Abstract
In recent years, cross-domain few-shot learning (CDFSL) has demonstrated remarkable performance in hyperspectral image classification (HSIC), partially alleviating the distribution shift problem. However, most domain adaptation methods rely on similarity metrics to establish cross-domain class matching, making it difficult to simultaneously account for intra-class sample size variations and inherent inter-class differences. To address this problem, existing studies have introduced a class weighting mechanism within the prototype network framework, determining class weights by calculating inter-sample similarity through distance metrics. However, this method suffers from a dual limitation: susceptibility to noise interference and insufficient capacity to capture global class variations, which may lead to distorted weight allocation and consequently result in alignment bias. To solve these issues, we propose a novel class-discrepancy dynamic weighting-based cross-domain FSL (CDDW-CFSL) framework. It integrates three key components: (1) the class-weighted domain adaptation (CWDA) method dynamically measures cross-domain distribution shifts using global class mean discrepancies. It employs discrepancy-sensitive weighting to strengthen the alignment of critical categories, enabling accurate domain adaptation while maintaining feature topology; (2) the class mean refinement (CMR) method incorporates class covariance distance to compute distribution discrepancies between support set samples and class prototypes, enabling the precise capture of cross-domain feature internal structures; (3) a novel multi-dimensional feature extractor that captures both local spatial details and continuous spectral characteristics simultaneously, facilitating deep cross-dimensional feature fusion. The results in three publicly available HSIC datasets show the effectiveness of the CDDW-CFSL.
1. Introduction
Hyperspectral images (HSIs) consist of continuous spectral bands and provide rich, detailed spectral–spatial information [1,2,3]. This unique characteristic has facilitated their extensive application in precision agriculture [4], land-use classification [5], and urban planning [6]. As a key technology in these applications, hyperspectral images classification (HSIC), which assigns pixels to different categories, plays a crucial role and has attracted significant research attention in recent years [7,8]. Many deep learning models have emerged especially for this purpose as a result of the notable advancements made in HSI-based land-cover categorization due to the quick growth of deep learning. Convolutional neural networks (CNNs), a well-known deep learning technique, have excelled in hyperspectral image categorization among them [9,10,11,12,13,14,15].
Notably, while the aforementioned deep learning approaches have demonstrated progress in HSIC, they generally require substantial quantities of labeled samples. To address the label insufficiency problem in hyperspectral data, researchers have adopted both semi-supervised [16,17,18,19] and unsupervised learning [20,21,22,23] strategies. Zheng et al. [24] employed semi-supervised learning for pseudo-label generation, achieving significant improvements in minority class classification accuracy, particularly in severely imbalanced datasets. Wang et al. [25] proposed an enhanced semi-supervised classification framework that tackles label scarcity by integrating active deep learning with random multi-graph algorithms. Zhang et al. [26] introduced an unsupervised multi-scale diverse feature learning (UMsDFL) method that synergistically combines CNN architectures with superpixel segmentation, effectively fusing multi-scale features with spectral information to substantially boost classification accuracy, thereby providing innovative solutions for HSIC.
While these methods effectively reduce reliance on annotated data, they often struggle to achieve accurate class discrimination when encountering novel categories absent from the training phase due to limited prior knowledge. In recent years, the effective learning process of the human visual system has sparked interest in few-shot learning (FSL) for HSIC. The ability of FSL to recognize new classes with extremely limited labeled samples makes it particularly attractive [27,28,29,30]. As a fundamental FSL paradigm, meta-learning enables rapid adaptation to new tasks by simulating multi-task learning processes. This approach has driven extensive applications of metric-based and embedding-based methods in HSIC [31,32,33,34]. Liu et al. [35] proposed a deep few-shot learning (DFSL) framework that leverages Euclidean distance metrics and nearest-neighbor classification to effectively tackle sample scarcity in hyperspectral imagery. Xi et al. [36] developed a FSL approach named CMFSL, which enhances classification performance under limited annotations via Mahalanobis distance optimization and class covariance estimation. Tang et al. [37] introduced a deep fuzzy metric learning method that employs fuzzy logic with Gaussian membership functions to establish robust distance metrics for addressing class uncertainty in HSIC.
Even though the current FSL methods demonstrate improved classification accuracy for novel categories with limited labeled samples, they predominantly rely on the strong assumption of identical data distributions between source domains and target domains [38,39,40,41]. However, practical applications frequently encounter domain shift issues caused by sensor variations and environmental changes [42,43], which substantially compromise model generalization capabilities. To address this challenge, Li et al. [44] pioneered a deep cross-domain FSL (DCFSL) framework that effectively mitigates distribution discrepancies in HSIC through domain adaptation strategies. Their approach outperforms conventional methods when TD samples are scarce. Additionally, Hu et al. [45] proposed a dual modulation cross-modality (DMCM) meta-learning approach, which integrates a 3D ghost attention network with class covariance metric, achieves significant accuracy improvements in cross-domain FSL scenarios. Similarly, Zhang et al. [46] developed a few-shot graph aggregation framework that aligns cross-domain non-local relationships through dynamic feature extraction. Finally, Qin et al. [47] proposed a feature disentanglement-based FSL (FDFSL) method that utilizes multi-order interaction and self-distillation strategies to reduce SD bias while enhancing TD feature learning in HSIC.
Although the aforementioned domain adaptation methods have partially addressed the domain shift problem, several limitations remain. Primarily, these approaches usually prioritize matching global feature distributions across SD and TD, ignoring the significance of accomplishing local feature alignment across various class-wise data distributions [48,49,50]. To overcome these limitations, Ye et al. [51] proposed an adaptive adversarial FSL (ADAFSL) framework that employs adaptive weight allocation and multi-scale feature extraction, prioritizing domain adaptation for classes exhibiting higher distribution mismatches between SD and TD. Similarly, Feng et al. [52] proposed a CCGDA approach, which simultaneously addresses both class imbalance and domain shift challenges through the coordinated optimization of a hierarchical capsule network and an adaptive sampler. Finally, the proposed global–local graph attention network (GLGAT-CFSL) [53] tackles domain adaptation in HSIC by utilizing dynamic triplet graph attention networks and local similarity learning, offering novel insights for future research directions.
Though current cross-domain few-shot learning methods based on domain adaptation have achieved certain success in feature matching through local feature alignment strategies, further mitigating the domain shift problem, their core alignment strategies still exhibit significant limitations. Specifically, when partial class overlap occurs between source and target domains, the sample distribution becomes imbalanced, some categories in the target domain suffer from extreme data scarcity, while others remain relatively sufficient. To address this issue, existing studies have proposed class-weighting methods. However, these methods relying solely on distance metrics for weight calculation fail to comprehensively characterize global cross-domain class differences, resulting in distorted weight allocation for certain categories. Furthermore, conventional hyperspectral feature extraction methods are generally incapable of simultaneously capturing continuous spectral information and local spatial features, leading to the loss of critical detailed information.
