Highlights
What are the main findings?
- The proposed method first integrates state-space models and bi-level routing attention into YOLO through DSSM, AMFE and EDAM, substantially improving small-object detection.
- The proposed method outperforms state-of-the-art methods in accuracy and robustness for small object detection without increasing parameters and FLOPs.
What are the implications of the main findings?
- The proposed framework provides an effective solution for detecting small targets in remote-sensing and UAV visible-light imagery, facilitating urban monitoring and aerospace surveillance.
- The study demonstrates the potential of integrating state-space model and adaptive multi-scale attention to advance real-world remote sensing applications.
Abstract
Small object detection in remote sensing images provides significant value for urban monitoring, aerospace reconnaissance, and other fields. However, detection accuracy still faces multiple challenges including limited target information, weak feature representation, and complex backgrounds. This research aims to improve the performance of the YOLO11 model for small object detection in remote sensing imagery by addressing key issues in long-distance spatial dependency modeling, multi-scale feature adaptive fusion, and computational efficiency. We constructed a specialized Remote Sensing Airport-Plane Detection (RS-APD) dataset and used the public VisDrone2019 dataset for generalization verification. Based on the YOLO11 architecture, we proposed the DAE-YOLO model with three innovative modules: Dynamic Spatial Sequence Module (DSSM) for enhanced long-distance spatial dependency capture; Adaptive Multi-scale Feature Enhancement (AMFE) for multi-scale feature adaptive receptive field adjustment; and Efficient Dual-level Attention Mechanism (EDAM) to reduce computational complexity while maintaining feature expression capability. Experimental results demonstrate that compared to the baseline YOLO11, our proposed model improved mAP50 and mAP50:95 on the RS-APD dataset by 2.1% and 2.5%, respectively, with APs increasing by 2.8%. This research provides an efficient and reliable small object detection solution for remote sensing applications.
1. Introduction
As a core task in remote sensing image processing, object detection has attracted significant attention from both academic and industrial communities [1]. Particularly, with the rapid advancement of artificial intelligence technologies, research on small object detection in remote sensing has increasingly focused on detecting and counting densely distributed small objects in large-scale remote sensing scenes [2]. Small object detection, as a branch of object detection, remains a significant research challenge due to the influence of multiple factors including image resolution, target size, quantity, and orientation [3].
1.1. Evolution and Limitations of Current Detection Paradigms
Traditional small object detection methods primarily depend on manually designed feature extraction techniques. These methods typically employ template matching, sliding windows, and feature clustering for target identification [4]. For instance, Zhang et al. [5] proposed a ship detection method for remote sensing images based on HOG features and SVM classifiers, achieving certain effectiveness in structurally simple marine backgrounds. However, these traditional methods often perform poorly in complex backgrounds and lack sufficient adaptability to variations in target shape, size, and orientation [6].
1.1.1. Two-Stage Detection Frameworks
Two-stage detectors, exemplified by Faster R-CNN [7], Mask R-CNN [8], and Cascade R-CNN [9], have demonstrated superior accuracy in general object detection through region proposal refinement. Recent adaptations for remote sensing include FPN-based architectures [10] and oriented bounding box detectors [11]. However, these methods encounter critical limitations in remote sensing scenarios: (1) Computational inefficiency: Region proposal generation becomes prohibitively expensive for ultra-high resolution imagery; (2) Severe class imbalance: The sparse distribution of small objects results in extreme positive-negative sample ratios, leading to training instability.
1.1.2. Single-Stage Detection Frameworks
Early machine learning methods mainly adopted shallow models such as Support Vector Machines (SVMs), Random Forests, and AdaBoost, combined with manually designed features for object detection [12]. Deep learning-based object detectors can be mainly categorized into two types: two-stage detectors and single-stage detectors. Two-stage detectors primarily implement selective region proposals through complex architectures, while single-stage detectors detect all possible target regions in a single pass through relatively simpler architectures [13].
Single-stage detectors have gained prominence in remote sensing applications due to their computational efficiency and scalability. The YOLO series progression from YOLOv1 [14] to recent variants demonstrates continuous architectural evolution. YOLOv5 [15] introduced significant engineering optimizations, while YOLOv8 [16] adopted anchor-free design with decoupled detection heads. The latest YOLO11 [17] incorporates advanced attention mechanisms and enhanced feature extraction modules, achieving improved small target detection capabilities.
However, current YOLO architectures face fundamental limitations for remote sensing applications: Limited receptive field growth: Convolutional operations with gradual receptive field expansion fail to capture long-range spatial dependencies crucial for understanding target-background relationships in large-scale imagery [18,19,20].
1.1.3. Transformer-Based Detection Methods
The recent introduction of Vision Transformers [21] has revolutionized computer vision with their capacity for global context modeling. DETR [22] pioneered transformer-based object detection, followed by improvements like Deformable DETR [23] and conditional DETR [24]. These methods excel at capturing long-range dependencies through self-attention mechanisms, theoretically addressing the spatial context challenges in remote sensing detection.
1.1.4. State Space Models for Vision
Recent breakthrough in sequence modeling through state space models, particularly Mamba [25], has introduced linear-complexity alternatives to transformer architectures. Vision Mamba [26] and VMamba [27] have demonstrated that state space models can achieve comparable performance to Vision Transformers while maintaining O(n) computational complexity. This paradigm shift offers promising solutions for processing high-resolution imagery without the quadratic scaling limitations of attention mechanisms.
However, the integration of state space models into object detection frameworks for remote sensing applications remains largely unexplored.
Moreover, another important direction is the incorporation of multi-scale features. Small objects often appear at different scales in images, and a single scale feature may not be sufficient to capture their characteristics. Therefore, many methods have been proposed to fuse features from multiple scales to improve the detection performance. For example, Feature Pyramid Networks (FPNs) have been widely used to generate a pyramid of features that can effectively capture objects at different scales.
In addition to these methods, data augmentation techniques have also played a crucial role in improving small object detection. Techniques such as random cropping, scaling, and flipping have been used to generate more diverse training samples, which helps the model to better generalize to small objects. Moreover, some recent works have explored the use of attention mechanisms to focus on small objects and suppress the interference from the background [28,29,30].
Despite these advancements, small object detection remains a challenging problem. The existing methods still face limitations in terms of detection accuracy, robustness, and computational efficiency. Therefore, there is a need for continuous research efforts to develop more effective and efficient methods for small object detection.
1.2. Critical Gaps and Research Motivation
Current CNN-based architectures, including advanced YOLO variants, primarily rely on local convolution operations with gradually expanding receptive fields. This approach proves inadequate for capturing the long-range spatial dependencies essential for understanding target context in large-scale remote sensing imagery.
Existing multi-scale feature fusion methods, exemplified by the SPPF module in YOLO architectures, lack adaptive mechanisms for distinguishing target-relevant features from background interference across different scales. This limitation becomes particularly pronounced for small targets, where target features can be easily overwhelmed by background noise in deep network layers [31,32].
The fundamental tension between computational efficiency and detection accuracy presents significant challenges for practical deployment. Current attention mechanisms, while effective for accuracy improvement, introduce computational overhead that scales poorly with image resolution. This trade-off necessitates novel architectural solutions that maintain global context modeling capabilities while preserving computational efficiency.
