
A Physics-Guided Machine Learning Model for Predicting Viscoelasticity of Solids at Large Deformation

Abstract
1. Introduction
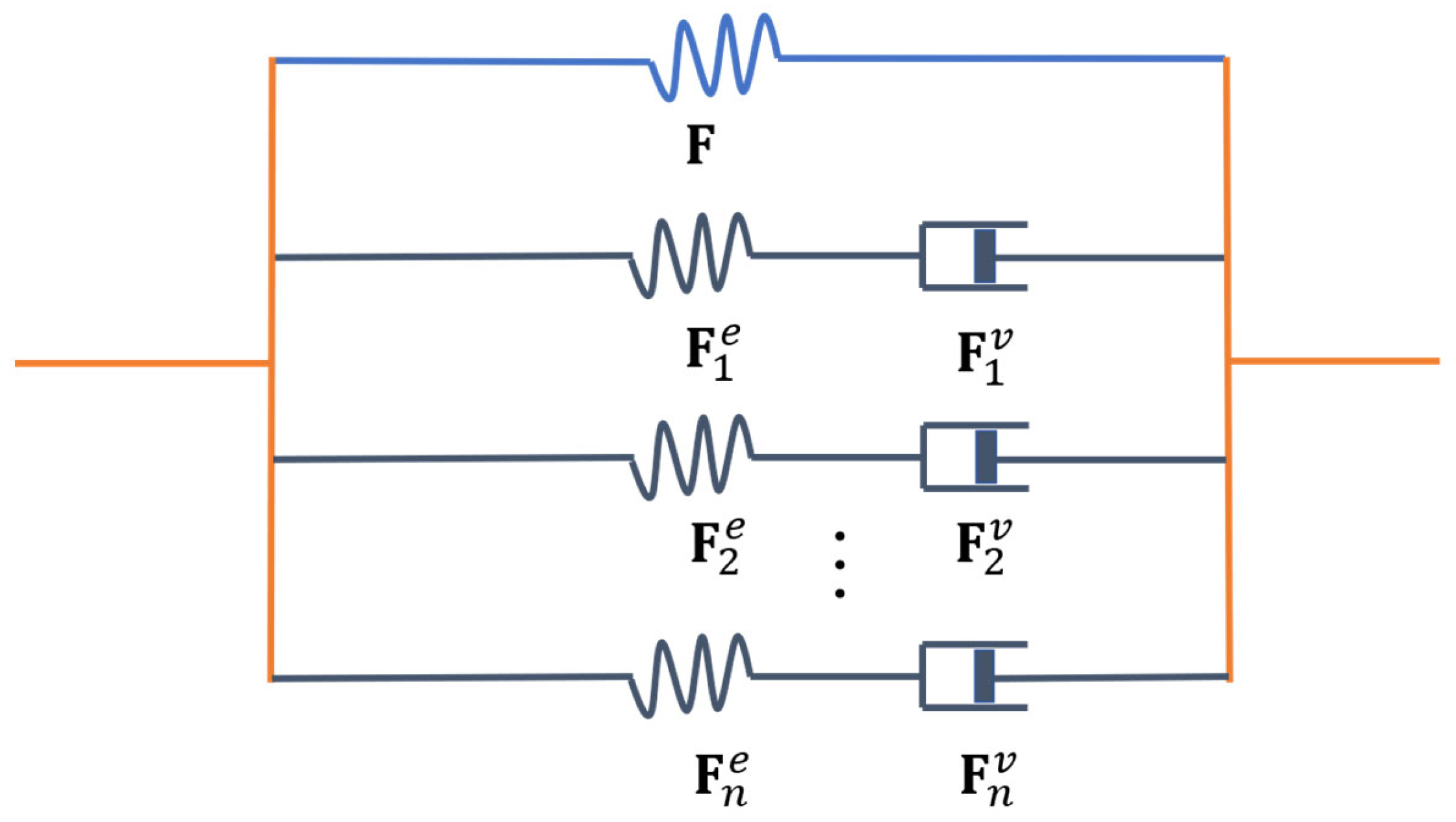
2. Thermodynamic Formulation of Constitutive Laws for Viscoelastic Solids at Large Deformation
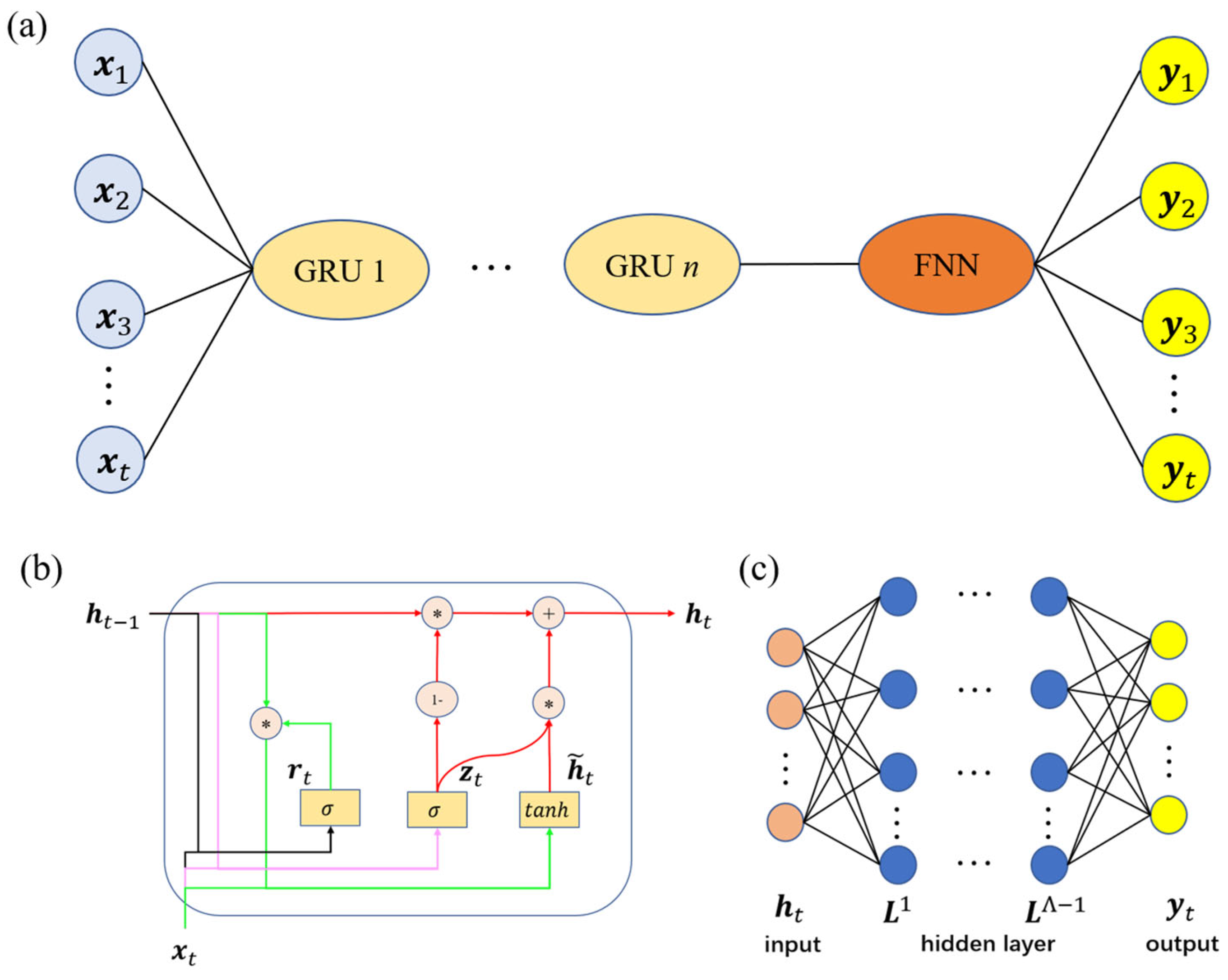
3. Machine Learning Method for Predicting Viscoelasticity
3.1. Gated Recurrent Unit
3.2. Feedforward Neural Network
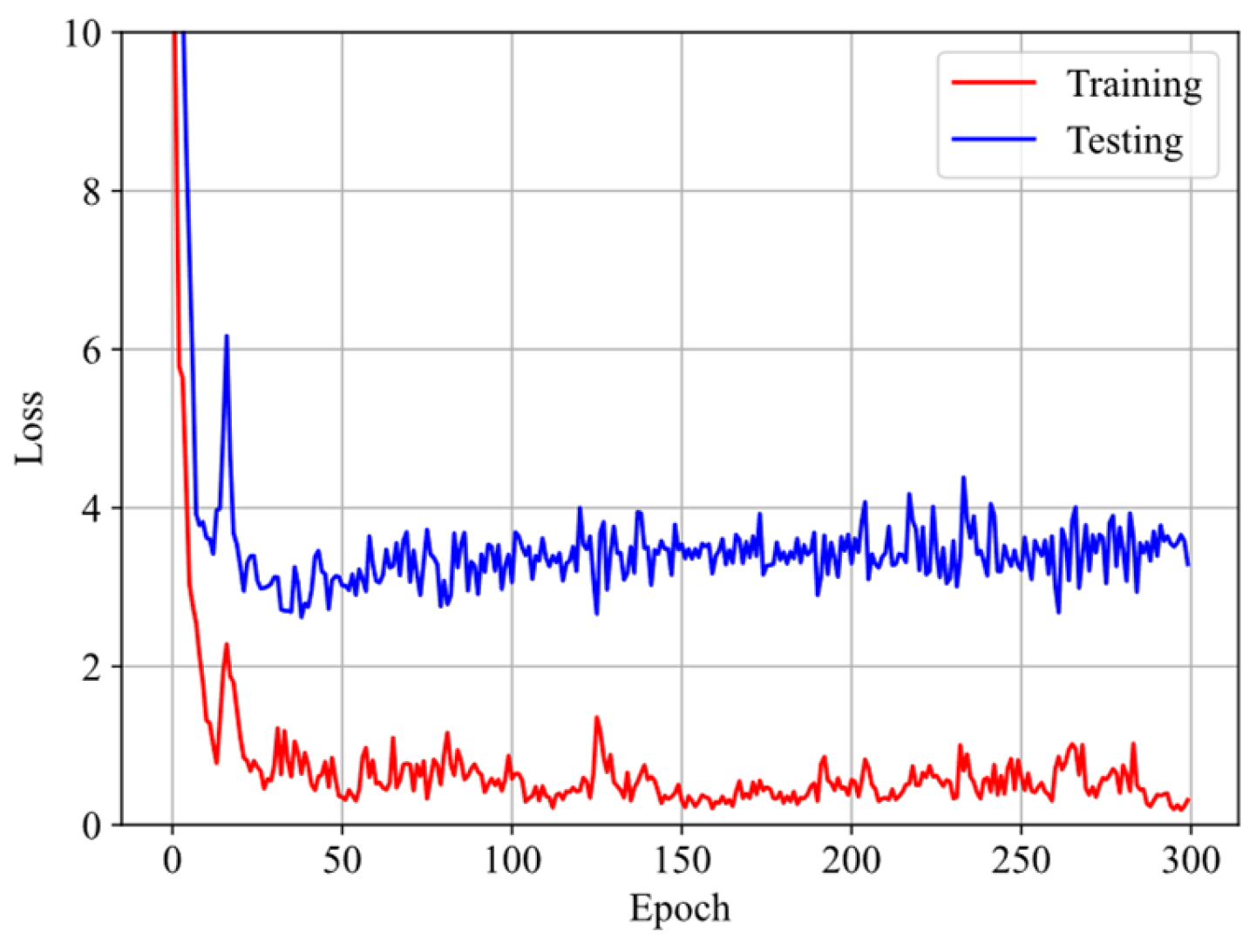
3.3. Training Procedure
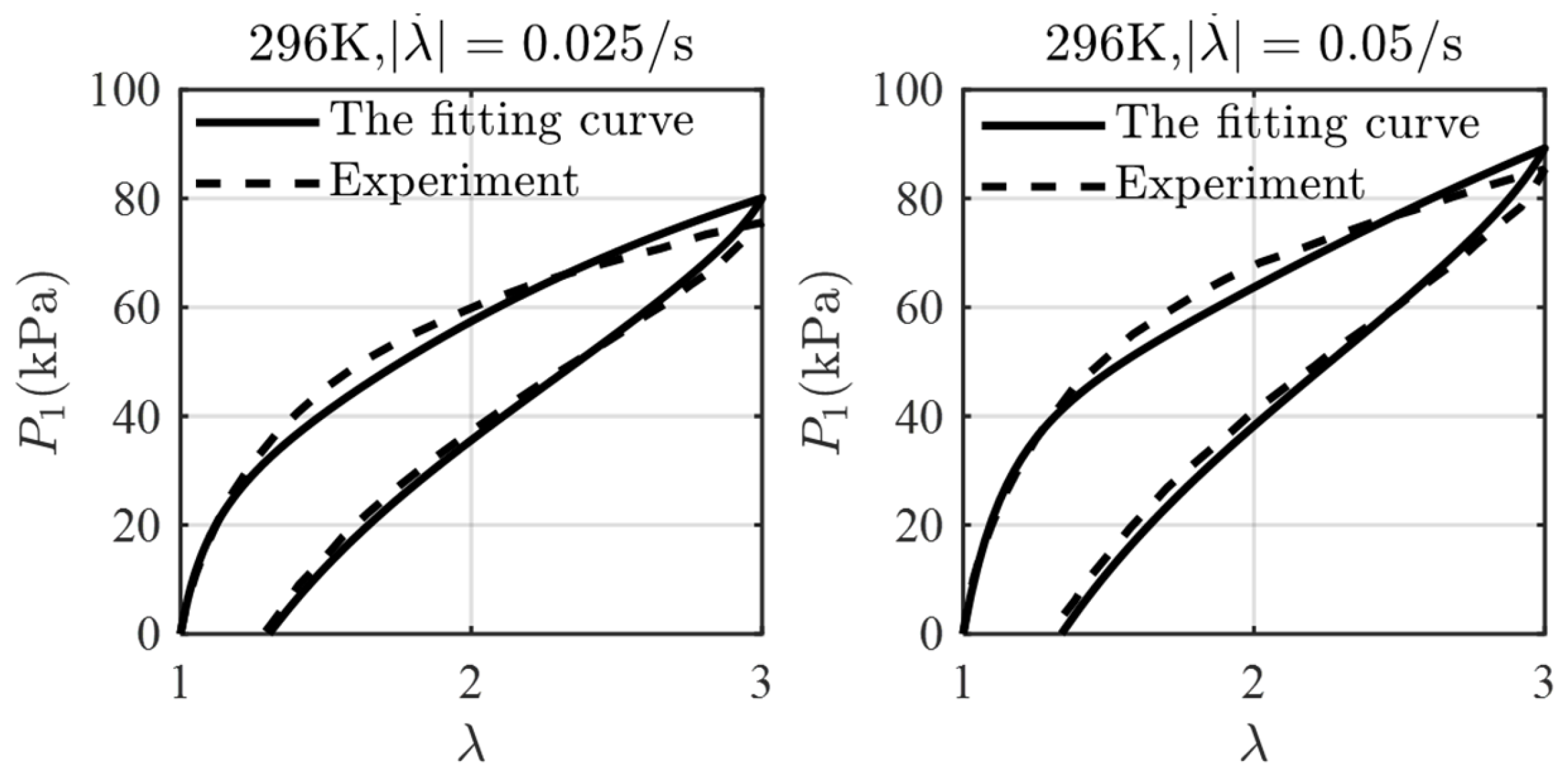
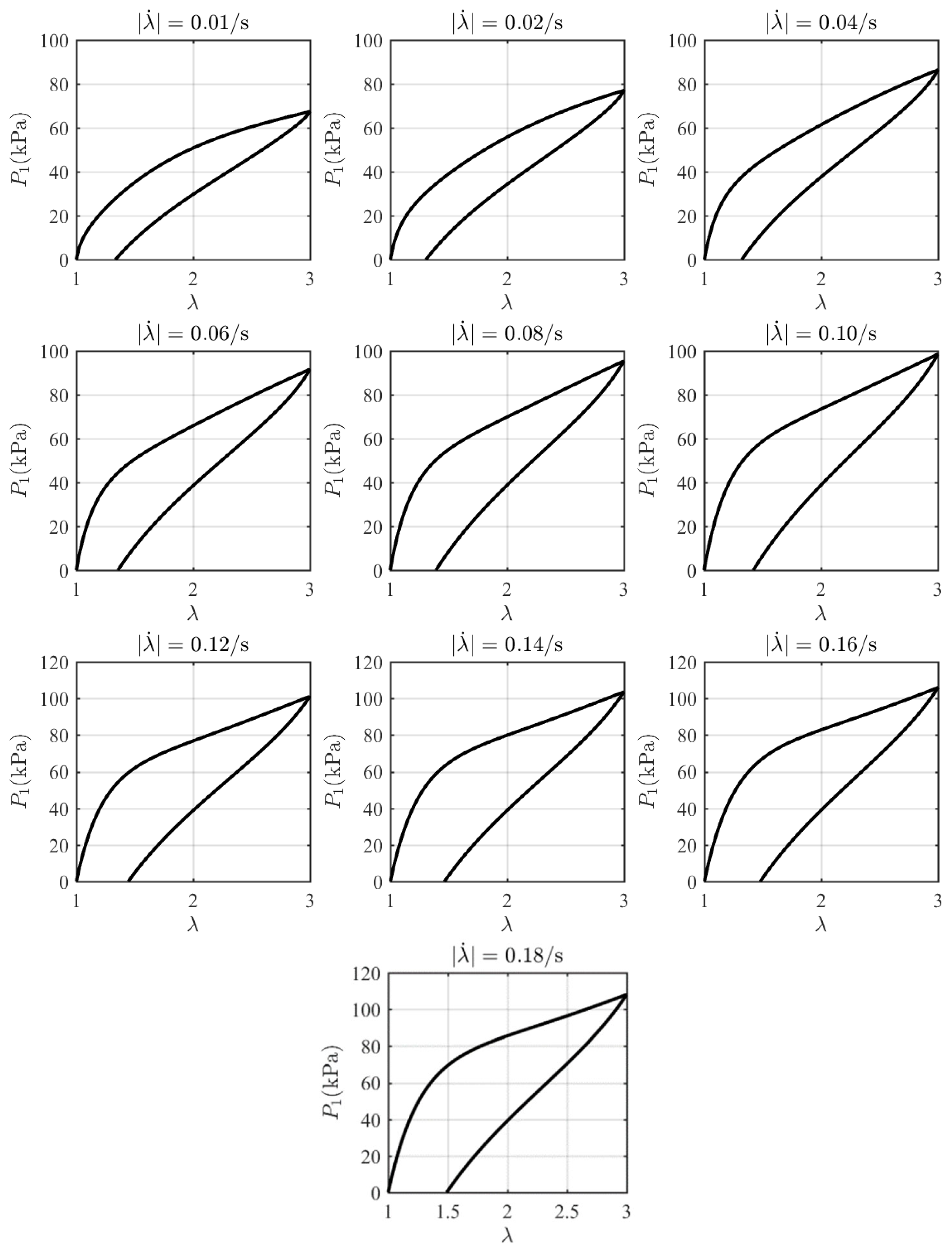
4. Results and Discussions
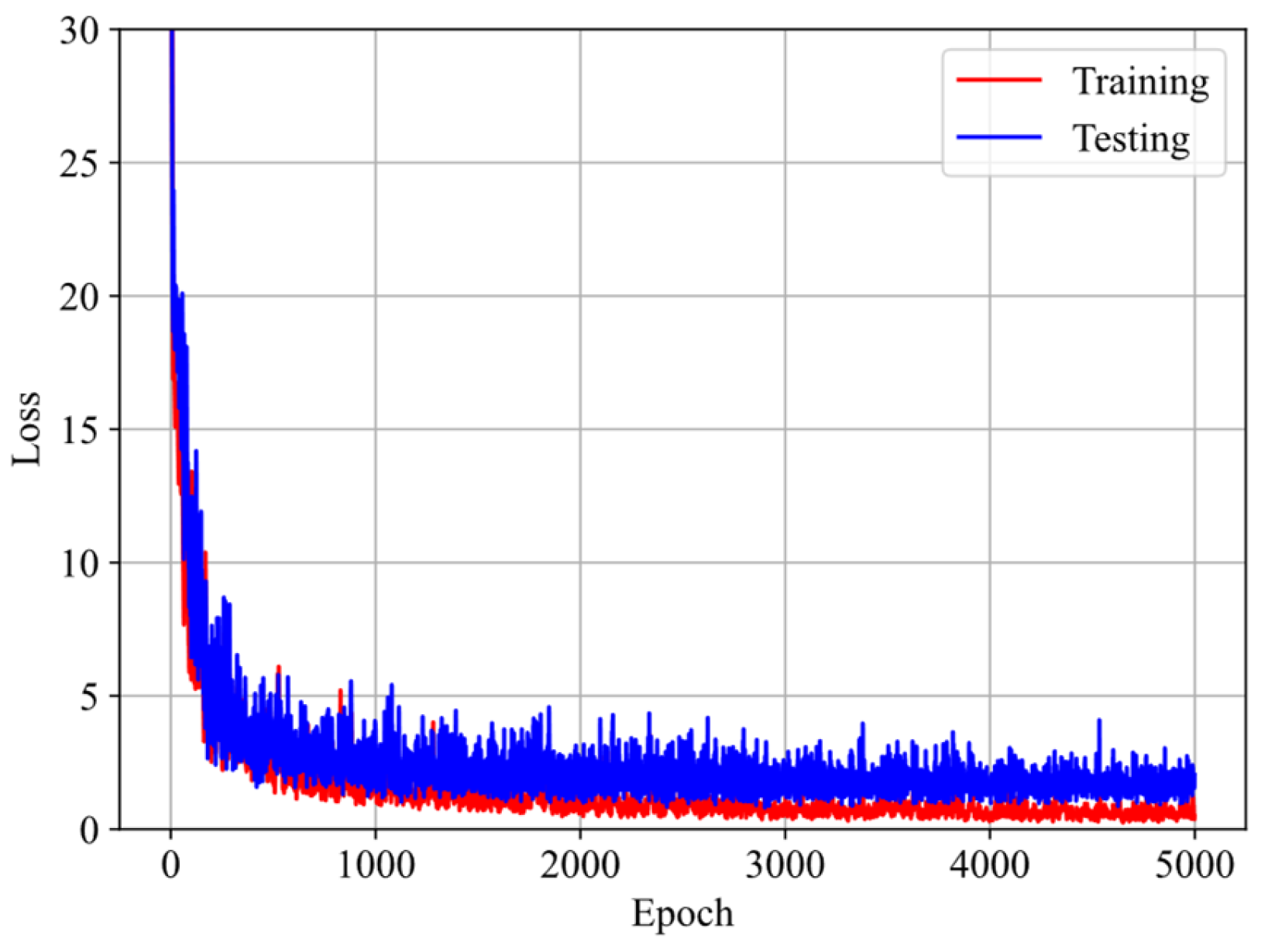
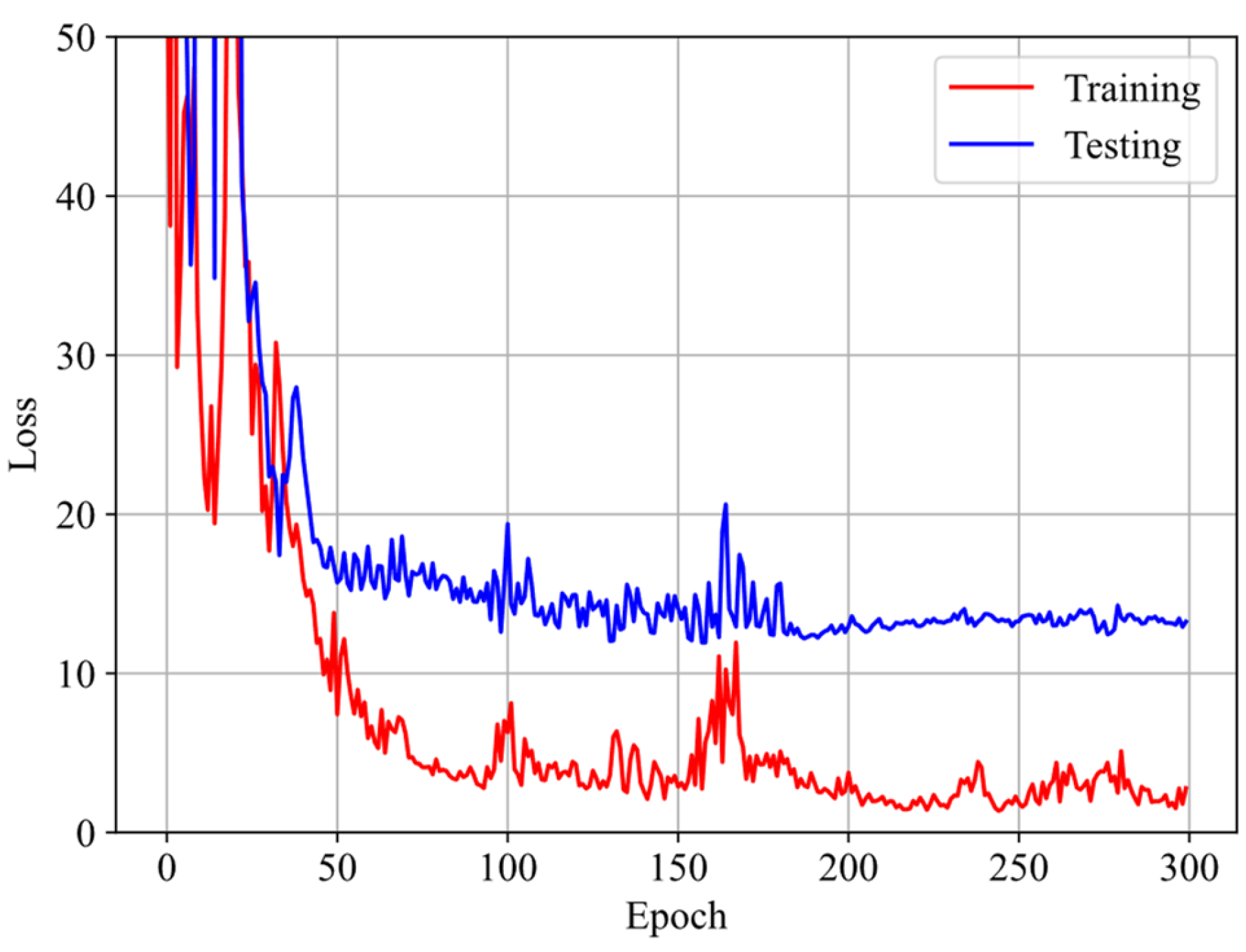
4.1. Initialization of GRU-FNN Parameters by Training Theoretical Data
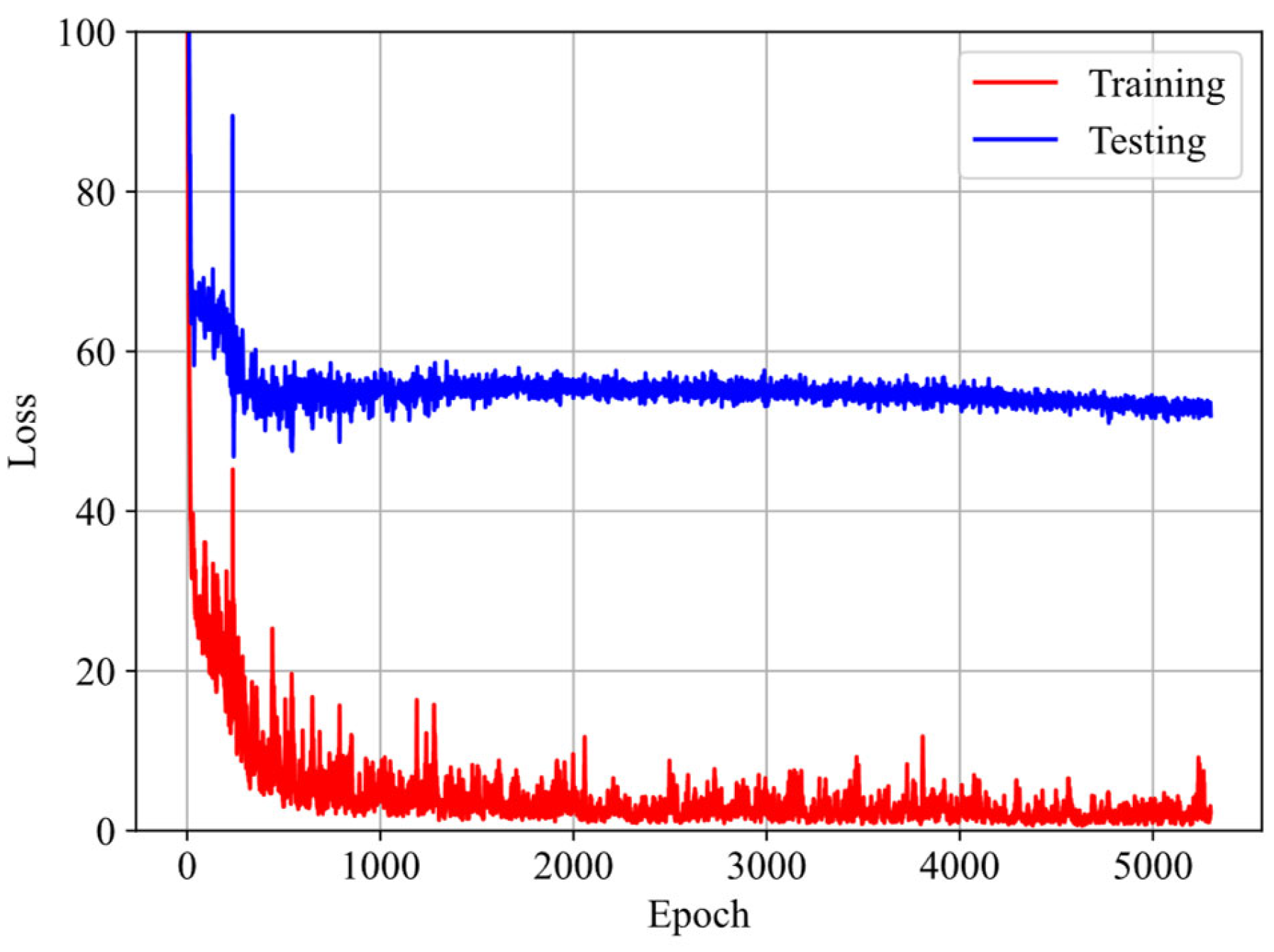
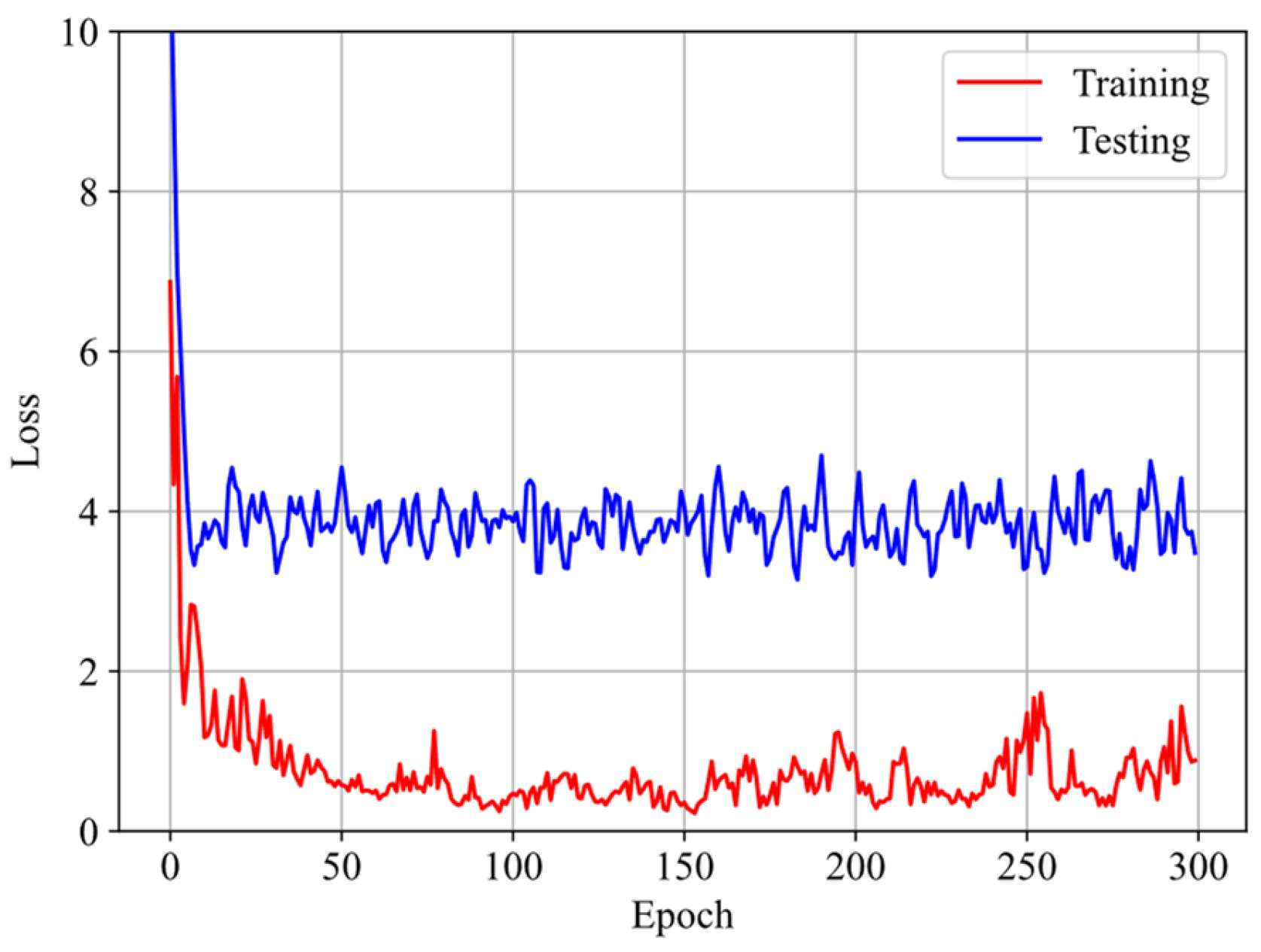
4.2. Initialization of GRU–FNN Parameters by Training Theoretical Data of Viscoelasticity of VHB4905 with Scarce Data from Experiments

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cases | Stretching Rates (/s) | RMSE Values (kPa) |
|---|---|---|
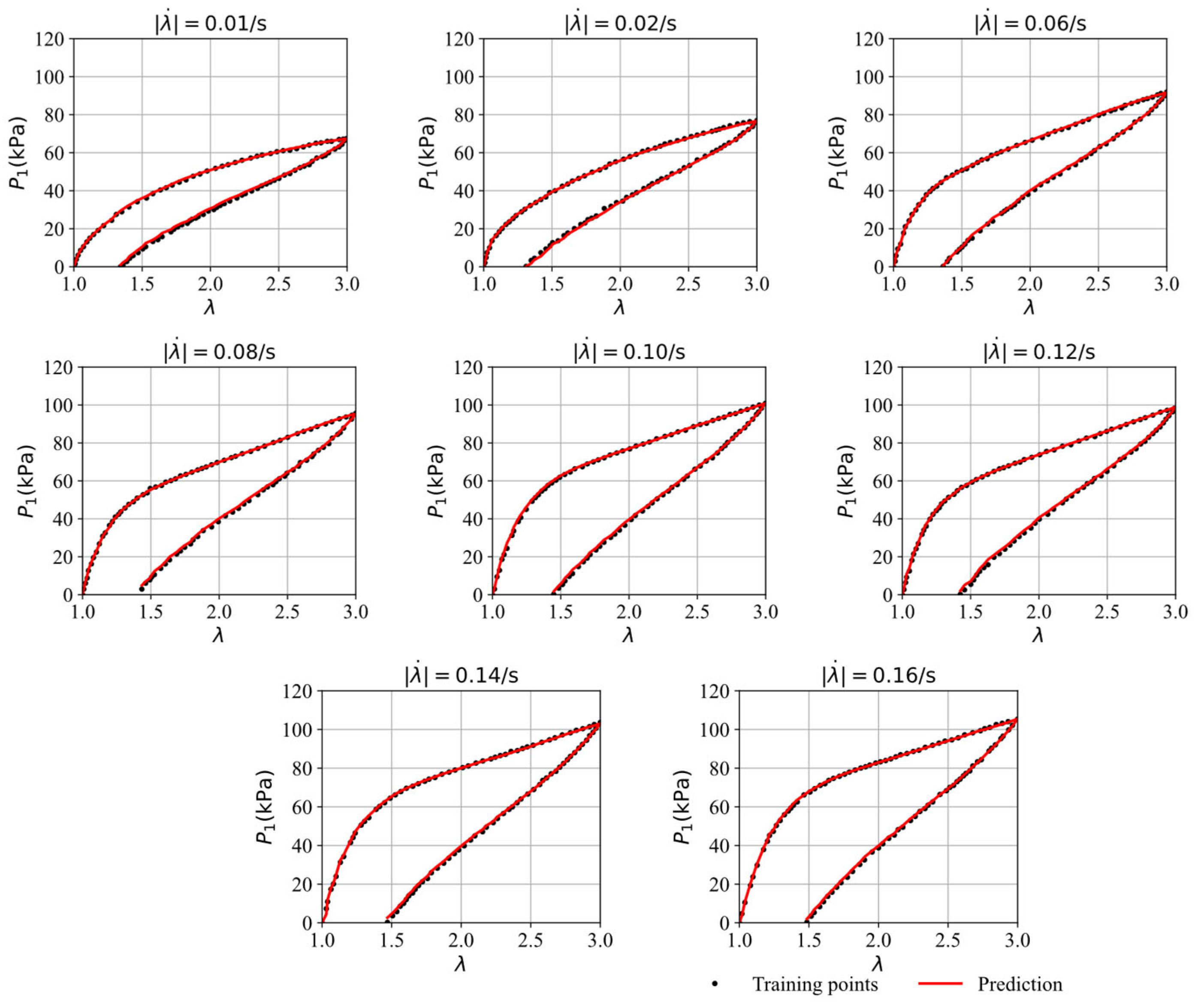
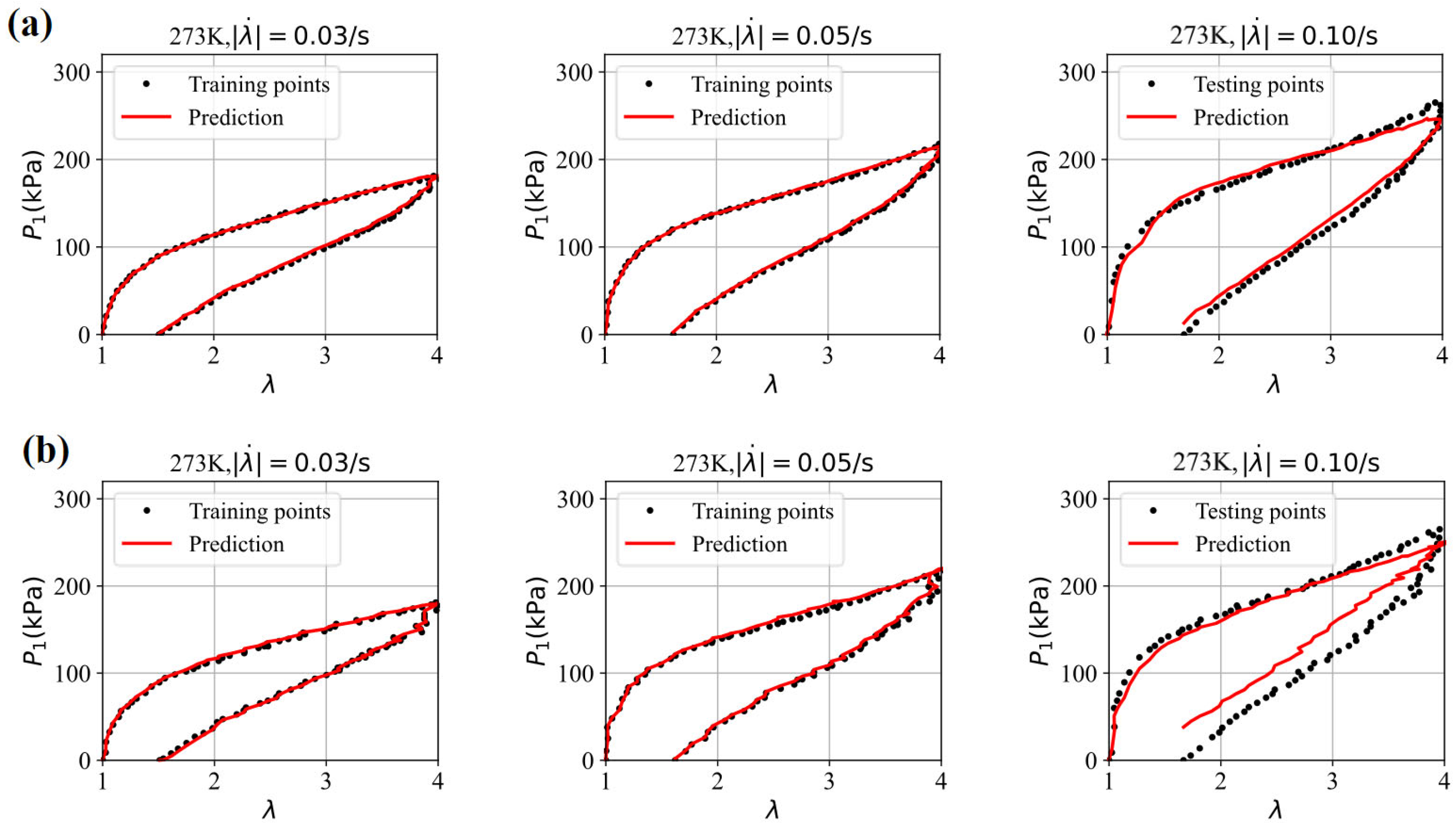
| Figure 6 | (0.01,0.02,0.06,0.08,0.10,0.12,0.14,0.16) | (0.76,0.56,0.53,0.71,0.85,0.83,0.73,0.63) |
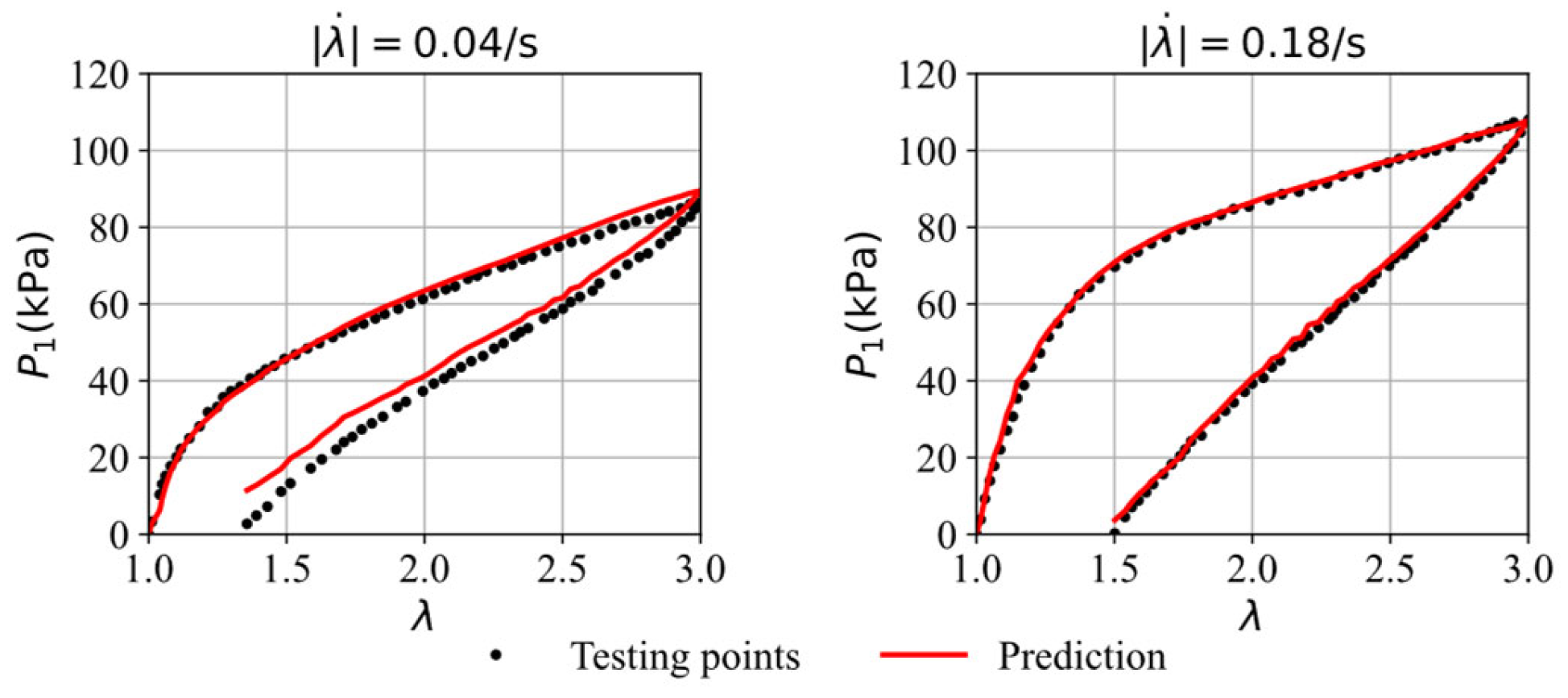
| Figure 7 | (0.04,0.18) | (3.41,1.52) |
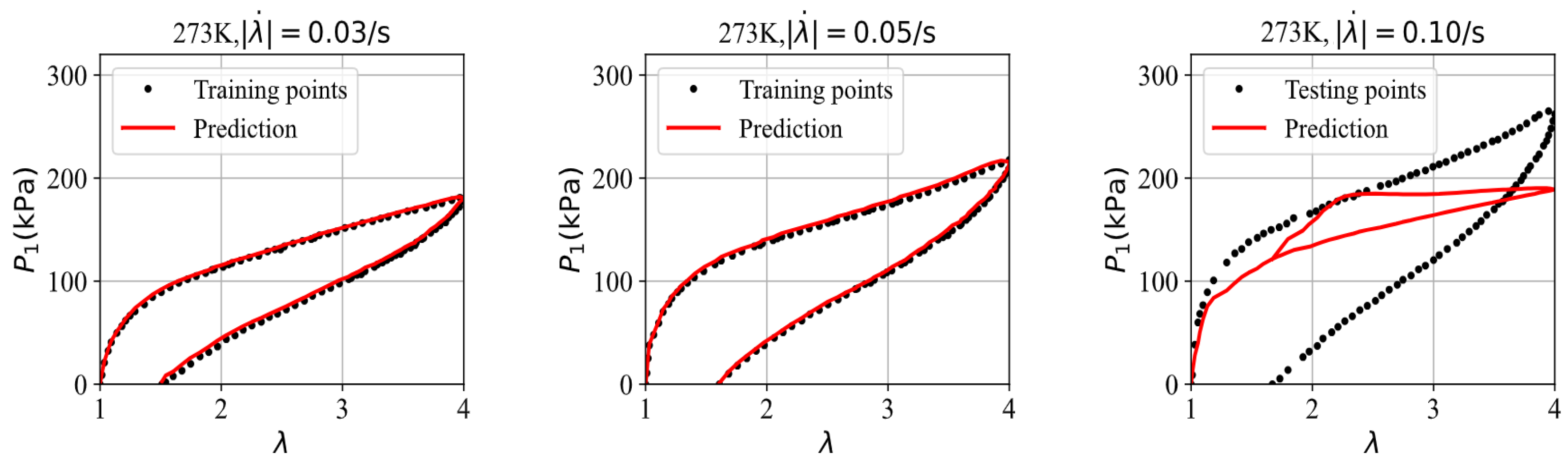
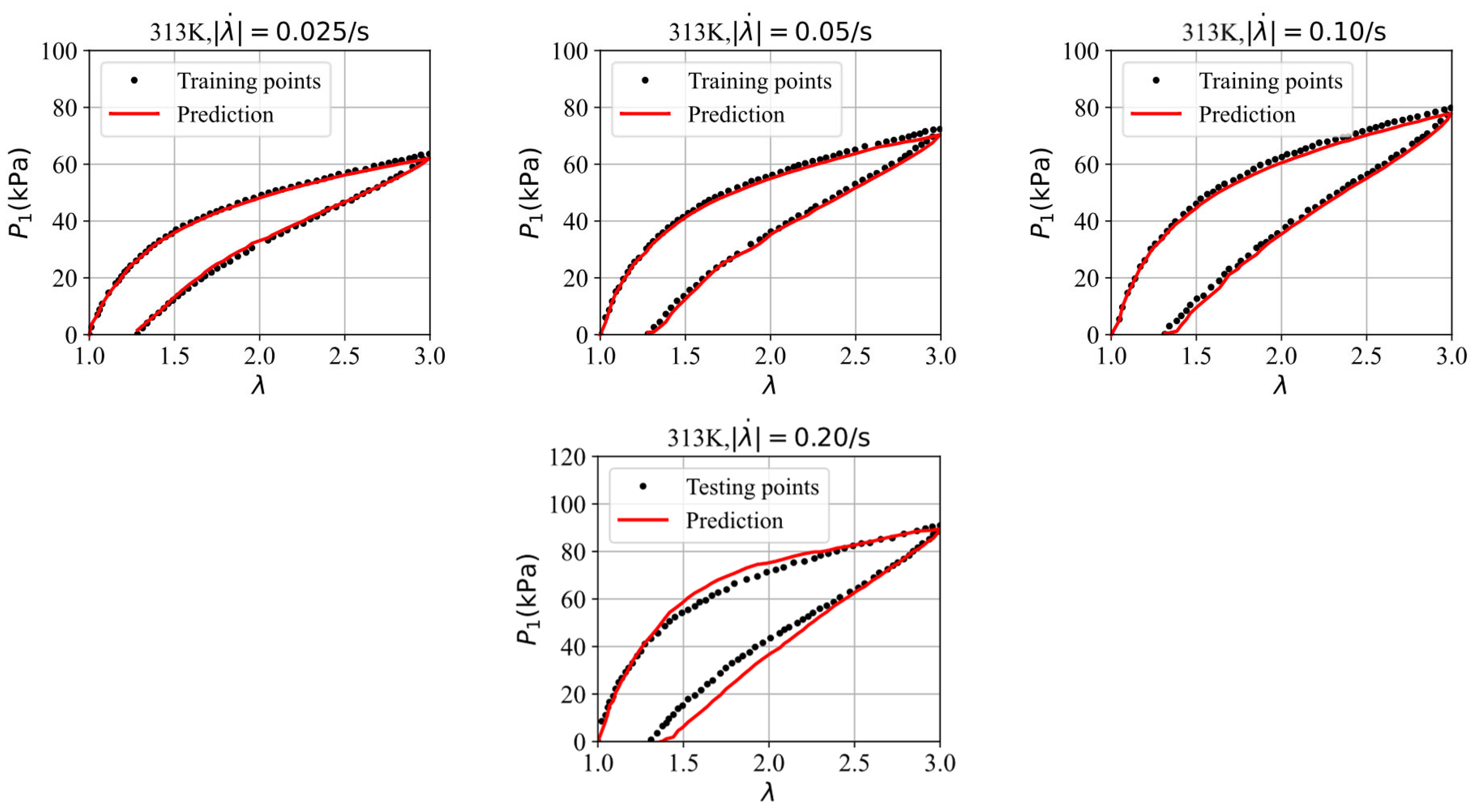
| Figure 9 | (0.03,0.05,0.10) | (2.84,3.07,62.49) |
