

An Autonomous Global Star Identification Algorithm Based on the Fast MST Index and Robust Multi-Order CCA Pattern

 , , ,
, , ,
Abstract
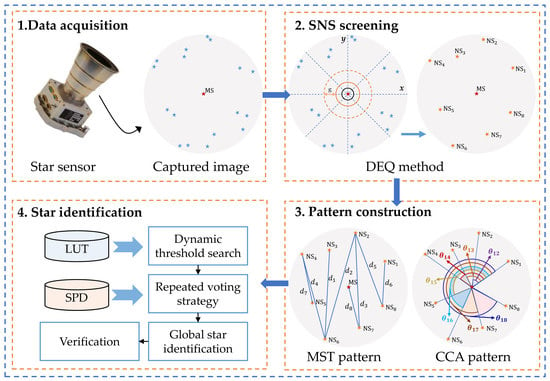
1. Introduction
- A dynamic eight-quadrant method for neighboring stars selection, which makes the guide stars in the FOV uniformly distributed and increases the identifiability of the constructed pattern, is proposed. This provides a novel idea for the selection of neighboring stars;
- The Prim algorithm is introduced into the field of star identification first, constructing the maximum spanning tree pattern for each main star, and is then combined with the K vector to define a fast index, which greatly improves the search efficiency of the main star;
- A multi-order continuous cycle angle pattern is designed and used to perform the global identification of neighboring stars, which improves the anti-noise performance of the pattern-based algorithm;
- Extensive experiments are conducted on simulated and real star images, and the experimental results show that the proposed algorithm is superior to most mainstream algorithms in terms of identification accuracy, memory, and time consumption.
2. Pre-Knowledge and Pattern Framework
2.1. Pre-Knowledge
2.2. Proposed Rotation-Invariant Pattern Frames
3. Proposed Methodology
3.1. LUT and SPD Generation
3.1.1. DEQ Method
3.1.2. MST and CCA Pattern Construction
- (1)
- Arrange vector Y in ascending order, that is, Y(1) =, . The average step size occupied by each element in vector Y is . Mortari et al. [15] pointed out that the straight line connecting (1, Y(1) − ), (, Y() + ) can ensure that each step contains Y(k). Therefore, a straight line y(x) is drawn according to the vector Y, which can be expressed as follows:
- (2)
- Define the K vector index function K(x) as follows:where k is the serial number of in the LUT, and x is the MST index value.
3.2. Star Identification Scheme
4. Experimental Results
4.1. Comparison Results of Different Star Selection Strategies
4.2. Comparison and Analysis Results of Identification Algorithms
4.2.1. Identification Accuracy Comparison
- (1)
- Positional noise effect
- (2)
- False star noise effect
- (3)
- Magnitude noise effect
4.2.2. Memory and Running Time Test
4.3. Real Star Image Test
5. Discussion
- The confidence factor is defined for each guide star, and the proposed DEQ method is used to select NSs. Compared with the BR and ED methods, in the proposed method, the probability of wrong NS selection is reduced, and the selected NSs are more evenly distributed, which increases pattern identifiability;
- Compared with the existing pattern-based algorithms, neither the MST nor the CCA pattern in the proposed algorithm depends on the reference star or edge. Therefore, the proposed algorithm is more robust to noise than the existing algorithms;
- The MST and CCA patterns fully consider the global characteristics of stars, thus significantly enhancing the anti-noise ability of the identification algorithm. In addition, the combination of MST and the K vector can significantly improve the efficiency of the candidate DMS search. Moreover, the dynamic threshold adopted in the proposed algorithm not only ensures the identification accuracy but also reduces the interval search time. The CCA pattern requires determining only one NS, and then it completes the global identification of other NSs by simply shifting to achieve an alignment.
