
The Classification of Medicinal Plant Leaves Based on Multispectral and Texture Feature Using Machine Learning Approach

 ,
,  ,
,  ,
,  ,
,  ,
, 
Abstract
1. Introduction
Contribution
- Collect multi-spectral and digital image dataset via computer vision laboratory setup.
- Crop exactly leaf region, and transform into the gray level format with (800 × 800) resolution.
- Employ seeds intensity-based edge/line detection utilizing Sobel filter.
- Draw 5 regions of observation on each image and extract fused features from the dataset.
- Optimize fused features dataset using chi-square feature selection approach.
- Apply machine learning based classifiers for observing medicinal plant leaves classification.
2. Materials and Methods
2.1. Proposed Methodology
2.2. Fused Features Extraction
2.2.1. Texture Feature
2.2.2. Spectral Features
2.2.3. Gray Level Run-Length Matrix (GLRLM)
2.3. Feature Selection
2.4. Classification
3. Results and Discussion
4. Conclusions
Limitation and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nawkar, M.G.; Maibam, P.; Park, J.H.; Sahi, V.P.; Lee, S.Y.; Kang, C.H. UV-induced cell death in plants. Int. J. Mol. Sci. 2013, 14, 1608–1628. [Google Scholar] [CrossRef] [PubMed]
- Salehi, B.; Kumar, N.V.; Şener, B.; Sharifi-Rad, M.; Kılıç, M.; Mahady, G.B.; Vlaisavljevic, S.; Iriti, M.; Kobarfard, F.; Setzer, W.N.; et al. Medicinal plants used in the treatment of human immunodeficiency virus. Int. J. Mol. Sci. 2018, 19, 1459. [Google Scholar] [CrossRef] [PubMed]
- Nelly, A.; Annick, D.D.; Frederic, D. Plants used as remedies antirheumatic and antineuralgic in the traditional medicine of Lebanon. J. Ethnopharmacol. 2008, 120, 315–334. [Google Scholar]
- Raskin, I.; Ribnicky, D.M.; Komarnytsky, S.; Ilic, N.; Poulev, A.; Borisjuk, N.; Brinker, A.; Moreno, D.A.; Ripoll, C.; Yakoby, N.; et al. Plants and human health in the twenty-first century. Trends Biotechnol. 2002, 20, 522–531. [Google Scholar] [CrossRef]
- Leonti, M. The future is written: Impact of scripts on the cognition, selection, knowledge and transmission of medicinal plant use and its implications for ethnobotany and ethnopharmacology. J. Ethnopharmacol. 2011, 134, 542–555. [Google Scholar] [CrossRef]
