
A BERT-Based Multimodal Framework for Enhanced Fake News Detection Using Text and Image Data Fusion



Abstract
1. Introduction
- BERT’s power in analyzing the text via social media as an accurate tool for fake news.
- Development of a new framework that combines text and image features for multimodal fake news detection.
- The effectiveness and generalizability of this system will be tested using actual datasets from real-world social media platforms.
2. Literature Review
2.1. Early Approaches
2.2. Bert and the Rise of Multimodal Approaches
2.3. Advances in Multimodal Fusion and Bert
2.4. Comparison with State-of-the-Art (Sota) Approaches
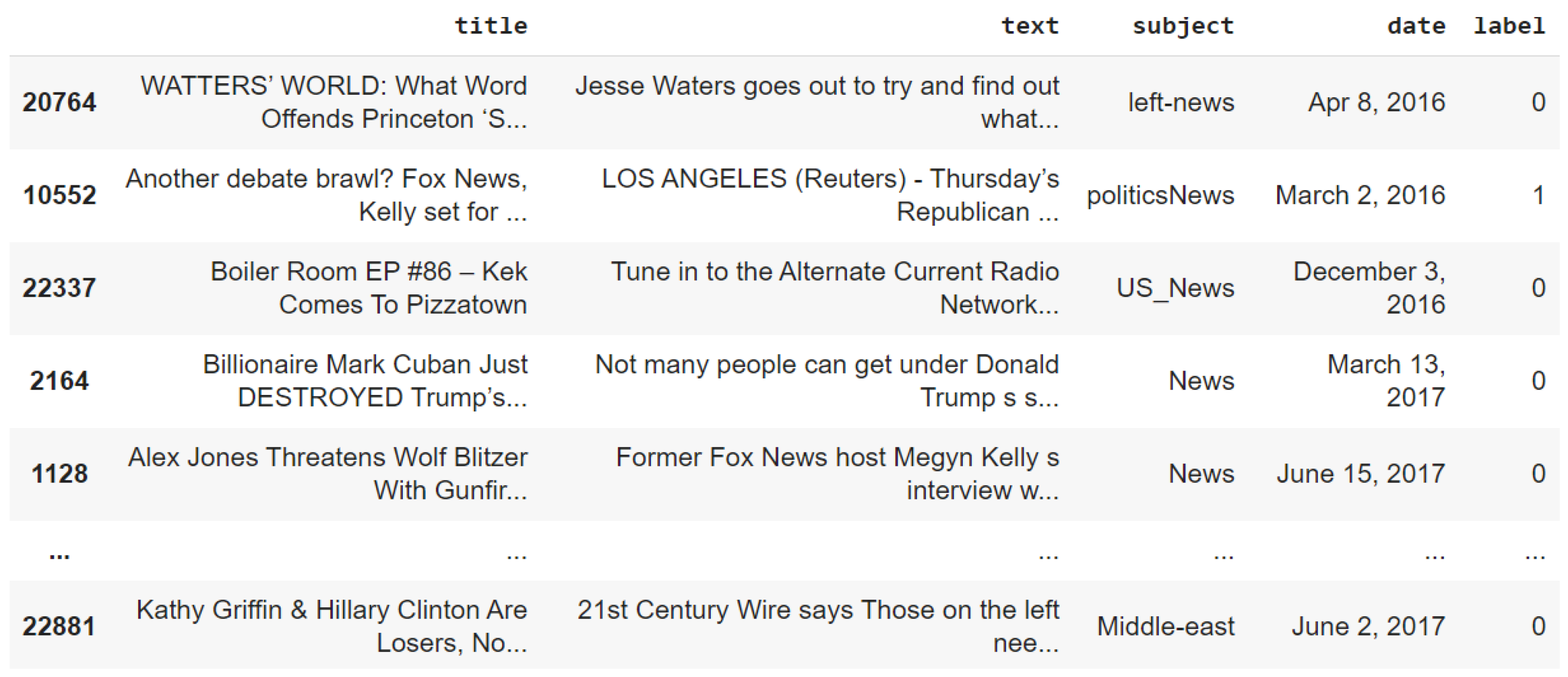
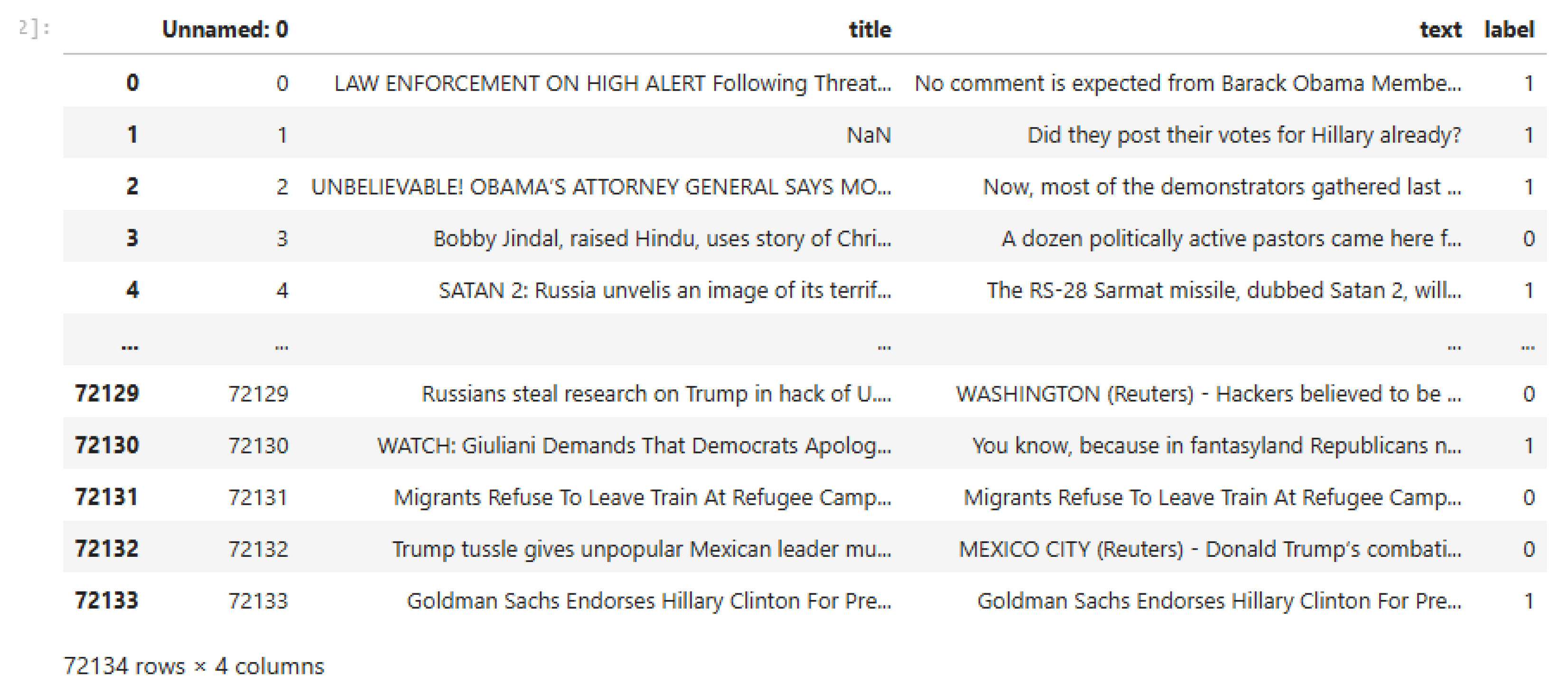
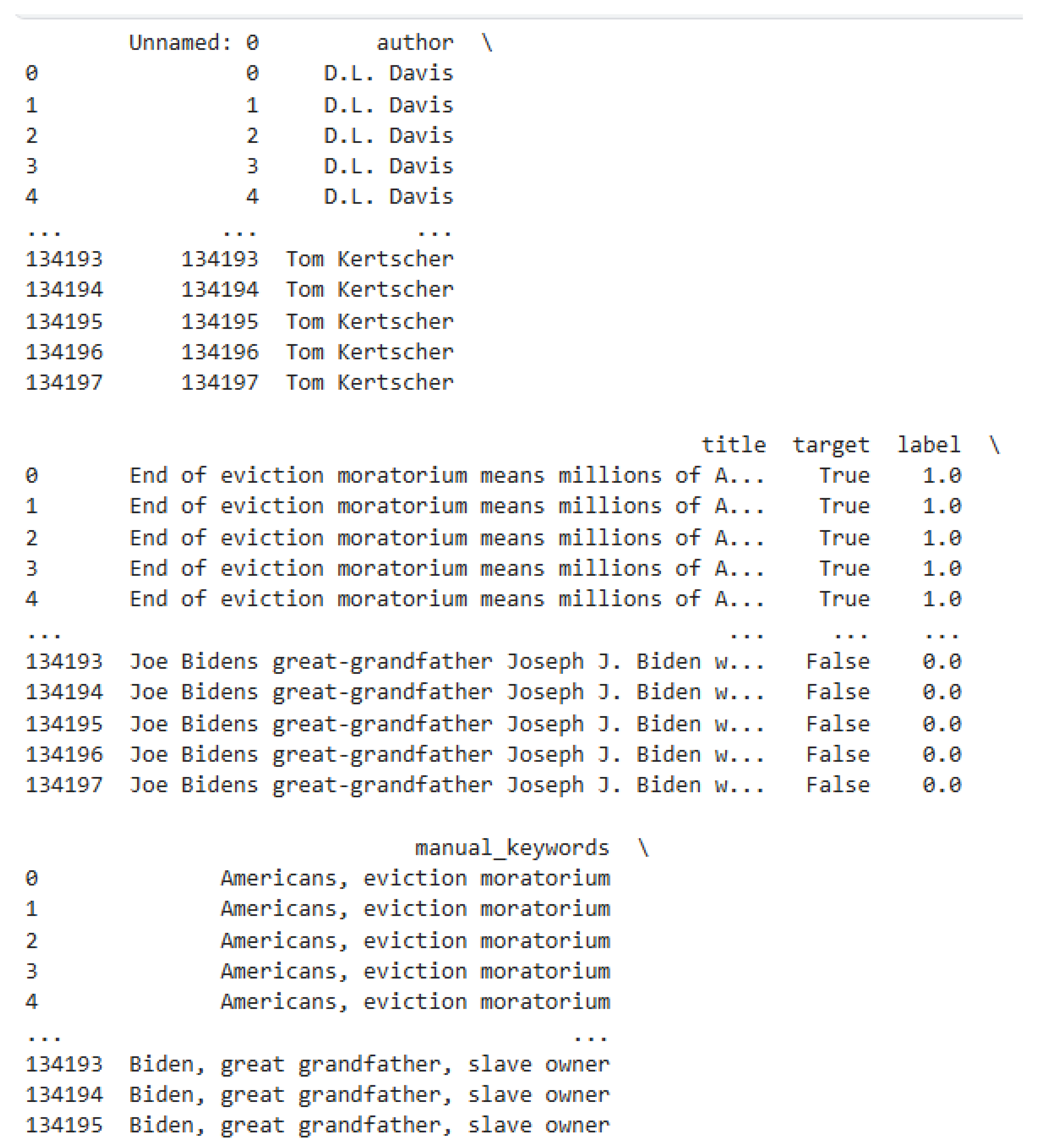
3. Dataset
4. Problem Statement
4.1. Computational Environment
4.2. Data Collection
4.3. Preprocessing
4.4. Feature Extraction
- -
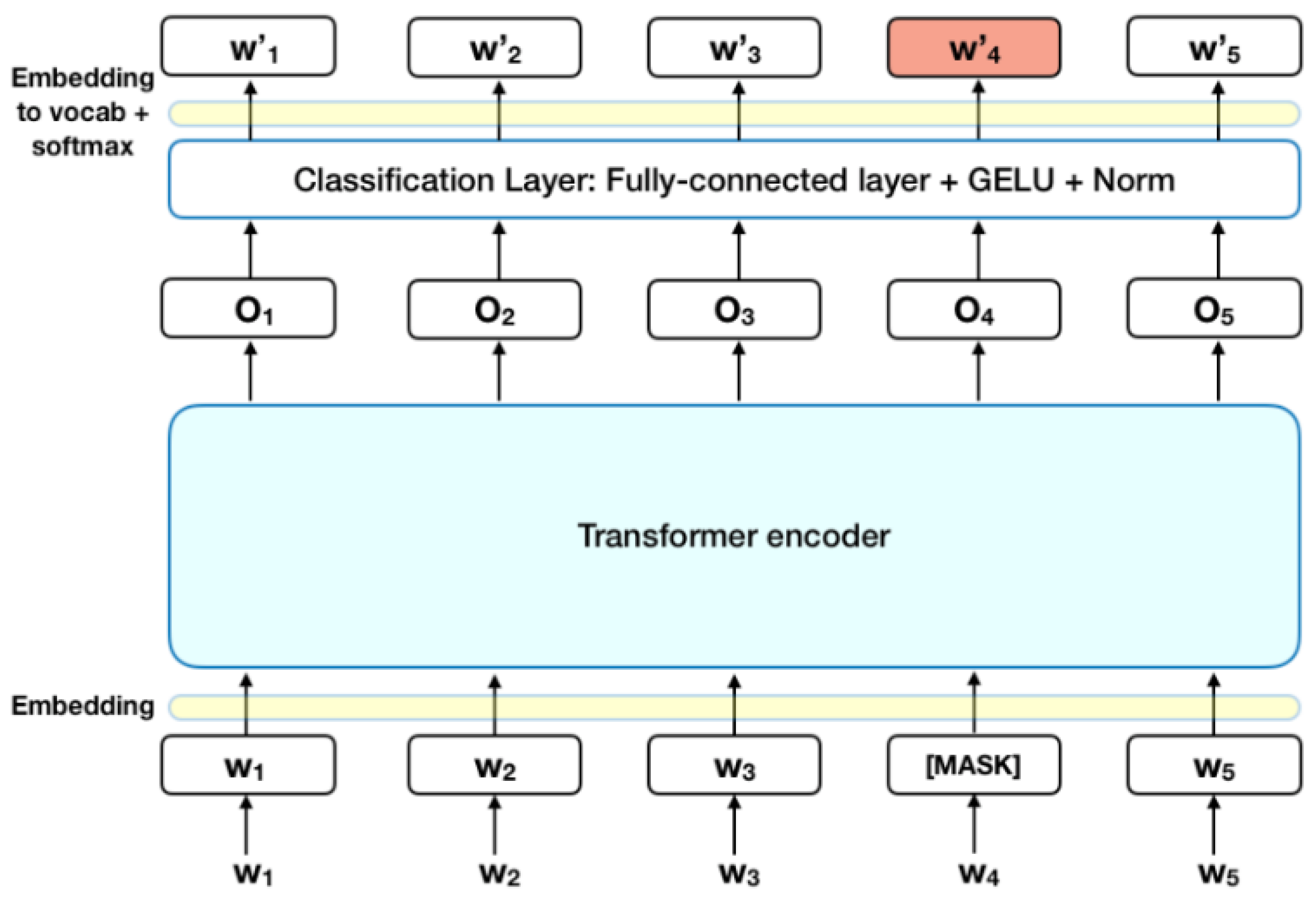
- BERT for Text Analysis: Pass the cleaned text data through the BERT model for deep contextual embeddings. Those embeddings would represent subtle nuances and semantic relationships in the text to be understood for the communication of the message.
- -
- Text Extraction by OCR: OCR technology was applied on the preprocessed images and the text content buried in them was extracted [52]. The text data extracted through OCR was found useful as a supplement especially when images contained headlines or news textual informationwhere refers to the embedded textual features and to the text extracted from images.
4.5. Multimodal Integration
- Query-Key-Value Construction:Each modality contributes to the construction of the query, key, and value matrices:where , , and are learnable weight matrices.
- Attention Score Computation:The attention scores are calculated as:where is the dimensionality of the key vectors, and the softmax function ensures that the scores are normalized.
- Weighted Aggregation of Features:The attention scores are then used to weight the value vectors:
- Integration with the Classifier:The enhanced features are passed to the classifier for final prediction:where represents the probability of the content being fake.
