Highlights
What are the main findings?
- A topology-aware multi-scale road extraction framework (SAM2-RoadNet) is proposed by adapting the SAM2 image encoder to high-resolution remote sensing imagery.
- The combination of adapter-based domain adaptation, receptive field blocks, and a weighted BiFPN significantly improves road continuity and segmentation accuracy.
What are the implication of the main findings?
- The proposed method effectively reduces road fragmentation and preserves topological connectivity in complex remote sensing scenes.
- The study demonstrates that large vision foundation models can be efficiently transferred to remote sensing tasks with strong robustness and cross-dataset generalization.
Abstract
Road extraction from high-resolution remote sensing images (HRSIs) is a fundamental task for many geospatial applications, yet it remains challenging due to complex backgrounds, frequent occlusions, and the requirement to preserve the topological connectivity of elongated road networks. To address these issues, this paper proposes SAM2-RoadNet, a topology-aware multi-scale road extraction framework that adapts the powerful representation capability of the Segment Anything Model 2 (SAM2) to HRSI road segmentation. Unlike prompt-driven segmentation paradigms, SAM2-RoadNet employs the SAM2 image encoder solely as a feature extractor and introduces an adapter-based domain adaptation strategy to efficiently transfer pretrained knowledge to the remote sensing domain. Receptive field blocks are further integrated to enhance contextual perception and align channel dimensions, followed by a weighted bidirectional feature pyramid network (W-BiFPN) to fuse hierarchical features across multiple scales. Moreover, a topology-aware training strategy based on the soft-clDice loss is incorporated to explicitly enforce structural continuity and reduce road fragmentation. Extensive experiments conducted on two challenging benchmarks, including DeepGlobe, Massachusetts, demonstrate that SAM2-RoadNet achieves superior overall performance across multiple evaluation metrics compared with state-of-the-art methods in both quantitative accuracy and qualitative visual quality, while demonstrating promising cross-dataset transferability without additional fine-tuning.
1. Introduction
High-resolution remote sensing images (HRSIs) have become a fundamental data source for a wide range of geospatial applications, including intelligent transportation systems, urban infrastructure monitoring, autonomous navigation, and emergency response [1]. Among these tasks, road extraction plays a critical role by providing essential priors for downstream applications such as route planning, traffic analysis, and large-scale map updating [2]. However, accurately extracting road networks from HRSIs remains a challenging problem due to the intrinsic complexity of real-world scenes.
Unlike generic semantic segmentation tasks, road extraction requires not only precise pixel-level classification but also the preservation of long-range structural continuity and topological correctness [3]. In complex HRSIs, roads are frequently occluded by vegetation, buildings, or shadows, and their appearances are further affected by illumination variations, sensor noise, and post-processing artifacts. These factors often lead to fragmented predictions or discontinuous road networks, severely limiting the practical usability of segmentation results [4]. Recent studies have further highlighted the challenges of maintaining structural consistency and connectivity in road extraction tasks, particularly in complex urban scenes [5,6]. Meanwhile, the rapid development of deep learning and transformer-based models has significantly advanced the capability of extracting road networks from high-resolution remote sensing imagery [7]. Consequently, maintaining a balance between accurate boundary delineation and global connectivity has become a central challenge in road extraction research.
To address these difficulties, deep learning-based methods have been extensively explored in recent years. Early convolutional neural network (CNN)-based architectures improved road extraction performance by leveraging encoder–decoder designs and multi-scale feature aggregation, enabling effective modeling of local textures and geometric patterns [8]. Subsequent studies introduced specialized convolutional modules, such as dilated convolutions and strip convolutions, to better capture elongated and curvilinear road structures [9]. More recently, transformer-based models have been incorporated to enhance global context modeling and long-range dependency reasoning, alleviating road fragmentation caused by local ambiguities [10,11]. Despite these advances, most existing methods are trained on limited datasets and exhibit restricted generalization capability when deployed across diverse geographic regions or imaging conditions.
Large-scale vision foundation models have recently emerged as a promising alternative to alleviate data dependency and improve robustness. Recent studies on large-scale self-supervised vision transformers have shown that foundation models can learn transferable and semantically rich representations that generalize well across diverse downstream tasks [12]. The Segment Anything Model (SAM), trained on the large-scale SA-1B dataset, demonstrates remarkable generalization ability in class-agnostic segmentation tasks [13]. Its successor, SAM2, further strengthens multi-scale feature representation through a hierarchical encoder design, enabling efficient and accurate segmentation across both image and video domains [14]. These properties suggest that SAM2 has strong potential as a universal feature extractor for downstream remote sensing applications. However, directly applying SAM or SAM2 to road extraction remains non-trivial. In the absence of explicit prompts, the class-agnostic nature of SAM often produces ambiguous masks, while its original mask decoder introduces unnecessary computational overhead for binary road segmentation tasks.
Several recent works attempt to adapt SAM-based models to remote sensing scenarios through parameter fine-tuning or architectural modifications [15]. Adapter-based approaches inject task-specific knowledge into frozen encoders to reduce training cost, whereas hybrid designs combine SAM encoders with CNN decoders to improve structural detail recovery. Nevertheless, existing SAM-based road extraction methods still face two key limitations. First, the domain gap between natural images and HRSIs hinders effective feature alignment, leading to suboptimal discrimination between roads and complex backgrounds [16]. Second, most methods focus primarily on pixel-wise accuracy while overlooking topological consistency, which is essential for constructing reliable road networks [17].
Motivated by these observations, we propose SAM2-RoadNet, a novel road extraction framework that systematically adapts the SAM2 encoder to high-resolution remote sensing imagery. Instead of directly relying on the original SAM2 mask decoder, we retain only the hierarchical image encoder as a strong and generalizable feature backbone. To bridge the domain gap and enhance task-specific discrimination, lightweight adapter modules and receptive field enhancement blocks are introduced to refine multi-level encoder features while maintaining parameter efficiency. Furthermore, a weighted bidirectional feature pyramid network (W-BiFPN) is employed to achieve effective multi-scale feature fusion, enabling complementary integration of local details and global contextual information.
In addition, to explicitly address the structural characteristics of road networks, we incorporate a topology-aware training strategy based on the soft-clDice loss. This design directly enforces skeleton-level consistency between predictions and ground truth, significantly reducing road fragmentation and improving connectivity in challenging scenarios. The proposed decoder is carefully designed to balance structural modeling capability and computational efficiency, making the overall framework suitable for large-scale remote sensing applications.
The main contributions of this work can be summarized as follows:
- We propose a novel SAM2-based road extraction framework that leverages the hierarchical encoder of SAM2 as a strong feature backbone, effectively transferring large-scale foundation model knowledge to high-resolution remote sensing imagery.
