
Temporal Denoising of Infrared Images via Total Variation and Low-Rank Bidirectional Twisted Tensor Decomposition

Abstract

1. Introduction
2. Related Works
2.1. Deep Learning Methods
2.2. Traditional Video Denoising Methods
2.3. Tensor Recovery Methods
3. Notations and Preliminaries
3.1. Notations
3.2. Anisotropic Spatiotemporal Total Variation Regularization
3.3. t-SVD and Rank Approximation Based on Laplace Operator
| Algorithm 1: t-SVD of a 3D Tensor |
| Input: 1. 2. for i = 1 to n3 Do 3. 4. End Do 5. , , Output: Orthogonal Tensors and , Diagonal Tensor |
4. Proposed Model
4.1. Bidirectional t-TNN in Spatiotemporal Domain
- Processing image data from a higher dimension allows for better utilization of potential information between image frames.
- By incorporating temporal information, the tensor-based denoising method can effectively suppress noise and improve the denoising results.
- Matrix processing methods such as total variation and low-rank decomposition can be extended to tensors. Many processing methods are available for tensor data.
4.2. Tensor Decomposition Based on Bidirectional Twisted Laplacian Nuclear Norm and Spatiotemporal Total Variation
4.3. Spatial Detail Recovery from Noise via RPCA
4.4. Optimization Procedure
| Algorithm 2: ADMM of (16) |
| Input: , η, ε Output: , Step 1: Step 2: Calculate the for each temporal slice through the following process. for do 1. 2. 3. end for for do end for Step 3: Calculate |
| Algorithm 3: bt-LPTVTD TRN denoise algorithm |
| Input: Image sequence , The number of images, n3, for building tensors, parameters λ, β, and μ greater than 0. Output: Denoised Tensor + , Noise Tensor . 1: Build tensor from image sequence. 2: Initialize: , , i = 1, 2, …, 5, , , k = 0, , . 3: While: not convergence do 4: Calculate the twisted tensor . Use the horizontally twisted tensor when k is odd, and use the vertically twisted tensor when k is even. 5: Using Algorithm 2 to update and obtain squeezing tensor . 6: Update using Formula (20). 7: Update , and using Formula (22). 8: Update using Formula (24). 9: Update M1, M2, M3, M4, and M5 using Formula (25). 10: Update μ using Formula (26). 11: Check the convergence conditions 12: k = k + 1. 13: end while 14: Construct by reducing the dimensionality of , separating the spatial and temporal domains into different dimensions. 15: Use RPCA to decompose into and . 16: Restore and to 3D tensors and , respectively. |
4.5. Image Sequence Denoising Procedure
- (1)
- Tensor Construction: For an image sequence , consecutive images are combined to form the original image sequence tensor, . For best results, is recommended to be between 30 and 50, balancing denoising and computation.
- (2)
- Algorithm 3 is used to decompose the original image sequence tensor into denoised image sequence tensor and noise tensor .
- (3)
- Detail Extraction: RPCA is used to decompose into a low-rank tensor and a noise tensor , thereby obtaining the denoised image sequence tensor + and completing the temporal denoising of n3 consecutive images.
- (4)
- Iterative Processing: The next consecutive images are combined into a new tensor. The above steps are then repeated to denoise the continuous image data flow block-wise. It is important to note that adjacent tensors are processed using the same set of parameters, ensuring consistency across the entire image sequence (this is valid when the noise intensity and scene information approximately constant).
