1. Introduction
With socio-economic development, population growth, and accelerated industrialization, most cities continue to expand. Urban expansion serves as the foundation for urban development; yet, during this process, substantial urban green spaces and suburban vegetation are frequently occupied and transformed into residential buildings and industrial facilities [
1]. Urban greenery plays a crucial role in achieving urban carbon neutrality and improving air quality [
2,
3,
4]. The reduction in green spaces has led to multiple environmental challenges, including intensified urban heat island effects and diminished urban ecosystem diversity [
5,
6]. Therefore, comprehensive planning of urban green spaces during urban development becomes an inevitable choice for environmental preservation [
7,
8,
9,
10].
Previous studies have proposed various methods for coordinated planning of urban green spaces, all requiring precise localization of vegetation within urban areas. Traditional manual field surveys demand on-site personnel inspections, proving time-consuming and cost-prohibitive for large-scale urban applications [
11,
12]. Advances in remote sensing technology enable automated all-weather collection of streetscape data, allowing researchers to locate urban green spaces through street view image analysis. Progress in artificial intelligence (AI) has led to automated localization methods using machine learning and deep learning algorithms, which employ automatically acquired streetscape data combined with image segmentation algorithms like FCN [
13] and PointNet++ [
14] to demarcate vegetation areas [
15]. However, there are two challenges in using these artificial intelligence algorithms [
16,
17,
18]. First, there are limitations in the performance of these algorithms, which cannot handle the boundary regions well during segmentation, and there is a lot of room for improvement in segmentation accuracy [
19]. Secondly, the urban climate is highly variable, and in some coastal cities there is often inclement weather such as storms, and most of the areas of the streetscape images collected under adverse weather are blurred and the data quality is poor, which leads to a low accuracy of the final localization [
20]. Furthermore, in order for these AI algorithms to function effectively in practice, it is imperative to consider their substantial computational costs and inference times [
21]. Therefore, providing urban managers with a method suitable for vegetation positioning in urban scenarios is of practical significance.
Fortunately, on the one hand, multimodal large language models have emerged as a dominant approach in various artificial intelligence applications and are widely adopted in image segmentation and object detection research. The Segment Anything Model (SAM) is a multimodal large language model designed for image segmentation [
22]. The SAM has demonstrated the high efficiency in performing diverse segmentation tasks through training on extensive datasets, and its pretraining model architecture and parameters make it able to quickly adapt to the greening recognition task of different scenes without complex parameter tuning [
23]. Consequently, this suggests that there is potential for resolving the issues associated with substantial computing resources and inference time when implementing the SAM in practice. Meanwhile, when applied to urban vegetation localization, the SAM effectively addresses the performance limitations of traditional algorithms. For example, compared with traditional image segmentation algorithms, the SAM performs better in dealing with complex backgrounds, occlusions, and morphological diversity of vegetation in street view images, and can effectively reduce segmentation errors caused by image complexity [
24,
25]. In addition, the multimodal characteristics of the SAM support the fusion of multiple information, and by combining image visual features and semantic information, it can significantly improve the accuracy and stability of greening area identification, provide strong technical support for accurately distinguishing vegetation and nonvegetation areas, and significantly improve the positioning accuracy of urban greening areas [
26,
27]. However, due to the complexity of urban scenes, directly applying the SAM to urban street view images may result in minor omissions in boundary regions. Therefore, enhancing the model’s capability to handle boundary areas becomes essential.