- We design a lightweight yet effective feature enhancement and fusion strategy by integrating adapter modules, receptive field blocks, and a weighted bidirectional feature pyramid, enabling robust multi-scale representation for complex road scenes.
- We introduce a topology-aware training scheme based on the soft-clDice loss to explicitly preserve road connectivity and structural integrity, addressing a critical limitation of conventional pixel-wise optimization.
- Extensive experiments on multiple large-scale benchmarks demonstrate that the proposed method achieves superior overall performance across multiple evaluation metrics compared with representative CNN-based, transformer-based, and SAM-based approaches in both quantitative metrics and qualitative structural fidelity.
2. Related Work
2.1. Traditional Methods for Road Extraction
Early research on road extraction from remote sensing imagery predominantly relied on traditional machine learning and image processing techniques [18]. Based on the degree of human involvement, these approaches can be broadly divided into semi-automatic and fully automatic methods. Semi-automatic techniques typically require user interaction in the form of seed point initialization, interactive tracing, or manual verification. Representative methods include active contour models, template matching, graph-based tracking, and heuristic rule-driven strategies [19]. Although these methods can achieve high accuracy under controlled conditions, their dependence on expert knowledge and manual intervention significantly limits scalability and automation [2].
Fully automatic traditional methods aim to reduce human interaction by employing handcrafted features combined with statistical learning models. Commonly used techniques include artificial neural networks, support vector machines, Bayesian classifiers, clustering-based algorithms, super-pixel segmentation, watershed transformation, and conditional random fields for post-processing refinement [20,21]. While these methods demonstrate acceptable performance in relatively structured environments, their reliance on scenario-specific feature engineering and hyperparameter tuning results in limited transferability. In practice, remote sensing imagery often originates from complex and dynamically evolving environments, such as cold-region cities, permafrost-affected areas, and high-latitude landscapes, where surface heterogeneity, seasonal variations, and environmental change introduce substantial appearance variability [22,23,24]. Under such conditions, traditional feature-driven approaches frequently struggle with complex backgrounds, occlusions, and varying illumination, which are ubiquitous in high-resolution remote sensing imagery [25]. These limitations motivated the transition toward data-driven deep learning approaches [26].
2.2. CNN-Based Road Segmentation Methods
With the success of deep learning in computer vision, road extraction has increasingly been formulated as a pixel-level semantic segmentation task. Early fully convolutional networks (FCNs) enabled end-to-end dense prediction by replacing fully connected layers with convolutional operations and employing transposed convolutions for resolution recovery [27]. Building upon this foundation, encoder–decoder architectures such as SegNet and U-Net introduced symmetric structures with skip connections, which significantly improved boundary localization and spatial detail preservation [28,29].
Subsequent CNN-based methods focused on enhancing feature representation through architectural refinements. Multi-scale context modeling was achieved using dilated convolutions, pyramid pooling modules, and multi-branch designs to capture features at different receptive field sizes [30]. Some studies explicitly exploited the morphological characteristics of roads by incorporating strip convolutions or directional filters to model elongated structures. Additionally, attention mechanisms were introduced to recalibrate channel-wise or spatial feature responses, further improving segmentation accuracy [31]. Despite these advances, CNN-based approaches remain inherently constrained by their localized receptive fields, which limits their ability to model long-range dependencies. This shortcoming often leads to fragmented predictions in scenarios with severe occlusions or complex road intersections [32,33]. Similar fragmentation issues have been reported in other remote sensing interpretation tasks conducted in environmentally complex regions, where surface deformation, freeze–thaw dynamics, and strong land–atmosphere interactions further complicate the extraction of coherent spatial structures [34,35]. In addition, lightweight and task-oriented network designs have been explored to improve efficiency and deployment feasibility in large-scale remote sensing applications [36,37].
2.3. Transformer and Hybrid Architectures for Road Extraction
The emergence of vision transformers (ViTs) has significantly advanced semantic segmentation by enabling global context modeling through self-attention mechanisms [38]. Transformer-based approaches address the limitations of CNNs by capturing long-range dependencies and global structural relationships [39,40]. In the context of road extraction, hybrid CNN–Transformer architectures have been proposed to combine the strengths of both paradigms. These models typically preserve the encoder–decoder framework while integrating transformer blocks into the encoding stage to enhance global reasoning [41,42].
Hierarchical transformer architectures further improve computational efficiency by restricting self-attention to local windows while maintaining cross-window interactions. Such designs have demonstrated improved robustness in complex scenes with large-scale context variation [10,43]. However, transformer-based models often require substantial training data to generalize effectively. When trained on limited road extraction datasets, their performance may degrade due to overfitting or insufficient domain adaptation. This limitation becomes more pronounced when models are deployed across geographically diverse regions experiencing rapid environmental change or strong human–environment interactions, such as Arctic and sub-Arctic areas, where surface structures and background conditions vary significantly across space and time [44,45,46]. Moreover, the high computational cost associated with transformers poses additional challenges for large-scale remote sensing applications [47].
2.4. Foundation Models for Segmentation and Domain Adaptation
Recently, large-scale vision foundation models pretrained on massive datasets have exhibited remarkable generalization capabilities across a wide range of downstream tasks [48]. The Segment Anything Model (SAM) represents a significant milestone by enabling prompt-driven, class-agnostic segmentation through extensive pretraining on the SA-1B dataset [13]. Its successor, SAM2, further enhances representation learning by adopting hierarchical encoders for multi-scale feature extraction and extending support to video segmentation [14].
Despite their strong generalization ability, directly applying prompt-based foundation models to road extraction remains non-trivial. Road segmentation is inherently a dense binary prediction task that demands precise localization and structural continuity, which is not fully aligned with the prompt-driven, category-agnostic design of SAM-based models [15]. To bridge this gap, recent studies have explored adapting foundation models through parameter-efficient fine-tuning strategies, such as adapter-based learning, or through architectural modifications that introduce auxiliary branches and multi-scale fusion modules [49].
While these adaptation strategies demonstrate promising improvements, several challenges persist. The discrepancy between the pretraining domain and remote sensing imagery can hinder effective feature alignment, particularly in scenarios characterized by strong seasonal variability and non-stationary surface processes. Furthermore, many existing methods emphasize pixel-level accuracy while overlooking topological consistency, which is critical for preserving road network integrity [4,50]. These limitations underscore the need for streamlined adaptation frameworks that fully exploit the representation power of foundation models while incorporating adaptive multi-scale fusion and topology-aware supervision tailored to the structural characteristics of road extraction [51,52].