- The proposed DEQ method can be used only in combination with a large-FOV star sensor. Namely, under the small-FOV conditions, with the increase in detection capability, the number of faint stars in the FOV increases significantly, and the confidence discrimination of guide stars decreases, resulting in an NS selection error. In the future, we will try to build a virtual FOV through multi-frame star images stitching and combine the incomplete star catalog to make it also suitable for small-FOV.
- The MST pattern is constructed based on the Euclidean distance between stars, but it is susceptible to positional noise. To address this shortcoming, in the proposed algorithm, an iterative dynamic threshold interval is defined to ensure identification accuracy, but this can be achieved at the cost of an increase in the running time. In the future, we will try to use optimization methods to determine an optimal static threshold to eliminate the running time of iterations.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviations | Definitions |
|---|---|
| DMS/SMS | Main star in database/image |
| DNS/SNS | Neighboring star of DMS/SMS in database/image |
| LIS | Lost-in-space |
| LUT | Look-up table |
| SPD | Star pattern database |
| ED | Euclidean distance method used to screen DNS/SNS for DMS/SMS |
| BR | Brightness method used to screen DNS/SNS for DMS/SMS |
| DEQ | Proposed method used to screen DNS/SNS for DMS/SMS |
| MST | Maximum spanning tree |
| CCA | Continuous cycle angle |
| AIT | Average running time |
| MIT | Running time under the maximum noise |
| AIA | Average identification accuracy |
| MIA | Identification accuracy under the maximum noise |
References
- Samirbhai, M.D. A Reliable and Fast Lost-in-Space Mode Star Tracker. Ph.D. Dissertation, Nanyang Technological University, Singapore, 2019. [Google Scholar]
- Du, J.; Wei, X.; Li, J.; Wang, G.; Zang, C. Star identification based on radial triangle mapping Matrix. IEEE Sens. J. 2022, 22, 8795–8807. [Google Scholar] [CrossRef]
- Pham, M.D.; Low, K.-S.; Chen, S. An autonomous star recognition algorithm with optimized database. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 1467–1475. [Google Scholar] [CrossRef]
- Jiang, J.; Liu, L.; Zhang, G. Star identification based on spider-web image and hierarchical CNN. IEEE Trans. Aerosp. Electron. Syst. 2019, 56, 3055–3062. [Google Scholar] [CrossRef]
- Lu, K.; Liu, E.; Zhao, R.; Tian, H.; Zhang, H. A Fast Star Identification Algorithm of Star Sensors in the LIS Mode. Remote Sens. 2022, 14, 1739. [Google Scholar] [CrossRef]
- Mehta, D.S.; Chen, S.; Low, K.S. A robust star identification algorithm with star shortlisting. Adv. Space Res. 2018, 61, 2647–2660. [Google Scholar] [CrossRef]
- Wang, G.; Li, J.; Wei, X. Star identification based on hash map. IEEE Sens. J. 2017, 18, 1591–1599. [Google Scholar] [CrossRef]
- Li, J.; Wei, X.; Zhang, G. Iterative algorithm for autonomous star identification. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 536–547. [Google Scholar] [CrossRef]