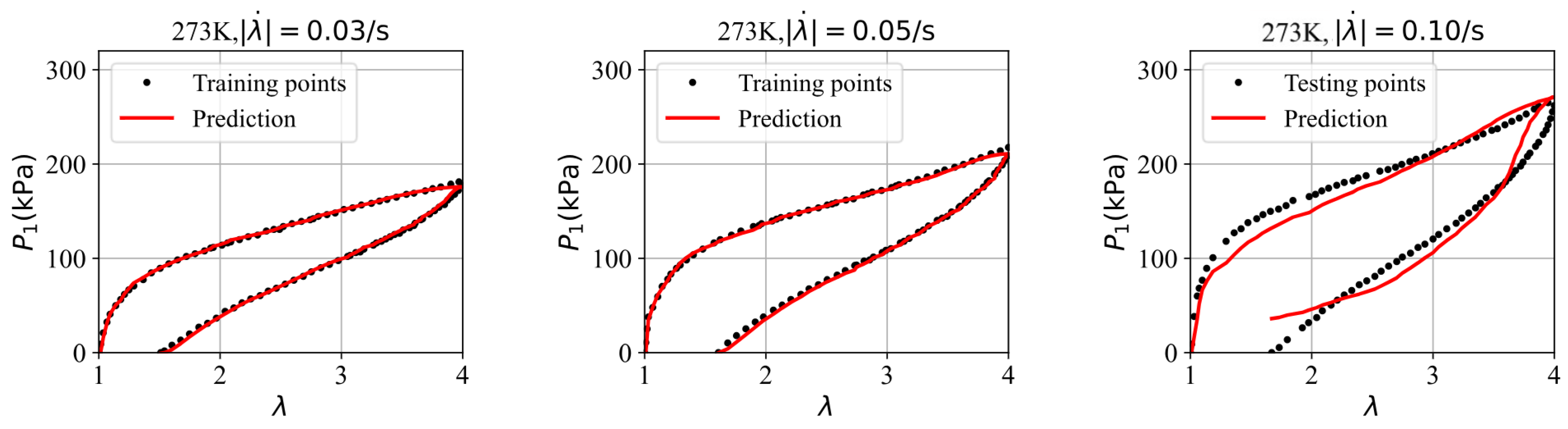
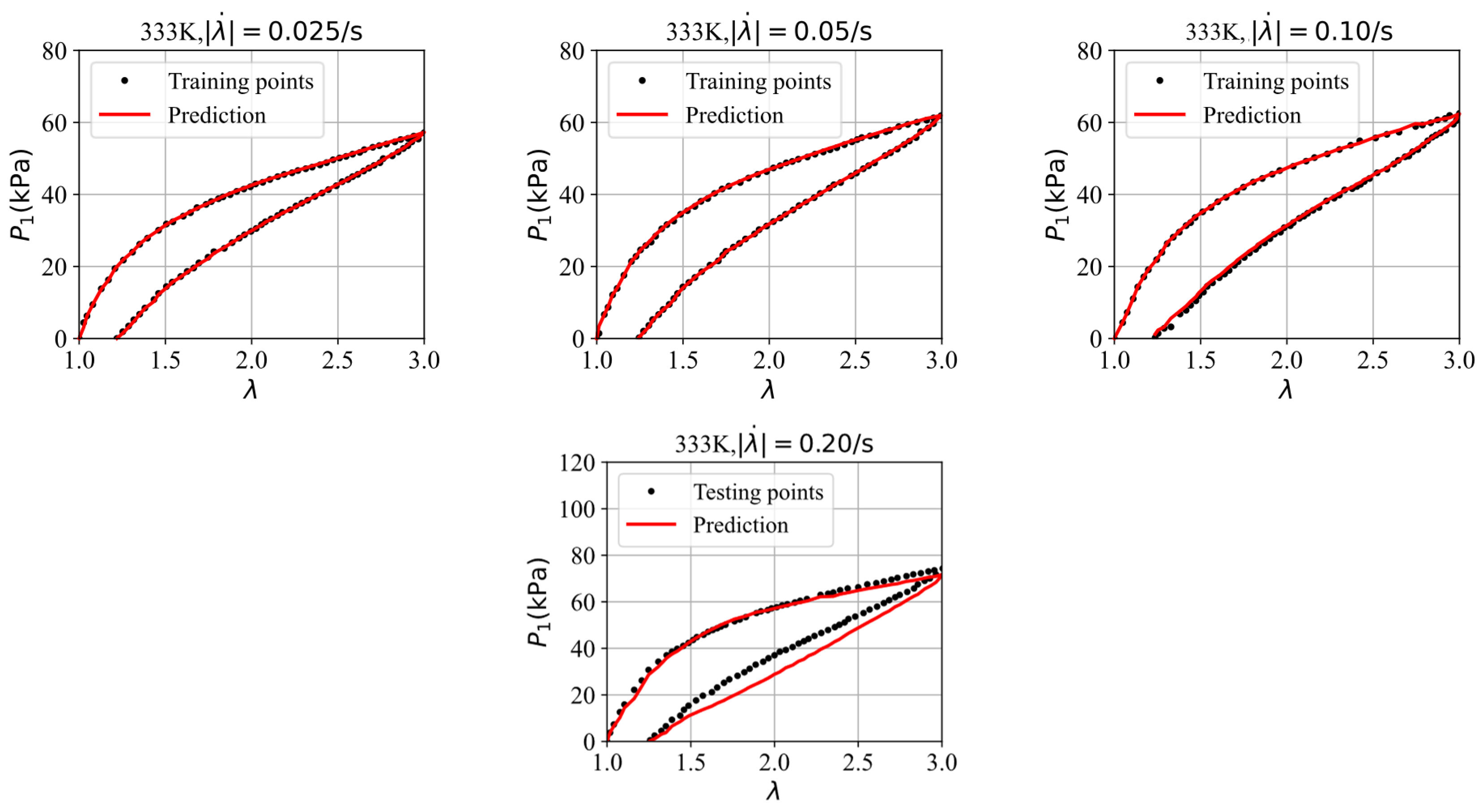
| Figure 11 | (0.03,0.05,0.10) | (1.90,2.62,15.70) |
| Figure 13 | (0.025,0.05,0.10,0.20) | (0.81,1.32,1.72,4.55) |
| Figure 15 | (0.025,0.05,0.10,0.20) | (0.24,0.31,0.53,4.27) |
4.3. Analyzing the Sensitivity of the GRU-FNN Model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech Recognition Using Deep Neural Networks: A Systematic Review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep Subdomain Adaptation Network for Image Classification. IEEE Trans. Neural Networks Learn. Syst. 2021, 32, 1713–1722. [Google Scholar] [CrossRef] [PubMed]
- Lake, B.M.; Salakhutdinov, R.; Tenenbaum, J.B. Human-level concept learning through probabilistic program induction. Science 2015, 350, 1332–1338. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Wang, Z.; Zhang, S.; Liu, X.; Tan, J. Reinforced quantum-behaved particle swarm-optimized neural network for cross-sectional distortion prediction of novel variable-diameter-die-formed metal bent tubes. J. Comput. Des. Eng. 2023, 10, 1060–1079. [Google Scholar] [CrossRef]
- Yang, C.; Li, Z.; Xu, P.; Huang, H. Recognition and optimisation method of impact deformation patterns based on point cloud and deep clustering: Applied to thin-walled tubes. J. Ind. Inf. Integr. 2024, 40, 100607. [Google Scholar] [CrossRef]
- Masi, F.; Stefanou, I.; Vannucci, P.; Maffi-Berthier, V. Thermodynamics-based Artificial Neural Networks for constitutive modeling. J. Mech. Phys. Solids 2021, 147, 104277. [Google Scholar] [CrossRef]
