Highlights
What are the main findings?
- We build a large-scale synthetic aerial–ground multi-view dataset (AGMV) that jointly incorporates aerial and ground camera views, enabling evaluation of multi-person labeling and cross-view association across diverse scenes and crowd densities.
- We propose a graph-constrained aerial–ground association framework that consistently outperforms strong baselines, especially under higher crowd densities.
What is the implication of the main finding?
- The AGMV dataset establishes a scalable benchmark for advancing aerial–ground multi-view association research, enabling evaluation across diverse scenes, camera configurations, and crowd densities.
- Graph-based global constraints enhance robustness in crowded scenarios by enforcing cross-view consistency, offering practical guidance for designing scalable multi-view labeling and association systems.
Abstract
Recent advances in remote sensing have increasingly emphasized multi-view vision, which integrates complementary viewpoints to deliver more complete scene understanding and effectively alleviate occlusion and limited fields of view in crowded environments. In particular, aerial imagery captured by drones provides holistic scene coverage, whereas ground-level cameras offer precise and fine-grained object details. Despite these advantages, large-scale multi-view datasets that jointly incorporate aerial and ground-level perspectives remain scarce, largely due to the practical difficulties of coordinating paired aerial and ground platforms. To overcome this challenge, we develop a ground–aerial camera system that emulates drone viewpoints and, based on this system, construct a large-scale synthetic dataset for aerial–ground multi-view person association. Leveraging this dataset, we propose a novel graph-constrained framework that enforces robust and globally consistent associations across aerial and ground views. Additionally, we introduce an aerial-view-guided people-number estimation module to provide a scene-level constraint for identity association. Extensive experimental results demonstrate that our method consistently outperforms state-of-the-art baselines in multi-view labeling across varying crowd densities.
1. Introduction
In recent years, multi-view vision has attracted increasing attention due to the extensive deployment of cameras in real-world environments. The task of multi-view labeling, which aims to accurately locate multiple people across various viewpoints in complex scenes, is a core problem in this domain (Figure 1). The downstream tasks, such as 3D pose estimation, 3D human reconstruction, and large-scale surveillance [1,2,3,4,5,6,7,8,9,10,11] can also be further extended to multiple-people scenarios. However, ground-level cameras often capture only partial human appearances due to severe occlusion, thus limiting accuracy and robustness.

Figure 1.
Illustration of the proposed aerial–ground multi-view labeling task. Multiple people observed across aerial and ground-level views are annotated using consistent colors, where each color belongs to a unique identity. This visualization highlights the significant appearance and viewpoint variations across heterogeneous camera perspectives.
The incorporation of aerial viewpoints can bring extra benefits. Unlike ground perspectives, aerial imagery typically has a wider baseline and broader scene coverage, enabling more reliable estimation of both the number of people and their spatial positions [12,13]. Despite these advantages, it is a challenging task to label multiple people across aerial–ground views, due to the large appearance variation and changing illumination.
Early multi-view labeling methods mainly rely on geometry-based techniques, such as the probabilistic occupancy map (POM) framework [14] and principal-axis alignment [15], to coarsely associate people across views. However, the geometry-based methods are sensitive to accurate geometric calibration, causing their performance to degrade significantly under heavy occlusions. With the advent of deep learning, deep learning-based methods have substantially improved the accuracy for multi-view labeling. However, these advances remain limited in several ways. For example, the method in [16] is applied on pairwise ground-view images. A representative graph-based method for multi-view labeling is introduced in [17]. It formulates cross-view identity association as graph inference, where nodes denote person instances and edges combine re-ID similarity with geometric cues. The method is built on ground-truth detections, which simplifies association but limits practicality when only detected bounding boxes are available. Furthermore, it is primarily designed for ground-view settings. Recent efforts in multi-view tracking also attempt to tackle the aerial–ground association problem by constructing new datasets. However, real-world aerial–ground data collection is costly, labor-intensive, and often restricted by flight regulations. Moreover, although multi-view video streams provide additional temporal cues that can facilitate association, it remains fundamentally challenging to solve the image-based multi-view labeling problem.
Despite these efforts, existing image datasets remain limited in scale, diversity, and scene complexity, especially for aerial viewpoints. To address these gaps, we construct a large-scale synthetic dataset for the aerial–ground labeling task, covering diverse aerial and ground-view configurations with multiple people in the scene. The dataset is generated by integrating 3D human models, realistic panoramas, fine rendering and aerial and ground camera settings, providing a comprehensive benchmark for aerial–ground multi-view labeling. Building upon this dataset, we further propose a novel aerial–ground multi-view labeling framework, which jointly estimates the number of people in the scene and performs cross-view association for label prediction based on graph-constrained matching. More specifically, we first propose a top-view-guided people-number estimation module, using top view detections to predict the number of people in the scene. Multi-view labeling is then formulated as a graph-based inference problem, where aerial-view-derived person-count predictions are incorporated as an additional structural constraint. In addition, a transformer-based network is employed to learn robust cross-view matching scores, which facilitates reliable aerial–ground association as well as consistent aerial–ground estimation within the graph.