To overcome the drawbacks of the previously described domain adaptation methods, we propose a novel cross-domain FSL framework based on class-discrepancy dynamic weighting (CDDW-CFSL) for domain-adaptive HSIC tasks. Firstly, the proposed class-weighted domain adaptation (CWDA) method dynamically assigns class-specific weights through calculating the mean discrepancy of corresponding categories between SD and TD. This approach enables a preferential focus on categories with more significant discrepancies between the source domain and the target domain during the domain adaptation phase. Furthermore, to ensure samples of the same class are more compact and make the class weights calculated by class means during the domain adaptation stage more representative, a class mean refinement (CMR) method is proposed. This approach imposes constraints on class prototypes, thereby providing more reliable class prototypes for subsequent domain adaptation. In addition, the framework introduces a cross-dimensional feature extraction mechanism, which mainly consists of the efficient multi-scale dimensional feature fusion (EMDF) method. The method separates hyperspectral imagery channel-wise into distinct components and then utilizes differently sized convolution kernels to derive features from every partitioned section. This allows for the effective integration of spectral and spatial information; more generalized and semantically rich feature representations are constructed across the source and target domains. By combining these multi-dimensional features, the framework facilitates feature alignment between SD and the TD. Finally, the framework can transfer knowledge across the rich labeled information in the SD and the limited labeled information in TD, thanks to the framework’s integration of the previously described methods and simultaneous FSL operations on SD and TD.
This work offers the following significant contributions:
- The proposed CWDA method calculates global class mean discrepancy to assign weights by directly comparing class centroid distances between SD and TD, effectively overcoming the limitations of conventional distance metric methods. This approach enables domain adaptation to more accurately identify and focus on categories with significant distribution discrepancies between SD and TD.
- To enhance the accuracy of class mean calculations, the CMR method innovatively computes the covariance distance between support set samples and class prototypes by incorporating class covariance distance. This enables a deeper analysis of the internal distribution characteristics within each class, allowing the final calculated class means to more accurately reflect the overall distribution properties of the categories.
- We propose a novel EMDF method that simultaneously captures local spatial details and continuous spectral information via a collaborative parallel multi-path structure. In addition to improving the extraction of complementary features, this structure successfully maintains the original data. Moreover, the method enables multi-perspective spectral and spatial feature extraction and integrates spectral–spatial information through multi-level feature fusion.
This study first systematically elaborates on the proposed CDDW-CFSL framework in Section 2, followed by the validation of the method’s effectiveness through extensive experiments in Section 3. Section 4 explores the features and benefits of the suggested approach. Section 5 concludes by summarizing the entire work and offering a prediction for future lines of inquiry.
2. Methods
In this section, we provide a comprehensive overview of the suggested method. As illustrated in Figure 1, the entire framework consists of a mapping layer, an integrated cross-dimensional feature extractor, an FSL module, a class-weighted domain adaptation (CWDA) method, and a class mean refinement (CMR) method. Firstly, the SD and TD are separated into support and query sets, respectively, and the mapping layer aligns SD and TD features into a shared feature space. Furthermore, the cross-dimensional feature extraction that was created is then used to thoroughly mine both spatial and spectral data, facilitating cross-modal interaction between spatial and spectral information. Additionally, FSL operations are performed on the data from SD and TD based on Euclidean distance, effectively achieving cross-domain knowledge transfer. Finally, to avoid the excessive reliance on local sample pairs in traditional methods, we propose a CWDA method. This method dynamically quantifies cross-domain local distribution shifts based on global class mean discrepancy, enabling a more comprehensive capturing of distribution discrepancies across domains and more effective local feature alignment between SD and TD. In addition, to ensure that the calculated sample means can more accurately reflect the true feature distribution of each class, we introduce the CMR method. This method optimizes the allocation of class prototypes in the feature space, reducing the biases introduced via cross-domain shifts.
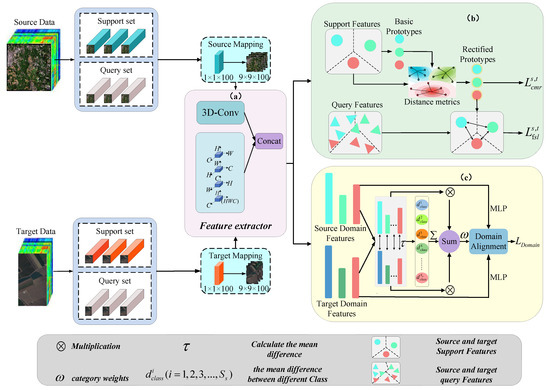
Figure 1.
Overall framework of the proposed CDDW-CFSL in the training phase. Including data preprocessing; (a) EMDF and FSL; (b) CMR; (c) CWDA.
During the testing phase, as illustrated in Figure 2, we classify the unlabeled samples in TD. Initially, the dimensionality of the input samples is adjusted to match that of the training phase via a mapping layer. Subsequently, the cross-dimensional feature extractor is employed to extract features from the input samples. Ultimately, these unlabeled data are classified using the K-nearest neighbor (K-NN) classifier.
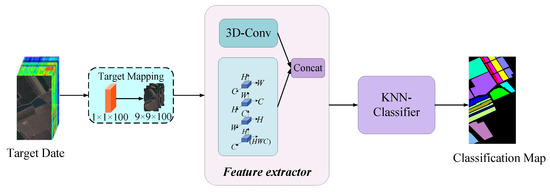
Figure 2.
Overall framework of the proposed CDDW-CFSL in the testing phase.
2.1. Data Preprocessing
We typically represent HSI from SD and TD as and , where and represent the datasets of SD and TD, respectively, , , , and denote the height and width of SD and TD images, respectively, and reflect SD and TD spectral dimensions. Firstly, take SD as an example; we extract a 3D pixel block centered on each pixel with a size of from ; similarly, we perform the same operation on TD to extract a 3D pixel block of size . Furthermore, to simulate the real FSL scenario, we divide the data of SD and TD into support sets and query sets. The method is trained on the support set, and its performance is assessed on the query set. Finally, to address the issue of spectral resolution mismatch between SD and TD caused by different imaging conditions or sensor differences. Prior to feature extraction, a mapping layer is adopted in our framework, which maps both SD and TD spectral features into an identical 100-dimensional representation space for dimensionality unification. Following processing through this mapping layer, the input data from the source domain (SD) is transformed into a tensor of , while the input data from the target domain (TD) is converted into a tensor of , where represents spatial dimensions and 100 denotes spectral dimensionality. This dimensional alignment strategy effectively mitigates spectral resolution discrepancies caused by sensor variations, ensuring data comparability between domains within a unified feature space. The standardized representation establishes a fundamental basis for subsequent cross-domain feature alignment and knowledge transfer.
2.2. Cross-Dimensional Feature Extraction
In cross-domain HSIC tasks, due to factors such as sensor differences, the SD and TD may exhibit not only spectral resolution discrepancies but also distinct feature distributions and data representations. Therefore, we propose a cross-dimensional feature extraction, our method simultaneously captures local spatial details and continuous spectral information, enabling the better identification of shared features across domains. The model demonstrates markedly improved operational efficacy and enhanced cross-domain generalization when applied to TD. The proposed feature extractor is illustrated in Figure 3. The feature extractor takes the output of the mapping layer as input, comprising two residual blocks, two max-pooling layers, and a convolutional layer. The residual blocks integrate 3D-CNN and the efficient multi-scale dimensional feature fusion (EMDF) method to thoroughly leverage the spatial–spectral characteristics of HSI. During feature extraction, the 3D-CNN extracts shallow features to capture the overall spatial structure of the image, which can be concisely represented as follows:
where r is the output of the mapping layer, is the output of , is the convolution operation, and is the activation function.