3. Method
3.1. Overview of the Proposed Framework
We address road extraction from remote sensing imagery as a pixel-wise dense prediction problem on RGB images, where the objective is to assign a binary road label to each pixel. As illustrated in Figure 1, the proposed framework takes an input image and produces an road segmentation map. The overall architecture follows a standard encoder–decoder paradigm while being specifically tailored to the structural characteristics of road networks. Specifically, the encoder is built upon a pretrained SAM2 image encoder, which is adapted to the remote sensing domain through lightweight adapter modules to extract hierarchical multi-scale features. To enhance the representation of elongated and thin road structures, receptive field blocks (RFBs) are employed to enrich contextual information and align feature dimensions across scales. Subsequently, a weighted bidirectional feature pyramid network (W-BiFPN) is introduced to adaptively fuse multi-scale features by learning the relative importance of different resolution levels, enabling effective integration of global semantics and local spatial details. On top of the fused features, a U-Net-style decoder progressively reconstructs high-resolution road masks via successive upsampling operations, with intermediate predictions used to facilitate deep supervision. Furthermore, during training, a topology-aware supervision strategy based on the soft-clDice loss is incorporated to explicitly enforce the connectivity and continuity of road structures at the skeleton level. By jointly leveraging strong foundation-model-based representations, adaptive multi-scale feature fusion, and topology-aware training, the proposed framework achieves accurate and structurally consistent road extraction from remote sensing imagery.
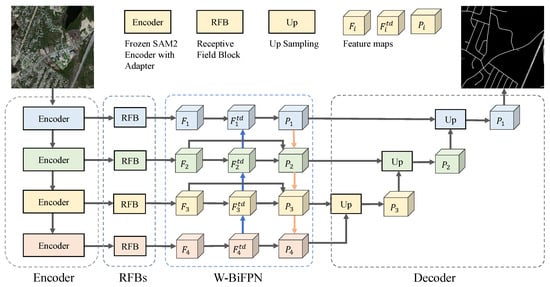
Figure 1.
Overall architecture of the proposed SAM2-RoadNet framework. The model leverages the hierarchical SAM2 encoder with adapter-based domain adaptation, followed by RFB-enhanced feature extraction, W-BiFPN multi-scale fusion, and a hierarchical decoder with topology-aware supervision during training. In the W-BiFPN module, the blue arrows indicate the top-down information flow from deep to shallow layers, while the orange arrows indicate the bottom-up feedback from shallow to deeper layers.
3.2. SAM2-Based Encoder with Domain Adaptation
In contrast to the original SAM2 model designed for prompt-driven generic segmentation, we repurpose the SAM2 image encoder as a pure feature extractor tailored for road extraction from high-resolution remote sensing imagery. The prompt encoder and mask decoder in SAM2 are removed, since road extraction is formulated as a binary dense prediction task and does not explicitly rely on point-, box-, or text-based prompts. Given an input RGB image , the SAM2 backbone produces hierarchical multi-level representations:
where denotes the SAM2 image encoder, is the spatial stride at level l, and is the corresponding channel dimension. These hierarchical features jointly capture fine-grained boundary cues and high-level semantic context, providing a strong basis for modeling elongated and structurally complex road patterns.
To adapt the pretrained SAM2 encoder to the remote sensing domain while keeping training efficient, we adopt a parameter-efficient fine-tuning strategy with adapter modules, as illustrated in Figure 2. Specifically, the parameters of the SAM2 encoder are frozen, and lightweight adapters are inserted before each encoder block to learn domain-specific transformations. Given the token/feature representation in a transformer block, the adapter computes
where and form a bottleneck projection, and is a non-linear activation. The adapted representation is then fed into the original frozen block, enabling effective knowledge transfer from the large-scale pretraining corpus to remote sensing imagery with minimal additional parameters.
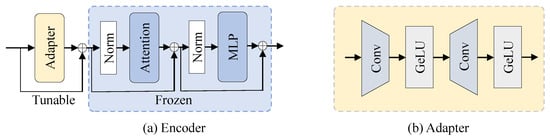
Figure 2.
SAM2-based encoder with domain adaptation. (a) Overall encoder architecture based on the hierarchical SAM2 image encoder. (b) Structure of the lightweight adapter module used for parameter-efficient domain adaptation in remote sensing road extraction.
After feature extraction, the multi-level encoder outputs are further processed by receptive field blocks (RFBs) to enhance contextual perception and align channel dimensions across scales, as illustrated in Figure 3. The RFB design follows the multi-branch receptive field modeling strategy originally proposed for efficient context aggregation [53]. Let denote the RFB at level l; the processed features are
where all levels are unified to a common channel size C to facilitate subsequent fusion. Each RFB employs parallel convolutional branches with different receptive fields, and can be abstracted as
where denotes channel-wise concatenation, represents a branch with specific kernel/dilation setting, ∗ is convolution, and are fusion and residual projections, and is a non-linear activation. This design enlarges the effective receptive field and strengthens strip-like structure modeling, which is particularly beneficial for roads.
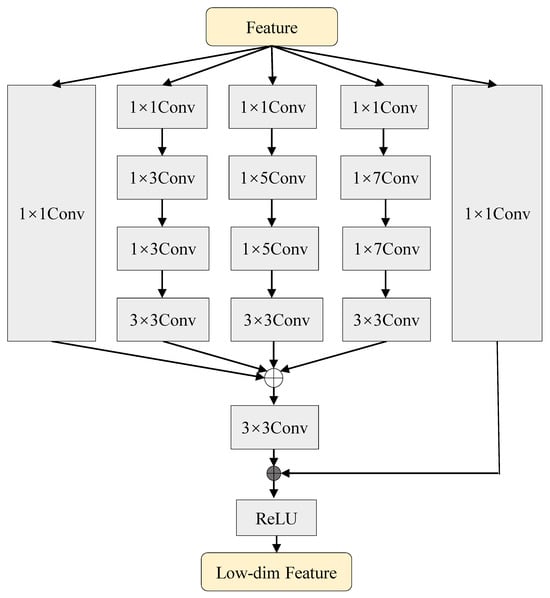
Figure 3.
Structure of the receptive field block (RFB). Multiple convolutional branches with different receptive fields are employed to aggregate multi-scale contextual information, and the fused features are refined through residual learning.
3.3. Multi-Scale Feature Fusion via W-BiFPN
Although the SAM2-based encoder equipped with RFBs yields rich hierarchical representations, directly forwarding them through standard skip connections is insufficient to fully exploit complementary information across scales. In remote sensing road extraction, shallow features preserve local boundary details while deeper features encode long-range continuity. Bidirectional feature pyramid designs with learnable fusion weights have been shown to be effective in multi-scale feature integration [54]. Motivated by this, we introduce a weighted bidirectional feature pyramid network (W-BiFPN) between the encoder and decoder to adaptively fuse multi-level features. For clarity, Figure 1 illustrates only one bidirectional fusion stage of the W-BiFPN.