4.6. Complexity Analysis
4.7. Convergence Analysis
5. Experimental Results and Analyses
5.1. Simulation Experiments
5.1.1. Experimental Settings
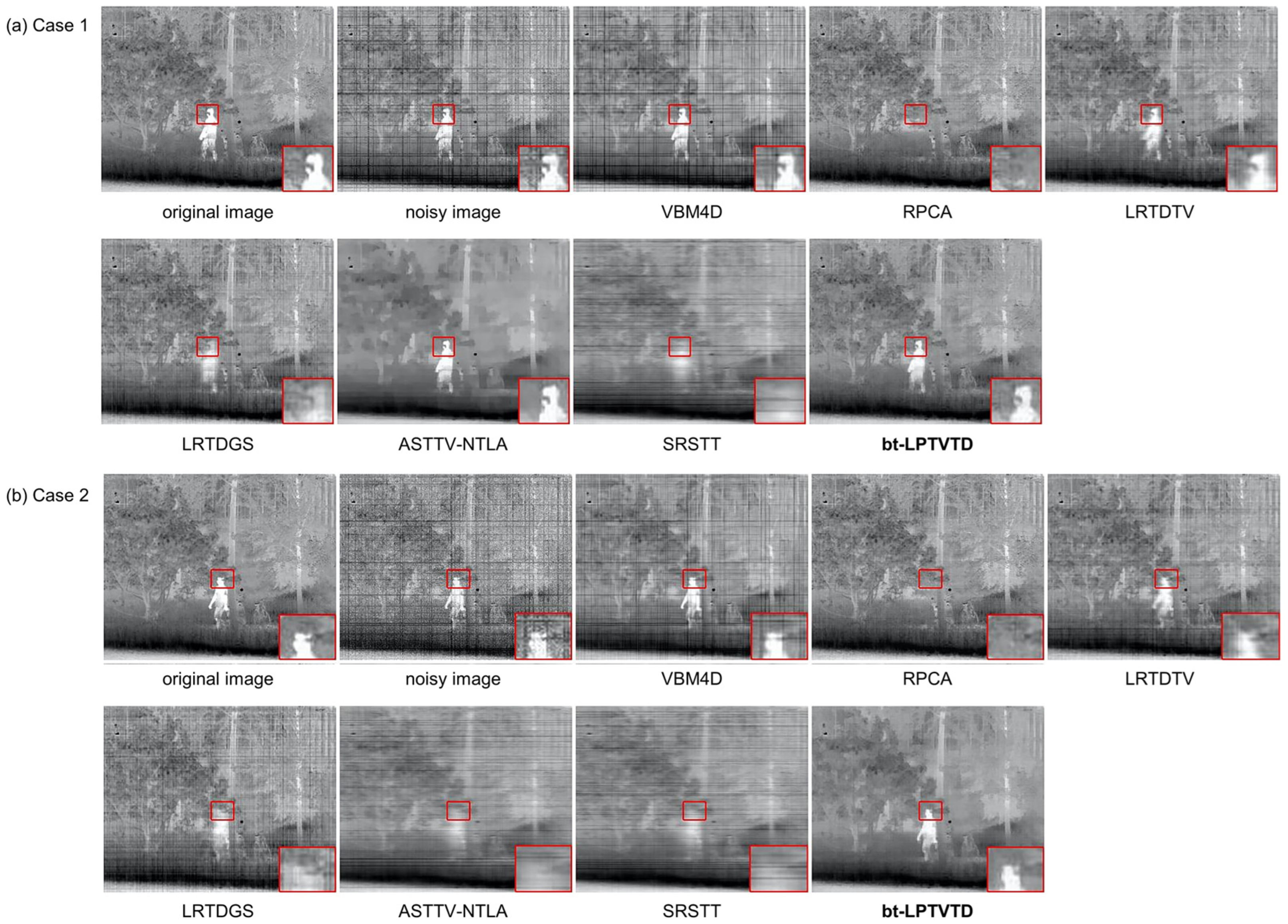
5.1.2. Subjective Evaluation
5.1.3. Quantitative Evaluation
5.2. Real Experiments
5.3. bt-LPTVTD for Visible Image Denoising
5.4. Ablation Study
5.5. Running Time
6. Discussion
7. Conclusions
- (1)
- A bidirectional twisted tensor truncated nuclear norm based on the Laplacian operator combined with a weighted spatiotemporal total variation regularization nonconvex tensor approximation method is proposed. The bidirectional twisted tensor can better capture temporal information while preserving horizontal and vertical spatial information. The improved tensor recovery estimation method demonstrates more significant TRN suppression and more effectively preserves moving-target details.
- (2)
- To recover spatial information that may be lost during the tensor estimation process, RPCA is further utilized to extract spatial information from the noise tensor. As a result, the proposed method achieves improved detail recovery for the static components of the scene.
