Highlights
What are the main findings?
- We propose an innovative asymmetric dual encoder architecture for cloud detection in remote sensing images, where spectral bands are grouped into RGB visible light bands and infrared/atmospheric correction bands processed independently to enhance detection accuracy.
- We introduce a multi-scale cloud feature module, the Optical Characteristics-Guided Multi-Scale Cloud Feature Module (OCGMSCFM), leveraging the Dynamic HOT Index and Full-Band Cloud Index to improve cloud feature representation.
What are the implications of the main findings?
- The dual encoder structure significantly improves the model’s ability to handle different spectral bands independently, enhancing cloud detection performance in complex imagery.
- Our method, which integrates a feature aggregation and filtering module with multi-interaction spatial and channel attention, results in improved cloud identification and noise suppression, leading to more accurate cloud masking in remote sensing applications.
Abstract
The rapid development of remote sensing satellite technology has enabled remote sensing images to be widely used in agriculture, meteorology, environmental monitoring and other fields. However, the presence of clouds in these images can lead to blurred and incomplete observations of the Earth’s surface, limiting the quality and applicability of the data. Current cloud detection networks usually adopt a single encoder–decoder structure that uniformly processes all spectral features without distinguishing between various spectral bands. To overcome this limitation, this paper proposes an Optical characteristics-guided Asymmetric Dual Encoder Feature Fusion cloud detection algorithm (OADEF2). The algorithm adopts an asymmetric dual encoder framework to divide the spectral bands of Sentinel-2A into two groups: RGB visible light bands and infrared/atmospheric correction bands, which are subsequently input into two different encoder branches. This method utilizes the unique physical characteristics of different spectral bands to improve the accuracy of cloud detection. In order to direct the focus of the network to cloud-related optical characteristics, an Optical characteristics-guided Multi-Scale cloud feature module (OCGMSCFM) based on Dynamic HOT Index and Full-Band Cloud Index is introduced. This module effectively solves the problem of insufficient representation of cloud features. In order to improve the efficiency of feature fusion, a Feature Aggregation and Filtering module (FAFM) is proposed. This module uses aggregation and techniques to filter basic features, thereby improving the accuracy of cloud detection. In order to overcome the limitations of feature modeling, a dual attention module that fuses Multi-interaction Local Spatial Attention mixed Channel Attention (MILSAMCAM) is added to the decoder. The experimental results validated the effectiveness of this algorithm in cloud detection tasks, achieving an F1-score of 97.30% on the S2-CMC dataset.
1. Introduction
Remote sensing satellite technology encompasses the deployment of sensor devices on satellite platforms to facilitate the observation of the Earth from beyond its terrestrial and atmospheric layers. This technology enables the collection of various parameters, including images, temperature, and humidity, pertaining to the Earth’s surface and atmosphere. The primary data derived from remote sensing satellite technology consists of remote sensing satellite images, which are integral to numerous domains, including agricultural production, urban planning, and disaster management.
However, the majority of remote sensing satellites are equipped with optical sensors, which are susceptible to atmospheric conditions during image acquisition. Specifically, these sensors are unable to penetrate cloud cover, leading to significant cloud interference in remote sensing images and resulting in the loss of critical ground information. Consequently, cloud obscuration in remote sensing imagery has emerged as a significant factor that constrains the effective application of this technology. As remote sensing technology continues to advance and the demand for its applications escalates, the need for precise cloud detection in remote sensing images has become increasingly urgent.
Despite the critical importance of cloud detection, achieving high-precision segmentation remains a formidable challenge due to the complex and dynamic nature of atmospheric conditions. Clouds in remote sensing images exhibit extreme variability in shape, thickness, and texture, ranging from large, opaque cumulus clouds to thin, semi-transparent cirrus clouds. Thin clouds, in particular, pose a significant difficulty as they partially transmit signals from ground features, resulting in mixed spectral responses that confuse traditional classifiers. Furthermore, the phenomenon of “spectral mimicry” presents another major obstacle; certain ground objects, such as snow, ice, and bright urban surfaces (e.g., white rooftops or concrete), share similar high-reflectance characteristics with clouds in the visible spectrum. In traditional spectral analysis, these objects often occupy the same feature space as clouds, leading to a high rate of false positives. Additionally, the presence of fragmented clouds and cloud shadows further complicates the scene, necessitating algorithms that can understand global context rather than relying solely on local pixel statistics. These challenges underscore the need for advanced methods capable of leveraging both spectral and spatial information effectively.
Cloud detection algorithms for remote sensing imagery can be classified into two primary categories based on their detection principles: traditional cloud detection methods and those utilizing deep learning techniques. Historically, traditional methods predominantly relied on thresholding and texture feature analysis. However, recent advancements in deep learning have significantly enhanced image processing capabilities, offering innovative approaches for cloud detection in remote sensing imagery.
1.1. Traditional Algorithms
Traditional cloud detection techniques differentiate between cloud and non-cloud entities based on their visual and imaging characteristics. These methods can be further subdivided into spectral threshold-based approaches and classical machine learning techniques.
Among them, the method based on spectral threshold is used to distinguish cloud pixels and non-cloud pixels by analyzing the spectral characteristics of clouds and other ground objects in remote sensing images and setting thresholds in each spectral band. In 1994, keglelmeyer et al. proposed using a single threshold to distinguish thin clouds, thick clouds and background in remote sensing images [1]. In 2000, Irish et al. proposed an automatic cloud amount estimation method for landsats-7 remote sensing data [2]. The most representative spectral thresholding algorithm is the Function of Mask (FMask) [3], originally proposed for Landsat imagery. The core principle of FMask is based on physical laws: it identifies potential cloud pixels by leveraging their high reflectance in the visible spectrum and low brightness temperature in the thermal infrared bands. To distinguish clouds from bright surfaces like snow and ice, FMask incorporates the Normalized Difference Snow Index (NDSI) and the whiteness index. Subsequent iterations addressed the limitations of fixed thresholds. Zhu et al. [4] extended FMask to Sentinel-2 data by utilizing the cirrus band for high-altitude cloud detection. Furthermore, FMask 4.0 [5] introduced the integration of auxiliary data, such as Digital Elevation Models (DEM), to correct for topographic shadows and improve the separation between cloud shadows and water bodies. Despite these methodological improvements, traditional algorithms remain fundamentally constrained by their reliance on hand-crafted features and statistical thresholds. While effective in simple scenarios, these rigid rules lack the semantic abstraction capability to handle complex surface textures (e.g., bright urban rooftops or salt pans) that spectrally mimic clouds, necessitating the data-driven approach offered by deep learning.
