1. Introduction
In modern communication networks, data plays a pivotal role, not only because of the transmitted data but also due to its utilization to optimize network performance. From traditional architectures to next-generation programmable infrastructures such as Software-Defined Networks (SDNs), data has consistently guided critical decisions in routing, load balancing, and traffic engineering. Network administrators have relied on data extracted from traffic to monitor it, identify its patterns, and determine the most appropriate routing strategies to ensure efficient flow transmission.
The rise of Artificial Intelligence has enabled a shift from static protocol configurations toward intelligent, data-driven network control. Across domains such as wireless networks, vehicular systems, and SDNs, data-centric methods have demonstrated clear benefits. For instance, Fortuna et al. [
1] proposed a multi-level modeling strategy using real-world wireless datasets to optimize performance and manage resources. Similarly, Jiang et al. [
2] introduced Data-Driven Networking (DDN), a paradigm that allows protocols to be dynamically adjusted in response to quality metrics collected in multiple sessions. Their approach emphasizes automatic control, using adaptive settings rather than a fixed one. In parallel, the adoption of machine learning in domains such as network intrusion detection has highlighted the strength of data-driven frameworks. Jiang et al. [
2] proposed a hierarchical classification strategy using both supervised learning and unsupervised autoencoders to detect and classify cyber attacks, emphasizing the importance of feature representation and balanced training data for effective intrusion detection in IP-based networks.
In the context of SDNs, the centralized control plane and the global view of the network offer an opportunity to integrate intelligent frameworks that can learn from the real-time state of the network. In addition, decoupling control from data planes in SDNs enable more flexible, programmable, and adaptive systems. However, the efficient detection and control of network congestion represents one of the persistent challenges in SDNs due to the high volume of traffic coming from large and dense networks such as data centers, and the complexity of the network topology that leads to reduced network performance in terms of packet loss, slow data transfer speeds, and reduced throughput. Kandula et al. [
3] highlight that a server cluster with around 1500 nodes may process close to 100,000 network flows every second. In a similar context, Kandula et al. [
4] report that, under peak load conditions, a network with 100 switches can experience up to 10 million flow requests per second. Additionally, even a modest delay of 10 milliseconds in flow setup, introduced by the SDN controller, can add approximately 10% latency to the large number of short-lived flows typically present in such environments. Yet, most existing congestion detection and control approaches rely on static thresholds or heuristics, which lack adaptability in dynamic environments.
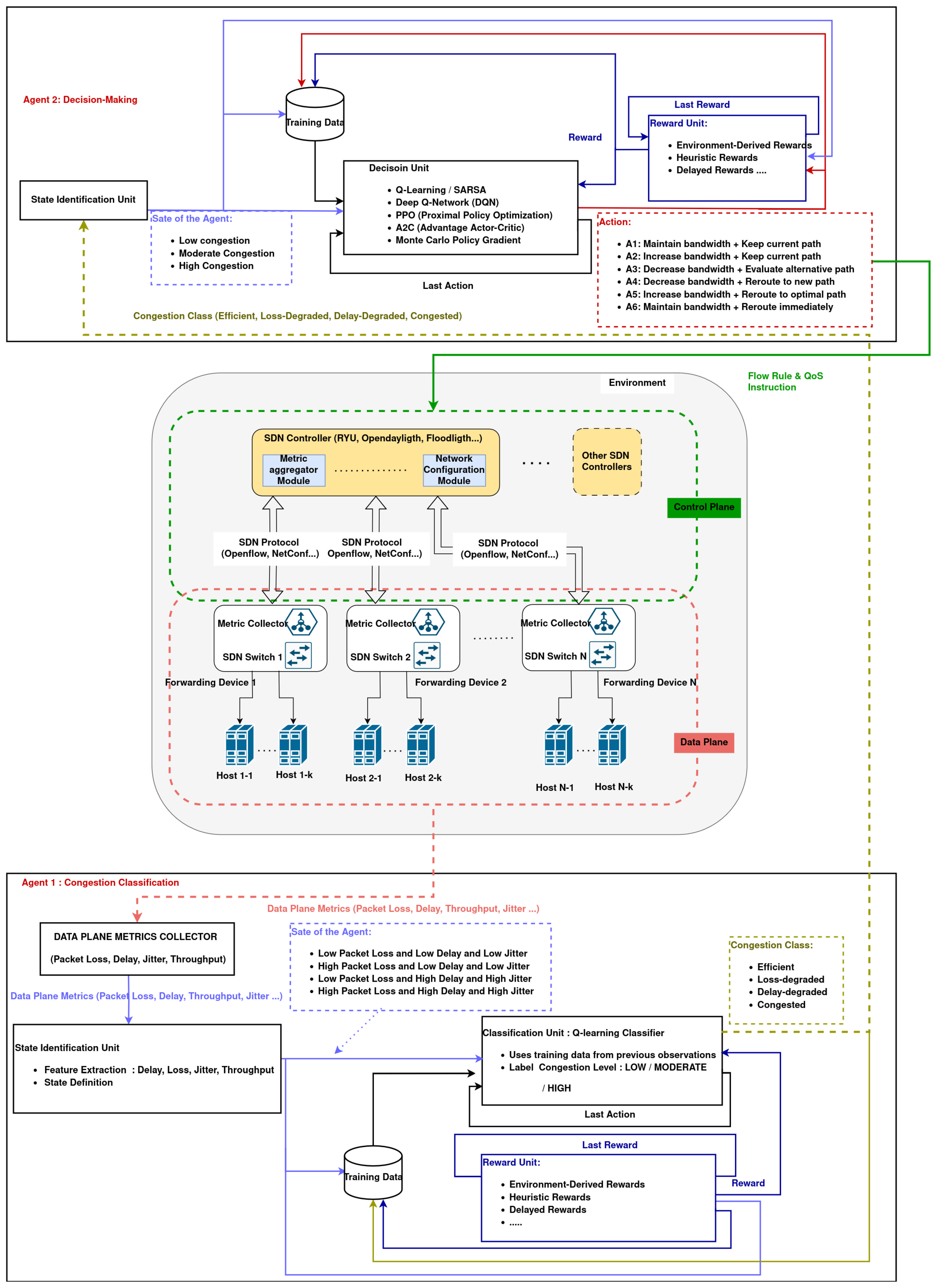
To address the limitations of static and monolithic congestion control approaches, we propose a data-driven Multi-Agent Reinforcement Learning (MARL) framework designed for congestion classification and adaptive decision-making in Software-Defined Networks (SDNs). The proposed framework leverages real-time network metrics—such as packet loss, delay, jitter, and throughput—collected from live traffic to dynamically assess network state and inform control actions. Guided by these observations and feedback from a tailored reward function, the system continuously learns to adjust bandwidth allocation and traffic routing strategies.
The architecture comprises two specialized and collaborative agents: (1) a Congestion Classification Agent responsible for evaluating network conditions and classifying the current state into predefined congestion levels, and (2) a Decision-Making Agent, which utilizes Deep Q-Learning (DQN or its variants) to select the optimal actions, including increasing, decreasing, or maintaining bandwidth, and rerouting or preserving current traffic paths.
In contrast to previous work employing a single-agent model to jointly handle perception and control, our approach introduces a decoupled agent structure. This modular design improves interpretability, allows for targeted training of each agent, and enhances learning efficiency and robustness.
The agents are initially trained offline using both synthetic and real traffic traces, including the MAWI dataset, to simulate heterogeneous environments. After the offline training phase, the trained agents are deployed for online testing in a simulated SDN environment built with Mininet and the Ryu controller. During online operation, the agents act on real-time traffic conditions without further training, enabling real-world evaluation of their generalization and adaptability.
To assess the framework’s effectiveness, we compare the MARL system against (i) a standalone Decision Agent without the classifier (ablation study), (ii) a Double DQN-based agent without classification, and (iii) a non-learning baseline based on random action selection. Experimental results demonstrate that the proposed MARL framework consistently achieves superior performance across key metrics such as throughput, delay, and packet loss, and shows stable reward convergence under dynamic traffic conditions.
This paper is organized as follows:
Section 2 introduces the foundational concepts of SDN and MARL.
Section 3 presents a review of existing techniques in congestion classification and control.
Section 4 outlines the architecture and design of our MARL-based framework.
Section 5 details the experimental setup, datasets, and evaluation methodology. Finally,
Section 6 concludes the paper and discusses potential directions for future research.
2. Overview of Key Concepts
This section overviews the key concepts critical to our research, namely Software-Defined Network, single-agent and multi-agent reinforcement learning.
2.1. Software-Defined Network
Software-Defined Networking (SDN) is considered a next-generation Internet technology, in which the control plane is separated from the data plane as first introduced by McKeown et al. [
5] through the development of OpenFlow in 2028. In this architecture, the control logic is no longer embedded at the hardware level but is abstracted and centralized through a software-based control management system. SDN adopts a three-layered architecture consisting of the following:
The
application layer, which consists of a set of applications and services responsible for tasks such as load balancing, traffic monitoring as described by N. L. M. Van Adrichem et al. [
6], and security as discussed by S. Shirali-Shahreza et al. [
7]. This is the programmable layer of SDN that allows the integration of third-party functionalities and applications.
The control layer, where low-level network functions and decisions are abstracted and managed. It acts as an intermediary between the application and infrastructure layers, interpreting application requirements and translating them into network behavior.
The infrastructure layer, which comprises forwarding devices such as switches and routers. These devices are responsible solely for packet forwarding based on the rules and policies defined by the control layer.
The Software-Defined Network relies on a central SDN-Controller that could be a standalone entity or multiple SDN-Controllers collaborating together to achieve the centralized control. It also depends on different protocols to enable and maintain the separation between the control and data plane, such as OpenFlow protocol. OpenFlow is one of the most widely adopted protocols in Software-Defined Networks (SDNs), serving as a standardized interface between the control plane and the data plane. It enables the SDN controller to communicate forwarding rules and network policies to the underlying network devices, thereby allowing centralized and programmable network management as it has been introduced by McKeown et al. [
5].
The SDN architecture, particularly the centralized control and global network view, provides a suitable environment for integrating intelligent control mechanisms. This architectural flexibility enables the deployment of learning-based agents at the controller level, capable of adapting to real-time network states. In this work, we build on these principles to introduce a data-driven congestion classification framework using multi-agent reinforcement learning.