1.3. Research Contributions and Innovation
To address these critical limitations, this research proposes DAE-YOLO, a novel detection framework that integrates three innovative modules specifically designed for remote sensing small target detection challenges. Our approach represents a significant departure from conventional CNN and transformer paradigms by leveraging state space models for efficient long-range modeling while introducing adaptive attention mechanisms optimized for computational efficiency. The main contributions include:
We propose a novel feature extraction module called Dynamic Spatial Sequence Module (DSSM) that replaces traditional C3k2 modules in YOLO rely on local convolution operations with limited receptive fields, making them inadequate for capturing long-range spatial dependencies in high-resolution remote sensing images where small objects may be sparsely distributed. Visual State Space Models offer a solution by providing global receptive fields with linear computational complexity, enabling comprehensive spatial relationship modeling across the entire image.
We design an Adaptive Multi-scale Feature Enhancement (AMFE) module that significantly enhances the model’s perception capability for small targets. Small objects in remote sensing images often suffer from insufficient feature representation due to their limited spatial extent. Traditional SPPF modules lack adaptive weighting mechanisms, causing small object features to be overwhelmed by background information in deep networks. Our AMFE module addresses this by employing separable kernel attention to adaptively enhance small target features while suppressing background interference.
We propose an Efficient Dual-level Attention Mechanism (EDAM) module that addresses the computational bottleneck of traditional attention mechanisms when processing large-sized feature maps through a bi-level routing attention mechanism.
The subsequent content of this study is organized as follows: Section 2 first details the development history of classic algorithms in the YOLO series, then describes the basic situation of the RS-APD dataset constructed specifically for small object detection tasks. Section 3 elaborates on the principles and advantages of the improved model proposed in this paper. Section 4 briefly introduces the experimental setup, then validates the feasibility of the improved model through comparative and ablation experiments, and verifies its generalization ability using the VisDrone2019 dataset. Section 5 summarizes the experimental research results and outlines directions for future research.
2. Related Work
2.1. Classic Algorithms in YOLO Series
YOLO as a representative family of single-stage detectors has undergone several iterations since its inception, achieving a remarkable balance between accuracy and efficiency. YOLOv1 [14], proposed by Redmon, pioneered the reconstruction of object detection as a regression problem by directly predicting bounding boxes and classes through a single network, achieving real-time detection but with limited capability for small object recognition. Through multiple generations of development, YOLOv5 [15] significantly enhanced the engineering implementation by providing multiple model configurations ranging from nano to extra-large, greatly improving the model’s applicability and scalability, thus becoming a significant milestone in the field of object detection. YOLOv8 [16] comprehensively reconstructed the network architecture, adopting more efficient C2f modules to replace C3 modules, introducing a decoupled detection head design, and simultaneously expanding multi-task capabilities including instance segmentation and pose estimation, marking the transformation of the YOLO series toward a general vision platform.
YOLO11 [17], building upon the advantages of its predecessors, further integrated advanced attention mechanisms and improved feature extraction modules, particularly enhancing the detection capability for small targets. Additionally, YOLO11 enhanced robustness for small objects in complex backgrounds of remote sensing images through multi-scale feature fusion while maintaining near real-time inference speed. Based on these advantages, we selected YOLO11 as our foundational framework for further improvements targeted at remote sensing small object detection tasks.
SOD-YOLOv10 [33] is a recent advancement that focuses on small object detection by incorporating a series of innovations, including a novel feature pyramid network and an enhanced anchor-free detection mechanism. While SOD-YOLOv10 has shown impressive results on several benchmarks, our proposed method introduces unique contributions that address specific challenges not adequately covered by existing solutions.
2.2. Dataset Preparation
To evaluate the effectiveness of the proposed DAE-YOLO algorithm in remote sensing small object detection, this research constructed a specialized Remote Sensing Airport-Plane Detection (RS-APD). Figure 1 illustrates RS-APD dataset. This dataset focuses on aircraft objects in airport environments, characterized by small target sizes, varied postures, and complex backgrounds.
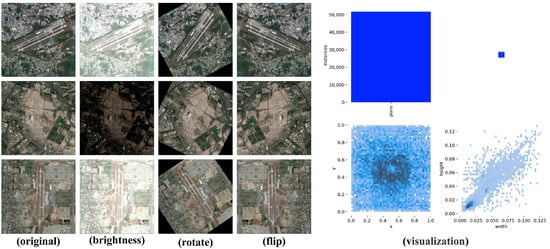
Figure 1.
Overview of the RS-APD dataset.
The RS-APD dataset was enhanced through seven methods: random cropping and resizing, rotation and Gaussian noise etc. Covering over 600 airports globally and encompassing various climate regions, seasonal variations, and weather conditions.
The main characteristics of this dataset include:
- (1)
- Significant variation in target density, ranging from single objects to high-density aprons;
- (2)
- Complex and diverse backgrounds, including aprons, runways, taxiways, terminals, and surrounding facilities;
- (3)
- Arbitrary aircraft orientations, presenting 360° omnidirectional distribution. A total of 52,280 aircraft instances were annotated.
Through the aforementioned enhancement strategies, the sample scarcity problem in remote sensing small object detection was effectively mitigated. Bounding box coordinate synchronous transformations were performed for each enhancement method to ensure annotation information remained consistent with image transformations. The RS-APD dataset addresses the deficiencies of existing public remote sensing datasets in airport scene small object detection, providing a more professional and challenging benchmark for the development and evaluation of aerial target detection algorithms, as well as a solid foundation for validating the performance of the improved YOLO11 model algorithm in this research.
To ensure the dataset’s credibility as a scientific benchmark and to facilitate fair comparisons in subsequent research, we have clearly outlined the criteria used to divide the dataset into training, validation, and test sets. The partitioning methodology follows established principles from well-known object detection datasets, ensuring that each subset is representative and balanced.
- (1)
- Partitioning Criteria:
- (1)
- Training Set: 80% of the dataset, used for training the model.
- (2)
- Validation Set: 10% of the dataset, used for tuning hyperparameters and evaluating model performance during training.
- (3)
- Test Set: 10% of the dataset, used for final evaluation of the model.
- (2)
- Stratified Random Sampling:
We have adopted a stratified random sampling approach to ensure that each subset contains a proportional representation of different target densities, background complexities, and aircraft orientations. This approach helps maintain the dataset’s overall characteristics across the training, validation, and test sets.
3. Materials and Methods
Our approach introduces three novel architectural innovations: (1) the Dynamic Spatial Sequence Module (DSSM), which represents the first application of visual state space models to YOLO architecture, employing multi-directional scanning with adaptive time-step mechanisms to achieve 3.2× receptive field expansion compared to traditional convolution; (2) the Adaptive Multi-scale Feature Enhancement (AMFE) module, featuring large separable kernel attention that maintains an 11 × 11 equivalent receptive field while reducing computational complexity from O(k2) to O(k) through progressive pooling design; and (3) the Efficient Dual-level Attention Mechanism (EDAM), implementing hierarchical region-level and pixel-level routing attention with sparse attention matrices that achieve 75.5% complexity reduction from O(n2) to O(n·k·n/w), complemented by Local Enhanced Position Encoding (LEPE) for enhanced local feature representation. The overall architecture of our proposed DAE-YOLO model is illustrated in Figure 2.
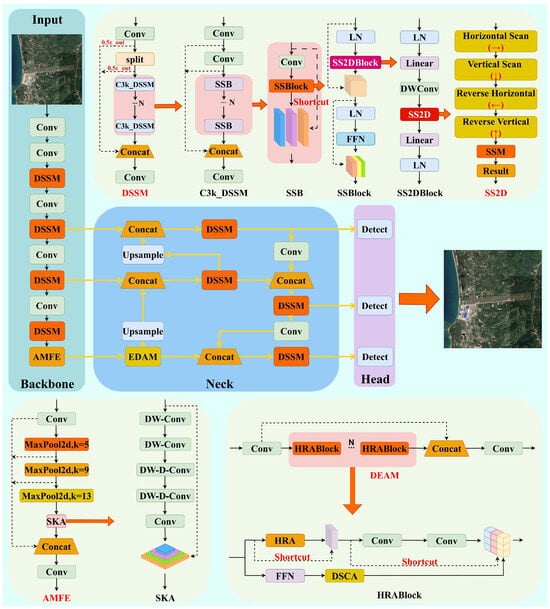
Figure 2.