4.6. Classification
4.7. Confidence Score Calculation
4.8. Block Diagram
5. Experimental Setup and Results
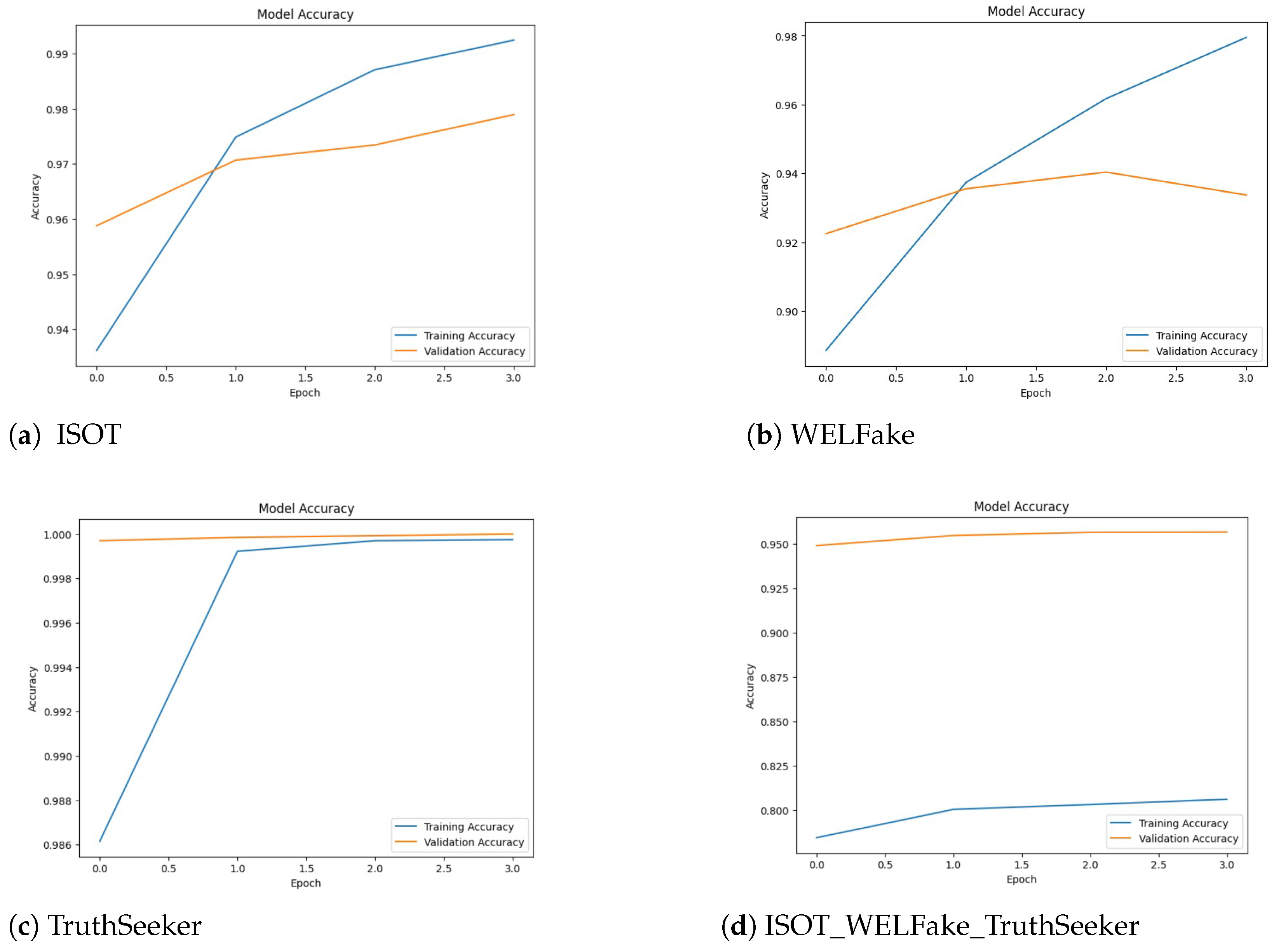
5.1. Model Training and Validation
| Algorithm 1 BERT Model Training and Evaluation Steps |
Input: Dataset D containing real and fake news Output: Trained BERT model, best model checkpoint, and evaluation metrics
|
| Algorithm 2 BERT Model Inference and Deployment |
Input: Best-performing BERT model from Algorithm 1, new unlabeled dataset Output: Predicted labels (real/fake) and evaluation metrics on
|
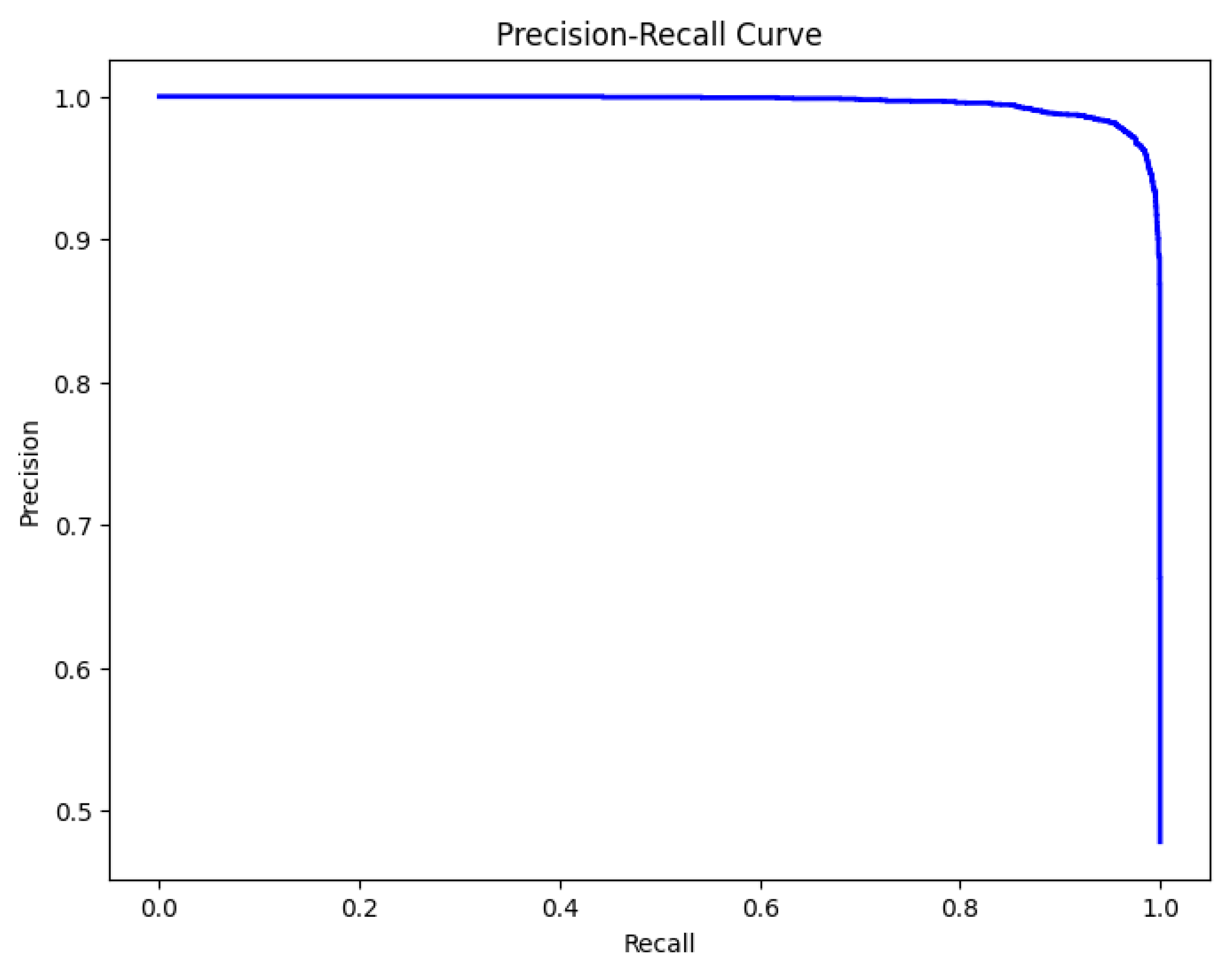
5.2. Classification Report
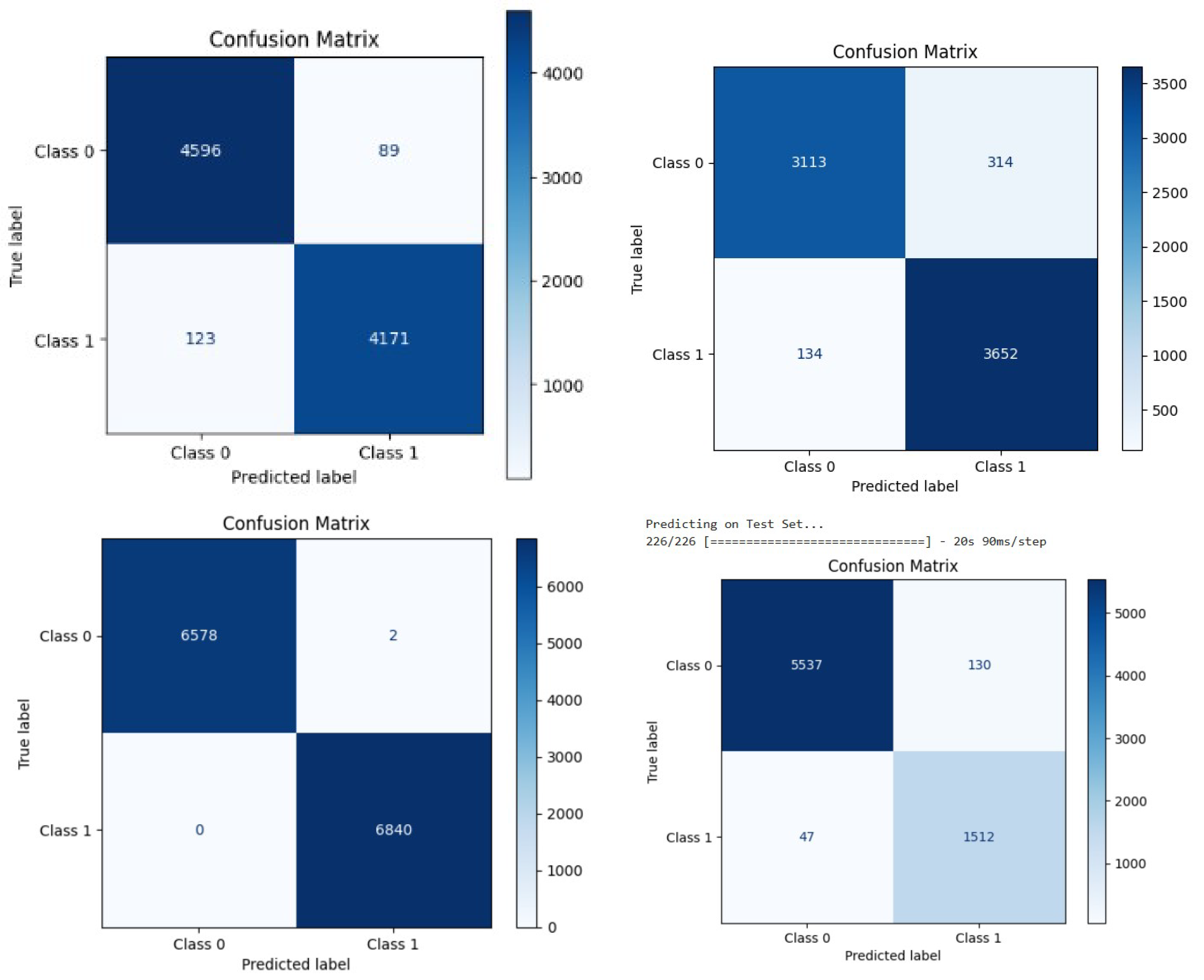
5.3. Model Accuracy, Loss, Confusion Matrix
5.4. Image News Classification Results
5.5. Advanced Critical Discussion
5.6. Future Directions in Model Development
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aimeur, E.; Amri, S.; Brassard, G. Fake news, disinformation and misinformation in social media: A review. Soc. Netw. Anal. Min. 2023, 13, 30. [Google Scholar] [CrossRef] [PubMed]
- Atske, S. Social Media and News Fact Sheet. Pew Research Center. Available online: https://www.pewresearch.org/journalism/fact-sheet/social-media-and-news-fact-sheet/ (accessed on 16 October 2024).
- Konopliov. Fake News Statistics & Facts (2024)—Redline Digital. Available online: https://redline.digital/fake-news-statistics/ (accessed on 26 June 2024).
- Zhao, J.; Zhao, Z.; Shi, L.; Kuang, Z.; Liu, Y. Collaborative mixture-of-experts model for multi-domain fake news detection. Electronics 2023, 12, 3440. [Google Scholar] [CrossRef]
- Ruffo, G.; Semeraro, A.; Giachanou, A.; Rosso, P. Studying fake news spreading, polarisation dynamics, and manipulation by bots: A tale of networks and language. Comput. Sci. Rev. 2023, 47, 100531. [Google Scholar] [CrossRef]
- Bontridder, N.; Poullet, Y. The role of artificial intelligence in disinformation. Data Policy 2021, 3, e32. [Google Scholar] [CrossRef]
- Al-Alshaqi, M.; Rawat, D.B. Disinformation Classification Using Transformer-Based Machine Learning. In Proceedings of the 2023 6th International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Batam, Indonesia, 11–12 December 2023; pp. 169–174. [Google Scholar] [CrossRef]
