
Comparison between Artificial Neural Network and Rigorous Mathematical Model in Simulation of Industrial Heavy Naphtha Reforming Process

 ,
,  , and
, and 
Abstract
:1. Introduction
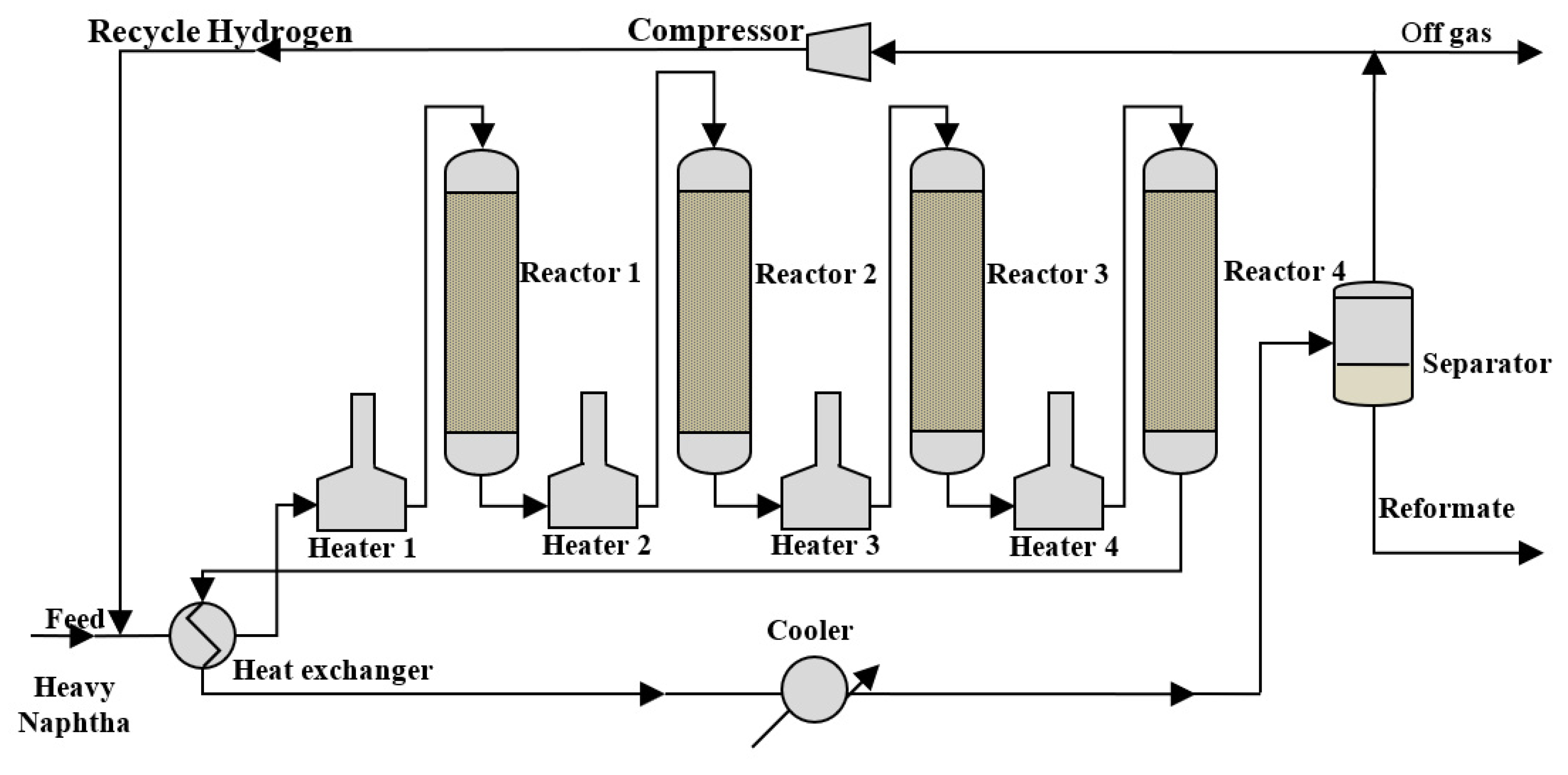
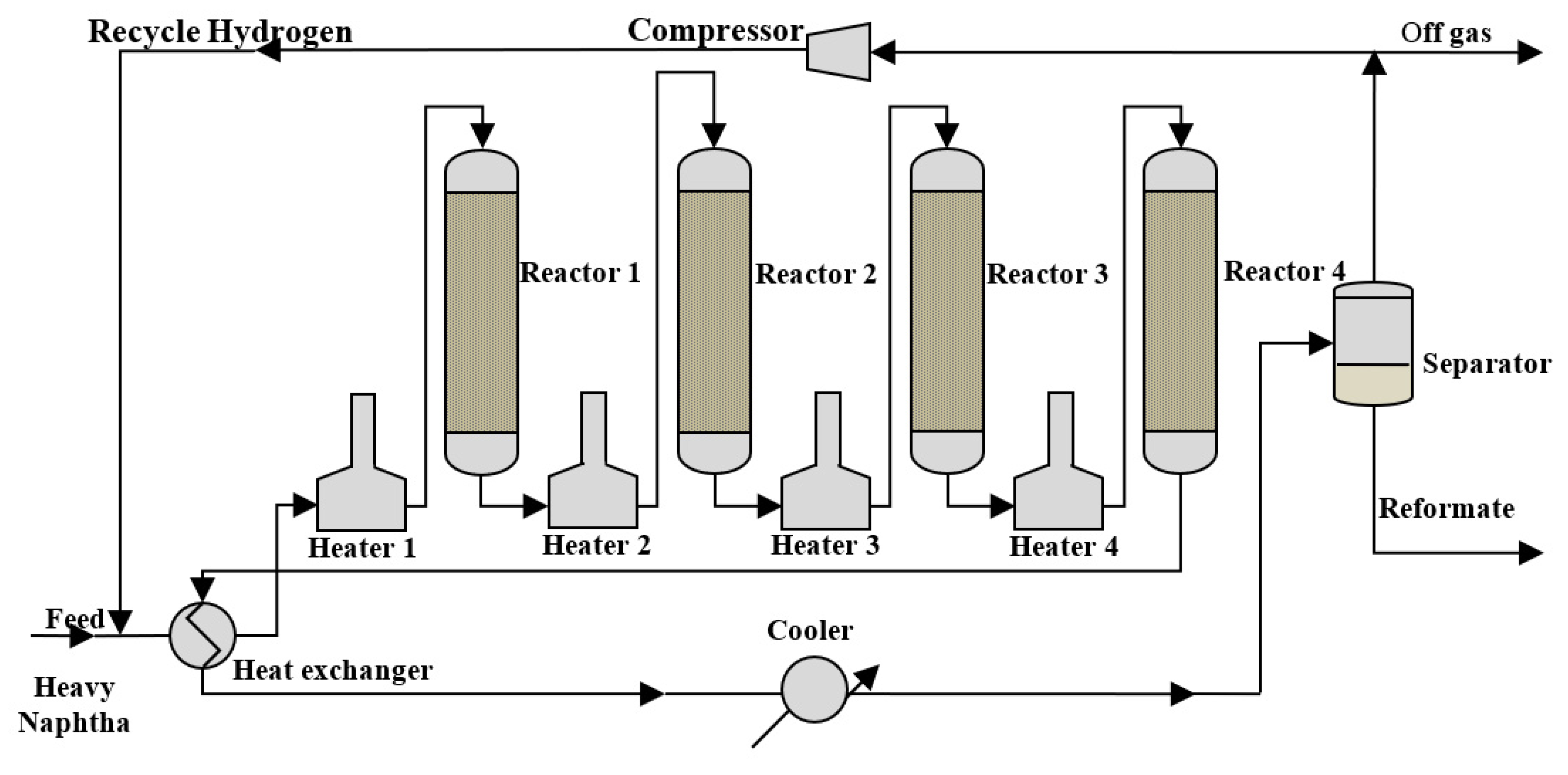
2. Process Description and Data Collection
3. Modeling
3.1. Rigorous Mathematical Model
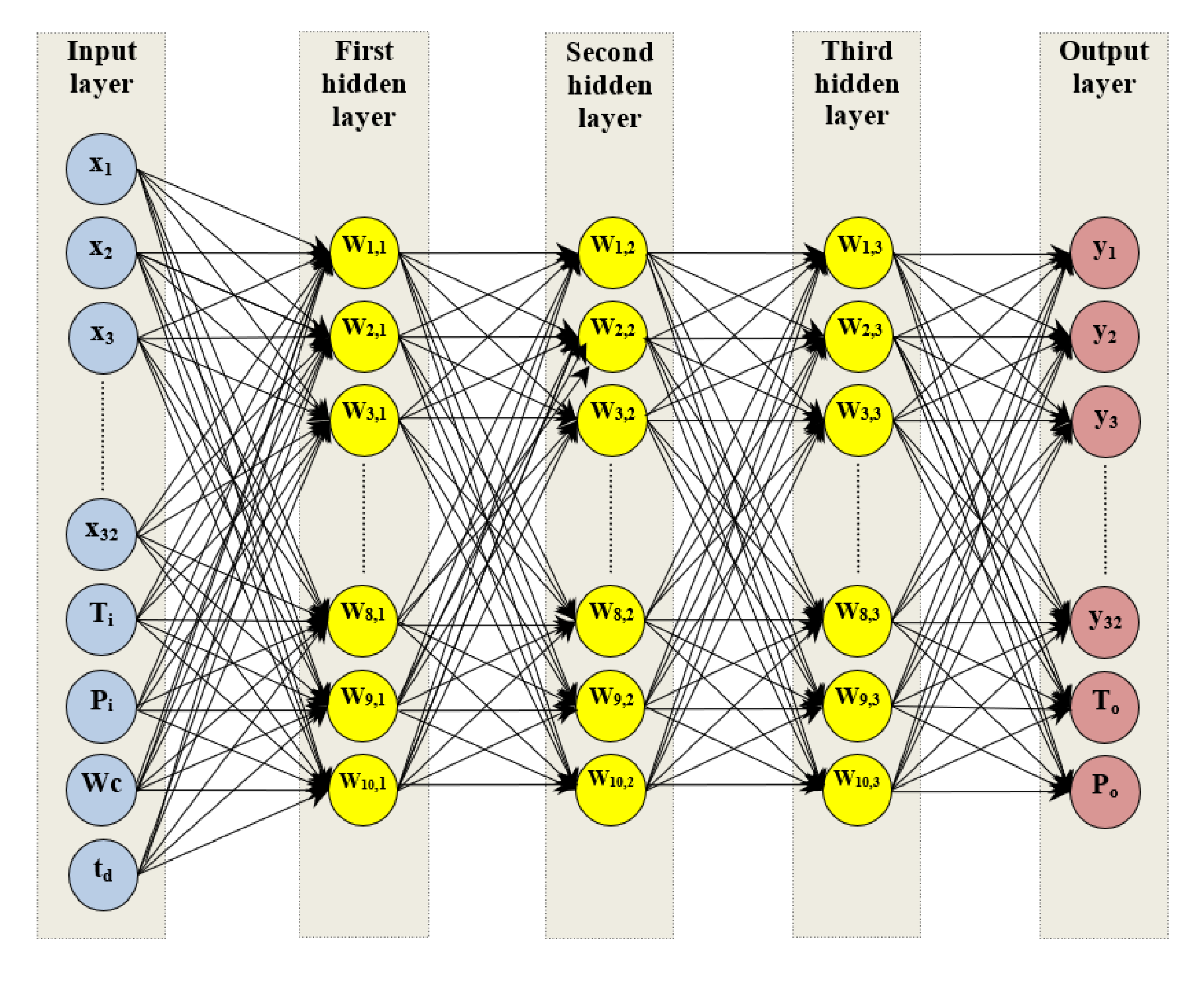
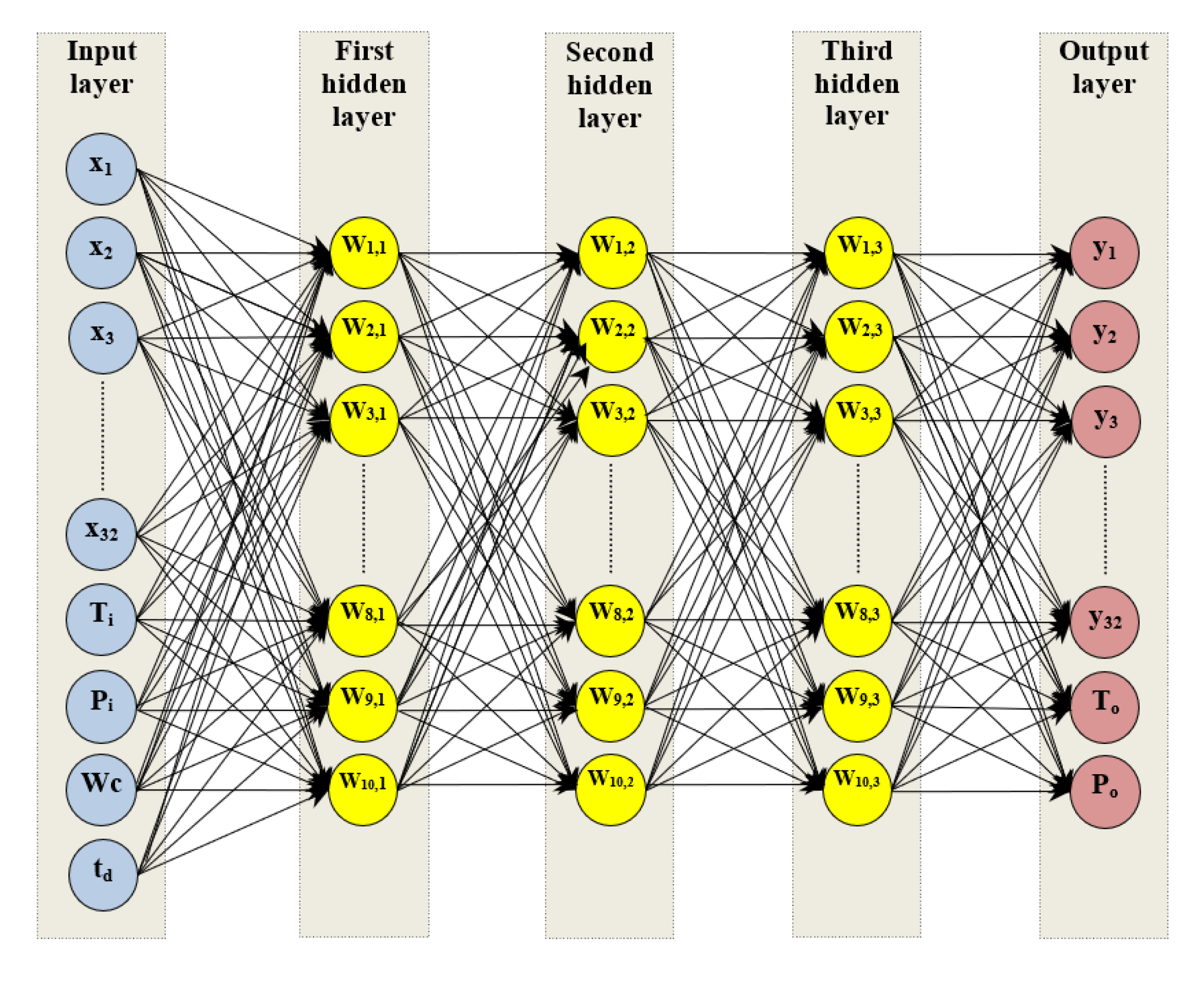
3.2. Artificial Neural Network Model
Designing an Artificial Neural Network
4. Statistical Analyses
5. Results and Discussion
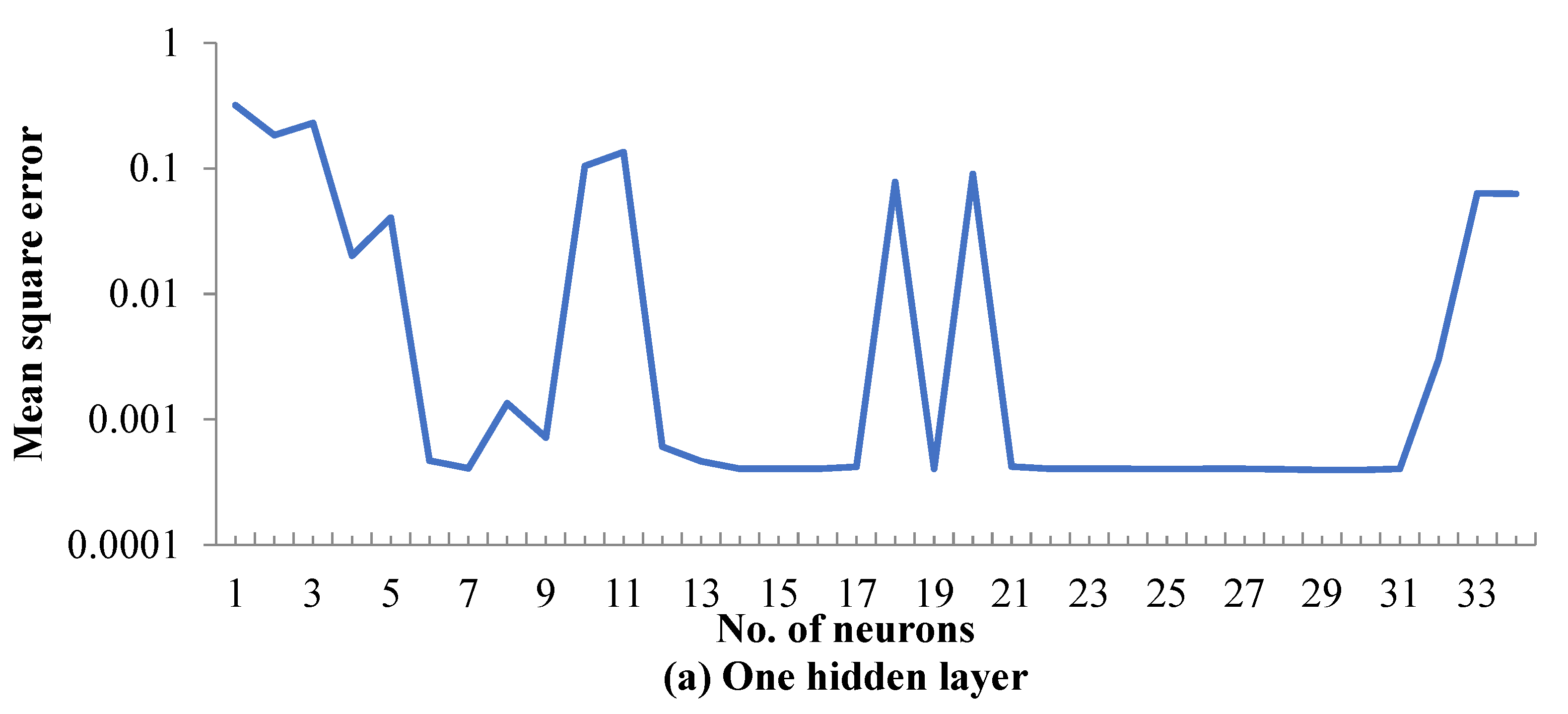
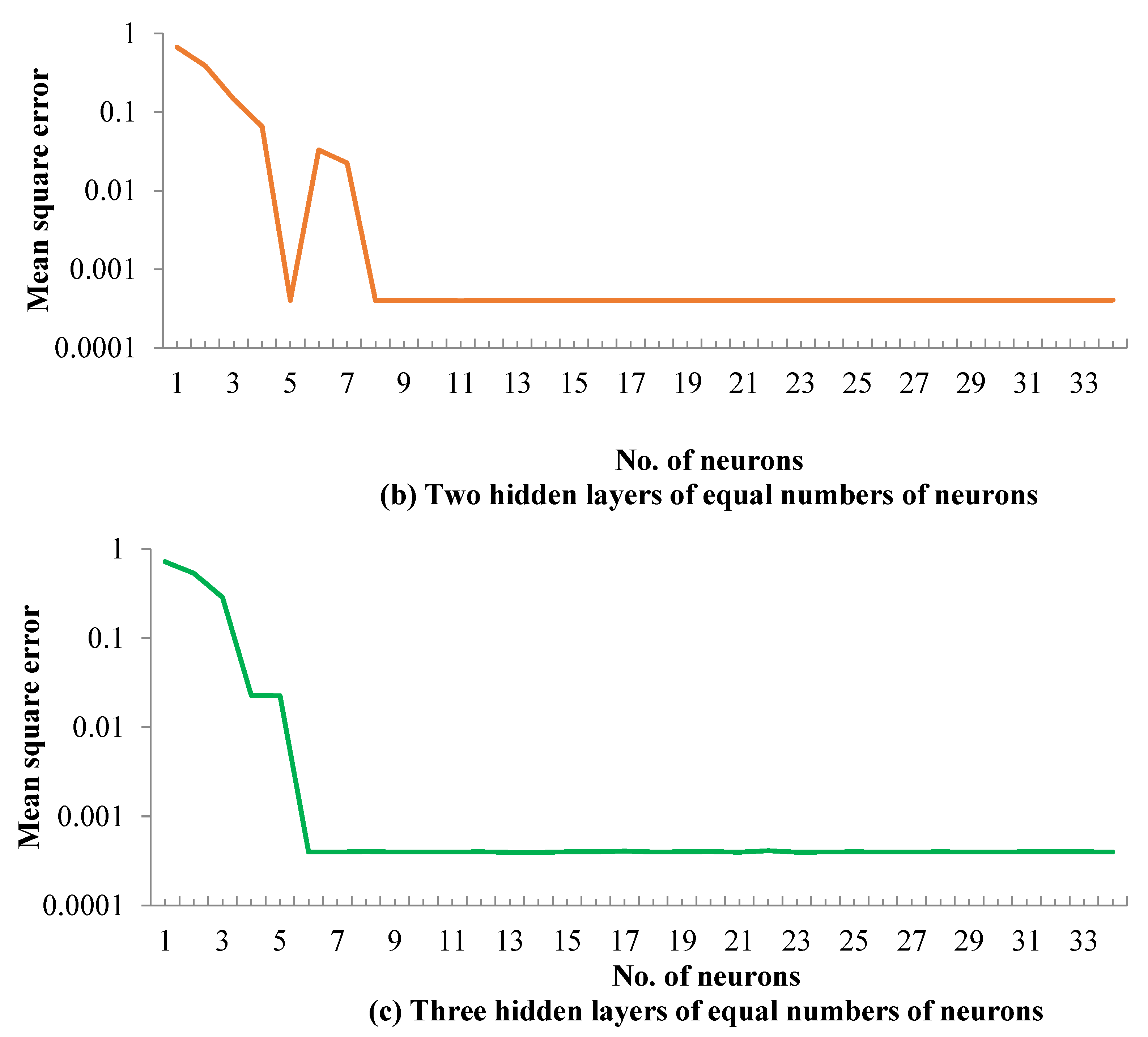
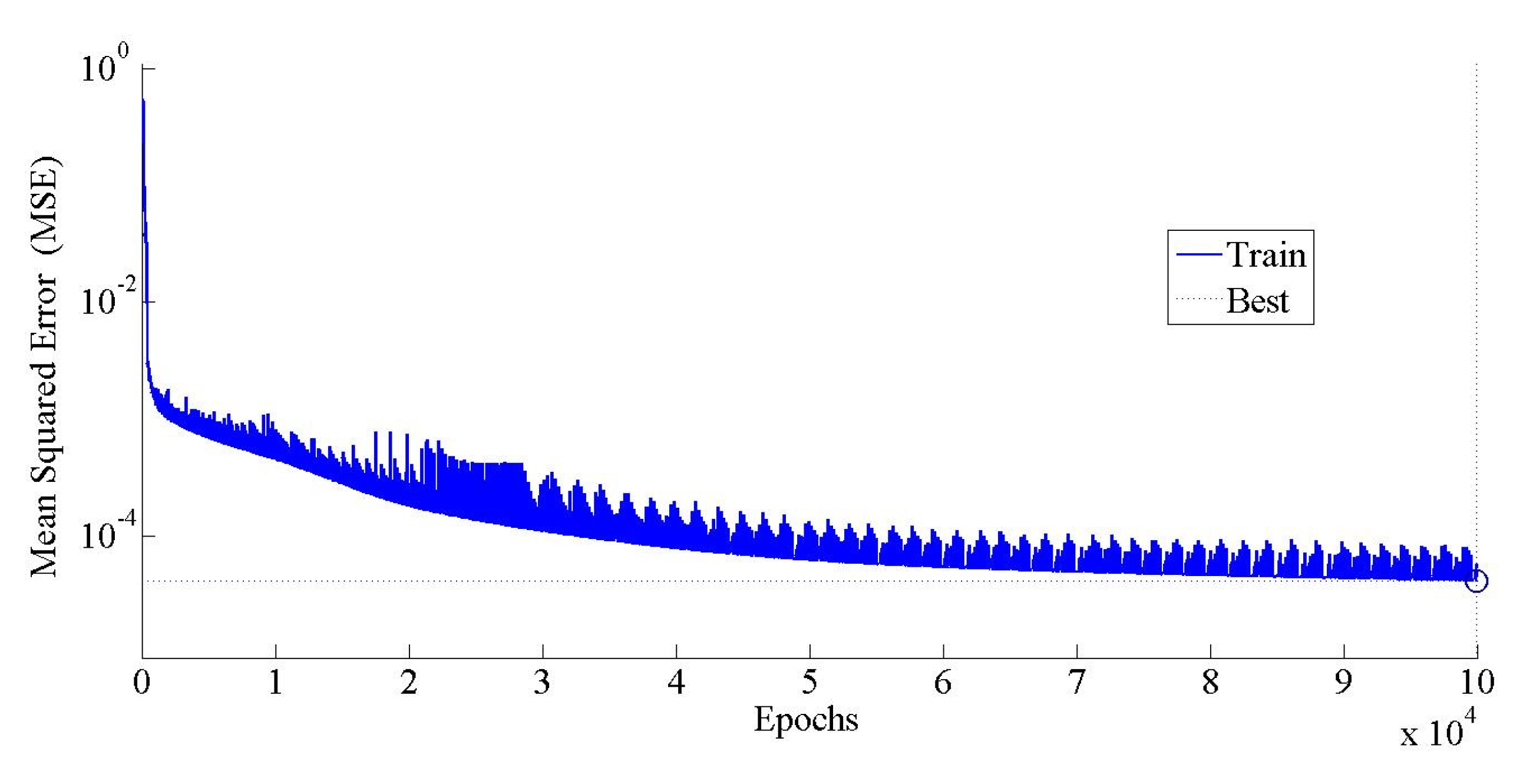
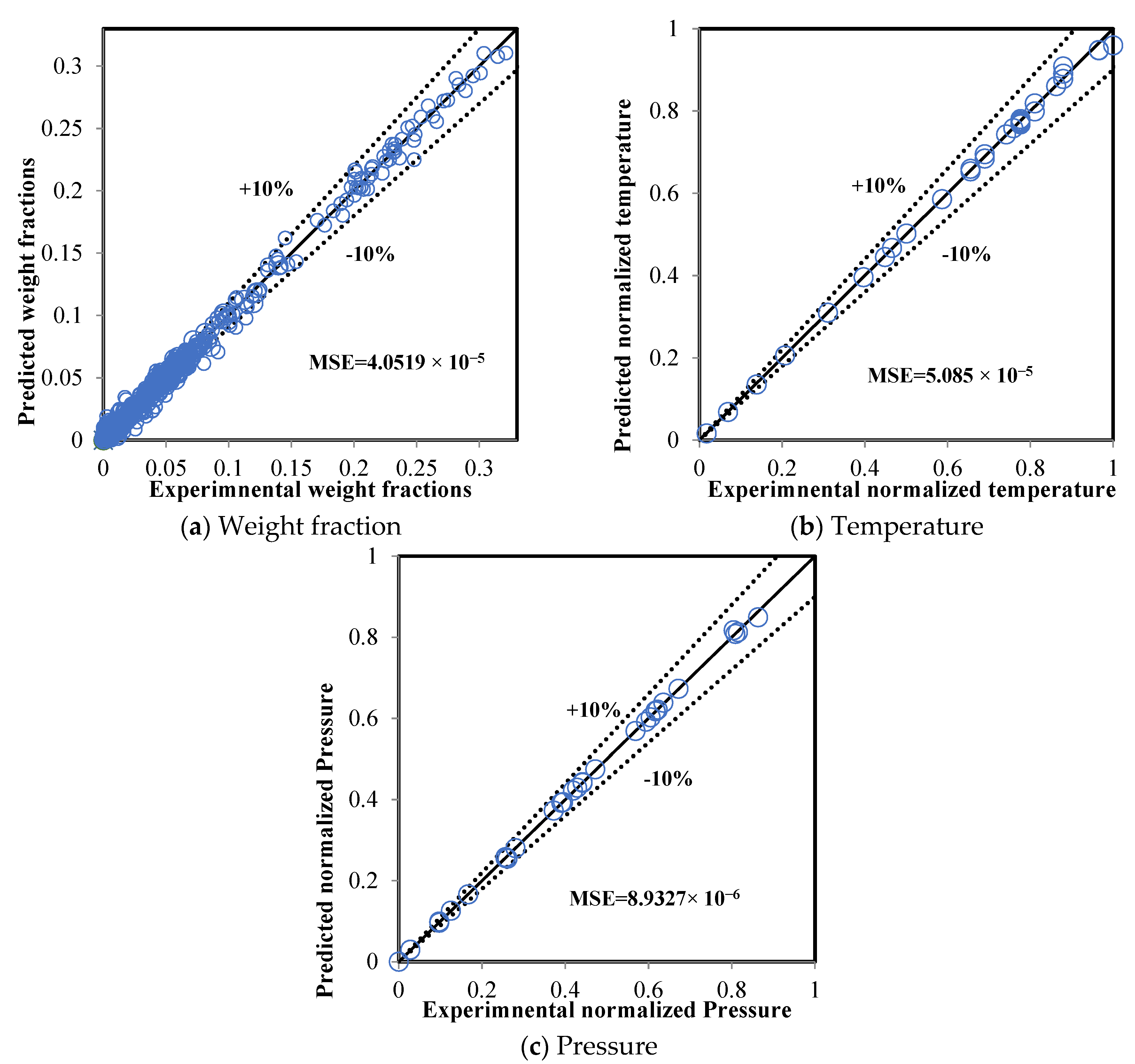
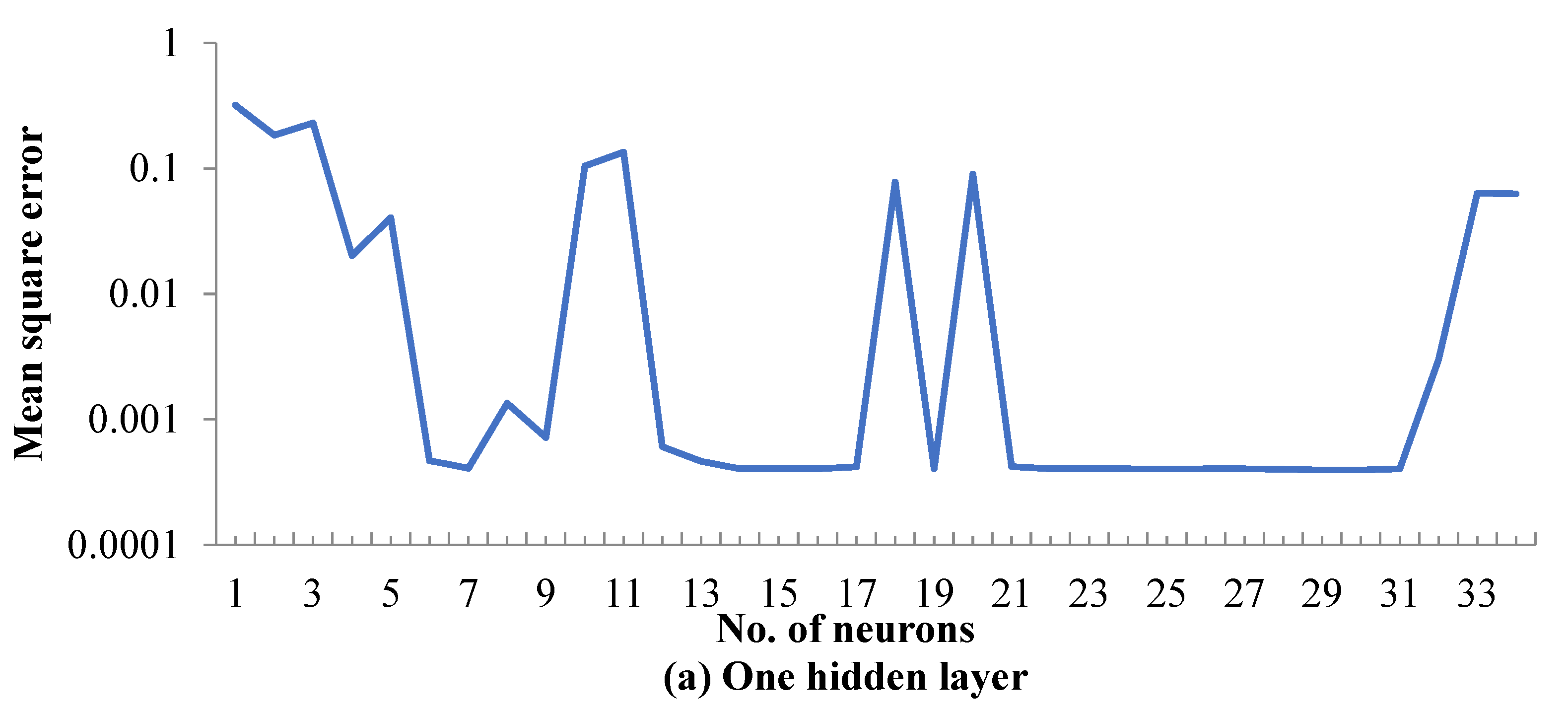
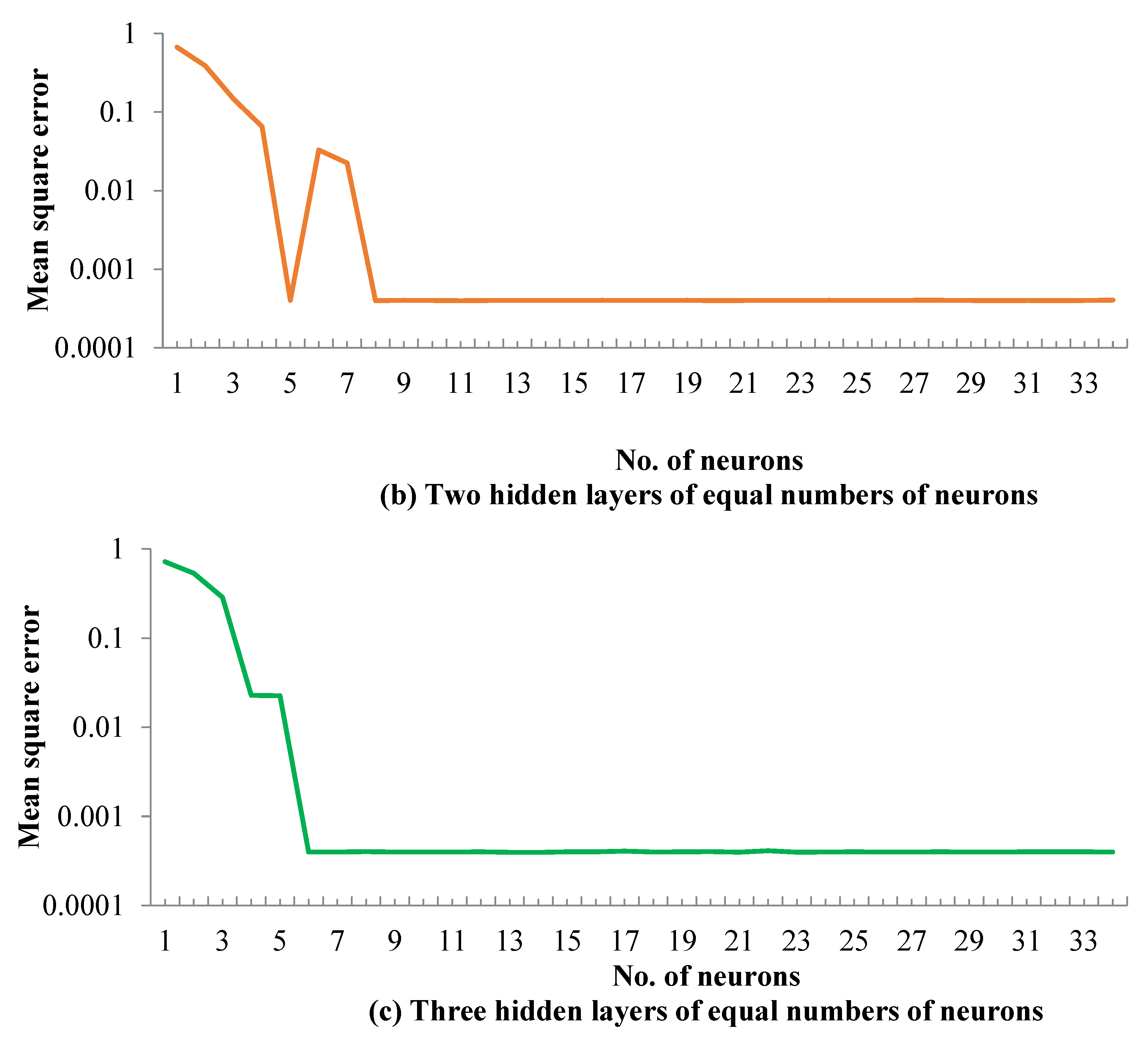
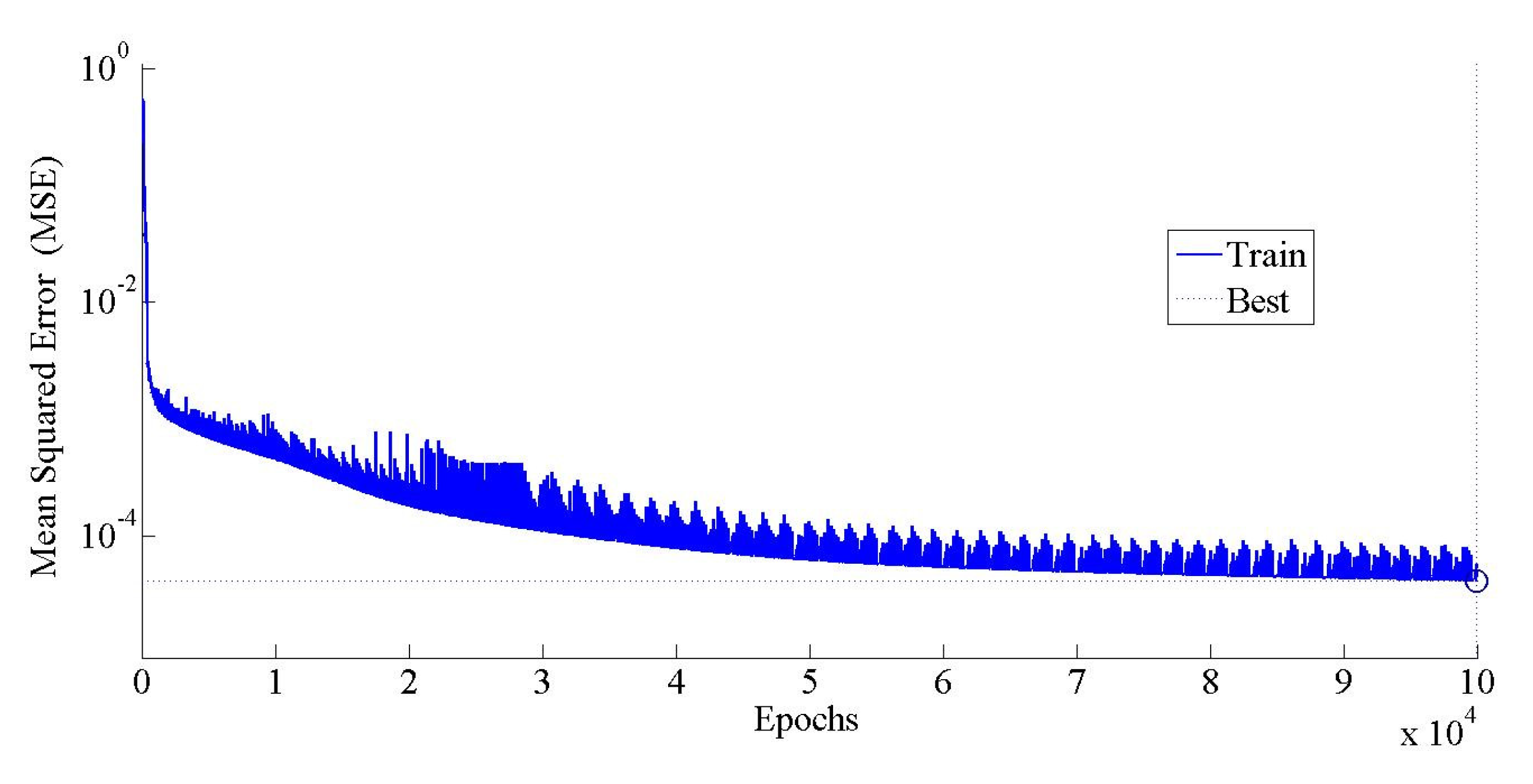
5.1. ANN Model Training
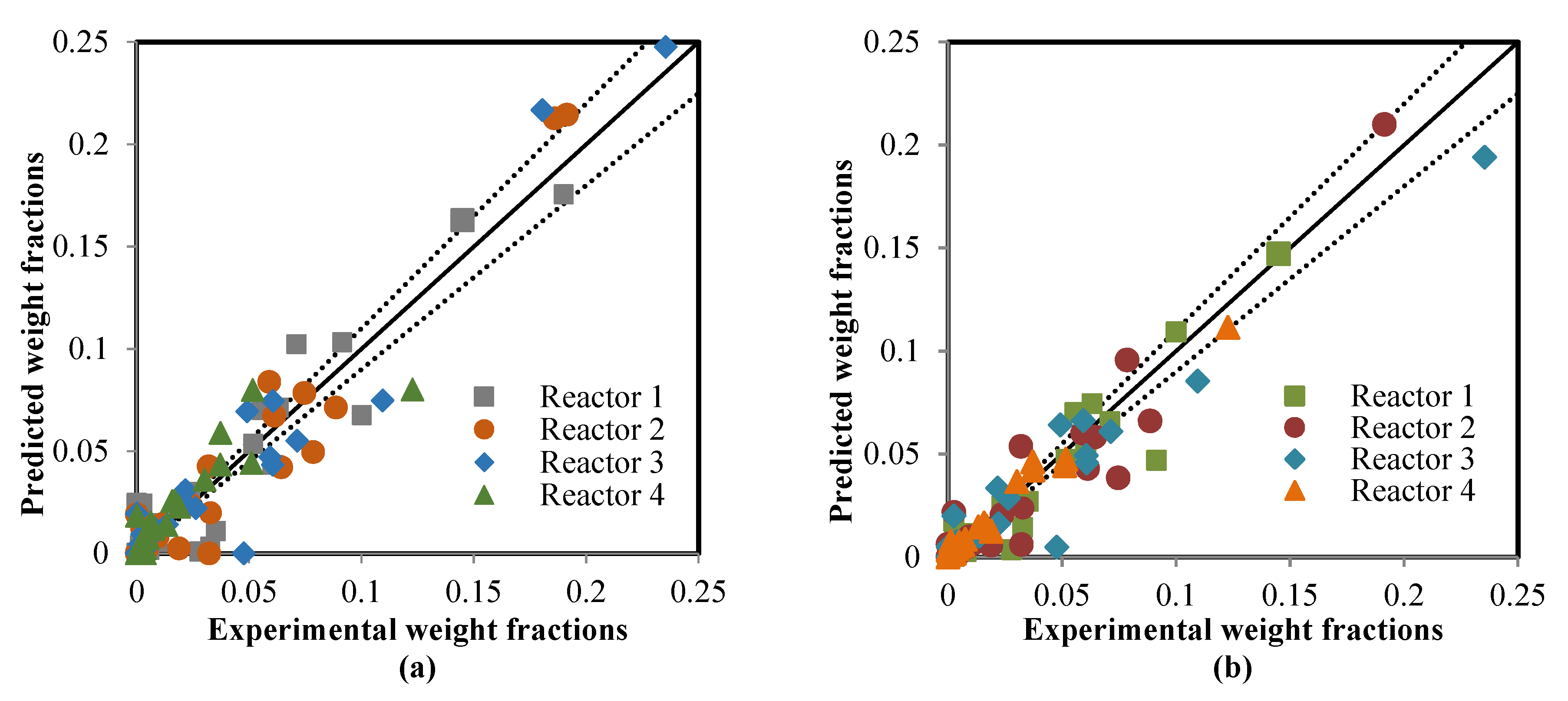
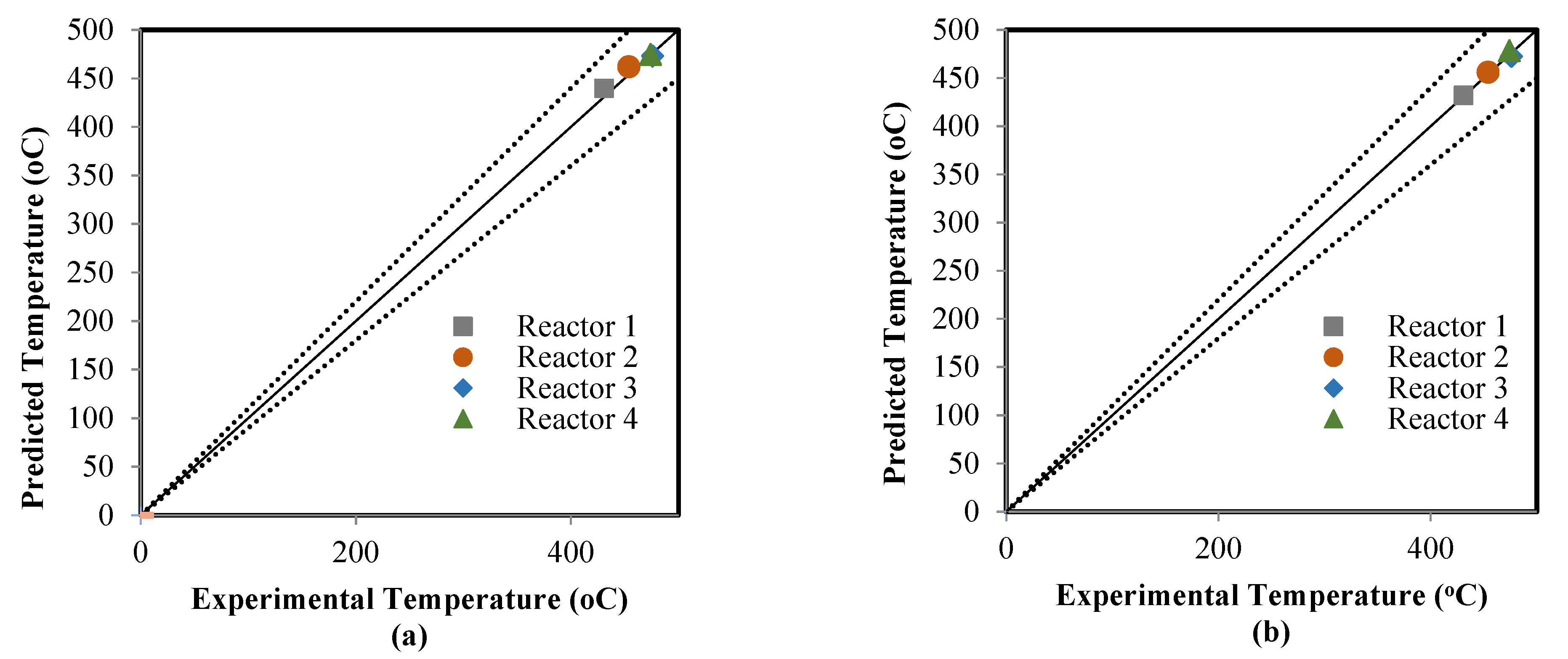
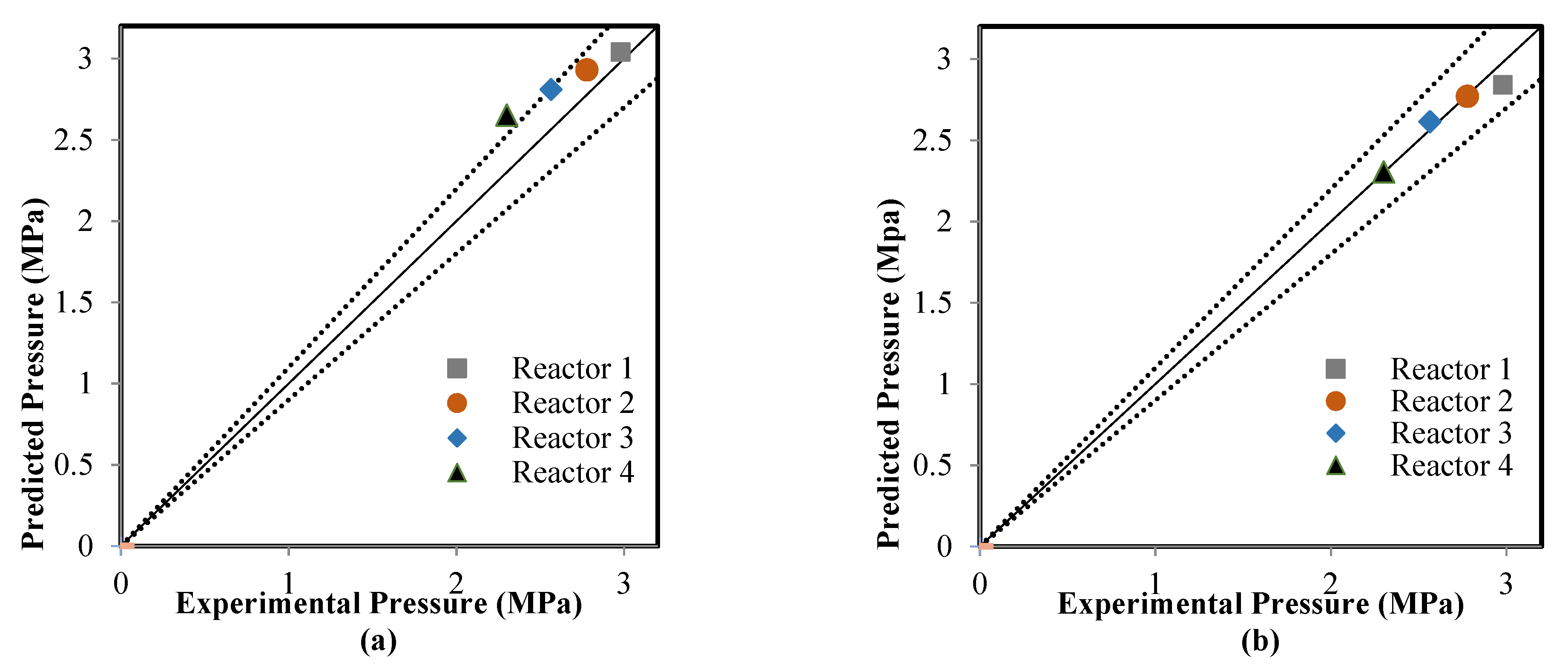
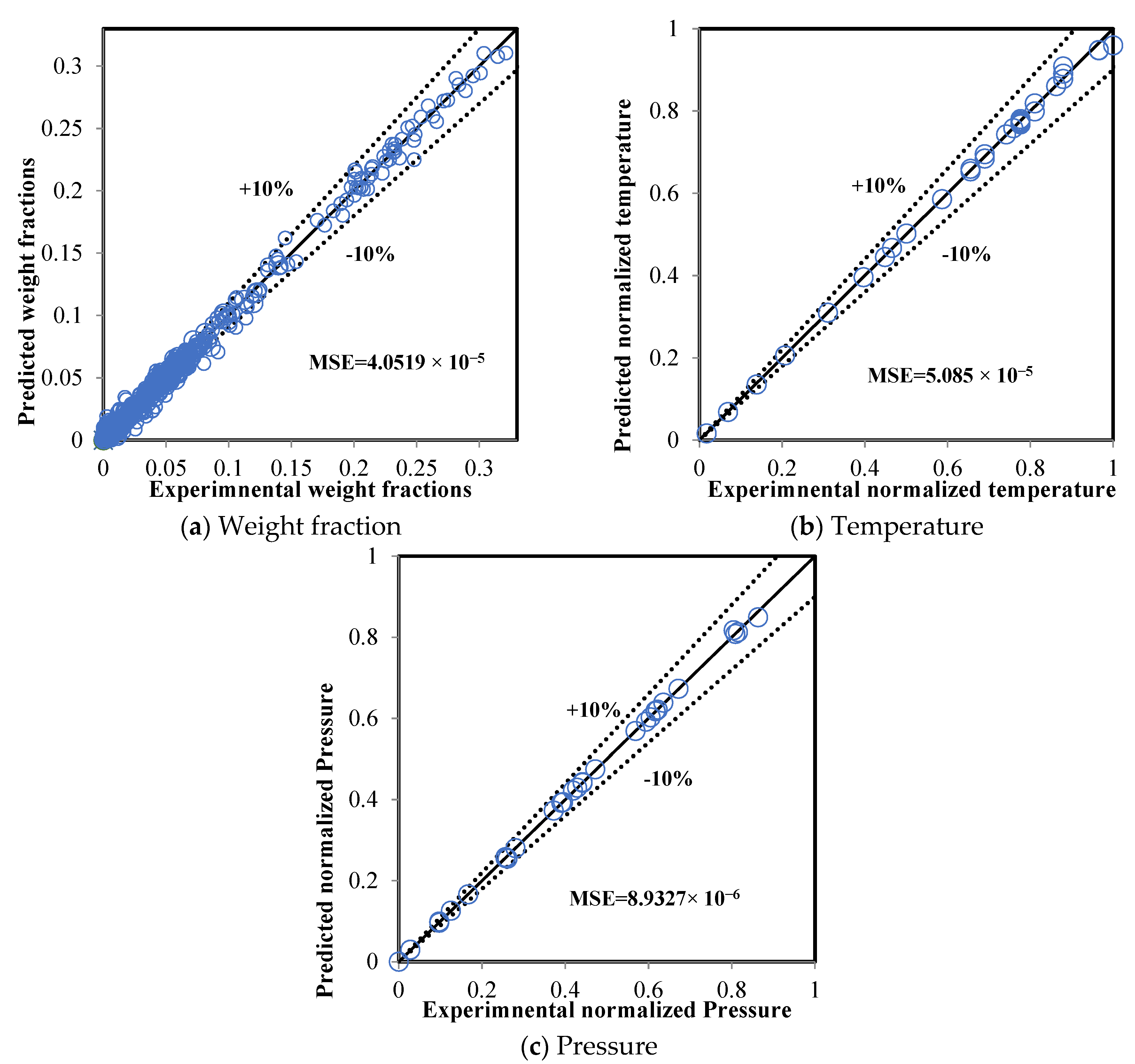
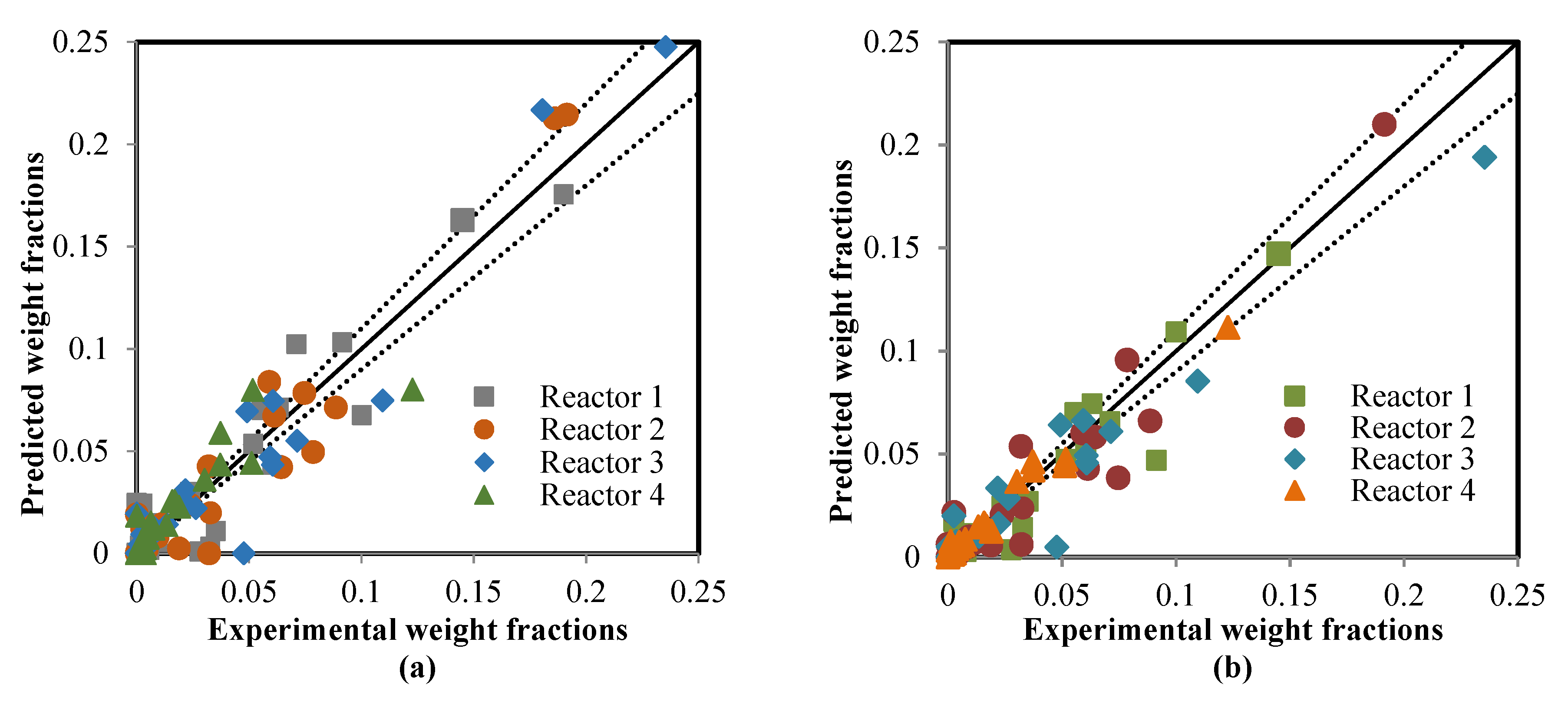
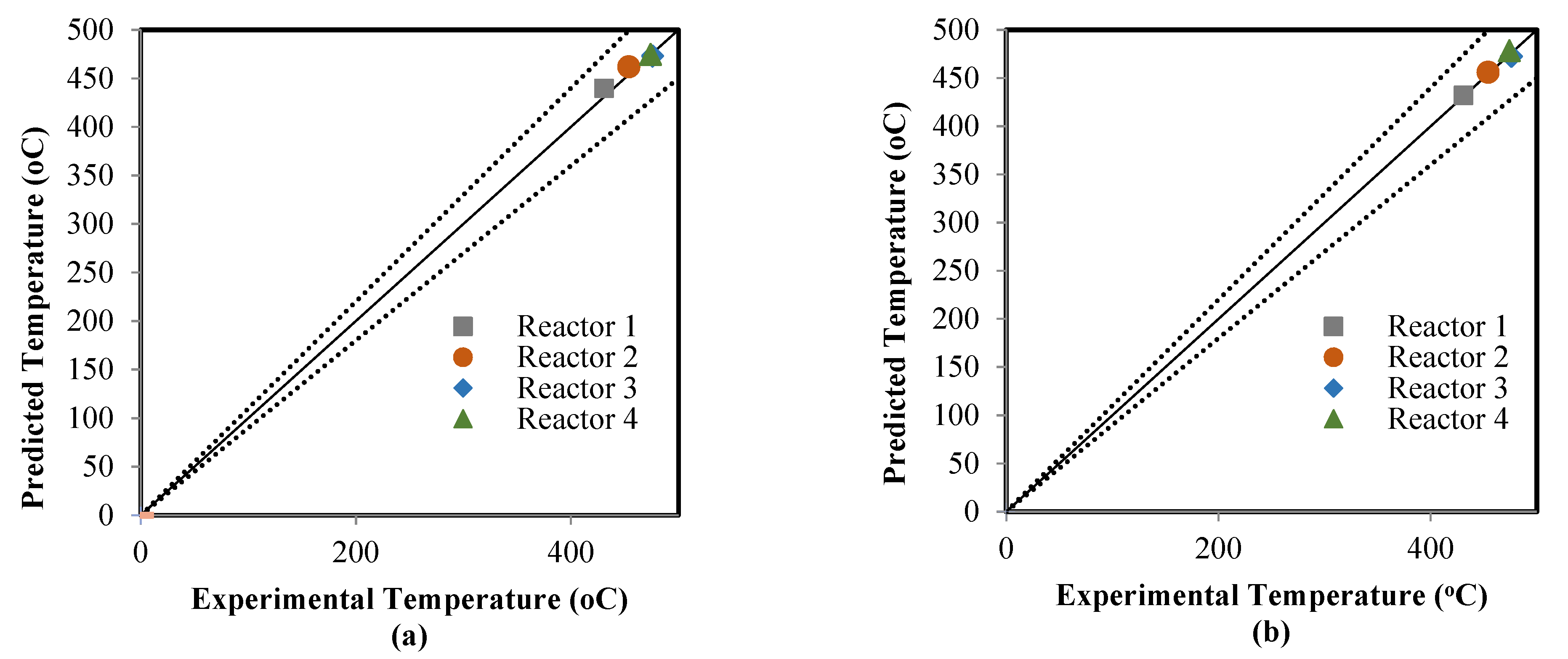
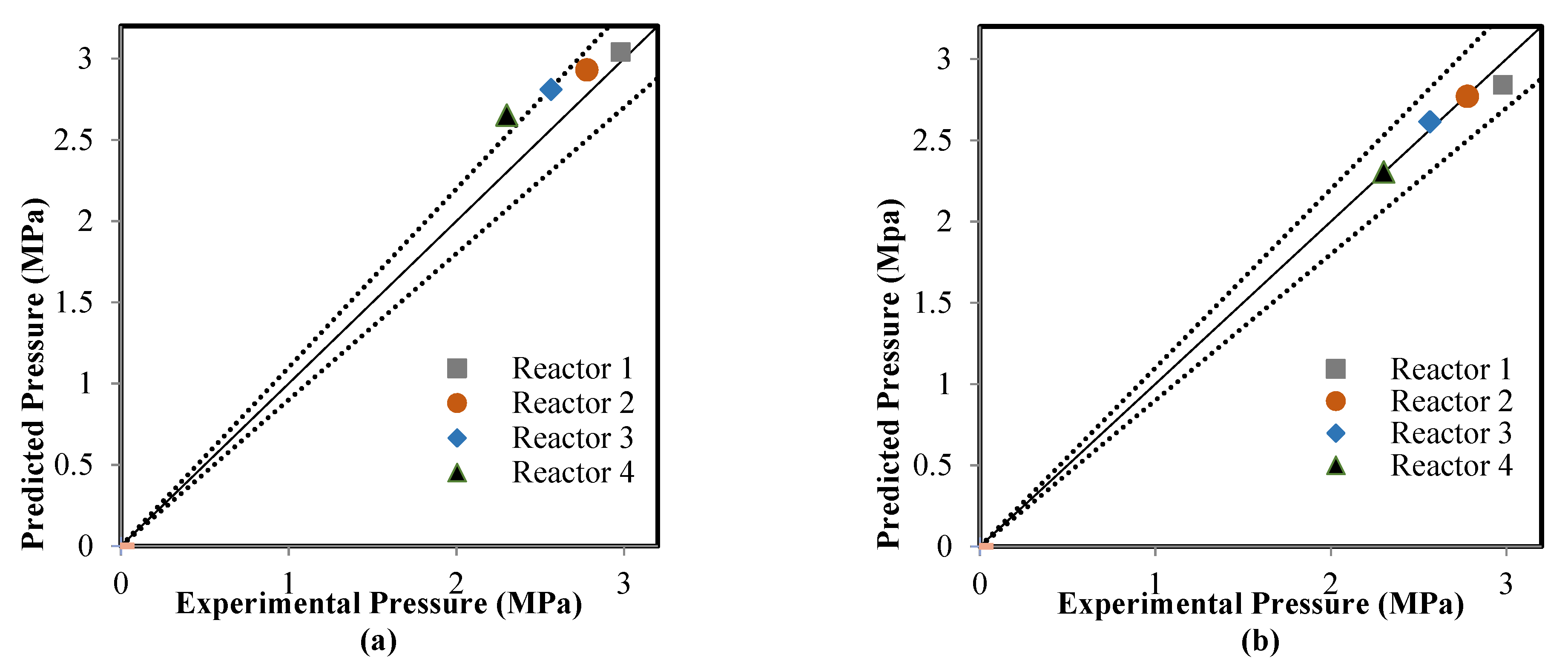
5.2. Comparison between the ANN and RMM Predictions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Ai, Bi, Ci, Di | Specific heat constants |
| Ac | Cross sectional area of the reactor (m2) |
| a | Catalyst activity |
| CP | Specific heat (kJ/kmole.K) |
| Dp | Catalyst particle diameter (m) |
| EA | Activation energy (J/mole) |
| Fi | Molar flow rate of species i (kmole/hr) |
| G | Mass flux (kg/m2 s) |
| gc | Acceleration of gravity (m/s2) |
| Hj | Molar enthalpy (kJ/kmol) |
| Enthalpy of formation (kJ/kmol) | |
| Pre-exponential factor | |
| ki | ith reaction rate (kmole hr−1) |
| Rate constant of catalyst deactivation (day−1) | |
| M | Dataset number |
| N | Component number |
| Partial pressure of ith component (MPa) | |
| Pt | Total pressure (MPa) |