The contributions of this paper are threefold. First, we generate a large-scale aerial–ground dataset for multi-view multiple-people labeling, comprising diverse scenes captured simultaneously from both aerial and ground viewpoints. This dataset bridges the gap between aerial and ground-level perspectives, establishing a new benchmark for advancing research on multi-view human understanding. Second, we formulate aerial–ground multi-view association as a graph-constrained global identity inference problem, where learned pairwise similarities are integrated with explicit scene-level structural priors (view consistency, view uniqueness, and cluster-count regulation) to obtain globally consistent identity partitions. Third, extensive experiments have been conducted, validating the robustness and effectiveness of the proposed method in diverse scenarios.
This paper is organized as follows. In Section 2, we present a comprehensive review of related work on both person re-identification and cross-view association. Section 3 introduces our methodology for multi-view labeling, detailing aerial-view-guided people-number estimation, cross-view matching confidence prediction, and the graph-based multi-view association strategy that enables accurate and consistent labeling across multiple views. Section 4 provides extensive experimental evaluations, including experimental setup, quantitative and qualitative results, and related analyses. In Section 5, we discuss relevant research insights and future works. Finally, Section 6 concludes the paper.
2. Related Work
In this section, we summarize the two relevant areas of aerial–ground multi-view multiple-people labeling, including person re-identification and multi-view association. The discriminative feature-representation learning is discovered in the person re-ID task, while the association of multiple people across different viewpoints is explored in the cross-view association.
2.1. Person Re-ID
As the core task of person re-identification, discriminative feature-representation learning for cross-camera people identification is broadly explored. In recent years, re-ID methods have achieved significant progress driven by deep representation learning, exploring global descriptors, part-based modeling, attention mechanisms, etc. [18,19,20,21]. In [22], an effective two-branch architecture named Batch DropBlock (BDB) network is proposed to enhance feature-representation learning. It utilizes local attentive feature learning by randomly dropping out a spatial region from images. In [23], Zhang et al. attempt to obtain the global structure information by designing two novel Relation-Aware Global Attention (RGA) modules. Both spatial attention and channel attention are utilized to boost performance. In [24], a novel method named AGW is proposed, consisting of an attention mechanism, generalized mean pooling, and a weighted triplet loss. As an extended area of person re-ID, person-search methods, focusing on both detection and discriminative feature learning, have attracted increasing attention recently. In [25], a cascade coarse-to-fine architecture is established to achieve end-to-end person search. In [26], long-tailed identity distribution learning, multi-scale convolutional transformers are utilized for improving robustness. In [27], a text-based person search is achieved by introducing a deep adversarial graph attention network. It establishes the semantic scene graphs and utilizes adversarial learning to bridge the modality gap. Recently, several works have tended to explore the aerial–ground person re-ID task [28,29,30,31,32,33]. In [29], a two-stream explainable re-ID model is proposed. It is achieved both by computing pairwise distance and incorporating person attributes. In [28], an explainable elevated-view attention mechanism is fulfilled by a transformer-based network. It thus can enhance the network to learn the head region of the person as well as the attribute attention maps. Although a large number of re-ID methods have been proposed for discriminative feature learning for persons with robustness of pose variation and partial occlusion, they focus on non-overlapping cameras, failing to explore the multi-view cues. In this paper, we establish a novel multi-view labeling framework to explore the consistency across aerial–ground images captured synchronously.
2.2. Cross-View Association
To obtain a consistent identity for multiple people across different viewpoints observed from the same scene, cross-view association methods have attracted more attention in recent years. Conventional methods mainly focus on multi-view geometry, such as 3D localization, epipolar geometry, etc. [14]. In [14], a generative model is proposed to estimate the probability for the occupancy of each ground-plane location. The method is achieved by pre-defined grids and camera calibration information. However, the geometry-based association methods tend to fail when the scene becomes crowded. An extra-deep network is used to predict additional key points used for matching. As deep learning has dominated the computer vision area, deep-based association has become mainstream. In [34], Xu et al. integrated trained re-ID features, geometry proximity, and motion consistency as a composition for both spatial and temporal association. In [35], two self-supervised constraints named symmetric similarity and transitive similarity are introduced to achieve both spatial and temporal association for multi-view tracking. In [36], a bipartite graph for feet position is established to achieve matching across views in the crowded scenes. In [16], an end-to-end multi-view labeling network is proposed for cross-view matching confidence prediction based on pairwise images. The Hungarian algorithm is then applied to the matching matrix for association. Then, in [37], the performance is further improved by introducing the transformer blocks. In [17], a graph neural network is proposed to accomplish multi-view people association. A message-passing network is used jointly for feature- and similarity-function learning. In [38], Chen et al. propose to learn multi-view consistency from image synchronization. An encoder-decoder model, along with two self-supervised linear constraints, including multi-view re-projection and pairwise edge association, is utilized to achieve multi-view association. Although recent progress has been made in cross-view association, the methods focus on ground views, where most of the body parts are visible. In this paper, we propose a novel graph-constrained matching framework and achieve cross-view association among aerial–ground images.