- Al-Alshaqi, M.; Rawat, D.B.; Liu, C. Emotion-Aware Fake News Detection on Social Media with BERT Embeddings. In Proceedings of the 2023 International Conference on Modeling & E-Information Research, Artificial Learning and Digital Applications (ICMERALDA), Karawang, Indonesia, 24 November 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Zhang, Z.; Hamadi, H.A.; Damiani, E.; Yeun, C.Y.; Taher, F. Explainable Artificial Intelligence Applications in Cyber Security: State-of-the-Art in Research. IEEE Access 2022, 10, 93104–93139. [Google Scholar] [CrossRef]
- Karlson, N. Reviving Classical Liberalism Against Populism; Springer Nature: Berlin/Heidelberg, Germany, 2024. [Google Scholar] [CrossRef]
- Ringsmuth, A.K.; Otto, I.M.; van den Hurk, B.; Lahn, G.; Reyer, C.P.; Carter, T.R.; Magnuszewski, P.; Monasterolo, I.; Aerts, J.C.; Benzie, M.; et al. Lessons from COVID-19 for managing transboundary climate risks and building resilience. Clim. Risk Manag. 2022, 35, 100395. [Google Scholar] [CrossRef]
- Hartzog, W.; Selinger, E.; Gunawan, J. Privacy Nicks: How the Law Normalizes Surveillance. SSRN Electron. J. 2023, 101, 717. [Google Scholar] [CrossRef]
- Barrett, C.M. Automated esSay Evaluation and the Computational Paradigm: Machine Scoring Enters the Classroom. Ph.D. Thesis, University of Rhode Island, Kingston, RI, USA, 2015. [Google Scholar] [CrossRef]
- Al-Alshaqi, M.; Rawat, D.B.; Liu, C. Ensemble Techniques for Robust Fake News Detection: Integrating Transformers, Natural Language Processing, and Machine Learning. Sensors 2024, 24, 6062. [Google Scholar] [CrossRef] [PubMed]
- Sándor, A.V. The Relationship Between Self-Representation on Social Media and Affective or Anxiety Disorders in the Perspective of the COVID-19 Pandemic. Ph.D. Thesis, Eötvös Loránd University, Budapest, Hungary, 2023. [Google Scholar] [CrossRef]
- Giachanou, A.; Zhang, G.; Rosso, P. Multimodal Multi-image Fake News Detection. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, Australia, 6–9 October 2020; pp. 647–654. [Google Scholar] [CrossRef]
