1. Introduction
Since 2010, China has been implementing the High-resolution Earth Observation System (HRES) project, which has launched a large number of high-resolution satellites and established a sophisticated and advanced high-resolution remote sensing system. This has resulted in a vast amount of valuable remote sensing imagery being transmitted back to the ground, leading to a significant improvement in both the quantity and quality of remote sensing data obtained by China. The massive amount of remote sensing data has played a crucial role in various fields, such as urban detection and planning, building 3D reconstruction [
1], and ground object recognition and classification [
2,
3,
4]. In recent years, deep learning methods have been applied in remote sensing, especially in computer vision tasks such as semantic segmentation, which has become a common application in remote sensing imagery analysis. The pixel-wise classification map obtained from semantic segmentation is of great significance, as it can be used to classify urban land, agricultural land, water areas, and vegetation areas [
5], which can be utilized to calculate forest coverage. Additionally, the identification of buildings and roads [
6] can provide reference information for urban planning and construction.
Semantic segmentation can achieve precise interpretation of remote sensing images. In recent years, significant breakthroughs have been made in deep neural network research, which has promoted the vigorous development of the semantic segmentation field. For example, classical convolutional neural network (CNN) architectures, such as FCN [
7] and UNet [
8], perform pixel-level classification using an encoder–decoder framework. However, these methods have limitations in handling complex multi-scale objects and struggle to effectively leverage specific spectral band information in multispectral data. To address these challenges, researchers have incorporated attention mechanisms and Transformer [
9] architectures to enhance the integration of global and local information. For instance, SegFormer [
10] utilizes Transformers as encoders, overcoming the limitations of traditional convolutional networks in modeling long-range dependencies and multi-scale features. Nevertheless, compared to ordinary images, multispectral remote sensing images exhibit greater scale variability, more spectral bands, and more complex details, which lead to the following shortcomings in existing semantic segmentation methods when applied to multispectral remote sensing images:
- 1.
The problem of model training being unable to adapt to scale variations and difficult to train, which is caused by the large-scale variations and imbalanced sample categories in remote sensing images.
- 2.
The low accuracy of some typical land cover segmentation, especially for vegetation and water bodies, is due to the confusion between special bands and visible light in multispectral images, resulting in the loss of information from special bands.
- 3.
The current algorithms have difficulty balancing local and global information, and cannot achieve good results in both detailed segmentation and global segmentation simultaneously. This is due to the inherent difficulty of multispectral remote sensing images, which are characterized by complex details and rich global information.
To address the problem of large-scale variations and imbalanced sample categories in remote sensing images, which cause difficulties in model training and adaptation, this paper proposes a remote sensing image segmentation algorithm, which incorporates group convolution and spatial–channel attention. The algorithm uses 32-group convolution to independently train the network convolution module from multiple perspectives, allowing a large number of different convolution kernels to group together to extract semantic features of various scales. By embedding channel–spatial attention and channel attention into different positions of the encoder, the features are enhanced by weighting the channel and spatial dimensions. In comparison to traditional approaches such as UNet [
8], the proposed method emphasizes the distinctions in cross-band features and the detailed extraction of local features. Unlike PSPNet [
11], which relies exclusively on global pooling for information extraction, this approach combines grouped convolutions with channel attention to more effectively capture multi-scale semantic information.A joint loss function combining Dice Loss and cross-entropy loss is designed to address class imbalance and prevent gradient loss during training.
To address the issue of low accuracy in segmenting land cover with unique reflectivity in special bands (such as water bodies and vegetation) due to confusion with visible light in multispectral images, which results in the loss of information from special bands, this paper proposes an extensible pseudo-Siamese semantic segmentation network based on the ideas of traditional remote sensing indices, such as the Normalized Difference Vegetation Index (NDVI) [
12] and the Normalized Difference Water Index (NDWI) [
13]. The framework separates visible light bands from special bands, such as infrared, and selects separate encoders and decoders for each to ensure that the features extracted from special channels such as infrared are not contaminated, thereby fully utilizing semantic information outside of visible light bands. In addition, this paper introduces a Transformer encoder that combines fusion convolution and multi-layer perceptron and designs a matching multi-scale decoder. Suitable feature extraction networks are selected for both RGB and infrared bands to improve the accuracy of semantic segmentation in this pseudo-Siamese network. Compared to approaches like SegFormer [
10], the decoupling design of the pseudo-Siamese network better emphasizes the advantages of infrared band characteristics in categories such as vegetation and water bodies. Unlike methods such as FuseNet [
14], which primarily address RGB-T images, the proposed method demonstrates more stable performance when processing high-resolution multispectral remote sensing images.
To address the problem of difficulty in feature fusion in the multispectral decoder output and the difficulty of balancing local and global information in space, this paper proposes a local and global feature fusion module called LGFF. When the feature fusion module works, the first step is to extract the local and global information of the input features, and the second step is to fuse the input features by weighting them based on this information. Since this module uses pointwise convolution extensively to extract features, embedding this module into the network does not significantly increase the model size, but it can better integrate local and global information. Compared to the fusion method in PAN [
15], which merely sums features from different layers, the LGFF module emphasizes a more dynamic balance between features. In contrast to the feature decoding approach of DeepLabV3+ [
16], the LGFF module more effectively integrates multi-scale features.
This research studied a series of neural network-based methods, and the specific research results are as follows; these research results have contributed significantly to the development of remote sensing image segmentation, and have practical applications in fields such as urban planning, land use, and environmental monitoring:
- 1.
A remote sensing semantic segmentation algorithm based on group awareness and feature enhancement addresses challenges such as large-scale variations and class imbalance in samples, which hinder model training and adaptation. The use of group convolution allows the model to capture multi-scale semantic information, while the integration of a channel attention module enhances salient features and suppresses redundant information.
- 2.
A feature-decoupled pseudo-Siamese network architecture effectively mitigates the issue of information confusion between spectral bands in multispectral images. By separating feature extraction for visible and infrared bands and employing a dedicated decoder structure, the architecture improves segmentation accuracy.
- 3.
A local and global feature fusion (LGFF) module resolves the challenge of integrating decoder outputs in multispectral data and balancing local and global information within spatial domains. Centered around lightweight pointwise convolution, LGFF achieves adaptive feature balancing through dynamic weighting mechanisms.
