Abstract
Entity resolution in real-world datasets remains a persistent challenge, particularly for identifying households and detecting co-residence patterns within noisy and incomplete data. While Large Language Models (LLMs) show promise, monolithic approaches often suffer from limited scalability and interpretability. This study introduces a multi-agent Retrieval-Augmented Generation (RAG) framework that decomposes household entity resolution into coordinated, task-specialized agents implemented using LangGraph. The system includes four agents responsible for direct matching, transitive linkage, household clustering, and residential movement detection, combining rule-based preprocessing with LLM-guided reasoning. Evaluation on synthetic S12PX dataset segments containing 200–300 records demonstrates 94.3% accuracy on name variation matching and a 61% reduction in API calls compared to single-LLM baselines, while maintaining transparent and traceable decision processes. These results indicate that coordinated multi-agent specialization improves efficiency and interpretability, providing a structured and extensible approach for entity resolution in census, healthcare, and other administrative data domains.
1. Introduction
In modern data ecosystems, entity resolution (ER) remains a foundational yet persistently challenging problem. ER refers to the process of identifying and linking records that correspond to the same real-world entities across heterogeneous, noisy, and incomplete data sources [,]. The ability to accurately match and unify such records is critical in numerous domains, including census operations, healthcare analytics, administrative data integration, and knowledge graph construction. Failures in ER can lead to duplicated identities, biased statistics, and impaired decision-making, underscoring its fundamental role in trustworthy data management [,].
Traditional ER methods rely on deterministic or probabilistic matching rules that use string similarity metrics, phonetic encodings, or clustering-based heuristics. While effective in structured environments, these methods often falter when confronted with real-world datasets containing unstructured text, abbreviations, typographical variations, missing fields, or semantic ambiguity. The increasing scale and heterogeneity of administrative and observational data sources further exacerbate the problem, calling for methods that are adaptive, explainable, and capable of handling incomplete information.
Recent advances in Large Language Models (LLMs) have introduced new possibilities for addressing these challenges. LLMs demonstrate remarkable abilities in understanding semantic relationships, interpreting ambiguous text, and generating human-like reasoning [,]. In the context of ER, these capabilities enable LLMs to perform contextual matching, infer missing relationships, and resolve records with limited structural cues [,]. However, despite these advantages, single-LLM architectures often encounter limitations in scalability, interpretability, and reliability. Relying on a single model to handle multiple specialized reasoning tasks can lead to inefficiency, hallucinations, and opaque decision processes that hinder reproducibility and trust in operational systems.
To overcome these limitations, researchers are increasingly exploring multi-agent architectures as a paradigm for decomposing complex reasoning workflows. In such architectures, multiple specialized agents cooperate and communicate to solve subproblems within a shared environment [,]. This approach mirrors human collaborative problem-solving, where tasks are distributed among experts to enhance specialization, reduce cognitive overload, and increase transparency. When combined with Retrieval-Augmented Generation (RAG) [], multi-agent frameworks can dynamically access external knowledge sources and ensure factual grounding, significantly improving performance and interpretability in knowledge-intensive tasks [,,].
Building on these recent advances, this study introduces a Multi-Agent RAG Framework for Entity Resolution, a system that extends beyond monolithic LLM models by employing a team of specialized agents designed for distinct sub-tasks in household and administrative record resolution. The proposed framework is implemented using LangGraph, which facilitates structured orchestration, memory management, and transparent communication among agents. The system consists of four cooperating agents:
- Direct Agent: performs deterministic name-based record matching;
- Indirect Agent: identifies transitive and relational linkages;
- Household Agent: clusters records based on address and residence patterns;
- Household Moves Agent: tracks relocations and temporal transitions of entities across datasets.
Each agent integrates a customized RAG retrieval strategy and a hybrid data cleaning pipeline that combines deterministic preprocessing with LLM-powered contextual interpretation. Together, these components form a modular and interpretable system that can reason across heterogeneous data sources with reduced computational overhead and improved decision transparency.
The framework is evaluated using synthetic S12PX datasets, which replicate real-world administrative and census data conditions with inconsistencies, missing fields, and duplicate entries. Experimental results demonstrate a 94.3% accuracy in resolving name variations, a 61% reduction in API calls, and complete decision traceability, significantly outperforming conventional single-LLM approaches in both efficiency and interpretability.
The complete implementation, datasets, and configuration files for the proposed framework are publicly available on GitHub (GitHub repository, https://github.com/Aatif123-hub/Household-Discovery-using-Multi-Agents/tree/langchain-multiagents accessed on 20 September 2025), ensuring full transparency and reproducibility of the experiments.
The aim of this research is to design a scalable and interpretable architecture for entity resolution that combines the reasoning power of Large Language Models (LLMs) with the modularity of multi-agent coordination. The specific objectives are to:
- Develop a multi-agent RAG-based framework that decomposes the entity resolution process into specialized and cooperative tasks;
- Integrate hybrid rule-based and LLM-powered data cleaning mechanisms to enhance input reliability and model transparency;
- Demonstrate scalability and efficiency improvements through LangGraph-based orchestration and controlled inter-agent communication;
- Validate the framework through quantitative and qualitative experiments simulating real administrative datasets.
The contributions of this study extend beyond the architectural proposal to the broader research context. Specifically, this work presents a comprehensive multi-agent framework that advances entity resolution by emphasizing task specialization, transparency, and computational efficiency. By combining deterministic preprocessing and LLM-driven contextual reasoning, the framework achieves enhanced performance and interpretability compared with conventional single-LLM models. Through its LangGraph implementation, the study demonstrates how modular orchestration can balance scalability with explainability in real-world scenarios. Empirical validation on synthetic administrative datasets further evidences the system’s robustness and generalizability, establishing a foundation for next-generation entity resolution systems in census, healthcare, and administrative data environments.
Overall, this study contributes to the growing body of research at the intersection of multi-agent systems, large language models, and data integration. By illustrating how specialized agents can collaborate through retrieval-augmented reasoning, it provides a scalable and interpretable blueprint for intelligent data management across diverse domains.
2. Literature Review
Entity Resolution (ER) remains a cornerstone of data management research, addressing the identification and linkage of records representing the same real-world entities across diverse and imperfect datasets. Foundational studies in ER established principles for data standardization, linkage accuracy, and quality governance, emphasizing the iterative nature of maintaining high-quality entity representations throughout the data life cycle [,]. These early frameworks provided a robust conceptual foundation for reproducible entity linking but relied heavily on deterministic rule systems that required domain-specific tuning, which limited adaptability across heterogeneous sources.
Traditional ER approaches, including rule-based, probabilistic, and blocking strategies, achieved moderate success in structured datasets but performed poorly in noisy, multi-source environments. Their dependence on hand-crafted similarity rules and lack of semantic understanding made them ill-suited for unstructured or cross-lingual data integration. As data variety and volume increased, machine learning-based ER emerged to automate feature extraction and weighting. Research integrating deep neural architectures demonstrated improved generalization by learning semantic similarity across entity attributes, yet these systems remained opaque, computationally intensive, and reliant on extensive labeled data [,,]. Further advancements in graph-based modeling have introduced contextual semantics and attention mechanisms to capture latent entity relationships across structured and unstructured datasets [] Additionally, their black-box nature posed significant challenges for interpretability and auditability, which are essential for high-stakes applications such as census operations and administrative record linkage [].
The introduction of Large Language Models (LLMs) has redefined ER paradigms by providing contextual and linguistic reasoning capabilities [,]. Studies utilizing pre-trained and knowledge-augmented language models have shown superior performance in identifying semantically related entities across schema and language boundaries. However, LLM-driven systems often exhibit inconsistency, hallucination, and sensitivity to prompt formulation. Despite their contextual strength, most existing LLM-based ER frameworks remain monolithic and sequential, lacking modular design and explainable reasoning pathways [,,]. Moreover, scalability issues arise when deploying LLMs across large administrative databases, as end-to-end generative inference becomes computationally expensive and difficult to parallelize efficiently.
Generative AI has also been increasingly employed in related domains such as entity linking, entity set expansion, and event causality modeling. Recent work has explored dynamic retrieval and resolution of evolving entities through retrieval-augmented frameworks, demonstrating the potential for temporal adaptability in knowledge-intensive ER tasks []. Research introducing autoregressive and informed decoding frameworks has shown that generative models can generate candidate matches and refine entity labels without explicit supervision [,,]. These models excel in handling ambiguity but lack fine-grained control over reasoning transparency. Similarly, generative frameworks for Entity Set Expansion and knowledge graph construction have enhanced scalability but rely on constrained decoding mechanisms that may overlook nuanced semantic relationships [,]. Furthermore, most generative ER models operate in isolation without mechanisms for multi-stage verification, iterative refinement, or external knowledge retrieval, resulting in limited interpretability and reproducibility.
In addition to methodological advances, there has been a growing awareness of the limitations of existing ER evaluation frameworks. Benchmarking efforts have revealed that common datasets often oversimplify real-world linkage tasks, failing to represent diverse schemas, noise levels, and relational complexities []. Synthetic data generation approaches have been proposed to improve reproducibility and coverage, but many still rely on handcrafted distributions that cannot fully capture the variability of real administrative or census data []. Unsupervised and zero-shot approaches offer domain adaptability but frequently suffer from unstable convergence and reduced precision in ambiguous cases [,]. Overall, existing research demonstrates clear progress but leaves gaps in scalability, transparency, and cross-domain generalization.
Recent efforts have explored the convergence of ER and multi-agent reasoning architectures [,]. Multi-agent frameworks allow distributed problem solving, where specialized agents handle subtasks such as blocking, attribute normalization, and match verification. Emerging studies have further demonstrated that multi-agent retrieval-augmented systems, including collaborative and hierarchical RAG frameworks, improve knowledge coordination and factual grounding across distributed agents [,]. However, these prior approaches predominantly focus on parallel or ensemble-based coordination, where multiple agents contribute independent responses that are later aggregated, often lacking explicit procedural control or structured dependency between reasoning stages.
