1. Introduction
Timely crop classification enables accurate assessment of crop distribution and area, which is critical for yield forecasting and food security assessment [
1,
2]. However, most studies on crop classification rely on full-year time-series data. This post-season classification, rather than early-season classification, has lower timeliness and cannot provide decision makers with timely data support [
3]. In contrast, early-season classification refers to crop classification based on the acquisition of time-series data in the early-to-mid stages of crop growth [
4]. The early acquisition of crop planting information is of great value for agriculture-related applications and government decision making. It not only provides reliable spatial information for risk management and crop insurance, but also enables precise intervention and effective management during the early stage of crop growth [
5,
6,
7].
Currently, early-season crop classification methods can be divided into two categories: machine-learning-based methods and deep-learning-based methods. Machine-learning-based methods, which operate without human intervention during training, automatically learn the differences exhibited by various crops in time-series data. This enables these methods to uncover underlying patterns in the data, thereby enhancing the accuracy of crop classification [
8,
9]. Therefore, machine learning clustering algorithms, such as Random Forest (RF) and Support Vector Machine (SVM), have been utilized in early-season crop classification [
10,
11,
12]. RF has been used in several studies, which ultimately deduced the identifiable timing for rice, corn and soybean [
13,
14]. Some previous studies have used different clustering algorithms, such as gaussian mixture model [
15] and multivariate spatiotemporal clustering [
16], to extract the feature information from vegetation index curves and aggregate remote sensing spectral data. These machine-learning-based methods achieved satisfactory overall accuracy in the mid-stages of crop growth. However, these machine-learning-based methods struggle to effectively model the complex nonlinear relationships of temporal dependencies [
17]. Consequently, this leads to the inability to achieve accurate classification earlier in the season.
Compared to machine-learning-based methods, deep-learning-based methods are more adept at handling time-series data with complex temporal dependencies and nonlinear relationships. This advantage is primarily attributed to their ability to automatically extract complex features and perform multi-layer nonlinear transformations, enabling effective temporal feature extraction [
18]. Therefore, some studies have begun adopting Transformer, Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) for early-season crop classification [
19,
20,
21]. Specifically, Transformer-based methods use multi-head attention mechanisms and encoder–decoder structures to extract global information from time-series data [
22,
23]. In contrast to Transformer, Long Short-Term Memory (LSTM) uses gating mechanisms to represent temporal dependencies over different time spans in recursive connections [
24]. For instance, Xu et al. [
25] proposed an attention-based bidirectional LSTM for the classification of corn and soybean, which enhanced the ability to capture temporal features. Furthermore, ELECT was proposed to balance the classification of earliness and accuracy [
26]. Mask-PSTIN was proposed to effectively aggregate time-series data by combining temporal random masking with pixel set spatial information [
27]. These two innovative LSTM-based models, ELECT and Mask-PSTIN, offer new perspectives for early-season crop classification. Nevertheless, these methods focus on extracting global features from time-series data while neglecting local features.
Additionally, several studies have leveraged the local receptive fields and multiple convolution kernels of CNNs to extract local features from time-series data [
28,
29]. Both 1D-CNN [
30] and 3D-CNN [
31] have been used to extract local features from time-series data, performing classification for cotton and wheat. To integrate the advantages of LSTM and CNN, Yang et al. [
32] proposed the EMET framework that combined the Super-Resolution Convolutional Neural Network (SRCNN) and LSTM to jointly extract global and local features from time-series data.
Nowadays, deep-learning-based methods improve feature extraction and fusion ability by using attention mechanisms, gating mechanisms or convolution operations [
27,
33]. These enhancements enable the extraction of more critical information, leading to better classification results compared to machine-learning-based methods. However, as classification is performed earlier, time-series data gradually become scarce. This limits the extraction of sufficient critical phenological information using these methods, leading to a decline in classification accuracy. When addressing this limitation, most studies focus on further improving the methods’ ability to extract features from the limited data. Nevertheless, the extracted information remains insufficient. To our knowledge, no approach has tackled this limitation from another perspective: completing the data to create a full-year time series before classification by leveraging accurate predictions.