Software-Defined Networking (SDN) is considered a next-generation Internet technology in which the control plane is decoupled from the data plane as first introduced by McKeown et al. [
5] through the development of the OpenFlow protocol. In traditional networks, control logic is tightly coupled with forwarding devices, making network management rigid and hardware dependent. In contrast, SDN abstracts and centralizes control logic through a software-based control management system, thus enabling more flexible, programmable, and dynamic network operation.
2.2. Multi-Agent Reinforcement Learning
Reinforcement learning (RL), as defined by R. S. Sutton et al. [
8], is a sequential decision-making framework where an agent learns an optimal behavior by interacting with an environment
over discrete time steps. At each time step
t, the agent observes a state
, selects an action
according to a policy
, and receives a reward
while transitioning to a new state
. The objective of the agent is to maximize the expected cumulative reward, often expressed as the return:
where
is the discount factor that prioritizes immediate rewards over distant ones.
The interaction can be formally modeled as a Markov Decision Process (MDP), a decision-making framework defined by states, actions, transition probabilities, rewards, and a discount factor. It was developed and improved by Bellman [
9] and Howard [
10], and is formally represented by the tuple
, where
denotes the transition probability and
the expected reward.
Traditional RL focuses on a single agent acting in a stationary environment, according to R. S. Sutton et al. [
8] and M. Bowling et al. [
11]. However, in many real-world systems like communication networks, multiple agents must operate simultaneously in a shared and dynamic environment. This leads to the Multi-Agent Reinforcement Learning (MARL) paradigm, where the environment becomes non-stationary from the perspective of each agent due to the presence of other learning agents.
In MARL, the environment is modeled as a Decentralized Partially Observable MDP (Dec-POMDP), represented by the tuple , where
is the number of agents;
Each agent i selects actions based on its observation ;
The joint action influences the transition ;
Each agent receives a local reward .
MARL provides several advantages, especially in distributed systems like Software-Defined Networks:
Parallelism: Tasks such as traffic monitoring, congestion detection, and control can be handled concurrently, allowing agents to operate simultaneously and independently across the network as presented by Zhang et al. [
12] and Elsayed et al. [
13].
Modularity: Each agent can specialize in a sub-task, making the system more manageable and scalable. Modular designs improve development and maintenance by isolating components as introduced by Hernandez-Leal et al. [
14] and Zhang et al. [
12].
Task Separation: Different aspects of network behavior (e.g., classification versus decision-making) can be independently optimized, improving overall system performance through decentralized specialization as demonstrated by Boehmer et al. [
15] and Foerster et al. [
16].
In cooperative settings, agents aim to maximize a shared objective. This often requires communication or indirect coordination through shared states or rewards. For example, a shared reward function can be used to encourage agents to take joint actions that lead to global optimal results. In our work, cooperation is achieved implicitly: Agent 1 classifies congestion levels, which then serve as input for Agent 2 to make informed bandwidth and routing decisions.
In general, MARL enables distributed intelligence in complex environments and aligns well with the architecture of SDNs, where multiple agents can operate at different levels of the control plane to improve responsiveness and performance.
3. Related Work
In the context of congestion management in Software-Defined Networks (SDNs), several studies have focused on traffic classification and traffic pattern identification as a vital step for intelligent routing, load balancing, and stable network performance. Due to the complexity and dynamics of network environments, traditional approaches often face limitations in detecting and mitigating congestion effectively. Consequently, this has led to increasing interest in the use of machine learning and data-driven techniques to analyze real-time traffic patterns, predict congestion, and make control decisions in advance. Using historical and real-time network data collected from network observations, these approaches aim to enhance adaptability and real-time decision-making by enabling the SDN controller to learn from the state of the network and optimize performance efficiently.
Poupart et al. [
17] utilize data mining techniques to predict the size of network flows at the early stages of transmission, which is critical to maintain network performance while traffic conditions change. Their method models the flow size as a statistical distribution rather than relying on a deterministic function that applied fixed conditions. By computing the mean or mode of this distribution based on initial packet observations, the approach provides a probabilistic estimate of whether a flow will become significant. This early prediction enables the controller to differentiate between short-lived and potentially high-impact flows and allocate resources accordingly.
While Poupart et al. [
17] rely on statistical modeling for flow size prediction, Bishop et al. [
18] use machine learning algorithms for traffic classification and flow size estimation. They evaluate the effectiveness of a range of machine learning algorithms by investigating the comparative accuracy of neural networks, Gaussian Process Regression (GPR) by M. Seeger [
19], and Online Bayesian Moment Matching (oBMM) by F. Omar [
20]. GPR provides a probabilistic model that captures uncertainty in flow prediction, while oBMM enables the online updating of flow classification based on sequential data without retraining from scratch. The results demonstrate that learning-based models can significantly outperform traditional rule-based systems, especially in dynamic network environments where traffic characteristics change frequently.
Shafiq et al. [
21] investigate application-level traffic classification using machine learning techniques to improve the identification of network application types based on flow-level features. Their study conducts a comparative analysis of multiple supervised learning algorithms, including Support Vector Machines (SVMs), BayesNet, and Naive Bayes, to evaluate their effectiveness in classifying traffic from common application protocols such as WWW, DNS, FTP, P2P, and Telnet. The classification is performed using flow features extracted from captured network flows, such as packet size, inter-arrival time, flow duration, and total bytes transferred, using the NetMate tool. This enables the models to identify the traffic pattern and make volumetric predictions. The results show that machine learning classifiers, when trained on pertinent features, can provide high accuracy and adaptability, making them suitable for real-time traffic classification in modern networks. Their work highlights the practicality of feature-based ML approaches for scalable and efficient network traffic analysis.
For traffic prediction, Lv et al. [
22] propose a deep learning framework based on Sparse Autoencoders (SAEs) to learn high-level traffic representations. Their architecture employs stacked autoencoders to extract spatial and temporal correlations embedded in network traffic patterns. The model is trained in two phases: first, using greedy layer-wise unsupervised pretraining to initialize weights effectively, and then applying supervised fine-tuning to optimize prediction performance. By using sparse representations, the model is able to focus on the most prominent traffic features, thereby improving generalization and robustness. Experimental results demonstrate that their approach achieves higher accuracy in predicting traffic volume compared to traditional models, making it suitable for dynamic and complex network environments.
J. Mao et al. [
23] propose a flow control mechanism based on the Deep Deterministic Policy Gradient (DDPG), by T. P. Lillicrap et al. [
24], a reinforcement learning algorithm designed for continuous action spaces. In this reinforcement learning framework, the agent observes network parameters such as bandwidth availability, latency, and traffic load, and learns to adjust the data sending rate in real-time. This allows for fine-grained congestion control, enabling the system to respond to minor variations in network dynamics with high precision. By leveraging the ability of DDPG to operate in continuous domains, the proposed approach achieves a more adaptive, continuous and refined control strategy compared to discrete action RL models.
Other studies have addressed congestion from a control plane perspective. Yu et al. [
25] propose DIFANE, a scalable flow management solution that minimizes switch-controller interactions by delegating most forwarding decisions to authority switches. By keeping decision logic within the data plane, DIFANE significantly reduces the communication bottleneck on the controller, thereby alleviating potential congestion in the control plane. Similarly, Curtis et al. [
26] introduce DevoFlow, an architectural enhancement that further limits control traffic by transferring greater responsibility to switches. DevoFlow aims to reduce controller overhead by handling frequent or short-lived flows locally, allowing the controller to focus on high-level policies and exceptional events.
R. Jin et al. [
27] explore congestion control within SDN-based data center environments using reinforcement learning algorithms such as SARSA and Q-learning. Although their approach shows promising results, it is primarily limited to single-task scenarios and cannot be generalize across diverse network conditions. Lei et al. [
28] introduce MTDQ-ER, (Multi-Task Deep Q-Learning with Experience Replay), a framework that utilizes the programmability of SDN to implement a multi-task RL agent capable of learning and applying optimal congestion control policies across multiple traffic scenarios.
As refined Q-learning, Zhang et al. [
29] present a method that dynamically adjusts transmission rates based on real-time bandwidth utilization. However, their approach employs a single-agent model with fixed-rate control logic, which lacks the adaptability needed in complex and rapidly evolving networks. This rigidity may lead to inefficiencies and even control plane congestion, as the system does not continuously monitor or respond to minor network change.
Beyond flow detection, machine learning techniques have also been explored for intelligent traffic routing in communication networks. These routing strategies generally fall into two categories: decentralized and centralized approaches. Kato et al. [
30] propose a decentralized deep reinforcement learning framework in which individual routers are modeled as neural network agents capable of learning and adapting their forwarding behavior. The system is initially trained using data collected from Open Shortest Path First (OSPF) routing, and then fine-tuned through continuous feedback from the network environment. This architecture enables each router to make autonomous, data-driven routing decisions based on real-time traffic conditions, enhancing flexibility and scalability in heterogeneous network infrastructures.
In contrast, Rusek et al. [
31] introduce RouteNet, a centralized routing framework built on Graph Neural Networks (GNNs). Unlike decentralized models, RouteNet operates at the controller level, leveraging the global view of the network provided by SDNs. By modeling the network as a graph—where nodes represent routers or switches and edges represent links—RouteNet learns to predict performance metrics such as average end-to-end delay. These predictions enable the controller to make informed, topology-aware routing decisions that adapt to changing traffic patterns, thereby improving the overall network efficiency and service quality.
In our previous research, we explored machine learning-based techniques for elephant flow detection in SDN environments. In [
32], we conducted a comparative performance evaluation of several supervised learning algorithms, including Decision Trees, Random Forests, and Support Vector Machines, to identify high-bandwidth flows contributing to network congestion. The study revealed that Random Forests provided superior detection accuracy with minimal false positives, underscoring the viability of traditional supervised learning for proactive traffic identification. In a later study, in [
33], we proposed a federated learning approach to elephant flow detection in distributed SDNs. This work emphasized bias mitigation and privacy preservation by enabling multiple domains to collaboratively train a global model without sharing raw data, effectively addressing class imbalance and data heterogeneity across controllers. While both studies achieved strong results in detection, they were focused exclusively on flow identification and did not incorporate adaptive decision-making or congestion control mechanisms.