2. Related Works
2.1. Semantic Segmentation Based on Convolution
Convolutional neural networks (CNNs) are among the earliest deep learning architectures applied to semantic segmentation. They effectively perform feature extraction and pixel-level classification through an encoder–decoder structure. While traditional CNN models have yielded significant results, they still face limitations in balancing global and local information when handling complex scenes. The following sections will discuss these classic convolution-based methods and their improvements in detail.
This type of algorithm is different from object detection algorithm frameworks, as it only consists of two necessary parts, the encoder and decoder, and a bottleneck layer can be optionally inserted in between. A classification head can also be optionally added to the end of the decoder.
The role of the encoder is to extract features by cascading convolutional and pooling layers to continuously compress the input image size while exponentially increasing the channel dimension. The result is a high-dimensional feature map that is compressed in height, width, and depth. The role of the decoder is to restore the image size and output the category mask. Since semantic segmentation is a pixel-dense prediction task, the output results need to be enlarged to the same size as the input image. The decoder is usually composed of multiple upsampling modules cascaded together.
UNet [
8] and FCN [
7] were both proposed in 2015 and are essentially encoder–decoder structures. FCN added convolutional operations after downsampling to increase the network’s learnable spatial information, and used skip connections to combine two input features.The advantage of FCN lies in its relatively simple structure and high computational efficiency. However, it tends to exhibit lower segmentation accuracy and lacks local detail when applied to the fine segmentation of complex objects in remote sensing images. UNet has a simpler structure: the encoder and decoder are completely symmetrical, and it is called “U-Net” because of its U-shape. To this day, UNet still has stable and excellent performance in medical image segmentation. In contrast, U-Net may suffer from the loss of local details or insufficient background information when dealing with complex remote sensing scenes, and its computational load is relatively high.
PSPNet [
11] is also based on an encoder–decoder architecture. To address the problem of too many downsampling layers in UNet affecting the segmentation of edge objects, PSPNet proposed the use of global average pooling to upsample the feature maps of different scales to the original image size. The resized feature maps are then concatenated together and a classification head is added for prediction. The overall structure still follows the architecture and ideas of UNet. Although PSPNet excels in handling complex backgrounds and multi-scale targets, it is computationally intensive and requires a highly diverse dataset for training.
Based on the UNet deep learning neural network, many improvements have been made on this basis, among which representative ones are UNet++ [
17] and UNet+++ (UNet3+) [
18].
UNet++ addresses two minor flaws in UNet: ① The UNet network always downsamples four times and then upsamples to restore the original image size, but the number of downsamplings is not theoretically supported. ② The feature fusion in UNet can only fuse feature maps with the same scaling ratio, and local and global information cannot be fused well. To address these issues, UNet++ has redesigned the network architecture. By densely connecting feature maps with different scaling ratios, UNet++ achieves the following ① the embedding of multiple depths of UNet, without explicitly specifying the depth of UNet. ② The skip connections of the UNet network have been redesigned to allow the feature maps at different scales to be cross-fused. U-Net++, on the other hand, features a more complex structure, which increases the difficulty of network training and computation, making it prone to overfitting when working with small datasets.
UNet+++ noticed that previous work did not extract sufficient information from multiple scales, and proposed full-size skip connections, allowing each decoder to “see” feature information from one level lower, the same level, and one level higher than the encoder. In addition, UNet+++ improved the convolutional method in the decoder part and reduced the number of parameters, so that the number of parameters in the decoder part is even less than that in the original UNet.
In summary, U-Net is suitable for small-scale datasets and simpler tasks, FCN is appropriate for tasks with lower computational demands, PSPNet is ideal for complex scenes requiring multi-scale information, and U-Net++ and U-Net+++ offer greater potential for fine segmentation and the handling of complex objects, albeit at the cost of increased computational overhead.
2.2. Application of Attention Mechanisms and Transformers in Semantic Segmentation
As deep learning research continues to advance, attention mechanisms and Transformer architectures have emerged as key areas of focus in semantic segmentation, offering significant advantages over traditional CNN structures in modeling long-range dependencies and fusing multi-scale information. The following sections will discuss, in evolutionary order, the traditional forms of attention mechanisms, the application of Transformers in semantic segmentation, and the breakthroughs in their latest architectures.
2.2.1. Evolution of Traditional Attention Mechanisms
The traditional attention mechanism enhances important information and suppresses redundant features by dynamically adjusting feature weights, enabling the network to focus on key regions and improving image analysis capabilities. Common attention mechanisms include channel attention, spatial attention, and self-attention.
The channel attention mechanism, exemplified by the Squeeze-and-Excitation (SE) [
19] module, extracts the importance of each channel through global average pooling and utilizes the Sigmoid activation function to generate a weight distribution, effectively reweighting the feature channels. This enhances the feature representation ability, particularly in remote sensing image processing. However, the SE module primarily focuses on the channel dimension, overlooking the multi-dimensional interaction of spatial information, which may limit its effectiveness in tasks that involve rich spatial information.The spatial attention mechanism strengthens the focus on target regions by evaluating the importance of feature maps along the spatial dimension. The Convolutional Block Attention Module (CBAM) [
20] combines both channel and spatial attention mechanisms, calculating spatial importance layer by layer to improve segmentation accuracy in complex boundary regions. The self-attention mechanism models global relationships by calculating the similarity between any two positions in the feature map. The Non-Local Network [
21] introduces self-attention into convolutional neural networks (CNNs), capturing contextual relationships of large-scale targets in remote sensing images and improving the modeling of long-range dependencies.
While traditional attention mechanisms have made significant contributions to semantic segmentation, their limitation lies in high computational complexity, particularly when processing high-resolution remote sensing images, where memory constraints often become a bottleneck.
2.2.2. Introduction of Transformer Architecture
Since its introduction from the natural language processing field to the computer vision field, the Transformer [
9] has demonstrated strong performance and generalization ability, and the addition of multi-head attention mechanisms has made the mapping of feature subspaces more flexible [
22]. Compared to traditional attention mechanisms, Transformers offer enhanced capabilities in modeling global information and capturing long-range dependencies.