- Zhang, P.; Yin, Z.-Y. A novel deep learning-based modelling strategy from image of particles to mechanical properties for granular materials with CNN and BiLSTM. Comput. Methods Appl. Mech. Eng. 2021, 382, 113858. [Google Scholar] [CrossRef]
- Tancogne-Dejean, T.; Gorji, M.B.; Zhu, J.; Mohr, D. Recurrent neural network modeling of the large deformation of lithium-ion battery cells. Int. J. Plast. 2021, 146, 103072. [Google Scholar] [CrossRef]
- Jiao, S.; Li, W.; Li, Z.; Gai, J.; Zou, L.; Su, Y. Hybrid physics-machine learning models for predicting rate of penetration in the Halahatang oil field, Tarim Basin. Sci. Rep. 2024, 14, 5957. [Google Scholar] [CrossRef]
- Hu, H.; Qi, L.; Chao, X. Physics-informed Neural Networks (PINN) for computational solid mechanics: Numerical frameworks and applications. Thin-Walled Struct. 2024, 205, 112495. [Google Scholar] [CrossRef]
- Herrmann, L.; Kollmannsberger, S. Deep learning in computational mechanics: A review. Comput. Mech. 2024, 74, 281–331. [Google Scholar] [CrossRef]
- Linka, K.; Kuhl, E. A new family of Constitutive Artificial Neural Networks towards automated model discovery. Comput. Methods Appl. Mech. Eng. 2023, 403, 115731. [Google Scholar] [CrossRef]
- Eggersmann, R.; Kirchdoerfer, T.; Reese, S.; Stainier, L.; Ortiz, M. Model-free data-driven inelasticity. Comput. Methods Appl. Mech. Eng. 2019, 350, 81–99. [Google Scholar] [CrossRef]