3. Methodology
3.1. Aerial–Ground Multi-View Dataset Generation
Recent advances in aerial imaging and multi-view vision have enabled drones to capture wide-baseline, holistic observations of crowded scenes. Compared with traditional ground-level cameras, aerial viewpoints offer broader coverage and reduced occlusion, facilitating more reliable estimation of pedestrian counts. However, despite these advantages, large-scale aerial–ground multi-view datasets remain scarce, owing to privacy considerations and the practical challenges associated with deploying drone-mounted cameras in real-world environments.
To address this gap, we extend the multi-view data generation pipeline in [16] to generate a comprehensive aerial–ground multi-view dataset named Aerial–Ground Multi-View (AGMV) dataset. Following the procedure, we employ Blender to construct realistic scenes using 3D human models, panoramic backgrounds, and motion-captured animations. Human models are randomly placed within predefined spatial limits.
Each scenario includes four cameras placed around the perimeter to emulate ground-level viewpoints and two additional high-mounted cameras positioned above the scene to simulate drones capturing aerial-view imagery. The cameras are synchronized for each scene to ensure consistent rendering from multiple viewpoints. The aerial cameras are set to an altitude of 40 units in Blender and tilted by 10° relative to the horizontal axis. This configuration provides complementary ground-level observations, along with wide-coverage aerial views, which are crucial for accurate multi-view labeling and cross-view association. The camera geometry and intrinsics in the dataset generation script specify a focal length of 35 mm, a sensor width of 32 mm, and a resolution of pixels. The intrinsic matrix is computed from these parameters, with the principal point located at the image center. Annotations are generated automatically. Specifically, each 3D human model is projected into every camera view to produce a per-instance mask. The ground-truth bounding box is then derived directly from the mask. Finally, the training and testing sets are created using different combinations of models and backgrounds, with a 3:1 train/test split.
The resulting dataset provides diverse and fully annotated aerial–ground observations, enabling the development and assessment of methods capable of localizing and associating multiple individuals across heterogeneous viewpoints, even in the presence of significant occlusion and appearance variation. It also serves as a benchmark for evaluating multi-view detection and labeling algorithms under conditions representative of practical aerial-vision applications. The examples for the AGMV dataset are provided in Figure 2.

Figure 2.
Examples from the AGMV dataset. From left to right: aerial view 1, aerial view 2, ground view 1, ground view 2, ground view 3, and ground view 4. These examples illustrate the viewpoint and appearance variations between aerial and ground-level cameras, demonstrating the challenges in multi-view human understanding.
3.2. Graph-Based Aerial–Ground Multi-View Association Framework
Building on the proposed AGMV dataset, we establish a novel framework for aerial–ground multi-view labeling task, consisting of an aerial-guided people-number estimation module, a graph construction model and a multi-view identity-assignment module based on post-processing steps. The illustration of the architecture is shown in Figure 3.
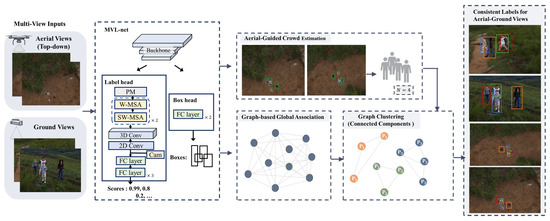
Figure 3.
The architecture for the proposed method. It consists of an MVL-net for pairwise image detection and matching confidence score prediction, an aerial-view-guided crowd-number estimation module, a graph construction component, and the following post-process steps for label assignment.
3.2.1. Aerial-View-Guided People-Number Estimation
Based on the multi-view inputs, we first employ the multi-view labeling network (MVL-net) [37] to obtain person detections for each image, together with the pairwise matching confidence across different views. For each aerial view and ground view , we extract the corresponding images and and obtain their detection sets and . We denote by and the number of detected persons in the aerial and ground images, respectively.
The two aerial views, captured by drone-simulated cameras, provide a global and largely occlusion-free observation of the entire scene. This top-down perspective ensures significantly more complete coverage compared with the ground views, which inherently suffer from occlusions, viewpoint limitations, and background clutter. By leveraging the superior visibility of the aerial views, we aim to obtain a reliable estimate of the number of people in the scene, which later serves as an important global constraint for identity association. Ideally, if all persons are fully visible in both aerial views, the two aerial detectors should yield identical counts. However, detection failures may still occur, leading to inconsistent estimates between and .
To address this, we incorporate ground-view detections as complementary detection. Although ground views may contain more severe occlusions, they can still provide additional information. The strategy is therefore defined as follows. If the two aerial detectors produce the same count, we directly adopt this value as the final estimate. Otherwise, we aggregate all aerial and ground-view estimates and select the largest count among them. Formally,
where indexes the aerial views and indexes the ground views.
This aerial-view-guided people-number estimation strategy effectively combines the strong global visibility of aerial views with the complementary ground-level observations, enabling a more stable estimate of the number of people in the scene. The final estimate N is subsequently used as a global constraint during the identity-assignment and post-matching refinement stages, ensuring consistency across the multi-view association pipeline.
3.2.2. Graph Construction
Based on the detection sets produced by MVL-net, we construct an undirected graph that encodes all cross-view association candidates. For each view or , we denote the corresponding detection set by or , and let
be the collection of all detections. Each node corresponds to a specific detection from one of the views, where x indexes a particular or .
