1.1. Background
In the field of remote sensing, hyperspectral imaging and synthetic aperture radar [
1,
2] have attracted widespread attention from researchers. With the development of hyperspectral imaging technology, the acquisition of hyperspectral images (HSIs) has become increasingly convenient and efficient [
3]. Unlike ordinary visual images that only have RGB channels, HSIs capture the spatial information of the target object while also capturing dozens or even hundreds of continuous spectra. Benefiting from this rich and detailed spectral information, HSIs enable more precise object identification through comprehensive characterization of material composition, structural properties, and physical states. Owing to these advantages, HSIs are widely used in various fields, such as medical imaging [
4,
5], agriculture [
6], mineral resource exploration [
7], and so on. HSI classification, as a key link in these applications, has always been a research hotspot.
HSI classification methods are generally categorized into traditional machine learning (ML) and deep learning (DL) methods. In early research, numerous ML-based methods were successfully applied to HSI classification, including support vector machines (SVMs) [
8], logistic regression [
9], random forests [
10], and k-means clustering [
11]. With the advancement of deep learning techniques, HSI classification has witnessed remarkable progress in recent years. Current mainstream DL architectures can be roughly divided into convolutional neural networks (CNNs) [
12,
13,
14], graph convolutional networks (GCNs) [
15,
16], and Transformers [
17]. HSI datasets acquired by optical sensors (e.g., AVIRIS, ROSIS, ITRES CASI 1500) encounter several notable challenges in land cover classification: (1) the high dimensionality of spectral data, which leads to the curse of dimensionality and redundant information; (2) spatial variability, where pixels of the same class exhibit distinct spectral responses due to varying illumination, background mixing, or environmental conditions; and (3) the scarcity of labeled samples, as pixel-level annotation in remote sensing is expensive and time-consuming. These challenges demand models that can efficiently capture both spectral and spatial dependencies while remaining robust under limited supervision. To address the above challenges, deep learning methods such as CNNs and Transformer have been widely applied to hyperspectral image classification. CNNs are effective at modeling local spatial structures but are inherently limited by their receptive fields, making it difficult to capture long-range spatial dependencies. Transformer-based methods, on the other hand, can model global contextual relationships, but they typically require large-scale labeled datasets and involve high computational complexity, which limits their applicability in low-sample settings. These inherent limitations of existing models hinder further improvements in HSI classification accuracy, highlighting the need for an efficient approach that can capture long-range spatial dependencies while maintaining relatively low computational complexity.
Recently, state-space models (SSMs) [
18] have aroused heated discussions in the field of DL; especially structured state-space sequence models (S4) [
19] have attracted widespread attention in sequence modeling. Mamba [
20] introduced a selection mechanism based on S4, enabling the model to selectively retain input-dependent information while maintaining indefinite memory. By employing a hardware-aware algorithm, Mamba achieves higher computational efficiency than Transformer. Benefiting from its linear complexity in modeling long-range dependencies, Mamba has achieved remarkable success in language modeling [
20]. Inspired by the success of Mamba in language modeling, more and more Mamba-based methods have been applied to the field of HSI classification [
21,
22,
23]. However, due to the image-spectrum merging characteristic of HSI, existing Mamba-based HSI classification methods still have the following limitations. On the one hand, unlike 1D sequences, the HSI spatial dimension is a 2D spatial structure. Current Mamba-based HSI classification methods [
24,
25,
26,
27] typically flatten the 2D spatial structure into the 1D sequence and then use a fixed scanning strategy to extract spatial features from the 1D sequence, which inevitably changes the spatial relationship between pixels, destroys the inherent contextual information in the image, and affects the classification results. On the other hand, current Mamba-based HSI classification methods [
21,
25] usually extract spectral features from the perspective of changing the spectral scanning direction, without considering the dependency of neighboring spectral information. In addition, these strategies of adding scanning directions inevitably increase the computational cost. These limitations compel us to design a structure-aware HSI classification model capable of capturing both spatial and spectral dependencies between neighboring features in the latent state space.
1.2. Related Work
HSI classification methods in early research primarily focused on spectral feature extraction from HSIs. Traditional approaches such as principal component analysis (PCA) [
28,
29], independent component analysis (ICA) [
30], and linear discriminant analysis (LDA) [
31] were commonly employed for HSI classification. However, these conventional methods exhibited limited generalization capability and weak representational capacity for the extracted features, resulting in unsatisfactory classification performance. In contrast, DL techniques not only demonstrate superior generalization ability but can also adaptively learn high-level semantic features. These advantages have led to their widespread application across various research domains, particularly in image classification [
32,
33,
34], object detection [
35,
36,
37,
38], and semantic segmentation [
39].
Among the prevalent backbone networks in DL, CNNs and their variants have been widely adopted for HSI classification. This is because they can effectively extract high-level semantic features and conveniently capture both spectral and spatial characteristics of HSIs. Hu et al. [
40] treated spectral information as objects and employed 1D-CNN to extract spectral-dimensional features for HSI classification. To incorporate spatial information, Makantasis et al. [
41] first reduced HSI dimensionality through R-PCA, then used patches of neighboring pixels around central pixels as training samples for 2D-CNN-based classification. However, using 2D-CNN alone cannot simultaneously capture joint spectral-spatial features. Hamida et al. [
42] segmented HSIs into 3D cubes suitable for 3D-CNN processing, stacking multiple 3D-CNN layers for classification. Roy et al. [
43] proposed a HybridSN network, combining 2D-CNN and 3D-CNN strategies, where 3D-CNN first extracted joint spectral-spatial features, followed by 2D-CNN learning more abstract spatial features. As network depth increases, models may encounter the gradient vanishing issue during training. To address this, He et al. [
44] introduced residual connections. Zhong et al. [
45] developed an end-to-end spectral-spatial residual network (SSRN) that complements feature information between each 3D convolutional layer and subsequent layers through residual blocks, achieving cross-layer feature enhancement and significantly improving classification performance. Zhang et al. [
46] proposed a CNN-based spectral partitioning residual network (SPRN) that divides input spectra into multiple sub-bands and employs parallel improved residual blocks for feature extraction, effectively enhancing spectral-spatial feature representation. However, these CNN-based methods are fundamentally limited by their kernel sizes, resulting in insufficient understanding of global HSI structures. Furthermore, CNNs cannot establish long-range dependencies, making them ineffective for comprehensive spectral information extraction.