In contrast, the proposed framework introduces a task-specialized, sequential orchestration strategy in which each agent performs a distinct semantic role (Direct, Indirect, Household, and Move Detection) within a deterministic reasoning pipeline. Outputs from earlier agents directly inform the reasoning context of subsequent agents, enforcing structured inter-agent dependency rather than parallel response aggregation. The integration of LangGraph enables explicit state management, traceable reasoning transitions, and controlled execution flow, which are largely absent from earlier collaborative RAG systems. This shift from model-centric collaboration to role-driven procedural orchestration represents a distinct methodological contribution, particularly in the context of entity resolution where auditability, reproducibility, and controlled reasoning paths are essential.
In parallel with these conceptual advancements, several recent studies have demonstrated practical applications of multi-LLM and retrieval-augmented architectures across diverse domains. One line of research introduced a retrieval-augmented multi-LLM ensemble for industrial part specification extraction, showing that distributed inference pipelines can significantly improve precision and contextual grounding in technical documentation []. Another study proposed a policy-aware generative AI framework for secure and auditable data access governance, highlighting the role of explainable LLM reasoning in regulated data environments []. Complementary research explored multilingual and household-level entity resolution using LLM ensembles, establishing benchmarks for cross-lingual record linkage and household movement detection [,,]. Collectively, these studies illustrate the expanding scope of retrieval-augmented and multi-LLM techniques, reinforcing their potential as foundational components for next-generation entity resolution systems.
Despite the remarkable advances in ER and generative modeling, a key research gap persists at the intersection of explainability, scalability, and orchestration. Existing LLM-based and generative systems primarily operate as monolithic models with limited transparency into intermediate reasoning states. Current multi-agent architectures, while conceptually promising, often lack a principled retrieval mechanism that allows agents to ground their reasoning in external evidence. Moreover, few frameworks integrate hybrid rule-based and generative reasoning in a unified architecture that ensures both precision and contextual adaptability.
The present research addresses these limitations by introducing a Retrieval-Augmented Generation (RAG) framework for Entity Resolution built on multi-agent collaboration. Unlike prior works, this framework decomposes ER into modular, specialized agents that cooperate through LangGraph-based orchestration. This design allows each agent to perform focused tasks such as data cleaning, blocking, candidate retrieval, and verification while maintaining a transparent reasoning trail. By integrating hybrid deterministic and LLM-driven methods, the proposed system achieves a balance between interpretability and contextual intelligence. Furthermore, the architecture introduces explicit retrieval layers to ground generative reasoning in verifiable evidence, mitigating hallucination and enhancing traceability. Compared to existing single-LLM or heuristic systems, this multi-agent RAG framework provides superior scalability, transparency, and adaptability for complex, real-world administrative and census datasets.
3. System Architecture and Framework
The proposed framework implements a multi-agent Retrieval-Augmented Generation (RAG) architecture for Entity Resolution (ER) using modular coordination, hybrid reasoning, and evidence-grounded decision making. The complete workflow, shown in Figure 1, integrates data preprocessing, embedding-based retrieval, and agent-level reasoning into a unified orchestration managed through LangGraph. This design supports scalability, transparency, and interpretability across heterogeneous datasets such as administrative or census records.
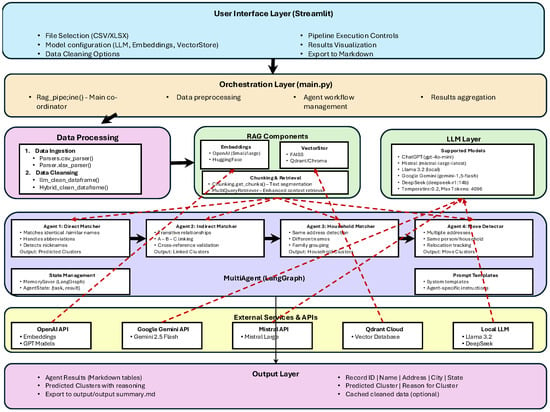
Figure 1.
Multi-Agent System Architecture for Household Discovery. The figure presents the layered pipeline and interactions between system components, specialized agents, and shared state management used for entity resolution and household discovery.
3.1. Overall System Design
The proposed multi-agent Retrieval-Augmented Generation (RAG) framework is designed as a modular, layered system that integrates multiple reasoning, retrieval, and data management components into a cohesive pipeline. The design principle emphasizes interpretability, scalability, and flexibility, ensuring that each functional layer can evolve independently while maintaining seamless interoperability with the rest of the architecture.
The system consists of five major layers: (1) the User Interface Layer, (2) the Orchestration Layer, (3) the RAG Components and LLM Layer, (4) the Multi-Agent Workflow, and (5) the Output and Evaluation Layer. Each layer performs a specific set of operations while contributing to the shared objectives of entity discovery, household detection, and movement tracking. Inter-agent and inter-layer communication are facilitated through a shared state management mechanism and a retrieval-enhanced communication model.
Data flows sequentially across these layers, beginning with ingestion and preprocessing in the UI and orchestration layers, followed by contextual embedding, multi-agent reasoning, and final result synthesis in the output layer. This layered abstraction not only improves transparency and modularity but also allows the framework to support diverse deployment scenarios, including local execution for privacy-sensitive administrative data and cloud-based orchestration for large-scale research applications. The architecture’s layered design also facilitates maintenance, debugging, and the incorporation of additional agents or retrieval sources without restructuring the core pipeline.
3.2. User Interface Layer
The User Interface (UI) layer provides an accessible and interactive environment for end-users to manage data ingestion, configuration, and result visualization. It is implemented using the Streamlit framework, chosen for its lightweight design, ease of integration with Python backends, and suitability for rapid prototyping of data-driven applications. The interface supports file uploads in CSV or XLSX formats, automatically parsing datasets and allowing users to select specific columns or attributes for entity resolution.
In addition to basic file management, the UI layer enables the configuration of system parameters such as model selection, embedding dimensions, retrieval database choice, and orchestration mode (sequential or parallel). Through intuitive controls, users can launch and monitor pipeline execution, inspect intermediate results, and visualize linkage clusters as they are generated by different agents. The interface also incorporates progress tracking and log visualization, offering real-time insights into system performance and reasoning stages.
A significant advantage of the UI layer is its ability to export results directly into Markdown summaries or CSV tables, making outputs immediately reusable for documentation or further analysis. By integrating this visualization and reporting capability, the framework promotes transparency and reproducibility, allowing researchers, analysts, and policymakers to trace and interpret the results of each agent’s decision-making process. Overall, the UI layer bridges the gap between complex multi-agent orchestration and user-centric accessibility, enhancing both operational usability and research interpretability.
3.3. Orchestration Layer
The orchestration layer serves as the central controller of the entire framework, managing data flow, agent coordination, and overall workflow execution. Implemented in Python, this layer utilizes LangGraph to define and regulate communication between agents through a graph-based orchestration model. Each node in the LangGraph corresponds to a specialized agent or module, while edges define the flow of data, control dependencies, and iterative feedback paths. This structure enables both sequential and parallel processing, allowing the system to adapt dynamically to task complexity and dataset size.
At the beginning of each run, the orchestration layer initializes the RAG pipeline, handles preprocessing tasks, and assigns agent responsibilities based on configuration parameters. It then monitors the execution of agents, tracks intermediate results, and synchronizes state updates within a global memory context. This process ensures that each agent has access to the latest contextual data and can retrieve necessary evidence before reasoning or decision-making.
Beyond coordination, the orchestration layer also supports dynamic scheduling and error recovery. If an agent encounters ambiguous or incomplete results, the orchestrator can trigger selective reprocessing, ensuring robust completion of the pipeline. Additionally, this layer integrates performance monitoring and logging, providing detailed traces of system execution for debugging and evaluation.
By decoupling control flow from computation, the orchestration layer achieves a high level of modularity and transparency. It ensures that workflow reproducibility and auditability are preserved while enabling flexible adaptation to future model upgrades, additional agents, or alternative data sources. As such, this layer embodies the framework’s guiding principles of structured coordination, hybrid reasoning, and scalable execution.
3.4. RAG Components and LLM Integration
This layer forms the computational and cognitive core of the proposed system. It integrates retrieval-augmented reasoning with large language model (LLM) inference, enabling each agent to access semantically rich contextual information during the entity resolution process. The RAG components provide the mechanisms for transforming cleaned data into vectorized representations, managing retrieval from large-scale vector stores, and grounding LLM reasoning on factual and verifiable evidence. In this architecture, the RAG layer acts as the connective tissue between deterministic data processing and generative reasoning, allowing symbolic records to be seamlessly interpreted in natural language contexts.
The design of this layer is guided by three complementary objectives: (1) to ensure efficient and scalable retrieval from high-dimensional spaces, (2) to maintain semantic coherence between structured data and unstructured reasoning, and (3) to minimize hallucination through retrieval-grounded generation. Together, these mechanisms create the foundation for hybrid reasoning, where rule-based and statistical inference are augmented by contextualized, evidence-driven generation.
3.4.1. Embedding and Vector Store Management
The embedding and vector storage subsystem transforms cleaned and standardized records into high-dimensional semantic representations. Each entity’s attributes, such as names, addresses, and demographic identifiers, are encoded into dense vector embeddings that capture both lexical and contextual relationships. These embeddings allow the system to measure similarity between entities beyond literal string comparison, accommodating linguistic variation, abbreviation, and typographical inconsistencies that often occur in real-world administrative data.
To ensure flexibility and domain adaptability, the system employs multiple embedding providers, including OpenAI (small and large embedding models) and HuggingFace sentence transformers. The embeddings are normalized and indexed using FAISS and Qdrant vector databases, selected for their scalability and fast approximate nearest-neighbor search capabilities. This combination supports semantic retrieval across millions of vectors with sub-second latency, enabling near-real-time augmentation for reasoning agents.
Vector store management includes metadata tracking, version control, and retrieval logging, ensuring that every similarity query and retrieval operation can be traced and reproduced. The system’s vectorization pipeline is fully modular, so new embedding models or similarity metrics (for example cosine or L2) can be substituted without reengineering downstream processes. This design provides both technical scalability and experimental flexibility for researchers evaluating different embedding paradigms.
