negative values reflect instances where the model failed to generalize to the testing set, often due to limited or uninformative training data. The RE metric was calculated as the percentage change in the squared correlation of GBLUP relative to GBLUP_Ad, which can result in large or undefined values when the baseline model’s correlation approaches zero or becomes negative. While such values may seem extreme, they are useful in highlighting the extent to which GBLUP_Ad improves prediction under sparse or biologically dissimilar training conditions. Importantly, these results also emphasize the need to carefully interpret low or negative correlations as signals of limited transferability between training and testing environments.
3.1. TPE_1_2021_2022
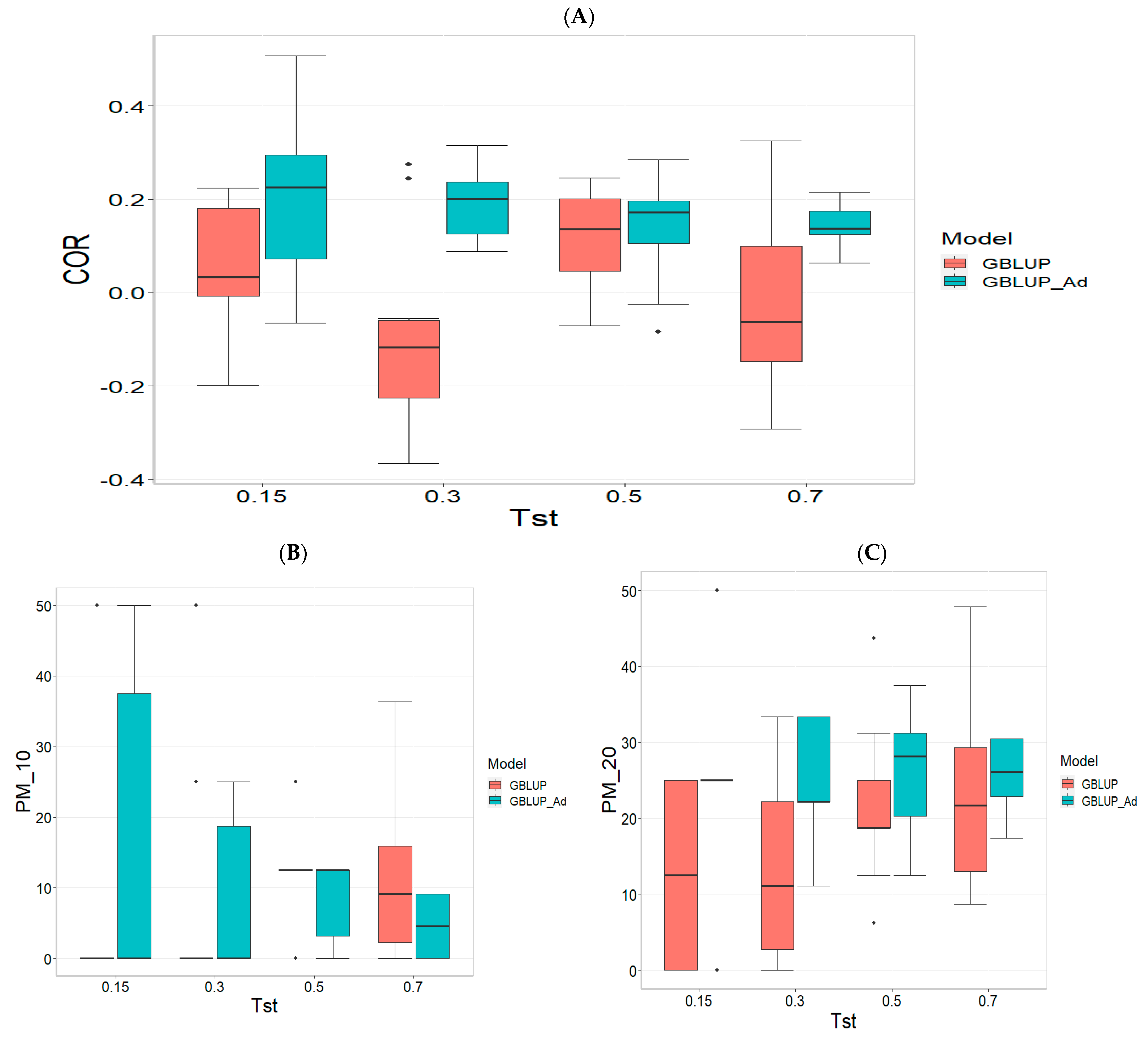
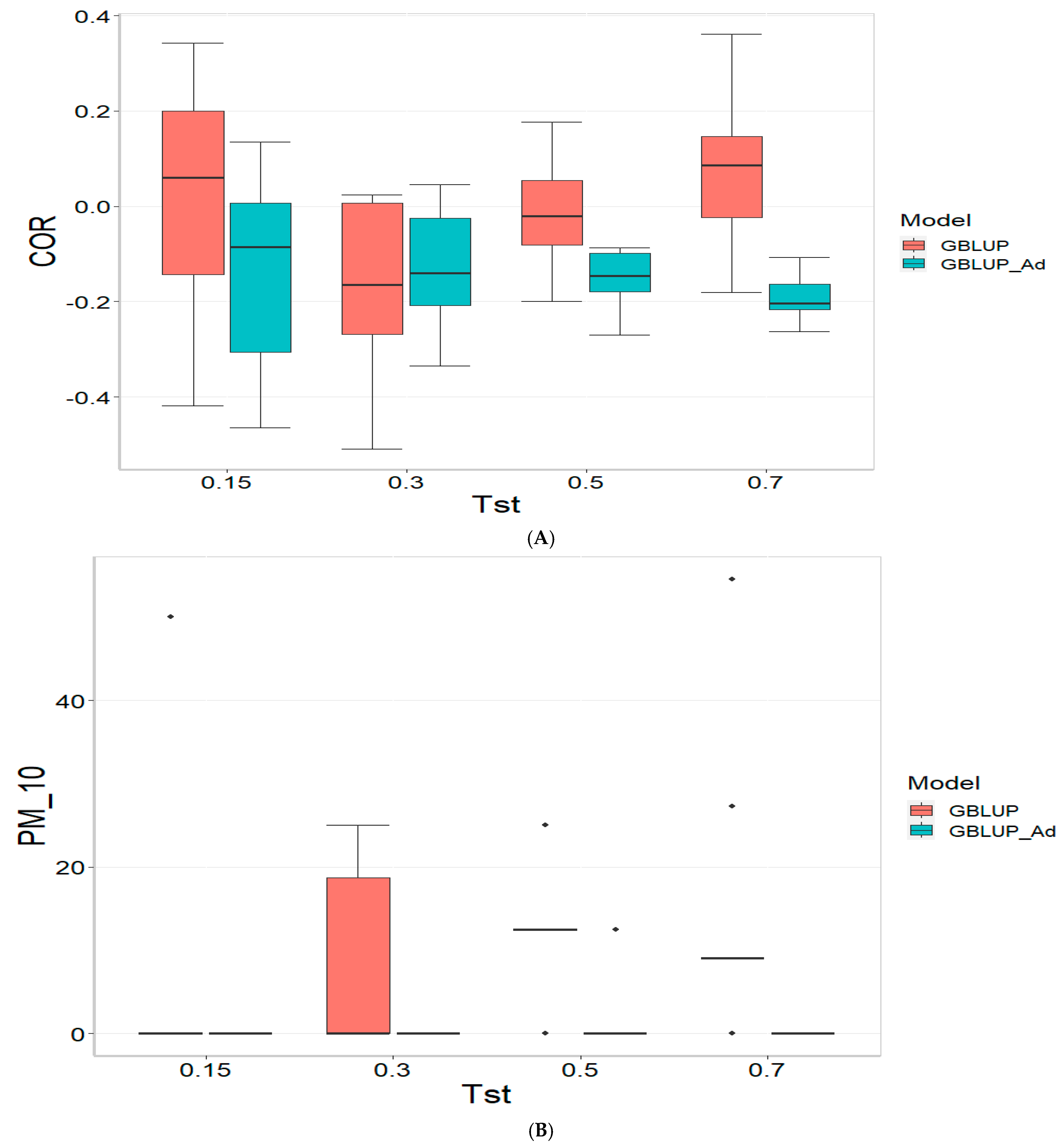
Figure 1 presents the results for the dataset TPE_1_2021_2022 under a comparative analysis of the models GBLUP and GBLUP_Ad in terms of their predictive efficiency, measured by Pearson’s correlation (COR), and the Percentage of Matching for the selected optimal lines in the top 10% and 20% (PM_10 and PM_20). For further details, please refer to
Table A1 in