- Linka, K.; Tepole, A.B.; Holzapfel, G.A.; Kuhl, E. Automated model discovery for skin: Discovering the best model, data, and experiment. Comput. Methods Appl. Mech. Eng. 2023, 410, 116007. [Google Scholar] [CrossRef]
- Linka, K.; Hillgärtner, M.; Abdolazizi, K.P.; Aydin, R.C.; Itskov, M.; Cyron, C.J. Constitutive artificial neural networks: A fast and general approach to predictive data-driven constitutive modeling by deep learning. J. Comput. Phys. 2021, 429, 110010. [Google Scholar] [CrossRef]
- Fuhg, J.N.; Bouklas, N. On physics-informed data-driven isotropic and anisotropic constitutive models through probabilistic machine learning and space-filling sampling. Comput. Methods Appl. Mech. Eng. 2022, 394, 114915. [Google Scholar] [CrossRef]
- Eghtesad, A.; Tan, J.; Fuhg, J.N.; Bouklas, N. NN-EVP: A physics informed neural network-based elasto-viscoplastic framework for predictions of grain size-aware flow response. Int. J. Plast. 2024, 181, 104072. [Google Scholar] [CrossRef]
- Abueidda, D.W.; Lu, Q.; Koric, S. Meshless physics-informed deep learning method for three-dimensional solid mechanics. Int. J. Numer. Methods Eng. 2021, 122, 7182–7201. [Google Scholar] [CrossRef]
- Abueidda, D.W.; Koric, S.; Abu Al-Rub, R.; Parrott, C.M.; James, K.A.; Sobh, N.A. A deep learning energy method for hyperelasticity and viscoelasticity. Eur. J. Mech. A/Solids 2022, 95, 104639. [Google Scholar] [CrossRef]