- Singhal, S.; Shah, R.R.; Chakraborty, T.; Kumaraguru, P.; Satoh, S. SpotFake: A Multi-modal Framework for Fake News Detection. In Proceedings of the 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), Singapore, 11–13 September 2019; pp. 39–47. [Google Scholar] [CrossRef]
- Duc Tuan, N.M.; Quang Nhat Minh, P. Multimodal Fusion with BERT and Attention Mechanism for Fake News Detection. In Proceedings of the 2021 RIVF International Conference on Computing and Communication Technologies (RIVF), Hanoi, Vietnam, 2–4 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Kshetri, N.; Hughes, L.; Slade, E.L.; Jeyaraj, A.; Kar, A.K.; Baabdullah, A.M.; Koohang, A.; Raghavan, V.; Ahuja, M.; et al. Opinion Paper: “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. Int. J. Inf. Manag. 2023, 71, 102642. [Google Scholar] [CrossRef]
- Uppada, S.K.; Patel, P. An image and text-based multimodal model for detecting fake news in OSN’s. J. Intell. Inf. Syst. 2023, 61, 367–393. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, D.; Chen, H.; Zeng, Z.; Guo, W.; Miao, C.; Cui, L. BDANN: BERT-Based Domain Adaptation Neural Network for Multi-Modal Fake News Detection. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Segura-Bedmar, I.; Alonso-Bartolome, S. Multimodal Fake News Detection. Information 2022, 13, 284. [Google Scholar] [CrossRef]
- Palani, B.; Elango, S.; Viswanathan K, V. CB-Fake: A multimodal deep learning framework for automatic fake news detection using capsule neural network and BERT. Multimed. Tools Appl. 2022, 81, 5587–5620. [Google Scholar] [CrossRef] [PubMed]
- Lindsay, G. Convolutional Neural Networks as a Model of the Visual System: Past, Present, and Future. J. Cogn. Neurosci. 2020, 33, 2017–2031. [Google Scholar] [CrossRef] [PubMed]
- Hua, J.; Cui, X.; Li, X.; Tang, K.; Zhu, P. Multimodal fake news detection through data augmentation-based contrastive learning. Appl. Soft Comput. 2023, 136, 110125. [Google Scholar] [CrossRef]
- Xue, J.; Wang, Y.; Tian, Y.; Li, Y.; Shi, L.; Wei, L. Detecting fake news by exploring the consistency of multimodal data. Inf. Process. Manag. 2021, 58, 102610. [Google Scholar] [CrossRef]