Classical machine learning methods have advanced cloud detection by replacing rigid thresholds with non-linear classifiers that learn from extracted features. These methods typically follow a ‘feature engineering plus classification’ paradigm. Fu et al. [6] proposed an ensemble approach that combines physical thresholding with the Random Forest (RF) algorithm to improve decision stability. Building on this, Wei et al. [7] enhanced the RF model by integrating a priori pixel databases and spectral indices as input vectors, effectively incorporating statistical priors into the learning process.
To address the specific challenge of distinguishing clouds from bright surfaces, Chen et al. [8] exploited the textural differences between clouds and ice/snow, employing Support Vector Machines (SVM) to find the optimal separating hyperplane in the texture feature space. Furthermore, Kang et al. [9] introduced a coarse-to-fine detection strategy that leverages complex feature transformations, including color space conversion, dark channel estimation, and Gabor filtering, to capture multi-dimensional cloud characteristics. Similarly, Sui et al. [10] utilized Simple Linear Iterative Clustering (SLIC) to group pixels into superpixels, enforcing local spatial consistency before classification.
While these methods offer better robustness than simple thresholding, they fundamentally rely on hand-crafted features (e.g., specific texture descriptors or geometric patterns). The design of such features requires extensive domain expertise and often lacks the adaptive generalization capability to handle the infinite variability in global remote sensing scenes, a limitation that motivates the transition to deep learning approaches.
1.2. Deep Learning Algorithms
Deep learning methods, especially convolutional neural networks (CNNs), have revolutionized cloud detection by automatically learning complex features from images. Early methods divided images into blocks for classification, but this approach often led to errors when blocks contained both cloud and non-cloud pixels.
In the early cloud detection methods based on deep learning, researchers, based on the idea of image classification, divided remote sensing images into small blocks and identified each image block as either a cloud or a non-cloud. In 2017, Mateo et al. proposed to segment the initial remote sensing image into blocks of different sizes and use convolutional neural networks to complete the classification of each image block [11]. Also in 2017, Xie et al. proposed a multi-level cloud detection method called Sil-CNN, which classifies clouds by improving the simple linear iterative clustering technique [12].
Some studies have implemented pixel-level classification cloud detection based on fully convolutional neural networks (FCN). In 2018, Yan et al. proposed the multi-level feature fusion segmentation network (MFFSNet) [13]. In 2018, Wu et al. proposed the cascaded network method to obtain fine cloud masks through composite image filtering technology [14]. In 2019, Francis et al. proposed CloudFCN, combining the U-Net model with the Inception module to integrate the shallowest and deepest layers of the network [15]. In 2019, Mohajerani et al. proposed Cloud-Net, a fully convolutional network that learns local and global features from scenes in an end-to-end manner [16]. In 2019, scholars such as Dev proposed a lightweight deep learning architecture, CloudSegNet [17]. Also in 2019, scholars such as Wieland proposed a data-driven technology based on the improved U-Net convolutional neural network [18]. Also in 2019, Jeppesen et al. proposed the classical remote sensing network RS-Net based on the U-Net architecture [19]. Still in 2019, Chai et al. proposed an adaptive algorithm for piecewise networks with 13 convolutional layers and 13 deconvolution layers [20]. In 2021, Hu et al. proposed CDUNet, introducing high-frequency feature extractors and multi-scale convolution to refine cloud boundaries and predict fragmented clouds [21]. The method based on fully convolutional neural networks can achieve high-precision detection. However, there is a lack of specialized design for cloud detection tasks, resulting in insufficiently fine segmentation results.
Meanwhile, there are also studies that focus on the preservation and fusion of multi-scale features, aiming to extract the features of clouds from remote sensing images. In 2019, Yang et al. proposed a cloud detection neural network (CDnet) with an encoder–decoder structure, feature pyramid modules and boundary refinement blocks [22]. Also in 2019, scholars such as Li proposed the multi-scale convolutional feature fusion (MSCFF) method [23]. Also in 2019, Shao et al. proposed the multi-scale feature convolutional neural network (MF-CNN) [24]. In 2020, Yu et al. proposed the multi-scale fusion gated network (MFGNet) [25]. In 2021, Wang et al. proposed the cloud detection network ABNet based on full-scale feature fusion [26]. Also in 2021, scholars such as Guo proposed CDNetV2 based on the adaptive feature fusion model. By using the adaptive feature fusion model and advanced semantic information to guide the flow, they further improved the detection of cloud-snow coexisting images [27]. In 2022, scholars such as Wu proposed Boundary Nets [28]. In 2024, Dong et al. proposed a multi-level cloud detection network (MCDNet) based on an integrated dual-perspective change guidance mechanism [29]. Also in 2024, Li et al. introduced the high-resolution cloud detection network (HR cloud Net) [30]. The method of multi-scale feature extraction and fusion improves the accuracy of cloud detection, but at the same time it also leads to an increase in computational complexity and an increase in the memory occupied by the model.
Furthermore, some scholars are dedicated to researching how to improve the performance of cloud detection through various spatial features and module designs. In 2020, Zhang’s team proposed a cloud detection network based on Gabor transformation [31]. In 2021, Wang et al. proposed a dark channel prior cloud detection method based on harr wavelet transform [32]. In 2022, Wang et al. proposed a deep learning cloud detection algorithm based on the attention mechanism and probabilistic upsampling [33]. In 2022, scholars such as He proposed DABNet, which enhances the adaptive modeling ability of the network through a deformable context module [34]. Also in 2022, Wu et al. proposed the cloud detection method CFCA_Net based on cascaded texture and color feature attention [35]. Also in 2022, scholars such as Zhang implemented cloud detection using multi-task-driven and reconfigurable networks (MTDR-Net) [36]. In 2023, Zhang et al. proposed a cloud detection network that combines spectral feature enhancement and spatial spectral feature fusion [37]. In 2023, scholars such as Hu developed the multi-branch convolutional attention network (MCANet) [38]. In 2023, Zhao et al. introduced the boundary-aware bilateral fusion network (BABFNet) to enhance cloud detection in easily confused regions through auxiliary boundary prediction branches [39]. The design of spatial features and modules can enhance the performance of the cloud detection network, but there is still room for exploration in the interpretability of the modules.
Furthermore, some scholars are dedicated to exploring weakly supervised and unsupervised cloud detection methods to reduce the cost of manual annotation. In 2019, Zou et al. proposed a weakly supervised cloud detection method based on the generative adversarial network (GAN) [40]. In 2020, scholars such as Li developed the cloud detection technology based on weakly supervised deep learning [41]. In 2021, Guo et al. proposed an unsupervised domain adaptive cloud detection method based on group feature alignment and entropy minimization strategy [42]. Although weakly supervised and unsupervised methods effectively reduce the annotation cost, their training process often takes more time, and the accuracy of their cloud detection is also lower than that of supervised methods.