In this study, we propose a novel idea. Specifically, crop classification is decomposed into two tasks: prediction and classification, which are interconnected through the cascade learning mechanism [
34]. In the prediction task, early-season data are utilized to predict future data. Then, the predicted and early-season data are concatenated to provide full-year time-series data for classification, thereby enabling the extraction of more critical phenological information. Meanwhile, the classification results are used to reverse-optimize the accuracy of the prediction task through the cascade learning mechanism.
Based on this idea, we design a Cascade Learning Early Classification (CLEC) framework. CLEC is composed of data preprocessing and a cascade learning model. Data preprocessing produces high-quality time-series data by integrating optical, radar and thermodynamic data. The cascade learning model performs both the prediction task and the classification task.
The main contributions of this study are as follows:
A Cascade Learning Early Classification framework is proposed. Through data preprocessing and the cascade learning model, the framework fundamentally addresses the issue of insufficient extraction of critical phenological information, thereby improving classification accuracy.
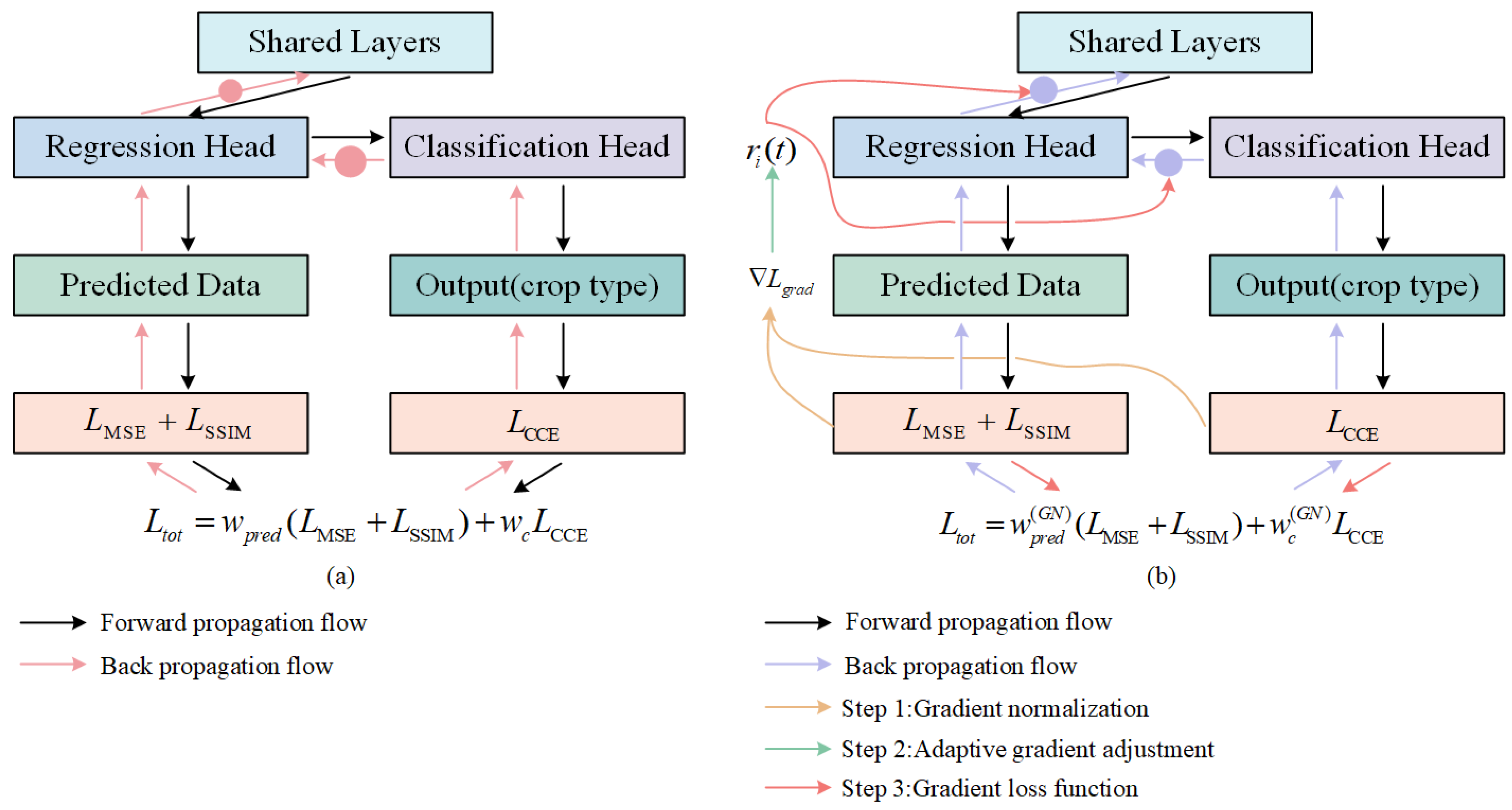
A cascade learning model is designed, and we enhance the model’s ability to handle time-series data by leveraging Attention encoder–decoder LSTM (AtEDLSTM) to capture global features and a 1D Convolutional Neural Network (1D-CNN) to capture local features. Furthermore, the GradNorm loss weighting method is introduced to balance the learning process of each task to prevent any single task from dominating the optimization process.