- Giachanou, A.; Zhang, G.; Rosso, P. Multimodal Fake News Detection with Textual, Visual and Semantic Information. In Proceedings of the Text, Speech, and Dialogue; Sojka, P., Kopeček, I., Pala, K., Horák, A., Eds.; Springer: Cham, Switzerland, 2020; pp. 30–38. [Google Scholar] [CrossRef]
- Jaiswal, R.; Singh, U.P.; Singh, K.P. Fake News Detection Using BERT-VGG19 Multimodal Variational Autoencoder. In Proceedings of the 2021 IEEE 8th Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), Dehradun, India, 11–13 November 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Ying, L.; Yu, H.; Wang, J.; Ji, Y.; Qian, S. Multi-Level Multi-Modal Cross-Attention Network for Fake News Detection. IEEE Access 2021, 9, 132363–132373. [Google Scholar] [CrossRef]
- Hangloo, S.; Arora, B. Combating multimodal fake news on social media: Methods, datasets, and future perspective. Multimed. Syst. 2022, 28, 2391–2422. [Google Scholar] [CrossRef]
- Ghorbanpour, F.; Ramezani, M.; Fazli, M.; Rabiee, H. FNR: A similarity and transformer-based approach to detect multi-modal fake news in social media. Soc. Netw. Anal. Min. 2023, 13, 56. [Google Scholar] [CrossRef]
- Peng, X.; Xintong, B. An effective strategy for multi-modal fake news detection. Multimed. Tools Appl. 2022, 81, 13799–13822. [Google Scholar] [CrossRef]
- Qian, S.; Wang, J.; Hu, J.; Fang, Q.; Xu, C. Hierarchical Multi-modal Contextual Attention Network for Fake News Detection. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’21, New York, NY, USA, 11–15 July 2021; pp. 153–162. [Google Scholar] [CrossRef]
- Yang, P.; Ma, J.; Liu, Y.; Liu, M. Multi-modal transformer for fake news detection. Math. Biosci. Eng. 2023, 20, 14699–14717. [Google Scholar] [CrossRef]
- Qi, P.; Cao, J.; Li, X.; Liu, H.; Sheng, Q.; Mi, X.; He, Q.; Lv, Y.; Guo, C.; Yu, Y. Improving Fake News Detection by Using an Entity-enhanced Framework to Fuse Diverse Multimodal Clues. In Proceedings of the 29th ACM International Conference on Multimedia, MM ’21, New York, NY, USA, 20–24 October 2021; pp. 1212–1220. [Google Scholar] [CrossRef]