- Yang, S.; Liu, L.; Zhou, J.; Zhao, Y.; Hua, G.; Sun, H.; Zheng, N. Robust and Efficient Star Identification Algorithm based on 1-D Convolutional Neural Network. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 4156–4167. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Z.-y.; Wang, B.-d.; Yu, Z.-q.; Jin, Z.-h.; Crassidis, J.L. An artificial intelligence enhanced star identification algorithm. Front. Inf. Technol. Electron. Eng. 2020, 21, 1661–1670. [Google Scholar] [CrossRef]
- Zhang, G. Star Identification: Methods, Techniques and Algorithms; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Sun, L.; Zhou, Y. Mvdt-si: A multi-view double-triangle algorithm for star identification. Sensors 2020, 20, 3027. [Google Scholar] [CrossRef]
- Liu, M.; Wei, X.; Wen, D.; Wang, H. Star identification based on multilayer voting algorithm for star sensors. Sensors 2021, 21, 3084. [Google Scholar] [CrossRef] [PubMed]
- Kolomenkin, M.; Pollak, S.; Shimshoni, I.; Lindenbaum, M. Geometric voting algorithm for star trackers. IEEE Trans. Aerosp. Electron. Syst. 2008, 44, 441–456. [Google Scholar] [CrossRef]
- Mortari, D.; Junkins, J.L.; Samaan, M. Lost-in-space pyramid algorithm for robust star pattern recognition. In Proceedings of the Guidance and Control 2001, Breckenridge, CO, USA, 31 January–4 February 2001; pp. 49–68. [Google Scholar]
- Cole, C.L.; Crassidis, J.L. Fast star-pattern recognition using planar triangles. J. Guid. Control Dyn. 2006, 29, 64–71. [Google Scholar] [CrossRef]
- Lee, H.; Bang, H. Star pattern identification technique by modified grid algorithm. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 1112–1116. [Google Scholar]
- Li, J.; Wei, X.; Wang, G.; Zhou, S. Improved grid algorithm based on star pair pattern and two-dimensional angular distances for full-sky star identification. IEEE Access 2019, 8, 1010–1020. [Google Scholar] [CrossRef]
- Aghaei, M.; Moghaddam, H.A. Grid star identification improvement using optimization approaches. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2080–2090. [Google Scholar] [CrossRef]
- Zhang, G.; Wei, X.; Jiang, J. Full-sky autonomous star identification based on radial and cyclic features of star pattern. Image Vis. Comput. 2008, 26, 891–897. [Google Scholar] [CrossRef]
- Mehta, D.S.; Chen, S.; Low, K.-S. A rotation-invariant additive vector sequence based star pattern recognition. IEEE Trans. Aerosp. Electron. Syst. 2018, 55, 689–705. [Google Scholar] [CrossRef]
- Jiang, J.; Ji, F.; Yan, J.; Sun, L.; Wei, X. Redundant-coded radial and neighbor star pattern identification algorithm. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 2811–2822. [Google Scholar] [CrossRef]
- Liu, H.; Wei, X.; Li, J.; Wang, G. A star identification algorithm based on recommended radial pattern. IEEE Sens. J. 2022, 22, 8030–8040. [Google Scholar] [CrossRef]
- Liebe, C.C. Pattern recognition of star constellations for spacecraft applications. IEEE Aerosp. Electron. Syst. Mag. 1993, 8, 31–39. [Google Scholar] [CrossRef]
- Padgett, C.; Kreutz-Delgado, K.; Udomkesmalee, S. Evaluation of star identification techniques. J. Guid. Control Dyn. 1997, 20, 259–267. [Google Scholar] [CrossRef]
- Padgett, C.; Kreutz-Delgado, K. A grid algorithm for autonomous star identification. IEEE Trans. Aerosp. Electron. Syst. 1997, 33, 202–213. [Google Scholar] [CrossRef]