| R | Universal gas constant (J/mole K) |
| r | Rate of reaction (kmole/kgcat hr) |
| S | Stoichiometry of reaction |
| t | Time (day) |
| T | Temperature (K) |
| To | Reference temperature (K) |
| w | Weight of catalyst (kg) |
| y | Weight fraction |
| Z | Reactor length (m) |
| Superscript | |
| norm | Normalized |
| Subscript | |
| exp | Experimental |
| i | Component number |
| j | Reaction number |
| min | Minimum |
| max | Maximum |
| pred | Predicted |
| Greek letters | |
| Void fraction (m3/m3) | |
| α | Power of pressure effect |
| Viscosity (kg/m·s) | |
| ρ | Density (Kg/m3) |
| ρc | Catalyst density (Kg/m3) |
| ∆HRj | Heat of reaction (kJ/kmole) |
References
- Shakor, Z.M. Catalytic Reforming of Heavy Naphtha, Analysis and Simulation. Diyala J. Eng. Sci. 2011, 4, 86–104. [Google Scholar]
- Saihod, R.H.; Shakoor, Z.M.; Jawad, A.A. Prediction of Reaction Kinetic of Al-Doura Heavy Naphtha Reforming Process Using Genetic Algorithm. Al-Khwarizmi Eng. J. 2014, 10, 47–61. [Google Scholar]
- Chang, A.; Pashikanti, K.; Liu, Y.A. Refinery Engineering; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Fahim, M.A.; Al-Sahhaf, T.A.; Elkilani, A. Fundamentals of Petroleum Refining; Elsevier: Amsterdam, The Netherlands, 2009. [Google Scholar]
- Tailleur, R.G. Cross-Flow naphtha reforming in stacked-bed radial reactors with continuous solid circulation: Catalyst deactivation and solid circulation between reactors. Energy Fuels 2012, 26, 6938–6959. [Google Scholar] [CrossRef]
- Iranshahi, D.; Karimi, M.; Amiri, S.; Jafari, M.; Rafiei, R.; Rahimpour, M.R. Modeling of naphtha reforming unit applying detailed description of kinetic in continuous catalytic regeneration process. Chem. Eng. Res. Des. 2014, 92, 1704–1727. [Google Scholar] [CrossRef]
- Elizalde, I.; Ancheyta, J. Dynamic modeling and simulation of a naphtha catalytic reforming reactor. Appl. Math. Model. 2015, 39, 764–775. [Google Scholar] [CrossRef]