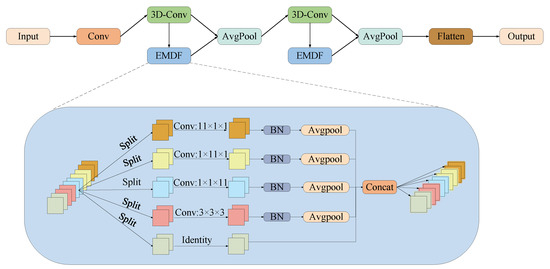
Figure 3.
Proposed EMDF method.
Additionally, to capture multi-scale features and reveal relationships between different dimensions, we use the EMDF method to deeply explore deeper-level information in the output features of the mapping layer across different dimensions. Then, we concatenate the features extracted via the 3D-CNN and EMDF method, allowing the model to understand and analyze hyperspectral images from different perspectives and improving the classification accuracy. The input to the EMDF method is the output from the 3D-CNN. Given an input tensor of dimensions C × H × W, firstly, we divide the input into five parts along the channel dimension. Furthermore, the first part remains unchanged; the second part captures interaction information between channel dimensions C, H, and W, while the third, fourth, and fifth parts use depthwise convolution operations with kernel sizes of , , and , respectively, to process the channel, width, and height dimensions. Finally, we concatenate the results of the five parts along the channel dimension, which can be simply represented as follows:
where represents the spectral dimension of each partitioned component after is divided equally along the channel dimension, represents the spectral segmentation function, and represents the output features obtained by each part through . Finally, the results of the five parts are concatenated along the channel dimension, and we concatenate the outputs from both the 3D-CNN and EMDF method, which can be simply represented as follows:
where represents the channel-wise concatenation operation, represents the output result of the EMDF method, and X represents the output result of the residual connection between the 3D-CNN and EMDF method.
The EMDF method utilizes multi-branch depthwise separable convolutions to extract features from different dimensions, aiming to capture more complex spatial and spectral features in HSI. This enables a more effective extraction of cross-domain shared features and enhances the model’s generalization performance in the TD.
2.3. FSL in Source and Target Domains
In cross-domain HSIC tasks, there are usually very few labeled samples in TD. The model can more effectively mine transferable information from SD when FSL is performed in both SD and TD. This increases the model’s capacity to handle unknown classes in TD in addition to its ability to generalize to new classes. Consequently, subsequent to feature extraction, we instantiate meta-learning-based FSL in both SD and TD. We assume that the source domain dataset is (SD) (containing classes ) and that the target domain dataset (TD) is (containing classes ). Specifically, taking FSL in SD as an example, we randomly select classes from SD’s classes, with each class containing k labeled samples as the support set . Then, we randomly select t unlabeled samples from the same classes as the query set . In each FSL task, we apply FSL by figuring out the Euclidean distance between each class prototype and the query set samples, and then we use the function to find the estimated likelihood of the query set samples; this may be represented as follows:
where is the revised prototype of the class, and represents the sample set in the support set, and and represent the sample set in the query set, represents the predicted probability of the query set samples, represents the Euclidean distance, and represents the probability that the model predicts the query set sample as a certain class.
Based on the predicted probabilities of the query set samples, the loss function of FSL in SD can be expressed as follows:
where symbolizes the magnitude of the query set in SD, and is the FSL loss value in SD.
Similarly, the expression for the FSL loss function in TD is as follows:
where symbolizes the magnitude of the query set in TD, and is the FSL loss value in TD.
In summary, the following is the overall loss of FSL in SD and TD:
2.4. Class-Weighted Domain Adaptation
Current FSL can transfer known knowledge from SD to TD by performing FSL simultaneously in both SD and TD when labeled samples in TD are limited, thereby improving the model’s performance in TD. However, in real-world cross-domain HSIC tasks, factors such as variations in lighting and sensor differences lead to inconsistent distributions between SD and TD. Moreover, the degree of distribution shift and the number of samples vary significantly across different categories. As shown in Figure 4a, the existing methods typically rely on distance metrics to calculate class weights for achieving local feature alignment. For categories with relatively stable spectral–spatial features (e.g., categories and ), basic alignment can be achieved. However, for categories with complex nonlinear structures (e.g., categories and ), traditional methods often struggle to achieve ideal matching results during local feature alignment.
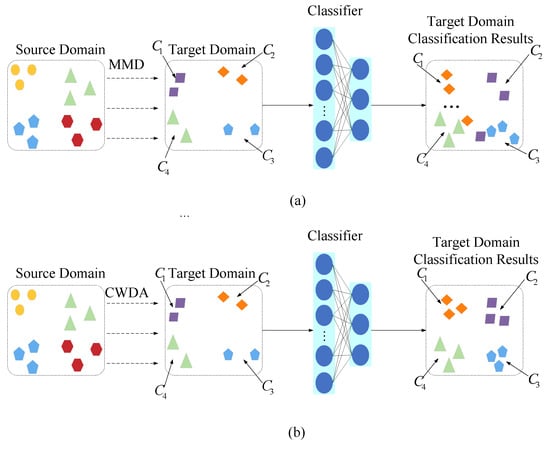
Figure 4.
Class-level domain adaptation. (a) Using regular MMD; (b) using class-weighted MMD.
Therefore, this paper proposes a class-weighted domain adaptation (CWDA) method. Unlike conventional approaches, as illustrated in Figure 4b, our proposed CWDA method employs global inter-class mean discrepancy to dynamically quantify cross-domain local distribution shifts. This enables the model to more precisely focus on categories exhibiting significant distribution differences between SD and TD. The method takes features extracted via the feature extractor from both domains as input. Specifically, it first performs domain adaptation between SD and TD using Maximum Mean Discrepancy (MMD). Subsequently, it calculates the feature means for each class in both the source and target domains separately. An element-wise subtraction operation is then applied to obtain a cross-domain class mean discrepancy matrix, which serves as a quantitative representation of distribution shifts. The empirical formulation of MMD is expressed as follows:
where are the sample sets of SD and TD, respectively, represents the SD sample, represents the TD sample, n represents the number of samples in the SD, m represents the number of samples in the TD, represents a kernel function that measures the similarity within SD samples, while measures the similarity between SD and TD samples. The SD and TD class means are shown as follows:
where and , respectively, represent the number of samples in the corresponding classes of the SD and the TD, respectively, and , respectively, represent the i-th sample belonging to the corresponding class in the SD and the j-th sample belonging to the corresponding class in the TD.
where represents the class difference between SD and TD.