In experiments for early-season classification of soybean, corn and rice in Northeast China, the proposed CLEC framework demonstrates superior classification accuracy and advances the earliest identifiable timing by 10–30 days compared to five state-of-the-art models.
5. Discussion
5.1. Relationship Between Classification Performance and Phenological Stages
This study proposes CLEC for early-season crop classification, which includes the cascade learning model that simultaneously performs data prediction and crop classification tasks, aiming to address the issue of extracting insufficient critical phenological information. The experimental results show that compared to baseline models, CLEC demonstrates superior classification accuracy and earlier identification capability.
Existing methods have primarily focused on improving feature extraction and fusion capabilities. Xu et al. [
25] proposed DeepCropMapping (DCM), which utilizes the AtBiLSTM module to perform crop classification. Weilandt et al. [
23] employed a temporal attention encoder to enhance data feature extraction. These methods utilize limited early data for classification without supplementing future crop growth information. As a result, when available data are scarce, these methods struggle to capture sufficient critical phenological information. In contrast, CLEC incorporates an additional prediction module, which is based on LSTM. This module is used to supplement the classification module with more data. Moreover, CLEC leverages the cascade learning mechanism to iteratively optimize both prediction and classification results.
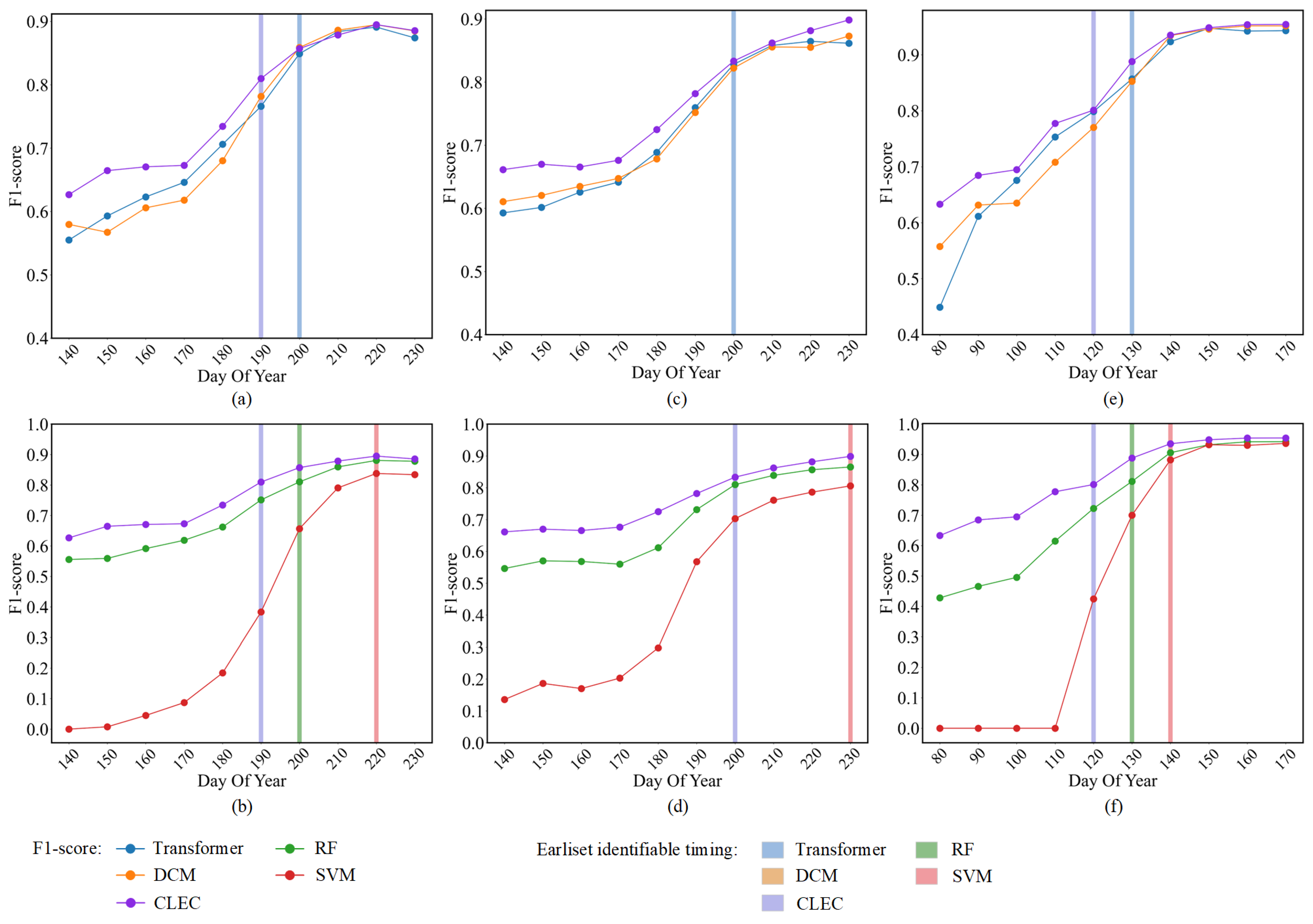
In the early stages of crop growth (DOY 110–180), CLEC achieved F1-scores of 62.7–71.4% for soybean, 66.1–72.5% for corn and 63.3–95.5% for rice. Specifically, rice reached its earliest identifiable timing at the beginning of the flooding stage (DOY 120). This is primarily due to the relatively high LSWI values of rice during the flooding/transplanting stage (DOY 120–150), which serve as a key feature for distinguishing rice from corn and soybean. Therefore, this phenological characteristic plays a crucial role in rice classification. Meanwhile, although the classification accuracy of soybean and corn has not yet reached the earliest identifiable timing (F1-score > 0.8), it still significantly outperforms other models in the comparative experiments.
In the mid-growth stage of crops (DOY 190–240), soybean and corn enter a vigorous growth stage, with gradually increasing vegetation cover. In this stage, vegetation indices play a crucial role in crop identification, with soybean reaching its earliest identifiable timing at the third true leaf stage (DOY 190) and corn at the stem elongation stage (DOY 200).
As crops enter the mid-to-late growth stages, the time-series data accumulate sufficient critical phenological information, leading to a gradual saturation of classification accuracy. At this stage, further increasing the time-series length results in only a slow improvement in accuracy.