The outstanding achievements in the field of natural language processing have helped researchers in the computer vision field draw on relevant experiences, and ViT [
23] has become a successful application of the Transformer in the computer vision field, even surpassing all convolution-based methods on the publicly available ImageNet dataset from the very beginning. This method creatively serializes images into image blocks and uses the self-attention mechanism of the Transformer to calculate the weight between any two sequences and output the classification results. After that, neural networks based on the Transformer architecture have been designed to solve various sub-tasks in computer vision, including but not limited to image classification [
24], object recognition [
25,
26], image segmentation [
27], and even image generation [
28].
Semantic segmentation using Transformer networks has seen new developments. SegFormer [
10] designs a hierarchical Transformer-based encoder for semantic segmentation tasks and cleverly avoids positional encoding. On the other hand, for the decoder, SegFormer uses the simplest multi-layer perceptron (MLP) decoder, and its lightweight design does not compromise its performance. However, when dealing with complex remote sensing scenarios, models may be constrained by data diversity. In cases where segmentation targets exhibit strong spatial constraints, models based on global self-attention may struggle to capture specific spatial relationships in remote sensing images.
In contrast, the Swin Transformer [
29] enhances the ability to learn local features. The Swin Transformer [
29] is a milestone achievement of the Transformer architecture network in the visual field. It uses the Window Multi-Head Self-Attention (MSA) mechanism to calculate self-attention only within each window. By using the common sliding window mechanism in the image field, shallow semantic information can flow across windows. Despite its advantages, the Multi-Scale Attention mechanism also results in significant memory consumption and has certain limitations in modeling long-range dependencies.
Inspired by the powerful global modeling capabilities of the Swin Transformer, He et al. proposed a novel semantic segmentation framework for remote sensing images, named ST-UNet [
30]. This framework integrates the Swin Transformer into the classic CNN-based UNet, creating a dual encoder structure with the Swin Transformer and CNN operating in parallel. Furthermore, they introduced a Spatial Interaction Module (SIM), designed a Feature Compression Module (FCM), and developed a Relationship Aggregation Module (RAM), all of which significantly enhance the framework’s performance in remote sensing image semantic segmentation tasks. However, ST-UNet still has limitations in feature boundary extraction. Future work will explore boundary feature encoding methods and model compression techniques to further enhance its performance.
2.2.3. Recent Advances in the Mamba Architecture
The Mamba architecture represents a significant advancement in segmentation [
31]. It introduces a multi-layer fusion self-attention mechanism that captures both global and local information across different scales and levels. Unlike traditional Transformers, the Mamba architecture enhances segmentation accuracy and computational efficiency by incorporating a dynamic weight adjustment module. In remote sensing image segmentation, the Mamba architecture has shown exceptional performance in segmenting complex terrains and buildings, demonstrating its considerable potential for practical applications.
Research on PyramidMamba [
32] highlights that the pyramid feature fusion method, based on the selective spatial state model (SSM), has substantially improved the accuracy of remote sensing image semantic segmentation, particularly when dealing with multi-scale features. As a model built on a novel architecture, it may face challenges in generalizing to complex scenarios. Additionally, RS-Mamba [
33] has introduced an omnidirectional selective scanning module to enhance the modeling of global information in remote sensing images, leading to improved performance in ultra-high-resolution image segmentation tasks. However, RS-Mamba also has limitations, including a simple model structure and a reliance on a large amount of labeled data.
2.3. Alternative Methods for Semantic Segmentation of Remote Sensing Images
In addition to mainstream CNN- and Transformer-based methods, some researchers have explored hybrid architectures and other innovative techniques to balance global perception with computational efficiency. These approaches offer supplementary solutions and extensions to the limitations of traditional algorithms. The following sections will introduce the design concepts and application examples of these alternative methods.
To address the trade-off between global perception and efficiency in CNN methods, as well as the high computational complexity of Transformers, Chen et al. proposed Sparse Token Transformers (STTs) [
34]. STTs introduce a novel sparse token sampler that represents buildings in the feature space as “sparse” feature vectors, significantly reducing computational complexity. They also employ a dual-path Transformer architecture capable of capturing long-range dependencies across both spatial and channel dimensions.
The RSPrompter [
35], based on a visual foundation model, integrates prompt learning into the Segment Anything Model (SAM)-based segmentation of remote sensing image instances, enabling SAM to automatically generate semantically recognizable segmentation results. This method effectively resolves the issue of SAM’s reliance on manual prompts and its inability to recognize categories in remote sensing image segmentation. The authors designed a lightweight feature enhancer and flexible prompt embedding to generate prompts from both anchor points and queries.
Osco et al. investigated the use of various input prompts, such as bounding boxes, single points, and text descriptors, to evaluate the application of SAM across multi-scale datasets in remote sensing [
36]. They also introduced a novel automation technique that combines general examples derived from text prompts with one-time training. This approach enhanced the segmentation accuracy of SAM on remote sensing images, demonstrating its potential for deployment in remote sensing applications while reducing the reliance on manual annotations.
2.4. Multispectral Semantic Segmentation
Compared to conventional images, multispectral image semantic segmentation necessitates paying particular attention to the unique spectral band information. This area of research, focused on multispectral semantic segmentation, is a key emphasis of this paper. Therefore, this section will primarily explore the origins of and current advancements in multispectral segmentation technologies.
The initial interest in the relationship between multispectral data and visual tasks arose from two main factors. The first was the challenge of using multispectral images for pedestrian target recognition, and the second was the insights drawn from traditional remote sensing image segmentation methods.
Most pedestrian detectors perform well on color images under favorable lighting conditions. However, under foggy or nighttime conditions, RGB imaging results degrade, significantly reducing the reliability of autonomous driving and all-weather surveillance systems [
37]. In contrast, traditional remote sensing algorithms often rely heavily on signals captured by infrared bands when calculating indices like NDVI and NDWI. Better utilization of spectral information from the infrared or other bands may lead to more accurate segmentation results. The RGB and other imaging bands may also have complementary relationships visually.