For two detections and originating from different views (), the matching network predicts a cross-view similarity score:
These scores populate the affinity matrix S, defining the weights of the cross-view edges:
Accordingly, edges are instantiated exclusively across detections observed in distinct views, and their weights encode the learned confidence of potential cross-view matches. This graph provides a unified representation of multi-view detection relationships and serves as the foundation for the subsequent identity-assignment stage.
3.2.3. Multi-View Identity Assignment
Based on the constructed graph, we then formulate multi-view identity assignment as a graph-partitioning problem on the affinity-weighted graph . Each node represents a detection, and each edge from two nodes are weighted by the matching confidence score. In this work, we attempt to obtain identity labels by maximizing
To achieve this, we apply a structured post-processing procedure to remove invalid associations, enforce scene-level constraints, and promote practical cycle consistency through algorithmic edge pruning. The post-process contains the following four steps:
- Step 1:
- Similarity-Threshold Pruning.
In this step, we first remove the edges with low-confidence scores with a fixed threshold to satisfy the minimum similarity requirement:
Following this rule, the edges with weights lower than the threshold will be removed.
- Step 2:
- View-Consistency Refinement.
As the node represents a detection in one view, it can at most connect to nodes, where denotes the total number of views. Therefore, we use view consistency to constrain the node degree:
where denotes the number of edges for node . For any node with degree exceeding the limit, we iteratively remove low-confidence edges connected to the node, with a bridge-aware rule to minimize connectivity disruption, until the degree constraint is satisfied.
- Step 3:
- View-Unique Enforcement.
Furthermore, for each identity cluster, it should contain at most one detection for each view. For a cluster , we denote as the view index of node . Then the view-uniqueness constraint can be represented as:
If a cluster contains multiple detections from the same view, we consider intra-cluster edges as edges whose endpoints lie in the same component, and remove the lowest-affinity edge implicated in the conflict, repeating until each cluster has at most one detection per view.
- Step 4:
- Cluster-Count Regulation.
As we have obtained the number of people in each scene from the aerial-view-guided people estimation module, we use it as the constraint for the number of clusters. Let the set of all clusters be denoted by . The constraint is:
where N represents the estimated number of people. When , we iteratively merge the most similar pair of camera-disjoint clusters and , with similarity measured as
We adopt max-link similarity, since the learned pairwise scores may be sparse while remaining highly reliable; average/complete linkage exhibits a stronger under-merging tendency under occlusion. To reduce chaining, we enforce camera-disjoint merging and a minimum similarity threshold .
Following the four steps, we can then obtain the identified clusters. Each cluster represents a person’s identity, containing detections across multiple views. The multi-view identity assignment is thus achieved.
4. Results
4.1. Experimental Setup
Dataset: To comprehensively evaluate the performance of aerial–ground multi-view multi-person labeling, we establish a new large-scale dataset comprising hundreds of scenes, which is detailed in Table 1. Both the training and testing sets contain independent scenes captured by two aerial views and four ground-level views, in which a total of 400 training and 100 testing scenarios are generated. In the testing set, each scene includes 4, 6, 8, or 10 individuals, with 25 scenes for each configuration. This design provides a thorough assessment of system performance under varying levels of crowd density.

Table 1.
Details for the proposed ground–aerial multi-view labeling dataset.
Metric: To quantitatively evaluate multi-view labeling performance, we adopt the widely accepted precision and recall metrics computed over pairwise image associations. Precision measures the proportion of correctly matched cross-view correspondences among all predicted matches, whereas recall reflects the proportion of true correspondences that are successfully identified. For each unordered camera pair, metrics are computed over GT identities. A GT identity is included if it appears in at least one camera. If it appears in both cameras, it is correct only when the same predicted identity matches it in both views; if it appears in only one camera, it is correct only when a predicted identity matches it exclusively in that view. Each predicted identity is counted at most once to prevent duplicates. These metrics provide a complete assessment for both the accuracy and completeness of the labeling baselines.
Compared method: To evaluate the effectiveness of our multi-view labeling framework, we compare it against existing state-of-the-art baselines. More specifically, we include three advanced person re-identification methods—BDB [22], RGA [23], and AGW [24]—as well as the recent person-search method COAT [25], which emphasizes learning discriminative cross-view feature representations. We also compare our method against MVL-net [37], which is a robust pairwise multi-view labeling approach that explicitly exploits geometric relations between camera views.
For all comparison methods, we adopt a unified evaluation protocol. Specifically, we evaluate three association strategies: (1) sequential identity association across adjacent camera views to produce complete multi-view labeling results; (2) joint identity association via clustering across all camera views; and (3) pairwise Hungarian assignment for all camera pairs followed by clustering over all camera views. This standardization ensures fair comparison by holding the matching procedure consistent across all baselines.
Implementation details: Unless otherwise specified, we adopt MVL-net as the default backbone for initial pairwise matching. The minimum confidence threshold for establishing a valid match is empirically set to 0.1, and all experiments assume the same six-camera configuration as employed in the dataset. For other implementation details, we follow the de facto settings in multi-camera association, to ensure reproducibility and fairness across all evaluating baselines.