Given the RFB-enhanced feature maps , W-BiFPN alternates top-down and bottom-up aggregation. We denote the top-down fused feature at level l as :
and the bottom-up output as :
where and denote bilinear upsampling and pooling/downsampling, respectively. The fusion operator implements learnable non-negative weighting:
where are learnable scalars and is a small constant for numerical stability. Such normalized weighted fusion enables the network to automatically emphasize informative scales while suppressing less relevant ones, which is especially important for cluttered backgrounds in HRSIs.
Through iterative bidirectional fusion, W-BiFPN produces multi-scale features with improved semantic coherence and spatial consistency, which are directly used as inputs to the decoder.
Compared with heuristic fusion (e.g., direct summation or explicit subtraction), the proposed W-BiFPN learns scale-aware fusion patterns in a data-driven manner, yielding representations that better preserve road continuity and reduce fragmentation.
3.4. Hierarchical Decoder for Road Segmentation
Based on the fused multi-scale features from W-BiFPN, we employ a U-Net-style hierarchical decoder to progressively reconstruct high-resolution road masks. Let denote the decoding block at stage l. Starting from the coarsest level, the decoder performs
where each consists of upsampling followed by feature concatenation and convolutional refinement. The final prediction is obtained by a convolution head:
where is the sigmoid function.
To stabilize optimization and encourage multi-level representation learning, we adopt deep supervision with auxiliary outputs. Denoting the side predictions at intermediate stages as , we compute
where upsamples to the input resolution. During training, these side outputs provide additional supervision signals from coarse structures to fine boundaries, while only the final prediction is used during inference.
3.5. Topology-Aware Loss Function
Pixel-wise supervision alone is often insufficient for road extraction from remote sensing imagery, as conventional segmentation losses primarily focus on region overlap and fail to explicitly enforce the structural continuity of elongated road networks. In practice, small gaps or fragmented predictions may result in only minor changes in pixel-level metrics, while severely degrading the topological integrity of road graphs. To address this limitation, we introduce a topology-aware training strategy based on the soft-clDice loss [50], which explicitly constrains the connectivity of predicted road structures at the skeleton level. As illustrated in Figure 4, this design complements standard segmentation losses by encouraging continuous and structurally consistent road predictions.
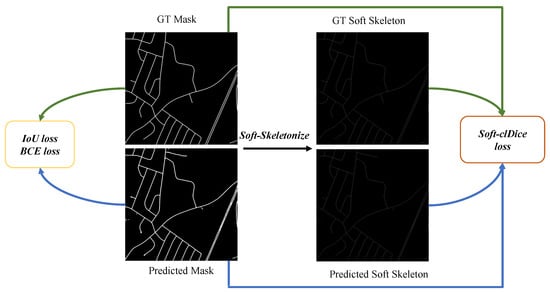
Figure 4.
Loss design of the proposed SAM2-RoadNet. The training objective combines a weighted IoU loss, a binary cross-entropy (BCE) loss, and a topology-aware soft-clDice loss to jointly optimize pixel-wise accuracy and structural connectivity of road networks.
The overall training objective is formulated as a weighted combination of pixel-wise segmentation loss and topology-aware loss:
where denotes the pixel-level road segmentation loss, represents the soft-clDice loss, and is a balancing coefficient controlling the contribution of topological supervision.
3.5.1. Pixel-Wise Segmentation Loss
Following common practice in remote sensing road extraction, the segmentation loss is defined as the sum of a weighted Intersection-over-Union (IoU) loss and a weighted binary cross-entropy (BCE) loss:
To emphasize hard pixels and boundary regions, we introduce a spatial weight map defined as
where denotes average pooling applied to the ground-truth mask to capture local structural differences.
The weighted IoU loss is then defined as
where H and W denote the height and width of the prediction map, is the ground truth label, and denotes the predicted probability of the pixel being classified as road.
The weighted BCE loss is formulated as
The spatial weighting mechanism assigns larger weights to boundary and hard-to-segment regions, which helps the model better preserve thin road structures and improves segmentation robustness under complex backgrounds. This formulation is similar to the structure-aware loss widely used in segmentation networks to emphasize boundary regions.
3.5.2. Topology-Aware Soft-clDice Loss
To explicitly enforce road connectivity, we adopt the soft-clDice loss, which measures the topological consistency between the predicted mask and the ground truth through soft skeleton representations. Given a predicted probability map P and a ground truth mask G, their corresponding soft skeletons and are obtained via an iterative differentiable soft-skeletonization operator. Based on these representations, the soft-clDice score is defined as
where
Here, denotes the element-wise inner product, and is an all-one tensor of the same size. The corresponding topology-aware loss is defined as
By penalizing discrepancies between the skeletons of predictions and ground truths, the soft-clDice loss effectively reduces fragmented road segments and promotes topologically coherent road extraction. Notably, this topology-aware supervision is only applied during training and introduces no additional computational overhead during inference.
4. Experiment
4.1. Dataset and Evaluation Metrics
The DeepGlobe Road Extraction Dataset [55] is a large-scale benchmark designed for road segmentation in high-resolution remote sensing imagery. It consists of satellite images with a spatial resolution of 0.5 m per pixel, covering diverse geographic regions and complex urban and suburban scenes. The dataset provides pixel-level binary annotations for road and non-road areas, where roads exhibit significant variations in width, direction, and appearance. Due to the presence of occlusions caused by buildings, trees, and shadows, as well as cluttered backgrounds, the DeepGlobe dataset poses substantial challenges for accurate and continuous road extraction. Following common practice, we use the official training and validation splits provided by the dataset to evaluate the performance of different models.
The Massachusetts Roads Dataset [56] is a widely used benchmark for evaluating road extraction methods from aerial imagery. It contains high-resolution aerial images with a spatial resolution of approximately 1 m per pixel, captured over urban and suburban areas in the state of Massachusetts, USA. The dataset includes manually annotated binary road masks, where roads often appear as thin and elongated structures with varying connectivity patterns. Compared to DeepGlobe, the Massachusetts dataset features relatively simpler backgrounds but places greater emphasis on the precise delineation and continuity of narrow road segments, as illustrated in Figure 5. In our experiments, we follow the standard train–test split adopted in prior studies to ensure fair comparison with existing methods.

Figure 5.