In recent years, Transformers have emerged as another mainstream framework for HSI classification due to their powerful long-range modeling capability and global spatial feature extraction ability. Dosovitskiy et al. [
47] pioneered the Vision Transformer (ViT), marking a significant attempt to apply Transformer in the visual domain by directly processing sequences of image patches. Subsequently, numerous ViT variants have been adapted for HSI classification. Hong et al. [
48] proposed a pure Transformer-based network named SpectralFormer for sequential information extraction in HSI classification. However, SpectralFormer underutilizes spatial positional information, resulting in suboptimal classification performance. To address this limitation, Sun et al. [
49] developed an SSFTT network, which first converts shallow spectral-spatial features extracted by convolutional layers into deep semantic tokens, then employs Transformer for semantic modeling. This CNN–Transformer hybrid architecture effectively captures high-level semantic features to improve classification accuracy. Roy et al. [
50] introduced a novel model named MorphFormer that integrates learnable spectral and spatial morphological convolutions with Transformer to enhance interactions between image tokens and class tokens regarding structural and shape information in HSI. Ma et al. [
51] proposed LSGA-ViT, incorporating a light self-Gaussian-attention (LSGA) mechanism with Gaussian absolute position bias to better simulate HSI data distribution, making attention weights more concentrated around central query patches. Zhao et al. [
52] observed that the inherent global correlation modeling in Transformer overlooks effective representation of local spatial-spectral features. To address this, they developed GSC-ViT, which specifically enhances the extraction of local spectral-spatial information. However, the self-attention mechanism [
17] presents computational challenges due to its quadratic complexity, which not only increases computational costs but also limits the model’s capacity for long-range dependency modeling [
53].
Recently, a new DL architecture, SSMs, has attracted widespread attention in the academic community. SSMs are good at capturing long-range dependencies and can be efficiently parallelized [
53], positioning them as a strong competitor to CNNs and Transformers. Mamba is a typical representative of SSMs, with excellent computational efficiency and powerful feature extraction capability. In computer vision, Zhu et al. [
53] designed a general vision backbone network named Vision Mamba (Vim) based on the location sensitivity of visual data and the global context requirements of visual understanding. The network uses a bidirectional Mamba structure to replace the self-attention mechanism. Liu et al. [
54] proposed a VMamba network, which introduced the Cross-Scan Module (CSM) to traverse the spatial domain and transform any non-causal visual image sequence patch sequence, which helps to narrow the gap between the orderliness of one-dimensional selective scanning and the non-sequential structure of 2D visual data. In the field of remote sensing, Chen et al. [
55] proposed an RSMamba for remote sensing image classification. The model proposed a dynamic multi-path activation mechanism to enhance Mamba’s ability to model non-causal data. Cao et al. [
56] proposed a model called M3amba, a new end-to-end CLIP-driven Mamba model for multimodal fusion, and designed a multimodal Mamba fusion architecture with linear complexity and a cross-attention module Cross-SS 2D for full and effective information fusion. In HSI classification, Sun et al. [
26] proposed a DBMamba model, which first used CNN to extract shallow spectral spatial features and then used bidirectional Mamba to extract higher-level semantic features based on the shallow features to achieve classification. Huang et al. [
23] proposed an SS-Mamba model, which first converts the HSI cube to spatial and spectral token sequences through a token generation module. The sequences processed by Mamba blocks are then fed into a feature enhancement module for final classification. Lu et al. [
57] developed the SSUM model, comprising the Spectral Mamba branch and the Spatial Mamba branch, where the features output from both branches are combined to produce classification results. Wang et al. [
25] proposed an LE-Mamba model for HSI classification, using a multi-directional local spatial scanning mechanism in the spatial dimension to improve the extraction of non-causal local features and a bidirectional scanning mechanism in the spectral dimension to capture fine spectral details. He et al. [
22] proposed a new 3DSS-Mamba framework. In order to overcome the limitations of the traditional Mamba algorithm that can only model causal sequences and is not suitable for high-dimensional scenes, an algorithm based on the 3D-Spectral-Spatial Selective Scanning (3DSS) mechanism was proposed, and five scanning paths were constructed to examine the impact of dimensional priority [
22]. Existing Mamba-based HSI classification methods attempt to solve the problem of aligning HSI spatial structure with sequential Mamba by continuously adjusting the scanning strategy, but there are limitations in effectiveness and efficiency. In addition, when processing HSI spectral information, only considering the spectral scanning direction cannot fully extract the intrinsic information of the spectrum.