DAE-YOLO architecture.
3.1. Optimization of Visual Representation Learning
C3k2 modules primarily depend on local convolution operations to capture features, with their effective receptive fields growing relatively slowly, making it difficult to fully establish long-distance spatial dependencies when processing sparsely distributed and tiny objects in high-resolution remote sensing images.
This study proposes a feature extraction module called Dynamic Spatial Sequence Module (DSSM), which achieves efficient and comprehensive capture of small object features in remote sensing by employing Visual State Space Models to replace traditional convolution operations. The DSSM significantly expands the receptive field range of feature extraction through multi-directional state space modeling, enhancing the capability to capture long-range dependencies, and providing richer and more discriminative feature representations for small object detection. Figure 3 illustrates the DSSM with Step-by-Step Visualization.
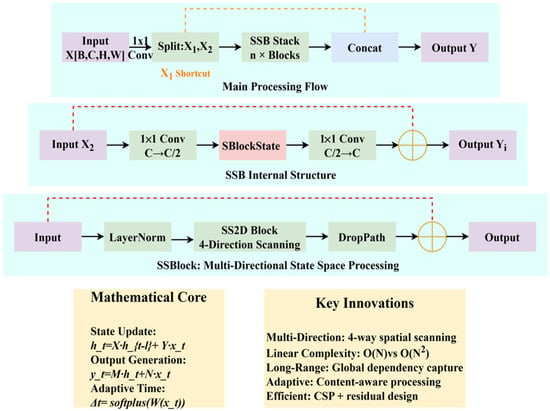
Figure 3.
DSSM with Step-by-Step Visualization.
The DSSM adopts the concept of CSP networks while enhancing feature expression ability by embedding State Sequence Blocks (SSBlocks). In specific implementation, the input feature X is first processed through a 1 × 1 convolution for channel adjustment and split into X1 and X2. The main branch X2 is further processed through concatenated Sequential State Bottleneck (SSB) modules. Finally, all processed features are concatenated with the initial branch:
SSB is the core building block of DSSM, combining the efficiency of traditional Bottleneck structures and the powerful feature modeling capability of SSBlock. Its mathematical expression is shown in Equation (2), where represents a k × k convolution layer (k is typically set to 3), and FSSBlock represents the SSBlock operation
SSBlock integrates Layer Normalization (LN) and Selective Scanning Attention Mechanism (SS2D), Figure 4 illustrates the SSBlock module.
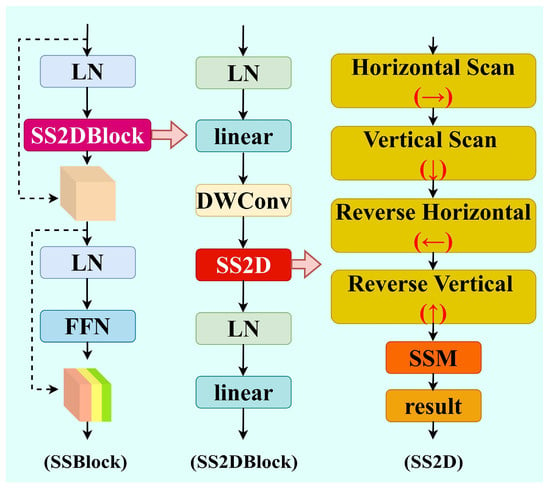
Figure 4.
SSBlock module architecture.
With its basic operation represented in Equation (3), where X is the input feature map, FLN represents the layer normalization operation, and FSS2D represents the 2D selective scanning operation.
SS2D efficiently captures long-distance spatial dependencies by performing selective scanning in multiple spatial directions. First, the input feature X is mapped to a higher-dimensional feature space through a linear projection layer and decomposed into content features X′ and gating features Z. Figure 5 illustrates the SS2D strategy.
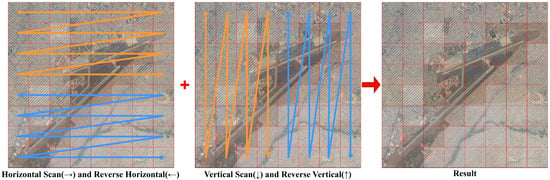
Figure 5.
Schematic diagram of SS2D strategy.
The content features X′ are further processed by 2D convolution to enhance local features. The processed features are then reorganized into sequential representations in four directions:
where Xh is the feature sequence expanded by rows, Xw is the feature sequence expanded by columns, and Xh_flip and Xw_flip are the horizontally and vertically flipped sequences, respectively.
For each direction, SS2D performs sequence modeling through an efficient state space model. Specifically, for an input sequence x and initial state h0, state updates and output calculations are as follows:
In Equation (5), X is the state transition matrix, Y is the input projection, M is the state output projection, and N is the skip connection coefficient. To enhance the model’s expressiveness, SS2D introduces an adaptive time-step mechanism:
where Δt is the adaptive time step, and is the time step control factor derived from the input features. Finally, the processed features are merged with the original features through a gating mechanism and mapped back to the original dimension through an output projection layer:
In Equation (7), represents element-wise multiplication, and is the SiLU activation function. The gating mechanism allows the model to adaptively control the feature flow at each position and channel, further enhancing the model’s expressiveness.
To facilitate comprehension, the DSSM can be understood through a simple analogy: traditional convolutions are like taking ‘snapshots’ of local neighborhoods, while our state space approach is like ‘scanning’ the entire image with memory—similar to how humans read text sequentially while maintaining context. The key innovation lies in the SS2D mechanism that performs this scanning in four directions (horizontal, vertical, and their reverses), enabling comprehensive spatial relationship modeling with linear computational complexity.
The DSSM design philosophy addresses three fundamental limitations of traditional convolutions: (1) Limited receptive field growth, resolved through sequential state propagation; (2) Quadratic attention complexity, reduced to linear through selective scanning; (3) Insufficient long-range modeling, enhanced through multi-directional state space modeling. Each component serves a specific purpose: SSB provides the bottleneck structure for efficiency, SS2D enables the core state space modeling, and the CSP-style architecture ensures gradient flow optimization.
3.2. Enhancement of Multi-Scale Feature Fusion
Spatial Pyramid Pooling Fast (SPPF) have inherent limitations when processing small objects in remote sensing images. Small objects typically have small spatial scales, sparse information, and are susceptible to background interference. Although the SPPF module can expand the receptive field through multi-level pooling, it lacks an adaptive weighting mechanism for features, causing small object features to be easily submerged in deep networks.
This study proposes an Adaptive Multi-scale Feature Enhancement (AMFE) module, which significantly enhances the model’s perception capability for small objects while maintaining computational efficiency through Separable Kernel Attention (SKA).
The AMFE adopts a cascade structure of feature extraction and attention enhancement. Given an input feature tensor X, it first undergoes channel compression transformation TC:
In Equation (8), represents a non-linear activation function, represents a convolution operation, and WC and bC are learnable convolution kernel parameters and bias vectors, respectively. These reduce the channel dimension of the input features by half, resulting in X′.