- Comito, C.; Caroprese, L.; Zumpano, E. Multimodal fake news detection on social media: A survey of deep learning techniques. Soc. Netw. Anal. Min. 2023, 13, 101. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Bai, J.; Al-Sabaawi, A.; Santamaría, J.; Albahri, A.; Al-dabbagh, B.; Fadhel, M.; Manoufali, M.; Zhang, J.; Al-Timemy, A.; et al. A survey on deep learning tools dealing with data scarcity: Definitions, challenges, solutions, tips, and applications. J. Big Data 2023, 10, 46. [Google Scholar] [CrossRef]
- Allan, J.; Aslam, J.; Belkin, N.; Buckley, C.; Callan, J.; Croft, B.; Dumais, S.; Fuhr, N.; Harman, D.; Harper, D.J.; et al. Challenges in information retrieval and language modeling: Report of a workshop held at the center for intelligent information retrieval, University of Massachusetts Amherst, September 2002. ACM SIGIR Forum 2003, 37, 31–47. [Google Scholar] [CrossRef]
- Martínez Hernández, L.A.; Sandoval Orozco, A.L.; García Villalba, L.J. Analysis of Digital Information in Storage Devices Using Supervised and Unsupervised Natural Language Processing Techniques. Future Internet 2023, 15, 155. [Google Scholar] [CrossRef]
- Ahmed, S.F.; Alam, M.S.; Hassan, M.; Rodela, M.; Ishtiak, T.; Rafa, N.; Mofijur, M.; Ali, A.B.M.S.; Gandomi, A. Deep learning modelling techniques: Current progress, applications, advantages, and challenges. Artif. Intell. Rev. 2023, 56, 13521–13617. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Ismagilova, E.; Hughes, D.L.; Carlson, J.; Filieri, R.; Jacobson, J.; Jain, V.; Karjaluoto, H.; Kefi, H.; Krishen, A.S.; et al. Setting the future of digital and social media marketing research: Perspectives and research propositions. Int. J. Inf. Manag. 2021, 59, 102168. [Google Scholar] [CrossRef]
- Li, W.; Gu, C.; Chen, J.; Ma, C.; Zhang, X.; Chen, B.; Wan, S. DLS-GAN: Generative Adversarial Nets for Defect Location Sensitive Data Augmentation. IEEE Trans. Autom. Sci. Eng. 2024, 21, 5173–5189. [Google Scholar] [CrossRef]
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of Things: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Kaggle. Fake-and-Real-News-Dataset. Available online: https://www.kaggle.com/datasets/clmentbisaillon/fake-and-real-news-dataset (accessed on 19 April 2024).