- (3)
- An augmented Lagrange multiplier algorithm is designed to solve the proposed bt-LPTVTD model.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Planinsic, G. Infrared Thermal Imaging: Fundamentals, Research and Applications. Eur. J. Phys. 2011, 32, 1431. [Google Scholar] [CrossRef]
- Rogalski, A. Infrared detectors: An overview. Infrared Phys. Technol. 2002, 43, 187–210. [Google Scholar] [CrossRef]
- Kruer, M.R.; Scribner, D.A.; Killiany, J.M. Infrared Focal Plane Array Technology Development for Navy Applications. Opt. Eng. 1987, 26, 263182. [Google Scholar] [CrossRef]
- Qu, Z.; Jiang, P.; Zhang, W. Development and Application of Infrared Thermography Non-Destructive Testing Techniques. Sensors 2020, 20, 3851. [Google Scholar] [CrossRef] [PubMed]
- Kaltenbacher, E.; Hardie, R.C. High Resolution Infrared Image Reconstruction Using Multiple, Low Resolution, Aliased Frames. In Proceedings of the IEEE 1996 National Aerospace and Electronics Conference NAECON 1996, Dayton, OH, USA, 20–22 May 1996; Volume 2, pp. 702–709. [Google Scholar]
- Ring, E.F.J.; Ammer, K. Infrared thermal imaging in medicine. Physiol. Meas. 2012, 33, R33–R46. [Google Scholar] [CrossRef]
- Jing, Z.; Li, S.; Zhang, Q. YOLOv8-STE: Enhancing Object Detection Performance Under Adverse Weather Conditions with Deep Learning. Electronics 2024, 13, 5049. [Google Scholar] [CrossRef]
- Scribner, D.A.; Kruer, M.R.; Killiany, J.M. Infrared focal plane array technology. Proc. IEEE 1991, 79, 66–85. [Google Scholar] [CrossRef]
- Rogalski, A. Infrared detectors: Status and trends. Prog. Quantum Electron. 2003, 27, 59–210. [Google Scholar] [CrossRef]
- Feng, T.; Jin, W.-Q.; SI, J.-J.; Zhang, H.-J. Optimal theoretical study of the pixel structure and spatio-temporal random noise of uncooled IRFPA. J. Infrared Millim. Waves 2020, 39, 143–148. [Google Scholar]
- Yuan, P.; Tan, Z.; Zhang, X.; Wang, M.; Jin, W.; Li, L.; Su, B. Fixed-pattern noise model for filters in uncooled infrared focal plane array imaging optical paths. Infrared Phys. Technol. 2023, 133, 104790. [Google Scholar] [CrossRef]
- Steffanson, M.; Gorovoy, K.; Holz, M.; Ivanov, T.; Kampmann, R.; Kleindienst, R.; Sinzinger, S.; Rangelow, I.W. Low-Cost Uncooled Infrared Detector Using Thermomechanical Micro-Mirror Array with Optical Readout. In Proceedings of the Proceedings IRS2 2013, Nurnberg, Germany, 14–16 May 2013; AMA Service GmbH: Wunstorf, Germany, 2013; pp. 85–88. [Google Scholar]
- Zhang, Y.; Chen, X.; Rao, P.; Jia, L. Dim Moving Multi-Target Enhancement with Strong Robustness for False Enhancement. Remote Sens. 2023, 15, 4892. [Google Scholar] [CrossRef]
- Wang, Y.; Pan, N.; Jiang, P. Anisotropic Filtering Based on the WY Distribution and Multiscale Energy Concentration Accumulation Method for Dim and Small Target Enhancement. Remote Sens. 2024, 16, 3069. [Google Scholar] [CrossRef]
- Aliha, A.; Liu, Y.; Zhou, G.; Hu, Y. High-Speed Spatial–Temporal Saliency Model: A Novel Detection Method for Infrared Small Moving Targets Based on a Vectorized Guided Filter. Remote Sens. 2024, 16, 1685. [Google Scholar] [CrossRef]
- Lu, X.; Li, F. Study of Robust Visual Tracking Based on Traditional Denoising Methods and CNN. In Proceedings of the 2021 International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Chengdu, China, 18–20 June 2021; pp. 392–396. [Google Scholar]
- Li, J.; Wang, W.; Tivnan, M.; Stayman, J.W.; Gang, G.J. Performance Assessment Framework for Neural Network Denoising. In Proceedings of the Medical Imaging 2022: Physics of Medical Imaging; Zhao, W., Yu, L., Eds.; SPIE: San Diego, CA, USA, 2022; p. 64. [Google Scholar]