Appendix A.
In the analysis, the GBLUP_Ad model demonstrates superior performance across all evaluated metrics (COR, PM_10, PM_20) compared to GBLUP for several scenarios, especially for COR. For the COR metric, GBLUP_Ad maintains positive averages, with means ranging from 0.101 to 0.179 across different Tst values (where Tst denotes the proportion of testing set with possible values of 0.15, 0.30, 0.50, and 0.70), while GBLUP shows negative averages for the lower Tst values, such as −0.017 for Tst = 0.15 and −0.045 for TST = 0.30, reflecting its lower performance.
Regarding the PM_10 and PM_20 metrics, GBLUP_Ad outperforms GBLUP for some cases. For Tst = 0.15 and PM_20, the mean value for GBLUP_Ad is 25.000 compared to 7.500 for GBLUP. Also, for Tst = 0.30 and PM_20, the mean is 27.778 for GBLUP_Ad compared for GBLUP having a mean of 17.778. For the other scenarios comparing the metrics PM_10 and PM_20, GBLUP outperforms GBLUP_Ad in terms of the mean.
Overall, the relative efficiency of GBLUP is negative or significantly lower, whereas GBLUP_Ad establishes itself as the reference model with a relative efficiency of 0%, consolidating its superiority in all evaluated aspects.