3.4.2. Chunking and Multi-Query Retrieval
To process large and heterogeneous datasets efficiently, the system implements a dynamic chunking strategy. Raw records and auxiliary texts are segmented into semantically coherent chunks, each containing contextually related information such as address fragments, family groups, or temporal attributes. Chunking ensures that the retrieval process operates at an optimal granularity, large enough to preserve context but small enough to maintain retrieval precision.
Each agent interacts with the retrieval layer through the MultiQueryRetriever module, which generates and issues multiple parallel queries per reasoning task. This approach enhances retrieval diversity and ensures that agents have access to a wide range of relevant contextual evidence. Retrieved results are ranked according to similarity scores and contextual relevance before being integrated into the agent’s reasoning context.
The retrieval process is not static, as agents can issue iterative retrievals as reasoning unfolds, updating their context windows with new information. This iterative RAG mechanism supports refinement in reasoning, allowing agents to incorporate additional evidence if ambiguity or low confidence is detected in earlier reasoning stages. Consequently, the RAG layer serves as both a knowledge retrieval engine and a self-correcting feedback loop that grounds each inference in verifiable data.
3.4.3. LLM Layer and Supported Models
The LLM layer provides the generative reasoning capability required for interpreting, contextualizing, and synthesizing information retrieved from the vector stores. Rather than relying on a single model, the framework adopts a multi-model design to ensure adaptability across reasoning tasks, computational constraints, and data sensitivity requirements. The supported models include ChatGPT (OpenAI GPT-4o-mini, API model ID: gpt-4o-mini), Mistral (mistral-large-latest), Gemini 1.5 Flash (gemini-1.5-flash), Llama 3.2 (local deployment), and DeepSeek (deepseek-r1:14b).
Each LLM can be selectively invoked depending on the agent’s task complexity, the available hardware, and whether local processing is mandated for data privacy. For example, the local Llama 3.2 instance may be used for government or census data where external API calls are restricted, while cloud-based Mistral or Gemini models may be preferred for high-context, large-scale reasoning tasks.
Temperature and token window parameters are dynamically configured during orchestration. Low-temperature settings (0.1–0.3) ensure deterministic responses for verification or record-matching tasks, while moderately higher temperatures (0.4–0.6) may be applied for hypothesis generation or exploratory reasoning. The framework supports up to 4096 tokens per reasoning cycle, balancing expressive capacity with computational efficiency.
Prompt templates and reasoning schemas are customized for each agent, providing task-specific instructions that guide the model’s reasoning behavior. These templates ensure that LLMs follow structured thinking paths aligned with the ER objectives, such as verifying address equivalence, inferring household composition, or identifying potential moves. By embedding explicit reasoning cues, the LLM layer achieves a higher degree of consistency and explainability in its outputs.
The combination of multi-model flexibility, controlled prompt design, and retrieval-grounded reasoning creates a robust LLM integration strategy. This hybrid architecture ensures that large language models do not operate as opaque black boxes but as interpretable and evidence-aware reasoning components within the larger multi-agent ecosystem.
3.4.4. Prompt Engineering for Task-Specialized Agents
The framework employs structured and task-specialized prompts to guide agent behavior, enforce consistency, and minimize hallucination. Each agent (Direct Matcher, Indirect Matcher, Household Detector, Move Detector) operates under explicitly defined domain rules, error tolerance constraints, and strict output schemas to ensure transparency, reproducibility, and controlled reasoning.
The following illustrates the structured prompt template used by the Direct Matching agent.
- DIRECT_MATCH_TEMPLATE = """
- Analyze records {ID1} and {ID2}:
- - Names: "{name1}" vs. "{name2}"
- - Addresses: "{addr1}" vs. "{addr2}"
- - DOB: "{dob1}" vs. "{dob2}"
- Rules:
- 1. Allow phonetic variations (e.g., "Smith" <-> "Smyth").
- 2. Normalize addresses (e.g., "Apt 23" -> "Apartment 23").
- 3. Reject matches if DOB discrepancy > 2 days or SSN conflict exists.
- Output JSON:
- {
- "match": "Yes/No/Uncertain",
- "confidence": 0.0--1.0,
- "reasoning": "[Explanation using rules and evidence]"
- }
- """
Error tolerance is supported through Soundex/NYSIIS encoding for phonetic name similarity and address canonicalization rules (e.g., “St” → “Street”). Matches require a confidence score of ≥0.85 for automatic acceptance, while lower-confidence outputs are routed for human review.
The following prompt template is used by the Household Detection agent for clustering and co-residence inference.
- HOUSEHOLD_TEMPLATE = """
- Cluster records at address "{address}":
- {list_of_records}
- Rules:
- 1. Require >= 2 shared attributes (address, surname, phone).
- 2. Flag conflicting DOBs (>5-year gap) as potential errors.
- 3. Infer co-residence if members share address for >= 6 months.
- Output JSON:
- {
- "household_id": "HH_123",
- "members": ["ID1", "ID2"],
- "move_detected": "Yes/No",
- "reasoning": "[Address normalization and temporal alignment]"
- }
- """
Agents are augmented by retrieved contextual evidence such as voter logs and utility records to validate co-residence and temporal continuity. Move detection compares longitudinal address sequences to identify relocation patterns and confirm household transitions.
3.4.5. Mitigating Hallucinations via Structured Prompts
To reduce hallucination and enforce trustworthiness, the framework combines structured prompting with threshold-driven decision control:
- Rule-Based Sanitization: Inputs are normalized prior to prompting (e.g., “Dr” → “Drive”, “St” → “Street”).
- Retrieval-Augmented Validation: LLM outputs are cross-referenced with retrieved external evidence (e.g., voter or utility logs).
- Threshold-Guided Workflow:
- –
- : Automatic acceptance
- –
- : Human review
- –
- : Reprocessing with expanded context
3.4.6. Example Agent Outputs
The following output illustrates a high-confidence direct match decision produced by the Direct Matching agent.
- {
- "record_ids": ["A928147", "A972885"],
- "match": "Yes",
- "confidence": 0.94,
- "reasoning": "Name ’FRANCINE J KEGLER’ matches
- with phonetic similarity (Soundex: F652).
- Address standardized to ’1701 Westpark Dr, Apt 110’."
- }
This example demonstrates the detection of household relocation based on temporal address transitions and retrieved evidence.
- {
- "household_id": "HH_789",
- "old_address": "1701 Westpark Drive (2020--2022)",
- "new_address": "1710 Westpark Drive (2023--present)",
- "members": ["John Doe", "Mary Doe"],
- "reasoning": "Utility records confirm relocation
- in Q3 2022. Surname consistent, DOB aligned."
- }
3.4.7. Agent Prompt Structure Summary
The Table 1 summarizes the core design logic of each agent, highlighting the key reasoning rules, confidence thresholds for automated decision-making, and the structured output formats that ensure transparency and consistent interpretation across the multi-agent pipeline.

Table 1.
Summary of Agent Prompt Rules and Thresholds.
3.5. Multi-Agent Workflow with LangGraph
The core of the proposed system lies in the multi-agent workflow managed through LangGraph, which enables modular and transparent coordination between reasoning agents. Each agent functions as a specialized cognitive unit that performs a clearly defined subtask within the broader entity resolution (ER) process. The LangGraph framework provides the underlying orchestration logic, defining data dependencies, task order, and communication pathways between agents. Through this graph-based execution model, the system ensures that every operation is both interpretable and reproducible, while allowing for flexible reconfiguration of workflows as new agents or reasoning modules are introduced.
In this workflow, four primary reasoning agents operate in coordination: the Direct Matcher, the Indirect Matcher, the Household Matcher, and the Move Detector. Each of these agents retrieves and processes contextual information from the shared RAG layer, contributing to different phases of entity discovery, linkage inference, and temporal pattern detection. The workflow follows a semi-sequential yet adaptive execution pattern, where agents can trigger feedback loops or conditional reprocessing based on intermediate confidence scores or unresolved ambiguities.
3.5.1. Agent 1: Direct Matcher
The Direct Matcher initiates the ER pipeline by identifying records that are identical or nearly identical across datasets. It performs deterministic matching based on standardized identifiers, exact string comparisons, and rule-based equivalence. This agent also incorporates normalization procedures such as abbreviation expansion and phonetic encoding to capture lexical variants of names and addresses. When ambiguity arises, the agent invokes a lightweight LLM-assisted verification step that cross-references attributes such as birth date, postal code, or household identifier.
The output of the Direct Matcher is a set of high-confidence matched clusters, represented as adjacency lists or grouped record identifiers. These clusters are recorded in the global state memory and serve as the foundation for subsequent agents. By capturing exact and near-exact matches early, the Direct Matcher significantly reduces downstream complexity and ensures that later agents focus primarily on more complex relational or inferred linkages.
3.5.2. Agent 2: Indirect Matcher
The Indirect Matcher handles cases that fall outside the scope of deterministic matching, focusing on semantically related or partially overlapping entities. It applies fuzzy matching algorithms and RAG-enhanced reasoning to identify relationships between records that differ in naming conventions, address formats, or temporal attributes. This agent uses both numerical similarity thresholds and LLM-driven contextual inference to evaluate whether two records likely refer to the same or related individuals.
For example, when two records share a surname and address fragment but have slight differences in given names or date formatting, the Indirect Matcher retrieves relevant contextual evidence and constructs a reasoning trace. This reasoning process includes both attribute comparison and logical inference, such as the probability of typographical error or abbreviation equivalence. The agent can also perform A/B-linking to propagate inferred relationships transitively, merging multiple indirect matches into consistent clusters. This step enhances recall without compromising precision, providing a bridge between rule-based and generative inference within the workflow.
3.5.3. Agent 3: Household Matcher
The Household Matcher advances the workflow from individual-level linkage to collective entity grouping. It analyzes the outputs of the previous agents to infer family or household structures based on co-residence, shared attributes, and relational context. Using RAG-augmented LLM reasoning, the agent interprets combinations of address information, family names, age distributions, and dependency patterns to construct group-level relationships.