Additionally, we compute class weights using a cross-domain feature weighting strategy. Specifically, first, we divide the mean difference of each corresponding class between the source and target domains by the sum of the mean differences across all classes. Furthermore, we divide the mean of each class in SD by the sum of the mean differences of all classes in SD. Finally, we perform a weighted summation of the results from the above two steps to obtain the corresponding class weights. Based on this process, the weight calculation formula can be expressed as follows:
Finally, by performing element-wise multiplication between the maximum mean discrepancy (MMD) loss and class weights, we exert different influences on the MMD loss in the class dimension, enabling classes with greater alignment difficulty to obtain stronger optimization intensity. This achieves true class-level weighting. It can effectively guide the model to pay more attention to classes with significant distribution shifts, thereby improving the overall cross-domain alignment effect. This can be simply expressed as follows:
where is the -calculated difference between SD and TD, is the class weight, and is the weight coefficient.
2.5. Class Mean Refinement
The proposed class-weighted domain adaptation (CWDA) method computes class means to transfer information from SD and TD. However, in few-shot learning, due to limited TD samples and noise, the alignment of local features exhibits suboptimal matching, causing suboptimal alignment. Therefore, this paper proposes a class mean refinement (CMR) method, as illustrated in Figure 1b, which leverages inter-class covariance distance to refine class prototypes. By capturing the intrinsic distribution characteristics within categories, this approach enhances the representativeness of prototypes. This mechanism strengthens the class weighting effect, enables more precise feature alignment, and consequently improves the generalization performance in cross-domain few-shot learning. The CMR method can be formally expressed as follows:
where is the class covariance distance, represents the basic class prototype, and represents the probability forecast of the support set samples, which is the rectified class prototype. Based on the prediction results of the support set samples, the loss in SD is as follows:
Similarly, the loss in the target domain is as follows:
In summary, the following is the overall loss of cmr in SD and TD:
Consequently, the complete loss function of SD may be formulated as follows:
Similarly, the complete loss function of TD may be formulated as follows:
3. Experiments
We performed comprehensive cross-domain hyperspectral classification experiments across four benchmark datasets to rigorously evaluate the efficacy of our proposed CDDW-CFSL framework. This section details the datasets and experimental configurations, and it analyzes the experimental results.
3.1. Dataset Description
3.1.1. Source Domain Dataset
The Chikusei dataset was captured via an airborne imaging spectrometer (Headwall Hyperspec VNIR) in Chikusei City, Japan. With a picture size of 2517 by 2335 pixels and an exterior sampling distance of 2.5 m, the image has 128 bands of spectrum that span the wavelength range of 363 nm to 1080 nm. Nineteen land cover types, such as rice fields, woods, highways, etc., are included in the dataset. Each land cover class’s names and sample numbers are included in Table 1, and the pseudo-color composite picture and matching ground truth map are displayed in Figure 5.

Table 1.
Land cover classes and sample counts in the Chikusei dataset.

Figure 5.
Chikusei dataset. (a) Ground-truth image. (b) Pseudo-color composite image. (c) Corresponding color labels.
3.1.2. Target Domain Datasets
NASA’s AVIRIS (Airborne Visible/Infrared Imaging Spectrometer) sensor collected the Indian Pines (IP) dataset in a northwest Indiana agricultural region. Farmland makes up the majority of the region, with a small amount of woodland and urban structures. The scene size is pixels, and the spatial resolution is 20 m (each pixel represents a ground area of m). There are 202 spectral bands in the picture, spanning the 400–2500 nm range. There are sixteen land cover categories in the dataset, such as woods, railroads, and residential areas. Each land cover class’s names and sample numbers are included in Table 2, and the pseudo-color composite picture and matching ground truth map are displayed in Figure 6.
Table 2.
Land cover classes and sample counts in the Indian Pines Dataset.
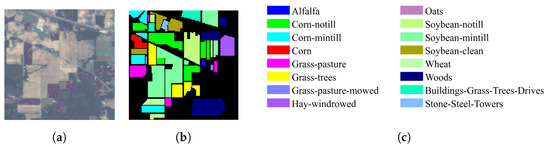
Figure 6.
Indian Pines dataset. (a) Ground-truth image. (b) Pseudo-color composite image. (c) Corresponding color labels.
The Pavia University (PU) dataset was captured via the ROSIS (Reflective Optics System Imaging Spectrometer) sensor near the University of Pavia, Italy. The region is mostly made up of agricultural and urban areas. With a scene size of pixels and a spatial resolution of 1.05 m, the image includes 103 spectral bands that span the wavelength range of 430–860 nm. Nine land cover types, such as highways, woods, and mining regions, are included in the dataset. Each land cover class’s names and sample numbers are included in Table 3, and the pseudo-color composite picture and matching ground truth map are displayed in Figure 7.
Table 3.
Land cover classes and sample counts in the Pavia University Dataset.
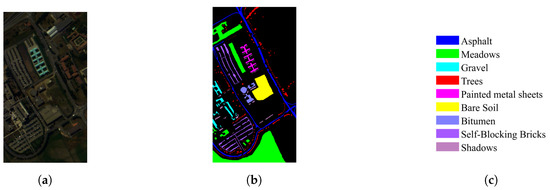
Figure 7.
Pavia University dataset. (a) Ground-truth image. (b) Pseudo-color composite image. (c) Corresponding color labels.
The Salinas dataset (SA) was captured via the AVIRIS sensor in an agricultural area in California, USA. With a scene size of pixels and a resolution in space of m, the image has 224 spectral bands that span the 400 nm to 2500 nm range. Sixteen land cover categories, such as farms, irrigated regions, grasslands, etc., are included in the dataset. Each land cover class’s names and sample numbers are included in Table 4, and the pseudo-color compound picture and matching ground truth map are displayed in Figure 8.
Table 4.
Land cover classes and sample counts in the Salinas Dataset.
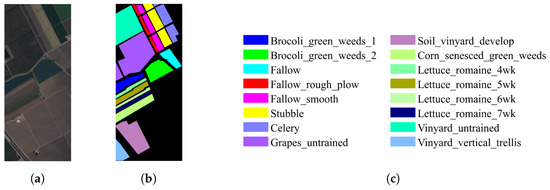
Figure 8.
Salinas dataset. (a) Ground-truth image. (b) Pseudo-color composite image. (c) Corresponding color labels.
3.2. Experimental Setup
All experiments were conducted on a computing platform equipped with an NVIDIA GeForce RTX 3060 GPU (NVIDIA Corporation, Santa Clara, CA, USA), 64 GB of RAM, and an Intel Core i7-10700 processor with a base clock speed of 2.90 GHz (Intel Corporation, Santa Clara, CA, USA). The software environment employed the PyTorch framework, with Python 3.9 and PyTorch 2.3.0 used. Following the experimental configuration described in [52], we randomly selected 200 labeled samples per class from the source domain dataset to construct the source dataset for transferable knowledge learning, while L = 5 labeled samples per class were randomly chosen from the target dataset for training. Input data was processed in the form of 9 × 9 × 100 image patches. For feature extraction across both SD and TD, the network’s convolutional layers were trained using the Adam optimizer. The model underwent 10000 training iterations to ensure thorough convergence, with a steady learning rate of 0.001 to maintain training stability and mitigate overfitting.