- Babaqi, B.S.; Takriff, M.S.; Kamarudin, S.K.; Othman, N.T.A. Mathematical modeling, simulation, and analysis for predicting improvement opportunities in the continuous catalytic regeneration reforming process. Chem. Eng. Res. Des. 2018, 132, 235–251. [Google Scholar] [CrossRef]
- Dong, X.J.; He, Y.J.; Shen, J.N.; Ma, Z.F. Multi-zone parallel-series plug flow reactor model with catalyst deactivation effect for continuous catalytic reforming process. Chem. Eng. Sci. 2018, 175, 306–319. [Google Scholar] [CrossRef]
- Yusuf, A.Z.; Aderemi, B.; Patel, R.; Mujtaba, I.M. Study of Industrial Naphtha Catalytic Reforming Reactions via Modelling and Simulation. Processes 2019, 7, 192. [Google Scholar] [CrossRef] [Green Version]
- Shakor, Z.M.; AbdulRazak, A.A.; Sukkar, K.A. A Detailed Reaction Kinetic Model of Heavy Naphtha Reforming. Arab. J. Sci. Eng. 2020, 45, 7361–7370. [Google Scholar] [CrossRef]
- Pishnamazi, M.; Taghvaie Nakhjiri, A.; Rezakazemi, M.; Marjani, A.; Shirazian, S. Mechanistic modeling and numerical simulation of axial flow catalytic reactor for naphtha reforming unit. PLoS ONE 2020, 11, e0242343. [Google Scholar] [CrossRef]
- Ebrahimian, S.; Iranshahi, D. Modeling and optimization of thermally coupled reactors of naphtha reforming and propane ammoxidation with different feed distributions. React. Kinet. Mech. Catal. 2020, 129, 315–335. [Google Scholar] [CrossRef]
- Yusuf, A.Z.; Johna, Y.M.; Aderemi, B.O.; Patel, R.; Mujtaba, I.M. Effect of hydrogen partial pressure on catalytic reforming process of naphtha. Comput. Chem. Eng. 2020, 143, 107090. [Google Scholar] [CrossRef]
- Ochoa-Estopier, L.M.; Jobson, M.; Smith, R. Operational optimization of crude oil distillation systems using artificial neural networks. Comput. Chem. Eng. 2013, 59, 178–185. [Google Scholar] [CrossRef]
- Osuolale, F.N.; Zhang, J. Energy efficiency optimisation for distillation column using artificial neural network models. Energy 2016, 106, 562–578. [Google Scholar] [CrossRef] [Green Version]