1.3. Motivation and Contribution
HSI classification is to classify each pixel into a certain category, and a single pixel shows a certain correlation with its spatially close pixels. Making full use of spatial structural information is conducive to improving the classification results. Conventional classification methods use image patches centered on classified pixels as the input of the model. However, Mamba-based models usually convert 2D image patches into 1D sequences for spatial feature scanning. Although existing scanning strategies partially solve the problem of insufficient feature extraction after the spatial structure is converted into a sequence structure, they have certain limitations in terms of effectiveness and efficiency. On the one hand, directional scanning inevitably changes the spatial relationship between pixels, thereby destroying the original semantic information. For example, the distance between a pixel and its left or right (horizontal) neighbor is 1, while the distance between its upper or lower (vertical) neighbor is equal to the width of the 2D image patch, which hinders the model from understanding the spatial relationship in the original HSI 2D image patch. On the other hand, fixed scanning paths [
24,
25,
26,
27], such as four-directional scanning [
25], cannot effectively capture the complex spatial relationship in the 2D image patch, and the introduction of more scanning directions requires additional calculations. In addition, HSI has spatial variability [
58]; that is, pixels of the same category present different spectral features in space, which increases the difficulty of the model in extracting spectral features and thus affects the overall classification performance.
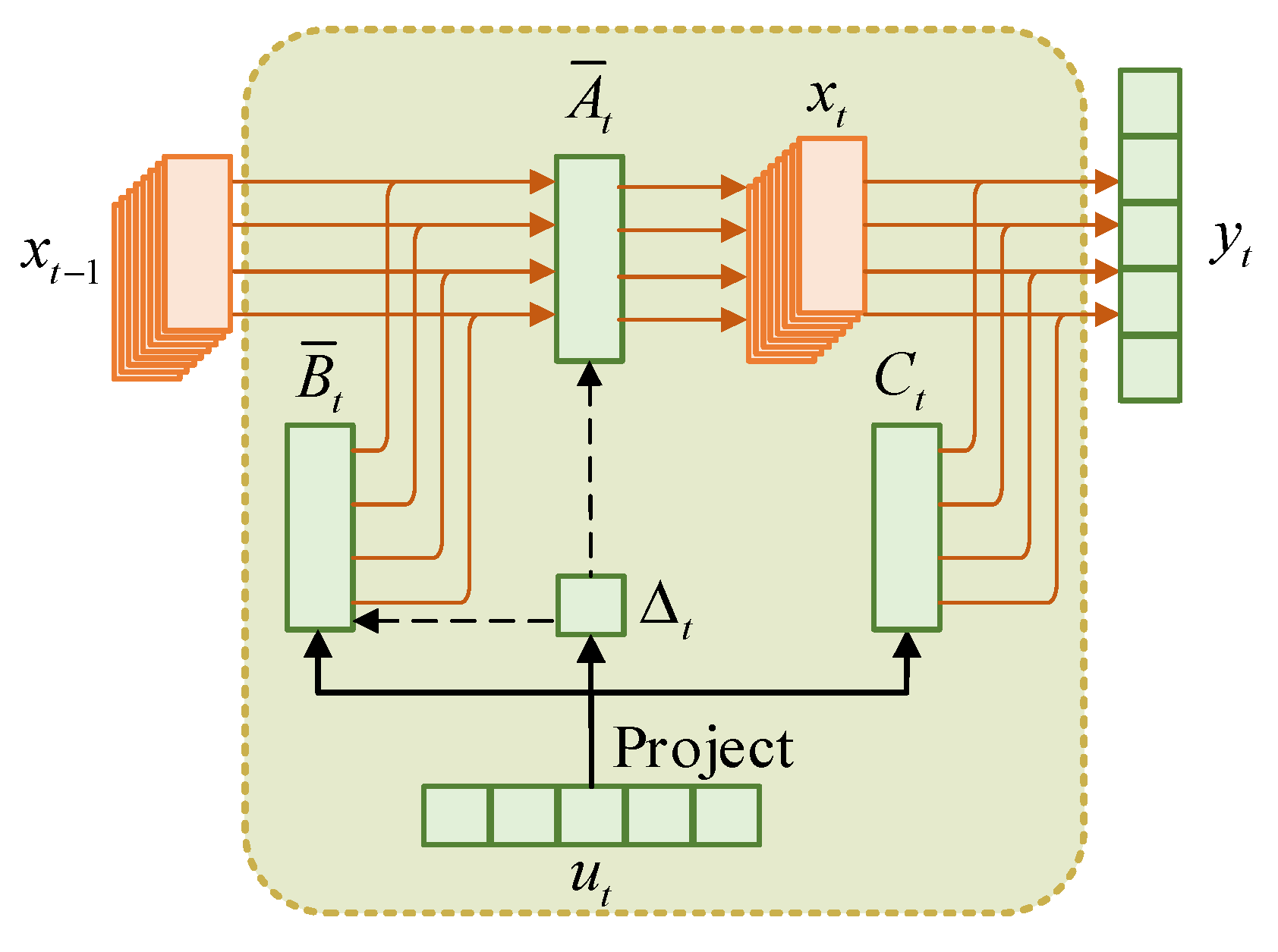
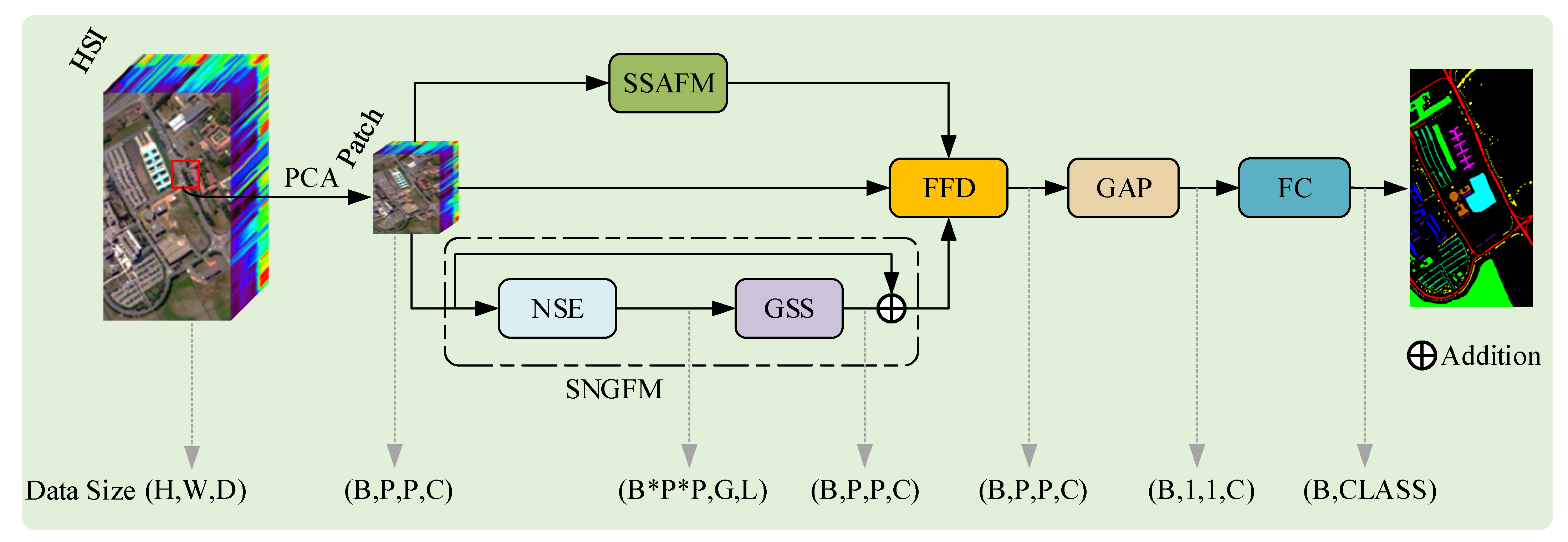
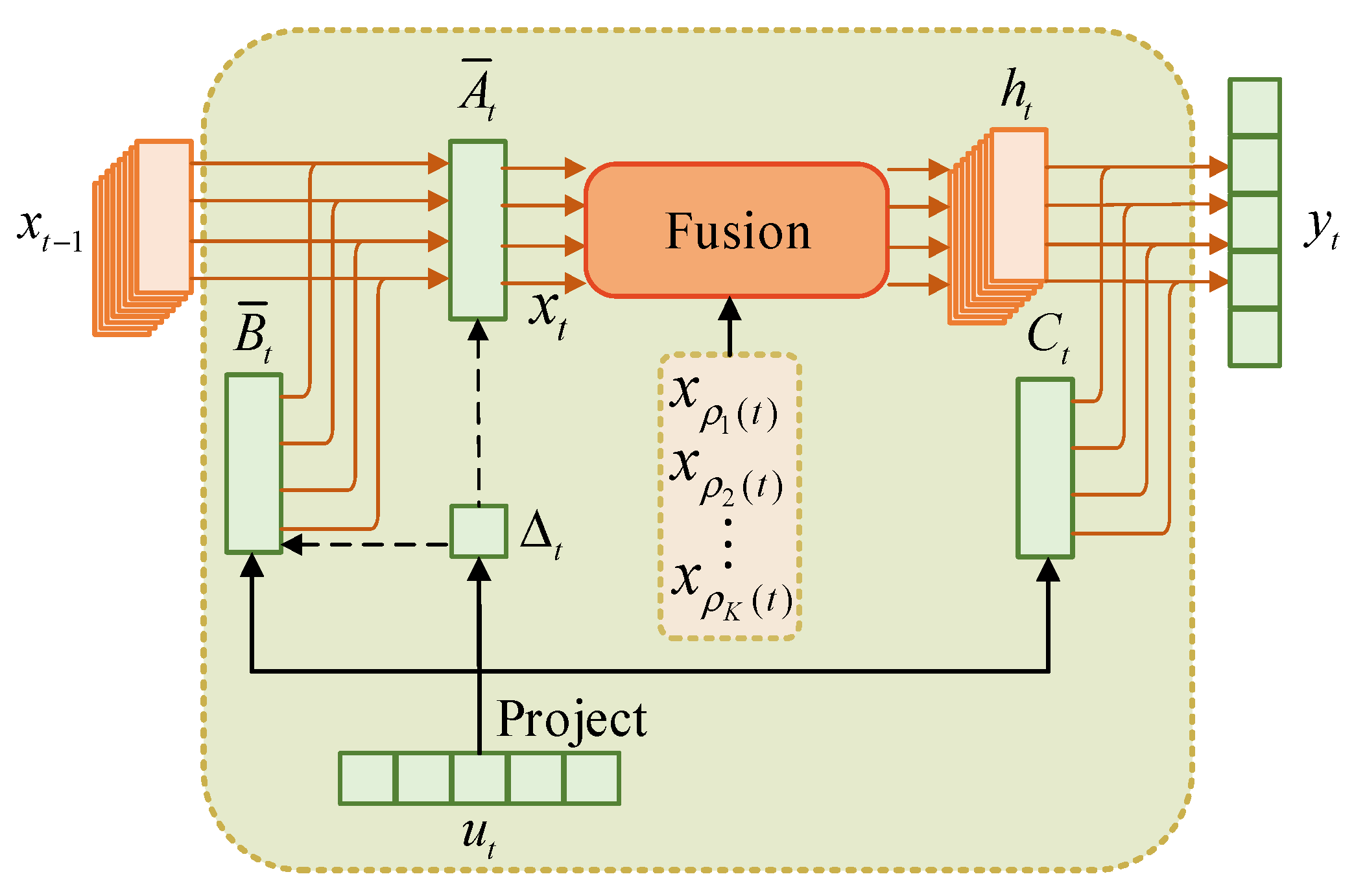
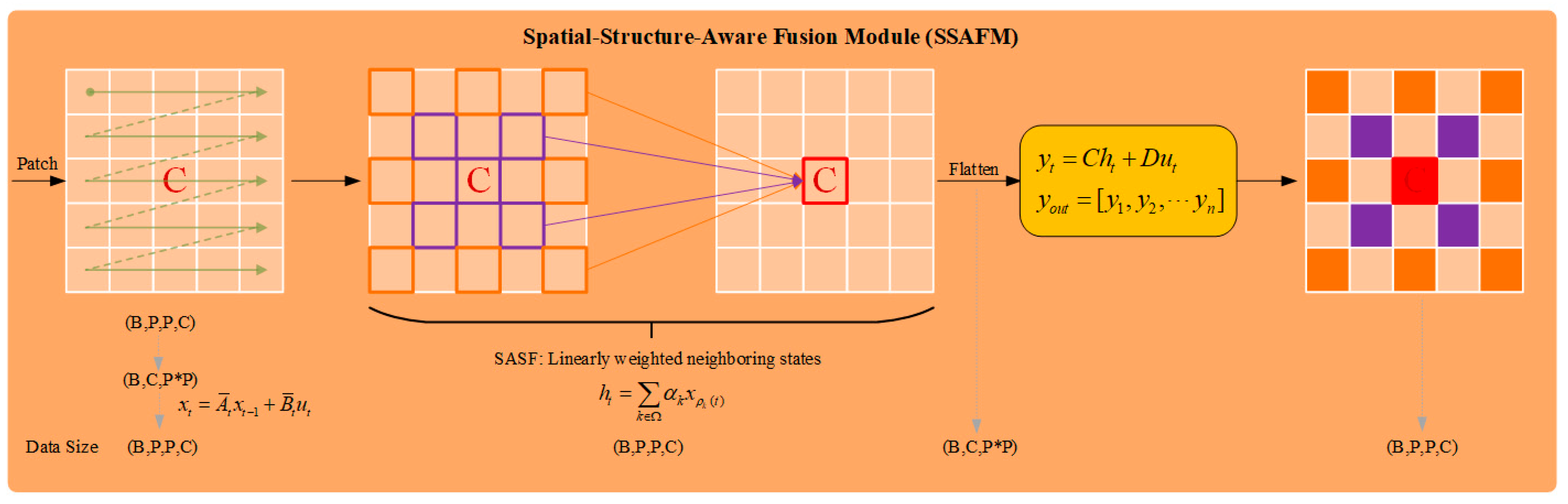
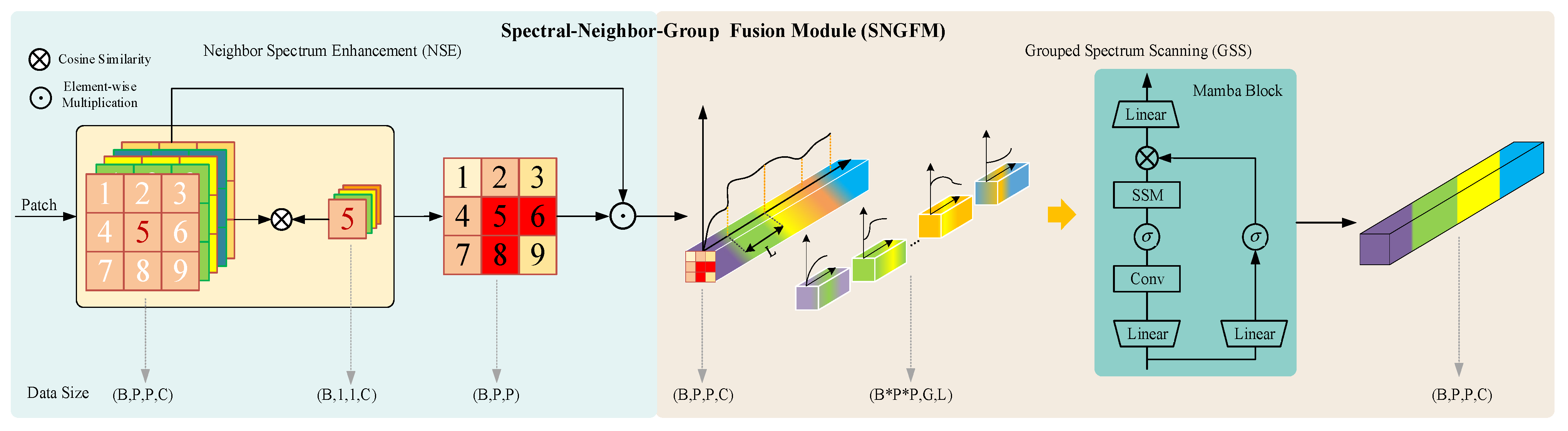
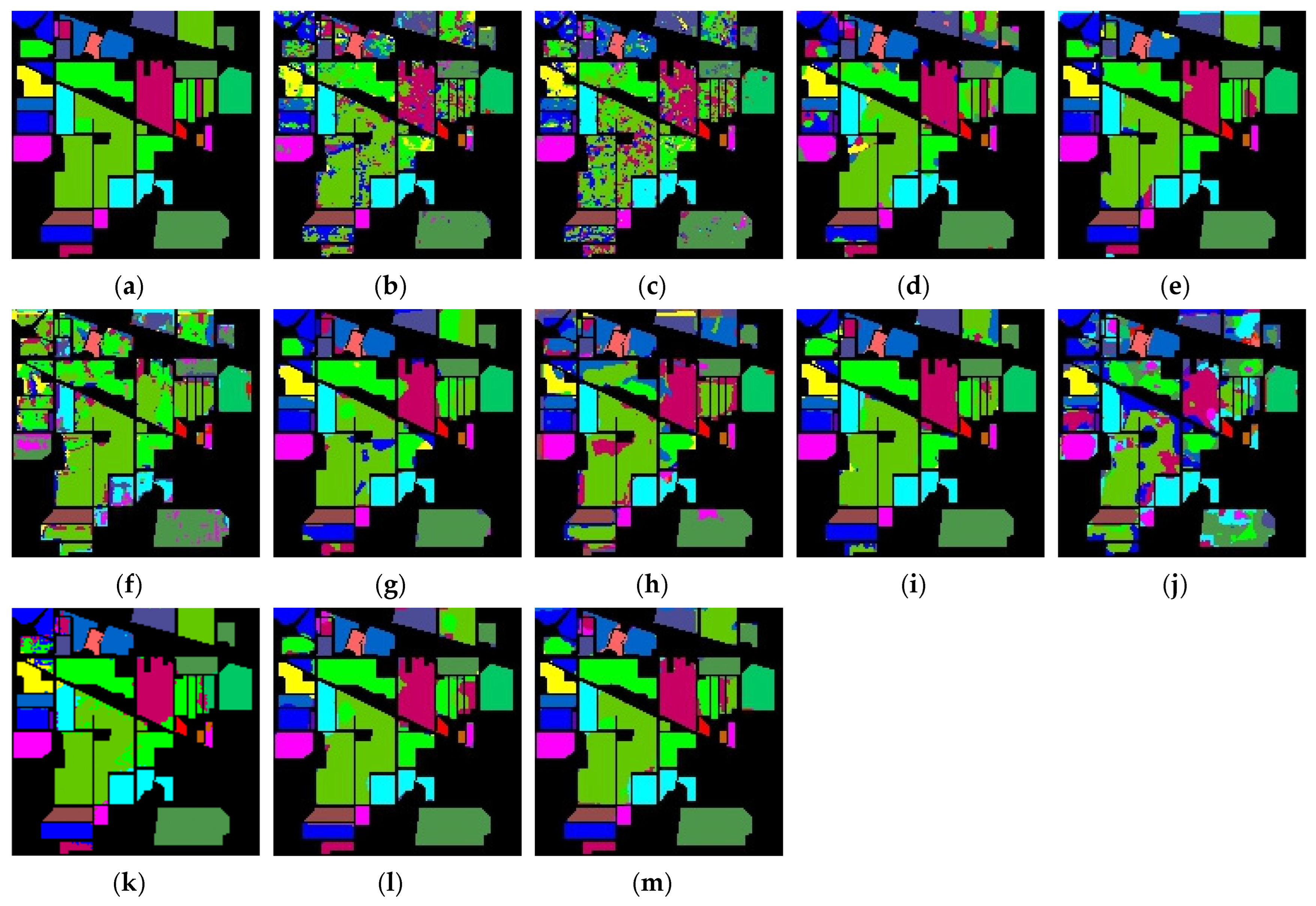
In order to overcome the limitations of existing scanning strategies and mitigate the impact of spatial variability, this paper proposes a new HSI classification framework named Dual-Aware Discriminative Fusion Mamba (DADFMamba). DADFMamba not only captures the spatial dependency of