3.2. TPE_2_2021_2022
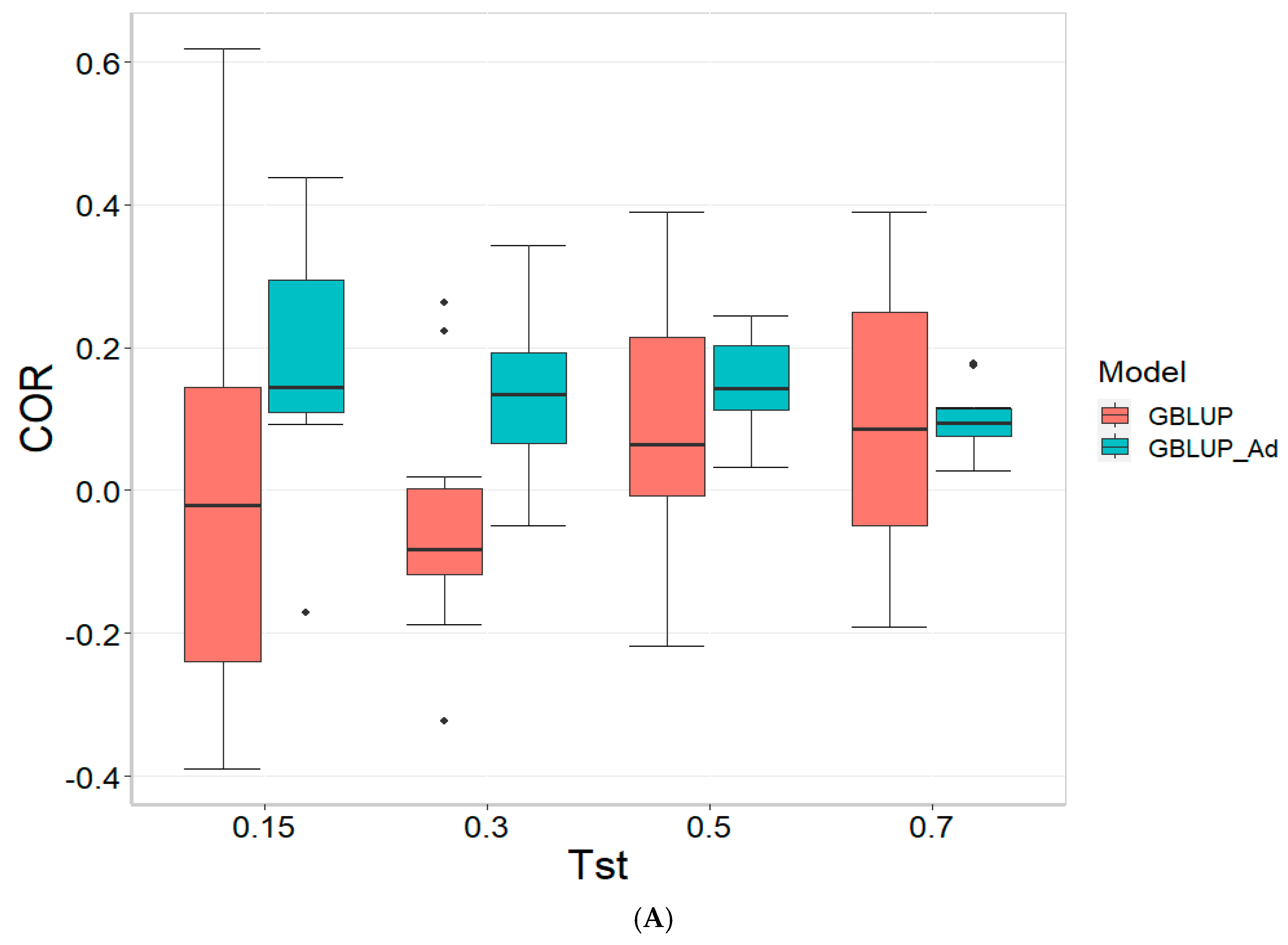
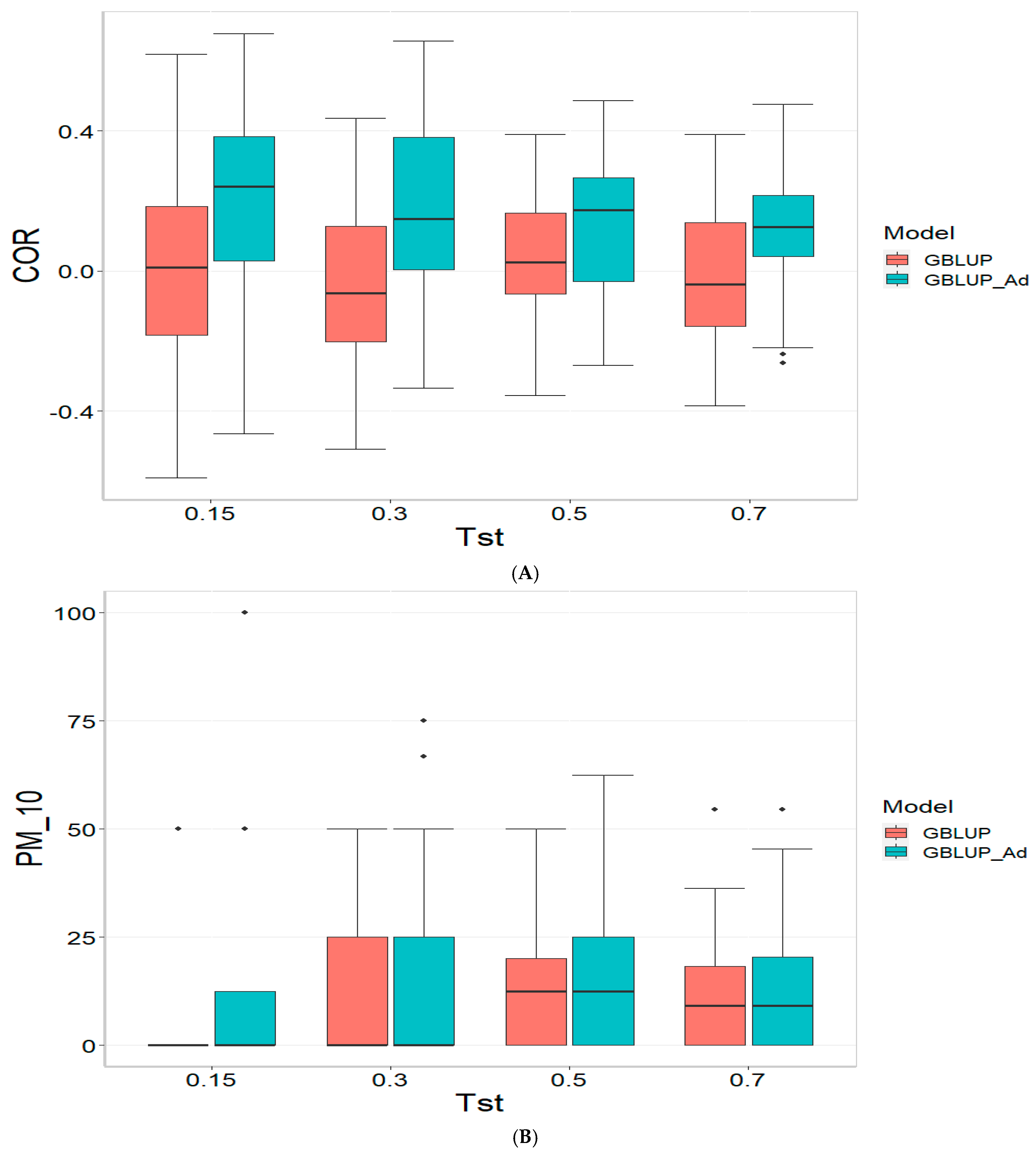
Figure 2 presents the results for TPE_2_2021_2022 under a comparative analysis of the GBLUP and GBLUP_Ad models in terms of COR, PM_10 and PM_20. For further details, please refer to
Table A2 in
Appendix A.
For the COR metric, GBLUP shows better performance at Tst = 0.15 and Tst = 0.70, with averages of 0.024 and 0.081, respectively, while GBLUP_Ad presents negative averages across all evaluated Tst, ranging from −0.148 to −0.194. However, the standard deviation of GBLUP_Ad is generally lower, suggesting more consistent predictions, although with overall lower performance. The relative efficiency (RE) of GBLUP is negative at Tst = 0.15 and Tst = 0.70, indicating inferior performance compared to GBLUP_Ad.