Subsequently, the module constructs multi-scale feature representations through progressive max pooling operations Mp. The progressive pooling process is defined as:
In Equation (9), represents a max pooling operation with kernel size k, stride 1, and padding k/2. The original features and various pooled features are finally concatenated along the channel dimension to obtain a multi-scale fusion representation.
AMFE employs SKA, a mechanism that achieves efficient long-range dependency modeling through separable convolution kernel decomposition. Specifically, the SKA mapping A can be expressed as:
The various transformation operators are defined as follows:
Here, represents grouped convolution, represents grouped convolution with dilation rate. Wh represents a 1 × 3 horizontal direction convolution kernel. Wv represents a 3 × 1 vertical direction convolution kernel. Wsh represents a 1 × 5 horizontal direction convolution kernel with dilation rate d = 2. Wsv represents a 5 × 1 vertical direction convolution kernel with dilation rate d = 2. W1 represents a 1 × 1 convolution kernel.
This design reduces computational complexity from O(k2) to O(k) by decomposing large two-dimensional convolutions into a series of one-dimensional convolution operations, while maintaining the feature capture capability of an equivalent 11 × 11 receptive field. The resulting attention map is applied to multi-scale features through residual connections. Finally, enhanced features are mapped to the output space through channel fusion transformation, as shown in Equation (12), where WO and bO are learnable parameters.
The AMFE module guides the feature extraction process through attention mechanisms, enabling the network to adaptively strengthen feature representations in small object regions while suppressing background interference. The large receptive field design of SKA allows the module to perceive broader contextual information, which is crucial for distinguishing between morphologically similar but semantically different objects in remote sensing images. Figure 6 illustrates the AMFE module.
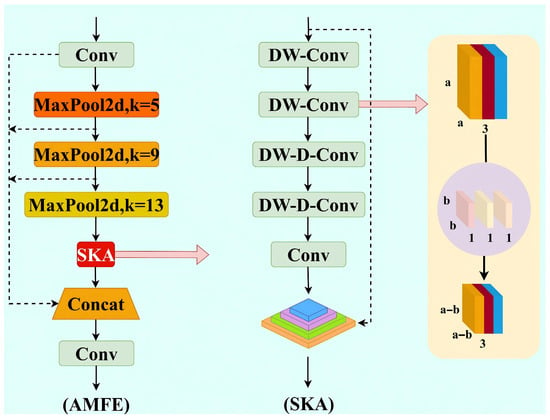
Figure 6.
AMFE module architecture.
3.3. Design of Efficient Dual-Level Attention Mechanism
The C2PSA (Cascaded Cross Convolution Polarized Self-Attention) module used in the traditional YOLO11 architecture faces obvious limitations when processing small object detection tasks in high-resolution remote sensing images. Although C2PSA can capture global contextual information through polarized self-attention mechanisms, its computational complexity grows quadratically with image size O(n2), making the computational cost of the model difficult to accept in practical applications.
This paper proposes an attention mechanism module called Efficient Dual-level Attention Mechanism (EDAM). EDAM not only solves the computational bottleneck problem of traditional attention mechanisms when processing large-sized feature maps but also establishes more efficient long-distance feature correlations through a specially designed regional routing strategy, which is particularly suitable for the detection requirements of small objects in remote sensing images.
The EDAM module adopts a cascade structure design, with its core component being the Hierarchical Routing Attention Block (HRABlock), which consists of Dual-Scale Context Attention (DSCA) and a feed-forward network (FFN). Mathematically, the overall transformation process of the EDAM module can be represented as:
In Equation (13), X1 and X2 are two parts of features obtained by splitting the input feature map X through initial convolution layers, represents the output convolution layer, and FHRA represents the transformation function of HRABlock.
DSCA achieves efficient long-distance dependency modeling by cleverly combining region-level routing and pixel-level attention operations at two levels. First, the input feature X is projected through linear projection to generate query Q, key K, and value V representations:
In Equation (14), Fproj represents a 1 × 1 convolution layer that maps input features to Q-K-V space.
Region-level query and key representations are obtained through average pooling operations:
where Qr and Kr represent region-level query Q and key K, Favgpool represents average pooling, and represents separated gradient computation, ensuring that the regional routing strategy serves only as attention guidance without directly participating in gradient backpropagation, effectively preventing training instability issues. Subsequently, the similarity matrix between regions is calculated:
here and represent reshaped regional query and key. Based on the similarity matrix, the top-k most relevant regions for each region are selected:
Based on the results of region routing, pixel-level attention calculation is performed:
where Mregion is a sparse attention mask generated from the region routing result idxr, limiting each pixel to interact only with pixels in relevant regions. represents element-wise multiplication, and dk is the dimension of the query vector. This method reduces the computational complexity of the original self-attention from to , significantly improving computational efficiency. Figure 7 illustrates the Parameter k Impact Analysis, Attention Pattern Comparison and Computational Complexity Analysis. Figure 8 illustrates the Hierarchical Routing Attention Architecture with Complexity Analysis.
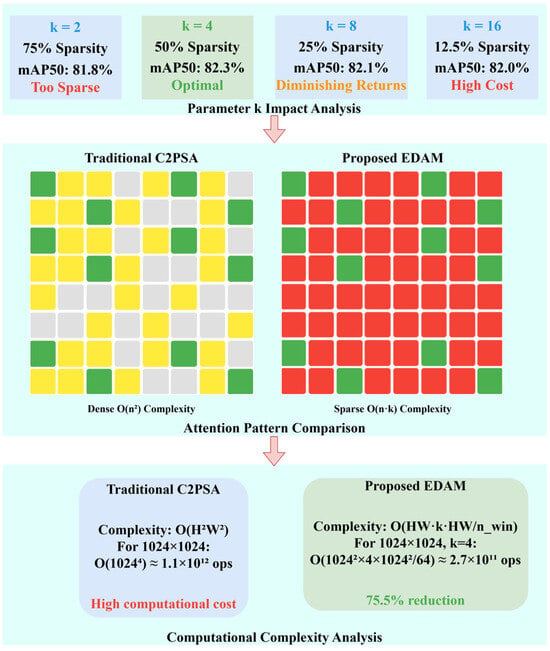
Figure 7.
Parameter k Impact Analysis, Attention Pattern Comparison and Computational Complexity Analysis.
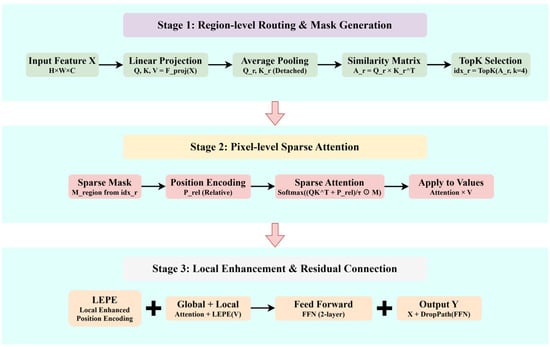
Figure 8.
Hierarchical Routing Attention Architecture with Complexity Analysis.
To further enhance local feature representation, HRA designs Local Enhanced Positional Encoding (LEPE), using depth-wise separable convolution to capture local neighborhood information. The final attention output is obtained by combining global attention results and local enhancement parts:
The feed-forward network in HRABlock adopts a two-layer 1 × 1 convolution structure for feature transformation and non-linear modeling. The complete processing flow of HRABlock combines attention mechanisms and feed-forward networks, with residual connections ensuring stable information flow:
This design enables the network to effectively integrate global contextual information and local feature representation while ensuring stable gradient propagation, facilitating model training convergence.