On the other hand, with the advent of image defogging technology, there is a possibility of utilizing these defogging technologies to address the impact of severe weather, such as heavy fog, frequently encountered in urban vegetation positioning tasks. Existing defogging methods can be categorized into traditional physical approaches and deep-learning-based techniques [
28]. Traditional physical defogging methods, such as DCP [
29], estimate atmospheric transmission and illumination components to achieve defogging. However, their reliance on strong assumptions about uniform fog distribution and scene brightness often leads to halo artifacts, color distortion, and difficulties in maintaining global consistency. With advancements in artificial intelligence, numerous deep-learning-based defogging methods have been developed. AOD-Net [
30], leveraging a deep learning framework, simplifies the joint optimization of transmission and atmospheric light by parameterizing the atmospheric scattering model. Nevertheless, its shallow network structure limits its dynamic adaptability to varying fog concentrations, resulting in incomplete defogging. EMRA-Net [
31] and GCANet [
32] further incorporate multiscale residual modules, channel attention mechanisms, and gated context aggregation strategies to enhance local texture recovery and noise suppression. Despite these improvements, they still struggle with heavy fog regions, leading to incomplete processing. Defogging methods based on Transformer architectures, including Dehamer [
33], DehazeFormer [
34], and PMNet [
35], utilize multihead self-attention mechanisms to focus on deeper image features. However, these methods tend to over-defog, causing the loss of original image characteristics. Moreover, algorithms based on the Transformer structure typically incur substantial computational costs and require extended inference times [
33,
34,
35]. Hence, current defogging techniques fail to meet the requirements of urban scenarios in practice. In other words, there is a need for a defogging method that achieves high defogging quality while preserving the original features of images across different fog concentrations to the greatest extent possible.
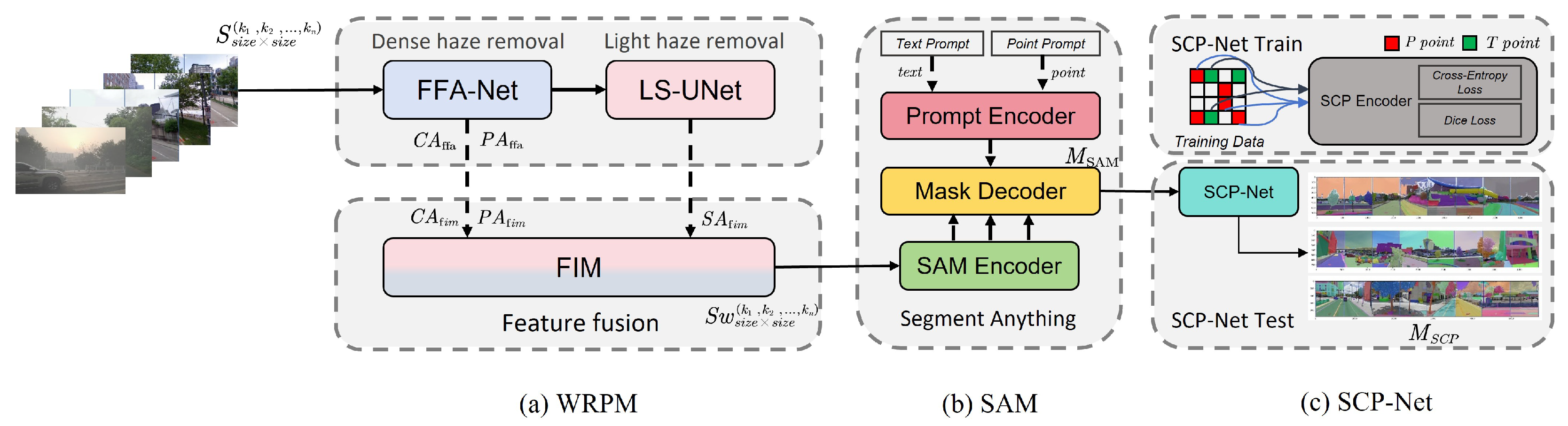
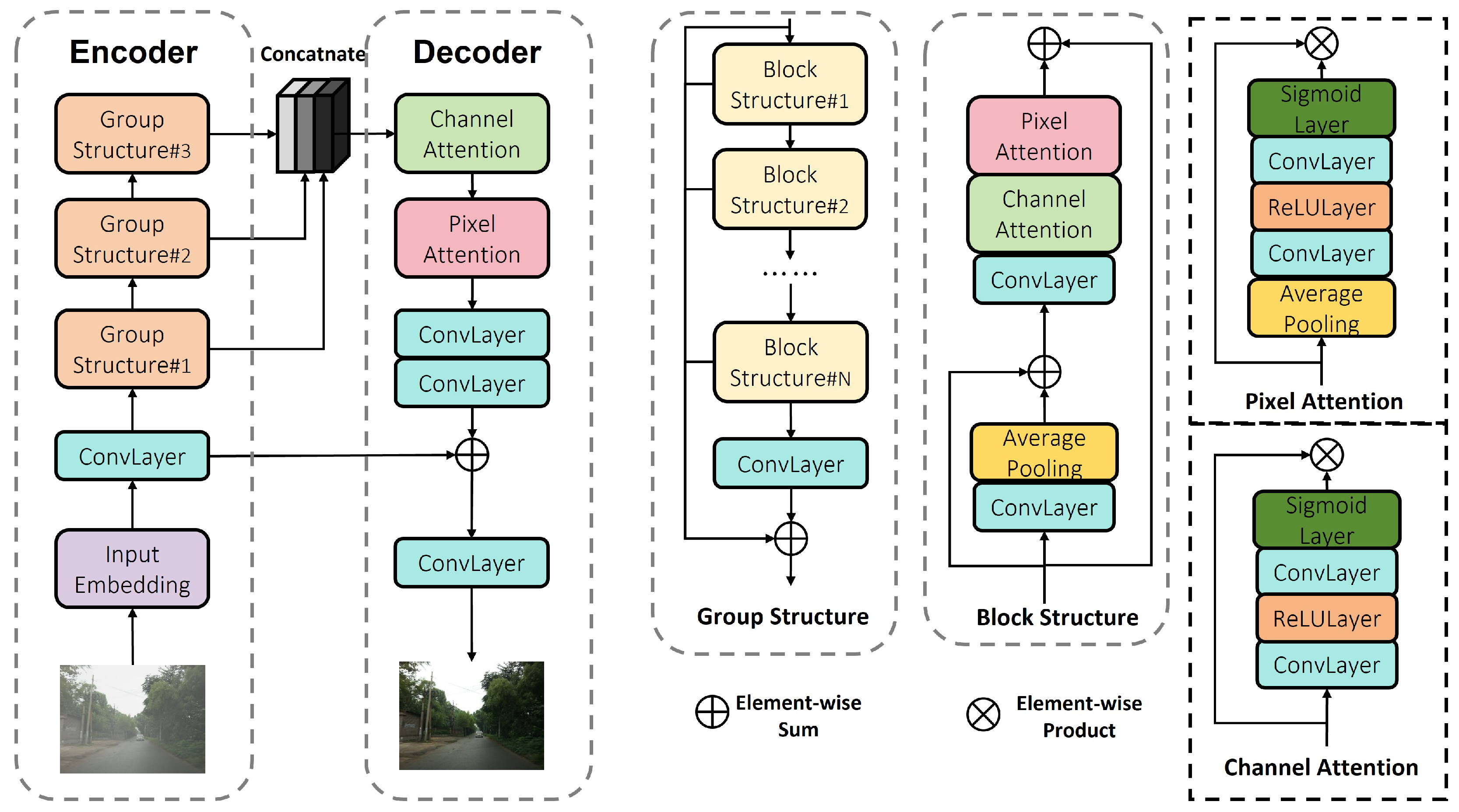
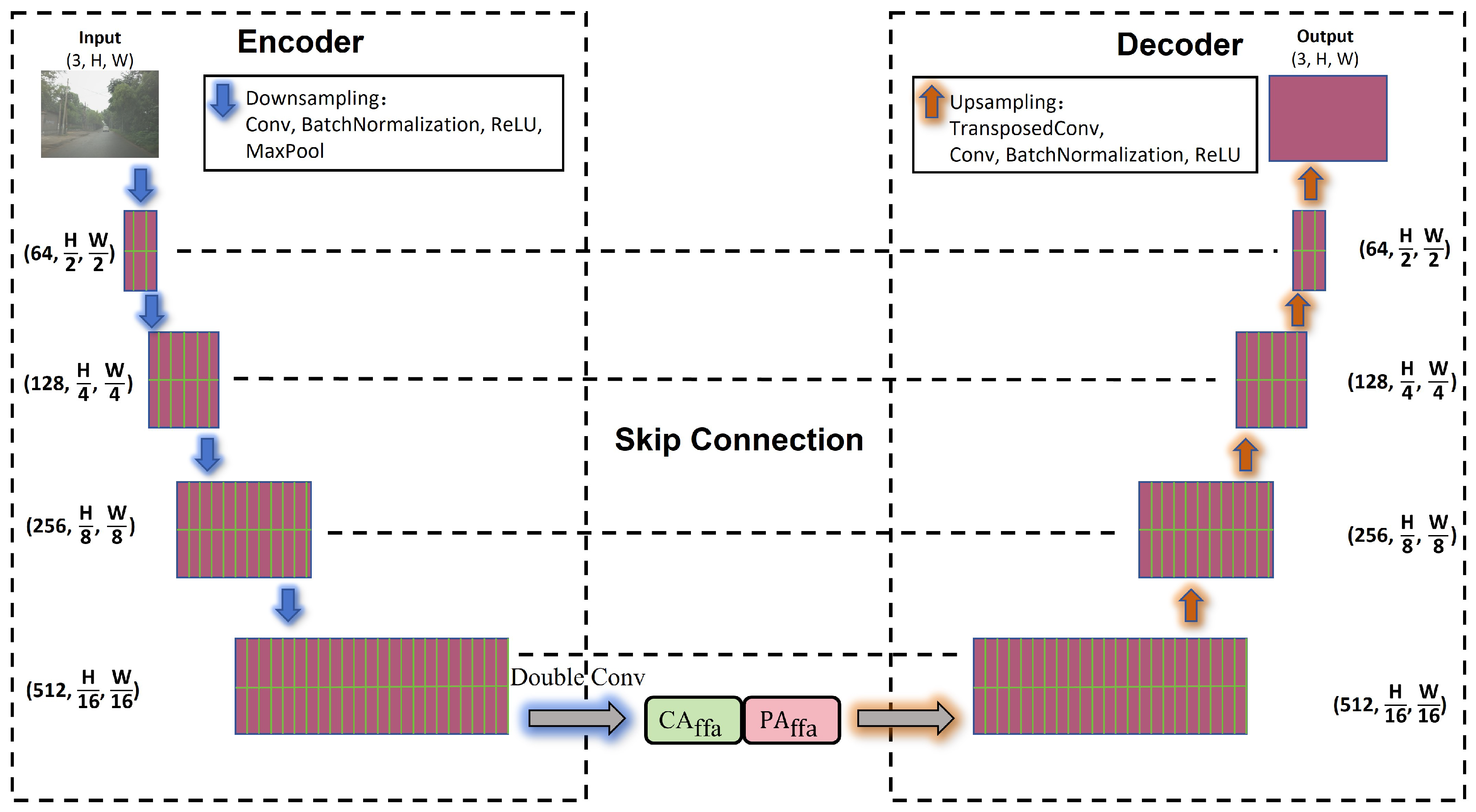
To this end, we first developed a specialized correction network, namely, the Streetscape-Correction Network (SCP-Net). SCP-Net employs an encoder–decoder architecture, where the encoder is based on ResNet and the decoder consists of multiple upsampling layers with skip connections. Additionally, it innovatively incorporates a multiloss function. This network effectively mitigates the issues of misclassification and omission of vegetation in boundary regions during image segmentation using SAM, while enabling directional correction through a dual-error correction mechanism. On the other hand, we designed the Weather-Robust Preprocessing Module (WRPM) to counteract the degradation of street view data quality caused by climatic factors. The WRPM adopts a parallel dual-branch structure for feature extraction, utilizing dense haze region processing network (FFA-Net) and light haze region processing network (LS-UNet) to, respectively, extract dense fog and light fog features from images. These branches enable dedicated processing pathways tailored to different fog concentration levels. Following feature extraction, the feature fusion module (FIM) adaptively fuses the extracted information. The WRPM not only effectively removes foggy regions from images but also preserves the original details of the image to the greatest extent possible. The low cost of training and the high inference efficiency of the backbone network suggest that its application in practice is both feasible and beneficial. We refer to this integrated approach as Urban Green Space SAM (UGSAM).
The main contributions of this work are as follows:
- 1.