- VO, N.D.; Oh, D.H.; Hong, S.H.; Oh, M.; Lee, C.H. Combined approach using mathematical modelling and artificial neural network for chemical industries: Steam methane reformer. Appl. Energy 2019, 255, 113809. [Google Scholar] [CrossRef]
- Ochoa-Estopier, L.M.; Jobson, M.; Smith, R. Retrofit of heat exchanger networks for optimizing crude oil distillation operation. Chem. Eng. Trans. 2013, 35, 133–138. [Google Scholar]
- Davoudi, E.; Vaferi, B. Applying artificial neural networks for systematic estimation of degree of fouling in heat exchangers. Chem. Eng. Res. Des. 2018, 130, 138–153. [Google Scholar] [CrossRef]
- Zamaniyan, A.; Joda, F.; Behroozsarand, A.; Ebrahimi, H. Application of artificial neural networks (ANN) for modeling of industrial hydrogen plant. Int. J. Hydrogen Energy 2013, 38, 6289–6297. [Google Scholar] [CrossRef]
- Farobie, O.; Hasanah, N.; Matsumura, Y. Artificial Neural Network Modeling to Predict Biodiesel Production in Supercritical Methanol and Ethanol Using Spiral Reactor. Procedia Environ. Sci. 2015, 28, 214–223. [Google Scholar] [CrossRef] [Green Version]
- Sadighi, S.; Mohaddecy, R.S. Predictive modeling for industrial naphtha reforming plant using artificial neural network with recurrent layers. Int. J. Technol. 2013, 4, 102–111. [Google Scholar] [CrossRef]
- Elfghi, F.M. A hybrid statistical approach for modeling and optimization of RON: A comparative study and combined application of response surface methodology (RSM) and artificial neural network (ANN) based on design of experiment (DOE). Chem. Eng. Res. Des. 2016, 113, 264–272. [Google Scholar] [CrossRef]
- Liang, K.; Guo, H.; Pan, S. A study on naphtha catalytic reforming reactor simulation and analysis. J. Zhejiang Univ. Sci. B 2005, 6, 590–596. [Google Scholar] [CrossRef] [Green Version]
- Ancheyta-Juárez, J.; Villafuerte-Macías, E. Kinetic Modeling of Naphtha Catalytic Reforming Reactions. Energy Fuels 2000, 14, 1032–1037. [Google Scholar] [CrossRef]