- Abueidda, D.W.; Koric, S.; Sobh, N.A.; Sehitoglu, H. Deep learning for plasticity and thermo-viscoplasticity. Int. J. Plast. 2021, 136, 102852. [Google Scholar] [CrossRef]
- As’ad, F.; Avery, P.; Farhat, C. A mechanics-informed artificial neural network approach in data-driven constitutive modeling. Int. J. Numer. Methods Eng. 2022, 123, 2738–2759. [Google Scholar] [CrossRef]
- Cen, J.; Zou, Q. Deep finite volume method for partial differential equations. J. Comput. Phys. 2024, 517, 113307. [Google Scholar] [CrossRef]
- Danoun, A.; Prulière, E.; Chemisky, Y. Thermodynamically consistent Recurrent Neural Networks to predict non linear behaviors of dissipative materials subjected to non-proportional loading paths. Mech. Mater. 2022, 173, 104436. [Google Scholar] [CrossRef]
- Wang, J.-J.; Wang, C.; Fan, J.-S.; Mo, Y. A deep learning framework for constitutive modeling based on temporal convolutional network. J. Comput. Phys. 2022, 449, 110784. [Google Scholar] [CrossRef]
- Benabou, L. Development of LSTM networks for predicting viscoplasticity with effects of deformation, strain rate and temperature history. J. Appl. Mech. 2021, 88, 071008. [Google Scholar] [CrossRef]
- Gorji, M.B.; Mozaffar, M.; Heidenreich, J.N.; Cao, J.; Mohr, D. On the potential of recurrent neural networks for modeling path dependent plasticity. J. Mech. Phys. Solids 2020, 143, 103972. [Google Scholar] [CrossRef]