4.2. Results on the AGMV Dataset
In this section, we present a comprehensive evaluation of the proposed method’s multi-view labeling performance, comparing it with several recent methods under different association strategies to ensure fairness. The quantitative results are reported in Table 2. The S represents the sequential association, C represents the clustering association, and H represents the hungarian algorithm with clustering association. As shown in the table, the proposed method consistently achieves superior performance across all levels of crowdedness in terms of both precision and recall. Specifically, for scenes containing four individuals, our approach attains precision and recall, exceeding the second-best MVL-net + S method by margins of and , respectively. When the number of individuals increases to ten, this performance advantage becomes even more pronounced, with improvements of and in precision and recall. These findings substantiate the effectiveness of the proposed method for the aerial–ground multi-view labeling task and further demonstrate its robustness. Notably, the proposed method exhibits the smallest performance degradation when the number of individuals increases from 4 to 10.
Table 2.
Quantitative results for two aerial and four ground views on the synthetic dataset with 4, 6, 8, and 10 people.
Figure 4 presents qualitative results for aerial–ground multi-view multi-person labeling across diverse backgrounds. In the figure, each individual is assigned a consistent color across both aerial and ground views. As illustrated, the proposed method successfully and reliably labels multiple individuals under substantial viewpoint variations, including the challenging appearance discrepancies between aerial and ground perspectives. Moreover, the method remains well-aligned with drone imagery, even when individuals captured from top-down views appear small. In addition, we further illustrated the qualitative result on all the methods for comparison in Figure 5. From the figure, we can see that the re-ID method achieves good performance on the ground-level view, but fails to explore the aerial views. This may explain the failure of labeling in the sense that these methods for discriminative learning are focusing on the method.

Figure 4.
Qualitative result on the four scenes from the ground–aerial multi-view dataset. The same people are identified with the same color. From top to bottom is aerial view1, aerial view2, ground view1, ground view2, ground view3 and ground view4.

Figure 5.
Qualitative results on the BDB, RGA, AGW, COAT, MVL-net and proposed method. The same people are identified with the same colors.
4.3. Ablation Study
To further analyse the effectiveness of each component in the proposed method, we conduct an ablation study on the proposed AGMV dataset in Table 3. In the ablation study, we denote the similarity-threshold pruning constraint as Component A (Step 1), the view-consistency constraint as Component B (Step 2), the view-uniqueness constraint as Component C (Step 3), and the estimated people-number constraint as Component D (Step 4). From Table 3, we can see that the use of component C dramatically increases the performance, from and in A+B to and in A+B+C for precision and recall, respectively, on the crowdedness of 10 people. Further, with the integration of component D, the precision and recall obtain additional gain on all the crowdedness. We can also observe that the sequence of adding different components will affect the extent of performance. It may cause saturation if increasing the performance. As the result shows in A+C+D and A+B+C+D, limited improvement has been found. On the contrary, the improvement is significant when adding the B component from A+D to A+B+D. Furthermore, the full model achieves the best performance among all the crowdedness.
Table 3.
Ablation study on the AGMV dataset.
5. Discussion
5.1. Influence of the Parameters for Different Components
In the ablation study, we validate the effectiveness of each constraint used in the proposed method. To further analyze the performance of each component and explore the impact of the hyperparameters of these constraints, additional experiments are conducted for detailed discussion.
First, we conduct the experiment on component A to investigate the impact of different values of similarity threshold . The averaged results for all the crowdedness are reported in Table 4. From Table 4, we can observe that the value of the similarity threshold has a slight impact on the labeling performance. The performance improves with increasing from to . Then it decreases when the increases to . Therefore, the best labeling performance is achieved when the similarity threshold is set to .
Table 4.
Results for different values of similarity threshold.
Then, in Table 5, we discuss the impact of the minimum similarity threshold for the edge merging constraint on the averaged results of all the crowdedness. From the table, we can see that the performance shows a decreasing trend when increases from to . When the equals 0.1, we obtain the best labeling performance with and for precision and recall, respectively. The results decrease by and for precision and recall, respectively, when the rises to . It shows that a low minimum similarity threshold allows the proposed method to achieve better performance.
Table 5.
Result for different values of minimum similarity threshold in edge merging.
5.2. Analysis of Various Combinations of Camera Views
To comprehensively evaluate the aerial–ground multi-view labeling performance and provide a comprehensive analysis based on the various combinations of aerial and ground views, we evaluate the multi-view labeling performance under different camera combinations. The results are reported in Table 6. From Table 6, we can see that the proposed method achieves superior aerial–ground multi-view labeling performance on the various combinations of camera views. It validates the robustness of the proposed method on different scenarios. With the crowdedness of 10 people in the scene, the results show that the labeling performance decreases when the number of aerial cameras increases from 1 to 2. For example, the precision and recall decrease by and , from 4G+1A to 4G+2A. This may be due to the limited appearance that can be observed from the aerial view, thus leading to the difficulty in matching across aerial views. In addition, when the ground views increase, the performance has a slight variation. For the crowdedness of 8 people, it has only a slight difference from 3G+2A to 4G+2A, with a decrease of and for precision and recall, respectively. In addition, we show a failure case in Figure 6, which includes one aerial view and three ground views. This example illustrates that when missed detections and appearance ambiguity occur, the association performance degrades.