- Reid, R.C.; Prausnitz, J.M.; Poling, B.E. The Properties of Gases and Liquids, 4th ed.; McGraw-Hill Book Company: New York, NY, USA, 1987. [Google Scholar]
- Stijepovic, M.Z.; Vojvodic-Ostojic, A.; Milenkovic, I.; Linke, P. Development of a Kinetic Model for Catalytic Reforming of Naphtha and Parameter Estimation Using Industrial Plant Data. Energy Fuels 2009, 23, 979–983. [Google Scholar] [CrossRef]
- Behin, J.; Kavianpour, H.R. A Comparative Study for the Simulation of Industrial Naphtha Reforming Reactors with Considering Pressure Drop on Catalyst. Pet. Coal 2009, 51, 208–215. [Google Scholar]
- Ergun, S. Fluid flow through packed columns. Chem. Eng. Prog. 1952, 48, 89–94. [Google Scholar]
- Argyle, M.; Bartholomew, C. Heterogeneous Catalyst Deactivation and Regeneration: A Review. Catalysts 2015, 5, 145–269. [Google Scholar] [CrossRef] [Green Version]
- Rostami, A.; Anbaz, M.A.; Gahrooei, H.R.E.; Arabloo, M.; Bahadori, A. Accurate estimation of CO2 adsorption on activated carbon with multi-layer feed-forward neural network (MLFNN) algorithm. Egypt. J. Pet. 2018, 27, 65–73. [Google Scholar] [CrossRef]
- Elçiçek, H.; Akdoğan, E.; Karagöz, S. The use of artificial neural network for prediction of dissolution kinetics. Sci. World J. 2014, 2014, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Aber, S.; Amani-Ghadim, A.R.; Mirzajani, V. Removal of Cr (VI) from polluted solutions by electrocoagulation: Modeling of experimental results using artificial neural network. J. Hazard. Mater. 2009, 171, 484–490. [Google Scholar] [CrossRef]
- Rene, E.R.; Veiga, M.C.; Kennes, C. Experimental and neural model analysis of styrene removal from polluted air in a biofilter. J. Chem. Technol. Biotechnol. 2009, 84, 941–948. [Google Scholar] [CrossRef] [Green Version]
- Montgomery, D.C. Design and Analysis of Experiments, 6th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Weight Fraction | |||||