Recent advancements focus on multi-scale feature fusion to enhance detection accuracy. Methods like CDnet (2019) [22] and MSCFF (2019) [23] integrate feature pyramids and fusion modules. Attention mechanisms are also incorporated, such as in CFCA_Net (2022) [35] and MTDR-Net (2022) [36], to improve spatial feature extraction. Weakly supervised and unsupervised methods, like GAN-based approaches (2019) [40] and WDCD (2020) [41], aim to reduce labeling costs but often require more training time and may have lower accuracy compared to supervised methods.
Although current deep-learning-based methods, including the advanced CDUNet [21] and MCDNet [29], have achieved remarkable accuracy, they largely adhere to a “uniform processing” paradigm. In this standard workflow, multi-spectral data (comprising Visible, Near-Infrared, and Short-Wave Infrared bands) is simply concatenated into a single multi-channel tensor and fed into a shared encoder. This approach, while computationally convenient, overlooks the fundamental physical heterogeneity of remote sensing data.
Specifically, Visible bands (RGB) are dominated by high-frequency spatial texture and color information, which are critical for delineating the visual boundaries of clouds. In contrast, Infrared (IR) and Atmospheric bands primarily convey physical properties such as temperature, moisture content, and cirrus reflectance, which are essential for identifying cloud types and separating clouds from snow. When a single convolutional branch is forced to process these distinct modalities simultaneously, the network tends to learn a “compromise” representation that may not be optimal for either modality. We define this phenomenon as “Spectral Feature Interference.” For instance, in scenarios where thin clouds are transparent in RGB but distinct in IR, a coupled network may struggle to balance these conflicting signals, leading to missed detections. Consequently, there is a compelling need for a decoupled architecture that can respect the unique statistical and physical characteristics of different spectral groups, extracting texture and physical features independently before fusion.
Existing cloud detection networks generally input all spectral features uniformly into the network, lacking differentiation among features from different spectral bands. In this paper, we propose an Optical characteristics-guided Asymmetric Dual Encoder Feature Fusion cloud detection network (OADEF2). This method aims to address the limitations of undifferentiated spectral processing by incorporating physical priors and adaptive feature fusion. The main contributions of this study are as follows:
- (1)
- To address the lack of distinction among spectral bands, a dual encoder structure is proposed. The spectral bands of Sentinel-2A are divided into two categories: RGB visible light bands and infrared/atmospheric correction bands, which are input into two separate encoder branches. This allows the network to distinguish and independently learn features from different spectral bands, thereby improving cloud detection accuracy. The 13 spectral bands of Sentinel-2A are categorized this way due to their distinct characteristics: visible light bands are suitable for monitoring surface cover, while infrared and atmospheric correction bands are better for detecting surface temperature. Inputting these bands into separate encoder branches helps fully utilize their physical properties to extract richer and more comprehensive features.
- (2)
- To enhance the representation of cloud characteristics, Optical characteristics-guided Multi-Scale cloud feature module (OCGMSCFM) is introduced. This module uses the Dynamic HOT Index to capture the scattering and absorption characteristics of clouds and the Full-Band Cloud Index to reflect the high brightness of clouds. Combined with a multi-scale structure, it deeply extracts cloud optical characteristics, enhancing feature expression and improving detection precision.
- (3)
- To address the issue of low feature fusion efficiency, Feature Aggregation and Filtering module (FAFM) has been proposed. This module effectively fuses features through aggregation operations, selects key features, and disregards redundant features, thereby effectively integrating features that match cloud characteristics. This structure enhances feature utilization and improves cloud detection performance.
- (4)
- To address the limitations of feature modeling, this paper proposes a Multi-Interaction Local Spatial Attention mixed Channel Attention module (MILSAMCAM). Multi-Interaction Local Spatial Attention (MLSA) utilizes depthwise separable convolution and hierarchical fusion to enhance spatial features. Channel Attention (CA) optimizes cross-channel features via global pooling and a learnable bottleneck. Their outputs are fused through 1 × 1 convolution for complementary enhancement. This design improves feature utilization and performance with low computational overhead.
2. Materials and Methods
In this section, OADEF2 was designed. The RGB visible spectral bands of Sentinel-2A and the other 10 spectral bands were input as two channels of features into the dual encoder structure cloud detection network. OCGMSCFM with Dynamic HOT Index and Full Band Cloud Index was designed to focus on the optical characteristics that match the cloud. FAFM is used to merge shallow and deep features from two channels. By independently extracting features from different spectral bands, this method can improve the accuracy of cloud detection.
2.1. Optical Characteristics-Guided Asymmetric Dual Encoder Feature Fusion Cloud Detection Network
In the existing deep-learning-based cloud detection networks, all spectral band information is generally input into the neural network indiscriminately, and a single-path encoder–decoder structure is used, lacking differentiation of spectral band features. There is a lack of specific design tailored to the characteristics of clouds, resulting in insufficiently refined cloud detection results. The feature fusion methods are not efficient enough, leading to the generation of redundant features or the loss of features. To address these issues, this paper designs OADEF2.
The cloud detection network designed in this paper, which is OADEF2, is illustrated in Figure 1. Compared to the existing symmetric single encoding and decoding structures, the entire network employs an asymmetric dual encoding and single decoding structure, incorporating two input features: one input is the RGB visible spectral bands from Sentinel-2A, while the other input consists of the other ten spectral bands from Sentinel-2A, which include seven infrared spectral bands and three atmospheric correction spectral bands. Both sets of equally important features are used as independent inputs to extract features through three convolutional layers, three max pooling layers, and two additional convolutional layers. After each convolution operation, the number of channels is adjusted to four times or twice the original; after each max pooling layer, the width and height of the feature maps are halved.
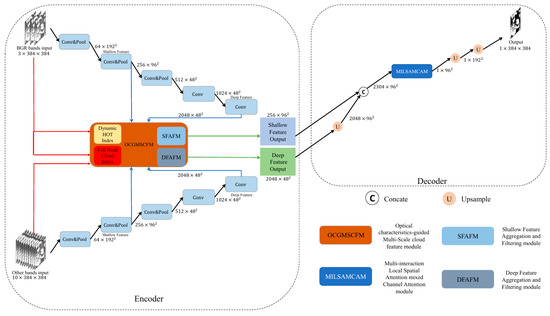
Figure 1.
Optical characteristics-guided Asymmetric Dual Encoder Feature Fusion cloud detection network (OADEF2).