- Na, M.; Zheng, D.; Jia, P. Modified grid algorithm for noisy all-sky autonomous star identification. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 516–522. [Google Scholar] [CrossRef]
- Wei, X.; Wen, D.; Song, Z.; Xi, J.; Zhang, W.; Liu, G.; Li, Z. A star identification algorithm based on radial and dynamic cyclic features of star pattern. Adv. Space Res. 2019, 63, 2245–2259. [Google Scholar] [CrossRef]
- Samirbhai, M.D.; Chen, S.; Low, K.S. A hamming distance and spearman correlation based star identification algorithm. IEEE Trans. Aerosp. Electron. Syst. 2018, 55, 17–30. [Google Scholar] [CrossRef]
- Zhang, G.; Zhang, G. Star Identification Utilizing Neural Networks; Springer: Berlin/Heidelberg, Germany, 2017; pp. 153–176. [Google Scholar]
- Alvelda, P.; San Martin, A. Neural network star pattern recognition for spacecraft attitude determination and control. Adv. Neural Inf. Process. Syst. 1989, 314–322. [Google Scholar]
- Wang, Y.; Zhang, H. Star recognition based on mixed star pattern and multilayer SOM neural network. In Proceedings of the 2017 IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2017; pp. 1–6. [Google Scholar]
- Myers, J.; Sande, C.; Miller, A.; Warren, W., Jr.; Tracewell, D. SKY2000-master star catalog-star catalog database. Bull. Am. Astron. Soc. 1997, 191, 128. [Google Scholar]
- Zhu, Z.; Ma, Y.; Dan, B.; Zhao, R.; Liu, E.; Zhu, Z. ISSM-ELM–a guide star selection for a small-FOV star sensor based on the improved SSM and extreme learning machine. Appl. Opt. 2022, 61, 6443–6452. [Google Scholar] [CrossRef]
- Ayegba, P.; Ayoola, J.; Asani, E.; Okeyinka, A. A comparative study of minimal spanning tree algorithms. In Proceedings of the 2020 International Conference in Mathematics, Computer Engineering and Computer Science (ICMCECS), Lagos, Nigeria, 18–21 March 2020; pp. 1–4. [Google Scholar]
- Jun, Z.; Yuncai, H.; Li, W.; Da, L. Studies on dynamic motion compensation and positioning accuracy on star tracker. Appl. Opt. 2015, 54, 8417–8424. [Google Scholar] [CrossRef]
- Sun, L.; Jiang, J.; Zhang, G.; Wei, X. A discrete HMM-based feature sequence model approach for star identification. IEEE Sens. J. 2015, 16, 931–940. [Google Scholar] [CrossRef]
















| Algorithm | Category | Methodology |
|---|---|---|
| Sun et al. [12] | Subgraph-based | Double-triangle with the star angle and distance |
| Liu et al. [13] | Subgraph-based | Triangle voting scheme |
| Kolomenkin et al. [14] | Subgraph-based | Geometric voting strategy |
| Mortari et al. [15] | Subgraph-based | Pyramid structure and K vector search |
| Cole et al. [16] | Subgraph-based | Area and polar moments of triangles |
| Lee et al. [17] | Pattern-based | Polar grid and multi-reference stars |
| Li et al. [18] | Pattern-based | Two-dimensional angular distances |
| Aghaei et al. [19] | Pattern-based | Optimization method |
| Zhang et al. [20] | Pattern-based | Radial and cyclic pattern |
| Samirbhai et al. [21] | Pattern-based | Rotation-invariant 2D vector |
| Jiang et al. [22] | Pattern-based | Redundant-coded star pattern |
| Liu et al. [23] | Pattern-based | A priori algorithm |
| Jiang et al. [4] | Learning-based | Hierarchical convolutional neural network (CNN) |
| Yang et al. [9] | Learning-based | 1D-CNN |
| Parameters | Illustration | Value |
|---|---|---|