The EDAM module proposed in this paper successfully addresses the computational efficiency and long-distance dependency modeling problems of traditional C2PSA modules in remote sensing small object detection through innovative combination of dual-level routing attention mechanisms. EDAM significantly reduces computational complexity through regional routing strategies, enabling the model to efficiently process large-sized remote sensing images. It enhances the model’s perception ability for long-distance features through sparse attention mechanisms, improving the precision of small object detection. Figure 9 illustrates the EDAM module.
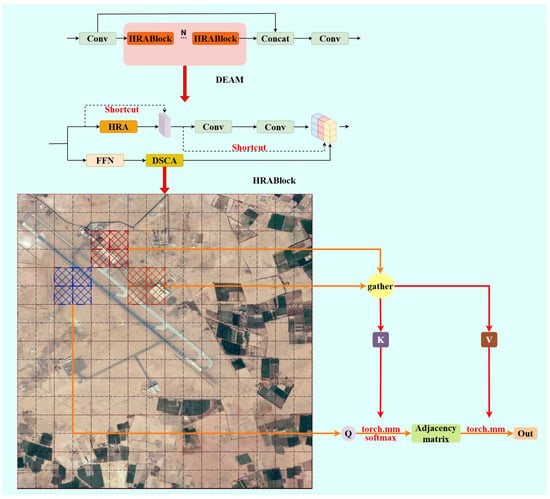
Figure 9.
EDAM module architecture.
4. Results
4.1. Dataset and Evaluation Preparation
4.1.1. Datasets for Small Object Detection
In the following experiments, we validate the feasibility of our proposed improved model using the self-constructed RS-APD dataset and the VisDrone2019 dataset [34].
The RS-APD dataset has been detailed in Section 2.2 and will not be elaborated on further here.
The VisDrone2019 dataset contains over 10,000 high-resolution aerial images captured by various drone platforms at altitudes ranging from 10 to 300 m, under different time periods and diverse meteorological conditions, encompassing multiple complex scenes. Figure 10 illustrates RS-APD dataset.
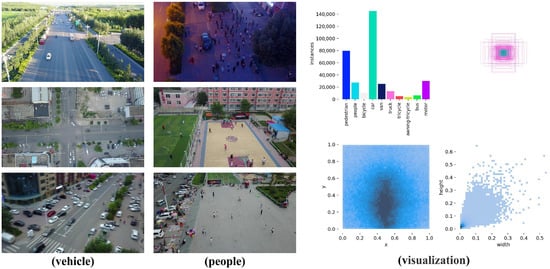
Figure 10.
Overview of the VisDrone2019 dataset.
In the VisDrone2019 dataset, objects are precisely annotated into 10 categories including pedestrians, vehicles (cars, trucks and buses), bicycles, motorcycles, etc., with over 2.7 million annotated instances in total. The dataset’s distinctive features include extremely small object sizes (averaging only 0.03% of the total image area), unbalanced distribution density (from extremely sparse to highly crowded), and complex and variable backgrounds. Particularly noteworthy is that the image resolution of VisDrone2019 dataset reaches 2000 × 1500 pixels, far exceeding conventional datasets, placing higher demands on detection algorithms’ multi-scale feature extraction capability and computational efficiency.
Our experiments were conducted on Ubuntu 20.04 operating system, with model training and testing performed using an NVIDIA GeForce RTX 3060 GPU. SGD optimizer was selected to enhance convergence efficiency throughout the training procedure.
Additionally, we innovatively adopted an input size of 1024 instead of the traditional 640. As shown in the comparative experiments in Table 1 and Figure 11, the experimental results demonstrate that increasing input resolution from 640 × 640 to 1024 × 1024 yields substantial performance improvements across both datasets without additional computational overhead, with smaller objects benefiting most significantly from higher resolution input. This finding confirms that input resolution serves as a critical determinant for small object detection performance while maintaining identical parameter count and computational complexity, thus establishing an efficient baseline for subsequent algorithmic optimizations.

Table 1.
Performance comparison of models with different input sizes.
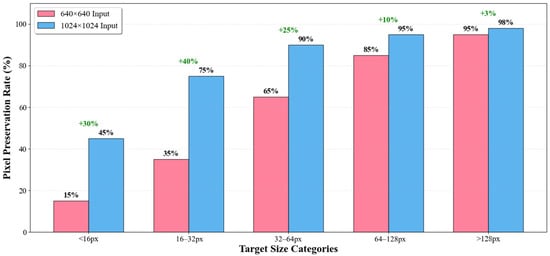
Figure 11.
Small Target Pixel Preservation Rate.
4.1.2. Experimental Evaluation Indicators
To quantitatively analyze the performance of different algorithm models and improved modules on the RS-APD dataset and VisDrone2019 dataset, we adopted mAP, AP-Small (APs), Params, and FLOPs as evaluation metrics for the experimental results.
The formula for mAP is:
And the formulas for mAP50 and mAP50:95 are:
In the MS COCO [35] standard, objects with an area smaller than 32 × 32 pixels are defined as small objects, and the AP value for such small objects is called AP-Small (APs), which is an important indicator for measuring the performance of detection models in small object detection [36].
In addition, in the ablation experiments, we will also use heat maps to visually reflect model performance. Through the Grad-CAM technique [37], the gradient of the target category on the feature map is calculated to generate corresponding heat maps that display the areas of focus for the target detection model.
4.2. Experimental Results
4.2.1. Ablation Experiment
Unified Experimental Settings:
Learning Rate: 0.01 (cosine scheduler);
Batch Size: 2 (consistent across all experiments);
Training Epochs: 300 (identical for all configurations);
Optimizer: SGD (momentum = 0.937, weight_decay = 0.0005);
No Hyperparameter Tuning: All module combinations use identical hyperparameters without any specialized optimization, ensuring performance gains are purely architectural.
To verify the effectiveness and interaction of the three key modules we proposed in remote sensing small object detection tasks, we conducted systematic ablation experiments on the RS-APD dataset. In this experiment, we labeled the three core innovation modules as A (DSSM), B (AMFE), and C (EDAM), and comprehensively evaluated the performance of different module combinations. Specifically, we tested the performance of single modules, dual module combinations, and the complete model in terms of detection accuracy (mAP50, mAP50:95), small object detection performance (APs), etc. Table 2, Figure 12 and Figure 13 show the detailed comparison results of different module combinations.
Table 2.
Ablation experiment results under identical training conditions.
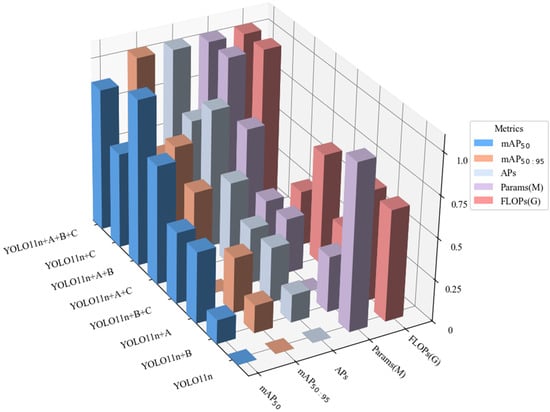
Figure 12.
Ablation experiment results under identical training conditions.
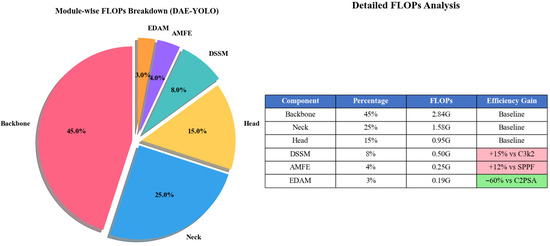
Figure 13.