- Huang, Y.; Sun, G.; Xing, M. A SAR Image Denoising Method for Target Shadow Tracking Task. In Proceedings of the 6th International Conference on Digital Signal Processing, Chengdu China, 25–27 February 2022; ACM: New York, NY, USA, 2022; pp. 164–169. [Google Scholar]
- Tang, J.; Zhang, F.; Ma, F.; Gao, F.; Yin, Q.; Zhou, Y. How SAR Image Denoise Affects the Performance of DCNN-Based Target Recognition Method. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 3609–3612. [Google Scholar]
- Liu, X.; Bourennane, S.; Fossati, C. Reduction of Signal-Dependent Noise from Hyperspectral Images for Target Detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5396–5411. [Google Scholar] [CrossRef]
- Endo, K.; Yamamoto, K.; Ohtsuki, T. A Denoising Method Using Deep Image Prior to Human-Target Detection Using MIMO FMCW Radar. Sensors 2022, 22, 9401. [Google Scholar] [CrossRef]
- Wei, Y.; Sun, B.; Zhou, Y.; Wang, H. Non-Line-of-Sight Moving Target Detection Method Based on Noise Suppression. Remote Sens. 2022, 14, 1614. [Google Scholar] [CrossRef]
- Sun, Q.; Liu, X.; Bourennane, S.; Liu, B. Multiscale denoising autoencoder for improvement of target detection. Int. J. Remote Sens. 2021, 42, 3002–3016. [Google Scholar] [CrossRef]
- Hou, F.; Zhang, Y.; Zhou, Y.; Zhang, M.; Lv, B.; Wu, J. Review on Infrared Imaging Technology. Sustainability 2022, 14, 11161. [Google Scholar] [CrossRef]
- Li, Y.; Jin, W.; Zhu, J.; Zhang, X.; Li, S. An Adaptive Deghosting Method in Neural Network-Based Infrared Detectors Nonuniformity Correction. Sensors 2018, 18, 211. [Google Scholar] [CrossRef]
- Li, Y.; Jin, W.; Liu, Z. Interior Radiation Noise Reduction Method Based on Multiframe Processing in Infrared Focal Plane Arrays Imaging System. IEEE Photonics J. 2018, 10, 6803512. [Google Scholar] [CrossRef]
- Li, Y.; Jin, W.; Li, S.; Zhang, X.; Zhu, J. A method of sky ripple residual nonuniformity reduction for a cooled infrared imager and hardware implementation. Sensors 2017, 17, 1070. [Google Scholar] [CrossRef] [PubMed]
- Lv, B.; Tong, S.; Liu, Q.; Sun, H. Statistical Scene-Based Non-Uniformity Correction Method with Interframe Registration. Sensors 2019, 19, 5395. [Google Scholar] [CrossRef]
- Sheng, Y.; Dun, X.; Jin, W.; Zhou, F.; Wang, X.; Mi, F.; Xiao, S. The On-Orbit Non-Uniformity Correction Method with Modulated Internal Calibration Sources for Infrared Remote Sensing Systems. Remote Sens. 2018, 10, 830. [Google Scholar] [CrossRef]
- Rota, C.; Buzzelli, M.; Bianco, S.; Schettini, R. Video restoration based on deep learning: A comprehensive survey. Artif. Intell. Rev. 2023, 56, 5317–5364. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Fan, Y.; Zhang, K.; Ranjan, R.; Li, Y.; Timofte, R.; Van Gool, L. Vrt: A video restoration transformer. arXiv 2022, arXiv:2201.12288. [Google Scholar] [CrossRef] [PubMed]
- Tassano, M.; Delon, J.; Veit, T. FastDVDnet: Towards Real-Time Deep Video Denoising Without Flow Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1351–1360. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Tassano, M.; Delon, J.; Veit, T. DVDNET: A Fast Network for Deep Video Denoising. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, China, 22–25 September 2019; pp. 1805–1809. [Google Scholar]
- Sheth, D.Y.; Mohan, S.; Vincent, J.L.; Manzorro, R.; Crozier, P.A.; Khapra, M.M.; Simoncelli, E.P.; Fernandez-Granda, C. Unsupervised Deep Video Denoising. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 1759–1768. [Google Scholar]