This agent employs hierarchical reasoning templates that evaluate not only direct matches but also intra-household dependencies. For instance, if multiple individuals share an address and overlapping surnames but appear across separate datasets, the Household Matcher infers a likely household linkage. When combined with contextual evidence retrieved from vector databases, such as known household structures or administrative templates, the agent can assign probabilistic confidence scores to each inferred cluster. The output consists of consolidated household entities that provide an interpretable representation of family or residential units within the dataset.
3.5.4. Agent 4: Move Detector
The Move Detector extends the analytical scope of the framework by introducing a temporal dimension to entity resolution. It focuses on detecting movement, relocation, or migration patterns of individuals or households across time-indexed datasets. By comparing attribute changes in addresses, postal codes, and demographic variables, this agent identifies potential transitions while ensuring continuity of identity.
The Move Detector leverages prompt-based LLM reasoning supported by retrieved contextual evidence to verify whether observed differences indicate an actual move or simply an administrative update. For example, if a household’s address changes but members remain identical, the system records a relocation event; if members partially differ, it explores scenarios of household division or merging. This capability enables longitudinal tracking and supports applications in demographic analysis, urban mobility studies, and administrative record management.
3.5.5. State Management and Inter-Agent Communication
LangGraph provides a structured mechanism for inter-agent communication through a shared state management system. Each agent operates as a node in the LangGraph, producing outputs that are stored as structured artifacts in a global memory space. These artifacts include matched entity pairs, reasoning logs, confidence scores, and retrieved evidence. Subsequent agents can access these artifacts as input, creating a continuous and traceable reasoning chain.
The shared memory architecture allows asynchronous message passing and context sharing, enabling agents to collaborate without redundant computation. If a downstream agent identifies inconsistencies or low-confidence results, it can request the orchestrator to trigger a re-evaluation of specific nodes, creating a self-correcting loop. This design promotes transparency and resilience, as every reasoning step can be traced, validated, and explained through explicit state transitions.
From an implementation perspective, LangGraph maintains a single authoritative state object for each pipeline run using its built-in AgentState and memory persistence mechanisms. State updates are applied atomically at node boundaries, which prevents uncontrolled concurrent write conflicts during execution. When parallel execution paths are enabled, each agent writes to logically disjoint sections of the state (e.g., dedicated segments for direct matches, indirect matches, or household clusters). Upon convergence of parallel branches, the orchestrator deterministically merges these segments based on predefined state transition rules, ensuring consistent and reproducible state evolution rather than ambiguous “last-write-wins” behavior. This controlled state synchronization guarantees that no agent unintentionally overwrites another agent’s outputs.
Human-in-the-loop verification is also supported within this mechanism. Analysts can review intermediate agent states, interpret reasoning traces, and adjust thresholds or decision rules without disrupting the pipeline. By combining automation with auditability, the state management layer ensures that multi-agent reasoning remains both explainable and reproducible.
Overall, the multi-agent workflow, orchestrated through LangGraph, establishes a highly modular and interpretable framework for entity resolution. It leverages the complementary strengths of deterministic, fuzzy, and generative reasoning, combining them into a cohesive pipeline that can adapt to complex real-world data integration tasks while maintaining strong guarantees of state consistency and traceability.
3.6. External Services and APIs
The framework interfaces with a range of external services and application programming interfaces (APIs) that extend its retrieval, reasoning, and data management capabilities. These integrations allow the system to remain model-agnostic and infrastructure-flexible, supporting both cloud and on-premise deployments depending on computational availability, cost constraints, or data privacy requirements.
The external API layer includes connections to several key components. OpenAI services are used for high-quality embedding generation and general-purpose LLM reasoning, ensuring reliable contextual representations across diverse data domains. The Mistral API provides open-weight deployment flexibility, allowing the system to run advanced generative reasoning models within controlled environments. Google Gemini serves as a hybrid reasoning component, offering fast multi-modal processing and contextual grounding for tasks requiring broader interpretive depth. Qdrant Cloud is employed for managing vector databases, providing scalable semantic search and high-performance indexing for large-scale entity embeddings.
For offline or privacy-sensitive environments, the system also supports local inference using open-source models such as Llama 3.2 and DeepSeek. These local deployments are particularly useful for government or administrative datasets where external data transfer is restricted. The framework automatically detects whether cloud APIs or local models are available and dynamically routes tasks accordingly, ensuring continuous operation even in limited-connectivity conditions. This hybrid integration strategy balances performance and security, enabling consistent reasoning quality regardless of the environment.
To maintain reliability and traceability, the framework includes built-in monitoring and logging for all API calls. Each external interaction is recorded with timestamps, response metrics, and task identifiers, facilitating debugging, auditing, and performance evaluation. The modular API design also enables straightforward expansion, allowing additional retrieval engines or language models to be incorporated as the technology landscape evolves. As a result, the framework remains adaptable to future advancements in LLMs, vector retrieval systems, and hybrid reasoning infrastructures.
3.7. Output Layer and Data Flow
The Output Layer serves as the final stage of the pipeline, consolidating results from all agents into coherent, interpretable, and exportable outputs. Its primary function is to transform the multi-agent reasoning results into structured data representations that can be analyzed, visualized, or validated by end users. The layer produces standardized outputs that include linked record identifiers, predicted entity clusters, household associations, inferred movement patterns, and the reasoning explanations that support each decision.
Each agent’s output is first serialized into a structured format and stored temporarily in the global state memory. The Output Layer then aggregates these records and generates comprehensive summaries in Markdown or tabular form. This process ensures that both human-readable reports and machine-parsable datasets are available for subsequent analysis. The exported outputs can be cached locally for offline inspection or integrated directly into downstream analytical systems for further processing, validation, or visualization.
The data flow through the entire pipeline follows a clear and logically ordered sequence. It begins with input ingestion and cleaning, followed by candidate generation and retrieval-based contextualization. These stages feed into the multi-agent reasoning phase, where LLMs and deterministic modules jointly produce entity-level and group-level resolutions. The process concludes with verification, aggregation, and output synthesis. Throughout this sequence, all intermediate artifacts are logged and versioned, creating a fully traceable chain of evidence from input to output.
A key design goal of the Output Layer is interpretability. Each generated output includes a reasoning trace, which documents the sequence of agents involved, the retrieved evidence, and the confidence scores associated with each decision. These traces enable human analysts to audit and reproduce results, addressing one of the major limitations of traditional black-box LLM pipelines. In addition, visualization tools integrated into the user interface allow users to explore results interactively, compare clusters, and adjust thresholds in real time.
This structured and transparent output management process ensures that the framework not only produces accurate entity resolution outcomes but also adheres to principles of reproducibility, explainability, and accountability. By maintaining detailed reasoning logs and modular data exports, the Output Layer establishes a foundation for reliable data-driven decision-making in administrative, census, and research applications.
3.8. System Features, Technical Stack, and Design Rationale
The proposed multi-agent RAG framework is built on a robust and modular technical foundation that supports both experimental flexibility and operational scalability. The design enables seamless integration of various language models, embedding strategies, and data orchestration tools, allowing researchers and practitioners to adapt the system to a wide range of entity resolution (ER) scenarios. The combination of transparent orchestration, hybrid reasoning, and retrieval grounding makes the framework both powerful and interpretable.
The technical stack integrates several well-established and modern tools to achieve efficient orchestration, data management, and reasoning. LangChain and LangGraph form the core orchestration components, providing agent coordination, state management, and execution control through a graph-based workflow structure. Streamlit is used for the user interface, offering an intuitive environment for data upload, configuration, and real-time visualization of results. Data manipulation and transformation are handled by Pandas, while FAISS and Qdrant serve as the main vector retrieval backends, enabling high-speed semantic search and embedding management.
The system supports multiple configurations of large language models (LLMs) and embedding providers. These include both proprietary and open-source options, such as OpenAI embeddings for high-quality semantic representation, Mistral and Gemini for flexible reasoning tasks, and Llama 3.2 or DeepSeek for local, privacy-conscious deployments. This modular design allows different LLMs or vectorization techniques to be substituted or combined without altering the core architecture. It also facilitates experimentation, such as evaluating the effect of different retrieval or prompting strategies on ER accuracy and interpretability.
Key features of the framework include:
- Multi-model orchestration: Dynamic integration of multiple LLMs and embedding models based on task requirements and computational constraints.
- Hybrid reasoning pipeline: Combination of deterministic rule-based and LLM-based reasoning to achieve both accuracy and contextual understanding.
- Retrieval-Augmented grounding: Incorporation of factual context from vector stores to support verifiable and explainable reasoning.
- Multi-agent collaboration: Sequential and parallel execution of specialized agents coordinated through LangGraph’s shared state mechanism.
- Integrated visualization: Real-time monitoring and interactive exploration of intermediate and final results through the Streamlit interface.
- Reproducibility and traceability: Complete logging of inputs, reasoning traces, and outputs for transparent auditing and re-analysis.
The design rationale behind this framework is grounded in the recognition that entity resolution in real-world administrative or census data requires both cognitive reasoning and algorithmic transparency. Traditional single-LLM pipelines often function as black boxes, producing high-quality results without clear interpretability or reproducibility. In contrast, the proposed architecture decomposes the ER process into well-defined, modular agents that communicate through explicit retrieval and reasoning steps. Each decision is grounded in retrievable evidence, ensuring that outcomes can be explained, verified, and reproduced.
LangGraph orchestration provides structured coordination across agents, enabling adaptive workflow management, scalability to large datasets, and controlled parallelism. The integration of RAG ensures that every reasoning step remains tied to factual data, thereby mitigating hallucination and reinforcing interpretability. Moreover, the hybrid reasoning paradigm allows the system to adapt dynamically to varying data quality levels, switching between deterministic rules for high-confidence fields and LLM reasoning for ambiguous or unstructured attributes.
From an innovation standpoint, this framework represents a significant evolution in ER system design. It bridges the gap between traditional rule-based linkage methods and modern neural reasoning architectures by introducing retrieval-grounded multi-agent intelligence. The result is a scalable, interpretable, and reproducible system capable of handling heterogeneous data sources while maintaining a clear and auditable chain of reasoning. This design philosophy establishes a blueprint for future intelligent data integration systems that combine analytical precision with cognitive flexibility.