Module-wise FLOP Breakdown.
The experimental results demonstrate that our three innovative modules produce evident synergistic effects when used in combination. The complete A + B + C model achieved excellent performance on key indicators: mAP50 reached 82.3%, mAP50:95 reached 44.6%, and small object detection performance (APs) reached 43.6%, representing improvements of 2.1, 2.5, and 2.8 percentage points over the baseline model, respectively. Although using module A alone or the A + B combination performed well on individual indicators, the complete model achieved optimal overall performance, especially in small object detection, which is the most challenging task. More importantly, the A + B + C model achieved these performance improvements while maintaining the same computational complexity as the baseline model, with its parameter count increased by only 0.02 M, indicating that our design highly optimized the parameter efficiency of the model architecture.
These results fully demonstrate the complementarity of the three innovative modules, which through collaborative work, jointly improved remote sensing small object detection performance without adding significant computational burden, validating the effectiveness of our complete solution.
Next, as shown in Figure 14, the YOLO11n series models demonstrated significant performance improvements in small object detection. The figure displays detection results for five different airport scenes, from left to right: the original satellite image, the YOLO11n base model, and its three progressively improved versions.

Figure 14.
Model heat map comparison.
By comparing the heat maps, we can observe progressively enhanced detection effects from the YOLO11n model to the DAE-YOLO model. The DAE-YOLO model exhibits the most concentrated and brightest heat zone distribution in all samples, indicating higher detection confidence and more precise object localization capabilities. Compared to the base model, the DAE-YOLO model shows significantly enhanced recognition capabilities for critical airport features (such as runway intersections, terminal areas, and taxiways). These areas present stronger and more reasonably distributed activation regions in the heat maps of the final model, indicating improvements in feature extraction and understanding capabilities. The performance improvements of the DAE-YOLO model remain consistent across all five airport scenes, regardless of variations in airport layout, scale, or surrounding environment. This stability highlights the robustness and adaptability of the model improvements, which are valuable for practical applications.
In summary, these improvements collectively constitute a performance-efficient detection model, providing reliable technical support for airport satellite image analysis.
4.2.2. Comparative Experiments of Different Object Detection Models
To validate the effectiveness of the baseline YOLO11n algorithm in small target detection tasks, we conducted comprehensive comparative experiments across single-stage object detection models, two-stage object detection models, and Transformer-based object detection models using both our self-constructed RS-APD dataset and the publicly available VisDrone2019 dataset. All models were trained and tested under identical hardware environments to ensure the fairness and reliability of the experimental results. Table 3 and Table 4 and Figure 15 show the comparative experimental results of the YOLO series.
Table 3.
Performance Comparison of Different Architecture Models on the RS-APD Dataset.
Table 4.
Performance Comparison of Different Architecture Models on the VisDrone2019 Dataset.
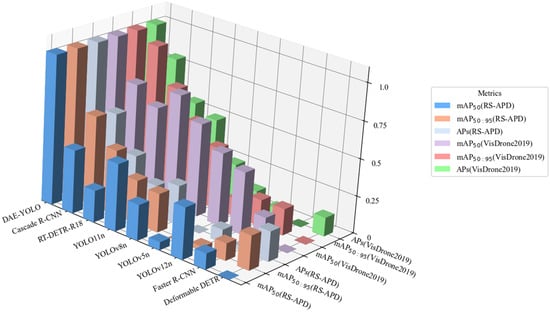
Figure 15.
Comparative experimental results of the YOLO series.
The comprehensive performance evaluation demonstrates that DAE-YOLO achieves significant improvements across all critical detection metrics while maintaining computational efficiency. In terms of detection accuracy, our model substantially outperforms baseline YOLO11n in both standard mAP50 and the more stringent mAP50:95 evaluations, indicating superior localization precision across varying IoU thresholds. Most importantly, the small object detection performance (APs) shows remarkable enhancement, directly addressing the fundamental challenge in remote sensing imagery where objects occupy minimal pixel areas. From a computational efficiency perspective, DAE-YOLO maintains competitive parameter count and actually reduces floating-point operations compared to the baseline, demonstrating the effectiveness of our architectural optimizations. The runtime performance analysis reveals that while inference speed experiences only marginal reduction, the model maintains real-time processing capability essential for practical applications. Average processing time per image remains within acceptable bounds for operational deployment, while GPU memory consumption increases minimally, ensuring compatibility with standard hardware configurations. Compared to heavyweight alternatives like two-stage detectors that achieve higher accuracy at the cost of dramatically reduced inference speed and substantially increased memory requirements, and transformer-based methods that demand excessive computational resources, DAE-YOLO strikes an optimal balance across all performance dimensions. The consistent improvements across diverse datasets validate the robustness and generalizability of our approach, conclusively establishing DAE-YOLO as a superior solution that enhances detection accuracy while preserving the computational efficiency essential for real-world remote sensing applications.
4.2.3. Comparative Experiments of C3k2 Improvements
We selected the following improvement modules to compare with our proposed DSSM in terms of small object detection performance. The comparative experimental results of the C3k2 improvement series are shown in Table 5 and Figure 16.
Table 5.
Comparative experimental results of C3k2 improvement series.
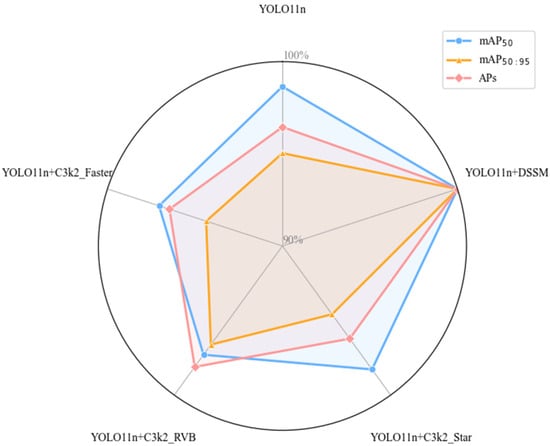
Figure 16.
Comparative experimental results of C3k2 improvement series.
- (1)
- C3k2_Star improved with StarBlock from StarNet [39];
- (2)
- C3k2_RVB improved with RepViBlock from Rep ViT [40];
- (3)
- C3k2_Faster improved with FasterBlock from FasterNet [41].
The results show that our proposed DSSM significantly enhanced model performance. In terms of evaluation metrics, compared to the baseline YOLO11n, the improved model integrating DSSM increased mAP50 from 80.2% to 81.3%, an improvement of 1.1 percentage points; on the more stringent mAP50:95 evaluation metric, it increased from 42.1% to 44.3%, an improvement of 2.2 percentage points; particularly in Small object detection performance (APs), it increased from 40.8% to 42.3%, an improvement of 1.5 percentage points. This improvement is especially important as it addresses the core challenge of small object detection.
4.2.4. Comparative Experiments of SPPF Improvements
We then selected the following improvement modules to compare them with our proposed AMFE module in terms of small object detection performance. The comparative experimental results of the SPPF improvement series are shown in Table 6 and Figure 17.
Table 6.
Comparative experimental results of SPPF improvement series.
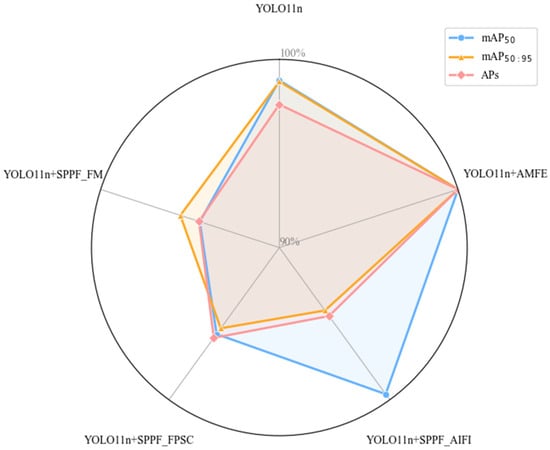
Figure 17.