Table 6.
Multi-view labeling performance on the AGMV dataset under various combinations of aerial (A) and ground (G) views.

Figure 6.
Failure case. The blue arrow indicates a missed detection, and the red arrows indicate incorrect associations caused by appearance ambiguity.
5.3. Analysis of People-Number Estimation
The estimated people number N provides a scene-level prior in our framework and is used to regulate the clustering process via the maximum-cluster constraint. We first quantify the counting accuracy using the mean absolute error (MAE) and mean absolute percentage error (MAPE). As reported in Table 7, the proposed estimator achieves consistently low errors for moderately crowded scenes (4/6/8 people), with MAE ≤ 0.28 and MAPE ≤ 3.50%. When the crowd size increases to 10, the error rises substantially (MAE = 1.08 and MAPE = 10.80%), indicating that dense scenes exacerbate occlusion and cross-view ambiguity, thereby making accurate people-count estimation more challenging.
Table 7.
MAE and MAPE results across different numbers of people.
We further evaluate the robustness of the downstream association to count perturbations by adjusting the estimated number with an offset and reporting the resulting precision and recall under (Figure 7). A notable observation is that mild under-estimation (Est−1 and Est−2) yields virtually identical performance to the unperturbed estimate across all crowd sizes. For instance, for the 8-people setting, Est, Est−1, and Est−2 all achieve the same precision and recall. This insensitivity is primarily attributed to the conservative clustering design: cluster merging is strictly constrained by camera uniqueness (i.e., clusters sharing the same camera are prohibited from merging), and is further gated by a similarity threshold to prevent over-merging. Consequently, once no admissible high-confidence merge exists, the clustering process terminates, rendering the final associations stable under moderate under-estimation of N.
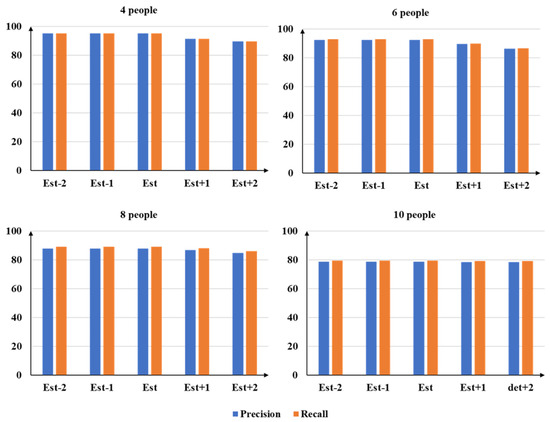
Figure 7.
Results under offsets of the estimated number of people (Est, Est±1, Est±2) for scenes with 4, 6, 8, and 10 people.
In contrast, over-estimation (Est+1 and Est+2) consistently degrades performance, with both precision and recall decreasing as increases. For example, in the 6-people setting, precision drops from to and further to as increases from 0 to 2. This trend is expected because a larger N relaxes the maximum-cluster constraint, leading to fewer enforced merges and thus more fragmented cross-view identities (i.e., over-clustering). Moreover, when the allowed cluster count exceeds the maximum number of reliably detectable identities across views, some clusters cannot be consolidated into valid multi-view associations, further amplifying fragmentation and reducing both precision and recall. Overall, these results suggest that the proposed framework is more tolerant to mild under-estimation than over-estimation, and that enforcing a conservative upper bound on the cluster count is critical for preventing identity fragmentation in dense scenarios.
5.4. Future Work
In this paper, we use a novel framework to solve the multiple-people association problem across aerial–ground multi-view images. With the deployment of cameras, the understanding of multi-camera scene and accurate detection and association are essential and popular for many applications, such as action recognition, 3D human reconstruction, 3D human pose estimation, etc. Future efforts will focus on advancing aerial–ground multi-view association along with several key technical directions. One promising direction is to combine the association task with action recognition. Based on multi-view association, it is beneficial to achieve aerial–ground action recognition for multiple people. Furthermore, the action consistency can provide extra cues for improved association performance. Another direction is to integrate with multi-modal cues, e.g., temporal cues and semantic attributes. In this way, the association can be extended to a broader area for aerial–ground multi-view tracking. Furthermore, an important next step is to evaluate and adapt the proposed framework on real-world aerial–ground datasets, including efforts toward building real aerial–ground benchmarks with synchronized multi-view observations and reliable identity annotations, in order to assess generalization and practical robustness.
6. Conclusions
In this paper, we have addressed the limitations of existing multi-view labeling task, particularly the scarcity of datasets that jointly include aerial and ground-level viewpoints. By simulating a ground–aerial camera system that effectively captured drone perspectives, we introduced the first large-scale synthetic dataset designed for aerial–ground multi-view multi-person association. Building upon this dataset, we have introduced a complete framework that integrated an aerial-view-guided people-number estimation module, a transformer-based cross-view similarity prediction network, and a graph-based model to ensure robust and globally consistent associations across views. Constraint-based heuristics are applied to infer person identities from the graph model. Extensive experiments on the synthetic dataset show that our approach achieves superior multi-view labeling performance against diverse baselines across a range of crowd densities, supporting its effectiveness and robustness under the evaluated setting. Evaluation on real-world aerial–ground datasets is a promising next step to further assess generalization and practical robustness.