The above conclusion is generally consistent with other studies [
13,
53,
54]. Regarding the earliest identifiable timing of crops, the results obtained by CLEC are reliable and achieve an earlier identification compared to other studies.
5.2. Explanation of the CLEC Advantages in the Early-Season Crop Classification
To further analyze the advantages of CLEC in early-season crop classification, we compared the trend variations between the generated data and the real to validate the accuracy of the predictions by AtEDLSTM. We selected three indices, EVI, NDVI and LSWI. EVI reflects changes during periods of high biomass [
55], and NDVI is sensitive to changes in green leaf area and biomass [
56]. LSWI is very sensitive to changes in leaf and soil moisture and plays a key role in the identification of rice, corn and soybean [
57].
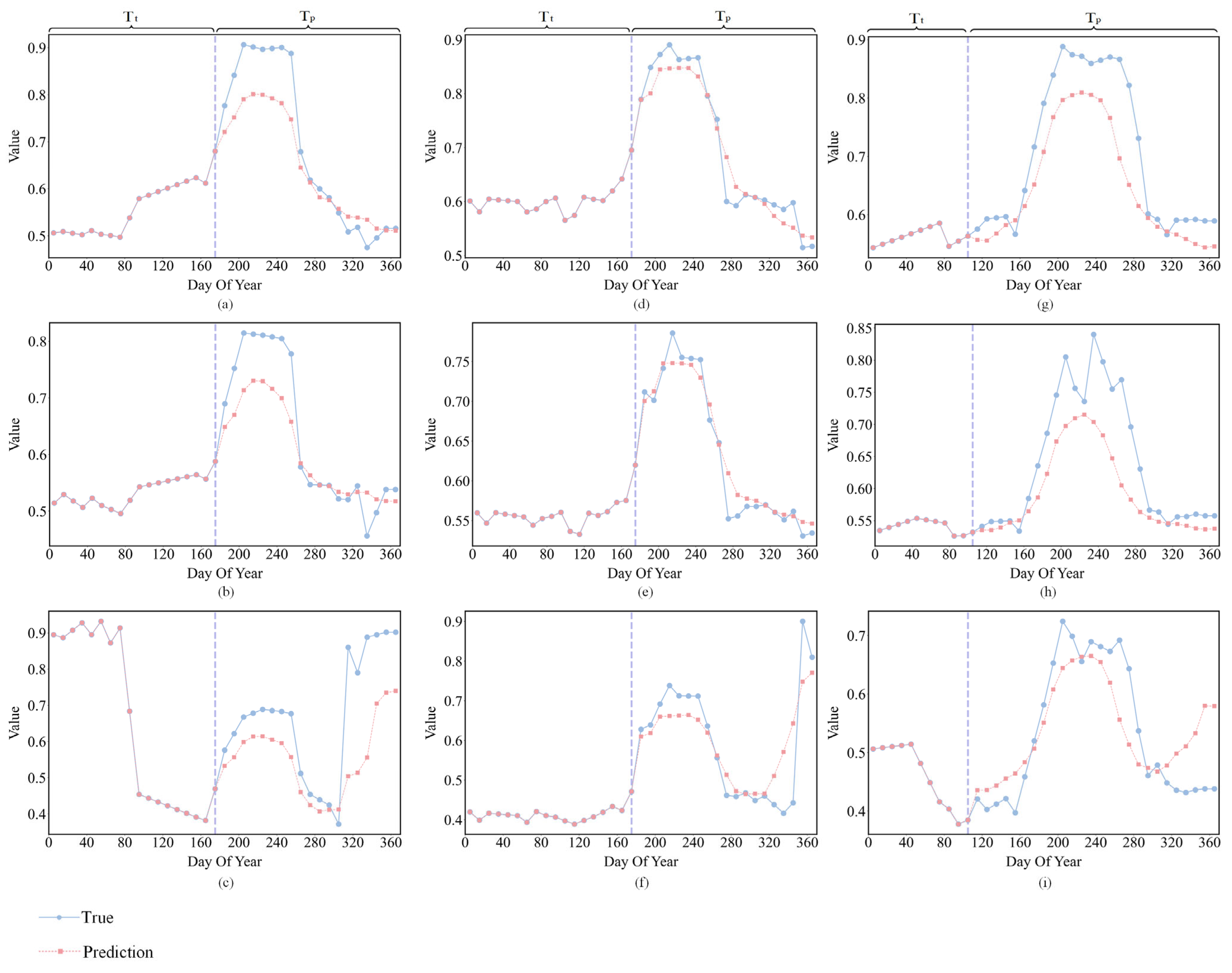
Figure 10 shows the comparative results of these three indices.