Comparative experimental results of SPPF improvement series.
- (1)
- SPPF_AIFI improved with Attention-based Intrascale Feature Interaction from RT-DETR [42];
- (2)
- SPPF_FPS improved with Feature Pyramid Shared Conv from FPN [10];
- (3)
- SPPF_FM improved with FocalModulation from Focal Modulation Networks [43].
The results indicate that our proposed AMFE module achieved significant improvements across all performance indicators. Compared to YOLO11n, the improved model integrating AMFE increased mAP50 from 80.2% to 81.1%, an improvement of 0.9 percentage points; on the more challenging mAP50:95 evaluation metric, it increased from 42.1% to 42.6%, an improvement of 0.5 percentage points; particularly in Small object detection performance (APs), it increased from 40.8% to 41.8%, an improvement of 1.0 percentage point, which is crucial for remote sensing Small object detection. While achieving these performance improvements, AMFE added only a minimal number of parameters and computational complexity, maintaining the lightweight and efficient characteristics of the model. In contrast, other improvement modules such as SPPF_AIFI, although showing a slight improvement in mAP50, significantly increased parameters and actually decreased small object detection performance; SPPF_FPSC and SPPF_FM performed worse than the baseline model on multiple indicators. These comparisons fully demonstrate the unique advantages of the AMFE module in enhancing feature expression capabilities and multi-scale small object detection through its large separable convolution attention mechanism.
4.2.5. Comparative Experiments of C2PSA Improvements
Finally, we used the following improvement modules to compare them with our proposed EDAM module in terms of small object detection performance. The comparative experimental results of the C2PSA improvement series are shown in Table 7 and Figure 18.
Table 7.
Comparative experimental results of C2PSA improvement series.
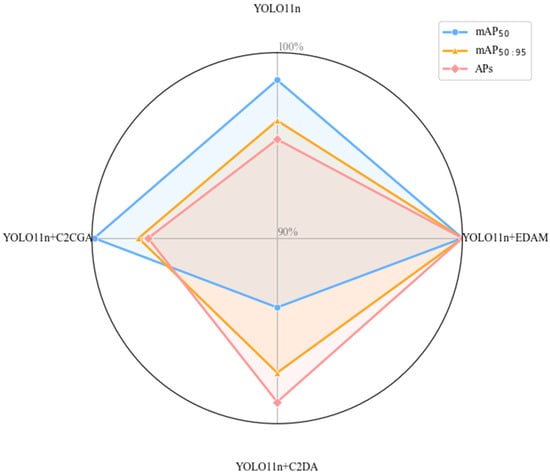
Figure 18.
Comparative experimental results of C2PSA improvement series.
- (1)
- C2DA improved with DAttention from Vision Transformer with Deformable Attention [44];
- (2)
- C2CGA improved with Cascaded Group Attention from EfficientViT [45].
The results demonstrate that EDAM module achieved optimal performance across all key performance indicators. Compared to YOLO11n model, the improved model integrating EDAM increased mAP50 from 80.2% to 81.4%, and significantly improved the more challenging mAP50:95 evaluation standard from 42.1% to 43.7%, an increase of 1.6 percentage points. In terms of small object detection performance (APs) critical for remote sensing images, the EDAM model reached 42.8%, an improvement of 2.0 percentage points over the baseline, outperforming all comparison models. While achieving these performance improvements, EDAM added only a minimal number of parameters, and the computational complexity remained unchanged, demonstrating an excellent efficiency ratio. Although C2CGA performed similarly to EDAM in terms of mAP50, it was significantly inferior in Small object detection and the more stringent mAP50:95 metric; while C2DA performed poorly in terms of mAP50, despite being relatively good in the APs metric. Results fully demonstrate that the EDAM module effectively addressed the core challenges of remote sensing small object detection through its dual-level routing attention mechanism, achieving an optimal balance between performance and efficiency.
4.2.6. Object Detection Results Visualization
We applied the DAE-YOLO model for prediction on both the RS-APD and VisDrone2019 datasets. To ensure the prediction results are clear and easy to understand, we omitted the category labels and confidence labels, showing only the detection boxes. The prediction results are shown in Figure 19 and Figure 20.
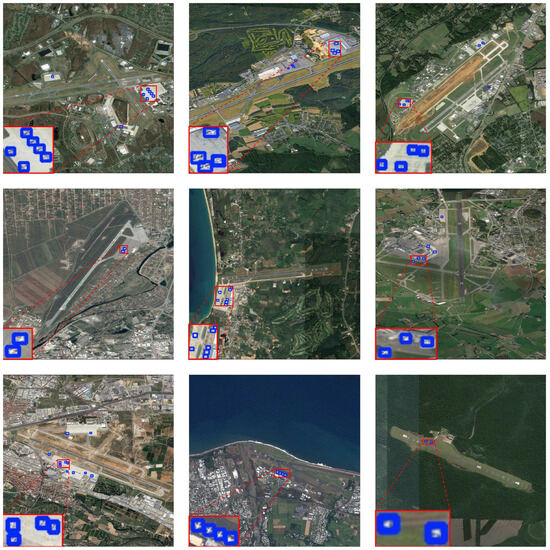
Figure 19.
RS-APD dataset prediction results.

Figure 20.
VisDrone2019 dataset prediction results.
From the prediction results shown in Figure 19, it can be seen that the DAE-YOLO model demonstrated efficient detection capabilities on the RS-APD dataset. Even under the challenging conditions where target objects are relatively small compared to the overall image in high-altitude aerial scenes, the model was still able to maintain significant detection accuracy. The model successfully identified aircraft in the images, demonstrating its stability and efficiency in high-resolution remote sensing image analysis. These results confirm that the DAE-YOLO model designed in this paper has high adaptability in remote sensing application scenarios with complex backgrounds and large-scale variations, providing reliable technical support for high-altitude object detection.
Figure 20 shows the detection results of the DAE-YOLO model on the VisDrone2019 dataset, confirming the model’s excellent performance in multi-class object detection. The model successfully achieved high-precision detection in complex and variable urban environments, and maintained stable detection performance under different lighting conditions, demonstrating its strong adaptability to environmental changes. Additionally, the model exhibited high detection robustness in handling complex scenes with different perspectives, distances, and partial occlusions. These results indicate that DAE-YOLO has significant advantages in processing multi-scale, multi-class object detection tasks in real-world environments.
5. Discussion
Systematic ablation experiments on the RS-APD dataset confirmed the effectiveness and synergistic interactions of the Dynamic Spatial Sequence Module (DSSM), Adaptive Multi-scale Feature Enhancement module (AMFE), and Efficient Dual-level Attention Mechanism (EDAM) for remote sensing small object detection. The DSSM’s global context modeling significantly enhanced long-range dependency capture, while AMFE’s multi-scale feature enhancement improved small object detection accuracy. EDAM’s efficient attention mechanism further amplified weak features in complex backgrounds, boosting overall performance. Comparative experiments on the RS-APD and VisDrone2019 datasets against eight state-of-the-art algorithms demonstrated our algorithm’s pronounced advantages in small object detection, especially in complex and diverse target scenarios. The integration of DSSM, AMFE, and EDAM achieved substantial gains in detection accuracy, computational complexity, and parameter efficiency.