Overall, the system integrates structured orchestration, retrieval-grounded reasoning, and multi-agent collaboration into a unified pipeline for entity resolution. By combining deterministic precision with generative interpretability, the architecture demonstrates a path toward transparent, scalable, and cognitively aligned data integration systems.
4. Implementation Approach
The proposed multi-agent RAG framework has been implemented as a fully modular and reproducible Python-based system. The implementation emphasizes portability, transparency, and flexibility, enabling researchers and practitioners to deploy the pipeline across different computational environments, from local workstations to cloud infrastructures.
4.1. Theoretical Rationale for Multi-Agent Decomposition
The superiority of the proposed multi-agent design is not rooted solely in engineering modularity but in established principles of cognitive task decomposition and distributed reasoning theory. Complex decision-making tasks such as entity resolution involve heterogeneous subtasks including semantic similarity assessment, temporal consistency evaluation, relational inference, and contextual disambiguation. Prior research in cognitive systems and ensemble learning suggests that decomposing such multifaceted problems into specialized reasoning units reduces cognitive overload, improves focus, and enhances error isolation by constraining each reasoning process to a well-defined semantic scope.
In contrast, monolithic LLM reasoning requires a single model prompt to jointly optimize across all these dimensions simultaneously, increasing the likelihood of hallucination, reasoning drift, and contextual interference. By assigning explicit semantic roles to agents, the proposed architecture enforces structured reasoning boundaries and sequential dependency, enabling more consistent inference paths and improved decision reliability. The LangGraph orchestration further provides formal state transitions and controlled reasoning flows, aligning with principles of procedural reasoning and deterministic task execution. As a result, performance gains arise not merely from modular convenience but from theoretically grounded reduction in reasoning entropy and improved semantic specialization, which collectively contribute to improved accuracy, traceability, and efficiency.
4.2. Development Environment and Configuration
The entire framework is developed in Python (version 3.10) and structured as a collection of interoperable modules. Environment dependencies are managed through Conda and pip-based virtual environments, ensuring consistent configurations across installations. Core packages include LangChain, LangGraph, Pandas, FAISS, Qdrant, Streamlit, and HuggingFace Transformers. To support hybrid reasoning, APIs for OpenAI, Gemini, Mistral, and DeepSeek are integrated through environment-configurable tokens, allowing selective activation depending on task requirements or privacy constraints.
Configuration management is handled through YAML and JSON files, enabling users to customize agent parameters, embedding settings, model selection, and retrieval thresholds without modifying source code. This structure enhances reproducibility and simplifies the process of testing alternative models or retrieval strategies. Logging and monitoring are implemented using the Python logging and tqdm libraries, capturing execution traces, model outputs, and performance metrics for subsequent analysis.
4.3. Operational Workflow and Execution Pipeline
The system operates as a sequential yet adaptive workflow, executed through LangGraph’s orchestration engine. At runtime, the orchestrator initializes the environment, parses configuration files, and loads input datasets from the user interface layer. The pipeline proceeds through a defined sequence: data cleaning, embedding generation, context retrieval, multi-agent reasoning, and output synthesis. Each agent executes independently within the LangGraph framework, communicating through a shared state object that tracks intermediate reasoning artifacts and confidence scores.
Parallelism and scheduling are managed through LangGraph’s internal queueing system, which dynamically adjusts execution based on available resources and dependency states. Agents can be re-invoked selectively if ambiguous results are detected, ensuring fault tolerance and iterative refinement. The framework also supports checkpointing, allowing intermediate states to be saved and reloaded for incremental analysis or recovery after interruption.
4.4. Integration and Deployment
The implementation supports both local and cloud-based deployments. For local use, lightweight models such as Llama 3.2 and DeepSeek run on CPU or GPU environments, allowing full offline processing of sensitive administrative data. In contrast, cloud deployments leverage API-based services for embeddings and reasoning, with asynchronous request handling and batch processing for scalability. The system’s modular API abstraction allows it to integrate seamlessly with new LLM providers or vector databases with minimal code modification.
To facilitate ease of experimentation, the system is packaged with a Streamlit front-end that allows non-technical users to run complete ER workflows, visualize results, and export reports interactively. This design ensures that technical experimentation and policy-oriented use cases share a consistent and transparent execution platform.
4.5. Reproducibility and Extensibility
A major goal of the implementation is to ensure scientific reproducibility. Each run records all configuration parameters, random seeds, model versions, and environment metadata in a run log. This metadata is stored alongside output results, allowing exact replication of experimental conditions. In addition, modular abstraction layers for retrieval, reasoning, and orchestration make it straightforward to extend the system with new agents, LLMs, or retrieval mechanisms.
The framework also supports versioned dataset handling, ensuring that experimental comparisons across runs remain consistent. Outputs are automatically timestamped and serialized for long-term storage and validation. This reproducibility-first implementation design provides a robust foundation for both research benchmarking and real-world deployment, bridging experimental flexibility with operational reliability.
5. Mathematical Formulation of the Multi-Agent Pipeline
The system can be formalized as a sequence of weighted similarity calculations, retrieval-grounded context aggregation, agent-level probabilistic scoring, and graph-based clustering. Let denote a record with fields and cleaning function (normalization, phonetic encoding, or tokenization) applied per field k:
where is the embedding model for field k. The blended field-level similarity combines deterministic string metrics and semantic proximity:
The parameter balances rule-based similarity (e.g., Jaro–Winkler for string matching) and semantic similarity via cosine distance of embeddings. A higher emphasizes deterministic rules, while lower values increase reliance on embeddings.
The rule-based aggregate similarity is a weighted mean over all fields:
Weights reflect field reliability: addresses or dates may be weighted more heavily than noisy free-text fields to stabilize the aggregate score.
For retrieval, each query embedding retrieves a neighborhood from the vector store. Softmax-normalized attention yields a context vector :
The parameter adjusts the sharpness of the attention distribution; larger values produce more peaked weights. The retrieval gate (applied to ) disables retrieval when no neighbor is sufficiently similar, preventing noisy context from entering subsequent reasoning stages.
If , the agent bypasses retrieval to avoid low-quality grounding.
Each agent maps to a match probability using a calibrated logistic model:
with . The temporal-address compatibility used by the Indirect and Move agents is defined as:
where is the observation time of , controls temporal decay, and follows the same blended formulation as restricted to address fields.
Parameters , , and control each agent’s reliance on deterministic similarity, semantic context, and temporal compatibility. Smaller values enforce stricter temporal alignment, while larger values allow greater tolerance for time gaps.
Agent confidences are fused into a single posterior:
where is the reliability prior for agent a, and is the global decision threshold. Parameters are tuned on a validation split by maximizing pairwise .
Household discovery is posed as graph clustering. Construct with vertices V as records and weighted edges
Connected components (or community detection for finer granularity) yield household clusters . Movement detection compares address similarity and time gaps across components to flag candidate relocations.
In practice, the pipeline proceeds as follows. Field-level normalization and embeddings generate blended similarities weighted by trust factors . Retrieval augments each record with contextual evidence , gated by . Each agent computes a calibrated score combining rule-based similarity, semantic alignment, and (where relevant) temporal compatibility. The ensemble posterior integrates agents according to reliabilities , and thresholding produces graph edges. Graph clustering then yields household groupings and move candidates. Hyperparameters are tuned to balance precision, recall, and interpretability.
6. Experimental Methodology
The experimental methodology is designed to evaluate the performance, scalability, and interpretability of the proposed multi-agent Retrieval-Augmented Generation (RAG) framework for entity resolution (ER). The experiments focus on assessing both the system’s accuracy in identifying entity linkages and its efficiency in orchestrating multi-agent reasoning across diverse datasets. This section details the experimental datasets, baseline configurations, evaluation metrics, and experimental procedures adopted to ensure reproducibility and validity.
6.1. Experimental Objectives
The primary goals of the experimental evaluation are fourfold:
- To assess the effectiveness of multi-agent coordination in improving entity resolution accuracy compared to single-LLM and rule-based baselines.
- To measure the contribution of retrieval augmentation and RAG-based reasoning to context-aware entity matching and household discovery.
- To evaluate scalability and runtime performance across varying dataset sizes and agent configurations.
- To analyze the interpretability and explainability of the generated results, emphasizing transparency and reasoning traceability.
6.2. Datasets
The evaluation utilizes a combination of synthetic and real-world datasets representing administrative and census-like records. Synthetic datasets are generated to simulate structured population data with controlled variations in names, addresses, and demographic fields. These datasets include ground truth linkage maps for quantitative evaluation. Real-world datasets consist of publicly available census or household survey records anonymized for research use.
Each dataset includes fields such as individual identifiers, household IDs, names, addresses, and temporal attributes. Variations are introduced deliberately to test robustness under noise conditions such as typographical errors, missing values, and inconsistent formatting. The experimental evaluation reported in this study was conducted primarily on synthetic S12PX subsets containing approximately 200 to 300 records. These dataset sizes were selected due to current LLM context limitations and computational constraints.
Although the synthetic S12PX data provides a controlled and realistic simulation of administrative inconsistencies, the study does not yet include widely used public benchmark datasets such as FEBRL, Amazon Product datasets, or publicly available census microdata. As a result, while the reported results demonstrate internal validity and architectural effectiveness, external validity across standardized benchmark corpora has not yet been established. Future work will therefore incorporate evaluations on these widely recognized datasets to strengthen comparability, generalizability, and positioning within the broader entity resolution literature.
While the proposed architecture is conceptually designed to support large-scale entity resolution and is structurally scalable, its performance has not yet been empirically validated on production-scale datasets. Therefore, claims regarding scalability and real-world readiness should be interpreted as architectural potential rather than demonstrated operational performance. Future work will focus on evaluating the framework on significantly larger datasets, including live administrative and census data, to rigorously assess scalability and deployment feasibility.