At DOY 110, rice enters the sowing stage but has not yet entered the flooding/transplanting stage (DOY 120–150), at which point the difference in LSWI between rice and corn and soybean is not significant (
Figure 10c,f,i). When this critical phenological information is lacking, the classification model struggles to effectively capture the phenological feature differences between rice and other crops during their growth stage. To address this problem, CLEC uses AtEDLSTM to supplement the time-series data. AtEDLSTM is capable of generating the trend variations of LSWI for rice in the flooding/transplanting stage (DOY 120–150) (
Figure 10i). This provides critical phenological information for the 1D-CNN, thereby effectively distinguishing rice from corn and soybean.
At DOY 180, corn enters the stem elongation stage with rapidly elongating stems, while soybean is in the third true leaf stage, when the spectral difference between the two is not significant. As shown in
Figure 10a–f, AtEDLSTM is able to predict the key feature variation trends for both crops during the peak growth stage (DOY 200–240), providing more critical information.
However, from the observation of
Figure 10, we can see that there is still room for improvement in the prediction performance of AtEDLSTM in CLEC. Currently, it can only predict the general trend of the feature curve (baseline). The learning and prediction of periodic patterns (peaks and valleys) that fluctuate around the baseline due to phenological events (such as planting, heading and harvest) are still not ideal and require further optimization. These localized fluctuations often correspond to critical phenological information and are essential for distinguishing crop types. Under non-standard growing conditions such as drought or late sowing, crop growth trajectories often deviate significantly from typical patterns. Due to the inherently small inter-species differences, particularly between soybean and corn, which exhibit highly similar spectral and phenological curves, these crops are more prone to misclassification. Identifying crops under such non-standard conditions presents two major challenges:
First, compared with historical years, the feature values at the same growth stage under non-standard conditions may fluctuate to some extent. For example, during droughts, the NDVI curve tends to be systematically lower. At the same time, the temporal distribution of growth stages on the calendar may shift, resulting in earlier or later development, or in stretching or compression of the phenological phases. These factors can lead to a significant increase in the prediction error of AtEDLSTM.
Second, since AtEDLSTM has difficulty capturing and predicting finer-grained fluctuations caused by phenological events, 1D-CNN must rely primarily on the overall trend of the feature curves. Under non-standard conditions, this overall trend is already subject to considerable uncertainty. Moreover, the lack of effective modeling of key variation points such as peaks and troughs further limits the model’s capacity to learn from detailed features. This limitation prevents 1D-CNN from leveraging prominent local features for correction, ultimately resulting in a decrease in classification accuracy.
These errors propagate progressively through the cascade learning pipeline, leading to a further decline in overall classification performance.
5.3. The Impact of Prediction Data Length and Prediction Mode on Classification Accuracy
In the cascade learning model, the predicted data are concatenated with early-season time-series data to form the full-year time series. However, as shown in
Figure 2, most crops reach their harvest stage between late September and early October (DOY 270–280). In the post-harvest stage (DOY 290–370), fluctuations in time-series data are primarily driven by non-crop growth factors. Therefore, predicting data at this stage may not improve early-season crop classification accuracy and could even negatively impact the classification results.