Building upon these insights, our work distinguishes itself by introducing a cooperative learning mechanism using Multi-Agent Reinforcement Learning (MARL). Our proposed Data-Driven MARL framework includes a Congestion Classification Agent that continuously assesses traffic conditions using packet loss and delay, and a Decision-Making Agent that selects routing and bandwidth actions via Deep Q-Learning. Together, they form a sequential control chain capable of real-time congestion state assessment and intelligent, policy-driven decision-making.
Although previous works have explored traffic classification, congestion control, and intelligent routing using various machine learning and reinforcement learning techniques, most approaches focus on single-task optimization, static rule-based strategies, or rely on a single-agent model that lacks adaptability in diverse and dynamic environments. In contrast, our proposed Data-Driven MARL framework introduces a multi-agent architecture designed for Software-Defined Networks, where one agent is dedicated to congestion classification based on real-time delay and packet loss, and the other learns optimal control actions using Deep Q-Learning. This cooperative design allows the real-time assessment of congestion states and adaptive routing and bandwidth decisions, making it more flexible and scalable than conventional methods. Unlike approaches such as RouteNet that focus solely on centralized predictions, or DDPG-based controllers that address continuous rate adaptation in isolation, our system integrates classification and control embedded in a sequential MARL chain, enabling intelligent, policy-driven network management in the face of realistic traffic conditions.
5. Simulation and Results Analysis
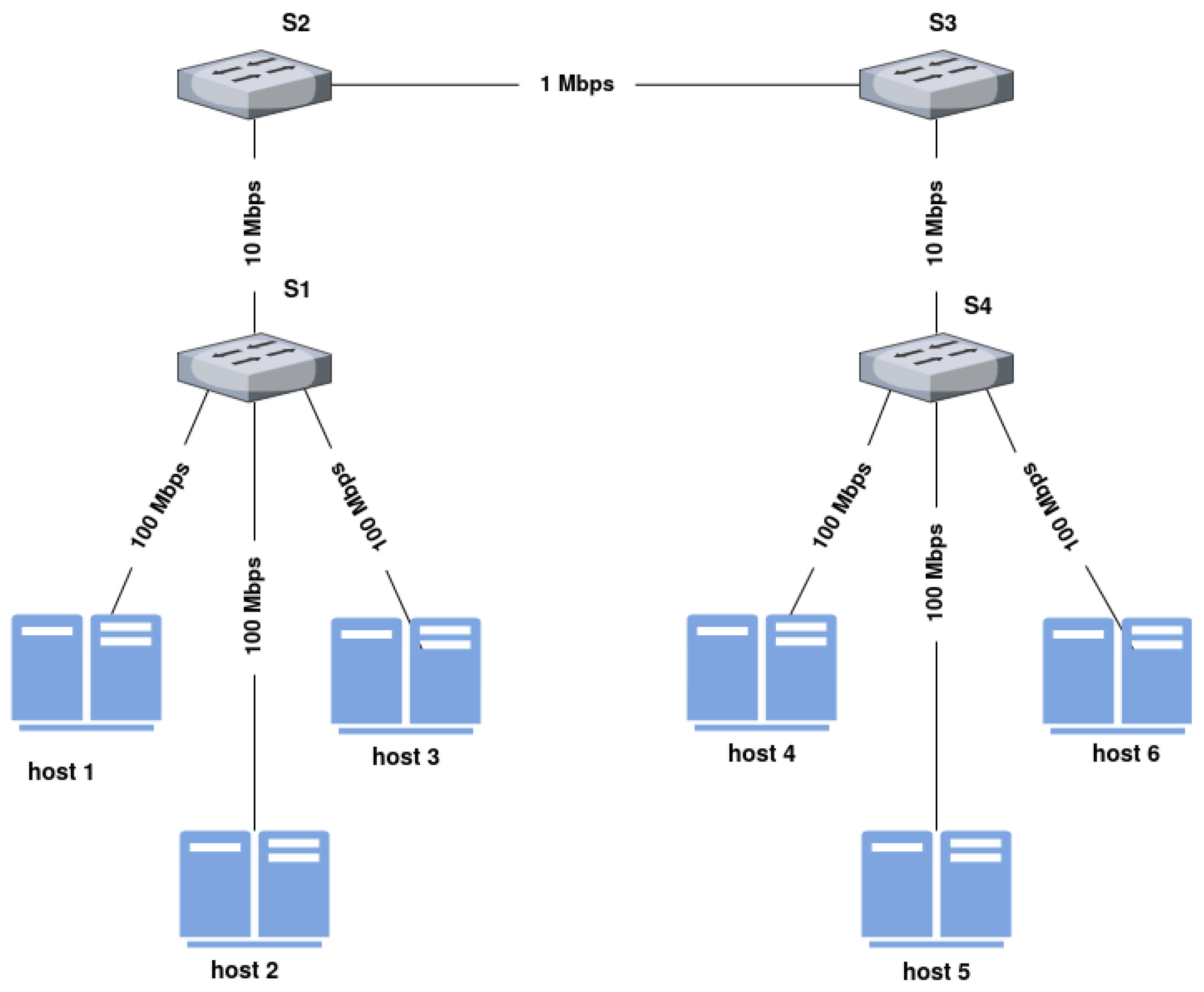
This section presents a detailed analysis of the proposed MARL framework’s performance across both offline training and online evaluation phases. We also provide a comparative evaluation of our Data-Driven MARL approach against three alternative baselines: Ablation (DQN-only), Double DQN, and a Random (rule-based) controller. Both the offline and online phases utilize a combination of synthetic traffic generated using iperf3 and real-world traces from the MAWI dataset to train the agents and validate their ability to generalize under realistic SDN conditions.
To assess the robustness of the proposed architecture, MAWI traces and synthetic traffic are replayed within our Mininet-based SDN environment. These traffic sources reflect a wide range of real-world and controlled congestion scenarios, including bursty flows and variable load conditions. This setup enables a comprehensive evaluation of whether agents trained on diverse traffic patterns can adapt and maintain performance under dynamic network conditions. Throughout both phases, we monitor key QoS metrics, throughput, delay, packet loss, and link utilization, and analyze the agents’ learning dynamics through cumulative reward trends and action selection distributions. The results demonstrate the strength of our multi-agent design in delivering stable and adaptive behavior across fluctuating traffic environments.
5.1. Performance Evaluation of the Classification Agent
To evaluate the effectiveness of the Classification Agent, we analyze its performance across both synthetic and MAWI-based traffic datasets. Specifically, we examine the classification precision, recall, and F1-score over the four defined congestion states. In addition to metric-based evaluation, we visualize the confusion matrix to assess prediction reliability and highlight areas of misclassification. This evaluation provides insights into the agent’s ability to generalize congestion state detection under variable traffic patterns and validates its standalone learning capacity before integration with the decision agent.
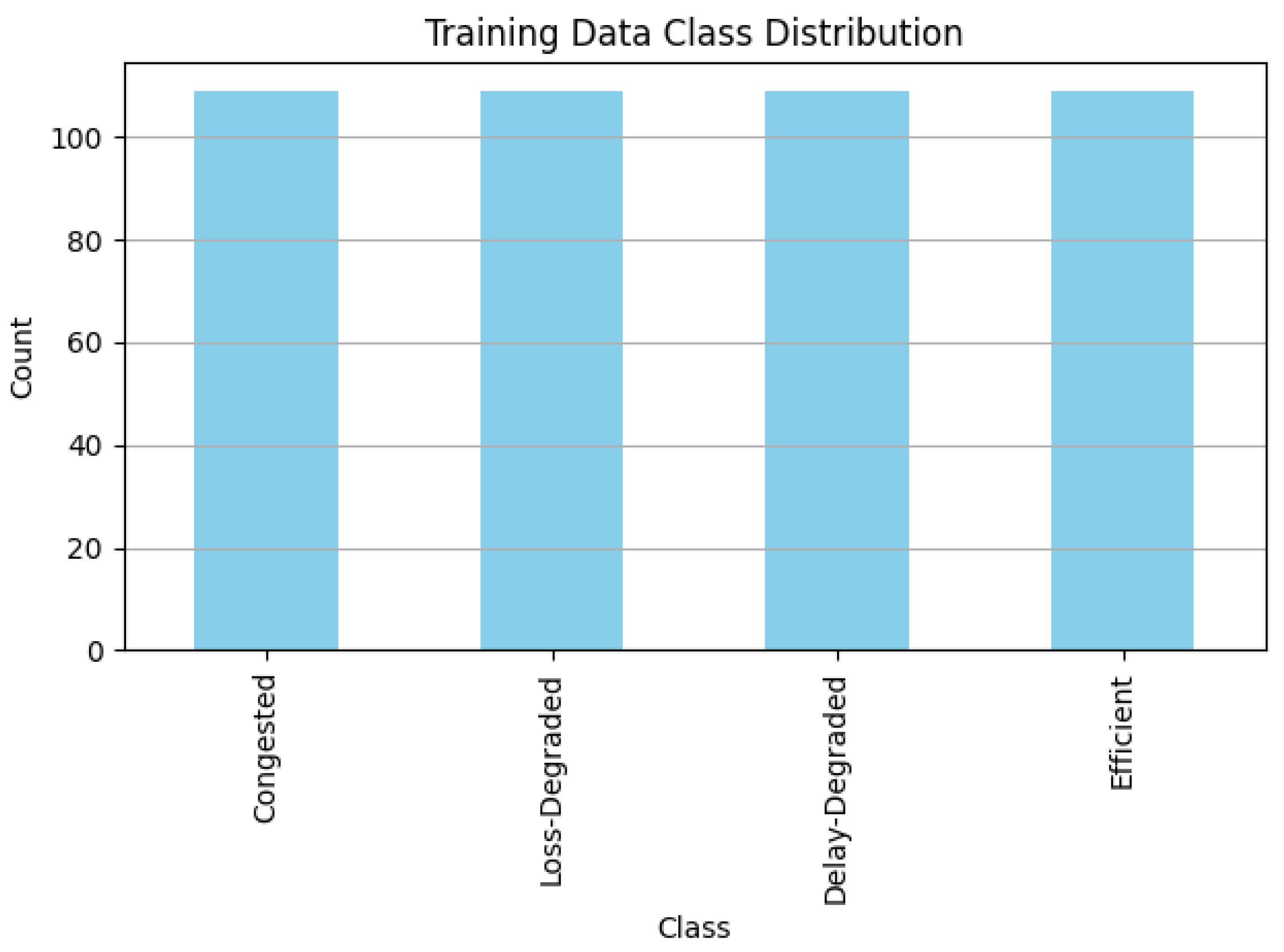
5.1.1. Class Distribution in Training Data
Figure 3 shows the distribution of classes used for training the Classification Agent. The dataset is well-balanced, with approximately equal counts for all four congestion states: Efficient, Loss-Degraded, Delay-Degraded, and Congested. This balance ensures that the agent does not develop bias toward overrepresented classes, which is critical for maintaining generalization accuracy.