The process can generate five different sizes of feature maps: 64 × 1922, 256 × 962, 512 × 482, 1024 × 482, and 2048 × 482. The feature map sized 256 × 962 is used as shallow features, while the feature map sized 2048 × 482 is used as deep features. The shallow features from the two channels are guided using the Dynamic HOT Index and the Full-Band Cloud Index, and then input into the Shallow Feature Aggregation and Filtering module (SFAFM) for feature fusion. The output size of the fused feature map is 256 × 962. At the same time, the deep features of the two channels are guided into the Deep Feature Aggregation and Filtering module (DFAFM). The size of the fused feature map is 2048 × 482. In the decoder section, the deep feature map is first upsampled to twice its original size using nearest neighbor interpolation, resulting in a size of 2048 × 962. The shallow and deep features are then concatenated, yielding a feature map size of 2304 × 962. This is followed by MILSAMCAM, which focuses on the spatial positional relationships in both horizontal and vertical directions of the feature map and adjusts the number of channels to 1, resulting in a 1 × 962 feature map. Then, use nearest neighbor interpolation to upsample the feature map twice in a row, obtaining a feature map of 1 × 3842. Finally, normalization is performed to obtain the binary cloud label output.
The superiority of the designed network lies in its ability to distinguish the characteristics of different spectral bands, making full use of the physical characteristics of the RGB visible light spectral bands and the infrared and atmospheric correction spectral bands. By independently extracting features from different spectral bands, the accuracy of cloud detection is significantly improved. In addition, the Dynamic HOT Index and Full-Band Cloud Index are introduced as auxiliary branches, see Section 2.2 for details; FAFM is also cited, see Section 2.3 for details, which can more comprehensively represent cloud features. At the same time, MILSAMCAM is introduced as a decoder, see Section 2.4 for details, which accurately locates key areas through multi-scale spatial attention and dynamically selects important feature channels with channel attention to achieve synergistic enhancement in the spatial-channel dimension.
2.2. Optical Characteristics-Guided Multi-Scale Cloud Feature Module
Clouds exhibit distinct physical characteristics in remote sensing images, such as high brightness, white color, low temperature, and high altitude. These characteristics can be quantified using specific indices to enhance cloud detection.
The Haze Optimized Transformation (HOT) Index [43] is a commonly used index in cloud detection, reflecting the optical characteristics of clouds in terms of light scattering and absorption. The traditional HOT Index is calculated as follows:
where and are the reflectance values of the blue and red bands, respectively, and γ is a constant typically set to 0.5.
In this paper, we propose a Dynamic HOT Index, where γ is treated as a learnable parameter within the neural network. This allows the index to adaptively capture the cloud characteristics in Sentinel-2A data, improving the flexibility and accuracy of cloud detection.
The cloud index is the average of the reflectivity values of multiple bands to reflect the high brightness characteristics of clouds. The traditional Landsat imagery cloud index calculation selects 6 bands, which are blue, green, and red bands; one near-infrared band and two short-wave infrared bands.
For Sentinel-2A imagery, we propose Full-Band Cloud Index that utilizes all 13 spectral bands to better capture the overall reflectance characteristics of clouds, the reason for this is that Sentinel-2A’s spectral information covers the spectrum from visible light to near infrared and short-wave infrared. Clouds have high reflectivity in multiple spectral bands, and using Full-Band data can reflect the overall reflectivity, the calculation formula is as follows:
To enhance the representation of cloud features in the network, we introduce OCGMSCFM, as shown in Figure 2. This module integrates the Dynamic HOT Index and Full-Band Cloud Index to guide the network to focus on cloud-relevant features.
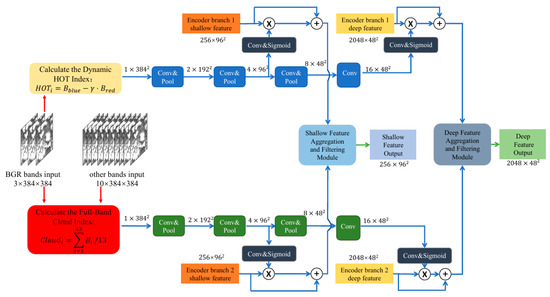
Figure 2.
Optical characteristics-guided Multi-Scale cloud feature module (OCGMSCFM).
For input Sentinel-2A data with 13 spectral bands and size of 384 × 384, we first calculate the Dynamic HOT Index and Full-Band Cloud Index. These indices are then processed through parallel convolutional and max-pooling layers to generate multi-scale feature maps. Specifically, after three rounds of convolution and max-pooling operations, we obtain feature maps of sizes 192 × 192, 96 × 96, and 48 × 48.
To further enhance the cloud feature representation, we use convolutional layers to extract attention weights from the feature map, and then perform Sigmoid normalization. Then, these attention weights are applied to the shallow and deep features from the encoder branch, respectively, twice to guide the network to focus on the optical features related to the cloud, and then enter FAFM, as detailed in Section 2.3. This multi-scale method ensures that the network can capture cloud features at different spatial resolutions, improving the robustness and accuracy of cloud detection.
The advantage of the designed module lies in significantly improving the expression ability of cloud features by mining the optical characteristics of clouds, making the network more focused on feature extraction in cloud regions. In addition, combining multi-scale structures can adapt to cloud features of different scales, improve the robustness of detection, and combine FAFM to select key features and ignore redundant features, effectively integrating features that match cloud features. Therefore, this module helps to more accurately identify cloud regions and reduce misjudgments and missed detections caused by insufficient feature expression.
2.3. Feature Aggregation and Filtering Module
This paper proposes FAFM to address the low efficiency of feature fusion in existing cloud detection networks. This module effectively solves the redundancy problem in multispectral feature fusion through an adaptive aggregation and filtering mechanism. Firstly, Encoder Branch 1 Feature and Encoder Branch 2 Feature are concatenated to form a combined feature map. To eliminate spatial redundancy, the combined features initially pass through a 1 × 1 convolution, followed by parallel average pooling and max pooling layers. This “aggregation operation” effectively compresses spatial details into global channel statistics. Then, to implement the “filtering mechanism,” these statistics are processed through shared fully connected layers and normalized via a Softmax function. A critical step here is the Split operation, which divides the normalized weights into two distinct gating vectors. These vectors are then applied to the original features via element-wise multiplication, which adaptively enhances key discriminative features while suppressing redundant spectral information. Finally, the optimized features from both branches are concatenated and fused through a 1 × 1 convolutional layer to generate the final output. This processing flow enables the module to significantly improve the expression efficiency of features while retaining effective spectral information. This module has dual applications in shallow and deep layers, ensuring that the network can efficiently integrate complementary information from different spectral bands, thereby significantly improving cloud detection performance, as shown in Figure 3.
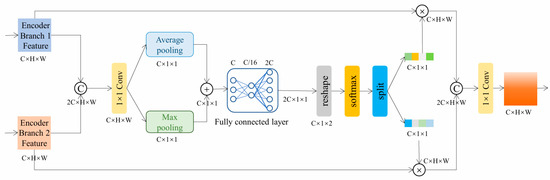
Figure 3.
Feature Aggregation and Filtering module (FAFM).