Visualization of the datasets used in this study. (a) Representative high-resolution remote sensing image from the DeepGlobe dataset along with its corresponding ground-truth road mask. (b) Representative high-resolution remote sensing image from the Massachusetts RoadsDataset and the associated ground-truth road mask.
4.1.1. Dataset Annotation and Partitioning
The DeepGlobe and Massachusetts road datasets adopt different annotation paradigms, which introduce distinct challenges for road extraction. DeepGlobe provides pixel-wise road annotations traced along actual road boundaries, resulting in high-fidelity masks that closely align with real road surfaces. This annotation strategy is particularly suitable for evaluating the geometric accuracy of segmentation models. In contrast, the Massachusetts Roads Dataset annotates road centerlines and generates road masks by applying fixed-width buffers, which emphasizes the preservation of road connectivity and global topology rather than precise boundary delineation. As a result, the annotated road regions may not fully cover the entire road surface but instead highlight the structural continuity of road networks.
To ensure unbiased and representative data partitioning, we follow the standard experimental protocols widely adopted in prior studies. Large remote sensing images are first cropped into fixed-size patches, which are then randomly shuffled and split into training and testing subsets according to the official dataset configurations. This strategy avoids spatial overlap between training and test samples and mitigates potential data leakage. Such partitioning ensures that the evaluation faithfully reflects the generalization capability of the proposed method under diverse scene layouts and road distributions.
4.1.2. Evaluation Metrics
To comprehensively assess road extraction performance, we employ a set of quantitative metrics that evaluate pixel-level classification accuracy, regional consistency, and overall prediction error. Let TP, TN, FP, and FN denote the number of true positives, true negatives, false positives, and false negatives, respectively. Based on these definitions, we first adopt precision and recall to measure the model’s ability to control false detections and missed road pixels. The F1-score, defined as the harmonic mean of precision and recall, provides a balanced assessment of classification performance:
4.1.3. Regional Consistency Metrics
To evaluate the spatial overlap between predicted and ground-truth road regions, we report the mean Intersection over Union (mIoU). This metric measures the agreement between predicted masks and annotations at the region level and is widely used in semantic segmentation to assess segmentation quality.
where , , and denote the numbers of true positives, false positives, and false negatives, respectively. A higher mIoU value indicates better overlap between the predicted road regions and the ground-truth annotations.
4.1.4. Error Analysis Metric
In addition to overlap-based metrics, we employ the mean absolute error (MAE) to quantify the overall pixel-wise prediction error. MAE measures the average absolute difference between the predicted probability map and the ground truth , providing an intuitive assessment of global prediction deviation:
where N denotes the total number of pixels. Lower MAE values correspond to more accurate and stable predictions.
4.1.5. Topology Consistency Metric
In addition to pixel- and region-level metrics, we further employ the Average Path Length Similarity (APLS) [57] to evaluate the topological correctness of the extracted road networks. Unlike overlap-based metrics that focus on pixel-wise agreement, APLS measures how well the connectivity and structural relationships of the road network are preserved.
Specifically, the road masks are first skeletonized to obtain centerline representations, from which graph structures are constructed. Each road graph consists of vertices representing road junctions or endpoints and edges representing road segments between them. For a randomly sampled pair of vertices in the ground-truth graph and their corresponding vertices in the predicted graph, the shortest path distances are computed respectively as and .
The path similarity error for each vertex pair is defined as
The final APLS score is computed as
where M denotes the number of sampled vertex pairs. The APLS score ranges from 0 to 1, where higher values indicate better preservation of road network topology and connectivity.
4.2. Implementation Details
All experiments are implemented using the PyTorch framework (v2.1.0). The network parameters are optimized with the AdamW optimizer, where the initial learning rate is set to . A cosine annealing learning rate scheduler is employed to gradually decay the learning rate to over the entire training process, with the scheduling period aligned with the total number of training epochs. This configuration enables stable convergence while effectively avoiding overfitting during later training stages.
Model training is conducted using distributed data parallelism on eight NVIDIA RTX 4090 GPUs, each equipped with 24 GB of memory. The total batch size is fixed to 16, corresponding to two samples per GPU. All models are trained for 50 epochs without early stopping. For computational efficiency analysis, including FLOPs and parameter counting, a single NVIDIA RTX 4060 GPU is used. Unless otherwise specified, the same training configuration is applied consistently across all datasets to ensure fair comparison.
To enhance the generalization capability of the proposed model, a series of data augmentation strategies are applied during training. Specifically, input images are randomly rotated within a range of and randomly flipped horizontally with a probability of 0.5. All images and corresponding ground-truth masks are resized to a fixed resolution of using bilinear interpolation for images and nearest-neighbor interpolation for labels. These augmentations effectively increase data diversity and improve the robustness of the model to variations in orientation and spatial layout commonly observed in remote sensing imagery.
4.3. Comparison with Other Methods
We conduct comparative experiments to evaluate the effectiveness of the proposed method against several representative baselines, including SwinUNet, SAM2UNet, and SAM2MS. These methods cover transformer-based encoder–decoder architectures, SAM-based fine-tuning approaches, and recent multi-scale SAM2 variants, thereby providing a comprehensive benchmark for assessing both segmentation accuracy and structural consistency. Quantitative performance comparisons on the DeepGlobe and Massachusetts datasets are reported in Table 1 and Table 2, respectively. In addition, model complexity and computational efficiency are summarized in Table 3. Qualitative visual comparisons are presented in Figure 6 and Figure 7.

Table 1.
Quantitative comparison on the DeepGlobe Road Extraction Dataset. The best results are highlighted in bold. ↑ indicates higher is better, and ↓ indicates lower is better.
Table 2.
Quantitative comparison on the Massachusetts Roads Dataset. This dataset emphasizes thin road structures and topological continuity. The best results are highlighted in bold. ↑ indicates higher is better, and ↓ indicates lower is better.
Table 3.
Model complexity and computational cost comparison. Params and FLOPs are reported for input resolution . ↓ indicates lower is better.

Figure 6.
Qualitative comparison of road extraction results on the DeepGlobe dataset. From top to bottom: (a) high-resolution remote sensing images, (b) ground-truth road masks, (c) results produced by SAM2UNet, (d) results produced by SAM2MS, and (e) results produced by the proposed SAM2-RoadNet. Compared with existing SAM2-based methods, SAM2-RoadNet generates more continuous road networks with fewer false positives and reduced fragmentation, particularly in challenging regions with occlusions and complex backgrounds.

Figure 7.
Qualitative comparison of road extraction results on the Massachusetts Roads Dataset. From top to bottom: (a) high-resolution remote sensing images, (b) ground-truth road masks, (c) results obtained by SAM2UNet, (d) results obtained by SAM2MS, and (e) results obtained by the proposed SAM2-RoadNet. In comparison with existing methods, SAM2-RoadNet produces more accurate and topology-consistent road predictions, effectively reducing discontinuities and false detections in complex urban and suburban scenes.