For the PM_10 metric, GBLUP_Ad shows little variability in the early Tst, with averages of 0.000 at several points, while GBLUP has higher averages, such as 13.636 at TST = 0.70. However, the relative efficiency of GBLUP is negative or low across all Tst, reinforcing the superiority of GBLUP_Ad in terms of efficiency and accuracy. Finally, for the PM_20 metric, GBLUP_Ad has lower averages and smaller standard deviations compared to GBLUP, which has averages like 28.696 for Tst = 0.70. The relative efficiency of GBLUP is negative in most cases, while GBLUP_Ad demonstrates greater consistency and efficiency.
Although GBLUP shows some positive average values in certain metrics and Tst, GBLUP_Ad excels in terms of consistency and lower variability, making it generally more efficient, as reflected by the low or zero relative efficiency rates compared to GBLUP.
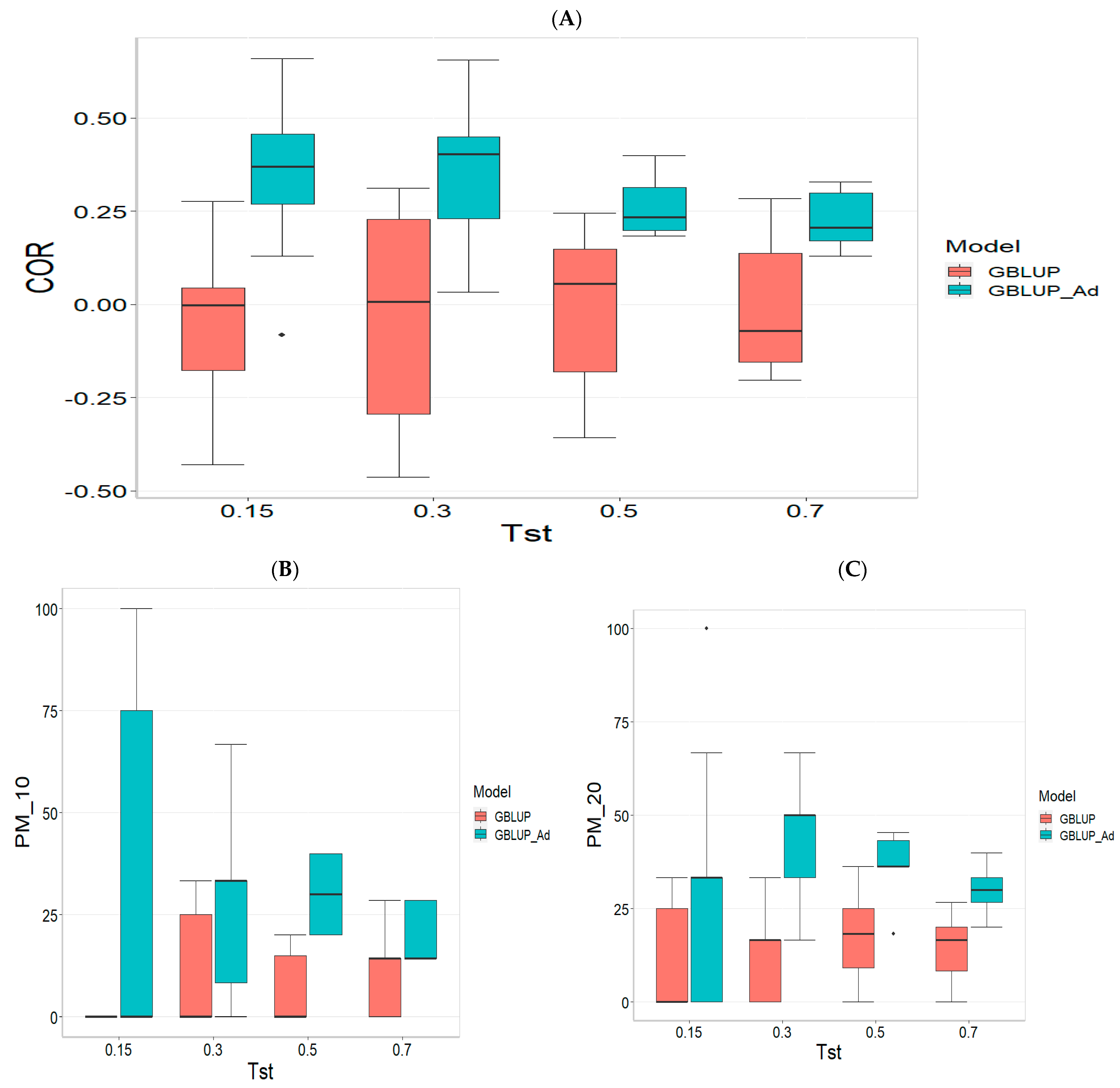
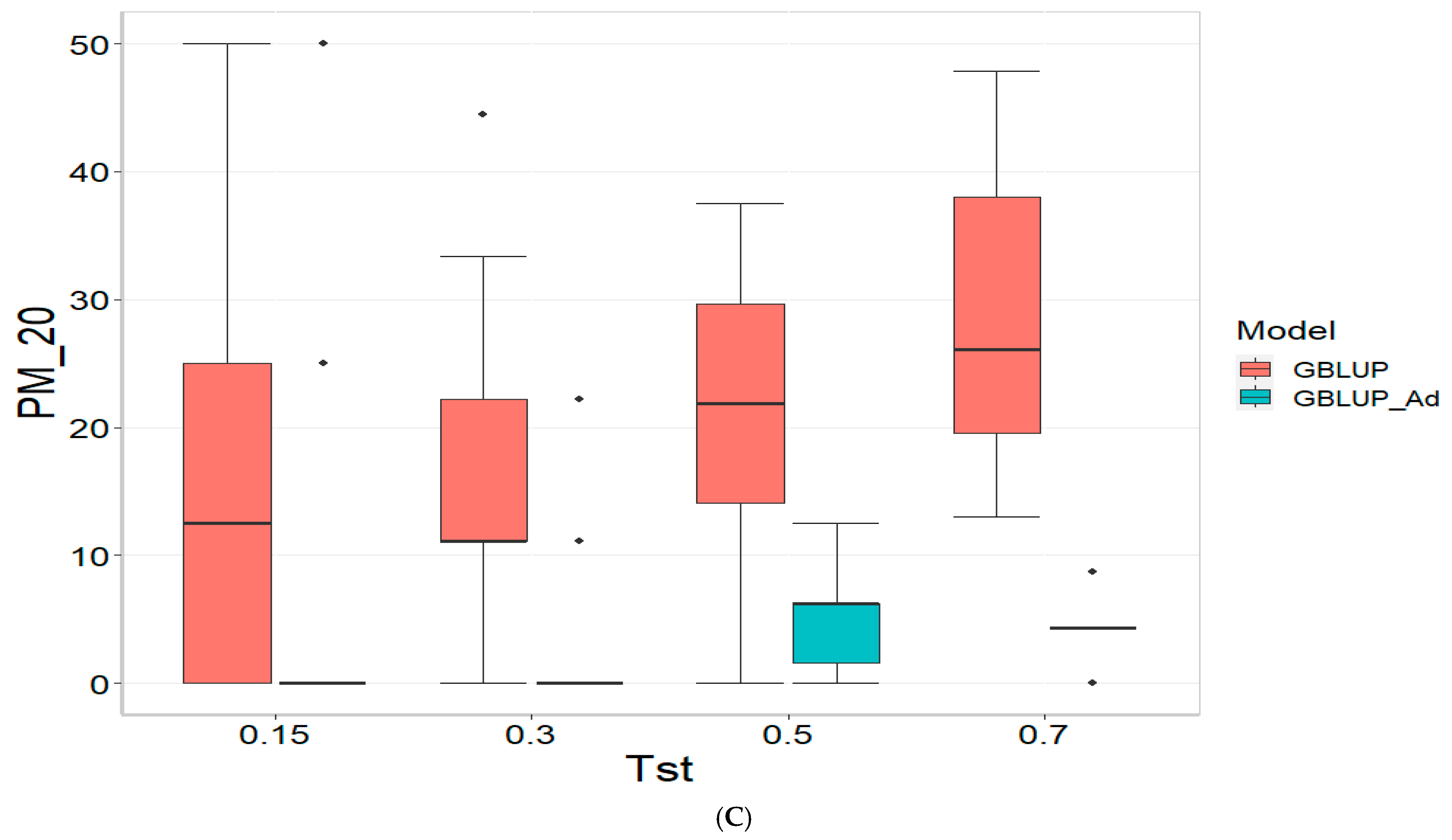
3.3. TPE_3_2022_2023
For the COR metric, for Tst = 0.15, the GBLUP_Ad model demonstrates superior performance with a mean value of 0.455 and a low standard deviation of 0.104, suggesting more consistent and accurate predictions. In contrast, GBLUP has a mean value of 0.073 and a higher standard deviation of 0.236, indicating lower accuracy. The relative efficiency (RE) of GBLUP is high, suggesting inferior performance compared to GBLUP_Ad. As Tst increases, GBLUP_Ad continues to outperform GBLUP. For example, at Tst = 0.70, GBLUP_Ad shows a mean of 0.418 and a standard deviation of 0.029, while GBLUP shows a negative mean of −0.029 and a standard deviation of 0.196, with a negative RE, reflecting significantly inferior performance.