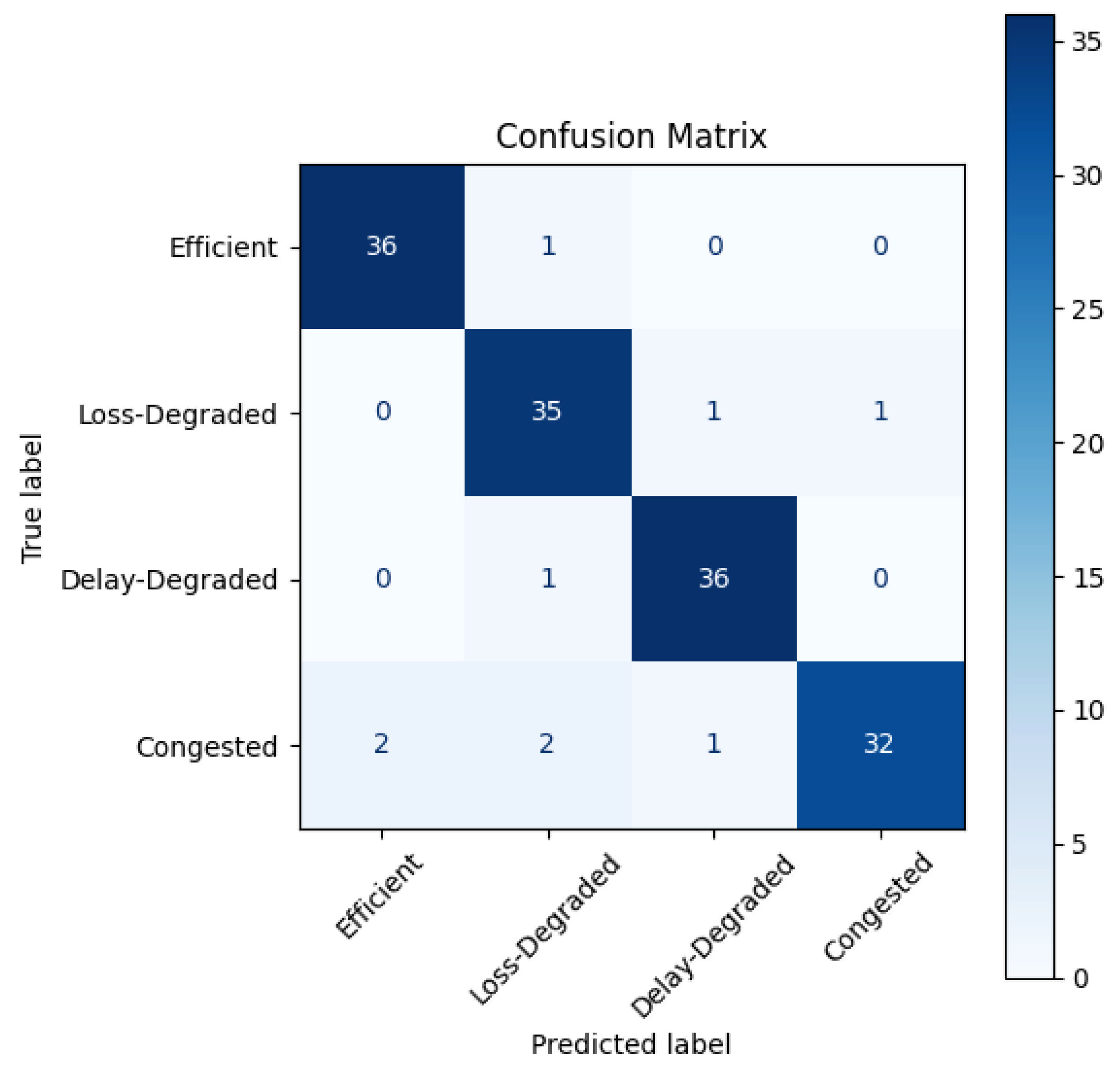
5.1.2. Confusion Matrix
Figure 4 illustrates the confusion matrix obtained from evaluating the agent on a held-out test set. The classifier shows strong overall accuracy:
Efficient and Delay-Degraded states are correctly identified in 36 out of 37 cases.
Loss-Degraded instances are predicted with high precision, with only 2 errors out of 38.
Congested states show slightly more confusion, with 3 misclassified cases (2 as other degraded states and 1 as Delay-Degraded).
The agent distinguishes well between the classes, especially the Efficient and Delay-Degraded conditions, while minor confusions appear among degraded categories—likely due to their similar network symptoms (e.g., delay and packet loss).
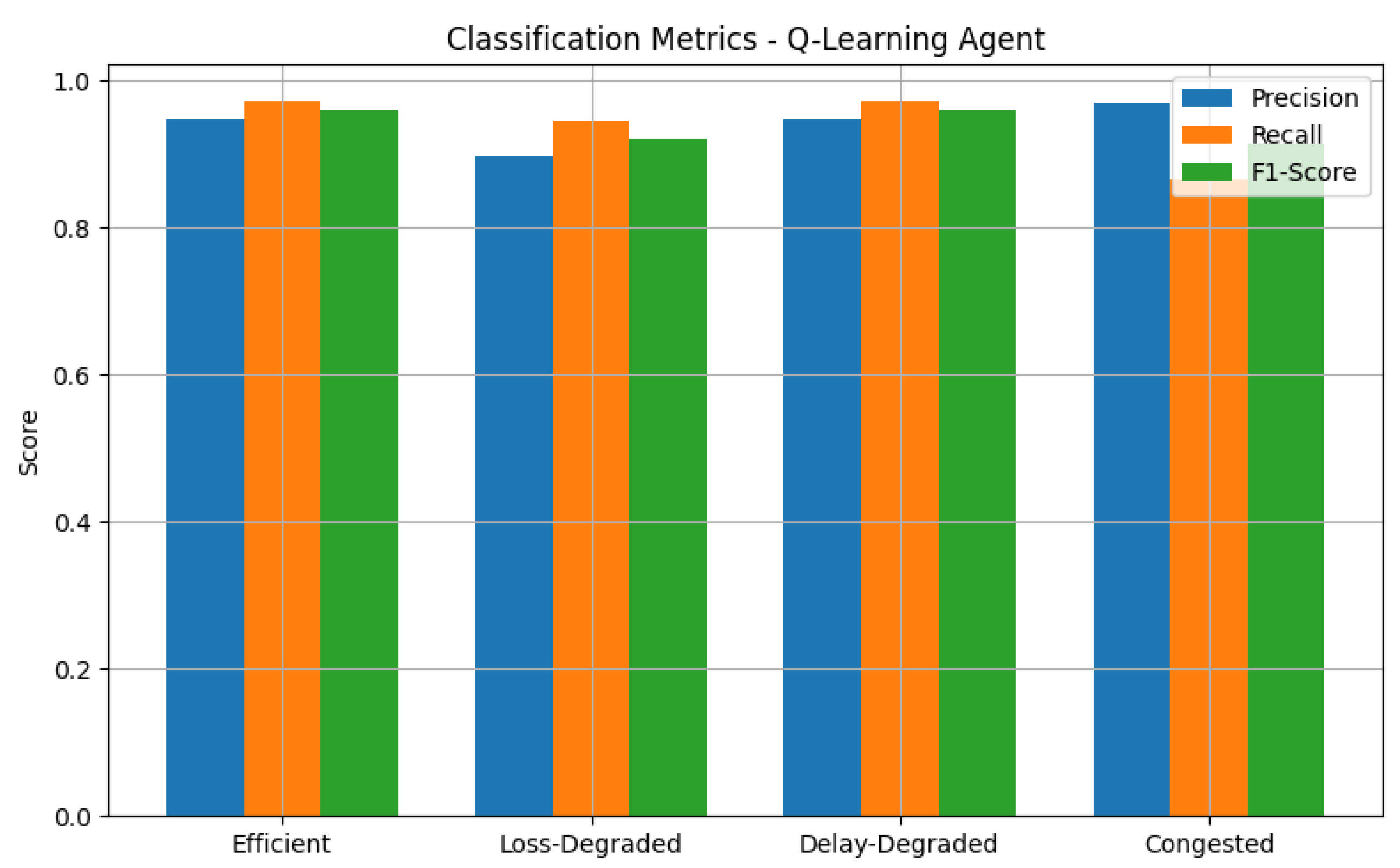
5.1.3. Classification Metrics
Figure 5 reports the precision, recall, and F1-score for each class. The agent achieves the following:
Precision ≥ 0.91 across all classes, showing few false positives.
Recall values ranging from 0.94 to 0.97, indicating high detection capability for each state.
F1-scores that are tightly clustered around 0.95, suggesting balanced performance across precision and recall.
These scores reflect a robust classification policy, making the agent reliable in real-time SDN congestion scenarios.