- Callard, F.; Fitzgerald, D. Rethinking Interdisciplinarity across the Social Sciences and Neurosciences; Palgrave Macmillan London: London, UK, 2015. [Google Scholar] [CrossRef]
- Sarstedt, M.; Danks, N.P. Prediction in HRM research–A gap between rhetoric and reality. Hum. Resour. Manag. J. 2022, 32, 485–513. [Google Scholar] [CrossRef]
- Roberge, J.; Lebrun, T. KI-Realitäten; Transcript Verlag: Bielefeld, Germany, 2023; pp. 39–66. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Hughes, L.; Ismagilova, E.; Aarts, G.; Coombs, C.; Crick, T.; Duan, Y.; Dwivedi, R.; Edwards, J.; Eirug, A.; et al. Artificial Intelligence (AI): Multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy. Int. J. Inf. Manag. 2021, 57, 101994. [Google Scholar] [CrossRef]
- Kaggle. Fake News Detection Datasets. Available online: https://www.kaggle.com/datasets/emineyetm/fake-news-detection-datasets (accessed on 7 December 2022).
- Kaggle. Welfake Dataset for Fake News. Available online: https://www.kaggle.com/datasets/syedsubahani/wel-fake-news-dataset (accessed on 19 February 2024).
- Dadkhah, S.; Zhang, X.; Weismann, A.G.; Firouzi, A.; Ghorbani, A.A. The Largest Social Media Ground-Truth Dataset for Real/Fake Content: TruthSeeker. IEEE Trans. Comput. Soc. Syst. 2024, 11, 3376–3390. [Google Scholar] [CrossRef]
- Salawu, S.; He, Y.; Lumsden, J. Approaches to Automated Detection of Cyberbullying: A Survey. IEEE Trans. Affect. Comput. 2020, 11, 3–24. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Ma, X.; Wu, J.; Xue, S.; Yang, J.; Zhou, C.; Sheng, Q.Z.; Xiong, H.; Akoglu, L. A Comprehensive Survey on Graph Anomaly Detection With Deep Learning. IEEE Trans. Knowl. Data Eng. 2023, 35, 12012–12038. [Google Scholar] [CrossRef]
- Cao, S.; Wang, L. CLIFF: Contrastive Learning for Improving Faithfulness and Factuality in Abstractive Summarization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic and Online, 7–11 November 2021; pp. 6633–6649. [Google Scholar] [CrossRef]
- Verma, G.; Mujumdar, R.; Wang, Z.J.; Choudhury, M.D.; Kumar, S. Overcoming Language Disparity in Online Content Classification with Multimodal Learning. Proc. Int. Aaai Conf. Web Soc. Media 2022, 16, 1040–1051. [Google Scholar] [CrossRef]
- Ferri Borredà, P. Deeep Continual Multimodal Multitask Modells for Out-of-Hospital Emergency Medical Call Incidents Triage Support in the Presence of Dataset Shifts. Ph.D. Thesis, Universitat Politècnica de València, Valencia, Spain, 2024. [Google Scholar] [CrossRef]
- Lampe, B.; Meng, W. Intrusion Detection in the Automotive Domain: A Comprehensive Review. IEEE Commun. Surv. Tutor. 2023, 25, 2356–2426. [Google Scholar] [CrossRef]
- Barnes, T.; Drake, R.; Paton, C.; Cooper, S.; Deakin, B.; Ferrier, I.; Gregory, C.; Haddad, P.; Howes, O.; Jones, I.; et al. Evidence-based guidelines for the pharmacological treatment of schizophrenia: Updated recommendations from the British Association for Psychopharmacology. J. Psychopharmacol. 2019, 34, 3–78. [Google Scholar] [CrossRef]
- Munger, K. The YouTube Apparatus; Cambridge University Press: Cambridge, UK, 2024. [Google Scholar] [CrossRef]
- Das, A.; Liu, H.; Kovatchev, V.; Lease, M. The state of human-centered NLP technology for fact-checking. Inf. Process. Manag. 2023, 60, 103219. [Google Scholar] [CrossRef]
- Ras, G.; Xie, N.; van Gerven, M.; Doran, D. Explainable Deep Learning: A Field Guide for the Uninitiated. J. Artif. Intell. Res. 2022, 73. [Google Scholar] [CrossRef]
- Gu, S.; Kelly, B.; Xiu, D. Empirical Asset Pricing via Machine Learning. Technical Report 25398, National Bureau of Economic Research. Rev. Financ. Stud. 2020, 33, 2223–2273. [Google Scholar] [CrossRef]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Subject | Model/Approach | Dataset | Features | Evaluation Metrics | Findings | Limitations |
|---|---|---|---|---|---|---|---|
| [16] | Multimodal fake news detection | Multimodal system with BERT and VGG-16 | Real-world dataset | Textual, visual, semantic | Accuracy, F1-score | Multimodal approach outperforms BERT baseline by 4.19% | Limited exploration of visual features |
| [17] | Multimodal fake news detection | SpotFake multimodal framework | Twitter and Weibo | Textual, visual | Accuracy | Outperformed state-of-the-art on Twitter and Weibo datasets | No sub-task consideration |
| [18] | Attention mechanism in fake news detection | Scaled dot-product attention with BERT and VGG-19 | Textual, visual | Accuracy | Improved accuracy over state-of-the-art by 3.1% | Challenges in fusing modalities | |
| [20] | CNN-based multimodal detection | Multimodal framework on Fakeddit | Fakeddit | Text and image data | Accuracy | Multimodal CNN achieved 87% accuracy | Limited impact on some categories |
| [21] | Domain adaptation in multimodal detection | BDANN with BERT and VGG-19 | Twitter and Weibo | Textual, visual | Accuracy | Outperformed state-of-the-art models | Noisy images in dataset |
| [22] | CNN-based multimodal detection | Multimodal approach with CNN | Fakeddit | Text and image data | Accuracy | Multimodal CNN outperforms text-only models | Limited dataset scope |
| [23] | Capsule networks for fake news detection | CapsNet with BERT | Politifact and Gossipcop | Textual, visual | Accuracy | CapsNet with BERT shows high accuracy | Focus on specific datasets |
| [25] | Autoencoder for fake news detection | BERT and VGG19-based autoencoder | MediaEval2015 and Weibo | Textual, visual | F-score | Competitive with state-of-the-art on Weibo | Complexity of multimodal features |
| [26] | CNN-based multimodal detection | Multimodal approach with CNN | Fakeddit | Text and image data | Accuracy | Text and image combination enhances performance | Limited dataset scope |
| [27] | Neural network for multimodal detection | Multimodal system with neural network | Three standard collections | Textual, visual, semantic | Accuracy | Improved detection with neural network approach | Focus on specific datasets |
| [28] | Variational autoencoder for fake news | Multimodal variational autoencoder | MediaEval2015 and Weibo | Textual, visual | F-score | High F-score achieved | Complexity of multimodal features |