For the PM_10 (Top 10% Prediction Accuracy) metric, at Tst = 0.15, GBLUP_Ad performs better with a mean of 30.000 compared to 20.000 for GBLUP. Both models have the same standard deviation of 25.820, indicating that GBLUP_Ad is superior in terms of prediction accuracy. As Tst increases, GBLUP_Ad continues to show better results. At Tst = 0.70, GBLUP_Ad has a mean of 34.545 and a standard deviation of 11.175, while GBLUP shows a mean of 12.727 and a similar standard deviation, highlighting the advantage of GBLUP_Ad.
Finally, for the PM_20 (Top 20% Prediction Accuracy) metric and for Tst = 0.15, GBLUP_Ad again outperforms GBLUP with a mean of 40.000 compared to 20.000. Although GBLUP_Ad has a higher standard deviation (21.082 vs. 15.811), its overall performance is superior. At Tst = 0.70, GBLUP_Ad maintains its advantage with a mean of 47.391 and a standard deviation of 8.056, while GBLUP has a mean of 20.435 and a slightly higher standard deviation, confirming the better performance of GBLUP_Ad with mean of 47.391.
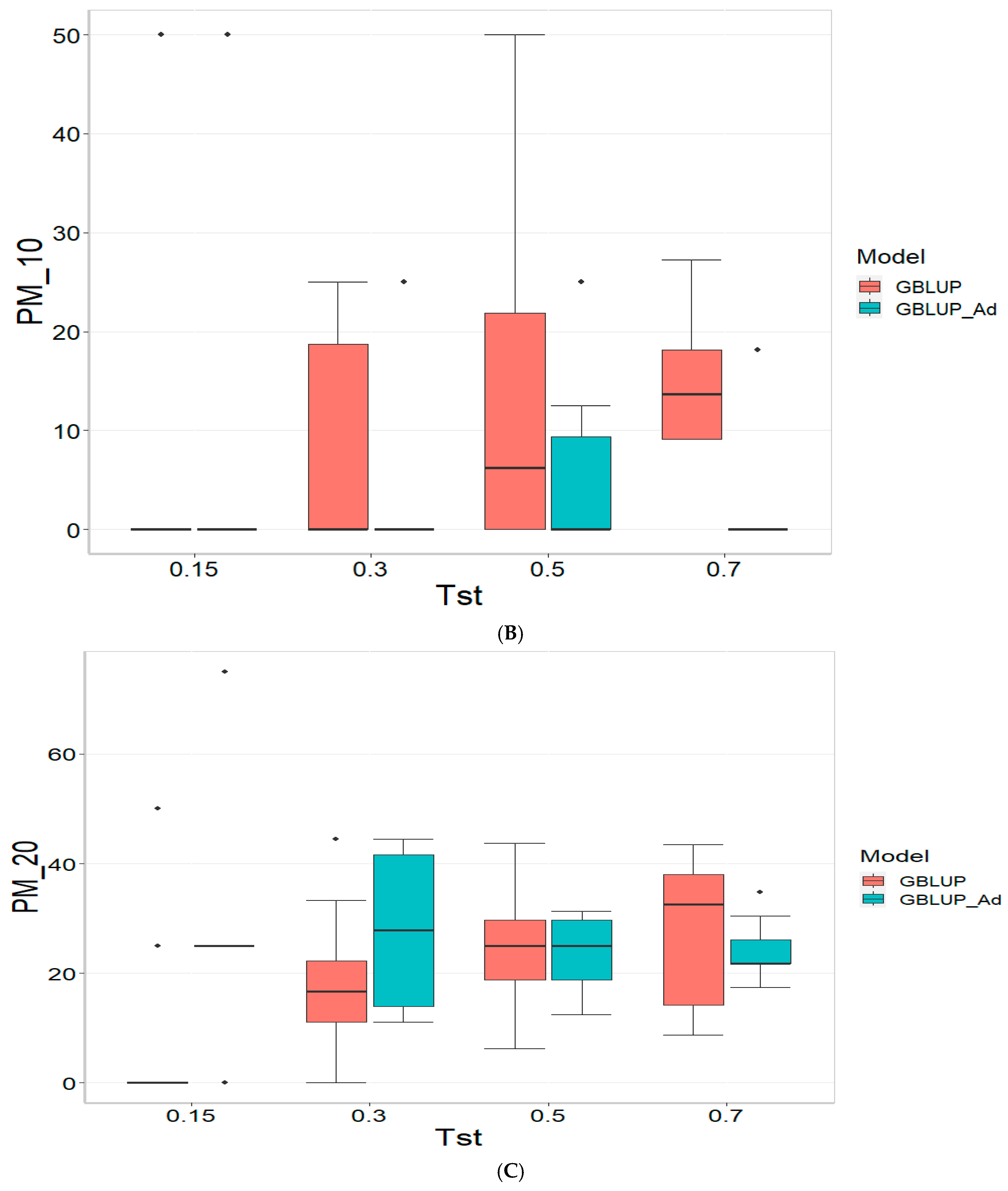
3.4. Across Data
For the COR (Correlation) metric and for TST = 0.15, GBLUP shows a mean value close to zero (−0.001) and a standard deviation of 0.243, indicating high variability in predictions. Additionally, the relative efficiency (RE) is extremely negative (−16,136.276), suggesting very poor performance compared to GBLUP_Ad. As Tst increases, GBLUP continues to show low or negative mean values and higher standard deviations, indicating inconsistent predictions. For instance, at TST = 0.70, GBLUP has a mean of −0.004 and a standard deviation of 0.186, with a negative RE of −3316.083.