To investigate the effect of predicted data length on early-season crop classification accuracy in the cascade learning model, we conducted an experiment. For soybean, we used early-season data from the first 190 days of the year (DOY: 0–190) as input in the model for further prediction. For corn, we used data from the first 200 days (DOY: 0–200), and for rice, the first 120 days (DOY: 0–120). These time points represent the earliest identifiable timing for each crop, ensuring that the model captures sufficient phenological information for reliable classification. By adjusting the length of the predicted data, we constructed varying time-series datasets to assess the impact of data length on classification accuracy.
As shown in
Table 9, soybean achieves its highest accuracy with a predicted data length of 60 days (predicted to DOY 250), yielding a 0.3% increase in Kappa and a 0.2% increase in F1-score compared to the full-year data, which are completed through prediction based on early-season data. Corn reaches its optimal accuracy at 80 days (predicted to DOY 280), with the Kappa improving by 1.7% and the F1-score increasing by 1.3% in the same comparison. Although the highest classification accuracy for rice is achieved at the final time point (DOY 370), the second-best accuracy is obtained with a predicted data length of 130 days (predicted to DOY 250), which is only 0.2% lower in Kappa and 0.4% lower in F1-score compared to the optimal values. This, however, results in substantial savings in both time and computational costs.
In summary, the length of the predicted data has a certain impact on the performance of CLEC in early-season crop classification. When the predicted data length is excessively long, the prediction performance may degrade because the model could introduce additional noise, leading to a certain impact on classification accuracy. In contrast, when the predicted data length is too short, the cascade learning model may fail to capture sufficient critical phenological information, which can significantly affect classification accuracy. Therefore, future research could further explore the optimal predicted data length for different crops to enhance the classification performance of CLEC.
In addition to investigating the effect of different prediction lengths, we further explored how different prediction modes (representing different prediction errors) affect the classification performance. Specifically, we evaluated three variants: (1) CLEC, our cascade learning framework, in which the prediction and classification modules are jointly optimized; (2) CLEC_V2, in which the prediction and classification modules are trained separately as two independent models, without cascade learning; and (3) CLEC_V3, our cascade learning framework which derives classification results based on the best prediction error of the AtEDLSTM output.
As shown in
Figure 11, CLEC outperforms both CLEC_V2 and CLEC_V3 in early-season crop classification accuracy. Notably, although other modes utilize the prediction module that minimizes prediction error, their classification performance remains suboptimal. This indicates that minimizing prediction errors alone does not necessarily lead to optimal classification performance. These results emphasize the critical role of cascade learning in aligning prediction outputs with classification. The cascade learning mechanism enables the prediction module to predict more discriminative features, even when the predicted data are not perfectly accurate.
5.4. Applicability of CLEC Across Agro-Climatic Zones
To further investigate the performance of CLEC in early-season classification across different climatic zones, we conducted experiments. We employed the dataset from the area near Hollfeld in Bavaria, Germany, which is the dataset used in Rußwurm et al.’s research [
26]. The region has a temperate continental climate with distinct seasonal variations. The dataset includes a full-year time series of Sentinel-2 imagery, which contains between 71 (every 5 days) and 147 (every 2.5 days) observations. The dataset consists of seven common crop types: meadow, summer barley, corn, winter wheat, winter barley, clover and triticale. The dataset was split into training, validation and test sets, with a ratio of 8:1:1.
We conducted comparative experiments between CLEC and the baselines used in
Section 4.2 and
Section 4.3. As shown in
Figure 12, CLEC significantly outperformed the other methods during the DOY 100–130 period, which is notably early in the crop growth stage. This highlights the practical value of the CLEC in enabling early and reliable crop classification, potentially offering considerable economic and societal benefits.
When more phenological information was accumulated (DOY 130–200), the classification advantage of CLEC diminished. After the earliest identifiable timing, its accuracy was comparable to or slightly inferior to that of DCM. This may be attributed to the reduced marginal benefit of the prediction module at later growth stages. Additionally, the classification performance in this stage may be affected by differences in region-specific feature patterns, which challenge the model’s generalization across different datasets. During this period, the classification accuracy of all models tended to saturate, which is consistent with the experimental results in
Section 4.2.