- Chan, K.C.K.; Zhou, S.; Xu, X.; Loy, C.C. BasicVSR\mathplus\mathplus: Improving Video Super-Resolution with Enhanced Propagation and Alignment. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Song, M.; Zhang, Y.; Aydın, T.O. TempFormer: Temporally Consistent Transformer for Video Denoising. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 481–496. [Google Scholar]
- Menghani, G. Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better. ACM Comput. Surv. 2023, 55, 259. [Google Scholar] [CrossRef]
- Maggioni, M.; Boracchi, G.; Foi, A.; Egiazarian, K. Video Denoising, Deblocking, and Enhancement Through Separable 4-D Nonlocal Spatiotemporal Transforms. IEEE Trans. Image Process. 2012, 21, 3952–3966. [Google Scholar] [CrossRef]
- Maggioni, M.; Katkovnik, V.; Egiazarian, K.; Foi, A. Nonlocal Transform-Domain Filter for Volumetric Data Denoising and Reconstruction. IEEE Trans. Image Process. 2013, 22, 119–133. [Google Scholar] [CrossRef]
- Sutour, C.; Deledalle, C.-A.; Aujol, J.-F. Adaptive Regularization of the NL-Means: Application to Image and Video Denoising. IEEE Trans. Image Process. 2014, 23, 3506–3521. [Google Scholar] [CrossRef]
- Arias, P.; Morel, J.-M. Video Denoising via Empirical Bayesian Estimation of Space-Time Patches. J. Math. Imaging Vis. 2018, 60, 70–93. [Google Scholar] [CrossRef]
- Li, M.; Liu, J.; Sun, X.; Xiong, Z. Image/Video Restoration via Multiplanar Autoregressive Model and Low-Rank Optimization. ACM Trans. Multimed. Comput. Commun. Appl. 2019, 15, 102. [Google Scholar] [CrossRef]
- Ji, H.; Liu, C.; Shen, Z.; Xu, Y. Robust video denoising using low rank matrix completion. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1791–1798. [Google Scholar]
- Zhang, X.; Yuan, X.; Carin, L. Nonlocal Low-Rank Tensor Factor Analysis for Image Restoration. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8232–8241. [Google Scholar]
- Shen, B.; Kamath, R.R.; Choo, H.; Kong, Z. Robust Tensor Decomposition Based Background/Foreground Separation in Noisy Videos and Its Applications in Additive Manufacturing. IEEE Trans. Autom. Sci. Eng. 2021, 20, 583–596. [Google Scholar] [CrossRef]
- Gui, L.; Cui, G.; Zhao, Q.; Wang, D.; Cichocki, A.; Cao, J. Video Denoising Using Low Rank Tensor Decomposition. In Proceedings of the Ninth International Conference on Machine Vision (ICMV 2016), Nice, France, 18–20 November 2016; SPIE: San Diego, CA, USA, 2017; Volume 10341, pp. 162–166. [Google Scholar]
- Fan, H.; Li, C.; Guo, Y.; Kuang, G.; Ma, J. Spatial–Spectral Total Variation Regularized Low-Rank Tensor Decomposition for Hyperspectral Image Denoising. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6196–6213. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, J.; Zhao, Q.; Leung, Y.; Zhao, X.-L.; Meng, D. Hyperspectral Image Restoration Via Total Variation Regularized Low-Rank Tensor Decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1227–1243. [Google Scholar] [CrossRef]
- Li, J.; Zhang, P.; Zhang, L.; Zhang, Z. Sparse Regularization-Based Spatial–Temporal Twist Tensor Model for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5000417. [Google Scholar] [CrossRef]
- Liu, T.; Yang, J.; Li, B.; Xiao, C.; Sun, Y.; Wang, Y.; An, W. Nonconvex Tensor Low-Rank Approximation for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614718. [Google Scholar] [CrossRef]
- Lee, C.; Wang, M. Tensor Denoising and Completion Based on Ordinal Observations. In InInternational Conference on Machine Learning; PMLR: New York, NY, USA, 2020; pp. 5778–5788. [Google Scholar]
- Gong, X.; Chen, W.; Chen, J.; Ai, B. Tensor Denoising Using Low-Rank Tensor Train Decomposition. IEEE Signal Process. Lett. 2020, 27, 1685–1689. [Google Scholar] [CrossRef]