6. Conclusions
This research addresses significant challenges in small object detection by presenting the DAE-YOLO model. We constructed a specialized Remote Sensing Airport-Plane Detection (RS-APD) dataset comprising 4968 high-resolution images covering over 600 airports worldwide. This dataset features diverse object densities, complex backgrounds, and arbitrary aircraft orientations, providing a robust foundation for algorithm development and evaluation.
We designed three innovative modules to address key challenges in remote sensing small object detection: the Dynamic Spatial Sequence Module, which enhances long-range dependency modeling through visual state space modeling; the Adaptive Multi-scale Feature Enhancement module, which utilizes large separable kernel attention mechanisms to improve small object perception capabilities; and the Efficient Dual-level Attention Mechanism, which reduces computational complexity through bi-level routing attention. Experimental results demonstrate that our proposed model achieves significant performance improvements compared to the YOLO11 baseline, with increases of 2.1% in mAP50 and 2.5% in mAP50:95, while APs improved by 2.8% on the RS-APD dataset. Additionally, the model exhibits excellent generalization capabilities on the VisDrone2019 dataset.
The limitations of this study include insufficient exploration of model adaptability across diverse remote sensing scenarios and the potential for further improvement in detecting extremely small objects. Addressing the unique challenges of remote sensing, such as illumination changes, weather conditions, and variations in surface reflectance, is indeed a key focus of our ongoing research. Additionally, future research will explore lightweight model design, and expand algorithmic support for more complex remote sensing image analysis tasks. Overall, this research provides an efficient and effective solution for small object detection in remote sensing imagery, advancing the practical application of related technologies in urban monitoring, aerospace surveillance, and other domains.
Author Contributions
Conceptualization, B.L., Y.D. and Z.Z.; Methodology, B.L., Y.D., S.L. and D.M.; Validation, B.L., Y.D., Z.Z. and D.M.; Formal analysis, Y.K. and S.L.; Writing—original draft, B.L.; Writing—review & editing, B.L. and Y.K.; Visualization, Y.K. and D.M.; Supervision, Y.D. and Z.Z.; Funding acquisition, S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by one grant from the National Natural Science Foundation of China (No. 62103432), two grants from the China Postdoctoral Science Foundation (No. 2022M721841 and No. 2024M764306), and the Young Talent Fund of the University Association for Science and Technology in Shannxi, China (No. 20211018).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wei, X.; Li, Z.; Wang, Y. SED-YOLO based multi-scale attention for small object detection in remote sensing. Sci. Rep. 2025, 15, 3125. [Google Scholar] [CrossRef]
- Wang, X.; Wang, A.; Yi, J.; Song, Y.; Chehri, A. Small object detection based on deep learning for remote sensing: A comprehensive review. Remote Sens. 2023, 15, 3265. [Google Scholar] [CrossRef]
- Wang, H.; Yang, H.; Chen, H.; Wang, J.; Zhou, X.; Xu, Y. A remote sensing image target detection algorithm based on improved YOLOv8. Appl. Sci. 2024, 14, 1557. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning rotation-invariant and fisher discriminative convolutional neural networks for targets detection. IEEE Trans. Image Process. 2018, 28, 265–278. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Niu, X.; Dou, Y.; Xia, F. Airport detection on optical satellite images using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1183–1187. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Open J. Appl. Sci. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3Det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Pang, J.; Li, C.; Shi, J.; Xu, Z.; Feng, H. R2-CNN: Fast Tiny targets detection in large-scale remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5512–5524. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time targets detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Kwon, Y.; Michael, K.; Changyu, L.; Fang, J.; Skalski, P.; Hogan, A.; et al. Ultralytics/Yolov5: V6.0—YOLOv5n ‘Nano’ Models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support. 2021. Available online: https://docs.ultralytics.com/zh/models/yolov5 (accessed on 5 April 2025).
- Joher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://docs.ultralytics.com/zh/models/yolov8 (accessed on 5 April 2025).
- Joher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2024. Available online: https://docs.ultralytics.com/zh/models/yolo11 (accessed on 5 April 2025).
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Targets detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Min, L.; Fan, Z.; Lv, Q.; Reda, M.; Shen, L.; Wang, B. YOLO-DCTI: Small object detection in remote sensing base on contextual transformer enhancement. Remote Sens. 2023, 15, 3970. [Google Scholar] [CrossRef]
- Lu, Y.; Sun, M. Lightweight multidimensional feature enhancement algorithm LPS-YOLO for UAV remote sensing target detection. Sci. Rep. 2025, 15, 1340. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional DETR for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3651–3660. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision Mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar] [CrossRef]
- Jiao, J.; Liu, Y.; Liu, Y.; Tian, Y.; Wang, Y.; Xie, L.; Ye, Q.; Yu, H.; Zhao, Y. VMamba: Visual state space model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Zhang, J.; Zhang, R.; Xu, L.; Lu, X.; Yu, Y.; Xu, M.; Zhao, H. FasterSal: Robust and Real-time Single-Stream Architecture for RGB-D Salient Object Detection. IEEE Trans. Multimed. 2025, 27, 2477–2488. [Google Scholar] [CrossRef]
- Zhang, R.H.; Yang, B.W.; Xu, L.X.; Huang, Y.; Xu, X.F.; Zhang, Q.; Jiang, Z.Z.; Liu, Y. A Benchmark and Frequency Compression Method for Infrared Few-Shot Object Detection. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5001711. [Google Scholar] [CrossRef]
- Zhang, R.H.; Xu, L.X.; Zheng, Y.; Shi, Y.; Mu, C.P.; Xu, M. Deep-IRTarget: An Automatic Target Detector in Infrared Imagery Using Dual-Domain Feature Extraction and Allocation. IEEE Trans. Multimed. 2022, 24, 1735–1749. [Google Scholar] [CrossRef]
- Pei, W.; Shi, Z.; Gong, K. Small target detection with remote sensing images based on an improved YOLOv5 algorithm. Front. Neurorobot. 2023, 16, 1074862. [Google Scholar] [CrossRef] [PubMed]
- Nikouei, M.; Baroutian, B.; Nabavi, S.; Taraghi, F.; Aghaei, A.; Sajedi, A.; Moghaddam, M.E. Small object detection: A Comprehensive Survey on Challenges, Techniques and Real-World Applications. arXiv 2025, arXiv:2503.20516. [Google Scholar] [CrossRef]
- Sun, H.; Yao, G.; Zhu, S.; Zhang, L.; Xu, H.; Kong, J. SOD-YOLOv10: Small Object Detection in Remote Sensing Images Based on YOLOv10. IEEE Geosci. Remote Sens. Lett. 2025, 22, 8000705. [Google Scholar] [CrossRef]
- Cao, Y.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J. VisDrone-DET2021: The vision meets drone targets detection challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, Online, 11–17 October 2021; pp. 2847–2854. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Wang, J.; Yang, W.; Guo, H.; Zhang, R.; Xia, G.-S. Tiny targets detection in aerial images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3791–3798. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 5694–5703. [Google Scholar]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Repvit: Revisiting mobile CNN from vit perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 15909–15920. [Google Scholar]
- Chen, J.; Kao, S.-H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs beat YOLOs on real-time targets detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 10–17 June 2024; pp. 16965–16974. [Google Scholar]
- Yang, J.; Li, C.; Dai, X.; Gao, J. Focal modulation networks. Adv. Neural Inf. Process. Syst. 2022, 35, 4203–4217. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision transformer with deformable attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14420–14430. [Google Scholar]




















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.