| Maximum number of NSs | 8 | |
| g | Dynamic step size | 1.25 (deg) |
| Initial radius | 5 (deg) |
| Parameters | Value |
|---|---|
| FOV () | 20° × 20° |
| Imaging plane () | 1536 × 1536 (pixels) |
| Single-pixel size () | 0.0055 × 0.0055 (mm) |
| Focal length (f) | 24.03 (mm) |
| No Noise | Position Noise | False Star Noise | Magnitude Noise | ||||
|---|---|---|---|---|---|---|---|
| AIA(%) | AIA(%) | MIA(%) | AIA(%) | MIA(%) | AIA(%) | MIA(%) | |
| Proposed | 99.95 | 99.23 | 98.63 | 98.95 | 97.91 | 98.95 | 98.03 |
| OGP | 98.63 | 98.01 | 97.39 | 95.92 | 91.29 | 95.92 | 96.42 |
| RCP | 97.59 | 95.09 | 92.42 | 89.63 | 80.18 | 89.63 | 92.17 |
| GMV | 97.54 | 93.30 | 88.35 | 88.58 | 76.46 | 88.58 | 93.29 |
| Pyramid | 99.12 | 97.53 | 94.89 | 97.30 | 95.33 | 97.30 | 96.84 |
| HMM | 98.72 | 98.22 | 97.81 | 96.89 | 94.26 | 98.10 | 97.13 |
| Memory (KB) | Position Noise | False Star Noise | Magnitude Noise | ||||
|---|---|---|---|---|---|---|---|
| AIT (ms) | MIT (ms) | AIT (ms) | MIT (ms) | AIT (ms) | MIT (ms) | ||
| Proposed | 1103.48 | 11.92 | 20.87 | 8.56 | 9.05 | 10.68 | 13.87 |
| OGP | 1638.43 | 77.86 | 89.95 | 83.29 | 126.78 | 81.41 | 110.36 |
| RCP | 573.44 | 9.65 | 13.53 | 8.71 | 11.03 | 8.12 | 10.68 |
| GMV | 1863.68 | 33.72 | 41.52 | 35.87 | 45.39 | 31.68 | 37.39 |
| Pyramid | 2068.48 | 24.75 | 29.49 | 27.64 | 10.35 | 29.09 | 44.92 |
| HMM | 2283.52 | 3.18 | 4.56 | 2.66 | 3.96 | 3.44 | 4.98 |
| Scheme | Centroids | Guide Star Catalog | ||||
|---|---|---|---|---|---|---|
| x (pixel) | y (pixel) | Serial Number in Star Catalog | Right Ascension (deg) | Declination (deg) | Star Magnitude | |
| 710.68 | 840.13 | 233 | 20.8790 | −30.9456 | 5.83 | |
| 1052.82 | 891.73 | 177 | 15.6101 | −31.5520 | 5.51 | |
| 1048.15 | 1458.62 | 176 | 15.3261 | −38.9165 | 5.59 | |
| 569.81 | 1295.78 | 256 | 22.2336 | −36.8652 | 5.50 | |
| 411.44 | 954.22 | 288 | 25.5358 | −32.3270 | 5.26 | |
| 501.81 | 765.63 | 265 | 24.0355 | −29.9073 | 5.70 | |
| 590.52 | 481.08 | 251 | 22.5954 | −26.2079 | 5.93 | |
| 575.54 | 792.00 | 255 | 22.9301 | −30.28 | 5.79 | |
| 1123.05 | 727.28 | 174 | 14.6515 | −29.3574 | 4.31 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Z.; Ma, Y.; Dan, B.; Liu, E.; Zhu, Z.; Yi, J.; Tang, Y.; Zhao, R. An Autonomous Global Star Identification Algorithm Based on the Fast MST Index and Robust Multi-Order CCA Pattern. Remote Sens. 2023, 15, 2251. https://doi.org/10.3390/rs15092251
Zhu Z, Ma Y, Dan B, Liu E, Zhu Z, Yi J, Tang Y, Zhao R. An Autonomous Global Star Identification Algorithm Based on the Fast MST Index and Robust Multi-Order CCA Pattern. Remote Sensing. 2023; 15(9):2251. https://doi.org/10.3390/rs15092251
Chicago/Turabian StyleZhu, Zijian, Yuebo Ma, Bingbing Dan, Enhai Liu, Zifa Zhu, Jinhui Yi, Yuping Tang, and Rujin Zhao. 2023. "An Autonomous Global Star Identification Algorithm Based on the Fast MST Index and Robust Multi-Order CCA Pattern" Remote Sensing 15, no. 9: 2251. https://doi.org/10.3390/rs15092251
APA StyleZhu, Z., Ma, Y., Dan, B., Liu, E., Zhu, Z., Yi, J., Tang, Y., & Zhao, R. (2023). An Autonomous Global Star Identification Algorithm Based on the Fast MST Index and Robust Multi-Order CCA Pattern. Remote Sensing, 15(9), 2251. https://doi.org/10.3390/rs15092251