Ding et al. proposed that RGB bands and other imaging bands may have complementary relationships visually [
37]. Based on Faster R-CNN [
38], they introduced four multispectral deep learning network fusion frameworks for pedestrian detection tasks. These frameworks focus on low-level, mid-level, high-level feature fusion, and confidence-based fusion. Their experiments on the KAIST [
39] dataset revealed that fusion at the mid-level features resulted in the best performance. Deng et al. proposed FEANet [
40] for RGB–Thermal (visible–near infrared) input images. This neural network is a two-stage network that enhances image boundaries and small targets. The module introduces FEAM (Feature-Enhanced Attention Module, FEAM) to enhance multi-level features and can modulate the fusion of RGB and thermal infrared information. Experimental comparisons have shown that FEANet outperforms other networks such as BiseNet [
41], MFNet [
42], FuseNet [
14], RTFNet [
43], and FuseSeg [
44], making it a state-of-the-art network.
Although RGB-T-based algorithms can handle four-channel images, these algorithms are specifically designed for images obtained from a horizontal perspective of urban scenes, with the additional band being the near-infrared band. Its target scenes, imaging principles, and shooting angles are different from those of remote sensing images, so it is necessary to conduct new experiments to test the best performance in remote sensing images.
3. Proposed Method
3.1. Overall Architecture
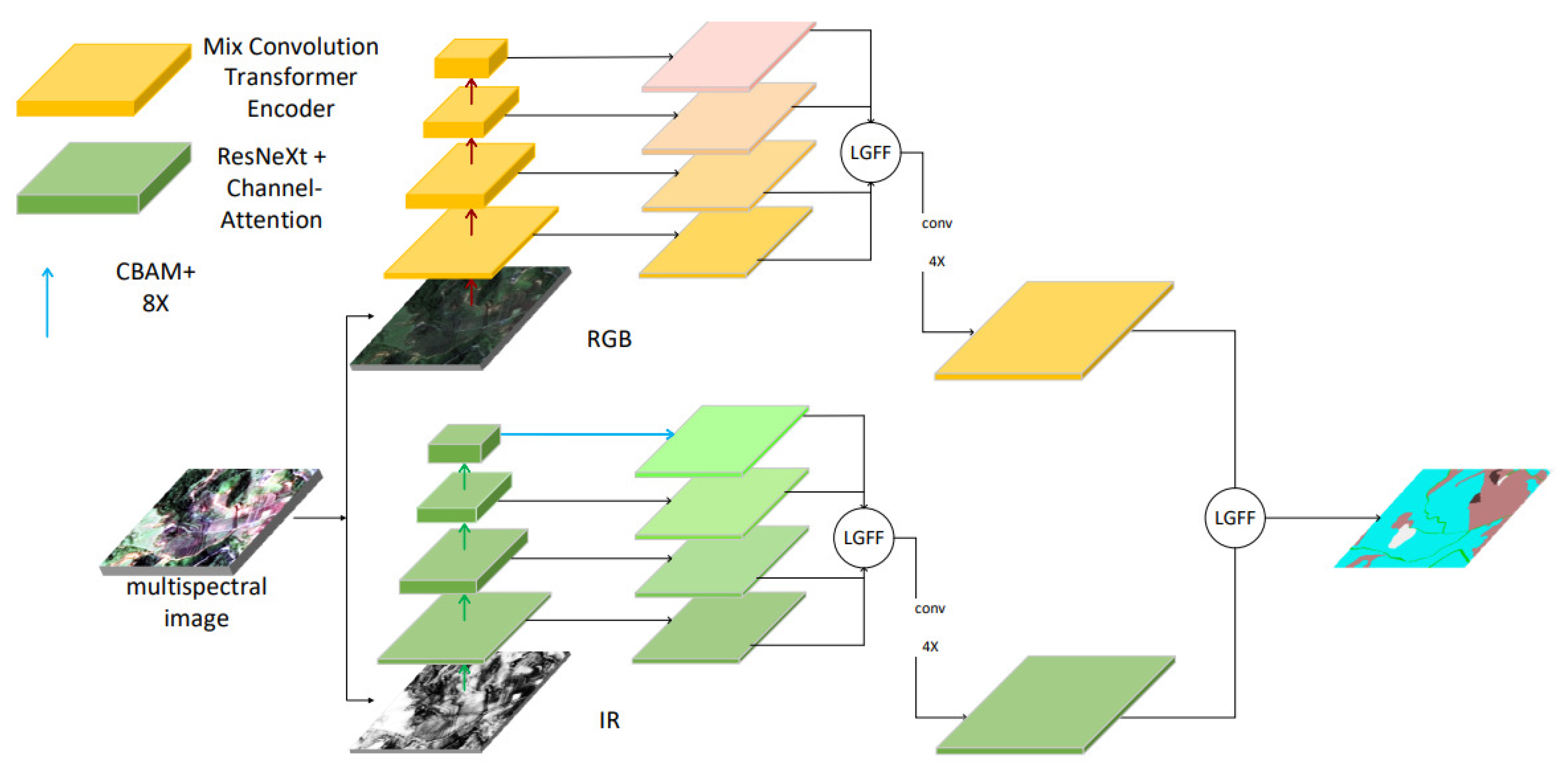
To prevent feature confusion between different bands, this section proposes a feature-decoupling pseudo-Siamese network architecture. Given that the semantic information in the infrared band significantly differs from that in the visible light band, as demonstrated by traditional remote sensing indices (such as NDVI and NDWI), the image is first split into visible and non-visible infrared bands as it enters the network, with the information flow accordingly separated. The two inputs are then passed through their respective feature extraction networks. To ensure the network’s scalability and compatibility with various decoders, the fusion of information occurs after the decoder. The semantic features derived from different bands are concatenated and aligned before being forwarded to the classification head, which produces pixel-wise classification results. The basic structure is shown in the following,
Figure 1.
For multispectral images, this pseudo-Siamese architecture semantic segmentation model has strong scalability. First, this framework is not limited to dual pathways. It only uses dual pathways because the dataset used in this paper is a combination of RGB and infrared. For situations with more channels, more parallel pathways can be set up. Secondly, the choice of encoder or decoder is not limited to the two backbones used in this paper. Whether it is based on a Transformer or a convolutional neural network, this architecture is compatible.