- Mamedov, N. Medicinal plants studies: History, challenges and prospective. Med. Aromat. Plants 2012, 1, e133. [Google Scholar] [CrossRef]
- Amenu, E. Use and Management of Medicinal Plants by Indigenous People of Ejaji Area (Chelya Woreda) West Shoa, Ethiopia: An Ethnobotanical Approach. Master’s Thesis, University in Addis, Ababa, Ethiopia, 2007. [Google Scholar]
- Hu, R.; Lin, C.; Xu, W.; Liu, Y.; Long, C. Ethnobotanical study on medicinal plants used by Mulam people in Guangxi, China. J. Ethnobiol. Ethnomed. 2020, 16, 1–50. [Google Scholar] [CrossRef]
- Pferschy-Wenzig, E.M.; Bauer, R. The relevance of pharmacognosy in pharmacological research on herbal medicinal products. Epilepsy Behav. 2015, 52, 344–362. [Google Scholar] [CrossRef]
- Oppong, P.K. The Influence of Packaging and Brand Equity on Over-the-Counter Herbal Medicines in Kumasi, Ghana. Ph.D. Thesis, University of KwaZulu-Natal, Durban, South African, 2018. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, X. Classification and quality evaluation of tobacco leaves based on image processing and fuzzy comprehensive evaluation. Sensors 2011, 11, 2369–2384. [Google Scholar] [CrossRef]
- Rahmatullah, M.; Azam, M.N.; Rahman, M.M.; Seraj, S.; Mahal, M.J.; Mou, S.M.; Nasrin, D.; Khatun, Z.; Islam, F.; Chowdhury, M.H. Chowdhury. A survey of medicinal plants used by Garo and non-Garo traditional medicinal practitioners in two villages of Tangail district, Bangladesh. Am. Eurasian J. Sustain. Agric. 2011, 5, 350–357. [Google Scholar]
- Dahigaonkar, T.D.; Kalyane, R. Identification of ayurvedic medicinal plants by image processing of leaf samples. Int. Res. J. Eng. Technol. (Irjet) 2018, 5, 351–355. [Google Scholar]
- Sabarinathan, C.; Hota, A.; Raj, A.; Dubey, V.K.; Ethirajulu, V. Medicinal plant leaf recognition and show medicinal uses using convolutional neural network. Int. J. Glob. Eng. 2018, 1, 120–127. [Google Scholar]
- Khirade, S.D.; Patil, A.B. Plant disease detection using image processing. In Proceedings of the 2015 International Conference on Computing Communication Control and Automation, Pune, India, 26–27 February 2015; pp. 768–771. [Google Scholar]