During the FSL phase, the HSIC task is decomposed into multiple C-way K-shot classification sub-tasks (where C denotes the number of classes in each episode’s support set, and K indicates the number of samples per class). The support set comprises 1 sample per class, whereas the query set contains 19 samples per class. Theoretically, increasing the number of query samples improves the network’s classification performance on TD. Three metrics are adopted for evaluation: the Kappa coefficient (Kappa), average accuracy (AA), and the overall accuracy (OA).
3.3. Ablation Study
In this part, we examine how the performance of the TD dataset is affected by significant components of the suggested framework. This innovative framework primarily consists of three core methods: (1) the basic few-shot learning (FSL) module, responsible for extracting cross-domain shared feature representations; (2) the class-weighted domain adaptation (CWDA) method, which achieves adaptive domain alignment based on class importance; and (3) the class mean refinement (CMR) method, designed to refine class prototype representations. To thoroughly examine the individual contributions and synergistic effects of each module, first constructing a baseline module containing only the FSL module (FSL-only) and then sequentially integrating the CWDA method to form an intermediate FSL + CWDA module, we add the CMR method to create a comparative FSL + CMR module and finally combine them into the complete framework (FSL + CWDA + CMR).
The findings of the ablation investigation are shown in Table 5, Table 6 and Table 7. Using the PU dataset as an example, the introduction of the CWDA method, which incorporates an adaptive class-weighting mechanism, leads to a notable improvement of 2%–3% in overall accuracy (OA), demonstrating the critical role of cross-domain class-weight adjustment in performance enhancement. Further integrating the CMR method, which optimizes the feature space distribution of classes, elevates the OA to 87.99%, validating the effectiveness of fine-grained feature alignment. Most importantly, the complete framework achieves a consistent 4% performance gain over the baseline model. This outcome not only validates the effectiveness of each method’s design but also reveals a synergistic enhancement effect among them. The organic integration of FSL’s feature extraction, CWDA’s domain adaptation, and CMR’s representation optimization can significantly mitigate domain shift in deep domain adaptation. These results fully demonstrate that the collaborative operation of these methods effectively alleviates the negative impact caused by domain shift.
Table 5.
Ablation experiments through combinations of modules on the Indian Pines Dataset.
Table 6.
Ablation experiments through combinations of modules on the Pavia University Dataset.
Table 7.
Ablation experiments through combinations of modules on the Salinas Dataset.
3.4. Comparative Experiments
To demonstrate the comparative improvements achieved with our framework, we compared it with traditional methods for HSIC such as SVM and 3DCNN, FSL-based methods like DFSL [35], and five advanced domain adaptation methods, including DCFSL [44], GIA-CFSL [46], ADAFSL [50], DMCM [45], and FDFSL [47]. For SVM, 3DCNN, and DFSL. To create the training set, we chose five labeled samples at random from each class, allocating the residual samples for testing purposes. We then directly trained and tested on hyperspectral datasets such as IP, PU, and SA. For cross-domain learning methods like DCFSL, GIA-CFSL, ADAFSL, DMCM, and FDFSL, as well as our framework, five labeled samples were chosen at random from each SD class to create the training set; the remaining TD samples were utilized for testing. The IP, PU, and SA datasets were TD for all approaches, while the Chikusei dataset served as SD.
As shown in Table 8, Table 9 and Table 10. The following is a summary of the categorization outcomes for each technique on the IP, PU, and SA datasets. The traditional SVM method performed the worst, highlighting its difficulty in extracting effective classification features from hyperspectral images (HSIs) and handling the small sample problem. Compared to SVM, the 3DCNN method, through 3D convolutional neural networks that process hyperspectral data to extract combined spatial–spectral signatures, demonstrated superior performance but still struggled to properly address the limited labeled data challenge in HSI. The deep learning-based FSL method DFSL, which leverages meta-learning principles, effectively performed knowledge inference and generalization with limited labeled samples, achieving better performance than 3DCNN. Meanwhile, cross-domain FSL methods, such as DCFSL, GIA-CFSL, ADAFSL, DMCM, and FDFSL, outperformed deep FSL methods. Our proposed framework, also a cross-domain FSL method, effectively mitigated the negative effects of domain shift through a class-weighted domain adaptation strategy, achieving the best classification performance. Compared to previous sophisticated domain adaptation-based FSL methods, with the IP dataset, our approach increased overall classification accuracy (OA) by 5%–15%, with the PU dataset by 2%–10%, and with the SA dataset by 1%–4%. Quantitative results confirm the efficacy of our approach, showing consistent advantages in cross-domain HSI classification.
Table 8.
Classification accuracies for different methods on target scenes and overall classification accuracy on Indian Pines Dataset (five labeled samples from TD).
Table 9.
Classification accuracies for different methods on target scenes and overall classification accuracy on Pavia University Dataset (five labeled samples from TD).
Table 10.
Classification accuracies for different methods on target scenes and overall classification accuracy on Salinas Dataset (five labeled samples from TD).
As shown in Figure 9, Figure 10 and Figure 11, the classification maps produced via SVM, 3DCNN, and DFSL contain significant noise and show more misclassification. Cross-domain FSL methods including DCFSL, GIA-CFSL, ADAFSL, DMCM, and FDFSL produce smoother classification maps, while there are still certain categories in which there is glaring misclassification. Compared to these methods, our proposed method generates the most accurate and seamless classification results, with more samples correctly classified. This provides additional evidence of the strong performance of our framework in handling cross-domain HSI classification tasks.
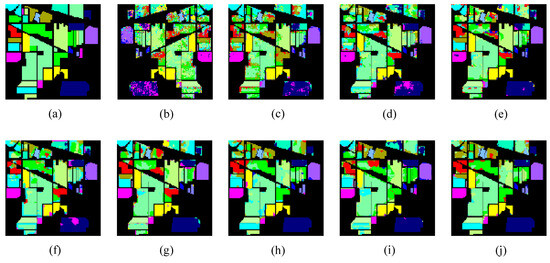
Figure 9.
Indian Pines. (a) Ground-truth map. Classification results for different methods: (b) SVM; (c) 3-D-CNN; (d) DFSL; (e) DCFSL; (f) GIA-CFSL; (g) ADAFSL; (h) DMCM; (i) FDFSL; (j) our method.

Figure 10.
Pavia University. (a) Ground-truth map. Classification results for different methods: (b) SVM; (c) 3-D-CNN; (d) DFSL; (e) DCFSL; (f) GIA-CFSL; (g) ADAFSL; (h) DMCM; (i) FDFSL; (j) our method.
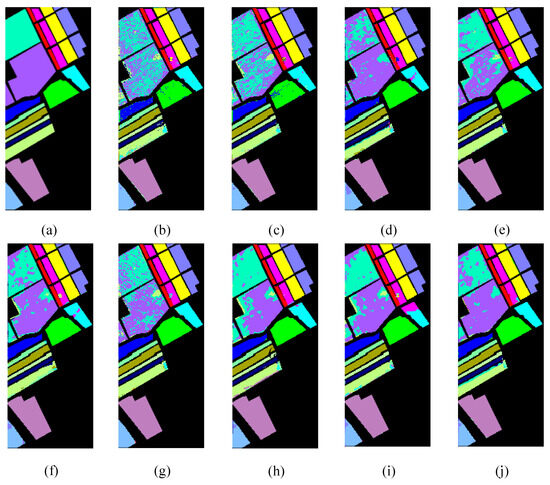
Figure 11.