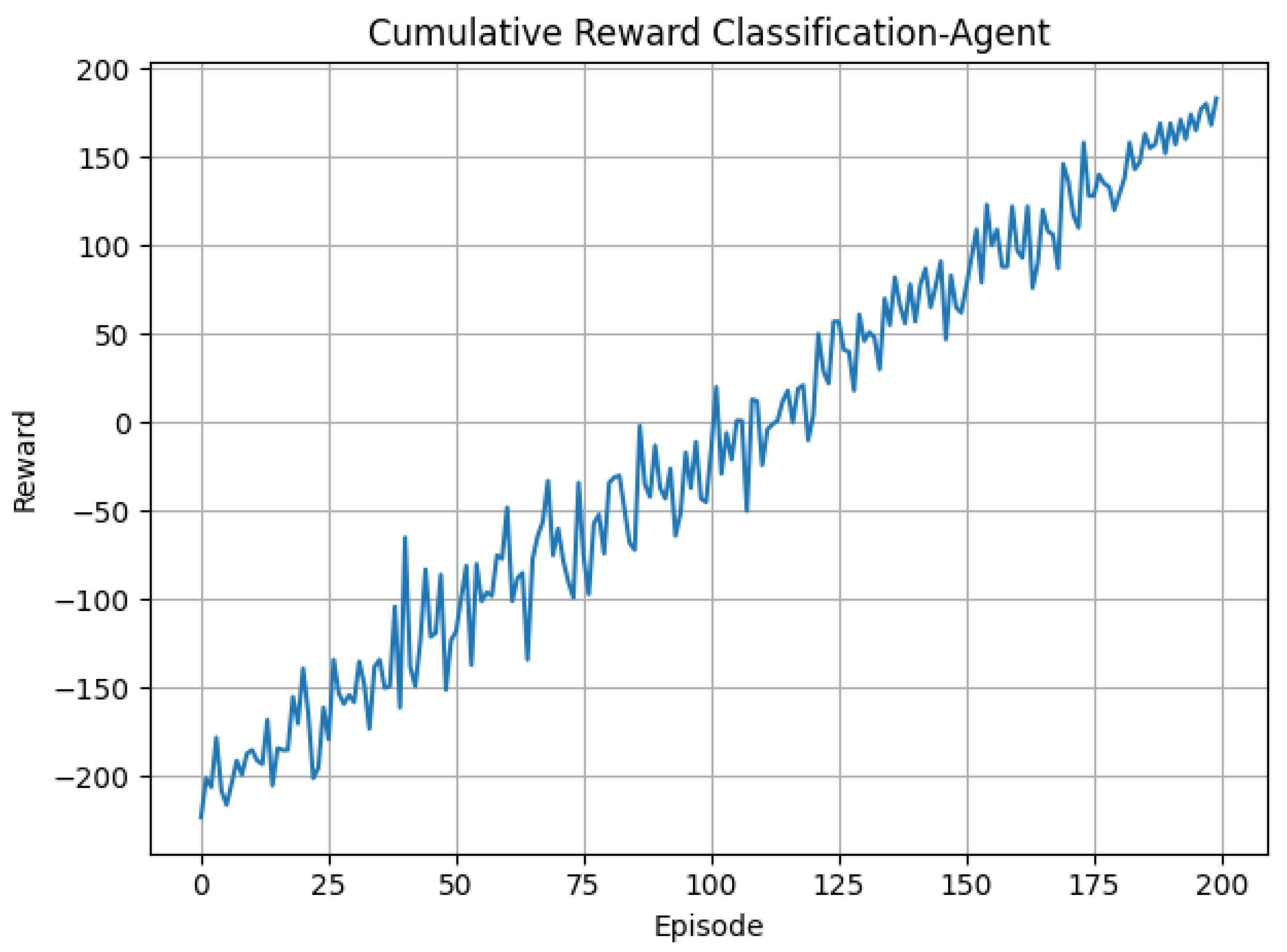
5.1.4. Cumulative Reward Curve
Figure 6 shows the learning curve of the Classification Agent during 200 training episodes. The cumulative reward starts negative, reflecting random or incorrect early decisions. However, a steady upward trend is observed as the agent gains experience and its policy improves. After approximately 100 episodes, the cumulative reward becomes consistently positive, confirming convergence to an effective classification strategy.
This trend validates the reward function design and the effectiveness of the -greedy exploration mechanism used during training.
Collectively, these results demonstrate that the Q-learning Classification Agent has been effectively trained offline. It generalizes well to new samples, maintains high classification accuracy across all QoS states, and converges rapidly under a stable training regime. This robustness ensures high-quality labels for guiding the Decision Agent in the subsequent decision-making process.
5.2. Performance Evaluation of Decision-Making Agent
In this section, we evaluate the performance of the Decision Agent trained using Deep Q-Networks (DQNs). The agent is responsible for selecting optimal actions involving bandwidth adjustments and routing strategies based on network conditions classified by the Classification Agent. We assess its behavior using both synthetic (iperf3) and real-world (MAWI) traffic traces in offline and online settings. The evaluation focuses on action selection diversity, cumulative reward trends, and critical QoS metrics, throughput, link utilization, delay, and packet loss. The goal is to determine the agent’s adaptability and learning consistency under variable SDN traffic dynamics.
5.2.1. Evaluation of Action Distribution
Figure 7 displays the frequency distribution of actions selected by the Decision Agent during offline training. The agent has access to six composite actions, combining different bandwidth adjustment levels and routing strategies. The observed distribution shows that the agent maintains a relatively balanced selection across all actions, with a slight preference for the actions
increase_bw_reroute_imm and
maintain_bw_reroute_optimal.
This distribution suggests that the agent did not fall into a narrow behavioral loop and instead explored diverse strategies. It also reflects a nuanced learning process where rerouting and adaptive bandwidth decisions are actively chosen based on the network state. The balanced usage of increase, decrease, and maintain operations indicates that the agent does not default to conservative policies but rather makes decisions that are responsive to dynamic QoS conditions.
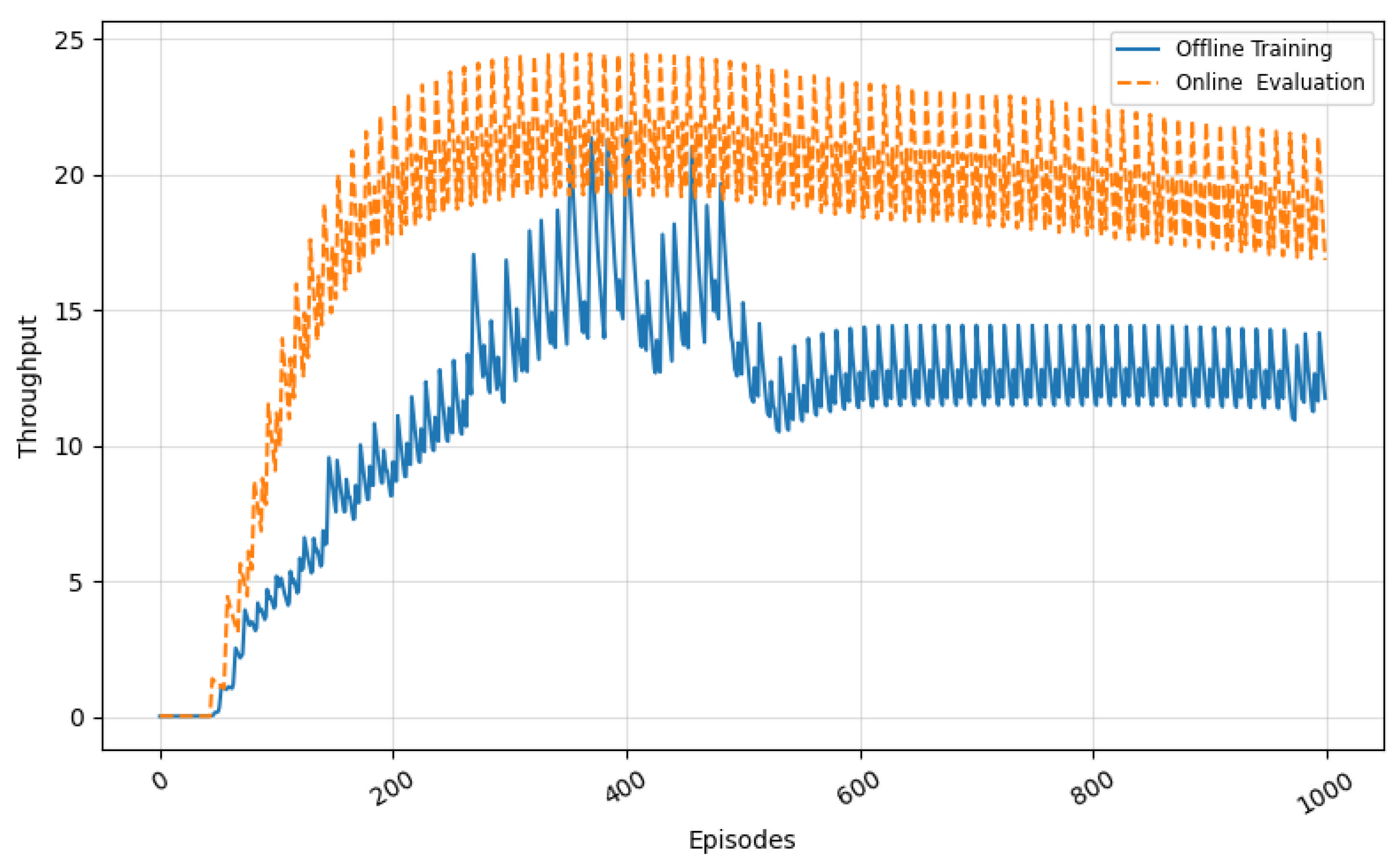
5.2.2. Evaluation of Throughput over Time
Figure 8 illustrates the average throughput measured during offline training and online evaluation. In the offline training phase, throughput shows a progressive increase over time, with oscillations attributed to the agent’s exploratory behavior. These fluctuations reflect the learning process as the agent attempts various actions before converging to optimal strategies. The throughput curve stabilizes mid-training, indicating that the agent has effectively learned to route traffic while minimizing congestion. During the online evaluation phase, the pretrained agent is deployed in a realistic environment using MAWI traffic. Here, the throughput remains consistently high with minimal fluctuation. This behavior is a direct consequence of the knowledge acquired during offline training. The online agent manages to maintain throughput levels above those achieved during most of the offline training, confirming the stability of the learned policy under dynamic and bursty traffic patterns.