Compared with SAM2UNet, SAM2MS introduces explicit multi-scale subtraction to reduce feature redundancy and achieves improved robustness under moderate occlusion and background clutter. Despite these improvements, its differential fusion strategy may suppress complementary information across scales, leading to missing or weakened predictions in densely connected road networks. In contrast, the proposed method consistently produces more continuous and topologically coherent road masks across different datasets. By leveraging weighted bidirectional multi-scale fusion, our approach adaptively balances global semantics and local details, enabling reliable recovery of elongated road structures even under severe occlusions and radiometric variations.
On the Massachusetts dataset, which features dense road networks and strong interference from surrounding buildings, SAM2UNet frequently generates blurred boundaries between road and non-road regions. SAM2MS improves road connectivity but may still fail to fully reconstruct complex intersections. As quantitatively shown in Table 2, the proposed method achieves superior performance in terms of F1-score and mDice, indicating enhanced structural completeness and topological consistency. These qualitative observations are well aligned with the quantitative results reported in Table 1 and Table 2. Following common practice, MAE values in all tables are normalized for ease of comparison.
The observed performance improvements can be attributed to two key design aspects of the proposed framework. First, the weighted bidirectional fusion mechanism enables more effective integration of shallow boundary cues and deep semantic context. This design allows the model to better capture both local geometric details and long-range road continuity, which is particularly important for thin and elongated structures in high-resolution remote sensing imagery. As a result, the proposed method produces more complete road segments and fewer disconnected predictions compared with SAM2UNet and SAM2MS.
Second, the topology-aware design encourages the model to preserve structural relationships between road segments. Unlike subtraction-based multi-scale fusion used in SAM2MS, which may suppress complementary information across scales, the proposed W-BiFPN adaptively learns the importance of different feature levels through learnable fusion weights. This adaptive aggregation helps retain informative features from multiple resolutions and improves the reconstruction of complex road patterns such as intersections and curved segments.
These advantages are particularly evident on the Massachusetts dataset, where dense urban structures and strong background interference make road extraction more challenging. The improved structural consistency and boundary accuracy lead to higher F1-score and IoU values, demonstrating the effectiveness of the proposed design in preserving road topology under complex scene conditions.
4.4. Ablation Study
To examine the contribution of individual components in the proposed framework, a series of ablation experiments are conducted on the DeepGlobe and Massachusetts datasets. The analysis focuses on three key modules: the receptive field block (RFB), the weighted bidirectional feature pyramid network (W-BiFPN), and the topology-aware soft-clDice loss. For all ablation settings, the same training protocol described in Section 4.2 is adopted, ensuring that performance differences can be attributed solely to architectural or loss-function variations.
4.4.1. Effect of RFB
The influence of the receptive field blocks is first investigated by removing them from the SAM2-based encoder, directly forwarding the encoder features to the multi-scale fusion stage. As shown in Table 4, excluding RFBs leads to a clear decline in performance, with notable drops in recall and mDice. This degradation indicates that the raw encoder features lack sufficient contextual awareness to robustly characterize thin, elongated road segments. In contrast, integrating RFBs expands the effective receptive field and strengthens multi-scale context modeling, which facilitates improved detection of narrow road structures and enhances the continuity of predicted road networks. This effect is particularly important for high-resolution remote sensing imagery, where roads often appear as long and thin structures surrounded by heterogeneous backgrounds. By enlarging the receptive field, the RFB modules allow the encoder to capture broader contextual cues, which helps distinguish roads from visually similar objects such as parking areas and building edges. Consequently, the model can better preserve road continuity and reduce broken predictions along narrow road segments.
Table 4.
Ablation study of key components on the DeepGlobe dataset. RFB denotes the receptive field block, W-BiFPN indicates weighted bidirectional multi-scale fusion, and clDice represents the topology-aware soft-clDice loss. The best results are highlighted in bold. ↑ indicates higher is better; ✓ indicates that the module is used; × indicates that the module is not used.
4.4.2. Effect of W-BiFPN
The effectiveness of adaptive multi-scale fusion is examined by replacing the proposed W-BiFPN with standard skip connections as commonly employed in U-Net-style architectures. The quantitative results in Table 4 reveal that conventional skip connections struggle to properly balance low-level spatial information with high-level semantic cues, often producing fragmented road predictions in visually complex scenes. By comparison, W-BiFPN achieves consistently higher F1-score and mIoU, owing to its ability to learn scale-aware fusion weights and perform bidirectional information exchange. The improvement mainly arises from the adaptive weighting mechanism in the W-BiFPN, which allows the model to dynamically balance shallow spatial details and deep semantic representations. In contrast to simple skip connections that treat features from different levels equally, the proposed fusion strategy learns scale-aware weights to emphasize informative feature maps. This capability is particularly beneficial for recovering thin roads that require both accurate boundary localization and global structural context. These results suggest that learnable and bidirectional fusion mechanisms are better suited for integrating heterogeneous multi-scale features in road extraction tasks.
4.4.3. Effect of Soft-clDice Loss
The impact of topology-aware supervision is analyzed by removing the soft-clDice loss and training the model using only pixel-wise segmentation objectives. While region-based accuracy remains competitive under this setting, the resulting predictions tend to exhibit pronounced fragmentation, particularly in occluded areas and at complex road intersections. As evidenced in Table 4, introducing the soft-clDice loss yields consistent improvements in recall and mDice. This observation confirms that topology-aware supervision provides complementary guidance beyond conventional pixel-level losses by explicitly encouraging structural connectivity in the predicted road networks. This behavior indicates that topology-aware supervision plays an important role in preserving the structural integrity of road networks. By explicitly penalizing topological disconnections, the soft-clDice loss encourages the model to produce more connected predictions, which is crucial for applications such as map generation and transportation analysis.
4.4.4. Combined Effect of Key Components
Different combinations of the proposed components are evaluated to assess their joint impact on overall performance. The results summarized in Table 4 show that the complete model, which incorporates RFB, W-BiFPN, and the soft-clDice loss, achieves the best performance across all evaluation metrics. Although each component individually contributes measurable gains, their integration leads to the most significant improvement, highlighting strong complementarity among contextual enhancement, adaptive multi-scale fusion, and topology-aware optimization. These findings demonstrate that the effectiveness of the proposed approach stems from the coordinated design of these modules rather than reliance on any single component alone.