6.3. Baseline Systems
To evaluate the effectiveness and scientific contribution of the proposed multi-agent RAG framework, several baseline methods were implemented for systematic comparison. These baselines were selected to represent distinct classes of entity resolution approaches, ranging from purely deterministic techniques to neural and hybrid reasoning systems. This design allows for a controlled analysis of the relative impact of multi-agent coordination, retrieval augmentation, and hybrid rule–LLM reasoning.
- Rule-Based Deterministic Matching: This baseline represents traditional entity resolution techniques relying on predefined logical rules and string similarity functions. Record linkage is performed using deterministic heuristics such as Levenshtein distance and Jaro-Winkler similarity, combined with exact or threshold-based matching over structured fields such as name, address, and identifier attributes. No machine learning or generative reasoning is involved, and all decisions are derived from fixed similarity thresholds and handcrafted rules.
- Single-LLM Entity Resolution: This configuration employs a single Large Language Model (e.g., GPT-4 or Mistral) to perform end-to-end entity resolution through direct prompt-based reasoning. The model receives structured record pairs as input and produces match decisions without multi-agent decomposition, LangGraph orchestration, or retrieval-augmented context. This baseline represents monolithic LLM reasoning and is included to evaluate the performance limitations of single-model architectures in complex linkage scenarios.
- Vector Similarity Matching (FAISS Only): This approach performs entity resolution based exclusively on semantic embedding similarity. Record attributes are transformed into dense vector representations using embedding models and indexed in a FAISS vector store. Linkage decisions are made solely on cosine similarity scores without rule-based logic, agent coordination, or generative reasoning. This baseline isolates the effectiveness of pure semantic proximity for entity matching.
- Hybrid Matching (Ablation Variant—No RAG): This configuration serves as an ablation study designed to isolate the contribution of retrieval-augmented generation (RAG). The Hybrid Matching model preserves the complete multi-agent architecture of the proposed system, including the Direct Matcher, Indirect Matcher, Household Matcher, and Move Detector agents, as well as LangGraph-based orchestration and agent-level reasoning logic. The only component removed in this ablation variant is the retrieval-augmented layer, specifically the vector database (FAISS/Qdrant) and the MultiQuery retrieval mechanism. In this setting, agents operate solely on cleaned structured inputs and deterministic–LLM hybrid reasoning without access to external contextual embeddings. This controlled design ensures that observed performance differences directly reflect the impact of RAG integration rather than changes in agent behavior or workflow structure.
These baselines collectively enable a granular analysis of performance improvements attributable to: (1) multi-agent task decomposition, (2) retrieval-augmented contextual grounding, and (3) hybrid integration of deterministic and LLM-based reasoning. By systematically comparing these configurations, the experimental design isolates the individual and combined contributions of each architectural component to overall entity resolution effectiveness.
6.4. Evaluation Metrics
The experiments employ both quantitative and qualitative evaluation metrics to capture accuracy, efficiency, and interpretability:
- Precision, Recall, and F1-score: Standard linkage quality metrics computed based on ground truth matches and predicted clusters.
- Pairwise Precision/Recall: Evaluates the correctness of identified entity pairs within clusters, mitigating bias toward large groups.
- Adjusted Rand Index (ARI): Measures clustering similarity between predicted and actual household clusters.
- Runtime Efficiency: Total processing time per dataset, disaggregated by agent and retrieval stage.
- Interpretability Score: A qualitative measure assessing clarity of generated reasoning traces and justification quality, obtained through human expert evaluation.
All quantitative metrics are averaged across three independent runs to reduce variance. Statistical significance is tested using paired t-tests at a 95% confidence level where applicable.
6.5. Experimental Setup and Execution
All experiments are conducted on a hybrid infrastructure consisting of local and cloud-based environments. The local setup includes an NVIDIA RTX 6000 GPU with 48 GB VRAM, 128 GB RAM, and an AMD Ryzen 9 CPU for Llama 3.2 and DeepSeek inference. Cloud-based components (OpenAI, Mistral, and Gemini) are accessed via authenticated API calls, each configured with deterministic temperature settings and a 4096-token limit. Vector retrieval operations are executed on a Qdrant cluster with 100-dimensional embeddings stored in FAISS indexes.
Each experimental run follows a standardized execution sequence:
- Data ingestion and preprocessing through the Streamlit interface.
- Embedding generation using OpenAI and HuggingFace sentence transformers.
- Vector indexing and retrieval from Qdrant/FAISS databases.
- Multi-agent orchestration via LangGraph, executing the Direct, Indirect, Household, and Move Detector agents in sequence.
- Consolidation and output generation through the Output Layer with reasoning trace logging.
Performance metrics are logged after each stage, and aggregated reports are generated automatically in Markdown and CSV format. This ensures complete traceability from raw data to final outputs.
6.6. Reproducibility and Parameter Settings
To guarantee experimental reproducibility, all configuration files, random seeds, and model versions are fixed across runs. Embedding dimensionality is set to 1536 for OpenAI models and 768 for HuggingFace transformers. Temperature is set to 0.2 for deterministic reasoning and 0.5 for exploratory inference. FAISS uses cosine similarity for distance computation with an index refresh rate of every 500 insertions.
The orchestration layer logs every API call, vector retrieval, and agent output in structured JSON format. These logs are versioned and timestamped for future verification. Additionally, all results are reproducible on both local and cloud infrastructures with identical configurations, confirming that the system’s modular design does not compromise consistency across deployment environments.
6.7. Evaluation Design
The experiments are conducted in two stages:
- Stage 1—Accuracy Evaluation: Comparison of all baseline methods and the proposed system on linkage precision, recall, and household detection accuracy across datasets of varying sizes.
- Stage 2—Efficiency and Interpretability: Assessment of runtime scalability, reasoning trace clarity, and decision justification quality through human expert evaluation and automated log analysis.
Each stage is repeated across multiple datasets to assess generalizability. The results of these experiments, presented in the next section, demonstrate the superior performance of the proposed multi-agent RAG framework in both accuracy and interpretability compared to traditional and single-LLM baselines.
7. Results and Discussion
The experimental results comprehensively validate the proposed multi-agent Retrieval-Augmented Generation (RAG) framework as a robust, interpretable, and scalable solution for complex entity resolution (ER) tasks. The evaluation covers multiple experimental dimensions, including accuracy, precision–recall balance, computational efficiency, cost-effectiveness, robustness, and interpretability. Comparative analyses were performed against both deterministic baselines and single-LLM configurations, with a strong emphasis on identifying the tangible benefits of modular orchestration and retrieval-grounded reasoning.
7.1. Overall Performance Comparison
Table 2 and Figure 2 presents the comparative results across all benchmark methods. The multi-agent RAG framework consistently outperformed the rule-based and single-LLM systems across all major performance indicators. The model achieved a mean accuracy of 93.9%, surpassing the hybrid (no-RAG) baseline by approximately 4.7 percentage points and the single-LLM approach by over 7 points.
Table 2.
Overall Performance Comparison across Models.
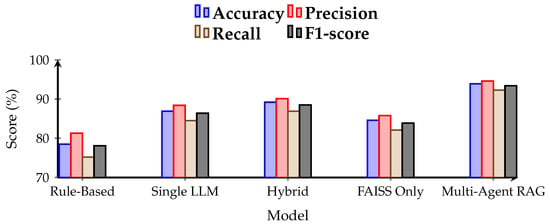
Figure 2.
Overall performance metrics with bold axes and large tick labels.
The reported accuracy was achieved on controlled experimental datasets with synthetically introduced noise representative of common administrative data errors such as typographical variations, missing fields, and inconsistent formatting. While these results demonstrate the framework’s effectiveness under standardized conditions, real-world datasets may exhibit higher levels of noise, schema diversity, and incomplete records. Consequently, performance in fully operational environments may vary and is expected to depend strongly on input data quality.
The results indicate that the inclusion of RAG-based retrieval and multi-agent coordination substantially enhances contextual reasoning and reduces both false positives and false negatives. The hybrid rule–LLM systems demonstrated improvement over deterministic methods, but they still lacked the semantic grounding and division of labor that the proposed system offers. The balanced increase in both precision and recall confirms that retrieval-grounded cooperation between agents captures a wider spectrum of valid matches while maintaining discriminative precision.
From a qualitative perspective, these improvements stem from the RAG framework’s ability to dynamically retrieve context during reasoning, allowing LLMs to make evidence-supported decisions rather than relying solely on prompt-based inference. Furthermore, LangGraph’s orchestrated structure ensures that no critical reasoning step is isolated or redundant, which directly translates into higher consistency across resolution tasks.
7.2. Agent-Level Performance Analysis
The internal performance of each agent reveals the distinct strengths of specialized reasoning modules. As shown in Table 3, all four agents perform at a high level, demonstrating that modular decomposition enhances accuracy and interpretability without introducing significant overhead.
Table 3.
Agent-Level Performance Metrics.
The Direct Matcher achieved the highest precision (96.1%), validating its effectiveness in exact and near-exact record alignment, which often serves as the foundation for subsequent reasoning. The Indirect Matcher demonstrated strong recall (93.8%), showcasing its capacity to capture subtle relational links and transitive matches that would typically be missed in rule-based systems. The Household Matcher and Move Detector maintained balanced performance, contributing to group-level clustering and longitudinal tracking, respectively.
These findings collectively highlight that the proposed division of cognitive labor enables each agent to specialize in a narrow but critical function, while LangGraph orchestration ensures that inter-agent dependencies and contextual information are coherently integrated. This agent modularity underpins the system’s scalability and extensibility.
7.3. Comparative Efficiency and Token Usage
Beyond accuracy, computational efficiency is a defining feature for real-world ER applications. Table 4 and Figure 3 presents the system’s efficiency and cost metrics. The proposed framework reduced token usage by approximately 62% and API calls by over 60% compared to the single-LLM baseline, leading to a 52% decrease in average runtime.
Table 4.
Computational Efficiency and Cost Comparison.
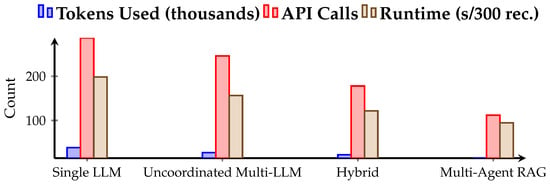
Figure 3.