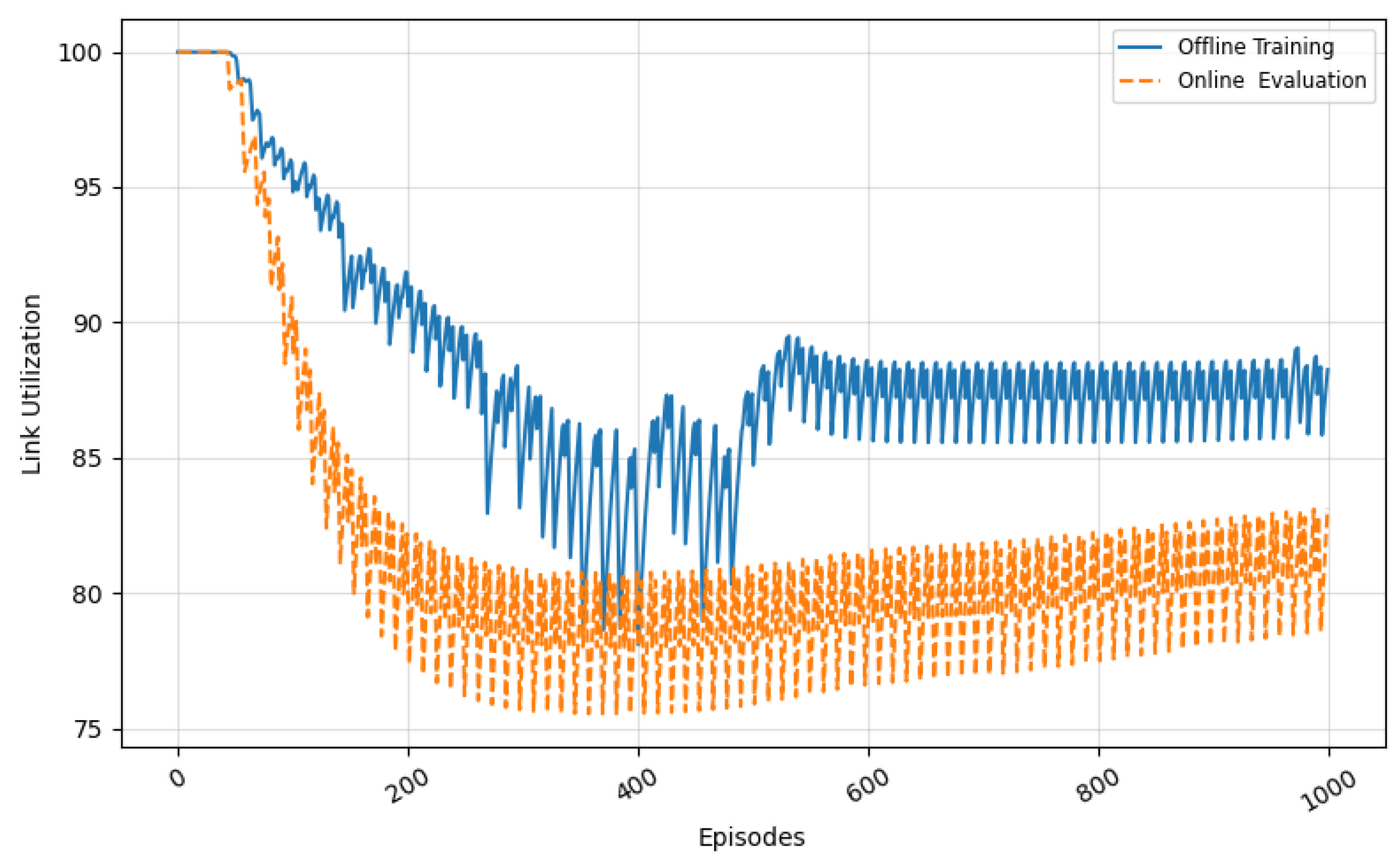
5.2.3. Evaluation of Link Utilization
Figure 9 presents the evolution of link utilization across training and evaluation. Initially, the offline agent permits over-utilization of the network core due to its untrained decision-making, resulting in congestion and inefficient bandwidth distribution. As training progresses, the agent learns to make more adaptive rerouting and bandwidth control decisions, leading to a gradual and controlled reduction in link saturation. In the online evaluation, link utilization starts at a lower level and remains within the 75–85% range, reflecting the agent’s conservative and congestion-aware policy. Unlike static baselines or heuristic approaches, the trained agent is able to preserve high throughput without aggressively saturating links. This equilibrium between utilization and stability demonstrates that the model learned to operate efficiently even under real-world conditions, avoiding buffer overflows and packet loss typically associated with high link usage.
5.2.4. Evaluation of Delay
As depicted in
Figure 10, the offline training phase begins with very high delay values, reaching peaks above
ms. This is expected due to the initial exploratory actions that cause suboptimal routing and bandwidth management. These delays are symptomatic of heavy queuing and congestion on the core bottleneck link. Over time, as the agent refines its policy, the delay sharply decreases, especially after episode 600, where the learned actions increasingly favor congestion-mitigating behaviors. Conversely, the online evaluation shows a markedly different pattern. From the beginning, delay values remain consistently low (below 10 ms), with minimal variance. This indicates that the model learned to generalize to unseen traffic patterns and could proactively avoid scenarios leading to excessive queuing. The steep drop in delay observed during the transition from exploration to exploitation demonstrates that the RL agent successfully internalized delay-sensitive policies.
5.2.5. Evaluation of Packet Loss
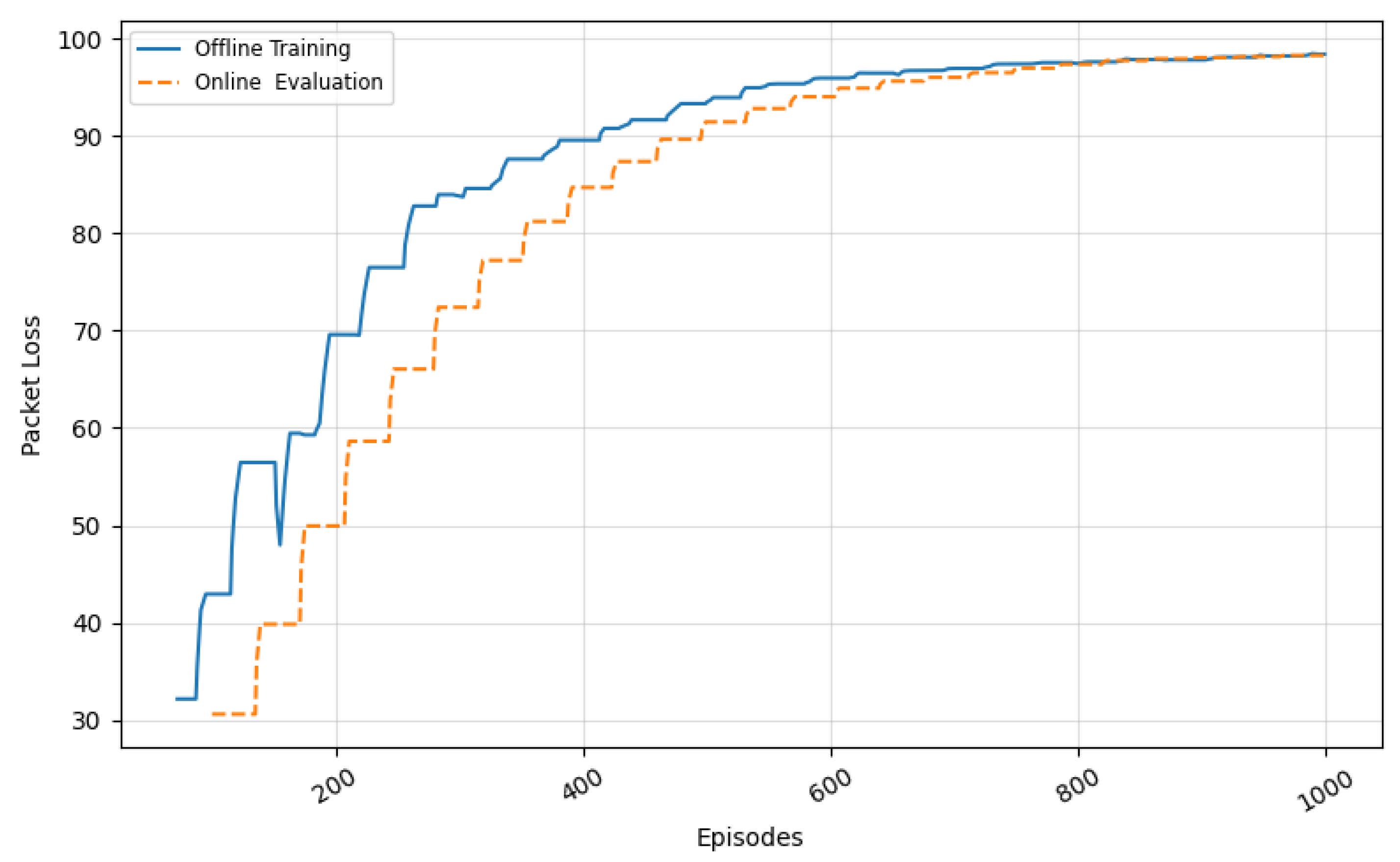
In
Figure 11, we observe the packet loss progression during training and evaluation. The offline agent begins with a relatively low loss rate, but this quickly escalates as congestion builds up due to uninformed routing and static bandwidth assignments. This reflects the agent’s need to experience poor network states in order to learn from them. Eventually, the agent stabilizes its strategy, and the packet loss curve flattens after approximately 700 episodes, indicating more intelligent traffic steering and bandwidth decisions. In contrast, the online evaluation demonstrates a slower and more controlled increase in packet loss. This smooth trend suggests the agent anticipates congestion before it results in buffer overflow or severe degradation. The online loss remains under 10% for most of the evaluation, highlighting the effectiveness of learned policies in mitigating packet drops even in bursty and non-deterministic environments. This validates the agent’s capacity to operate within realistic SDN deployments where buffer limits and queue dynamics are not ideal.
5.2.6. Evaluation of Cumulative Reward over Episodes
Figure 12 illustrates the cumulative reward progression of the Data-Driven MARL architecture across episodes, comparing offline training and online evaluation.