- Bi, Y.; Lu, Y.; Long, Z.; Zhu, C.; Liu, Y. Tensors for Data Processing; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Claus, M.; Gemert, J.V. ViDeNN: Deep Blind Video Denoising. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019; pp. 1843–1852. [Google Scholar]
- Monakhova, K.; Richter, S.R.; Waller, L.; Koltun, V. Dancing Under the Stars: Video Denoising in Starlight. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 16220–16230. [Google Scholar]
- Wu, C.; Gao, T. Image Denoise Methods Based on Deep Learning. J. Phys. Conf. Ser. 2021, 1883, 012112. [Google Scholar] [CrossRef]
- Reeja, S.R.; Kavya, N.P. Real Time Video Denoising. In Proceedings of the 2012 IEEE International Conference on Engineering Education: Innovative Practices and Future Trends (AICERA), Kottayam, India, 19–21 July 2012; pp. 1–5. [Google Scholar]
- Han, J.; Kopp, T.; Xu, Y. An estimation-theoretic approach to video denoiseing. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4273–4277. [Google Scholar]
- Ponomaryov, V.I.; Montenegro-Monroy, H.; Gallegos-Funes, F.; Pogrebnyak, O.; Sadovnychiy, S. Fuzzy color video filtering technique for sequences corrupted by additive Gaussian noise. Neurocomputing 2015, 155, 225–246. [Google Scholar] [CrossRef]
- Samantaray, A.; Bhattacharya, S. Fast Trilateral Filtering for Video Denoising. In Proceedings of the 2020 IEEE 5th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 30–31 October 2020; pp. 554–558. [Google Scholar]
- Hu, W.; Tao, D.; Zhang, W.; Xie, Y.; Yang, Y. The Twist Tensor Nuclear Norm for Video Completion. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2961–2973. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Y.; Zhou, G.; Zhao, Q.; Xie, S. Noisy Tensor Completion via Low-Rank Tensor Ring. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 1127–1141. [Google Scholar] [CrossRef]
- Chen, Y.; He, W.; Yokoya, N.; Huang, T.-Z. Hyperspectral Image Restoration Using Weighted Group Sparsity-Regularized Low-Rank Tensor Decomposition. IEEE Trans. Cybern. 2020, 50, 3556–3570. [Google Scholar] [CrossRef]
- Hu, T.; Li, W.; Liu, N.; Tao, R.; Zhang, F.; Scheunders, P. Hyperspectral Image Restoration Using Adaptive Anisotropy Total Variation and Nuclear Norms. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1516–1533. [Google Scholar] [CrossRef]
- Zheng, Y.-B.; Huang, T.-Z.; Zhao, X.-L.; Jiang, T.-X.; Ma, T.-H.; Ji, T.-Y. Mixed Noise Removal in Hyperspectral Image via Low-Fibered-Rank Regularization. IEEE Trans. Geosci. Remote Sens. 2020, 58, 734–749. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, J.; Long, Y.; An, W. Infrared Small Target Detection via Spatial-Temporal Total Variation Regularization and Weighted Tensor Nuclear Norm. IEEE Access 2019, 7, 56667–56682. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, L.; Wang, X.; Shen, F.; Pu, T.; Fei, C. Edge and Corner Awareness-Based Spatial–Temporal Tensor Model for Infrared Small-Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10708–10724. [Google Scholar] [CrossRef]
- Li, X.; Ye, Y.; Xu, X. Low-Rank Tensor Completion with Total Variation for Visual Data Inpainting. Proc. AAAI Conf. Artif. Intell. 2017, 31, 2210–2216. [Google Scholar] [CrossRef]
- He, W.; Yokoya, N.; Yuan, L.; Zhao, Q. Remote Sensing Image Reconstruction Using Tensor Ring Completion and Total Variation. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8998–9009. [Google Scholar] [CrossRef]
- Wang, Y.; Lin, L.; Zhao, Q.; Yue, T.; Meng, D.; Leung, Y. Compressive Sensing of Hyperspectral Images via Joint Tensor Tucker Decomposition and Weighted Total Variation Regularization. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2457–2461. [Google Scholar] [CrossRef]