- Mozaffar, M.; Bostanabad, R.; Chen, W.; Ehmann, K.; Cao, J.; Bessa, M.A. Deep learning predicts path-dependent plasticity. Proc. Natl. Acad. Sci. USA 2019, 116, 26414–26420. [Google Scholar] [CrossRef]
- Abdolazizi, K.P.; Linka, K.; Cyron, C.J. Viscoelastic constitutive artificial neural networks (vCANNs)–A framework for data-driven anisotropic nonlinear finite viscoelasticity. J. Comput. Phys. 2024, 499, 112704. [Google Scholar] [CrossRef]
- Banks, H.T.; Hu, S.; Kenz, Z.R. A brief review of elasticity and viscoelasticity for solids. Adv. Appl. Math. Mech. 2015, 3, 1–51. [Google Scholar] [CrossRef]
- Hong, W. Modeling viscoelastic dielectrics. J. Mech. Phys. Solids 2011, 59, 637–650. [Google Scholar] [CrossRef]
- Reese, S.; Govindjee, S. A theory of finite viscoelasticity and numerical aspects. Int. J. Solids. Struct. 1998, 35, 3455–3482. [Google Scholar] [CrossRef]
- Zhou, J.; Jiang, L.; Khayat, R.E. A micro–macro constitutive model for finite-deformation viscoelasticity of elastomers with nonlinear viscosity. J. Mech. Phys. Solids. 2018, 110, 137–154. [Google Scholar] [CrossRef]
- Su, X.; Peng, X. A 3D finite strain viscoelastic constitutive model for thermally induced shape memory polymers based on energy decomposition. Int. J. Plast. 2018, 110, 166–182. [Google Scholar] [CrossRef]
- Qin, B.; Zhong, Z.; Zhang, T.-Y. A thermodynamically consistent model for chemically induced viscoelasticity in covalent adaptive network polymers. Int. J. Solids. Struct. 2022, 256, 111953. [Google Scholar] [CrossRef]