HSI neighboring features from the latent state space, but also uses the spectral features of the target pixel’s neighbors to reduce spatial variability, thereby improving the classification performance. DADFMamba consists of the Spatial-Structure-Aware Fusion Module (SSAFM), the Spectral-Neighbor-Group Fusion Module (SNGFM) and the Feature Fusion Discriminator (FFD). In SSAFM, a new structure-aware state fusion (SASF) equation is introduced into the original Mamba to effectively capture the HSI spatial features. In SNGFM, a neighbor spectrum enhancement (NSE) strategy is proposed to overcome the interference caused by spatial variability. On this basis, a new scanning mechanism, grouped spectrum scanning (GSS), is proposed, which divides the enhanced spectral features into several small groups to better distinguish the subtle differences in spectral information. At the same time, this mechanism makes the model computationally friendly. Finally, FFD with a residual structure is used to implement HSI classification.
The main contributions of this paper are summarized as follows:
A new Mamba-based HSI classification method named Dual-Aware Discriminative Fusion Mamba (DADFMamba) is proposed. It achieves dual awareness of HSI spatial and spectral structures by modeling spatial structure context and spectral neighborhood correlation in a unified framework.
In SSAFM, to address the challenge of spatial structure loss in existing Mamba-based HSI classification methods, we introduce a novel structure-aware state fusion (SASF) equation. This equation not only enables effective skip connections between non-sequential elements in the sequence but also enhances the model’s ability to capture spatial relationships in HSIs.
In SNGFM, in order to overcome the interference caused by spatial variability, a new NSE strategy is proposed. In addition, in order to better distinguish the subtle differences in spectral features, a new GSS mechanism is developed. Through the organic combination of the two, both the spectral feature extraction capability and computational efficiency are improved.
The remainder of this paper is organized as follows.
Section 2 introduces the State Space Model and presents the detailed architecture of the proposed DADFMamba.