In the PM_10 (Top 10% Prediction Accuracy) and PM_20 (Top 20% Prediction Accuracy) metrics, GBLUP also demonstrates lower performance compared to GBLUP_Ad. For example, at TST = 0.15, GBLUP has a mean of 7.500 in PM_10 and 14.167 in PM_20, with relatively high standard deviations, indicating variability in predictions. In comparison, GBLUP_Ad has higher means in both metrics. As Tst increases, GBLUP continues to show lower means and considerable standard deviations. At TST = 0.70, GBLUP has a mean of 10.909 in PM_10 and 20.995 in PM_20, with standard deviations that indicate significant dispersion in the results compared to means of 13.030 and 26.415 for GBLUP_Ad for PM_10 and PM_20, respectively.
4. Discussion
Predicting the performance of tested lines in new environments poses significant challenges in genomic prediction due to the complexity of genotype-by-environment (G × E) interactions [
13]. When moving to new environments, conditions such as climate, soil quality, and local agricultural practices may vary considerably, impacting the expression of genetic traits in ways that are often unpredictable from data in known environments [
5]. This variability in environmental factors can interact with the genetic composition of a line, complicating the extrapolation of performance predictions [
13].
Another major issue is the limited data on how different lines perform across diverse environments. Genomic prediction models rely on historical data, which often represents only a subset of possible conditions, limiting the models’ ability to generalize to new environments [
1]. Moreover, these models are usually calibrated with specific environmental trials, making them highly tailored to those conditions. As a result, predictions in new settings may fail to accurately capture relevant environmental interactions, leading to reduced prediction accuracy [
5,
14].
Addressing these limitations often requires collecting extensive multi-environment trial data or developing sophisticated models that can better capture and adjust for G × E interactions. These approaches, however, involve significant resource investments, underscoring the ongoing challenge of predicting performance in new environments for genomic selection and plant breeding programs [
14,
15].
Our results show that across datasets, the proposed strategy of enriching the training set with data from other environments significantly outperforms the approach of using only target environment data. Gains observed in Pearson’s correlation were notable across all tested proportions of the testing set. For instance, with a testing proportion of 15%, 30%, 50% and 70%, the observed Pearson’s correlation gains were at least of 189.00%, 219.23%, 328.125%, and 2950%, respectively. Similarly, improvements in PM_10 were observed, with gains of 100% (in 15% testing), 69.84% (in 30% testing), 18.42% (in 50% testing), and 19.44% (in 70% testing), while PM_20 gains reached 82.35%, 61.83%, 20.79%, and 25.82%, respectively. These findings underscore the importance of incorporating data from additional environments into the training set. However, it is worth noting that despite the substantial relative gains, the absolute prediction accuracies achieved in these environments were generally below 0.5 in terms of Pearson’s correlation. This suggests a limited relationship between the environments used for enrichment and the target environment, India. This observation aligns with the fact that the enrichment environments included data from Obregon, Mexico, as well as from India in a previous year, and in some cases, from both locations combined.
These results underscore the potential of enriching target environments with information from other environments. However, the gains achieved are not uniform, which can be attributed to the significant heterogeneity among the environments used for enrichment. Consequently, it is recommended to prioritize enrichment using environments that closely resemble the target environment. Nonetheless, this approach is not always practical, as the number of available environments for enrichment may be limited, and they may not closely align with the target environment. Despite these challenges, the findings are generally promising, as they demonstrate that enriching target environments with data from similar environments can effectively enhance prediction performance.
These challenges are well-documented in the literature [
14,
15], and they underscore the need for models that can more effectively account for non-additive G × E patterns or integrate environmental covariables directly into prediction frameworks. For example, Taïbi et al. (2015) [
16] demonstrated how phenotypic plasticity and local adaptation strongly influenced reforestation success in
Pinus halepensis, underlining the critical role of G × E interaction and environmental fit in predictive performance. Our findings highlight the practical reality faced by breeders: even when model improvement is observed, absolute prediction accuracy may remain modest due to underlying biological complexity and environmental divergence between training and testing sets.