Due to the variable climate in cities, rainy and foggy weather greatly affects the clarity of urban street scene images. Currently, there are few algorithm models for all-weather urban vegetation positioning. We propose a high-precision urban vegetation positioning algorithm UGSAM that can perform well in bad weather. The UGSAM consists of a multimodal large model SAM, a defogging module WRPM, and a correction network SCP-Net. We find that this algorithm performs excellently in bad weather and also has certain performance improvements in normal weather.
- 2.
To ensure that the UGSAM can maximize defogging while minimizing the damage to the original features of the image, we propose a dual-branch structure WRPM based on channel attention and pixel attention. WRPM includes the dense fog feature network FFA-Net and the light fog feature network LS-UNet, which can fully extract the diverse features of the image. Finally, the features are fused through FIM to achieve refined defogging. To further improve the positioning accuracy, we trained the correction network SCP-Net to conduct a secondary verification on the segmented image, obtaining more accurate results.
- 3.
The experimental results show that the UGSAM has the best positioning accuracy in all weather conditions. Meanwhile, it requires less time for training and inference and has certain transferability, making it suitable for deployment in urban scenarios.
4. Discussion
4.1. Analysis of Method Performance Superiority
This study demonstrates the significant advantages of the UGSAM model in image defogging and semantic segmentation tasks through multidimensional metrics. The WRPM module within UGSAM employs a dual-channel branch structure to process dense fog and light fog regions in images in parallel, and subsequently integrates the extracted features via a fusion module. This approach maximizes defogging effectiveness while preserving as many original image characteristics as possible. The WRPM is capable of addressing images with reduced clarity caused by adverse weather conditions such as rain and fog, thereby enhancing the accuracy of vegetation localization. Additionally, the SCP-Net component of the UGSAM refines the segmentation results produced by the SAM, further improving localization precision.
In the comparative experiments, on one hand, we conducted a performance comparison between the defogging WRPM and other defogging networks. The results are presented in
Table 4. In the experimental results, the LPIPS metric indicates that the defogged images by the WRPM are perceptually closer to ground truth and possess richer details. The results of SSIM and PSNR suggest that the defogged images generated by the WRPM have the minimal difference from the ground truth. In
Figure 5,
Figure 6 and
Figure 7, the results processed by different defogging methods are visualized. Through comparison, it can be found that the WRPM is always the closest to the ground truth.
On the other hand, we tested the vegetation segmentation performance of the UGSAM method under normal and adverse weather conditions. The segmentation accuracy directly determines the positioning accuracy. The results under normal weather conditions are presented in
Table 5, and those under adverse weather conditions are shown in
Table 6. In adverse weather conditions, the UGSAM achieved extremely significant improvements over the SAM in multiple indicators, with OA increasing by 16.29%, and realized high-precision positioning of vegetation areas. Under normal weather conditions, the OA of the UGSAM was only 1.03% higher than that of the SAM, which is not significant. However, the main contribution of this study lies in the scenarios of severe weather. Therefore, the improvement brought about by normal weather is an additional contribution. In the future, we hope to achieve a breakthrough in the positioning accuracy of vegetation under normal weather conditions.
In the ablation experiments, we conducted three distinct tests. Firstly, we performed split tests on the three modules within the WRPM, with the results detailed in
Table 7. The findings indicate that the integration of FFA-Net and LS-UNet via FIM yields optimal performance. Secondly, we evaluated the performance of SCP-Net, as presented in
Table 8. The results demonstrate that SCP-Net significantly enhances positioning accuracy. Finally, we examined various loss functions employed in SCP-Net, with the outcomes reported in
Table 9. The experimental data reveal that our proposed composite loss function outperforms all alternatives tested.
4.2. Computational Resource Cost
The primary objective of this study is to implement the proposed method in the practical application of vegetation area positioning within urban environments. A critical discussion on the feasibility of deploying this method at the edge in urban scenarios is essential. The challenges associated with model deployment and the computational resources consumed during operation are the key determinants of its deployment viability. Given that this research involves large-scale models, which are typically characterized by high computational demands, it is imperative to evaluate the computational resources required for operation. For this analysis, the arithmetic power of the NVIDIA RTX4090 (82.58 TFLOPS with FP32) was used as a benchmark.