|---|---|---|---|---|---|
| Lump | Feed | Reactor A | Reactor B | Reactor C | Reactor D |
| P1 | 0 | 0 | 0 | 0 | 0 |
| P2 | 0 | 0 | 0 | 0 | 0 |
| P3 | 0.72 | 0 | 0 | 0 | 0 |
| n-P4 | 0.43 | 0.22 | 0.32 | 0.31 | 0.21 |
| n-P5 | 0.52 | 0.81 | 0.86 | 0.79 | 0.63 |
| n-P6 | 3.67 | 2.38 | 2.37 | 2.22 | 1.68 |
| n-P7 | 0 | 3.53 | 3.28 | 2.63 | 1.89 |
| n-P8 | 8.87 | 5.57 | 3.2 | 2.17 | 1.58 |
| n-P9 | 6.58 | 0.26 | 0.25 | 0.25 | 0.48 |
| n-P10 | 2.42 | 3.28 | 1.88 | 0.22 | 0.17 |
| n-P11 | 0.2 | 0.25 | 0.33 | 0.36 | 0.11 |
| i-P4 | 0.35 | 0.15 | 0.32 | 0.15 | 0.18 |
| i-P5 | 0.36 | 0.94 | 0.93 | 0.79 | 0.75 |
| i-P6 | 3.17 | 5.19 | 6.12 | 6.07 | 5.16 |
| i-P7 | 4.57 | 6.05 | 6.43 | 6.05 | 5.11 |
| i-P8 | 9.77 | 7.11 | 5.9 | 4.92 | 3.72 |
| i-P9 | 13.28 | 10.02 | 7.85 | 5.93 | 3.71 |
| i-P10 | 9.02 | 9.15 | 7.46 | 7.14 | 3.02 |
| i-P11 | 1.19 | 2.8 | 3.22 | 4.77 | 0.36 |
| MCP | 0.26 | 0.23 | 0.28 | 0.28 | 0.27 |
| N6 | 2.07 | 0 | 0 | 0 | 0 |
| N7 | 4.84 | 0.57 | 0.45 | 0.39 | 0.37 |
| N8 | 7.02 | 0.86 | 0.81 | 0.68 | 0.49 |
| N9 | 0.95 | 0 | 0 | 0 | 0 |
| N10 | 3.9 | 0 | 0 | 0 | 0 |
| N11 | 0 | 0 | 0 | 0 | 0 |
| A6 | 0.35 | 0.8 | 1.15 | 1.35 | 1.32 |
| A7 | 2.84 | 6.33 | 8.86 | 10.95 | 12.27 |
| A8 | 8.31 | 14.5 | 19.14 | 23.53 | 26.94 |
| A9 | 3.97 | 19 | 18.59 | 18.05 | 29.58 |
| A10 | 0.37 | 0 | 0 | 0 | 0 |
| A11 | 0 | 0 | 0 | 0 | 0 |
| Catalyst loading (kg) | 2700 | 4500 | 4750 | 5875 | |
| Feed temperature (°C) | 470 | 470 | 475 | 475 | |
| Outlet temperature (°C) | 431 | 454 | 476 | 474 | |
| Liquid feed flow rate (m3/hr) | 33.5 | ||||
| Inlet pressure to reactor A (MPa) | 3.04 | ||||
| Outlet pressure from reactor D (MPa) | 2.25 | ||||
| Reaction Step | ko | Reaction Step | ko | Reaction Step | ko | Reaction Step | ko |
|---|---|---|---|---|---|---|---|
| 0.0034 | 0.0074 | 0.0002 | 0.0011 | ||||
| 0.0002 | 0.0010 | 0.3145 | . | 0.8036 | |||
| 0.0111 | 0.0007 | 0.0155 | 0.0317 | ||||