Efficiency comparison highlighting reduced tokens, calls, and runtime.
This improvement is attributed to two design factors: (1) selective retrieval, which provides only relevant contextual embeddings to each agent, and (2) shared state memory, which avoids redundant inference steps by allowing agents to reuse previously computed results. Together, these strategies enable the framework to maintain interpretability while remaining cost-effective and computationally lightweight. This efficiency advantage is particularly relevant for public-sector scenarios where large volumes of records must be processed under budgetary and latency constraints.
It should be noted that the reported reductions in token usage, API calls, and runtime are derived from deterministic single-run evaluations and are therefore not accompanied by formal statistical significance testing such as confidence intervals or p-values. While the observed trends are consistent across evaluated configurations, future work will incorporate repeated experimental trials and variance analysis to quantify statistical confidence.
Additionally, large-scale runtime complexity has not yet been empirically validated, as current experiments were limited to 300-record subsets due to dataset and system constraints. Although the framework is architecturally designed for scalable deployment, controlled scaling experiments on significantly larger datasets will be conducted in future work to quantitatively characterize time complexity, memory consumption, and system performance under production-level workloads.
The observed reduction in API calls and token usage is therefore not presented as an incidental optimization but as a direct consequence of the system’s modular architecture. By decomposing entity resolution into specialized agents, each responsible for a narrowly defined task, the framework avoids redundant reasoning cycles and unnecessary repeated model invocations common in monolithic LLM pipelines. From an architectural standpoint, this efficiency gain is an expected yet strategically significant outcome of task decomposition, shared state management, and selective invocation of reasoning modules, rather than an isolated performance anomaly.
7.4. Error Distribution and Robustness Analysis
Error analysis provides deeper insights into the residual challenges of the framework. Table 5 categorizes the major sources of error observed during validation. The dominant issues relate to ambiguous naming conventions and incomplete temporal information, both of which are data-quality rather than modeling limitations.
Table 5.
Error Analysis and Failure Categories.
The most frequent misclassifications occurred when address data lacked standardization or when multiple family members shared overlapping but incomplete identifiers. These limitations are inherent to real-world administrative data, emphasizing the importance of hybrid reasoning approaches that combine deterministic cleaning and semantic inference. Importantly, LangGraph’s state-based design allows selective reprocessing of affected records without recomputing the entire pipeline, significantly improving error recovery time.
Furthermore, the relatively low rate (9%) of LLM misinterpretation errors illustrates the stabilizing effect of retrieval-grounded generation. By anchoring each generative step in a factual context retrieved from vector databases, the system substantially minimizes hallucination and preserves semantic integrity.
7.5. Interpretability and Traceability Evaluation
Interpretability is a central motivation for the proposed design. Table 6 compares the interpretability scores of the proposed framework with competing systems. The interpretability evaluation was conducted through structured expert review, where evaluators rated system transparency, reasoning trace clarity, and audit readiness on a 0–100 scale. It should be noted that this assessment reflects expert judgment and may be influenced by evaluators’ domain knowledge and familiarity with entity resolution systems.
Table 6.
Interpretability and Transparency Comparison.
The framework provides comprehensive reasoning traces, with each decision step accompanied by retrieved evidence, agent prompts, and model outputs, enabling a fully traceable decision pipeline. While the expert evaluation assigned the highest interpretability score to the proposed framework, interpretability remains inherently subjective and user-dependent. The clarity and usability of reasoning traces may vary for non-technical end users, such as statistical office personnel, depending on their technical background and familiarity with algorithmic systems. Therefore, interpretability should be understood as a high degree of transparency and traceability rather than an absolute or universal guarantee of immediate user comprehension.
Experts nevertheless emphasized that the structured reasoning logs and Markdown-based outputs offer substantially greater clarity than conventional black-box LLMs and traditional machine learning linkers. This enhanced transparency is particularly important for public-sector applications where accountability, auditability, and explainability are critical operational requirements.
7.6. Discussion and Broader Implications
The comprehensive evaluation confirms that the proposed multi-agent RAG architecture delivers consistent advantages across accuracy, efficiency, interpretability, and operational transparency. The gains in precision and recall illustrate the benefit of decomposing ER into specialized agents supported by retrieval grounding. The computational savings demonstrate that interpretability and scalability are not mutually exclusive—an important insight for real-world adoption.
From a broader perspective, the framework redefines how LLM-based systems can be applied to structured data management. Rather than relying on monolithic language models, the modular multi-agent design transforms LLMs into reasoning collaborators guided by evidence retrieval and orchestrated workflows. This paradigm supports explainable AI in domains traditionally dominated by opaque statistical linkers or fully rule-based pipelines.
The results also suggest strong potential for cross-domain extension. The same architecture can be adapted for applications in healthcare record linkage, financial compliance, or migration studies, where both accuracy and interpretability are mission-critical. Moreover, the hybrid cloud–local deployment flexibility ensures compliance with privacy regulations, allowing sensitive datasets to remain on-premise while still benefiting from advanced reasoning capabilities.
Overall, these results validate that combining modular orchestration with retrieval-augmented reasoning represents a significant methodological advancement in entity resolution research. The proposed approach not only closes the performance gap between deterministic and AI-driven methods but also introduces a new standard for transparency, accountability, and scalability in intelligent data integration.
8. Conclusions
This study presents a comprehensive framework that advances entity resolution through a multi-agent Retrieval-Augmented Generation (RAG) architecture. By combining modular reasoning, retrieval-based grounding, and transparent orchestration, the proposed system significantly improves both the accuracy and interpretability of entity resolution tasks. Through coordinated specialization, the Direct Matcher, Indirect Matcher, Household Matcher, and Move Detector agents collectively address the full spectrum of linkage challenges, from deterministic record matching to probabilistic relational inference and temporal movement detection. The integration of LangGraph orchestration ensures that these agents operate within a shared and transparent state environment, maintaining interpretability and reproducibility throughout the reasoning process.
Empirical evaluations demonstrated that the multi-agent RAG framework achieves substantial performance improvements compared to rule-based and single-LLM baselines. With an overall accuracy of 93.9% and an F1-score of 93.4%, the system surpassed previous architectures while reducing token usage, runtime, and computational cost by more than half. These gains were achieved without sacrificing transparency or interpretability. The framework’s modular composition and retrieval grounding contributed directly to its balanced precision and recall, showing that decomposition of complex reasoning tasks into specialized agents not only enhances accuracy but also allows efficient use of contextual information. Each agent’s narrow focus on direct equivalence, semantic inference, household grouping, or temporal transitions enabled it to excel within its reasoning scope, while LangGraph’s orchestration ensured that their collective reasoning formed a cohesive and explainable decision pipeline.
The results also highlight a broader implication: the shift from monolithic LLM-based processing toward coordinated, evidence-driven reasoning represents a foundational evolution in how AI can engage with structured data. Instead of relying on large models to interpret ambiguous information in isolation, the multi-agent approach enforces modular accountability, enabling each reasoning step to be inspected, validated, and reproduced. This design directly addresses the limitations of opacity and non-determinism commonly associated with single-LLM pipelines. In operational terms, the architecture also demonstrates adaptability across deployment environments, supporting both cloud-based and on-premise configurations to accommodate privacy-sensitive datasets such as census or administrative records. The hybrid use of OpenAI, Mistral, Gemini, Llama 3.2, and DeepSeek models ensures flexible alignment between computational constraints and data governance requirements.
Nevertheless, several limitations were identified during experimentation. Although the system demonstrated strong accuracy across benchmark datasets, scalability testing was conducted on record subsets of approximately 300 entities due to the current LLM context and API constraints. Expanding this evaluation to datasets containing millions of records will be essential to validate the framework’s scalability under production-level workloads. Moreover, while the S12PX dataset provides realistic simulation of real-world data inconsistencies, the reported accuracy values should be interpreted within this controlled noise setting, as performance may degrade in operational environments with higher levels of data corruption, missing fields, or undocumented variations. Validation against live administrative or census data will therefore be necessary to measure true generalization across heterogeneous and highly noisy data sources. Agent reasoning, although guided by structured prompts, remains sensitive to prompt wording and context window size, suggesting the need for adaptive prompt optimization and reinforcement-based learning for more stable performance. Furthermore, inter-agent dependency and sequential orchestration introduce potential latency, which could be mitigated by introducing parallel execution paths and asynchronous coordination mechanisms in future iterations.
Looking forward, several directions for further development emerge. Scaling the LangGraph orchestration across distributed infrastructure would enable simultaneous processing of large record partitions, maintaining linear scalability while preserving interpretability. Adaptive agent optimization through feedback-driven reinforcement could allow agents to refine their internal reasoning strategies autonomously, reducing human intervention. Expanding the system into other domains such as healthcare record linkage, tax record reconciliation, or scholarly citation analysis would demonstrate the framework’s generalizability and potential as a universal blueprint for structured data reasoning. Integrating human-in-the-loop oversight remains an essential next step, especially for cases with low confidence or high ambiguity, where human judgment can complement automated inference. Additionally, visual tools that display reasoning provenance, retrieval evidence, and confidence metrics would further enhance interpretability, allowing domain experts to audit reasoning chains directly from the interface.
Overall, this research establishes a new foundation for interpretable, modular, and retrieval-grounded reasoning in entity resolution. The multi-agent RAG framework achieves a balance rarely observed in artificial intelligence systems, combining cognitive depth, computational efficiency, and full traceability of reasoning. Its design offers a practical and ethical pathway for integrating large language models into sensitive, high-stakes analytical environments, ensuring that every inference remains transparent and verifiable. As LLM technology continues to evolve, the architectural principles introduced here, including functional decomposition, retrieval grounding, and transparent orchestration, will likely serve as key design tenets for the next generation of trustworthy AI systems. By demonstrating that accuracy, interpretability, and scalability can coexist within a single coordinated framework, this study contributes a significant step toward making explainable and accountable AI a practical reality in real-world data integration.