- Xu, T.; Huang, T.-Z.; Deng, L.-J.; Zhao, X.-L.; Huang, J. Hyperspectral Image Superresolution Using Unidirectional Total Variation with Tucker Decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4381–4398. [Google Scholar] [CrossRef]
- Sun, L.; Zhan, T.; Wu, Z.; Jeon, B. A Novel 3D Anisotropic Total Variation Regularized Low Rank Method for Hyperspectral Image Mixed Denoising. ISPRS Int. J. Geo-Inf. 2018, 7, 412. [Google Scholar] [CrossRef]
- Xu, W.-H.; Zhao, X.-L.; Ji, T.-Y.; Miao, J.-Q.; Ma, T.-H.; Wang, S.; Huang, T.-Z. Laplace function based nonconvex surrogate for low-rank tensor completion. Signal Process. Image Commun. 2019, 73, 62–69. [Google Scholar] [CrossRef]
- Goyette, N.; Jodoin, P.-M.; Porikli, F.; Konrad, J.; Ishwar, P. Changedetection.net: A New Change Detection Benchmark Dataset. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Rhode Island, RI, USA, 16–21 June 2012; pp. 1–8. [Google Scholar]
- Wen, F.; Ying, R.; Liu, P.; Qiu, R.C. Robust PCA Using Generalized Nonconvex Regularization. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1497–1510. [Google Scholar] [CrossRef]
- Boyd, S. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. FNT Mach. Learn. 2010, 3, 1–122. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Explanations |
|---|---|
| Tensor/Matrix/Vector/Scalar | |
| The (i, j, k)-th element | |
| or | Temporal/Vertical/Horizontal slice |
| The i-th iteration value of | |
| Mode-i decomposition of tensor | |
| Inner product of tensors and | |
| Frobenius norm of tensor | |
| Nuclear norm of tensor , the sum of all singular values | |
| The Mode-n product of and , represented in matrix form as | |
| The twisted tensor of |
| Comparative Algorithms | Parameter Settings | Output Data | |
|---|---|---|---|
| 2D algorithm expansion | VBM4D | profile = ‘np’, do_wiener = 0, sharpen = 1, deflicker = 0.5, verbose = 1, est_noise = 1 | Denoised Tensor |
| RPCA | λ = 0.003 | Denoised Tensor , Noise Tensor | |
| Hyperspectral image denoising algorithms | LRTDTV | τ = 1, λ = 100,000, β = 100 | Denoised Tensor , Noise Tensor + |
| LRTDGS | λ1 = 0.8, λ2 = 10 | Denoised Tensor , Noise Tensor + | |
| Small object detection algorithms | ASTTV-NTLA | λtv = 0.01, λs = 0.1, λ3 = 0.5 | Denoised Tensor + , Noise Tensor |
| SRSTT | λ1 = 10,000, λ2 = 0.1, λ3 = 0.5 | Denoised Tensor + , Noise Tensor | |
| The proposed algorithm | bt-LPTVTD | λ = 0.0005, β = 0.01, λN = 0.003 | Denoised Tensor + , Noise Tensor |
| Datasets | Cases | Index | Noisy | VBM4D | RPCA | LRTDTV | LRTDGS | ASTTV-NTLA | SRSTT | bt-LPTVTD |
|---|---|---|---|---|---|---|---|---|---|---|
| Infrared Dataset 1 (Static) | Case 1 | PSNR | 21.2587 | 21.9832 | 28.1573 | 24.6760 | 26.8218 | 23.8302 | 22.6063 | 26.7460 |
| SSIM | 0.6020 | 0.5907 | 0.9083 | 0.8306 | 0.8169 | 0.6654 | 0.6123 | 0.8754 | ||
| Case 2 | PSNR | 19.9059 | 22.5059 | 23.3729 | 24.6535 | 23.7046 | 22.4778 | 22.6332 | 25.1003 | |
| SSIM | 0.4713 | 0.6059 | 0.8961 | 0.8226 | 0.7815 | 0.6049 | 0.6115 | 0.8707 | ||
| Infrared Dataset 2 (Moving Target) | Case 1 | PSNR | 21.1069 | 21.9183 | 25.7344 | 24.6713 | 26.7003 | 24.5505 | 22.6308 | 27.0484 |
| SSIM | 0.4859 | 0.4851 | 0.8728 | 0.7748 | 0.7640 | 0.6876 | 0.5340 | 0.8358 | ||
| Case 2 | PSNR | 19.9271 | 22.6795 | 22.2955 | 24.6825 | 23.7482 | 22.5716 | 22.6049 | 25.3411 | |
| SSIM | 0.3607 | 0.5257 | 0.8602 | 0.7723 | 0.7087 | 0.5393 | 0.5373 | 0.8858 | ||
| Infrared Dataset 3 (Moving Camera) | Case 1 | PSNR | 21.2205 | 21.8206 | 20.8103 | 23.0913 | 24.1542 | 23.7634 | 21.5072 | 24.8054 |