- Wallelign, S.; Polceanu, M.; Buche, C. Soybean plant disease identification using convolutional neural network. In Proceedings of the Thirty-First International Flairs Conference, Melbourne, FL, USA, 10 May 2018. [Google Scholar]
- Simion, I.M.; Casoni, D.; Sârbu, C. Classification of Romanian medicinal plant extracts according to the therapeutic effects using thin layer chromatography and robust chemometrics. J. Pharm. Biomed. Anal. 2019, 163, 137–143. [Google Scholar] [CrossRef] [PubMed]
- Dhingra, G.; Kumar, V.; Joshi, H.D. A novel computer vision based neutrosophic approach for leaf disease identification and classification. Measurement 2019, 135, 782–794. [Google Scholar] [CrossRef]
- Turkoglu, M.; Hanbay, D. Leaf-based plant species recognition based on improved local binary pattern and extreme learning machine. Phys. A Stat. Mech. Appl. 2019, 527, 121297. [Google Scholar] [CrossRef]
- Qadri, S.; Furqan Qadri, S.; Husnain, M.; Saad Missen, M.M.; Khan, D.M.; Muzammil-Ul-Rehman Razzaq, A.; Ullah, S. Machine vision approach for classification of citrus leaves using fused features. Int. J. Food Prop. 2019, 22, 2072–2089. [Google Scholar] [CrossRef]
- The Islamia University of Bahawalpur, Pakistan. 2020. Available online: https://www.iub.edu.pk/faculty-of-agriculture-and-environmental-sciences?1=1forAgriculturalfarms (accessed on 1 October 2020).
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O’Reilly Media, Inc.: Newton, MA, USA, 2008. [Google Scholar]
- Galloway, M. Texture analysis using gray level run lengths. Comput. Graph. Image Process 1975, 4, 172–179. [Google Scholar] [CrossRef]
- Naeem, S.; Ali, A.; Qadri, S.; Mashwani, W.K.; Tairan, N.; Shah, H.; Fayaz, M.; Jamal, F.; Chesneau, C.; Anam, S. Machine-Learning Based Hybrid-Feature Analysis for Liver Cancer Classification Using Fused (MR and CT) Images. Appl. Sci. 2020, 10, 3134. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. ManCybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Bantan, R.A.; Ali, A.; Naeem, S.; Jamal, F.; Elgarhy, M.; Chesneau, C. Discrimination of sunflower seeds using multispectral and texture dataset in combination with region selection and supervised classification methods. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 113142. [Google Scholar] [CrossRef]