Limitations. A primary limitation is the reliance on a synthetic training/testing benchmark, which may introduce a domain gap relative to real aerial–ground deployments (e.g., differences in rendering realism, background statistics, and sensor/illumination effects). In addition, the framework’s global consistency depends on detection quality and on the count-estimation heuristic (e.g., resolving aerial-view disagreement by selecting the maximum count across views), which may make the final association sensitive to missed/false detections and counting errors that propagate into downstream identity assignment.
Author Contributions
Conceptualization, Y.Z. and M.X.; methodology, Y.Z.; validation, Y.Z. and L.J.; formal analysis, Y.Z.; investigation, Y.Z.; resources, L.J.; data curation, Y.Z.; writing—original draft preparation, Y.Z. and L.J.; writing—review and editing, Y.Z., L.J. and M.X.; visualization, Y.Z.; supervision, M.X.; project administration, M.X.; funding acquisition, L.J. and M.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (62231002 and 62401027).
Data Availability Statement
The AGMV dataset is publicly available at https://github.com/yz-mvcv/AGMV-dataset/ (accessed on 1 September 2025). The implementation code is available upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hong, J.G.; Noh, S.Y.; Lee, H.K.; Cheong, W.S.; Chang, J.Y. 3d clothed human reconstruction from sparse multi-view images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2024; pp. 677–687. [Google Scholar]
- Liang, J.; Lin, M.C. Shape-aware human pose and shape reconstruction using multi-view images. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: Piscataway, NJ, USA, 2019; pp. 4352–4362. [Google Scholar]
- Holte, M.B.; Moeslund, T.B.; Nikolaidis, N.; Pitas, I. 3D human action recognition for multi-view camera systems. In Proceedings of the 2011 International Conference on 3D Imaging, Modeling, Processing, Visualization and Transmission; IEEE: Piscataway, NJ, USA, 2011; pp. 342–349. [Google Scholar]
- Yu, Z.; Zhang, L.; Xu, Y.; Tang, C.; Tran, L.; Keskin, C.; Park, H.S. Multiview human body reconstruction from uncalibrated cameras. Adv. Neural Inf. Process. Syst. 2022, 35, 7879–7891. [Google Scholar]
- Baltieri, D.; Vezzani, R.; Cucchiara, R.; Utasi, A.; Benedek, C.; Szirányi, T. Multi-view people surveillance using 3D information. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops); IEEE: Piscataway, NJ, USA, 2011; pp. 1817–1824. [Google Scholar]
- Shang, L.; Min, C.; Wang, J.; Xiao, L.; Zhao, D.; Nie, Y. Aerial-Ground Cross-View Vehicle Re-Identification: A Benchmark Dataset and Baseline. Remote Sens. 2025, 17, 2653. [Google Scholar] [CrossRef]
- Shen, B.; Zhang, R.; Chen, H. An adaptively attention-driven cascade part-based graph embedding framework for UAV object re-identification. Remote Sens. 2022, 14, 1436. [Google Scholar] [CrossRef]
- Xie, S.; Zhang, L.; Jeon, G.; Yang, X. Remote sensing neural radiance fields for multi-view satellite photogrammetry. Remote Sens. 2023, 15, 3808. [Google Scholar] [CrossRef]
- Luo, H.; Zhang, J.; Liu, X.; Zhang, L.; Liu, J. Large-scale 3d reconstruction from multi-view imagery: A comprehensive review. Remote Sens. 2024, 16, 773. [Google Scholar] [CrossRef]
- Zhou, W.; Shi, Y.; Huang, X. Multi-view scene classification based on feature integration and evidence decision fusion. Remote Sens. 2024, 16, 738. [Google Scholar] [CrossRef]
- Shao, Z.; Yang, N.; Xiao, X.; Zhang, L.; Peng, Z. A multi-view dense point cloud generation algorithm based on low-altitude remote sensing images. Remote Sens. 2016, 8, 381. [Google Scholar] [CrossRef]
- Abbas, Y.; Jalal, A. Drone-based human action recognition for surveillance: A multi-feature approach. In Proceedings of the 2024 International Conference on Engineering & Computing Technologies (ICECT); IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Tariq, R.; Rahim, M.; Aslam, N.; Bawany, N.; Faseeha, U. Dronaid: A smart human detection drone for rescue. In Proceedings of the 2018 15th International Conference on Smart Cities: Improving Quality of Life Using ICT & IoT (HONET-ICT); IEEE: Piscataway, NJ, USA, 2018; pp. 33–37. [Google Scholar]
- Fleuret, F.; Berclaz, J.; Lengagne, R.; Fua, P. Multicamera people tracking with a probabilistic occupancy map. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 267–282. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Hu, M.; Zhou, X.; Tan, T.; Lou, J.; Maybank, S. Principal axis-based correspondence between multiple cameras for people tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 663–671. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Caliskan, A.; Hilton, A.; Guillemaut, J.Y. A Novel Multi-View Labelling Network Based on Pairwise Learning. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP); IEEE: Piscataway, NJ, USA, 2021; pp. 3682–3686. [Google Scholar]