Salinas. (a) Ground-truth map. Classification results for different methods: (b) SVM; (c) 3-D-CNN; (d) DFSL; (e) DCFSL; (f) GIA-CFSL; (g) ADAFSL; (h) DMCM; (i) FDFSL; (j) our method.
4. Discussion
4.1. Learning Rate
When training a deep learning model, the learning rate is a key hyperparameter whose setting has a major influence on the model’s performance and pace of convergence. A reasonable learning rate can accelerate model convergence, and it assists the weights in rapidly approaching the global optimum. To find the optimal learning rate, as shown in Table 11, we explored the impact of different learning rate settings, including l × 10−5, l × 10−4, l × 10−3, l × 10−2, and l × 10−1, on model training. The model performed best in classification on the IP, PU, and SA datasets when the learning rate was set to l × 10−3, according to the experimental results. This suggests that, during optimization, a learning rate of l × 10−3 balances the convergence speed and stability, avoiding oscillations caused by a rate that is too large and overcoming slow convergence caused by a rate that is too small. Therefore, we ultimately selected 1 × 10−3 as the learning rate.
Table 11.
Influence of different learning rates on model performance.
4.2. Comparison of Feature Extractor Modules
This section presents a comparative analysis of the efficient multi-scale dimensional feature fusion (EMDF) method’s influence on the classification accuracy of TD datasets. To validate the method’s effectiveness, we designed rigorous comparative experiments evaluating both the original framework and the improved framework, incorporating the EMDF method on three representative hyperspectral remote sensing datasets: Indian Pines (IP), Pavia University (PU), and Salinas Valley (SA). As shown in Figure 12, Figure 13 and Figure 14, a quantitative analysis demonstrates significant accuracy improvements across all three benchmark datasets after the EMDF method was implemented: the IP dataset achieved a 3.01% accuracy increase, PU improved by 2.55%, and SA showed a 1.59% enhancement. The experimental results confirm that the proposed EMDF method, through its unique cross-scale feature fusion mechanism, effectively integrates local detail features with global contextual information. This integration improves both the model’s classification accuracy and its ability to generalize across different datasets.
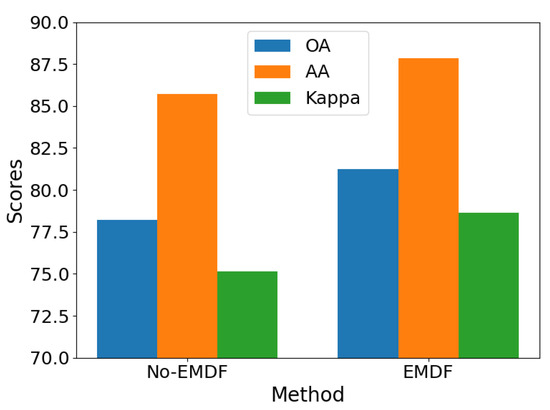
Figure 12.
Feature extractor module comparison on Indian Pines.
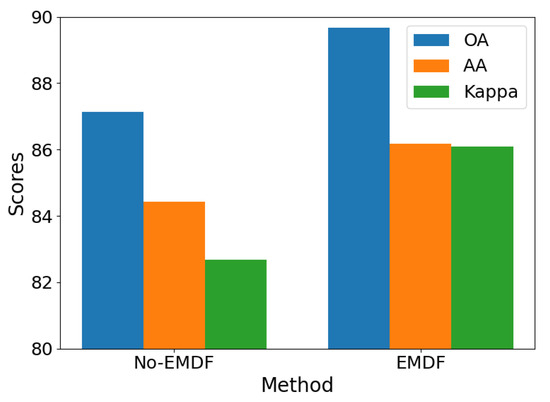
Figure 13.
Feature extractor module comparison on Pavia University.
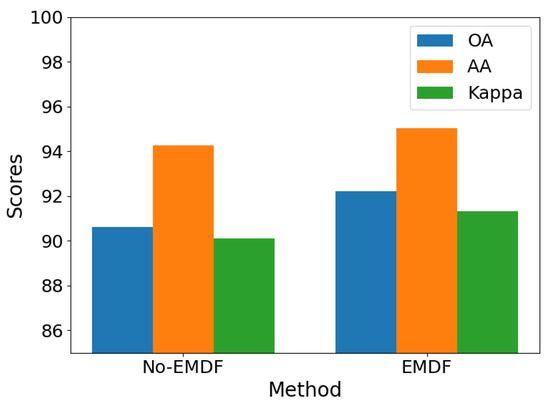
Figure 14.
Feature extractor module comparison on Salines.
4.3. Different Numbers of Training Samples
The number of training samples greatly influences the model’s performance in cross-domain FSL. This subsection confirms the efficacy of our suggested framework by examining the precise effects of the amount of training samples on the performance of SVM, 3DCNN, DFSL, and cross-domain FSL techniques. As shown in Figure 15, Figure 16 and Figure 17, from the set 1, 2, 3, 4, 5, we chose at random how many labeled samples there were in each class. The findings of the experiment demonstrate that the classification accuracy and generalization capacity of each approach may be considerably enhanced by suitably expanding the number of training samples in TD. The model has a tendency to overfit when there are few training samples available; however, as the number of samples increases, the model can better learn class features, thereby improving classification accuracy. Notably, our suggested framework continuously outperformed all other approaches, irrespective of the quantity of training samples. This outcome clearly shows how successful our system is.
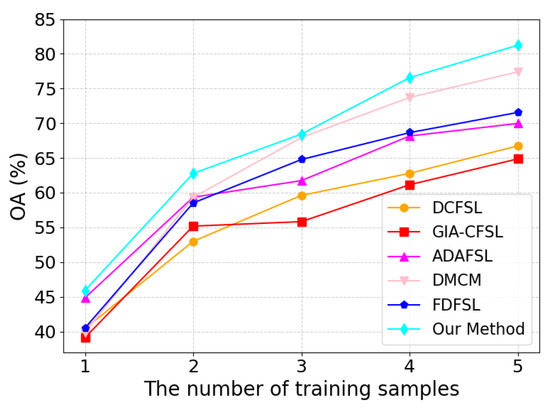
Figure 15.
Impact of varying training sample sizes on the performance of various methods on Indian Pines.
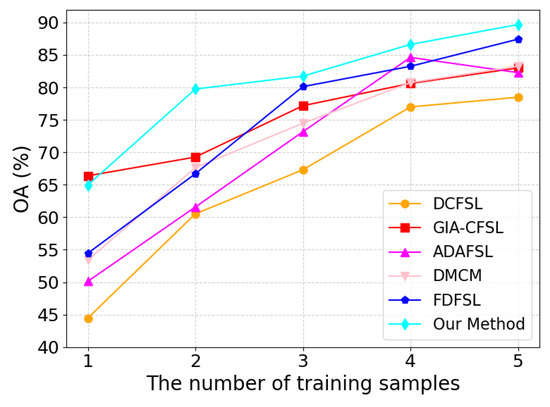
Figure 16.