4.5. Cross-Dataset Generalization
To further evaluate the transferability of the proposed method, we conduct cross-dataset experiments on the DeepGlobe and Massachusetts road datasets. In these experiments, models are trained on one dataset and directly evaluated on another without any fine-tuning. This setting provides an evaluation of the model’s robustness under moderate domain shifts, since the two datasets differ in scene complexity, annotation style, and road topology characteristics, as summarized in Table 5.
Table 5.
Cross-dataset generalization performance. Models are trained on one dataset and evaluated on another without fine-tuning. The best results are highlighted in bold. ↑ indicates higher is better, and ↓ indicates lower is better.
Specifically, DeepGlobe provides dense pixel-wise road annotations with complex backgrounds and large appearance variations, while the Massachusetts dataset adopts centerline-based annotations that emphasize road connectivity and topological continuity. Such differences introduce noticeable challenges for cross-dataset transfer and may lead to performance degradation for models that overfit to dataset-specific characteristics.
Despite these differences, the proposed framework maintains relatively stable performance across datasets, as summarized in Table 6. This behavior can be attributed to the multi-scale representation capability introduced by the W-BiFPN and the topology-aware supervision provided by the soft-clDice loss, both of which encourage the model to learn structural road patterns rather than relying solely on dataset-specific appearance cues.
Table 6.
Performance degradation from in-domain to cross-dataset evaluation. Lower performance drop indicates better robustness to domain shift.
Nevertheless, since both datasets consist of optical remote sensing imagery with comparable spatial resolutions, the current experiments mainly reflect robustness under moderate domain differences rather than fully heterogeneous conditions. Future work will evaluate the proposed framework on more diverse datasets to further investigate its generalization capability.
Additionally, some failure cases still occur in extremely challenging scenarios, such as heavy occlusions by trees or vehicles, where the visual continuity of roads is severely disrupted. Incorporating stronger structural priors or long-range contextual reasoning may further improve robustness in such cases.
5. Conclusions
In this paper, we presented a topology-aware road extraction framework based on the SAM2 foundation model for high-resolution remote sensing imagery. By reformulating road extraction as a dense prediction task and discarding prompt-dependent components, the proposed method leverages the strong representation capability of the SAM2 image encoder while remaining well suited to binary road segmentation. The overall architecture follows an encoder–decoder paradigm and is specifically designed to address the challenges of thin structures, occlusions, and complex backgrounds commonly observed in remote sensing scenes.
To enhance multi-scale representation learning, we introduced receptive field blocks (RFBs) to enrich contextual information and align feature dimensions, followed by a weighted bidirectional feature pyramid network (W-BiFPN) to adaptively fuse features across different scales. Unlike fixed fusion strategies, the proposed W-BiFPN learns scale-aware weights to balance global semantic context and local spatial details. Furthermore, a topology-aware training strategy based on the soft-clDice loss was incorporated to explicitly enforce road connectivity at the skeleton level, complementing conventional pixel-wise segmentation losses.
Extensive experiments conducted on the DeepGlobe and Massachusetts datasets demonstrate that the proposed method achieves superior overall performance across multiple evaluation metrics compared with representative baselines, including SAM2UNet, SAM2MS, in terms of both quantitative metrics and qualitative visual results. Ablation studies further verify the effectiveness and complementarity of the key components, confirming that the performance improvements arise from the joint design of contextual enhancement, adaptive multi-scale fusion, and topology-aware supervision.
Despite the promising results, predicting extremely dense road networks and highly complex intersections remains challenging. Future work will explore more explicit graph-level modeling and lightweight topology refinement modules to further improve structural completeness. In addition, extending the proposed framework to multi-source remote sensing data and large-scale cross-domain scenarios represents a promising direction for future research.
Author Contributions
R.F.: conceptualization, methodology, formal analysis, writing—original draft, visualization. Z.G.: software, investigation, data curation, writing—review and editing. X.D.: methodology, validation, formal analysis, resources, writing—review and editing. T.W.: supervision, project administration, writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program of China (No. 2020YFA0714103).
Data Availability Statement
The datasets used in this study are publicly available benchmark datasets for road extraction from remote sensing imagery. The DeepGlobe Road Extraction Dataset is available from the official DeepGlobe website: http://deepglobe.org/index.html (accessed on 20 October 2025). The Massachusetts Roads Dataset can be obtained from the University of Toronto Computer Vision Group website: https://www.cs.toronto.edu/~vmnih/data/ (accessed on 21 October 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 210–223. [Google Scholar]
- Mena, J.B. State of the art on automatic road extraction for GIS update: A novel classification. Pattern Recognit. Lett. 2003, 24, 3037–3058. [Google Scholar] [CrossRef]
- Wegner, J.D.; Montoya-Zegarra, J.A.; Schindler, K. Road networks as collections of minimum cost paths. ISPRS J. Photogramm. Remote Sens. 2015, 108, 128–137. [Google Scholar] [CrossRef]
- Mosinska, A.; Marquez-Neila, P.; Koziński, M.; Fua, P. Beyond the pixel-wise loss for topology-aware delineation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2018; pp. 3136–3145. [Google Scholar]
- Mo, S.; Shi, Y.; Yuan, Q.; Li, M. A survey of deep learning road extraction algorithms using high-resolution remote sensing images. Sensors 2024, 24, 1708. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Weng, Q. Deep learning-based road extraction from remote sensing imagery: Progress, problems, and perspectives. ISPRS J. Photogramm. Remote Sens. 2025, 228, 122–140. [Google Scholar] [CrossRef]
- Zhu, X.; Huang, X.; Cao, W.; Yang, X.; Zhou, Y.; Wang, S. Road extraction from remote sensing imagery with spatial attention based on swin transformer. Remote Sens. 2024, 16, 1183. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops; IEEE: New York, NY, USA, 2018; pp. 182–186. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 10012–10022. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution transformer for dense prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar] [CrossRef]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 9650–9660. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2023; pp. 4015–4026. [Google Scholar]