| SSIM | 0.5051 | 0.5157 | 0.5314 | 0.6505 | 0.6100 | 0.7084 | 0.4923 | 0.7374 | ||
| Case 2 | PSNR | 19.8845 | 22.6072 | 19.7699 | 23.0571 | 22.6151 | 21.5046 | 21.4709 | 23.0607 | |
| SSIM | 0.3751 | 0.5646 | 0.5095 | 0.6388 | 0.5797 | 0.4912 | 0.4885 | 0.6556 |
| Datasets | Index | Noisy | VBM4D | RPCA | LRTDTV | LRTDGS | ASTTV-NTLA | SRSTT | bt-LPTVTD |
|---|---|---|---|---|---|---|---|---|---|
| Visible Dataset 1 (Static) | PSNR | 23.0471 | 33.2106 | 30.9034 | 32.0976 | 31.8630 | 28.6229 | 25.6912 | 32.3759 |
| SSIM | 0.5107 | 0.9061 | 0.9076 | 0.9065 | 0.8998 | 0.8151 | 0.7838 | 0.9147 | |
| Visible Dataset 2 (Moving Target) | PSNR | 23.0788 | 31.8301 | 23.6049 | 27.0679 | 26.7372 | 27.0442 | 22.8561 | 30.3463 |
| SSIM | 0.5384 | 0.8993 | 0.7728 | 0.8057 | 0.7969 | 0.7901 | 0.6888 | 0.8894 | |
| Visible Dataset 3 (Moving Camera) | PSNR | 23.0618 | 29.9263 | 19.6028 | 24.9982 | 24.6559 | 26.1916 | 20.8633 | 28.4749 |
| SSIM | 0.5149 | 0.8767 | 0.5144 | 0.7269 | 0.7032 | 0.7720 | 0.5407 | 0.8506 |
| Datasets | Index | Noisy Image | With Bidirectional Twisted Tensor | Without Bidirectional Twisted Tensor |
|---|---|---|---|---|
| Visible Dataset 1 (Static) | PSNR | 23.043 | 32.6948 | 32.3837 |
| SSIM | 0.5132 | 0.9241 | 0.9216 | |
| Running time (s) | / | 69.6815 | 99.5749 | |
| Visible Dataset 2 (Moving Target) | PSNR | 23.0728 | 29.5692 | 28.8052 |
| SSIM | 0.5463 | 0.8857 | 0.8705 | |
| Running time (s) | / | 70.9823 | 94.9965 | |
| Visible Dataset 3 (Moving Camera) | PSNR | 23.0702 | 28.926 | 28.0386 |
| SSIM | 0.5109 | 0.8684 | 0.8456 | |
| Running time (s) | / | 69.9584 | 101.4699 |
| Datasets | Index | Noisy Image | With Bidirectional Twisted Tensor | Without Bidirectional Twisted Tensor |
|---|---|---|---|---|
| Visible Dataset 1 (Static) | PSNR | 23.043 | 32.6948 | 28.9195 |
| SSIM | 0.5132 | 0.9241 | 0.7755 | |
| Visible Dataset 2 (Moving Target) | PSNR | 23.0728 | 29.5692 | 27.5202 |
| SSIM | 0.5463 | 0.8857 | 0.7683 | |
| Visible Dataset 3 (Moving Camera) | PSNR | 23.0702 | 28.926 | 27.5034 |
| SSIM | 0.5109 | 0.8684 | 0.7470 |
| Datasets | Index | Noisy Image | With Bidirectional Twisted Tensor | Without Bidirectional Twisted Tensor |
|---|---|---|---|---|
| Visible Dataset 1 (Static) | PSNR | 23.043 | 32.6948 | 29.4027 |
| SSIM | 0.5132 | 0.9241 | 0.8487 | |
| Visible Dataset 2 (Moving Target) | PSNR | 23.0728 | 29.5692 | 28.0195 |
| SSIM | 0.5463 | 0.8857 | 0.8419 | |
| Visible Dataset 3 (Moving Camera) | PSNR | 23.0702 | 28.926 | 28.8142 |
| SSIM | 0.5109 | 0.8684 | 0.8654 |
| Methods | VBM4D | RPCA | LRTDTV | LRTDGS | ASTTV-NTLA | SRSTT | bt-LPTVTD |
|---|---|---|---|---|---|---|---|
| Running time | 6.7856 | 1.4288 | 11.1344 | 7.8910 | 11.8338 | 29.0100 | 2.0809 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Jin, W.; Li, L. Temporal Denoising of Infrared Images via Total Variation and Low-Rank Bidirectional Twisted Tensor Decomposition. Remote Sens. 2025, 17, 1343. https://doi.org/10.3390/rs17081343
Liu Z, Jin W, Li L. Temporal Denoising of Infrared Images via Total Variation and Low-Rank Bidirectional Twisted Tensor Decomposition. Remote Sensing. 2025; 17(8):1343. https://doi.org/10.3390/rs17081343
Chicago/Turabian StyleLiu, Zhihao, Weiqi Jin, and Li Li. 2025. "Temporal Denoising of Infrared Images via Total Variation and Low-Rank Bidirectional Twisted Tensor Decomposition" Remote Sensing 17, no. 8: 1343. https://doi.org/10.3390/rs17081343
APA StyleLiu, Z., Jin, W., & Li, L. (2025). Temporal Denoising of Infrared Images via Total Variation and Low-Rank Bidirectional Twisted Tensor Decomposition. Remote Sensing, 17(8), 1343. https://doi.org/10.3390/rs17081343