2.4. Multi-Interaction Local Spatial Attention Mixed Channel Attention Module
Since the decoder structure is simpler than the encoder, the overall network presents an asymmetric design. The module consists of two parts: Multi-interaction Local Spatial Attention (MLSA) and Channel Attention (CA), as shown in Figure 4.
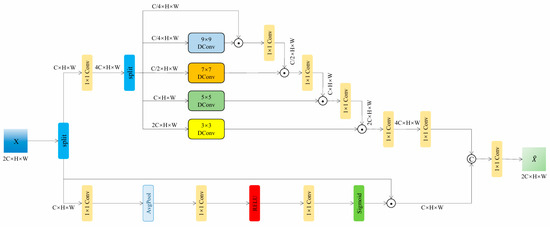
Figure 4.
Multi-interaction Local Spatial Attention mixed Channel Attention module (MILSAMCAM).
The proposed MLSA achieves efficient feature extraction through multi-scale convolutional kernels and dynamic interaction mechanisms. This module uses four different sized convolution kernels (9 × 9, 7 × 7, 5 × 5, and 3 × 3) to capture local features of multiple receptive fields, and uses channel index grouping strategy for feature allocation: the input features are expanded by 1 × 1 convolution to split into a value vector V and four weight vectors (W1~W4), with the channel numbers allocated in a ratio of 1:1:2:4:8. Multi-scale feature interaction is achieved through cascaded matrix multiplication operations, where the number of output feature channels in each stage is doubled, and finally restored to the original number of channels through 1 × 1 convolution. This design ensures efficient extraction of deep abstract features by small convolution kernels while reducing the computational overhead of large convolution kernels through channel allocation strategies, achieving dynamic fusion and optimization of multi-scale features.
CA enhances the representation of key features through an efficient channel feature recalibration mechanism. Firstly, the input feature X (C × H × W) is linearly transformed using a 1 × 1 convolution, and then compressed into a global descriptor vector of C × 1 × 1 through spatial adaptive average pooling. The vector undergoes nonlinear transformation through a bottleneck structure consisting of two 1 × 1 convolutional layers (with ReLU activation in between), and finally generates channel attention weights through the Sigmoid function. By multiplying the weights with the original features channel by channel, adaptive enhancement in important channels is achieved, effectively improving the discriminative ability of features.
The collaborative mechanism operates through a dual-path architecture: MLSA extracts multi-scale spatial patterns to suppress noise while preserving edges, while CA filters semantically critical features across channels to reduce redundancy. A 1 × 1 convolutional layer fuses their outputs as follows:
It achieves complementary enhancement. This design enables MLSA’s dynamic receptive field to adapt to complex texture variations and optimizes feature distribution through CA’s global channel calibration. It achieves a precise balance between detail preservation and noise suppression in real-world scenarios.
3. Result
To evaluate the performance of the proposed algorithm, experiments were conducted on the S2-CMC dataset, which includes 513 scenes from Sentinel-2 data, each with a resolution of 20 m.
3.1. Datasets and Implementation Details
3.1.1. Experimental Dataset
This study uses remote sensing images from Sentinel-2A satellite because it has rich spectral information, which is beneficial for exploring the role of each spectral feature in cloud detection. The Sentinel-2A satellite was launched by the European Space Agency and has the capability of wide swath, high-resolution multispectral imaging. It is widely used in remote sensing analysis for forest monitoring, water quality analysis, land cover change, and natural disaster management. The satellite is equipped with 13 spectral bands with a wavelength range of 0.443 to 2.190 μm, covering spectral information from visible light to near-infrared and shortwave infrared, providing three spatial resolutions of 10 m, 20 m, and 60 m. Among them, the spatial resolution of shallow water and aerosols, water vapor, short wave infrared light and cirrus cloud bands is 60 m; the spatial resolution of four vegetation red edges and two short wave infrared light bands is 20 m; the spatial resolution of blue, green, red, and near-infrared light bands is 10 m. The resolution here refers to the actual spatial distance represented by each pixel.
The S2-CMC [44] dataset is a random sample of Level-1C Sentinel-2 data from 2018, containing 513 scenes. Each scene has a size of 1022 × 1022 × 13 (width = 1022, height = 1022, 13 spectral channels) and is provided at a unified spatial resolution of 20 m. Specifically, to ensure that all spectral bands are spatially aligned and share the same pixel grid, S2-CMC resamples the Sentinel-2 bands with native resolutions of 10 m and 60 m onto a common 20 m reference grid using bilinear interpolation. In this process, the 10 m bands (blue, green, red, and NIR) are downsampled to 20 m, while the 60 m bands (coastal aerosol, water vapor, and cirrus) are upsampled to 20 m; the native 20 m bands remain at 20 m but are co-registered to the same 20 m grid for consistency. This unified resampling strategy preserves multi-spectral completeness (all 13 bands) while simplifying model training by avoiding multi-resolution inputs. This standardization ensures consistent analysis across all scenes and facilitates the training of machine learning models on the dataset.
Among these scenes, 359 scenes (70%) are used for training and 154 scenes (30%) are used for testing. For ease of training, each scene is further cropped into 9 non-overlapping patches of size 384 × 384 × 13, resulting in 3231 training patches and 1386 testing patches.
3.1.2. Loss Function and Training Details
Cross-entropy (CE) loss was used as loss functions to guide network training. CE loss can be expressed as follows:
where represents the label of the sample: a positive class is assigned a value of 1, whereas a negative class is assigned a value of 0. is the probability that the sample is predicted to be positive.
During the model training process, gradient descent algorithm is used for parameter optimization, and Adam optimizer is chosen. The training process is divided into 100 epochs, with the initial learning rate for the first 50 epochs set to 1 × 10−4, the learning rate for the last 50 epochs adjusted to 1 × 10−5, and the exponential weight decay rate set to 0.92.
The experimental platform uses the Ubuntu-22.04.5 LTS operating system (Canonical Ltd., London, UK), paired with the CUDA-12.0 environment, and is trained on a single card NVIDIA GeForce GTX 4090Ti GPU (NVIDIA Corp., Santa Clara, CA, USA) with a video memory capacity of 24.564 GB. The deep learning framework used is Pytorch (v2.5.1), with a batch size set to 16. The training time for the proposed network model is approximately 8 h.
3.1.3. Evaluation Metrics
To evaluate the effectiveness of the proposed method, the commonly used evaluation indexes were selected: F1-score, intersection over union (IOU) and accuracy (ACC). Their expressions are as follows:
where (true positive) represents true positive examples, which are the number of samples that are actually positive and correctly predicted as positive, (true negative) represents true negative examples, which are the number of samples that are actually negative and correctly predicted as negative, (false positive) represents false positive examples, which are the number of samples that are actually negative but incorrectly predicted as positive, and (false negative) represents false negative examples, which are the number of samples that are actually positive but incorrectly predicted as negative. In this study, negative examples refer to the background category, and positive examples refer to the cloud category.