3.2. Encoder-Feature Extraction
For the selection of the encoder, considering that the three RGB bands of visible light are the most common, can be directly observed by the human eye, and have rich global information, this section uses the efficient perception-convolution Transformer of SegFormer as the encoder to extract features [
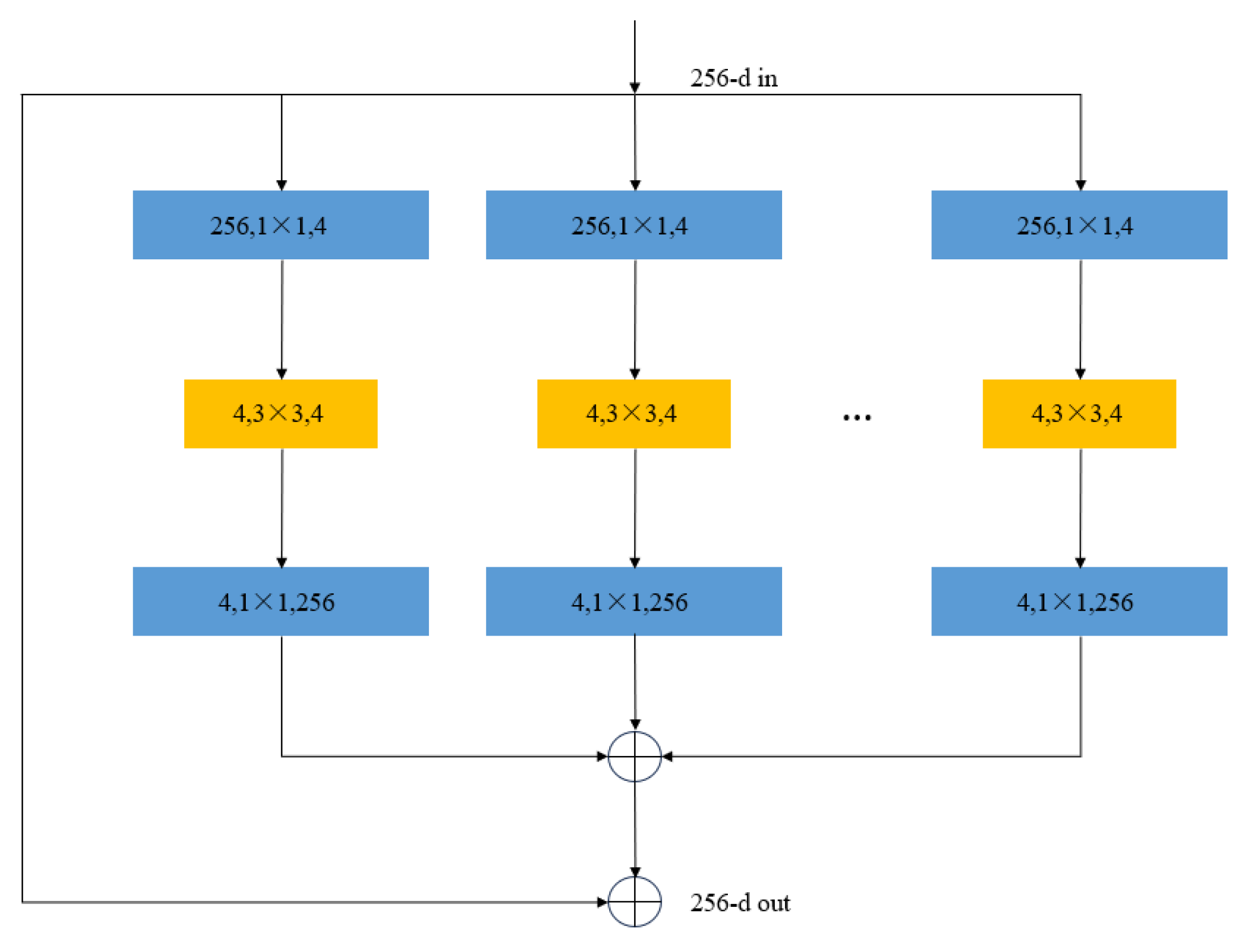
10]. For the single-channel input image of the infrared band, the local information in this band is relatively rich, so a convolutional encoder based on grouped convolution and feature enhancement is proposed to extract features from the infrared band specifically. Grouped convolution is shown in the following,
Figure 2.
The decoder cascades channel attention after each grouped convolution, helping the network to recalculate the attention of each channel after channel-wise convolution. Meanwhile, the channel–spatial attention module is used to enhance the deepest feature map. It adapts to images with different resolutions from the highest-level features.
3.3. Decoder-Feature Fusion and Resolution Restoring
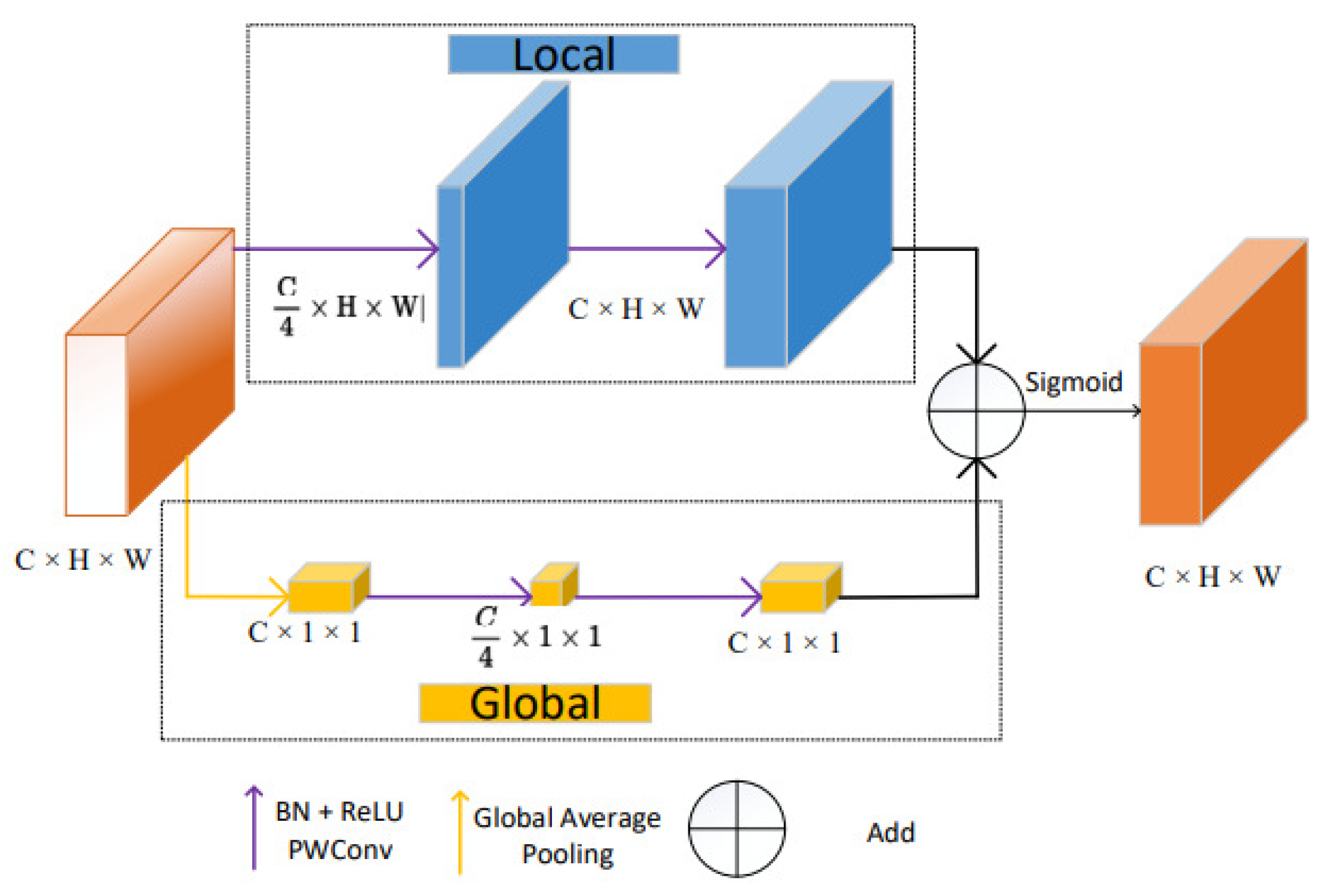
For the decoder, inspired by the Panoptic FPN network proposed by He et al., this paper uses four groups of convolutional modules for the four-layer pyramid-shaped feature maps generated by the above two networks. Each module contains a nearest-neighbor interpolation upsampling and a skip-connection module. After these two modules are concatenated, they are added to the input for residual connection. Except for the input of the highest-level feature map, which is only the upsampled result of that layer, the output of each module is upsampled by a factor of 2 and then skip-connected with the same-level feature map of the pyramid. The two channels each obtain their own set of features. The outputs obtained by the two decoders are fused using a feature fusion module based on global and local features. To selectively choose features, a module that can describe the features is needed. This feature fusion module is inspired by Dai’s work [
45] on extracting local and global attention. Its structure is shown in
Figure 3:
This module is mainly based on pointwise convolution with an extremely low computational cost to extract local and global features separately, and then add them together to obtain the output. The extraction methods for local and global features and the formula to compute the overall feature are described as follows:
In the above formula, “Local” represents the local feature extraction function, “X” represents the input feature, “BN” represents batch normalization, “PWConv” represents 2D pointwise convolution, “ReLU” represents the activation layer with ReLU as the activation function, “Global” represents the global feature extraction function, and “GAP” represents global average pooling. The final “LG” represents the extracted local–global attention feature.
The feature obtained from the local–global attention extraction module is used as the weight to help fuse the two input features. In order to prevent the mean value of the output feature from shifting, the weight of the two features is set to 1. Therefore, the local–global feature fusion module (LGFF) can be seen in
Figure 4 and can be represented by the following formula:
In the above formula, “LG” represents the local–global attention extraction module proposed in the previous section, “” and “” represent the two input features to be fused, and “⊕” and “⊗”, respectively, denote element-wise addition and multiplication, which are used for the preliminary fusion of features and the weighted mapping between features and attention.
3.4. Loss Function
For pixel-dense semantic segmentation tasks, pixel-level cross-entropy loss is a natural choice. To address the class imbalance problem in the datasets used in the experiments, Dice Loss is incorporated to mitigate the foreground–background imbalance. Based on the task and dataset characteristics mentioned above, a joint loss function is proposed in this paper, which is expressed by the following formula:
The in the equation is obtained by adding the cross-entropy loss and Dice Loss function with a ratio of , where the value of in all experiments is set to 1.5 to place more emphasis on handling the class imbalance issue. Both losses are calculated based on and , where represents the probability that a pixel belongs to the -th class during inference, and is the true label of the pixel, which can only take values 0 and 1. A value of 0 indicates that the pixel does not belong to the iii-th class, while 1 means that the pixel’s actual label is the -th class. The Dice Loss uses a hyperparameter , a very small value used to ensure that the denominator is not zero.
4. Experiments and Results
4.1. Dataset
This paper selects two representative datasets to verify the effectiveness of the proposed semantic segmentation network. One includes satellite remote sensing images with a resolution of 0.8 m, and the other includes aerial remote sensing images with a resolution of 5 centimeters.
- 1.
Suichang: The first dataset, “Suichang”, was acquired by a high-resolution satellite and consists of RGB and infrared (IR) images in four bands. The dataset is from the public dataset available on Baidu’s deep learning platform, PaddlePaddle, in the AI Studio community. It can be downloaded by searching for “Suichang” on the following website:
https://aistudio.baidu.com/datasetoverview (accessed on 15 January 2024). The annotations are divided into 10 categories, including cultivated land, forest land, grassland, roads, urban construction land, rural construction land, industrial land, construction sites, water, and bare land. There are over 32,000 images in total, with a resolution of 256 × 256, and were taken in Suichang, Zhejiang.
- 2.
The second dataset, Potsdam-s, comes from an open dataset used in the ISPRS 2D Semantic Labeling Contest. The dataset consists of remote sensing images captured by drones and includes four bands of RGB and infrared. The dataset is available for download at
https://www.isprs.org/education/benchmarks/UrbanSemLab/Default.aspx (accessed on 20 January 2024). The images were taken in Potsdam, Germany, and are annotated based on different land cover types, including water, buildings, low vegetation, forests, cars, and background. There are a total of 38 high-resolution (6000 × 6000) remote sensing images, but two images were removed due to labeling errors, leaving a total of 36 images. The images were cropped into non-overlapping 256 × 256 patches and simple images (images with only one type of land cover) were removed, resulting in over 20,000 images.