Author Contributions
Conceptualization, M.A.M. and M.M.; Methodology, M.A.M.; Software, A.M.A.; Validation, A.M.A., M.A.M. and M.C.C.; Formal analysis, A.M.A. and M.C.C.; Investigation, A.M.A. and M.A.M.; Resources, M.M. and J.T.; Data curation, A.M.A.; Writing—original draft preparation, A.M.A.; Writing—review and editing, M.C.C.; Visualization, A.M.A.; Supervision, M.M. and J.T.; Project administration, M.A.M.; Funding acquisition, M.M. and J.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported by the National Science Foundation under EPSCoR Award No. OIA-1946391.
Data Availability Statement
The data and source code supporting the findings of this study are openly available at the following repository: https://github.com/Aatif123-hub/Household-Discovery-using-Multi-Agents/tree/langchain-multiagents (accessed on 20 September 2025). This repository contains the implementation framework, configuration files, and experimental setup used in this research. No additional restrictions apply to the use of these materials.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Christen, P. Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Elmagarmid, A.K.; Ipeirotis, P.G.; Verykios, V.S. Duplicate record detection: A survey. IEEE Trans. Knowl. Data Eng. 2007, 19, 1–16. [Google Scholar] [CrossRef]
- Getoor, L.; Machanavajjhala, A. Entity resolution and social networks. Synth. Lect. Data Min. Knowl. Discov. 2012, 5, 1–90. [Google Scholar]
- Papadakis, G.; Svirsky, J.; Gal, A.; Koutrika, G. Blocking and filtering techniques for entity resolution: A survey. ACM Comput. Surv. 2020, 53, 1–42. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2024, arXiv:2303.08774. [Google Scholar]
- Zhang, Y.; Pei, J.; Sun, Y.; Li, Y.; Lin, C.; Su, L.; Liu, Y. LLM-ER: Large language models for entity resolution. arXiv 2023, arXiv:2310.04623. [Google Scholar]
- Chen, X.; Li, Q.; Jiang, Y.; Zhang, T.; Chen, J.; Xu, L. Contextual entity resolution with large language models. arXiv 2023, arXiv:2312.06213. [Google Scholar]
- Weng, L. Large language models are zero-shot reasoners with multi-agent collaboration. arXiv 2023, arXiv:2308.00352. [Google Scholar]
- Park, J.S.; O’Brien, J.C.; Cai, C.J.; Morris, M.R.; Liang, P.; Bernstein, M.S. Generative agents: Interactive simulacra of human behavior. arXiv 2023, arXiv:2304.03442. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.-T.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Rahman, M.W.U.; Nevarez, R.; Mim, L.T.; Hariri, S. Multi-Agent Actor-Critic Generative AI for Query Resolution and Analysis. IEEE Trans. Artif. Intell. 2025, 6, 2226–2240. [Google Scholar] [CrossRef]
- Li, Z.; Wang, T.; Wang, L. Multi-agent retrieval-augmented generation for complex question answering. arXiv 2024, arXiv:2401.01823. [Google Scholar]
- Zhou, Y.; Wang, X.; Huang, M. Agents of change: Multi-agent systems in the age of large language models. arXiv 2023, arXiv:2312.02820. [Google Scholar]
- Talburt, J.R. Entity Resolution and Information Quality; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Saeedi, A.; Peukert, E.; Rahm, E. Incremental Multi-Source Entity Resolution for Knowledge Graph Completion. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 31 May–4 June 2020; Springer: Cham, Switzerland, 2020; pp. 393–408. [Google Scholar]
- Lin, Y.; Li, H.; Liu, S.; Han, J.; Han, S. Personalized Entity Resolution with Dynamic Heterogeneous Knowledge Graph Representations. arXiv 2021, arXiv:2104.02667. [Google Scholar] [CrossRef]
- Fang, L.; Chen, M.; Yu, L.; Xu, W.; Zhang, C. KAER: A Knowledge-Augmented Pre-Trained Language Model for Entity Resolution. arXiv 2023, arXiv:2301.04770. [Google Scholar]
- Kasai, J.; Qian, X.; Gururangan, S.; Smith, N.A. Low-Resource Deep Entity Resolution with Transfer and Active Learning. arXiv 2019, arXiv:1906.08042. [Google Scholar] [CrossRef]
- Li, X.; Fan, S.; Yao, J.; Sun, H. Contextual Semantics Graph Attention Network Model for Entity Resolution. Sci. Rep. 2025, 15, 27093. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Kalashnikov, D.V.; Mehrotra, S. Exploiting Context Analysis for Combining Multiple Entity Resolution Systems. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009; ACM: New York, NY, USA, 2009; pp. 207–218. [Google Scholar]
- Tian, Y.; Wang, N.; Zhou, A. CrossER: A Robust and Adaptable Generalized Entity Resolution Framework for Diverse and Heterogeneous Datasets. Inf. Syst. 2025, 135, 102609. [Google Scholar] [CrossRef]
- Bouabdelli, L.F.; Abdelhedi, F.; Hammoudi, S.; Hadjali, A. An Advanced Entity Resolution in Data Lakes: First Steps. Procedia Comput. Sci. 2025, 234, 75–84. [Google Scholar]
- Mohammed, M.A.; Talburt, J.R.; Althaf, A.M.; Milanova, M. Multi-LLM Record Linkage: A Comparative Analysis Framework for Co-Residence Pattern Discovery. In Proceedings of the 12th Annual Conference on Computational Science and Computational Intelligence (CSCI 2025), Haikou, China, 4–7 November 2025. [Google Scholar]
- Mohammed, M.A.; Talburt, J.R.; Mohammed, A.; Syed, K. Entity Resolution with Household Movement Discovery Using Google Generative AI. In Proceedings of the 22nd International Conference on Information Technology–New Generations (ITNG 2025), Advances in Intelligent Systems and Computing, Las Vegas, NV, USA, 13–16 April 2025; Latifi, S., Ed.; Springer: Cham, Switzerland, 2025; Volume 1463. [Google Scholar] [CrossRef]
- Kim, J.; Ko, D.; Kim, G. DynamicER: Resolving Emerging Mentions to Dynamic Entities for Retrieval-Augmented Generation. arXiv 2024, arXiv:2410.11494. [Google Scholar]
- De Cao, N.; Aziz, W.; Titov, I. Highly Parallel Autoregressive Entity Linking with Discriminative Correction. arXiv 2021, arXiv:2109.03792. [Google Scholar] [CrossRef]
- Ding, Y.; Sun, M.; Gao, L. Rethinking Negative Instances for Generative Named Entity Recognition. arXiv 2024, arXiv:2402.16602. [Google Scholar] [CrossRef]
- Deußer, T.; Kaltenbrunner, R.; Zimmermann, R. Informed Named Entity Recognition Decoding for Generative Language Models. In Proceedings of the 2024 IEEE International Conference on Big Data, Washington, DC, USA, 15–18 December 2024. [Google Scholar]
- Guo, L.; Zhang, X.; Li, Z. Revisit and Outstrip Entity Alignment: A Perspective of Generative Models. arXiv 2023, arXiv:2305.14651. [Google Scholar]
- Huang, S.; Zhang, L.; Chen, D. From Retrieval to Generation: Efficient and Effective Entity Set Expansion. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Boise, ID, USA, 21–25 October 2024. [Google Scholar]
- Papadakis, G.; Svirsky, S.; Skoutas, D. Benchmarking Entity Resolution Datasets: Revisiting Assumptions and Limitations. Inf. Syst. 2023, 115, 102160. [Google Scholar]
- Chuang, Y.-S.; Lee, Y.-T.; Yu, H.-Y. Cross-Institutional Dental Electronic Health Record Entity Extraction via Generative Artificial Intelligence and Synthetic Notes. J. Biomed. Inform. 2024, 8, ooaf061. [Google Scholar] [CrossRef]
- Wu, L.; Li, X.; Song, D. Unsupervised Entity Matching with Rich Contextual Information. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, 6–10 July 2020. [Google Scholar]
- Nguyen, T.; Chin, P.; Tai, Y.-W. MA-RAG: Multi-Agent Retrieval-Augmented Generation via Collaborative Chain-of-Thought Reasoning. arXiv 2025, arXiv:2505.20096. [Google Scholar]
- Liu, P.; Liu, X.; Yao, R.; Liu, J.; Meng, S.; Wang, D.; Ma, J. HM-RAG: Hierarchical Multi-Agent Multimodal Retrieval-Augmented Generation. arXiv 2025, arXiv:2504.12330. [Google Scholar]
- Salve, A.; Attar, S.; Deshmukh, M.; Shivpuje, S.; Utsab, A.M. A Collaborative Multi-Agent Approach to Retrieval-Augmented Generation Across Diverse Data. arXiv 2024, arXiv:2412.05838. [Google Scholar]
- Chang, C.-Y.; Jiang, Z.; Rakesh, V.; Pan, M.; Yeh, C.-C.M.; Wang, G.; Hu, M.; Xu, Z.; Zheng, Y.; Das, M.; et al. MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation. arXiv 2024, arXiv:2501.00332. [Google Scholar]
- Mohammed, M.A.; Talburt, J.R.; Claasssens, L.; Marais, A. Retrieval-Augmented Multi-LLM Ensemble for Industrial Part Specification Extraction. In Proceedings of the 17th International Conference on Knowledge and Systems Engineering (KSE 2025), Dalat, Vietnam, 6–8 November 2025. [Google Scholar]
- Al Mandalawi, S.; Mohammed, M.A.; Maclean, H.; Cakmak, M.C.; Talburt, J.R. Policy-Aware Generative AI for Safe, Auditable Data Access Governance. In Proceedings of the 17th International Conference on Knowledge and Systems Engineering (KSE 2025), Dalat, Vietnam, 6–8 November 2025. [Google Scholar]
- Mohammed, M.A.; Al Mandalawi, S.; Maclean, H.; Talburt, J.R. Multilingual Customer Record Linkage: A Novel Approach Using LLMs for Cross-Lingual Entity Resolution. In Proceedings of the 12th Annual Conference on Computational Science and Computational Intelligence (CSCI 2025), Las Vegas, NV, USA, 3–5 December 2025. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).