Impact of varying training sample sizes on the performance of various methods on Pavia University.
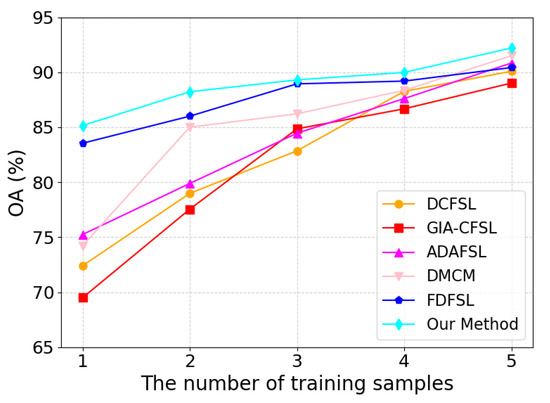
Figure 17.
Impact of varying training sample sizes on the performance of various methods on Salines.
4.4. Computational Complexity
In order to thoroughly assess the computational effectiveness of various approaches, we conducted a systematic analysis of the computational complexity of deep learning approaches from four perspectives: training time, testing time, floating-point operations (FLOPs), and the number of parameters. In the comparative experiments, we focused on FSL (few-shot learning-based methods. To ensure fairness, every method was evaluated in several TD under uniform circumstances and trained on the same SD. As shown in Table 12, five labeled examples per class were employed in the experimental setting, and the majority of the testing time was devoted to predicting unlabeled samples from the HSI dataset, whereas the majority of the training time was devoted to the transfer learning procedure. Although our approach is not the best in terms of computational complexity, all metrics remain within acceptable ranges, demonstrating good computational efficiency.
Table 12.
Training time, testing time, flops, and parameters on each dataset with different methods.
5. Conclusions
This paper has introduced an innovative CDDW-CFSL framework designed to solve the issue of domain shift in HSIC. By integrating a multi-dimensional feature extraction module with a class-weighted domain adaptation method, the framework significantly enhances the adaptability and classification accuracy of cross-domain HSI. The multi-dimensional feature extraction module is capable of thoroughly excavating multi-level information within the images, including spatial, spectral, and textural features. Meanwhile, by dynamically modifying class weights, the class-weighted domain adaptation method successfully reduces the distribution disparity between SD and TD, demonstrating exceptional performance, especially in scenarios of class imbalance. The experimental results indicate that, compared to traditional domain adaptation methods, the CDDW-CFSL framework achieves notable performance improvements across multiple public datasets.
Author Contributions
Conceptualization: C.D. and J.Y.; methodology: C.D. and J.Y.; validation: J.Y. and S.Z.; investigation: J.Y. and S.Z.; writing—original draft preparation: C.D. and J.Y.; writing—review and editing: C.D., Y.D., W.H., X.C., Y.X., S.Y., W.W. and L.Z.; supervision: C.D., Y.D., W.H., X.C., Y.X., S.Y., W.W. and L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62472350, Grant 62472359, and Grant 62372379 and in part by the National Key Laboratory of Science and Technology on Space-Born Intelligent Information Processing Foundation under Grant TJ-04-23-04; and partially by the Science and Technology Department of Shaanxi Province (Grant No. 2024JCYBQN-0651) and the Shaanxi Provincial Department of Education (Grant No. 23KJ0669).
Data Availability Statement
The Chikusei dataset is available online at https://hyper.ai/cn/datasets/21684 (accessed on 20 April 2025). The Indian Pines, University of Pavia, and Salinas datasets are available online at https://ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scenes#userconsent (accessed on 20 April 2025).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Zhang, M.; Qu, Y.; Tao, R.; Qi, H. Topological structure and semantic information transfer network for cross-scene hyperspectral image classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 2817–2830. [Google Scholar] [CrossRef]
- Zou, J.; He, W.; Zhang, H. Lessformer: Local-enhanced spectral-spatial transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5535416. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, D.; Hu, X.; Ye, X.; Li, Y.; Liu, S.; Cao, K.; Chai, M.; Zhou, W.; Zhang, J. The advanced hyperspectral imager: Aboard China’s GaoFen-5 satellite. IEEE Geosci. Remote Sens. Mag. 2019, 7, 23–32. [Google Scholar] [CrossRef]
- Huang, Y.; Shen, Q.; Fu, Y.; You, S. Weakly-supervised semantic segmentation in cityscape via hyperspectral image. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 1117–1126. [Google Scholar]
- Lu, J.; Liu, H.; Yao, Y.; Tao, S.; Tang, Z.; Lu, J. HSI road: A hyperspectral image dataset for road segmentation. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5966–5978. [Google Scholar] [CrossRef]
- Liu, J.; Feng, Q.; Liang, T.; Yin, J.; Gao, J.; Ge, J.; Hou, M.; Wu, C.; Li, W. Estimating the forage neutral detergent fiber content of Alpine grassland in the Tibetan Plateau using hyperspectral data and machine learning algorithms. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–17. [Google Scholar] [CrossRef]
- Dong, Y.; Liu, Q.; Du, B.; Zhang, L. Weighted feature fusion of convolutional neural network and graph attention network for hyperspectral image classification. IEEE Trans. Image Process. 2022, 31, 1559–1572. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5518615. [Google Scholar] [CrossRef]
- Dong, Y.; Liang, T.; Yang, C.; Luo, H.; Zhang, Y. Joint distance transfer metric learning for remote-sensing image classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506205. [Google Scholar] [CrossRef]
- Su, Y.; Chen, J.; Gao, L.; Plaza, A.; Jiang, M.; Xu, X.; Sun, X.; Li, P. ACGT-Net: Adaptive cuckoo refinement-based graph transfer network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Lu, S.; Zhang, M.; Huo, Y.; Wang, C.; Wang, J.; Gao, C. SSUM: Spatial—Spectral Unified Mamba for Hyperspectral Image Classification. Remote Sens. 2024, 16, 4653. [Google Scholar] [CrossRef]
- Shi, C.; Wu, H.; Wang, L. A positive feedback spatial–spectral correlation network based on spectral slice for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5503417. [Google Scholar] [CrossRef]
- Zhang, L.; Zeng, Y.; Zhao, J.; Lan, J. A novel global–local block spatial–spectral fusion attention model for hyperspectral image classification. Remote Sens. Lett. 2022, 13, 343–351. [Google Scholar] [CrossRef]
- Ding, C.; Zheng, M.; Zheng, S.; Xu, Y.; Zhang, L.; Wei, W.; Zhang, Y. Integrating prototype learning with graph convolution network for effective active hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–16. [Google Scholar] [CrossRef]
- Qu, J.; Zhang, L.; Dong, W.; Li, N.; Li, Y. Shared-Private Decoupling-Based Multilevel Feature Alignment Semi-Supervised Learning for HSI and LiDAR Classification. IEEE Trans. Geosci. Remote Sens. 2024; in press. [Google Scholar] [CrossRef]
- Manian, V.; Alfaro-Mejía, E.; Tokars, R.P. Hyperspectral image labeling and classification using an ensemble semi-supervised machine learning approach. Sensors 2022, 22, 1623. [Google Scholar] [CrossRef]