| 0.0073 | 0.0010 | 0.0012 | . | 0.1057 | |||
| 0.0053 | 0.0005 | 0.0021 | 0.0058 | ||||
| 0.0001 | 0.0012 | 0.0011 | 0.0083 | ||||
| 0.0013 | 0.0019 | 0.0000 | 0.0041 | ||||
| 0.0763 | 0.0024 | 0.0018 | 7.5196 | ||||
| 0.0037 | 0.0031 | 0.0039 | 0.1008 | ||||
| 0.0016 | 0.0162 | 0.0296 | 1.4912 | ||||
| 0.0014 | 0.0003 | 0.0072 | 0.0018 | ||||
| 0.0006 | 0.0126 | 0.3902 | 0.0025 | ||||
| 0.0000 | 0.0261 | 0.0021 | 0.0011 | ||||
| 0.0670 | 0.0021 | 0.0003 | 0.0009 | ||||
| 0.0412 | 0.0001 | 0.0007 | 0.0137 | ||||
| 0.0003 | 0.0009 | 0.0248 | 0.0126 | ||||
| 0.0011 | 0.0037 | 0.0230 | 0.0152 | ||||
| 0.0006 | 0.0005 | 0.0994 | 0.0029 | ||||
| 0.0001 | 0.0351 | 0.0097 | 0.0098 | ||||
| 0.1052 | 0.0099 | 0.0035 | 0.0010 | ||||
| 0.0116 | 0.0045 | 0.4533 | 0.0165 | ||||
| 0.0017 | 0.0001 | 0.0100 | 0.0508 | ||||
| 0.0023 | 0.0155 | 0.6178 | 0.0033 | ||||
| 0.0006 | 0.0344 | 0.0016 | 0.0028 | ||||
| 0.0001 | 0.0037 | 0.0086 | 0.0033 | ||||
| 0.4088 | 0.0044 | 0.7168 | 0.7510 | ||||
| 0.0070 | 0.0003 | 0.0373 | 0.9012 | ||||
| 0.4301 | 0.0001 | 0.1945 | 0.0038 | ||||
| 0.0331 | 0.0861 | 0.0013 | 0.0008 | ||||
| 0.0035 | 0.0149 | 0.5233 | 0.0179 | ||||
| 0.0004 | 0.0047 | 0.0020 | 0.0501 | ||||
| 0.0052 | 0.0004 | 0.0182 | 0.0038 | ||||
| 0.0592 | 0.0008 | 0.0026 | 0.0435 |
| ) | 52,712 | −0.66 |
| ) | 72,254 | 0.20 |
| ) | 135,455 | 0.00 |
| ) | 40,528 | 0.11 |
| ) | 186,470 | 0.49 |
| ) | 23,345 | 0.96 |
| ) | 138,888 | 0.29 |
| ) | 138,635 | 1.17 |
| ) | 149,622 | 0.70 |
| Variable | Minimum | Maximum |
|---|---|---|
| Mole fraction | 0 | 0.2353 |
| Temperature (°K) | 697.1500 | 743.1500 |
| Pressure (MPa) | 2.6700 | 3.0400 |
| Catalyst weight (kg) | 2700 | 5875 |
| Time (day) | 0 | 1225 |
| Input Layer | Input Data (36 Features) |
|---|---|
| Number of hidden layers | 3 |
| Hidden neuron for each hidden layer | 10 |
| Output layer | Prediction of naphtha reforming performance (34) |
| Performance function | Mean squared error (MSE) |