3.2. Experimental Comparison by Using S2-CMC
3.2.1. Comparison of Algorithm
It was trained and tested on the S2-CMC dataset. The selected Cloud-Net, CFCA Net, RS-Net, Boundary Nets, CloudSegNet, MCDNet, BABFNet, CDUNet, HR Cloud Net were compared with the algorithm in this paper. It should be noted that CD-FM3SF was omitted in the comparison algorithm because the CD-FM3SF network only supports inputs of three resolutions and is not suitable for this single resolution dataset. The experimental results of the comparative algorithm are shown in Table 1. It can be seen that the proposed algorithm performs well, with ACC of 97.10%, IOU of 94.74%, and F1-score of 97.30%. The effectiveness of the proposed method in cloud detection in Sentinel-2 images.

Table 1.
Comparison Of Sota Methods On S2-CMC.
3.2.2. Qualitative Analysis
Figure 5 shows the subjective result graph on the S2-CMC dataset, comparing our method with three models: Cloud Net, Boundary Nets, and CloudSegNet.

Figure 5.
Cloud detection results from S2-CMC dataset.
Among them, Figure 5a selected four remote sensing scenes covered by clouds, and Figure 5b shows the corresponding cloud labels, with white pixels representing clouds and black pixels representing non cloud backgrounds. Figure 5c–f respectively show the subjective result graphs of Cloud Net, Boundary Nets, CloudSegNet, and the method proposed in this paper. By observing the cloud containing images and labels, it can be found that the distribution of clouds in the S2-CMC dataset is relatively scattered, and in some scenes, the clouds are blurry, making it difficult to distinguish them correctly even with the naked eye. Despite these difficulties, the proposed method still achieved excellent detection results. In contrast, comparative algorithms have serious omissions. Boundary Nets and CloudSegNet showed more false positives (yellow pixels) in the first scenario, and more missed detections (purple pixels) in the second, third, and fourth scenarios. Although Cloud Net displays fewer error detections, it shows a large number of missed detections in every scenario, especially in the first and third scenarios. In the lower right corner of the fourth scene, it can be seen that the other three comparison methods all have obvious missed detection problems, and only the proposed method achieves roughly correct detection of cloud regions. Overall, the proposed method has the least number of error detections and missed detections, is closest to real labels, and outperforms all comparison algorithms. This validates the effectiveness of our proposed module in correctly extracting cloud features and reducing missed detections.
3.3. Ablation Study
In order to evaluate the performance of the network architecture and its modules constructed in this chapter in remote sensing image cloud detection tasks, and quantify the contribution of each module to model performance improvement, ablation experiments were conducted in this section. To ensure the rigor of the experiment, a dual encoder single decoder network structure was used as the basis, and the ablation experiment was conducted by gradually modifying the network and adding modules. The specific experimental design is as follows:
Experiment 1: Adopting a single-stream encoder and single decoder network structure, no additional modules need to be added. All spectral bands are directly concatenated along the channel dimension to form a unified input. A single backbone branch is used to extract features. Finally, decoding is performed through simple convolution and upsampling to generate the prediction result.
Experiment 2: Adopting a dual encoder and single decoder network structure, no additional modules need to be added. These two encoder branches are the same as shown in Figure 1, using simple addition to fuse the shallow and deep features of these two encoding branches. Then, shallow and deep features are fused through upsampling and cascading, resulting in a feature size of 2304 × 96 × 96. Finally, decoding is performed through convolution and two upsampling.
Experiment 3: On the basis of the network in Experiment 2, OCGMSCFM is introduced. Guide the shallow and deep features of the encoder through optical characteristics before performing subsequent summation and fusion.
Experiment 4: On the basis of the network in Experiment 3, FAFM is added. An aggregation and filtering method is used to replace the simple summation approach for merging shallow and deep features from two encoder branches in order to achieve feature filtering.
Experiment 5: On the basis of the network in Experiment 4, MILSAMCAM is embedded in the decoder.
All experiments were conducted under uniform training conditions. The results of the ablation experiment are shown in Table 2.
Table 2.
Ablation Study.
The Single-Stream baseline, which inputs all spectral bands uniformly, yielded an F1-score of 81.13%, an IOU of 68.25%, and an ACC of 75.74%. By adopting the proposed Asymmetric Dual-Encoder architecture, the performance improved significantly: the F1-score surged by 13.52% to 94.65%, the IOU increased by 21.67%, and the ACC rose by 18.70%. This substantial gain confirms the effectiveness of the differentiated feature extraction strategy.
Subsequently, the contributions of each module were evaluated based on the dual-encoder backbone. Specifically, after adding OCGMSCFM, the performance metric F1-score increased by 1.72%, the Intersection over Union (IOU) increased by 3.1%, and the Accuracy (ACC) increased by 1.64%. After introducing FAFM, the F1-score increased by 0.43%, the IOU increased by approximately 0.79%, and the ACC metric increased by 0.51%. Finally, after adding the simplified cross-space attention module, the performance metric F1-score increased by 1.22%, ultimately reaching 97.30%. At the same time, the IOU increased by approximately 0.93% to 94.74%, and the ACC increased to 97.10%.
4. Discussion
4.1. Analysis of Detection Performance
The quantitative results on the S2-CMC dataset demonstrate that the proposed OADEF2 method achieves superior performance compared to state-of-the-art methods, with an F1-score as high as 97.30%. In addition to numerical metrics, subjective plots (Figure 5) also show that our method significantly suppresses false positives and false negatives. Traditional methods such as Cloud-Net often struggle to handle bright surface features (e.g., snow or white sand) due to spectral similarity. In contrast, OADEF2 effectively distinguishes these features. This improvement is primarily attributed to OCGMSCFM, which explicitly embeds physical prior information (Dynamic HOT Index and Full-Band Cloud Index) into the feature learning process. By guiding the network to focus on optically meaningful features rather than just statistical patterns, the model exhibits greater robustness to complex background interference.
4.2. Mechanism Analysis: Addressing Spectral Penetrability
A critical challenge in multi-spectral cloud detection is the differing physical behaviors of spectral bands. Specifically, infrared (IR) bands possess higher penetrability and may “see through” thin cirrus clouds to the ground, potentially causing missed detections if the network over-relies on IR features. Our Asymmetric Dual Encoder design specifically addresses this issue by decoupling the spectral inputs.
Complementary Processing: While the IR branch is crucial for distinguishing thick clouds from snow (based on reflectance differences in SWIR), the RGB branch remains highly sensitive to the scattering texture of thin clouds.
Adaptive Fusion: The FAFM serves as a dynamic gate. In scenarios involving thin clouds where IR signals might be weak due to penetration, the attention mechanism in FAFM adaptively assigns higher weights to the texture-rich RGB features. This ensures that the “visual” presence of clouds is preserved even when their “thermal/spectral” signature is ambiguous, effectively preventing the leakage problems observed in single-stream networks.