- Luna, E.; SanMiguel, J.C.; Martínez, J.M.; Carballeira, P. Graph neural networks for cross-camera data association. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 589–601. [Google Scholar] [CrossRef]
- Ning, E.; Wang, C.; Zhang, H.; Ning, X.; Tiwari, P. Occluded person re-identification with deep learning: A survey and perspectives. Expert Syst. Appl. 2024, 239, 122419. [Google Scholar] [CrossRef]
- Dai, Y.; Liu, J.; Sun, Y.; Tong, Z.; Zhang, C.; Duan, L.Y. Idm: An intermediate domain module for domain adaptive person re-id. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: Piscataway, NJ, USA, 2021; pp. 11864–11874. [Google Scholar]
- Li, Y.; He, J.; Zhang, T.; Liu, X.; Zhang, Y.; Wu, F. Diverse part discovery: Occluded person re-identification with part-aware transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2021; pp. 2898–2907. [Google Scholar]
- Zhang, G.; Zheng, C.; Ye, Z. Transformer-based feature compensation network for aerial photography person and ground object recognition. Remote Sens. 2024, 16, 268. [Google Scholar] [CrossRef]
- Dai, Z.; Chen, M.; Gu, X.; Zhu, S.; Tan, P. Batch DropBlock network for person re-identification and beyond. In Proceedings of the IEEE International Conference on Computer Vision; IEEE: Piscataway, NJ, USA, 2019; pp. 3691–3701. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-Aware Global Attention for Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C.H. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Yu, R.; Du, D.; LaLonde, R.; Davila, D.; Funk, C.; Hoogs, A.; Clipp, B. Cascade Transformers for End-to-End Person Search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2022; pp. 7267–7276. [Google Scholar]
- Lee, S.; Oh, Y.; Baek, D.; Lee, J.; Ham, B. OIMNet++: Prototypical Normalization and Localization-Aware Learning for Person Search. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 621–637. [Google Scholar]
- Liu, J.; Zha, Z.J.; Hong, R.; Wang, M.; Zhang, Y. Deep adversarial graph attention convolution network for text-based person search. In Proceedings of the 27th ACM International Conference on Multimedia; Association for Computing Machinery: New York, NY, USA, 2019; pp. 665–673. [Google Scholar]
- Nguyen, H.; Nguyen, K.; Sridharan, S.; Fookes, C. AG-ReID. v2: Bridging aerial and ground views for person re-identification. IEEE Trans. Inf. Forensics Secur. 2024, 19, 2896–2908. [Google Scholar] [CrossRef]
- Nguyen, H.; Nguyen, K.; Sridharan, S.; Fookes, C. Aerial-ground person re-id. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME); IEEE: Piscataway, NJ, USA, 2023; pp. 2585–2590. [Google Scholar]
- Zhang, G.; Wang, Z.; Zhang, J.; Luo, Z.; Zhao, Z. Multi-scale image-and feature-level alignment for cross-resolution person re-identification. Remote Sens. 2024, 16, 278. [Google Scholar] [CrossRef]
- Grigorev, A.; Liu, S.; Tian, Z.; Xiong, J.; Rho, S.; Feng, J. Delving deeper in drone-based person re-id by employing deep decision forest and attributes fusion. ACM Trans. Multimed. Comput. Commun. Appl. (Tomm) 2020, 16, 1–15. [Google Scholar] [CrossRef]
- Zhang, G.; Li, J.; Ye, Z. Unsupervised Joint Contrastive Learning for Aerial Person Re-Identification and Remote Sensing Image Classification. Remote Sens. 2024, 16, 422. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, W.; Yan, Y.; Ge, B.; Hou, W.; Gao, F. A Re-Identification Framework for Visible and Thermal-Infrared Aerial Remote Sensing Images with Large Differences of Elevation Angles. Remote Sens. 2025, 17, 1956. [Google Scholar]
- Xu, Y.; Liu, X.; Liu, Y.; Zhu, S.C. Multi-view people tracking via hierarchical trajectory composition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2016; pp. 4256–4265. [Google Scholar]
- Gan, Y.; Han, R.; Yin, L.; Feng, W.; Wang, S. Self-supervised multi-view multi-human association and tracking. In Proceedings of the 29th ACM International Conference on Multimedia; Association for Computing Machinery: New York, NY, USA, 2021; pp. 282–290. [Google Scholar]
- Chen, H.; Guo, P.; Li, P.; Lee, G.H.; Chirikjian, G. Multi-person 3d pose estimation in crowded scenes based on multi-view geometry. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 541–557. [Google Scholar]
- Zhang, Y.; Caliskan, A.; Xu, M.; Hilton, A.; Guillemaut, J.Y. MVL-Net: Pairwise Learning for Multi-View Multiple People Labelling. IEEE Trans. Multimed. 2025, 27, 4736–4751. [Google Scholar] [CrossRef]
- Chen, K.; Srivastav, V.; Mutter, D.; Padoy, N. Learning from Synchronization: Self-Supervised Uncalibrated Multi-View Person Association in Challenging Scenes. In Proceedings of the Computer Vision and Pattern Recognition Conference; IEEE: Piscataway, NJ, USA, 2025; pp. 24419–24428. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.