- Ravi, N.; Gabeur, V.; Hu, Y.T.; Hu, R.; Ryali, C.; Ma, T.; Khedr, H.; Rädle, R.; Rolland, C.; Gustafson, L.; et al. Sam 2: Segment anything in images and videos. arXiv 2024, arXiv:2408.00714. [Google Scholar]
- Wu, J.; Wang, Z.; Hong, M.; Ji, W.; Fu, H.; Xu, Y.; Xu, M.; Jin, Y. Medical sam adapter: Adapting segment anything model for medical image segmentation. Med. Image Anal. 2025, 102, 103547. [Google Scholar] [CrossRef]
- Peng, J.; Huang, Y.; Sun, W.; Chen, N.; Ning, Y.; Du, Q. Domain adaptation in remote sensing image classification: A survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9842–9859. [Google Scholar] [CrossRef]
- Hu, X.; Li, F.; Samaras, D.; Chen, C. Topology-preserving deep image segmentation. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Trinder, J.C.; Wang, Y. Automatic road extraction from aerial images. Digit. Signal Process. 1998, 8, 215–224. [Google Scholar] [CrossRef]
- Laptev, I.; Mayer, H.; Lindeberg, T.; Eckstein, W.; Steger, C.; Baumgartner, A. Automatic extraction of roads from aerial images based on scale space and snakes. Mach. Vis. Appl. 2000, 12, 23–31. [Google Scholar] [CrossRef]
- Hinz, S.; Baumgartner, A. Automatic extraction of urban road networks from multi-view aerial imagery. ISPRS J. Photogramm. Remote Sens. 2003, 58, 83–98. [Google Scholar] [CrossRef]
- Senthilnath, J.; Rajeshwari, M.; Omkar, S. Automatic road extraction using high resolution satellite image based on texture progressive analysis and normalized cut method. J. Indian Soc. Remote Sens. 2009, 37, 351–361. [Google Scholar] [CrossRef]
- Li, X.; Yang, X.; Zhang, Z.; Zhai, J.; Meng, X. Evaluating of ground surface freeze–thaw and the interrelationship with vegetation cover on the Qinghai-Xizang Plateau. Geoderma 2025, 453, 117141. [Google Scholar] [CrossRef]
- Li, X.L.; Zhang, Z.; Lu, J.X.; Brouchkov, A.; Yan, Q.K.; Yu, Q.H.; Zhang, S.R.; Melnikov, A. Evaluating the thermal environment of urban land surfaces in Yakutsk, a city located in a region of continuous permafrost. Adv. Clim. Change Res. 2024, 15, 113–123. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Z.; Wei, H.; Yan, Q.; Sun, J.; Jin, D. Evaluations of ground surface heat fluxes and its potential vegetation effects in the permafrost region of northeastern China. Catena 2024, 246, 108449. [Google Scholar] [CrossRef]
- Mokhtarzade, M.; Zoej, M.V. Road detection from high-resolution satellite images using artificial neural networks. Int. J. Appl. Earth Obs. Geoinf. 2007, 9, 32–40. [Google Scholar] [CrossRef]
- Song, M.; Civco, D. Road extraction using SVM and image segmentation. Photogramm. Eng. Remote Sens. 2004, 70, 1365–1371. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2017; pp. 1925–1934. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2017; pp. 2881–2890. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2020; pp. 4003–4012. [Google Scholar]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Z.; Zheleznyak, M.; Jin, H.; Zhang, S.; Wei, H.; Zhai, J.; Melnikov, A.; Gagarin, L. Time-series InSAR monitoring of surface deformation in Yakutsk, a city located on continuous permafrost. Earth Surf. Process. Landf. 2024, 49, 918–932. [Google Scholar]
- Yan, Q.; Zhang, Z.; Li, X.; Yan, A.; Qiu, L.; Zhang, A.; Melnikov, A.; Gagarin, L. Time-Series InSAR Monitoring of Permafrost-Related Surface Deformation at Tiksi Airport: Impacts of Climate Warming and Coastal Erosion on the Northernmost Siberian Mainland. Remote Sens. 2025, 17, 1757. [Google Scholar] [CrossRef]
- Sun, S.; Yang, Z.; Ma, T. Lightweight remote sensing road detection network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6510805. [Google Scholar]
- Tao, J.; Chen, Z.; Sun, Z.; Guo, H.; Leng, B.; Yu, Z.; Wang, Y.; He, Z.; Lei, X.; Yang, J. Seg-road: A segmentation network for road extraction based on transformer and cnn with connectivity structures. Remote Sens. 2023, 15, 1602. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2021; pp. 6881–6890. [Google Scholar]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 12077–12090. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 205–218. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar] [CrossRef]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 6824–6835. [Google Scholar]
- Sun, J.; Zhang, Z.; Yan, Q.; Li, X.; Liu, S.; Qiu, L.; Yan, A.; Jin, H. Climate Warming and Arctic Coastline Erosion at Tiksi, Laptev Sea, Yakutia, Russia: A Study on Shoreline Changes and Future Projections. Estuaries Coasts 2025, 48, 164. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, Z.; Yan, Q.; Li, X.; Zhang, A.; Ju, M.; Jiang, X. Morphological evolution of the Arctic Tiksi coastline and driving mechanisms. Geomorphology 2025, 490, 110013. [Google Scholar] [CrossRef]
- Tang, J.; Jin, X.; Mu, H.; Yang, S.; He, R.; Li, X.; Wang, W.; Huang, S.; Zu, J.; Wang, H.; et al. Impacts of human footprint on habitat quality and permafrost environment in Northeast China. Ecol. Indic. 2025, 175, 113587. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Z.; Wan, J.; Zhang, J.; Xi, Y.; Liu, R.; Miao, Q. RoadFormer: Road extraction using a swin transformer combined with a spatial and channel separable convolution. Remote Sens. 2023, 15, 1049. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning; PmLR: Birmingham, UK, 2021; pp. 8748–8763. [Google Scholar]
- Luo, M.; Zhang, T.; Wei, S.; Ji, S. SAM-RSIS: Progressively adapting SAM with box prompting to remote sensing image instance segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4413814. [Google Scholar] [CrossRef]
- Shit, S.; Paetzold, J.C.; Sekuboyina, A.; Ezhov, I.; Unger, A.; Zhylka, A.; Pluim, J.P.; Bauer, U.; Menze, B.H. clDice-a novel topology-preserving loss function for tubular structure segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2021; pp. 16560–16569. [Google Scholar]
- Xiong, X.; Wu, Z.; Tan, S.; Li, W.; Tang, F.; Chen, Y.; Li, S.; Ma, J.; Li, G. Sam2-unet: Segment anything 2 makes strong encoder for natural and medical image segmentation. Vis. Intell. 2026, 4, 2. [Google Scholar] [CrossRef]
- Zhang, P.; Li, J.; Wang, C.; Niu, Y. SAM2MS: An Efficient Framework for HRSI Road Extraction Powered by SAM2. Remote Sens. 2025, 17, 3181. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2018; pp. 385–400. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2020; pp. 10781–10790. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops; IEEE: New York, NY, USA, 2018; pp. 172–181. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Doctoral Dissertation, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Van Etten, A.; Lindenbaum, D.; Bacastow, T.M. Spacenet: A remote sensing dataset and challenge series. arXiv 2018, arXiv:1807.01232. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.