Overall, CLEC still demonstrates a clear advantage in early-season classification, while also exhibiting promising cross-regional transferability in early-season crop identification.
5.5. Limitations and Future Work
Our experiments show that, in the early-to-mid stages of crop growth, CLEC achieves better classification results, demonstrating a certain advantage. However, there are still some limitations that need to be improved in future studies. As shown in
Table 3,
Table 4 and
Table 5 and
Figure 8 and
Figure 12, CLEC outperforms the baseline methods when the available data are scarce. However, after reaching the earliest identifiable timing, the framework achieves only marginal improvements over the best-performing baselines or performs comparably.
Additionally, we evaluated the computational complexity of CLEC. As shown in
Table 10, although CLEC consumes less memory than DCM and Transformer, it requires the longest training time among all methods. CLEC exhibits limitations in computational efficiency due to its more complex structure in the classification process. As shown in
Table 10, the use of GradNorm for dynamic multi-task loss balancing significantly contributes to the increased training time of CLEC. This is primarily due to the additional computational steps introduced by GradNorm in each training iteration. These steps include multiple backward passes to compute gradient norms, dynamic adjustment of task loss weights and extra gradient tracking via hooks. These operations result in approximately double the training time compared to a variant without GradNorm (CLEC_NoGrad). When time complexity is not a major constraint, CLEC can effectively achieve high performance in early-season crop classification. Future work could investigate more efficient multi-task optimization strategies to enhance scalability and deployment feasibility.
Future work can be developed in the following two aspects. On the one hand, the cascade learning model of CLEC consists of two independent cascading output backbone modules, which possess strong transferability and allow flexible replacement of certain parts within the model. Based on this characteristic, future work could attempt to replace the models for the prediction and classification tasks with other models, optimizing the performance of both tasks and thus enhancing the overall performance of CLEC. On the other hand, further exploration of adaptive loss weighting methods could be pursued to better achieve the mutual optimization between the two tasks, thereby improving the overall performance and stability of CLEC.
6. Conclusions
This study proposes the Cascade Learning Early Classification (CLEC) framework with data preprocessing and a cascade learning model. It aims to address the issue of insufficient phenological features in the very early stages of crop classification. In the data preprocessing stage, we generated high-quality time-series data by integrating optical, radar and thermodynamic data. Meanwhile, we designed a cascade learning model that simultaneously performs prediction and classification tasks to address the issue of insufficient feature extraction. Both the prediction and classification results were jointly optimized through the cascade learning mechanism. Specifically, the cascade learning model was composed of two components: the AtEDLSTM for capturing global temporal dependencies, and the 1D-CNN for extracting local features from time-series data. Additionally, the GradNorm loss weighting method was introduced to dynamically adjust the contribution of each task during training.
To validate the effectiveness of the proposed CLEC framework, we conducted experiments in Northeast China. The experimental results show that CLEC exhibits significant superiority over the baseline 1D-CNN model in early-season crop classification, with the classification Kappa increasing by an average of 3.4–6.9%. CLEC achieved the highest Kappa values in the early growth stage for soybean, corn and rice, significantly improving the classification accuracy compared to four other models. CLEC was able to achieve the earliest identifiable timing for the crops 10 to 30 days earlier than RF, Transformer, DCM and SVM. Additionally, we also conducted ablation experiments on CLEC, and the results demonstrate the effectiveness of each module.
We further explored the relationship between classification accuracy and the phenological stages of crop growth, as well as the advantages of CLEC in early-season classification. This further demonstrates the reliability of our results, which outperform other studies. Additionally, we investigated the impact of varying predicted data lengths in the cascade learning model on classification accuracy, providing a potential direction for future research. Overall, this study provides new ideas for solving the problem of early-season crop classification and demonstrates the great potential of cascade learning in this area.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}