As illustrated in
Table 10, we compared the number of parameters and GFLOPs of the model in this study with those of multimodal large models during the training phase. The results indicate that WRPM trains 34.4 M parameters and consumes 3.72 GFLOPs, whereas SCP-Net trains 1.7 M parameters and consumes 0.46 GFLOPs. These figures demonstrate significantly lower computational resource consumption compared to the training requirements of the three SAM weight variants, highlighting superior cost-effectiveness and enabling scalable, low-cost deployment of the algorithm in urban settings.Models based on the Transformer architecture have a large amount of computation due to the self-attention mechanism and generally have more than 100 M parameters, which is much higher than the computational cost of the UGSAM [
33,
34].
Table 11 presents the training time of the SAM, the WRPM and SCP-Net, as well as the time required for inferring a standard image. All computations were carried out on a single NVIDIA RTX4090 graphics card.
It can be observed from the table that the total training duration for the entire UGSAM is approximately 16 h and 30 min. Additionally, the time required to infer a single image using the Vit-B weights is around 32 s. Compared to the extensive training periods lasting several months and the requirement for hundreds of high-memory GPUs associated with large models, the UGSAM introduced in this study demonstrates remarkable cost-effectiveness and efficiency, rendering it highly suitable for large-scale deployment in urban environments.
4.3. Limitations and Scalability
Although the UGSAM offers low cost and high accuracy, its application may be constrained in certain urban environments. In regions susceptible to natural disasters or those affected by conflict, the spatial layout alterations may diverge from established social and economic development models, complicating the model’s ability to provide consistent estimates. In these specific urban contexts, employing the UGSAM necessitates relabeling the data and training the SCP-Net.
Fortunately, SCP-Net has a relatively small parameter count, resulting in significantly lower time and cost requirements for training compared to larger models. If deployment is essential in these particular scenarios or if enhanced accuracy is desired, we can opt to freeze both the encoder and decoder of the SAM while flexibly increasing the number of network layers during SCP-Net training to improve precision. This approach will incur a slight increase in cost. However, it remains substantially less than that associated with fine-tuning the SAM.
Additionally, the WRPM serves as a universal defogging module characterized by strong transferability and is not limited by scene transitions.
5. Conclusions
This study proposes an efficient real-time monitoring method for urban street vegetation conditions. The research develops an innovative solution using deep learning and multimodal visual large models. We present the UGSAM, a method for real-time analysis of street view images to extract vegetation areas, which meets urban greening management requirements with high accuracy and low operational costs.
The UGSAM integrates feature fusion with a multiattention mechanism Weather-Robust Processing Module, the WRPM, combined with a segmentation correction protocol network, SCP-Net. This architecture enables effective handling of image degradation caused by variable urban weather conditions while improving recognition accuracy. The correction network helps refine vegetation segmentation results by identifying overlooked vegetation areas, enhancing overall segmentation precision.
We conducted comprehensive comparative experiments and ablation studies on benchmark datasets. The superior performance of the UGSAM was validated through multiple perspectives and task scenarios. In standard weather conditions, the OA of the UGSAM achieved 0.8776 for vegetation segmentation tasks, representing a 1.2% improvement over the SAM. The mIoU reached 0.8681, showing a 1.5% enhancement compared with the SAM. Under adverse weather conditions, the UGSAM demonstrated exceptional capability, with OA and mIoU surpassing the SAM by 18.9% and 25.5%, respectively, showing significant performance advantages.
In the ablation experiments, we designed three sets of experiments to validate the effectiveness and superiority of each component in the UGSAM. First, we tested the performance of the UGSAM using the WRPM with fused features against using FFA-Net and LS-UNet individually. The results showed that the model with the WRPM performed the best. Second, we tested the performance of the UGSAM with and without SCP-Net, and the results demonstrated that the incorporation of SCP-Net improved the model’s performance. Finally, we experimented with multiple loss function strategies during the training of SCP-Net to determine the optimal approach. The results indicated that the combination of cross-entropy loss and Dice loss yielded the best performance, which is consistent with the strategy used in the UGSAM.
In conclusion, these results are of significant importance, as they are likely to be used for potentially important findings in the field of urban greening distribution recognizing.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