Finally, these results further strengthen the empirical evidence supporting the effectiveness of the GS methodology in uni-environment settings. When genetic material is relatively homogeneous and management practices are well-standardized, GS demonstrates a remarkable ability to deliver accurate predictions. This is particularly advantageous in controlled breeding programs where minimizing environmental variability is crucial for isolating genetic effects. The consistency of GS in such settings not only enhances prediction reliability but also supports more efficient selection decisions, ultimately accelerating genetic gain. Furthermore, these findings highlight the importance of carefully managing experimental conditions and selecting environments with minimal heterogeneity to maximize the utility of GS in practical applications [
3,
17].
4.1. Contrasting Sparse Testing Methodologies and Results from This Study, Montesinos et al. (2024) [8], and Burgueno et al. (2012) [7]
4.1.1. Montesinos et al. (2024) [8]
This study explored genomic predictions under sparse conditions, employing both incomplete block design (IBD) and random allocation of genotypes to environments. Six GBLUP models were assessed, with one model (GBLUP_TRN) directly utilizing observed data without imputing missing values. The primary goal was to ascertain the benefits or disadvantages of pre-imputation versus the direct use of available genomic and phenotypic information. The practical advantages are no reliance on imputation, reduced computational complexity, and a realistic scenario for breeding programs with resource constraints.
4.1.2. This Research
In this study, the authors advanced the CV2 concept by assessing prediction strategies for tested genotypes in previously untested environments. The genomic prediction was implemented through two major approaches: training exclusively on the target environment data and training enriched by additional relevant environments, notably Obregon (Mexico) and historical Indian trials. Predictive accuracy was evaluated using correlations and the percentage of top-performing lines correctly identified (PM_10, PM_20), emphasizing practical implications in selection efficiency. Enhanced predictive accuracy through enriched training datasets and improved identification of high-performing genotypes in untested environments are some advantages, whereas disadvantages include dependency on the availability and relevance of external historical data and potential biases if external data differ significantly from target environments.
4.1.3. Burgueño et al. (2012) [7]
This foundational study served as a benchmark for evaluating various statistical models’ robustness and predictive capabilities under realistically masked data. Advantages are the robust framework for evaluating model performance under realistic breeding conditions and the comprehensive modeling of G × E interactions; however, the method requires extensive computational resources for factorial analysis model implementation and may be overly complex for small-scale or less-resourced breeding programs.
Collectively,
Table 2 shows that the results from [
7], this study, and [
6] underscore the critical role CV2 validation plays in realistically assessing genomic prediction models in plant breeding. Each study uniquely contributes to the methodological refinement and application of CV2 schemes, demonstrating different advantages: direct genomic prediction from sparse testing conditions [
7], leveraging enriched datasets to enhance accuracy in untested environments (this study), and comprehensive model comparison under structured masking conditions [
6].
Overall, the strategic use of CV2 validations, combined with methodological adaptations tailored to practical breeding scenarios and the integration of environmental covariables, highlights a powerful pathway toward more accurate and resource-efficient genomic selection in plant breeding programs.
4.2. Factors Limiting Prediction Accuracy Across Environments
Despite the consistent performance improvement of GBLUP_Ad over GBLUP, we observed that the overall Pearson’s correlation values remained below 0.5 in many cases. This is not unexpected in multi-environment genomic prediction involving sparse testing across heterogeneous environments. One major factor limiting predictive accuracy is the presence of strong genotype-by-environment (G × E) interactions, where the expression of genetic effects varies with environmental context. The contrasting environmental conditions and agronomic management practices between the Indian test sites and Obregon (Mexico) likely contribute to non-transferable genotype performance, especially for yield-related traits that are highly sensitive to local stresses. These challenges are well-documented in the literature [
13,
14]; for example, Taïbi et al. (2015) [
16] demonstrated how phenotypic plasticity and local adaptation strongly influenced reforestation success in
Pinus halepensis, underlining the critical role of G × E interaction and environmental fit in predictive performance. Our findings highlight the practical reality faced by breeders: even when model improvement is observed, absolute prediction accuracy may remain modest due to underlying biological complexity and environmental divergence between training and testing sets.
5. Conclusions
From our results, we conclude that utilizing data from diverse environments can significantly enhance prediction accuracy in new environments with sparse testing. By integrating information from multiple environmental contexts, genomic prediction models can capture a broader range of genotype-by-environment (G × E) interactions, thereby improving their ability to generalize to unfamiliar conditions. This approach allows models to more accurately estimate genetic responses under varying environmental pressures, increasing their robustness and reliability in settings with limited testing data. While challenges in data collection and model complexity remain, leveraging multi-environment data offers a promising strategy to overcome the limitations of sparse testing, facilitating better decision making in plant breeding and selection. However, even with improved prediction accuracy through data from diverse environments, the overall accuracy remains relatively low. This limitation arises because G × E interactions are highly complex and often specific to environmental conditions, which are challenging to fully capture and generalize. While multi-environmental data enrich the model, they cannot account for all potential environmental variables or their interactions with genotypes in every new setting. Thus, despite gains from this approach, prediction accuracies in new environments remain constrained by the inherent variability and unpredictable nature of G × E interactions, underscoring the need for continuous model refinement and advanced strategies to enhance prediction reliability in plant breeding.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}