4.2. Training Details
The experimental software was based on Ubuntu 20.04.4, and Python was used as the main algorithm programming language. The algorithm model was mainly built on pytorch [
45], and mainly relies on Python packages such as numpy, PIL, pytorch_toolbelt, and segmentation_models_pytorch.The hardware experimental conditions and configuration can be seen in
Table 1. The algorithm training configuration and hyperparameters are as follows:
- 1.
Image size: cropped to 256 × 256 size by sliding window.
- 2.
Image augmentation: during training, the image and its label are vertically flipped, horizontally flipped, rotated 90 degrees clockwise (counterclockwise), transposed, elastically distorted, cut into grid units and randomly arranged, and optically distorted with a 35% probability.
- 3.
Model parameter initialization is performed using the parameter initialization model proposed by He [
46].
- 4.
Related hyperparameter configuration: the learning rate is initially set to 0.0001, the AdamW optimizer is used for optimization, and the learning rate adaptive adjustment algorithm is CosineAnnealingWarmRestarts, which completes one cosine oscillation in the first 15 epochs, and the period of learning rate oscillation doubles thereafter.
4.3. Evaluation Metrics
There are mature and widely accepted evaluation metrics for semantic segmentation. In order to accurately evaluate the effectiveness of the model, this article selects six metrics, including PA, MPA, MIOU, FWIOU, and Kappa, as standards for evaluation.
- 1.
:
is the abbreviation of Pixel Accuracy, which means the accuracy of pixels. Its calculation method is shown in Formula (
8). Here,
represents the number of pixels that are actually of class
and are identified as class
.
- 2.
:
is the abbreviation of Mean Pixel Accuracy, which means the accuracy of classifying pixels. Its calculation formula based on pixel values is shown in Formula (
9).
- 3.
:
is the abbreviation of Mean Intersection over Union, which means the average intersection over union. The calculation method is to obtain the intersection over union of each class and then take the average of the classes. The ratio of intersection over union can be transformed into the true positive (
) divided by the sum of the true positive (
), false negative (
), and false positive (
). Therefore, the formula for
is shown in Formula (
10), and the formula for
is shown in Formula (
11).
- 4.
:
is the abbreviation of Frequency-Weighted Intersection over Union, which is the intersection over union weighted by frequency. The calculation method is to calculate the intersection over union of each category and then weight them based on frequency. The formula is shown in Formula (
12).
- 5.
Kappa: The Kappa coefficient is a measure of accuracy for remote sensing image classification. After obtaining the confusion matrix of the classification, it can be calculated using the following formula. The formula for calculating the Kappa coefficient is shown in Formula (10), where
represents the accuracy, and its calculation formula is shown in Formula (11), where
is the trace of the confusion matrix and the denominator is the sum of all elements in the confusion matrix. The calculation formula for
is shown in Formula (12), where
and
represent the sum of elements in the
-th column and the
-th row of the confusion matrix, respectively. The Kappa coefficient is between −1 and 1, and a value of 0.6–0.8 indicates high consistency, while a Kappa coefficient greater than 0.8 is considered a sign of almost complete perfection.
4.4. Results and Analysis
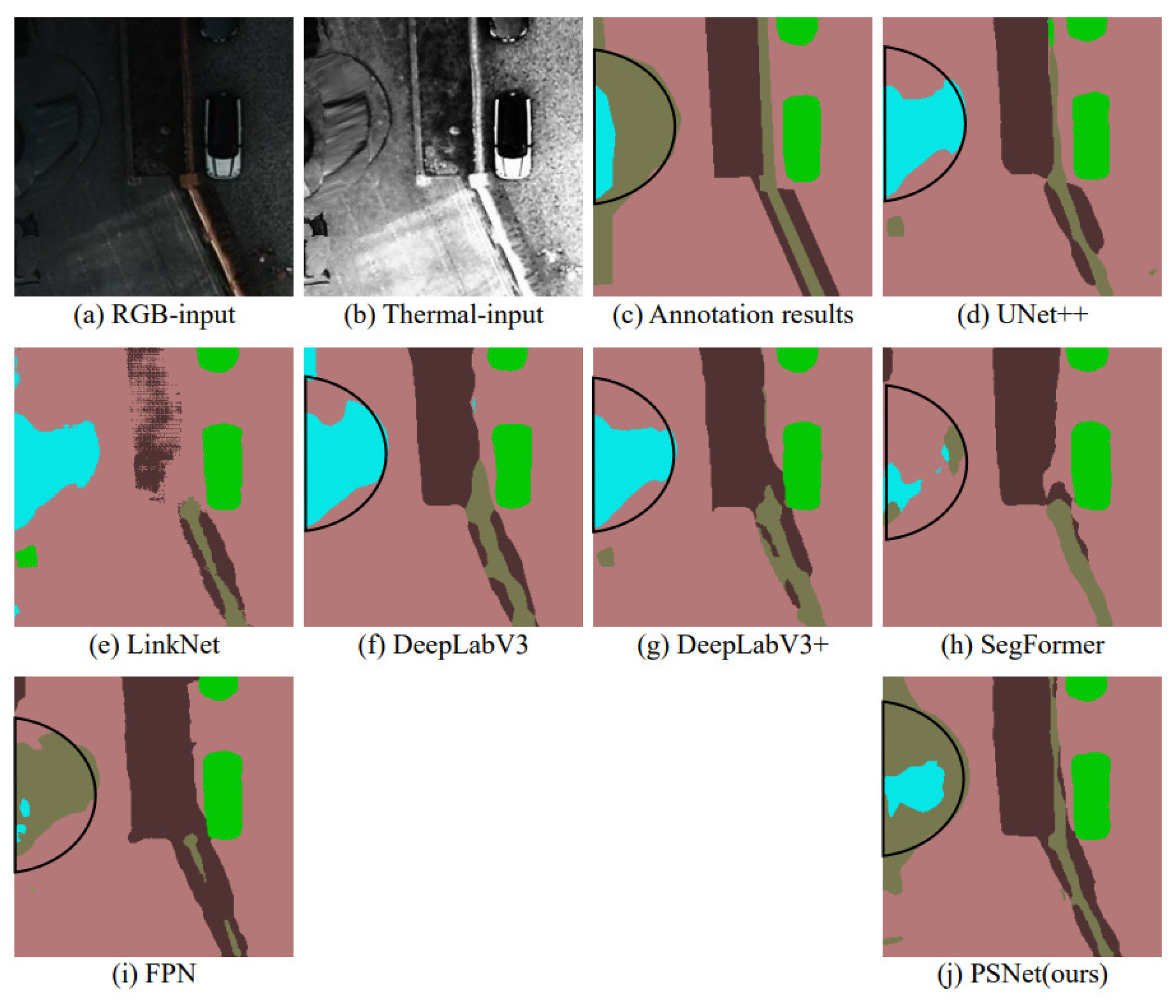
In the comparison of results, the quantitative indicators of eight classic semantic segmentation networks, including UNet, UNet++, PSPNet, Linknet, PAN, DeepLabV3, DeepLabV3+, and SegFormer, are used as references. In order to save space, the visualization comparison will select the result images of the UNet++, LinkNet, DeepLabV3, DeepLabV3+, and SegFormer networks that perform better on the corresponding dataset for qualitative comparison.