In both curves, the agent starts with minimal reward, reflecting early-stage exploratory behavior. The offline training curve shows a steady and gradual increase, demonstrating consistent learning over time. Around episode 500, the slope begins to flatten, suggesting the agent is converging toward a stable and effective policy. By episode 1000, the cumulative reward stabilizes around 175, indicating successful offline training with well-tuned parameters and reward structure.
The online evaluation curve, on the other hand, rises more rapidly and reaches higher cumulative rewards—surpassing 200 by the end of the run. This highlights two key points:
The policy trained offline successfully transfers to real-time environments, generalizing to dynamic and unpredictable traffic conditions.
The online agent benefits from continuous interaction with live network feedback, allowing it to refine decisions and accumulate higher long-term rewards.
The absence of reward dips or oscillations in both curves confirms stable learning behavior and a reward function that encourages quality of service (QoS) optimization. The performance gap between online and offline indicates that while offline training provides a strong foundation, online adaptation further enhances decision-making efficiency under real-world SDN traffic conditions.
5.3. Comparative Evaluation of Our Data-Driven MARL vs. Ablation, Double DQN, and Random Baselines
To validate the effectiveness and robustness of our proposed Data-Driven MARL framework, we conduct a comparative evaluation against three alternative control strategies under identical experimental conditions. The evaluation includes the following:
Decision-Only DQN: A single-agent Deep Q-Network model that uses raw input features (delay, loss, jitter, throughput, and utilization) without any classification of congestion states. This ablation removes the classifier to assess its contribution to performance.
Two-Stage Double DQN (DDQN): An enhanced version of our MARL framework where the Decision Agent is implemented using Double DQN instead of standard DQN. This variant addresses overestimation bias and improves learning stability through decoupled target selection.
Rule-Based Baseline Controller: A static heuristic controller that selects predefined bandwidth and routing actions based on fixed QoS thresholds, without learning or adaptation. It serves as a non-learning benchmark.
All reinforcement learning-based models (MARL, DDQN, and DQN-only) were trained offline using synthetic traffic generated via iperf3 and MAWI Traffic. After training convergence, each agent was deployed in an online SDN environment where it controlled routing and bandwidth allocation in real-time using realistic MAWI traffic traces replayed in the Mininet emulation platform.
The comparison focuses on key performance indicators:
Throughput: The average end-to-end data delivery rate.
Link Utilization: The extent of bandwidth usage relative to capacity.
Delay and Packet Loss: Critical quality-of-service metrics under varying network loads.
Cumulative Reward: Reflects the agent’s ability to maximize long-term performance.
This comprehensive evaluation aims to quantify the benefit of our two-agent modular architecture, assess the impact of using classification in decision-making, and highlight the advantages of learning-based controllers over non-adaptive baseline strategies.
5.3.1. Throughput and Link Utilization Across Models
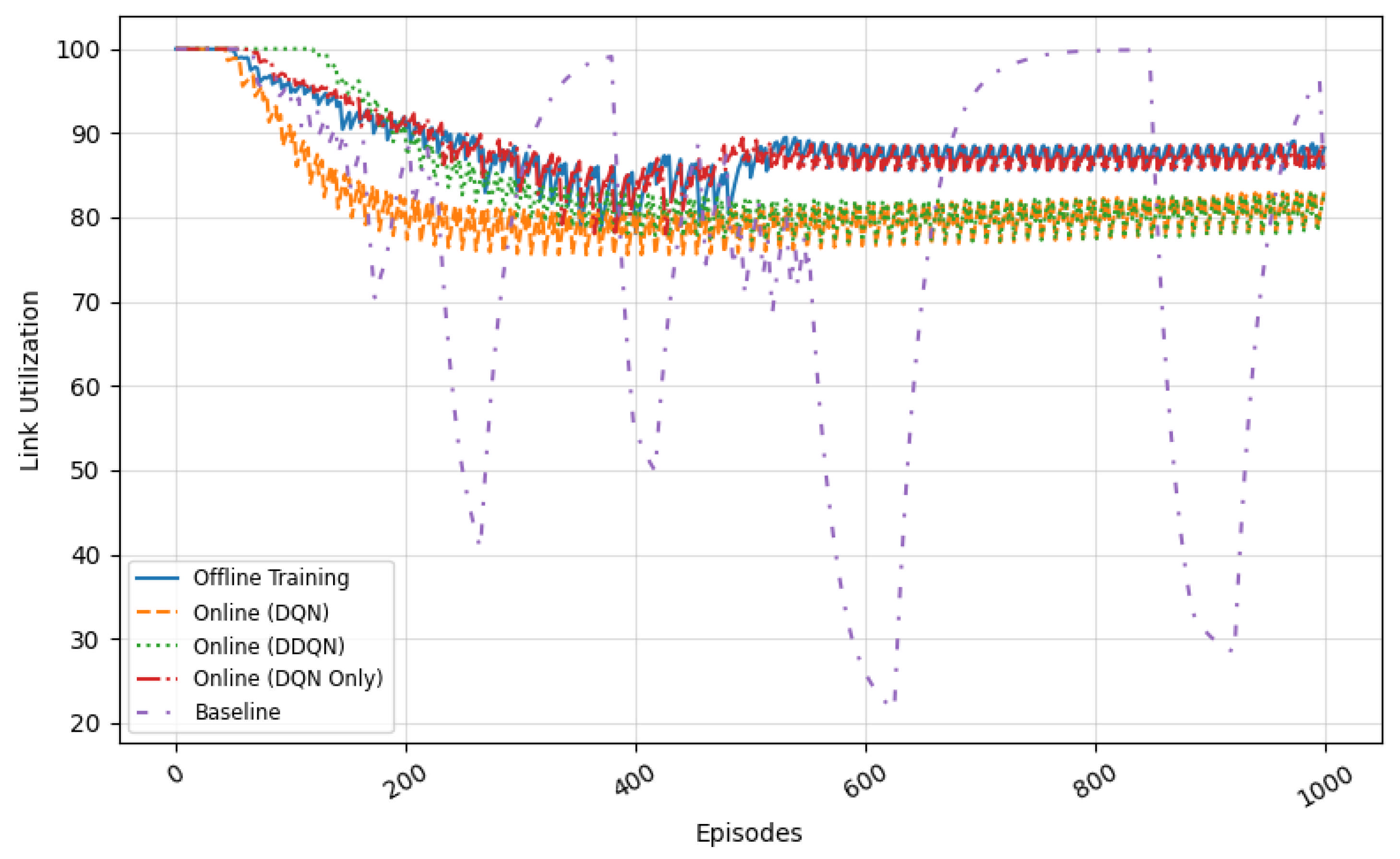
Figure 13 illustrates the average throughput achieved by each agent during training and evaluation. Both two-stage configurations (DQN and DDQN) significantly outperform the Decision-Only DQN and the static baseline. Notably, the Two-Stage DDQN achieves the highest throughput across most episodes, reflecting superior convergence stability and policy refinement. The Decision-Only DQN, although capable of moderate performance, fails to match the throughput levels of the full MARL setups. In contrast, the baseline controller exhibits erratic and suboptimal throughput due to its inability to adapt to traffic fluctuations.
Figure 14 shows the link utilization trends across the same agents. The Two-Stage DDQN maintains a consistent utilization between 80 and 90%, efficiently using the available capacity without inducing overload. The Decision-Only DQN initially suffers from over-utilization but stabilizes with continued learning. Meanwhile, the static baseline controller frequently overloads links, leading to high congestion and inefficient bandwidth distribution due to its fixed, non-reactive behavior.
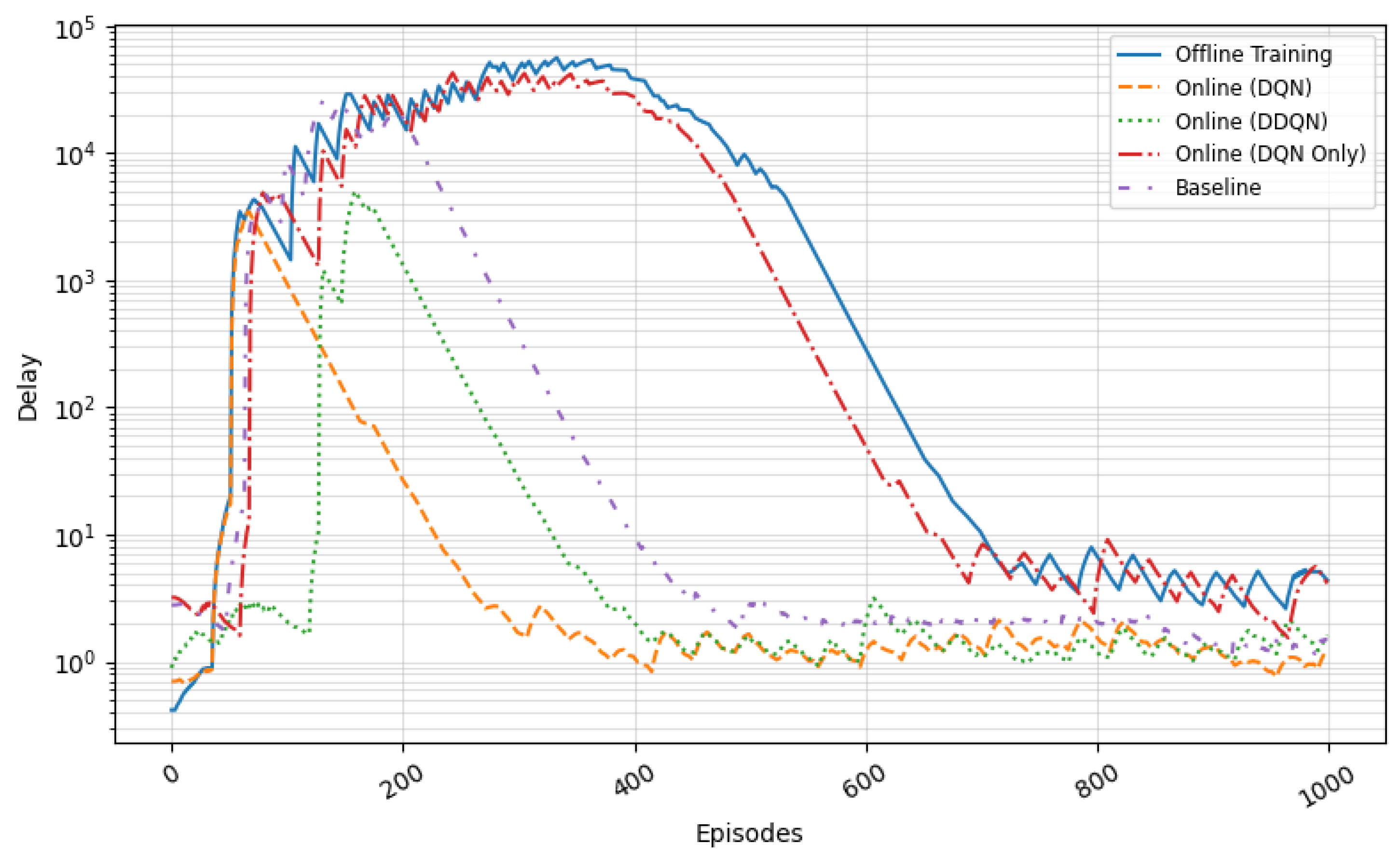
5.3.2. Delay and Packet Loss Across Models
Figure 15 highlights the agents’ performance in terms of end-to-end delay. The Two-Stage DDQN consistently maintains the lowest delay values—below 10 ms beyond episode 500—demonstrating its ability to mitigate queuing and congestion early. The Two-Stage DQN follows closely with slightly higher variance. The Decision-Only DQN shows instability during initial episodes, with delays peaking above 100 ms before improving. In contrast, the baseline controller suffers from persistent high latency (often exceeding 200 ms), attributed to its lack of responsiveness to congestion signals.