4.3. Model Complexity and Efficiency Analysis
To comprehensively evaluate the practicality of our proposed method in real-time remote sensing applications, we compared it with CDUNet (the model whose F1-score is closest to ours) [21] in terms of model complexity, memory usage, and inference speed. To ensure a fair comparison, both models were evaluated on workstations equipped with a single NVIDIA GeForce GTX 4090Ti GPU under identical hardware conditions. Inference speed was strictly evaluated using standard single-precision (FP32) computation with a batch size of 1, without using mixed precision.
Specifically, CDUNet [21] contains 47.83 million parameters and requires 59.83 GFLOPs of computation, but its inference speed is only 35.37 FPS, with a peak memory usage of 0.30 GB. In contrast, our proposed OADEF2 model, despite having a larger parameter size (61.46 million parameters) and a theoretically higher computational cost (176.22 GFLOPs), achieves a significantly faster inference speed of 126.62 FPS, with a peak memory usage of only 0.51 GB. This observation, that the theoretically more complex model achieves a 3.58× speedup in actual inference, can be attributed to differences in architectural efficiency. OADEF2’s asymmetric dual-encoder structure enables highly parallelized feature extraction, effectively maximizing the parallel computing capabilities of GPUs. Conversely, CDUNet’s complex nested skip connections introduce significant memory access costs (MACs) and serial processing bottlenecks, severely limiting its actual throughput despite its theoretically lower number of computations. The slight increase in peak memory in our method (+0.21 GB) remains within reasonable limits and is entirely feasible for modern hardware. Therefore, OADEF2 demonstrates a far superior balance between performance and efficiency compared to CDUNet [21].
4.4. Limitations and Future Work
Despite the superior performance of OADEF2 on the Sentinel-2A dataset, there are still some limitations that need to be addressed in future research. First, the current validation is primarily confined to the S2-CMC dataset. Although this dataset covers diverse global scenes, the model’s adaptability to other sensors with significantly different spatial resolutions and spectral response functions (e.g., Landsat-8 or Gaofen series) has not been fully explored. Direct application of the current architecture to lower-resolution data (like the 30 m resolution of Landsat-8) may introduce domain gaps due to scale discrepancies. Therefore, exploring Unsupervised Domain Adaptation (UDA) techniques to guarantee robust cross-sensor generalization between Sentinel-2 and other remote sensing platforms will be a primary focus of our future work.
Secondly, although the strict single-image inference speed of 126.62 FPS is highly efficient and more than sufficient for many real-time applications, the parameter size (61.46 M) is relatively large compared to some extremely lightweight networks. While our peak memory usage during inference remains well-constrained (approximately 0.51 GB), the parameter scale may still pose challenges for deployment on severely resource-constrained edge devices, such as on-board satellite processing units. In the future, we plan to investigate model compression techniques, such as network pruning and knowledge distillation, to further reduce the memory footprint and parameter count without compromising the detection accuracy.
5. Conclusions
In this paper, we proposed a novel cloud detection network, OADEF2, to address the limitation of undifferentiated spectral band processing in existing methods. By employing an Asymmetric Dual Encoder structure, the Sentinel-2A bands are decoupled into RGB and Infrared/Atmospheric streams, allowing the network to fully leverage the textural details of visible light and the physical properties of infrared bands.
To enhance feature representation, we introduced the OCGMSCFM, which integrates the Dynamic HOT Index and Full Band Cloud Index to refine cloud feature extraction based on physical priors. Furthermore, FAFM was proposed to suppress background noise and improve fusion efficiency, while the MILSAMCAM was incorporated into the decoder to capture long-range dependencies and refine boundary details.
Extensive experiments on the S2-CMC dataset demonstrate that OADEF2 achieves state-of-the-art performance with an F1-score of 97.30% and an IOU of 94.74%, effectively reducing false detections in complex scenes compared to other algorithms. Although the complex architecture results in a relatively large parameter size (61.46 M), the model maintains a highly efficient single-image inference speed of 126.62 FPS on a single GTX 4090Ti GPU, with a tightly constrained peak memory footprint of approximately 0.51 GB. This confirms that OADEF2 achieves a favorable balance between detection accuracy and processing throughput, making it highly suitable for both real-time and high-throughput offline processing tasks.
In future work, we plan to explore Unsupervised Domain Adaptation (UDA) techniques to guarantee robust cross-sensor generalization between Sentinel-2 and other remote sensing platforms. Additionally, we will investigate model compression techniques (e.g., pruning) to reduce the computational overhead without compromising accuracy, aiming to extend the model’s applicability to resource-constrained edge devices.
Author Contributions
Conceptualization, J.Z. and Q.L.; methodology, J.Z. and Q.L.; software, Q.L.; validation, J.Z., Q.L. and X.S.; formal analysis, Q.L.; investigation, J.Z. and Q.L.; resources, J.Z. and Q.L.; data curation, Q.L.; writing—original draft preparation, Q.L., X.S. and J.L.; writing—review and editing, Q.L. and X.S.; visualization, Q.L.; supervision, J.Z.; project administration, J.Z. and Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Science Foundation of China under Grant No. 62371362.