- Ali, A.; Qadri, S.; Khan Mashwani, W.; Kumam, W.; Kumam, P.; Naeem, S.; Goktas, A.; Jamal, F.; Chesneau, C.; Anam, S.; et al. Machine Learning Based Automated Segmentation and Hybrid Feature Analysis for Diabetic Retinopathy Classification Using Fundus Image. Entropy 2020, 22, 567. [Google Scholar] [CrossRef] [PubMed]
- Abbas, Z.; Rehman, M.; Najam, S.; Rizvi, S.M.D. An e_cient gray-level co-occurrence matrix (GLCM) based approach towards classification of skin lesion. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, UAE, 4–6 February 2019; pp. 317–320. [Google Scholar]
- Ali, A.; Mashwani, W.K.; Tahir, M.H.; Belhaouari, S.B.; Alrabaiah, H.; Naeem, S.; Nasir, J.A.; Jamal, F.; Chesneau, C. Statistical features analysis and discrimination of maize seeds utilizing machine vision approach. J. Intell. Fuzzy Syst. 2021, 40, 703–714. [Google Scholar] [CrossRef]
- Behura, A. The Cluster Analysis and Feature Selection: Perspective of Machine Learning and Image Processing. Data Anal. Bioinf. A Mach. Learn. Perspect. 2021, 249–280. [Google Scholar] [CrossRef]
- Cardinali, F.; Bracciale, M.P.; Santarelli, M.L.; Marrocchi, A. Principal Component Analysis (PCA) Combined with Naturally Occurring Crystallization Inhibitors: An Integrated Strategy for a more Sustainable Control of Salt Decay in Built Heritage. Heritage 2021, 4, 13. [Google Scholar] [CrossRef]
- Ali, A.; Qadri, S.; Mashwani, W.K.; Brahim Belhaouari, S.; Naeem, S.; Rafique, S.; Jamal, F.; Chesneau, C.; Anam, S. Machine learning approach for the classification of corn seed using hybrid features. Int. J. Food Prop. 2020, 23, 1110–1124. [Google Scholar] [CrossRef]
- Gnanambal, S.; Thangaraj, M.; Meenatchi, V.T.; Gayathri, V. Classification algorithms with attribute selection: An evaluation study using weka. Int. J. Adv. Netw. Appl. 2018, 9, 3640–3644. [Google Scholar]