- Wang, Z.; Du, B. Unified active and semi-supervised learning for hyperspectral image classification. GeoInformatica 2023, 27, 23–38. [Google Scholar] [CrossRef]
- Cao, Z.; Li, X.; Feng, Y.; Chen, S.; Xia, C.; Zhao, L. ContrastNet: Unsupervised feature learning by autoencoder and prototypical contrastive learning for hyperspectral imagery classification. Neurocomputing 2021, 460, 71–83. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, B.; Yu, X.; Yu, A.; Gao, K.; Ding, L. Perceiving spectral variation: Unsupervised spectrum motion feature learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Wei, W.; Xu, S.; Zhang, L.; Zhang, J.; Zhang, Y. Boosting hyperspectral image classification with unsupervised feature learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5502315. [Google Scholar] [CrossRef]
- Yang, S.; Jia, Y.; Ding, Y.; Wu, X.; Hong, D. Unlabeled data guided partial label learning for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5503405. [Google Scholar] [CrossRef]
- Zheng, X.; Jia, J.; Chen, J.; Guo, S.; Sun, L.; Zhou, C.; Wang, Y. Hyperspectral image classification with imbalanced data based on semi-supervised learning. Appl. Sci. 2022, 12, 3943. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, M.; Zhang, J.; Kang, S.; Wang, Y. Improved active deep learning for semi-supervised classification of hyperspectral image. Remote Sens. 2021, 14, 171. [Google Scholar] [CrossRef]
- Zhang, S.; Xu, M.; Zhou, J.; Jia, S. Unsupervised spatial-spectral cnn-based feature learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5524617. [Google Scholar] [CrossRef]
- Gao, K.; Liu, B.; Yu, X.; Zhang, P.; Tan, X.; Sun, Y. Small sample classification of hyperspectral image using model-agnostic meta-learning algorithm and convolutional neural network. Int. J. Remote Sens. 2021, 42, 3090–3122. [Google Scholar] [CrossRef]
- Wu, H.; Li, M.; Wang, A. A novel meta-learning-based hyperspectral image classification algorithm. Front. Phys. 2023, 11, 1163555. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, L.; Zhao, R.; Shi, Z. A Bayesian meta-learning-based method for few-shot hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–13. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, M.; Yang, Y.; Li, Z.; Du, Q.; Chen, Y.; Li, F.; Yang, H. Heterogeneous few-shot learning for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 5510405. [Google Scholar] [CrossRef]
- Yuan, H.; Huang, K.; Duan, J.; Lai, L.; Yu, J.; Huang, C.; Yang, Z. Generalized few-shot learning for crop hyperspectral image precise classification. Comput. Electron. Agric. 2024, 227, 109498. [Google Scholar] [CrossRef]
- Zhao, Y.; Sun, J.; Hu, N.; Zai, C.; Han, Y. Residual channel attention based sample adaptation few-shot learning for hyperspectral image classification. Sci. Rep. 2024, 14, 26746. [Google Scholar] [CrossRef]
- Xiao, F.; Xiang, H.; Cao, C.; Gao, X. Neural architecture search-based few-shot learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5513715. [Google Scholar] [CrossRef]
- Zhao, Y.; Sun, J.; Zai, C.; Han, Y.; Hu, N. Attention-Based Sample Adaptation Few-Shot Learning for Hyperspectral Image Classification. Res. Sq. 2024. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep few-shot learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2290–2304. [Google Scholar] [CrossRef]
- Xi, B.; Li, J.; Li, Y.; Song, R.; Hong, D.; Chanussot, J. Few-shot learning with class-covariance metric for hyperspectral image classification. IEEE Trans. Image Process. 2022, 31, 5079–5092. [Google Scholar] [CrossRef]
- Tang, H.; Zhang, C.; Tang, D.; Lin, X.; Yang, X.; Xie, W. Few-Shot Hyperspectral Image Classification with Deep Fuzzy Metric Learning. IEEE Geosci. Remote Sens. Lett. 2025. [Google Scholar] [CrossRef]
- Li, X.; Yang, X.; Ma, Z.; Xue, J. Deep metric learning for few-shot image classification: A review of recent developments. Pattern Recognit. 2023, 138, 109381. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, H.; Zhang, W.; Lu, G.; Tian, Q.; Ling, N. Few-shot image classification: Current status and research trends. Electronics 2022, 11, 1752. [Google Scholar] [CrossRef]
- Xin, Z.; Wang, L.; Xu, M.; Li, Z. Hyperspectral image few-shot classification network with Brownian distance covariance. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Bai, J.; Huang, S.; Xiao, Z.; Li, X.; Zhu, Y.; Regan, A.C.; Jiao, L. Few-shot hyperspectral image classification based on adaptive subspaces and feature transformation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Wang, S.; Wang, B.; Zhang, Z.; Heidari, A.A.; Chen, H. Class-aware sample reweighting optimal transport for multi-source domain adaptation. Neurocomputing 2023, 523, 213–223. [Google Scholar] [CrossRef]
- Li, Y.; Guo, L.; Ge, Y. Pseudo labels for unsupervised domain adaptation: A review. Electronics 2023, 12, 3325. [Google Scholar] [CrossRef]
- Li, Z.; Liu, M.; Chen, Y.; Xu, Y.; Li, W.; Du, Q. Deep Cross-Domain Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Hu, L.; He, W.; Zhang, L.; Zhang, H. Cross-domain meta-learning under dual-adjustment mode for few-shot hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Zhang, M.; Wang, S.; Tao, R.; Du, Q. Graph information aggregation cross-domain few-shot learning for hyperspectral image classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 1912–1925. [Google Scholar] [CrossRef]
- Qin, B.; Feng, S.; Zhao, C.; Li, W.; Tao, R.; Xiang, W. Cross-domain few-shot learning based on feature disentanglement for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024. [Google Scholar] [CrossRef]
- Luo, Y.; Zheng, L.; Guan, T.; Yu, J.; Yang, Y. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–19 June 2019; pp. 2507–2516. [Google Scholar]
- Li, Y.; Li, Z.; Su, A.; Wang, K.; Wang, Z.; Yu, Q. Semi-supervised Cross-domain Remote Sensing Scene Classification via Category-level Feature Alignment Network. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Xue, J.; Zhao, Y.; Wu, T.; Wang, H.; Liu, Q. Tensor Convolution-Like Low-Rank Dictionary for High-Dimensional Image Representation. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 13257–13270. [Google Scholar] [CrossRef]
- Ye, Z.; Wang, J.; Liu, H.; Zhang, Y.; Li, W. Adaptive domain-adversarial few-shot learning for cross-domain hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5532017. [Google Scholar] [CrossRef]
- Feng, J.; Zhou, Z.; Shang, R.; Wu, J.; Zhang, T.; Zhang, X.; Jiao, L. Class-aligned and class-balancing generative domain adaptation for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5509617. [Google Scholar] [CrossRef]
- Ding, C.; Deng, Z.; Xu, Y.; Zheng, M.; Zhang, L.; Cao, Y.; Wei, W.; Zhang, Y. GLGAT-CFSL: Global-Local Graph Attention Networks Based Cross-Domain Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–19. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).