- Gent, A.N. A new constitutive relation for rubber. Rubbery Chem. Technol. 1996, 69, 59–61. [Google Scholar] [CrossRef]
- Arruda, E.M.; Boyce, M.C. A three-dimensional constitutive model for the large stretch behaviour of rubber elastic materials. J. Mech. Phys. Solids. 1993, 41, 389–412. [Google Scholar] [CrossRef]
- Lecun, Y. A Theoretical Framework for Back-Propagation. In Artificial Neural Networks; Mehra, P., Wah, B., Eds.; IEEE Computer Society Press: Piscataway, NJ, USA, 1992. [Google Scholar]
- Cho, K.; Merrïenboer, B.V.; Gulcehre, C.; Bougares, F.; Schwenk, H.; Bahdanau, D.; Bengio, Y. Learning phrase representations using RNN encoder–decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078v3. [Google Scholar]
- Amini Niaki, S.; Haghighat, E.; Campbell, T.; Poursartip, A.; Vaziri, R. Physics-informed neural network for modelling the thermochemical curing process of composite-tool systems during manufacture. Comput. Methods Appl. Mech. Engrg 2021, 384, 113959. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980v9. [Google Scholar]
- Liao, Z.; Hossain, M.; Yao, X.; Mehnert, M.; Steinmann, P. On thermo-viscoelastic experimental characterization and numerical modelling of VHB polymer. Int. J. Non-Linear Mech. 2020, 118, 103263. [Google Scholar] [CrossRef]
- Mehnert, M.; Hossain, M.; Steinmann, P. A complete thermo–electro–viscoelastic characterization of dielectric elastomers, Part I: Experimental investigations. J. Mech. Phys. Solids. 2021, 157, 104603. [Google Scholar] [CrossRef]