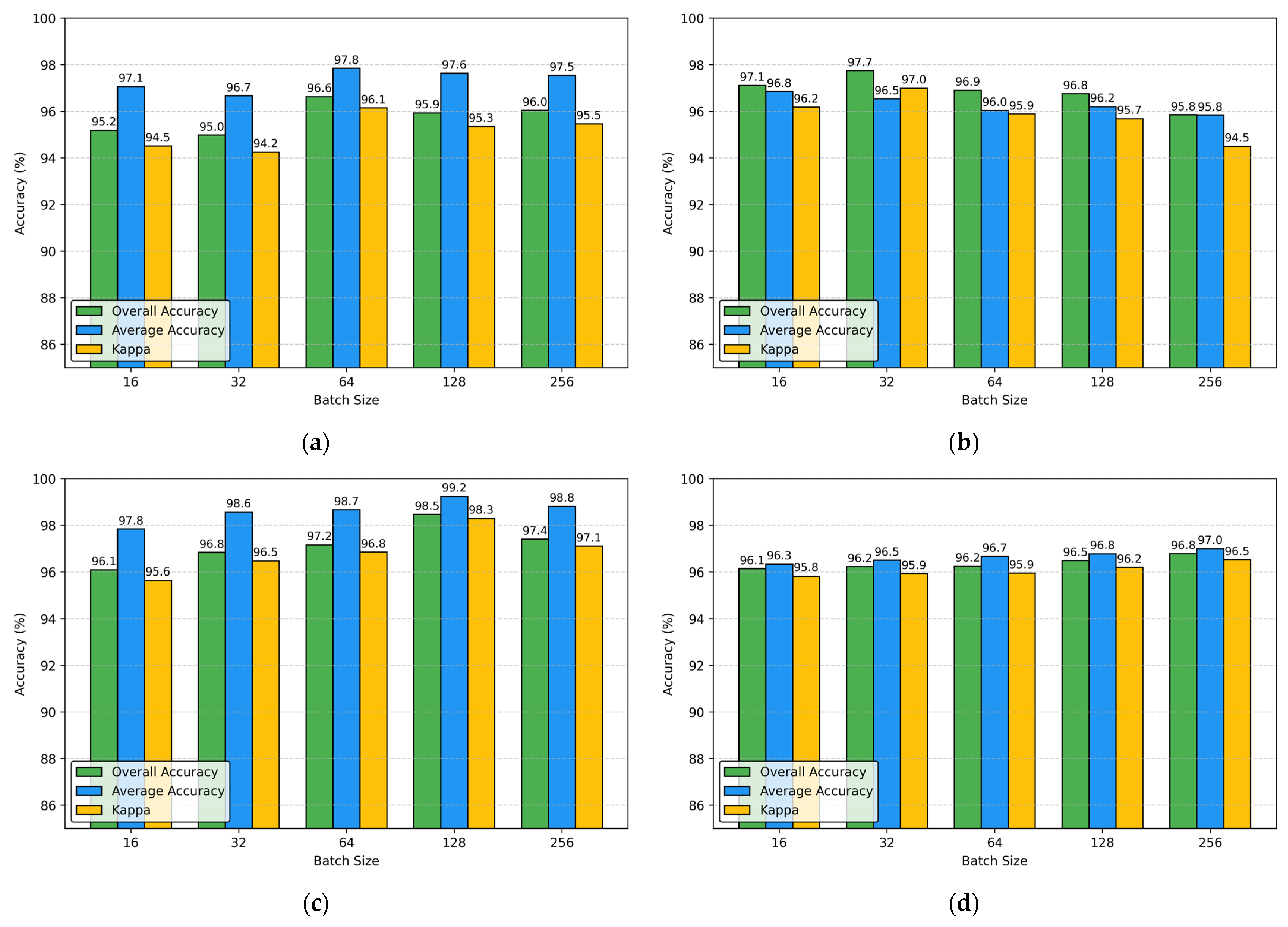
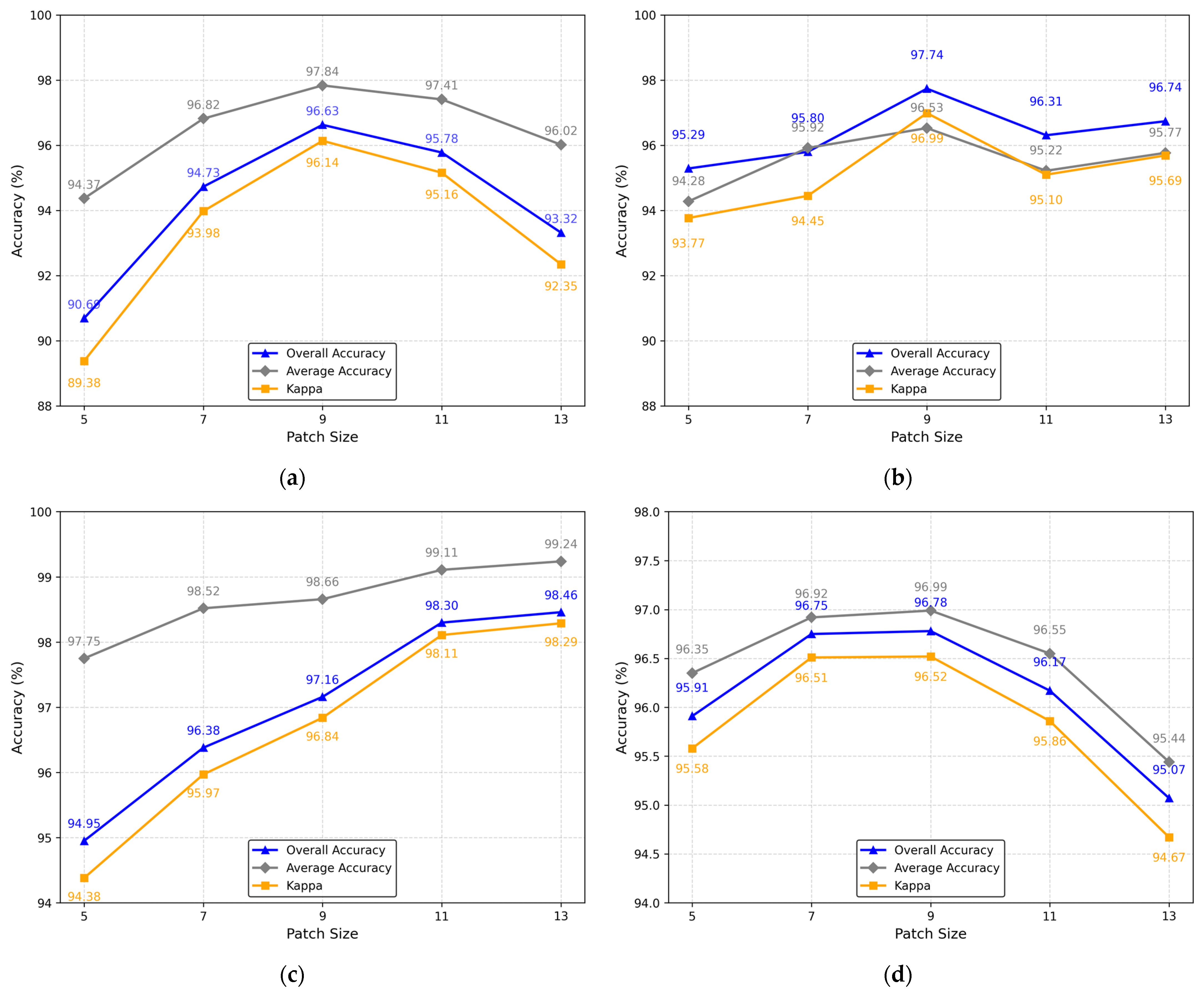
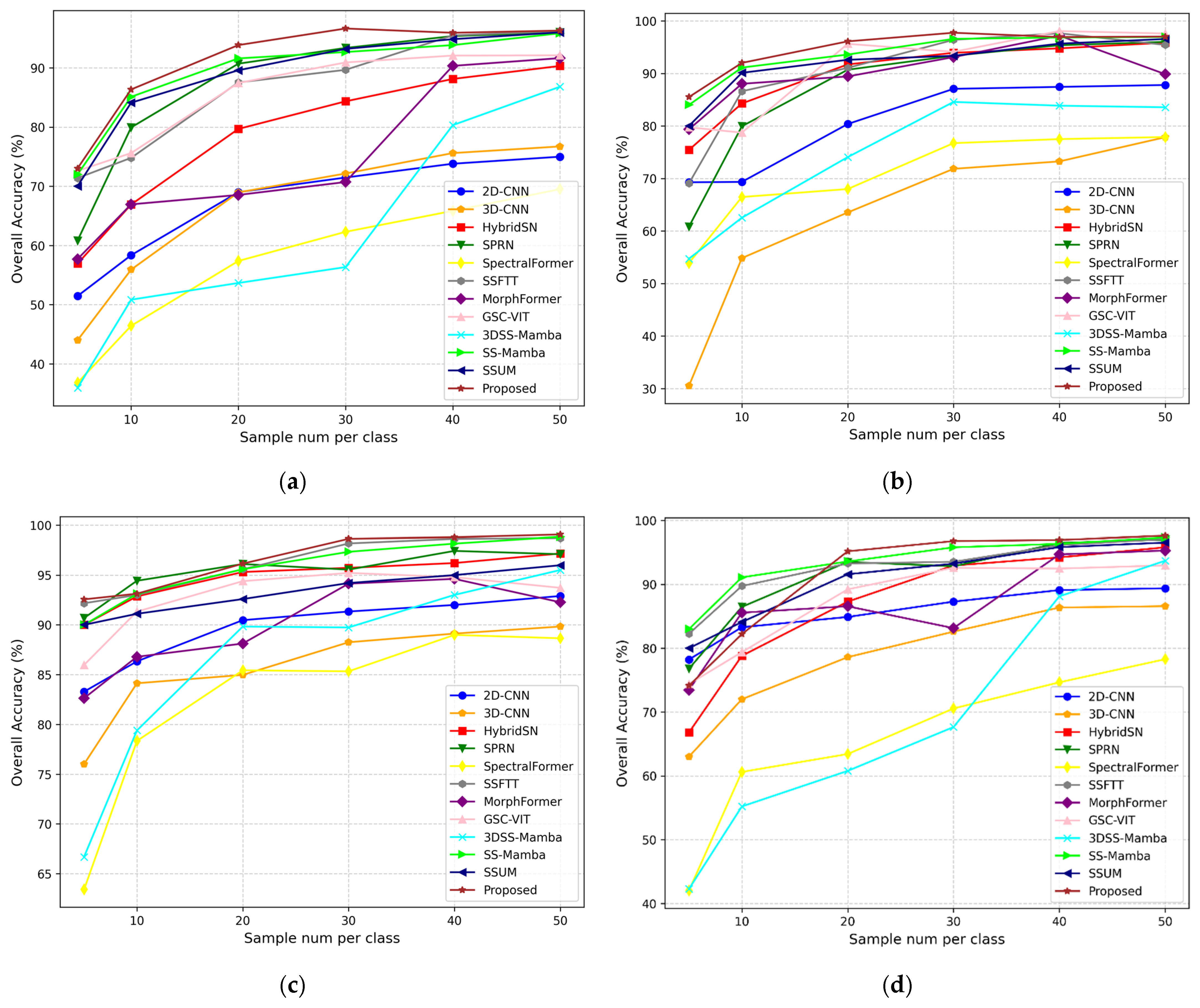
Section 3 comprehensively describes the experimental process, including dataset selection, implementation details, comparative experiments, parameter analysis, and ablation studies. Finally,
Section 4 concludes this work and provides suggestions for future research directions.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}