Data Availability Statement
Data are contained within this article. The data are not publicly available due to privacy.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kegelmeyer, W.P., Jr. Extraction of Cloud Statistics from Whole Sky Imaging Cameras (No. SAND-94-8222); Sandia National Laboratories (SNL-CA): Livermore, CA, USA, 1994. [Google Scholar]
- Irish, R.R. Landsat 7 automatic cloud cover assessment. In Proceedings of SPIE: Algorithms for Multispectral, Hyperspectral, and Ultraspectral Imagery VI; Society of Photo-Optical Instrumentation Engineers: Bellingham, WA, USA, 2000; pp. 348–355. [Google Scholar]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4–8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Fu, H.; Shen, Y.; Liu, J.; He, G.; Chen, J.; Liu, P.; Qian, J.; Li, J. Cloud detection for FY meteorology satellite based on ensemble thresholds and random forests approach. Remote Sens. 2019, 11, 44. [Google Scholar] [CrossRef]
- Wei, J.; Huang, W.; Li, Z.; Sun, L.; Zhu, X.; Yuan, Q.; Liu, L.; Cribb, M. Cloud detection for Landsat imagery by combining the random forest and superpixels extracted via energy-driven sampling segmentation approaches. Remote Sens. Environ. 2020, 248, 112005. [Google Scholar] [CrossRef]
- Chen, G.; E, D. Support vector machines for cloud detection over ice-snow areas. Geo-Spat. Inf. Sci. 2007, 10, 117–120. [Google Scholar] [CrossRef]
- Kang, X.; Gao, G.; Hao, Q.; Li, S. A coarse-to-fine method for cloud detection in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 110–114. [Google Scholar] [CrossRef]
- Sui, Y.; He, B.; Fu, T. Energy-based cloud detection in multispectral images based on the SVM technique. Int. J. Remote Sens. 2019, 40, 5530–5543. [Google Scholar] [CrossRef]
- Mateo-García, G.; Gómez-Chova, L.; Camps-Valls, G. Convolutional neural networks for multispectral image cloud masking. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS); Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2017; pp. 2255–2258. [Google Scholar]
- Xie, F.; Shi, M.; Shi, Z.; Yin, J.; Zhao, D. Multilevel cloud detection in remote sensing images based on deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3631–3640. [Google Scholar] [CrossRef]
- Yan, Z.; Yan, M.; Sun, H.; Fu, K. Cloud and cloud shadow detection using multilevel feature fused segmentation network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1600–1604. [Google Scholar] [CrossRef]
- Wu, X.; Shi, Z. Utilizing multilevel features for cloud detection on satellite imagery. Remote Sens. 2018, 10, 1853. [Google Scholar] [CrossRef]
- Francis, A.; Sidiropoulos, P.; Muller, J.P. CloudFCN: Accurate and robust cloud detection for satellite imagery with deep learning. Remote Sens. 2019, 11, 2312. [Google Scholar] [CrossRef]
- Mohajerani, S.; Saeedi, P. Cloud-Net: An end-to-end cloud detection algorithm for Landsat 8 imagery. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS); Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2019; pp. 1029–1032. [Google Scholar]
- Dev, S.; Nautiyal, A.; Lee, Y.H.; Winkler, S. CloudSegNet: A deep network for nychthemeron cloud image segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1814–1818. [Google Scholar] [CrossRef]
- Wieland, M.; Li, Y.; Martinis, S. Multi-sensor cloud and cloud shadow segmentation with a convolutional neural network. Remote Sens. Environ. 2019, 230, 111203. [Google Scholar] [CrossRef]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Chai, D.; Newsam, S.; Zhang, H.K.; Qiu, Y. Cloud and cloud shadow detection in Landsat imagery based on deep convolutional neural networks. Remote Sens. Environ. 2019, 225, 307–316. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, D.; Xia, M. CDUNet: Cloud detection UNet for remote sensing imagery. Remote Sens. 2021, 13, 4533. [Google Scholar] [CrossRef]
- Yang, J.; Guo, J.; Yue, H.; Liu, Z. CDnet: CNN-based cloud detection for remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6195–6211. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud detection in remote sensing images based on multiscale features-convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Yu, J.; Li, Y.; Zheng, X.; Zhong, Y.; He, P. An effective cloud detection method for Gaofen-5 images via deep learning. Remote Sens. 2020, 12, 2106. [Google Scholar] [CrossRef]
- Wang, W.; Shi, Z. An all-scale feature fusion network with boundary point prediction for cloud detection. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8020705. [Google Scholar] [CrossRef]
- Guo, J.; Yang, J.; Yue, H.; Tan, H. CDnetV2: CNN-based cloud detection for remote sensing imagery with cloud-snow coexistence. IEEE Trans. Geosci. Remote Sens. 2020, 59, 700–713. [Google Scholar] [CrossRef]
- Wu, K.; Xu, Z.; Lyu, X.; Ren, P. Cloud detection with boundary nets. ISPRS J. Photogramm. Remote Sens. 2022, 186, 218–231. [Google Scholar] [CrossRef]
- Dong, J.W.; Wang, Y.H.; Yang, Y.; Yang, M. MCDNet: Multilevel cloud detection network for remote sensing images based on dual-perspective change-guided and multi-scale feature fusion. Int. J. Appl. Earth Obs. Geoinf. 2024, 129, 103820. [Google Scholar] [CrossRef]
- Li, J.; Xue, T.; Zhao, J.; Ge, J.; Min, Y.; Su, W.; Zhan, K. High-Resolution Cloud Detection Network. arXiv 2024, arXiv:2407.07365. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, Q.; Wu, J.; Wang, Y.; Wang, H.; Li, Y.; Chai, Y.; Liu, Y. A cloud detection method using convolutional neural network based on Gabor transform and attention mechanism with dark channel SubNet for remote sensing image. Remote Sens. 2020, 12, 3261. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, H.; Wang, Y.; Zhou, Q.; Li, Y. Deep network based on up and down blocks using wavelet transform and successive multi-scale spatial attention for cloud detection. Remote Sens. Environ. 2021, 261, 112483. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Y.; Wang, H.; Wu, J.; Li, Y. CNN cloud detection algorithm based on channel and spatial attention and probabilistic upsampling for remote sensing image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5404613. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Yan, Z.; Fu, K. DABNet: Deformable contextual and boundary-weighted network for cloud detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5601216. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, J.; Wang, H.; Wang, Y.; Li, Y. Cloud detection method using CNN based on cascaded feature attention and channel attention. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4104717. [Google Scholar] [CrossRef]
- Zhang, G.; Gao, X.; Yang, J.; Yang, Y. A multi-task driven and reconfigurable network for cloud detection in cloud-snow coexistence regions from very-high-resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2022, 114, 103070. [Google Scholar] [CrossRef]
- Zhang, J.; Shi, X.; Wu, J.; Song, L. Cloud detection method based on spatial-spectral features and encoder-decoder feature fusion. IEEE Trans. Geosci. Remote Sens. 2023, 61, 29206. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. Mcanet: A multi-branch network for cloud/snow segmentation in high-resolution remote sensing images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Zhao, C.; Zhang, X.; Kuang, N.; Luo, H. Boundary-Aware Bilateral Fusion Network for Cloud Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5403014. [Google Scholar] [CrossRef]
- Zou, Z.; Li, W.; Shi, T.; Shi, Z.; Ye, J. Generative adversarial training for weakly supervised cloud matting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 201–210. [Google Scholar]
- Li, Y.; Chen, W.; Zhang, Y.; Tao, C.; Xiao, R.; Tan, Y. Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens. Environ. 2020, 250, 112045. [Google Scholar] [CrossRef]
- Guo, J.; Yang, J.; Yue, H.; Li, K. Unsupervised domain adaptation for cloud detection based on grouped features alignment and entropy minimization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603413. [Google Scholar] [CrossRef]
- Zhang, Y.; Guindon, B.; Cihlar, J. An image transform to characterize and compensate for spatial variations in thin cloud contamination of Landsat images. Remote Sens. Environ. 2002, 82, 173–187. [Google Scholar] [CrossRef]
- Francis, A.; Mrziglod, J.; Sidiropoulos, P.; Muller, J.-P. Sentinel-2 Cloud Mask Catalogue. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B3-2020, 1101–1108. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.