- McHugh, M.L. The chi-square test of independence. Biochem. Med. 2013, 23, 143–149. [Google Scholar] [CrossRef]
- Ali, A.; Nasir, J.A.; Ahmed, M.M.; Naeem, S.; Anam, S.; Jamal, F.; Chesneau, C.; Zubair, M.; Anees, M.S. Machine Learning Based Statistical Analysis of Emotion Recognition using Facial Expression. RADS J. Biol. Res. Appl. Sci. 2020, 11, 39–46. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
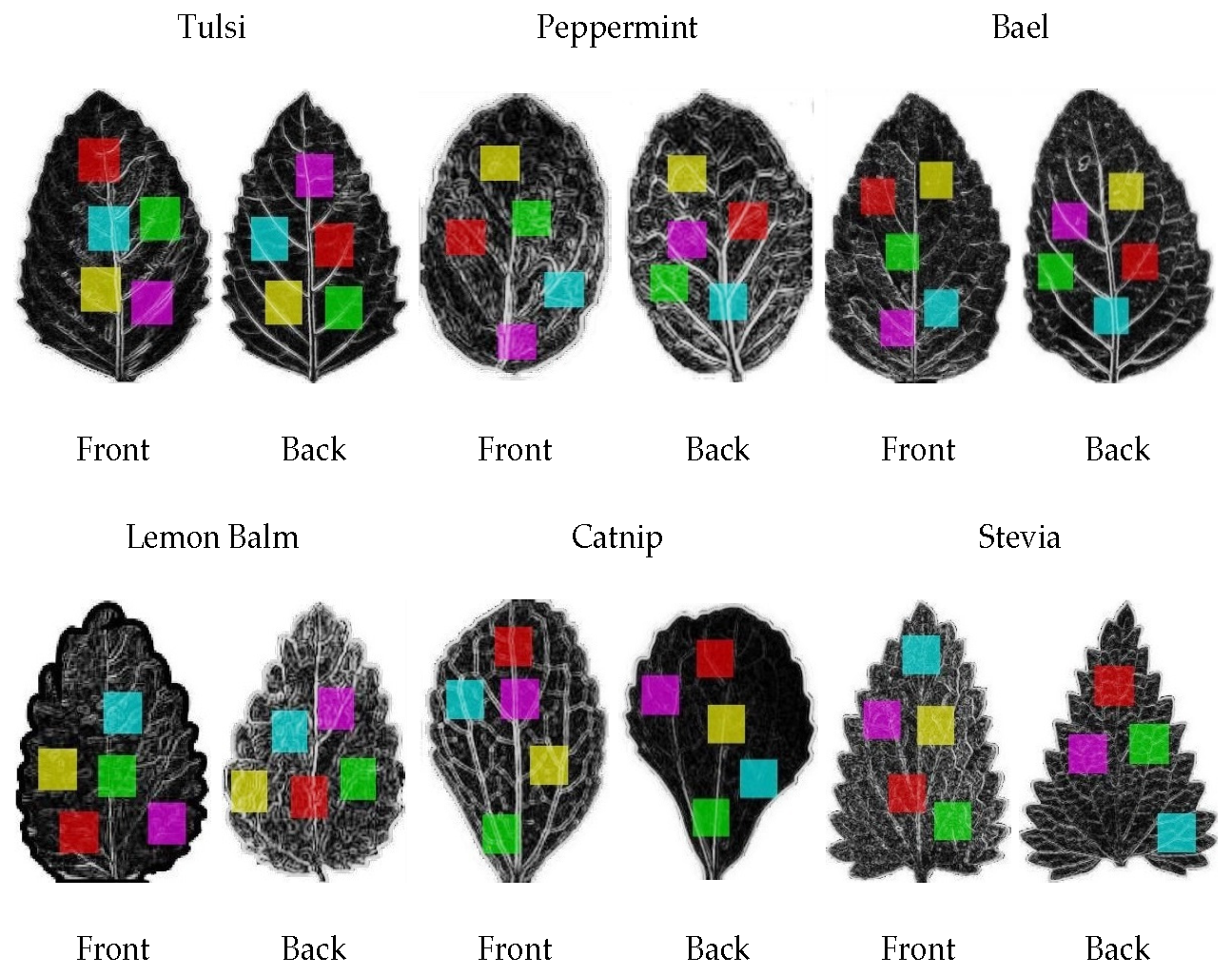{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr. No. | Features | Sr. No. | Features |
|---|---|---|---|
| 1 | Texture Energy Average | 8 | Skewness |
| 2 | Correlation Range | 9 | 135dgr_RLNonUni |
| 3 | Inverse Diff Range | 10 | R |
| 4 | Texture Entropy Range | 11 | G |
| 5 | 45dgr_GLevNonU | 12 | B |
| 6 | Vertl_GLevNonU | 13 | NIR |
| 7 | S (5, 5) Entropy | 14 | SWIR |
| Parameter | Value |
|---|---|
| Input Layers | 1 |
| Hidden Layers | 14 |
| Neurons | 18 |
| Learning Rate | 0.4 |
| Momentum | 0.5 |
| Validation Threshold | 18 |
| Epochs | 500 |
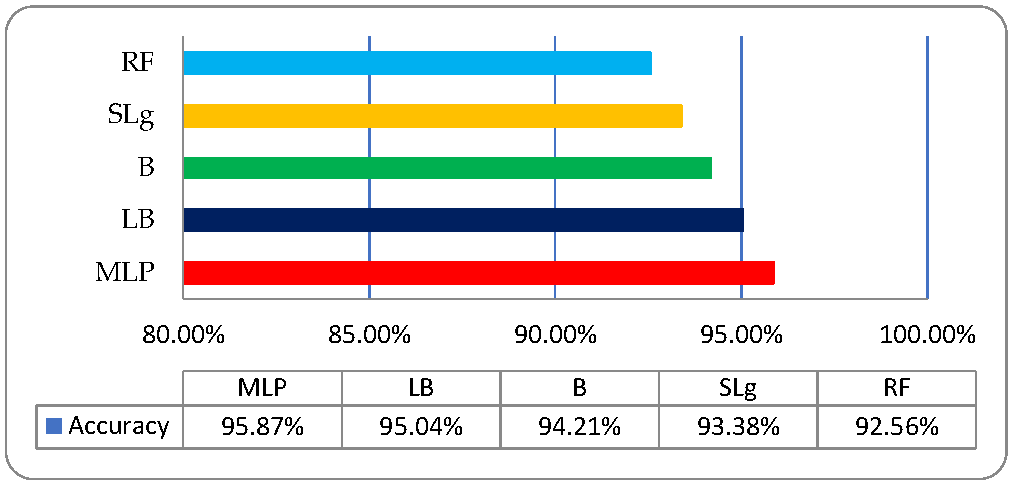
| Classifiers | Kappa Statistics | TP Rate | FP Rate | Recall | F-Measure | ROC | Time (Sec) | Precision |
|---|---|---|---|---|---|---|---|---|
| MLP | 0.9504 | 0.959 | 0.008 | 0.959 | 0.958 | 0.999 | 0.19 | 0.961 |
| LB | 0.9405 | 0.950 | 0.010 | 0.950 | 0.950 | 0.989 | 0.11 | 0.951 |
| B | 0.9306 | 0.942 | 0.012 | 0.942 | 0.941 | 0.991 | 0.3 | 0.944 |
| SLg | 0.9207 | 0.934 | 0.013 | 0.934 | 0.934 | 0.960 | 0.10 | 0.935 |
| RF | 0.9107 | 0.926 | 0.015 | 0.926 | 0.926 | 0.955 | 0.7 | 0.927 |
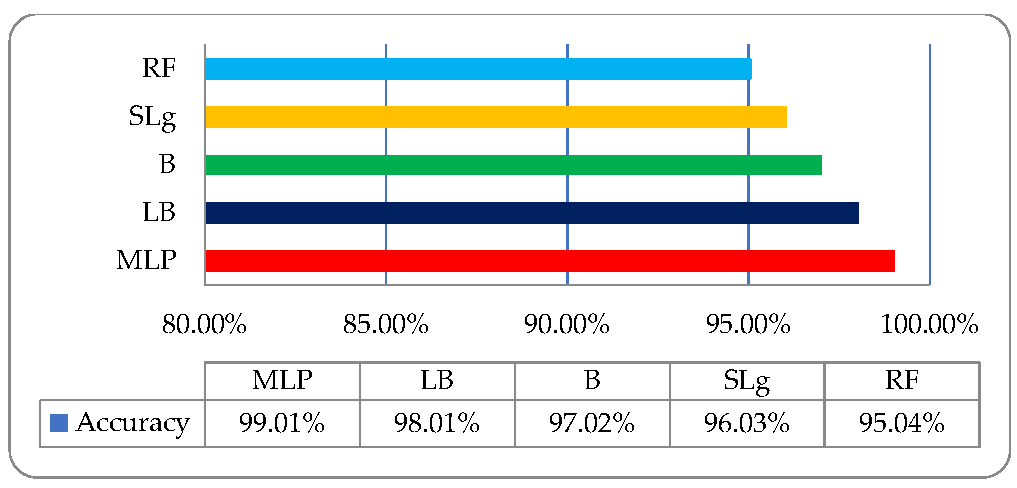
| Classifiers | Kappa Statistics | TP Rate | FP Rate | Recall | F-Measure | ROC | Time (Sec) | Precision |
|---|---|---|---|---|---|---|---|---|
| MLP | 0.9876 | 0.990 | 0.002 | 0.990 | 0.990 | 0.998 | 0.13 | 0.991 |
| LogitBoost | 0.9752 | 0.980 | 0.005 | 0.980 | 0.981 | 0.999 | 0.19 | 0.981 |
| Bagging | 0.9629 | 0.970 | 0.007 | 0.970 | 0.971 | 0.995 | 0.11 | 0.974 |
| SLg | 0.9506 | 0.960 | 0.007 | 0.960 | 0.965 | 0.984 | 0.13 | 0.970 |
| RF | 0.9381 | 0.950 | 0.013 | 0.950 | 0.951 | 0.985 | 0.9 | 0.956 |
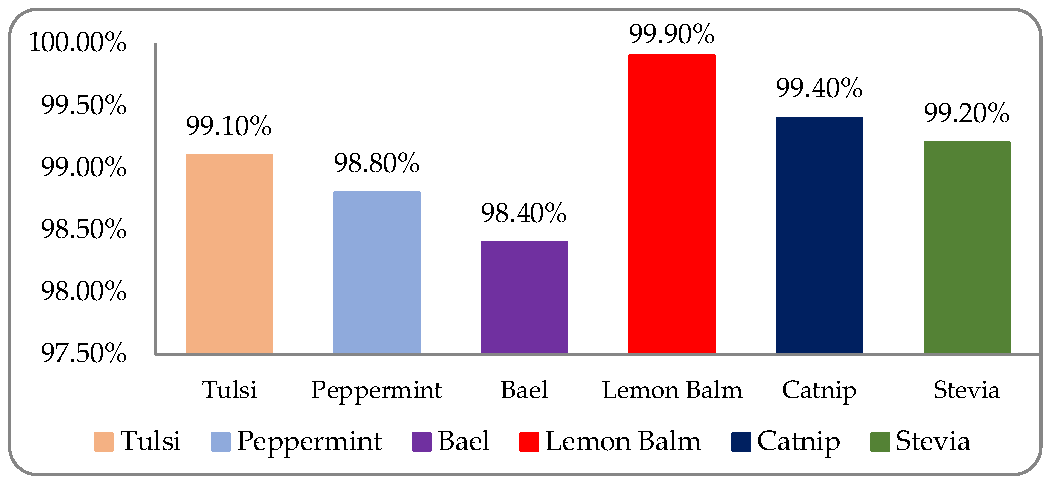