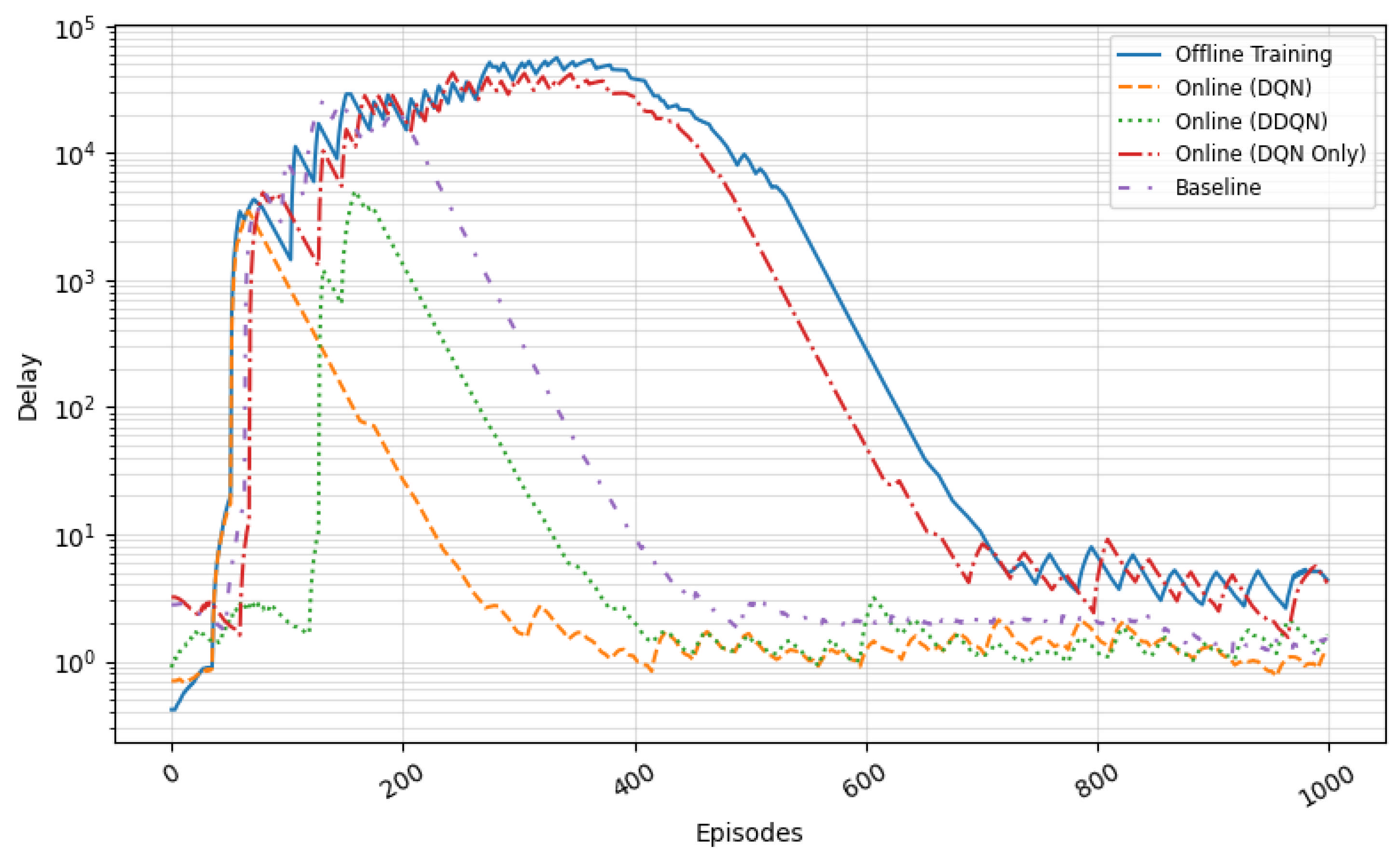
The packet loss results are shown in
Figure 16. The Two-Stage DDQN maintains the lowest loss ratio, consistently under 5% in the final evaluation episodes. The Two-Stage DQN demonstrates similar behavior, although it fluctuates slightly between 8 and 10%. The Decision-Only DQN requires more time to stabilize and eventually settles around 15% packet loss. Due to logging inconsistencies encountered during simulation runs, complete baseline controller data could not be included in this figure. Nonetheless, based on prior experiments and established observations, the baseline controller—lacking adaptive control—typically exhibits the highest packet loss, often exceeding 20% under MAWI traffic bursts. This expected behavior is consistent with previous trends and reinforces the observed advantages of adaptive learning-based approaches.
5.3.3. Cumulative Reward Comparison Across Models
Figure 17 presents the cumulative reward progression for all evaluated agents. The proposed Data-Driven MARL framework, implemented with a DQN-based Decision Agent, demonstrates consistently strong performance. It accumulates rewards at a stable and increasing rate, significantly outperforming both the Decision-Only and baseline controllers.
Among all configurations, the Two-Stage DDQN achieves the highest cumulative reward. This is attributed to its reduced overestimation bias and improved convergence behavior, made possible by decoupled action selection and value estimation. The standard DQN-based MARL agent follows closely, validating the effectiveness of our modular multi-agent structure even without Double DQN enhancements.
The Decision-Only DQN, representing an ablation of our architecture, accumulates rewards at a slower pace and plateaus at a lower level. This highlights the essential role of the congestion classifier in enabling accurate and timely decisions. The static baseline lags significantly behind all learning agents, reflecting the limitations of non-adaptive, rule-based strategies in dynamic SDN environments.
These results collectively demonstrate the importance of combining classification and decision-making in a multi-agent setup, and confirm that our Data-Driven MARL framework delivers superior learning stability and QoS optimization over both heuristic and partially informed baselines.
6. Conclusions
In this study, we proposed a novel Data-Driven Multi-Agent Reinforcement Learning (MARL) framework for congestion classification and proactive traffic control in Software-Defined Networks (SDNs). By leveraging the centralized control of SDN and the adaptive learning capabilities of reinforcement learning, the framework dynamically optimizes network performance under varying traffic conditions. Our architecture includes two cooperative agents: (1) a classification agent that assesses congestion levels using real-time metrics such as packet loss and delay, and (2) a Decision-Making Agent that selects optimal actions involving bandwidth adjustment and path rerouting based on learned policies.
To assess the effectiveness and robustness of the proposed MARL-based controller, we conducted an extensive evaluation using real-world traffic traces. We compared the performance of our model against several baselines, including a single decision-agent configuration (ablation), a Double DQN variant, and a non-learning baseline based on random action selection. The results clearly show that our model consistently learns to take context-aware decisions that alleviate congestion and improve performance across key QoS indicators. It outperformed all baselines in terms of action consistency, responsiveness under congestion, and overall metric stability.
The MARL controller achieved lower average delay and packet loss, while also maintaining consistent throughput. Specifically, end-to-end delay was kept consistently below 10 ms during online evaluation, and packet loss remained under 10% for most episodes. Compared to the baseline controller—which experienced delays exceeding 200 ms and packet loss above 20%—our model demonstrated significant improvement in managing congestion. The action distribution analysis showed that the MARL agent gradually adopted stable and purposeful decision-making strategies, balancing between rerouting and bandwidth adjustment based on the network state. Moreover, the Classification Agent achieved a precision of 0.91 and F1-scores around 0.95 across all classes, indicating the reliable detection of congestion states. Cumulative reward progression also showed steady growth, confirming the stability of the learning process and the effectiveness of the reward design.
These findings validate the adaptability and efficiency of the proposed MARL approach for real-time traffic control in SDNs. For future work, we plan to explore cooperative learning techniques to further enhance inter-agent coordination and decision-making. Approaches such as centralized training with decentralized execution (CTDE), parameter sharing, and attention-based communication mechanisms could enable agents to share knowledge more effectively and adapt collectively to dynamic network environments. These strategies have shown promise in improving learning stability, responsiveness, and scalability in multi-agent systems.
Furthermore, our evaluation shows that the Double DQN variant performs competitively, demonstrating stable convergence and strong cumulative reward accumulation. While our current architecture is based on standard DQN, these results suggest that more advanced single-agent learning techniques could complement our modular framework without diminishing the benefits of classification-driven decision-making. Finally, we aim to validate the real-time applicability of our framework by deploying it in a physical SDN testbed such as ONOS or a P4-enabled environment. This will allow us to evaluate operational effectiveness under real-world constraints, including hardware variability, control plane latency, and unstructured traffic dynamics.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}