① Suichang
From
Table 2, it can be seen that the LGFF PSNet proposed in this chapter exceeds all the models used for comparison in all technical indicators, achieving the milestone of an average IoU of 80% and a Kappa of 0.9. We have also visualized the comparison between our algorithm and other algorithms on the Suichang dataset in
Figure 5. The results show that our algorithm has the clearest segmentation details.
② Potsdam-s
For the Potsdam-s dataset, as shown in
Table 3, the network proposed in this article exceeds or equals the comparison models in all indicators.We have also visualized the comparison between our algorithm and other algorithms on the Potsdam dataset in
Figure 6. The results show that our algorithm can accurately segment the contours of regions even under conditions of poor image quality.
4.5. Ablation Study
In this chapter, four sets of ablation experiments will be conducted on two datasets: (1) To verify the effectiveness of the LGFF module proposed in this chapter, this article will compare the effects of four fusion methods—LGFF, Concat, Add, and FeaNet—and conduct the first set of validity ablation experiments. (2) In order to explore the best usage of the LGFF module proposed in this chapter, the LGFF module will also be tested at the primary and advanced feature fusion locations of the FPN pyramid network, and at the multi-channel feature fusion location of the Siamese network, followed by another set of ablation experiments. Different data indicators will be provided for each usage. (3) To validate that separately processing specific spectral bands can improve the accuracy of remote sensing image segmentation, we will compare the network without channel separation to our proposed PSNet in a third set of ablation experiments. In this case, the decoder remains unchanged. For the former, we use a CNN-based encoder without channel separation, which will be referred to as PSNet_CNNonly for clarity. (4) For the same backbone network, the infrared band, which primarily affects heat-emitting objects and lacks global information, will utilize a CNN-based encoder. In the fourth set of ablation experiments, we will fix the encoder for the infrared band and compare the effect of using a CNN-based encoder versus a Transformer-based encoder for the RGB band. For clarity, we will refer to the RGB band with a CNN-based pseudo-Siamese network as PSNet_CNN, and the RGB band with a Transformer-based MCT pseudo-Siamese network as PSNet.
① Suichang
As shown in
Table 4, the LGFF fusion method exhibits a significant advantage in the key metrics, mIoU and FWIoU, outperforming all but one of the other methods. Specifically, it achieves the highest value in 4 out of 5 indicators, with the exception of the mPA metric, where the Add fusion method slightly outperforms LGFF.
Table 5 demonstrates that LGFF, when applied to both high- and low-level feature fusion in the feature pyramid and in the pseudo-Siamese network, delivers the best network accuracy.
Table 6 highlights that PSNet outperforms PSNet_CNNonly across all metrics, strongly supporting the notion that processing specific spectral bands separately enhances remote sensing image segmentation accuracy. Finally,
Table 7 shows that PSNet outperforms PSNet_CNN in all metrics, further validating that a transformer-based encoder is better suited for extracting information from the RGB bands of remote sensing images.
② Potsdam-s
For the Potsdam-s dataset, as shown in
Table 8, the LGFF fusion method achieves the highest mIoU and demonstrates the most stability, consistently ranking among the top in all indicators across the four fusion methods.
Table 9 shows that LGFF, when applied to both high- and low-level feature fusion in the feature pyramid and in the pseudo-Siamese network, delivers the best network accuracy.
Table 10 reveals that for the Potsdam dataset, PSNet outperforms PSNet_CNNonly across all metrics, strongly supporting the notion that processing specific spectral bands separately improves remote sensing image segmentation accuracy.
Table 11 demonstrates that PSNet outperforms PSNet_CNN in all metrics, further validating that a transformer-based encoder is better suited for extracting information from the RGB bands of remote sensing images. Both the Suichang and Potsdam-s datasets validate the effectiveness of our network design.
5. Conclusions
The research presented in this paper has been validated using the Suichang satellite remote sensing dataset and the Potsdam aerial remote sensing dataset. To address large-scale variations in remote sensing images, prevent feature confusion between different bands, and resolve the challenge of local and global feature fusion, we designed a pseudo-Siamese architecture. This architecture employs a CNN-based network and a Transformer-based network for feature extraction, and incorporates the LGFF module to integrate features from different bands while preserving both local and global information. These innovations have significantly enhanced the performance of semantic segmentation tasks. By combining these three improvements in the network, multispectral information is fully leveraged, resulting in a marked improvement in semantic segmentation performance compared to the baseline model.
For the semantic segmentation task of multispectral or hyperspectral images, the algorithm proposed in this paper still has several areas for improvement. Despite incorporating three key innovations, the proposed network shows significant improvements over the baseline model. However, the model size has doubled, and processing speed has decreased. These issues can be addressed in two ways. First, knowledge distillation can be employed to transfer the learned information from the large model to a smaller one, thereby achieving model compression. Second, network pruning and reducing numerical precision where permissible can help reduce storage requirements.The feature fusion in this paper occurs after upsampling, which requires the parallel network decoders to align with the corresponding encoders. While this approach benefits feature fusion in later stages, it also increases the overall network size. A potential solution would be to explore feature alignment strategies that allow features extracted by different encoders to be fused immediately after encoding, followed by decoding with a unified decoder.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}