| [29] | Cross-attention in multimodal detection | Multi-level multi-modal cross-attention network | Weibo and PHEME | Textual, visual | Accuracy | Advantageous performance over state-of-the-art | Complex relationships not fully captured |
| [30] | Survey of DL techniques in detection | Survey of DL techniques | Various multimodal datasets | Textual, visual, multimodal | Various metrics | Highlighted limitations and future directions | Limited exploration of datasets |
| [31] | Similarity and transformer-based detection | Fake News Revealer with BERT | Social media datasets | Textual, visual | Accuracy | Novel mechanism improves detection | Requires further testing |
| [32] | Adversarial fusion in fake news detection | Attention adversarial fusion method with BERT | Chinese public dataset | Textual, visual | F1-score | 5% improvement in F1 | Specific to Chinese dataset |
| [33] | Hierarchical attention network | Hierarchical multi-modal contextual attention network | Various datasets | Textual, visual | Accuracy | State-of-the-art performance | Hierarchical semantics challenge |
| [34] | Transformer-based multimodal fusion | TGA with transformers | Various datasets | Textual, visual | Effectiveness | Improved performance with feature similarity | Limited exploration of text-image interaction |
| [22] | CNN-based multimodal detection | Multimodal approach with CNN | Fakeddit | Text and image data | Accuracy | Images enhance detection accuracy | Limited to Fakeddit dataset |
| [35] | Entity-enhanced fusion for detection | Entity-enhanced multimodal fusion | Various multimodal datasets | Visual entities, text | Performance metrics | Superior to state-of-the-art models | Focus on visual entities |
| [36] | Survey on multimodal detection | Survey on multimodal fake news detection | Survey | Textual, visual, multimodal | Survey analysis | Discusses state-of-the-art and future directions | Survey highlights lack of large-scale datasets |
| [41] | Dataset collection challenges | Various multimodal datasets | - | Textual, visual, dynamic data | Dataset diversity | Challenges in acquiring diverse datasets | Lack of large-scale datasets |
| [43] | Explainability in AI | Explainable AI datasets | - | Textual, visual, explainable | Explainability metrics | Importance of explainability in complex models | Need for better explainability techniques |
| [38] | BERT’s role in multimodal detection | BERT-integrated datasets | - | Textual, visual, multimodal | Accuracy, performance | BERT improves multimodal detection accuracy | Limited visual feature exploration |
| [39] | Fusion techniques in BERT | Advanced fusion datasets | - | Textual, visual, semantic | Accuracy, fusion effectiveness | Enhanced performance with advanced fusion | Challenges in integrating fusion techniques |
| [40] | Model interpretability and trust | Interpretability datasets | - | Textual, visual, interpretability | Trustworthiness, explainability | Importance of trust in model decision-making | Complexity in model explanation |
| [41] | Unified BERT for real-time analysis | Unified text-image datasets | - | Textual, visual, unified | Real-time accuracy | Unified BERT model enhances efficiency | Challenges in real-time processing |
| Dataset | Training Accuracy | Validation Accuracy | Test Accuracy |
|---|---|---|---|
| ISOT | 0.9997 | 1.0000 | 0.9999 |
| WELFAKE | 0.94 | 0.94 | 0.94 |
| TRUTHSEEKER | 0.98 | 0.98 | 0.98 |
| ISOT_WELFAKE _TRUTHSEEKER | 0.80 | 0.96 | 0.98 |
| Dataset | Precision (Class 0) | Recall (Class 0) | F1-Score (Class 0) | Precision (Class 1) | Recall (Class 1) | F1-Score (Class 1) | Overall Accuracy |
|---|---|---|---|---|---|---|---|
| ISOT | 0.99 | 0.97 | 0.98 | 0.95 | 0.97 | 0.98 | 99.25% |
| WELFAKE | 0.96 | 0.91 | 0.93 | 0.92 | 0.96 | 0.94 | 97.95% |
| TRUTHSEEKER | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 99.99% |
| ISOT_WELFAKE_ TRUTHSEEKER | 0.98 | 0.99 | 0.98 | 0.96 | 0.91 | 0.94 | 80.67% |
| Dataset | Input Image/Source | Extracted News | Text Output |
|---|---|---|---|
| ISOT |  | Stock Price Levels Stabilized |  |
| WELFAKE | https://www.kaggle.com/datasets/saurabhshahane/fake-news-classification/data, accessed on 1 May 2024 | Pakistan Rangers attack Indian border |  |
| TRUTHSEEKER | https://doi.org/10.1109/TCSS.2023.3322303, accessed on 1 May 2024 | Pakistan Rangers attack Indian border |  |
| ISOT-WELFAKE-TRUTHSEEKER |  | Stock Price Levels Stabilized |  |
| Model | Dataset | Accuracy | Precision | Recall | F1-Score | Features |
|---|---|---|---|---|---|---|
| Multimodal system with BERT and VGG-16 | Real-world dataset | 0.76 | - | - | 0.7955 | Textual, visual, semantic |
| BERTweet | 0.812 | 0.813 | 0.874 | 0.843 | Textual, visual | |
| Multimodal framework on Fakeddit | Fakeddit dataset | 91.94% | 93.43% | 93.07% | 93% | Text and image data |
| Multimodal CNN | Fakeddit | 0.87 | 0.88 | 0.86 | 0.87 | Text and image data |
| TGA with transformers | Weibo & Twitter | 0.969 | 0.886 | 0.922 | 0.925 | Textual, visual |
| Proposed Model | ISOT FND | 97.36 | 0.97 | 0.97 | 0.97 | Textual, visual |
| Configuration | Accuracy | F1-Score |
|---|---|---|
| Full Model (BERT + OCR + Cross-Attention) | 99.99% | 0.98 |
| Without OCR | 96.2% | 0.94 |
| Without Cross-Attention | 97.5% | 0.96 |
| Replace BERT with LSTM | 93.8% | 0.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-alshaqi, M.; Rawat, D.B.; Liu, C. A BERT-Based Multimodal Framework for Enhanced Fake News Detection Using Text and Image Data Fusion. Computers 2025, 14, 237. https://doi.org/10.3390/computers14060237
Al-alshaqi M, Rawat DB, Liu C. A BERT-Based Multimodal Framework for Enhanced Fake News Detection Using Text and Image Data Fusion. Computers. 2025; 14(6):237. https://doi.org/10.3390/computers14060237
Chicago/Turabian StyleAl-alshaqi, Mohammed, Danda B. Rawat, and Chunmei Liu. 2025. "A BERT-Based Multimodal Framework for Enhanced Fake News Detection Using Text and Image Data Fusion" Computers 14, no. 6: 237. https://doi.org/10.3390/computers14060237
APA StyleAl-alshaqi, M., Rawat, D. B., & Liu, C. (2025). A BERT-Based Multimodal Framework for Enhanced Fake News Detection Using Text and Image Data Fusion. Computers, 14(6), 237. https://doi.org/10.3390/computers14060237