| Activation function | Sigmoid |
| Learning rate | 0.0001 |
| Maximum number of iterations | 100,000 |
| Gradient | 0.00001 |
| Type of activation sigmoid | Tan-Sigmoid |
| Algorithm used for training | Levenberg–Marquardt |
| Mathematical Model | Artificial Neural Network | |||||
|---|---|---|---|---|---|---|
| Composition | Temperature | Pressure | Composition | Temperature | Pressure | |
| Coefficient of determination (R2) | 0.9318 | 0.8951 | 0.4859 | 0.9403 | 0.9736 | 0.9467 |
| Mean absolute error (MAE) | 0.0070 | 4.0939 | 1.6248 | 0.0062 | 2.2246 | 0.4010 |
| %Mean relative error (MRE) | - | 0.5679 | 6.4959 | - | 0.4774 | 1.4129 |
| Mean square error (MSE) | 2.284 × 10−4 | 37.329 | 5.303 | 2.0443 × 10−4 | 21.6587 | 1.1988 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Shathr, A.; Shakor, Z.M.; Majdi, H.S.; AbdulRazak, A.A.; Albayati, T.M. Comparison between Artificial Neural Network and Rigorous Mathematical Model in Simulation of Industrial Heavy Naphtha Reforming Process. Catalysts 2021, 11, 1034. https://doi.org/10.3390/catal11091034
Al-Shathr A, Shakor ZM, Majdi HS, AbdulRazak AA, Albayati TM. Comparison between Artificial Neural Network and Rigorous Mathematical Model in Simulation of Industrial Heavy Naphtha Reforming Process. Catalysts. 2021; 11(9):1034. https://doi.org/10.3390/catal11091034
Chicago/Turabian StyleAl-Shathr, Ali, Zaidoon M. Shakor, Hasan Sh. Majdi, Adnan A. AbdulRazak, and Talib M. Albayati. 2021. "Comparison between Artificial Neural Network and Rigorous Mathematical Model in Simulation of Industrial Heavy Naphtha Reforming Process" Catalysts 11, no. 9: 1034. https://doi.org/10.3390/catal11091034
APA StyleAl-Shathr, A., Shakor, Z. M., Majdi, H. S., AbdulRazak, A. A., & Albayati, T. M. (2021). Comparison between Artificial Neural Network and Rigorous Mathematical Model in Simulation of Industrial Heavy Naphtha Reforming Process. Catalysts, 11(9), 1034. https://doi.org/10.3390/catal11091034