| Layer | Output Shape | Parameters |
|---|---|---|
| GRU 1 | (None, 100,100) | 31,200 |
| GRU 2 | (None, 100,100) | 60,600 |
| GRU 3 | (None, 100,100) | 60,600 |
| Dense | (None, 100,1) | 101 |
| Cases with Noise | Stretching Rates (/s) | RMSE Values (kPa) |
|---|---|---|
| 273 K_0.5% | (0.03,0.05,0.10) | (1.93,2.17,8.28) |
| 273 K_1.0% | (0.03,0.05,0.10) | (2.16,3.80,20.30) |
| 313 K_0.5% | (0.025,0.05,0.10,0.20) | (0.45,0.59,0.84,4.55) |
| 313 K_1.0% | (0.025,0.05,0.10,0.20) | (1.84,1.23,0.83,4.73) |
| 333 K_0.5% | (0.025,0.05,0.10,0.20) | (1.37,0.84,0.66,5.27) |
| 333 K_1.0% | (0.025,0.05,0.10,0.20) | (0.50,0.54,0.59,5.16) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, B.; Zhong, Z. A Physics-Guided Machine Learning Model for Predicting Viscoelasticity of Solids at Large Deformation. Polymers 2024, 16, 3222. https://doi.org/10.3390/polym16223222
Qin B, Zhong Z. A Physics-Guided Machine Learning Model for Predicting Viscoelasticity of Solids at Large Deformation. Polymers. 2024; 16(22):3222. https://doi.org/10.3390/polym16223222
Chicago/Turabian StyleQin, Bao, and Zheng Zhong. 2024. "A Physics-Guided Machine Learning Model for Predicting Viscoelasticity of Solids at Large Deformation" Polymers 16, no. 22: 3222. https://doi.org/10.3390/polym16223222
APA StyleQin, B., & Zhong, Z. (2024). A Physics-Guided Machine Learning Model for Predicting Viscoelasticity of Solids at Large Deformation. Polymers, 16(22), 3222. https://doi.org/10.3390/polym16223222