| Classes | Tulsi | Peppermint | Bael | Lemon Balm | Catnip | Stevia | Total | Accuracy |
|---|---|---|---|---|---|---|---|---|
| Tulsi | 991 | 1 | 2 | 0 | 6 | 0 | 1000 | 99.1% |
| Peppermint | 0 | 988 | 0 | 2 | 5 | 5 | 1000 | 98.8% |
| Bael | 4 | 6 | 984 | 0 | 3 | 3 | 1000 | 98.4% |
| Lemon Balm | 0 | 1 | 0 | 999 | 0 | 0 | 1000 | 99.9% |
| Catnip | 0 | 4 | 0 | 0 | 994 | 2 | 1000 | 99.4% |
| Stevia | 3 | 0 | 2 | 3 | 0 | 992 | 1000 | 99.2% |
| Reference | Features | Classifiers | Accuracy |
|---|---|---|---|
| [13] | Shape and Color Features | SVM | 96.66% |
| [14] | Texture Features | CNN | 97.80% |
| [16] | Morphological Features | CNN, LeNet | 98.32% |
| [17] | Texture Features | PCA, LDA | 92.90% |
| [18] | Fused Features | RF | 98.40% |
| [19] | Texture Features | LBP | 93.50% |
| [20] | Multi Features | MLP | 98.14% |
| Proposed Methodology | Multi Spectral + Texture Features | MLP | 99.01% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naeem, S.; Ali, A.; Chesneau, C.; Tahir, M.H.; Jamal, F.; Sherwani, R.A.K.; Ul Hassan, M. The Classification of Medicinal Plant Leaves Based on Multispectral and Texture Feature Using Machine Learning Approach. Agronomy 2021, 11, 263. https://doi.org/10.3390/agronomy11020263
Naeem S, Ali A, Chesneau C, Tahir MH, Jamal F, Sherwani RAK, Ul Hassan M. The Classification of Medicinal Plant Leaves Based on Multispectral and Texture Feature Using Machine Learning Approach. Agronomy. 2021; 11(2):263. https://doi.org/10.3390/agronomy11020263
Chicago/Turabian StyleNaeem, Samreen, Aqib Ali, Christophe Chesneau, Muhammad H. Tahir, Farrukh Jamal, Rehan Ahmad Khan Sherwani, and Mahmood Ul Hassan. 2021. "The Classification of Medicinal Plant Leaves Based on Multispectral and Texture Feature Using Machine Learning Approach" Agronomy 11, no. 2: 263. https://doi.org/10.3390/agronomy11020263
APA StyleNaeem, S., Ali, A., Chesneau, C., Tahir, M. H., Jamal, F., Sherwani, R. A. K., & Ul Hassan, M. (2021). The Classification of Medicinal Plant Leaves Based on Multispectral and Texture Feature Using Machine Learning Approach. Agronomy, 11(2), 263. https://doi.org/10.3390/agronomy11020263